
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
What is a Data Catalog?
A data catalog helps companies organize and find data that’s stored in their many systems. It works a lot like a fashion catalog. But instead of detailing swimsuits or shoes, it has information about tables, files, and databases from a company’s ERP, HR, Finance, and E-commerce systems (as well as social media feeds). The catalog also shows where all the data entities are located.
A data catalog contains lots of critical information about each piece of data, such as the data’s profile (statistics or informative summaries about the data), lineage (how the data is generated), and what others say about it.
The catalog is the go-to spot for analysts and others, who are trying to find data to build insights, discover trends, and identify new products for the company.
Why does a company need a data catalog?
According to Forrester research, only 14% of business stakeholders make thorough use of customer insights. That’s because most companies don’t have access to their data.
Just consider a typical data stack for a company:
A Typical Data Stack of a Company
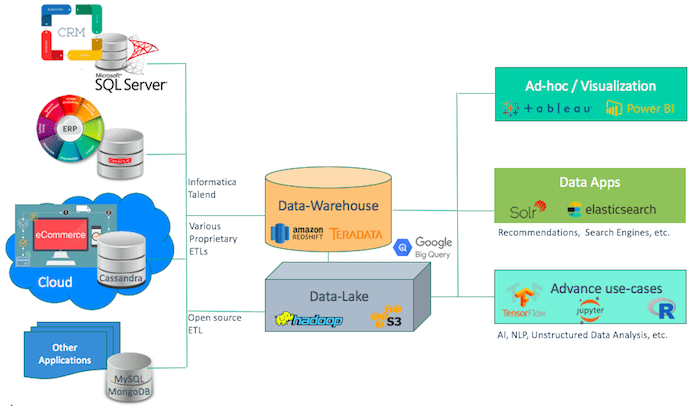
A data catalog solves multiple problems. It gives a comprehensive view of each piece of data across databases. Plus, it makes the data easy to find. It also can put guardrails on the data and govern who can access it.
The step-by-step process of building a data catalog
Accessing Metadata of all databases
The first step for building a data catalog is collecting the data’s metadata. Data catalogs use metadata to identify the data tables, files, and databases. The catalog crawls the company’s databases and brings the metadata (not the actual data) to the data catalog.
Some data catalogs have restrictions about the types of databases it can crawl. OvalEdge doesn’t. It can crawl:
- Transactional databases (RDBMS) – Oracle, SQL Server, MySQL, DB2, etc.
- Data warehouse – Teradata, Vertica etc.
- Hadoop
- NoSQL databases – Cassandra, MongoDB
- Cloud Storage – Google Big Query, MS Azure Data Lake, AWS – Athena & Red Shift
- Tableau and Power BI
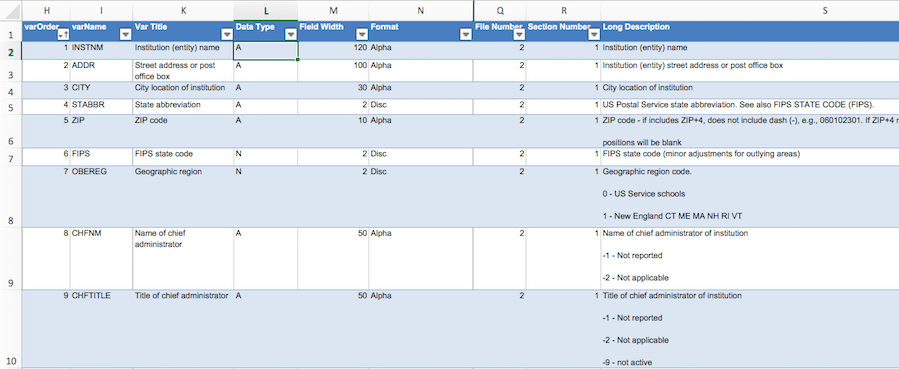
Building a Data dictionary
The second step is to build a data dictionary or upload an existing one into the data catalog. A data dictionary contains the description and Wiki of every table or file and all their metadata entities.
Employees can collaborate to create a data dictionary through web-based software or use an excel spreadsheet.
An image of a data dictionary
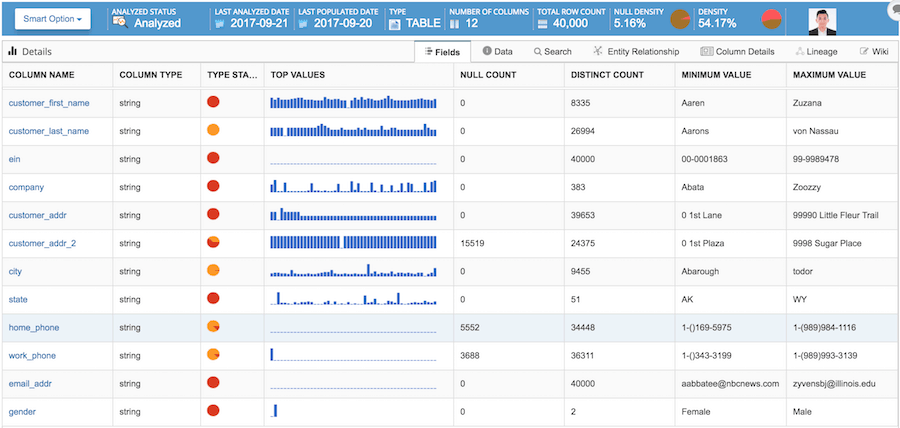
Profiling to See the Data Statistics
The next step is to profile the data to help data consumers view and understand the data quickly. These profiles are informative summaries that explain the data.
