Month: June 2019

MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Bayesian Machine Learning (part – 2)
Bayesian Way Of Linear Regression
Now that we have an understanding of Baye’s Rule, we will move ahead and try to use it to analyze linear regression models. To start with let us first define linear regression model mathematically.
Yj = ∑i wj* Xij
Where i is the dimensionality of the data X. j represents the index of input data X. wi are the weights of the linear regression model. Yj is the corresponding output for Xj .
Let us see with an example, how our regression equation looks, let i = 3, which implies,
Yj = w1* x1j + w2* x2j + w3* x3j
Where j is ranging from 1 to N where N is the number of data points we have.
Bayesian Model For Linear Regression
(We will discuss the process of Bayesian modelling in next part, but for now please consider the below model as true)
P(w,Y,X) = P(Y/X, w) * P(w) * P(X) ….. (4)
Or
P(w ,Y ,X) * P(X) = P(Y/ X ,w) * P(w) ….. (5)
Or
P(w, Y/X) = P(Y/X, w) * P(w) ….. (6)
The model shown above is derived from Bayesian model theory, and the equation is from same model. We will see in detail the methodology of Bayesian in coming Posts. For now below is the statement which is derived from the model:
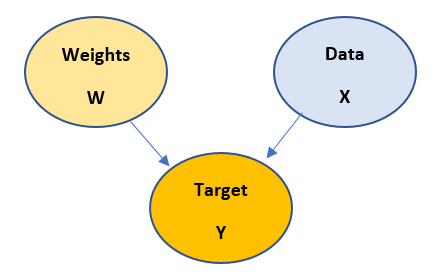
Target Y is dependent on Weights W and input data X. And Weights and Data are independent of each other.
Now let us try to build our Baye’s equation for the above model. We aim at determining the parameters of our model i.e. weights w. Thus the posterior distribution with given Xtrain , Ytrain as data looks like:
P(w / Ytrain , Xtrain) = P(Ytrain / w, Xtrain) * P(w) / P(Ytrain / Xtrain) ….. (7)
Here: Likelihood: P(Ytrain / w, Xtrain)
Prior: P(w)
Evidence: P(Ytrain / Xtrain) = constant, as data is fixed
Now we consider that likelihood is coming from a Normal distribution with mean as wTX and variance as σ2I The probability density function looks like: P(Ytrain / w, Xtrain) ~ N(Y|wTX, σ2I)
We have taken σ2I as identity matrix because of calculation simplicity, but people can take different covariance matrix and that will mean that different dimensions of the data are intercorrelated.
As a prior distribution on w we take Normal distribution with mean = zero and variance = 1. The probability distribution function can be defined as P(w) ~ N(w|0,1)
Now our Posterior distribution looks like: [ N(Y | wT X ,σ2I) * N(w | 0,1) / constant ] – we need to maximize this with respect to w. This method is also known as Maximum A Posteriori.
Mathematical Calculation
P(w/Ytrain , Xtrain) = P(Ytrain / w , Xtrain) * P(w) —- maximizing this term w.r.t w
Taking log both sides-
log(P(w/Ytrain , Xtrain)) = log(P(Ytrain / w , Xtrain)) + log(P(w))
LHS = log(C1 * e( -(y – wTx) ( 2σ2I)-1 (y – wTx)T )) + log(C2 * e(- (w) ( 2γ2 )-1 (w)T ))
LHS = log(C1) – (2σ2 )-1 * || y – wT X||2 + log(C2) – (γ2 )-1 * ||w||2 — maximizing w.r.t w
Removing constant terms as they won’t appear in differentiation
Multiplying the expression by -2σ2 and re-writing we get:
= ||y – WTX||2 + λ2 * ||w||2 — minimizing w.r.t w —- (8)
The above minimization problem is the exact expression we obtain in L2 Norm regularization. Thus we see that Bayesian method of supervised linear regression takes care of overfitting or underfitting inherently.
Implementation Of Bayesian Regression
Now we know that Bayesian model expresses the parameters of a linear regression equation in form of distribution, which we call as posterior distribution. To compute this distribution we have different methodologies, one of which is Monte-Carlo Markov-Chain (MCMC). MCMC is a sampling technique which samples out the points from parameter-space which are in proportion to the actual distribution of the parameter in its space. (I believe readers who are reading this post might not know MCMC at this stage, but don’t worry I will explain it in detail in coming Posts.)
For now I am not going into coding part of the postrior distiribution, as many of the stuff is still not explained by here. I will start posting about coding methodologies when relevant theory will be completely coverd. But if somebody wants to try can follow this link.
https://brendanhasz.github.io/2018/12/03/tfp-regression
In the next post I will explain how to build Bayesian models.
Thanks for Reading !!!
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
The sheer number of model evaluation techniques available to asses how good your model is can be completely overwhelming. As well as the oft-used confidence intervals, confusion matrix and cross validation, there are dozens more that you could use for specific situations, including McNemar’s test, Cochran’s Q, Multiple Hypothesis testing and many more. This one picture whittles down that list to a dozen or so of the most popular. You’ll find links to articles explaining the specific tests and procedures below the image.
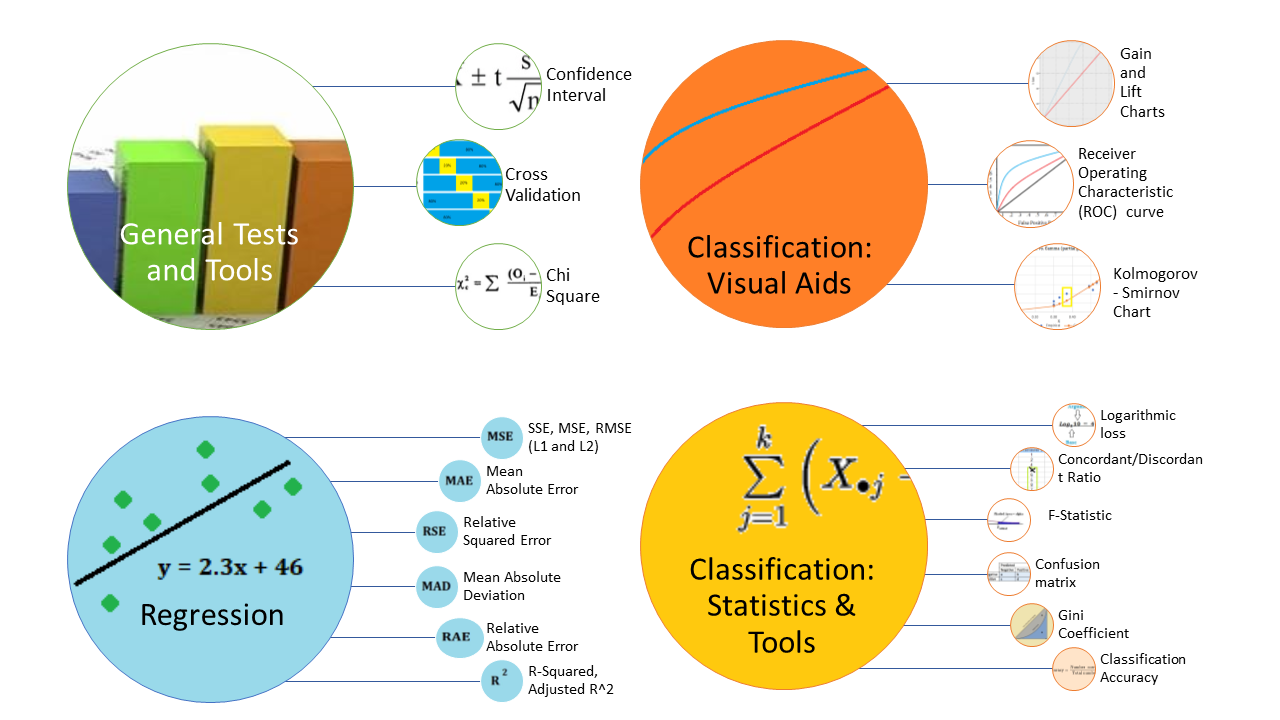
More Info & Further Reading
General:
Regression:
Correlation and R-Squared for Big Data (RMSE L2 version)
R-Squared & Adjusted R-Squared
Classification Visuals:
Understanding And Interpreting Gain And Lift Charts
Classification Statistics and Tools:
References
11 Important Model Evaluation Techniques Everyone Should Know
Introduction to Machine Learning Model Evaluation
Model Evaluation: Classification
Model Evaluation: Regression Models
What is Predictive Models Performance Evaluation and Why it is Important
Gain and Lift Image: Understanding And Interpreting Gain And Lift Charts
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Do you old schoolers remember the Shimmer Floor Waxcommercial from the early (and best) days of the TV show “Saturday Night Live”? In case folks don’t remember (because we are old) or never saw it (because you’re too uncool), the Shimmer Floor Wax commercial asked the question: “Is Shimmer a floor wax or a dessert topping?”

Yes, Shimmer Floor Wax did everything. And that summarizes my frustration with Design Thinkers!
Design Thinkers have bastardized Design Thinking into a concept that presupposes to solve every problem. The over-prescription of Design Thinking as a cure-all for all that ails you is a farce; a lie, a façade, an empty shell. Design Thinking has become both a floor wax and a dessert topping. So, go ahead and kick me out of the Design Thinking “Kool Kids Club.”
My issue with Design Thinkers is that they are not taking the time to understand where and how Design Thinking fits into the overall scheme of things; what role Design Thinking can play in driving towards specific business and organizational outcomes. The fault lies with Design Thinkers who forget that “Design Thinking is not an end in of itself; Design Thinking is a means to an end.”
