
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
This article was written for The Data Incubator by Jay Kaiser, a Fellow of our 2018 Winter cohort in Washington, DC.

The Question
The 2016 Presidential Election was, in a single word, weird. So much happened during the months leading up to November that it became difficult to keep track with what who said when and why. However, the finale of the election that culminated with Republican candidate Donald J. Trump winning the majority of the Electoral College and hence becoming the 45th President of the United States was an outcome which at the time I had thought impossible, if solely due to the aforementioned eccentric series of events that had circulated around Trump for a majority of his candidacy.
Following the election, the prominent question that could not leave my mind was a simple one: how? How had the American people changed so much in only a couple of years to allow an outsider hit by a number of black marks during the election to be elected to the highest position in the United States government? How did so many pollsters and political scientists fail to predict this outcome? How can we best analyze the campaigns of each candidate, now given hindsight and knowledge of the eventual outcome? In an attempt to answer each of these, I have turned to a perhaps unlikely source.
The Data
Reddit is an online social platform netting millions of American users each day. With the purpose of providing a medium where users can semi-anonymously share ideas and content, Reddit is a perfect testing ground for gathering data on individuals and groups and the beliefs held by both. Additionally, the site is further subdivided into thousands of communities each dedicated to a specific topic or purpose, known as subreddits. Subreddits range in topic from user hobbies like handbells and kayaking to adherence of ideologies like economics and anarchism. These subreddits, when isolated, paint a clear picture of the types of individuals who participate in them. By comparing the individuals between subreddits, we can see how closely their bases are to each other; therefore, we can visualize relationships between subreddits based on their followers.
Behind the Scenes…
To complete this project, I downloaded the entirety of the Reddit comment corpus for free from Jason Baumgartner’s pushshift.io (though also consider donating to him in thanks for maintaining his resources and for sharing them all freely with the public). The data was originally received in month-by-month compressed JSON files of all Reddit comments given that month. From these, the comments were extracted and converted from their original format to a CSV format that could more easily be saved and analyzed using Pandas. This amounted to around 850 GB of data, though for the purpose of this project, only about half of that was used. Though originally all years and months’ worth of data was to be used in analysis, only data since late 2011 (directly following the election of Barack Obama for his second term) was deemed of a large and high enough quality to make analyses.
To complete this project, I downloaded the entirety of the Reddit comment corpus for free from Jason Baumgartner’s pushshift.io (though also consider donating to him in thanks for maintaining his resources and for sharing them all freely with the public). The data was originally received in month-by-month compressed JSON files of all Reddit comments given that month. From these, the comments were extracted and converted from their original format to a CSV format that could more easily be saved and analyzed using Pandas. This amounted to around 850 GB of data, though for the purpose of this project, only about half of that was used. Though originally all years and months’ worth of data was to be used in analysis, only data since late 2011 (directly following the election of Barack Obama for his second term) was deemed of a large and high enough quality to make analyses.
Analyzing Changing Subreddits Over Time
We can measure the similarities between two subreddits based on a simple metric I’ve used throughout this project. Let a poster be someone who has created an account on Reddit and has actually written up and submitted a comment to a subreddit; these contrast with lurkers, those who have an account on Reddit and frequent certain subreddits, but who never actually provide original content themselves. Because posters actually create original content and provide feedback on other posters through comments, they generate the bulk of the influence of a subreddit. If a subreddit is seen by many but participated in by only a few, then it can be said that the subreddit is of little influence, as the subject material is not of enough importance to be debated or even backed by followers. Conversely, if a subreddit contains a number of comments made only by a single individual or by individuals who only post in that subreddit and not in others, then it too can be seen of little influence, as very few people are involved or interested in discussion of those concepts. With this in mind, we can devise some new terminology that will be used to measure subreddit similarity, based on the metric of shared users between subreddits.
If some poster p has made a comment in any two subreddits S1 and S2 , then p is a shared poster of those subreddits. If p is the only poster who has commented in both S1 and S2 , then S1 and S2 have a shared cardinality of 1. If any two subreddits have a very high shared poster cardinality, that means that the same users post in both of them; hence, they can be seen as containing a very similar user-base. With the exception of some default subreddits that are used by all members of Reddit on a more communal basis, we can learn some interesting inferences through this assumption.
Behind the Scenes…
Using Spark, statistics were gathered month-by-month on each individual subreddit. For each subreddit, these included average comment length, average comment upvotes, the total number of comments, and the complete set of users who had commented in that subreddit. From these, network graphs were created that linked together subreddits based on the counts of their shared users. It is from these network graphs that the data shown below was extracted.
