MongoDB Inc. (NASDAQ:MDB) has a beta value of 0.82 and has seen 1.21 million shares traded in the last trading session. The company, currently valued at $25.80B, closed the last trade at $373.05 per share which meant it gained $21.54 on the day or 6.13% during that session. The MDB stock price is -58.16% off its 52-week high price of $590.00 and 36.2% above the 52-week low of $238.01. If we look at the company’s 10-day average daily trading volume, we find that it stood at 1.43 million shares traded. The 3-month trading volume is 1.01 million shares.
The consensus among analysts is that MongoDB Inc. (MDB) is an Overweight stock at the moment, with a recommendation rating of 1.90. 0 analysts rate the stock as a Sell, while 0 rate it as Overweight. 5 out of 19 have rated it as a Hold, with 14 advising it as a Buy. 0 have rated the stock as Underweight. The expected earnings per share for the stock is -$0.22.
3 Tiny Stocks Primed to Explode
The world’s greatest investor — Warren Buffett — has a simple formula for making big money in the markets. He buys up valuable assets when they are very cheap. For stock market investors that means buying up cheap small cap stocks like these with huge upside potential.
We’ve set up an alert service to help smart investors take full advantage of the small cap stocks primed for big returns.
Sporting 6.13% in the green in last session, the stock has traded in the red over the last five days, with the highest price hit on Friday, 01/28/22 when the MDB stock price touched $373.05 or saw a rise of 5.28%. Year-to-date, MongoDB Inc. shares have moved -29.53%, while the 5-day performance has seen it change -0.67%. Over the past 30 days, the shares of MongoDB Inc. (NASDAQ:MDB) have changed -30.66%. Short interest in the company has seen 4.79 million shares shorted with days to cover at 4.69.
Wall Street analysts have a consensus price target for the stock at $572.21, which means that the shares’ value could jump 34.81% from current levels. The projected low price target is $461.00 while the price target rests at a high of $700.00. In that case, then, we find that the current price level is -87.64% off the targeted high while a plunge would see the stock gain -23.58% from current levels.
MongoDB Inc. (MDB) estimates and forecasts
Figures show that MongoDB Inc. shares have outperformed across the wider relevant industry. The company’s shares have gained 3.94% over the past 6 months, with this year growth rate of 26.26%, compared to -2.80% for the industry. Other than that, the company has, however, increased its growth outlook for the 2022 fiscal year revenue. Growth estimates for the current quarter are 33.30% and -13.30% for the next quarter. Revenue growth from the last financial year stood is estimated to be 43.80%.
12 analysts offering their estimates for the company have set an average revenue estimate of $241.76 million for the current quarter. 13 have an estimated revenue figure of $253.75 million for the next quarter concluding in Apr 2022.
If we evaluate the company’s growth over the last 5-year and for the next 5-year period, we find that annual earnings growth was -24.70% over the past 5 years.
MDB Dividends
MongoDB Inc. is expected to release its next earnings report between March 07 and March 11 this year, and investors are excited at the prospect of better dividends despite the company’s debt issue.
MongoDB Inc. (NASDAQ:MDB)’s Major holders
Insiders own 5.76% of the company shares, while shares held by institutions stand at 91.05% with a share float percentage of 96.62%. Investors are also buoyed by the number of investors in a company, with MongoDB Inc. having a total of 717 institutions that hold shares in the company. The top two institutional holders are Capital World Investors with over 6.8 million shares worth more than $3.21 billion. As of Sep 29, 2021, Capital World Investors held 10.19% of shares outstanding.
The other major institutional holder is Price (T.Rowe) Associates Inc, with the holding of over 6.68 million shares as of Sep 29, 2021. The firm’s total holdings are worth over $3.15 billion and represent 10.01% of shares outstanding.
Also the top two Mutual Funds that are holding company’s shares are Growth Fund Of America Inc and Smallcap World Fund. As of Sep 29, 2021, the former fund manager holds about 7.20% shares in the company for having 4.81 million shares of worth $2.27 billion while later fund manager owns 1.91 million shares of worth $898.76 million as of Sep 29, 2021, which makes it owner of about 2.86% of company’s outstanding stock.
The Computer Weekly Developer Network (CWDN) continues its Infrastructure-as-Code (IaC) series of technical analysis discussions to uncover what this layer of the global IT fabric really means, how it integrates with the current push to orchestrate increasingly cloud-native systems more efficiently and what it means for software application development professionals now looking to take advantage of its core technology proposition.
This piece is written by Jeff Carpenter in his special role overseeing developer relations advocacy at DataStax.
DataStax is the company behind a ‘highly available’ cloud-native NoSQL data platform built on Apache Cassandra, which is a free and open source, distributed, wide column store, NoSQL database management system.
Carpenter writes as follows…
Infrastructure as Code developed as an approach to help developers take control of the complexity of managing ad-hoc deployments. Turning infrastructure management into code makes these deployments easier to inspect for potential issues and makes them repeatable over time.
IaC grew as developers began to appreciate the efficiencies that come with storing infrastructure configurations in the same source code repositories alongside the applications that rely on them.
IaC advantage in terms of data
Now it’s time to apply these same IaC principles to data. Most developers would love to spend less time worrying about deploying and managing databases and other data infrastructure. Rather than implementing these services themselves, it’s often much simpler to make use of existing services to deliver what they need.
This has led to a range of database-as-a-service (DBaaS) offerings entering the market over the past few years; serverless database products have expanded as well.
Data management by APIs
While it’s useful to be able to automate database deployment or use a managed database service, another alternative is emerging at a higher level of abstraction: the ability to deploy services that make data accessible through APIs. This matches the way developers are accustomed to interacting with other services. Over time, all the data that applications create will be managed via APIs. The data services providing these APIs will be deployable using IaC techniques; using them will be based on code that is easier to understand, faster to replicate, and simpler to deploy again.
So then, thinking about data within Infrastructure as Code.
Carpenter: (Most) developers would typically love to spend less time worrying about deploying & managing databases & other data infrastructures.
To implement this approach will require having your data reside on the same cloud infrastructure as the rest of your applications. Given the continuing trend toward cloud native architectures that consist of microservices and serverless functions, this means targeting environments like Kubernetes. Let’s look at the elements of these solutions.
Kubernetes ground zero
First, databases will need to run on Kubernetes. The best way to handle this is via a Kubernetes operator. Operators handle the creation of new database nodes, provisioning storage resources, monitoring database health, backups, replacing failed nodes, and, in advanced cases, can even automate scaling up and scaling down as the capacity needed by the application goes up and down.
All of this is managed in the background automatically, so that the service itself remains reliable and available. Kubernetes operators are available for most popular databases.
Next, building on the automation at the database layer, the database itself should be invisible to the developer. Instead, they should work solely through APIs. To make this work, developers can leverage the emerging data gateway approach that abstracts the database from the service.
The data gateway
Let’s examine the data gateway concept.
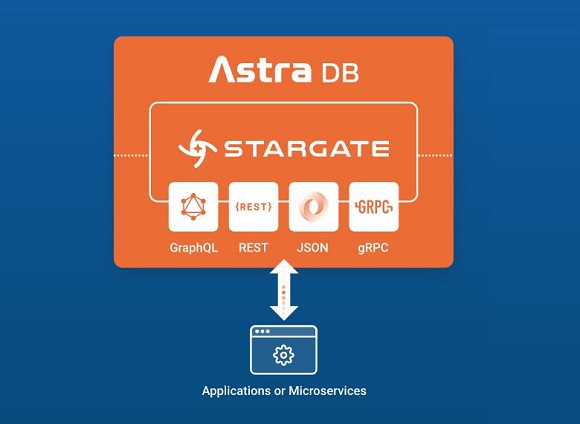
Over the years, many development teams have created internal abstraction layers for their databases to help shield application developers from the specifics of interacting with the underlying database, or to adapt an application written with a specific database query pattern to sit on top of a database with a different query language. These custom data gateways can now be replaced by more general-purpose gateways. One example of this is theStargate project, which was launched to provide APIs such as REST, GraphQL, Document and gRPC over multiple databases, starting with Apache Cassandra.
Using a data gateway is the next step in automating data infrastructure using IaC. Developers can focus on writing to well-known APIs and hand over operational tasks such as schema management or potentially even data loading to the data gateway. Linking this developer-facing abstraction layer with automated database instances makes it easier to implement and run databases within an application. Finally, Infrastructure as Code is the glue that will enable developers to automate the entire process of building, managing and interacting with both data and data infrastructure over time.
