Month: March 2023

MMS • RSS
Posted on mongodb google news. Visit mongodb google news
![]() Diversified Trust Co bought a new stake in MongoDB, Inc. (NASDAQ:MDB – Get Rating) during the fourth quarter, according to its most recent filing with the Securities & Exchange Commission. The firm bought 1,234 shares of the company’s stock, valued at approximately $243,000.
Diversified Trust Co bought a new stake in MongoDB, Inc. (NASDAQ:MDB – Get Rating) during the fourth quarter, according to its most recent filing with the Securities & Exchange Commission. The firm bought 1,234 shares of the company’s stock, valued at approximately $243,000.
Several other hedge funds have also recently bought and sold shares of MDB. Ieq Capital LLC increased its stake in MongoDB by 23.2% during the 3rd quarter. Ieq Capital LLC now owns 1,962 shares of the company’s stock valued at $390,000 after buying an additional 370 shares during the period. Cubist Systematic Strategies LLC lifted its holdings in shares of MongoDB by 198.1% during the second quarter. Cubist Systematic Strategies LLC now owns 69,217 shares of the company’s stock valued at $17,962,000 after purchasing an additional 45,994 shares during the last quarter. Asset Management One Co. Ltd. lifted its stake in MongoDB by 3.1% during the third quarter. Asset Management One Co. Ltd. now owns 61,243 shares of the company’s stock valued at $12,106,000 after buying an additional 1,829 shares in the last quarter. Whittier Trust Co. of Nevada Inc. boosted its holdings in shares of MongoDB by 8.0% in the third quarter. Whittier Trust Co. of Nevada Inc. now owns 15,645 shares of the company’s stock worth $3,106,000 after buying an additional 1,156 shares during the period. Finally, Oppenheimer & Co. Inc. increased its position in shares of MongoDB by 14.8% in the third quarter. Oppenheimer & Co. Inc. now owns 4,672 shares of the company’s stock worth $927,000 after acquiring an additional 602 shares in the last quarter. 84.86% of the stock is currently owned by institutional investors.
Wall Street Analysts Forecast Growth
A number of equities analysts recently commented on MDB shares. Tigress Financial decreased their price objective on shares of MongoDB from $575.00 to $365.00 and set a “buy” rating for the company in a research note on Thursday, December 15th. Credit Suisse Group decreased their price objective on MongoDB from $305.00 to $250.00 and set an “outperform” rating for the company in a research report on Friday, March 10th. UBS Group upped their target price on MongoDB from $200.00 to $215.00 and gave the company a “buy” rating in a report on Wednesday, December 7th. Sanford C. Bernstein started coverage on shares of MongoDB in a report on Friday, February 17th. They set an “outperform” rating and a $282.00 price target for the company. Finally, The Goldman Sachs Group decreased their target price on shares of MongoDB from $325.00 to $280.00 and set a “buy” rating for the company in a research note on Thursday, March 9th. Four research analysts have rated the stock with a hold rating and twenty have given a buy rating to the stock. According to MarketBeat, the stock has a consensus rating of “Moderate Buy” and an average price target of $253.87.
MongoDB Stock Performance
Shares of NASDAQ:MDB opened at $213.93 on Wednesday. The firm’s 50 day simple moving average is $213.90 and its 200 day simple moving average is $195.51. The company has a debt-to-equity ratio of 1.54, a current ratio of 3.80 and a quick ratio of 3.80. The company has a market capitalization of $14.98 billion, a price-to-earnings ratio of -42.45 and a beta of 1.00. MongoDB, Inc. has a fifty-two week low of $135.15 and a fifty-two week high of $471.96.
MongoDB (NASDAQ:MDB – Get Rating) last announced its earnings results on Wednesday, March 8th. The company reported ($0.98) earnings per share (EPS) for the quarter, beating analysts’ consensus estimates of ($1.18) by $0.20. MongoDB had a negative return on equity of 48.38% and a negative net margin of 26.90%. The business had revenue of $361.31 million for the quarter, compared to analyst estimates of $335.84 million. As a group, sell-side analysts forecast that MongoDB, Inc. will post -4.04 earnings per share for the current year.
Insider Activity at MongoDB
In related news, CEO Dev Ittycheria sold 40,000 shares of the stock in a transaction that occurred on Wednesday, March 1st. The stock was sold at an average price of $207.86, for a total transaction of $8,314,400.00. Following the completion of the transaction, the chief executive officer now directly owns 190,264 shares of the company’s stock, valued at $39,548,275.04. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which is accessible through the SEC website. In other news, insider Thomas Bull sold 399 shares of MongoDB stock in a transaction that occurred on Tuesday, January 3rd. The stock was sold at an average price of $199.31, for a total transaction of $79,524.69. Following the completion of the transaction, the insider now directly owns 16,203 shares in the company, valued at approximately $3,229,419.93. The sale was disclosed in a filing with the Securities & Exchange Commission, which is accessible through this hyperlink. Also, CEO Dev Ittycheria sold 40,000 shares of the business’s stock in a transaction on Wednesday, March 1st. The shares were sold at an average price of $207.86, for a total value of $8,314,400.00. Following the completion of the sale, the chief executive officer now owns 190,264 shares of the company’s stock, valued at $39,548,275.04. The disclosure for this sale can be found here. Over the last 90 days, insiders sold 110,994 shares of company stock valued at $22,590,843. Corporate insiders own 5.70% of the company’s stock.
MongoDB Company Profile
MongoDB, Inc engages in the development and provision of a general-purpose database platform. The firm’s products include MongoDB Enterprise Advanced, MongoDB Atlas and Community Server. It also offers professional services including consulting and training. The company was founded by Eliot Horowitz, Dwight A.
