Month: September 2018


MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
For some organizations the title might not be too meaningful, but it is meant to emphasize a conceptual point. The managers in an organization do the managing. They do this at least theoretically by managing resources – including people. Then in the end, if fortune is smiling, the markets will adhere to the game plan, and the company will succeed. However, companies routinely fail, creating products and services that the markets don’t care to purchase. They sometimes use methods that don’t agree with the needs of the market – perhaps operating for decades totally disassociated from the reality of their changing market. So I hope readers appreciate the general concept: although the markets don’t manage companies in a literal sense, perhaps in an abstract sense they should. The question is how – and what different roles people have to play to enable the shift in paradigm.
In my previous blog about the “Wrongness of the Nogs,” I said that people tend to internalize their success: “I am successful. I am a success.” They associate their success with their intrinsic attributes. It is the result of something special inside them. They are less likely to externalize their success: “I was at the right place at the right time doing what comes naturally.” Whether in reference to a person or company, this blog is not about the individual that is intrinsically successful: i.e. the success is genuinely from superior design, a winning formula, or a fabulous way of doing things. This blog is for the rest of us who must accept the circumstances and context of success. The boundaries of interaction between the organism and its environment represent a major consideration: i.e. in operational terms, the market tells us or give us signs of our level of success or failure. Yet those that control resources in the organization might make use of metrics that disagree with the market.
Consider an example. A police department decides to drastically reduce spending by cutting the number of officers. The department also intends to use efficiency and performance improvement programs to improve service. The chief says, although it is true that staffing is being reduced, services levels will remain about the same through the sophisticated use of metrics. This example has a bit of joke which I will explain in a moment. Rather suddenly there is a sharp increase in shootings and murders in the city. The metrics, although it is true that they seem indicate a certain aspect of service, appear to provide little or no guidance in terms of controlling and reducing the shootings and murders. Here is an example of a management regime managing resources in a manner that is alienated or disassociated from reality.
My joke is that I work with all sorts of metrics to improve employee performance. This blog is not about my workplace, I should say flatly. But when I work with metrics, I routinely take into consideration the likely disconnection that exists between the management function – i.e. keeping the organization running smoothly and efficiently – and the markets. The market has the ability to throw all of the management efforts out the window, changing what seems like an asset into a liability. Keeping the ship “on course” or at its present direction isn’t necessarily a good thing. In fact, it isn’t a thing at all. It is irrelevant. The purpose of the voyage is to reach the destination. For many companies and I imagine for humans too that destination is elusive and constantly moving. Most organisms on the planet are products or survivors of change. Either we change with the times, or we die trying. We could also die without trying. But like I said, survivorship dynamics made us into what we are. Our interaction with “the market” defines who we are and whether or not we persist.
So back to the police department that recently cut staff and implemented an alienating metrics regime. I want readers to think about this carefully, because the suggestion is a bit radical. Which individuals in the police department are probably most familiar with shootings and murders in the city? It is true the person gathering stats has a statistical understanding of the situation; but this individual likely doesn’t have the foggiest idea about the difficult-to-quantify-but-nonetheless-critical lived experiences of residents. The police officers likely have the greatest amount of intellectual capital. But they are not normally used as a source of guidance for management. This is not to say that management necessarily ignores its workers: the lens merely tends to be tiny. It is an instrumental lens – meant to achieve particular objectives.
I recall hearing on local radio about a pilot program for community policing in Toronto – where officers would live and stay within particular communities for many years. Gun and gang violence has risen sharply recently. So I admit that my “example” in this blog is not entirely fabricated. For some people, community policing is mostly a public relations exercise. But actually, if handled to gain intellectual capital, the underlying “placement of ontology” could be shifted away from managers and brought closer to communities. This could also be regarded as a power shift, because the decision-making infrastructure would likewise be repositioned. I am not saying this would occur in relation to physical buildings but rather in relation to the data, which would become more community oriented.
Routinely do established frontrunners in an industry become threatened and overwhelmed by recent entrants. Due to the pervasive tendency to dismiss the perspectives of workers, there has become no need to hire workers that effectively rationalize, conceptualize, and convey the needs of the market. Workers are hired for their compliance and conformance. When they interact with the market, conveyance flows from their managers to the market, which is likewise expected to comply and conform. But it won’t. The company like many organisms incapable of adapting to change – like some people that find themselves disassociated from reality – become competitively disadvantaged. At some point, such companies might face displacement. The public – the market – interacts with companies through its workers. Thus when deep problems arise, companies might have vast amounts of internal data (operational data) and pinholes of reality through disconnected stats that don’t actually deal with “external” conditions. In effect, the market might be silenced perhaps rather oppressively through an alienating metrics regime.
Am I part of an alienating metrics regime? I don’t think so – because I am aware of traps – things that might lead to systemic dysfunction. Change is something to embrace rather than dismiss or ignore. The challenge for me is giving voice to the market – incorporating its needs into the data. It is so easy – and in fact easier – to ignore than to take into account the market. If the objective is to persist within a given environment, its market must always be the primary participant, stakeholder, and consideration in the data. The main task of the organization is to serve its needs, which includes configuring or shaping the organization’s processes and controlling its resources; this requires that data be sensitive to the market. It is an issue of ontology. Clearly, ontology has “placement.” It can emerge from those that control resources. Or it can be from those near the market. Every organization has to decide which place of origin is subordinate to the other.
About a month ago, I was asked to develop the logistics, to administer, and follow the progress of a new performance incentive program. Many companies have performance incentive programs; so this isn’t the interesting part of the story. Without necessarily sharing too much information, I would say that I had some preconceptions about which metrics would be most useful to measure the effectiveness of the program. I have since concluded that these metrics are likely much less effective than those that I now favour. Moreover, some of those metrics that I now favour didn’t exist a month ago, or they never received much attention from me. I believe that the main metric surrounding my preconceptions – and perhaps those of the industry more broadly – involve what I would call the “success rate”: given a certain number of opportunities, in what percentage of this would an employee succeed? The question makes sense from an operational standpoint. I have found that this metric cannot be clearly connected to the program.
This is actually a good example regardless of the nature of the business or organization. There is a socially constructed perception that money can improve the abilities of people. But in all likelihood, money cannot improve their “abilities.” It can influence the outcomes of what they do with their abilities. Consequently, if a metric is designed to measure changes in ability, then incentive might not alter the metric – unless of course employees have been holding back on their abilities due to absence of incentive. On the other hand, if the ontology is shifted away from the social construct and moved closer to the market, the underlying weakness of the metric becomes apparent. Regardless of people’s abilities, the actual objective of a reward-for-sale incentive is to increase their interaction with the market and to capture as many of the opportunities available in that market. Abilities matter in order to maximize the likelihood of success. But an organization can actually become more successful without necessarily changing its success rate simply by anchoring its metrics closer to the market – that is to say, to increase the number of opportunities.
Even a lousy car salesperson can sell more cars by approaching more customers entering the dealership. Their success rate would remain lousy – although both the agent and dealership would gain more business. Now just pretend – this being a data science blog – more than just money is actually at play. The agent is actually trying to obtain data from as much of the market as possible. The agent wants to determine whether the client is interested in buying a car – the type, price range, specific characteristics. Once the data is at hand, the entire dealership infrastructure sets its wheels in motion to make things happen for the client. Why would this be? Its existence is premised on letting the market do the managing: all of the fulfilment apparatus fires up when these human tendrils dressed as sales agents spread and latch to the market to gather as much data as possible. The business is actually a data-gathering facility. It doesn’t just respond to emotionless data. It interacts with living data. There are cars on display. There are human agents to intercept data about feelings, desires, and expectations.
I return to my community policing example in conclusion. I said that some people might think of this program as an exercise in public relations. I certainly can’t argue against the general gist that “interaction is good.” Specially trained officers who can speak several languages and who might themselves reflect the ethnicity of the neighbourhood will be placed in high risk communities. Their mission is – or at least it should be – to gather living data to help make the service apparatus operate more effectively. Whether or not somebody whose role is to “police” a neighbourhood – normally involving the conveyance of authority from the top to bottom – can in certain respects learn to operate in reverse – enriching the system with data – is a big question. I certainly have my doubts of the ability of the feedback mechanism to deliver data in an actionable manner. Also unclear is the extent to which the system receiving the data is willing to shift the ontological placement or perspective of metrics so that resources are more closely aligned with the needs of the community – rather than some kind of alien management regime. Certainly when an organization has been operating for decades with clients – and yet it seems to lack the intellectual capital to serve them – this is a sign of deep and systemic disassociation. It doesn’t matter if the organization is a police department or mega-corporation. Displacement from the market has severe consequences.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Reactive, distributed applications must decide how to handle uncertainty regarding the delivery of messages, including multiple delivery and out-of-order delivery.
- Domain-Driven Design can aid with managing uncertainty through the use of good modeling.
- Rules for handling uncertainty must be defined in business logic that domain experts have agreed to, not buried in a technical implementation.
- The implementation of a message de-duplicator or re-sequencer may initially sound straightforward, but gets unwieldy when operating at real-world scale.
- When the rules have been defined using ubiquitous language, the implementation can be very simple and still robust.
Domain-Driven Design is the way I think software should be developed. It’s been a bit of an uphill climb from Evan’s original publication of Domain-Driven Design, Tackling Complexity in the Heart of Software, and we’ve come a long way since. Now there are actually conferences on Domain-Driven Design, and I see a lot of growing interest, including business people getting involved, which is really key.
Reactive is a big thing these days, and I’ll explain later why it’s gaining a lot of traction. What I think is really interesting is that the way DDD was used or implemented, say back in 2003, is quite different from the way that we use DDD today. If you’ve read my red book, Implementing Domain-Driven Design, you’re probably familiar with the fact that the bounded contexts that I model in the book are separate processes, with separate deployments. Whereas, in Evan’s blue book, bounded contexts were separated logically, but sometimes deployed in the same deployment unit, perhaps in a web server or an application server. In our modern day use of DDD, I’m seeing more people adopting DDD because it aligns with having separate deployments, such as in microservices.
One thing to keep clear is that the essence of Domain-Driven Design is really still what it always was — It’s modeling a ubiquitous language in a bounded context. So, what is a bounded context? Basically, the idea behind bounded context is to put a clear delineation between one model and another model. This delineation and boundary that’s put around a domain model, makes the model that is inside the boundary very explicit with very clear meaning as to the concepts, the elements of the model, and the way that the team, including domain experts, think about the model.
You’ll find a ubiquitous language that is spoken by the team and that is modeled in software by the team. In scenarios and discussions where somebody says, for example, “product,” they know in that context exactly what product means. In another context, product can have a different meaning, one that was defined by another team. The product may share identities across bounded contexts, but, generally speaking, the product in another context has at least a slightly different meaning, and possibly even a vastly different meaning.
We’re making an effort with DDD to recognize that there is no practical way to have a canonical, enterprise data model where every single element in the model is representative of how every team in the enterprise would want to use it. It just doesn’t happen. There’s always some difference, and many times there are many differences that make it very painful for one team to try to use the model that another team has created. That’s why we’re focused on the bounded context with a ubiquitous language.
Once you understand that there is one, very definite definition for an entity, in one team situation, with one ubiquitous language, then you realize that there are other models, developed by other teams. Perhaps even the same team developing this model could be responsible for other models. You have a situation where you have multiple bounded contexts because, naturally, we cannot define every meaning in a single enterprise, or within a single system, for every single concept that we’re going to use.
Given that we have multiple contexts and multiple languages, we have to collaborate and integrate between them. To do that, we use a technique called context mapping or a tool called a context map.
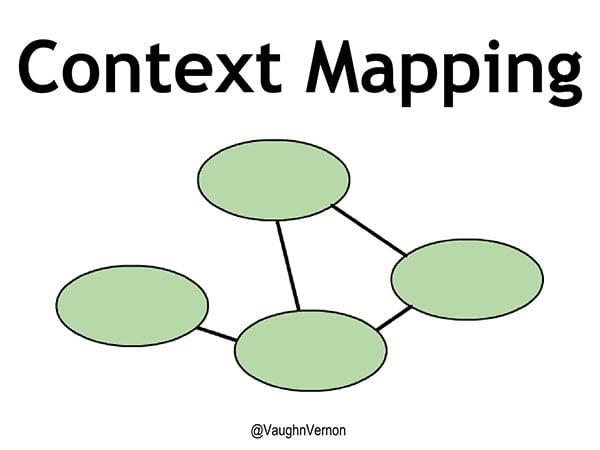
Figure 1 – Context Mapping
In this simple diagram, the lines between the bounded contexts are contextual mappings, and could appropriately be called a translation. If one of the bounded contexts speaks one language, and a connected context speaks a different language, what do you need to have between languages so that you can understand one model to another? A translation. Typically, we will try to translate between models to keep each separate model pure and clean.
When creating your context map, don’t confuse yourself or place limits on what the line means. While it can cover the technical integration, style or technique, it’s very important to define the team relationship between contexts. Whether I’m using RPC or REST isn’t important. Who I am integrating with is more important than how I am integrating.
It’s very important to define the team relationship between contexts. Who I am integrating with is more important than how I am integrating.