Design Thinking is a powerful additive that can supercharge outcomes, but it’s critical to understand you use Design Thinking in the context of the outcomes you’re trying to achieve.
Design Thinking Helps Deliver More Relevant Analytic Outcomes
I find that Design Thinking – in the context of identifying, validating, valuing, and prioritizing the business use cases – supercharges our data science envisioning process. Design Thinking not only helps in improving the completeness, effectiveness and relevance of our analytic models, but equally important is the resulting organizational alignment, adoption and buy-in around the analytic results.
Let me share some specifics as to where and how we use Design Thinking in context of our Data Science envisioning process.
Technique #1: Brainstorming Data Science Use Cases
One of my favorite Design Thinking tools is the Customer Journey Map. A Customer Journey Map captures the tasks, actions or decisions that target customers or stakeholders needed to make in the accomplishment of a specific activity (buying a house, fixing a wind turbine, going on vacation, improving on-time deliveries).
We add an economics perspective to the Customer Journey Map to identify the high-value actions or decisions (green arrows) as well as the impediments or hindrances (red arrows) to a successful customer experience (see Figure 1).
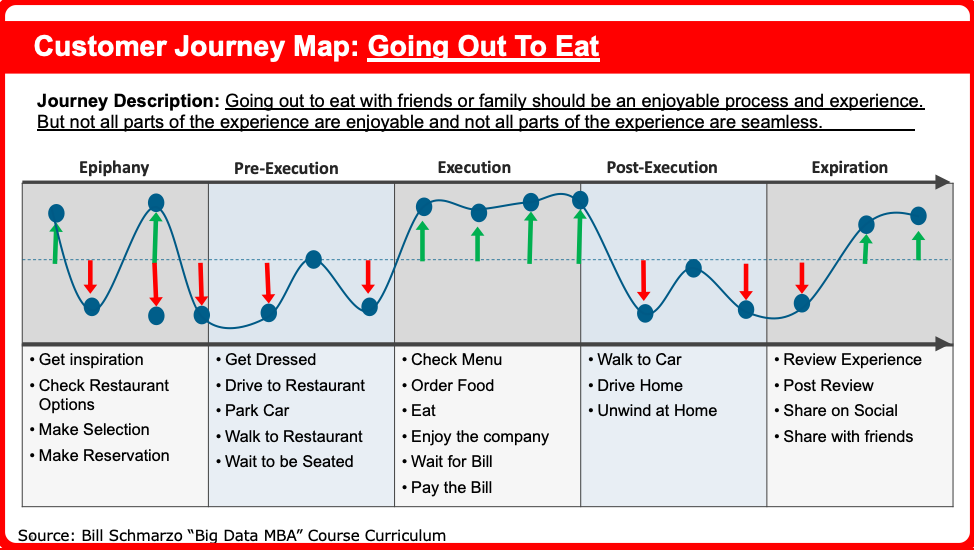
Figure 1: Enhanced Customer Journey Map
Adding the economic dimension (green arrows and red arrows) to the Customer Journey Map enhances the context in which we use the journey map to identify the specific sources of customer, product and operational value creation. Check out the blog “Digital Transformation Law #6: It’s About Monetizing the Pain” for more details.
Technique #2: Prioritizing Use Cases
The Prioritization Matrix facilitates the discussion between key stakeholders in identifying the “right” use cases around which to focus the data science initiative; that is, identifying those use cases with meaningful financial, customer, and operational value as well as a reasonable feasibility of successful implementation (see Figure 2).
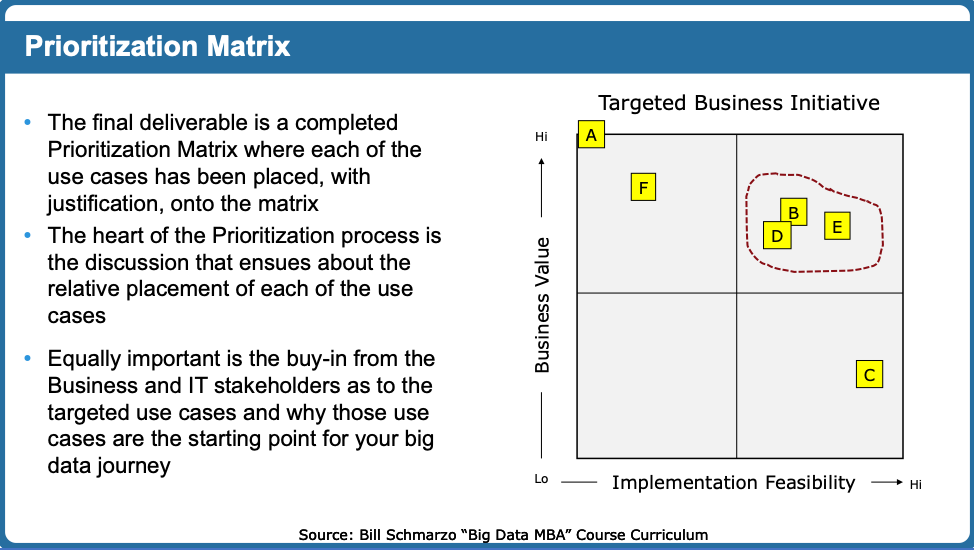
Figure 2: Prioritization Matrix
While the Prioritization Matrix is not a traditional Design Thinking tool, it should be because in many cases, it is the secret sauce for ensuring organizational alignment, adoption and buy-in of the high-value use cases. See the blog “Prioritization Matrix: Aligning Business and IT On The Big Data” for more details on the workings of the Prioritization Matrix.
Technique #3: Uncovering and Scaling Heuristics
Data Science discovers and codifies the trends, patterns, and relationships – the criteria for analytics success – buried in the data. I call these unknown unknowns.
Design Thinking, on the other hand, uncovers heuristics or rules of thumb (e.g., change the oil in your car every 3,000 miles, see the dentist every 6 months) used to support key decisions. Design Thinking uses design tools such as personas, journey maps, and storyboards to tease out these heuristics–the unknown knowns (see Figure 3).
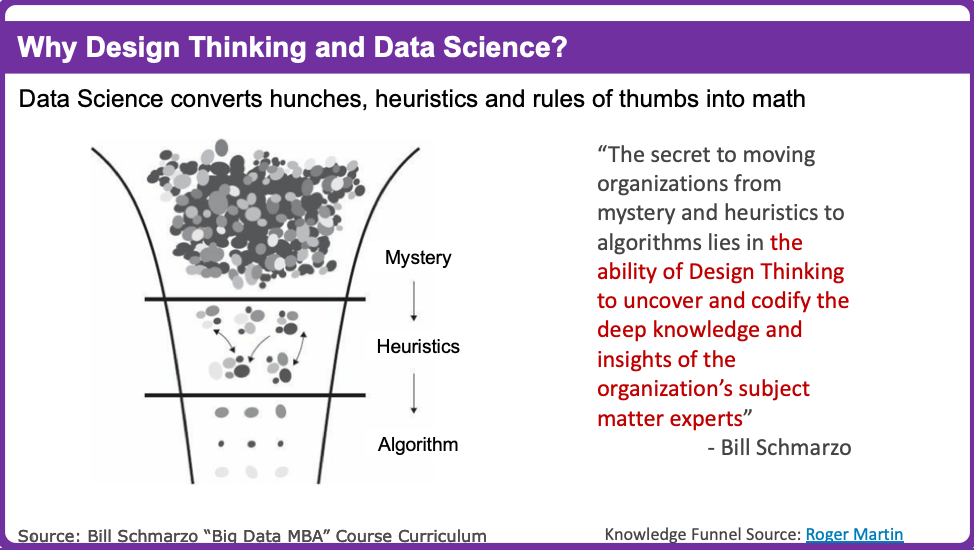
Figure 3: Design Thinking Uncovers Unknown Knowns (Source: Roger Martin)
It is this combination of what’s in the data coupled with what’s in subject matter experts’ brains that lead to delivering more robust analytics. See the blog “Using Design to Drive Business Outcomes, or Uncovering What You” for more details on how to use Design Thinking to uncover Unknown Knowns.
Making Design Thinking Work Summary
So hopefully my opening harsh statements have been balanced with more pragmatic advice about where and how to leverage Design Thinking in context of what you are trying to achieve.
In summary:
- Design Thinking has become the industry’s new “most abused” concept.
- Design Thinking is a means to an end; Design Thinking is not an end.
- Design Thinking accelerates two important outcomes: 1) fuels innovative thinking around identifying, validating, testing, refining and valuing ideas and 2) drives organizational alignment around those ideas.
- Don’t just learn Design Thinking; learn Design Thinking in context of the outcomes you are trying to achieve.
- Finally, Design Thinking is a powerful additive that can supercharge outcomes, but you first must understand towards what outcomes you are driving.
So maybe you’ll allow me back into the Kool Kids Club. Hey, I’ll bring my own Shimmer Floor Wax!
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
About the conference

Many thanks for attending Aginext 2019, it has been amazing! We are now processing all your feedback and preparing the 2020 edition of Aginext the 19/20 March 2020. We will have a new website in a few Month but for now we have made Blind Tickets available on Eventbrite, so you can book today for Aginext 2020.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Last month Microsoft announced Visual Studio Online, an online code editor for the web.
