Amazon Comprehend Announces the Reduction of the Minimum Requirements for Entity Recognition

MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ
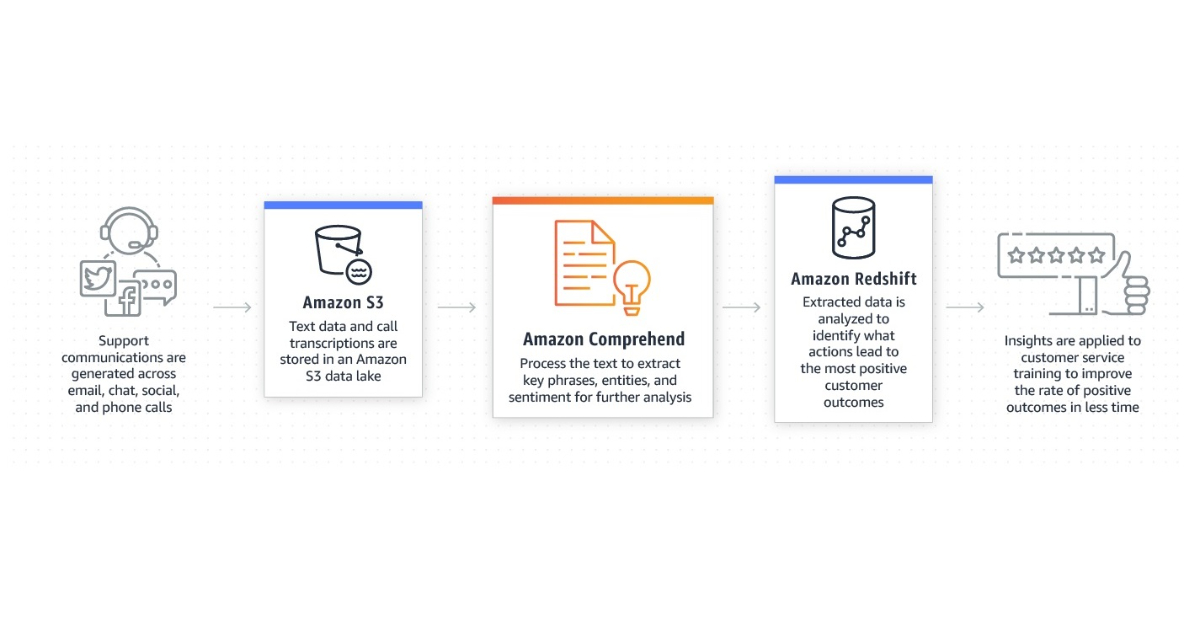
Amazon is announcing that they lowered the minimal requirements for training a recognizer with plain text CSV annotation files as a result of recent advances in the models powering Amazon Comprehend. Now, you just need three documents and 25 annotations for each entity type to create a unique entity recognition model.
You can use Amazon Comprehend, an NLP service, to automatically extract entities, key phrases, language, sentiments, and other information from documents. For instance, using the Amazon Comprehend console, AWS Command Line Interface, or Amazon Comprehend APIs, you may start detecting entities right away, such as persons, places, commercial products, dates, and quantities.
Additionally, you can build a custom entity recognition model if you need to extract entities that aren’t included in the built-in entity types of Amazon Comprehend. This will enable you to extract terms that are more pertinent to your particular use case, such as product names from a product catalog, domain-specific identifiers, and so forth.
Creating an accurate entity recognizer on your own using machine learning libraries and frameworks can be a complex and time-consuming process. Amazon Comprehend simplifies your model training work significantly. All you need to do is load your dataset of documents and annotations, and use the Amazon Comprehend console, AWS CLI, or APIs to create the model.
You can send Amazon Comprehend training data in the form of entity lists or annotations to train a custom entity recognizer. In the first scenario, you offer a set of documents together with a file that has annotations indicating the locations of entities inside the set of documents. As an alternative, entity lists allow you to supply a list of entities together with a label designating the entity type for each one, as well as a collection of unannotated documents that you anticipate containing your entities. Both methods can be used to successfully train a bespoke entity recognition model, however in some cases one can be preferable.
Up until now, you needed to provide a collection of at least 250 documents and a minimum of 100 annotations for each entity type in order to begin training an Amazon Comprehend custom entity recognizer. Amazon is revealing that the minimal requirements for training a recognizer with plain text CSV annotation files have been lowered as a result of recent enhancements to the models underpinning Amazon Comprehend. With as few as three documents and 25 annotations for each entity type, you can now create a unique entity recognition model.
Given that both the quality and quantity of annotations have an effect on the resulting entity recognition model, annotating documents can take a significant amount of time and effort. Poor outcomes may stem from insufficient or inaccurate annotations. Tools like Amazon SageMaker Ground Truth, can be used to annotate documents more rapidly and create an augmented manifest annotations file, to assist in setting up a procedure for collecting annotations.