Month: January 2019

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

Artificial Intelligence and the technology behind it are growing at a furious pace. Marketers have realized its vast potential and are striving to extract the technology’s opportunities in full. There are numerous advancements being made in this regard, and many organizations have taken center stage of the AI world with in depth data analysis and data discovery solutions.
I’m excited to partner with Io-Tahoe. Io-Tahoe is one of the few organizations that have taken on the complications of AI and are endeavoring to achieve something big from this enormous feat. They provide smart data discovery and AI-driven catalog solutions to their clients and help them get actionable insights from their clients’ data..
Potential of AI
The potential of Artificial Intelligence is obvious. Adobe has estimated that they can expect 31 percent of all organizations will start using AI over the coming 12 months. This statistic is backed up by the fact that there are more startups than ever focusing their operations on AI and the services that it provides to the masses.
Roughly 61 percent of organizations that follow innovative strategies have turned to AI for taking extracts from the data that they previously might have missed. Innovation is an earmark of Artificial Intelligence, and startup ideas that believe in this ideology can seldom live without the oxygen that is AI.
Not only are marketers confident about AI, but consumers are also starting to grasp its vast potential. About 38 percent of consumers are beginning to believe that AI will improve customer service. With this growing awareness and popularity, we can expect these numbers to increase further down the line.
Challenges before you Start with AI
Organizations are finding it hard to find their footing under the four V’s of big data; Volume, Variety, Veracity and Velocity. Over 38 percent of the analytics and data decision makers from the market reported that their unstructured, semi structured and structured data pools made an increase of 1,000 TB in the year 2017.
The growth of data is increasing rapidly, as are the initiatives organizations are taking to extract value from it. Herein lie numerous challenges that organizations must overcome to extract full value from AI.
These complications are:
Getting Quality Data
Your inference tools would only be as good as the data you have with you. If the data that you’re feeding your machines isn’t structured and flawless, the inference gained from it would barely make the cut for your organization. Thus, the first step of the process is to have quality data.
Without the presence of trust in the quality of the data, they wouldn’t proceed with their AI initiative. This demonstrates the importance of data quality in AI, and how it changes the perspective of stakeholders involved.
The pareto concept applies here, as data scientists are bound to spend almost 80 percent of their time making data ready for analysis and then the remaining 20 percent for performing analysis on the prepared data. The creation of these data sets for the ultimate analysis is key to the overall success of the program, which is why scientists have to allot their time.
The 80/20 phenomenon has been noted by many analysts online, who believe that 80 percent of a data scientist’s valuable time is spent finding, reorganizing and cleaning up huge amounts of data.
Getting the Best Talent
Once you have quality data you need to understand the importance of recruiting and retaining the best talent in the industry. Since AI is relatively new, the labor market hasn’t matured yet. Thus, you have to be patient in your search for the right talent.
Two thirds of the current AI decision makers present within the market struggle with acquiring the right AI talent for their firm. With hiring done, 83 percent of these companies struggle with retaining their prized employees. The talent shortage obviously goes beyond all technical flaws, as firms need a wide range of expertise to handle AI systems. What is understood here is that traditional recruitment practices are barely implementable, and that organizations need to look for other options.
Access to Data
With the increasing rate of data regulations on the horizon, any organization can easily end up on the wrong side of the law if proper measures are not taken. The GDPR or the General Data Protection Regulation by the European Union is one of the most advanced and up-to-date privacy policies for data at the state level. Complying with such policies is mandatory, as non-compliance can leave you in a dire situation.
Trust and Data Transparency
There is a trust deficit and the market for AI and analytics isn’t showing any signs of decreasing over time. While the market has increased and progressed by leaps and bounds, this trust deficit still stands as it is and isn’t showing any signs of decreasing.
Strategies You Can Follow to Start with AI
With the complications mentioned above, we most definitely will not leave you hanging here. There are certain strategies you can follow for widespread AI implementation. These include:
Create an AI Vision
Organizations that know what to expect from their AI campaign fare better than those that have no idea about this technology and are just getting involved because their competition has. An AI vision can also act as a list of objectives for the future, so you can tally your end goals with what you planned out before.
Build and Manage Customer Journey Centric Teams
The end goal or the mega vision behind AI is to improve customer experience and add value to your offerings. To do this better, you can make customer journey centric teams that follow customers throughout their journey and improve their experience along the way. Your task goes beyond just making a team, as you will also have to monitor their progress moving forward.
Data Accessibility and Culture
While three fourths of all businesses want to be data driven, only around 29 percent can agree that they are good at connecting their analytics and data to actively generate insights. If the data you have isn’t ready for you to get actionable insights, unite your organization around that analysis and make business decisions based on that.
Data accessibility and culture are necessary for your organization because accessible data enables you to focus on business decisions, move on quickly and build an informed culture where data helps you make better decisions and take better actions.
End-to-End AI Lifecycle Management
End-to-end AI lifecycle management relates to the management of data from its extraction to when it is presented in the form of actionable insight. The process entails different stages like the acquisition, storage, dissemination, learning and implementation of the data. By implementing end-to-end management, you can ensure that your data is always in safe hands.
AI is the future for generating actionable insights for your organization. With the correct tools you can get your desired results and overcome the initial complications.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Before I get started, I want you all to take a minute and think about your definition of work-life balance. So, you don’t have to say it out loud. I’m not going to make you talk to each other, but just take a moment and reflect on it. And when you think about work-life balance, are there any words, images, or even people that come to mind? What does it feel like when you have work-life balance, and is it something that you feel like you have today?
My guess is probably not, otherwise, you wouldn’t be attending a talk on the subject. So, you may still be thinking of your definition, and I’d encourage you to continue thinking about it throughout this talk because what I’m going to share with you today is how my definition of work-life balance has changed significantly over the past couple of years. For much of my career, when I thought of work-life balance, the image that immediately came to my mind was of a balancing scale. My work and my personal life were the two opposing forces on the scale. And in order to achieve work-life balance, I needed to dedicate equal amounts of time to each.
And the problem with this definition was that my scale was always imbalanced no matter how hard I tried to even it out. And on top of that, I often found that a lot of the advice and conversation around work-life balance focused on setting boundaries so that I could dedicate an equal amount of time to my work and to pursuing hobbies, passions, relationships, and other things outside of work.
But I felt that it was a little bit more nuanced than that and that something was missing from all of that conversation. I often had questions such as, what if I’m working 60, 70, 80 hours per week, but I’m doing something that I love? Or what if I’m going through something really hard or even really exciting in my personal life and it distracts me from work and I’m not able to dedicate as much time to it? I don’t have the answers to those questions, but I happened to have experienced both of those extremes of imbalance over the past couple of years. And that’s what inspired me to give this talk to you all today.
So, a little bit about the format of the talk. Like Harry [Brumleve] said, this is the unplugged version, so I don’t have any slides. And instead of showing you slides, I’m going to tell you a story. And it’s a story of how I’ve experienced imbalance during several times in my life, how that felt, and how that shifted my definition of work-life balance. And my hope for you all is that in hearing that, it will help you come to terms a little bit with your own imbalance and potentially give you some ideas to feed back into your own definition of work-life balance.
I’ll set a little bit of context before getting started with that. I’m Cameron [Jacoby], and I work on the engineering team at Stitch Fix. And since I’ll be spending a lot of our time together today talking about my job, I want to make sure to get everyone on the same page in terms of what Stitch Fix does and what I do there. Stitch Fix is an online personal styling service, and the way that it works is that we combine algorithmic recommendations with the expertise of human stylists to send our clients clothes, shoes, and accessories that they will love.
And at the heart of our technology organization is the belief that we should rely on computers to do the things that they’re good at such as pulling insights from large amounts of data, and we should rely on humans for the things they’re good at, such as creativity and building relationships. And the way that we’re able to bring this to life is that we do something at Stitch Fix that I think is really unique, and that’s the fact that we build all of our internal software in-house. And so, that means that a lot of us on the engineering team work on tools that other Stitch Fix employees use to do their jobs. You’ll also often hear this called Expert Use software. And I’ll use the two terms interchangeably throughout the talk.
The Context Story
For most of my time at Stitch Fix, I have worked on internal tools for the merchandising team, specifically for our merchandise buyers who are responsible for deciding what inventory we’re going to have in stock and then placing orders for that inventory with our external vendors. And to illustrate that, I’ll give you an example of one of these pieces of internal software that I worked on for our merchandise buyers. And that’s actually the first part of the story that I’m going to tell, so I’ll go ahead and get started with that.
So, to anchor us in time, the story starts in April of 2017, and I was the lead engineer on a project where we were building a tool for our merchandise buyers to surface recommendations for styles that would do well for our clients. So, the way that it worked was that our buyers would log into the tool and they would see a ranked list of styles. And these styles were ranked based on algorithms developed from our data science team. So, the reason that the buyers were getting these recommendations is that so they could more quickly make decisions about which assortment of inventory we would carry for the following months or quarters.
I was really excited to lead this project for a couple of different reasons. The first one was that it was going to have a huge impact on efficiency for our merchandise buyers. And that’s because this process of our data science team recommending styles for our buyers already existed before we had software to support it, but it was an incredibly manual process. It involved our data scientists manually creating spreadsheets of the recommendations, sending them over to our buyers, and then our buyers would make their initial selections on the spreadsheets, send them back to our data scientists who would then run further algorithms on the Google sheets. They would send it back to the buyers and then they would go back and forth like that for several days, sometimes for even several weeks.
I was really excited to build software to support this process because it would allow both our buyers and our data scientists to spend time on more valuable parts of their jobs. And the other reason that I was really excited to work on this is because the project posed some challenges that were a stretch for my existing skillset. We decided to build this recommendations tool in React, and I’m a pretty tried and true Rails developers. So, front-end frameworks are not exactly my specialty, so it’s a new challenge for me. And in addition to that, this was also the first time we were integrating our merchandising software with APIs from our data science team. So, there was a lot of ground to break there and the potential to set a precedent for future integrations to come.
I worked on this buying recommendations projects during the spring and summer of 2017. And during that, I literally worked all the time. It felt like an exponential ramp up as each month passed. And in the last six weeks before launching, I was working at least 70 hours per week, if not more. On weekdays, I worked from the moment I woke up in the morning until I was too tired to keep going at night. I worked from home two days per week and that’s when I wrote most of the code. And then on the days I came into the office, I did everything else that was needed to manage the project, from gathering feedback from our buyers, working through API implementation with our data scientists, and fielding questions and feature requests about the project. And on those days, I wrote code at night when I got home.
I would also typically work for most of the day on either Saturday or Sunday, but never both weekend days. The other day was always dedicated to resting so that I would be ready to go for whatever the following week threw at me. And this wasn’t the first time I had pushed hard on a project or worked more than 40 hours per week, but it was the longest I had ever sustained it for. I was inherently motivated by building this tool that was going to greatly increase the efficiency of this buying recommendation process. And that’s why I do this job. That’s why I joined Stitch Fix, and that’s why I work on Expert Use software specifically. I love building internal tools because I love improving the lives of our users who are right there with us in the office. And this project really resonated with me because I was getting to do exactly that.
And the funny thing is that when looking back on that time, I don’t ever really remember feeling tired. I was having a ton of fun. It was this weird mix of fear and joy that I’m not sure I’ll ever be able to replicate. The fear came from the fact that every aspect of the project was a stretch for my existing skillset. I didn’t know if I could pull it off, but I wanted to find out. And the joy came from the strong sense of partnership I felt from working towards a shared goal with our buyers and our data science team. So, it was those reasons that propelled me to continue working long beyond the typical 9 to 5 workday.
And when I was doing this, I knew it wasn’t perceived as normal. One of the things that we often talk about at Stitch Fix is that it’s such a great place to work because it’s a place that supports work-life balance. And I knew I wasn’t holding up this standard of work-life balance that I often heard my coworkers refer to. And on top of that, at various points in my career, I’ve read blog posts, listened to conference talks, and received advice that all told me I should have work-life balance. In addition to keeping myself happy and healthy, it would also set a positive example for others around me.