There are various context mapping tools for different types of relationships, including partnership, customer-supplier, or conformist relationships. In a partnership relationship, one team will know a lot about the model on another team. A customer-supplier relationship features an anti-corruption layer between two very separate models, one upstream and one downstream. We will anti-corrupt the upstream model as it’s being consumed by the downstream model. If the downstream model needs to send something back to the upstream, then it will translate it back to the upstream model so that data can be consistently and reliably exchanged, with clear meaning.
The strategic design that I’ve described so far is really the essence of, and therefore the most important part, of Domain-Driven Design.
In some cases, we will decide to model a particular ubiquitous language in a very careful, even fine-grained way. If you think of strategic design as painting with broad brush strokes, then think of tactical design as using a fine brush to fill in all the details.
General Guidance on DDD Modeling
Based on my observations of conference presentations that mention DDD, and my time working with teams, I’ve been able to identify a few little tips to help with modeling. These aren’t meant to call out any specific actions as wrong. Rather, I hope to provide some guidance to nudge you in the right direction.
One thing that we have to remember about DDD when we’re modeling, especially tactically, is we need help from domain experts — It shouldn’t just be programmers. We have to limit our use of their time, because the people who play the role of a domain expert on a team will be very busy with other matters relating to the business. Therefore, we have to make the experience very rewarding for them.
Another thing we want to do is avoid the anemic domain model. Whenever you see a presentation about a domain model that includes annotations that will automatically create the getters and setters, Equals(), GetHashCode(), etc., think seriously about running away from that. If our domain models were only about data, then that might be a perfect solution. However, there are some questions we need to ask. How does the data come about? How do we actually get data into our domain model? Is it being expressed according to the mental model of the business and any domain expert who’s working with us? Getters and setters do not give you an explicit indication of what the model means — it’s only moving data around. If you’re thinking in tactical DDD, then you have to think getters and setters are ultimately the enemy, because what you really want to model are behaviors that express the way that the business considers how work should get done.
When modeling, be explicit. For example, say you saw the business identity of an entity or an aggregate being called a UUID. There’s nothing wrong with using a UUID as a business identifier, but why not wrap that in an ID type that is strongly typed? Consider that another bounded context that is not using Java may not understand what a UUID is. You will most likely have to generate a UUID ToString(), and then hold that string in another type, or translate that string from the type when you’re sending out events between bounded contexts.
Instead of using BigDecimal directly, why not think about a value object called Money. If you’ve used BigDecimal, you know that identifying the rounding factor is a common difficulty. If we let BigDecimal slip in all over our model, then how do we round some amount of money? The solution is to use a Money type that standardizes on what the business says should be the rounding specification.
One other little tip is to not worry about what persistence mechanism is used, or what messaging mechanism is used. Use what meets your specific service level agreements. Be reasonable about the throughput and performance you need, and don’t complicate things. DDD is not really talking about technology so much as it is in need of using technology.
Reactive Systems
I have been seeing, at least in my world, a trend towards reactive systems. Not just reactive within a microservice, but building entire systems that are reactive. In DDD, reactive behavior is also happening within the bounded context. Being reactive isn’t entirely new, and Eric Evans was far ahead of the industry when he introduced eventing. Using domain events means we have to react to events that happened in the past, and bring our system into harmony.
If you were to visualize all the connections at different layers of a system, you’ll see patterns that repeat themselves. Whether you’re looking at the entire internet, or all the applications at an enterprise level, or individual actors or asynchronous components within a microservice, every layer has a lot of connections and associated complexity. That gives us a lot of very interesting problems to solve. I want to emphasize that we shouldn’t solve those problems with technology, but model them. If we are developing microservices in the cloud as a means to form a business, then distributed computing is part of the business that we’re working in. Not that distributed computing makes our business (in some cases, it does), but we are definitely solving problems with distributed computing. Therefore, make the distributed computing aspects explicit by modeling them.
I need to take a minute to address what some developers use as an argument against asynchrony, parallelism, concurrency, or any technique that either gives the impression of, or actually facilitates, multiple actions happening at once. Donald Knuth is often quoted as saying, “Premature optimization is the root of all evil.” But that’s just the end of his expression. He really said, “We should forget about small efficiencies… premature optimization is the root of all evil.” Said another way, if we have big bottlenecks in our system, we should address those. We can address those with reactive.
Donald Knuth also said something else very interesting: “People who are more than casually interested in computers should have at least some idea of what the underlying hardware is like. Otherwise, the programs they write will be pretty weird.” He’s simply saying we need to take advantage of the hardware we have today by how we write our software.
If we go back to 1973 and look at the way processors were being manufactured, there were very few transistors, and the clock speed was below 1MHz. Moore’s Law said we’d see the doubling of transistors and processor speed every couple of years. And yet, when we reached 2011, the clock speeds started to fall off. Today, what used to take a year and a half or two years to double clock speed, is now taking about ten years, if not longer. The number of transistors is continuing to increase, but the clock speeds aren’t. Today, what we have are cores. Instead of being faster, we have more cores. So what do we do with all these cores?
If you’ve been keeping up with Spring and the Reactor project, which uses reactive streams, this is essentially what we’re able to do now. We have a publisher, and a publisher is publishing something, let’s call them domain events, the little orange boxes in Figure 2. These events are being delivered to each of the subscribers on the stream.
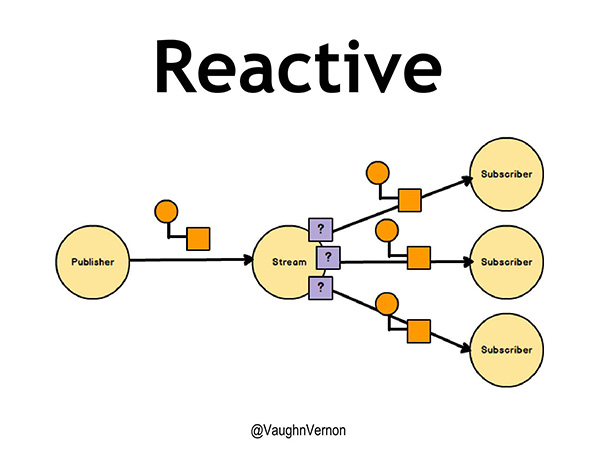
Figure 2 – Reactive
Notice the lilac boxes on the stream that have question marks on them. That is actually a policy. And that policy is between the stream and the subscriber. For example, a subscriber may have a limit on how many events or messages it can handle, and the policy specifies the limit for any given subscriber. What’s important is that separate threads are being used to run the publisher, the stream, and all three of the subscribers. If this is an intelligently implemented, large, complex component, then the threads are not being blocked at any point in time. Because if the threads are being blocked, then some other piece of the puzzle is starving for a thread. We have to make sure that the implementation underneath is also making good use of threads. This will become more important as we dive deeper into modeling uncertainty.
Within a microservice, we are reactive. But, when we look inside, there are all kinds of components that could be running concurrently, or in parallel. When an event is published inside one of those microservices, it’s ultimately being published outside the bounded context to some sort of topic, possibly using Kafka. To keep it simple, let’s say there’s just one topic. All the other microservices in our reactive system are consuming the events published on the topic, and they’re reactively doing something inside their microservice.
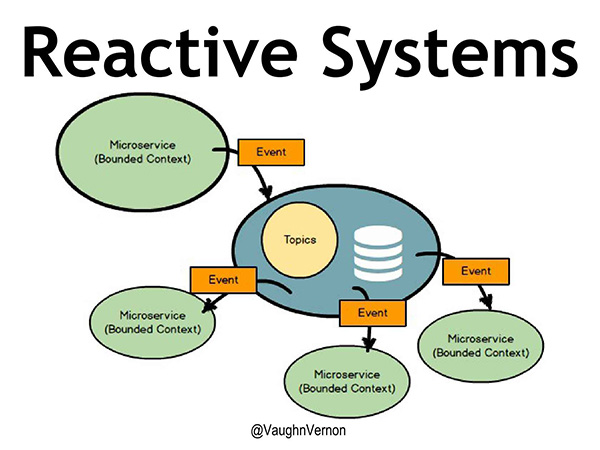
Figure 3 – Reactive Systems
Ultimately, this is where we want to be. When everything is happening asynchronously everywhere, what happens? That brings us to uncertainty.
Welcome Uncertainty
In an ideal situation, when we publish a series of events, we want those events to be delivered sequentially, and exactly once. Each subscriber will receive Event 1, followed by Event 2, followed by Event 3, and each event appears once and only once. Programmers have been taught to jealously guard this scenario because it makes us feel certain about what we are doing. And yet, in distributed computing, it just doesn’t happen.
With microservices and reactive comes uncertainty, starting with uncertainty about what order events might be delivered in, and if an event has been received more than once, or not at all. Even if you’re using a messaging system like Kafka, if you think you’re going to consume them in sequential order, you’re fooling yourself. If there is any possibility of any message being out of order, you have to plan for all of them being out of order.
If there is any possibility of any message being out of order, you have to plan for all of them being out of order.
I found a succinct definition for uncertainty: The state of being uncertain. Uncertainty being a state means we can deal with it, because we have ways of reasoning about the state of a system. Ultimately, we want to be in a state where we’re certain and can feel comfortable, even if that only lasts a millisecond. Uncertainty creeps up and it makes things unpredictable, unreliable, and risky. Uncertainty is uncomfortable.
Addiction
Most developers learned the “right way” to develop software that leads down a path of addiction. When you have two components that need to communicate with each other, it’s helpful to refer to one as the client and the other as the server. That doesn’t mean it has to be a remote client. The client is going to invoke a method, or call a function, on the server. While that invocation occurs, the client is just sitting there, waiting to receive a response from the server, or possibly an exception will be thrown. In any case, the client is certain that it will get control again. That certainty of execution flow is one type of addiction we have to deal with.
The second type of common addiction is an addiction to the ordering of things, with no duplicates. This is taught to us in school at a young age, when we learn to count, in order. It makes us feel good when we know the order in which things happened.
Another addiction is the locking database. If I have three nodes in my data source, when I write to one of those nodes, I believe I have a firm lock on the database. Which means that when I get back a success response, I believe that the data is persisted on all three nodes. But then you start using Cassandra, which doesn’t lock all the nodes, how do you query for a value that hasn’t propagated across the cluster, yet?
All of these things create an uncomfortable feeling in us, and we have to learn to deal with that. And yet, it’s okay to feel uncomfortable.
Defense Mechanisms
Because we’re addicted to certainty, blocking, and synchronization, developers tend to deal with the uncertainty by building a fortress. If you’re creating a microservice that is modeled as a bounded context, you design it so that everything within that context is blocking, synchronized, and non-duplicate. That’s where we build our fortress, so all the uncertainty exists outside our context, and we get to develop with certainty.
Starting at the infrastructure layer, we create a de-duplicator and a re-sequencer. These both come from Enterprise Integration Patterns.
De-Duplicator
If events 1, 2, 1, and 3 come in, when they pass through the de-duplicator, we’re certain that we only have events 1, 2, and 3. That doesn’t seem too difficult a problem to solve, but think about the implementation. We’ll probably have some caching enabled, but we can’t store infinite events in memory. This means having some database table to store the event ID, to allow checking every incoming event to know if it’s been seen before.
If an event hasn’t been seen before, pass it along. If it has been seen it before, then it can be ignored, right? Well, why has it been seen before? Is it because we didn’t acknowledge receiving it? If so, should we acknowledge that we’ve received it again? How long do we keep those IDs around to say we’ve seen the event? Is a week enough? How about a month?
Talk about uncertainty. Trying to solve this by throwing technology at it can be very difficult.
Re-Sequencer
For an example of re-sequencing, imagine we see event 3, then event 1, then event 4. For whatever reason, event 2 just hangs out for a really long time. We first have to find a way to re-order events 1, 3, and 4. If event 2 hasn’t arrived, have we effectively shut down our system? We may allow event 1 through, but we could have some rule that says to not process event 1 until event 2 arrives. Once event 2 arrives, then we can safely let all four events into the application.
With any implementation you choose, all of these things are hard. There is uncertainty.
The worst part is we haven’t solved any business problems, yet. We’re just solving technology problems. But, if we acknowledge that distributed computing is part of our business now, then we can solve these problems in the model.
We want to say, “Stop everything. Okay, I’m ready now.” But there is no “now.” If you think your business model is consistent, it may only be consistent for a nanosecond, and then it’s inconsistent again.
A good example of this is a Java call to LocalTime.now(), which is simply not true. As soon as you call into it, it’s no longer now. When you get a response back, it’s no longer now.
Uncertainty of Distributed Systems
This all brings us back to the fact that distributed systems are all about uncertainty. And distributed systems are here to stay. If you don’t like it, change careers. Maybe open a restaurant. However, you’ll still be dealing with distributed systems, you just won’t be writing them.
Modeling uncertainty matters. It matters because multiple cores are here to stay. It matters because the cloud is here to stay.
Microservices matter, because it’s the way everyone is going. Most people approach me about learning Domain-Driven Design because they see it as a great way to implement microservices. I agree with that. Also, people and companies want out of the monolith. They’re stuck in the mud, and it takes months to get a release out.
Latency matters. When you have a network as part of your distributed system, latency matters.
IoT matters. Lots of little, cheap devices, all talking over the network.
DDD and Modeling
What I refer to as Good Design, Bad Design, and Effective Design.
You can completely design software well, and yet miss what the business needs. Take SOLID, for example. You can design 100 classes to be SOLID, and completely miss what the business wants. Alan Kay, the inventor of OO and Smalltalk, said the really important thing about objects was the messages sent between them.
Ma, a Japanese word that means “the space between.” In this case, the space between the objects. The objects need to be designed well enough so they are able to play their single, responsible role. But it’s not just about the insides of the objects. We need to care about the names of the objects and the messages that we send between them. That is where the expressiveness of the ubiquitous language comes in. If you are able to capture that in your model, that is what makes your model effective, not just good, because you will be meeting the needs of the business. That is what Domain-Driven Design is about.
We want to develop reactive systems. We’re going to deal with the fact that uncertainty is a state. We’re going to start solving some problems.
In his paper, Life Beyond Distributed Transactions, an Apostate’s Opinion, Pat Helland wrote, “In a system that cannot count on distributed transactions, the management of uncertainty must be implemented in the business logic.” This realization came after a long history of implementing distributed transactions. However, while working at Amazon, he determined that the scale they needed could not be achieved by using distributed transactions.
In the paper, Helland talks about activities. An activity between two partner entities occurs when one entity has a state change and raises an event describing that change, and the second entity eventually, hopefully, it receives that message. But when will it receive the message? What if it is never received? There are a lot of “what ifs” and Pat Helland says these “what if” should be handled by activities.
Between any two partners, each partner has to manage the activity that it has seen from its partner to itself. Figure 4 is how I interpret what Pat Helland meant by these.

