
MMS • RSS
By Ben Paul, Solutions Engineer – SingleStore
By Aman Tiwari, Solutions Architect – AWS
By Saurabh Shanbhag, Sr. Partner Solutions Architect – AWS
By Srikar Kasireddy, Database Specialist Solutions Architect – AWS
 |
| SingleStore |
 |
The fast pace of business today often demands the ability to reliably handle an immense number of requests daily with millisecond response times. Such a requirement calls for a high-performance, non-schematic database like Amazon DynamoDB. DynamoDB is a serverless NoSQL database that supports key-value and
document data models that offers consistent single-digit millisecond performance at any scale. DynamoDB enables customers to offload the administrative burdens of operating and scaling distributed databases to AWS cloud so that they don’t have to worry about hardware provisioning, setup and configuration, throughput capacity planning, replication, software patching, or cluster scaling.
Perform near real-time analytics on DynamoDB data allows customers to quickly respond to changing market conditions, customer behavior, or operational trends. With near real-time data processing, you can identify patterns, detect anomalies, and make timely adjustments to your strategies or operations. This can help you stay ahead of the competition, improve customer satisfaction, and optimize your business processes.
SingleStore is an AWS Data and Analytics Competency Partner and AWS Marketplace Seller. It’s SingleStore Helios is a fully managed, cloud-native database that powers real-time workloads needing transactional and analytical capabilities.
By combining DynamoDB with SingleStore, organizations can efficiently capture, process, and analyze DynamoDB data at scale. SingleStore has high-throughput data ingestion and near-real time analytical query capability for both relational and JSON data. This integration empowers businesses to derive actionable insights from their data in near real time, enabling faster decision-making and improved operational efficiency.
SingleStore has the ability to stream Change Data Capture (CDC) data from DynamoDB and serve up fast analytics on top of its Patented Universal Storage. SingleStore has native support for JSON so DynamoDB items can be stored directly in their own JSON column. Alternatively, key-value pairs from DynamoDB can be stored as own column in SingleStore.
In this blog post we will cover two architectural patterns to integrate DynamoDB with Singlestore in order to perform near real-time analytics on your DynamoDB data –
- Using DynamoDB Stream and AWS Lambda
- Using Amazon Kinesis Data Streams connector with Amazon MSK
Using DynamoDB Stream and AWS Lambda
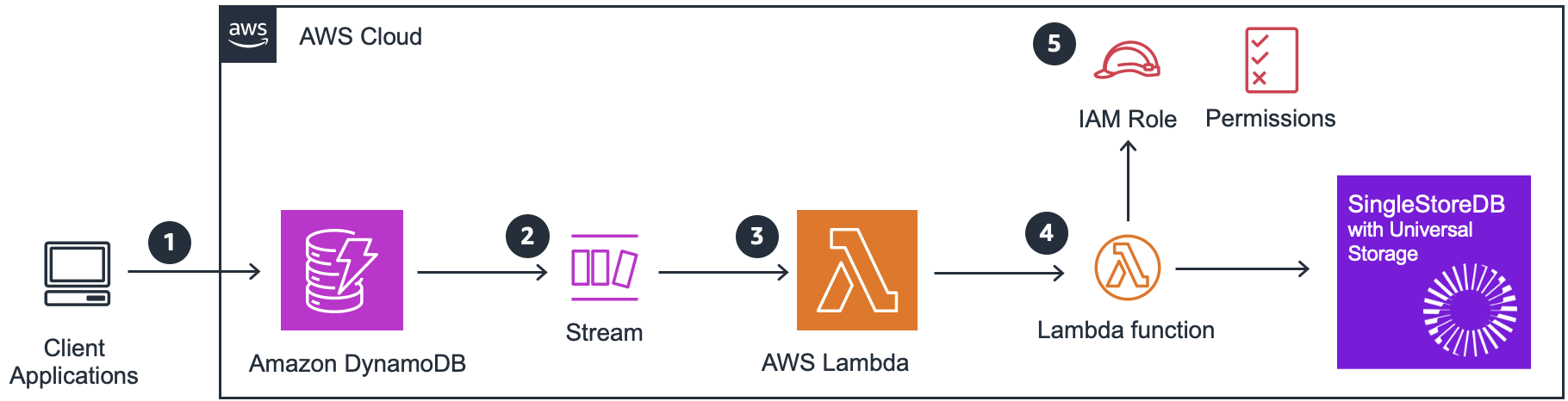
Figure 1 – Architecture pattern for Amazon DynamoDB CDC to SingleStore using DynamoDB Stream and AWS Lambda
The design pattern described leverages the power of DynamoDB Stream and AWS Lambda to enable near real-time data processing and integration. The following is the detail workflow for the architecture:
1. Client applications interact with DynamoDB using the DynamoDB API, performing operations such as inserting, updating, deleting, and reading items from DynamoDB tables at scale.
2. DynamoDB Stream is a feature that captures a time-ordered sequence of item-level modifications in a DynamoDB table and durably stores this information for up to 24 hours. This allows applications to access a series of stream records containing item changes in near real-time.