Further Reading

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

@media screen and (min-width: 1201px) {
.dbemy6423ebf50b74d {
display: block;
}
}
@media screen and (min-width: 993px) and (max-width: 1200px) {
.dbemy6423ebf50b74d {
display: block;
}
}
@media screen and (min-width: 769px) and (max-width: 992px) {
.dbemy6423ebf50b74d {
display: block;
}
}
@media screen and (min-width: 768px) and (max-width: 768px) {
.dbemy6423ebf50b74d {
display: block;
}
}
@media screen and (max-width: 767px) {
.dbemy6423ebf50b74d {
display: block;
}
}
There is an IT security warning for MongoDB. Here you can find out which vulnerabilities are involved, which products are affected and what you can do.
The Federal Office for Security in der Informationstechnik (BSI) published an update on March 28th, 2023 to a vulnerability for MongoDB that became known on June 14th, 2021. The operating systems UNIX, Linux and Windows as well as the products Red Hat Enterprise Linux and Open Source MongoDB are affected by the vulnerability.
The latest manufacturer recommendations regarding updates, workarounds and security patches for this vulnerability can be found here: Red Hat Security Advisory RHSA-2023:1409 (Status: 03/27/2023). Other useful sources are listed later in this article.
Security advisory for MongoDB – risk: medium
Risk level: 3 (medium)
CVSS Base Score: 6,8
CVSS Temporal Score: 5,9
Remoteangriff: Ja
The Common Vulnerability Scoring System (CVSS) is used to assess the severity of security vulnerabilities in computer systems. The CVSS standard makes it possible to compare potential or actual security vulnerabilities based on various criteria in order to better prioritize countermeasures. The attributes “none”, “low”, “medium”, “high” and “critical” are used for the severity of a vulnerability. The base score assesses the prerequisites for an attack (including authentication, complexity, privileges, user interaction) and its consequences. The Temporal Score also takes into account changes over time with regard to the risk situation. According to the CVSS, the risk of the vulnerability discussed here is rated as “medium” with a base score of 6.8.
MongoDB Bug: Vulnerability allows manipulation of files
MongoDB is an open source document database.
A remote, authenticated attacker can exploit a vulnerability in MongoDB to manipulate files.
The vulnerability is identified with the unique CVE serial number (Common Vulnerabilities and Exposures) CVE-2021-20329 traded.
Systems affected by the MongoDB vulnerability at a glance
operating systems
UNIX, Linux, Windows
Products
Red Hat Enterprise Linux (cpe:/o:redhat:enterprise_linux)
Open Source MongoDB GO Driver 1.5.1 (cpe:/a:mongodb:mongodb)
General recommendations for dealing with IT vulnerabilities
-
Users of the affected systems should keep them up to date. When security vulnerabilities become known, manufacturers are required to remedy them as quickly as possible by developing a patch or a workaround. If security patches are available, install them promptly.
-
For information, consult the sources listed in the next section. These often contain further information on the latest version of the software in question and the availability of security patches or tips on workarounds.
-
If you have any further questions or are uncertain, please contact your responsible administrator. IT security officers should regularly check the sources mentioned to see whether a new security update is available.
Manufacturer information on updates, patches and workarounds
Here you will find further links with information about bug reports, security fixes and workarounds.
Red Hat Security Advisory RHSA-2023:1409 vom 2023-03-27 (28.03.2023)
For more information, see: https://access.redhat.com/errata/RHSA-2023:1409
MongoDB Github vom 2021-06-13 (14.06.2021)
For more information, see: https://github.com/mongodb/mongo-go-driver/releases/tag/v1.5.1
Version history of this security alert
This is the 3rd version of this IT security notice for MongoDB. If further updates are announced, this text will be updated. You can read about changes or additions in this version history.
06/14/2021 – Initial version
2021-10-05 – Reference(s) added: GHSA-F6MQ-5M25-4R72
03/28/2023 – Added new updates from Red Hat
+++ Editorial note: This text was created with AI support based on current BSI data. We accept feedback and comments at [email protected]news.de. +++
follow News.de already at Facebook, Twitter, Pinterest and YouTube? Here you will find the latest news, the latest videos and the direct line to the editors.
roj/news.de
@media screen and (min-width: 1201px) {
.sgttt6423ebf50b7eb {
display: block;
}
}
@media screen and (min-width: 993px) and (max-width: 1200px) {
.sgttt6423ebf50b7eb {
display: block;
}
}
@media screen and (min-width: 769px) and (max-width: 992px) {
.sgttt6423ebf50b7eb {
display: block;
}
}
@media screen and (min-width: 768px) and (max-width: 768px) {
.sgttt6423ebf50b7eb {
display: block;
}
}
@media screen and (max-width: 767px) {
.sgttt6423ebf50b7eb {
display: block;
}
}
Related
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts
Q&A
Q&A with Ken Muse: Designing Azure Modern Data Warehouse Solutions

The Modern Data Warehouse (MDW) pattern makes it easier than ever to deal with the increasing volume of enterprise data by enabling massive, global-scale writes operations while making the information instantly available for reporting and insights.
As such, it’s a natural fit for cloud computing platforms and the field of DataOps, where practitioners apply DevOps principles to data pipelines built according to the architectural pattern on platforms like Microsoft Azure.
In fact, Microsoft has published DataOps for the modern data warehouse guidance and a GitHub repo featuring DataOps for the Modern Data Warehouse as part of its Azure Samples offerings.

And, speaking of GitHub, one of the leading experts in the MDW field is Ken Muse, a senior DevOps architect at the Microsoft-owned company who has published an entire series of articles on the pattern titled “Intro to the Modern Data Warehouse.” There, he goes into detail on storage, ingestion and so on.
It just so happens that Muse will be sharing his knowledge at a big, five-day VSLive! Developer Conference in Nashville in May. The title of his presentation is Designing Azure Modern Data Warehouse Solutions, a 75-minute session scheduled for May 16.
