
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Continuous Delivery is about working in a way so that the system is always in a releasable state. It often requires organisational, technical and development-cultural changes to achieve. It is not Continuous Delivery if you cannot release to Production now!
- There are many incremental wins to be had on the way to Continuous Delivery. It is an adoption process rather than a single switch.
- Adopting Continuous Delivery requires all roles in the project to share common goals. We work together to learn quickly and deliver great software to our users..
- In any organization, different teams will adopt different bits of Continuous Delivery at different rates. The transformation is not going to be one-size-fits-all.
- Continuous Delivery requires that we get the fundamentals right. We practice disciplines such as reliable automated testing, establishing the correct scope for deployment pipelines as well as an effective breakdown of requirements.
Overview
Continuous Delivery is about working in a way that keeps the system in a releasable state throughout its development. This, seemingly simple idea, requires rethinking of all aspects of a traditional software development process.
In this article, we will describe how a large software development organization at Siemens Healthineers started the transformation towards Continuous Delivery. We will describe the strategy and tactics used to gradually and safely change the development process in a regulated medical domain.
teamplay is developed by Siemens Healthineers. It is a performance management solution for medical institutions that brings together healthcare professionals in order to advance medicine and human health in a team effort.
By connecting medical institutions and their imaging devices, teamplay apps aspire to create the biggest radiology and cardiology team in the world and provide its members with tools to tackle big data and the challenges of increasing cost pressure in these departments.
The cloud-based solution teamplay with its apps will help to make prompt and well-informed decisions by offering an intelligible overview of performance data.
It monitors quantities such as imaging throughput or dose levels, utilization of staff, rooms and resources of your whole department down to every device and procedure, simplifying reporting and showing where workflows need adjustments.
It links to other users of teamplay and their data to offer comparable benchmarks and an effortless exchange of images and reports with other healthcare providers.
Applications
Examples of applications hosted by teamplay network are teamplay Usage and teamplay Dose. teamplay Usage allows healthcare institutions to monitor scores and trends like patient change times or the number of examinations performed at different imaging scanners.