Using Spark, statistics were gathered month-by-month on each individual subreddit. For each subreddit, these included average comment length, average comment upvotes, the total number of comments, and the complete set of users who had commented in that subreddit. From these, network graphs were created that linked together subreddits based on the counts of their shared users. It is from these network graphs that the data shown below was extracted.
For example, let’s take a look at some most similar subreddit pairs during November, 2017. The main subreddit is listed at the top, and the following fifteen subreddits for each are ranked by shared poster count of users with that subreddit. Note that a hand-curated set of default subreddits has been omitted from these listings; they are by default shared among all users of Reddit and hence frequent the top rankings of any shared subreddits, providing little informative gain.
| Politics | Gaming | Nutrition | |||
| PoliticalHumor | 11393 | StarWarsBattlefront | 20569 | Fitness | 154 |
| nfl | 9581 | pcmasterrace | 17970 | loseit | 102 |
| interestingasfuck | 9035 | Overwatch | 14117 | vegan | 99 |
| BlackPeopleTwitter | 8823 | BlackPeopleTwitter | 12285 | keto | 86 |
| nba | 7722 | Games | 11139 | Health | 76 |
| StarWarsBattlefront | 7705 | xboxone | 10563 | Supplements | 68 |
| conspiracy | 6498 | NintendoSwitch | 9966 | AskWomen | 66 |
| The_Donald | 6362 | dankmemes | 9110 | Cooking | 66 |
| pcmasterrace | 6300 | DestinyTheGame | 8806 | EatCheapAndHealthy | 65 |
| CFB | 5942 | trashy | 8644 | Nootropics | 64 |
| trashy | 5667 | PoliticalHumor | 8630 | Frugal | 61 |
| Games | 5510 | StarWars | 8557 | AskMen | 59 |
| atheism | 5175 | nfl | 8512 | relationships | 58 |
| CringeAnarchy | 4806 | leagueoflegends | 8452 | running | 58 |
| insanepeoplefacebook | 4726 | UpliftingNews | 8367 | bodybuilding | 52 |
There are three very interesting things to note here:
- As can be seen, some subreddits are far more popular than others; in this case, both r/politics (dedicated to American politics) and r/gaming (dedicated to video games) are default subreddits, while r/nutrition is not. The numbers of shared posters displays this.
- Some subreddits are more alike to one another than others, based on shared subreddits. For example, r/politics and r/gaming share several subreddits in their rankings of shared subreddits. In comparison, r/nutrition shares no subreddits with either of them in its top rankings.
- The top subreddits under this metric tend to be rather indicative and expected: the top most similar to r/gaming are mostly video game related; a couple of r/politics’ most similar involve political parties and politically relevant subreddits; and all of r/nutrition’s top shared subreddits are related to health and personal betterment.
For the sake of fun (and to show the merit of this politically), three more subreddits’ top fifteen most-similar shared subreddits using this metric are listed below.
| r/The_Donald | r/hillaryclinton | r/SandersForPresident | |||
| conspiracy | 3841 | EnoughTrumpSpam | 93 | PoliticalHumor | 954 |
| The_Congress | 2952 | PoliticalHumor | 83 | conspiracy | 630 |
| CringeAnarchy | 2925 | Enough_Sanders_Spam | 83 | Political_Revolution | 623 |
| PoliticalHumor | 2215 | BlueMidterm2018 | 80 | BlackPeopleTwitter | 603 |
| pcmasterrace | 1937 | neoliberal | 65 | StarWarsBattlefront | 598 |
| StarWarsBattlefront | 1849 | democrats | 57 | pcmasterrace | 578 |
| nfl | 1752 | (r)esist | 54 | LateStageCapitalism | 513 |
| dankmemes | 1728 | SubredditDrama | 53 | (r)esist | 511 |
| BlackPeopleTwitter | 1519 | Fuckthealtright | 49 | atheism | 465 |
| trashy | 1503 | BlackPeopleTwitter | 48 | CringeAnarchy | 453 |
| Bitcoin | 1483 | nfl | 47 | reactiongifs | 437 |
| uncensorednews | 1401 | PoliticalDiscussion | 45 | trashy | 396 |
| ImGoingToHellForThis | 1319 | conspiracy | 38 | nba | 390 |
| nba | 1312 | Trumpgret | 38 | The_Donald | 381 |
| Conservative | 1293 | TwoXChromosomes | 35 | UpliftingNews | 379 |
Additionally, by looking at month-by-month shared poster data, we can see how a subreddit shifts through the overall user-base pool over time. Below, we have the top fifteen shared subreddits with r/politics from the start to the end of Donald Trump’s first year in office.