Figure 4 – Activity
Every partner has a PartnerActivities object that represents the activities of one related entity we receive activities from. When we see some activity directed toward us, we can record that. Then, at some future time, I can ask, “have I seen this partner activity?” This handles both the case where I’m dependent on that activity having occurred, or to check if I’m seeing it again.
This is fairly straightforward, but gets more complicated in a long-lived entity. Even Pat Helland says this can grow enormously. Any given long-lived entity, potentially with a lot of partners, can result in collecting huge entities, or what DDD would call an Aggregate, just to try and track the activities. Furthermore, this isn’t explicit — it doesn’t say a thing about the business itself.
I think we should go further than a PartnerActivity. The technique I’m proposing is to put this in the heart of the software, in the domain model. We eliminate those elements in the infrastructure layer (the de-duplicator and re-sequencer) and we let everything through as it happens. I believe this makes the system less complex.
In an explicit model, we listen to events and send commands that correspond to business actions. Our domain aggregates each contain the business logic for how to handle those commands, including how to respond to the uncertainty. The communication of events and commands is handled by a Process Manager, as depicted in Figure 5. While the diagram may look complex, it’s actually fairly straightforward to implement, and follows reactive patterns.
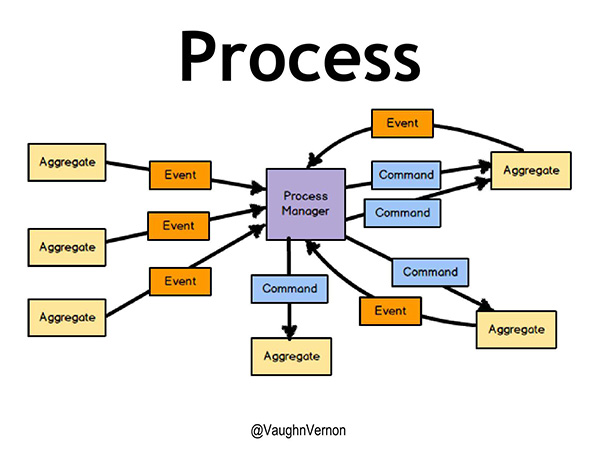
Figure 5 – Process Manager
Each domain entity is responsible for tracking its state, based on the commands it receives. By following good DDD practices, the state can be safely tracked based on these commands, and using event sourcing to persist the state change events.
Each entity is also responsible for knowing how to handle any potential uncertainty, according to decisions made by domain experts. For example, if a duplicate event is received, the aggregate will know that it has already seen it, and can decide how to respond. Figure 6 shows one way to handle this. When a deniedForPricing() command is received, we can check the current progress, and if we already have seen a PricingDenied event then we won’t emit a new domain event, and instead respond indicating that the denial was already seen.