I heard from an array of people and sources that I should be careful with how much I was working because it could set a bad example for the rest of the team. And this idea that I was negatively impacting those around me with my working style made me feel, at best, uncomfortable and at worst, guilty and ashamed. I cared a lot about my coworkers, and I wanted to set a good example for them. But at the same time, I loved to work. And I didn’t necessarily want to stop what I was doing either. I felt like something was wrong with me because I didn’t have work-life balance, and I wasn’t sure if I wanted it.
I can’t tell you what to do if you ever feel like this, but I can tell you how I reacted, and that was to attempt to hide how much I was working. By the time I started the buying recommendations project, I already knew how to do this, and I pulled out all the tricks. My favorite one was to write code at night and then wait to push up the commits until a more acceptable hour the next morning. I never went as far as rebasing to change timestamps on commits, so it would have been obvious what was going on to anyone looking closely. But for the most part, no one was.
So, when August of 2017 came around, we launched the first version of this buying recommendations project. And I had never felt prouder of anything else I had done at work. And quite honestly, it ranks pretty highly against my personal accomplishments as well. Like everything we do as software engineers, there would be many more iterations of the project to come. But when I got to see the entire merchandise buying team using this tool to do a critical part of their job, it was an incredibly rewarding experience for me.
Shortly after launching that first version of the buying recommendations tool, I moved on to a new project in merchandising engineering. At the time, at Stitch Fix, we were ramping up and moving towards a service-oriented architecture. We had, and we still have today, a large shared database that’s a single point of failure for all the applications that connect to it. So, the project I was working on during the fall of 2017 was to move applications off of the shared database and onto a new service for merchandising-related data. And this project was really different than anything I had worked on before, especially after coming straight from the buying recommendations project. There was no product work or direct interaction with the merchandising team, and I spent most of my time during the day writing code. And I found that I didn’t have the same inherent motivation to continue coding after work as I did when I was working on something where I was directly interacting with our users. I noticed that there was a real limit to the amount of service migration I could do in a day, and that left me with a lot more free time outside of work.
I remember the first week I worked on the service migrations, I finished my work between 5 and 5:30 each day and I literally didn’t know what to do with myself. This was a completely new experience for me. And I know that might sound sad, and maybe it was a little bit sad, but pouring my entire self into work had just been the norm for me for so long. I was really unsure what other parts of my identity even existed or if there even were any. And I also realized that I didn’t have a great idea of what I even enjoyed doing outside of working.
In the past, when someone would ask, my honest answer was, “I like to go home and work more.” And I knew that wasn’t a normal thing to say, so I would often hang back from those types of conversations. But it was with this new found free time that I decided to explore this a little bit more and see if I could figure out if there were any other parts to my identity besides working. And I thought that if I could figure out some things that I was passionate about doing outside of work, that I would have a more well-rounded personal identity and that maybe I would figure out this work-life balance thing.
It seemed achievable enough to me at the time, at least in my head, so I did a few different things to try to experiment with this. I talked to people inside and outside Stitch Fix about work-life balance. I read books and blog posts on the topic, and I thought back to hobbies that I had enjoyed in the past. And I tried a bunch of things. I tried meditation and journaling, which were common pieces of advice from others. I tried adjusting when and how much I slept and what I ate, which are the cornerstones of any blog post about self-care. I tried art and running, which are two hobbies I have enjoyed in the past, and I tried some new things too, like learning how to play the piano.
And at any given point, I was often trying many of these things at the same time. I think the technical term for this is multivariate testing. And this wasn’t working quite as well as I expected. I was often left feeling exhausted from trying to achieve a balanced mix of exercise, mindfulness, and creativity all on top of getting my work done each day. So, I was pretty frustrated at this point. My energy was low. I still felt imbalanced, and I still felt like something was wrong with me for not being able to figure this out.
So, at this point in the story, we’re in December of 2017. So, I worked on the service migrations all throughout the fall. And at this point, I got an opportunity to join a brand new engineering team at Stitch Fix. And it’s the team that I’m currently on today. So, my current engineering team is called The Expansion Team, and we’re responsible for making the engineering changes necessary to expand Stitch Fix into the UK, which is happening at some point next year. So, this was super exciting for me. I was the third member of this brand new team, and I would get to expand my scope outside of merchandising, engineering and get to work across all of our engineering systems at Stitch Fix.
So, work was going really well. There was this exciting new change, but I think one thing that I didn’t totally account for, in that having more time in the fall to reflect on my identity and my life and what I wanted that to look like, is that it would make me realize that there were some other changes that needed to happen in my personal life at the same time as this big change that was happening at work.
Feeling Imbalanced
So, at this point in the story, we’re in January of 2018, so we’ve made it to this year. And about a week after new year’s, on Sunday, January 7th, I left my apartment with my backpack and a suitcase containing barely a week’s worth of clothing, which marked the end of my five-year-long relationship with my ex-boyfriend. I didn’t know where I was going, and I didn’t know when I’d be back to get more clothes or the rest of my belongings. Through the shock and adrenaline in that moment, the only thing I could focus on was finding a place to sit down and figure out what was next, at least for that night. I remember calling a Lift, but I must’ve been on autopilot since I don’t consciously remember typing in the Stitch Fix office as the destination.
When I got to the office, I walked into the kitchen, popped open a La Croix, made myself a sandwich, and booked a hotel across Market Street to stay in that night. The next morning I woke up, and I called my parents. From 3,000 miles away, I could feel their sadness and fear when I told them what had just happened. I hung up the phone, checked out of the hotel room and walked back across Market Street in time for my 9:00 a.m. standup.
The reaction that I had just felt from my parents was not completely off base. I had just walked away from the life that my ex-boyfriend and I had built together for the past five years, which was both heartbreaking and terrifying. But the weight of that hadn’t hit me yet. I didn’t know where I was going to live or what my life would look like that week or even for the rest of that day. But the thing that worried me the most on that short walk to work was, “What am I going to say when people ask me how my weekend was?”
So, as I’ve been talking about this whole time, work has always made up a significant part of my personal identity, so much so that I’ve struggled to even figure out what the other parts were. But what this experience of my breakup made me realize is that my personal life also has a significant impact on who I am at work. When someone asks me the question, “How are you?” Or, “How was your weekend?” If the answer is somewhere in between, “Not great” and, “My personal life just went up in flames”, hiding that information drains my energy and makes me feel worse.
But at the same time, I know that some people prefer to keep their work and their lives outside work more separate. And I want to be respectful of that. I often worry that sharing the details of my personal life, especially when things aren’t going well is going to make my coworkers feel uncomfortable. So, in the days and weeks following my breakup, I was hyper-aware of these types of “How are you?” questions at work. Every time someone asked, I felt like I was doing mental somersaults to try to figure out how honest I should be with that person in that moment. I was constantly weighing the tradeoffs of covering up what was going on and taking the additional hit to my energy level, versus speaking up at the risk of causing discomfort for someone else.
During the week of January 7th, I don’t remember the code I wrote, the meetings I went to, or the interviews I conducted, but there are a few things I do remember very clearly. I remember that leaving my old apartment was inconveniently timed during the J.P. Morgan Annual Healthcare Conference, which is one of the worst times to find a place to stay in San Francisco. I remember telling each of my team members about my breakup, and not knowing what I expected them to do with that information, but just that I wanted them to know. I remember breaking down in tears during a yoga class because sometimes crying when I’m not in public is too much to ask for. I remember telling people at work how I was really doing when they asked me, “How are you?” And I remember it being okay.
So, after getting through that first week, a lot of change was in store over the following months. I moved out of my old apartment. And from January through March, I stayed in two different hotels and three different Airbnb’s. So, this meant that all of my belongings were scattered between a storage unit, my temporary housing arrangements, and a lot of times, the office. And this desperate state of my possessions was a pretty accurate outward representation of how scattered I was on the inside as well. I was often late for stand up for no other reason than I couldn’t get myself together before at 9 in the morning.
While all of this was going on, I pulled much less weight at work than I was used to, and I had to learn to be okay with that. I had never experienced such a large amount of change and instability in such a short amount of time than I did in those few months. My personal life had to take priority in a way that I wasn’t used to. And so, in case it wasn’t clear, I definitely didn’t feel any type of balance. I felt like I lacked the time, energy, and emotional capacity to dedicate even half of myself to work, and certainly not my whole self, in the way that I had done in the past. I want to say that I felt guilty about that, but I honestly don’t know if I even did. Looking back on that time, what stands out to me the most is an overwhelming feeling of being drained for weeks and months on end.
So, to wrap up this part of the story on a more positive note, I’m happy to report that my life outside work is a lot more stable now. Towards the end of March, I moved into a new apartment that has some of the best views of San Francisco I’ve ever seen. And I have two roommates who I absolutely love living with. So, why am I telling you all this? I’m telling you this because life can be really messy, and that’s true for all of us. Whether it’s a breakup or something else, hard things are going to happen that completely derail our lives. And that includes the work part of our lives. Going through something difficult outside work cannot be contained or kept separate or balanced out. It affects how we feel at work, how we relate to work, and how much time and energy we can devote to our work.
So, tying this back to the beginning of the talk when I was describing the excitement and sense of purpose I experienced from working, that’s the other extreme when it comes to feeling imbalanced. I’ve spent a lot of time trying to reconcile these two periods of my life and figure out what that means for work-life balance, and I have a few thoughts about that that I want to share with you all.
So, the first thing is that I’ve realized that I’m never going to feel an overwhelming sense of balance or equilibrium, so I need to stop making that the goal. The amount of time and energy I’m able to devote to work is going to be different depending on what else is going on in my life at that time. And it may not be as drastic as the two extremes I’ve talked about, but it will always lean at least a little off-balance. And recognizing that there will be this ebb and flow has actually made me really grateful of the times when I could dedicate most of myself to work. Working a lot, especially on things that were way outside my comfort zone, allowed me to gain a ton of valuable skills in a short amount of time. And it’s those skills that I consistently rely on to get my job done, especially on days when I’m not feeling my best.
But it’s not all positive. One thing I want to make sure I’m honest about is that working a lot can be rewarding, but it can also lead to some really bad habits. I’m horrible at prioritization and time management because I got by for a frighteningly long time without having to learn those skills. When I had what felt like endless energy to work, if I didn’t finish something I said I would do during the workday, it was totally fine because I would just work more when I got home to get it all done. It’s been extremely painful to realize that habit is unsustainable, and it’s been an uphill battle to try to recover from it. And to be completely transparent, I still don’t have that figured out.
Empathy
The other main learning that I have from these events is around empathy. And this goes back to the anxiety that I experienced when answering those “How are you?” questions after my breakup. That experience made me realize that we don’t always have the full picture of what’s going on in someone’s life when we interact with them at work. Recognizing that I’m operating on a limited set of information has helped me in trying to approach my interactions at work with a little bit more empathy than I have in the past.
When I ask someone how they’re doing, I try to leave more space for a real answer if they want to give it. And if I notice myself feeling annoyed or offended by something that happens at work, I try to remind myself that we’re all just doing our best. I still fall short all the time at being empathetic and often rush through my days wrapped up in my own problems, but it’s something I’m trying to get better at.
Revisiting the Definition of Work-Life Balance
I want to revisit the definition of work-life balance that I shared at the beginning of the talk, and that was the balancing scale with my work and my personal life on either side. I mentioned that I’ve stopped trying to make it a goal to feel like I’ve reached any sort of balance or equilibrium. So, I want to talk a little bit about what I have shifted that definition towards. So, instead of thinking about work-life balance as a scale, I try to focus more on the interaction between my work and my personal life. And I try to pay attention to whether or not those are interacting in a way that’s making me happy and making me feel fulfilled.