| r/politics | |||||
| January 2017 | June 2017 | November 2017 | |||
| The_Donald | 20347 | nba | 10514 | PoliticalHumor | 11393 |
| nfl | 13853 | The_Donald | 9956 | nfl | 9581 |
| EnoughTrumpSpam | 11952 | MarchAgainstTrump | 8171 | interestingasfuck | 9035 |
| BlackPeopleTwitter | 11142 | BlackPeopleTwitter | 8143 | BlackPeopleTwitter | 8823 |
| atheism | 10216 | pcmasterrace | 7809 | nba | 7722 |
| TwoXChromosomes | 9487 | PoliticalHumor | 7760 | StarWarsBattlefront | 7705 |
| conspiracy | 9202 | atheism | 6673 | conspiracy | 6498 |
| pcmasterrace | 8582 | nfl | 6109 | The_Donald | 6362 |
| SandersForPresident | 8127 | (r)esist | 6104 | pcmasterrace | 6300 |
| nba | 7362 | trashy | 5929 | CFB | 5942 |
| Overwatch | 7343 | Games | 5840 | trashy | 5667 |
| PoliticalHumor | 7321 | EnoughTrumpSpam | 5501 | Games | 5510 |
| facepalm | 7033 | facepalm | 5492 | atheism | 5175 |
| StarWars | 6523 | CringeAnarchy | 5455 | CringeAnarchy | 4806 |
| Games | 6240 | Overwatch | 5418 | insanepeoplefacebook | 4726 |
Across the span of a single year, the prominence of r/The_Donald has fallen by two-thirds, while the prominence of r/PoliticalHumor has nearly doubled. In addition, some subreddits (e.g. r/MarchAgainstTrump and r/esist) have appeared with prominence suddenly before then dropping into obscurity.
However, this method of viewing the change in popularity of top shared subreddits over time is unideal. It is difficult to be able to view just how sharply a subreddit enters and then leaves the general Reddit political sphere in this way. Hence, let’s analyze these shifts in a different manner.
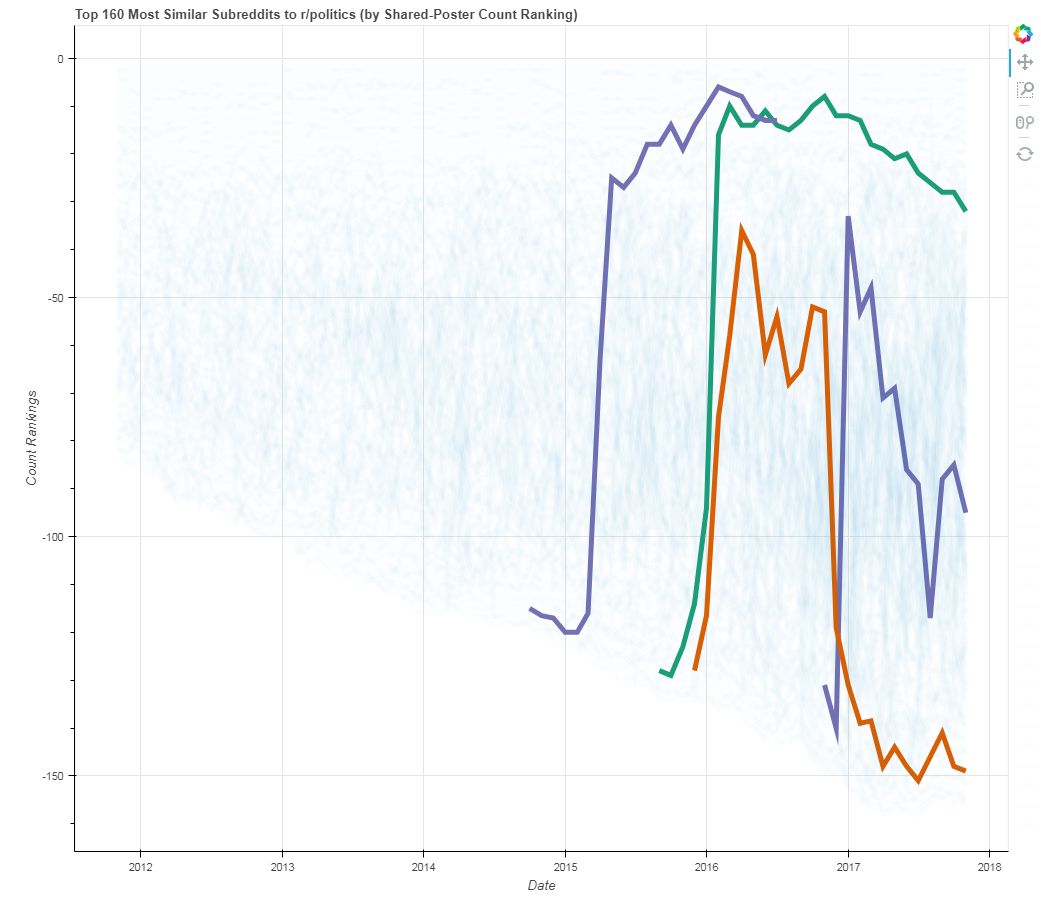
Above, we have a graph of the change of rankings of three top subreddits with that of r/politics. As a subreddit’s line ascends the y-axis, this displays an increase in the ranking of shared poster count between that subreddit and r/politics. The x-axis displays time. Here, the green line represents r/The_Donald (supporting Republican candidate Donald Trump), the orange line represents r/hillaryclinton (supporting Democrat candidate Hillary Clinton), and finally, the blue line represents r/SandersForPresident (supporting Democrat candidate Bernie Sanders).