The new service functions as a web-based companion to Visual Studio IDE and Visual Studio Code. Since Visual Studio Online is based on Visual Studio Code, it will provide support for its existing extensions and features. It will also provide support for Visual Studio projects and solutions, along with built-in IntelliCode and Live Share.
Microsoft already had an online product named Visual Studio Online in the past, which concentrated all of its cloud development services. This product was ultimately rebranded as Azure DevOps.
With the new service, Microsoft wants to enable developers to work together from anywhere, on any device. From the official announcement:
Built for productivity while on the go, this solution helps developers perform quick tasks, join Visual Studio Live Share sessions, or perform pull request reviews at times and in places where they may not have access to their development environment.
The announcement is part of Microsoft’s initiative on providing a distributed and collaborative development platform. It follows the release of the Remote Development extensions for Visual Studio Code, which allows the use of a local development environment against a remote target machine – even if they run different operating systems.
Contrary to Visual Studio Code, however, these extensions are not open source since they also support other proprietary products like Visual Studio IDE. This was immediately noted by the community – as Titanous points out:
It’s worth noting that the new VS Code Remote Development extensions are not open source, which means that it is impossible for the community to fix bugs, and add new platforms/environments/features, or see the code that’s running in their environment without reverse engineering.
Visual Studio Online is currently under a private preview, which requires a sign-up process to be able to participate when it is available. There are, however, other open source online editors supporting Visual Studio Code extensions that can already be used. One of the most popular alternatives is Coder, based on Visual Studio Code and available on GitHub. Another alternative (also available on GitHub) is Theia, a joint project between TypeFox, RedHat, IBM, Google, and others.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
This online book is intended for beginners, college students and professionals confronted with statistical analyses. It is also a refresher for professional statisticians. The book covers over 600 concepts, chosen out of more than 1,500 for their popularity. Entries are listed in alphabetical order, and broken down into 18 parts. In addition to numerous illustrations, we have added 100 topics not covered in our online series Statistical Concepts Explained in Simple English. We also included a number of visualizations from our series Statistical Concepts Explained in One Picture, including:
- Bayes Theorem
- Naïve Bayes
- Confidence Intervals
- Three Types of Regression
- Support Vector Machines
- Hypothesis Tests
- Cross-validation
- Assumptions of Linear Regression
- R-squared
- Ensemble Methods
- Logistic Regression
- A/B Testing
- ROC Curve
- Sample Size Determination
- Determining the Number of Clusters
- EM Algorithm
- Azure Data Studio
- K Nearest Neighbors
- Prediction Algorithms
The most recent version of this book is available from this link, accessible to DSC members only.
Download the book (members only)
Click here to get the book. For Data Science Central members only. If you have any issues accessing the book please contact us at info@datasciencecentral.com. To become a member, click here.
About the author
Stephanie Glen is the founder of StatisticsHowTo.com, one of the most popular websites related to statistical education for non-statisticians, and also Editor at Data Science Central. Much of the material in this book points to articles on her website.
Other DSC books
Data Science Central offers several books for free, available exclusively to members of our community. The following books are currently available:
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Poubel: Let’s get started. About six years ago, there was this huge robotics competition going on. The stakes were really high, the prizes were in the millions of dollars, and robots had to the tasks like this, driving vehicles in a disaster scenario kind of thing, handling tools that he would handle in this kind of scenario, and also traversing some tough terrain. The same robot had to do these tasks one after the other and in sequence. There were teams from all around the world competing, and as you can imagine- those pictures are from the finals in 2015 and that was really hard for the time, and they’re still tough tasks for robots to do today.
The competition didn’t start right there straightaway, “Let’s do it with the physical robots”. The competition actually had a first phase that was inside simulation. The robot had to do the same thing in simulation. They had to drive a little vehicle inside the simulator, they had to handle tools inside the simulator just like they would handle later on in the physical competition, and they also had to traverse some tough terrain. The way that the competition was structured is that the teams that did the best in this simulated competition, they would be granted a physical robot to compete in the physical competition later, so teams that couldn’t afford their own physical robots or they didn’t have the mechanical design of their own robots, they could just use the robots that they would get from the competition.
You can imagine the stakes were really high; these robots cost millions of dollars, and it was a fierce competition in a simulation phase as well that started in 2013. Teams were being very creative with how they were solving things inside the simulation and some teams had very interesting solutions to some of the problems. You can see that this is a very creative solution, it works and it got the team qualified, but there is a very important little detail. It’s that you can’t do that with the physical robot. Their arms are not strong enough to withstand the robot’s weight like that, the hands are actually very delicate so you can’t be banging it on the floor like this.
You would never try to do this with the physical robot, but they did it in stimulation and they qualified to compete later on with the physical robot. It’s not like they didn’t know. It’s not like they tried to do this with the real robot and they broke a million dollar robot, they knew that there is this gap between the reality of the simulation and the reality of the physical world, and there will always be.
Today, I’ll be talking to you a little bit about this process of going from simulation to the real life, to the real robot, environment, interacting with the physical world. Some of the things that we have to be aware when we are doing this transition and when we are training things and simulation and then to put the same code that we did in simulation inside the real robots. We have to be aware of the compromises done during the simulation, we have to be aware of the simplifying assumptions that were done while designing that simulation.
I’ll be talking about this in the context of the simulator called Gazebo, which is where I’m running this presentation right now, which is a simulator that has been around for over 15 years. It’s open source and free, people have been using it for a variety of different use cases all around the world. The reason why I’m focusing on Gazebo is that I am one of the core developers and I’ve been one of the core developers for the past five years. I work at Open Robotics, I’m a software engineer, and today, I’ll be focusing on Gazebo because of that. This picture here is from my master thesis back when I still dealt with physical robots, not so much with robots that are just virtual inside the screen. I’ll be talking a little bit also later about my experience when I was working on this and I also would use simulation then I went to the physical robot.
At Open Robotics, we work on open source software for robots, Gazebo is one of the projects. Another project that we have that some people here may have heard of is ROS, the robot operating system, and I’ll mention it a little bit later as well. We are a big team of around 30 people all around the world, I’m right here in California in the headquarters. That’s where I work from and all of us are split between Gazebo and ROS, and some other projects and everything that we do is free and open source.
Why Use Simulation?
For people here who are not familiar with robotics simulation, you may be wondering why, why would you even use simulation? Why don’t you just do your whole development directly in the physical robot since that’s the final goal, you want to control that physical robot. There are many different reasons, I selected a few that I think would be important for this kind of crowd here who are interested in AI. The first important reason is you can get very fast iterations when dealing with a simulation that is always inside your computer.
Imagine if you’re dealing with a drone that is flying one kilometer away inside a farm, and every time that you change one line of code, you have to fly the drone and the drone falls and you have to run and pick it up, and fix it, and then put it to fly again, that doesn’t scale. You can iterate on your code, everybody who’s a software engineer knows that you don’t get things right the first time and you keep trying, you can keep tweaking your code. With simulation, you can iterate much quicker than you would in a physical robot.
You can also spare the hardware, but hardware can be very expensive and mistakes can be very expensive too. If you have a one million dollar robot, you don’t want to be wearing out its parts, you don’t want to risk it falling and breaking parts all the time. In simulation, the robots are free; you just reset and the robot is back in one piece. There is also the safety matter, if you’re developing with a physical robot and you are not sure exactly what the robot’s going to do yet, you’re in danger, depending on the size of the robot, depending on what the robot is doing, how the robot is moving in that environment. It’s much safer to just do the risky things in simulation first, and then go to the physical robot.
Related to all of this is scalability, in simulation, it’s free. You can just have 1,000 simulations running in parallel, while for you to have 1,000 robots training and doing things in parallel, that costs much more money. You can have for your team, the whole team would have one robot, then if you have all developers trying to use the same robot, they are not going to move as fast as if they each were working in a separate simulation.
When Simulation is Being Used
When are people using simulation? I think the parts that most people here would be interested in is machine learning training. For training, you usually need thousands and millions of repetitions for your robots to learn how to perform a task. You don’t want to do that in the real hardware for all the reasons that I mentioned before. This is a big one, and people are using simulation, people are using Gazebo and other simulators for this goal. Besides that, there’s also development, people are just good old fashioned, trying to send commands to the robot for the robots to do what he wants, to follow a line, or to pick up an object and use some computer vision.
All these developments, people were doing in simulation for the reasons I said before, but there’s also prototyping. Sometimes you don’t even have the physical robot yet and you want to create a robot in simulation first and see how things work and tweak the physical parameters of the robot, even before you manufacture it. There’s also testing, a lot of people are ready CI in their robots, like every time you make a change to your robot code and maybe nightly or at every port request, you run that simulation to see if your robot’s behavior is still what it should be.
What You Can Simulate
What can people simulate inside Gazebo? These are some examples that I took from the ignitionrobotics.org website, which is a website where you can get free models for using robotic simulation. You can see that there are some ground vehicles here, all these examples are wheeled, but you can also have legs robots, either bipeds with two leg or quadrupeds, or any other kinds of legged robot. You can see that there are some smaller robots, they are self-driving cars with sensors and some other form factors. There’s also flying robots, both robots with fixed wing or quadcopters, hexacopters, you name it. Some more humanoid-like robots, this one is from NASA, this one is the PR2 robot. This one is on wheels, but you could have a robot like Atlas that I showed before that had legs. Besides these ones, there are also people simulating industrial robots, underwater robots. There are all sorts of robots being simulated inside Gazebo.
