Month: December 2021

MMS • RSS
Posted on mongodb google news. Visit mongodb google news
![]() MongoDB, Inc. (NASDAQ:MDB) was the target of unusually large options trading on Wednesday. Stock investors purchased 23,831 put options on the stock. This is an increase of 2,157% compared to the typical daily volume of 1,056 put options.
MongoDB, Inc. (NASDAQ:MDB) was the target of unusually large options trading on Wednesday. Stock investors purchased 23,831 put options on the stock. This is an increase of 2,157% compared to the typical daily volume of 1,056 put options.
Several brokerages have commented on MDB. UBS Group upped their price objective on MongoDB from $300.00 to $450.00 and gave the company a “neutral” rating in a research report on Friday, September 3rd. The Goldman Sachs Group upped their price objective on MongoDB from $475.00 to $545.00 and gave the company a “buy” rating in a research report on Wednesday, December 8th. Mizuho increased their price target on MongoDB from $475.00 to $490.00 and gave the stock a “neutral” rating in a research report on Tuesday, December 7th. Zacks Investment Research downgraded MongoDB from a “buy” rating to a “hold” rating in a research report on Friday, September 10th. Finally, Piper Sandler increased their price target on MongoDB from $525.00 to $585.00 and gave the stock an “overweight” rating in a research report on Tuesday, December 7th. Four research analysts have rated the stock with a hold rating and thirteen have given a buy rating to the company. According to data from MarketBeat, the stock has a consensus rating of “Buy” and an average target price of $539.59.
In related news, CRO Cedric Pech sold 279 shares of the stock in a transaction on Monday, October 4th. The stock was sold at an average price of $460.55, for a total transaction of $128,493.45. The transaction was disclosed in a document filed with the SEC, which is accessible through this hyperlink. Also, Director Charles M. Hazard, Jr. sold 1,667 shares of the stock in a transaction on Friday, October 1st. The shares were sold at an average price of $470.01, for a total value of $783,506.67. The disclosure for this sale can be found here. Insiders have sold a total of 76,223 shares of company stock worth $37,834,146 over the last ninety days. Insiders own 7.40% of the company’s stock.
(Ad)
Access our premier research platform that includes MarketBeat Daily Premium, portfolio monitoring tools, stock screeners, research tools, a real-time news feed, email and SMS alerts, the MarketBeat Idea Engine, proprietary brokerage rankings, extended data export tools and much more. Save 50% Your 2022 Subscription. Just $1.00 for the first 30 days.
A number of institutional investors and hedge funds have recently modified their holdings of MDB. Price T Rowe Associates Inc. MD boosted its stake in shares of MongoDB by 191.2% in the second quarter. Price T Rowe Associates Inc. MD now owns 5,766,896 shares of the company’s stock worth $2,084,848,000 after acquiring an additional 3,786,467 shares during the last quarter. Moors & Cabot Inc. purchased a new position in MongoDB during the third quarter worth approximately $601,000. Vanguard Group Inc. lifted its position in MongoDB by 7.9% during the second quarter. Vanguard Group Inc. now owns 5,378,537 shares of the company’s stock worth $1,944,448,000 after buying an additional 391,701 shares in the last quarter. Growth Interface Management LLC purchased a new position in MongoDB during the third quarter worth approximately $86,758,000. Finally, Caas Capital Management LP purchased a new position in MongoDB during the second quarter worth approximately $65,542,000. 88.50% of the stock is currently owned by institutional investors.
MongoDB stock traded down $5.66 during midday trading on Thursday, hitting $532.35. 222,557 shares of the company were exchanged, compared to its average volume of 820,014. The firm has a market capitalization of $35.54 billion, a PE ratio of -113.64 and a beta of 0.66. MongoDB has a fifty-two week low of $238.01 and a fifty-two week high of $590.00. The business has a fifty day simple moving average of $521.81 and a two-hundred day simple moving average of $449.41. The company has a debt-to-equity ratio of 1.71, a quick ratio of 4.75 and a current ratio of 4.75.
MongoDB (NASDAQ:MDB) last issued its quarterly earnings data on Monday, December 6th. The company reported ($0.11) EPS for the quarter, beating the consensus estimate of ($0.38) by $0.27. MongoDB had a negative return on equity of 101.71% and a negative net margin of 38.32%. The company had revenue of $226.89 million for the quarter, compared to analyst estimates of $205.18 million. During the same period last year, the company earned ($0.98) earnings per share. MongoDB’s quarterly revenue was up 50.5% compared to the same quarter last year. As a group, equities analysts expect that MongoDB will post -4.56 earnings per share for the current year.
MongoDB Company Profile
MongoDB, Inc engages in the development and provision of a general purpose database platform. The firm’s products include MongoDB Enterprise Advanced, MongoDB Atlas and Community Server. It also offers professional services including consulting and training. The company was founded by Eliot Horowitz, Dwight A.
See Also: What is the Bid-Ask Spread?
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to [email protected]
Should you invest $1,000 in MongoDB right now?
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.
Article originally posted on mongodb google news. Visit mongodb google news
In-Memory Database Market is expected to grow at a CAGR of 19% to 21% from 2021 to 2026
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

“Trends and Forecast for the Global In Memory Database Market”
Trends, opportunities and forecast in In-memory database market to 2026 by data type (relational, NoSQL and NewSQL), application (transaction, reporting, analytics, and others), processing type (online analytical processing (OLAP), and online transaction processing (OLTP)), organization size (large enterprises and small and medium enterprises), end use industry , and region
Lucintel’s latest market report analyzed that in-memory database provides attractive opportunities in the healthcare and life science, BFSI, manufacturing, retail and consumer goods, IT and telecommunication, and transportation industries. The In-memory database market is expected to grow at a CAGR of 19% to 21%. In this market, NewSQL is the largest segment by data type, whereas BFSI is largest by end use industry.
Download Brochure of this report by clicking on https://www.lucintel.com/in-memory-database-market.aspx Based on data type, the in-memory database market is segmented into relational, NoSQL and NewSQL), application (transaction, reporting, analytics, and others. The NewSQL segment accounted for the largest share of the market in 2020 and is expected to register the highest CAGR during the forecast period, due to better performance to scale online transaction processing as compared to other in-memory database solutions.
Browse in-depth TOC on “In-Memory Database Market”
XX – Tables
XX – Figures
150 – Pages
The In-Memory Database Market is marked by the presence of several big and small players. Some of the prominent players offering in-memory database include Microsoft, IBM, Oracle, SAP SE, Teradata, Amazon Web Services, Tableau, Kognitio, VoltDB, and DataStax
This unique research report will enable you to make confident business decisions in this globally competitive marketplace. For a detailed table of contents, contact Lucintel at +1-972-636-5056 or click on this link helpdesk@lucintel.com.
About Lucintel
Lucintel, the premier global management consulting and market research firm, creates winning strategies for growth. It offers market assessments, competitive analysis, opportunity analysis, growth consulting, M&A, and due diligence services to executives and key decision-makers in a variety of industries. For further information, visit www.lucintel.com.
Media Contact
Company Name: Lucintel
Contact Person: Brandon Fitzgerald
Email: Send Email
Phone: 303.775.0751
Address:8951 Cypress Waters Blvd., Suite 160
City: Dallas
State: TEXAS
Country: United States
Website: www.lucintel.com
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
If you’re looking for a VPN server to host in-house, look no further than the AlmaLinux/Pritunl combination. See how easy it is to get this service up and running.

Getty Images/iStockphoto
Pritunl is an open source VPN server you can easily install on your Linux servers to virtualize your private networks. This particular VPN solution offers a well-designed web UI for easy administration and management. All traffic between clients and server is encrypted and the service uses MongoDB, which means it includes support for replication.
I’ve walked you through the process of installing Pritunl on Ubuntu Server 20.04 and now I want to do the same with AlmaLinux 8.5. You should be able to get this VPN solution up and running in minutes.
SEE: Password breach: Why pop culture and passwords don’t mix (free PDF) (TechRepublic)
What you’ll need
To successfully install Pritunl on AlmaLinux, you’ll need a running/updated instance of the OS and a user with sudo privileges. You’ll also need a domain name that points to the hosting server (so users can access the VPN from outside your network).
How to configure the firewall
The first thing we’ll do is configure the AlmaLinux firewall. Let’s start by allowing both HTTP and HTTPS traffic in with the commands:
sudo firewall-cmd --permanent --add-service=http sudo firewall-cmd --permanent --add-service=https
Then, we’ll reload the firewall with:
sudo firewall-cmd --reload
How to install MongoDB
Next, we’ll install the MongoDB database. Create a new repo file with:
sudo nano /etc/yum.repos.d/mongodb-org-4.4.repo
Paste the following into the new file:
[mongodb-org-4.4] name=MongoDB Repository baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.4/x86_64/ gpgcheck=1 enabled=1 gpgkey=https://www.mongodb.org/static/pgp/server-4.4.asc
Note: There’s a newer version of MongoDB (version 5), but I have yet to successfully get it to install on AlmaLinux. Because of that, I’m going with version 4.4.
Save and close the file.
Install MongoDB with:
sudo dnf install mongodb-org -y
Start and enable MongoDB with:
sudo systemctl enable --now mongod
SEE: VPN and mobile VPN: How to pick the best security solution for your company (TechRepublic Premium)
How to install Pritunl Server
Next, we’ll install Pritunl. Create the repo file with:
sudo nano /etc/yum.repos.d/pritunl.repo
In that file, paste the following:
[pritunl] name=Pritunl Repository baseurl=https://repo.pritunl.com/stable/yum/centos/8/ gpgcheck=1 enabled=1
Save and close the file.
Install the EPEL repository with:
sudo dnf install epel-release -y
Import the Pritunl GPG keys with:
gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 7568D9BB55FF9E5287D586017AE645C0CF8E292A gpg --armor --export 7568D9BB55FF9E5287D586017AE645C0CF8E292A > key.tmp; sudo rpm --import key.tmp; rm -f key.tmp
Install Pritunl with the command:
sudo dnf install pritunl -y
When the installation completes, start and enable the service with:
sudo systemctl enable pritunl --now
How to increase the Open File Limit
To prevent connection issues to the Pritunl server when it’s under a higher load, we need to increase the open file limit. To do this, issue the following commands:
sudo sh -c 'echo "* hard nofile 64000" >> /etc/security/limits.conf' sudo sh -c 'echo "* soft nofile 64000" >> /etc/security/limits.conf' sudo sh -c 'echo "root hard nofile 64000" >> /etc/security/limits.conf' sudo sh -c 'echo "root soft nofile 64000" >> /etc/security/limits.conf'
How to access the Pritunl web UI
Give the service a moment to start and then point a web browser to https://SERVER (where SERVER is either the IP address or domain of the hosting server). You should be greeted by the Pritunl database setup window (Figure A).