[Click on the image to enlarge it]
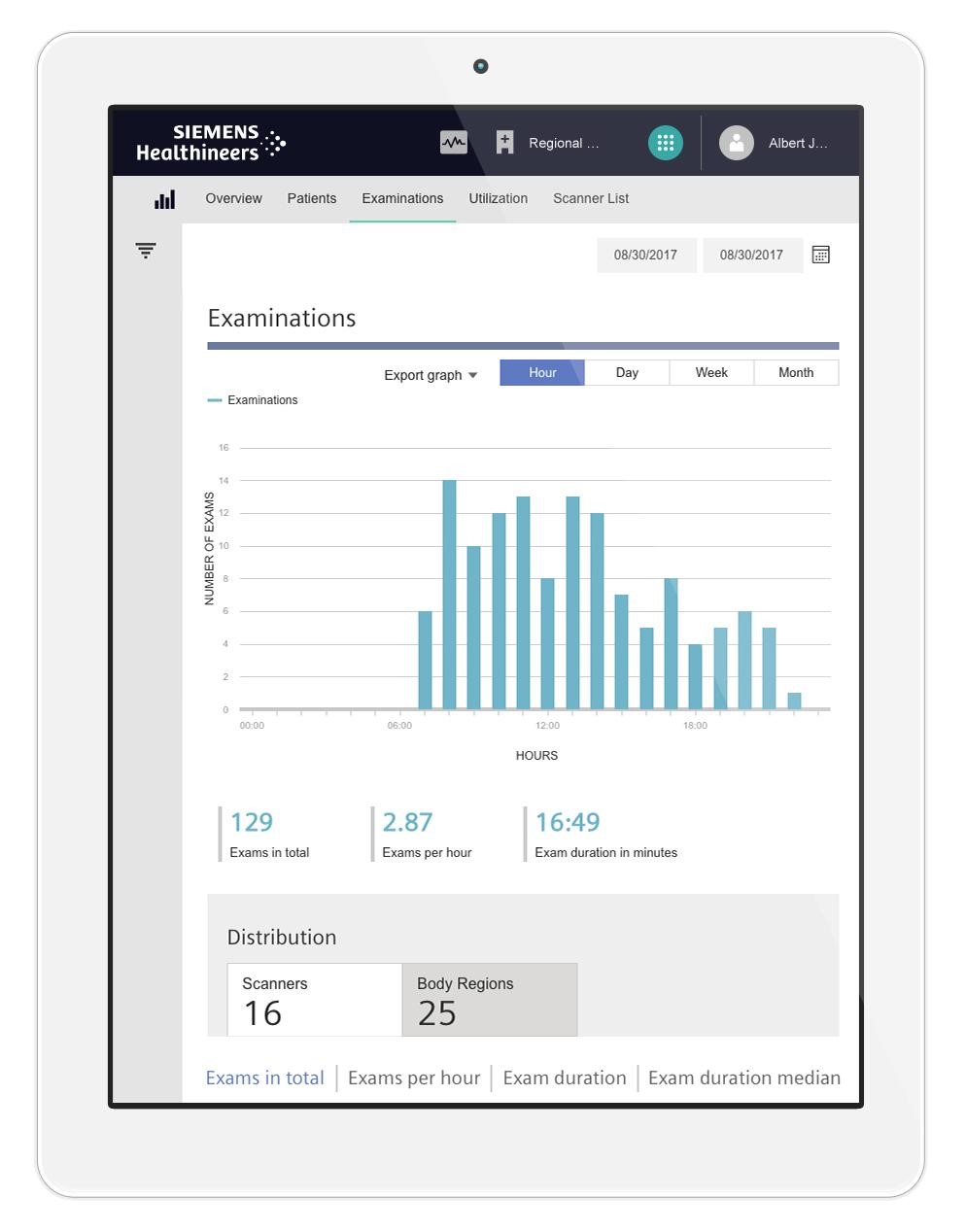
teamplay Dose provides health institutions with insight into radiation dose levels used by scanners and highlights deviations from both internal and national thresholds.
More than 2550 teamplay connects, and growing, are now part of the network. The number of applications plugged into teamplay public APIs by 3rd parties is steadily growing as well. Once a healthcare institution is connected to the network, the imaging scanners of the institution send data to the Cloud on a continuous basis.
The Technology
This data is consumed by teamplay services that run in Microsoft Azure Cloud. Users interact with services via a user interface, implemented as a Single Page Application, in AngularJS. Frontend integration is simple, via iFrames, and so 3rd party applications that use teamplay public APIs are able to pick their own technology.
Improving the Development Process
Changes to the teamplay system are currently released on a quarterly basis. We aim to speed this up significantly. This would allow us to release features more quickly and so to be more responsive to user demand. From the technical point of view, faster delivery and shorter cycle-times should help us to reduce batch-sizes, making changes simpler and so lower-risk, and to reduce the stabilization phase, that is currently required, at the end of each release. By improving quality throughout the process, we intend to improve the predictability of our release dates.
With these goals in mind, the teamplay development team started working on deployment automation. First, we worked to automate development deployments. Then we added automated sanity-tests, that check the main functionality of our applications. These tests determine whether, or not, a deployment is in a usable state. They are executed immediately after a deployment has taken place and signal to the development team whether a build is fit to be used for exploratory testing.
The automation of our deployment and sanity-tests brought a very significant improvement in the stability of the product. However, it still remained challenging to make more frequent releases and to reduce the stabilization phase that precedes each release.
Adopting Continuous Delivery
Continuous Delivery (CD) is an approach to software development grounded in a more disciplined engineering approach. It is about much more than the technicalities of deployment-automation and automated testing. The goal of CD is to maintain the software, throughout its development, in a releasable state. This simple idea impacts on every aspect of an organisation’s approach to software development. Releasability is required from both technical and business standpoints. To achieve that both technical engineering and requirement engineering need to be adjusted.