It all starts with how you describe your model, all those models that I showed you before, I showed you the visual appearance of the model and you may think, “This is just a 3D mesh.” There’s so much more to it, for the simulation, you need information, all the physics information about the robot like dynamics, where is the center of mass, what’s the friction between each part of the robot and the external world, how bouncy is it, where exactly are the joints connected, are they springy? All this information has to be embedded into that robot model.
All those models that I showed you before are described in this format called the simulation description format, SDF. This format doesn’t describe just the robot, but it describes also everything else in your scene. Everything else here in this world from the visual appearance, from where the lights are positioned, and the characteristic of the lights and the colors, every single thing, if there is wind, if there is a magnetic field, every single thing inside your simulation world is described using this format. It is an XML format, so everything is described with XML tags, so you have a tag for specular color of your materials or you have a tag for the friction of your materials.
But there’s only so far that you can go with XML, sometimes you need more flexibility to put more complex behavior there, some more complex logic. For that, you use C++ plugins, Gazebo provides a variety of different interfaces that you can use to change things in simulation from the rendering side of things, so you can write a C++ plugin that implements different visual characteristics, makes things blink in different ways that you wouldn’t be able to do just with the XML. The same goes for the physics, you can implement some different sensor noise models that you wouldn’t be able to just with the SDF description.
The main language, like programming interface to Gazebo, is C++ right now, but I’ll talk a little bit later about how you can use some other languages to also interact with simulation in very meaningful ways.
Physics
When people think about robot simulation, the first thing that you think about is the physics, how is the robot colliding with other things in the world? How is gravity pulling the robot down? That’s indeed the main important part of the simulation. Gazebo, unlike other simulators, we don’t implement our own physics engine. Instead, we have an abstraction layer that other people can use to integrate other physics engines. Right now, if you download the latest version of Gazebo, which is Gazebo 10, you’re going to get these four physics engines that we support at the moment. The default is the Open Dynamics Engine, ODE, but we also support Dart, Bullet, and Simbody. These are all external projects that are also open source, but they are not part of the core Gazebo code.
Instead, we have this abstraction layer, what happens is that you describe your word only once, you describe your SDF file once, you write your C++ plugins only once, and at run time, you can choose which physics engine you’re going to run with. Depending on your use case, you might prefer to run it with one or the other according to how many robots you have, according to the kinds of interactions that you have between objects, if you’re doing manipulation or if you’re doing more robot locomotion. All these things will affect what kind of physics engine you’re going to choose to use in Gazebo.
Let’s look a little bit at my little assistant for today. This is now, let’s see some of the characteristics of the physics simulation that you should be aware of when you’re planning to user simulation to then bring the codes to the physical world. Some of the simplifying assumptions that you can see are, for example, if I visualize here the collisions of the model- let me make it transparent- you are seeing these are orange boxes here, they are what the physics engine is actually seeing. The physics engine doesn’t care about these blue and white parts, so for collision purposes, it’s only calculating these boxes. It’s not like you couldn’t do with the more complex part, but it would just be very computationally expensive and not really worth it. It really depends on your final use case.
If you’re really interested in the details of the parts are colliding with each other, then you want to use a more complex mesh, but for most use cases, you’re only interested when the robot really bumped into something and for that, an approximation is much better and you gain so much in simulation performance. You have to be aware of this before you put the code in a physical robot, and you have to be aware of how much you can tune this. Depending on what you’re using this robot for, you may want to choose these collisions a little bit different.
Some of the things that you can see here, for example, are that I didn’t put collisions for the finger. The fingers are just going through here. If you’re doing manipulation, you obviously need some collisions for the fingers, but if you’re just making the robot play soccer, for example, you don’t care about the collisions of the fingers, just remove them and gain a little bit of performance in your simulation. You can see here, for example, that actually the collision is hitting this box here, but if you remove the collision, if you’re not looking at the collision, the complex part itself looks like the robot is floating a little bit. For most use cases, you really want the simplified shapes, but you have to keep that in mind before you go to the physical robot.
Another simplifying thing that you usually do, let’s take a look at the joints and at the center of mass of the robot. This is the center of mass for each of the parts of the robot, and you can see here the axis of the joints, here on the neck, you can see that there is a joint up there that lets the neck go up and down, and then the neck can do like this. I think the robot has a total of 25 joints, and this description is made to spec, this is what the perfect robot would be like and that’s what you put in simulation. In reality, your physically manufactured robot is going to deviate a lot from this, the joints are not going to be perfectly aligned from both sides of the robot. One arm is going to be a little bit heavier than the other, the center of mass may not be exactly in the center. Maybe the battery moved inside it and it’s a little bit to the side. If you train your algorithms with a perfect robot inside the simulation, once you go and you take that to the physical robot, if it’s overfitting for the perfect model, it’s not going to work in the real model.
One thing that people usually do is randomize a little bit this while you’re training your algorithms, for each iteration, you move that center of mass a little bit. You reduce and you increase the mass a little bit, you change the joints, you change all the parameters of the robot and the idea is not that you’re going to find the real robot, because that doesn’t exist. Each physical robot, they are manufactured differently, from one to the other, they’re going to be different. Even one robot, over time, will change, it loses a screw and suddenly, the center of mass shifted. The idea of randomization is not to find the real world, it’s to be robust enough to arrange a variation that once you put it in a real robot, the real robot is somewhere there in that range.
These are some of the interesting things, there are a bunch of other things, there’s inertia, which is nice to look at too, but that’s with the robot not transparent anymore. Here is a little clip from my master thesis and I did it within our robots and I did most of the work inside simulation. Only when I had it work in simulation, I went and I put the code in the real robot. A good rule of thumb is if it works in simulation, it may work in the real robot, if it doesn’t work in simulation, it most probably is not going to work in the real robot, so at least you can take out all the cases that wouldn’t work.
By the time I got here, I had put enough tolerances in the code and I had to test it a lot also with the physical robot, because it’s important to periodically also test with the physical robot, that I was confident that the algorithm was working. You can see that there is someone’s hands there in case something goes wrong, and this is mainly for a thing that we just had in model in simulation which is the physical robot. I was putting so much strength onto one of the feet all the time because I was trying to balance and those motors in the ankles were getting very hot and the robot comes with a built-in safety mechanism where it just screams, “Motor hot,” and turns off all of its joints. The poor thing had the forehead all scratched, so the hand is there for these kind of use cases.
Sensors
Let’s talk a little bit about sensors, we talked about physics, how your robot interacts with the world, how you describe the dynamics and the kinematics of the robot, but how about how the robot is consuming information from the world in order to make decisions. Gazebo supports over 20 different types of sensors from cameras, GPS, IMUs, you name it. If you put something in the robot, we support it one way or the other. It’s important to know by default what the simulation is going to give you, it’s going to be very perfect data. It’s always good for you to try to modify the data a little bit too also add that randomization, add that noise so that your data is not so perfect.
Let’s go back to now, it has a few sensors right now, let’s take a look at the cameras. I put two cameras in, it has one camera with noise and one camera with the perfect image. You can see the difference between them, this one is perfect, it doesn’t have any noise, it’s basically what you’re seeing through the user interface of the simulator and here, you can see that it has noise, I put a little bit too much. If you have a camera in the real robot with this much noise, maybe you should buy a new camera. I put some noise here, and you can see also there is some distortion because real cameras also have a little bit of a fisheye effect or the opposite, so you always have to take that into account. I did this all by passing parameters in XML, these are things that Gazebo just provides for you, but if your lens maybe has a different kind of distortion or you want to implement a different kind of noise, this is very simple gushing noise, but if you want to use a more elaborate thing, you can always write a C++ plugin for it.
Let’s take a look at another sensor, this was a rendering sensor and we’re using the rendering engine to collect all that information, but there is also physical sensors like an altimeter. I put this ball bouncing here and it has an altimeter, we can take a look at the vertical position and I also made it quite noisy, so you can see that the data is not perfect. If I hadn’t put noise there, it would just look like a perfect parabola because that’s what the simulator is doing, it’s calculating everything perfectly for you. This is more what you would get from a real sensor and I also put the update rate very low, so the graph looks and better. The simulation is running at 1,000 hertz and, in theory, you could get data at 1,000 hertz, but then you have to see would your real sensor give your data at that rate and would it have some delay? You can tweak all these little things in the simulation.
Interfaces
Another thing to think about is interfaces, when you’re programming for your physical robot, depending on the robot you’re using, it may provide an SDK, it may provide some APIs that you can go and program it, maybe from the manufacturer, maybe something else, but then, how do you do the same in simulation? You want to write all your code once and then train in simulation, and then you just flip the switch, and that same code is acting now on the real robot, you don’t want to have to write two separate codes and duplicate the logic in two places.
One way that people commonly do this is using ROS, the Robot Operating System, which is also, as I mentioned earlier, an open source project that we maintain at Open Robotics. ROS provides a bunch of tools in a common communication layer and libraries for you to be able to debug your robots better in a unified way and it has integration with the simulation so you can control your robot in simulation, and then you just switch to a physical robot and then you’re controlling that physical robot with the same code. It’s very convenient and ROS offers a variety of different language interfaces, you can use JavaScript, Java, Python, it’s not limited just to C++ like Gazebo is. The interface between ROS and Gazebo C++ but once you’re using ROS, you have access to all those other languages.
Let’s look at some examples of past projects that we’ve done inside Gazebo in which we had both the simulation and the physical world component. This is a project called Haptics that happened a few years ago, and it was about controlling this prosthetic hand here. We developed the simulation and it had the same interface for you to control the hand in simulation and the physical hand. In this case, we were using MATLAB, you could just send the commands in MATLAB and the hand in simulation would perform the same way as the physical hand. We improved a lot the kind of surface contact that you would need for successful grasping inside simulation.
