Month: March 2020

MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Recently Amazon announced Global Datastore, a new feature of Amazon ElastiCache for Redis that provides fully managed, fast, reliable and secure cross-region replication.
With the Global Datastore, Amazon delivers a feature to its ElastiCache for Redis following customer demand for replication of clusters across AWS regions. Writing data into ElastiCache for a Redis cluster in one region leads to the data available for reading in two other cross-region replica clusters when creating a Global Datastore – thus enabling low-latency reads and disaster recovery across regions.
Users can setup a Global Datastore by starting with an existing cluster, or by creating a new cluster to be used as a primary using either the AWS Management Console for ElastiCache – or through automation by downloading the latest AWS SDK or CLI. By using the AWS Console, users can create the Global Datastore specifying an existing primary cluster or creating a new one.

Source: https://aws.amazon.com/blogs/aws/now-available-amazon-elasticache-global-datastore-for-redis/
Next, the user fills in the details for the secondary cluster hosted in another region, and potentially adds another cluster if necessary. Note that users can add up to two secondary clusters in other regions which will receive updates from the primary.
Julien Simon, artificial intelligence & machine learning evangelist for EMEA, stated in the blog post about the Global Store feature:
Last but not least, clusters that are part of a global datastore can be modified and resized as usual (adding or removing nodes, changing node type, adding or removing shards, adding or removing replica nodes).
OpsGuru, an AWS and Google Cloud partner which provides consulting, implementation and managed services for a wide range of cloud-native workloads, said in a tweet:
Though #Redis has been introduced as a temporary cache, many use cases use Redis as a key-value data store; that’s why this new feature of multi-region replication is so vital for a Redis-dependent workflow to be truly resilient across regions.
Other major cloud vendors also provide disaster recovery capabilities with their caching services. Google, for instance, offers a caching service with Memorystore, which on the standard tier supports replication in a region for failover. And Microsoft has Azure Redis Cache, which supports clustering on their premium tier.
The new Global Datastore feature is available with Amazon ElastiCache for Redis 5.0.6 or above and supported on M5 and R5 nodes. Furthermore, the Global Datastore feature in ElastiCache for Redis is available in various AWS regions in the US, Asia Pacific, and Europe at no additional cost. Note that Amazon ElastiCache node-based pricing is applicable for all nodes created as a part of Global Datastore and standard AWS data transfer out rates apply. More details on pricing are available on the pricing page of Amazon ElastiCache for Redis.
MMS • Bruno Couriol
Article originally posted on InfoQ. Visit InfoQ
Google recently presented MediaPipe graphs for browsers, enabled by WebAssembly and accelerated by the XNNPack ML Inference Library. As previously demonstrated on mobile (Android, iOS), MediaPipe graphs allow developers to build and run machine-learning (ML) pipelines, to achieve complex tasks.
MediaPipe graphs are visualized in a browser environment with MediaPipe Visualizer, a dedicated web application that allows developers to build a graph consisting of nodes representing different machine learning or other processing tasks. The following figure corresponds to the running of the MediaPipe face detection example in the visualizer.
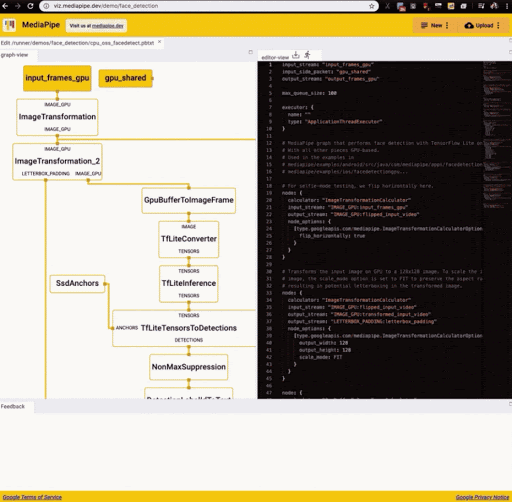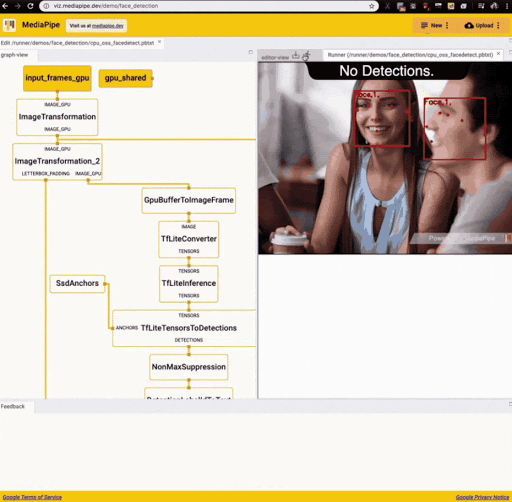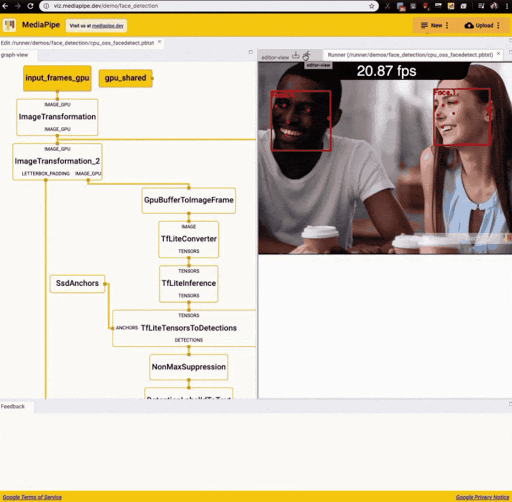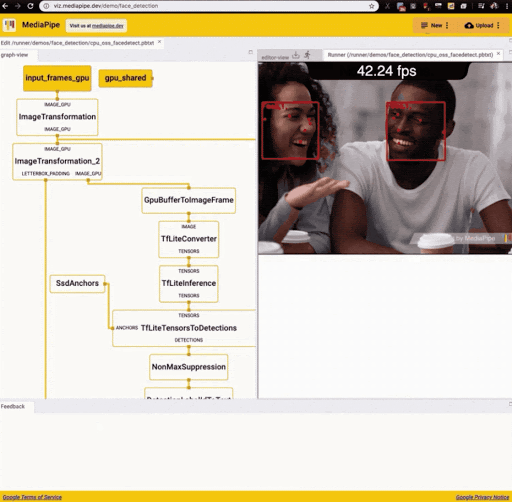
Source: https://developers.googleblog.com/2020/01/mediapipe-on-web.html
As is apparent from the graph, the face detection application transforms input frames (input_frames_gpu) into output frames (output_frames_gpu) through a series of transformations including the conversion of incoming frames into image tensors (TfLiteTensor), posterior processing by a TFLite model for face detection, and overlaying of annotations on the output video.