Figure A
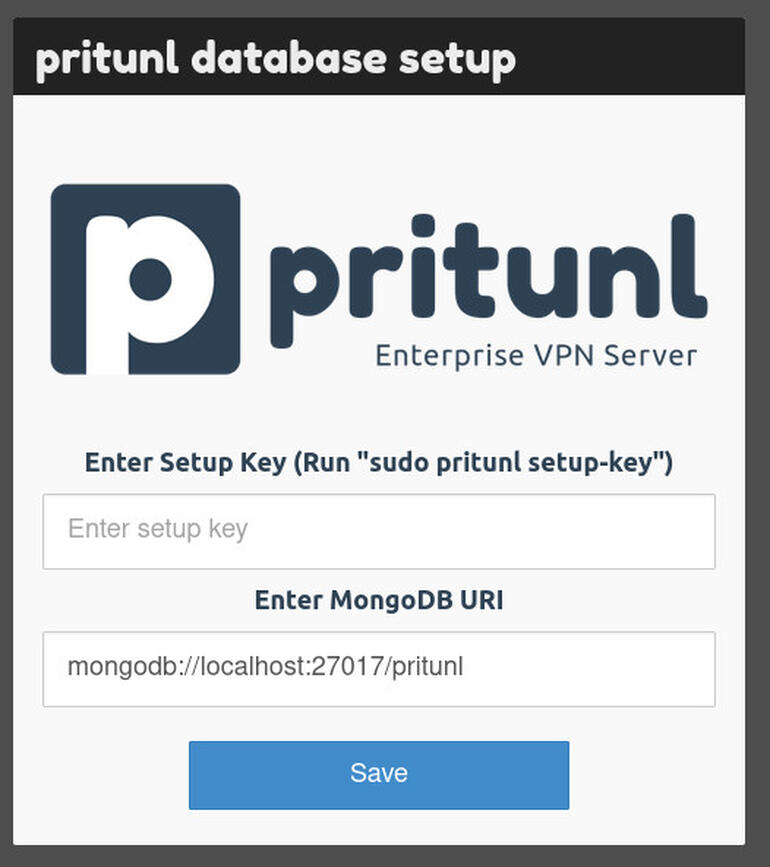
The Pritunl database setup window is ready for you to continue.
To continue, you must generate a setup key with the command (run on the hosting server):
sudo pritunl setup-key
This will generate a random string of characters that you copy and paste into the Setup Key text area of the Pritunl database setup window. After pasting the key, click Save and wait for the database to be upgraded. You will then be presented with the Pritunl login window. Before you log in, you must retrieve the default login credentials with the command:
sudo pritunl default-password
The above command will print out both the username and password for you to use to log into the Pritunl web UI. Make sure to save those credentials. Once you’ve successfully logged in, you’ll be prompted to change the admin user’s password and complete the initial setup (Figure B).
Figure B
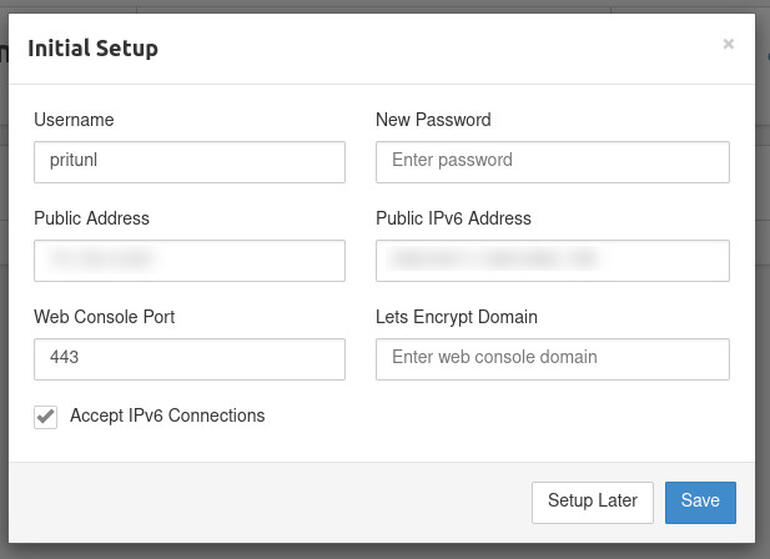
Completing the Pritunl initial setup
And there you go. You now have the Pritunl VPN server up and running on AlmaLinux 8.5. At this point, you can configure the server to meet the needs of your business and users.

Also see
Subscribe to TechRepublic’s How To Make Tech Work on YouTube for all the latest tech advice for business pros from Jack Wallen.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

New Jersey, United States,- The latest report published by Verified Market Research shows that the NoSQL Database Market is likely to garner a great pace in the coming years. Analysts examined market drivers, confinements, risks and openings in the world market. The NoSQL Database report shows the likely direction of the market in the coming years as well as its estimates. A close study aims to understand the market price. By analyzing the competitive landscape, the report’s authors have made a brilliant effort to help readers understand the key business tactics that large corporations use to keep the market sustainable.
The report includes company profiling of almost all important players of the NoSQL Database market. The company profiling section offers valuable analysis on strengths and weaknesses, business developments, recent advancements, mergers and acquisitions, expansion plans, global footprint, market presence, and product portfolios of leading market players. This information can be used by players and other market participants to maximize their profitability and streamline their business strategies. Our competitive analysis also includes key information to help new entrants to identify market entry barriers and measure the level of competitiveness in the NoSQL Database market.
Get Full PDF Sample Copy of Report: (Including Full TOC, List of Tables & Figures, Chart) @ https://www.verifiedmarketresearch.com/download-sample/?rid=129411
Key Players Mentioned in the NoSQL Database Market Research Report:
Objectivity Inc, Neo Technology Inc, MongoDB Inc, MarkLogic Corporation, Google LLC, Couchbase Inc, Microsoft Corporation, DataStax Inc, Amazon Web Services Inc & Aerospike Inc.
NoSQL Database Market Segmentation:
NoSQL Database Market, By Type
• Graph Database
• Column Based Store
• Document Database
• Key-Value Store
NoSQL Database Market, By Application
• Web Apps
• Data Analytics
• Mobile Apps
• Metadata Store
• Cache Memory
• Others
NoSQL Database Market, By Industry Vertical
• Retail
• Gaming
• IT
• Others
The global market for NoSQL Database is segmented on the basis of product, type, services, and technology. All of these segments have been studied individually. The detailed investigation allows assessment of the factors influencing the NoSQL Database Market. Experts have analyzed the nature of development, investments in research and development, changing consumption patterns, and growing number of applications. In addition, analysts have also evaluated the changing economics around the NoSQL Database Market that are likely affect its course.
The regional analysis section of the report allows players to concentrate on high-growth regions and countries that could help them to expand their presence in the NoSQL Database market. Apart from extending their footprint in the NoSQL Database market, the regional analysis helps players to increase their sales while having a better understanding of customer behavior in specific regions and countries. The report provides CAGR, revenue, production, consumption, and other important statistics and figures related to the global as well as regional markets. It shows how different type, application, and regional segments are progressing in the NoSQL Database market in terms of growth.
Get Discount On The Purchase Of This Report @ https://www.verifiedmarketresearch.com/ask-for-discount/?rid=129411
NoSQL Database Market Report Scope
| ATTRIBUTES | DETAILS |
|---|---|
| ESTIMATED YEAR | 2022 |
| BASE YEAR | 2021 |
| FORECAST YEAR | 2029 |
| HISTORICAL YEAR | 2020 |
| UNIT | Value (USD Million/Billion) |
| SEGMENTS COVERED | Types, Applications, End-Users, and more. |
| REPORT COVERAGE | Revenue Forecast, Company Ranking, Competitive Landscape, Growth Factors, and Trends |
| BY REGION | North America, Europe, Asia Pacific, Latin America, Middle East and Africa |
| CUSTOMIZATION SCOPE | Free report customization (equivalent up to 4 analysts working days) with purchase. Addition or alteration to country, regional & segment scope. |
Geographic Segment Covered in the Report:
The NoSQL Database report provides information about the market area, which is further subdivided into sub-regions and countries/regions. In addition to the market share in each country and sub-region, this chapter of this report also contains information on profit opportunities. This chapter of the report mentions the market share and growth rate of each region, country and sub-region during the estimated period.
• North America (USA and Canada)
• Europe (UK, Germany, France and the rest of Europe)
• Asia Pacific (China, Japan, India, and the rest of the Asia Pacific region)
• Latin America (Brazil, Mexico, and the rest of Latin America)
• Middle East and Africa (GCC and rest of the Middle East and Africa)
Key questions answered in the report:
1. Which are the five top players of the NoSQL Database market?
2. How will the NoSQL Database market change in the next five years?
3. Which product and application will take a lion’s share of the NoSQL Database market?
4. What are the drivers and restraints of the NoSQL Database market?
5. Which regional market will show the highest growth?
6. What will be the CAGR and size of the NoSQL Database market throughout the forecast period?
For More Information or Query or Customization Before Buying, Visit @ https://www.verifiedmarketresearch.com/product/nosql-database-market/

Visualize NoSQL Database Market using Verified Market Intelligence:-
Verified Market Intelligence is our BI-enabled platform for narrative storytelling of this market. VMI offers in-depth forecasted trends and accurate Insights on over 20,000+ emerging & niche markets, helping you make critical revenue-impacting decisions for a brilliant future.
VMI provides a holistic overview and global competitive landscape with respect to Region, Country, and Segment, and Key players of your market. Present your Market Report & findings with an inbuilt presentation feature saving over 70% of your time and resources for Investor, Sales & Marketing, R&D, and Product Development pitches. VMI enables data delivery In Excel and Interactive PDF formats with over 15+ Key Market Indicators for your market.
Visualize NoSQL Database Market using VMI @ https://www.verifiedmarketresearch.com/vmintelligence/
About Us: Verified Market Research®
Verified Market Research® is a leading Global Research and Consulting firm that has been providing advanced analytical research solutions, custom consulting and in-depth data analysis for 10+ years to individuals and companies alike that are looking for accurate, reliable and up to date research data and technical consulting. We offer insights into strategic and growth analyses, Data necessary to achieve corporate goals and help make critical revenue decisions.
Our research studies help our clients make superior data-driven decisions, understand market forecast, capitalize on future opportunities and optimize efficiency by working as their partner to deliver accurate and valuable information. The industries we cover span over a large spectrum including Technology, Chemicals, Manufacturing, Energy, Food and Beverages, Automotive, Robotics, Packaging, Construction, Mining & Gas. Etc.
We, at Verified Market Research, assist in understanding holistic market indicating factors and most current and future market trends. Our analysts, with their high expertise in data gathering and governance, utilize industry techniques to collate and examine data at all stages. They are trained to combine modern data collection techniques, superior research methodology, subject expertise and years of collective experience to produce informative and accurate research.
Having serviced over 5000+ clients, we have provided reliable market research services to more than 100 Global Fortune 500 companies such as Amazon, Dell, IBM, Shell, Exxon Mobil, General Electric, Siemens, Microsoft, Sony and Hitachi. We have co-consulted with some of the world’s leading consulting firms like McKinsey & Company, Boston Consulting Group, Bain and Company for custom research and consulting projects for businesses worldwide.
Contact us:
Mr. Edwyne Fernandes
Verified Market Research®
US: +1 (650)-781-4080
UK: +44 (753)-715-0008
APAC: +61 (488)-85-9400
US Toll-Free: +1 (800)-782-1768
Email: [email protected]
Website:- https://www.verifiedmarketresearch.com/
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts
The main objective of NoSQL databases is improved efficiency. It is somewhat achieved with the use of new technologies and thinking outside the box.
An example of the new technologies applied could be opting for solutions that require more storage space. In the past, we used to mind storage requirements more, but lately, it has become less of an issue as a result of the cost of this resource dropping significantly.