Attendees will learn:
- Define and understand how to implement the MDW architecture pattern
- How to determine appropriate Azure SQL and NoSQL solutions for a workload
- Understand how to ingest and report against high volume data
We caught up with Muse, a four-time Microsoft Azure MVP and a Microsoft Certified Trainer, to learn more about the MDW pattern in a short Q&A.
VisualStudioMagazine: What defines a Modern Data Warehouse in the Azure cloud?
Muse:
A Modern Data Warehouse combines complementary data platform services to provide a secure, scalable and highly available solution for ingesting, processing, analyzing and reporting on large volumes of data. This architectural pattern supports high-volume data ingestion as well as flexible data processing and reporting. In the Azure cloud, it often takes advantage of services such as Azure Data Lake Storage, Azure Synapse Analytics, Azure Data Factory, Azure Databricks, Azure Cosmos DB, Azure Analysis Services, and Azure SQL.
How does the cloud improve a MDW approach as opposed to an on-premises implementation?
The cloud provides an elastic infrastructure that can dynamically scale to meet ingestion and analysis needs. Teams only pay for what they need, and they have access to virtually limitless storage and compute capacity that can be provisioned in minutes. This makes it faster and easier to turn data into actionable insights.
With an on-premises environment, the infrastructure must be sized to meet the peak needs of the application. This often results in over-provisioning and wasted resources. Hardware failures and long supply chain lead times can restrict teams from scaling quickly or exploring new approaches.

“Maintaining and optimizing each service can be time-consuming and complex. The cloud eliminates these issues by providing optimized environments on demand.”
Ken Muse, Senior DevOps Architect, GitHub
In addition, maintaining and optimizing each service can be time-consuming and complex. The cloud eliminates these issues by providing optimized environments on demand.
As developers often struggle to figure out the right tools — like SQL vs. NoSQL — for implementation, can you briefly describe what goes into making that choice, like the benefits and/or drawbacks of each?
The choice between SQL and NoSQL is often driven by the type of data you need to store and the types of queries you need to run. SQL databases are optimized for highly structured data, complex queries, strong consistency, and ACID transactions. They are natively supported in nearly every development language, making it easy to get started quickly. They can be an optimal choice for applications that commit multiple related rows in a single transaction, perform frequent point-updates, or need to dynamically query structured datasets. The strong consistency model is often easier for developers to understand. At the same time, horizontal scaling can be challenging and expensive, and performance can degrade as the database grows.
NoSQL (“not only SQL”) solutions are optimized for unstructured and semi-structured data, rapidly changing schemas, eventual consistency, high read/write volumes, and scalability. They are often a good choice for applications that need to store large amounts of data, perform frequent reads and writes, or need to dynamically query semi-structured data. They can ingest data at extremely high rates, easily scale horizontally, and work well with large datasets. They are often the best choice for graph models and understanding complex, hidden relationships.
At the same time, eventual consistency can be challenging for developers to understand. NoSQL systems frequently lack support for ACID transactions, which can make it more difficult to implement business logic. Because they not designed as a relational store, they are often not an ideal choice for self-service reporting solutions such as Power BI.
This is why the MDW pattern is important. It rely on the strengths of each tool and selects the right one for each job. It enables using both NoSQL and SQL together to support complex storage, data processing, and reporting needs.
What are a couple of common mistakes developers make in implementing the MDW pattern?
There are three common mistakes developers make in implementing the MDW pattern:
- Using the wrong storage type for ingested data: Teams frequently fail to understand the differences between Azure storage solutions such as Azure Blob Storage, Azure Files, and Azure Data Lake Storage. Picking the wrong one for the job can create unexpected performance problems.
- Forgetting that NoSQL solutions rely on data duplication: NoSQL design patterns are not the same as relational design patterns. Using NoSQL effectively often relies on having multiple copies of the data for optimal querying and security. Minimizing the number of copies can restrict performance, limit security, and increase costs.
- Using Azure Synapse Analytics for dynamic reporting: Azure Synapse Analytics is a powerful tool for data processing and analysis, but it is not designed for high-concurrency user queries. Direct querying from self-service reporting solutions such as Power BI is generally not recommended. It can provide a powerful solution for building the data models that power self-service reporting when used correctly or combined with other services.
With the massive amounts of data being housed in the cloud, what techniques are useful to ingest and report against high-volume data?
For ingesting high volume data as it arrives, queue-based and streaming approaches are often the most effective way to capture and land data. For example, Azure Event Hubs can be used to receive data, store it in Azure Data Lake Storage, and optionally deliver it as a stream to other services, including Azure Stream Analytics. For larger datasets, it can be advisable to store the data directly into Azure Blob Storage or Azure Data Lake Storage. The data can then be processed using Azure Data Factory, Azure Synapse Analytics, or Azure Databricks. They key is to land the data as quickly as possible to minimize the risk of data loss and enable downstream rapid analysis.
For reporting, it’s important to optimize the data models for the queries that will be run. The optimal structures for reporting are rarely the same as those used for ingestion or CRUD operations. For example, it’s often more efficient to denormalize data for reporting than it is to store it in a normalized form. In addition, column stores generally perform substantially better than row-based storage for reporting. As a result, separating the data capture and data reporting aspects can help optimize the performance of each.
How can developers support high volumes of read/write operations without compromising the performance of an application?
An important consideration for developers is the appropriate separation of the read and write operations. When read and write operations overlap, it creates contention and bottlenecks. By separating the data capture and data reporting aspects, you can optimize the performance of each. You can also select services which are optimized for that scenario, minimizing the development effort required.
For applications that need to support CRUD (create, read, update, delete) operations, this can require changing the approach. For example, it may be necessary to use a NoSQL solution that supports eventual consistency. It may also be necessary to persist the data in multiple locations or use change feeds to propagate updates to other services.