The visualized graph matches the facing text which contains a description of the nodes’ content and the expected processing to realize. The MediaPipe Visualizer will react in real-time to changes made within the editor in order to maintain the correspondence between text and graph. The configuration of the previous TFLite model is for instance as follows:
# Converts the transformed input image on GPU into an image tensor stored as a
# TfLiteTensor.
node {
calculator: "TfLiteConverterCalculator"
input_stream: "IMAGE:transformed_input_video_cpu"
output_stream: "TENSORS:image_tensor"
}
Google created four demos (Edge Detection, Face Detection, Hair Segmentation, Hand Tracking) to be run in the browser.
The browser-enabled version of MediaPipe graphs is implemented by compiling the C++ source code to WebAssembly using Emscripten, and creating an API for all necessary communications back and forth between JavaScript and C++. Required demo assets (ML models and auxiliary text/data files) are packaged as individual binary data packages, to be loaded at runtime.
To optimize for performance, MediaPipe’s browser version leverages the GPU for image operations whenever possible, and resort to the lightest (yet accurate) available ML models. The XNNPack ML Inference Library is additionally used in connection with the TensorflowLite inference calculator (TfLiteInferenceCalculator), resulting in an estimated 2-3x speed gain in most of applications.
Google plans to improve MediaPipe’s browser version and give developers more control over template graphs and assets used in the MediaPipe model files. Developers are invited to follow the Google Developer twitter account.
MediaPipe is a cross-platform framework for mobile devices, workstations and servers, and supports GPU acceleration. MediaPipe is available under the MIT open source license. Contributions and feedback are welcome and may be provided via the GitHub project.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ

Introduced in Git 2.18, Git wire protocol version 2 is now used by default in Git latest version, 2.26. Git 2.26 also improves configuration option handling and sparse-checkouts, among other things.
Git’s wire protocol defines how Git clients and servers communicate with each other. The new Git protocol version improves performance by enabling server-side filtering of references, which include not only branches and tags but also, e.g., pull request heads and others. Clients adopting Git protocol version 2 will be able to specify which references they are interested in, thus reducing the amount of data the server sends back. Contrast this with Git original protocol behaviour, where the server starts by sending back a list of all references in the repository, which could amount to many megabytes.
According to figures provided by Google engineer Brandon Williams at the time of Git protocol version 2 announcement, the new protocol can be significantly faster than the old one, especially with large repositories such as Chrome’s, which contains more than 500k references. Additionally, noted Williams,
Protocol v2 has also enabled a reduction of 8x of the overhead bytes (non-packfile) sent from googlesource.com servers. A majority of this improvement is due to filtering references advertised by the server to the refs the client has expressed interest in.
The reason for the delay in making Git protocol version 2 the default, notes Taylor Blau on GitHub blog, has been giving enough time for developers to catch any bugs in the protocol implementation. Interestingly, Git protocol version 2 is designed so any client implementing it can still talk to a Git server only supporting the old Git protocol.
As usual for Git releases, Git 2.26 includes a very long list of performance improvements, fixes, and new features. For example, git clone --recurse-submodules --single-branch now applies the --single-branch option to submodules as well.
Additionally, the git sparse-checkout command, introduced in Git 2.25, has got a new add subcommand which can be used to add new directories to your sparse checkout one at a time. Sparse checkouts are mostly useful with large repositories, where you are not interested in the whole repo content but only on some of its subdirectories. In Git 2.25, to add a new directory to those already included in your sparse checkout, you were required to list all of them when using the set subcommand.
Worth of mention is also an improvement to the diff family of commands, which enables git add -p to better deal with whitespace problems.
As a final note, Git 2.26 makes it easier for you to know where one default option is defined, whether at repository, user, or system level, using git config --show-origin.