As can be seen, support for Donald Trump always dwarfed that of Hillary Clinton in the Reddit community; moreover, while discussion in Hillary Clinton’s subreddit rapidly died off following her loss in November, Donald Trump’s subreddit is still one of the most popular shared subreddits with r/politics, even a year after his inauguration. Perhaps the most interesting point to make from this graph involves the third candidate, however; Bernie Sanders held a consistently high following on Reddit, outpacing even Donald Trump. For a few months in 2016, r/SandersForPresident disappears from the dataset as his subreddit was deleted following his loss of the Democratic nomination, his subreddit was deleted; however, he makes a rapid and strong comeback following its recreation, before more slowly again descending down the ranks of subreddit popularity. Take this information as you will, but I would argue that if Sanders were the official Democratic candidate in the 2016 Presidential Election, the outcome today might have differed significantly.
Just for fun, let’s analyze one more graph below: the change in popularity of r/PoliticalHumor:
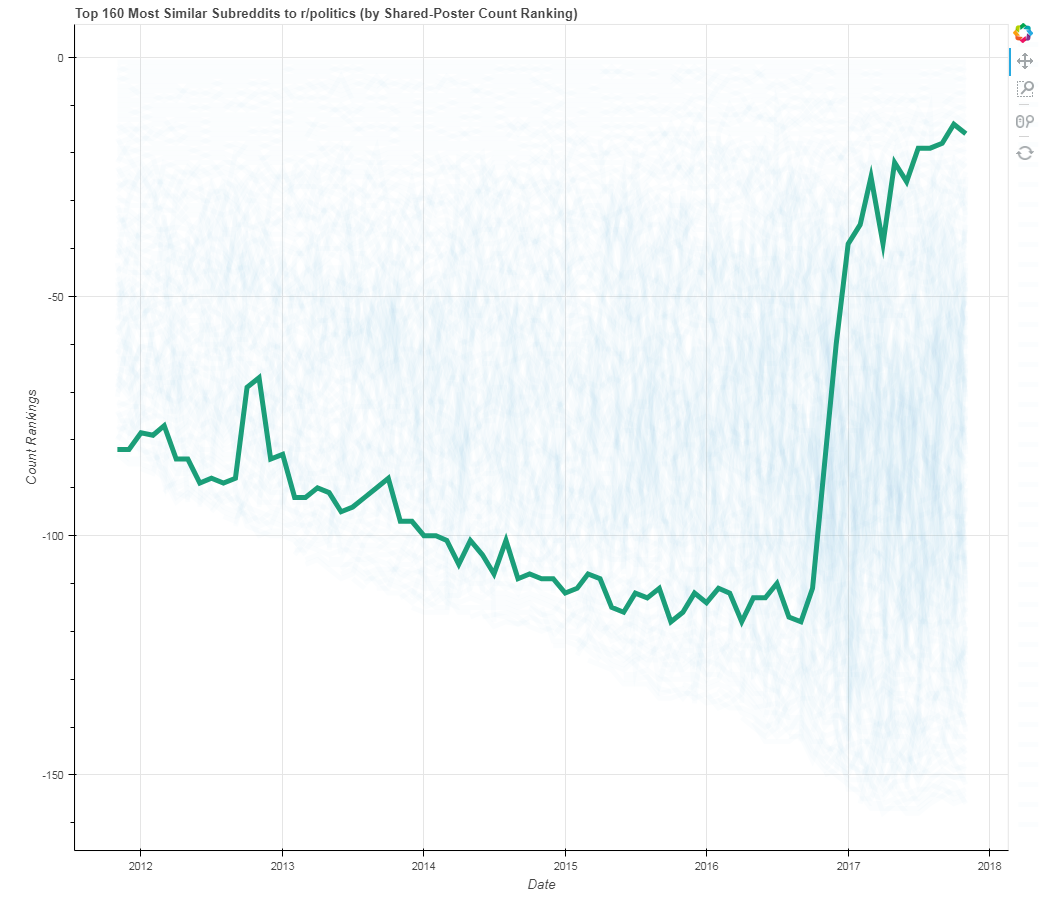
A drastic spike of popularity of this subreddit has only continued to grow in the months following Donald Trump’s election. I wonder why…
Behind the Scenes…
On my website, there are four distinct types of graphs of this nature that can be viewed: Raw Poster Count, Raw Poster Count with Ranking Normalization, Poster Frequencies, and Poster Frequencies with Ranking Normalization. Though each display the same data, they do it in different manners: the Raw Poster Count graph shows rankings based on the number of shared posters between each subreddit and r/politics, while the Poster Frequencies graph shows rankings based on the total proportion of shared posters between each subreddit and r/politics, out of all of the posters who have posted in r/politics. Both of these graphs appear very similar for the most part, although I myself prefer the Raw Poster Count graphs for the sake of their simplicity in explainability.