In other cases, tools such as Azure Data Factory may be more appropriate. It can periodically copy the data to a different data store during off-peak hours. This can help minimize the impact of the changes to the application. This can be important when the needs of the application change suddenly or when the application does not have to provide up-to-the-moment reporting data.
What are some key Azure services that help with the MDW pattern?
The key services used in the MDW pattern are typically Azure Data Lake Storage Gen2, Azure Synapse Analytics, Azure Databricks, Azure SQL, and Azure Event Hubs.
That said, there are many other services that can be used to support specific application and business requirements within this model. For example, Azure Machine Learning can be used to quickly build insights and models from the data. Azure Cosmos DB can be used to support point-queries and updates with low latency. Services like Azure Purview can be used to understand your data estate and apply governance. The MDW pattern is about understanding the tradeoffs between the different services to appropriate select ones that support the business requirements.
As AI is all the rage these days, do any of those Azure services use hot new technology like large language models or generative AI?
Absolutely! A key part of the Modern Data Warehouse pattern is supporting machine learning, and that includes generative AI and new techniques that development teams might be working to create themselves.
Azure’s newest offering, Azure OpenAI Service, is a fully managed service that provides access to the latest state-of-the-art language models from OpenAI. It is designed to help developers and data scientists quickly and easily build intelligent applications that can understand, generate, and respond to human language.
In addition, Azure recently announced the preview of the ND H100 v5 virtual machine series. These are optimized to support the training of large language models and generative AI. These virtual machines boost the performance for large-scale deployments by providing eight H100 Tensor Core CPUs, 4th generation Intel Xeon Processors, and high-speed interconnects with 3.6 TBps of bidirectional bandwidth among the eight local GPUs. You can learn more here.
About the Author
David Ramel is an editor and writer for Converge360.
MMS • Roland Meertens
Article originally posted on InfoQ. Visit InfoQ

At the recent QCon London conference, Mathew Lodge, CEO of DiffBlue, gave a presentation on the advancements in artificial intelligence (AI) for writing code. Lodge highlighted the differences between Large Language Models and Reinforcement Learning approaches, emphasizing what both approaches can and can’t do. The session gave an overview of the state of the current state of AI-powered code generation and its future trajectory.
In his presentation, Lodge delved into the differences between AI-powered code generation tools and unit test writing tools. Code generation tools like GitHub Copilot, TabNine, and ChatGPT primarily focus on completing code snippets or suggesting code based on the context provided. These tools can greatly speed up the development process by reducing the time and effort needed for repetitive tasks. On the other hand, unit test writing tools such as DiffBlue aim to improve the quality and reliability of software by automatically generating test cases for a given piece of code. Both types of tools leverage AI to enhance productivity and code quality but target different aspects of the software development lifecycle.
Lodge explained how code completion tools, particularly those based on transformer models, predict the next word or token in a sequence by analyzing the given text. These transformer models have evolved significantly over time, with GPT-2, one of the first open-source models, being released in February 2019. Since then, the number of parameters in these models has scaled dramatically, from 1.5 billion in GPT-2 to 175 billion in GPT-3.5, released in November 2022.
OpenAI Codex, a model with approximately 5 billion parameters used in GitHub CoPilot, was specifically trained on open-source code, allowing it to excel in tasks such as generating boilerplate code from simple comments and calling APIs based on examples it has seen in the past. The one-shot prediction accuracy of these models has reached levels comparable to explicitly trained language models. Unfortunately, information regarding the development of GPT-4 remains undisclosed. Both training data and information around the number of parameters is not published which makes it a black box.
Lodge also discussed the shortcomings of AI-powered code generation tools, highlighting that these models can be unpredictable and heavily reliant on prompts. As they are essentially statistical models of textual patterns, they may generate code that appears reasonable but is fundamentally flawed. Models can also lose context, or generate incorrect code that deviates from the existing code base calling functions or APIs which do not exist. Lodge showed an example of code for a so-called perceptron model which had two difficult to spot bugs in them which essentially made the code unusable.
GPT-3.5, for instance, incorporates human reinforcement learning in the loop, where answers are ranked by humans to yield improved results. However, the challenge remains in identifying the subtle mistakes produced by these models, which can lead to unintended consequences, such as the ChatGPT incident involving the German coding company OpenCage.
Additionally, Large Language Models (LLMs) do not possess reasoning capabilities and can only predict the next text based on their training data. Consequently, the models’ limitations persist regardless of their size, as they will never generate text that has not been encoded during their training. Lodge highlighted that these problems do not go away, no matter how much training data and parameters are actually used during the training of these models.
Lodge then shifted the focus to reinforcement learning and its application in tools like DiffBlue. Reinforcement learning differs from the traditional approach of LLMs by focusing on learning by doing, rather than relying on pre-existing knowledge. In the case of DiffBlue Cover, a feedback loop is employed where the system predicts a test, runs the test, and then evaluates its effectiveness based on coverage, other metrics, and existing Java code. This process allows the system to iteratively improve and generate tests with higher coverage and better readability, ultimately resulting in a more effective and efficient testing process for developers. Lodge also mentioned that their representation of test coverage allows them to only run relevant tests when changing code, resulting in a decrease of about 50% of testing costs.
To demonstrate the capabilities of DiffBlue Cover, Lodge conducted a live demo featuring a simple Java application designed to find owners. The application had four cases for which tests needed to be created. Running entirely on a local laptop, DiffBlue Cover generated tests within 1.5 minutes. The resulting tests appeared in IntelliJ as a new file, which included mocked tests for scenarios such as single owner return, double owner return, no owner, and an empty array list.
In conclusion, the advancements in AI-powered code generation and reinforcement learning-based testing, as demonstrated by tools like DiffBlue Cover, have the potential to greatly impact the software development and testing landscape. By understanding the strengths and limitations of these approaches, developers and architects can make informed decisions on how to best utilize these technologies to enhance code quality, productivity, and efficiency while reducing the risk of subtle errors and unintended consequences.