We asked Dave Farley to help teamplay with a variety of aspects of our software development approach. Our fundamental goals were to improve the safety, stability and efficiency of our development process.
Safety is of critical importance, teamplay develop software used, and regulated within, the sphere of healthcare. Compliance with regulation and the production of high-quality products is extremely important.
teamplay’s fairly traditional approach to development had some of the traditional problems. Perhaps most importantly, a continual reduction in the team’s ability to produce new features at the desired rate as the software and the organisation grew in complexity.
Our aim was to overcome these difficulties through the application of good engineering discipline. We aimed to increase the quality and frequency of feedback, improve collaboration across the entire organization, and begin moving the development culture to a more disciplined, high-quality, engineering approach.
Efficient processes and mechanisms that provide high-quality feedback are fundamental to allow teams and individuals to better see the outcomes of their work and decisions. Good feedback is a hallmark of any high-quality process.
Effective collaboration is vital. We aimed to optimize for a more distributed mission-focused leadership style. The distributed nature of the teamplay organisation means that it is even more important to ensure that decisions could be made locally, close to the work. Establishing effective team structures and good working practices encourage a more distributed approach to decision-making. This is an important, enabling, step towards a stronger engineering culture.
We approached these changes through a mixture of training, coaching and thinking more broadly in terms of culture-change. Each team had some training in the ideas and philosophy of Continuous Delivery. This improved the understanding of what was being asked of everyone to achieve this kind of change.
We followed this up with more detailed, hands-on training around some of the specific skills that we were asking people to adopt. We had people with experience of CD working alongside the teams that were learning this new approach.
At the more technical end we worked on improving feedback through better automated tests and more efficient deployment pipelines. Story-mapping to help in the requirements process and the use of techniques like the use of Domain Specific Languages which link with the stories generated by the story-mapping to provide a linked-up approach to development based on these “executable specifications”.
Many of these changes are still in progress. Adoption varies by team and some of the more technically difficult, and wide-spread culture, changes are yet to be completed. However this was always to be expected. This is a long-term process of change aimed at increasing the development process safely and incrementally.
Choosing a Strategy for Change
Given where the teamplay development process was when we started the transformation to Continuous Delivery, it was clear that the feedback cycle from tests back to the teams needed to be shortened. It took us between 24 and 48 hours to learn the outcome of a test run. We wanted to shorten this to 1 hour via a series of steps aimed to improve the quality of our feedback.
To do so a fundamental decision needed to be taken. We could stay with our existing pipeline, that deployed and evaluated teamplay in one go, and work on making it faster. This would involve scaling our build servers, both up and out. We would need to explore incremental compilation, and work to execute only the tests impacted by a change to the software. Alternatively, we could decompose our architecture into microservices and create a dedicated pipeline per microservice.
We decided on a middle-ground solution. Something in-between these two orthogonal options. We decided, instead, to create a dedicated pipeline per teamplay application.
This approach did not require us to invest in complex engineering to make monolithic deployments and accompanying test runs faster. It also did not require us to break down the architecture into very small pieces and engineer backwards compatible contracts between them. We may consider the microservice approach in future but for now we are just focussing on making each application as a whole independently releasable from the rest of teamplay.
Once the decision to create a dedicated pipeline per teamplay application was made, we needed to look closely at how the teams worked to create new features and how to keep the pipeline fed. In other words, we needed to look at how the teams worked to define, implement and test features.
Improving Quality
It is essential to have a process that ensures that the input to the pipeline created by the teams is of a quality necessary to allow for full and reliable automation. Just having a pipeline, or a pipeline per application, is not a goal in itself. The goal is to be able to make high quality application releases to production. Achieving this requires high quality input to the pipeline by the teams, and an efficient pipeline that can run that input as fast as possible in order to provide the feedback that helps the teams to do high-quality work.