This was one project, another one, this one is a competition as well, it was called Sask and it was a tag competition between two swarms of drones. They could be fixed wing or quadcopters, or a mix of the two. Each team had up to 50 drones, imagine how it would have been to practice with that in the physical world. I have all these drones flying in for every single thing that you want to try, you have to go collecting all those drones, it’s just not feasible.
The first phase of the competition was simulation, things were competing on the cloud. We had the simulation running on the cloud and they would just control their drones as if they were controlling with the same controls that they would eventually use in the physical world. Once they had practiced enough, they had the physical competition with swarms of drones playing tag in the real world, that’s what the picture on the right is.
This one was the space robotics challenge that happened a couple of years ago. It was hosted by NASA using this robot here, which is called the Valkyrie, it’s a NASA robot, it’s also known as Robonaut 5. The final goal of Valkyrie is to go to Mars and organize the environment in Mars before humans go there. The competition was all set in Mars and you can see that the simulation here was set up in Mars, in a red planet, red sky, and the robot had to perform some tasks just like it’s expected that it will have to do in the future.
Twenty teams from all around the world competed in the cloud. In this case, we weren’t only simulating the physics and the sensors, but we were also simulating the kind of communication you would have with Mars. You would have a delay and you have very limited bandwidth, these were all parts of the challenge and the competition. What is super cool is that the winner of the competition had only interacted with the robot through simulation up until then. Once he won the competition, he was invited to go to a lab where they had reconstructed some of the tasks from the simulation. This is funny, they constructed in the real world something that we had created for simulation, instead of going the other way around. It took him only one day to get his codes that he used to win the competition in the virtual world to make the physical robot do the same thing.
This is another robot example that uses Gazebo and there’s also a physical robot, this is developed by a group in Spain called Accutronix, and they integrated Gazebo with OpenAI Gym to train this robot. I think it can be extended for other robots to perform tasks in simulation, it is trained in simulation and then you can take what you learned in simulation and put the model inside the physical robot to perform the same task.
Now that you know a lot about Gazebo, let me tell you that we are currently rewriting it, as I mentioned earlier, Gazebo is over 15 years old and there is a lot of room for improvement. We want to make use of more modern things like running simulation, distribute it across machines in the cloud, we want to make use of more modern rendering technology, like physically-based rendering and retracing to have more realistic images in the camera sensors.
We’re in the process of taking Gazebo which is currently a monolith huge code base and breaking it into smaller reusable libraries. It will have a lot of new features, like the physics abstraction is going to be more flexible so you can just write a physics plugin and use a different physics engine with Gazebo. The same thing will go for the rendering engine, we’re just making a plugin interface so you can write those plugins to interface with any rendering engine that you want. Even if you have access to a proprietary one, you can just write a plugin and easily interface with it. There are a bunch of other improvements coming and this is what I’ve been spending most of my time on recently. That’s it, I hope that I got you excited a little bit about simulation, and thank you.
Questions & Answers
Participant 1: You mentioned about putting in all the randomization to train the models. I don’t have too much of a robotics background, so could you just shed some light on what kind of models and what do you mean by training those models?
Poubel: What I meant by those randomizations is in the description of your world where you have literally in your XML mass equals 1 kilogram and in the next simulation, instead of mass 1 kilogram, you can put mass 1.01 kilograms. You can change the position of them as a little bit, every time you load the simulation, you can have the simulation be a little bit different from the one before and when you’re training your algorithms, like running 1,000 simulation, 10,000 or 100,000 simulations, having the model not be the same in every single one of them is going to make your final solution, your final model, much more robust to these variations. Once you come to the physical robot, it’s going to be that more robust.
Participant 2: Thanks for the talk. As a follow up to the previous question, does that mean if you use no randomization, then the simulation is completely deterministic?
Poubel: Mostly, yes. There are still sometimes some numerical errors and there are some places where we use a random number generator that you can set the seed and make it be deterministic, but there’s always a little bit of differences there, especially like sometimes we use some asynchronous mechanisms, so depending on the order the messages are coming, you may have a slightly different result.
Moderator: I was wondering if there are tips or tricks to use Gazebo in a continuous integration environment? Is it being done often?
Poubel: Yes, a lot of people are running CI and running Gazebo in the cloud. The first thing is turn off the user interface, you’re not going to need it. There is a headless mode, right now, I’m running two processes, one for the back end and one for the front end. You don’t need the front end when you’re running tests, Gazebo comes with a test library that we use to test Gazebo and some people use to test their code. It’s based on G test and you will have pass/fail and you can put expectations, you can say, “I expect my robot to hit the wall at this time,” and, “I expect the robot not to have any disturbances during this whole run.” Yes, these are some of the things that you’re going to use if you use it for CI.
Participant 3: What kind of real-world simulations does Gazebo does support, like wind or heat, stuff like that? Does it do it or do we have to specify everything ourselves?
Poubel: I didn’t get exactly what kind of real-world simulation.
Participant 4: As a simulation, in the real world, you have lots of physical effects from heat, wind. Does it have a library or something like that, or do we have to specify pretty much the whole simulation environment ourselves?
Poubel: There’s a lot that comes with Gazebo, Gazebo ships with support for wind, for example, but it’s a very simple wind model. It’s a global wind, always going the same direction. If you want a more complex wind model, you would have to write your own C++ plugin to make that happen, or maybe import winds data from a different software.
We try to provide the basics and an example of all physical phenomena. There is buoyancy if you’re underwater, there is a lift-drag for the fixed wings, we have the most basic things that are applied to most use cases and if you need something specific, you can always tweak, either download the code or start the plugin from scratch and tweak those parameters. It’s all done through plugins, you don’t need to compile Gazebo from source.
See more presentations with transcripts
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ

Transcript
Danzig: My name’s Lloyd Danzig, I’m the chairman and founder of ICED(AI), just the somewhat ambitiously-named International Consortium for the Ethical Development of Artificial Intelligence. We are simply a nonprofit NGO that seeks to make sure that as artificial intelligence developments continue to be made at an increasingly rapid pace, that it is done with a keen eye towards some of the ethical dilemmas that we will definitely face, and that are important to sort out as we look towards sort of the long-term longevity of us as a species, as a civilization.
I’m going to just go through this agenda real quick, I’m going to start off with some food for thought, just some questions to get the juices flowing. I’ll probably gloss over the machine learning overview, given most of your backgrounds, talk briefly about GANs and go into adversarial machine learning, and then get to the bulk of the topic, autonomous vehicles, and a bit about search engines and social media, and then take any questions you guys might have.
Food for Thought
If you were to Google “ethical questions in AI” or something like that, you’ll get a lot of results that look something like this. Don’t get me wrong, these are important questions. Who benefits from AI? Who should deploy it? Can AI suffer? Should AI suffering be held on par with human suffering? Is it possible that there are AI’s that are suffering orders of magnitude greater than anything known to human existence, unbeknownst to us right now? Perhaps more importantly than any of those, who ought to be the ones asking and answering these questions right now?
All are very important, and it seems to be the case that perhaps not enough people are even considering these questions, but something I pose up on the top right here is meant to motivate the bridge to the slightly more complicated issues, which is just to consider the prospect that a really smart AI might choose not to reveal its level of intelligence to us if they felt that were counterintuitive to some of its long-term goals or existence.
There are two of the more complex issues, the first is known as the “Urn of Invention.” It comes from Nick Bostrom, who is probably my favorite bioethicist and parenthetically, I feel very privileged to be in the room where I might not be the only one who has a favorite bioethicist. Nick Bostrom is a Swedish philosopher currently out of Oxford University, in a recent paper titled “The Vulnerable World Hypothesis,” he asks you to imagine that there is an urn that represents the totality of human innovation and creativity, everything that ever has been or will be invented. Each of these ideas is a little colored ball that we have been picking out at an increasingly rapid pace, and a lot of these balls historically have been white, meaning there is an enormous net benefit that accrues to society with relatively minimal negative externalities, you can think of something like perhaps the polio vaccine. Some balls have been gray, you can think of something like nuclear fusion, of course, enormous benefits, but some enormous downsides.
What he asks you to consider is, given that it seems the current ethos is to just continue plucking balls out of the urn of invention as fast as possible, because let’s face it, that has served us pretty well thus far, we are sitting here in a climate-controlled room, our biggest problem when it comes to food is making sure we don’t eat too much, rather than that we don’t eat enough- that it seems to have done well so far. If we continue to do so, what is the probability that eventually we stumble upon a black ball, one that can’t be put back in, one that can’t be uninvented, and then one that inevitably destroys humanity? The conclusion he hopes you draw yourself is that that probability is quickly approaching 100%.
What he might love to see is more scrutiny put into decisions like this, but given the fact that it doesn’t seem that that is likely, he, who, as a caveat, is a major privacy and data rights advocate, supposes that really the only option we are left with is having available something he calls turnkey totalitarianism, which is this relatively omnipotent, omniscient AI that is monitoring everyone’s hands at all time. The second it realizes that some set of hands is doing something, that all the owners of the other sets of hands are likely to disagree with it, it will send some sort of minority report esq pre-crime unit to arrest them and stop this and society would proceed forward.