On my website, there are four distinct types of graphs of this nature that can be viewed: Raw Poster Count, Raw Poster Count with Ranking Normalization, Poster Frequencies, and Poster Frequencies with Ranking Normalization. Though each display the same data, they do it in different manners: the Raw Poster Count graph shows rankings based on the number of shared posters between each subreddit and r/politics, while the Poster Frequencies graph shows rankings based on the total proportion of shared posters between each subreddit and r/politics, out of all of the posters who have posted in r/politics. Both of these graphs appear very similar for the most part, although I myself prefer the Raw Poster Count graphs for the sake of their simplicity in explainability.
However, for both the Raw Poster Count and Poster Frequencies graphs, outliers cause a large number of less popular subreddits to become mashed at the bottom of the graph, preventing easy analysis. Hence, there are ‘with Ranking Normalization’ alternatives to each of these graphs; these display the same data, but instead of displaying raw counts or frequencies, they convert each to a ranking, where the subreddit with the highest number of shared posters is ranked 1, the subreddit with the second highest number is ranked 2, etc. These graphs do not display as well the actual change in popularity of subreddits, but they allow for a more refined analysis between subreddits to be observed.
Analyzing Term-Importance Over Time
Though these graphs show us how subreddits become more or less politically-relevant over time, they don’t show us how important issues have developed throughout the course of the election. For this, we will need a new approach.
Enter Term-Frequency, Inverse Document-Frequency, or TF-IDF for short. TF-IDF follows a simple design: convert any list of documents into individual words (i.e. tokens), and find which tokens appear most often across documents. The result will be a list of the most informative words from the documents, automatically extracted through nothing but the power of math and magic.
Behind the Scenes…
Why use TF-IDF? Well, let’s say we were just collecting the words that appear the most in our comments as the most important words. This is known as term-frequency, and it appears as the first half of TF-IDF. If we gathered only the commonest terms, we’d end up with a list of small, uninformative stop words, as they are known in linguistics, like ‘a’, ‘and’, ‘am’, ‘the’, ‘at’, etc. These are part of the grammatical glue of English. They are in every sentence, but they don’t really give us any information. (Note that often, stop-words are manually removed from the document first before calculating term-frequency, to ensure they don’t find their way in the final list of words.)
Why use TF-IDF? Well, let’s say we were just collecting the words that appear the most in our comments as the most important words. This is known as term-frequency, and it appears as the first half of TF-IDF. If we gathered only the commonest terms, we’d end up with a list of small, uninformative stop words, as they are known in linguistics, like ‘a’, ‘and’, ‘am’, ‘the’, ‘at’, etc. These are part of the grammatical glue of English. They are in every sentence, but they don’t really give us any information. (Note that often, stop-words are manually removed from the document first before calculating term-frequency, to ensure they don’t find their way in the final list of words.)
This is where inverse document-frequency comes in. IDF counts how many documents each word appears in. If a word appears in every document, most likely, there is not much information to gain from it. This removes those extremely frequent stop words mentioned above. The trick is to find the words that appear often, but not too often; these are the words we search for when aiming for informational importance.
For this project, scikit-learn’s TfIdfVectorizer was utilized on a list of all comments from r/politics across time. From this, a list of the top 300 or so politically-relevant words was extracted. The first alphabetical 48 are listed below:
| aca | accusations | action | actually | agree | america |
| american | aren | argument | article | assange | attack |
| automatically | bad | ban | banks | back | believe |
| bernie | best | better | biden | big | black |
| bot | bp | bush | business | campaign | candidate |
| candidates | care | carson | case | change | cheney |
| civil | clinton | come | comey | comment | comments |
| companies | company | compose | concerns | congress | constitution |
Overall, for having no human involvement, these words are pretty spot-on! We have a large number of candidates, political issues, and historic incidents, all found automatically.