Mapping Continuous Delivery
In a series of workshops, coaching sessions and training courses we established our Model for Continuous Delivery illustrated below.

The picture shows the way we want to define, test, implement and deploy changes to the product.
At the top of the picture, the methodologies that we use are listed: Test-Driven Development (TDD), Behavior-Driven Development (BDD), Domain-Driven Design (DDD), Pair Programming and Pair Rotation (Pairing) as well as Team Deployment Pipeline. All these methodologies applied together by all team members are going to bring us to the point where our applications will be in an always releasable state. The decision to release will then not be hindered by the time period necessary to achieve the technical readiness for release but rather be done based on pure business and regulatory considerations.
Whenever you see a little colorful small person icon in the picture, it denotes the role that should be doing a particular step of the process: Product Owner (PO), Business Analyst (BA), Designer (Des), Architect (AR), Developer (Dev), Operations Engineer (Ops). The colors of the main lines in the picture denote the methodology (TDD, BDD, DDD, Pairing) that should be used by the respective role, as illustrated by the legend at the top of the picture.
Also at the top of the picture, the way we want to specify the product using a User Story Map and BDD scenarios is shown. On the right of the picture, the way we want to test the product creating a Domain Specific Language (DSL) to express our test cases, Acceptance Tests and TDD is illustrated. At the bottom of the picture, the way we want to deploy the product using a Team Pipeline with 4 stages (Accept 1, Accept 2, Staging, Production) is shown.
This diagram has been very useful. As well as helping us to organise our thinking, with the picture, people in the project can now quickly find out what they should be doing to contribute to Continuous Delivery based on their current role.
Process Run-Through
Let us demonstrate by running a feature through our process, shown in the picture above.
Hypothesis
Imagine someone on the team has an idea for a new feature. The first step is to state a hypothesis we want to test. This is done using a triple:
- We believe that this <capability>
- Will result in this <outcome>
- We will know we have succeeded when we see a <measurable signal>
All the subsequent steps of the process are there to prove the stated hypothesis right or wrong. It is important to state the hypothesis as it provides the scope for work: we only need to implement as much functionality and production instrumentation as needed to be able to test the hypothesis.
Lo-Fi Prototype
The next step in the process is to prototype the idea to get early feedback from the customer whether the idea resonates with them and should be invested in further. This is done by the PO and Designer as a low-fidelity prototype (e.g. a paper prototype or wireframe of the concept quickly created by hand).
Next, the PO and Designer sketch the feature in a low-fidelity way just to be able to explain it to other roles in the project.
Story Mapping
With the next step, everybody gets involved in the creation of a User Story Map. The User Story Map shows user journeys associated with the feature in a hierarchical way. Product Owners, Architects, Business Analysts, Designers and Developers all engage in a discussion to understand, and map out, the journeys the user will take when working with the feature. It is important to take into account all of the steps the user will go through, also those performed outside the product, if any. Everyone on the team needs to understand the user journeys.
Once the User Story Map is created, the next step is to prioritise the work and decide on a small set of stories that will be released first. This set of stories will form our Minimal Viable Product (MVP). After that a single story out of the MVP set is chosen for refinement.
Creating BDD Scenarios
The refinement is done using so-called BDD Scenarios. Each scenario is expressed in the Gherkin language using Given / When / Then Statements. It is important to make sure that Product Owners, Architects, Business Analysts, Developers and Operations all contribute to the set of scenarios for a story because each role looks at the project from a different perspective.
The PO usually contributes an initial set of scenarios from a functional perspective. The entire team together can extend the initial list of functional scenarios. The Architect can for example additionally contribute scenarios from load and security perspective. The Operations Engineers can contribute scenarios related to monitoring and logging. The Business Analyst is responsible for making sure that the team covers all the perspectives (or “ilities”).