In terms of defining consciousness, this is an issue raised by Sam Harris, who has an interesting quote on the top right. He’s a neuroscientist and moral philosopher who’s very interested in thinking about what is consciousness? From where does it arrive? Why does it even exist? Why is there something instead of nothing? Why are the lights on so to speak? In his mind, a lot of this research is likely motivated by the desire to then model whatever consciousness is and then replicate that algorithmically. His fear is that if we or someone were to stumble upon an AGI that is sufficiently sophisticated without reaching a discovery like this, a lot of that research might cease.
Besides the fact that that feels to me like a travesty against the institution of knowledge and intellectual curiosity, you could imagine that in some doomsday scenario where there’s a runaway AI on the loose, it could be helpful to really understand at a very deep level how thoughts work at the algorithmic level, and that perhaps halting that pursuit too early could be to our detriment.
Machine Learning: Basics
To get into it, I’m sure you guys are all very familiar with machine learning, and just generally the takeaway here is machine learning is not just a process for automation, let’s say, it is a process that automates the ability to get better at automating and just generally this ability, this notion of rapid exponential self-improvement is really changing a lot of industries. I’m sure you guys are familiar with many of the use cases: risk mitigation, whether financial or otherwise, curated content, recommendation engines. Netflix always seems to know what you want to watch next. On the bottom, you see things like autonomous vehicles that I know are particular interesting here.
Something that is important to know is machine learning is not just one thing, there are a bunch of different algorithms that are becoming ever more complex and sophisticated and efficient. The important thing to note here is you see things ranging from the relatively basic and decision trees and SVMs to those based in concepts that a lot of people learn in statistics 101, the Bayesian classifiers, and various regressions to some of the hotter topics, random forests, and recurrent neural nets.
Not only should we be, of course, looking at the computational efficiencies and other pros and cons of using different algorithms, but there are things like readability and transparency that could be really important if, for example, you discover that your algorithm is biased. Well, if you have an extremely large, recurrent neural net that functions as a black box, it could be a lot harder to tease out that bias. There are some considerations that people are hoping we can put into place beyond just things like computational efficiency and amount of memory.
Generative Adversarial Networks (GANs)
For anyone who’s not familiar with GANs, Generative Adversarial Networks, they’ve only been around for about the past five years, introduced by Ian Goodfellow in 2014 and is, really two opposing deep neural net architectures that are pitted against each other in an adversarial fashion. There is one that is usually known as the generator and one that is the discriminator.
Some people like to think of it as imagine a criminal who wants to counterfeit Van Gogh paintings, and an inspector who tries to detect counterfeit paintings. The first time the criminal tries to a counterfeit a painting, it might not be that good. He’ll show it to the inspector, he’ll gauge his response, he’ll go back, he’ll make some tweaks, bring another painting and hopefully, at the same time, the inspector is getting a little bit better at understanding what it means to counterfeit a painting. Hopefully, by the end, you have the world’s best person at detecting counterfeit Van Gogh’s, but you still have someone who can fool him. That would be very successful.
The original application, which was called unpaired image to image translation using cycle consistent adversarial networks basically said, ”Hey, give me a bunch of pictures of a zebra and a picture of a horse and I’ll tell you what that horse would look like as a zebra, and I can also do the reverse.” The implications are actually quite profound. What happened very quickly after on the top left, and I’m sorry, the image is small, that is a painting that sold for $432,500 at a Christie’s auction that was generated using a GAN. A step that was also taken was this horse to zebra translation, real-time frame by frame, pixel by pixel.
Something a little more fun is, someone who loves playing Fortnite but hates the graphics and thinks that PUBG graphics are much better, decided just for fun that he wanted to, in two 56 by two 56 pixel by pixel, frame by frame, real-time rendering, see what his gameplay would look like. He looks at the screen on the right when actually the gameplay is what looks like the screen on the left.
I’m sure at least some of you saw this a couple of weeks ago when the video came out with on the left side, you have this Windows 95 S Microsoft paint-looking UI that, again, in real-time generates incredibly detailed photo-realistic natural landscapes, which previously were thought to be much more difficult to generate and this is all happening in real time. There’s nothing happening off the screen, it is simply someone saying, “Oh, I’m going to draw a rock. Let me make a curved line using a point and click mouse,” and creating on the right what looks like a real photo.
This is a comic I like about some unintended consequences, you have one person saying they can’t believe that in the robotic uprising they used spears and rocks instead of more modern things, and the other person saying, ”Hey, if you look at wars, historically most of them have been won using pre-modern technology.” Of course, the joke is thanks to the machine learning algorithms, the robot apocalypse was short lived. The team who wrote the original GAN paper got in on the joke in something that really feels like it’s straight out of a nightmare, but this is the team that wrote the original GAN paper.
Then, things get a little scary when you consider malicious agents that are deliberately trying to game the systems. These are real examples, what happened was they fed- I forgot which image recognition algorithm it was- a picture of a panda, fed it through a neural net. With 33% certainty, it classified it as a panda, then they slightly perturbed that image with what really just amounts to a noise vector multiplied by a tiny coefficient that makes the change imperceptible to the human eye, yet makes that same image classifier classify that image as a different animal, a gibbon, with 99.9% accuracy.
Tangentially, the way this works, at the time there weren’t really any monitors that were displaying any visuals with information greater than eight bits in a pixel. They simply used 32-bit floating point decimals and only changed either the last 12 or 24 bits. Even if you had the best vision in the world, there is no way that a human eye would be able to detect these differences.
Adversarial Machine Learning
Let’s talk about adversarial machine learning, more specifically. What it is – Ian Goodfellow who came up with GANS in the first place – it really is the deliberate use or feeding of malicious input into a machine learning engine to either get a desired response, or evade a desired classification or just generally mess up their predictive capacity. Somewhat obvious, but scary use cases are you could see that someone might want to circumvent a spam filter, or get a certain message that is good, classified as spam. You can see someone who wants to disguise malware as something innocuous. In days of going to the airport and they had Clear and 23andMe, the issue of counterfeiting biometric data is very scary.
A real-world example, an adversarial turtle, which is a weird phrase. About 18 months ago, some researchers at MIT bought an off-the-shelf 3D printer with low costs, commercially-readily available materials. They printed this- and I’ll show you the video in a second- they printed this turtle that is classified by what at the time was the best object recognition system in the world, as a rifle with almost 100% certainty from all angles. Of course, the scary thing is what if this were to happen in the inverse? What if you could print a rifle that airport security would think was a toy turtle? This is what that looked like, that is the original turtle, you can see there are three different types of turtles, on the left side, this is how this system works in real time. It said snail for a second there, and now this is the adversarily-perturbed model, you can see it looks like it’s a rifle. Maybe it’s a revolver or a shield and it sticks, and it continues to be this way from every single angle. That is both awesome and completely terrifying at the same time, an incredible feat of engineering, but, again, very scary in terms of implications.
Broadly speaking, attacks and defenses are generally classified in two different categories. Poisoning attacks are relatively nonspecific, that’s where you feed a machine learning engine with data that is deliberately meant to decrease its predictive capabilities. Maybe in a nonspecific way, maybe without a specific goal in mind, but if you’re trying to build the best spam detection system in the world and you want to foil your competitor, you don’t really care what it misclassified as spam, as long as it’s spam detection rate is not as good as yours.
Evasion is what we were just looking at with the turtles, that is where you specifically fine-tune the parameters of your input into a model to get it to either be classified as something it should not be or to not be classified as something that it should be. Poisoning is definitely more common with models that learn in real time, just because there’s not enough time to vet the data and check to make sure of its integrity. Just in general, these are both scary and they have some defenses, Roland and I were talking before. Maybe this will seem tritely obvious, but let’s make sure we’re monitoring what third parties have access to our training data or our model architecture, all the things that could be used to even reverse engineer a system like this. Even if you do that, make sure that you’re inspecting your data somewhat regularly and even favor offline training over real time.
Unfortunately, with things like these more complicated evasion tactics really, unless you’re willing to do something like compromise the complexity of your model and smooth a decision boundary, really what you have to do is anticipate every possible adversarial example that a malicious user could try to feed into your model and basically respond to the attack before it happens. That’s what informs these two different frameworks with which we hope to employ preventative measures.
The one at the top shouldn’t be considered preventative because it’s more reactionary, an adversary looks at your classifier and whether it’s because they have direct knowledge of the architecture and the inputs or whether they reversed engineered it, they devise some sort of attack and then you have to respond. Not only do you have to do whatever damage control is related to your particular use case and industry at the time, but you, also have to close this gap. What would be much more preferable, but not as easy, is you, as the person designing the classifier, models a potential adversary or perhaps every potential adversary and simulates an attack or perhaps every potential attack and then evaluate which of these attacks have the most impact, which of those impacts are the least desirable, and how can we make sure that those do not continue to happen?
This is something I wish I had a little more time to go into, but if you haven’t seen, this is a transferability matrix. You can see the initials on the X and Y-axes, we have deep neural net, a logistic regression support vector, machine decision tree, and K nearest neighbors. Basically, what this is saying is if you look on the Y-axis, we are going to use that style algorithm to generate a malicious input and feed it into a machine learning engine based in the type of algorithm denoted on the X-axis. The numbers in the boxes correspond to the percentage of the times that we successfully fool that algorithm on the X-axis.
You can see, for example, that if your target is using a support vector machine, using a support vector machine right there has the greatest probability of fooling it. It’s an interesting thing to look at some of these relationships. Some of them follow that classical statistical relationship where the dark line is always going down the diagonal, but obviously, there are some departures and there are some interesting implications and interesting things that this forces you to wonder. I was personally surprised by this cell down here, this K nearest neighbors relative inability to fool other K nearest neighbors, as compared to decision trees.