Now, for the metaphorical box, it can represent the strict limits of a SQL schema. We are opening it up to find out what else there is that can allow us to connect data in a meaningful whole, manipulate it and exploit it with the least friction.
What is a graph database?
A graph database certainly is outside that box. It focuses on relationships between pieces of data as much as it does on the data itself, thus managing to store data purposefully. Using a graph data model positively helps visualize data. It is highly appreciated as in the world of big data; it is always good to be able to make a quick sense of the data in front of you.
The elements
Based on the graph theory, these databases consist of nodes and edges. Nodes are the entities of a graph database. Simply put, they are the agents and objects of relationships and can be presented as answers to questions “who” and “whom.”
Each of the entities holds a unique identifier. They can also have properties consisting of key-value pairs and can have labels with or without metadata assigning a role of a particular node in a domain. There are also the incoming and outgoing edges. Think of them as different ends of an arrow showing you who is the agent and who is the object of a relationship.
Edges are equally as important as nodes because they hold a vital piece of information. They represent relationships between entities. A SQL database would likely have a designated table for each class of relationships. A graph database does not require such mediation because it connects its entities directly. Edges also have unique identifiers and, just like nodes, can have other properties apart from the defined type, direction and the starting and ending node.
Graph database models
There are two common graph database models: Resource Description Framework (RDF) graphs and Property graphs. They have their similarities but are built with a focus on different purposes. One focuses on data integration, whereas the other focuses on analytics.
RDF graphs focus on data integration. They consist of the RDF triple — two nodes and an edge that connects them (subject, predicate, object). Each of the three elements is identified by a unique resource identifier. You can find them in knowledge graphs, and they are used to link data together. RDFs are often used by healthcare companies, statistics agencies, etc.
Property graphs are much more descriptive and each of the elements carries properties, attributes that further determine its entities. They also consist of nodes and edges connecting the nodes and are better suited for data analysis.
Advantages
The emphasis placed on the edges of a graph database model means these databases represent a powerful way of getting to understand even the most complex relationships between data. The beauty of it is that this way of storing relationships also enables quick execution of queries.
With a clear representation of relationships in a graph database, it is easier to spot trends and recognize elements with the most influence.
Disadvantages
Graph databases share the common downfall of NoSQL databases — the lack of uniform query language. While this can be an obstacle for the use of a database, it does not affect the performance of this database type. Certain graph databases are more prominent than others; so are the languages they use. Some of the most common graph database languages are PGQL, Gremlin, SPARQL, AQL, etc.
Another downfall is the scalability of these databases because they are designed for one-tier architecture meaning that they are hard to be scaled across a number of servers.
As with all other NoSQL databases, they are designed to serve a specific purpose and excel at it. They are not a universal solution designed to replace all other databases.
Use cases and examples
Graph databases are designed with a focus on relationships and, coincidentally, so are social networks. A graph database is a great way to store all users of a certain social media platform and their engagements to analyze them. You can determine how “lively” or active a social media platform is based on the activity volume of its users. Furthermore, you can identify the “influencers,” analyze user behavior, isolate target groups for marketing purposes, etc.
By being able to track and map out the most complex networks of relationships, graph databases are a good tool for fraud detection. Connections between elements that are hard to detect with traditional databases suddenly become prominent with graph databases.
Some of the most popular graph databases — as well as multimodel databases including graph data models — are Neo4j suitable for a variety of business-related purposes and followed by the multimodel Microsoft Azure Cosmos DB, OrientDB, ArangoDB, etc.

Graph databases vs. relational databases
A major advantage of any NoSQL over a SQL database is the flexibility of storing data with NoSQL. Whenever there is a case of less structured data or highly complex data, there is room for NoSQL application. If you are considering introducing new relationship types and properties, to place them in a SQL database, depending on what it is, you would have to add new tables.
On the other hand, with a graph database, it is as simple as adding a new edge or a property. By tracing the edges between nodes, you can get to the depth of the most complex relationship between two nodes in a database.
The need for a graph database is recognized by the level of connectedness between data — where the data is highly connected, there could be room for a graph database. Furthermore, seeing how powerful these connections are, a graph database is a better choice for data analysis rather than simple data storage. Finally, if you want to be flexible with data that is changing often, a NoSQL graph database is likely the better option for you.
MMS • Ben Linders
Article originally posted on InfoQ. Visit InfoQ

Blockchain technology can be used to build solutions that can naturally deliver better software quality. Using blockchain we can shift to smaller systems that store everything in a contract. We have to understand our data needs and decide what is stored in the chain and what off-chain, and think about how requirements, defects and testing history can be built into the contract models.
Craig Risi spoke about testing in the blockchain at Agile testing Days 2021.
Risi mentioned that the key design principles that any Blockchain application should be designed around are data integrity, data transparency, scalability, reliability and availability. The trick is to start checking for all these attributes early in the design phase and have regular checks to ensure you are meeting them throughout the entire design process, Risi said.
In his talk, Risi provided several architecture design tips for working with Blockchain:
You want to work with small services and APIs to allow for the system to scale as needed and avoid single points of failure and build in redundancy so that your system remains highly available even when certain services are down.
To ensure your system meets these above requirements you want to spend a lot of time understanding your solution’s data needs; what is stored in the chain and what off-chain, how large the data elements that need to be stored are and how the encryption will happen.
Having clear requirements allows you to put automated tests in place that can verify the integrity of data in test environments, as you have the required information to mock and test effectively. Along with this functional test effort, effort should be invested in security to ensure that the endpoints that interact with smart contracts are incredibly secure.
Blockchain technology will improve the way we approach software design, Risi mentioned. He gave some suggestions for utilizing blockchain technology to build better quality solutions:
We will see a shift from big systems that work with millions of lines of data to smaller systems that store everything that is needed in a contract. This smaller focus, while it comes with its own problems, could make software development and test automation simpler, improving our ability to deliver features faster.
I also see traceability improvement, as requirements, defects and testing history can be built into the contract models, making it simpler for teams to have evidence built into their test contract, while also making debugging contracts easier if all evidence is stored on it and give a clearer picture of the impact code has on the greater system.
Lastly, some of the basic principles of Blockchain technology, which include distributed databases, transparency with pseudonymity and irreversibility of records, make the impacts of mistakes far more reaching than ever before. While this doesn’t have a direct impact on software quality, it is forcing teams to think about it more and place more emphasis on verification, which has an indirect impact on the overall quality of a software solution.
InfoQ interviewed Craig Risi about building quality in blockchain systems.
InfoQ: What advice would you give to companies wanting to develop Blockchain solutions?
Craig Risi: I think the key thing is not just jumping onto the Blockchain train because it’s popular. Too many companies want to build blockchain solutions to try and gain access to funding, but if you’re going to try and develop a new solution where Blockchain is simply just a replacement and doesn’t add value, you are unlikely to reap any benefit from it.
As an example, some of the work currently being done to move health records to the blockchain are working out because of the way we are making this data more legitimate and open to the public. If we are simply going to replace medical databases with blockchain technology but not put the control in the hands of consumers, we are simply moving data around to a format that isn’t suited for it.
It’s also important to be aware of the different international regulations and rules with regards to Blockchain and the handling of data. While the world is warming up to the technology, there are different rules that different countries require from a data perspective and it’s important that you cater for this in your final solution.
We see this with cryptocurrencies where different rules between countries affect how they are handled and taxed, with some countries blocking their use entirely. The work that is currently being done on medical records is facing this problem as certain countries require health practitioners to keep this data themselves and restrict where this data can be stored, limiting the effectiveness of a blockchain solution until regulations are adapted.
InfoQ: How blockchain will impact future software development?
Risi: One of the key fundamental changes that Blockchain introduces is the way we work with data and it could effectively bring about the end of the database as we know it, with all operations taking place directly on a contract rather than big database systems. This will remove one of the key complexities that generally affects software architectures and is a change in the way we work with data. This could also lead to an increase in the adoption of infrastructure as code or cloud computing more aggressively, as the data concerns are largely removed.
This affects things like data collection and machine learning, and companies may need to build models where certain data is stored on the blockchain and others in traditional data stores for AI/ML purposes.
Blockchains data ownership model can make a massive change to the tech industry as a whole. Think of medical applications around the world that interact with a common blockchain for patients, where a patient provides the needed access to their information and history, allowing them to have control over their data.
Blockchain technology can also be improved to act as a source of digital identity documents that can be used to store all your private details and even things like baking records, making transactions and even voting in elections. In fact, Blockchain contracts can be even integrated into social media sites, giving you the power to store your own data and choose when it is shared and with whom.
There is still a long way for this technology to go before it will become mainstream, but there is no doubt that it has the potential to drastically change the way we think about certain aspects of data and privacy and it holds remarkable potential to transform the way we interact with technology.
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central

There are constant changes in the software development trends, but a few trends seem to be dominant in 2022. With the evolution of advanced technology, there has been a significant change in the software development landscape. Businesses need to keep up with these changes in order to compete in the next-gen world.
To help you be aware of the latest software trends, we have come up with a list of the top software development trends that will work in 2022 and beyond that in the software industry. Let’s take a look at the top software trends in 2022.
Major Software Development Trends in 2022
- Rigid software quality standards
With the growing demand for software, it will be required to follow software quality standards as proposed by ISO in the near future. We will see ISO certification in our day-to-day lives and in most of the devices we use as software solutions become a major part of our lives. Companies will see benefits such as improved quality, more efficient processes, and more respect following ISO certification.
- Code standards & guidelines
It is expected that companies will be employing style consistency and language conventions in the software development process to raise coding standards following clear guidelines. This will help both existing as well as new developers to write standard code with clear guidelines.
- Focus on cybersecurity
Cybersecurity is another most popular software development trend which is expected to grow more in 2022. Businesses will focus more on the modernization of their systems, applications, and technology stack with regular assessments for cybersecurity.
- The Internet of Things
The Internet of Things (IoT) is expected to create more than $6 trillion economic value by the end of 2022. When the Internet of Things (IoT) is combined with cloud computing and connected data, software development will be transformed. Mobile devices are likely to become even more specialized for vertical markets (such as healthcare or aerospace) in the future as sensors and analytics allow real-time control.
- Cloud computing
Cloud computing is another yet more growing software development trend, which is broadly used by many startups, businesses, institutions, and even by government organizations. In addition to this, the value of cloud computing technology can be seen in security offices, hospitals, and legal authorities.
We can expect a huge transition of cloud computing technology in various industries, businesses, and organizations around the world.
Tech giants like Microsoft, Google, and Amazon have already been providing cloud computing to individuals, businesses, and enterprises. It offers complete flexibility to businesses and allows them to scale as they grow.
- Rise of Python
Python is the most popular and ever-growing programming language widely used for creating complex and enterprise-grade web and app development applications to meet the modern needs of businesses and their customers.
It is widely known for addressing modern software needs and providing one-stop-solution for web development, mobile development, or enterprise projects.
Python provides developers with the ability to conduct complex mathematical processes, huge data analysis, machine learning, and more.
- JavaScript is still in the headline
Seeing the growing trend of software development, JavaScript is still on the rise and is a perfect language for building modern and innovative software development solutions. JS is assumed to be the growing software development trend in 2022 even after the introduction of AngularJS.
It is quite perfect and capable of handling many backend operations at the same time without requiring much load. The frameworks of JS are expected to be the next big surprise in the software development trend due to their compatibility and ease to use both ways: applicants and clients’ server-side.
