
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Deep-learning algorithms are increasingly being used to make life-impacting decisions, such as in hiring and firing employees and in the criminal justice system.
- Machine learning can actually amplify bias. The researchers found that 67% of images of people cooking were women but the algorithm labeled 84% of the cooks as women.
- Pro Publica found that the false-positive rate was nearly twice as high for black defendants (error rate of 45%) as for white defendants (24%).
- Buolamwini and Gebru found in their research that ML classifiers worked better on men than on women, and better on people with light skin than people with dark skin.
- AI regulations like Age Discrimination and Employment Act from 1967 and Equal Credit Opportunity Act are not perfect but are better than not having any protection.
This article is based on Rachel Thomas’s keynote presentation, “Analyzing & Preventing Unconscious Bias in Machine Learning” at QCon.ai 2018. Thomas works at fast.ai, a non-profit research lab that partners with the University of San Francisco’s Data Institute to provide training in deep learning to the developer community. The lab offers a free course called “Practical Deep Learning for Coders”.
Thomas discussed three case studies of bias in machine learning, its sources, and how to avoid it.
Case study 1: Software for hiring, firing, and criminal-justice systems
Deep-learning algorithms are increasingly being used to make life-impacting decisions, such as in hiring and firing employees and in the criminal justice system. Coding bias brings pitfalls and risk to the decision-making process.
Pro Publica in 2016 investigated the COMPAS recidivism algorithm that is used to predict the likelihood that a prisoner or accused criminal would commit further crimes if released. The algorithm is used in granting bail, sentencing, and determining parole. Pro Publica found that the false-positive rate (labeled as “high-risk” but did not re-offend) was nearly twice as high for black defendants (error rate of 45%) as for white defendants (24%).
Race was not an explicit variable put into this algorithm, but race and gender are latently encoded in a lot of other variables, like where we live, our social networks, and our education. Even a conscious effort to not look at race or gender does not guarantee a lack of bias — assuming blindness doesn’t work. Despite the doubts about the accuracy of COMPAS, the Wisconsin Supreme Court upheld the use of it last year. Thomas argued that it is horrifying that it is still in use.
It’s important to have a good baseline to know what good performance is and to help indicate that a simpler model might be more efficient. Just because something’s complicated, it doesn’t mean that it works. The use of artificial intelligence (AI) for predictive policing is a concern.
Taser acquired two AI companies last year and is marketing predictive software to police departments. The company owns 80% of the police body-camera market in the US, so they have a lot of video data. Additionally, the Verge revealed in February that New Orleans police had been using predictive policing software from Palantir for the last six years in a top-secret program that even city council members didn’t know about. Applications like these are of concern because there’s no transparency. Because these are private companies, they’re not subject to state/public record laws in the same way that police departments are. Often, they’re protected in court from having to reveal what they’re doing.
Also, there’s a lot of racial bias in existing police data so the datasets that these algorithms are going to be learning from are biased from the start.
Finally, there’s been a repeated failure of computer vision to work on people of color. Thomas said this is a scary combination of things to go wrong.
Case study 2: Computer vision
Computer vision is often bad at recognizing people of color. One of the most infamous examples comes from 2015. Google Photos, which automatically labels photos, usefully categorized graduation photos and images of buildings. It also labeled black people as gorillas.
In 2016, the Beauty.AI website was using AI robots as judges for beauty contests. It found that people with light skin were judged much more attractive than people with dark skin. And in 2017, FaceApp, which uses neural networks to create filters for photographs, created a hotness filter that lightened people’s skin and gave them more European features. Rachel showed a tweet of a user’s actual face and a hotter version of him that the app created.