Do not miss Git 2.26 official release notes if you are interested in the full detail about this release.



MMS • Joe Duffy
Article originally posted on InfoQ. Visit InfoQ

In this podcast, Daniel Bryant sat down with Joe Duffy, founder and CEO at Pulumi, and discussed several infrastructure-themed topics: the evolution of infrastructure as code (IaC), the way in which the open source Pulumi framework allows engineers to write IaC using general purpose programming languages such as JavaScript and Go, and the future of multi-cloud environments.
Subscribe on:
Show Notes
Could you briefly introduce yourself to the listeners?
- 01:10 My name is Joe Duffy, founder and CEO of Pulumi, an infrastructure-as-code startup in Seattle, Washington.
- 01:15 My background – I was in Microsoft before, I did some things before that – but most people know me from my work there as an early engineer on .NET, developer tools, distributed OS Midori.
- 01:35 I’ve been focussed on the cloud space for the last few years.
Can you briefly introduce what problem infrastructure-as-code is trying to solve?
- 01:55 Infrastructure-as-code helps you automate the provisioning and management of your cloud infrastructure.
- 02:05 If you’re just getting started with cloud, the obvious thing to do is point and click inside the AWS console, and start that way.
- 02:15 That’s a fine way to explore, but what happens if you delete something, or you want to create a second copy of your infrastructure, or have a staging environment.
- 02:25 At scale, you need an automated solution for provisioning and managing this infrastructure.
- 02:30 Infrastructure-as-code is a way to do that in code, rather than having to do CLI commands or bash scripts.
- 02:40 There’s a variety of solutions, such as markup based solutions like YAML or JSON, through to Chef and Puppet using Ruby based DSLs.
- 02:55 Pulumi takes the approach of using general purpose languages to provision infrastructure.
How would you say that Pulumi is different from Puppet, Chef or Ansible?
- 03:05 The configuration tools – I split the infrastructure-as-code space into provisioning and configuration.
- 03:15 Provisioning is about creating and updating and versioning the infrastructure itself.
- 03:20 A lot of the configuration tooling like Chef, Puppet, and Ansible are more about what’s happening inside of the virtual machine.
- 03:30 You spin up some VMs, then you have to install some packages, then you have to configure some services with systemd – or patching the server upgrades in an automated way.
- 03:45 Over the years, especially as we have adopted containers and serverless, and the infrastructure itself has become more fine-grained.
- 03:55 If you think of all the IAM roles and policies and all of the moving pieces, provisioning is more interesting now than configuration.
- 04:05 There’s this other trend, which is towards immutable infrastructure; if you want to deploy a new version of a web server, one approach is to patch your existing server.
- 04:10 Then you have to think about all the N-to-N+1 of the server’s possibilities, of what the current state is and how do you move it to the new desired state.
- 04:20 With immutable infrastructure, you spin up a new webserver, redirect all the references to the new server, and destroy the old one.
- 04:30 We see a lot of people moving to that model with provisioning tools instead.
How does Pulumi differ from Terraform or CloudFormation?
- 04:40 Pulumi is imperative, but with a declarative core to it – that’s the special thing about Pulumi.
- 04:50 A lot of people are familiar with Boto, write some Python code, go out to AWS SDK and make a bunch of calls and spin up servers.
- 05:00 The thing that CloudFormation, Terraform, and now Pulumi do is based on the notion of this goal state.
- 05:10 Your program, when you run it, says that you want a VPC, these subnets, an EKS cluster, and an RDS database.
- 05:20 The deployment engine (whether it’s Terraform, CloudFormation or Pulumi) now can say that’s the desired state, and I will make that happen.
- 05:25 That works for the first deployment you do, but maybe you want to re-run it, to scale up the number of node pools in your Kubernetes cluster from 2 to 3.
- 05:40 The deployment engine can then diff that desired state from the current known state, and produce a plan of how to change it – in this case, an increase of 1 node pool.
- 05:50 What Pulumi does is allow you to express your goal state in a declarative language.
- 05:55 The goal state is still declarative; it represents your end state – you’re just using for loops and classes and all those familiar constructs to declare it.
- 06:05 We also support .NET, so you can do this in F# and it becomes a more functional approach, which is a completely different way of thinking about your infrastructure.
How do people get started with Pulumi?
- 06:30 Pulumi is an open-source tool, so you can download it from GitHub and you have a CLI which hosts an engine, which knows how to interact with different language runtimes.
- 06:45 You download this tool, and then you say you want to create a new project in Python, JavaScript, or whatever language of choice is, and the Pulumi engine knows how to spawn those runtimes.
- 06:55 For state storage (part of the infrastructure-as-code approach) we have a hosted service which we make available for free if you want to use it (you can opt-out if you don’t).
- 07:10 It’s super convenient, because you don’t have to think about state management.
- 07:15 When you use CloudFormation, it feels like there’s no state management, because CloudFormation is in AWS, and they’re mapping the state for you.
- 07:25 Terraform is an off-line tool, so it gives you the state and you have to manage it – and if you do that wrong, you shoot yourself in the foot.
- 07:30 We tried to make Pulumi more like CloudFormation model than Terraform – but if you want to take the state with you, you can do that.
What languages does Pulumi currently support?
- 07:40 We support Python, and any Node.JS supported language; most people use TypeScript or JavaScript.