- Cloud-Native Apps & Framework
Cloud-native apps and frameworks are expected to be the ever-growing software development trend in 2022, allowing developers to create highly efficient and robust cloud-native applications quickly and more efficiently.
With Node.js, you can create servers, data layers, applications, and web apps with JavaScript using a single platform. A cloud-native app can be built using many frameworks.
- DevOps
DevOps is a modern development approach used for creating custom software by combining software development with IT operations to streamline workflows and improve efficiency. DevOps also combines various Agile elements that seem to rise in top software development trends.
Considering both employees and user experiences, it is expected that companies will adopt a more agile and development DevOps methodology that can kill two birds with an arrow.
- Artificial Intelligence for Improved user experiences
Believe it or not, Artificial Intelligence (AI) is one of the most popular and fastest-growing software development trends used for modern and highly innovative technologies. With the evolution of artificial intelligence, there has been a dramatic change in deep learning, and artificial neural networks and are predicted to have a great impact on software development trends in 2022, and beyond.
Artificial Intelligence (AI) uses high technology for giving more accurate predictions about user behaviors, customer data, and human psychology. Businesses are assumed to use AI for giving predictions about industrial machinery maintenance, robotics, or other complicated systems.
- The Rise of Microservices Architecture
The rise of microservices architecture is significantly increasing as the new standards for the modern software development needs, resulting in the decline of monolithic architectures.
Microservices architecture is a hot topic in the top 10 software development trends, which provides a modular approach where small and independent components work together and can be adapted easily. Using microservice architecture can help businesses take competitive advantage of achieving greater results.
- Low-code and no-code development
Anyone can build applications using drag-and-drop or low-code editors, providing no programming experience is required. Some predict the beginning of a new era of no-code coding in which technology will soon reach the average person even more.
Bottom Line
In the software world, there are many factors influencing it, such as technologies, consumer preferences, and underlying factors. In order to develop modern and innovative applications, startups need to understand the latest software trends in 2022. With the ever-growing technologies, there will be more software development trends in the upcoming years.
Database Software Market Size, Analysis, Forecast to 2029 | Key Players – Industrial IT
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
New Jersey, United States,- The latest report published by Verified Market Research shows that the Database Software Market is likely to garner a great pace in the coming years. Analysts examined market drivers, confinements, risks and openings in the world market. The Database Software report shows the likely direction of the market in the coming years as well as its estimates. A close study aims to understand the market price. By analyzing the competitive landscape, the report’s authors have made a brilliant effort to help readers understand the key business tactics that large corporations use to keep the market sustainable.
The report includes company profiling of almost all important players of the Database Software market. The company profiling section offers valuable analysis on strengths and weaknesses, business developments, recent advancements, mergers and acquisitions, expansion plans, global footprint, market presence, and product portfolios of leading market players. This information can be used by players and other market participants to maximize their profitability and streamline their business strategies. Our competitive analysis also includes key information to help new entrants to identify market entry barriers and measure the level of competitiveness in the Database Software market.
Get Full PDF Sample Copy of Report: (Including Full TOC, List of Tables & Figures, Chart) @ https://www.verifiedmarketresearch.com/download-sample/?rid=85913
Key Players Mentioned in the Database Software Market Research Report:
Teradata, MongoDB, Mark Logic, Couch base, SQLite, Datastax, InterSystems, MariaDB, Science Soft, AI Software.
Database Software Market Segmentation:
Database Software Market, By Type of Product
• Database Maintenance Management
• Database Operation Management
Database Software Market, By End User
• BFSI
• IT & Telecom
• Media & Entertainment
• Healthcare
The global market for Database Software is segmented on the basis of product, type, services, and technology. All of these segments have been studied individually. The detailed investigation allows assessment of the factors influencing the Database Software Market. Experts have analyzed the nature of development, investments in research and development, changing consumption patterns, and growing number of applications. In addition, analysts have also evaluated the changing economics around the Database Software Market that are likely affect its course.
The regional analysis section of the report allows players to concentrate on high-growth regions and countries that could help them to expand their presence in the Database Software market. Apart from extending their footprint in the Database Software market, the regional analysis helps players to increase their sales while having a better understanding of customer behavior in specific regions and countries. The report provides CAGR, revenue, production, consumption, and other important statistics and figures related to the global as well as regional markets. It shows how different type, application, and regional segments are progressing in the Database Software market in terms of growth.
Get Discount On The Purchase Of This Report @ https://www.verifiedmarketresearch.com/ask-for-discount/?rid=85913
Database Software Market Report Scope
| ATTRIBUTES | DETAILS |
|---|---|
| ESTIMATED YEAR | 2022 |
| BASE YEAR | 2021 |
| FORECAST YEAR | 2029 |
| HISTORICAL YEAR | 2020 |
| UNIT | Value (USD Million/Billion) |
| SEGMENTS COVERED | Types, Applications, End-Users, and more. |
| REPORT COVERAGE | Revenue Forecast, Company Ranking, Competitive Landscape, Growth Factors, and Trends |
| BY REGION | North America, Europe, Asia Pacific, Latin America, Middle East and Africa |
| CUSTOMIZATION SCOPE | Free report customization (equivalent up to 4 analysts working days) with purchase. Addition or alteration to country, regional & segment scope. |
Geographic Segment Covered in the Report:
The Database Software report provides information about the market area, which is further subdivided into sub-regions and countries/regions. In addition to the market share in each country and sub-region, this chapter of this report also contains information on profit opportunities. This chapter of the report mentions the market share and growth rate of each region, country and sub-region during the estimated period.
• North America (USA and Canada)
• Europe (UK, Germany, France and the rest of Europe)
• Asia Pacific (China, Japan, India, and the rest of the Asia Pacific region)
• Latin America (Brazil, Mexico, and the rest of Latin America)
• Middle East and Africa (GCC and rest of the Middle East and Africa)
Key questions answered in the report:
1. Which are the five top players of the Database Software market?
2. How will the Database Software market change in the next five years?
3. Which product and application will take a lion’s share of the Database Software market?
4. What are the drivers and restraints of the Database Software market?
5. Which regional market will show the highest growth?
6. What will be the CAGR and size of the Database Software market throughout the forecast period?
For More Information or Query or Customization Before Buying, Visit @ https://www.verifiedmarketresearch.com/product/database-software-market/
Visualize Database Software Market using Verified Market Intelligence:-
Verified Market Intelligence is our BI-enabled platform for narrative storytelling of this market. VMI offers in-depth forecasted trends and accurate Insights on over 20,000+ emerging & niche markets, helping you make critical revenue-impacting decisions for a brilliant future.
VMI provides a holistic overview and global competitive landscape with respect to Region, Country, and Segment, and Key players of your market. Present your Market Report & findings with an inbuilt presentation feature saving over 70% of your time and resources for Investor, Sales & Marketing, R&D, and Product Development pitches. VMI enables data delivery In Excel and Interactive PDF formats with over 15+ Key Market Indicators for your market.
Visualize Database Software Market using VMI @ https://www.verifiedmarketresearch.com/vmintelligence/
About Us: Verified Market Research®
Verified Market Research® is a leading Global Research and Consulting firm that has been providing advanced analytical research solutions, custom consulting and in-depth data analysis for 10+ years to individuals and companies alike that are looking for accurate, reliable and up to date research data and technical consulting. We offer insights into strategic and growth analyses, Data necessary to achieve corporate goals and help make critical revenue decisions.
Our research studies help our clients make superior data-driven decisions, understand market forecast, capitalize on future opportunities and optimize efficiency by working as their partner to deliver accurate and valuable information. The industries we cover span over a large spectrum including Technology, Chemicals, Manufacturing, Energy, Food and Beverages, Automotive, Robotics, Packaging, Construction, Mining & Gas. Etc.
We, at Verified Market Research, assist in understanding holistic market indicating factors and most current and future market trends. Our analysts, with their high expertise in data gathering and governance, utilize industry techniques to collate and examine data at all stages. They are trained to combine modern data collection techniques, superior research methodology, subject expertise and years of collective experience to produce informative and accurate research.
Having serviced over 5000+ clients, we have provided reliable market research services to more than 100 Global Fortune 500 companies such as Amazon, Dell, IBM, Shell, Exxon Mobil, General Electric, Siemens, Microsoft, Sony and Hitachi. We have co-consulted with some of the world’s leading consulting firms like McKinsey & Company, Boston Consulting Group, Bain and Company for custom research and consulting projects for businesses worldwide.
Contact us:
Mr. Edwyne Fernandes
Verified Market Research®
US: +1 (650)-781-4080
UK: +44 (753)-715-0008
APAC: +61 (488)-85-9400
US Toll-Free: +1 (800)-782-1768
Email: [email protected]
Website:- https://www.verifiedmarketresearch.com/
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Chris Palmer
Article originally posted on InfoQ. Visit InfoQ

Transcript
Palmer: I’m Chris Palmer from the Chrome security team. I’m going to talk about getting the most out of sandboxing, which is a key defensive technique for software that faces the internet, like a browser or a server application, or any sorts of things. I’m going to talk about the limitations and benefits that we found while doing this. We’ve had about 10 years of experience. I’m going to talk about what else to do in addition to that once you’ve hit those limits, but you probably haven’t yet.
I’ve been on the Chrome security team for about nine-and-a-half years. Before that I was on the Android team. I’ve done a bunch of different things. I’ve done usability, HTTPS, and authentication stuff. These days I’m on what we call the platform security team, where we focus on under the hood, low-level security defense mechanisms, like memory safety, and sandboxing, obviously, and exploit mitigations. We try to make sure we’re making the best possible use of the operating system to get the maximum defensive value out of that.
What Is Sandboxing?
First, let me give you an idea of what sandboxing even is. I’ll talk about how we do it, what it means, and how you can use it. Then, I’ll talk about stuff that comes after that as well. Here’s a picture from Chromium’s website, chromium.org, where we have a simple picture of what sandboxing looks like for us. Chrome is a complex application, obviously. We break it up into multiple pieces, and each of those pieces runs in a separate process. We have like the browser process, here it’s called the broker, and that runs at full privilege. It has all the power of your user account when you’re logged into your machine. Then we fire off a bunch of other processes called renderer processes. Their job is to render the web for a given website. If you go to newyorktimes.com, there’s one renderer for that. Then when you go to Gmail, or Office 365, or Twitter, that’s three more renderer processes. They’re each isolated from each other, and they’re isolated from the browser process itself. They also have their privileges limited as much as we can manage in ways that are specific to each operating system. What that gives us is, if they crash, of course, the whole browser does not go down. If site A causes its renderer to crash, all your other sites are still up and running. You get reliability and stability. Also, if the process is compromised by malicious JavaScript, or HTML, or CSS that helps take over a website, usually it’s JavaScript or WebAssembly, then the damage is contained, we hope, in that renderer process. If site A gets compromised, sites B and C and D, have some protection against that compromise. The browser process itself up here, is protected against that compromise. The attacker to take over your whole computer, for example, would need to find additional bugs, whether in the browser process, in the operating system kernel. If they want to extend the reach of their compromise, they have to do more work. It’s a pretty darn good defensive mechanism, and we use it heavily.