MMS • Anthony Alford
Article originally posted on InfoQ. Visit InfoQ

The PyTorch Foundation recently released PyTorch version 2.0, a 100% backward compatible update. The main API contribution of the release is a compile function for deep learning models, which speeds up training. Internal benchmarks on 163 open-source AI projects showed that the models ran on average 43% faster during training.
Plans for the 2.0 release were announced at the PyTorch Conference in December 2022. Besides the new compile function, the release also includes performance improvement for Transformer-based models, such as large language models and diffusion models, via a new implementation of scaled dot product attention (SDPA). Training on Apple silicon is accelerated via improved Metal Performance Shaders (MPS), now with 300 operations implemented in MPS. Besides the core release, the domain libraries, including TorchAudio, TorchVision, and TorchText, were updated with new beta features. Overall, the 2.0 release includes over 4,500 commits from 428 developers since the 1.13.1 release. According to the PyTorch Foundation blog,
We are excited to announce the release of PyTorch® 2.0 which we highlighted during the PyTorch Conference on 12/2/22! PyTorch 2.0 offers the same eager-mode development and user experience, while fundamentally changing and supercharging how PyTorch operates at compiler level under the hood with faster performance and support for Dynamic Shapes and Distributed.
In his keynote speech at the PyTorch Conference 2022, PyTorch co-creator Soumith Chintala pointed out that thanks to increases in GPU compute capacity, many existing PyTorch workloads are constrained by memory bandwidth or by PyTorch framework overhead. Previously the PyTorch team had addressed performance problems by writing some of their core components in C++; Chintala described PyTorch as “basically a C++ codebase,” and said that he “hates” contributing to the C++ components.
The new compile feature is based on four underlying components written in Python:
- TorchDynamo – performs graph acquisition by rewriting Python code representing deep learning models into blocks of computational graphs
- AOTAutograd – performs “ahead of time” automatic differentiation for the backprop step
- PrimTorch – canonicalizes the over 2k PyTorch operators down to a fixed set of around 250 primitive operators
- TorchInductor – generates fast hardware-specific backend code for accelerators
To demonstrate the performance improvements and ease of use of the compile function, the PyTorch team identified 163 open-source deep learning projects to benchmark. These included implementations of a wide variety of tasks including computer vision, natural language processing, and reinforcement learning. The team made no changes to the code besides the one-line call to the compile function. This single change worked in 93% of the projects, and the compiled models ran 43% faster when trained on NVIDIA A100 GPUs.
In a Hacker News discussion about the release, one user noted:
A big lesson I learned from PyTorch vs other frameworks is that productivity trumps incremental performance improvement. Both Caffe and MXNet marketed themselves for being fast, yet apparently being faster here and here by some percentage simply didn’t matter that much. On the other hand, once we make a system work and make it popular, the community will close the performance gap sooner than competitors expect. Another lesson is probably old but worth repeating: investment and professional polishing [matter] to open source projects.
The PyTorch code and version 2.0 release notes are available on GitHub.
The AI Revolution Is Just Getting Started: Leslie Miley Bids Us to Act Now against Its Bias and CO2
MMS • Olimpiu Pop
Article originally posted on InfoQ. Visit InfoQ

At his inaugural keynote of the QCON London conference, Leslie Miley – Technical Advisor for the CTO at Microsoft, spoke about AI Bias and Sustainability. How the march towards transformative technologies, like large-scale AI and even crypto, has an inherent cost in the increased CO2 that comes with deployment at scale.
His presentation started by creating the appropriate frame: why he chose to give this talk. Growing up and now living in Silicon Valley, allowed him to see the impact(positive or negative) that transformative technologies have on communities.
You cannot name a technology that was transformative without being damaging
Making reference to articles in the media he stated that generative AI has a dirty secret because it requires more energy than other cloud services. Even if big technology companies like Google, Meta or Microsoft are making efforts to ensure that most of their new data centres are as green as possible, the amount of energy consumed is too high. To emphasize the impact the thirst for the energy of new technological trends has, he underlines that coal power plants that didn’t operate in years are now in operation again.
To ensure that the impact is properly understood he makes the connection between the growing CO2 emissions and global warming and the extreme weather conditions that are recorded all over the globe. He states that the high amount of rainfall and snow was only once matched in the recorded history of California.
One of the fascinating things is human beings have this great ability to solve their problems with more complexity. We know it will emit more CO2, but we will make it more efficient.
He continues to underline, that until humanity manages to find a solution people are affected now. Due to flooding, for instance, fragile communities were affected.
How do you fix somebody who doesn’t have a home anymore?
Next, he brings up the problem in the engineering space stating that generative AI will need a different infrastructure. According to him, we need to rethink the way we build infrastructure, one that will support the new ChatGTP era. To think of a new data centre design that allows us to benefit from machine learning(ML) in a manner that doesn’t impact the environment. HyperScale Data Centers might be a solution as they:
- Move Data Faster
- Own Energy Sources
- Are Eco Friendlier
He compares the building of the interstate highway network in the US and its impact with the building of new data centres for generative AI. The technology will have multiple benefits, but the impact that will have on the local communities should not be ignored. He references the work of Dr Timnit Gebru from Distributed AI Research institute and that of Dr Joy Buolamwini from Algorithm Justice League when it comes to AI bias and how to ensure its fairness.
We know that AI is biased. The data we feed it with is biased. What do we say? We’ll fix it later!
He continuously encourages action now especially as we can make decisions that would help everybody “Not because it is expedient, but because it is the right thing to do”. Similar calls to action could be heard in other formal presentations or informal open conversations on security and gender equality. Rebeca Parsons, ThoughtWorks CTO used the following quote from Weapons of Math Destruction:
Cathy O’Neil: We can make our technology more responsible if we believe we can and we insist that we do
The last part focused on mitigation strategies each one can use. Using smaller models with enhanced societal context might provide a better output than big, resource-consuming models. Knowing Your Data(KYD) and Knowing Your Data Centre(KYDC) will allow you to take better decisions. All big cloud vendors provide dashboards for CO2 footprint measuring.