Figure 6 – Handling Duplicate message
This example is almost underwhelming, but that’s intentional. It shows that treating uncertainty as part of our domain means we can use DDD practices to make it just another aspect of our business logic. And that really is the point of DDD; to help manage complexity, such as uncertainty, in the heart of our software.
About the Author
 Vaughn Vernon is author of Reactive Messaging Patterns with the Actor Model (2016) and Implementing Domain-Driven Design (2013). Vernon has taught his Implementing DDD Workshop around the globe to hundreds of software developers and speaks frequently at leasing industry conferences. He specializes in consulting on DDD, as well as DDD using the Actor model with Scala and Akka.
Vaughn Vernon is author of Reactive Messaging Patterns with the Actor Model (2016) and Implementing Domain-Driven Design (2013). Vernon has taught his Implementing DDD Workshop around the globe to hundreds of software developers and speaks frequently at leasing industry conferences. He specializes in consulting on DDD, as well as DDD using the Actor model with Scala and Akka.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
This question was recently posted on Quora: What is a full stack data scientist? Below is my answer.
Most answers focus on the technical skills a full stack data scientist should have. This is only the tip of the iceberg. Put it differently, a full stack data scientist is also able to start a company, any company, from the ground-up, and leverage analytics in all aspects that make a business succeed. It requires the ability to run a business, hire people, automate, find the tools, and outsource as needed to optimize business performance and client satisfaction. A full stack data scientist might not even spend time coding or have a degree in data science. You may as well call it an executive data scientist.

Among the qualities needed to qualify:
- Strong business acumen and domain expertise in several fields.
- Ability to leverage competitive, internal, external, marketing, sales, advertising, web , accounting, financial and various other sources of data, find the data and get it integrated, design the success metrics and get them tracked, and make decisions based on sound predictive models (with a zest of vision and intuition) to successfully operate any company, working with engineers, sales, finance and any other team.
- Negotiation skills. Ability to raise money, internal or external, by providing convincing analytic arguments.
- A PhD may help (or hurt in some cases!) but is not required.
A full stack data scientist (I prefer the word executive data scientist) is unlikely to get hired by any company. This is not the role hiring managers are looking for. Instead hiring managers call them unicorns and believe they don’t exist. In reality, they come from various fields, are not interested in working for a boss who will only allow them to produce code (but instead love to work with equal partners) and will compete with your company instead of becoming an employee — a role that is not suited for them anyway.
I hope this dispels the myth of the unicorn data scientist. Yes they exist in large numbers, but you won’t find them on LinkedIn if you are hunting for talent, and most — the successful ones at least — make more money and have a more exciting career than corporations can offer. In short, you are burying your head in the sand if you think they don’t exist, in the meanwhile they are eating your lunch, they are very lean (call it agile) and efficient. One of their skills is to create and market products that automate a bunch of tasks, replacing lawyers, doctors, astronauts and many others, by robots.
Some also succeed by arbitraging systems (stock market, sport bets, click arbitraging on advertising platforms) and have no employee, no client, no boss, no salary, yet make a great income working from home. Once in a while, a full stack data scientist will accept an interview with your company, not to get the job, but solely to gain competitive intelligence and leverage the information learned during the interview, for instance to trade your company on the stock market. These data hackers know and play with data and numbers better than everyone else. They are very quick to find and identify information pipelines that can be turned in an opportunity. They also can play with various data sources and business models, and combine them to produce value. They shoot at targets that no one can see.
For related articles from the same author, click here or visit www.VincentGranville.com. Follow me on on LinkedIn, or visit my old web page here.
DSC Resources
- Invitation to Join Data Science Central
- Free Book: Applied Stochastic Processes
- Comprehensive Repository of Data Science and ML Resources
- Advanced Machine Learning with Basic Excel
- Difference between ML, Data Science, AI, Deep Learning, and Statistics
- Selected Business Analytics, Data Science and ML articles
- Hire a Data Scientist | Search DSC | Classifieds | Find a Job
- Post a Blog | Forum Questions
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Here I am writing my first post, I posponed it for a long time… In this article I would like to share my experience installing and testing basic Apache Kafka features. If you are new in the Big Data ecosystem let me give you some short concepts.
Kafka is a distributed streaming platform which means is intended for publish and subscribe to streams of records, similar to a message queue or enterprise messaging system [1]
Kafka has four core APIs but in this post I will test 2 of them:
- The Producer API allows an application to publish a stream of records to one or more Kafka topics. [2]
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them. [3]
Another important concept necessary for this article is Topic. A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it. [4]
[Kafka schema] 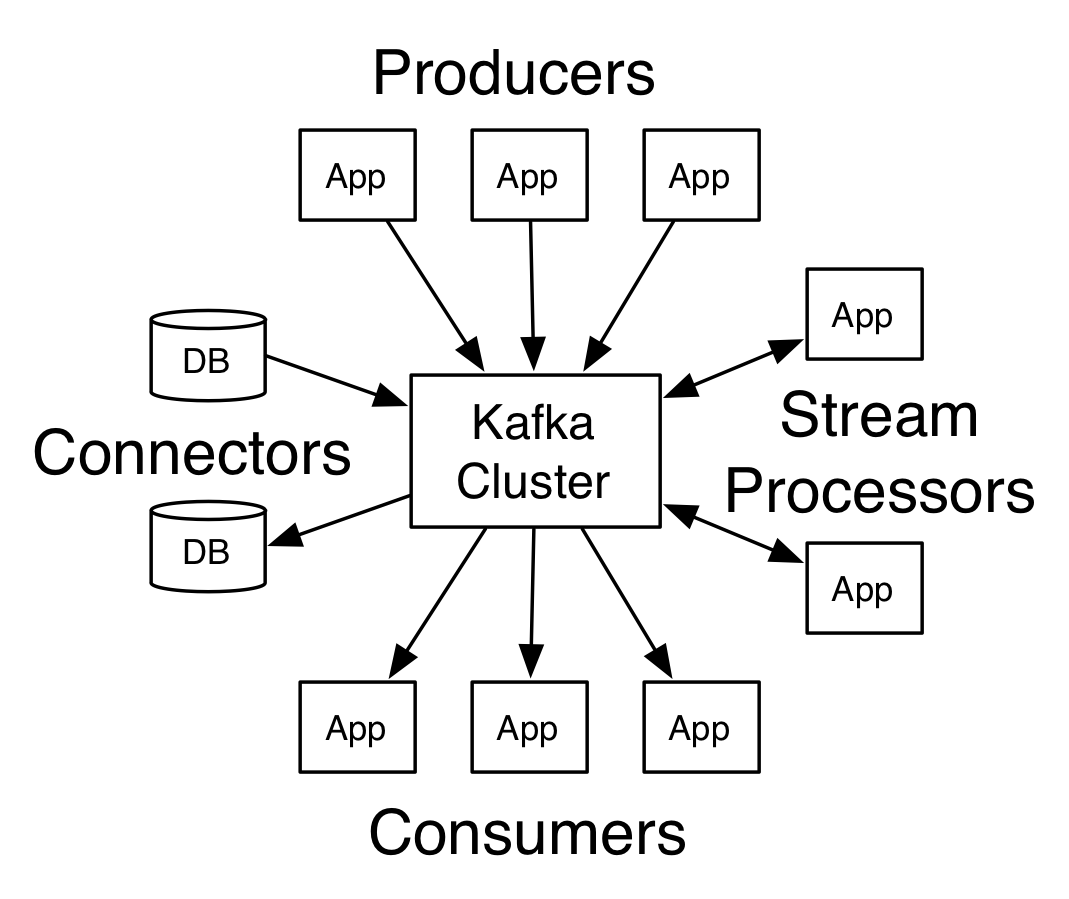
After this brief introduction we can start the tutorial.
1. Google Cloud account: create a google cloud account is free and you will get $300 of credit to try any of their products for one year.
[Google Cloud account]