We aim to keep stories small. If the number of scenarios for a user story is more than 6 or so, the user story is too big and needs to be divided into smaller features in the User Story Map.
We also aim to keep our stories focussed on user need, stories and scenarios should not contain any technical details (no references to implementation details or UI) but rather be purely written from the user’s perspective.
A good test of that is to imagine providing the 1st level support with the user stories and scenarios to be used when customer calls need to be answered regarding the features implemented. If the user stories and scenarios are written from the user perspective without implementation details, they should be really useful to the 1st level support when answering customer calls.
BDD and DSL
Once a set of BDD Scenarios for a user story has been agreed by the team, the work begins to test and implement the scenarios one by one. We take a real test-first approach where no product code is produced until the right test harness is in place. This ensures that tests are abstracted, have a good separation of concerns, from the product code, which in turn helps reduce test maintenance costs.
The first step to test a scenario is to start a new, or extend an existing, so-called Domain-Specific Language (DSL) or, in this case, a Test DSL. The Test DSL is inspired by the Domain-Driven Design (DDD) methodology to use the same language in all conversations occurring between an idea discussion over user story and scenario definition all the way to the actual code.
With the Test DSL we define the BDD Scenarios written in Gherkin language in an executable and reusable form. The reusability is only possible, however, if the scenarios are previously defined without implementation details. Another advantage of this is that the Test DSL can be written by less technical people, who understand the problem domain well. This allows them to specify their requirements very precisely, because the specification is executable.
Once the Test DSL for a scenario is defined, it is implemented by developers in an Acceptance Test. This is the first time we are making implementation decisions. We want to test as much as possible through APIs because these tests run fast and are much less brittle than UI tests. However, in some cases, we still want to test through the UI to be sure that a given functionality is working in combination of frontend and backend.
Another point to make here is that our Acceptance Test Case is effectively defined at the DSL level without implementation details. This means that, as and when, we adapt the Acceptance Test Implementation as we go along, our Acceptance Test Case Definition does not change. We can easily verify adapted product functionality and adapted acceptance test case implementation based on the previously defined test case using the Test DSL.
An additional advantage of the DSL is the reusability of scenario parts’ implementation across scenarios. For instance, if a DSL defines a way to bootstrap the system for a “When” clause of a scenario, the same implementation parameterized differently can be reused in other scenarios. This helps increase the test code reuse and, therefore, the speed of test implementation.
At the same time, it helps with functional isolation of the Acceptance Tests. This is an important point because functionally isolated tests can be executed in parallel without interfering with each other. The parallelization helps reduce the feedback cycle time from tests.
Finally, functional aliasing can be incorporated in the DSL so that when domain objects like e.g. Imaging Scanners are created, they are appended with UIDs that ensure functional isolation without making it necessary to specify the UIDs explicitly in the test code.
Acceptance Testing
Dave recommended adopting a four-layer architecture for the construction of Acceptance test infrastructure. This allows for the levels of abstraction, and separation of concerns, described above.
Without this separation, high-level functional tests are brittle when the system under test changes.
The four layer model is:
- Layer 1 Test Cases
- Layer 2 DSL
- Layer 3 Protocol Adapters
- Layer 4 System Under Test
By writing Test Cases (Layer 1) in an abstract DSL that captures user-intent, rather than the technical details of interactions, these “Executable Specifications” remain very loosely-coupled to the system under test.
Layer 2 implements the DSL. Shared domain-level concepts common to many test cases. e.g. AddScannerToHospital, CalculateRadiationDoseByScan, DistributeScanProtocol.
Layer 3 is in the form of a collection of “Protocol Adapters”. These adapters translate domain (DSL) concepts into real interactions with Layer 4, the System Under Test.
This allows test case writers to focus exclusively on “WHAT” the system needs to do rather than “HOW” the system does it.
You can see a more detailed description of this approach here: Acceptance Testing for Continuous Delivery – Dave Farley.