- 07:50 We use Go, which is great for embedding infrastructure-as-code for into larger systems.
- 07:55 We also support .NET, so any .NET language, which includes C#, F#, VisualBasic – even Cobol.NET if you want!
How does using functional languages like F# work with Pulumi?
- 08:10 Functional languages themselves are declarative in a sense, because you don’t have mutable state – new states are computed out of old states.
- 08:20 F# itself has had notion of these workflows for a while – in the early days of async programming, we had these F# workflows.
- 08:30 Declaring your infrastructure feels like declaring your workflow of how all these infrastructure pieces related to each other.
- 08:35 Ultimately, all of these languages interact with the Pulumi engine in fundamentally the same way – it’s just the syntax of how you’re describing the infrastructure and the facilities of the language that are available to you.
So you can use modules and libraries?
- 08:55 Exactly, which is great – because how many times have you written the same 2000 line CloudFormation or Terraform code to spin up a virtual VPC in Amazon?
- 09:05 Now you can stick it in a package, share it with your team, the community or just re-use it yourself next time you need it.
Is Pulumi a transpiler to convert a language like TypeScript into AWS commands?
- 09:15 It’s fairly complicated, and it took us four attempts to get it right.
- 09:30 We started by writing our own language runtime, because the challenge you have is what happens when a resource depends on another in your program – you need to capture that dependency.
- 09:40 You need to provision things in the right order, and for destroying them, in the right order as well.
- 09:45 You also want to parallelise where you can so that you can build everything as fast as possible.
- 09:50 In Pulumi, in the code, you declare a directed acyclic graph (DAG) – a graph of resources that depend on each other.
- 09:55 The Pulumi runtime takes that DAG, and creates a plan out of it, lets you see the plan before you’ve applied it, and works the first time or diffs in subsequent runs, and you can apply it.
- 10:15 You can run those in separate steps if you want.
- 10:20 When you choose to apply it, Pulumi takes that plan, and orchestrates all of the AWS calls or Kubernetes or whatever cloud you’re using.
What backends do you support?
- 10:35 All the major clouds: AWS, Azure, GCP – also Alibaba Cloud and Digital Ocean.
- 10:45 We also support Kubernetes, which is a popular package for us.
- 10:50 The full object model in Kubernetes model is available, so you can not only provision Kubernetes clusters using Pulumi, you can install services into them with Helm Charts.
- 11:00 You can also write your application config with this model, and have dependencies between them, which is nice.
- 11:05 Often provisioning a new Kubernetes cluster means spinning up EKS, provision some AWS resources like CloudWatch logs, and then maybe install some Kubernetes services using Helm.
- 11:20 With Pulumi, you can actually provision resources across all of these clouds using one program, and Pulumi will orchestrate it in the right order.
Is Pulumi similar to the AWS Cloud Development Kit (CDK)?
- 11:35 There’s a lot of similarities – we came out a bit before CDK so we’ve had more bake-time.
- 11:40 The main difference is the multi-cloud nature; we support Kubernetes, Azure, GCP – and also on-prem technologies like vSphere, OpenStack, F5 Big IP.
- 11:55 The other difference is that CDK is a transpiler; it turns out that Pulumi is a runtime.
- 12:05 CDK spits out CloudFormation YAML, and if you have an error, tracing it back to the program isn’t quite as first class.
- 12:15 I love what they’re doing, and they’re taking the idea of infrastructure-as-code and seeing the same vision that we see.
- 12:25 We talk with the CDK team a lot about our experiences, but there are some fundamental differences.
How does debugging with Pulumi work?
- 12:50 We have what we call PDBs – I used to manage a C++ team at Microsoft, and we spent a lot of time making sure that the debug symbols mapped back to the source code.
- 13:05 We sort of have the equivalent of debugging symbols for your infrastructure, where you know exactly where it came from down to the program source code.
- 13:10 Because we’re using general purpose languages, you can use your favourite editor, IDE, debugger, test tools … the language is like the surface area, but the toolchain and ecosystem is more powerful.
Are there any disadvantages of using Pulumi?
- 13:40 I think that some people are uncomfortable with a full blown language to start – especially if you’re coming from a limited DSL or YAML dialect.
- 13:55 A lot of people may be worried about creating webserver factories and you are an architect astronaut with huge layers of abstractions and no-one can understand what’s going on …
- 14:05 The same arguments apply also to application code, and we’ve somehow figured it out there so it doesn’t worry me as much.
- 14:15 Not everybody understands full-blown languages, so there is a learning curve – but a lot more people these days are learning languages such as Python from school.
- 14:35 I think ultimately it is better for folks to learn and come outside their comfort zone a little bit, and come out the other side a bit better off.
Is Pulumi skewed towards developers rather than ops?
- 15:10 I thought that was going to be teh case, and it turns out where we’re resonating the most in DevOps teams who have used Chef and Pupppet and Boto and Python.
- 15:25 They maybe have used enough Terraform to know the limitations that they’re hitting.
- 15:30 For developers, it’s a no-brainer, but for folks who are already doing infrastructure, and also want to work better with developer teams.
- 15:35 We tend to have these silos sometimes, and the devops movement has helped to break some of those down, but we’ve seen some infrastructure teams who want to hand over control to the developers but don’t know how.