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
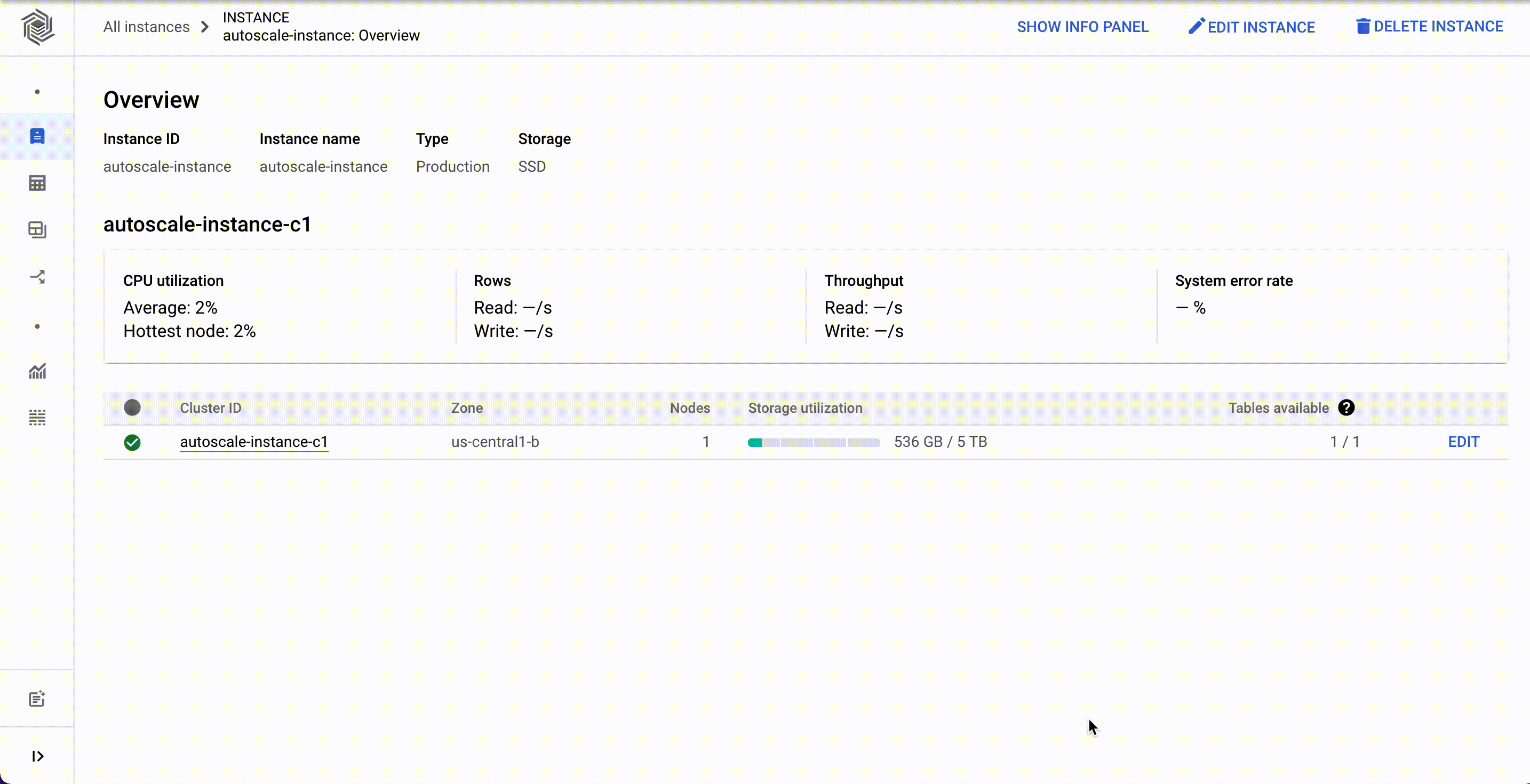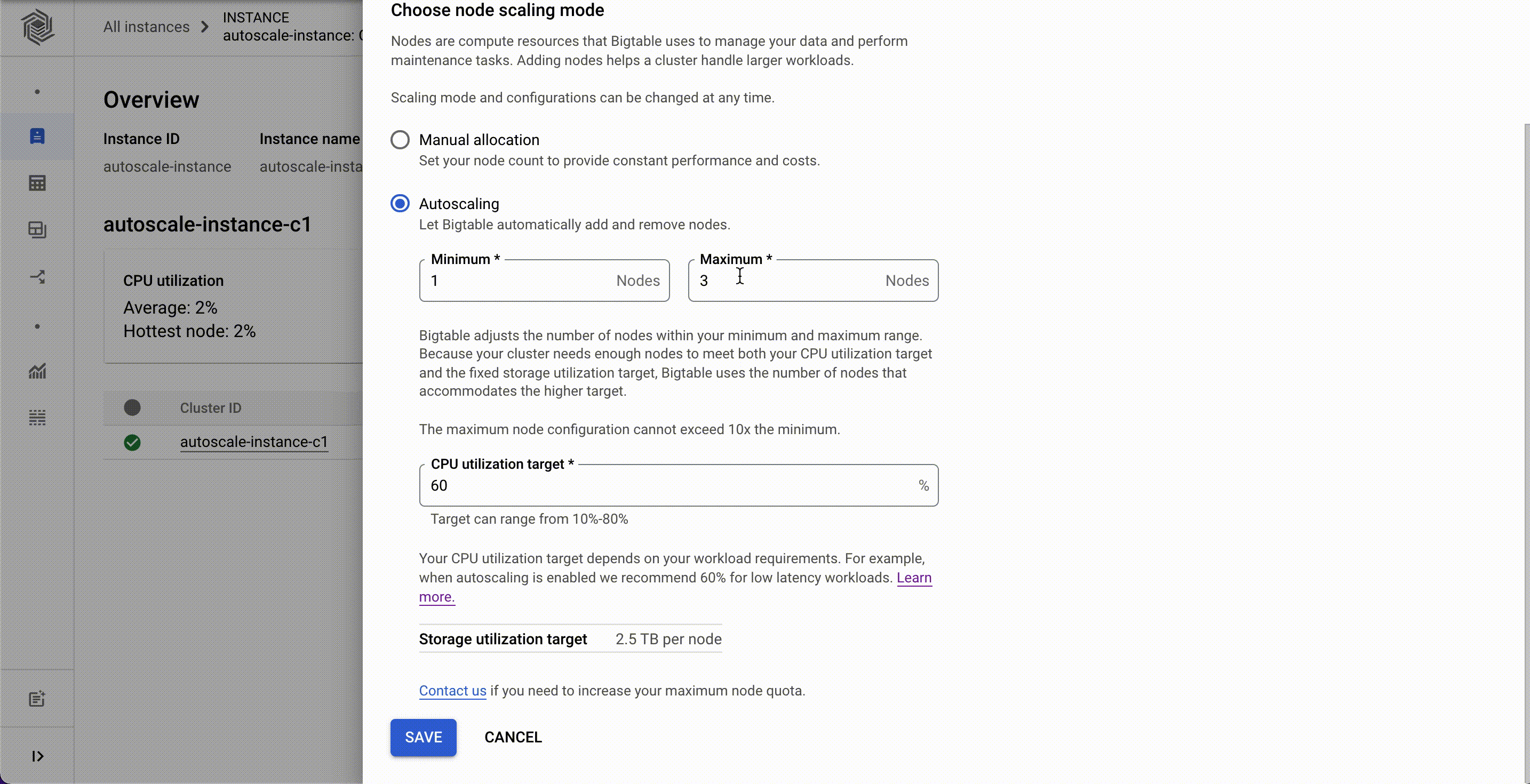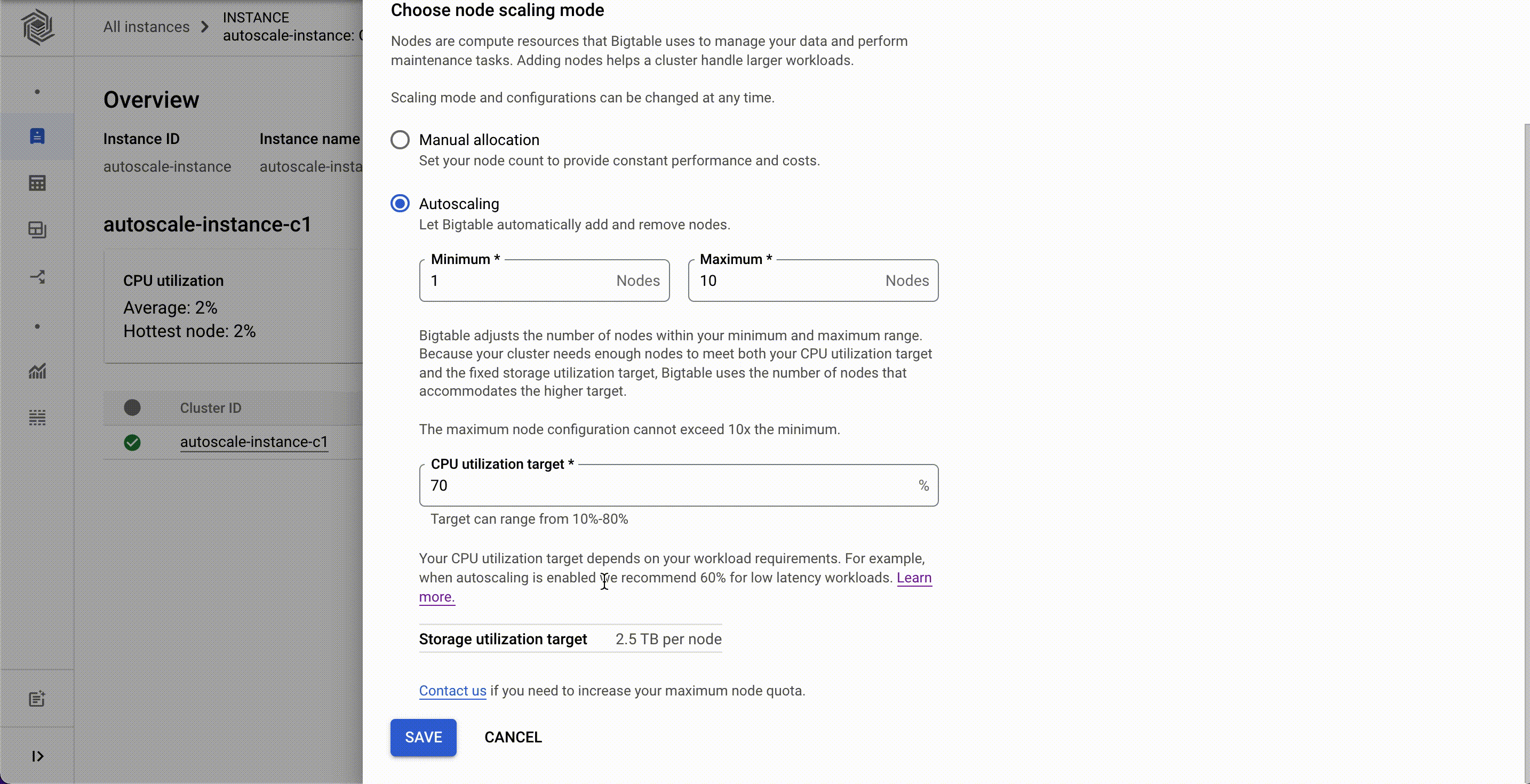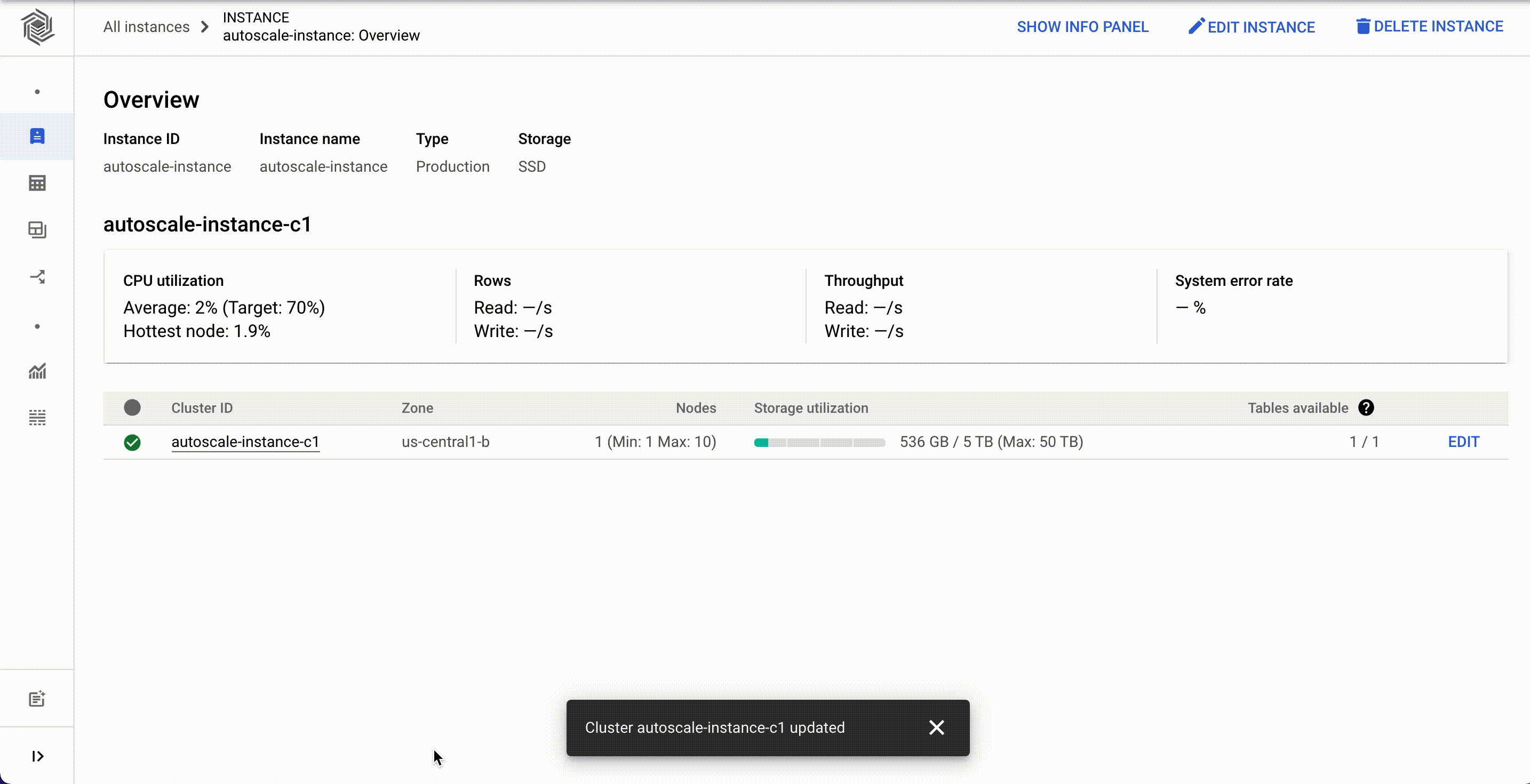
Cloud Bigtable is a fully-managed, scalable NoSQL database service for large operational and analytical workloads on the Google Cloud Platform (GCP). And recently, the public cloud provider announced the general availability of Bigtable Autoscaling, which automatically adds or removes capacity in response to the changing demand for applications allowing cost optimizations.