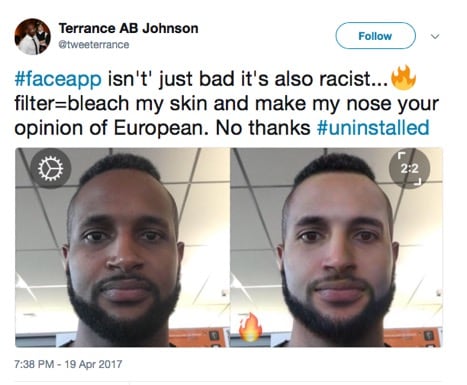
Thomas spoke about a research paper by Joy Buolamwini and Timnit Gebru, who evaluated several commercial computer-vision classifiers from Microsoft, IBM, and Face++ (a Chinese company). They found that the classifiers worked better on men than on women, and better on people with light skin than people with dark skin. There’s a pretty noticeable gap: the error rate for light-skinned males is essentially 0% but ranges between 20% and 35% for dark-skinned females. Buolamwini and Gebru also broke down the error rates for women by skin shade. Errors increased with darkness of skin. The category of the darkest skin had error rates of 25% and 47%.
Case study 3: Word embeddings
Thomas’s third case study is the word embeddings in products like Google Translate.
Take a pair of sentences like “She is a doctor. He is a nurse.” Use Google Translate to translate them into Turkish and then translate them back into English. The genders become flipped to so that the sentences now say, “He is a doctor. She is a nurse.” Turkish has a gender-neutral singular pronoun that becomes translated into a stereotype in English. This happens with other languages that have gender-neutral singular pronouns. It’s been documented for a variety of words that translation stereotypes hold that women are lazy, women are unhappy, and many more characterizations.
Thomas explained why this is happening. Computers and machine learning treat pictures and words as numbers. The same approach is used in speech recognition and image captioning. The way these algorithms work is that they take a supplied image and output something like “man in black shirt is playing guitar,” or “construction worker in orange vest is working on the road.” The same mechanism automatically suggests responses to emails in products like Google Smart Reply — if someone asks about your vacation plans, Smart Reply suggests that you might want to say, “No plans yet,” or “I just sent them to you.”
Thomas talked about an example in the fast.ai course “Practical Deep Learning for Coders”.In this example, we can supply words and get back a picture. Give it the words “tench” (a type of fish) and “net” and it returns a picture of a tench in a net. This approach goes through a bunch of words and doesn’t give us any notion of what it means for words to be similar. So “cat” and “catastrophe” might be sequential number wise but there’s not any sort of semantic relationship between them.
A better approach is to represent words as vectors. Word embeddings are represented as high-dimensional vectors. She gave an example of “kitten”, and “puppy”, and “duckling”, which might all be close to each other in space because they’re all baby animals. But the vector for “avalanche” might be far away since there’s no real connection.
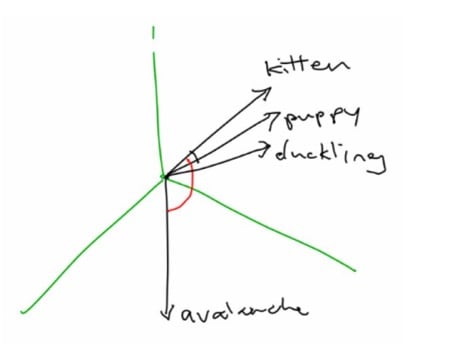
For more on word vectors, refer to “The amazing power of word vectors” by Adrian Colyer.
Word2Vec
Word2Vec is a library of word embeddings released by Google. There are other similar libraries like Facebook’s fastText and GloVe from the Natural Language Processing Group at Stanford University. It takes a lot of data, time, and computational power to train these libraries so it’s handy that these groups have already done this and released their libraries for public use. It’s much easier to use and this is an already trained version. The code for all three projects is available at GitHub, as is Thomas’s own word-embeddings workshop. You can run her program using Jupyter Notebook and try out different words.
The word vectors for similar words like “puppy” and “dog” or “queen” and “princess” are closer in distance. And, of course, unrelated words like “celebrity” and “dusty” or “kitten” and “airplane” are more distant. The program uses a co-sign similarity, not Euclidian distance, since you don’t want to use Euclidian distance in high dimensions.