For example, the profile of a database often includes the number of tables, files, row counts, etc.. For a table, the profile may include column description, top values in a column, null count of a column, distinct count, maximum value, minimum value and much more.
An image of a table profile in the data catalog, Ovaledge
Marking Relationship Amongst Data
Marking relationships is the next vital step. Through this step, data consumers can discover related data across multiple databases. For example, an analyst may need consolidated customer information. Through the data catalog, she finds that five files in five different systems have customer data. With OvalEdge data catalog and the help of IT, one can have an experimental area where you can join all the data, clean it. Then use that consolidated customer data to achieve your business goals.
An image of relationships marked for Table ‘Accounts’ with other tables
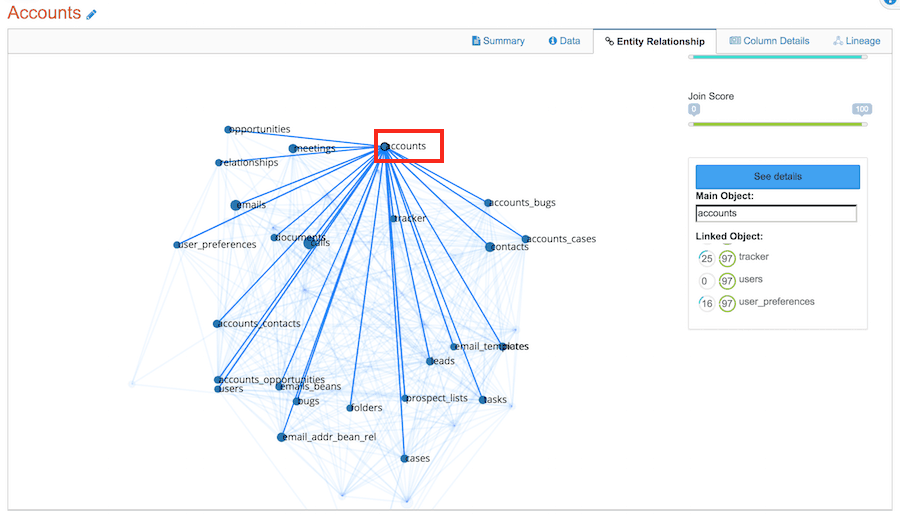
The many ways relationships can be marked
The relationship can be marked amongst data in several ways:
1. Through human knowledge
2. An advanced algorithm can find out the connection. For example, in a table under the column name ‘vendor,’ you have an entity ‘Amazon.’ In another table, for column V1 you also have an entity ‘Amazon.’ The algorithm will figure out that there is a relationship between these tables.
3. Gathering intelligence from queries – Some developers know the connection between different data sets from experience. Their query logs can be examined and then parsed to mark relationships.
Building Lineage
After marking relationships, a data catalog builds lineage. A visual representation of data lineage helps to track data from its origin to its destination. It explains the different processes involved in the data flow. Hence, it enables the analyst to trace errors back to the root cause in the analytics.
Generally, ETL ( Extract, Transfer, Load) tools are used to extract data from source databases, transform and cleanse the data and load it into a target database. A Data Catalog parses these tools to create the lineage. Some of the ETL tools which can be parsed are –
- SQL Parsing
- Alteryx
- Informatica
- Talend
Organizing Data
In a table/file data is arranged in a technical format and not in a way to make the most sense to a business user. So we need human collaboration on data assets so that they can be discovered, accessed and trusted by business users. Below are a few techniques by which we can arrange data for easy discovery –
- Tagging
- Organizing by an amount of usage
- Organizing by specific users usage
- Through automation – Sometimes when there is a large amount of data we can use advanced algorithms to organize data.
Making the catalog easily accessible
For high usage by data consumers, a data catalog should be easily accessible by the web app, mobile app, Android and IOS apps. It should have chat features.
Security is critical
Since a data catalog houses all the data, it’s critical that there are guardrails protecting the most sensitive files. A data catalog should have the following features to ensure that only the right eyes see the data –
- Role-based security
- Information that who accessed what data at what time
- Auditing
- encryption
Data catalogs are the new dynamic and agile tools needed by today’s data-driven organizations. They serve as a single source of reference for all your data needs. Static metadata repositories requiring expert IT users and loads of manual curation are a thing of the past.
Estimated time to build a data catalog
The time it takes to build a data catalog with OvalEdge depends on the number of databases to be cataloged. As mentioned above, data cataloging has multiple steps and each step takes its time.
Crawling and profiling can be done in a day or two. Uploading an existing data dictionary and building lineage and marking relationships can be done in one week for a database with the help of that database stakeholder. So if an organization ten databases it may take four to five weeks. A big corporation can build its data catalog in about three months and a medium-sized company can do that in two to four weeks.