Behind the Scenes…
Let’s, however, note a few flaws of this system. In the total listing of words, a couple singular-plural noun pairs exist of the same term (e.g. company, companies). These words are not identified as the same underlying concept, so they are both seen as important. Using additional linguistic concepts like stemming or lemmatizing would reduce these errors, at the cost of additional computational processing time.
Let’s, however, note a few flaws of this system. In the total listing of words, a couple singular-plural noun pairs exist of the same term (e.g. company, companies). These words are not identified as the same underlying concept, so they are both seen as important. Using additional linguistic concepts like stemming or lemmatizing would reduce these errors, at the cost of additional computational processing time.
Another issue arises with the inclusion of ‘aren’ in the list above. This refers not to any real life entity, but instead to the beginning of the contraction ‘aren’t’. In the tokenizing process, apostrophes are recognized as a word divider (just like spaces and other punctuation). However, although most contractions are seen as stop words, few stop word lexicons contain ‘aren’ as an entry, hence its appearance here.
Finally, further on, we have a number of swear words included in our listing. These words appear at just the right ratio to be seen as informationally informative. Note that while on their own, they don’t provide very much information, they may be able to show sentiment or change of emotion over time. Apart from utilizing an actual sentiment parser, these may be a quick and dirty way to see the emotional state of each subreddit as time went on during the election.
Now, we can see how often each of these words appeared in a subreddit over time. By tracking these, let’s see if we can make any inferences over the importance of certain concepts in each subreddit. Note that the list of political subreddits used here was taken from r/politics itself; the list has been curated by moderators as related subreddits that are politically relevant to r/politics, using a metric unknown (that is most likely just common sense).
For example, let’s graph the appearance of the word debate in r/politics by frequency of comments that contain that word over time.
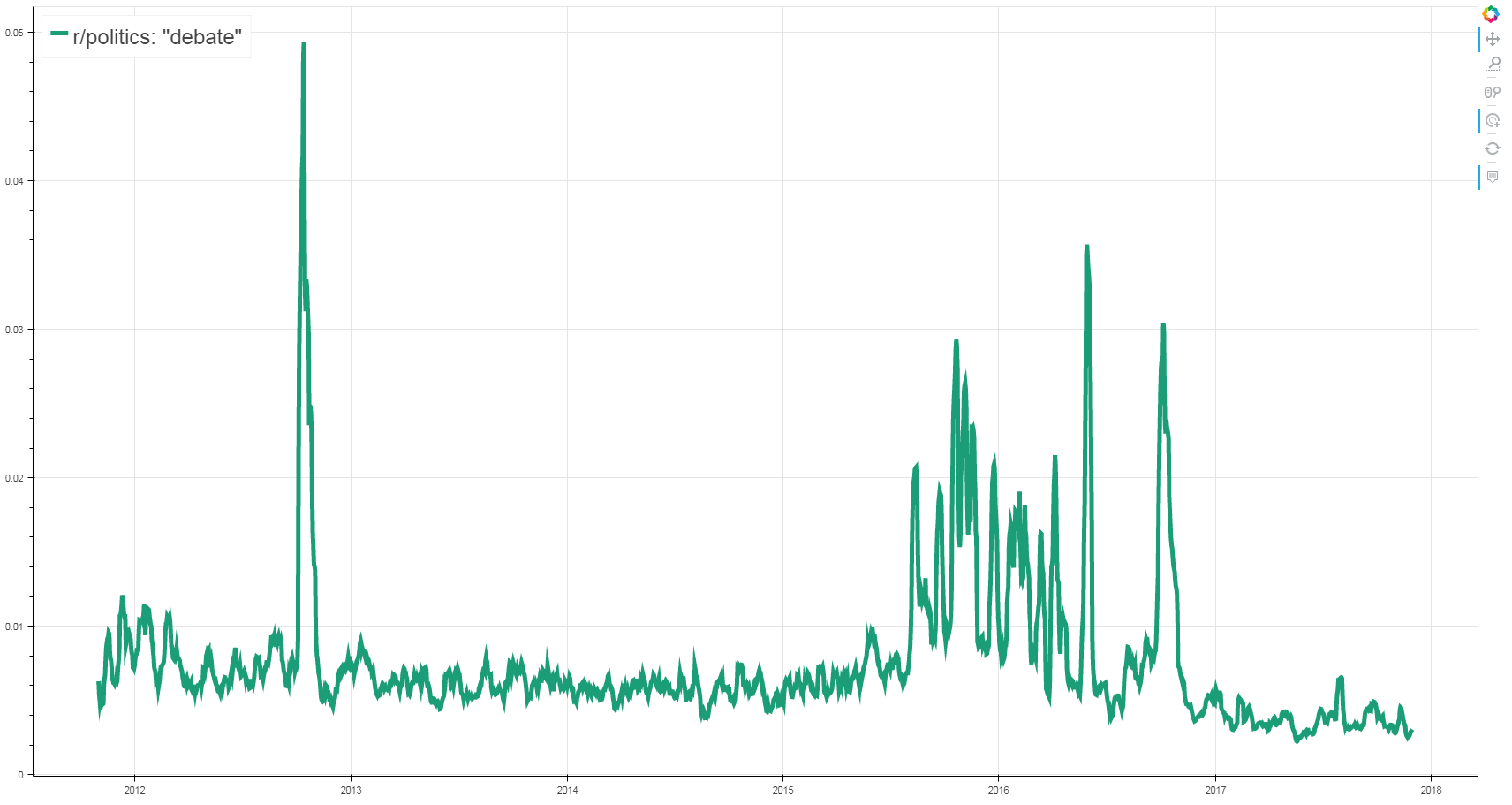