So, instead of asking myself, “Am I dedicating equal amounts of time to my work and my personal life?” I ask myself questions like, “Am I working on things that motivate me? Am I working with people that I can learn from and who are kind? Am I doing things outside of work that make me feel rested? And am I spending my time with people outside of work who are bringing a positive energy into my life?” So, I know that this idea of work and personal life interacting might sound a little bit abstract, and I think that’s why we often fall back on time as a measure of work-life balance because it’s a little bit more straightforward to measure, unless you’re trying to write a program to measure time, in which it’s not straightforward at all.
I want to spend our last few minutes together kind of talking about how I have tried to make this idea of interaction a little bit more concrete and what that looks like in my life on a daily basis. So, the caveat to this part is that I’m going to share some of the things that have worked for me, and it’s an ongoing process to figure out what that looks like. They may not necessarily work for you, and you have to do the work to figure out what your definition of work-life balance looks like and how that manifests in your daily life. But I’ll share a little bit about what works for me in case that gives you ideas of things that you can try.
Focusing on the Energy Level
So, instead of focusing on this measure of time, I’ve shifted my focus more towards trying to pay attention to my energy level. The idea is that I want to feel like I’m recharged each day to the extent that I’m able to focus on work and also enjoy my life outside of work. So, feeling like I have enough energy to be fully present in whatever I’m doing at the time. So, this idea of energy and recharging kind of has two different parts to it. And so, the first part is trying to minimize things that drain my energy and then the second part is trying to focus on things that replenish my energy. And I think the hardest part about that is actually figuring out what those things are and also kind of figuring out how do you even measure what an energy level looks like.
And so, to provide a little bit more detail into that, what I mean when I say energy level, is the first thing I ask myself is, “Am I feeling tired?” And what I’ve learned, that was kind of a big unlock for me, is that there’s a difference between feeling tired because of lack of sleep, and feeling tired because something is draining my energy. And so, pinpointing that is really the first step for me and trying to figure out how to feel recharged. And it takes a good amount of self-awareness to get to this point, and that’s a skill that you can practice like anything else. But one thing that has helped me is framing it similar to how we talk about the five whys in retrospectives. So, when something happens, you ask why and then you keep asking why five times until you get to the bottom of it.
When focusing on my energy level, I’ve started to do the same thing. If I’m feeling like I have low energy, going through that exercise of the five whys, trying to pinpoint what’s draining my energy, and then hoping that that will also provide some insight into how I can replenish my energy as well. And it takes practice. And over time, that does get a little bit easier, and you can start to notice patterns and build habits around those patterns. So, since I’ve shifted my focus to thinking more about energy, I’ll start with sharing some of the things that I do to limit activities that are draining my energy.
Reduce External Noise
What that looks like for me on a daily basis is that I try as hard as I can to reduce external noise. So what this means is that I don’t use social media, I don’t watch TV, I don’t read the news aside from a daily summary email. And my phone is always on silent and do-not-disturb except, of course, when I’m on call. And I know that might sound like a lot of rules, but they’re actually reactions to feeling like I have too much mental clutter to either focus on work, enjoy my life outside work, or both. And rather than making me feel restricted, not doing things like checking Instagram or responding to texts right away gives me the freedom to focus on things that do give me energy.
So, speaking of the things that do give me energy, this one’s actually a little bit harder for me to figure out what those things are. But one thing that helped a lot with that is the period of experimentation that I talked about a little bit earlier where I was trying out a bunch of routines and activities almost to the point of exhaustion. And while that definitely wasn’t sustainable to try to fit as much as possible into one day or one week, it did give me a lot of data points that I could use in terms of activities that would replenish my energy level. So, some examples of this are reading fiction and autobiographies, practicing yoga and riding my bike, all of which I really enjoy, but I wouldn’t consider any of those things to be my life’s passion.
A few things I learned through this process. One that was a little bit surprising to me is that it’s less important for me to feel an overwhelming sense of passion for the hobbies that I do outside work. It’s more important for them to be concrete ways to clear my mind and replenish my energy level. And another thing that I learned that was counter-intuitive is that I don’t need to be building a routine where I’m doing the same things every day. I think one of the pitfalls I ran into when trying to achieve work-life balance is thinking that if I can just find the perfect routine where I go to bed at the same time every night, wake up the same time each morning, work for the same amount of time and do the same hobbies outside work, I’ll be super energized, productive and happy all the time.
But that mindset always set me up for failure because whatever I was trying to achieve was unrealistic. So what this means for me is that each day looks a little bit different, and that goes back to the high value I place on reducing noise and mental clutter. I try to pay attention to what I need and leave space to do those things, as opposed to pre-planning everything out in a set routine. So, like I said, those are just some of the things that I’ve discovered that work for me in figuring out how I want my work and my personal life to interact, how to replenish my energy, but it’s definitely an ongoing process. And I’m still self-reflecting and learning about these things every day.
Conclusions
To wrap up, there’s a couple things I want you all to do when you leave here today. The first one is think back to periods of your life when you’ve experienced imbalance, and you might be going through that right now, and think about how that felt and revisit that definition of work-life balance that I asked you to reflect on at the beginning of the talk. Does it need to change at all? And if you’re feeling stuck and you’re not sure where to get started, the advice I’ll give you is that I think storytelling is a very powerful way to do this.
So to get a little bit meta for a second, preparing this talk and giving this for you all today was a very important part of my process in working through what these times of imbalance meant for my life. And you don’t have to share your story in a forum like this. You don’t even have to tell it to someone else, but I would encourage you to at least write it down or reflect on it. And you might be surprised at what comes out of that. So, the final thought I’ll leave you with today is this. If you ever feel imbalanced, and if you struggle to figure out how your work and your life outside work relate, you’re not the only one.
See more presentations with transcripts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcripts
What I’m going to talk about today- well, while preparing to the talk, I found this nice quote from Rosabeth Moss Kanter, a professor of Harvard Business School, who says that, “Change is disturbing when done to us, but exhilarating when it’s done by us.” I think that quote really represents the theme, the topic of what I’m going to talk about, and actually that’s related to the growth.
This talk is called “Optimizing You,” but I would like to go one step above: how you can help other people optimize themselves, how can you build a community, or how can you help other people to grow? And that starts with the overview of how the growth career path can look like at the organization. Booking.com looks like this. If you’re a core contributor, you can either select to go to the management path as a team leader, as a manager, and as a director, and so on, so forth, or you could go to the senior development and then principal development.
In this talk we’re going to focus on that shift from core contributor to senior. Harry did a nice survey here, about who you are, and do you have more career levels? But the question I have, do you think that the core contributor to senior is a straight line? Who thinks it’s like this? Like you need to do something, you need to go there. Who think that it’s something like that? At Booking we are good in defining what career levels are. So we have expectations of the core contributor role, we have expectations written for the senior, we have expectations written for the management. It’s all good. It’s all written; you can read, maybe cross out some of the check boxes and say, “Okay, I’m kind of ready.”
Being Senior Means …
In fact, it’s not that easy, it’s not that simple, and it is still that tangled as in the picture. And the reason is that senior is not a promotion; basically it’s a recognition of your work. At booking.com it works like this. You start doing things which are not expected from you, you start acting as a senior developer, and then you get a promotion as a result of your actions. And being senior means that you have to have more impact, you have to have more ownership, responsibility. You need to work on not only your team project; you should go beyond, you should go and influence, to track the department, the company maybe sometimes. You need to mentor people, you need to coach them, you need to be involved in the community projects. All those kind of things which are not clearly defined what you need to do. Yes. If the document says, “Hey, you need to mentor,” or the document says, “Hey, you need to influence the other departments,” what exactly do you do? Go figure.
So the thing is that senior is not only skills and knowledge. It’s basically a behavior. And the thing is that behavior, you cannot teach behavior. Of course, you can go on the training, like, classroom training for a day or two and listen to the teacher, and you can obtain skills and knowledge. But I can hardly mention this that after visiting one day of the training, you will start behaving differently. Unfortunately, you will not, most likely. But you can create an environment where behavior will show up. You can create something where people who would like to grow will get this opportunity to grow. And this is what I’m going to talk about.
Basically this idea came to me and another guy, Denis Yakunin, who is also a senior software developer at booking.com. Idea came to us just during having coffee. We met each other at the cafeteria and we’re sitting, and we’re chatting, and we’re talking about, “Being senior developers we are supposed to help people to grow. So how can we help them? ” Because we clearly notice that there is a lack of clarity of how to become a senior. And then Denis just mentioned that he was part of the Facebook group, online Facebook group to help people grow, self-develop and think on some sort of life thinking. And then he described it to me and told me what it was about.
And we thought that we could apply the same principles to actually create the career growth framework, career growth training for our developers. And the three key principles of that work was this. First it has to be marathon: two weeks of 10 days, 10 working days, every day we submit a new task. We’ll give the new task to our people, so that they can keep having the momentum going during those two weeks. The goal of it is to create a habit of doing things which they were not supposed to do before. The second part is working in groups, because working together, learning together is actually much more efficient than learning individually. And the third, it should be online, because we do not want to disturb people from their daily routines, we don’t want to put them in the class. We want to give them a task and let to finish it whenever they want, being like, asynchronous as possible.
Game of Roles
And we came up with a cool name, because who likes “Game of Thrones”? Everybody likes “Game of Thrones” and we came up with Game of Roles, because Game of Roles is actually the opportunity for you to try and play the different role; the role of a senior developer for a while with no obligations, nothing like that. And the slogan we had is, “Being a senior means playing the role, and to become a senior, you have to try playing this.” So what do we wanted to do, we wanted to create for you the safe environment that you could start acting as a senior developer with our help, of course. But then with no obligations to fail, with no obligations to becoming a senior or not becoming a senior, with no kind of risk.
So when you sit up and you think, what do you do? At Booking we do experiments a lot and me and Denis also decided to have an experiment. We wanted to start really low and fail fast in order to collect feedback and get better. So we came up with an MVP of the training, the quick prototype. We wanted to pilot with a limited amount of people, we wanted to collect feedback from them and then reiterate. If you look at the timeline of how things happened, day one, we met together and had this idea born. Day five, we started discussing details and thinking how can we actually do this. Day 10, we made the public online announcement. We committed ourselves that we’re going to deliver this training, because without committing, you will never do anything. And then a couple days later, we made the final polishing of the things, and in two weeks from when the original idea was born, we started the training. Essentially two weeks of preparation, two weeks of the real training. In a month span, we could create a completely new thing which never existed at booking.com before, which I think was really, really awesome and which represents the agile way of making things live no matter whatever you do.
Format
So let’s talk about what it is exactly. As I said, the format, it’s marathon, online, it should have some rules. And I said marathon, 10 days over two weeks, every day we were going to post new assignments to our people, so that they could do this on their own pace on the online activity at Facebook at work. We have to create some rules; what do we expect from them, and what they can do, what they should not do. And of course, the code of conduct. The code of conduct is, yes, it’s usual; it has to be you. We wanted to create a trust environment with privacy being safe, safety, group, and be open to receive feedback. So basically when we proclaim this, we’d say, “These are things we are restricting you to.” And by saying this, we say, “You are our group that we trust, and we create a safe environment for you.” So there is no manager in the group, there is no HR in this group. You are on your own. You are learning. We will not share your information out there anywhere else, so that people could come up with answers, with their sincere answers. And you get the idea why we need them being sincere, because the questions are not only practical tasks, but something more.
So going further about the format, about the thing, it has to be groups. As I already said, if you learn individually, you can only learn from your past experience. Of course, you have some sort of things you know, things you value, things you heard about, and while getting new things, you of course, settled them on your own background, on your own experience, and you can learn only from yourself.
But whenever you learn as a group and whenever you help each other as a group to learn, this becomes the next level of learning. Because if you, for example, look at how that person did an answer, did a problem, you might wonder, “Why did this person did it that way?” You can ask, “Hey, John or Mary, why?” And then she or he replies to you and then you can reflect on that as well. And then he or she can also learn from you, why did you solve it that way. So together with talking to each other, with community activities, you can learn even more.