His closing statement reads:
When ChatGPT occurred I knew it is something crazy big. Something seminal like the advent of the World Wide Web. Technology is meeting people where they were at. We have an obligation to meet it with compassion, and humility, and try to understand the social and cultural impact before we do it. We have the only chance for it. Otherwise, the world will look different than what we want it to be.
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
MongoDB (MDB) appears an attractive pick given a noticeable improvement in the company’s earnings outlook. The stock has been a strong performer lately, and the momentum might continue with analysts still raising their earnings estimates for the company.
Analysts’ growing optimism on the earnings prospects of this database platform is driving estimates higher, which should get reflected in its stock price. After all, empirical research shows a strong correlation between trends in earnings estimate revisions and near-term stock price movements. Our stock rating tool — the Zacks Rank — is principally built on this insight.
The five-grade Zacks Rank system, which ranges from a Zacks Rank #1 (Strong Buy) to a Zacks Rank #5 (Strong Sell), has an impressive externally-audited track record of outperformance, with Zacks #1 Ranked stocks generating an average annual return of +25% since 2008.
For MongoDB, strong agreement among the covering analysts in revising earnings estimates upward has resulted in meaningful improvement in consensus estimates for the next quarter and full year.
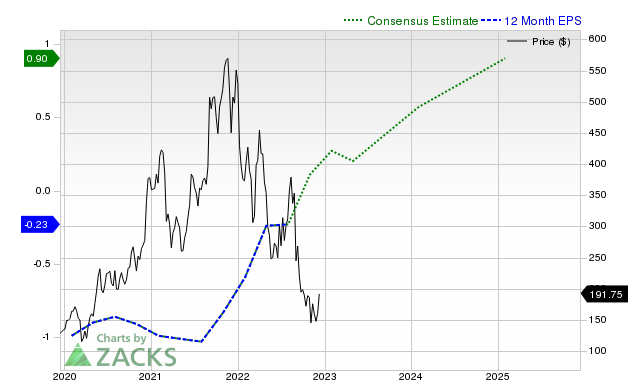
The chart below shows the evolution of forward 12-month Zacks Consensus EPS estimate:
12 Month EPS
Current-Quarter Estimate Revisions
The earnings estimate of $0.19 per share for the current quarter represents a change of -5% from the number reported a year ago.
Over the last 30 days, five estimates have moved higher for MongoDB while one has gone lower. As a result, the Zacks Consensus Estimate has increased 8.36%.
Current-Year Estimate Revisions
The company is expected to earn $1.03 per share for the full year, which represents a change of +27.16% from the prior-year number.
The revisions trend for the current year also appears quite promising for MongoDB, with eight estimates moving higher over the past month compared to no negative revisions. The consensus estimate has also received a boost over this time frame, increasing 12.93%.
Favorable Zacks Rank
The promising estimate revisions have helped MongoDB earn a Zacks Rank #2 (Buy). The Zacks Rank is a tried-and-tested rating tool that helps investors effectively harness the power of earnings estimate revisions and make the right investment decision. You can see the complete list of today’s Zacks #1 Rank (Strong Buy) stocks here.
Our research shows that stocks with Zacks Rank #1 (Strong Buy) and 2 (Buy) significantly outperform the S&P 500.
Bottom Line
Investors have been betting on MongoDB because of its solid estimate revisions, as evident from the stock’s 5.3% gain over the past four weeks. As its earnings growth prospects might push the stock higher, you may consider adding it to your portfolio right away.
Want the latest recommendations from Zacks Investment Research? Today, you can download 7 Best Stocks for the Next 30 Days. Click to get this free report
MongoDB, Inc. (MDB) : Free Stock Analysis Report
To read this article on Zacks.com click here.
Article originally posted on mongodb google news. Visit mongodb google news
MMS • RSS
Posted on mongodb google news. Visit mongodb google news
What happened
Shares of cloud software stars Datadog (DDOG 0.55%), MongoDB (MDB -2.83%), and DocuSign (DOCU 0.97%) were all falling hard today, down 4.1%, 4.4%, and 4.8%, respectively, as of 2:07 p.m. EDT.
The decline marks a reversal from the past week when most high-growth software stocks rallied as the unfolding banking crisis caused short- and long-term yields to fall significantly.
However, as the U.S. government and large U.S. banks took aggressive action to contain the fallout from the demise of Silicon Valley Bank and other regional banks, and as Europe forced the acquisition of troubled bank Credit Suisse by UBS Group, investors seem to be betting on a stabilization in the financial system and the economy.
In a bout of “good news for the economy is bad news for profit-less tech stocks,” long-term yields bounced back higher, which can be a headwind for unprofitable growth stocks even if the economy turns out to be in less bad shape than feared.
So what
Some may be confused as to why economic troubles in the banking sector may be good for tech and vice versa. After all, each of these stocks fell after their recent earnings reports as all three revealed the hyper-growth they experienced through the pandemic would slow markedly this year, with each of these stocks’ management teams giving rather tepid full-year outlooks.
A lot of the recent moves in these software-as-a-service (SaaS) stocks really comes down to interest rates. While each of these companies is no doubt seeing a material deceleration in their outlook, each should still grow at a faster pace than the economy over the medium-to-long term, as cloud-based digitization will be an ongoing trend, albeit at a slower pace.
However, none of these companies makes material profits today. Given that the intrinsic value of any stock is the present value of all future cash flows, and that these stocks’ profits are all well out into the future, one could say that the long-term Treasury bond yield may even have a larger impact on these stocks than the near-term economic environment. This is because the higher long-term yields are, the less these companies’ 2030 profits are worth in present-day terms.