2. Creating a project : a project is necessary to create the VM
[Image Creating a project]

3. Creating VM instance : in this occasion I used Debian OS and the default parameters, then we need to connect using the web SSH.
[Creating VM instante 1]

[Creating VM instante 2]

[Starting SSH]

4. Installing Java 8
sudo apt-get install software-properties-common
sudo add-apt-repository “deb http://ppa.launchpad.net/webupd8team/java/ubuntu xenial main”
sudo apt-get update
sudo apt-get install oracle-java8-installer
javac -version
[Oracle will prompt some terms and conditions to install ]

5. Installing and starting Zookeeper
wget http://www-eu.apache.org/dist/zookeeper/zookeeper-3.4.10/zookeeper-3.4.10.tar.gz
tar -zxf zookeeper-3.4.10.tar.gz
sudo mv zookeeper-3.4.10 /usr/local/zookeeper
sudo mkdir -p /var/lib/zookeeper
cat > /usr/local/zookeeper/conf/zoo.cfg << EOF
> tickTime=2000
> dataDir=/var/lib/zookeeper
> clientPort=2181
> EOF
export JAVA_HOME=/usr/java/jdk1.8.0_181
sudo /usr/local/zookeeper/bin/zkServer.sh start
[Installing]

[Starting]

6. Installing and starting Kafka
wget http://www-eu.apache.org/dist/kafka/2.0.0/kafka_2.12-2.0.0.tgz
tar -zxf kafka_2.12-2.0.0.tgz
sudo mv kafka_2.12-2.0.0 /usr/local/kafka
sudo mkdir /tmp/kafka-logs
export JAVA_HOME=/usr/java/jdk1.8.0_181
sudo /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
[Installing]

7. Creating a topic
sudo /usr/local/kafka/bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic llamada

8. Verifying a topic
sudo /usr/local/kafka/bin/kafka-topics.sh –zookeeper localhost:2181 –describe –topic llamada

9. Producing a message (ctrl+c to end producing messages)
sudo /usr/local/kafka/bin/kafka-console-producer.sh –broker-list localhost:9092 –topic llamada
>hello kafka
>second message

10. Consuming messages
sudo /usr/local/kafka/bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic llamada –from-beginning

11. Listing topics
sudo /usr/local/kafka/bin/kafka-topics.sh –list –zookeeper localhost:2181

12. Getting details about a topic
sudo /usr/local/kafka/bin/kafka-topics.sh –zookeeper localhost:2181 –describe –topic llamada