Autoscaling for Bigtable automatically scales the number of nodes in a cluster up or down based on changing usage demands. As a result, it reduces the risk of over-provisioning and incurring unnecessary costs and under-provisioning, resulting in missed business opportunities.
Earlier, scaling of Bigtable could be done programmatically as Bigtable’s Cloud Monitoring API exposes several metrics. A customer could programmatically monitor these metrics for a cluster and then add or remove nodes based on the current metrics using one of the Bigtable client libraries or the gcloud command-line tool.
Now, customers can configure autoscaling for their Bigtable clusters via the Cloud Console, gcloud, the Bigtable admin API, or client libraries. They can set the minimum and the maximum number of nodes for their Bigtable autoscaling configuration instead of doing it programmatically.
In a deep-dive blog post on Bigtable Autoscaling, Billy Jacobson, a developer advocate Bigtable, and Justin Uang, a software engineer Bigtable, explained the enabling of the autoscaling feature:
Autoscaling can be enabled for existing clusters or configured with new clusters. You’ll need two pieces of information: a target CPU utilization and a range to keep your node count within. No complex calculations, programming, or maintenance are required. One constraint to be aware of is the maximum node count in your range cannot be more than 10 times the minimum node count. Storage utilization is a factor in autoscaling, but the targets for storage utilization are set by Bigtable and not configurable.
In addition to Autoscaling, Google also added features to further optimize cost and reduce management overhead, such as:
Double the storage amount to let customers store more data for less, particularly valuable for optimized storage workloads. Bigtable nodes now support 5TB per node (up from 2.5TB) for SSD and 16TB per node (up from 8TB) for HDD.
Cluster groups provide flexibility for determining how customers can route their application traffic to ensure a better customer experience. For example, customers can deploy a Bigtable instance in up to 8 regions to place the data as close to the end-user as possible.
More granular utilization metrics improve observability, faster troubleshooting, and workload management. For instance, the recent CPU utilization by app profile metric includes method and table dimensions, which provide more granular observability into the Bigtable cluster’s CPU usage and how your Bigtable instance resources are used.
Lastly, the autoscaling feature is available in all Bigtable regions and works on HDD and SSD clusters.
About the Author
Steef-Jan Wiggers
Show moreShow less
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
The Database Management Software market report is a perfect foundation for people looking out for a comprehensive study and analysis of the Database Management Software market. This report contains a diverse study and information that will help you understand your niche and concentrate of key market channels in the regional and global market for Database Management Software. To understand competition and take actions based on your key strengths you will be presented with the size of the market, demand in the current and future years, supply chain information, trading concerns, competitive analysis and the prices along with vendor information. The report also has insights about key market players, applications of Database Management Software, its type, trends and overall market share.
To set your business plan into action based on our detailed report, you will also be provided with complete and accurate prediction along with future projected figures. This will provide a broad picture of the market and help in devising solutions to leverage the key profitable elements and get clarity of the market to make strategic plans. The data present in the report is curated from different publications in our archive along with numerous reputed paid databases. Additionally, the data is collated with the help of dealers, raw material suppliers, and customers to ensure that the final output covers every minute detail regarding the Database Management Software market, thus making it a perfect tool for serious buyers of this study.
The Database Management Software market report includes information on the product launches, sustainability, and prospects of leading vendors including: (Embarcadero Technologies, Couchbase Server, EnterpriseDB Software Solution, MongoDB, Teradata, Informatica Corporation, CA Technologies, HP (Vertica System), Oracle Inc., InterSystems, MetaMatrix, IBM Inc., Actian Corporation, iWay Software, BMC Software)
All the regional segmentation has been studied based on recent and future trends, and the market is forecasted throughout the prediction period. The countries covered in the regional analysis of the Global Database Management Software market report are U.S., Canada, and Mexico in North America, Germany, France, U.K., Russia, Italy, Spain, Turkey, Netherlands, Switzerland, Belgium, and Rest of Europe in Europe, Singapore, Malaysia, Australia, Thailand, Indonesia, Philippines, China, Japan, India, South Korea, Rest of Asia-Pacific (APAC) in the Asia-Pacific (APAC), Saudi Arabia, U.A.E, South Africa, Egypt, Israel, Rest of Middle East and Africa (MEA) as a part of Middle East and Africa (MEA), and Argentina, Brazil, and Rest of South America as part of South America.
Key Benefits of the report:
This study presents the analytical depiction of the global Database Management Software industry along with the current trends and future estimations to determine the imminent investment pockets.
The report presents information related to key drivers, restraints, and opportunities along with detailed analysis of the global Database Management Software market share.
The current market is quantitatively analyzed from 2021 to 2028 to highlight the global Database Management Software market growth scenario.
Porter’s five forces analysis illustrates the potency of buyers & suppliers in the market.
The report provides a detailed global Database Management Software market analysis based on competitive intensity and how the competition will take shape in the coming years.
Market Overview: It incorporates six sections, research scope, significant makers covered, market fragments by type, Database Management Software market portions by application, study goals, and years considered.
Market Landscape: Here, the opposition in the Worldwide Database Management Software Market is dissected, by value, income, deals, and piece of the pie by organization, market rate, cutthroat circumstances Landscape, and most recent patterns, consolidation, development, obtaining, and portions of the overall industry of top organizations.
Profiles of Manufacturers: Here, driving players of the worldwide Database Management Software market are considered dependent on deals region, key items, net edge, income, cost, and creation.
Market Status and Outlook by Region: In this segment, the report examines about net edge, deals, income, creation, portion of the overall industry, CAGR, and market size by locale. Here, the worldwide Database Management Software Market is profoundly examined based on areas and nations like North America, Europe, China, India, Japan, and the MEA.
Application or End User: This segment of the exploration study shows how extraordinary end-client/application sections add to the worldwide Database Management Software Market.
Market Forecast: Production Side: In this piece of the report, the creators have zeroed in on creation and creation esteem conjecture, key makers gauge, and creation and creation esteem estimate by type.
Research Findings and Conclusion: This is one of the last segments of the report where the discoveries of the investigators and the finish of the exploration study are given.
Key questions answered in the report:
What will the market development pace of Database Management Software market?
What are the key factors driving the Global Database Management Software market?
Who are the key manufacturers in market space?
What are the market openings, market hazard and market outline of the market?
What are sales, revenue, and price analysis of top manufacturers of Database Management Software market?
Who are the distributors, traders, and dealers of Database Management Software market?
What are the Database Management Software market opportunities and threats faced by the vendors in the Global Database Management Software industries?
What are deals, income, and value examination by types and utilizations of the market?
What are deals, income, and value examination by areas of enterprises?
About US
Credible Markets is a new-age market research company with a firm grip on the pulse of global markets. Credible Markets has emerged as a dependable source for the market research needs of businesses within a quick time span. We have collaborated with leading publishers of market intelligence and the coverage of our reports reserve spans all the key industry verticals and thousands of micro markets. The massive repository allows our clients to pick from recently published reports from a range of publishers that also provide extensive regional and country-wise analysis. Moreover, pre-booked research reports are among our top offerings.
The collection of market intelligence reports is regularly updated to offer visitors ready access to the most recent market insights. We provide round-the-clock support to help you repurpose search parameters and thereby avail a complete range of reserved reports. After all, it is all about helping you reach an informed strategic decision about purchasing the right report that caters to all your market research demands.
Contact Us
Credible Markets Analytics 99 Wall Street 2124 New York, NY 10005 Email:[email protected]
Ben Sangster, staff software engineer at e-commerce company Etsy, recently detailed the reasoning behind Etsy’s migration from React v15.6 to Preact 10. Going beyond the difference in library size, Sangster argued that adopting Preact lowered the risk associated with migrating Etsy’s large codebase. As Preact was already used by Etsy’s front-end team, migrating to Preact for seller-facing pages would avoid maintaining a fragmented stack.
We migrated all of the React v15.6 code at Etsy to use Preact. It was a huge win, and the migration was significantly easier (with far fewer rewrites or refactors of old code) than going to v16 would have been. The Preact team was amazing through the whole process. […] It was so seamless that I was able to put the migration behind a flag and literally use the exact same client with one bundle that used React v15.6 and one bundle that used Preact. We ramped up slowly and could track library-specific errors in Sentry using the flag.
In an accompanying blog post, Sangster explained in detail the three reasons that led to migrating parts of Etsy’s codebase to Preact instead of the latest version of React.
First, adopting Preact reduced the risk of migration the most. Developers have welcomed React 16’s new features (e.g., error boundaries, fragments, portal, better error stack traces, custom DOM attributes, hooks in React 16.8). While the React 16.0 documentation mentions few breaking changes in exchange for those new features, some developers reported migration pains. Usage of React.PropTypes or React.createClass, and depending on pre-React 16’s internals are typical migration pain points. While errors or warnings in the console will help in many cases, updating dependencies may be tedious. Discord’s Michael Greer said:
But not all package errors are so easily discovered, and herein lies the real pain.
We ran into an error which took us 2 days to track down to a library, and you may find the same.
The routing library, a key dependency of many web applications, may also cause migration pains. Sangster explained that, overall, Preact presented a better migration risk profile:
Preact is API compatible with React, which means that we are not making any changes by using Preact which would be incompatible with migrating to React at a later date.
The migration to Preact v10.4.2 would be significantly easier and require far fewer steps to complete, due to Preact’s emphasis on compatibility with both React v15 and React v16. […] there are a number of code updates we won’t have to make if we move to Preact. We should do them anyways, but the process will be slow and require refactoring a fair amount of code in somewhat tricky places.
There do not seem to be any major obstacles from a developer tooling perspective to adopting Preact.
Second, Etsy’s Front-End Systems team was already using Preact. Using Preact everywhere in Etsy was likely to make developer life easier. Sangster said:
[…] ensuring that we use only one Preact / React library for all of Etsy would greatly reduce developer difficulty over time. Among other things, having to support/test in React and Preact for tools like the Web Toolkit would add a lot of overhead for that team and others working on shared tooling and architecture.
Third, Preact’s bundle size (Preact v10.4.5 is 4KB) is six times smaller than React’s (React v16.13.1 is 38.5KB when adding react and react-dom).
Developers often strive to reduce the JavaScript shipped by web pages. As a matter of fact, JavaScript scripts need to be downloaded from the network, parsed, and executed. Latency (time to interactive), memory and CPU usage generally increase with the amount of JavaScript. On low-end mobile devices, the heavier consumption profile may reduce battery life.
Sangster’s migration announcement tweet attracted the attention of many developers. To Dr. Axel Rauschmayer who enquired about the hurdles present in React 16 that Preact didn’t have, Sangster answered:
We have a lot of oooooold code that’s unowned and a lot of old libraries — including a number checked into the codebase and manually modified to work with React v15. Upgrading to React 16 caused some API issues (esp. Portals/legacy Context/refs) that would require lots of work. Instead, we migrated to Preact and could refactor that code in place to the most modern stuff available — it made a lot of stuff way easier to think about, rather than some components/libraries which would have to get upgraded in lockstep.
Elastic has released their official Terraform provider for configuring the Elastic Stack. The provider enables configuring ElasticSearch, Kibana, Fleet, and other Elastic Stack components. This follows closely on their release of the Elastic Cloud Terraform provider.