- 15:45 The development team doesn’t want to use a YAML templating thing, but rather their favourite language – and this gives them a way to have that conversation and empower them a bit more.
How does collaboration in general work with Pulumi?
- 16:10 It varies by team.
- 16:15 If you’re just bringing up a new service, and doing initial development – a lot of times, that happens at the command line.
- 16:20 On our command line, it shows you the whole diff, you can drill into the details, you run the command ‘pulumi up’ and will show you the difference to the plan, and you can apply that.
- 16:40 In production settings, we are moving more towards a git-based deployments where we integrate with your source code systems.
- 16:45 When you open a pull request, Pulumi will actually augment the pull request with the full diff of infrastructure changes.
- 16:55 It’s not always obvious when you are diffing your code what the infrastructure changes would be.
- 17:00 It will show you if you deploy this, it will deploy a webserver, modify a Route53 record – and then this links over to Pulumi so you can drill in.
- 17:10 You can have a conversation on the review process in the team around rolling out changes – that’s how we manage our on-line servers.
How do I go about testing Pulumi code?
- 17:35 There’s a lot of different kinds of testing; you could mean unit testing, integration testing; there’s also policies as code, so you don’t violate a team policy.
- 17:55 One of the more interesting kinds of testing we see is ephemeral environments, where you take a pull request and spin up a new copy of the infrastructure temporarily to run tests against.
- 18:10 That really unlocks some workflows.
- 18:15 Because it’s just your existing language, you can use tools and techniques that you know about already – you don’t have to learn a bunch of new tools and techniques.
Are there any tips on dealing with the cost of spinning up bit ephemeral systems?
- 18:35 We have a config system built into Pulumi – you can create smaller versions of your environments for ephemeral testing.
- 18:45 Instead of having three nat gateways spread across all AZs, maybe you have one or skip it and have a mock instead.
- 19:00 We tend to find mocking is really complicated, because you might pass the test against a mock and then fail when you go to production.
- 19:10 Usually it’s better if you can afford to create an approximation that’s maybe a bit smaller.
What does a continuous delivery pipeline look like with Pulumi?
- 19:25 We made the decision early on not to try and create a separate CI/CD environment – we wanted to integrate with existing ones, like Travis, Jenkins, GitHub actions, GitLab pipelines, Azure pipelines.
- 19:40 We have over a dozen of these integrations – when you open up a pull request, it’s going to run the preview, and once you merge and commit it runs the apply.
- 19:55 For a lot of us, this is how we do it internally as well, we have different branches representing different environments.
- 20:00 When we deploy a new production version of a Pulumi service, we have a separate production branch, and so we open a pull request from the staging branch to the production branch.
- 20:10 Pulumi knows how to do a rolling deployment, and diff between the two environments, which is a nice way of modelling it – it maps well to git concepts.
Does Pulumi manage traffic rollover for a blue/green deployment?
- 20:35 Where we can, we do – so for Kubernetes we give you detailed updates about where the rollout is happening, where the traffic is being migrated to.
- 20:45 We do mini blue/green deployments at the resource level – we prefer to spin up new infrastructure, and then drain traffic and redirect to the new infrastructure before tearing down the old.
- 21:00 We’ve architected Pulumi to work in that way.
- 21:05 If you’re using ECS, we’ve integrated into the health checking to make sure that task definitions roll out at the right time.
- 21:10 We’re trying to make it so that you don’t have to think about it.
- 21:15 There’s a blue/green deployment at a much higher level, so for folks wanting to do zero-downtime upgrades of Kubernetes clusters, for example, we have patterns you can use to blue/green the entire cluster level.
- 21:30 Some of this can be expensive, but if you really need zero downtime then there are ways you can accomplish it.
How important do you think multi-cloud is going forward?
- 21:45 I think it’s reality for almost every company we work with, for a number of reasons.
- 21:55 I think multi-cloud can have a bad rap; to some people, it sounds like it means lowest common denominator across all of the clouds.
- 22:05 To us, that’s not what multi-cloud is: in some cases, that makes sense – especially if you’re doing Kubernetes where your workload can be multi-cloud.
- 22:10 For us, it’s really most large enterprises where the entire organisation may have to deal with multiple clouds; on-prem, AWS, Azure.
- 22:20 For SaaS companies like ourselves, we are selling to customers who may want to run it in their own cloud, and that cloud is going to be AWS/Azure/GCP/on-prem.
- 22:30 We don’t want to limit who we can sell our own product to, so it’s in our best interest to think about multi-cloud.
- 22:40 We have customers where they get acquired, and their parent company is an Azure shop – they were all in on AWS, and now they’re an Azure shop.
- 22:50 You don’t expect them to rewrite everything to run on Azure – they didn’t plan on being multi-cloud, but now they are.
- 22:55 For us, multi-cloud is more about the workflow, the authoring, the techniques, the tools – it’s not about the lowest common denominator.
- 23:00 Pulumi gives you one workflow that you can standardise across the organisation, regardless of whether you are doing hybrid or multi-cloud.
Is there a migration path to bring things together with Pulumi?
- 23:25 Most people have solutions for infrastructure already – we can either co-exist temporarily during the transition or permanently if it makes sense.
- 23:45 There’s ways of importing infrastructure, so even if you’ve created a resource from the CLI you can take it under the control of Pulumi going forward.