Using “Executable Specifications” to Guide TDD
Once an Acceptance Test has been written, we expect it to fail! It goes red when executed, because the product code has not yet been written. This is by intent. We want to adopt the “red → green → refactor → commit” way of working. The test is implemented first. Once executed, it goes red due to lack of product code, yet.
We make enough changes to the production code to make the test pass. Once passing, it goes green! The final step before committing the change to the pipeline is to refactor, to tidy it up.
After that, we commit the change. “Red → green → refactor → commit” is beneficial because it ensures good abstraction between the test code and the product code.
We only write product code on behalf of an already existing test that tells the product exactly what to do. Since the test code was written first, it is inherently loosely coupled with the product code.
This, allows us to change the product code later without having to change lots of test code. As a result, developers can go fast when implementing new user stories. With “red → green → refactor → commit” way of working ongoing refactoring is an integral part of the process. We encourage developers to focus on quality in their work for every single commit.
After an Acceptance Test has been written and gone to red, we start creating code to meet that specification. We use TDD to write the code and so the code is tested at two different, distinct, levels. For us this means that we write a unit test first. Red-Green-Refactor again! This guides the design of the product code allowing us to focus on a tiny bit of functionality. Then we write the product code according to what the unit test told it to do. Once the new unit test is passing, we refactor a bit and commit the unit test with the product code slice together to the team pipeline (“red → green → refactor → commit”).
Pair Programming
All the tasks that involve programming such as DSL, Acceptance Tests, TDD, Product Code Implementation, Pipeline are carried out by developers working in pairs.
A pair works according to the Driver-Navigator concept. The Driver actively types the code and thinks about the constructs of the programming language used. The Navigator navigates the Driver regarding what to do and thinks at a slightly more conceptual level.
A pair switches the Driver-Navigator roles regularly. Moreover, once the work on a user story is finished, the pair usually gets dismantled and the developers join other pairs on the team. This process ensures team-based ownership of the code, the ability of the team to react to test failures fast because many people can fix a test, the ability of the team to accommodate attrition without major productivity hits as well as the ability of the team to incorporate new team members in a fast and efficient manner.
The Value of Pair Programming
Pair programming seems like an expensive approach, but it is not. It allows teams to produce higher-quality work more quickly[1][2][3].
However, even if these advantages were not the case, the value of pair-programming to helping teams adopt new techniques, processes, technologies is hard to overstate.
Pair programming is a very powerful tool that allows teams to learn more quickly and to establish, and strengthen, team culture. It allows development teams to reinforce the necessary disciplines within the team as well as promote higher-quality and foster innovation.
The Build and Deployment Pipeline
Coming back to the team pipeline: once a Commit has reached the pipeline, it goes through 5 stages: Build Agent, Accept 1, Accept 2, Staging and Prod.
On the Build Agent, we run all our unit tests that were created during the TDD stage of the process as well as applying static code analysis rules defined for the project. We aim for a feedback cycle from this stage of the pipeline of around 5 minutes. The 5 minutes cycle is important because it is roughly the period of time a developer pair can take a short rest without starting to work on something else. If the feedback comes within 5 minutes, the developer pair remains mentally focussed on the Commit and can fix the failure immediately without incurring a switching-cost between tasks. Any unit test failure leads to this stage of the pipeline being declared red. The change is rejected!
If all unit tests have passed on the Build Agent, we deploy the part of the product a given team is working on to the next stage of the team pipeline called Accept 1. Once deployed, we run all Acceptance Tests for that team. Any Acceptance Test failure again results in the change being rejected. This stage of the pipeline is declared red.
If all Acceptance Tests pass in the Accept 1 environment we know that the part of the product the team is working on works in isolation. To make sure, that part of the product works with its dependencies to other teams, we employ another environment called Accept 2. In the Accept 2 environment, we deploy the part of the product from Accept 1 environment and its dependencies to other teams. Once deployed, we run some Acceptance Tests in the Accept 2 environment that really test the integration points – Contract Integration Testing.