At the tallest spike on this graph, 5% of all comments in r/politics contained the word debate, highlighting its importance in discussion. But what was happening at each of these times to warrant such spikes? Each spike aligns to a major debate that occurred during an election, with exception to the very high, yet less clear period that occurs in late 2015 and early 2016. This time instead highlights a frequent discussion of certain comments said during debates by a specific candidate that circulated long after the debate had finished, perhaps displaying the messiness of this election in comparison to others. On my site, you yourself can click anywhere on this graph to see a list of top news results at this time that result from a Google search of the keyword and the word politics.
For another example, let’s see how the appearance of the word healthcare changes over time for each of the three most popular political candidates from the 2016 election.
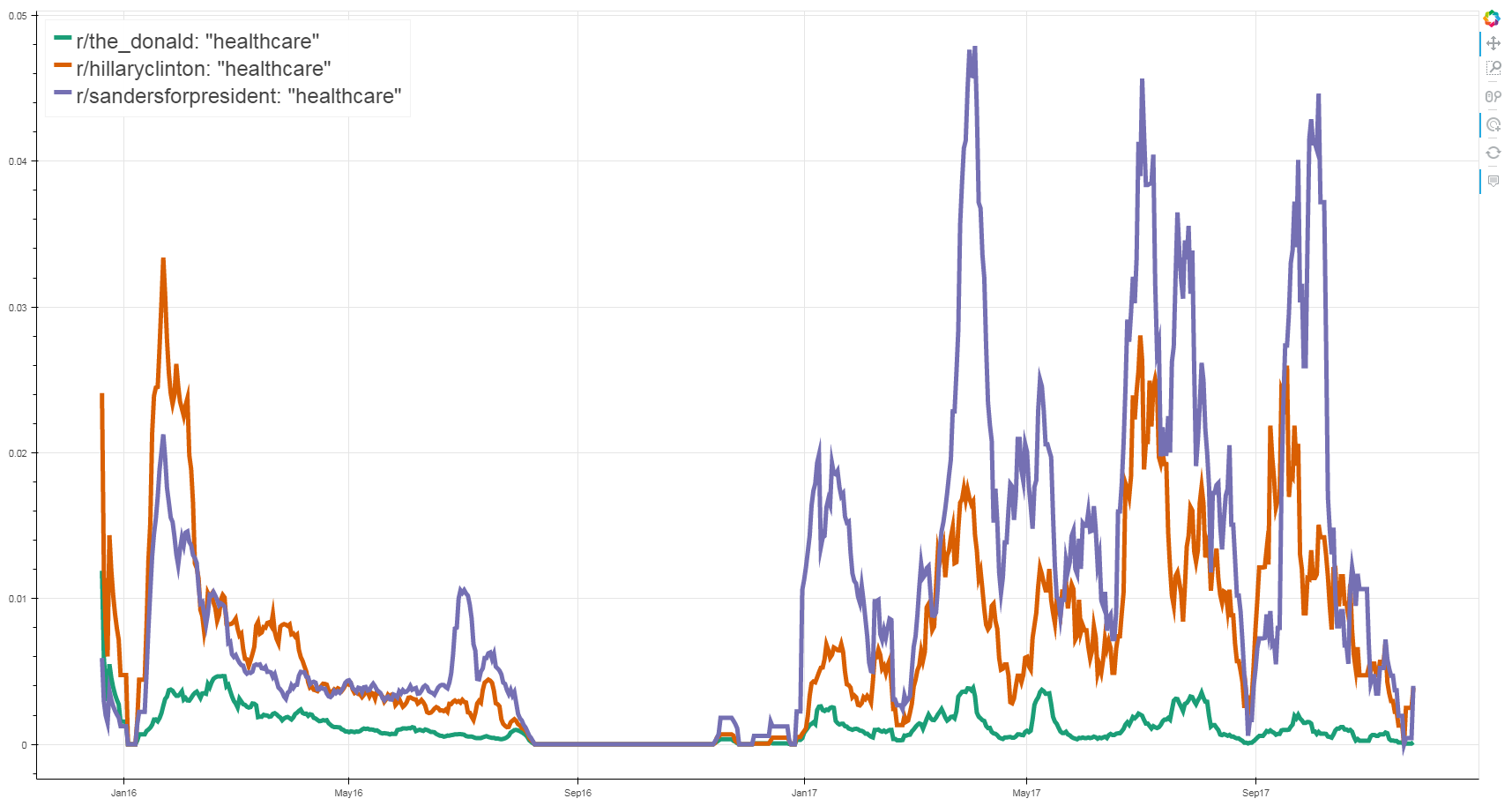
What do we notice? Overall, there is either surprisingly little talk of healthcare in r/The_Donald, or the discussion of it is being drowned out by a number of other topics. In comparison, r/hillaryclinton and r/SandersForPresident shows a strong discussion of it, prominently at three particular times. The three highest spikes here occurred as the GOP was attempting to pass different iterations of their replacement of Obamacare, and the spikes may display the fervor Sanders’ followers hold to his ideology, particularly to that of his believe in universal healthcare. Despite their losses in the election, followers of both Hillary Clinton and Bernie Sanders still heavily debate the platforms of their candidates after the election when these issues become relevant in the media.
With so many combinations of keyword and graphs, there are endless possible inferences that can be discovered through Reddit data. Feel free to visit the site yourself and see what you can come up with!
Some Caveats to This Project, and Their Rebuttals
There are several important points that can be raised in opposition to the validity of this project, both regarding the dataset I chose to use for this project and the metrics I used to measure subreddit similarities.
Claim
Only a certain subset of the population uses Reddit (i.e. younger audiences more comfortable with the internet). Moreover, people from all over the world can post in any subreddit (i.e. they are not country-restricted), and there is no way to track where each user comes from. Therefore, surely this does not provide a realistic view of voters and the politically active in the United States, especially given how publicized the 2016 Presidential Election was around the world.
Rebuttal
