
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
The Forrester report “Predictions 2018: A year of reckoning” predicted that 80% of firms affected by the GDPR will not be able to comply with the regulation by the time it comes into force on May 25. Of those noncompliant firms, 50% will intentionally not comply.
Compliance does not have to be difficult. Imagine if it were possible to facilitate GDPR compliance with a mature technology that facilitates the significant reduction in costs associated with traditional replication methods of data integration. This is possible! Data virtualization is a mature, cost-effective technology that enables the three pillars of GDPR compliance.
Three Pillars of GDPR Compliance
GDPR compliance requires the right combination of people, processes, and technology. From a technology perspective, no single tool can implement compliance; Companies need multiple technologies, such as data governance, data quality, and data integration solutions. Data virtualization can play an important role in this compliance ecosystem, supporting the three most important pillars of GDPR compliance:
1. A Single View of Data Entities — The ability to create a complete view of a data subject in an agile manner, which enables companies to present the most accurate data about an individual
2. A Self-Service Data Catalog — enabling companies to find the data assets that are in scope for GDPR compliance, and then categorize, annotate, and document them
3. Privacy by Design — ensuring that privacy is considered during the design process so that data delivery and access mechanisms are compliant from the outset, rather than added in retrospect.
Pillar 1: Data Virtualization Helps Provide a Single, Complete View of Information
Companies may have existing master data management (MDM) systems that consolidate and master entities, but these lack the context of the transactional information that may exist in other systems. Data virtualization is ideally suited to combine the sources of master data with transactional information distributed around the enterprise to provide a full 360-degree view of up-to-date customer information.
Data virtualization greatly assists with providing single views of entities like customers and is typically used in MDM initiatives in three ways:
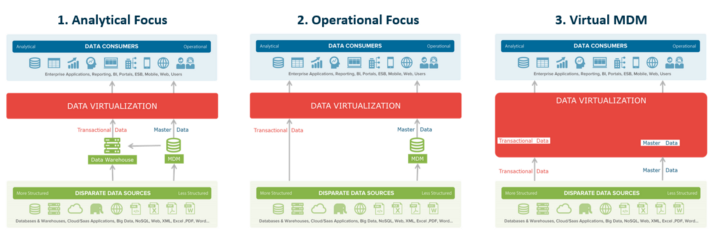
- The first has an analytical focus. In these situations, a company typically has some form of master data system, yet transactional history resides in a data warehouse. In this scenario, data virtualization is used to combine the master data in the MDM system with the historical transactional information in the warehouse, to give the full context to the entity. In addition to compliance, this approach is also frequently used in financial services use cases.
- The second approach has a more operational focus. In these situations, the company still has some form of master data system, however they are interested in the current picture of the entity. In this scenario, data virtualization is used to combine master data from the MDM system with the latest transactional information from operational systems, to give the full real-time context to the entity. This approach is common in more operational use cases such as providing 360-degree details for customer call center applications.
- In some cases, companies are unable to store master data in a central hub. In this case, data virtualization can be used in a registry style approach. Companies store registries of keys, which can be combined, using data virtualization, to match and merge the master data attributes from the systems of record. Registries of keys can be virtual or physical, however data virtualization can then augment the virtual master records with the transactional data from the source systems to provide the full context of the entity. This type of approach is used more to support operational applications, where storing master data outside of the systems of record is not possible.
Pillar 2: Self-Service Data Catalogs
Often, self-service initiatives designed to provide easier access to data for consumers fail to deliver. Exposing more data sources to consumers ends up in more requests to IT, more complexity and backlogs, and more data replication, resulting in increased governance and compliance issues.
Data virtualization provides a solution to this: exposing curated information in a business-friendly form that is easy to access. However, unlike traditional approaches, which physically consolidate and transform the data, approaches that are also slow and expensive to maintain, data virtualization provides a more agile means of virtually consolidating the data.