We anticipate that as our contracts between the teams become more solid we may be able to abandon the Accept 2 environment in future.
We aim for the feedback cycle from Accept 1 & Accept 2 to be about 1 hour. This is important because it enables the developer pairs to perform multiple commits per day, meaning that, if a failure happens in Accept 1 or Accept 2, the developers have multiple chances through the day to fix the problem Once fixed changes can be re-committed and seen to be green all the way to the end of the Accept 2 environment.
This short feedback-cycle allows developer pairs to move fast, and to fail fast, resulting in a very high team velocity.
Another important point regarding the feedback cycle of 1 hour is that it encourages good behavior with the developer pairs in terms of fixing test failures by going back to the beginning of the pipeline and doing a new commit instead of patching environments like Accept 1 and Accept 2.
If the feedback cycle is much longer than 1 hour, say 6 hours, developers often have no choice but to patch an environment to make tests pass because this is faster than waiting until a new commit goes from the beginning of the pipeline all the way to Accept 2 environment (in all likelihood it will be only on the next business day).
The Importance of Short Feedback Cycles
Continuous Delivery is about working in a way that ensures that your software is always in a releasable state.
There is a relationship between the speed with which feedback on a change is delivered to a development team and the ability of that team to keep the software working.
In CD we reject changes that fail ANY test. The means that any test failure means that our software is not in a “releasable state”. If we want to perform CD, we need short feedback cycles!
Working to establish Short Feedback Cycles is an extremely effective mechanism for driving healthy change in a team.
Work iteratively, and empirically, to reduce time, from concept to working, releasable software and you are forced to:
- Adopt good team structures
- Improve automation
- Improve modularity
- Improve automated testing
- Eliminate manual bottle-necks
- Improve Requirements Processes
- Improve design.
- (and many other good things)
Creating Release Candidates
Once all the Acceptance Tests pass in the Accept 2 environment, the business can decide to roll out that release candidate to a customer acceptance test environment called Cut. In this environment selected customers can use the release candidate and provide real feedback to the development team. Again, due to the envisioned 1 hour feedback cycle from the Accept 1 & Accept 2 environments, bug fixes can be deployed to the Staging environment several times a day on demand.
Once a release candidate has been deployed to cut, production grade monitoring and alerting are applied. The same applies to the production environment.
The developers can see the commits flowing through the pipeline and the current state of each environment on the Team Information Radiator. Red on the Information Radiator catches attention easily, which prompts the developers to take action fast.
Adoption
Different teams in teamplay are adopting our Continuous Delivery Model at different rates. Some teams are practicing TDD and Pairing as their regular mode of operation. Some teams are applying BDD to selected features. It is a gradual process where different teams adopt different methodologies at different rates. Some teams move faster, some slower depending on many technical and human factors.
Nearly all teams have adopted User Story Mapping. We had external consultants pairing with our Product Owners to create initial User Story Maps for upcoming features. After that we involved all the other team roles into User Story Mapping activities to familiarize them with the methodology as well. We did offline Story Mapping with Post It notes on the walls as well online Story Mapping using suitable tools. Tool support is essential given our teams are distributed geographically. Using Story Mapping not only for shared understanding of user journeys / goals but also for release prioritization proved to be very useful because it made the prioritization decisions transparent and allowed every team member to take part in the process.
Some teams have implemented a Team Pipeline and are optimizing the feedback cycle from different environments. We are encouraging a culture of experimentation and self-measurement within the teams to drive the adoption more and more until it becomes a regular modus operandi for all new user stories in all teams.
For experimentation, some teams dedicate a day per fortnight for learning new things related to work. Additionally, all the methodologies such as TDD, BDD, Pairing, User Story Mapping, DSL, Acceptance Testing, Red-Green-Refactor-Commit, were initially adopted by teams as experiments on a very small scale, e.g. within the scope of a single user story. After the team gained confidence with a methodology on a small scale, and saw its effectiveness, e.g. implementing a single story with TDD, they extended the use of the methodology to more and more stories.