I will admit that both these facts are true; however, given that around 1.5 billion unique users visited Reddit on average per month in 2017, and given that around 40% of those were from the United States, it is hard not to see the influence of Reddit on the American users of the web.* Even given only six percent of internet users use Reddit in their spare time, that is still six percent of the population from which strong inferences can be made regarding their political views and beliefs. Finally, although it is true that most people who use Reddit are younger, they are very diverse in income, race, and education.* This provides a nice cross-section of the general population, especially from those who utilize social media the most in not only consuming facts, but in questioning them as well. I will admit that this project does not fully represent the country; however, generalizations and trends are entirely worth attempting to dissect from this data, especially given the rise of misinformation following the election.
Claim
Using shared poster-count between subreddits does not paint an accurate picture of followers of those subreddits, given people may post in subreddits to provide opposing views or to spur discussion for those who frequent the subreddit. This is lumping together users who believe in an ideology and those who debate against it.
Rebuttal
This is true. My metric does nothing to prevent users who debate against a certain subreddit from being classified as users of that subreddit. However, I feel the impact of this is much smaller than one may think; instead, most subreddits pose more as echo chambers for a topic more often than as proper debate forums. Reddit even uses a term for this–circlejerking–to describe when users simply upvote and give praise to one another and discourage those who don’t believe in the same ideology. Although there are some subreddits whose sole purpose is to provide a positive space for structured debate, most political subreddits do not function with this same purpose.
Conclusion
Overall, this project has not answered the questions formulated at the beginning of this blog. Instead, I have created a medium to allow myself and others to try to discover electoral influences based on the data at hand. With hundreds of keywords across hundreds of subreddits, only time is the limit in attempting to find correlations between users of certain subreddits and results from the election. More work will be done on the project over time (not only to streamline and advance the pipeline, but to make a much prettier and more user-friendly website), but for now, you can visit my site yourself to learn more and to play around with the data.
Author
Jay Kaiser completed the 2018 Winter Cohort at The Data Incubator in Washington, D.C. He received his Masters of Science in Computational Linguistics from Indiana University just prior to participating in the program, and is working to continue my knowledge and application of natural language processing in any and all future endeavors. If you’d like to learn more about Jay, you can visit his personal website here.