*If you get error about replication factor, please try starting Kafka
sudo /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
Finally I encourage to check the web https://kafka.apache.org/ there you will find excellent information about other Kafka’s capabilities to go further. Also I recommend you to read Kafka: The Definitive Guide by Neha Narkhede; Gwen Shapira; Todd Palino.
See you in the next article!
[1] https://kafka.apache.org/intro
[2] https://kafka.apache.org/documentation.html#producerapi
[3] https://kafka.apache.org/documentation.html#consumerapi
[4] https://kafka.apache.org/intro#intro_topics
[5] https://www.safaribooksonline.com/library/view/kafka-the-definitive/9781491936153/ch11.html
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Welcome to this AI-themed edition of The Morning Paper Quarterly. I’ve selected five paper write-ups which first appeared on The Morning Paper blog over the last year. To kick things off we’re going all the way back to 1950! Alan Turing’s paper on “Computing Machinery and intelligence” is a true classic that gave us the Turing test, but also so much more. Here Turing puts forward the idea that instead of directly building a computer with the sophistication of a human adult mind, we should break the problem down into two parts: building a simpler child program, with the capability to learn, and building an education process through which the child program can be taught. Writing almost 70 years ago, Turing expresses the hope that machines will eventually compete with men in all purely intellectual fields. But where should we start? “Many people think that a very abstract activity, like the playing of chess, would be best.”
That leads us to my second choice, “Mastering chess and shogi by self-play with a general reinforcement learning algorithm.” We achieved super-human performance in chess a long time ago of course, and all the excitement transferred to developing a computer program which could play world-class Go. Once AlphaGo had done it’s thing though, the Deep Mind team turned their attention back to chess and let the generic reinforcement learning algorithm developed for Go try to teach itself chess. The results are astonishing: with no provided opening book, no endgame database, no chess specific tactical knowledge or expert rules – just the basic rules of the game and a lot of self-play – AlphaZero learns to outperform Stockfish in four hours elapsed of training time.
Of course chess (and Go) are very constrained problems. When we take deep learning into the noisy, messy, real world things get harder. In “Deep learning scaling is predictable, empirically,” a team from Baidu ask “how can we improve the state of the art in deep learning?” One of the major levers that we have is to feed in more data by creating larger training data sets. But what’s the relationship between model performance and training data set size? Will an investment in creating more data pay off in increased accuracy? How much? Should we spend our efforts building better models that consume the existing data we have instead? The authors show that beyond a certain point training data set size and generalization error are connected by a power-law. The results suggest that we should first search for ‘model-problem fit’ and then scale out our data sets.
Another critical question for systems deployed in the real world is how we can have confidence they will work as expected across a wide range of inputs. In “DeepTest: automated testing of deep-neural-network-driven autonomous cars,” Tian et al. consider how to test an autonomous driving system. The approaches they use could easily be applied to testing other kinds of DNNs as well. We’re all familiar with the concept of code coverage, but how is your neuron coverage looking?
My final choice for this issue is “Deep code search.” It’s a great example of learning joint-embeddings mapping associations between two different domains. In this case, natural language descriptions, and snippets of code. The result is a code search engine that I’m sure InfoQ readers will relate to. It let’s you ask questions such as “where (in this codebase) are events queued on a thread?” and be shown candidate code snippets as results.
Free download
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
In the panel discussion at the recent Event-Driven Microservices Conference in Amsterdam, Frans van Buul from AxonIQ, the conference organizer, started by noting that if you look at a popularity graph, the adoption of microservices really took off at June 2014, and since then it has increased substantially. Since microservices are quite mainstream today, he asked the panel to look back at what we have learned, but to also think about where we will be heading in the next couple of years.
The panel consisted of Michael Kazarian, Promontech, Prem Chandrasekaran, Barclays, Bert Jan Schrijver, Open Value, Allard Buijze, AxonIQ and David Caron, Pivotal. Van Buul’s first question was why we should use microservices.
- For Schrijver, it’s all about scalability. In terms of teams it’s the ability to work with multiple teams on one product. In terms of operations it’s the ability to independently scale different parts of a system. He thinks that if you build a microservices system the right way you can have almost unlimited horizontal scalability.
- Buijze pointed out that technically it doesn’t matter whether we work with monoliths or microservices; in theory you can scale out a monolith just as well as microservices. What microservices gives us is a strong and explicit boundary to every service. Although the architects draw limits for communication between components, we as developers are good at ignoring them. If it’s technically possible to directly communicate with another component we will do that, ignoring any rules the architects have set up. Keeping those boundaries intact is much easier when they are explicit and even more so if a component is managed by another team.
- Kazarian and his company started with microservices about three years ago. Their goal was to start by focusing on building business capabilities in their core domain. He believes microservices help him define where a feature should be implemented and help the teams to keep the boundaries.
- Chandrasekaran agreed that the boundaries are more explicit, which makes it much harder to abuse what doesn’t belong to you. He pointed out that the hardware advances have made microservices possible and that the infrastructure provided by all the cloud providers has simplified a lot. All of this together is for him a compelling story, but he points out that there still are problems to be solved.
- For Caron, a key factor for success is if you are going in strategically as a company or not. If you set up some form of innovation lab to let some of your best developers try microservices, you will not benefit. Also, if you are not willing to invest in the culture change needed and focus on delivery of value, then you will have a hard time achieving the benefits available.
A question van Buul sometimes struggles with, is why we were doing SOA with small service for 10 years, but suddenly found out that it was really bad, and that now we should be doing microservices. Why is that?
- Allard claimed that SOA and microservices are essentially the same idea. What went wrong with SOA was in marketing and adoption, when the big vendors started to sell big SOA suites with the aim of making money. He also believed that the Netflix architecture in some respect influenced the move to microservices with their new technologies. Another important difference is that the infrastructure we have today is much more up to par to help us deliver small components in a simpler way.
- Chandrasekaran was cautiously optimistic, but noted that microservices are still work in progress. We mostly hear the successful stories, but he is sure people have experienced tons of problems. He doesn’t think we yet have enough proof to say that microservices makes us move faster.
Van Buul then asked about the prerequisites for doing microservices: what kind of skills and organization do you need?
- For Chandrasekaran it’s about automation; how fast can you deliver a business idea to production, gather feedback, enhance it and deploy again? The only way to do this repeatedly and reliably is through high levels of automation in the whole continuous delivery process. He also noted that development takes very little time, both for monoliths and microservices, it’s the things after, like security, that take time.
- Kazarian comes from a big bank and they don’t have all the automation skills. For him a challenge is how to help his developers write the right code in the right area with the benefits that come with that, like isolation and testability. What microservices give him is a path that allows him to start splitting his monolithic deployment into numerous independent deployments. He also claims that microservices are not a one-size-fits all; the right size differs between companies.
In his last question, van Buul looked into the future. What is missing, what will we be talking about next year?
- Shrivjer believed we need services that can help in creating new services, without having to worry about infrastructure. As a developer he wants to deploy a service, nothing else.
- Chandrasekaran believed interservice testing without the entire eco system present will get a lot more support. He notes that it’s probably fashionable to say we are going to deploy functions, but he thinks there are still problems to be solved, like latency.
- Kazarian was looking for operational efficiency that gets the code that aligns with what the business is asking for done quicker and with higher quality. For him it’s about simplifying the complexity around infrastructure. His engineers should be DDD specialists in the domain, but instead they are struggling with infrastructure.
Finallz, Buijze noted that AxonIQ is focused on simplifying at the application level to allow developers to focus on business capabilities. The most difficult part is the people; how you actually build the right thing, making software development more of a people thing since the technology will be there.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
After officially delivering Swift 4.2, the Swift team is now focusing on Swift 5 by kicking off the final phase of its release process. Planned to be released early 2019, Swift 5 aims to bring ABI stability to the language while preserving source compatibility.
ABI stability can be roughly understood as “binary compatibility” across Swift versions. ABI stability would enable linking a framework into a program irrespective of which compiler versions were used to compile them, provided both compilers produce code conforming to the upcoming Swift ABI. This is a crucial feature for third party framework developers as well as to broaden Swift adoption inside of Apple. ABI stability was originally planned for Swift 3, but then got delayed due to the large amount of new language features that were in the workings.
As noted, ABI stability does not include what Apple is calling module stability, which can be described as interface to libraries being forward-compatible with future compiler versions. In other words, while ABI stability affects the linkability of a framework into a program at runtime, module stability concerns the possibility of using a library built with a previous compiler version (e.g., Swift 5) when building a program using a newer compiler (e.g., Swift 6). Module stability is surely desirable to have, since it can make developers life easier on a number of accounts, but is not critical. It is not yet clear whether Module stability will make it into Swift 5 or not.
Swift 5 will also include a number of new language features, some of which have already been implemented, so there are no doubts about them making into the release. Those include, among others:
- Identity key path, which provides a way to reference the entire value a key path is applied to using the
selfpseudo-property. count(where:), which adds the possibility to count the number of elements in aSequencethat satisfy a boolean expression.- Raw string delimiters, which allow developers to include any characters that would otherwise require escaping in a string delimited through
"""as opposed to using simple quotes (").
Other features that are still under development include flattening nested optionals from try?, simd vectors, user-defined dynamically "callable" types, and more.