Where we saw fast mass-adoption, however, was Kanban and #NoEstimates. We were surprised to see that the majority of teams switched from Scrum to Kanban and from Sprint Estimates to #NoEstimates by themselves within several weeks of being granted the permission to choose.
For self-measurement we created an internal CD Maturity Model that enables a team to self-assess themselves regarding the adoption of the CD methods outlined in the paper. The teams took up the self-assessments on a monthly basis, which proved useful to keep the envisioned development process at the top of people’s mind and do small steps each month to iterate towards it.
Additionally, we offered teams automatically generated dashboards with CD Metrics measuring deployment stability. These proved useful to see in aggregated form whether the methodologies described above are applied correctly to yield stable deployments. Using the metrics, it became possible to guide the CD transformation in some teams.
Conclusions
We are just at the beginning of adoption of Continuous Delivery but the steps undertaken so far already yielded proven outcomes! For instance, after applying TDD and Pairing to a new feature on a single team in a code base area where lots of production bugs were discovered in the past, we were able to deliver that feature without any production bugs.
With the implementation of Continuous Delivery we want to become an experimental organization. We want to move away from being too busy delivering to plans full of assumptions and, instead, run business experiments in production at all times to validate our assumptions fast.
It is about being able to run small experiments in production on a regular basis to try out new ideas from technical and product perspective as well as integrate successful experiments into the product on an ongoing basis.
References
- “The Case for Collaborative Programming” Nosek 1998
- “Strengthening The Case for Pair Programming” Williams, Kessler, Cunningham & Jeffries 2000
- “Pair Programming is about Business Continuity” Dave Hounslow
About the Authors
 Dave Farley is a thought-leader in the field of Continuous Delivery, DevOps and Software Development in general. He is co-author of the Jolt-award winning book ‘Continuous Delivery’ a regular conference speaker and blogger and one of the authors of the Reactive Manifesto. Dave is now an independent software developer and consultant, and founder and director of Continuous Delivery Ltd. You can find Dave Farley on Twitter @davefarley77, his blog, or company website.
Dave Farley is a thought-leader in the field of Continuous Delivery, DevOps and Software Development in general. He is co-author of the Jolt-award winning book ‘Continuous Delivery’ a regular conference speaker and blogger and one of the authors of the Reactive Manifesto. Dave is now an independent software developer and consultant, and founder and director of Continuous Delivery Ltd. You can find Dave Farley on Twitter @davefarley77, his blog, or company website.
 Dr. Vladyslav Ukis graduated in Computer Science from the University of Erlangen-Nuremberg, Germany and, later, from the University of Manchester, UK. He joined Siemens Healthineers after each graduation and has been working on Software Architecture, Enterprise Architecture, Innovation Management, Private and Public Cloud Computing, Team Management and Engineering Management. In recent years, he has been driving the Continuous Delivery Transformation in the Siemens Healthineers Digital Ecosystem Platform helping a large, distributed and rapidly growing development organization adopt new ways of working, adapt the architecture and achieve culture changes required to keep the system throughout its development always in a releasable state – reaching Continuous Delivery.
Dr. Vladyslav Ukis graduated in Computer Science from the University of Erlangen-Nuremberg, Germany and, later, from the University of Manchester, UK. He joined Siemens Healthineers after each graduation and has been working on Software Architecture, Enterprise Architecture, Innovation Management, Private and Public Cloud Computing, Team Management and Engineering Management. In recent years, he has been driving the Continuous Delivery Transformation in the Siemens Healthineers Digital Ecosystem Platform helping a large, distributed and rapidly growing development organization adopt new ways of working, adapt the architecture and achieve culture changes required to keep the system throughout its development always in a releasable state – reaching Continuous Delivery.