And the groups have to be small. Since it’s online format, it’s a Facebook group, imagine that people are posting their answers online everyday. So the more people you get, the more mess you have. So we decided to limit our groups only to 15 people each, assuming that half of them will not do anything, which is unfortunately true. If we assume that 15 people, half of them, say 8, will start doing something, then it’ll be easy for us to manage and easier for them to navigate through those answers. And those groups have to be really close. As I said, there is no manager, there is no HR, there are only people who are at the training, who are learning in this moment, and us, like, trainers and moderators. And by this, we allow them to post whatever they feel, whatever they think, and be open to each other.
Funny fact actually, because we had 15 people in the first group. When we were launching this training, we were thinking, “Okay, how many people should we get? Like 15. All right.” And we were really doubtful about can we get 15 people out there, because it’s a new thing, people might not be really enthusiastic. However, when we did our first announcement on a company meeting saying, “Okay. We’re going to launch this. There is a link you can sign in,” we got 80 people; 80 people willing to sign in for this training. So it was so, so, so unpredictable to us and so exciting. We were so excited. So we created actually two groups of 15 people each. So we started with bigger pilot group of 30 people, so that we could also compare them between each other.
Tasks
Now, moving forward towards tasks, and I think that’s the most important thing, what tasks did we ask them. Well, first of all, they have to be clear. You have to say, “This is what you need to do. This is what the outcome should look like.” For example, “You need to go to the errors and warnings monitor and pick one of the errors and warnings, and fix it”. They have to be simple. As I said we are not the kind of classical training. We are not the classroom. We don’t have well defined time of the training. So we wanted them to be able to complete those tasks on their own pace, assuming that they are also going to work on a day-by-day job. So we said, “You will probably need one hour of your time to complete everyday’s tasks.” So that’s small.
It has to be relevant. They have to be clearly representing what senior developer job is about. So basically, it’s actually the reason of why you are in this training. We are simulating things for you. Usually, senior developers do this, so you can also try to do this and so on, so forth. And the solution has to be a separate post in the workplace. So each person at the end of the day needs to create a separate text post on Facebook where they describe how did they approach the solution, how did they solve it, and maybe share some results, etc. The reason for this that people will see this in their workplace … How do you call it? Flow. And then they could comment on this. They could provide feedback on that, they can also, I don’t know, just have written, get the record of what people are answering.
And there are two different types of tasks we were offering them. First is a pretty straightforward one: testing hard skill, excelling in hard skills. As I said, fix some errors and warnings, describe and draw a diagram of your service or product. These are the tasks which are heavily focused on the impact and hard skills, and technical, and craftsmanship things, so what senior developers should do.
But these are not the most important ones. The most important ones, in my opinion, are self-reflection. How many of you, whenever you want to do something, really spend time on self-reflection and understand where you are at the moment? Do you ever do this? Few hands. So people naturally, when they want to grow, when they want to get a promotion, they really start thinking about where they are at this moment, why they are not getting a promotion, or what they need to do become a senior, for example. So by the self-reflecting tasks, we wanted to make people, explicitly make people to think about their own reality. The very first question we were asking them, “Hey, go to the senior developer expectations Wiki page. Go through all of the check boxes which are defined there and try to answer where you are matching and where you do not match and why.” So that was the very first task, and people did not expect this. People expected to do some sort of error fixing, community project, all sort of that. That was a surprise to them, but that was the most key thing in their progression; to actually self-reflect.
This is how it looks like in the workplace feed, both about the task which was submitted in the day of the task. This is a sample of an answer. The person describes which error they picked on the monitor, how did they approach it, how did they solve it, what was the reason, what are the next following steps. This is really a nice already thought process; not only just fixing things, but also going, producing the learning, producing the, let’s say, knowledge sharing document, whatever. And then it basically impacts their way of thinking, that not only fixing is good, but also making the documentation of it or making sure that people learn from this fix is important.
Moderators
To help with this training, we also invited people as mentors, or moderators. Those are also experienced people; they were all senior developers and one principal developer who helped us during the process. And their responsibility was to actually coach people. So not only coach and support, but the most important thing was coaching. An example of the coaching was asking more questions. If the person answers and most importantly on the self-reflection topic, for example, there was a question we ask, “Hey, what do you like or what do you don’t like in your daily job?” And the person just answered for example, “I don’t like being confused about what I’m supposed to work on. I don’t like not knowing what I’m working on is going to accomplish. I don’t like meetings. I don’t like complicating.” And so on, and so forth. That’s an answer, but that’s not the full answer. That’s just a statement, “I don’t like doing this.”
And then the moderator comes in, the coach comes in saying, “Hey, those things you mentioned, you’re trying to avoid uncertainty. What could you do to make it more clear for itself?” And then the person answers more deeply and then we ask one more question, and then the person answers again. And since no one expects us to coach them, they were really open to this. Because usually when you say, “Hey, I’m going to coach you,” you start to like, “I don’t really like being coached.” Special developers, they’re like, “You know, I’m good. Don’t bother me with your five why questions or something.” But when you do it naturally, while you do it with just commenting on workplace, they don’t expect this kind of trick from you and they start being open, and they start to think more about what they need to achieve.
Another example from the coaching was that you don’t have to read the answer, but just the amount of text the person has written to the question, to the additional question, not to the topic itself, is remarkable. It’s again one more proof that people start becoming more open and becoming more thoughtful about what they are doing.
And the last part was the feedback and AMA. As I said, we want to learn fast, we want to fail fast. So the very last meeting we had with them after two weeks of training was the AMA session where we answered their questions, like, how did we become seniors, what did we do, what is our personal story? But most importantly, we were trying to collect their feedback regarding the training: what did they like, what didn’t they like, what could we improve?
What Did We Learn?
So what actually did we learn? Lesson first, we have to meet in real life before the training starts. Even though it’s online, even though it’s proclaimed as being totally online, we wanted people to actually gather in one single room before the whole two weeks marathon starts. It makes people more open to each other when they know who they are. Whenever you put people in a group, if I can see your face, if I can understand that you are the person you are, then whenever I pull something on Facebook, I know that you are a nice person to me. At least I know you, then it gets more connected.
Second lesson is keeping the work-life balance. In the first run we were posting the questions on the evening of the day before the question, the topic has to be answered. So 7:00 p.m., I was posting the question and I noticed that 7:05 or 7:10, people start answering on this topic. I was like, ”Come on, guys. You are not supposed to work after 7:00 p.m. You are not supposed to work when you are supposed to be at the bar or with your family.” So we changed that to post topics in the morning of the same day. And In order to be easier for us, we automated this with Facebook. You can make a schedule post, so we don’t have to bother and wake up early to submit the topic which people are expecting to have.
Second lesson, that’s one of the most important things we’ve learned, that we need to give people some time to rest. What we noticed, that you get the first task, you finish it pretty good. Next day, you get the second task. The third day, you get the third one. The fourth, you get the fourth. And it’s a snowball if you, for example, need to answer on the day three, you get a new task on day four, and now you become anxious about, “Hey, I didn’t finish the previous one, I get the new one.” Now, day five comes, he didn’t finish two days and now, you get more and more and like a snowball, you start thinking, “Okay, I didn’t do something there. I wouldn’t even bother reading the next question.”
So actually, before we introduce the catch-up days, the response rate was like this. Those are how many people completed how many tasks, and we see that after, say day four, there’s a huge drop down in completion because people start getting overwhelmed. So what we did, we said, “First Friday, the day five would be the day of your catching up.” We didn’t post any new assignment. We just said, “Hey, this is the time for you to catch up on whatever is left and if you’ve done everything, go and read other people’s posts and comment on them. So help your colleagues.” And it helped. More people got to the last end of spectrum. More people completed eight tasks which now becomes the full training.
One more thing to improve the statistics is introducing OKRs, or at least something like clearly set the expectations. We got from the feedback, we got that people sometimes were perfectionists and they were thinking, “If I didn’t finish one of the tasks, there is no point for me to finish the other ones because I didn’t complete anything. I would not complete 100%.” So what we did on that, we said explicitly, “Hey, guys. We are not expecting for you to complete everything. We only expect that you’ll complete some of those tasks.” Let’s say you will finish OKR 0.3 if you complete four of the tasks. You will reach 0.7 OKR if you complete, let’s say, six tasks. And you will reach 1.0 OKR if you will complete everything and also we’ll provide some feedback to your peers.
So what we noticed to go from here, we went to here. This gave people extra motivation to do things. This gave people extra safety of feeling that they are not supposed to complete everything, and by this, they did actually complete more, because they were not under pressure anymore. And there was an example of a person who said, “I wasn’t supposed to finish one of the tasks because I felt that this is easy and I usually do this on my own already. But since there is an OKR 1.0 saying that if I complete everything, I will reach this OKR, I decided to complete this task as well. So thanks for introducing that kind of motivating thing.” So that worked.
Can We Measure Value?
And then there were lessons five and six, and seven. We collected feedback. We learned, we learned, we learned, we learned. But how can we measure if it was successful or not? How do you know that the training you’ve been through helped you, and how do you know that this training that you create helps people? Any ideas by the way? How do you by the way measure if the training helped you or not?
Participant 1: Number of promotions.
Mogelashvili: Number of promotions. I have a question to you, how do you know this promotion happened because of that training?
Participant 1: We don’t know.
Mogelashvili: Actually, you can’t, you can’t measure this. Well, in shortened term, of course, you cannot measure the success of any training, because unless this is a training specifically on hard skills, how to work in that particular certain technology, then you can evaluate if the person can do this. If we focus on something which is soft skills, if we focus on something which is behavior, if you want to change people’s behavior, you cannot measure this straight away. But you can collect feedback, as I said. And this is the only metric we could use in our evaluation. So we were collecting feedback right after the training finished and we were collecting the feedback two, three months after, so that we could compare what people think immediately and what people think while time passes, while they have settled things, and if they really change their behavior with time.
And then a few feedbacks I would like to share with you that we’ve received. So this is actually the thing we were aiming for. The person here writes that, “I think the most important insight I got from Game of Roles is that there is no checklist or roadmap to become a senior. It is not about the number of programming languages you know. It is not about of developer tools you can work with. It’s more about the way of thinking and solving issues, the way of sharing your knowledge with the community.” It is exactly what we were aiming for people to understand that it’s that.
The other feedback is that, “I liked the environment we had in a workplace group which made it easy and it also helped a lot to learn about other people.” So that’s the proof to our assumption that group learning is something which makes you learn even faster, even more. And the third feedback was just remarkable: “It motivated me to do things which I would otherwise postpone forever.” While I was reading this, it was, like, so, so, so great a feeling to me, “Yes, we did the right thing. People liked it.” And also we got a lot of positive scoring like, NPS or something like that. Would you recommend it to your colleague? How did you value this? And everything was really above 80%, 90%
So in general, so far we have trained 80 people in total, which is around 10% of our development headcount. We have 50 more people in the waiting list for the next month and we got the support from talent development. They promote this as a part of the recommended training if you want to get promoted, all this kind of thing. So it got noticed by somebody whose job was basically to train our developers. We are not trainers, as I want to remember. We were just developers. We were doing this on our own time, on our own enthusiasm.
What’s Next?
So what’s next? There was one feedback which actually helped us to figure out what we can do next. “Most of the tasks and questions given seem like they would apply to other senior roles as well, not just backend developers. Any thoughts of opening it to everyone and give people the opportunity to interact with people in other roles?” Hell yes, why not? So we decided to build a kind of so-called franchise. There is a Game of Roles senior developer edition, there is a Game of Roles team leader edition. I hope they will have a senior designer edition. I hope now, we are talking with senior front end developer. The Game of Roles now is somewhat more just a training for developers. It’s a framework for helping people grow no matter which role you would like to grow in.