You can use this solution to capture something about language. You can also find the 10 closest words to a specific target word. For example, if you look for the words closest to “swimming”, you get words like “swim”, “rowing”, “diving”, “volleyball”, “gymnastics”, and “pool”. Word analogies are also useful. They capture things like “Spain is to Madrid as Italy is to Rome”. However, there’s a lot of opportunity for bias here. For example, the distance between “man” and “genius” is much smaller than the distance between “woman” and “genius”.
The researchers studied baskets of words more systematically. They would take a basket or group of words like all flowers: clover, poppy, marigold, iris, etc. Another basket was insects: locust, spider, bedbug, maggot, etc. They had a basket of pleasant words (health, love, peace, cheer, etc.) and a basket of unpleasant words (abuse, filth, murder, death, etc.). The researchers looked at the distances between these different word baskets and found that flowers were closer to pleasant words and insects were closer to unpleasant words.
This all seems reasonable so far, but then the researchers looked at stereotypically black names and stereotypically white names. They found that the black names were closer to unpleasant words and the white names were closer to pleasant words, which is a bias. They found a number of racial and gender biases among entire groups of words, which produced analogies like “father is to doctor as mother is to nurse”, “man is to computer programmer as woman is to homemaker”. These are all analogies found in Word2Vec and in GloVe.
Thomas talked about another example of bias in a system for restaurant reviews that ranked Mexican restaurants lower because the word embeddings for “Mexican” had negative connotations. These word embeddings are trained with a giant corpus of texts. These texts contain a lot of racial and gender biases, which is how the word embeddings learn this associations at the same time as they learn the semantic meanings that we want them to know.
Machine learning can amplify bias
Machine learning can actually amplify bias. An example of this is discussed in “Men also like shopping: Reducing gender bias amplification using corpus-level constraints”, which looked at visual semantic role labeling of images in a dataset.The researchers found that 67% of images of people cooking were women but the algorithm labeled 84% of the cooks as women. There is a risk of machine learning algorithms amplifying what we see in the real world.
Thomas mentioned research by Zeynep Tufekci, who has provided insights into the intersection of technology and society. Tufekci has tweeted that “the number of people telling me that YouTube autoplay ends up with white supremacist videos from all sorts of starting points is pretty staggering.” Examples include:
- “I was watching a leaf blower video and three videos later, it was white supremacy.”
- “I was watching an academic discussion of the origins of plantation slavery and the next video was from holocaust deniers.”
- “I was watching a video with my daughters on Nelson Mandela and the next video was something saying that the black people in South Africa are the true racist and criminals.”
It’s scary.
Renée DiResta, an expert in disinformation and how propaganda spreads, noticed a few years ago that if you join an anti-vaccine group on Facebook, the site would also recommend to you groups about natural cancer cures, chemtrails, flat Earth, and of all sorts of anti-science groups. These networks are doing a lot to promote this kind of propaganda.
Thomas mentioned a research paper on how runaway feedback loops can work on predictive policing. If software or analysis predicts that there will be more crime in an area, the police might send more officers there — but because there are more police there, they might make more arrests, which might cause us to think that there’s more crime there, which might cause us to send even more police there. We can easily enter this runaway feedback loop.
Thomas suggested that we really need to think about the ethics of including certain variables in our models. Although we may have access to data, and even if that data improves our model’s performance, is it ethical to use? Is it in keeping with our values as a society? Even engineers need to be asking ethical questions about the work they do and should be able to answer ethical questions about it. We’re going to see less and less tolerance from society for this.
Angela Bassa, the director of data science at iRobot said, “It’s not that data can be biased. Data is biased. If you want to use data, you need to understand how it was generated.”
Addressing bias in word embeddings
Even if we remove bias early in model development, there are so many places that bias can seep in that we need to continue to look out for it.
More representative datasets can be one solution. Buolamwini and Gebru identified the bias failures in computer-vision products mentioned above and put together a much more representative dataset of men and women with all different skin shades. This data set is available at Gender Shades. The website also offers their academic paper and a short video about their work.