Good Sandboxing is Table Stakes
I want to say, first of all, that sandboxing is table stakes for a browser, and every browser does some: Firefox, Safari, all the Chromium based browsers like Edge, Brave, Opera, Chrome itself, obviously. They all do sandboxing. It’s not just for browsers. I think you can get a lot of benefit from sandboxing in a wide variety of different application types. For example, the problem is, we are reading in complicated inputs, like JavaScript, HTML, images, videos, from anywhere on the internet, and there’s a risk there because we’re processing them in C++ or C. There’s all sorts of memory safety concerns. There’s buffer overflows, type confusion, use-after-free, bugs like that, that can allow an attacker to compromise the code that’s parsing and rendering these complicated formats. Any application that parses and renders and deserializes complicated stuff has the same problem, and it has to somehow defend against it. That includes your text messenger, a web server that takes in PDFs from users and processes them, for example. If you have a web application that converts images from one format to another, or takes videos from users or a font sharing website, or all sorts of things like that, you have the same basic problem. You don’t want to let a bug in your image decoder or your JavaScript interpreter, take over your whole server. You don’t want to let an attacker have that power.
In Chromium, we’ve been working on this for about 10 years. We think we’ve taken sandboxing just about as far as we can go with it. I’ll talk about how we face certain special limitations that you might not, depending on your application. You may be able to go further with it than we can, or maybe not as far as we can. It all depends on a bunch of design factors you have to take into consideration. I’ll talk about what those are. Again, in any case, sandboxing is like your step one of all the things you want to do to defend against bad inputs from the internet. I think it’s table stakes. You got to start there.
How to Build a Sandbox
How do you build a sandbox? It depends what you can do. It varies with each operating system. Android is very different than macOS, and Linux is a whole different thing. Windows is a whole different thing. They all provide different options to us, the defender, they give us different kinds of mechanisms. We have separate user accounts in Windows that are called SIDs, security identifiers. There’s various access tokens. You can take a token away from a process or give them a restricted token. That’s a Windows thing. You can filter the system calls that a process can call. We do a lot of that on Linux based systems, Chrome OS, Android, Linux desktop. You can do it on macOS with a Seatbelt system. We bend the rules and define our own Seatbelt policy, but Apple gives you some baked in ones with Xcode. I think these days the default is not to have full privilege anymore. They make it easy for you to reduce your own privilege with Seatbelt. That is very powerful, very good defense. Another idea is that you could segment memory within the same process. What if we had a zone that code could not escape from and then another zone that other code could not escape from? I’ll talk a bit more later about how we are looking at that thing, and Firefox people are also. It’s a very cool idea. For the most part, our basic building block is the process. Then we apply controls to different types of processes.
OS Mechanisms (Android)
On Android, it’s very different than Windows and Linux, the key mechanism is what is called the isolated process service. It’s a technique that they invented for us. We asked them, could we have this on Android, and then we can make Chrome better? They said, sure. They built it for us. It does a couple things. It runs a new process. It runs an Android service, in its own special separate process with a random user ID separate from your main application, and then you can talk to it and get data out, and parse data in. That’s our first line of defense on Android. Renderers run as isolated services. It works pretty good. There’s a couple things that come with it. There’s some system call filtering. It comes with a policy that Android platform people define for us. They also define a SELinux profile for us. SELinux stands for Security-Enhanced Linux. It’s an additional set of policies you can use to say, don’t let this process access these files, or, raise an alarm if it tries to do this or that. That’s useful for us too. It comes with the isolated process service. That’s number one on Android.
OS Mechanisms (Linux, Chrome OS)
On Linux and Chrome OS, we put together what we want by hand. We use Seccomp-BPF. Again, it’s a system call filtering mechanism. We can define whatever policy we want, so we have all sorts of finer-grained policies for different types of processes. We also use Linux’s user and PID and network namespaces feature, where you can create a little isolated world for a process, and it doesn’t get to see the whole system. It doesn’t get to see processes that it shouldn’t know about. It doesn’t get to see network stuff that it shouldn’t know about, and so on. Where we don’t have that, not all Linux systems enable that subsystem of the kernel. We have a set UID helper that does some of that stuff itself, and that it spawns children and takes away their privilege, and then those are the renderers. We consider that to be a bit of a legacy thing. We think the future and certainly our present is the namespaces idea. It’s not risk-free. Namespaces come with bugs of their own because they change the assumptions of other parts of the kernel. That’s why some distributions don’t turn it on, but we do on Chrome OS, certainly. We think it’s pretty useful.
Limitations and Costs
The key thing here is that you can’t sandbox everything. If you think about the most extreme form of sandboxing, you could sandbox every function call or sandbox every class. Especially if you had that segmented memory idea that I was talking about, you could give each component of your code its own little zone to live in, and it couldn’t escape, we hope. As it is now, for the most part, we have to pretty much create a new process for each thing that we want to sandbox. You’ll see in the pictures that are coming up, we use fairly coarse-grained form of sandboxing, because processes are our main thing, and processes are expensive. On Windows and Android, processes are a big deal, and threads are cheap. They want you to do that. The way the systems are designed, you’d have one process for your application, and many threads used during different things. That’s not enough of a boundary for us. We have to be careful in how we use them. Then starting up a new process on Android and Windows, a new process gives you a lot of stuff that you typically want, like all the Android framework stuff, and all the nice Windows libraries. It costs time and memory to create those things for us. They’re not quite as free on those two platforms. On Linux and Chrome OS, they’re very cheap, indeed. macOS also quite cheap to make a process. We face different headwinds on different platforms.
Site Isolation
A key thing I mentioned before, and this is going to be the introduction to how you should think about sandboxing for yourself, for your application, different sites are in their own renderers, and so we have to have a way of deciding when to create a new one. We would like to create a new process for each web origin, which is the principle in the web platform, the security principle. The origin is defined as the scheme, host, and port like HTTPS, google.com, Port 443, or HTTP, example.org, Port 80, things like that. Each of those should be separated. We can’t always afford to make that many new processes. Instead, we group several origins together, if they belong to what we call the site, and that is just the scheme, like HTTPS or HTTP, and just the second level domain after the first register or bold domain, like google.com, everything under google.com counts as one site. Example.org, everything under that counts as one site. It’s a bit of a tradeoff to save some time and memory, but if we had our way we’d isolate each origin in its own process.
Here’s a simple view. This is a bit like what the status quo is, but it’s a little trickier. We have the browser process with full privilege. It creates different renderers for different sites. We also have the graphics processing interface, the stuff that talks to the graphics system of your operating system. We put that in its own process to separate it. It might be crashy. We can reduce its privilege a little bit, so we do. It doesn’t need the full power of the browser process. We have coming up on most platforms, a separate process to handle all the networking too, all the HTTP, all the TLS, all the DNS, all that complicated stuff, we’re putting it in its own process. We’re, on each platform, gradually reducing the privilege of that process on each platform. It’s an ongoing adventure. It’s done on macOS. It’s starting to happen on Windows. We got a plan for Android.
Now, you might imagine that, if we had all the memory and time we wanted, we could make a separate networking process for each site, and then it would be linked to its renderer. That would be great. We would do that if we could, if we could afford it. Similarly, we’re creating a new storage process to support all the web APIs that handle storage, like the local storage cookies. There’s an IndexedDB database API for the web. That stuff is also complicated and makes sense to put in its own process, so that’s happening. You could imagine, we could have a separate storage process for each site also. Again, it would be linked to its renderer. Again, they would all be isolated from each other. Security would go up, resilience and reliability would go up. It would be cool. For us on the platforms that are popular for Chrome, mainly Android and Windows, it’s just too expensive, so we can’t do it. That might not be true for you, on for example, a Linux server, where processes are cheap and fast to start up. You might be able to have many different sandbox processes supporting different aspects of your user interface, or doing the things for your users that you need to do, whether it’s database processing, giving them their own frontend web server, maybe hosting some JavaScript for them, things like that. It depends.
Moving Forward: Memory Safety
That doesn’t get us everything we need, though, but it does get us a lot. The key thing you may have gotten so far is that we’re using sandboxes to contain the damage of the problems of memory unsafety, like C++, and C, are just hard to use. It’s all sorts of, out-of-bounds Reads, out-of-bounds Writes, objects leaking and they never get cleaned up when you’re not using them anymore. That can happen. Or you use them after they’ve been cleaned up, use-after-free. It’s an exploitable vulnerability, a lot of the time. Or type confusion if you have an animal, and it’s actually a dog, but you cast it to a cat, and then you call the Meow method on it. That’s not going to work, and trouble may ensue. C++ will let you do that a lot of the time, whereas other languages wouldn’t. Java, for example, would notice at runtime, this is a cat, and it would raise an exception. Not so necessarily in C++.
Containing memory unsafety is a key benefit of sandboxing. It also gives us some defense against stranger problems, like Spectre and Meltdown, the hardware bugs where, even with perfect memory safety, you could do strange things and the hardware would accidentally leak important facts about the memory that’s in your process. You can get a free out-of-bounds Reads, even if the code were perfect, which is pretty wild. We get some defense against that from sandboxing. However, the real fix for that is at the hardware level. As an application, I and we can only do so much. It’s a little tricky. There are variants of that problem that can in fact go across processes and even into the kernel. That’s pretty exciting. We have to just wait for better hardware to get rid of that problem. There’s a lot we can handle before we can get there, before that’s our biggest problem. C++ is dangerous. C is dangerous. Sandboxing helps a lot. To get all the way to Wonderland in software, we really would like to have a language that defends against memory unsafety, baked in.
Investigating Safer Language Options
You could think, obviously Java has a lot of that, Kotlin. Swift on macOS and iOS has a lot of safety baked in. Rust, that’s their selling point. WebAssembly has a chance to give us that isolated box inside a process so we could create little sandboxes without having to spawn new processes, and so we could have cheaper sandboxing and we could sandbox more stuff. We’re actually experimenting on that now this quarter. Firefox also is. They have a thing called RLBox. We call ours WasmBox, for WebAssembly Box. The basic idea is the same. There’s different efficiency tradeoffs and different technical ways of going about it. The basic idea is, you give a function or a component, a chunk of memory, and then you by various means enforce that it can never read or write outside that area. If it goes wrong, it’s at least mostly stuck in there. It might still give you a bad result, and you’ll have to evaluate the result for correctness. It can at least, hopefully, not destroy your whole process and compromise the process and take it over. We’ll see how that goes. We’re hoping to maybe ship something with it soon. It could be a very big deal for us, and perhaps for you.
Migrating to Memory-Safe Languages
We’d also like to migrate to a safer language to the extent that’s possible. No one’s saying we’re going to rewrite everything in Rust or replace all of our C++. That’s not possible. What we can do is find particular soft targets that we know attackers are attacking, and we can replace those particular things with a safer language. Like you could take your image processors, your JSON parser, your XML parser, for example, and get Java, or Kotlin, or Rust versions of those and put them in place. Then you could have a much smaller memory safety problem. That would be a complementary benefit to sandboxing. Neither one by itself gets you all the way there. I think they’re both necessary. Neither is sufficient on its own. Together, I think you have a really solid defense story, at least as far as software can go. That’s where we’re heading. Of course, hardware continues to be a difficulty.
There’s also the matter of the learning curve of a new language. To get everybody to learn C++ is hard. It’s a complicated language. Any language that can do what it does is likely to be at least as complex. Rust does a lot. It takes a while to learn it. Swift does a lot. It takes a while to learn it. There’s a way to use Java well. It takes a while to learn it. We’re asking more of our developers, but we’re thinking in the end that we’re going to get better performance, better safety, for sure. That it will be beneficial to the people who use our application.