- 23:55 We also have translation tools, that can convert Terraform’s HCL to Python or JavaScript or whatever language you like, and some for Helm charts.
What is policy as code?
- 24:25 Policy as code is the notion of expressing policies like you can’t expose an RDS database to the internet, or your RDS database must be MySQL version 5.7 or greater.
- 24:35 The idea is you can express these policies using a language, either a DSL like Open Policy Agent (OPA) with Rego.
- 24:45 Just like infrastructure-as-code, we allow you to use your own language choice for policy-as-code.
- 24:55 You can then enforce this, so that every time someone does a deployment, if it fails the policy then block the deployment.
- 25:05 We also allow you to scan the existing infrastructure and find all of the violations that you already have.
- 25:10 You’ve got a path to incrementally remediate that over time.
What does the next 18 months look like for Pulumi?
- 25:25 We shipped our 1.0 release in September, which was a really major milestone for us, where we’re sticking to compatibility – we know infrastructure is the lifeblood of the business.
- 25:35 We’re now ramping up for our 2.0 release which is bringing policy-as-code and some more testing tools, which is going to be out pretty soon.
- 25:45 Now we’ve got this really solid foundation, and we’ve seen some of the patterns and practices that people are having problems with; I mentioned the VPC case – why would you write 3000 lines of code?
- 26:05 We’re focussed in the future on some of these patterns and jobs to be done, and make it really easy to spin up a new microservice in an afternoon.
- 26:15 Now we’ve laid the foundation, how do we improve the time to create these things, reduce the boilerplate, make it 10 times easier than it was before.
- 26:30 Today we rely on NPM and other module registries, but we are looking at if we could have a central place for people to go to find all of these patterns and practices.
- 26:50 Long term, we want to make it easier for developers too.
- 26:55 Infrastructure is still hard: even though you can use your favourite language, the concept count is really high for infrastructure.
- 27:00 If all you want to do is spin up a new microservice in a docker container, you shouldn’t have to become an expert in all of these things.
If people want to follow you on line, what’s the best way?
. From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Andrew Davis
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- The shift from project to product continues, with an eye towards long-term maintainability and adaptability.
- The shift to small, semi-autonomous teams continues, as does the market for platforms that integrate and aggregate information from disparate tools.
- The growing importance of data science and analytics on the development lifecycle.
- Concepts such as Value Stream Mapping that look at the entire Dev lifecycle become increasingly important, and pre-built tools to support this become more common.
- Increasingly specialized vendors and SI partner offerings arise to assist with DevOps needs.
The DevOps movement continues to grow in terms of its impact and influence in the IT ecosystem. There’s no question that the DevOps movement is maturing to the point that it has a power and a voice comparable to that of other movements such as cloud and agile. One interesting characteristic of the DevOps movement is that it arose from a wish within IT to optimize and harmonize the activities of different teams; but it’s matured to take into consideration the needs of end users and a holistic view of how organizations need to operate in order to be both flexible and efficient at scale.
Business leaders may complain that IT workers don’t appreciate the underlying business context in which they’re operating; and historically the IT department has been seen as a cost centre and not a value centre for organisations. The net result of that is that IT struggled to justify infrastructure and process improvements that would increase costs, unless they were specifically tied to a new business-facing initiative. But IT is becoming increasingly central to business operations. Done well, the flexibility of software allows organisations to adapt much more quickly than in a pre-digital infrastructure, thus making effective IT teams the biggest enablers of value.
Project to Product
Digital transformation has become an incredibly popular buzzword in recent decades, but it is essential for companies to recognize that digital transformation is not a one-time activity. The work done by Mik Kersten in his book ‘Project to Product‘ highlights the fallacy of thinking of IT improvements as one-time projects. Digging into the history of technological revolutions and witnessing the most advanced manufacturing processes of today helped Kersten recognize that shifting to a product-focused mindset is a far more beneficial way for companies to frame IT.
What does it mean to approach internal IT initiatives as products? One aspect is recognising that IT systems entail long-term maintenance responsibilities, and are not something that should simply be created and turned over to an unrelated team. Another aspect is re-thinking the way we finance projects. The annual budgeting cycle is optimised for relatively stable systems, where change can be anticipated a year in advance. Teams vie for a share of the budget, and ensure that they never underspend their allocation, lest they receive less the following year. The requirement to get up-front funding tends to promote large, expensive projects, while budget for subsequent operation is often not factored in. The result of this are complex IT systems that are maintained by teams other than the ones who built them, that are excessively complex, and that often don’t meet the needs of end users. Agility needs to extend into every aspect of a business, from how teams are structured, to how work is financed, to how and when an organization decides to make improvements.
An example of a product-mindset is to have the team in charge of a CPQ (Configure – Price – Quote) system be responsible for both building and maintaining that system over time – the “you build it, you own it” mantra. The power of this mindset is in promoting stability and flexibility in what is built. When a team has long-term responsibility for building and maintaining the product, and for getting feedback on how it’s used in production, they greatly increase the chances of this product bringing lasting value to the organisation. Feedback on how systems are used in production is the essential input for ongoing improvement. It’s for this reason that in the DevOps community the assembly line motif of software development has given way to a circular or infinity loop motif for software development. The loop indicates that ongoing feedback from end-users is as important as the original specifications.