Today, investors appeared to reverse last week’s skittishness that we are going into some sort of recession. The 10-year Treasury bond yield, after falling from about 4% to 3.4% in less than two weeks, bounced higher to 3.5% today. The bounce seemed to be a sigh of relief after regulatory action in both the U.S. and Europe appeared to stem the banking crises — at least for now.
The synchronous moves across all three of these companies therefore likely come from the moves in interest rates and a rotation from investors back into more cyclical sectors like banks, industrials, and energy that sold off hard last week despite much lower valuations.
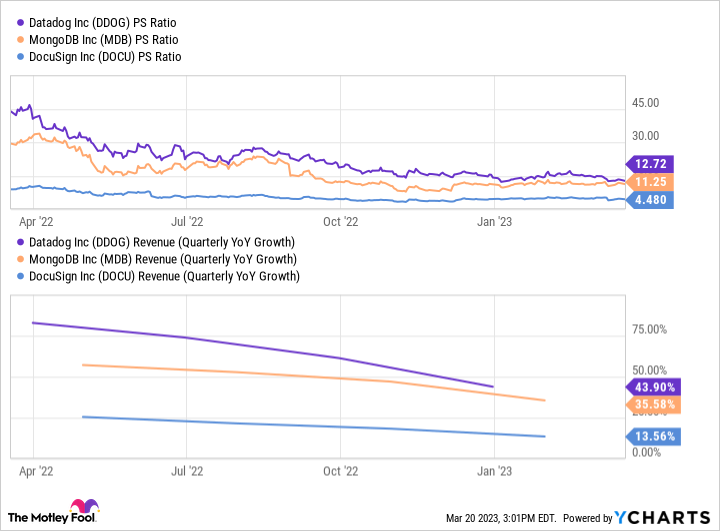
DDOG PS Ratio data by YCharts.
Now what
It remains to be seen whether the banking crisis is in fact fully contained, if a recession will occur, and how severe it will be if it does.
Still, it seems like a long shot interest rates will go back to the lows seen in 2020 and 2021 in response to the pandemic, or even back to where they were in the pre-pandemic period. These high-growth software stocks have only really operated in a low-rate environment, and they still aren’t “cheap” by conventional metrics.
None of the companies mentioned have generally accepted accounting principles (GAAP) profits today, and at least Datadog and MongoDB still have very high price-to-sales (P/S) ratios of 12.7 and 11.2, respectively. DocuSign is a bit more reasonable at 4.5 times sales, but DocuSign’s new management team only forecasts a tepid 8% growth this year, down from 19% in 2022.
In order for these stocks to get back to their 2021 highs, growth would have to reaccelerate, which would likely require the economy to improve, while interest rates would also need to remain low. Given recent inflation trends, that doesn’t appear to be in the cards any time soon.
SVB Financial provides credit and banking services to The Motley Fool. Billy Duberstein has no position in any of the stocks mentioned. His clients may own shares of the companies mentioned. The Motley Fool has positions in and recommends Datadog, DocuSign, MongoDB, and SVB Financial. The Motley Fool has a disclosure policy.
Article originally posted on mongodb google news. Visit mongodb google news
Industry Voice: How MongoDB enabled M&S ‘build’ over ‘buy’ Strategy for new Sparks loyalty platform
MMS • RSS
Posted on mongodb google news. Visit mongodb google news

In 2020, Marks & Spencer relaunched “Sparks”, its digital-first loyalty scheme, offering customers greater personalisation and ease-of-use.
With the change of loyalty program from Points based system to Offer based system and encountering limitations scaling the app with its existing partner, Marks & Spencer made the decision to build in-house rather than opting for an off-the-shelf product.
In order to build the right product, the right people and the right database platform were needed. MongoDB’s document-based database enabled Marks & Spencer to achieve the desired scalability, agility and reliability to reach even more customers.
Amit Vij is the head of software engineering at Marks & Spencer, leading its customer engagement portfolio. Computing spoke with Amit to find out how the new and improved Sparks app was made possible thanks to MongoDB’s developer data platform.
What features were you looking to provide to customers through the relaunch of the Sparks app?
In 2020, M&S relaunched its digital-first loyalty scheme. Before 2020 it wasn’t a digital scheme. You’d have to purchase a physical card, register online and you’d go on a website to see what offers were on the card. You’d have to take that physical card into the store and then go to the tills and scan it. The customer experience was quite modest and quite slow and we could not scale our customer base.
In 2020, we launched a digital-only scheme. You have your digital Sparks card within the mobile app and you can see offers on a real-time basis.
It has been a successful journey; we had 7 million customers we had to transfer over to this scheme and within 3 years we have gone from 7 million customers to 17.2 million customers, with 10 million active customers on Sparks.
Our Sparks customers shop five times more often with us and spend eight times as much. So it was very critical to get this Sparks loyalty programme operating properly.
Why did you decide to build the application in-house rather than buying off-the-shelf?
There are two main reasons for this. Our loyalty scheme was simpler, we moved from a tiered points based loyalty program to an offer-based program. The complexity of building an offer-based system in-house was more palatable to the organisation. When we launched in 2020, we worked with our existing partner. And on the day of the launch, the application went down for six hours. So it wasn’t a positive experience for customers or the team that built it. At that point it was decided that the platform it was built on was not scalable, it wasn’t on the cloud and it had a lot of issues over the years such as network cables being pulled out and the application going down. So we decided to build this application rather than buy it.
At M&S we have a Tech North Stars system that is guided by principles we want to live up to and we use these as a benchmark whenever we create something new. We look at five key factors when deciding whether we should go and buy something from the market or build it.
The first one, which is very critical, is vitality versus utility. Anything which is a strategic product for us we call a vitality product. For MongoDB for example, database storage is a vitality product. So we are not going to build that ourselves. But for us, our loyalty programme is a vitality product and we wanted to scale it from 20 million to 30 million customers in the next five years. That’s a strategic product where we want to own the data ourselves.