Improving Memory-Unsafe Languages
Again, you can think along the same lines, don’t use C++ if you can avoid it. If you’re starting something new, have a plan to migrate away to the extent you can. Getting the two languages to work together is a key aspect of the problem, and it’s improving. In the last year alone, we made great headway with a thing called CXX and autocxx. It’s a way to get Rust and C++ to talk to each other in a more easy to use way. It’s very cool. We’re also doing things with C++ as much as we can, garbage collection, new types of smart pointer that know if the thing they own still exists or not. Then it’ll stop you from doing use-after-free, for example. Then there’s new hardware features coming that can help us with the memory safety problem. There’s memory tagging coming from ARM. Control-flow integrity, we’re already shipping some of that in Chrome now. We’re very happy about that, and there’s more coming. Generally, we can replace some of the undefined behavior that’s in C++’s libraries with our own. We’ve done a lot of that already too. For example, does operator brackets on a vector allow you to go out of bounds? In standard C, they don’t guarantee that it’s not, but we can define our own vector that does guarantee that it will not allow you to go out of bounds, and so we do.
These bugs are real and important, memory safety bugs, I should say. We have a wide variety. We have a lot of use-after-free, managing lifetimes is very hard. There’s other bugs too.
The Future
The future is, sandboxing is giving us 10 good years. We’re going to keep using it, of course. It’s great. We need to move to our next stage of evolution, which is adding strong memory safety on top of that.
Questions and Answers
Schuster: How much variance is there for different architecture builds of Chrome?
Palmer: For different architecture builds, I assume you mean like ARM versus Intel, that hardware architecture? We don’t yet have a huge variance, but we do expect to see a lot more coming in the future. For example, on Intel, there’s a feature called CET, Control-Flow Enforcement Technology. It helps you make sure that when you’re returning from a function, that you’re returning to the same function you came from, which turns out to be pretty important. Attackers love to change that. The hardware is going to help us make sure we always return back to the right place. That doesn’t exist in the same form on ARM. ARM has other mechanisms, for example, Pointer Authentication Codes, or PAC. It covers more and it covers things differently. It’s along the same lines of the basic idea of control-flow integrity. We do different things there.
Then, similarly, there’s a thing for ARM called Memory Tagging Extensions, where you can say, this area of memory is of type 12, and this other area is of type 9. Then it will raise a hardware fault if you try to take a pointer to type 9, and instead make it point to some memory of type 12. That’ll explode. Similarly, you get a little bit of type safety in a super coarse-grained way, not in the same way you would get from Java, where it’s class by class. You can get a pretty good protection against things like use-after-free, type confusion, and even can stop buffer overflows in certain cases. If you’re about to overflow from one type into another, that can in certain cases become detectable. That doesn’t exist on Intel. On ARM, we’re hoping to make good use of it. Increasingly, we’re seeing more protections of that kind from hardware vendors.
Someone also asked about memory encryption. Again, if we were to ever use that, it would be very different from one hardware vendor to another, and we have to do different things. As the future comes at us, I expect that our different hardware platforms may become, from a security perspective, as different operating systems. We can maybe have a roughly similar big picture, but the details are going to be totally different.
Schuster: You mentioned CET, which I think is being rolled out now. Has that been circumvented yet by the attacker community because it seems like every time some new hardware mitigation comes along, you think that’s it, all buffer overflows are now fine. Then they come along, and say, “No, it broke ASLR and all that stuff.”
Palmer: Yes. For example, there’s already ways of working around PAC on ARM. There’s three benefits to this. One is, they can make software defenses more efficient. Like for example, I mentioned earlier, a thing called MiraclePtr, where we’re inventing a type of smart pointer that knows whether or not the thing it points to is still alive. There’s another variant of the thing called StarScan, and that’s like a garbage collection process where it looks around on the heap to see if there’s any more references to the thing you’re about to destroy. The trouble with that is it can be slow, because it has to search the whole heap. With memory tagging, it can speed up the scan by a factor of however many tags there are. If you have 16 different memory tags, it’s weak type safety, but it speeds up scanning by a factor of 16, because you only have to even search for the particular one of 16 types on the heap. You don’t have to scan the whole heap, you scan 1/16th of the heap. It speeds up software defenses.
Two is, the various hardware defenses work best together. If you combine control-flow integrity like CET and software control-flow integrity for forward jumps, like calls and jumps, and you combine them with Data Execution Prevention, where you can stop a data page from being used as a code page, for example, and you combine that with tagging, it starts to cover more of the attack techniques. You’re probably never going to get all the way there, just by throwing hardware features at the problem. We can close the gap. We can speed up software based defenses. Then, performance, combining them to get a better benefit.
Then three, is, it really does make the attacker do more work, at least at first, but maybe even in continuing. It’s like, yes, some very smart people can work around PAC or maybe even break it. Doing so, can be anywhere from, they had to invent a technique to do it once, and then ever after it’s easy. Sometimes that happens, and that’s terrible. Sometimes they invent a technique, and then they have to reapply it every time they develop a new exploit, and it’s just a pain in the butt. It becomes an ongoing cost for attackers, and that’s what we want. Like ASLR, address space layout randomization is a terrible technique. It annoys me. It’s very silly. Attackers do have to have a way of bypassing it every time they write, or most of the time when they write an exploit. They often can, but they have to. Even though it annoys me, it’s still valuable, on 64-bit. On 32-bit, it’s maybe not.
Schuster: Yes, there’s not enough room to do it.
Why does it annoy you? Does it make anything more difficult to bug or anything like that?
Palmer: No, not really. What annoys me about it is just that it’s ugly. It’s a hack. What I want is something like a language that just doesn’t allow these problems in the first place. Why are we trying to hide things from the attacker? Like, “No, they might find where the stack is and then they’ll know where to overwrite the return pointer.” Why do we let them get to that point in the first place? That bothers me, because the software bug that let that happen, has no reason to exist. It’s just, you didn’t check the bounds on your buffer. Let’s fix that. Let’s fix that at scale by using a language that makes it easy rather than making every C programmer remember every single time. I want to fix the problem for real.
Schuster: There’s lots of legacy software, lots of C, C++.
Do you have a lot of legacy backwards compatibility versus security tradeoffs?
Palmer: The main thing is, we support old versions of operating systems for some years. Then very gradually, we announce that we’re going to not support Windows Vista anymore. I think Windows 7 is the oldest version we currently support. It might not be long before we don’t support Windows 7 anymore. What we’re able to do for the most part is we can do the best we can for you on each platform. If you have the latest version of Android, we can take advantage of what it offers. If you don’t, we’ll do the best we can with what we got. It doesn’t really stop us from doing new things. It’s just that we can’t promise as much as we can on the newest version. As for hardware, it’s a similar thing. If you’ve got some hardware that doesn’t have CET yet, you don’t have it, but we’ll still do everything else for you.
Schuster: Since sandboxing can be expensive, is there a sense of maybe scaling it back on weaker clients?
Palmer: Absolutely. There’s runtime configuration options in Chromium. I was talking about how I wish we could do site isolation on a per origin basis. Actually, there is an option in Chrome to turn that on. You can do that. It just uses up more processes, but if you have the memory, you can do it. On Android, we have a dynamic thing where we face a lot of memory pressure on Android, there’s just less free memory available to make more processes. What we did was we said, if we notice that you’ve been logging in to a certain site, then we take that as a signal that it’s important to you. Then we site isolate those. Then sites that you’re using anonymously, like just the news or whatever, Reddit, if you’re just reading Reddit, not logging in, then we don’t need to spend a process on that. We can make several sites share the anonymous process, and then dedicate our resources to the ones that seem important to you. Where logging in is a signal, or if you use it heavily, that looks important to us, things like that. We do do some dynamic scaling. You could do a similar thing that makes sense for your application. If you’ve got a server application, you could say, this is for clients who have logged in, and then clients who haven’t logged in, maybe they share some resources. It depends on how much resource pressure you face. I wouldn’t adopt such mechanisms until you’ve measured that you have resource pressure. As long as you don’t, you might as well sandbox everything.
Schuster: In what functional areas are your main challenges, so rendering, JavaScript, networking, stuff like that?
Palmer: It’s mostly JavaScript. Networking is tricky. WebAssembly is tricky. When we give the attacker the ability to run code, like with JavaScript, or WebAssembly, and it used to be Flash before Flash was removed, you’re giving the attacker a lot of power and a lot of chances to win. Those have always been tricky. The renderer, therefore, we sandbox it the most heavily because the most dangerous stuff is in there. Similarly, the network process has to parse and deserialize a ton of complicated stuff. QUIC and TLS and HTTP are quite complicated, actually, and there’s a fair amount of risk there for attack. We have had some nasty bugs. It’s not as dangerous as JavaScript, but it’s not exactly easy. I really would like to break out the network process into one per site, because if you take over the network process now, you get access to networking for every site. That’s not great. It’s harder, but you get more power, and so I’d like to stop that.
See more presentations with transcripts
MMS • Lena Reinhard
Article originally posted on InfoQ. Visit InfoQ

Transcript
Reinhard: I’m really excited to be here and talk with you about change, because change is at the core of modern software delivery and at the core of our work as leaders. All of us are here to talk about optimizing our organizations for speed, and how to improve velocity and flow of our teams. Putting DevOps into practice helps us with this, and I want to share with you how you can utilize it for your teams.
When we talk about DevOps culture, we fundamentally talk about making change easier. DevOps culture is fundamentally about change. It’s about reducing friction to improve our ability to change, and change continuously in service of improving our products for our customers. As leaders in modern software delivery organizations, we choose continuous improvement, continuous change over being satisfied with the status quo. We do so for the benefit of our customers, our business, and our teams. We’re also humans, and sometimes change is hard for us and for our teams. From many conversations with leaders, I know that the last year has brought many difficult changes for teams and leaders as well. It may have been difficult for you too, and I find that important to acknowledge. Yet for us as leaders, change isn’t just an annoying side effect of what we do. Change is the work. Initiating, responding to change, that’s what we do every single day. As leaders, we want confident teams that thrive and deliver business great value regularly.
CircleCI
I want the same thing for my teams too. CircleCI sits at the heart of helping teams manage change. We’ve been around for almost 10 years, we have over 500 global employees. We’ve always been distributed. We just celebrated our 100 million Series F funding round, two weeks ago. We power some of the Earth’s best engineering teams at companies like PagerDuty, Spotify, Ford, Samsung, and support open source projects like PyTorch and ELEKTRONN. This means that we have a front row seat to how teams move code from idea to delivery. How teams handle change, and also in helping leadership teams support their teams in moving to better practices. My engineering team has grown quite a lot. Our department overall has grown 5x in the last 3 years, from 45 to over 200 employees. We use our own product and other modern software development practices and processes. This means that we lead change ourselves, we help other teams do the same. We’ve learned some things along the way. This talk is not just about frameworks and principles, but it’s also a case study. In just one of those years, we doubled our engineering team and increased our customer facing deliverables by 2.5x. I’ll sprinkle a lot of examples of how we’ve done that throughout this talk.