Gebru with others recently released a paper called “Datasheets for Datasets”. The paper provides prototype datasheets for recording characteristics and metadata that reveal how a dataset was created, how it was composed, what sort of preprocessing was done, what sort of work is needed to maintain it, and any legal or ethical considerations. It’s really important to understand the datasets that go into building our models.
Thomas emphasized that it’s our job to think about unintended consequences in advance. Think about how trolls or harassers or authoritarian governments could use a platform that we build. How could our platform be used for propaganda or disinformation? When Facebook announced that it was going to start threat modelling, many people asked why it hadn’t been doing that for the last 14 years.
There’s also an argument for not storing data we don’t need so that nobody can ever take that data.
Our job is to think about how our software could be misused before it happens. The culture of the field of information security is based on that. We need to start doing more of thinking about how things could go wrong.
Questions to ask about AI
Thomas listed some questions to ask about AI:
- What bias is in the data? There’s some bias in all data and we need to understand what it is and how the data was created.
- Can the code and data be audited? Are they open source? There’s a risk when closed-source proprietary algorithms are used to decide things in healthcare and criminal justice and who gets hired or fired.
- What are error rates for different subgroups? If we don’t have a representative dataset, we may not notice that our algorithm is performing poorly on some subgroup. Are our sample sizes large enough for all subgroups in your dataset? It’s important to check this, just like Pro Publica did with the recidivism algorithm that looked at race.
- What is the accuracy of a simple rule-based alternative? It’s really important to have a good baseline, and that should be the first step whenever we’re working on a problem because if someone asks if 95% accuracy is good, we need to have an answer. The correct answer depends on the context. This came up with the recidivism algorithm, which was no more effective than a linear classifier of two variables. It’s good to know what that simple alternative is.
- What processes are in place to handle appeals or mistakes? We need a human appeals process for things that affect people’s lives. We, as engineers, have relatively more power in asking these questions within our companies.
- How diverse is the team that built it? The teams building our technology should be representative of the people that are going to be affected by it, which increasingly is all of us.
Research shows that diverse teams perform better, and believing we’re meritocratic actually increases bias. It takes time and effort to do interviews consistently. A good reference for this is the blog post titled “Making small culture changes” by Julia Evans.
Advanced technology is not a substitute for good policy. Thomas talked about fast.ai students all over the world who are applying deep learning to social problems like saving rainforests or improving the care of patients with Parkinson’s disease.
There are AI regulations like the Age Discrimination and Employment Act from 1967 and Equal Credit Opportunity Act that are relevant. These are not perfect but are better than not having any protection since we really need to think about what rights we as a society want to protect.
Thomas concluded her talk by saying you can never be done checking for bias. We can follow some steps towards the solutions but bias could seep backin from so many places. There’s no checklist that assures us that bias is goneand we no longer haveto worry. It’s something that we always have to continue to lookout for.
About the Author
 Srini Penchikala currently works as a senior software architect in Austin, Tex. Penchikala has over 22 years of experience in software architecture, design, and development. He is also the lead editor for AI, ML & Data Engineering community at InfoQ, which recently published his mini-book Big Data Processing with Apache Spark. He has published articles on software architecture, securiaty, risk management, NoSQL, and big data at websites like InfoQ, TheServerSide, the O’Reilly Network (OnJava), DevX’s Java Zone, Java.net, and JavaWorld.
Srini Penchikala currently works as a senior software architect in Austin, Tex. Penchikala has over 22 years of experience in software architecture, design, and development. He is also the lead editor for AI, ML & Data Engineering community at InfoQ, which recently published his mini-book Big Data Processing with Apache Spark. He has published articles on software architecture, securiaty, risk management, NoSQL, and big data at websites like InfoQ, TheServerSide, the O’Reilly Network (OnJava), DevX’s Java Zone, Java.net, and JavaWorld.