All new language features will not break source compatibility, meaning that the majority of sources compatible with the Swift 4.2 compiler should compile with the Swift 5.0 compiler. Swift versions previous to 4.2 will not be source compatible, though, and should be upgraded at least to Swift 4.2. The development team will regularly post downloadable snapshots of intermediate releases towards 5.0.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
In this tutorial, we are going to use the K-Nearest Neighbors (KNN) algorithm to solve a classification problem. Firstly, what exactly do we mean by classification?
Classification across a variable means that results are categorised into a particular group. e.g. classifying a fruit as either an apple or an orange.
The KNN algorithm is one the most basic, yet most commonly used algorithms for solving classification problems. KNN works by seeking to minimize the distance between the test and training observations, so as to achieve a high classification accuracy.
As we dive deeper into our case study, you will see exactly how this works. First of all, let’s take a look at the specific case study that we will analyse using KNN.
Our case study
In this particular instance, the KNN is used to classify consumers according to their internet usage. Certain consumers will use more data (in megabytes) than others, and certain factors will have an influence on the level of usage. For simplicity, let’s set this up as a classifiction problem.
Our dependent variable (usage per week in megabytes) is expressed as a 1 if the person’s usage exceeds 15000mb per week, and 0 if it does not. Therefore, we are splitting consumers into two separate groups based on their usage (1= heavy users, 0 = light users).
The independent variables (or the variables that are hypothesised to directly influence usage – the dependent variable) are as follows:
- Income per month
- Hours of video per week
- Webpages accessed per week
- Gender (0 = Female, 1 = Male)
- Age
To clarify:
- Dependent variable: A variable that is influenced by other variables. In this case, data usage is being influenced by other factors.
- Independent variable: A variable that influences another variable. For instance, the more hours of video a person watches per week, the more this will increase the amount of data consumed.
Load libraries
Firstly, let’s open up a Python environment and load the following libraries:
import numpy as np
import statsmodels.api as sm
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
import mglearn
import os;
As we go through the tutorial, the uses for the above libraries will become evident.
Note that I used Python 3.6.5 at the time of writing this tutorial. As an example, if one wanted to install the mglearn library, it can accordingly be installed with the pip command as follows:
pip3 install mglearn
Load data and define variables
Before we dive into the analysis itself, we will first:
1. Load the CSV file into the Python environment using the os and pandas libraries
2. Stack the independent variables with numpy and statsmodels
Firstly, the file path where the CSV is located is set. The dataset itself can be found here, titled internetlogit.csv.
path="/home/michaeljgrogan/Documents/a_documents/computing/data science/datasets"
os.chdir(path)
os.getcwd()
Then, we are loading in the CSV file using pandas (or pd – which represents the short notation that we specified upon importing):
variables=pd.read_csv('internetlogit.csv')
usage=variables['usage']
income=variables['income']
videohours=variables['videohours']
webpages=variables['webpages']
gender=variables['gender']
age=variables['age']
Finally, we are defining our dependent variable (usage) as y, and our independent variables as x.
y=usage
x=np.column_stack((income,videohours,webpages,gender,age))
x=sm.add_constant(x,prepend=True)
MaxMinScaler and Train-Test Split
To further prepare the data for meaningful analysis with KNN, it is necessary to:
1. Scale the data between 0 and 1 using a max-min scaler in order for the KNN algorithm to interpret it properly. Failing to do this results in unscaled data given that our dependent variable is between 0 and 1, and the KNN may not necessarily give us accurate results. In other words, if our dependent variable is scaled between 0 and 1, then our independent variables also need to be scaled between 0 and 1.
2. Partition the data into training and test data. In this instance, 80% of the data is apportioned to the training segment, while 20% is apportioned to the test segment. Specifically, the KNN model will be built with the training data, and the results will then be validated against the test data to gauge classification accuracy.
x_scaled = MinMaxScaler().fit_transform(x)
x_train, x_test, y_train, y_test = train_test_split(x_scaled, y, test_size=0.2)
Now, our data has been split and the independent variables have been scaled appropriately.
To get a closer look at our scaled variables, let’s view the x_scaled variable as a pandas dataframe.
pd.DataFrame(x_scaled)
You can see that all of our variables are now on a scale between 0 and 1, allowing for a meaningful comparison with the dependent variable.
0 1 2 3 4 5
0 0.0 0.501750 0.001364 0.023404 0.0 0.414634
1 0.0 0.853250 0.189259 0.041489 0.0 0.341463
2 0.0 0.114500 0.000000 0.012766 1.0 0.658537
.. ... ... ... ... ... ...
963 0.0 0.106500 0.061265 0.014894 0.0 0.073171
964 0.0 0.926167 0.033951 0.018085 1.0 0.926829
965 0.0 0.975917 0.222488 0.010638 1.0 0.634146
Classification with KNN
Now that we have loaded and prepared our data, we are now ready to run the KNN itself! Specifically, we will see how the accuracy rate varies as we manipulate the number of nearest neighbors.
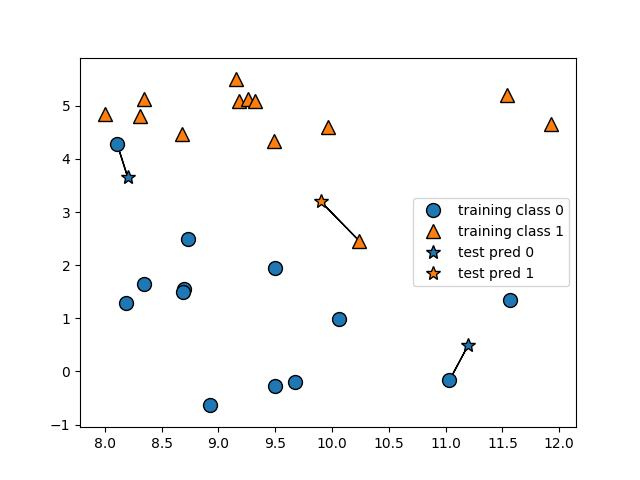
n_neighbors = 1
Firstly, we will run with 1 nearest neighbor (where n_neighbors = 1) and obtain a training and test set score:
print (x_train.shape, y_train.shape)
print (x_test.shape, y_test.shape)
knn = KNeighborsClassifier(n_neighbors=1)
model=knn.fit(x_train, y_train)
model
print("Training set score: {:.2f}".format(knn.score(x_train, y_train)))
print("Test set score: {:.2f}".format(knn.score(x_test, y_test)))
We obtain the following output:
Training set score: 1.00
Test set score: 0.91
With a training set score of 1.00, this means that the predictions of the KNN model as validated on the training data shows 100% accuracy. The accuracy decreases slightly to 91% when the predictions of the KNN model are validated against the test set.
Moreover, we can now visualise this using mglearn:
mglearn.plots.plot_knn_classification(n_neighbors=1)
plt.show()
n_neighbors = 5
Now, what happens if we decide to use 5 nearest neighbors? Let’s find out!
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train, y_train)
print("Training set score: {:.2f}".format(knn.score(x_train, y_train)))
print("Test set score: {:.2f}".format(knn.score(x_test, y_test)))
We now obtain a higher test set score of 0.94, with a slightly lower training set score of 0.95:
Training set score: 0.95
Test set score: 0.94
When we analyze this visually, we see that we now have 5 nearest neighbors for each test prediction instead of 1:
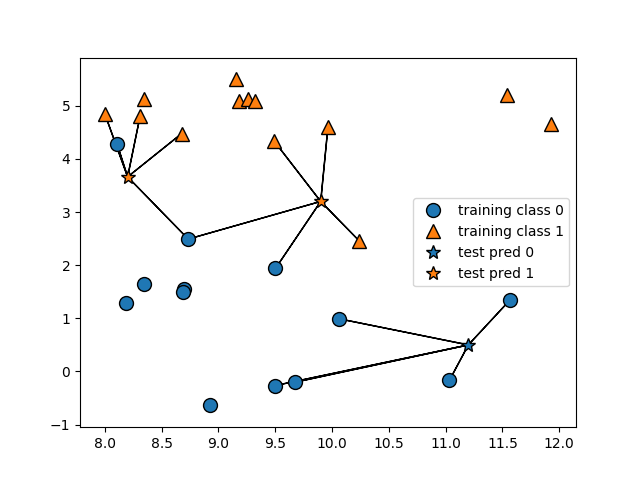
In this instance, we see that increasing the number of nearest neighbors increased the accuracy rate against our test data.
Cross Validation
One important caveat to note.
Given that we have used the train-test split method, there is always the danger that the split data is not random. i.e. the test data may be overly similar to the training data. This would mean that while the KNN model would demonstrate a high degree of accuracy on the training data, this would not necessarily be the case if new data was introduced outright.
In our case, given that the test set score is not that much lower than the training set score, this does not appear to be an issue here.
However, what method could we use to guard against this issue? The most popular one is a method called cross validation.
How Does Cross Validation Work?
Essentially, this works by creating multiple train-test splits (called folds) with the training data. Specifically, the algorithm is trained on k-1 folds while the final fold is referred to as the “holdout fold”, meaning that the final fold is used as the test set.
Let’s see how this works. In this particular instance, cross validation is unlikely to be of use to us here, since both the training and test set score was quite high on our original train-test split.
However, there are many instances where this will not be the case, and cross validation therefore becomes an important tool in splitting and testing our data more effectively.
For this purpose, suppose that we wish to generate 7 separate cross validation scores. We will first import our cross validation parameters from sklearn:
from sklearn.cross_validation import cross_val_score, cross_val_predict
Then, we generate 7 separate cross validation scores based on our prior KNN model:
scores = cross_val_score(model, x_scaled, y, cv=7)
print ("Cross-validated scores:", scores)
Here, we can see that the cross-validated scores do not increase as we add to the number of folds.
Cross-validated scores: [0.96402878 0.85611511 0.89855072 0.93478261 0.94202899 0.89051095 0.91240876]
This is expected since we still got quite a high test set score on our original train-test split.
With this being said, cross validation is quite commonly used when there is a large disparity between the training and the test set score, and the technique is quite useful under these circumstances. In other words, if we had a high training and low test set score, it becomes much more likely that the cross validation score would increase with each added fold.
Summary
In this tutorial, you have learned:
- What is a classification problem
- How KNN can be used to solve classification problems
- Configuring of data for effective analysis with KNN
- How to use cross validation to conduct more extensive accuracy testing
Many thanks for reading, and feel free to leave any questions in the comments below!
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Java 10 introduces a shiny new feature: type inference for local variables. For local variables, you can now use a special reserved type name “var” instead of actual type.
- This feature is provided to enhance the Java language and extend type inference to declarations of local variables with initializers. This reduces the boilerplate code required, while still maintaining Java’s compile time type checking.
- Since the compiler needs to infer the var actual type by looking at the Right-Hand Side (RHS), this feature has limitations in some cases, such as when initialising Arrays and Streams.
- Experiment with this hands-on tutorial on how to reduce the boilerplate code using new “var” type.
In this article I am going to introduce, by example, the new Java SE 10 feature “var” type. You will learn how to use it properly in your code, and also when you can’t use it.
Introduction
Java 10 introduces a shiny new feature: type inference for local variables. For local variables, you can now use a special reserved type name “var” instead of actual type, as demonstrated by the following:
var name = “Mohamed Taman”;
This feature is provided to enhance the Java language and extend type inference to declarations of local variables with initializers. This reduces the boilerplate code required, while still maintaining Java’s compile time type checking.
Since the compiler needs to infer the var actual type by looking at the Right-Hand Side (RHS), this feature has limitations in some cases. I am going to mention this after a while, just keep reading. Let’s go through some quick examples now.
Hey, wait, wait and wait! Before jumping into the code, you will need to use an IDE to try out the new features as usual. The good news is that there are many in the market, so you can choose your favorite IDE that supports Java SE 10 among many IDEs like Apache NetBeans 9, IntelliJ IDEA 2018, or new Eclipse.
Personally, I always prefer to use an interactive programming environment tool, to quickly learn Java language syntax, explore new Java APIs and its features, and even for prototyping complex code. This is instead of the tedious cycle of editing, compiling and executing code which typically involves the following process:
- Write a complete program.
- Compile it and fix any errors.
- Run the program.
- Figure out what is wrong with it.
- Edit it.
- Repeat the process.
The great news again is that you are going to use the JShell tool that is built-in and shipped with Java SE JDK since Java SE 9, which was a flagship feature of that release.
What is JShell