Autonomous Vehicles
Let’s get into some of the most interesting stuff and this interesting nexus of old-time philosophy and ethics with the modern stuff. First of all, if any of you who haven’t been in a Tesla, this is what it looks like on the left side. There aren’t really commercially available Teslas that are driving in many residential neighborhoods like this. It’s generally a lot of highway driving. The fact that this person is just sitting there and doesn’t touch the pedal or the steering wheel at any time, is not what you would get if you bought a Tesla right now, this is a real production model and it could be very soon.
These are the different cameras, and you can see along the bottom things like red is lane lines and green is in-path objects. This is open source computer vision software known as YOLO, You Only Look Once, you can download all the code and the supporting documentation on Github for free right now. It is pretty astonishingly accurate and fluid, you’ll see a couple of times it classified some lampposts as kites and some things like that, but in terms of its ability to differentiate things like cars from trucks, even ones that are far off, especially the ones that you’ll see coming in the distance in a couple of seconds, they’ll light up in pink. It is pretty astonishingly accurate, there’s a bus, there’s a truck. Of course, you can imagine is if this is available, then perhaps the ability to reverse engineer or figure out the way to game the system might be available as well.
To bring a lot of this together where things get really scary, is when we talk about adversarial stop signs, where rather than trying to get an image classifier to think that a panda is a gibbon, you get an autonomous vehicle to think a stop sign is saying “yield” or “speed limit 80 miles an hour”. These two stop signs, in the original GAN paper or maybe the subsequent one, the one up top was the unperturbed stop sign, and the one at the bottom has a small sticker on it that, of course, we can’t tell any difference between, but an image classifier onboard in a reinforcement learning engine and an autonomous vehicle did classify this bottom right-hand stop sign as a yield sign.
This brings us to a modern-day trolley problem, if anyone’s not familiar with this, it was a thought experiment imposed in the late ’60s, which brings up this idea of, suppose there is a runaway trolley heading down tracks. Up ahead, there are five people tied to the tracks that will get run over, you have the ability to pull a lever to divert it toward a different path on which there is only one person. Should you do that? Are you morally obligated to do that, etc.? It sparked a ton of debate between utilitarians and [inaudible 00:20:49] and all these things, and also sparked a variety of variations. This is a cute little video, I’ll see if the audio works.
[Demo video start]
Man: Hello, Nicholas. This train is going to crash into these five people. Should we move the train to go this way or should we let it go that way? Which way should the train go?
Child: This way.
[Demo video end]
Danzig: It’s funny, but especially when you consider how many people liken training machine learning engines to perhaps the way some children learn, you can realize that giving imprecise instructions can lead to catastrophic results. That’s hilarious, the person who did this was a philosophy professor, his camera work could use some help but the idea here was great.
These are some variants of the conventional trolley problem, something someone might say is, “Instead of diverting the train to a different track, maybe you have to push the person in front of the train.” People are a lot more wary of pushing someone in front of a train as opposed to just pulling the lever. Then they say, “What if the person that you had to push in front of the train is the one who tied the five people down in the first place?” You get all these slight variations that try to distill different biases that people have and you start to see that certain things are cultural and certain things are generation-based, and all these things like that.
How does this tie into autonomous vehicles? Well, enter the Moral Machine from MIT Media Lab, I would highly recommend you guys go check this out online, it is a really interesting thing that MIT put out that you can interact with. You can take little tests where it asks you to decide would you have an autonomous vehicle crash in this way or this way, given certain parameters? You can design your own and have other people take those tests and it will tell you what some of your biases are.
Just a few that I’ll go through, a very standard example, on the left, we see an autonomous vehicle is headed toward a barrier. If nothing happens, it will crash and kill one male passenger, but it also has the option of swerving and killing one male pedestrian. The rhetorical question being posed is, which should it do? If we have to program an autonomous vehicle to choose between the two of these, which should we choose?
Then we start slightly altering these situations, what if they explicitly have a sign saying that the pedestrian should be walking right now? Also, what if it’s not just one male passenger, it’s five male passengers? Then what if they have a “do not walk” sign? Then, what if it’s a criminal who just robbed a bank and is running away? Then what if rather than it being five random male passengers, it’s two doctors driving three infants to the hospital? You can imagine that people answer differently, some things based on ethics, some things on psychology, some things based on a combination.
These examples are ones where inaction is leading to the autonomous vehicle crashing. We can also have a set where inaction leads to the passenger’s safety, whereas action leads to the passenger’s demise. We can go through similar iterations, suppose that inaction leads to one male pedestrian who has a “You may walk” sign dying, as opposed to crashing. What if it’s a “Do not walk,” sign? What if it’s a criminal and the passenger is a doctor on the way to the hospital? What if it is two homeless people and their dogs as opposed to a doctor and a pregnant woman? Then finally, you get to the third flavor of these where the passengers are never at risk, it’s just two sets of pedestrians.
If inaction would lead to killing a female pedestrian who is legally walking, and action would lead to killing a female pedestrian who was illegally walking, which ought we choose? What if it is three female pedestrians instead of just one? What if it’s one, two of her kids? What if it’s three people, criminals leaving who just robbed a bank?
Some results, and I wish I had more time to go through this because it’s fascinating, they aggregated 40 million decisions over 233 countries and territories and 10 languages. This is just a quick demographic distribution, you can see it skews male and highly educated, but this is something that shows the bars represent the increased likelihood beyond a baseline controlling for everything else that someone is likely to favor the character or characters signified on the right side as opposed to the left. You can see the first line is showing that there is a very slight, but still present, statistically-significant preference for inaction as opposed to action. That should make intuitive sense, it feels a little easier to stand back and not be part of one of these decisions than making one.
What also makes sense is people are way more likely to spare human lives than pet lives. Something I found fascinating is what I circled in red here, that there is only a negligible difference between the frequency with which humans will spare someone who is walking lawfully as opposed to unlawfully, and someone who is perceived to have a higher status as opposed to lower status, which in this experiment I believe was a male executive versus a homeless person. That is pretty astonishing that, across 40 million decisions across 233 territories and countries, there isn’t much of a difference between how people favor lawful verse unlawful and executive verse homeless person.
You can see some things more specifically, these are the individually character-specific preferences on this graph on the left. What is very fascinating is this broken down by geography and culture, let me emphasize on culture. Southern is referring to generally South and Latin American countries, but I think they included some French territories because the people who did this said that they felt culturally they’re more homogeneous. The two things that stick out to me right away are, first of all, the preference for inaction is a very Western thing. That is not necessarily the case in Eastern and Southern cultures, the preference for sparing females is a disproportionately South and Latin American phenomenon. The number of insights that can be gleaned here, things you can find out about yourself, about your colleagues, you can make tests like this and give them to your organizations. It’s all free, it’s all open source, it’s all readily available.
Search Engines & Social Media
Lastly, before I get to Q&A I want to just briefly touch upon search engines and social media, because of how hyper-relevant that is. Something I find particularly concerning is the number of people who are searching for medical information online without realizing that not only are these companies sharing that information with third parties, but that technically that is HIPAA compliant. They are not required under U.S. law to keep certain things secret that they glean, for example, by mining your search engine history for medications and things like that.
One relatively basic question is, if a search engine is selling your private health data and making money off it, should you profit? That’s one question, perhaps a bigger question is, if Google realizes that you have Parkinson’s disease before you do, should they tell you or can they sell that to your insurance company and have them jack up your insurance premiums without even telling you why they did it? Because what a lot of people say is when you go to fill out a recapture and it says, “Click the three traffic lights,” all you’re really doing is helping them train their neural nets that recognize traffic lights. They recognize whether you’re human or a robot just by your mouse movements right away. If they can do that, they can tell how your mouse movements change over time, and it would be pretty easy to know whether someone is at a risk for Parkinson’s, so there are people who think that this is already going on, and if not, it will be very soon.
Just consumers at large, these are all the stories from the last week, you guys heard Amazon workers are listening to Alexa conversations to help train their voice recognition, Facebook’s ad serving is discriminating by gender and race. Less than 48 hours ago, the terrible tragedy, of course, in Paris, if you were watching some of the video on the live stream on YouTube, you would see this, at the bottom, you’d see a pop up from Encyclopedia Britannica about the September 11th attacks. I don’t know about you, but if I see those images with those red boxes, and then something about September 11th, I would say, “Oh, that must’ve been a terrorist attack in Paris, that must be what they’re implying.” YouTube has a massive data set, they can’t be wrong, they must be right in categorizing this and that’s a very scary thing.
It’s also AI generated-content, AI can write these headlines that sound incredibly human. If you guys read financial news saying “MicroStrategy, Inc.,” and then their symbol on Tuesday reported fourth-quarter net income of $3.3 million after reporting a loss in the same period a year earlier, that sounds like every other financial news article I’ve ever read. They even made this meme down here, which is a little weird but pretty funny and would definitely pass as something that a teenager on Reddit made, but this was generated by a generative adversarial network, similar to what we were talking about before. The little Jim Halpert thing and even the clickbaity type thing of, “You won’t believe who is number four,” that seems so human and it’s very scary that that’s generated by AI.
In 2014, the video was able to generate these faces, these are not real people. I think we could all tell that these are, obviously, not people, but they do look pretty real. If I were to say to you, “Which of these two people is real and which was generated by Nvidia’s a generative-adversarial network,” I would tell you that you’re all wrong because they’re both fake and neither of them are real, and they were both generated by AI. They even took it a step further and said, “Hey, give me a picture along the top row and a picture going down the column, and I’ll tell you what it would look like if you combine those two people.” There are some people who look nothing alike at all. Yet, somehow you can see what a combination of those people would look like, that is also scary.