And the good part about it is that the framework itself doesn’t change. It’s still a marathon, it’s still online, it’s still group. What changes is just the relevancy of tasks you are going to present. For example, if you want to teach people to become a team leader, then of course, you need to focus more about how to give feedback, how do you manage performance, all those kind of things. We were making more offline activities to them in a group, they were working together, whatever, to train the feedback and something like that. But the key framework didn’t change.
What I wanted to end with, I want to repeat again this nice quote, “Change is disturbing when it’s done to us, but exhilarating when it’s done by us.” When you are being told by someone, you think, “This is obligatory. The person teaches me. All right.” But you can receive it well, you can receive it not that well. But whenever you teach on your own, with your own peers and colleagues, you start changing and start behaving differently, much faster.
So what I want from you from this talk – I don’t want you to implement exactly Game of Roles or I don’t want you to do something, like start and change the way you learn. But I want you to not wait for someone to make training for you. If you feel that there is a need in your organization for this sort of activities, if you feel that there is lack of clarity of how to become senior developer, how to get promoted, act on it, change this way. You don’t have to be a trainer. You don’t have to be a certified whatever, master, blah. You can do it as a developer. You can do it on your spare time Just be proactive. And if set up right, people are able to help themselves. If you make the environment that will help people grow, people will grow. And I think it will be even more beneficial because you are not an authority to them; you’re yet another developer who wants to help yet another developer. So by doing this, you will help yourself grow and you will help other people grow, which is just much better.
How to Create Game of Roles
And that’s how you can create the Game of Roles. Find a partner. That’s really important that you find somebody who will help you to set it up, because first of all, this person will keep you challenged, this person will keep you motivated, this person will help you not slack off in the middle of this preparation. And of course, it’s easier for you to handle all of this, you can distribute the load. Go online. I think it’s a much better idea to help people learn on their own pace through the platform they would like to be on, not in the classroom. Also you don’t have to have a classroom in your organization, you can go online.
Marathon, that’s important. That’s really important because if you want to obtain a new habit, you have to do this for 21 days. So by this, by training, spend two weeks or maybe three weeks, you will create the habit for people to actually do something more they are not used to do. Make it as work as group. Find moderators to help you with. Define small practical tasks which are relevant to your organization, to your definition of what senior is. Don’t ask people to complete everything. We are not perfectionists. We are there to learn. We are not there to compete to each other. Give them time to rest, give them time to catch-up. And always collect feedback; what do they think you are doing good, and what do you think they can learn more.
That is it. This QR code is linked. There are tasks which we created to our training. So you can just have it as an inspiration, but of course, they probably will not be applicable to your organization, but as a reference. You can connect with me on Facebook, on Twitter, wherever.
Questions and Answers
Moderator: How small of a group you think you could have?
Mogelashvili: I’d say 10. Assuming that half of them will just do nothing. You still want to have some people contributing to the activities. Because if you make a group of five and you say three of them will bail out, then there are only two person. And two persons will not learn much from each other, then you can just set up a meeting with them. So I would say 10 might be an okay number.
Moderator: Five active participants.
Mogelashvili: Yes, something like that. As long as you can have a constant sharing and communication within the group.
Participant 2: Do you think that one person because we’re ready for the promotion, but not so many promotions are available? Did you observe that thing also? Everybody is now trained and they’re all ready for senior positions.
Mogelashvili: No. Unfortunately. So as I said, we are not training to become seniors. We are giving them opportunity to understand what the role is about, and then it’s up to them if they want to continue acting as senior developers or not. So I think out of the statistics, 30% of people got promoted since they first participated in the training. Again, I cannot say if that’s related to what we did or just the way they were doing things. You cannot clearly say, “Hey, go to our training and then you’ll get promoted.” You should never say that because then you will put yourself in a pretty bad station if they didn’t get promoted.
What we were saying is just, “Hey, you can go to this training to understand what this role is about and maybe you can understand if it’s not for you.” Because I had a feedback from a person from the team leader training, who said after the training that, you know, “I now understand what team leading is about and I don’t want to become a team leader.” This is the perfect feedback. This is the perfect scenario. I like this because if the person would become a team lead and understand this after being in a role for a while, it would be much more destructive for them and for his team. So it’s better to figure it out early.
Participant 3: I share your enthusiasm for how much you can learn from other people’s experience. So it made me wonder, going back to your childhood beginning where you’ve got these two separate branches of the management in technical careers, do you think there is scope for doing this so that the management branch do a task with the people in the technical branch at the same levels? So you haven’t got the hierarchy thing, but so that they can learn about each other’s jobs and understand those issues from a different perspective.
Mogelashvili: That’s a good suggestion. I didn’t think about it. Well, the way we put the training was to actually give you clarity about your future role and we didn’t think about that, “Hey, maybe managers would be interested in becoming seniors and the vice versa.” I can’t answer you right now. I think I will take it as a suggestion, not as a question, if you please, because I don’t know how to answer that right now. I need to give it a thought.
Participant 4: So in this framework we’ve got eight tasks. How much thought do you put into selecting those tasks and into picking the habits or traits you want to train? And can you talk about the process?