The second factor is agility. We wanted to build an application that is agile and scalable. Our business is continually changing and we have to be very adaptive to market demand. With socio-economic factors like Covid, war, floods, and inflation, the market dimensions keep changing. Equally, our tech stack keeps changing as well. What we cannot do is every two years keep swapping our products and changing vendors. So, we wanted to build something where we can scale up.
The third one is we needed an application that can be loosely coupled. We want to build something with a microservices architecture where services are independent of each other and can be reused and deployed on demand. We’ve already built a new loyalty platform, trialled voice enabled devices and Sparks only pricing. There was no chance of building these on our legacy platform.
Previously, we didn’t have cloud capabilities. The application was sitting in a data centre, so we had to move to the cloud to get our data disaster recovery, scale, AI capabilities and availability in place.
And then last but not least, we wanted an application that was reliable by design. We want to ensure our technology works when needed for the right cost as well. By moving to a new platform, we saved £1.4 million in OpEx costs yearly. Obviously, we do have an operational cost of running this ourselves, but having a non-reliable product was very costly for us.
What were the factors that made you decide to go with MongoDB versus one of their competitors?
MongoDB is a document-based database, which was key for us. We followed iterative migration for our programme, which was done in multiple stages. We could not have done it overnight. The data we were receiving from multiple sources was unstructured and in multiple formats. We also wanted easy updates to schemas and fields because we didn’t know the right architecture when we started this journey. We wanted a database that could support this.
The other key reasons were availability and scalability. We built in resilience with data stored in multiple regions and MongoDB provided the flexibility and ease of use for engineers to tailor the application to M&S needs.
One aspect we sometimes ignore is the support you get from the technical professional services. The expert opinions, plus the engagement we have had with MongoDB on a day-to-day basis to solve critical problems, to get our platform up and running, and to the scale we wanted has been the game changer.
We have also used MongoDB Atlas Search for some projects that add full text search functionality to our application as well as analytics nodes which allow for real-time analytical queries on our data without impacting our workloads or how customers interact with the application. These are both features that we plan to expand our use of in the future.
How have your developers found working with the MongoDB platform?
When we started designing this application, we used to do 1 million offer allocation an hour. Now we are able to do 1.2 million allocations in five minutes, which is 14.5 million allocations per hour, and 350 million allocations a day. Now this is the scale we wanted to achieve from a business perspective, but to make that happen, engineers need to understand the product in depth.
With the support we have from MongoDB, it has been a seamless process for the engineers to get their hands dirty and actually build this application.
The other aspect I would highlight is the performance. We have achieved API response rate (latency) of less than 100 milliseconds, which was previously more than 1 second, so that’s a massive growth for us.
So for our developers, that’s a big, big win. If we take the DevOps approach, we haven’t had a SEV1 issue on our loyalty platform since moving it to MongoDB. And in the past, we had multiple issues a month. I would say developer life has definitely been made easier with the platform.
What plans do you have to develop the loyalty scheme further?
The first thing is to really go global. The existing platform only tailors to the UK and Republic of Ireland. But Sparks as a brand launched in Q4 last year to global customers. So we have launched it to 4 million loyalty programme customers in India and to 24 pure play markets – France, Germany, Spain, Australia, and the USA are some of those markets.
Because Sparks is such a big brand for M&S, we want to scale it up, making it a key identity for our customers so they are happy to engage with us. In the future, we would like to connect our banking and Sparks programmes and personalise offers and rewards through mobile app. We want to reach 30 million customers in the next three years.
To find out more about MongoDB visit mongodb.com
This post was funded by MongoDB
Article originally posted on mongodb google news. Visit mongodb google news
MMS • Shaaf Syed
Article originally posted on InfoQ. Visit InfoQ

Oracle has introduced the new Java SE Universal subscription and pricing, replacing the now legacy Java SE and Java SE Desktop subscriptions as of January 2023. According to the FAQ, Oracle’s goal is to simplify tracking and management of licensed environments with universal permitted use across desktops, servers, and third-party clouds.
Oracle has changed its licensing and policies several times over the last few years. In 2019, Oracle announced that Java SE would no longer be free. In 2020, Oracle introduced the NFTC (No-Fee Terms and Conditions) for JDK 17 and later, which permitted free use for some use cases.
Applications that are running Oracle JDK 8 and 11 do not need updates and can continue to run uninterrupted using these versions, either free for personal use or paid updates. The only path for users who want to update these older versions will be to choose the latest Java SE Universal subscription when it’s time for renewal.
Developers using the latest LTS version, Java 17, could remain on the Java 17 update path until the next LTS version, Java 21, which is planned to be released in September 2023. Oracle released Java 17 on September 15, 2021. Since then, there have been eight minor updates.
For Java SE Universal subscription, Oracle has also granted free use for up to 50,000 processors (Oracle defined processors). This would mostly apply to server deployments. This applies to the new employee licensing model only. Oracle states in the pricing document that any customer exceeding that limit should contact Oracle for a special price. The grant, however, is a step towards simplification.
These new changes address the complexities of licensing for any organization that runs multiple versions of Java. In certain cases, the simplification might cost more than the previous licensing model, as explained by IDC and Nathan Biggs, CEO of House of Brick, in this blog post.
While Oracle’s licensing changes might be a step towards simplification of licensing for OracleJDK, commercial alternatives do exist. OpenJDK has been the upstream community for Java since Java 8. It includes many vendors that contribute together with Oracle to make Java an enterprise language that backs billions of devices and serves millions of developers worldwide. There are almost no technical differences between OracleJDK and OpenJDK today.
The specifics of Oracle’s licensing policies can be complex and are subject to change. Customers should consult with Oracle to determine the best licensing options for their specific needs.