The Spirit of CI/CD
I want to get us started by looking at some principles in CI/CD, continuous integration, continuous delivery. Our mission at CircleCI is to help teams quickly and confidently validate and seamlessly ship change to end users. Some of the core principles can be summarized in the word VALUE. The first part is visibility. I really think it’s crucial because it means visibility into changes for everyone. Accountability is another one. Continuous feedback and transparency, and encouraging teams to take responsibility and hold themselves accountable is a crucial part of CI/CD. We lead with frequent and small changes that everyone contributes to. Obviously, we do all of that in service of user value delivery for quick feedback loops with our customers and ultimately continuous enhancement.
I want to pull out here that it’s not just about change, but it’s about changing confidently. Our job as leaders is to be confident in change and help our teams be confident in the changes that they’re making. Confidence isn’t in a trait. It means being conscious of our powers, but I also think there’s an action component to it. Confidence is what greases the wheels. It turns our thoughts into actions. It makes us go from, can we do this? To, let’s give it a shot. It’s not just the state of being, it’s action oriented. It means we’re willing to take risks, struggle, fail, and eventually achieve mastery. That’s really the mindset at the heart of CI/CD. Change isn’t just a detractor for confidence, also, it’s a prerequisite for it. Confident organizations and teams they act on opportunities, rise to new challenges, take control of difficult situations, and take responsibility when things go wrong, ultimately to learn from this failure.
Let’s translate those core CI/CD principles into leadership strategies and frameworks that you can use with your teams. We’ll cover visibility, accountability, leadership, user value delivery, and enhancement. I’ll show you some frameworks and tools, as well as how we utilize those in my team at CircleCI. Your team and your company may be in a very different place, so take what works for you or make modifications to that. Ultimately, again, it’s all about continuous improvement.
Accountability and Ownership
We’ll dive in with A for accountability. I want to pull accountability up first, because I think it’s foundational. If you don’t know who’s accountable for which work, your efforts will inevitably fall short. A lot of accountability because of that ties back to ownership. We want to empower teams to do the best thing for the business and drive impact to make the right decisions. A crucial factor here is that teams have to have clear ownership of metrics and feel connected to those. This is done when you connect team metrics to business goals, strategy and business impact. Accountability also means that teams own their progress and reporting. Only if we’re owning our progress and mistakes, we’re able to actually develop this confidence that we’ve talked about.
There are a couple ways that we’ve done this in practice. Like many of these other things that I’m going to talk about, we’re continuously learning, continuously improving in those areas. That’s a key factor that I want you to keep in mind. Metrics ownership for teams is a really important part of this. I think this ownership is key. First of all, we’ve involved our teams in defining the metrics for them. Their subject matter experts use their input for figuring out what the best metrics for them will be. Use business goals and strategy to help support those conversations. Clarify roles and responsibilities. Make sure that it’s clear who owns what and who’s ultimately responsible, but also accountable for which parts.
Another aspect is, clearly define service ownership. We have service ownership for the teams defined, but we also regularly review if the boundaries that we have in place are still working, and if the interfaces and interaction patterns between teams are aligned with what we want them and our business to do. We need teams to have the right amount of context, but also the right interaction patterns to be able to really own their domain. Then, I think it’s not just about service ownership, but ultimately end-to-end ownership. The service ownership is just a way to get there. I think the team shouldn’t just own services, they ultimately should own the user experience, because in the end, that’s where the real impact is. Then we usually have a mix of metrics that we end up with between SLIs, SLOs, as well as some primary business metrics that we’re looking for the team to impact. Those metrics are all aligned with our corporate goals. Transparency in all of that is really important as well, we’ll cover more about that in the visibility part. Teams should have access to metrics. They should be able to review their progress report on it, and also make changes to their execution based on it. It’s an important part of the empowerment component in the accountability.
Leadership at All Levels
Next, let’s look at leadership. I believe that there’s a difference between management and leadership. I like the definition that management is about coping with complexity. Leadership is about coping with ambiguity and change. I believe that organizations need leadership at all levels, because it helps us carry our organizations forward and ultimately succeed. This is not about a dichotomy between leaders and followers. Leadership at all levels is about growing people at all levels, who can handle ambiguity, who can drive change. This will mean that your organization can take a much more active role overall in leading change. Ultimately, it will accelerate your ability to improve for the sake of your business and customers.
Let’s talk about a couple practical ways how we do that. One big part is context. I and many of the leaders in my organization regularly share context with our respective staff about the meetings that we’re in, the things that we’re hearing, the initiatives that we’re driving, or just observations across the organization. This really helps with the bigger picture and exposes people to larger amounts of ambiguity, to higher complexity, and to topics that may not have easy or straightforward resolutions. This context can really help in building out this ability to deal with ambiguity and take leadership.
Another part is sharing problems or objectives instead of projects. Delegating larger stretch opportunities is a really good way to grow leaders, but making sure that those aren’t delegated as basically a task list but as outcomes impact that you’re looking for this person to have, and having them figure out how they’re going to do that. Similarly, we usually have projects in the domains or organizations that people run. Usually, those projects are again tied to impact and objectives that we’re looking for people to achieve. We have those at different levels, and both for people managers, as well as technical leaders in any level. It means that people can go from having impact in their team, or in part of their team, to larger impact across several teams, to then organization-wide. Another aspect is a growth framework. We have a competency matrix in place, one for engineers, and we also have one for managers. Those kinds of frameworks which outline expectations and roles again, can help support growth conversations. Leadership skills are an entire section within this. There’s something that we expect, again, from engineers at all levels.
Leadership: Shared Goals
Another aspect of fostering leadership is communication specifically around goals. I believe in high transparency when it comes to goal setting. Business goals should be visible to everyone, the same for team goals. It helps with alignment, but also makes sure that teams have a better view of what’s going on around them and how to stay aligned across. Communication around those goals as well as strategy is key. Communicate your purpose, mission, strategy, operating plan, and do so regularly. Especially in times of change and uncertainty, it helps people stay connected with the purpose. It also builds confidence in your plans and your leadership. Communicate your strategy continuously at a high frequency. I believe there’s no such thing as talking about strategy too much. Then utilize the power of connections. Don’t just share strategy, but help people understand how it relates to them. Draw the connection from, here’s the strategy to here’s what this means for you, for your domain, your team, as well as your individual job every day.
A couple ways for how we do this are, we regularly communicate strategy. We have kickoff meetings in the quarters. We have strategy overview sessions. At the domain level, we host different calls to connect those higher level with team goals as well. All of those things also get recorded. It’s a small detail, but it also means we can share those contents with new folks as they’re joining us. We use OKRs as a goal setting framework to help us with all of that. We lead with the company direction and strategy. Then, the teams align their goals on this overall direction, as well as in alignment with the metrics that they own that we talked about earlier. This helps the teams with alignment while also opening up space for the teams to contribute and prioritize work that they know that matters in their domain. Again, we’re relying on teams as subject matter experts.
We do OKRs on a quarterly cadence. They’re visible in share places for the entire company. We review progress against them regularly with the entire company. I know that people in our industry, there’s a lot of opinions about OKRs and how to do them the right way. I believe that most of all, like any framework, it’s about how you use it. We have been continuously iterating on our use of OKRs. I’m 100% sure that we will continue doing so, because ultimately, it’s never about the framework but about making it work for you. We also do individual goal setting, and those goals again, are aligned with our OKRs. We can draw the connection between what the company is looking to do and what individuals are doing on a quarterly basis. Ultimately, all of this instills confidence because it helps teams know that we’re doing the right thing.
Visibility: Defining Metrics that Work
Let’s talk about how to define metrics that work. I’ve often encountered two different problems scenarios here. One, in an organization where there’s a strong data driven culture, or people who are very keen on observability, there can be a huge temptation to measure everything. On the flip side, sometimes there are cultures that aren’t at that point yet, and then it can feel really daunting. I’m mentioning a lot of metrics, and you may be really unsure where to start. I want to give you some tools to establish good metrics with some examples baked in for how we approach that. The first point I’d say is, measure what matters and measure what you want to know very regularly. In my team, we incremented our way towards the dashboards that we’re using today. We started with a handful of metrics that seemed like they’d be good to keep an eye out for on a weekly basis, and a very simple spreadsheet, and built that out over time.
The second point is figure out how you will know what’s working or not, and how you will know quickly. My favorite example there is our hiring goal. Ultimately, for me, the biggest goal is having people join my organization, have their first day, and then succeed in their onboarding. That’s usually a couple weeks or even months out from when we start hiring for a role. I look at metrics that are much quicker and tell me much faster whether we’re succeeding or not. For example, time to a certain interview stage, or time to application review even. Another part is the impact. Focus on impact. For team goals, for example, you can convey team goals by measuring features, or by measuring the impact that teams are having, when you focus on user adoption or other much more user centric metrics. Align teams on business metrics that you’re looking for them to drive. It’s much more motivational because it connects them to meaning, big picture, and to users. It also helps with accountability because it gives teams a clear sense of ownership and purpose.
Then, use a good baseline. There is a lot of industry baselines out there for DevOps metrics, hiring metrics, team health metrics, and other metrics where you can also look at cohorts or companies similar to you in size or stage. These baselines add meaning and direction, and are really helpful context for any metrics that you set. Then, just a word of caution, avoid driving the wrong incentives or encouraging counterproductive behaviors. There are a lot of anti-patterns in our industry around metrics, and a couple that I just want to caution against. One, individual metrics. I believe they’re not helpful. We’re all looking to build great teams and organizations, and not incentivize hero culture. The second, avoid metrics that pull teams in opposite directions. A classic example is between product and engineering teams. I run a product engineering organization, so there’s always some tension, which is healthy, but in many organizations, there’s conflict. Oftentimes, it’s because metrics are misaligned. The third part, teams should know what they’re measured on. Don’t run shadow measuring systems in the background, not great. Then also, fourth point to caution against, avoid metrics like lines of code. I think they’re not really helpful. They don’t really entail meaning or really capture the impact of work.
Visibility: Metrics Used by Successful Teams
There is no one-size-fits-all approach in metrics. Every team is different. Pick what works for yours. I’ll show you just a couple metrics that I found useful. We see a lot of teams handling change, and move from idea to value delivery every day. We’ve observed patterns on our platform, especially from top delivery teams. These show patterns that suggest benchmarks that other teams can use. There are four key metrics that show team performance. Those execution metrics in CI/CD have been mentioned by many others, Puppet and DORA have been talking about them or flavors of them for a while as well. You can see the medians that we’ve observed in our platform, as well as suggested benchmarks in this chart. First one is for throughput, so the average number of workflow runs per day. Second is for duration, so length of time it takes for workflow to run. Mean time to recovery is for the average time between failures and their next success. Then there’s the success rate, so passing builds divided by the number of runs over a period of time.
These benchmarks we suggest for teams, these are the ability to merge at will. Then builds that run between 5 to 10 minutes. Time to recovery under an hour, and a 90% or better success rate on your default branch. The interesting part there is also that high performing IT organizations outperform their peers in those significantly, with 200 times higher deployment frequency and 24 times faster recovery from failure. A much higher success rate and shorter workflow duration. If you’re using the CircleCI product by any chance, these metrics are also all visible in our Insights tool, so can be accessed there by anyone on your team, again, helping with the visibility part.