The Elastic Stack Terraform provider allows for managed ElasticSearch resources such as index templates, snapshot repositories, snapshot policies, index lifecycle management (ILM) policies, users, and roles. For example, the following Terraform will set up an index named my-index along with two aliases, one of which is a filtered alias. Index settings are also supported such as setting the number of replicas or the idling period.
provider "elasticstack" {
elasticsearch {}
}
resource "elasticstack_elasticsearch_index" "my_index" {
name = "my-index"
alias {
name = "my_alias_1"
}
alias {
name = "my_alias_2"
filter = jsonencode({
term = { "user.id" = "developer" }
})
}
mappings = jsonencode({
properties = {
field1 = { type = "keyword" }
field2 = { type = "text" }
field3 = { properties = {
inner_field1 = { type = "text", index = false }
inner_field2 = { type = "integer", index = false }
} }
}
})
settings {
setting {
name = "index.number_of_replicas"
value = "2"
}
setting {
name = "index.search.idle.after"
value = "20s"
}
}
}
Authentication can be performed via static credentials, environment variables, or the elasticsearch_connection block. For environment variables, ELASTICSEARCH_USERNAME, ELASTICSEARCH_PASSWORD, and ELASTICSEARCH_ENDPOINTS are used to specify the username, password, and a comma-separated list of API endpoints.
Elastic also released a Terraform provider for Elastic Cloud which can be used to configure the Elasticsearch Service (ESS), Elastic Cloud Enterprise (ECE), and Elasticsearch Service Private (ESSP). Omer Kushmaro, senior product manager at Elastic, shares that:
This initial provider release allows you to manage and deploy Elastic Cloud deployments, and traffic filters as Terraform resources. It also enables you to query Elastic Cloud APIs as Terraform data sources for the latest available Elastic Stack versions and existing cloud deployments.
For example, the following creates an Elastic Cloud deployment of ElasticSearch and Kibana:
# Create an Elastic Cloud deployment
resource "ec_deployment" "example_minimal" {
# Optional name.
name = "my_example_deployment"
# Mandatory fields
region = "us-east-1"
version = data.ec_stack.latest.version
deployment_template_id = "aws-io-optimized-v2"
# Use the deployment template defaults
elasticsearch {}
kibana {}
}
The ElasticSearch provider supports Elastic Stack versions from 7.x and up. It is available via GitHub and documentation is available on the Terraform registry. The Elastic Cloud provider is also available via GitHub with documentation on the Terraform registry.
About the Author
Matt Campbell
Show moreShow less
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
Shane Hastie: Good day folks. This is Shane Hastie, the InfoQ Engineering Culture podcast. Today, I have the privilege of sitting down across many miles with Patricia Kong. Patricia, welcome. Thanks for taking the time to talk to us today.
Patricia Kong: Thank you for having me Shane across many, many, many, many miles. I’d rather be in-person.
Shane Hastie: Me too. It would’ve been great to be able to get together in-person. You are the product owner for Enterprise Agility at Scrum.org. First of all, I suppose, tell us a little bit about you and what brought you to that space and then what does product owner for Enterprise Agility do?
Patricia Kong: Oh, that’s a good question. That might be the hardest question you’re going to ask me throughout this podcast, isn’t it? So backing into where I am now, what’s interesting is I studied in business school, organizational behavior. And so I’ve always had this interest in how people work. I don’t know if I like people that much, but just how they work are very interesting to me. And what that found me into… This is a little bit dodgy, but I was really persuaded to go into a corporate financial career, right? That’s typical Asian American going into finance. That’s what I did, very corporate. And then that found me into different areas. Once I had enough of that, I was going through research, really coming into the marketing strategy IT space. And I actually ended up moving to France where I was working in startups and looking at product management and product development.
And like most people, my back’s against the wall. And then we go, “What’s this agile stuff?” Well, we need an audit on all of the code of our product. How do we do that effectively? We were working with different teams around the world. And so I was doing that, doing a lot of different things and then found myself coming back to the Boston area where I’m based and connected up with Ken Schwaber at that time who owns Scrum.org. And who’s the co-creator of Scrum. And at that time, the company’s not big, but the company was much smaller in the scale. And so we were looking at things around just streamlining the business, but also thinking about professionalism, learning. And then he was working on something called the continuous improvement framework at that time. And so this is probably about 10 years back.
Patricia Kong: And it almost seemed when we were talking about it with the industry, that it was a little bit too early. And so he was trying different potential ways to think about this. How could we take something like Scrum and work it at the enterprise level, so that we could work on continuous improvement together. And to be honest, the only thing that landed solidly from that because there was a lot of just taking different attempts, looking at different methodologies, were two things. It was this notion that you should inspect and adapt at the organization. So what evidence would you use to manage that? And then other thing was the Nexus framework. So Nexus is the scaling Scrum framework.
And the reason that that came up was because of the whole rush for companies to get to scaling. And he said, “Wait a second, if you want to scale, let’s talk about just a few teams work together. What would that look like? What does that core that we have to address there?” And then the other one is to say, “Hey, show me the evidence that agile is actually working for you. And so that you know how to progress.” So that’s a really long story, but I think in a nutshell, that’s how I am, where I am now. And so I think about those things, those boundaries. You’re using agile, you’re doing things. What does it mean when you hit that boundary and it’s not working anymore because of the enterprise?
Shane Hastie: This is something, this concept of Scrum or one of these approaches hitting the organizational boundaries, is something we see and hear about a lot. If I think of the audience who are listening to this, probably a number of them will have hit that boundary and bounced. What’s some advice in terms of, we want to be able to bring in some of the empirical approaches that agile methods and Scrum in particular talk about, and yet we’re hitting whether it’s the annual budgeting process or the HR recruitment process. How do I influence those changes?
Patricia Kong: I think about this one from, I think a soft skill standpoint. There’s this notion that the way that we’ve seen this rushed to agile, rushed to Scrum, rushed to scaling, rushed to that. And the question of why do we even need to be agile, gets lost? Why are we trying to pursue that? What was it in the first place? And when it’s really pointed to, and it’s fine, it actually makes sense. When an executive says, “That’s really working well.” And says the whole organization should do it. Let’s get the training. Let’s get it on the training schedule. There’s a lot that’s lost in understanding when you set up all of that training on all that stuff. When we come back and say, “Was it worth it? Was my money worth it?” We have nothing to show. We might just, so we have 20 teams, we have a hundred teams.
This is organized this way. And so there’s no real evidence. And there’s two things here: is that when the leadership says we’re going to do something like an agile transformation or there’s an interest from the people that you’re listening to. The question that I would have back is which way did you bounce? Did you profit? Did you gain power from this kind of transformation and this is looking good for you? Or is this something that you’ve really struggled for and you are championing? Because there’s two things that happen here, which is there’s a lot of times when change happens and leadership see themselves above the change, the change is not being done to them. And so that requires coaching and a lot of serious conversations. And then the other thing is that we invest in things that, sadly, we just have to say, we’re going to say that this works.
Using empirical evidence to guide decision making [06:07]
Patricia Kong: And if not in four or five years, I’m out anyways, we’re rotating door. So it’s really which way are you bouncing? What we’ve been working on this notion of evidence based management is saying, “I don’t want you to even come in and say, Scrum is the way. And just bring Scrum all to the teams.” That doesn’t work too, right? You’re going to have a waterfall team and a Scrum team, and everybody’s going to get very confused. We think about the dynamics of organizational practices, product practices, technical practices. So what I want to know first is I would look at something like EBM, where we’ve said, “Let’s get into a outcome based way of thinking,” right? So really talking about customers, why are we doing these things so that we can get more lean about the work that we pursue? And then just say, when we think about value, Scrum.org has defined that in four key value areas, unrealized value, current value, time to market and ability to innovate.
Four key value areas and associated metrics [06:56]
Patricia Kong: Unrealized value, current value, it’s really looking at the marketplace saying, “What’s that future potential value that’s out there, which is unrealized value, right?” So what are those satisfaction gaps? And the current value is where are we now? And then ability to innovate and time to market. Can we do it? And how long would it take us to learn from something? What we find from organizations that they’re just focused in one area. So let’s have a conversation about that. That’s where I would encourage the people who are listening to think about where are they really focused and is that at risk of them ignoring some other stuff that could help them make better decisions?
Shane Hastie: You touched on a really important factor around metrics. It’s really hard to identify the value. And personally, I really struggle with the idea of organizational transformation that implies an end state. If we take a Kaizen continuous improvement approach, I would hope that organizations are constantly looking to get better and better. And when we take that approach, what are the metrics? What are the measures we should be looking at around improving as an organization and how do they relate to me as a technical influencer, or a technical team leader?
Patricia Kong: And that’s the million dollar question where people try to nail me down and say, “Patricia, tell me exactly what to measure.” So what we think about, so the way that I would want to talk about this from a organizational perspective is I agree with you 100%, right? Not only does a transformation to note, there’s a beginning and end state. It makes it look like there was no journey, right? It was really quick. It’s like a before and after picture of a person who went on a very long diet or something, right? We don’t see the struggle in between and the consistency and the hard work that they have to do to maintain it. When I think about the measures, so each one of these key value areas, we suggest different metrics called key value measurements in there. And there’s going to be ones that are quite obvious, especially from the technical perspective.
So from a software perspective and ability to innovate, we’re going to obviously look at things like technical debt, that’s holding you back. We’re going to be thinking about installed version index and make decisions, hopefully by looking at, “Hey, how many of your users are actually on your current version?” We’re going to look at time to market. People should know their lead time and cycle time and those different things. But what we want people to think about is having an understanding of your flow measures or different measures there, is good if you understand, and can communicate to your organization, the value that it is in pursuit of. So that’s one way. I would use these different key value areas to think about a lens of where we can improve. So for an organization where they say we’ve released one time a year and you go, is that good?
That’s about context because maybe before it was three years, right? And now if they’re saying, hey, four times a year, that’s great. In what context, what value is that in pursuit of? So that’s where we really focus on the holistic thing. And a lot of the times when I’m talking to my colleagues or associates, there’s this still this surprise of, “Patricia, we go into organizations and it kills me to see that software teams, the developers are still being gaoled on exactly what I was gaoled on, which was velocity to deem that as progress.” And so the other conversation here is to not only look at the key value areas, but really understand and have it communicated to think about agility perspective. What is that outcome focus, that customer focus goal that we’re trying to get to? And how would you actually know if that was successful?
So the whole thing about inspection and adaptation, what we don’t see and why I feel so passionate about EBM is because the adaptation isn’t there. And I might even say the adaptation isn’t there is because a lot of the times we don’t say, how will we know when this goal is met and what would we do to adapt from it? And so we break down goals thinking usually about them from a time perspective and looking at not only what capability you have as an organization, but are you really on that journey of understanding how you’re improving? Right, exactly. Like what you’re saying, Kaizen EBM is very inspired by the Kanban model, things like that.
Shane Hastie: One of the most common shifts that we talk about with organizations in this space, and it’s an area I’m personally am passionate about, have truly written a book on it is the move from project to product. How do we inspire that sort of a shift in organizations?
Patricia Kong: We’ve been trying for so many years. I don’t know. We just keep trying. What is this? Over two decades? I think there’s going to be this pressure that if you don’t, it’s not going to work. So there’s this slightness of that. And there’s so much industry data, right? When we think about just the way that companies make decisions and they’re doing that, and it just gets so siloed, there’s actually a lot of decisions that get made from an organizational perspective that either hurt performance or they don’t do anything. And so they’re not really taking a look like you said, at the product perspective, I think we went project to such a product. I wonder if there’s something else there, right? If it’s going to be something that’s a lot more nimble. But the thing that I think about is if you really understand value, then you’re going to start thinking about how you invest for value, which is how I think about how would you invest understanding your goals?
The problem is when there’s product implications some people will say, when we’re scaling, we’re just scaling, not because of a product and what that needs, but because of just the amount of people we have. And I don’t think that we’re right now in an economic situation that will tolerate that for much longer. And I don’t even mean the people, I just mean the market. So what we’re trying to do is encourage people to think about, again, those outcomes, the gaps, the personas, all that good stuff, and then say, “You don’t actually have a scaling problem. You have a product problem. You are trying to architect your products around an ancient system from years ago. And I understand that that used to be optimized for cost, but how do we have those conversations?” So all the other are things that come into play.