Now Java has a rich REPL (Read-Evaluate-Print-Loop) implementation with JShell tool, referred as an Java Shell as an interactive programming environment. So, what’s the magic? It’s simple. JShell provides a fast and friendly environment that enables you to quickly explore, discover and experiment with Java language features and its extensive libraries.
Using JShell, you can enter program elements one at a time, immediately see the result, and make adjustments as needed. Therefore JShell replaces the tedious cycle of editing, compiling and executing with its read-evaluate-print loop. Rather than complete programs, In JShell you write JShell commands and Java code snippets.
When you enter a snippet, JShell immediately reads, evaluates, and prints its results. Then it loops to perform this process again for the next snippet. So, JShell and its instant feedback keeps your attention, enhances your performance and speeds up the learning and software development processes.
That is enough introduction for JShell, and InfoQ have recently published a thorough introduction to the tool. To deep dive and learn more about all JShell features, I have recorded an entire video training about this topic titles “Hands-on Java 10 Programming with JShell [Video]” that should help you to master the topic, and can be reached either from Packt or Udemy.
So now, let’s go through some quick examples to understand what can be done with this new var type feature using JShell.
Required Software
To work probably with JShell, I am assuming that you have Java SE or JDK 10+ installed and tools in JDK bin folder is configured to be accessible from anywhere in your system, if not here is the link to install the JDK 10+ latest release.
Starting a JShell Session
To start a JShell session in:
- Microsoft Windows open a Command Prompt then type jshell and press Enter.
- On Linux, open a shell window then type jshell and press Enter.
- While on macOS (formerly OS X), open a Terminal window, then type the following command “jshell” and press Enter.
Taraaa! This command executes a new JShell session, and displays this message at the jshell> prompt:
| Welcome to JShell -- Version 10.0.1
| For an introduction type: /help intro
jshell>
Working with “var” type.
Now you have JDK 10 installed, let’s start playing with JShell, so let’s jump right ahead to the terminal to start hacking var type feature capabilities with examples. Just enter each of upcoming snippets I am introducing next at the jshell prompt, and I will leave the result for you to explore as an exercise. If you had a sneaky look ahead at the code, you will notice that it looks wrong, as there is no semicolons. Try it and see if it works or not.
Simple type inference case
This is the basic usage of var type, in the following example, the compiler can infer the RHS as a String literal:
var name = "Mohamed Taman"
var lastName = str.substring(8)
System.out.println("Value: "+lastName +" ,and type is: "+ lastName.getClass().getTypeName())
No semicolon is required because JShell is an interactive environment. A semicolon is only required when there are multiple statements on the same line, or statements inside a declared type or method, and you will see this the following examples.
var type and inheritance
Also, polymorphism still works. In the world of inheritance, a subtype of var type can be assigned to super type of var type as normal cases as the following:
import javax.swing.*
var password = new JPasswordField("Password text")
String.valueOf(password.getPassword()) // To convert password char array to string to see the value
var textField = new JTextField("Hello text")
textField = password
textField.getText()
But a super type var cannot be assigned to subtype var as the following:
password = textField
This is because JPasswordField is a subclass of JTextField class.
var and compile time safety
So now, what about wrong assignment?It is an easy answer; incompatible variable types cannot be assigned to each other. Once compiler has inferred actual type of var, you cannot assign wrong value as the following:
var number = 10
number = "InfoQ"
So, what happens here? the compiler here has just replaced “var number = 10” with “int number = 10” for further checking, safety is still maintained.
var with Collections & Generics
Okay let’s see how var works with Collection element type inference and Generics. Let’s start first with collections. In the following case, the compiler can infer what the type of collection elements is:
var list = List.of(10);
There is no need to cast here, as compiler has inferred correct element type int
int i = list.get(0); //equivalent to: var i = list.get(0);
In following case the situation is different, the compiler will just take it as collection of objects (not integers) that’s because when you use the diamond operator, Java already needs a type on the LHS (Left Hand Side) to infer type on the RHS, let’s see how;
var list2 = new ArrayList<>(); list2.add(10); list2
int i = list2.get(0) //Compilation error
int i = (int) list2.get(0) //need to cast to get int back
In the case of generics, you better need to use a specific type (instead of diamond operator) on the RHS as the following:
var list3 = new ArrayList<Integer>(); list3.add(10); System.out.println(list3)
int i = list3.get(0)
Let’s jump right to see how var type works inside the different kind of loops:
var type inside for loops
Let’s check first the index based normal For Loop
for (var x = 1; x <= 5; x++) {
var m = x * 2; //equivalent to: int m = x * 2;
System.out.println(m);
}
And here is how it used with For Each Loop
var list = Arrays.asList(1,2,3,4,5,6,7,8,9,10)
for (var item : list) {
var m = item + 2;
System.out.println(m);
}
So now I have a question here, does var works with a Java 8 Stream? Let’s see with the following example;
var list = List.of(1, 2, 3, 4, 5, 6, 7)
var stream = list.stream()
stream.filter(x -> x % 2 == 0).forEach(System.out::println)
var type with Ternary operator
What about the Ternary operator?
var x = 1 > 0 ? 10 : -10
int i = x
Now, what if you use different types of operands on RHS of the ternary operator? Let’s see:
var x = 1 > 0 ? 10 : "Less than zero"; System.out.println(x.getClass()) //Integer
var x = 1 < 0 ? 10 : "Less than zero"; System.out.println(x.getClass()) // String
Do those two examples show that the type of the var is decided during runtime?Absolutely not! Let’s do the same thing in the old way:
Serializable x = 1 < 0 ? 10 : "Less than zero"; System.out.println(x.getClass())
Serializable, It’s a common compatible and the most specialized type for the two different operands (the least specialized type would be java.lang.Object).
Both String and Integer implement Serializable. Integer auto-boxed from int. In other words, Serializable is the LUB(Least Upper Bound) of the two operands. So, this suggests that in our third last example, var type is also Serializable.
Let’s move onto another topic: passing var type to methods.
var type with methods
Let’s first declare a method called squareOf with one argument of type BigDecimal, which return the square of this argument as the following:
BigDecimal squareOf(BigDecimal number) {
var result= number.multiply(number);
return result;
}
var number = new BigDecimal("2.5")
number = squareOf(number)
Now let’s see how it works with generics; again let’s declare a method called toIntgerList with one argument of type List of type T(a generic type), which returns an integer-based list of this argument using the Streams API as the following:
<T extends Number> List<Integer> toIntgerList(List<T> numbers) {
var integers = numbers.stream()
.map(Number::intValue)
.collect(Collectors.toList());
return integers;
}
var numbers = List.of(1.1, 2.2, 3.3, 4.4, 5.5)
var integers = toIntgerList(numbers)
var with Anonymous Classes
Finally, let’s look at using var with anonymous classes. Let’s take advantage of threading by implementing Runnable interface as the following:
var message = "running..." //effectively final
var runner = new Runnable(){
@Override
public void run() {
System.out.println(message);
}}
runner.run()
So far I have introduced the shiny new Java 10 feature “var” type, which reduces the boilerplate coding while maintaining Java’s compile time type checking. And you went through examples shows what can be done with it. Now you will learn about the limitations of the var type, and where it is not allowed.
“var” limitations
Now you are going to take a look at some quick examples to understand what cannot be done with var type feature. So, let’s jump right ahead to the terminal to hack limitations with some examples.
The results of jshell prompt will explain what is wrong with code, so you can take advantage of interactive instant feedback.
You should initialize with a value
The first, and easiest, thing is that a variable without an initializer is not allowed here;
var name;
You will get a compilation error; because the compiler cannot infer type for this local variable x.
Compound declaration is not allowed
Try to run this line;
var x = 1, y = 3, z = 4
And you will get this error message, ‘var’ is not allowed in a compound declaration.
No Definite Assignment
Try to create a method called testVar as the following, just copy and paste the method into the JShell:
void testVar(boolean b) {
var x;
if (b) {
x = 1;
} else {
x = 2;
}
System.out.println(x);
}
It will not create the method, and will instead throw a compilation error. You cannot use ‘var’ on variable without an initializer. Even assignments like the following (known as Definite Assignment) do not work for var.
Null Assignment
Null assignment is not allowed, as shown in the following;
var name = null;
This will throw an Exception “variable initializer is ‘null’” . Because null is not a type.
Working with Lambdas
Another example, with no Lambda initializer. This is just like diamond operator case, RHS already needs the type inference from LHS.
var runnable = () -> {}
This Exception will be thrown, “lambda expression needs an explicit target-type”.
var and Method Reference
No method reference initializer, similar case to lambda and diamond operator:
var abs = BigDecimal::abs
This Exception will be thrown: “method reference needs an explicit target-type”
var and Array Initializations
Not all array initializers work, let’s see how var with [] does not work:
var numbers[] = new int[]{2, 4, 6}
The error will be: ‘var’ is not allowed as an element type of an array.
The following also does not work:
var numbers = {2, 4, 6}
The error is: “array initializer needs an explicit target-type”
Just like the last example, var and [] cannot be together on LHS:
var numbers[] = {2, 4, 6}
error: ‘var’ is not allowed as an element type of an array
Only the following array initialization works:
var numbers = new int[]{2, 4, 6}
var number = numbers[1]
number = number + 3
No var Fields allowed
class Clazz {
private var name;
}
No var Method parameters allowed
void doAwesomeStuffHere(var salary){}
No var as Method return type
var getAwesomeStuff(){ return salary; }
No var in catch clause
try {
Files.readAllBytes(Paths.get("c:temptemp.txt"));
} catch (var e) {}
What happens behind the scene for var type at compile time?
“var” really is just a syntactic sugar, and it does not introduce any new bytecode construct in the compiled code, and during runtime the JVM has no special instructions for them.
Conclusion.
Wrapping up the article, you have covered what the “var” type is and how this feature reduces the boilerplate coding, while maintaining Java’s compile time type checking.
You then learned about the new JShell tool, Java’s REPL implementation, that help you to learn quickly Java language, and explore new Java APIs and its features. You can also prototype complex code using JShell, instead of the traditional tedious cycle of editing, compiling and executing code.
Finally, you learned about all of the var type capabilities and limitations, such as where you can and can’t use it. It was fun writing this article for you, and so I hope you liked it and found it useful. If so, then please spread the word.
Resources
- JDK 10 Documentation
- Hands-on Java 10 Programming with JShell.
- Getting Started with Clean Code Java SE 9.
- Overview of JDK 10 and JRE 10 Installation.
- JEP 286: Local-Variable Type Inference.
- Definite Assignment
About the Author
 Mohamed Taman is Sr. Enterprise Architect / Sr. Software Engineer @WebCentric, Belgrade, Serbia | Java Champions | Oracle Developer Champions | JCP member | Author | EGJUG Leader | International Speaker. Tweeter Taman @_tamanm
Mohamed Taman is Sr. Enterprise Architect / Sr. Software Engineer @WebCentric, Belgrade, Serbia | Java Champions | Oracle Developer Champions | JCP member | Author | EGJUG Leader | International Speaker. Tweeter Taman @_tamanm