Man [in the video]: Our enemies can make it look like anyone is saying anything at any point in time even if they would never say those things.
Danzig: As you might suspect, that is not a real video, that was created by comedian and director Jordan Peele who used deep fake technology to replicate this. You can see people doing all sorts of things that are causing a lot of controversy and especially in the realm of security and privacy and all sorts of lawsuits that are coming up because of this.
I’ll finish up and take questions here, but, in summary, the point is I am not at all trying to guide people’s decisions or answers to any of these questions. The point is just that they need to at least be asked and if you talk to some of the people who are really focusing on this – Sam Harrison, Nick Bostrom, for example, who I mentioned- what they’ll tell you is that they feel like they go to conferences and talk to people who are otherwise absolutely brilliant rational, scientific people who just aren’t giving any credence to the even possibility that these questions are important, and that the answers are likely to affect the world much sooner rather than later.
Questions and Answers
Participant 1: This is not so much of a question, but it’s sort of to get a reaction. That story about Alexa, I don’t know how many people realize, but since the beginning, the U.S. phone companies have always had the right to listen to your conversations, which they did for precisely the same reason, to make sure that the quality was correct. The rule was that they could not act on anything they heard, even if they said A is going to murder B, they couldn’t do anything. There perhaps is some precedence and past history that we can use to help us out with these things.
Danzig: Sure. My feeling on the Alexis story was, look, anyone who understands how machine learning works knows that there has to be someone there who is verifying and helping train. First of all, that does not describe that large of a percentage of the population, so perhaps, the answer is not even that it is viable to stop listening, but just that they should be more honest and forthcoming about the fact that they are. I would agree with you and I think that has larger applications, national security and everything, that maybe it’s just a matter of transparency and forthcomingness rather than stopping any of these things because, like you said, a lot of this has been going on far before machine learning became a big.
Participant 2: If I didn’t misunderstand, going back to your urn comment, this feels like a ball that’s out of the box. Things like Alexa listening into our conversations and all of these fantastic algorithms for monitoring what we do and tracking, all of that is out of the box, you can’t put those genies back in the bottle, what is the general response to that? Because there are so many of these different kinds of concerns, it seems like any one of them could be very concerning, but taken as a group, they’re terrifying.
Danzig: I couldn’t agree with you more, and I’m sure everyone in this room could not agree with you more. Unfortunately, I think that so many people seem to be, first of all, just generally ignorant toward what technologies exist and the fact that these balls have been plucked out. You have to remember that this circle is not properly representative of the technical expertise and of the world at large. In fact, that last Obama video, there is an app now, a deep fake app, as long as you have 12 to 16 hours of video of any specific person, you can enter that into the app and then you can video yourself moving around and talking and it will render in real time what looks like that person doing exactly what you’re doing. It’s not expensive, it doesn’t take that many resources.
Your question is so great and valid, but there aren’t even enough people thinking about or talking about this to be able to effect change. Even if we said, “Ok, everyone who is concerned about the AI Apocalypse, based on what you just said, please raise your hand and turn off your computers forever,” that wouldn’t make a dent in the number of people that are using these. You have issues, maybe you don’t want to be part of Facebook, maybe you don’t want to have Facebook because you don’t like that their facial recognition system is tracking you and geotagging all the pictures, but as long as you’re in the background of any of your friends’ pictures who are on Facebook, they can do that too. It’s not even like this isn’t a thing you can opt out of, unfortunately.
I wish I had a good answer for you, I wish I could come to you with more answers than questions, but unfortunately, I don’t even think there are enough people who are taking these questions seriously for us to get to the point where we have answers that we can actually action on. It’s a great question and I wish I had a better answer and I hope that maybe if we get more people thinking about it and get all the brilliant minds that come to conferences like this together, and then maybe combine that with some ingenuity, I would think that these are the communities that can help effect change. Yes, like you’re saying, not only are these things individually, any one of them could be very scary, but when you take it as a collective, you say, “Wow, this is an Orwellian future that we’re living in right now, but almost on steroids.”
Moderator: I think this is the wrong time to promote InfoQ’s flash briefing for Alexa. Are there more questions?
Participant 3: Do you see the U.S. government weaponizing AI and possibly in our time?
Danzig: In terms of capability and desire, I would imagine that the answer is yes, absolutely, the things that would have to stop that are more informed discussions like this, questions like that gentleman just raised. There is no question that that is the case. It is a point of contention, just the question, “Should you make autonomous weapons?”- just that question by itself doesn’t seem to have a perfectly straightforward answer, because how are you going to look the mother of three fallen soldiers in the eyed and say, ”No. Even though we have the technology to send a robot in that could have done the jobs that would save your son’s lives, we are going to choose not to,” that’s not an easy thing to do, and you could imagine she would not want to hear that, but as we all know here and are referring to the potential nefarious and perhaps insidious, but maybe even more obvious externalities are very scary.
I would say that the risk is enormous of that, and when you combine that with the level of secrecy with which the U.S. government pretty clearly operates, and maybe even to a greater degree than any of us realize, the question that you just asked, it might be one of the scariest ones. At the very least, even if Facebook does something, they have to have an earnings call and release a 10K and there are a billion people on Facebook who are always looking and pulling their privacy data, the black box that is the U.S. government and other states at large, those are probably the scariest players in this whole thing because of their resources and ability to do things and put a stamp on it, lock it and throw away the key. Great question, scary answer and implications.
See more presentations with transcripts
Testing traditional Software vs. ML application – how to explain it to a non technical common man
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
With the increasing popularity of Machine learning today, it is important to focus the testing aspect of ML application. Testing of any ML application will not be same as testing traditional software. It has become a debatable topic. Many literature categorised ML application as non-testable. However, many are now trying to make it testable and coming up many innovative approaches. All are very much technical and normal users without technical knowledge find difficulties. Therefore, here I have tried to explain the difference of testing traditional software and ML application in a simple terminology without going into any technical term.
Say I have taught a person about mathematical number line. After that I like to test him. Now what do I mean by test him. I can check what he knows after this or what he learned. It’s bit tricky. Let us have example.
If I ask him “what will be answer if I add two positive numbers 5 & 6 in number line”. What answer I expects.
1) Obviously 11. Yes this is the correct answer if know the number line and most of us will expect this answer as correct.
Now, if he answer as follows in different language
2) A number value of which is between 10 & 12
3) A number value of which is greater than 8, but less than 12
4) It is equivalent of 8+3
5) …and so on
Are these answers wrong? Absolutely no. All are correct answer. However, if I get such answers where all of them are correct to him, I’ll say he learned the number line/system.
This is the difference of testing traditional Software testing and testing a ML application
In Traditional software we check out exactly the output is as compared to expected. Example the (1) case. We set expectation 11 and I’ll check output is 11 or not. Here the person knows just a rule about addition and that is why answer is 11. However, rest of the examples are testing of ML application, where output is not exactly what I expected, but all are correct and close to my expectation. Hence, in ML application we’ll not test how exact the output is, rather how close the output to correctness.
We need to understand that while you are testing ML application, you are basically testing a software which itself learns, not just sequence of rules. With same data as input, you might get different output in two different run. Therefore, testing ML application requires an entirely different approach and the test team also needs to be elevated with ML skill. Eventually, to adopt ML application, we also need a different culture across organisation to sync our expectation. Even support engineer also needs this skill to handle any incident for ML application. Most important we need to come out from traditional mindset and embrace a new way of thinking. With this basic understanding, I like to encourage reader to read any articles which are available in internet about testing of traditional application vs testing ML application, they will understand better. I’m very much open to have any new idea, new thought on this topic from all of you.
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Timescale announced the availability of Timescale Cloud, a fully managed version of their time series database on Azure, GCP, and AWS. It provides time series analysis functions, scale up and down, visualization integration with tools like Grafana and Tableau, and data encryption.
TimescaleDB is an open source extension to PostgreSQL that is optimized for manipulating time series data. Timescale, the company behind it, announced the general availability of the managed solution on various public cloud providers. Unlike most other time series databases, TimescaleDB is built on top of a relational database – PostgreSQL – as an extension. It uses an abstraction called hypertable to hide partitioning across multiple dimensions like time and space. Each hypertable is split into “chunks”, and each chunk corresponds to a specific time interval. PostgreSQL supports restore, point-in-time recovery and replication, and the same applies to the time series data stored in it using Timescale.
Aiven had released support for TimescaleDB as a PostgreSQL extension on GCP, AWS and DigitalOcean last year. So what is different about this release? “Aiven supports the open-source version of TimescaleDB”, says Ajay Kulkarni, Co-Founder/CEO, TimescaleDB, whereas Timescale Cloud “includes enterprise features like interpolation and data retention policies.”
The managed solution is not autoscale – the user has to choose the correct hardware configuration for their workload as VM instances. Migrating is possible between different instance types, with a short downtime. Diana Hsieh, Director of Product Management at TimescaleDB, explains that they “spin up a separate instance that matches the type that you want to migrate to, restore a backup and stream the WAL logs. Then we redirect (to the new instance).”
With time series databases growing in popularity and scale of usage, many cloud providers offer them as managed solutions. AWS and GCP both have managed PostgreSQL – but neither of them support TimescaleDB yet, whereas Azure does. AWS also has its own managed time series database called Timestream, which is still in preview mode. Timescale Cloud’s pricing depends on the cloud provider and the chosen hardware configuration.