3. The AWS Lambda service polls the stream for new records four times per second. When new stream records are available, your Lambda function is synchronously invoked. You can subscribe up to two Lambda functions to the same DynamoDB stream.
4. Within the Lambda function, you can implement custom logic to handle the changes from the DynamoDB table, such as pushing the updates to a SingleStore table. If your Lambda function requires any additional libraries or dependencies, you can create a Lambda Layer to manage them.
5. The Lambda function needs IAM execution role with appropriate permissions to manage resources related to your DynamoDB stream.
This design pattern allows for an event-driven architecture, where changes in the DynamoDB table can trigger immediate actions and updates in other systems. It’s a common approach for building real-time data pipelines and integrating DynamoDB with other AWS services or external data stores.
This pattern is suitable for most DynamoDB customers, but is subject to throughput quotas for DynamoDB table and AWS Region. For higher throughput limit you can consider provisioned throughput or the following design pattern with Amazon Kinesis Data Streams connector.
Using Amazon Kinesis Data Streams connector with Amazon MSK
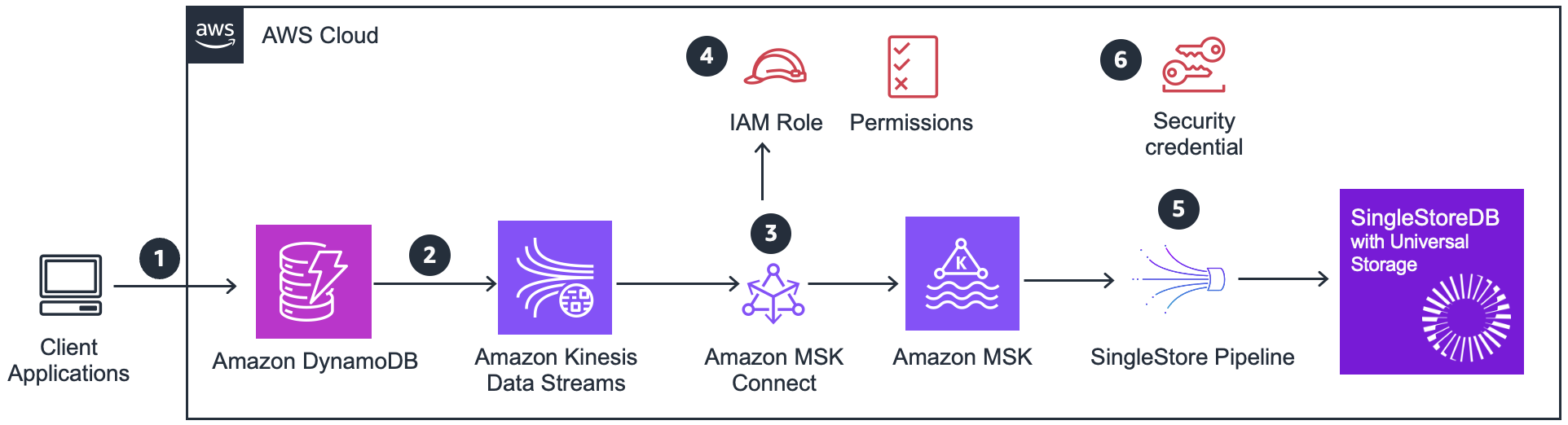
Figure 2 – Architecture pattern for Amazon DynamoDB CDC to SingleStore using Amazon Kinesis Data Streams
This design pattern leverages Amazon Kinesis Data Streams and Amazon MSK to enable more flexible data processing and integration. The following is the detail workflow for the architecture:
1. Client applications interact with DynamoDB using the DynamoDB API, performing operations such as inserting, updating, deleting, and reading items from DynamoDB tables at scale.
2. Amazon Kinesis Data Streams captures changes from DynamoDB table asynchronously. Kinesis has no performance impact on a table that it’s streaming from. You can take advantage of longer data retention time—and with enhanced fan-out capability, you can simultaneously reach two or more downstream applications. Other benefits include additional audit and security transparency.
The Kinesis data stream records might appear in a different order than when the item changes occurred. The same item notifications might also appear more than once in the stream. You can check the ApproximateCreationDateTime attribute to identify the order that the item modifications occurred in, and to identify duplicate records.
3. Using an open-source Kafka connector from the GitHub repository deployed to Amazon MSK Connect to replicate the events from Kinesis data stream to Amazon MSK. With Amazon MSK Connect, a feature of Amazon MSK, you can run fully managed Apache Kafka Connect workloads on AWS. This feature makes it easy to deploy, monitor, and automatically scale connectors that move data between Apache Kafka clusters and external systems.
4. Amazon MSK Connect needs IAM execution role with appropriate permissions to manage connectivity with Amazon Kinesis Data Streams.
5. Amazon MSK makes it easy to ingest and process streaming data in real time with fully managed Apache Kafka. Once the events are on Amazon MSK, you get the flexibility to retain or process the messages based on your business need. It gives you the flexibility to bring in various downstream Kafka consumers to process the events. SingleStore has a managed Pipelines feature, which can continuously load data using parallel ingestion as it arrives in Amazon MSK without you having to manage code.