Mogelashvili: Yes. As I said in one of the slides, we had only three. I think we had three meetings regarding what do we want to put there. So the first meeting we had, it was only me and Denis. And we were just framing out and drafting what we want them to ask. But later on, we shared this idea with other senior people and with principal developers. At the brainstorm session we had six or seven people in the room, seniors and principals, thinking of what we could ask our people, what would be the most beneficial thing to ask to help them grow. So we were selecting those things and focusing on communication, craftsmanship, what we also call commercial awareness. So those things which we care about while promoting people. So we wanted to cover all of those topics. We focus more on soft skills and hard skills going beyond their responsibility. So we had I think maybe three, four meetings together to kind of brainstorm what we wanted to ask.
Participant 5: When you organize a group, so what kind of member do you think is the most efficient? You have to come with different roles and, you know, you don’t have HR, right? So you have architecture, a senior, and a team leader, or something. How do you pick, I think, this kind of member, the most efficient in the group?
Mogelashvili: First come, first serve. So we announced that, “the new training will happen on date X.” So people could just sign in to be there. The only thing we had as a restriction that you have to work at booking.com for a year because we think that during the year, you will just get more knowledge. Sorry. Six months. Anyway, it doesn’t matter. We wanted people, not just the fresh starters, but somebody who already spent some time working at Booking to understand how the culture works, how everything works. So we think that it’s the right time they can think about their promotion. And then whoever signs in, everybody is welcome. So we didn’t handpick people who want to train.
Participant 5: For example, they have at big companies, they have different teams, engineering teams. So different teams probably have different requirements for certain rules. Basically, how do you more efficiently treating your members, like, your club members?
Mogelashvili: No. At Booking we have team leads and senior developers, and all the other roles are defined, so that they can be interchangeable. So there are no senior developer payments. There are no senior development bookings. Every senior developer has the same profile same with the team leader. We don’t have to choose between what type of senior or what type of team lead you need to be trained. It’s just generic team leader, generic senior developer.
Participant 6: They are all backend developers already? It’s not that you mix different technical people with different …
Mogelashvili: No. We started with backend developers because I’m a backend that just understands what that does it mean, but basically we are now talking with front end people because behaviors are mostly the same. It’s just maybe some technical things we should change a little bit.
Participant 6: But you don’t set task, like, more technical tasks between those eight?
Mogelashvili: When we set technical tasks, we were focused on backend developers. So that’s why we didn’t mix people together because we could only come up with technical backend tasks, not front end.
Participant 7: How did you choose who your moderators were? Or was it just open to anyone who wanted them?
Mogelashvili: We were begging them. The trick is that, as I said, it’s really hard to measure the value of this, and by this, it’s really hard to get people onboard because they question, “What’s in it for me?” And we say, like, “You will teach people.” And they’re like, “Why?” “Because it’s good.” “Can you show me numbers?” “No.” “I’ll think about it.” So the usually response is, “You are doing great, but I have other things to do.” So we were really chasing people to help us with moderating things. We would really lucky in the first round because it was a fresh new thing. People didn’t know what to expect, many people jumped onboard. Later on, it’s only me now.
See more presentations with transcripts
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Diving into the many underlying trends throughout the entire 1.5 Billion rows of NYC Taxi data with Pivot Billion
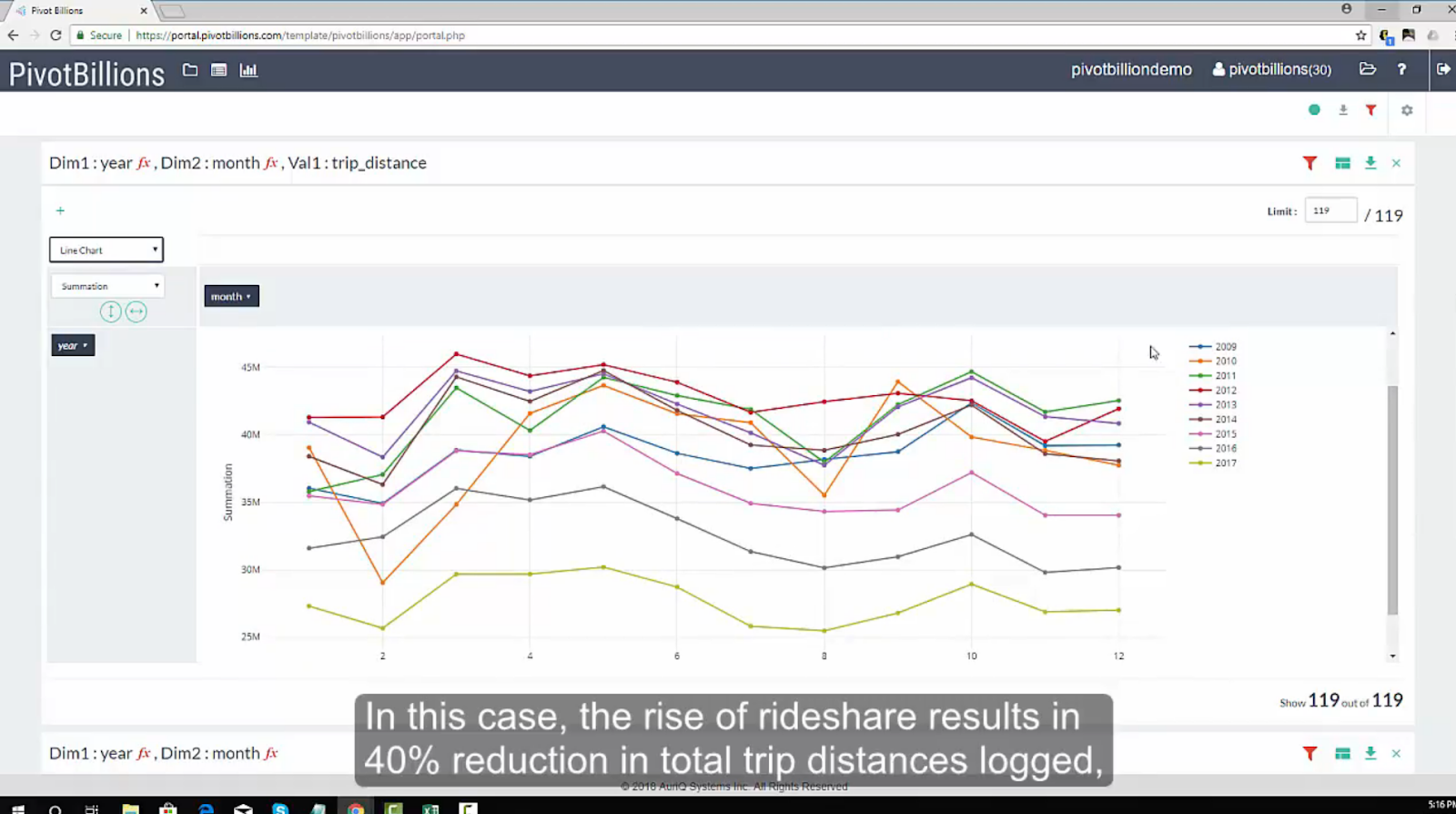
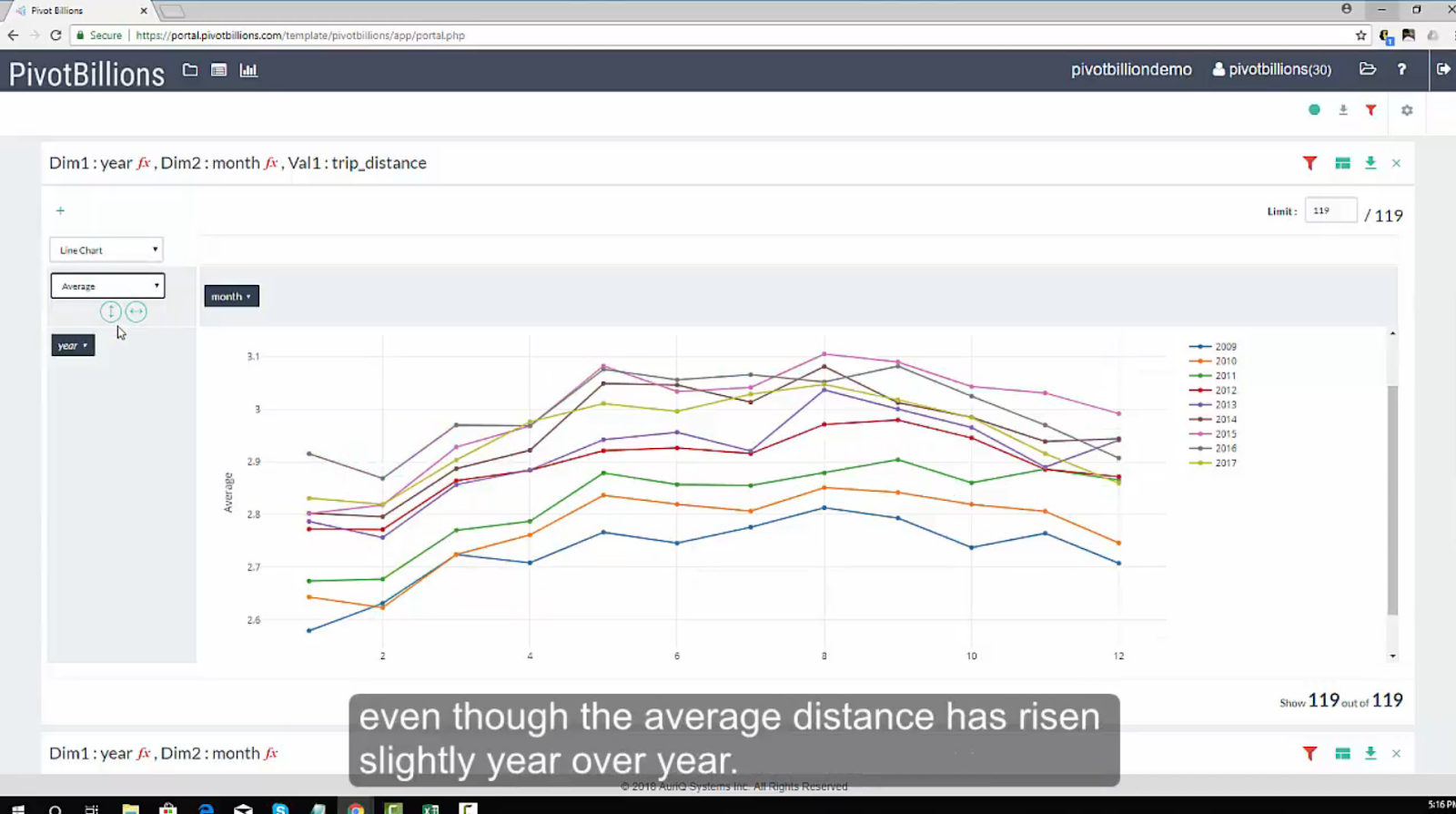
The age of data has arrived. With it, more and more datasets are created and they just keep getting bigger. Whether dealing with private or open data, individuals and organizations across the world are realizing that there are enormous amounts of information and insights to be gained from massive data. I wanted to dive into one of these accumulated datasets, the public NYC Taxi and Limousine Commission Trip Record Data, to explore passenger and taxi trends over the years. I decided to use Pivot Billions to analyze the data due to its scalability to handle massive datasets.
Using Pivot Billions, I took the over 208 compressed csv files to load 1.5 Billion rows of data into 170 Amazon c4.large instances in 3 minutes. Now that the data was loaded, I explored the data using Pivot Billions’ reorganization and transformation features. One thing I noticed right away is the data had tip and total taxi cost as separate columns. It’s more useful to compare percentages so I created a new tip percent metric from those columns using Pivot Billions’ f(x) function (took about 4 seconds). Another messy data property I noticed was overlapping payment type codes. As seen in the following column distribution, the codes were modified over the years and came in both cases as well as abbreviated and even numeric.
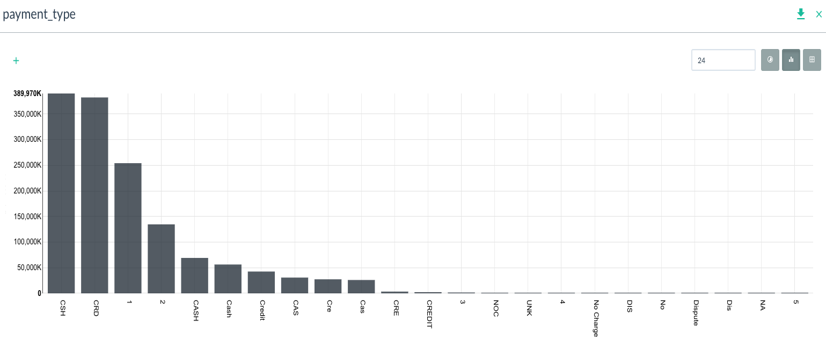
I quickly applied a lookup table in Pivot Billions to create a new, cleaner transformed column called PayType. Now that my data was clean and enhanced enough to draw some meaningful insights, I simply pivoted my data to get the number of taxi trips and taxi payment statistics by PayType, year, and tip_percent.
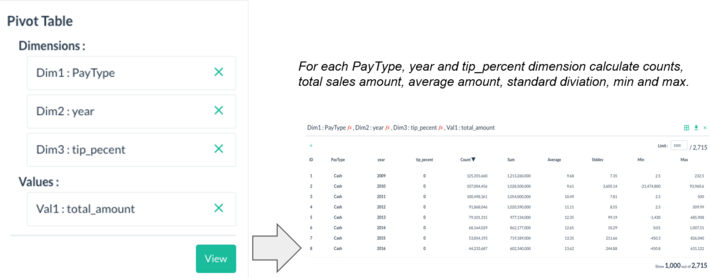
By entering Pivot Billions’ PivotView, I visualized the data using a heatmap to compare the distribution of tips for cash and credit card passengers.
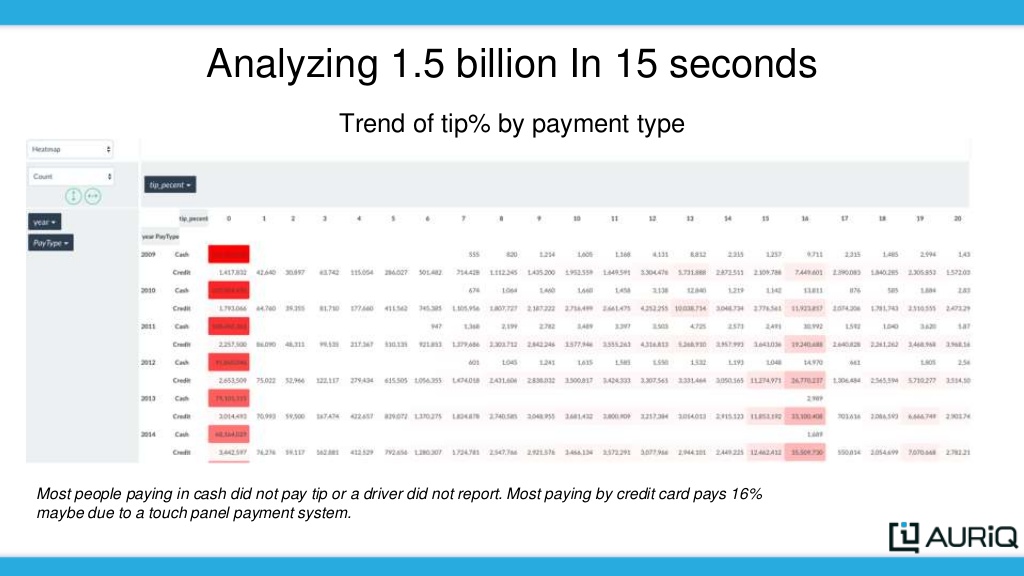
It was immediately clear that people paying in cash generally did not pay a tip or, more likely, the driver did not report a tip. However, credit card users typically paid ~16% tip, possibly due to the ease of the taxis’ touch panel payment system for credit card users.
Now that I understood a bit more about passenger and taxi tip behavior I wanted to see if I could find any other trends underlying the data. Quickly pivoting the data again to view the number of trips and trip distance statistics by year and month, I started to draw some new insights. By visualizing the data as a LineChart in PivotView and comparing the total trip distances by year to the average trip distances by year, I noticed an interesting discrepancy.
Though the total trip distances were decreasing year over year, the average distances were rising slightly. The growing popularity of ridesharing in recent years is likely responsible for this trend, a nearly 40% reduction in total trip distances logged from 2009 to 2017.
By incorporating the rideshare data from the NYC Taxi and Limousine Commission Trip Record Data , and doing a quick comparison of total 2015 -2018 trips in the months of January, it shows a pretty remarkable shift in the riding habits in NYC.
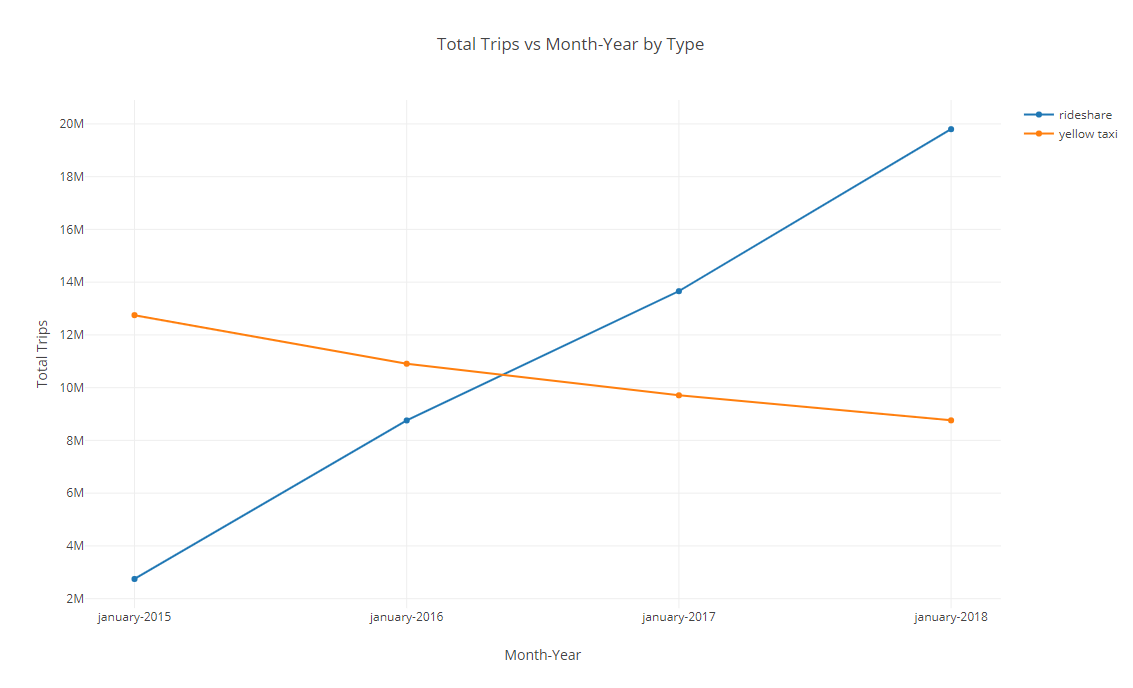
This chart seems to validate the underlying trend surmised in the prior analysis, that rideshare growth has eroded yellow taxi ridership by nearly 40%.

MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Microsoft recently expanded its Microsoft Learn platform with an introductory class on Azure Government. Azure Government is Microsoft’s solution for hosting United States government solutions on its cloud.
Government services have unique requirements in terms of security and compliance. On the other hand, cloud solutions can provide scale, elasticity and resilience that is not easy to be achieved with on premises solutions. Microsoft Azure Government is a completely separate on a physical level instance of Azure. Available in eight U.S. regions, namely Chicago, Dallas, New York, Phoenix, San Antonio, Seattle, Silicon Valley, and Washington DC it is specifically built for the U.S. government needs. As such, it follows numerous compliance standards, from both the U.S. and abroad (E.U., India, Australia, Chine, Singapore and others). Some of the compliance standards are Level 5 Department of Defence approval, FedRAMP High and DISA L4 (42 services) and L5 (45 services in scope).
{kind=link}
Azure Government comes with its own marketplace, which is different than the Azure global marketplace. The main difference is that it supports a different set of images. Another difference is that only Bring Your Own License (BYOL) and Pay-as-you-Go (PayGo) images are available. Azure Government comes with its own blog, extensive documentation and offers a 90-days free trial of up to $1500.
Azure Government is competing head on head with Amazon AWS GovCloud US. GovCloud US is similar to AWS, available in two US regions (US-East and US-West) and offers its own marketplace.. AWS GovCloud US is supporting a similar set of compliance standards as Azure Government, with support for standards such as FedRAMP, DoD CC SRG IL2, IL4 and IL 5, Criminal Justice Information Services (CJIS), International Traffic and Arms Regulations (ITAR) and others. Govcloud US supports a wide range of AWS services. Both clouds are available not just to federal agencies and ministries, but also to state and locally based agencies, which would benefit quite a lot by moving their workflows to Azure Government or AWS GovCloud.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The next release of F#, F# 4.6, will most notably bring anonymous record types and structs to the language, along with a few additions to the standard library.
Anonymous record types remove the need to provide a name for a record type and bring a bit of structural typing to an otherwise strictly nominal language.
Although they are unlikely to fundamentally change how you write F# code, they do fill many smaller gaps F# programmers have encountered over time, and can be used for succinct data manipulation that was not previously possible.
The following snippet shows how to define and call a function that takes an anonymous record and how equality works:
let foo (args: {| a: Int; b: Int |}) =
...
foo {| a=2; b=4 |}
{| a = 1+1 |} = {| a = 2 |} // true
{| a = 1+1 |} > {| a = 1 |} // true
{| a = 1+1 |} = {| a = 2; b = 1|} // error, record type mismatch
It is worth noting that anonymous records are at their heart still nominal types and thus do not support structural sub-typing. This has the effect that pattern matching cannot be used over them.
As mentioned, you can also define anonymous structs, which differ from records in that they are allocated on the stack, using the struct {| ... |} syntax. Two anonymous records or structs are recognized as belonging to the same type only if the label fields match exactly. For example, a copy-and-update expression will generate a different anonymous record type:
let data = {| X = 1; Y = 2 |}
let expandedData = {| data with Y = 3 |} // {| X:Int; Y:Int |}
let expandedData' = {| data with Z = 3 |} // {| X:Int; Y:Int; Z:Int |}
You can also extend a normal record into an anonymous record:
type R1 = { X: int }
let r1 = { X=1 }
let data1 = {| r1 with Y=1 |} // {| X:Int; Y:Int |}
One useful use of anonymous record types is when serializing/deserializing lightweight JSON data, since an anonymous record type definition can be used as a type specification:
let networkData = "{"age":28,"name":"Phillip"}"
let person = JsonConvert.DeserializeObject<{|name: string; age: int|}>(str)
Another scenario where anonymous record types will simplify F# syntax is with record types that are mutually recursive, as the following example shows:
type FullName = { FirstName: string; LastName: string }
type Employee =
| Engineer of FullName
| Manager of {| Name: FullName; Reports: Employee list |}
| Executive of {| Name: FullName; Reports: Employee list; Assistant: Employee |}
In F# 4.5, you would use the following syntax with named record types:
type FullName = { FirstName: string; LastName: string }
type Employee =
| Engineer of FullName
| Manager of Manager
| Executive of Executive
and Manager = { Name: FullName; Reports: Employee list }
and Executive = { Name: FullName; Reports: Employee list; Assistant: Employee }
On the standard library front, F# 4.6 includes the following improvements:
-
ValueOptions, struct-basedOptiontype introduced in F# 4.5, is now on-a-par with theOptiontype thanks to support forDebuggerDisplay,IsNone,IsSome,None,Some,op_Implicit, andToString. -
List,Array, andSeqsupporttryExactlyOnemethod, which works likeexactlyOnebut returning an option type wrapping the only element of the collection orNoneif zero or more than one elements are present.
F# 4.6 is available in Visual Studio 2019 Preview 2 and requires the .NET SDK 2.1.6xx or 2.2.6xx preview of the .NET SDK.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
At VueConf Toronto, Evan You, creator and project lead of Vue.js, previewed Vue 3, the next major iteration of the Vue.js framework.
Vue is a progressive framework for building user interfaces, including single-page applications. The current Vue 2 release brought performance improvements in the form of a smaller library, and a faster, lighter-weight Virtual DOM implementation, forked from Snabbdom, in addition to server-side rendering.
The planned Vue 3 release goes further along these lines and aims at providing an ever smaller and more performant Vue and better developer experience.
Size improvements are to be reached by the combination of greater code modularity, a smaller core runtime, and a tree-shaking-friendly compiler. The new core would thus be reduced from about 20KB to 10KB gzipped. You explains:
The compiler will generate tree-shaking-friendly code. If you use a feature that requires a function in your template, the compiler will automatically generate code that imports it. But if you don’t use a feature, then we generate code that does not import it, which means the feature will be tree-shaken.
Beyond performance improvements through a smaller core, Vue 3 also touts speed improvements. You plans a complete rewrite of the virtual DOM implementation, with the objective to lead to 100% faster mounting and patching of virtual DOM nodes into the real DOM tree. Mounting of virtual nodes is the operation by which virtual nodes are displayed in a specific location on screen. Patching involves comparing virtual DOM nodes representing the target DOM tree, with the actual DOM tree. The objective is to compute a list of changes that transform the actual DOM nodes so that the updated DOM tree matches exactly the targeted virtual one. Among the techniques which would enable faster virtual DOM operations are the compiling of view templates into functions whose source code can be better optimized by the JavaScript compiler.
You mentions, as techniques of significant interest for Vue 3, fast component paths, monomorphic calls, children type detection, optimized slots generation, and hoisting and inlining of static parts of the component tree. Performance at runtime is further improved by switching the current observation mechanism (based on property getters and setters implemented with Object.defineProperty) towards using a proxy-based mechanism. The new mechanism traps update operations on objects, leveraging ES2015 proxies natively implemented in modern browsers. Benchmarks show this improvement potentially doubling the speed while slashing memory usage by half. IE11, which does not implement proxies natively, will still be supported by falling back on the current observation mechanism.
ES2015 is now becoming more universally available in browsers, once we take advantage of that, and explore the opportunity of using ES2015 proxies to reimplement our observation mechanism, the results are actually fantastic : we get full coverage, we get rid of a bunch of caveats in the current vue change detection system (…) it results in better performance.
Vue aims to improve developer experience with version 3 getting rewritten in TypeScript with TSX support. TSX is the TypeScript enhanced version of JSX used by React developers working with TypeScript as well as other projects like Dojo. The switch to TypeScript provides better type checking and useful error messages displayed inside the IDE. The Vue core will also be platform agnostic, making it even easier to target mobile operating systems (iOS, or Android). The debugging cycle should also get shortened as it will be possible to identify what caused a component to re-render.
Experimental features such as a React-inspired Hooks API and Time Slicing Support may also contribute further to a better developer and end-user experience.
Vue.js is available under the MIT open-source license. Contributions are welcome via the Vue.js GitHub package and should follow the Vue.js contribution guidelines.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Testers will sooner or later be asked to test IT-solutions that incorporate blockchain technology. Software development is different for blockchain-based applications; blockchain impacts the way we are used to working, said Sanne Visser, a software tester at Dutch Railways. She spoke about how professionals can deal with blockchain-based software at European Women in Tech.
The first proof of concept at Dutch Railways was a supply chain project where we as a group were inexperienced; for the entire team, it was the first time we were dealing with and figuring out blockchain, explained Visser. They ended up building a minimal viable product (MVP) on hyperledger fabric. Although it worked, Visser claimed it was awful. The main thing that saved them was that they had so much fun along the way, each of them working on it voluntarily, and as such, motivation and spirits were high.
The impact of blockchain on testing is significant mostly because the technology impacts the way we are used to working, said Visser. Each of the usual four stages of software development, development, testing, user acceptance and finally production, is different for blockchain-based applications.
As an example, she mentioned the testing environment where testers control which version of an application is installed and manipulate this to test specific application attributes. With blockchain technology a tester is faced with either no testing environment, or testing on a blockchain “testnet”, that is not in their control, said Visser. And even testnets are dissimilar enough to a blockchain in production in a lot of aspects (such as international distribution of nodes) so that testing some quality attributes, such as performance, is difficult or even (for now) impossible, she argued.
Visser encouraged companies to be very experimental to explore blockchain technology. Wherever possible, allow space for investigating whether blockchain technology can add value to an IT-solution, she said. When there is a chance that an immutable, shared ledger offers an added benefit, build an MVP to see if it works for your business, was her advice.
Visser suggested looking at the ecosystem in which you operate, your business partners, competitors, and customers. She stated, “The reason is that shared ledgers work best when they are exactly that, shared. The best use-cases for this technology go across the company borders.”
InfoQ is covering European Women in Tech with Q&As and summaries, and interviewed Sanne Visser about her experiences with blockchain.
InfoQ: You mentioned in your talk that people find it hard to understand blockchain technology, or only get parts of it. Why is that?
Sanne Visser: People understand new technology in terms of familiar concepts. Very few people can explain how their cell phone works, but basic concepts are familiar, such as processors or wireless signals. In the same way people understand blockchain technology in bits and pieces, my audience will understand peer-to-peer sharing for instance, but be unfamiliar with merkle trees.
What makes blockchain particularly hard to understand is needing to conceive of software acting as a third party. For example, we understand that banks facilitate payments between us and businesses we buy from; to understand blockchain you need to make the leap that it’s not an entity like a bank that facilitates a payment, but software, and this software is called blockchain. That’s a big conceptual change in the way we usually think about transactions and ledgers.
InfoQ: What did you do to introduce and spread knowledge about blockchain in your company, and how did that work out?
Visser: To introduce blockchain, I tried a trusted method first. I held presentations explaining how blockchain works. What I wanted to achieve was to start experimenting with the technology within the company, so I was looking for blockchain project opportunities. The presentations were well received but didn’t get me the result I was looking for. I tried many different ways to reach my goal; I had a booth at an internal IT market, I published on our intranet, and so forth.