A couple other metrics that you could use if they work or are useful for your team, engineering quality. You’ve looked at DevOps metrics. There’s also availability, which is obviously important for customers. Then for the delivery metrics, like lead time, cycle time, how long does it actually get us to go from idea to value delivery? Investments, we look at how we distribute our time between technical investments and maintenance feature work or escalations for our customers. Another is of course goal progress. OKR status and progress towards other goals that we may have. Hiring metrics, time to get to a certain stage, or pass-through rates to identify if your process is working. These metrics are all only useful if you have clear ownership. They need to be visible to help with transparency. Metrics are only a part of the story. It’s always context and complexity that matter. I ask my teams not to share just their metrics but also something around them, their projection, their confidence in those metrics. Because anyone can throw numbers out there, but it gets really interesting when you understand the story behind them, and your teams take accountability for sharing that story with you.
User Value Delivery: External Users
Let’s talk about user value delivery, because that’s come up a few times as well already. Because ultimately, everything that we’ve talked about so far impacts this part. Confident teams will result in happy users. There is the external actual value delivery to users. Incremental value delivery allows us to get user feedback quickly, address it, and build on it. Ultimately, increase our team’s confidence through continuous learning. In my team, we use a modified dual track agile delivery process to help us not only deliver in increments, but also combine discovery. Learning about our users and their needs in our daily work. There’s also the more leadership facing part of user value delivery. If we set up our team in such ways that they’re continuously learning, growing, and changing in increments, it’s much more manageable, because it helps continuously enhance the value that our teams are delivering.
Enhancement: The Real Failure Is Not Learning from Failure
This value delivery is really tied closely to enhancement, the last letter in our VALUE acronym. Because I believe that the real failure is not learning from failure. Getting feedback regularly from customers and key teams is crucial. I want to give you an example of that, because I feel like this is much more convincing in concrete terms. A couple months ago, there was an issue in my organization, and I had a couple discussions with my boss, our CTO about it. Ultimately, any issue in my organization is to me to own up to. The conversations we had were not about blaming, finger pointing, or anything like that. That’s not how we work. My boss wanted to make sure that we are learning from this, and that we have the culture, the tools, and the visibility in place to prevent something like this issue happening again. The focus of the discussions that I had with my teams was, do we have the right structures, tools, visibility in place? Do we have the right culture? Are we able to own up to mistakes that happen? Are we able to learn from them? Because that’s the part that matters, not how we got there, but what we do with where we got going forward. I believe that having this culture, these open conversations is crucial for teams. Another part of that is skill development, having an open feedback culture, hosting team retrospectives, and open incident reviews.
That segues us nicely into how we do these things in my team. We run regular incident reviews, and they’re blameless. We also hold retrospectives for teams and projects. It’s nice to just have a cadence for learning. We have different training and development programs. I also use these kinds of check-ins regularly to figure out if we have the right visibility, accountability, learning, user value delivery, and enhancement. Are we actually learning and are we continuously improving?
Confidently and Continuously Delivering
Ultimately, these continuous integration approaches to engineering leadership, they mean a comprehensive system where all parts are woven together and highly connected. We empower teams and build confidence when teams own their metrics and their learning, and we give them the tools to do so. We use metrics that work for our teams, and organization. Metrics that are visible to everyone so that we know confidently that we’re working on the most impactful thing for our customers. Our goals are all connected, and they’re visible for everyone. It means we’re confident, we’re doing the right thing, and that it’s aligned with our strategy. Everyone on our team contributes and leads, which helps us thrive in times of ambiguity and change. We make incremental changes for our teams and for our customers to continuously improve. Ultimately, all of those are about handling change with confidence and delivering value continuously. From all these ideas that I’ve shared with you, pick what works for your team, and use it to help your teams become confident. Lead them towards being a team that delivers value confidently and continuously.
Resources
If you’re looking to learn more about the metrics that I mentioned, and other data backed benchmarks for delivery teams, we have our state of software delivery report on our website as well.
Questions and Answers
Shoup: As you start to introduce KPIs and SLOs, how do you make sure that people feel confident in their failure and not get too risk averse?
Reinhard: I think that there’s a lot that goes into that. I would want to tackle two parts here. I think where the one is about which metrics you set and also how you introduce them. The other is then setting the right environment for people to be comfortable with failure. I think they can’t be separated. I think the first part is really, go slowly. I’ve mentioned a couple times like building your way towards metrics that work. I don’t think it’s helpful to overload a team with several metrics that they have to observe all at once. Introducing those things slowly, incrementing your way towards what you actually want can be really helpful, because it also helps people get comfortable with this. Because, ultimately, it’s a culture change. It’s a very different way of looking how teams operate. That just takes time.
The other is also, making sure you’re not setting the wrong incentives. I’ve in many cases seen that you basically need at least two metrics in order to balance and get to the impact that you actually want to have. Let’s just say you would measure a team on the customer impact that they’re having. At the same time, you want to make sure that they’re not neglecting technical investments, because you need those two for scalability and for actually supporting more customers. In those cases, you would probably want to actually have both, because you want to make sure that there’s a good balance. Thinking about, what’s the outcome that you actually want and the impact that you want the team to have? What are the best metrics to get there that help drive the right behaviors in people, and not set the wrong incentives.
Then the other part is really the comfort with failure. I think that one’s a really tough one, because it’s often really hard to measure why people may be uncomfortable with. I think digging into it with the team and having some open conversations about that can be one start. The other factor, I’d say, is definitely looking into how does your leadership team talk about failure? How are issues being addressed? How is criticism being voiced? How are the public discussions that are happening in chats, or in larger meetings, around when things go wrong? What are leadership reactions? There’s a lot that can go between the lines. I think asking people what their impressions are can be a big factor. Then, in combination with the right metrics, you’ll have a good foundation, at least.
The last point I’d say on the comfort with failure is, do you actually have an environment where you can learn? Because the failure is ok, if people understand that it’s an opportunity to learn. In order for that to be true, you have to have an environment where that learning is the focus and not the failure. If you’re getting too focused on the KPIs, it can easily become not about the learning anymore, but with an over-focus on failures, basically. Looking at how can you use the KPIs that you’re introducing for the team as a means to help with the learning for the team as well?
Shoup: Iterating on the metrics, the countervailing or balancing metrics, or the so important, and making sure you set the right incentives, everything is so good.
What happens when teams don’t want ownership? Then there was another person that asked about, this DevOps stuff, but I don’t want to be on-call, or team X doesn’t want to on-call.
Reinhard: This is so interesting, because DevOps transformation and culture, I think, has often gotten slightly reduced in some conversations. I love the nuance that is going on in the conversation that everyone’s having now as part of this track. I do think understanding that sometimes people are concerned about the complexity or about all the things that may change as part of it is really, I think, foundational, and digging into just what’s going on. Obviously, I don’t know the teams that this person was talking about, as I can only ask some questions, but things like, what’s concerning people. Are the systems set up in a way where if they were to move on-call, they’d probably get paged every night? What’s the risk that comes with moving to a different approach like this? Are people concerned about the change or are they concerned about probably having to own more than they might be able to? What’s the context of the team boundaries? Is the area that the team owns quite large? Is there a huge responsibility? Do the teams actually have the right staff for that? In those kinds of hesitations, I think there’s a lot to learn about the organizational culture and how it can be improved. Because, ultimately, I shared a lot of how we do things here in my team, but all of that was a learning as well. We had to increment our way towards it. A lot of that happens through learning from folks and digging into their impressions and addressing those things.
Shoup: I would just also say, just from my own personal experience, the companies that we look at, where they’re like, “Those guys are amazing at DevOps.” They didn’t all start that way. A lot of them started with the places where a lot of traditional organizations still are in terms of like a very classic Ops team is separate from development. Even the industry leaders, very much to your point, Lena, have iterated their way toward learning about how to do this.
I love that framing of management is about complexity, and leadership is about ambiguity. Say more, because that’s really neat.
Reinhard: First of all, I think a lot for me has to do with the time horizons that you’re looking at. Management in a lot of ways to me is about the short term. It’s about taking a piece of work, breaking it into smaller chunks, handling those. Making sure that there’s pure scope, that there’s deliverables to certain timelines, those kinds of things. It’s a very execution focus test. I’m not saying that in any diminishing way, it’s also really important work. It’s very tactically focused. Whereas the leadership aspect has a lot to do with creating space for the uncertainty. Thinking about the longer term. Setting direction, making sure people understand that direction. Having a vision that they’re aligned against. Having different approaches for how you’re handling those kinds of situations, or conversations about that longer term, depending on who you’re talking to. Modifying leadership approaches, and then connecting people with all of that.
In a lot of ways, I think it is opposites or dichotomies, because it means that in leadership there’s no easy answers necessarily. There’s a lot of things that don’t get resolved immediately. There’s a lot that you’re just collectively holding as a leadership team. I often tell my staff that it’s part of our job just to collectively hold some ambiguity for the organization and still show we’re still pushing our way forwards in it, and we’re still working through it one week at a time, but there’s a lot of things that we just can’t answer. That in itself, that ability to handle ambiguity, the ability to think about the longer term, the implications, the systems that are involved, that’s something that I think everyone can develop. I think it’s not exclusive to leadership roles or management roles. I find that a really important part because the more people you have in the organization who possess those traits, who are able to think about that bigger picture, and about the strategic level, the more you’ll be able to also move the organization forward.
Shoup: When I was running engineering at Stitch Fix, I participated in an internal training that they’d been doing, before I even joined, about leadership. I love this framing too, which is very analogous to what you’re just saying, leadership is making something happen that otherwise wouldn’t. It’s not dismissive to say, everybody’s a leader. We expect everybody to make something happen that wouldn’t otherwise.
Reinhard: I love that because it also opens up this space, I think, where management is more reactive. There’s this creative, in the literal sense, creating a component of leadership that really helps with all that. That’s a good way to put it.
Shoup: Yes, 100%. It’s not fun to be in a job where you’re just order taking, as opposed to like, “Here’s a problem to solve. I’ll help you.”
If you could elaborate more on your experiences with building a healthy culture, I think it would be very insightful.
Reinhard: Start with values. Think about what you actually want to drive towards. I love this definition of culture as the behaviors that we reward and punish. Culture is something that happens every day, and we create a set culture through any interaction that we have. Being cognizant of that is a really good start. Then having values that you can align people on, that everyone shares, and that you can also use, again, to reward behaviors that you think contribute to the culture that you want ultimately, is another. I think a lot of the aspects that I covered in the talk around leadership, and the visibility, accountability, basically, everything that’s part of this VALUE acronym, all of those things are ultimately driving culture. Because they set a standard around transparency, a standard around ownership. They foster a certain leadership approach. All of those things contribute to culture in themselves. I think culture happens with every interaction, basically, keep that in mind. Then start with what you want to drive towards.
Shoup: Can you share any situation where you had to impact culture change across teams and divisions? How did you go about that? How do you deal with things that cross organizational boundaries, like stuff that you need to do?
Reinhard: It depends. There was this model of impact, influence, and soup. Looking at which areas you can actually change yourself versus which parts you may be able to influence which are just completely outside of your control. I think a lot depends on the culture change you’re driving towards. If you’re looking to introduce DevOps culture in an organization that doesn’t have any of it so far, my recommendation probably is, start small, show impact. In a lot of ways that is a really smart approach, because you can demonstrate that you’re able to do things and they’re impacting things in the positive. If it’s about other types of culture change of how teams operate, or things like that, partnerships, relationships are often a really good foundation. A lot can also be used with metrics where you set metrics for how you expect to partner, what turnaround times look like, or things like that. It’s a squishy topic. I think visibility in all cases is a really important part because it means you’re showing impact. You’re communicating what expectations are, and how teams are doing. That helps.
See more presentations with transcripts