6. SingleStore pipeline supports connection LINK feature, which provides credential management for AWS Security credentials.
This pattern gives you the flexibility to use the data change events in MSK to incorporate other workloads or have the events for longer than 24 hours.
Customer Story
ConveYour, a leading Recruitment Experience Platform, faced a challenge when Rockset, their analytical tool, was acquired by OpenAI and set for deprecation. Demonstrating remarkable agility, ConveYour swiftly transitioned to SingleStore for their analytical needs.
ConveYour CEO, Stephen Rhyne said “Faced with the impending deprecation of Rockset’s service by the end of 2024, ConveYour recognized the urgent need to transition our complex analytical workloads to a new platform. Our decision to migrate to SingleStore proved to be transformative. The performance improvements were remarkable, particularly for our most intricate queries involving extensive data sets. SingleStore’s plan cache feature significantly enhanced the speed of subsequent query executions. Furthermore, the exceptional support provided by SingleStore’s solutions team and leadership was instrumental in facilitating a swift and efficient migration process. This seamless transition not only addressed our immediate needs but also positioned us for enhanced analytical capabilities moving forward.”
Conclusion and Call to Action
In this blog, we have walked through two patterns to set up a CDC stream from DynamoDB to SingleStore. By leveraging either of these patterns, you can utilize SingleStore to serve up sub-second analytics on your DynamoDB data.
Start playing around with SingleStore today with their free trial, then chat with a SingleStore Field Engineer to get technical advice on SingleStore and/or code examples to implement the CDC pipeline from DynamoDB.
To get started with Amazon DynamoDB, please refer to the following documentation – https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/GettingStartedDynamoDB.html.

.
SingleStore – AWS Partner Spotlight
SingleStore is an AWS Advanced Technology Partner and AWS Competency Partner that provides fully managed, cloud-native database that powers real-time workloads needing transactional and analytical capabilities.
Contact SingleStore | Partner Overview | AWS Marketplace
About the Authors

Ben Paul is a Solutions Engineer at SingleStore with over 6 years of experience in the data & AI field.

Aman Tiwari is a General Solutions Architect working with Worldwide Commercial Sales at AWS. He works with customers in the Digital Native Business segment and helps them design innovative, resilient, and cost-effective solutions using AWS services. He holds a master’s degree in Telecommunications Networks from Northeastern University. Outside of work, he enjoys playing lawn tennis and reading books.

Saurabh Shanbhag has over 17 years of experience in solution integration for highly complex enterprise-wide systems. With his deep expertise in AWS services, he has helped AWS Partners seamlessly integrate and optimize their product offerings, enhancing performance on AWS. His industry experience spans telecommunications, finance, and insurance, delivering innovative solutions that drive business value and operational efficiency.

Srikar Kasireddy is a Database Specialist Solutions Architect at Amazon Web Services. He works with our customers to provide architecture guidance and database solutions, helping them innovate using AWS services to improve business value.