Product companies and product teams are by nature more stable than teams who just build and move on. Project teams work great in construction and civil engineering, where infrastructure rarely needs to change once built. But software allows for an utterly different level of agility. It can be replatformed or refactored without end users being aware; its design or functionality can be changed at the last minute before release to users; and different versions can be exposed to different users to solicit feedback. This agility is why the knowledge that went into creating a software product must be retained in the team if at all possible. There is a “cone of uncertainty” where at the outset of building something we know the minimum that we will ever know about it. As we proceed with development and a system comes under use, we necessarily learn things that could never have been predicted even by the most intelligent and thoughtful planning team.
Team Topologies
Related to this topic of “project to product” is the research that has been done around team cognitive load, and the importance of structuring teams in a way that optimises for communication and trust. There are both mathematical and empirical bases for saying that smaller teams that can act independently will perform more effectively than large teams or teams with many dependencies. Amazon’s two-pizza team size was not created to simplify their catering needs. It’s a wise structure that maximizes the power of teamwork while minimising the overhead required for constant coordination. Conway’s Law dictates that your architecture will come to reflect your team structure. Given that an optimal team size is constrained to five to ten people, modular architecture is essential if you want to be able to maintain your velocity over time. The idea is to give teams relative autonomy over particular systems. This feeds into topics like continuous integration which strives to reduce the impact of parallelisation. These kinds of DevOps best practices began with research and experimentation in the field, moved to being DevOps community lore, became substantiated through the research of teams like DevOps Research and Assessment, and will gradually become the basis for dedicated tools and entrenched ways of working.
Much of the tool growth that we are seeing today includes integration and Value Stream Management platforms such as Copado, Tasktop, Plutora, Xebialabs, GitLab and Cloudbees who are striving to bring information from many disparate systems together into one tool. I expect this integration and aggregation trend to continue as a practical way of dealing with the diverse reality of enterprise systems. In fact, teams benefit greatly from being able to choose their own tools. In the book ‘Team Topologies’ by Matthew Skelton and Manuel Pais, they refer to standardization as one type of monolith, “monolithic thinking”, that can interfere with maximum effectiveness. If you are striving to avoid monolithic thinking, but nevertheless need an integrated view of your systems and processes, data integrations are your only option.
Tool Evolution
LaunchDarkly showed that there is a market for products that facilitate particular DevOps practices, in this case separating deployments from releases. That practice is integral to activities like A/B testing and canary deployments, which have become recognised as powerful ways to reduce risk and enable experimentation. I would expect that more tools continue to appear to enable DevOps practices that otherwise would require custom coding.
Although this is not a new trend, definitely expect to see services like Amazon Web Services (AWS), Azure and Google Cloud Platform (GCP) continue to roll out new service offerings, compete with one another, and gain market share from legacy infrastructure. Azure and GCP are still playing catch-up in terms of the variety of products that they offer as well as the market share that they control, but expect them to be following close on the heels of AWS. Offerings such as kubernetes-as-a-service help to reduce the complexity of managing underlying infrastructure. Expect other kinds of complex systems to continue to be bundled into turnkey applications.
Data Science
The State of DevOps Reports from Puppet and Google have set the standard for using data science to evaluate the effectiveness of development practices. Expect to see more tools begin to integrate analytics and data science into their offerings. And expect to see more teams requesting and making use of such capabilities to facilitate experimentation and to validate the results of those experiments.
Business functions such as marketing have been using A/B testing and quantifying their effectiveness for many years. There are a huge number of marketing-oriented tools that have been highly tuned to give metrics on click through rate, adoption, time on site, return on investment, etc. The most long-standing of these is Google Analytics, but marketers have a vast range of tools to choose from. Ironically, IT teams are late to the party in terms of practices such as A/B testing and ensuring that applications are being adopted by users. It is often left to business teams to track adoption of an application created by an IT department. But internal IT departments are the ones who have the greatest opportunity to make improvements to meet the needs of users.
Expect to see tools for usage monitoring and even embedded feedback and user satisfaction surveys becoming more frequently used by internal development teams. These practices help close the gap between end users and development teams in the same way that marketing teams have been striving to close the gap between companies and their customers for many years. This kind of feedback is exceptionally powerful since there’s an inefficiency introduced by involving a business analyst every time you want to solicit user feedback. Selective feedback initiatives also suffer from sample bias.
Lean and Agile
DevOps is aimed at “actualizing agile” by ensuring that teams have the technical capabilities to be truly agile, beyond just shortening their planning and work cadence. Importantly, DevOps also has Lean as part of its pedigree. This means that there is a focus on end-to-end lifecycle, flow optimisation, and thinking of improvement in terms of removing waste as opposed to just adding capacity. There are a huge number of organisations and teams that are still just taking their first steps in this process. For them, although the terminology and concepts may seem overwhelming at first, they benefit from a wide range of well-developed options to suit their development lifecycle needs. I anticipate that many software tools will be optimizing for ease-of-use, and continuing to compete on usability and the appearance of the UI.
Whereas most early DevOps initiatives were strictly script and configuration file based, more recent offerings help to visualise processes and dependencies in a way that is easily digested by a broader segment of the organization. Especially as companies try to capture the attention and wallet share of CIOs, CTOs and other organizational decision-makers, reducing the difference between the actual UI of a tool and how it can be visualized and marketed becomes even more important. The most beautiful and graphical tools just sell themselves (to both business and technical users). Value Stream Mapping and delivery pipelines are particularly popular and effective ways to visualize the delivery process, while also providing day-to-day access to metrics and monitoring.