But I think what we’ve seen with EBM is when we were able to do that, right? Just start where we can, is that when we started to use the measures to show progress around the goals of what we were doing, it created a true alignment, and this is where it needed from really top down support and bottom up. We started to have a conversation. And what was amazing was the developers, the teams were saying, “I understand why I’m doing this now. And this is how we’re making progress toward that. And not only that, here are some ideas and solutions that I would suggest because I’m very close.”
Measuring and setting goals around outcomes not outputs [13:31]
Patricia Kong: So everybody is talking in that same language. We’ve seen in that same structure for this product, the middle management, which we usually call the frost layer. Right? All of a sudden, they’re not being gaoled on output. They’re go being gaoled on that same outcome. So now they’re really expressing qualities of servant leadership. How can I remove the impediments? What are you struggling with? And we even saw it up to the executive level where when they’re looking at these charts and these graphs, and they’re having conversations, it’s no longer about the progress of a project, but of a product. And that was really powerful that to understand that, and that behavior starts to slowly change some of the things. But honestly, I think we’ll be having this conversation still in five years.
Shane Hastie: So let’s explore some of the factors that you were talking about, the elements of value as a starting point, current value, unrealized value. Current value makes sense to most of us, unrealized value, the potential ability to innovate. Why is that a business value metric?
Patricia Kong: What we actually look at this, it goes, if you have anything you want to pursue, well, then the ability to innovate is going to tell you from a value perspective, these things for us, really all contribute to value is that it’s going to talk about how can we maximize the organization’s ability to deliver new capabilities, right? So we’re going to ask two questions, which is what is preventing the organization from delivering new value? And what prevents the customers or the users from actually benefiting from that innovation? Even if we’ve come just straight in here for an organization, a lot of the times, what we see is we just need to build new stuff, build new stuff and features. And we said, well, actually, here’s some numbers that we’ve been taking on different versions that your customers are on, and you are spending $10,000 a month on your support team to support people who are all on older versions of your products.
So what do we need to do now? And this was, we chose from a technical perspective to start to make things a little bit more seamless instead of just throwing and adding more features. That’s what the CIO wanted. He was saying, “Let’s just build and add more stuff, add more stuff.” And we said, wait a second. You’re actually spending a lot of money here. If you want to improve your customer satisfaction and your employee satisfaction. That’s the thing. Another interesting thing about ability to innovate that we’ve been thinking about is the relationship between innovation and ability to innovate and employees and humans and their ability to ask questions and to be curious. And if your employees aren’t there, they hold a lot of knowledge, then that’s going to hinder your ability to innovate. So that’s something that I’ve been thinking about, and it’s closely obviously related to your time to market because if you can’t innovate, that’s going to potentially affect your progress toward your goals.
Shane Hastie: And for again, the technical team leader, how do I influence this? How do I help?
Questions technical leaders should be asking [16:17]
Patricia Kong: So there’s different things that I would start looking at. I would start saying, you know what, if I wanted to measure one thing, maybe two things. And I’m really thinking about my ability to innovate and how that helps or increases our time to market. I would start look at things like what is our time to learn and what is our time to pivot? So I would be working with a team to really basically answer those questions. What is preventing us from delivering new value? Do we have several branches? Are we scaled? And we can’t integrate. We can’t integrate, what is that cost? Right.
So now, now when we start to bring numbers and ability to innovate and time to market, when we look at something like scale and balance and all that, you will quickly find, I think in my experience that you will find a lot of costs that are being incurred because of all this overhead that we have. And that’s going to be something that relates to your ability to innovate. When people will talk about value stream mapping or those things. That’s a great place to look. What I would encourage is that for those technical leaders is to think of yourself as technical leaders, but also from a business perspective. So always driving that conversation back to value or else. I think that there will always be the stance that we’re just technical leaders.
Shane Hastie: That’s a bit of a mindset shift to culture shift. How do we help people along that journey?
Patricia Kong: I think the gurus of that are small children who created the five whys, right? The management technique they go, why, why, why? And honestly, that’s what’s gotten me onto my path right now, but really of being very curious and asking some questions that are very focused, not only to gather information from a fact, but when you are talking to the right people that have influence and also to the people who have influence on what could be the best solution is to ask them questions, to get them very curious. As a leader, those are the things that we should be doing that servant leadership is really pulling that out. And what I found that to be necessary is with not only at the management level, but also with the team level. So I was recently doing some research. And what they found was that from this curious perspective, that executives and management, think that curiosity is pervasive in organizations.
There was a study done by two gentlemen, I’m missing their names right now, but they did a study over 16,000 people. And over 80% of executives and management thought that curiosity existed in the organization. Super great. You get incentivized for these things, but that was much, much lower for the actual individual, contributors, the people on the team, they did not feel that it was okay to be curious. And the number one reason why was because they did not think that if they asked a question that they would get an honest answer, it’s not because it was unsafe or risky. And so there’s two things that are interesting there, especially from a leader perspective, from an agile perspective, is how do we encourage that so that we can actually innovate and not lock the great ideas, the innovation, the power up top, which additionally gets locked into annual budgeting, or once every two years, maybe we’re doing really good now at six months.
So there’s those things from a larger level that I would look at, but from just like, what could I do today? I would actually really start to have this conversation of who are my customers? What do they really want? How can that increase my time to market and ability to innovate? We have a gentleman in Canada who is working with a bank where they were convinced that they needed to develop this whole scaling initiative because they needed their mobile app to mirror their website up for the banking services. And when they actually went back and they said, “You know what, what do people actually want from a mobile experience?” And they said, the people who use the mobile, they only trust it for two things, look at their balance and transfer balances, maybe pay some other people.
And so they said, “Wow, we don’t need to mirror everything on the website. Now we can have a really simple app. We can do this much faster to time to market.” Current value customers were happier and they didn’t need to have five teams. They were able to do this with two teams. And so when you start to lead with that stuff too, and you have numbers, now everybody can have some evidence to actually be curious about, and let’s make some adaptations off of that. And I think obviously it’s from at Scrum.org, we have the Scrum framework to drive that focus of how do we incrementally do these things? And to actually see that something’s working because people will ask me, “Patricia, how do you know if EBM’s working?” I said, “One way I know it’s not working is nothing changes.” So that’s what we would look at.
Shane Hastie: Let’s explore this concept of in the white paper that you’ve published. You’ve got this thing called the experiment loop and the small steps. What’s the experiment loop to start with?
Patricia Kong: The experiment loop is exactly that. You have a hypothesis, you’re going to try some stuff and you’re going to measure it. And you’re going to find out if it works. And if it doesn’t, you make a decision, if it does, you make a decision and that’s really just the cut Kanban model, right? It’s just, let’s just run an experiment. And we find that that is interesting because a lot of people, I think still don’t think of, for instance, the product backlog items in their product, backlog, as an experiment, as a hypothesis. They’re not thinking of about them in terms of, or is there a way to have that conversation? The other reason that this is really important. So for us, we’ll say, “Okay, you want to be somewhere, you have the next goal that you’re trying to reach. What is experiment that you’re going to try to do to reach that goal in pursuit of a larger goal?” Is important because that gives us some time to eventually say, is that goal still valid?
And I think that, that’s really something to think about right now as we are existing going back into the pandemic. And there’s a lot of different other factors that we’re looking at now, right? So people talk about the future work. How do we think about all these other dynamics of what being demanded from not only the customer, but from employees. There are a lot of goals and a lot of things that we are working on that are not valid anymore. And so what is really important to me is to think about this experiment loop, right? We’re going to try something. We think about what the outcome is. We’re going to figure out if it worked or not is to really think about that in a way that allows conversations so that we don’t only go, hey, success for us as a team. If a leader is thinking about how they can help their team improve, it’s not that success is just, hey, work’s completed.
Things were done or it was just activity and output, really easy things to measure like you were kind of hinting at before. But it’s really, if we’re done, if success is here, we’re trying to push that to the level of we’re done. When we understand what value is delivered, we include that notion of feedback in there. So that’s really what I want people to start to get that muscle of cycling through. It’s essentially a empiricism, isn’t it? That’s all it is, is that we’re really, really, really looking at that. But in the times that we’ve been seeing organizations work on this, especially when you talk about, I’m going to make structural changes, scaling as a game changer because we are starting to make decisions based off of information and an evidence rather than the loudest person in the world.
Shane Hastie: Again, that requires culture shift in many organizations, getting the honest answer, the fear of failure experimentation almost by definition says, sometimes we’re going to get it wrong. How do we make it okay to get it wrong?
Patricia Kong: Well, we keep those experiments small. It’s the same thing, right? So if we’re going to say, hey, as we, and this requires a mindset shift, it really requires a lot of things. It requires a power shift. It requires a recognition of how power exists in our systems and in a company. But I think if is an experiment where we’re going to say, we’re going to try something and we’re going to show information that, that worked, and we’re going to start to realize why we’re doing something and what’s important. And that there’s outcomes there it’ll be a better place of working. The culture shift is interesting because people say, “Oh, you have to change the culture first.” And we get it a lot of their stuff. And there may be some people, myself included who feel like, you know what, there’s no better way to change a culture than just to get something done.
So this is again about what can the teams actually do, and let’s get transparent and use the retrospectives and use those way to figure out how do we work together better so that we can be more effective in delivering value. There’s so many other things that coaches, it’s so valuable to see things, examine and help teams improve. And it might be those little shifts first, right? So is there I empiricism? Is there curiosity embedded in the meetings for us in the Scrum events that are there? Are they talking about outcomes? Are they talking about experiments or is everybody silent? And just saying, “This is a status update. This is the work that’s been done.” My best that’s lipstick on a pig, isn’t it? So there is that, but I would say can we see what successes are existing from the teams that are already doing this type of work?
And the reason that I think capturing evidence to do it, so saying, “Hey, how’s our time to market? How’s our ability to innovate?” And if that’s the world you live in and that’s all you can do because maybe you live in another country and you’re responsible for this box of code, that’s going to go into a car in Germany that you’ll never see a first, some German person. If that’s all you can do, that’s great. If you understand why you’re doing it, that might motivate you better.
But if we can have all this concept of value and what we’re doing, I think that that evidence will be really handy. When for instance, the agile transformation is still trying to exist in the organization, but the CEO has swapped out. You now have to sell agile again, or do you? You can just take evidence and say, this is what’s happened in this way that we work. This is what we’ve learned. I think that, that’s important. And that culture shift like you were talking at marrying the notion of psychological safety, curiosity with accountability that creates a learning organization. And I think that, that’s the future of where people want to work.
Shane Hastie: This concept of unrealized value, potential value. How do we even make that visible?
Making unrealized or potential value visible [26:24]
Patricia Kong: So that one is usually pretty hard for people to grasp. And there’s something that we ask people to consider called dissatisfaction gap. And what I see from a lot of people who have a traditional mindset is that they look internally to what their satisfaction gap is. Where am I unsatisfied? Where are we dissatisfied with our organization? This is saying, where is that satisfaction gap for an end user or a customer using your product or service? What is their card experience? What is their desired experience? And is it worth it? In between for me, is it worth it to close that value? So that can look like something like, yes, there’s a new feature. Yes. There’s a new something. And how I’ve experienced a lot is actually quality issues because a quality issue means that I am unhappy with the experience that I’m having. Now, it’s not quality. We need to close it.
There was a company in Germany… Really quick story. They created a COVID app really fast so that they could track people. If they’d been to a restaurant, all that was great. Right? We’re helping the system, except all their data got exposed, right? So they did it really fast. It was really great. The government invested millions of dollars in it. And then all the data was exposed and they said, is it worth it for us to close it? That’s an example for me, of unrealized value. Should we just maybe randomize the data? What are small things that we can do? Is there value in that? Or will people just keep using it because they don’t care about their data anymore, it’s COVID? Those kind of things I would think about.
Shane Hastie: If people want to find out more and keep in touch with you, where do they find more and where do they find you?
Patricia Kong: I’m reachable through the internet, just like you are now. So LinkedIn is a great way to connect with me, Patricia Kong, K-O-N-G. When people write a note, I’m really happy to have chats and talk about how to get started. But evidence based management, there’s a guide just like the Scrum guide and Nexus guide that’s available on the Scrum.org website. And this has been eight years coming. We recently released a one day workshop. That’s available virtually that’s in our leadership curriculum called PAL EBM. So professional agile leadership.
There’s an assessment. Like we have those assessment certifications and people want to give their hand at that, but there’s also an open assessment. And the reason I bring up the assessment is not so much for the certification, but we have a really great suggested resources page that we’ve put together for people to think about this notion of business agility, how to invest for business agility? What does it mean if you were to think about this with OKRs, how do we make those better with evidence based management? How do we think about outcomes? So there’s a lot of stuff out there on the Scrum.org website.
Shane Hastie: Patricia, thank you very much for taking the time to talk to us.
Patricia Kong: Thank you for having me, Shane.
Mentioned
About the Author
Patricia Kong
Show moreShow less
QCon brings together the world’s most innovative senior software engineers across multiple domains to share their real-world implementation of emerging trends and practices.
Find practical inspiration (not product pitches) from software leaders deep in the trenches creating software, scaling architectures and fine-tuning their technical leadership
to help you make the right decisions. Save your spot now!
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
Lorenc: My name is Dan Lorenc. I’m a software engineer at Google, on our open source security team. I’m going to be talking about resilience and the role it plays in supply chain security. If you’ve been following the software news lately, you’ve seen that there have been a ton of supply chain attacks. It hit everything from governments, to large companies and small companies alike. Open source has played a crucial role in preventing and causing a lot of this. This is a topic near and dear to my heart. It’s a space I’ve been in for a while. I’m excited to talk about this, particularly how resilience plays in.
I’ve been at Google for about nine years now. I’ve been on Google Cloud Platform pretty much the entire time since before it was called cloud. I’ve worked in pretty much every level of the stack here, from high scale backend systems, all the way up to what I currently focus on, developer UX, so tools to make developers’ lives easier. I’ve been lucky enough to be working in open source for about the last six years. That’s what got me started worrying about supply chain security, particularly in open source. I’ve been worried about this and trying to build tools to make supply chain security easier for the last few years now. It’s awesome to see it in the news now and to have people start paying attention to this topic.
Outline
I’m going to start out by talking about what the problems are that are facing open source security, and open source supply chain security. If you’re a software company today, open source is probably in your supply chain somewhere, whether you know it or not. I’m going to be talking about the problems you’re facing, and the problems that the open source community is facing as well, and how we can deal with some of these together. I’m going to talk about resilience. I’m going to cover why resilience is important here. What role it plays in supply chains, and how you, as the user of open source software can architect a more resilient software supply chain.
Part 1: The Problems with Supply Chain Security
I’ll talk about what the problems are with open source supply chain security. I like to break it down as two problems. I think there are two problems facing security of open source software. The first problem is right here in the name. The first problem with securing open source is that it’s open source. Open source is great. It’s open. It’s free. Anyone can contribute to it. The communities are powerful. It does pose some unique problems when it comes to supply chain security. Finally, open source software is just like the rest of software, it’s software. All software has bugs, whether it’s written by me, whether it’s written by you, whether it’s written by a large community of maintainers. All software has bugs, whether we like to think about it or not. These are the easiest ways to break down the two problems that I see. I have different ways of addressing it, so that’s why I like to break them down this way. Here are some examples of each of the problems next, and then some of the things we can do about them.
Problem 1: It’s Open Source
First, it’s open source. What does that actually mean, and what do USB thumb drives have to do with that at all? I like to use this metaphor a lot. I think it starts to really convey the problem and worry people a little bit in the right direction. I hope most people at companies or not have been trained and scared by the news enough to know, if you’re walking down the street, and you find a thumb drive on the ground, you should not pick up this thumb drive and plug it into your computer to see what’s on it. This is a classic supply chain attack. I hope most people know not to do that. If you don’t, then public service announcement, do not pick up random USB thumb drives on the ground and plug them into your computer. This is a great way to get compromised. This does happen. There have been a lot of supply chain attacks carried out this way, including some that even got into air-gapped environments, and took out nuclear reactors in certain companies. Do not do this. Do not plug thumb drives into your computer. Definitely do not take one of these into your data center though, and plug one of these into your servers. That would be even worse than plugging it into your laptop.
What does this have to do with open source software? I want to step back a bit and ask, what is the difference between plugging one of these into your computer and running npm install? There’s not really a lot of a difference. In both of these situations, you’re taking arbitrary code that you just found lying around on the sidewalk, you have no idea who wrote it, you have no idea where it came from. You haven’t looked at it. You’re executing it on your own computer. In fact, the second half of what I just started saying about plugging one of these into your data center in production is basically what’s happening with npm. It’s even worse than plugging a thumb drive in. If you’re plugging the thumb drive in, it’s at least limited to your laptop, usually. When you’re taking arbitrary package managers, installing code from them, and running them in production, you’re giving it more privileges in a lot of ways than these thumb drives. This should be terrifying to people if that’s how we started building software, which is taking code that we’ve never looked at, and running it with access to our most confidential information. We really don’t have many protections in place for this today. Open source software is great. It lets us build applications much faster. It lets people collaborate together. It is pretty scary when you have no idea where the code is coming from.
Opportunities of Open Source
What else can this cause? Here’s some other ways I like to think about it. Open source is awesome, but a lot of these benefits can cause problems. Let’s look at some of these benefits, break it down. Then after this, we’re going to do some actual examples of each of these compromises. Some of the problems here. First off, open source is free. That’s awesome. It’s one of the main reasons people use it. If you look at this comic here on the right, sometimes free isn’t worth it. We’ve heard of free as in beer, free as in speech. I say sometimes open source is free as in lunch. You’re paying for it somehow, whether or not you’re writing a check upfront. A lot of maintainers of open source software aren’t supported. A lot of open source software doesn’t even have maintainers. In some cases, this can cause problems, this whole digital infrastructure thing on the right, standing on the back of one person who’s been maintaining something thanklessly. You don’t know who they are. You might not even know how to find out who’s maintaining some of these things. If that person moves on, and stops maintaining software, doesn’t merge security fixes, that’s a problem. We don’t really ever get to complain to that person. We’ve never rewarded them or paid them or compensated them for their work. It works out great in a lot of cases. Sometimes that free lunch comes back to get you later on.
The other benefit here, anyone can contribute to open source. That’s why we get so much done together by collaborating. Fortunately, I hope this isn’t news to people here. Anybody that’s spent time on the internet should realize this. Not everyone on the internet is nice. A lot of people have bad intentions. There are a lot of attackers and hackers out there that submit bad software. They do typosquatting, where they publish packages under fake names and try to trick people into installing it. People send malicious code on purpose trying to get it into popular packages to exploit it later. Anyone can contribute. That also works out great just like open source is free, but sometimes people can take advantage of this. We need to figure out how to prevent people from taking advantage of the welcoming communities in open source.
Open source is easy to use. The great developers in the great open source communities made it super easy to install and find and discover useful packages. That’s how communities in open source get built. Sometimes you can pull in, in your code without realizing it. It’s too easy to pull down thousands of dependencies when you’re only trying to install a couple, and it’s hard to keep track of what’s happening. This has led to numerous supply chain attacks lately, developers are adding code they didn’t know they were adding, that was compromised.
Finally, this last one is a misnomer. A lot of people tend to think that open source is transparent. It is. You can see the source code usually. Most people aren’t looking at the source code, definitely not in the way that we’re consuming open source. If you’re installing binaries, you’re grabbing pre-built packages, you’re installing Android applications on your phone that are compiled versions of open source software, it’s actually opaque. You can’t reverse engineer those binaries. In a lot of cases, you don’t even know if those binaries came from the open source software you started out with. It gives the appearance of transparency, but unless you’re taking advantage of it, and ensuring you’re building everything from source code yourself, it’s actually opaque in reality.
Real World Examples
Let’s cover some real world examples of all those attacks I just talked about, when it comes to cheap and free. The Great Suspender is a Chrome extension that was developed on GitHub. It’s a very popular one, for all the people out there watching this that have thousands of Chrome tabs running at a time. I can’t handle that myself. I start to garbage collect on my own once I get past five or six. I’ve heard that if you have thousands of them open, it decreases your battery life. The Great Suspender was designed to solve that. It was able to suspend Chrome tabs in the background that you weren’t using to save battery life and let your computer run more efficiently. This was maintained for free on GitHub by one maintainer, who eventually moved on. This maintainer sold the rights to this extension, as I think people do all the time, they sell popular code to a person who wanted to buy it. Immediately after, that person stopped publishing builds from GitHub, and actually inserted some malware into this. We had this popular package installed in browsers all over the world, and it was not compromised. The person walked in and bought it for pretty cheap, because the maintainer wasn’t doing this as a full time job. This can keep happening. When you look at larger, more sophisticated attackers, the cost to buy the rights to small packages like this, pennies. It’s nothing. These attacks are happening and they’re going to keep happening because these products aren’t supported by large companies with large budgets. Bad people on the internet. This one’s a little bit tricky, a little bit different, but it did show the possibility that the code can come from anywhere.
This was all over the news recently, again. A research group at the University of Minnesota tried to show the feasibility of sneaking bad commits into the Linux kernel. This resulted in a pretty controversial paper draft that was withdrawn. The Linux community didn’t like being experimented on, but it does show that this is possible. The Linux community acknowledged it was possible. Their review process actually caught all of these, but less thorough communities might not catch some of these malicious commands being snuck in. Don’t do this as an experiment, but do take away that this is happening and can happen to the open source you use.
Easy to use. Here’s another great one, in February of 2021, the popular Dependency Confusion attack. You can just type a command and install something on your computer. A lot of companies run internal mirrors to try to create a choke point where all the open source coming in, is first funneled through these mirrors. These clients, the command line clients do such a good job of trying to install things that if it wasn’t found in the mirror you tried, it would fall back and try the public mirror. An attacker was able to trick a bunch of these clients into downloading external packages rather than the internal ones they thought they were. Luckily, this was a researcher and not an attacker. They were able to get packages and arbitrary code execution in a lot of large companies, and were hopefully rewarded with a very large bounty.
Transparency. This was another great example. People look at open source code, they think it’s fine. Then it gets bundled up into a package manager like RubyGems, or PyPI, or Distro package managers. It’s not necessarily the same thing. It was in the GitHub repository. This is an example of a RubyGem that added some malicious code as part of the install script, to set up cryptominers. There are a whole bunch of these packages that keep getting found. They keep getting discovered by automated tools and security researchers, and taken down. Back in December, there were a couple hundred packages that are mining crypto on people’s laptops after they were installed. This keeps happening. If you look back through history, you see a ton of these crypto examples. In a lot of cases, crypto mining is a blessing in disguise, because it’s much better than having a ransomware attack taken out on your computer or data exfiltrated. You just have to look for cryptominers.
These were some big attacks. There have been some huge ones recently too. Another important thing to note is that these are just in the last six months. These aren’t stretching back very far. Lots of examples here of attacks, everything ranging from language package managers to operating systems, because of some unique properties of open source.
Problem 2: It’s Software
First, it was all unique stuff about open source. The second problem here is that even if you factor out all the bad things, even if you factor out all the malicious attackers inserting bugs at every step in the supply chain, the second problem is that it’s still software. It’s written by humans. All software has bugs, really. The software I write has bugs, whether it’s open source or closed source. The software you write has bugs. We can find them together over time, but it does take that time and it takes people looking. We’re never going to find them all. Some of these bugs can cause security issues. That’s the problem. We haven’t found them all. There’s too much open source out there to do that. A lot of these bugs with security issues can get exploited. We can’t treat open source completely differently, we have to treat it just like the rest of software.
Examples of Bugs
These ones are probably more well-known than the supply chain attacks I talked about. These ones get fancy logos. They get press releases. A lot of them need CVE disclosures, and they get headlines. We’ve got a bunch of examples here. Heartbleed was one of the most popular ones that woke people up to the whole issue of maintainer is not being paid, not being supported. Not as many people working on these critical packages as we thought. Heartbleed was a bug in one of the most popular most commonly used crypto libraries, OpenSSL, that was securing and ensuring privacy across much of the internet at the time. After this happened, it was fixed. People realized there just weren’t many people working on OpenSSL even though everyone was using it. This ranged all the way up the stack too.
This other example here, is all of the JWT parsing libraries that are written in open source. These aren’t audited. These aren’t reviewed. This is really tricky code to get right, yet huge companies rely on them all the time. This website, how many days since the last alg=none JWT vulnerability, keeps track of how long it’s been since the last time one of these bugs has caused a CVE. This has been happening for years now, but the counter keeps resetting. These bugs are everywhere.
Zero Days
Everybody knows about the big, flashy Zero Days. It’s hard for humans to plan around those. You don’t know when the next Heartbleed is going to be. We don’t know when the next cryptographic advance is going to render all of our encryption obsolete is going to be. We really need to talk about them. It’s hard to come up with plans for them. These are what people are probably worried about when they think about CVEs in open source software, because they get so much news and attention. My advice for these, have a plan in place to deal with them. Think about them at your company. Think about what you would do if there was a vulnerability in all the big, important packages that you use, all the different layers of your stack. You can have fun with this. You can wargame out these scenarios. You can write playbooks. There’s not really much else you can do. Think about how you would recover from them. You’re going to be caught surprised though. The whole industry is going to be caught surprised by this. We’re all going to have to fix them together. You can get ahead by thinking about it ahead of time, but you can’t really prevent or plan for every single one. These are black swan events.
The ones I like to tell people to worry about more though, especially when you’re trying to make resilient supply chains are known bugs. These are the boring mechanical fixes. These are updating years later and finding all of your systems, from the flashy ones we just talked about, and even some of the boring ones. You have to fix every single one of your services that’s exposed to the internet, constantly, all the time. You can’t lose your vigilance, otherwise an attacker can get in. Supply chains are huge, complicated, and vast things. They’re going to be released in your supply chain. You need to prevent as many of them as you can. You need to put processes in place to prevent these things. They’re not as exciting, but someone at your company needs to do it. The easiest way to strengthen your supply chain here, rewarding and automating this work. Reduce the toil. Make it easy. You do not want to get caught by these. These are the embarrassing ones when you forgot to update a piece of software that’s had a known CVE in it for five years, and an attacker or a script finds it and uses that to get a foothold and pivot around inside of your company. You need to have a plan for the first news of Zero Days. You need to make sure you don’t get caught by the old known bugs. These are what you should be worried about.
Part 2: Resiliency – What Do We Do?
That’s a good topic to transition into the second part here of the talk, resiliency. The first part of the talk was designed to wake you up a little bit, show all the different possibilities, all the ways things can go wrong in your supply chain, because they’re so complicated. What does resiliency mean here? What do we need to do? This is a perfect metaphor here. This is a rubber band chain. Supply chains are as strong as their weakest link. If you pull on a chain too much it’ll snap. When you’re trying to build a resilient supply chain, if you’re trying to build one that doesn’t snap completely, then build one that can bend. You want to build one that’s resilient, and can come back from failure, and can come back from being stretched and exercised. These bugs are going to happen. If we’re using way too much open source software, vulnerabilities are going to happen. You’re going to have CVEs in the code you’re running, no matter how hard you try to keep them out. Should we rewrite every single line of software completely bug free, and 100% test coverage, audited every single day by professionals, formal proofs for every algorithm? You’re going to get bugs in your code in production that come in through your supply chain, no matter how hard you try. I’m not telling you not to try to prevent these things. I’m just telling you to plan for bugs, plan for security incidents. Have a plan to recover from them. That’s what separates the companies that do well and the companies that don’t handle these incidents correctly.
Overall Scope of the Problem
Open source is everywhere. Supply chain attacks are everywhere, really. You need to pay attention. You need to wake up to these. You need to plan and figure out how to recover from them when they do happen. Open source is growing. It’s not going anywhere, and supply chain attacks are happening more and more. Supply chain attacks aren’t a new concept, but they are rising. That’s because we’ve done such a good job locking down all the other ways in. We’re now using encryption everywhere. Developers are now turning on two-factor authentication, with strong passwords. We’ve locked down the rest of the doors of the way in. Supply chain attacks are the easiest way in for people. They haven’t really gotten easier. Open source has spread so there are more ways attackers can come into your supply chain, and all the other doors are getting locked and tightened up enough that this is becoming a more attractive option. Open source is still increasing in spite all of this. Even if you think you’ve locked everything down today, a year from now, it might not be the case when your open source usage has doubled, and your supply chain has gone up exponentially from there.
Takeaways and Tips
The first philosophy is when you’re thinking about how to make a resilient supply chain, is how to stop an attack from getting worse after it happens. You’re going to have a bad day. Somebody is going to lose a password. Somebody is going to leave a laptop on an airplane. You want to prevent that bad day from becoming a bad year. What does that mean? You want to prevent something from spreading. You want to detect it early. You want to prevent an attacker from pivoting. You want to do some basic hygiene, to make it so that a single compromised instance can’t be turned into a long term compromise and pivoted out to the rest of your company. These are basic things. Nothing here should be a surprise. A lot of people don’t think about their build pipelines, their CI/CD systems as production environments. You need to treat them that way. Just like you have audit logging in your databases with your billing information, put audit logging on your CI/CD systems. Use ephemeral environments, so if somebody does break in, or somebody does get an SSH connection into your machine, it’s recycled. It’s killed. You hit anew when starting fresh. Stop persistent threats and persistent attacks, by reusing everything, rebuilding everything from scratch constantly. The same thing with your credentials. You’re going to get leaked. Scope your credentials. Time bound them. Don’t use long-lived bearer tokens that are going to be a nightmare to clean up years later, when they leak. Scope everything as small as possible, principle of least privilege. Basic production hygiene, just think about it and apply it to your build pipeline. This prevents these incidents that are going to happen and are happening constantly to you at a big enough company from turning into a bad year.
A secret is defined as something you told to only one person at a time. Secret aren’t secrets. Secrets that you keep to yourself forever are boring. They’re going to leak. They’re going to get out. I like the takeaway from this, anybody that pretends they can keep long term secrets forever, is lying to themselves. What does that mean? You will lose them. Every single YubiKey is going to get lost. Every single signing key that you use for your software is going to get leaked or compromised. If you plan for these events to never happen, when they do happen, you’re in for a world of hurt. Figure out how you’re going to revoke credentials. Figure out how you’re going to rotate keys. Treat your keys like databases. Everybody knows the saying, backing up the database isn’t what’s important. It’s the ability to restore when you have to. Secrets only account if you can revoke and rotate them. Figure out what you’re going to do for every single secret you create. How long it’s going to last. How you’re going to get a new one. If you have a secret that’s valid for a month, and it gets lost, and you don’t detect it, that’s a problem only for that month. If you have a secret that’s good forever, and it gets lost, that’s a much different situation.
When it comes to delivery pipelines, there’s even a whole field of research and publication about this. The update framework is designed entirely around the principle of resilience and recovering from key compromise, recovering from key loss, particular for signing and delivering updates to packages, important package managers, and things like this. It’s completely designed around this concept. Instead of trying to prevent secrets from being leaked, which still does, it’s designed around how to recover from them gracefully.
Finally, the last takeaway, hope is not a strategy. It’s a very common saying in SRE. If you pretend your database is never going to go down, that’s fine until it does, when you’re rushing, scrambling trying to figure out how to get it back up. The same applies in security. Just trying to prevent incidents without having a response plan is naive. It’s going to happen no matter how good you are at preventing things.
All the stuff I’ve been talking about: playbooks, wargames, simulations, exercises, brainstorm what to do. Don’t just brainstorm how to stop things, but brainstorm what to do after they do happen and how to recover. What’s the worst case scenario for you right now? What’s the most important secret at your company? What would happen if it gets lost or leaked or compromised? How would you recover from it? You can do this with your team. You can do this in one day. You can do this regularly, one day a month. We do it regularly at Google. We do it in open source projects I work on. Don’t just try to prevent compromises, have a plan for what to do when they do happen.
Summary
Supply chain attacks are coming. Open source is particularly at risk. It’s in everyone’s supply chains. It’s easy to get into because of the distributed nature of the work. Don’t give up on hardening. The message here is not, stop trying to lock down your systems. The message is to expect compromises to happen and have a plan for them. That’s the entire point of resiliency: coming back from failure, coming back from compromises, coming back from attacks. That’s the important thing to take away.
Questions and Answers
Rettori: The first thing that comes to my mind is, I’m scared. Is there any hope? Should I move to a different industry?
Lorenc: Software was a mistake, I think that’s what people keep saying.
Rettori: What is the hope that there is for us? We’re seeing folks that are malicious people that are indeed just exploiting really open source for their own benefit, and all of our upsets. What hope is there for us in this?
Lorenc: There’s nothing really new here, it’s just a different place people are attacking. Attackers will always move around and find the easiest way in to do their jobs. People are attacking open source now. They’re doing supply chain attacks in general now, because it’s the easiest way in. We’ve finally done such a good job as an industry hardening all the other things and fixing up all the other table stakes. Stuff like HTTPS Everywhere is only really new in the last couple years. Strong passwords, two-factor auth. Stealing somebody’s password from one of those, Have I Been Pwned dumps, which was way easier before, now we’ve finally hardened all of that. Doing these open source supply chain attacks is getting easier, relatively, compared to all these other mechanisms. I don’t think there’s anything too much to panic about. We’re always as an industry reacting to what threats are out there and coming up with solutions. Sometimes we’re a little bit slower than others. I think now we’ve seen enough of these big ones that we’ll come together and figure out how to do this quickly.
Rettori: Then, if I look at overall supply chain, which is like all of the pieces that participate in the process of building my software, I think I often see that we do not take the chain or the mechanics that ships software with the same level of seriousness, that we treat the app itself. What are your thoughts on this?
Lorenc: The easiest thing is just saying it, like you just said. I’m guilty of it before. How many people are running Jenkins instances on your Mac minis or something under their desks at work? You’d never run an actual data center app or a server or a database that way, but for some reason, we thought it was ok to do that with our build systems before. It’s not. It’s just like all those movies and TV shows where somebody’s trying to break in or break out of a bank vault, or a prison, or something like that, they hide in the food delivery cart. You’ve got to treat your build system the same way. It’s like building a giant fence and then leaving the door wide open. Just acknowledging it, thinking about it. Taking it seriously, I think is really the biggest step.
Rettori: I’ve seen companies where even the security classification, or the availability classification of the build system and of the supply chain is classified internally as lower than the app itself. That doesn’t make much sense. How do you treat something that builds what you ship with a lower level of security?
Lorenc: It needs to be at least as secure as the environment you’re deploying it into.
Rettori: Provide some tips on how to protect from these attacks, and what to do if they actually happen.
Lorenc: How to protect from these attacks? First one, we already know how to harden systems. We know how to monitor for intrusion. We know how to put things behind firewalls. Just do that with your build servers, like we were just talking about. Lock down your source repositories. If you’re using GitHub, set up branch protection and all that stuff you know should do but you might not be monitoring and checking.
What to do if they actually do happen. This is step one, and I see it as like the Maslow’s hierarchy of needs in security, for stuff like this. Audit log everything. Log all of your builds. Log all the information. Log all the hashes of all of your tools. Log all of the versions. Log all of that stuff somewhere safe, so that if something bad does happen, you can actually search all of those logs. Figure out how effective you are. You don’t want to be in a position of just finding out there are some Zero Day or something, and you have no idea how many builds, how many environments are affected by it. Just make sure you have the data somewhere you can search if you need to. That’s the biggest way to recover from this.
Rettori: Open source software and the software itself, should they be treated as two different things?
Lorenc: Yes, two risk points. It’s open source and it’s software, is how I broke it down. I don’t want the recommendation here to be, start using proprietary software. That doesn’t really help unless you know and trust the people that are writing it. Just because you’ve had to pay somebody for it at a company doesn’t mean it’s better than the open source equivalent. Start paying attention to what you’re using first, don’t just npm install anything, and pull in 500 other dependencies. Be thoughtful about it, and figure out what you’re using first. Then every time somebody wants to add something new, at least have a conversation about it. Make sure you take a quick look at it. That’ll help you catch most of the least obvious ones like typosquatting, or dependency confusion, a lot of these attacks where people just never even looked at the name of the thing they installed. Then for software itself, test your dependencies, just like you would test your actual application. Make sure that all those code paths are followed. Make sure you’re using safe things. If you can use memory safe languages, that’ll help out a lot, too. You don’t have to worry about a whole class of attacks.
Rettori: Tools and ideas for scanning vulnerabilities in the dependencies themselves.
Lorenc: There’s a whole bunch of these. It really depends on what language and what framework, and all that stuff you’re using. Some free ones for open source are Snyk, Trivy. There’s a ton of them. It really depends, if you’re scanning Docker containers, if you’re scanning like a packaged JSON in a repo. GitHub even has a bunch built in if your code is there. Turn on Dependabot too, that’s another great tip, if you’re in a language or framework or ecosystem that supports it on GitHub. That monitors for not just vulnerabilities, just for new versions in general. It’ll automatically send you a pull request that you can just merge to update. You want to make sure you’re updating quick and frequently, even if you’re not updating to fix a vulnerability, updating in small increments, like 1.1 to 1.2 to 1.3, is way easier than going from 1.1 straight up to 1.9 when you have to in a rush because there’s a security vulnerability. Stay as close to updated as you can all the time.
Rettori: Any language ecosystem, which is particularly strong or weak, in terms of supply chain?
Lorenc: It really depends on the angle, like things that are in unsafe languages just have that as a huge disadvantage. It doesn’t matter how great your package manager or scanner is. In C++, you have to worry about things that you don’t have to worry about at all in something like Go or Rust. That’s one way to compare. All the package managers today I think are relatively close in terms of the feature sets that they need. It wasn’t the case maybe two years ago of being able to actually understand what version of the dependencies that is. Being able to lock all of that, being able to make sure that it can’t change. I think I still see stuff in Python, where people tend to pin their dependencies a little bit less. You can do it. I wouldn’t really classify it against Python, but there’s always cases where people are using like the less than or greater than operators in their requirements.txt, and getting surprised when things update and break them. I think most of the tooling at least supports all the basic table stakes stuff you need.
Rettori: There’s potentially a risk in updating the dependencies. What are the ways to fix or reduce the risk in the dependency chain down there that’s not really as risky?
Lorenc: That’s really what tests are for. I’m talking to engineers who get bored or sick of writing tests or feel like it’s a chore. Don’t think of it as writing tests to get your own bugs. Sometimes you can shift and think of it as writing tests to prevent other people from breaking your code. Your dependencies are just like somebody else on your team as they come in and stuff. Tests is the biggest thing. Then do it quickly in small increments wherever you can. Update just one thing at a time, as often as possible by automating it in Dependabot. If you do break something, because one package bumped a minor version, then it’s usually a lot easier to narrow down and trace and fix all the conflicts, and update everything. Than if you’re updating 100 dependencies across 50 versions each, just small increments, continuously.
Rettori: We talked a little bit about the dependency attack on the popular proxy. I think by now, maybe you can talk a little bit about that. The attack on Codecov.
Lorenc: Codecov is a popular testing tool to tell you your test coverage. They got hit with a supply chain attack. It wasn’t really open source software people were using, this was part of a service. Their infrastructure got compromised, and it was used by thousands probably of open source projects on GitHub. All those projects now need to treat any secrets that they were using in their CI as compromised. If you were relying on one part of the supply chain to be secure, now you’ve got to trace this through the whole rest of the graph. Everybody using that service had to rotate secrets and do full audits. It’s scary stuff.
Rettori: I’ve seen some companies that are starting to build everything from source, like anything open source that they use, they actually have it in-house first. They build everything from source, and then publish to their internal repos. It’s not cheap to do this by any means, to build every single dependency from source. What are your thoughts on this? Could it be an alternative for this?
Lorenc: Yes, I don’t think it has to be binary. I think there are a lot of benefits to it. Google’s famous for doing a lot of that with our monorepo. We pull stuff in and check it into this special third-party directory and redo all the build systems, in most cases, to build using our internal stuff. It has a lot of benefits, but it also has a lot of problems where you may not be building things the same way the open source community does. You run into your own bugs and your own maintenance headaches, if you have to apply patches to get them to build the right way. I would encourage you to think about it, at least, if there’s something critical to your application. You might want to be contributing back to it anyway. Then figuring out how to build that and distribute it yourself from source can have a bunch of benefits on top of just supply chain. You can think about it for, it will make it easier for you to apply custom patches if you have to, or make it easier for you to maintain your own feature set, if you can’t get some changes upstream. It also makes you familiar with the development process and makes it easier for you to send patches upstream to fix bugs you find on top of that. There are a bunch of benefits. I don’t think you have to look at it as a big boil the ocean effort of take everything from dependency managers or compile everything from scratch, you can look at it one at a time and figure out where it would make sense to rebuild stuff on your own.
Rettori: Application architects love to look at the security of the app, and sometimes forget about the security of everything else that shapes our apps. I think the resiliency of a system is that, is like, what are all of the pieces in the system of your app.
Google announced a series of generally available feature updates today for its Cloud Bigtable database service, designed to help improve scalability and performance.
Google Cloud Bigtable is a managed NoSQL database service that can handle both analytics and operational workloads. Among the new updates that Google is bringing to Bigtable is increased storage capacity, with up to 5 TB of storage now available per node, an increase from the prior limit of 2.5 TB. Google is also providing improved autoscaling capabilities such that a database cluster will automatically grow or shrink as required based on demand. Rounding out the Bigtable update is enhanced visibility into database workloads, in an effort to help enable better troubleshooting of issues.
The new capabilities announced in Bigtable demonstrate ongoing focus in increased automation and augmentation that is becoming table stakes for modern cloud services. Adam RonthalAnalyst, Gartner
“The new capabilities announced in Bigtable demonstrate ongoing focus in increased automation and augmentation that is becoming table stakes for modern cloud services,” said Adam Ronthal, an analyst at Gartner. “They also further the goal of improved price and performance — which is rapidly becoming the key metric to evaluate and manage any cloud service — and observability, which serves as the basis for improved financial governance and optimization.”
How autoscaling changes Google Cloud Bigtable database operations
A promise of the cloud has long been the ability to elastically scale resources as needed, without requiring new physical infrastructure for end users.
Programmatic scaling has always been available in Bigtable, according to Anton Gething, Bigtable product manager at Google. He added that many Google customers have developed their own autoscaling approaches for Bigtable through the programmatic APIs. Spotify, for example, has made an open source Cloud Bigtable autoscaling implementation available.
“Today‘s Bigtable release introduces a native autoscaling solution,” Gething said.
He added that the native autoscaling monitors Bigtable servers directly, to be highly responsive. As a result as demand changes, so, too, can the size of a Bigtable deployment.
The size of each Bigtable node is also getting a boost in the new update. Previously, Bigtable had a maximum storage capacity of 2.5 TB per node; that is now doubled to 5 TB.
Gething said users don’t have to upgrade their existing deployment in order to benefit from the increased storage capacity. He added that Bigtable has a separation of compute and storage, enabling each type of resource to scale independently.
“This update in storage capacity is intended to provide cost optimization for storage-driven workloads that require more storage without the need to increase compute,” Gething said.
Optimizing Google Cloud Bigtable database workloads
Another new capability that has landed in Bigtable is a feature known as cluster group routing.
Gething explained that in a replicated Cloud Bigtable instance, cluster groups provide finer-grained control over high-availability deployments and improved workload management. Before the new update, he noted that a user of a replicated Bigtable instance could route traffic to either one of its Bigtable clusters in a single cluster routing mode, or all its clusters in a multi-cluster routing mode. He said cluster groups now allow customers to route traffic to a subset of their clusters.
Google has also added a new CPU utilization by app profile metric, that enables more visibility into how a given application workload is performing. While Google has provided some CPU utilization visibility to Bigtable users prior to the new update, Gething explained that the new update provides new visibility dimensions into data query access methods and which database tables were being accessed.
“Before these additional dimensions, troubleshooting could be difficult,” Gething said. “You would have visibility of the cluster CPU utilization, but you wouldn’t know which app profile traffic was using up CPU, or what table was being accessed with what method.”
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
At the heart of the Austrian data regulator ruling, which hinges on a
2020 ruling by the European Court of Justice, is the argument
that the transmission of personal data to the US breaks the
requirement of their adequate protection due to US surveillance laws.
The Second Respondent [Google], as providers [of] electronic
Communications services within the meaning of 50 US Code §1881 and,
as such, is subject to surveillance by US intelligence agencies
pursuant to 50 US Code §1881a (“FISA 702”).
Section 702
of the Foreign Intelligence Surveillance Act (FISA) establishes that
any non-US person located abroad can be the target of surveillance
activities, and this without special requirements like being a suspect
terrorist, spy, or agent of a foreign power. FISA also regulates how
US government agencies such as the NSA, FBI, or CIA can require and
get access to transferred data directly from service providers,
e.g. Apple or Google.
This is not the whole story, though. In fact, the Austrian regulator
also considers that additional measures taken to protect the data,
such as data encryption at rest in Google’s datacenters, are not
effective since they do not eliminate the monitoring and access
possibilities by US intelligence services.
This is a very tough strike against the usual approach that major
US-based companies take to enforce the idea they reasonably protect
the data they receive from their customers. What the Austrian DPA
comes to say is that EU data travelling to the US do not receive
adequate protection regardless of what service providers may attempt
to do.
While the Austrian DPA ruling is of application exclusively within
Austrian borders, nevertheless it finds its grounding in the
aforementioned ruling from the European Court of Justice
(ECJ), which substantially knocks down the idea of an adequate
“Privacy Shield” existing between the EU and the US. This leads to
think that the Austrian ruling could be easily mirrored in other EU
countries.
It is not clear at the moment how US-based Cloud service providers
could change the way they handle their EU-based customers’ data in a
way that is compliant with the GDPR, and it is surely appropriate to
wait for their attempt to comply with the GDPR. Yet, it may be
reasonable for EU-based companies which have mostly an EU-based
audience to start thinking of alternatives granting higher privacy
standards.
This may include services and tools hosted and/or developed in the EU
by European companies. On the front of analytics services, for
example, some alternatives to Google Analytics are Fathom, Plausible, SplitBee, and others. The list of alternative services and tools developed in the EU
is much longer, though, and encompasses a number of categories,
including SaaS, monitoring, VPNs, CDNs, and more.
Albeit not yet final, the Austrian DPA ruling can be seen as only the
most recent step in a confrontation that has been going on for at
least 15 years and saw first the dismissal of the “Safe Harbor”
doctrine, then of the “Privacy Shield”.
About the Author
Sergio De Simone
Show moreShow less
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)