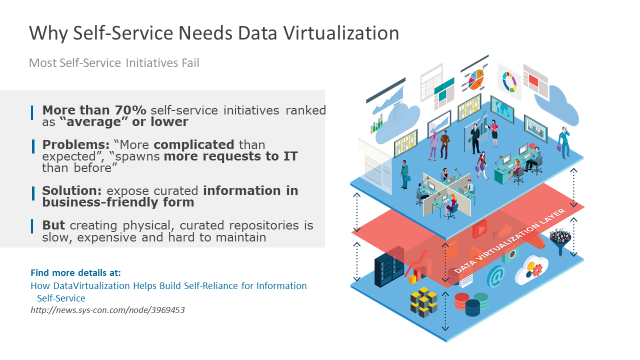
With data virtualization, data sources can be quickly exposed through a curated logical layer via a canonical model that is more easily consumed and understood by the business. Business analysts and developers are then able to build their own views of the data based on this model to suit their needs, with less reliance on IT.
To support this, data virtualization platforms provide a data catalog that exposes the metadata of the curated views defined in the virtual layer. This allows users to discover the data that is available in the virtualization layer through a web browser, promoting re-use of the data and self-service for business users.
From a compliance perspective, users can use the catalog to categorize and annotate information published via the views provided in virtual layer, by adding business terms and descriptions, business categories, and tags. These can be searched, together with view metadata and lineage information, enabling companies to understand where their sensitive information resides and how it is published to consumers. Combined with the operational audit information provided by data virtualization platforms, which identify which views were created or are being queried and by whom in the virtual layer, this greatly facilitates compliance and data governance processes.
Data catalogs should be tightly linked with the data delivery infrastructure so that data consumers can easily access the most up-to-date data once they have discovered it. With a data virtualization solution, the data catalog provides a direct view on the data delivery layer itself (i.e. the data virtualization layer), so once stakeholders have located relevant data objects, they can immediately inspect the data without switching to a different tool.
Pillar 3: Enabling Regulatory Compliance by Design
The GDPR requires companies to ensure that regulatory compliance is included in the design of any data processing initiative.
Businesses need access to complete, pre-integrated information. The challenge is that data is becoming more and more distributed across the enterprise in different formats and technologies. Companies resort to physical replication and point-to point interfaces to provide the integrated information, but this creates unnecessary duplicates.
With all this distribution and data duplication, compliance with GDPR principles such as ensuring the data is processed in a manner that ensures appropriate data security, or that the data is kept in a form that enables the subject to be identifiable no longer than is necessary, or that the data you are viewing is accurate and up-to-date, can be difficult.
In addition, companies face the added technical challenges of integrating highly distributed data across on-premises and cloud sources, proving that data access has been audited effectively, providing access to the most up-to-date data, anonymizing the data, and providing consistent data security, not to mention the challenge of managing multiple data copies.
Data virtualization simplifies this integration landscape and enables data sources to be brought quickly under control by publishing them through a virtual abstraction layer. Data virtualization offers a single logical point of access, avoiding point-to-point connections from consuming applications to data sources. As a single point of access for applications, it is the ideal place to enforce access and security restrictions that can be defined in terms of the published logical model, with a fine level of granularity.

Data virtualization platforms include user and role-based authentication and authorization mechanisms that can limit access at a schema level and implement data-specific permissions. User access can, for example, be easily limited to specific data views or specific rows or columns in a virtual view. Data can even be selectively masked for specific attributes.
To comply with the GDPR, companies need to be able to ensure that data is used in a lawful way. So, not only is it required to restrict access to appropriate consumers, but companies also need to keep track of who is accessing what information. Enabling data access through a virtual layer enables organizations to audit who is using their data, from a single point of control. The Denodo Platform, for example, provides an audit trail of all the queries and other actions performed on the virtual layer. At any time, companies can check who is accessing the data, what queries they executed, and what changes they made to the virtual model.
Data Virtualization Facilitates Compliance
In summary, using an abstraction layer provided by data virtualization technology facilitates GDPR compliance. Data can be quickly brought under control and consumed through a single virtual access layer to facilitate GDPR initiatives, helping to bring context to master data, ensuring that data is easily discoverable for new initiatives and governance processes, all while reducing the governance headaches associated with data replication.
This blog was originally published here.