System Integrators
Finally, it’s clear that the market and demand for practices such as DevOps exceeds the availability of skilled people to implement it. Thus system integrators will continue to have a role in helping teams to ramp up on these technologies and processes, and in some cases to even help manage the development lifecycle for organizations. Research in the State of DevOps Reports indicates that functional outsourcing is predictive of low performance, so organizations should be very careful about delegating one particular activity such as testing or deployment to an outsourced contractor. Unless done carefully, functional outsourcing goes against the spirit of DevOps which focuses on bringing all of the relevant stakeholders (from Dev to Ops) together with aligned goals, shared visibility, and shared technologies.
Consulting partners are an extremely powerful way of getting help in the absence of in-house talent. But they necessarily introduce organisational boundaries unless consultants are deeply embedded in the organisation, working long-term alongside full-time employees. Rely on DevOps consultants as enablers to help you to adopt technologies, improve your processes, design your metrics and so forth. But be careful about outsourcing a particular part of your process (such as testing) that is on the critical path to production.
It may work better to give the entire development process for a particular application to a consulting company. But consider the long-term lifecycle of this and how you want that company to maintain the application over time. In the spirit of project to product, there is risk in having one team build an application and a separate team maintain it. Think of the knowledge that you are building within the team as a critical part of your architecture. Just as it’s foolhardy to rip out a substantial chunk of your architecture just after go-live, so too it’s unwise to rip out a substantial chunk of knowledge from your team just after go-live.
Summary
In summary, the DevOps movement continues to grow, flourish, and gain influence in the IT world and the business world at large. As our organisations become increasingly digital, the agility of our IT systems becomes critical to the life and health of our companies. DevOps as a movement blends together psychology, sociology, technical management, automation, security, and practices such as lean and agile to optimise an organisation’s ability to thrive in a digital world. The consulting, tooling, infrastructure, and training ecosystem to support this is still evolving. The market for DevOps is in fact the market for digital success, thus expect continued growth through 2020 and beyond.
About the Author
 Andrew Davis is a Salesforce DevOps specialist who’s passionate about helping teams deliver innovation, build trust, and improve their performance. He currently works as Senior Director of Product Marketing for Copado, helping people understand the importance of DevOps for scaling Salesforce implementations.
Andrew Davis is a Salesforce DevOps specialist who’s passionate about helping teams deliver innovation, build trust, and improve their performance. He currently works as Senior Director of Product Marketing for Copado, helping people understand the importance of DevOps for scaling Salesforce implementations.
MMS • Dylan Schiemann
Article originally posted on InfoQ. Visit InfoQ

Rome is an experimental JavaScript toolchain created by Babel and yarn creator Sebastian McKenzie and the React Native team at Facebook. Rome includes a compiler, linter, formatter, bundler, and testing framework, aiming to be “a comprehensive tool for anything related to the processing of JavaScript source code.”
Unlike similar projects which combine various tools into a workflow, Rome is a rethink of the JavaScript ecosystem with a bold approach to the entire toolchain with no pre-existing third-party dependencies.
Rome is authored in TypeScript and is a monorepo with internal packages to delineate code boundaries. Rome is self-hosted and compiles itself with an old version of Rome. Rome provides support for processing JSX, Flow, and TypeScript code.
The Rome Getting Started documentation is currently intentionally very sparse, with information about initializing Rome, defining settings in a JSON file, and actions including running, linting, compiling and parsing source code.
Preact and Jason Miller created an overview of Rome and detail usage of the available CLI commands, compare its bundling output to Rollup, provide a few examples, and other early insights.
The Rome project has a clear set of development guidelines, from clear and easy to understand error messages, as small of an API footprint as possible, and strongly typed code. The Rome Team is currently focused on linting and maintain a list of actively considered issues. As explained by McKenzie:
The current area of focus for Rome is linting. This is the path of least resistance for finishing a part of Rome that can be used most easily.
Rome offers a promising rethink to perhaps remove cruft from the current state of JavaScript development and tooling, though it is far too early to determine if this approach will change the status quo or simply lead to another option for the JavaScript toolchain. Community interest is strong and includes discussion on whether Rome might include future support for WebAssembly.
Rome is available under the MIT license though it is not ready for production use and currently can only get used by building from source. Rome is open for contributors interested in experimental tools following the contribution guidelines and code of conduct.
MMS • Portia Tung
Article originally posted on InfoQ. Visit InfoQ
InfoQ Homepage Presentations Playful Leadership: The Art and Science of Emotions
Summary
Portia Tung explores the role of emotions and how they are made, showing the way towards authentic leadership through greater emotional intelligence.
Bio
Portia Tung is a Personal and Executive coach, Agile coach and play researcher creating transformative change in a range of organizations including the Prime Minister’s Office, the NHS, British Airways and global financial institutions. Portia is the author of The Dream Team Nightmare.
About the conference
Aginext is for advanced agilists. That means we need to listen to feedback and be eager to adapt to change. The COVID-19 pandemic makes our conference untenable in its existing co-located form. After careful consideration and collaboration with our team, our brilliant speakers, and our venue, we are moving the 2020 Aginext Conference Online.

Mar 26, 2020