In the end what worked best was specifically reaching out to business managers at senior levels, arranging an introduction and then sitting down with them for a cup of coffee. Presentations work well for spreading awareness, but they did not lead to any blockchain projects; the coffee meetings did.
InfoQ: What did you learn from the proof of concept?
Visser: We made so many mistakes, and without expert help we weren’t able to correct or even confirm that we had made mistakes. The main lesson from the first PoC, is that we would have liked to have expert help to steer us away from the worst errors. Just to give an example: we had entire photographs uploading to the blockchain, and I now know you shouldn’t store huge amounts of data like that on a blockchain. The alternative to reaching out for expert help would be to turn to the blockchain development community; unfortunately, this was not an option for us as we had to keep all project details incompany.
InfoQ: How does blockchain technology impact the testing profession?
Visser: I think software testers, sooner or later, will be asked to test IT-solutions that incorporate blockchain technology, and that the number of blockchain testing projects will grow. There are some good resources for blockchain testers, but they are scattered and hard to find. I want to develop a testing framework for dealing with blockchain-based applications, that combines all the best efforts already out there and hopefully add to them.
Also, I want to form a blockchain testing group to share this knowledge to benefit the entire testing community. I recently received the EuroSTAR Rising Star award; 32 supporters have committed to support me with a half-day of their time. In the next year, I will use that support to help me develop a workshop with a demo-blockchain environment, allowing me to teach testers about the technology, and to let them experiment with ways it might be tested.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
This article was written by Sondos Atwi.
What is Cross-Validation?
In Machine Learning, Cross-validation is a resampling method used for model evaluation to avoid testing a model on the same dataset on which it was trained. This is a common mistake, especially that a separate testing dataset is not always available. However, this usually leads to inaccurate performance measures (as the model will have an almost perfect score since it is being tested on the same data it was trained on). To avoid this kind of mistakes, cross validation is usually preferred.
The concept of cross-validation is actually simple: Instead of using the whole dataset to train and then test on same data, we could randomly divide our data into training and testing datasets.
There are several types of cross-validation methods (LOOCV – Leave-one-out cross validation, the holdout method, k-fold cross validation). Here, I’m gonna discuss the K-Fold cross validation method.
K-Fold basically consists of the below steps:
- Randomly split the data into k subsets, also called folds.
- Fit the model on the training data (or k-1 folds).
- Use the remaining part of the data as test set to validate the model. (Usually, in this step the accuracy or test error of the model is measured).
- Repeat the procedure k times.

How can it be done with R?
In the below exercise, I am using logistic regression to predict whether a passenger in the famous Titanic dataset has survived or not. The purpose is to find an optimal threshold on the predictions to know whether to classify the result as 1 or 0.
Threshold Example: Consider that the model has predicted the following values for two passengers: p1 = 0.7 and p2 = 0.4. If the threshold is 0.5, then p1 > threshold and passenger 1 is in the survived category. Whereas, p2 < threshold, so passenger 2 is in the not survived category.
However, and depending on our data, the 0.5 ‘default’ threshold will not alway ensure the maximum the number of correct classifications. In this context, we could use Cross-validation to determine the best threshold for each fold based on the results of running the model on the validation set.
In my implementation, I followed the below steps:
- Split the data randomly into 80 (train and validation), 20 (test with unseen data).
- Run cross-validation on 80% of the data, which will be used to train and validate the model.
- Get the optimal threshold after running the model on the validation dataset according to the best accuracy at each fold iteration.
- Store the best accuracy and the optimal threshold resulting from the fold iterations in a dataframe.
- Find the best threshold (the one that has the highest accuracy) and use it as a cutoff when testing the model against the test dataset.
To read the full article, click here.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Summary: Not enough labeled training data is a huge barrier to getting at the equally large benefits that could be had from deep learning applications. Here are five strategies for getting around the data problem including the latest in One Shot Learning.

A 2016 study by Goodfellow, Bengio and Courville concluded you could get ‘acceptable’ performance with about 5,000 labeled examples per category BUT it would take 10 Million labeled examples per category to “match or exceed human performance”.
Any time there is a pain point like this, the market (meaning us data scientists) responds by trying to solve the problem and remove the road block. Here’s a brief review of the techniques we’ve introduced to help alleviate this, concluding with ‘One Shot Learning’, what that really means and whether it actually works.
Active Learning
Active learning is a data strategy more than a specific technique. The goal is to determine the best tradeoff between accuracy and the amount of labeled data you’ll need. Properly executed you can see the increases in accuracy begin to flatten as the amount of training data increases and it becomes an optimization problem to pick the right point to stop adding new data and control cost.
You can always employee your own manpower to manually label additional training images. Or you might try a company like Figure 8 that has built an entire service industry around their platform for automated label generation with human-in-the-loop correction. Figure 8 is a leading proponent of Active Learning and there’s a great explanatory video here.
New data can be labeled in one of two ways:
- Using human labor.
- Using a separate CNN to attempt to predict the label for an image automatically.
This second idea of using a separate CNN to label unseen data is appealing because it partially eliminates the direct human labor, but adds complexity and development cost.
The folks at the Stanford Dawn project for democratizing deep learning are working on several aspects of this including their open source application Snorkel, for automated data labeling.
Whether you use humans or machines, there will need to be a process for humans to check the work so that the new data doesn’t introduce errors into your models. All things considered, if you’re building a de novo CNN at scale, you should incorporate Active Learning in your data acquisition strategy.
Transfer Learning

Then we retrain the new hybrid TL with your problem data which can be remarkably successful with far less data. Sometimes as few as 100 items per class but 1,000 is a more reasonable estimate.
Transfer Learning services have been rolled out by Microsoft (Microsoft Custom Vision Services, https://www.customvision.ai/, and Google (in beta as of last January Cloud AutoML) as well as some of the automated ML platforms.
One Shot Learning – Facial Recognition
There are currently at least two versions of One Shot Learning, the earliest of which addresses a facial recognition problem – suppose you have only one picture of an individual, an employee for example, how do you design a CNN to determine if that person’s image is already in your file when they present their face for scanning to gain access to whatever you’re trying to protect. In practice it works for any problem where you need to determine if the new image matches any image already in your database. Have we seen this person or thing before?
Ordinary CNN development would require retraining the CNN for each new employee to create a correct classifier for that specific person, because the CNN does not retain weights that can be applied to new unseen data it means basically training from scratch. It’s easy to see this would be a practical non-starter.
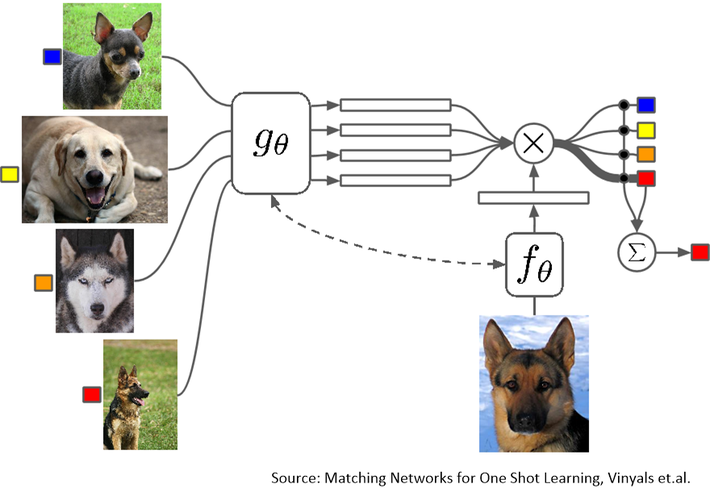
The original CNN is a fully trained network but lacks the classifier layer.
The second CNN analyzes the new image and creates the same dense vector layer as the original CNN.
The ‘similarity’ function compares the new image to all available stored image vectors and derives a similarity score (aka discriminator or distance score). High scores indicate no match and low scores indicate a match.
Although this is called a ‘One Shot’ learner, like all solutions in this category it works best with a few more than one, perhaps more like five or ten in the original CNN scoring base. Also, this approach solves for a specific type of problem comparing images but does not create a classifier required for more general problem types.
One Shot Learning – With Memory
In 2016 researchers at Google’s Deep Mind published a paper with the results of their work on “One Shot Learning with Memory Augmented Neural Networks” (MANN). The core of the problem is that deep neural nets don’t retain their node weights from epoch to epoch and if they could then the researchers reasoned they would be able to learn intuitively, more like humans.
Their system worked, using feed forward neural nets or LSTMs as the controller married to external memory storage at each node level.
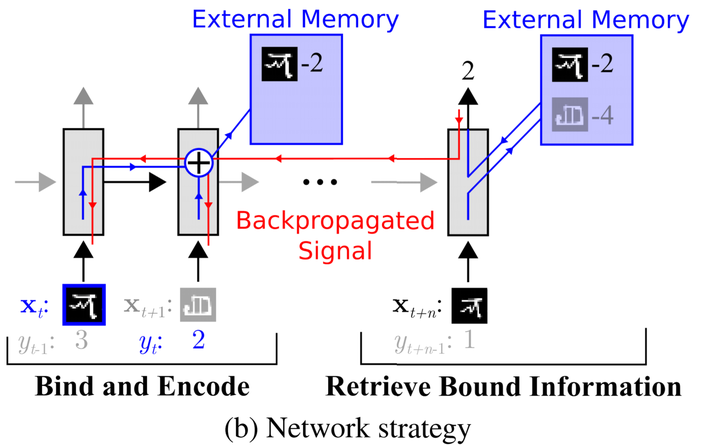
The MANN was then trained over more than 10,000 episodes with about 1600 separate classes with only a few examples each. After some experimental tuning the MANN was achieving over 80% accuracy after having seen a class object only four times, and over 95% accuracy having seen the class object ten times.
Where this has proven valuable is for example in correctly classifying hand written numbers or characters. In a separate example a MANN trained on numbers (the MNIST database) was repurposed to correctly identify Greek characters that it had not previously seen.
This may sound experimental but in the last two years it’s now possible to implement this fairly simply with the ‘one shot handwritten character classifier’ in Python.
GANNs – Generative Adversarial Neural Nets
Correctly classifying unseen objects based on only a few examples is great but there’s another way to come at creating training data and that’s with GANNs.
You’ll recall that this is about two neural nets battling it out, one (the discriminator) trying to correctly classify images and the second (the generator) trying to create false images that will fool the first. When fully trained the generator can create images that will make the discriminator identify them as a true image. Voila, instant training data.
You probably know GANNs from their more recent application, creating life like fakes of celebrities doing inappropriate things, or creating realistic images of non-existent people, animals, building, and everything else.
Personally I think GANNs are not quite ready for commercial rollout but they’re getting close. You should think of this as a bleeding edge application that may work out for you and it may not. There’s a lot we don’t yet really know about those generated images.
But Do They Generalize
If you need training data to differentiate dogs from cats, staplers from wastebaskets, or Hondas from Toyotas then by all means to ahead. However, I was asked by a Pediatric Cardiologist if GANNs could be used to create training data of infant hearts for the purpose of training a CNN to identify the various lobes of the tiny heart.
She would then use the inferenced CNN image to guide an instrument into the infant heart to repair defects. She didn’t yet have enough training data based on real CT scans of infant hearts and her application wasn’t sufficiently accurate.
It’s tempting to say that GANN generated images would be legitimate training data. The problem is that if she missed her intended target with her instrument it would puncture the heart leading to death.
Since all of our techniques are inherently probabilistic with both false positives and false negatives, there was no way I was comfortable advising that artificially created training data was OK.
So in all of these techniques from Transfer Learning to One Shot to GANNs, be sure to consider whether the small number of images you are using for training are sufficiently representative of the total environment and what the consequences of error might be.
Other articles by Bill Vorhies.
About the author: Bill is Editorial Director for Data Science Central. Bill is also President & Chief Data Scientist at Data-Magnum and has practiced as a data scientist since 2001. He can be reached at: