Month: February 2022

MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

Executive Summary:
The latest NoSQL Software market research report includes a detailed assessment of this business sphere by underlining the major growth catalysts and limitations, along with some further insights regarding expansion opportunities that are swaying the industry’s profitability graph over the projected timeline.
Request Sample Copy of this Report @ https://www.getnewsalert.com/request-sample/34028
According to the expert analysts, the NoSQL Software market is anticipated to expand with a CAGR of XX% during the analysis timeframe (20XX-20XX).
Important information related to the geographical landscape as well as the market segmentations are included in the report. A detailed overview of the competitive landscape is elaborated by assessing the leading companies as well as their latest development trends in this marketplace.
Market rundown:
Regional outlook:
- The report categorizes the regional landscape of NoSQL Software market into North America, Europe, Asia-Pacific, South America, Middle East & Africa.
- Economic summary of key geographies and their impact on the overall industry development are given in the report.
- Estimated growth rate and market share in terms of consumption for every region over the study period are mentioned as well.
Product terrain outline:
- As per the report, the product range of the NoSQL Software market is classified into Cloud Based and Web Based.
- Consumption market share captured by each product type is included in the report.
- Data related to the revenue amassed and sales price of each product segment is provided in detail.
Application scope overview:
- The application range of different product offerings is bifurcated into E-Commerce , Social Networking , Data Analytics , Data Storage and Others.
- Estimations related to the consumption value and share for each application listed over the forecast duration is validated.
- Market share obtained by each application segment has also been included.
Competitive landscape review:
- The report offers a comprehensive evaluation of the competitive sphere of the NoSQL Software market, which is mainly defined by prominent players like MongoDB , OrientDB , Amazon , Azure Cosmos DB , Couchbase , ArangoDB , CouchDB , MarkLogic , SQL-RD , RethinkDB , RavenDB , Microsoft and Redis.
- Basic information and business overview of each company is presented in the report.
- Figures pertaining to the pricing model, sales, gross margins, and revenue share of the enlisted companies have also been enumerated in the report.
- Details with respect to the manufacturing base, operational area, as well as the distribution channels of the prominent players is assessed in detail.
- Summary of the market concentration ratio, mergers & acquisitions, new product launches, and potential entrants are included in the research document.
Important Features of the report:
- Scope of the market
- Fluctuating market dynamics of the industry
- Historical, current, and projected market size in terms of volume and value
- Detailed market segmentation
- Recent industry trends and developments
- Competitive landscape of the Market
- Strategies of key players and product offerings
- Potential and niche segments/regions exhibiting promising growth
- A neutral perspective towards market performance
Request Customization on This Report @ https://www.getnewsalert.com/request-for-customization/34028
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

NoSQL database maker Couchbase has released Couchbase Mobile 3, its edge-ready mobile database, introducing a new C API to embed Couchbase Lite on embedded platforms, Kotlin support on Android, a new administration REST API, and security enhancements.
Couchbase Mobile is a NoSQL database solution that can run in the Cloud, at the edge, and on mobile devices. It aims to bring data closer to where it is used, thus reducing access latency in comparison to Cloud-based databases. Additionally, says Couchbase, Couchbase Mobile 3 can work in offline-mode transparently to the user.
Couchbase Mobile 3 uniquely ensures data integrity by automatically synchronizing data across the entirety of an organization’s edge and mobile infrastructure, with or without internet connectivity.
At the heart of Couchbase Mobile lies Couchbase Lite, an embeddable and syncable database engine that is available both in a Community and Enterprise edition on a number of platforms, including iOS, Android, .NET, and Java.
With its latest release, Couchbase Mobile adds a new C API around it to make it possible to embed Couchbase Lite on almost any embedded platform. Developers can build their apps in C directly or leverage C compatibility with almost any language, including Python, Dart, Go, etc., and use their programming language of choice.
On the Android Platform, Couchbase Mobile 3 brings support for Kotlin through a new idiomatic Kotlin API, including nullability annotations, named parameters, and asynchronous event handling through Kotlin Flows. In addition to Kotlin, Couchbase also supports Swift on iOS and C# on .NET.
Couchbase Lite has also got support for textual SQL-like queries based on the N1QL query language, which brings it on a par with Couchbase Server. This allows developers to reuse the same SQL-like queries both on the client and the server.
Besides functional features, Couchbase Mobile 3 also introduces a number of features aiming to simplify its administration and to improve security. Specifically, the new Sync Gateway 3.0 introduces a new administrative REST API that enforces authentication and role-based access control by default. This enable secure access to the admin API from external clients using HTTPS instead of more complex setups based on SSH tunnels or firewall rules.
The new admin REST API allow users to configure a number of additional features, including cluster-wide Sync Gateway databases, access control policies, inter-Sync Gateway replications, etc. Sync Gateway 3.0 additionally supports user-defined Extended Attributes (XATTRs) for Access Control Metadata, which greatly simplify the management of access right.
Couchbase Mobile 3 can be downloaded from Couchbase website.
MMS • Sergio De Simone
Article originally posted on InfoQ. Visit InfoQ
NoSQL database maker Couchbase has released Couchbase Mobile 3, its edge-ready mobile database, introducing a new C API to embed Couchbase Lite on embedded platforms, Kotlin support on Android, a new administration REST API, and security enhancements.
Couchbase Mobile is a NoSQL database solution that can run in the Cloud, at the edge, and on mobile devices. It aims to bring data closer to where it is used, thus reducing access latency in comparison to Cloud-based databases. Additionally, says Couchbase, Couchbase Mobile 3 can work in offline-mode transparently to the user.
Couchbase Mobile 3 uniquely ensures data integrity by automatically synchronizing data across the entirety of an organization’s edge and mobile infrastructure, with or without internet connectivity.
At the heart of Couchbase Mobile lies Couchbase Lite, an embeddable and syncable database engine that is available both in a Community and Enterprise edition on a number of platforms, including iOS, Android, .NET, and Java.
With its latest release, Couchbase Mobile adds a new C API around it to make it possible to embed Couchbase Lite on almost any embedded platform. Developers can build their apps in C directly or leverage C compatibility with almost any language, including Python, Dart, Go, etc., and use their programming language of choice.
On the Android Platform, Couchbase Mobile 3 brings support for Kotlin through a new idiomatic Kotlin API, including nullability annotations, named parameters, and asynchronous event handling through Kotlin Flows. In addition to Kotlin, Couchbase also supports Swift on iOS and C# on .NET.
Couchbase Lite has also got support for textual SQL-like queries based on the N1QL query language, which brings it on a par with Couchbase Server. This allows developers to reuse the same SQL-like queries both on the client and the server.
Besides functional features, Couchbase Mobile 3 also introduces a number of features aiming to simplify its administration and to improve security. Specifically, the new Sync Gateway 3.0 introduces a new administrative REST API that enforces authentication and role-based access control by default. This enable secure access to the admin API from external clients using HTTPS instead of more complex setups based on SSH tunnels or firewall rules.
The new admin REST API allow users to configure a number of additional features, including cluster-wide Sync Gateway databases, access control policies, inter-Sync Gateway replications, etc. Sync Gateway 3.0 additionally supports user-defined Extended Attributes (XATTRs) for Access Control Metadata, which greatly simplify the management of access right.
Couchbase Mobile 3 can be downloaded from Couchbase website.
MMS • Renato Losio
Article originally posted on InfoQ. Visit InfoQ

AWS recently announced the availability of the AWS managed prefix list for CloudFront. Customers can now limit inbound HTTP/HTTPS traffic to a VPC and an application from only IP addresses that belong to CloudFront’s origin-facing servers.
The new managed prefix list can be referenced in VPC security group rules, subnet route tables or common security group rules using AWS Firewall Manager. The cloud provider keeps the list up-to-date with the IP addresses of CloudFront’s origin-facing servers. Kaustubh Phatak, senior solution architect at AWS, highlights the main benefit:
This feature will simplify your security group management – no more workarounds to update the security groups when cloudfront IPs change. You can use Firewall manager to centrally configure your managed prefix list across all your AWS accounts.
A prefix list is a collection of one or more CIDR blocks to make it easier to configure and maintain security groups and route tables. There are customer-managed prefix lists and AWS-managed prefix lists, sets of IP address ranges for AWS services managed by the cloud provider. Maksim Aniskov, infrastructure architect at Endeva, comments:
A long-awaited feature, really: simplify app protection by leveraging VPC’s AWS-managed prefixes for CloudFront. Before this feature it required more moving parts.
Jon Zobrist, systems development manager at AWS, highlights the benefits for an application load balancer:
Now you can reference the managed prefix list for CloudFront in your Security Groups on your ELB. No more insert header and WAF/ALB rule it!
As for other AWS managed lists, customers cannot create, modify or share the CloudFront prefix list and the addition significantly affects VPC quotas: the managed list counts as 55 rules in a security group and in a route table, allowing by default only 5 additional rules in a security group and requiring a quota increase in a route table.
In a Reddit thread, user jamsan920 writes:
No more Lambda functions to maintain a security group with the list of Cloudfront Origin IPs, hooray!
Relying on a Lambda function was an alternative approach that was suggested and updated multiple times by AWS in the past. Other users think that the scope of the new feature is too narrow and all AWS services that expose IP addresses should offer prefix lists. User Nick4753 warns:
Even if you restrict traffic to CloudFront IP ranges, there is no enforcement that anyone account’s CloudFront distributions can only talk to anyone account’s origins.
The CloudFront managed prefix list is available in all regions except Jakarta and Osaka in Asia Pacific. The list can be referenced in CloudFormation templates and there are no additional costs for using it.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
Someone with a lot of money to spend has taken a bearish stance on MongoDB MDB.
And retail traders should know.
We noticed this today when the big position showed up on publicly available options history that we track here at Benzinga.
[MUST WATCH] New traders just like you are getting massive wins using this unique options trading strategy. One trader even tripled there account in just 2 months. Click Here to See How
Whether this is an institution or just a wealthy individual, we don’t know. But when something this big happens with MDB, it often means somebody knows something is about to happen.
So how do we know what this whale just did?
Today, Benzinga‘s options scanner spotted 16 uncommon options trades for MongoDB.
This isn’t normal.
The overall sentiment of these big-money traders is split between 43% bullish and 56%, bearish.
Out of all of the special options we uncovered, 5 are puts, for a total amount of $185,450, and 11 are calls, for a total amount of $572,016.
What’s The Price Target?
Taking into account the Volume and Open Interest on these contracts, it appears that whales have been targeting a price range from $210.0 to $475.0 for MongoDB over the last 3 months.
Volume & Open Interest Development
Looking at the volume and open interest is a powerful move while trading options. This data can help you track the liquidity and interest for MongoDB’s options for a given strike price. Below, we can observe the evolution of the volume and open interest of calls and puts, respectively, for all of MongoDB’s whale trades within a strike price range from $210.0 to $475.0 in the last 30 days.
MongoDB Option Volume And Open Interest Over Last 30 Days
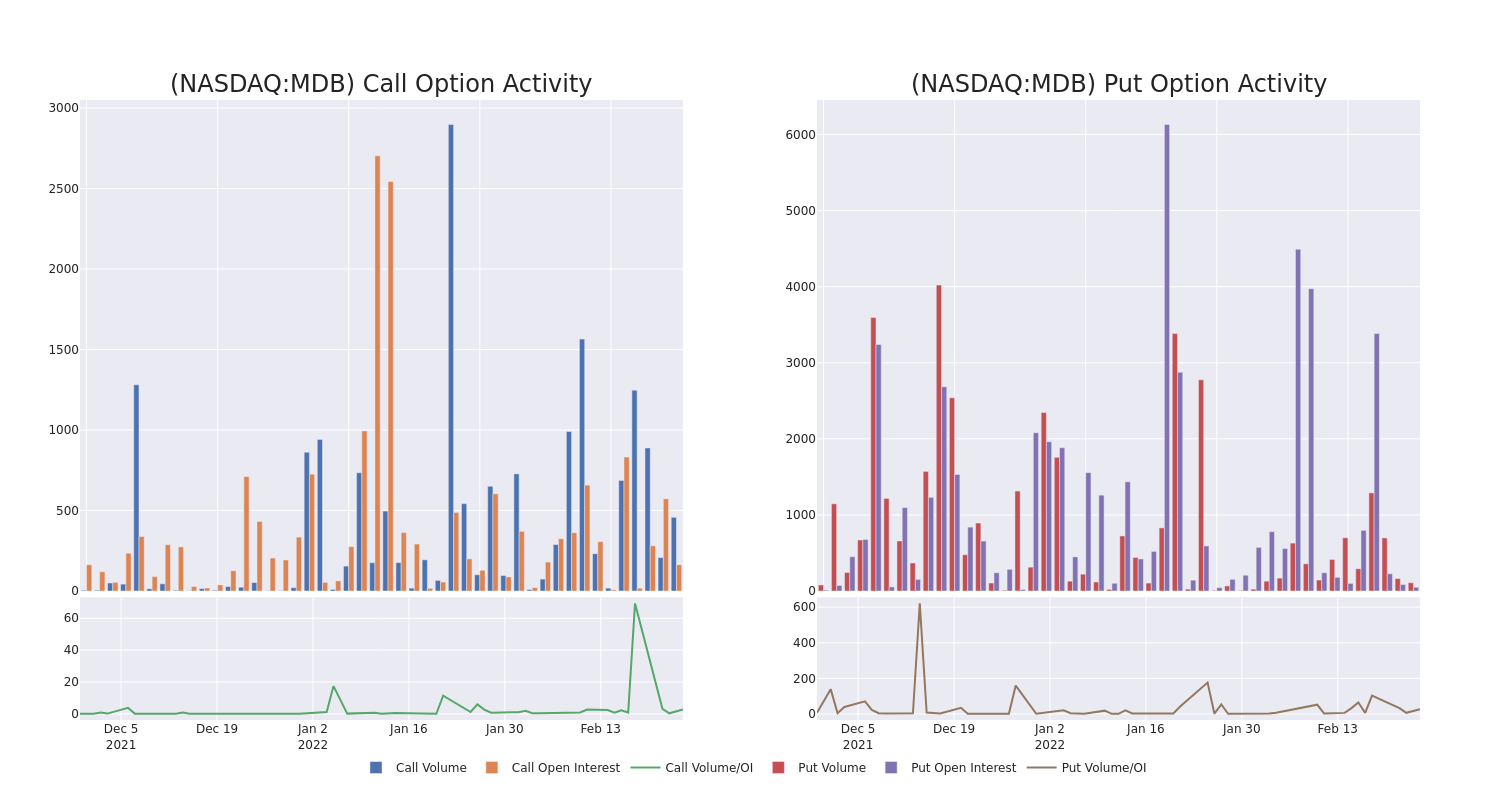
Biggest Options Spotted:
| Symbol | PUT/CALL | Trade Type | Sentiment | Exp. Date | Strike Price | Total Trade Price | Open Interest | Volume |
|---|---|---|---|---|---|---|---|---|
| MDB | CALL | SWEEP | BULLISH | 08/19/22 | $380.00 | $128.9K | 2 | 21 |
| MDB | CALL | TRADE | NEUTRAL | 03/18/22 | $365.00 | $87.7K | 6 | 28 |
| MDB | CALL | TRADE | BEARISH | 03/11/22 | $375.00 | $71.4K | 11 | 60 |
| MDB | PUT | SWEEP | BULLISH | 03/11/22 | $375.00 | $64.8K | 5 | 64 |
| MDB | CALL | SWEEP | BULLISH | 04/08/22 | $420.00 | $58.2K | 0 | 31 |
Where Is MongoDB Standing Right Now?
- With a volume of 633,460, the price of MDB is down -0.03% at $375.26.
- RSI indicators hint that the underlying stock may be approaching overbought.
- Next earnings are expected to be released in 11 days.
What The Experts Say On MongoDB:
- Mizuho has decided to maintain their Neutral rating on MongoDB, which currently sits at a price target of $400.
- Tigress Financial downgraded its action to Buy with a price target of $630
Options are a riskier asset compared to just trading the stock, but they have higher profit potential. Serious options traders manage this risk by educating themselves daily, scaling in and out of trades, following more than one indicator, and following the markets closely.
If you are already an options trader or would like to get started, head on over to Benzinga Pro. Benzinga Pro gives you up-to-date news and analytics to empower your investing and trading strategy.
Article originally posted on mongodb google news. Visit mongodb google news
NoSQL Databases Software Market Report Covers Future Trends With Research 2022 to 2029
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts
“
A2Z Market Research published new research on Global NoSQL Databases Software covering micro level of analysis by competitors and key business segments (2022-2029). The Global NoSQL Databases Software explores comprehensive study on various segments like opportunities, size, development, innovation, sales and overall growth of major players. The research is carried out on primary and secondary statistics sources and it consists both qualitative and quantitative detailing.
Some of the Major Key players profiled in the study are MongoDB, Amazon, ArangoDB, Azure Cosmos DB, Couchbase, MarkLogic, RethinkDB, CouchDB, SQL-RD, OrientDB, RavenDB, Redis,
Get PDF Sample Report + All Related Table and Graphs @:
https://www.a2zmarketresearch.com/sample-request/601478
Various factors are responsible for the market’s growth trajectory, which are studied at length in the report. In addition, the report lists down the restraints that are posing threat to the global NoSQL Databases Software market. This report is a consolidation of primary and secondary research, which provides market size, share, dynamics, and forecast for various segments and sub-segments considering the macro and micro environmental factors. It also gauges the bargaining power of suppliers and buyers, threat from new entrants and product substitute, and the degree of competition prevailing in the market.
Key market aspects are illuminated in the report:
Executive Summary: It covers a summary of the most vital studies, the Global NoSQL Databases Software market increasing rate, modest circumstances, market trends, drivers and problems as well as macroscopic pointers.
Study Analysis: Covers major companies, vital market segments, the scope of the products offered in the Global NoSQL Databases Software market, the years measured and the study points.
Company Profile: Each Firm well-defined in this segment is screened based on a products, value, SWOT analysis, their ability and other significant features.
Manufacture by region: This Global NoSQL Databases Software report offers data on imports and exports, sales, production and key companies in all studied regional markets
Market Segmentation: By Geographical Analysis
The Middle East and Africa (GCC Countries and Egypt)
North America (the United States, Mexico, and Canada)
South America (Brazil etc.)
Europe (Turkey, Germany, Russia UK, Italy, France, etc.)
Asia-Pacific (Vietnam, China, Malaysia, Japan, Philippines, Korea, Thailand, India, Indonesia, and Australia)
Get Special pricing with up to 30% Discount on the first purchase of this report @:
https://www.a2zmarketresearch.com/discount/601478
The cost analysis of the Global NoSQL Databases Software Market has been performed while keeping in view manufacturing expenses, labor cost, and raw materials and their market concentration rate, suppliers, and price trend. Other factors such as Supply chain, downstream buyers, and sourcing strategy have been assessed to provide a complete and in-depth view of the market. Buyers of the report will also be exposed to a study on market positioning with factors such as target client, brand strategy, and price strategy taken into consideration.
Key questions answered in the report include:
- who are the key market players in the NoSQL Databases Software Market?
- Which are the major regions for dissimilar trades that are expected to eyewitness astonishing growth for the NoSQL Databases Software Market?
- What are the regional growth trends and the leading revenue-generating regions for the NoSQL Databases Software Market?
- What will be the market size and the growth rate by the end of the forecast period?
- What are the key NoSQL Databases Software Market trends impacting the growth of the market?
- What are the major Product Types of NoSQL Databases Software?
- What are the major applications of NoSQL Databases Software?
- Which NoSQL Databases Software Services technologies will top the market in next 7 years?
Table of Contents
Global NoSQL Databases Software Market Research Report 2022 – 2029
Chapter 1 NoSQL Databases Software Market Overview
Chapter 2 Global Economic Impact on Industry
Chapter 3 Global Market Competition by Manufacturers
Chapter 4 Global Production, Revenue (Value) by Region
Chapter 5 Global Supply (Production), Consumption, Export, Import by Regions
Chapter 6 Global Production, Revenue (Value), Price Trend by Type
Chapter 7 Global Market Analysis by Application
Chapter 8 Manufacturing Cost Analysis
Chapter 9 Industrial Chain, Sourcing Strategy and Downstream Buyers
Chapter 10 Marketing Strategy Analysis, Distributors/Traders
Chapter 11 Market Effect Factors Analysis
Chapter 12 Global NoSQL Databases Software Market Forecast
Buy the Full Research Report of Global NoSQL Databases Software Market @: :
https://www.a2zmarketresearch.com/checkout
If you have any special requirements, please let us know and we will offer you the report as you want. you can also get individual chapter wise section or region wise report version like North America, Europe or Asia.
About A2Z Market Research:
The A2Z Market Research library provides syndication reports from market researchers around the world. Ready-to-buy syndication Market research studies will help you find the most relevant business intelligence.
Our Research Analyst Provides business insights and market research reports for large and small businesses.
The company helps clients build business policies and grow in that market area. A2Z Market Research is not only interested in industry reports dealing with telecommunications, healthcare, pharmaceuticals, financial services, energy, technology, real estate, logistics, F & B, media, etc. but also your company data, country profiles, trends, information and analysis on the sector of your interest.
Contact Us:
Roger Smith
1887 WHITNEY MESA DR HENDERSON, NV 89014
+1 775 237 4147
Related Reports:
Vulvodynia Treatment Market is Booming Worldwide with Eli Lilly, Depomed, Allergan plc.
Hemostatic Cotton Market to Witness Growth Acceleration | Nova Argentia, Vitorgan, Vitorgan Pharma
Document Databases Software Market is Booming Worldwide with MongoDB, Amazon, ArangoDB
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
“
Document Databases Software Market is growing at a High CAGR during the forecast period 2021-2029. The increasing interest of the individuals in this industry is that the major reason for the expansion of this market.
Document Databases Software Market research is an intelligence report with meticulous efforts undertaken to study the right and valuable information. The data which has been looked upon is done considering both, the existing top players and the upcoming competitors. Business strategies of the key players and the new entering market industries are studied in detail. Well explained SWOT analysis, revenue share and contact information are shared in this report analysis.
Get the PDF Sample Copy (Including FULL TOC, Graphs and Tables) of this report @: https://www.a2zmarketresearch.com/sample-request/601479
Note – In order to provide more accurate market forecast, all our reports will be updated before delivery by considering the impact of COVID-19.
Some of the Top companies Influencing in this Market includes:
MongoDB, Amazon, ArangoDB, Azure Cosmos DB, Couchbase, MarkLogic, RethinkDB, CouchDB, SQL-RD, OrientDB, RavenDB, Redis, .
The key questions answered in this report:
- What will be the Market Size and Growth Rate in the forecast year?
- What are the Key Factors driving Document Databases Software Market?
- What are the Risks and Challenges in front of the market?
- Who are the Key Vendors in Document Databases Software Market?
- What are the Trending Factors influencing the market shares?
- What are the Key Outcomes of Porter’s five forces model?
- Which are the Global Opportunities for Expanding the Document Databases Software Market?
Various factors are responsible for the market’s growth trajectory, which are studied at length in the report. In addition, the report lists down the restraints that are posing threat to the global Document Databases Software market. This report is a consolidation of primary and secondary research, which provides market size, share, dynamics, and forecast for various segments and sub-segments considering the macro and micro environmental factors. It also gauges the bargaining power of suppliers and buyers, threat from new entrants and product substitute, and the degree of competition prevailing in the market.
Global Document Databases Software Market Segmentation:
Market Segmentation: By Type
Cloud Based
Web Based
Market Segmentation: By Application
Large Enterprises
SMEs
Get Up to 30% Discount on the first purchase of this report @: https://www.a2zmarketresearch.com/discount/601479
Regions Covered in the Global Document Databases Software Market Report 2022:
• The Middle East and Africa (GCC Countries and Egypt)
• North America (the United States, Mexico, and Canada)
• South America (Brazil etc.)
• Europe (Turkey, Germany, Russia UK, Italy, France, etc.)
• Asia-Pacific (Vietnam, China, Malaysia, Japan, Philippines, Korea, Thailand, India, Indonesia, and Australia)
The cost analysis of the Global Document Databases Software Market has been performed while keeping in view manufacturing expenses, labor cost, and raw materials and their market concentration rate, suppliers, and price trend. Other factors such as Supply chain, downstream buyers, and sourcing strategy have been assessed to provide a complete and in-depth view of the market. Buyers of the report will also be exposed to a study on market positioning with factors such as target client, brand strategy, and price strategy taken into consideration.
The report provides insights on the following pointers:
Market Penetration: Comprehensive information on the product portfolios of the top players in the Document Databases Software market.
Product Development/Innovation: Detailed insights on the upcoming technologies, R&D activities, and product launches in the market.
Competitive Assessment: In-depth assessment of the market strategies, geographic and business segments of the leading players in the market.
Market Development: Comprehensive information about emerging markets. This report analyzes the market for various segments across geographies.
Market Diversification: Exhaustive information about new products, untapped geographies, recent developments, and investments in the Document Databases Software market.
Table of Contents
Global Document Databases Software Market Research Report 2022 – 2029
Chapter 1 Document Databases Software Market Overview
Chapter 2 Global Economic Impact on Industry
Chapter 3 Global Market Competition by Manufacturers
Chapter 4 Global Production, Revenue (Value) by Region
Chapter 5 Global Supply (Production), Consumption, Export, Import by Regions
Chapter 6 Global Production, Revenue (Value), Price Trend by Type
Chapter 7 Global Market Analysis by Application
Chapter 8 Manufacturing Cost Analysis
Chapter 9 Industrial Chain, Sourcing Strategy and Downstream Buyers
Chapter 10 Marketing Strategy Analysis, Distributors/Traders
Chapter 11 Market Effect Factors Analysis
Chapter 12 Global Document Databases Software Market Forecast
Buy Exclusive Report: https://www.a2zmarketresearch.com/checkout
If you have any special requirements, please let us know and we will offer you the report as you want.
About A2Z Market Research:
The A2Z Market Research library provides syndication reports from market researchers around the world. Ready-to-buy syndication Market research studies will help you find the most relevant business intelligence.
Our Research Analyst Provides business insights and market research reports for large and small businesses.
The company helps clients build business policies and grow in that market area. A2Z Market Research is not only interested in industry reports dealing with telecommunications, healthcare, pharmaceuticals, financial services, energy, technology, real estate, logistics, F & B, media, etc. but also your company data, country profiles, trends, information and analysis on the sector of your interest.
Contact Us:
Roger Smith
1887 WHITNEY MESA DR HENDERSON, NV 89014
+1 775 237 4147
Related Reports:
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Shannon Morrison Scott Behrens
Article originally posted on InfoQ. Visit InfoQ

Transcript
Behrens: My name is Scott Behrens. We’re here to discuss modeling application risk at scale at Netflix. We’re going to start with a big number, 5500 applications. For 5500 applications at Netflix, we forecasted risk scores based in frequency in dollars for application compromised events that led to data exposure. We did this by training a machine learning model, with risk forecasters who were presented features to inform their forecasts based on information and facts we collected about our environment automatically. Our approach actually mirrors the traditional risk assessment, but it allows us to scale the function to thousands of risk scenarios and assets.
Problems
We really are here to talk about just how broad we as security practitioners categorize risk. We use buckets like high, medium, and low. If we haven’t had enough coffee, everything is high risk. If we had too much coffee, everything is low risk. The way we treat those risks are very different. The way we treat a high risk issue, or a high risk application is different than a medium risk issue. Those inconsistencies or those broad categorizations really lead to also inconsistency, how we treat those risks, and inconsistencies with how we talk about risk. We might have different ideas of what high, medium, and low mean. We might use the risk terminology interchangeably. All of that can lead to confusion for end users and partners that we work with. We also as security practitioners have uncertainty, are we really working on the right things? Are we recommending the most important security things? Are we even responding to the right applications during a systemic incident? Are we looking at the things that present the most risk?
Our Goals
Our goals are really to improve our decision making. We figured if we could have a better, more quantifiable, accurate understanding of an asset’s risk, we can make better decisions, improving things like security self-service. Having more confidence we’re recommending the right controls, and really understanding risk on an analytical level so we can make strategic decisions. What organizations are increasing in risk or technologies are increasing in risk? We want to be able to slice and dice risk information to find hotspots and patterns for investment. As well as also to confirm if our security partnerships were driving down risk. We wanted to improve our confidence in incident response.
Risk Assessment
We started out partnering with our risk assessment practitioners who perform risk analyses. Risk assessments actually mitigate a lot of the concerns we’re talking about. They can allow us to identify a scenario. The risk forecasters will collect information, external information, incident information to present that to the forecasters, and ultimately end up with a really highly accurate, with a 90% confidence interval frequency and dollar number that we can use to make decisions. They’re manual efforts that require time and people to conduct. We’re not going to really be able to scale that to the thousands of assets that we aim to protect.
FAIR Primer
A quick primer into the methodology that our risk practitioner uses, FAIR, which is a model that codifies and monetizes risk. Really, the two most important parts are right below the word risk, frequency and magnitude. You can think of frequency as, how often does the bad thing happen? Think of magnitude as, how much does it cost when a bad thing happens? Joining those two things together, we get the risk in dollars.
Introducing Sage: An Asset Risk Management Framework for Netflix
We wanted to introduce Sage, which is really our asset risk modeling framework that allows us to enable at scale risk measurement across a broad range of risk scenarios so that we can achieve more efficient at prioritization and several of the goals I mentioned. One of the things that Sage needs, or the forecasters need is a risk scenario. Here’s an example of one. Analyze the risk of an external actor impacting the confidentiality of sensitive data via application attacks. A risk scenario really needs four components, it needs that threat. Something like an external actor. The effect, something like confidentiality. The asset, something like sensitive data, and a method application attack.
What Features Do We Use For Modeling?
What features do we use for modeling and presenting to the forecasters? We need a few things. We need assets, the things of value. That could be applications, laptops, mobile devices, databases. We need risk factors for a given asset. These are things that contribute to the likelihood or magnitude of risk. Think of these as things such as your application is internet facing, it has a critical vulnerability, you’re missing critical security patches. Think of paved road controls as security controls. At Netflix, the paved road is really our preferred supported best experience for a given product. Here, we’re really referring to security controls that reduce the likelihood or magnitude of risk. That would include things like single sign-on, or laptop encryption, or application firewall. We provide the forecasters, information on security incidents and vulnerabilities that we all also store automatically. That provides prior evidence of loss event frequency, which is helpful. If the forecasters also like, we can provide observations such as like what language the software is written in, if that helps them improve the accuracy of their forecasts.
Asset Inventory
We actually store these features in our asset inventory product. We do this automatically. All the things I was describing before, are actually included in the asset inventory product, which provides a way to navigate and query relationships between disparate infrastructure data sources, such as application metadata, laptops, databases. It lets us answer really hard questions about our environment. Some of the features that we include in asset inventory that we use in some of our models, things like, is the application internet facing? Is it missing authentication? Does it have critical vulnerabilities or insecure ports? Then some of the controls we measure are, does it include single sign-on? Does it include mTLS protection for API access? Does it leverage our secure application proxy?
Asset Inventory Demo – Data Model
Let’s take a quick look at the data model. There’s a lot of stuff that we store in asset inventory. Our main goal is really to connect the common edges between these different entity types: applications, authentication policies, code repositories, databases, devices that access applications, Jenkins jobs, and load balancers. What I really wanted to draw attention to here is that, because we store all this information in the asset inventory, and the relationships, we also then store the risk score to an application. Then we can slice and dice that risk context and group it based on any of these different types of relationships. We’ll talk a little bit about that in some of the visuals you’ll see later in our discussion.
I’m going to go ahead and step over to our GraphQL interface for the asset inventory product. We see, we’re first filtering on applications that are internet facing that contain Java, and are maybe in the streaming path. We’re also looking at if they communicate with a relational database, what risk factors they have. A lot of stuff here that we’re bringing in. Paved road practices, as well as the risk scores, and what those are. On the right here, we redacted the application names, but we get all this information back. What risk factors it has. Paved road practice scores, or what paved road practices it has and the risk scores. We have this for all these different applications. That’s just a really quick overview of the asset inventory product.
How Do We Survey?
Morrison: We’re going to talk about how we do the surveying. Since we’re going to build a machine learning model, we wanted to do a supervised model, so we needed labeled data. Our surveying process is how we gather that labeled data that we’re going to use to build our model. We start with an in-person meeting, where we meet with the experts and talk through what we’re going to be forecasting. That risk scenario that Scott talked about is one of the most important things that we talk about. We’re going to make sure that we’re all answering the same question. We also talk through the features we’re using. What they mean. How they interact with one another. Make sure that everybody has a good similar understanding of the data they’re going to be providing. Another thing that’s helpful, our risk team offers a calibration training, which is helpful in improving accuracy for forecasters. The risk team will ask some simple bar trivia, and ask people also to provide a range of how confident they are in their answer. That gives people insight into how over or under confident they might be when providing a score. This can help people again, provide more accurate forecasts. Then they survey, so this is a lot of work that our experts go through, and for 50 applications they will give us a forecast. That’s what we can use as our y variable in our model, and so they go through on their own time and fill out that survey. Once they’ve been through that process, we’ll go through the results. Make sure that they’re consistent, look for outliers, and also get feedback on the process.
This is an example of one application that a forecaster might look at. This just shows, here’s the feature. Then if it’s true or false. If it has, for example, critical vulnerabilities, a number from zero to infinity, where this just gives people an idea of the application. Then they’ll provide the frequency, which is a number from again, zero to infinity, where these are the number of times that they think that that loss event might occur. The loss event frequency is again, a number from zero to infinity. Often, when we’re talking about application risks, is really going to be a number from zero to one. Instead of something happening five times a year, it might happen one time over the next five years.
This is the y value that they’re providing us. This visualization shows the results of our surveying. This is the loss event frequency on the y-axis, the application on the x-axis, and then the individual colors per forecaster. We review this to make sure that the answers are consistent if we’re answering high for similar apps, low, so that we all have the same understanding.
In this example, the forecasts are represented in purple, had scores that were for certain applications quite a bit higher than the others. We just wanted to review this to make sure that that forecaster had the same understanding of the controls, the risks in the question. This could be fine. The method that we’re using here is called, in the risk terminology, a lens model. This is where we take scores from experts, and then we take the mean of those scores. Using the mean of those scores can help correct for different people having different knowledge. It can be fine that somebody has higher scores, we just want to make sure that everybody’s understanding the question in the same way. Once we have reviewed that data, then we’re also going to look for outliers. You can see in green over here, we’ve got something that looks quite high. Again, you could have outliers that are ok, but it’s good to review the data and make sure that you’re not modeling errors.
Build Model of Loss Event Frequency
Once we have our labeled dataset, we can use that to build a model. The features that we pulled from the asset inventory and provided to the forecasters, this will be our x value. Then our y value is the mean of the loss event frequency provided by the experts. We tried a few different models, we tried a Linear Regression, Random Forest, SVM, and the best model for us was an XGBoost model, so that builds gradient boosted trees. We fit that model with the 50 applications that our experts had provided. Then we pulled back those same features from asset inventory for all of our applications, and used the model to predict a frequency for each of those. This is how we scaled the loss event frequency just using 50 applications to get a score for our 5500 apps.
Feature Importance
Something that was interesting, XGBoost will provide you a feature importance. This just gives us some understanding about which features were important to the forecasters as they were going through and providing us a loss event frequency. We went through this model building surveying process a few times, and this feature importance was really important because sometimes we had features that really were not important at all. This helped us figure out as we’re asking this question, what data do we need to provide the forecasters to get the best answer? This is something that’s really useful.
Magnitude
That is the frequency. If you think back to the diagram that Scott showed about FAIR, we had the loss event frequency, which is the number of times something bad might happen. The other side of the model is the magnitude. That’s how bad that loss might be. It’s good to think about the magnitude as a range of possibilities. For magnitude, we use the type of data that might be lost, and it was a proxy to figure out how bad something might be if an application were compromised. Our risk team had loss tables, and this would have loss tables per data type, so PI data, or PCI data, or response cost. We use that frequency to run simulations in our riskquant library. That’s something we’ve open sourced and there’ll be a link to that. We can use riskquant to map the loss to a lognormal distribution, which just can’t go below zero, but also has a long tail to represent extreme events. This is how we get magnitude. At a higher level, just a helpful way to think about this, we use the mean of that magnitude distribution times the frequency to get the annualized loss dollar. This is the dollar that Scott showed in the asset inventory demo, where we can give people just a single dollar value. That way, we can rank applications and see which ones are carrying more risk.
The magnitude distribution mean, so if you think about impact as a low loss and a high loss. If you have some event or type of data, where if you lost it, the low loss would be $100,000, the high loss would be a million dollars, if you map that to a lognormal distribution, the mean would be $400,400. This gives us the magnitude distribution mean. The frequency is the number that came out of our model. Our experts provided the forecast, we built a model. Each application is going to have a frequency. We take that mean times the frequency to get the annualized loss in dollars. This is just a screenshot of what Scott showed earlier, we can write the risk in dollars back to the asset inventory, and that way multiple teams can use this data to see which applications have a higher risk.
Security Guide and Dashboard Demo
We have a couple ways that we visualize that data. One way is our security guide. Our user focused security team has a really nice dashboard that shows each person’s team view. One of the panels in that dashboard is risky applications that pulls data from our asset inventory, and shows just a ranking of applications that are carrying the most risk. This is helpful, so people can know where they’re carrying risk. That can help them figure out if they want to invest in controls, or detections, or if they’re just comfortable carrying that risk. This gives people visibility into what applications have risk that they own.
I’m going to switch over to Tableau. The Tableau dashboard was useful for the security teams, and particularly my team, I’m on detection engineering. One of the ways that we can prioritize detections is looking at applications that are higher risk. Then we can say, ok, are they missing controls? Is this a place where maybe the application is just risky, and they have all the controls that we recommend, but because of the data that they have they are higher risk? That might be a good place for detections. Or a place where some controls are difficult to be implemented. That’s another good spot where my team can come in and help. This dashboard that we built, this is obviously fake data, but it shows what we use internally. We also mapped it over time. We can see if there are applications that are changing, hopefully, I think risk is going down. If we see risk going up, then we can maybe make some adjustments or prioritized it for work. Generally, the dashboard we have earlier, is more useful, but we also have at the org level, so we can see which org to carry more risk. This is just another way where people can drill down and see, from my org, what applications do I have? How are they changing? Which controls are they missing, so that maybe we can invest in making improvements there.
How well does our model do? The accuracy, we’re at 94%, looking at the overall dollar value that we’re providing. This 94% is a percent of applications that had a bug bounty, or incident loss event, that were 94% of those applications or within the range. We had some error where something cost a bit more than our model predicted. Where we’re inaccurate is also useful, because perhaps there’s data or a feature that we excluded. This can help us when we go back and remodel. We can add new features in, and also get a more accurate representation of risk. The other number that we’re really proud about is this 10%. That means every application that had an incident or a bug bounty was in our top 10 percentage of frequency. That just means that when our experts provided us that frequency score, they were really accurate. If they said this combination of features makes this application higher risk, it means they were right. We’re really proud of that number.
What We Got Wrong
What did we get wrong? A lot of things. The worst thing that we got wrong, as we went through this a few times, is having an unclear scenario. Scott talked about our risk scenario where we’re saying, how many times did this bad thing happened? We were not clear about creating that at first, and also, our forecasters had different understandings. Our risk team was really helpful with giving us a clear statement so that we’re all answering the same question. Also, using too many features, not understanding what the features meant. Then, as Scott pointed out, not enough coffee.
Sage Limitations
Behrens: There are some limitations to the Sage model. We have an emphasis on the paved road, which means we’re really good at understanding risk where we can measure the types of factors that we think increases risk, and the types of controls we think decrease risk. If teams roll their own controls, or have risks that we’re not measuring, we’re going to miss out on those opportunities. We also have a fair bit of uncertainty on magnitude. We’re using tables right now to drive that. We have some ideas on how to improve magnitude, but it’s definitely something we’re going to be working on over the next several quarters to get better. Data incongruities have also been a challenge, but again, over the last several quarters, we’ve actually made really good improvements there. Experts can be wrong. We find the best way to manage this is twofold. It’s making sure that we have a fair number of forecasters so that mean can help us normalize outliers. Then we do training with the risk team, which is really helpful.
Also, a lot of risk scenarios happen infrequently. We see the number zero a lot, and we have some ideas on how to represent risk in those zeros. If a risk event only happens once every 12 years, how do we show a dollar value every year? We have some ideas on how to work with that. Some of the folks at FAIR recommend that we represent when the loss happens, if it is a million dollars, if it’s over 10 years, you save $100,000 a year. We have potentially some ideas on how we can present that information, but we’re still working through it.
Conclusion
Sage is really helpful for driving strategic decision making. We talked about how we’re using it to look over time series and see how risk is changing over time, and slicing and dicing that by things like organization. Allows us to understand how our partnerships are working or where we should be investing. It’s also helped us improve operational and tactical decision making. Better incident response and better security self-service tooling, which was some of our goals that we set out, out of the gate. A lot of people came together to make this project happen. This was a cross engineering collaboration with data scientists, incident response, risk practitioners, application security engineering.
How to Deal with Modeling Extremely Unlikely Risks that Could Cause Damage
How do you deal with modeling extremely unlikely risks, but could cause great damage? We could think of this as like black swan events.
Morrison: There are two ways that we can think about this. The best way is what Scott talked about a little bit, a full FAIR analysis, where if we think that this is a really high risk to the business, our risk team would go in and do a detailed review. Go through all the possible scenarios and look at the magnitude and how much data would be lost. Specific to what we did here. What we like about this model is that we’re able to find unlikely things in places that we don’t know about. There might be a specific combination of features that leads to really high risk. Maybe we know about an application because it’s had an incident in the past where something bad could happen. There’s also possibilities that an application could be deployed and we don’t know about it, and it could have these same combination of features. This model gives us some insight just automatically by scaling out all of our applications using all the data from asset inventory. This model would give us some view into some apps maybe that have similar really high risks that we don’t know about.
The other part of this answer is when we’re talking about risk. It’s hard to visualize, and it’s hard to understand this. It’s helpful to think about risk as a range. When we talked about the magnitude of loss, we tend to look at a number of pieces of sensitive data that could be lost, and so, that could be a huge range. When we do the modeling, when we’re mapping the magnitude, we map that to a lognormal distribution, and that lognormal distribution will include a long tail that could account for these extremely unlikely events. Then, again, when we take the mean sometimes that can be lost. This is something where we have to think about carefully how we’re going to visualize the results and how we’re going to communicate the results.
How to Ensure Risks Are Actually Mitigated
Behrens: How do you check that risks are mitigated, that people are actually mitigating the risk.
We have a couple of different strategies for that. We talked a little bit about the inputs for the model being risk factors, and then paved road controls or security controls that mitigate those risk factors. Since we have all that information, and we know that that’s what makes up our risk score. With our self-service tooling, what we do is we recommend users use those controls when the risks that are relevant for their mitigation are present. We have tooling that goes out and validates that those controls are set up. Depending on the control type, we do a little bit of confidence and correctness checking. You could think of this as a security assurance light. We make sure you’re using single sign-on. We’re also making sure all the routes are protected with single sign-on. We can build in additional checks to give us confidence that the control isn’t just used, but it’s used correctly. Over time, I think one of our strategies is to get better at confidence and correctness, because it’ll give us more trust in our model. It’ll give us more trust that our security controls are working correctly.
Percentage of Apps Covered by Sage Risk Forecasting
What percentage of apps are covered by Sage risk forecasting now? Can you explain again how you measure the model’s accuracy using bug bounty payouts?
Morrison: Any application that’s deployed through our paved road, so deployed through Spinnaker is covered. We have future plans to look at apps that are deployed in other ways. Where we don’t have good visibility into the app deployment, it’s difficult to know an exact percentage. Everything that’s deployed through the paved road is covered by the model.
How to Measure a Model’s Accuracy Using Bug Bounty Payouts
Then, yes, the bug bounty payouts was good. One of the outputs of our model is this range of loss. For any application that had a bug bounty payout, we looked at how much we paid. We also looked at any app that had a security incident. Our security incident response team has a really cool cost model that figures out how much each incident costs. We use both of those dollar values, and looked at applications that had security incidents and bug bounty payouts. Then we line that up with the magnitude range. We had a little bit of error where an application didn’t have as high of a range as we paid out. That is interesting, because that can give us additional features where we can go back. When we go back and remodel, we can say, what did we miss about this application that made it riskier than we thought? Overall, though, we were pretty happy with the magnitude accuracy, but not as happy as we were with the frequency. We were really good on the frequency, and more work to do on magnitude.
Questions and Answers
Potoczny-Jones: I was curious if you’re modeling in any way, how difficult a vulnerability or risk is to mitigate, because that can get to some of the challenges around, it is high impact, low likelihood risk, but it’s not that hard to fix, so we might as well. Versus something where all those numbers are high, because of much harder decisions. You were really only modeling on the risk side or also on the mitigation and security control side as far as costs or investments you mitigate.
Behrens: We were thinking about building out a vulnerability model, to address your concern, because we feel like there’s a lot more facets to CVSS that we want to take into consideration, if there’s a given vulnerability in an open source project. I know that supply chain is really on the top of folks’ minds. We’re starting to think about what that could look like. I think in that circumstance, if we were to build a model out for vulnerabilities, remediate complexity and stuff like that would be taken into consideration for that. I think that one of the things that we have to think about then is, we can start to imagine if we have a model that produces risks or vulnerabilities. Those vulnerabilities could lead to the risk scenario that we’re scoring for applications. There starts to be this place where we have all these models, and we have to figure out, how do we make them work together? That’s something that I think is going to be an exciting challenge for us. We absolutely are going to start exploring the vulnerability space I think in the next year or so.
Morrison: I think what we learned from the feature importance wasn’t like when I have the ranking of features that are important, it doesn’t necessarily mean that those features also lead to high risk, although they could. The XGBoost model is a tree-based model, so this is just good places where the trees can branch. We just use that to tell which features are giving information to the forecasters, so not necessarily which features directly correlate to high risk. Although, we did do some review of that. We were able to tell of certain combinations of features that led to higher risk. I didn’t represent that with the feature importance.
Behrens: How far left in the SDLC can the modeling be done? Can the risk be forecasted before an app is deployed in production? Just thinking about the lifecycle and how we can leverage this to make decisions.
I think, for us, a lot of the components that you see that are included in the model today are almost like real timers checks. Is this thing on the internet? Is this thing using the firewall correctly? We do have code level checks. We do have shift left checks along the way that we could consider to the risk model. Today, a lot of the checks that we’re actually looking at are dynamic. That really doesn’t allow us to potentially flag stuff from a risk score perspective early in the SDLC. We have several other workflows and functions to make sure that we’re steering folks to those controls that mitigate the risk. That’s part of our tiered strategy. Two ways that we do that is we try to make sure whenever possible, things are secure by default. The next thing that we look at is to make sure that’s really easy for security self-service. We generally find that application owners early in the SDLC can get the context they need to make the right decisions. Of course this risk model helps us find outliers, legacy, and things like that.
Then you also mentioned apps with too high risk be stopped from deployment. One of the interesting things about Netflix is we generally don’t gate on code deploy. What we really try to do is provide developers all the context they need to make the right decision. If I gave you a giant risk score number, and you see this number, and you realize that your risk presents a million dollars of risk to the business every year, because you’re not using the right security controls, you might be more interested in remediating that. We just found that it builds better trust with our developers to provide them the context, as opposed to providing gates. We find out that most of the time they do the right thing. Since we don’t provide gates, they don’t go around us, and they want to work with us. We actually think that building trust is a better risk mitigator than potentially blocking a code push in the long term interest of the business.
Morrison: The other thing about that, too, is sometimes just based on the data that the application has access to, it’s going to be high risk, regardless of what controls they implement. That’s also a good place where my team can come in. I’m on the detection engineering team. If an application has to deploy something, and I know it’s really risky, my team can come in and help. If we can’t prevent the risk then we can detect it early and reduce the magnitude. That’s why it’s been really useful for my team. Also, having a ranking in dollars is useful to you, because if you tell everybody that they’re high risk, people are ok with that, but you don’t want to be the worst. At least if somebody is at the very top, if there are things that they can do, sometimes showing somebody that they have the highest risk can lead to additional action being taken. Nobody wants to really be the worst, if they can help it. That’s been a little interesting too.
Potoczny-Jones: Your team has obviously a ton of experience here in doing expert based process as well as machine learning process. For organizations that are starting at a little bit of a lower level in risk management, how would you suggest folks like developers, advocate to their management to use more best practices in risk management?
Morrison: I think what was interesting for me, I skimmed a book called “How to Measure Anything in Cybersecurity Risk,” which was really just a different way of thinking about it. I think, when you’re talking to leaders, this process is more quantifiable. You don’t have to compare yellow to yellow, this gives you an actual ranking, so that you can see, not only like, where do you have the most risk, but also, what can you do that will be the most effective? You have a limited amount of time, and some things are a lot easier than others. If you can say, I can take this small step and buy down quite a bit of risk, just having those actual numbers in dollars is something that leaders understand pretty well, I think. It’s a really different way of thinking about things. Though, I definitely was used to high, medium, low for a really long time. It’s definitely a big change.
Potoczny-Jones: I certainly can understand why quantification dollars to business leaders are the metric they’re used to dealing with. When security professionals come with metrics that they’re used to dealing with, eventually, over time, I’m sure they’ll get better calibrated. I’m sure that really helps with decision making.
Morrison: There was a question about a risk leaderboard. We don’t really call it a risk leaderboard. Our user focused security team has a really nice view of each person and the apps that they own. The higher you go in the org, you can see the apps that are carrying the most risk. It ends up being a risk leaderboard, but that’s not what they call it. There’s definitely visibility into who owns what and how much risk it’s carrying.
Behrens: Shannon and Markus De Shon open sourced our riskquant library that you can use to do this type of modeling.
See more presentations with transcripts
MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ

OpenAI overhauled the GPT-3 language model and introduced a new default tool called InstructGPT to address complaints about toxic language and misinformation.
GPT-3, like other large language models, was created in part to generate human-like text in a convincing way. To make the models safer, helpful, and aligned to follow instrunctions, OpenAI used reinforcement learning from human feedback (RLHF) to fine-tune GPT-3.
Compared to GPT-3, the new InstructGPT models are better at following instructions in English, less inclined to produce misinformation, and at least slightly less likely to produce toxic results.
To transform GPT-3 models into InstructGPT models, OpenAI designed a three-step procedure. First is the fine-tuning of the model. Second is building a reward model (RM). Third is to take the Supervised Fine-Tuning (SFT) model and further fine-tune it using reinforcement learning.
One positive aspect is that InstructGPT is better performance-wise than GPT-3. Not necessarily in terms of NLP benchmarks, in which GPT-3 often surpasses InstructGPT, but it’s better adapted to human preference, which ultimately is a better predictor of real-world performance. The reason is InstructGPT is more aligned with human intention through a reinforcement learning paradigm that makes it learn from human feedback.
On the other hand, InstructGPT being better than GPT-3 at following instructions has a dark side. A malicious user could take advantage of that to make the model less truthful and helpful, and more harmful. Given that the model is also more powerful than GPT-3, the damage could be greater.
However, InstructGPT isn’t just better than GPT-3 at following instructions, it’s also better aligned with human intention. The AI alignment problem is a well-known problem in the field. It defines the difficulty of designing AI systems that understand our values, beliefs, and desires, and that behave in a way that won’t interfere with them.
According to OpenAI, this is the first application of alignment and the results show that these techniques are effective at significantly improving the alignment of general-purpose AI systems with human intentions. The InstructGPT models are now deployed as the default language models on the OpenAI API.
New CodeGuru Reviewer Features: Detector Library and Security Detectors for Log-Injection Flaws
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
Amazon CodeGuru Reviewer is a developer tool that leverages machine learning to detect security defects in code (Java and Python) and offers suggestions for code quality improvement. Recently, AWS introduced two new features for the tool with a new Detector Library and security detectors for Log-Injection Flaws.
Amazon CodeGuru, released to general availability in July 2020, consists of Amazon CodeGuru Profiler and Amazon CodeGuru Reviewer. The latter received several updates with CI/CD integration with Github and detecting hard-coded secrets in code. In addition, with a new Detector Library and security detectors for Log-Injection Flaws, the CodeGuru component receives more features to hardness developer code.
The CodeGuru Reviewer Detector Library is a resource that contains detailed information about the security and code quality detectors in CodeGuru Reviewer. In an AWS News blog post on the new features for Amazon CodeGuru Reviewer, Danilo Poccia, a Chief Evangelist (EMEA) at AWS, explains:
These detectors help you build secure and efficient applications on AWS. In the Detector Library, you can find detailed information about CodeGuru Reviewer’s security and code quality detectors, including descriptions, their severity and potential impact on your application, and additional information that helps you mitigate risks.
Each detection page in the Detector Library includes a description of the detector, non-compliant and compliant example code snippets (Java and Python repositories), severity, and other information to assist developers in mitigating its risks (such as CWE numbers).

Following the recent Apache Log4j vulnerability, AWS added new detectors to CodeGuru Reviewer that check if a developer logs anything that is not sanitized and potentially executable. These detectors address the issue described in CWE-117: Improper Log Output Neutralization. In addition, the detectors work with Java and Python code and, for Java, are not limited to the Log4j library.
Holger Mueller, principal analyst and vice president at Constellation Research Inc., told InfoQ:
Coding is no longer the traditional diet of writing code and waiting for compiler errors. Today, the IDE is looking over the shoulders of the developers’ shoulders while they are coding. One key area is to make code safer, and that is what AWS is doing in the latest version of CodeGuru.
The new Amazon CodeGuru Reviewer features are available in all AWS regions offering Amazon CodeGuru. Pricing of Amazon CodeGuru Reviewer is available on the pricing page.