
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Low overhead and horizontal-scaling-friendly design of Kafka makes it possible to use inexpensive commodity hardware and still run it quite successfully.
- Provide ZooKeeper with strong network bandwidth using the best disks, storing logs separately, isolating the ZooKeeper process, and disabling swaps to reduce latency.
- Increase Kafka’s default replication factor from two to three, which is appropriate in most production environments.
- More partitions mean a greater parallelization and throughput but partitions also mean more replication latency, rebalances, and open server files.
- Monitor system metrics such as network throughput, open file handles, memory, load, disk usage, and JVM stats like GC pauses and heap usage.
Apache Kafka certainly lives up to its novelist namesake when it comes to the 1) excitement inspired in newcomers, 2) challenging depths, and 3) rich rewards that achieving a fuller understanding can yield. But quickly turning away from Comparative Literature 101, being certain that you’re following the latest Kafka best practices can make managing this powerful data streaming platform much, much easier – and considerably more effective.
Here are ten specific tips to help keep your Kafka deployment optimized and more easily managed:
- Set log configuration parameters to keep logs manageable
- Know Kafka’s (low) hardware requirements
- Leverage Apache ZooKeeper to its fullest
- Set up replication and redundancy the right way
- Take care with topic configurations
- Use parallel processing
- Configure and isolate Kafka with security in mind
- Avoid outages by raising the Ulimit
- Maintain a low network latency
- Utilize effective monitoring and alerts
Let’s look at each of these best practices in detail.
Set log configuration parameters to keep logs manageable
Kafka gives users plenty of options for log configuration and, while the default settings are reasonable, customizing log behavior to match your particular requirements will ensure that they don’t grow into a management challenge over the long term. This includes setting up your log retention policy, cleanups, compaction, and compression activities.
Log behavior can be controlled using the log.segment.bytes, log.segment.ms, and log.cleanup.policy (or the topic-level equivalent) parameters. If in your use case you don’t require past logs, you can have Kafka delete log files of a certain file size or after a set length of time by setting cleanup.policy to “delete.” You can also set it to “compact” to hold onto logs when required. It’s important to understand that running log cleanup consumes CPU and RAM resources; when using Kafka as a commit log for any length of time, be sure to balance the frequency of compactions with the need to maintain performance.
Compaction is a process by which Kafka ensures retention of at least the last known value for each message key (within the log of data for a single topic partition). The compaction operation works on each key in a topic to retain its last value, cleaning up all other duplicates. In case of deletes, the key is left with ‘null’ value (which is called ‘tombstone’ as it denotes, colorfully, a deletion).
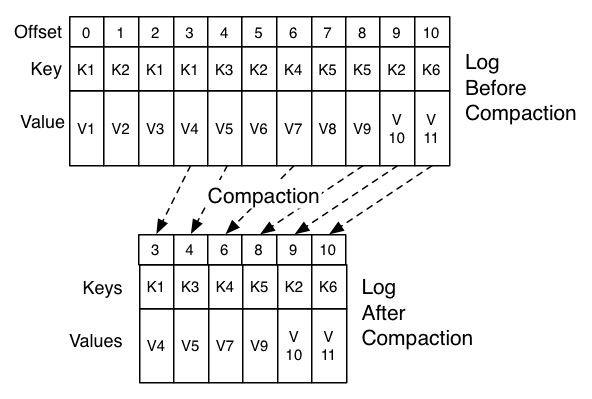
Image 1 – The Kafka commit log compaction process (source)
Kafka commit log documentation:
Know Kafka’s (low) hardware requirements
While many teams unfamiliar with Kafka will overestimate its hardware needs, the solution actually has a low overhead and a horizontal-scaling-friendly design. This makes it possible to use inexpensive commodity hardware and still run Kafka quite successfully:
- CPU: Unless SSL and log compression are required, a powerful CPU isn’t needed for Kafka. Also, the more cores used, the better the parallelization. In most scenarios, where compression isn’t a factor, the LZ4 codec should be used to provide the best performance.
- RAM: In most cases, Kafka can run optimally with 6 GB of RAM for heap space. For especially heavy production loads, use machines with 32 GB or more. Extra RAM will be used to bolster OS page cache and improve client throughput. While Kafka can run with less RAM, its ability to handle load is hampered when less memory is available.
- Disk: Kafka thrives when using multiple drives in a RAID setup. SSDs don’t deliver much of an advantage due to Kafka’s sequential disk I/O paradigm, and NAS should not be used.
- Network and filesystem: XFS is recommended, as is keeping your cluster at a single data center if circumstances allow. Also, deliver as much network bandwidth as possible.
The Apache Kafka website also contains a dedicated hardware and OS configuration section with valuable recommendations.
Other useful links about Kafka load/performance testing:
Leverage Apache ZooKeeper to its fullest
A running Apache ZooKeeper cluster is a key dependency for running Kafka. But when using ZooKeeper alongside Kafka, there are some important best practices to keep in mind.
The number of ZooKeeper nodes should be maxed at five. One node is suitable for a dev environment, and three nodes are enough for most production Kafka clusters. While a large Kafka deployment may call for five ZooKeeper nodes to reduce latency, the load placed on nodes must be taken into consideration. With seven or more nodes synced and handling requests, the load becomes immense and performance might take a noticeable hit. Also note that recent versions of Kafka place a much lower load on Zookeeper than earlier versions, which used Zookeeper to store consumer offsets.
Finally, as is true with Kafka’s hardware needs, provide ZooKeeper with the strongest network bandwidth possible. Using the best disks, storing logs separately, isolating the ZooKeeper process, and disabling swaps will also reduce latency.
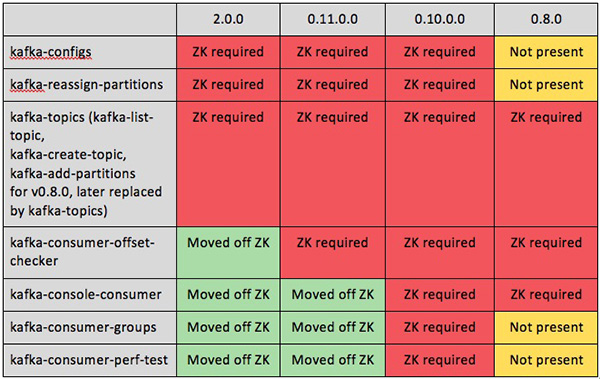
The table below highlights some of the console operations dependent on Zookeeper in different Kafka versions. The earlier version, 0.8.0, didn’t have a lot of functionality available on console. Starting from 0.10.0.0 onward, we can see a few major functionalities moved off Zookeeper – resulting in lower Zookeeper utilization.
Proper management means everything for the resilience of your Kafka deployment. One important practice is to increase Kafka’s default replication factor from two to three, which is appropriate in most production environments. Doing so ensures that the loss of one broker isn’t cause for concern, and even the unlikely loss of two doesn’t interrupt availability. Another consideration is data center rack zones. If using AWS, for example, Kafka servers ought to be in the same region, but utilize multiple availability zones to achieve redundancy and resilience.Set up replication and redundancy the right way
The Kafka configuration parameter to consider for rack deployment is:
broker.rack=rack-id
As stated in the Apache Kafka documentation:
When a topic is created, modified or replicas are redistributed, the rack constraint will be honoured, ensuring replicas span as many racks as they can (a partition will span min(#racks, replication-factor) different racks).
An example:
Let’s consider nine Kafka brokers (B1-B9) spreads over three racks.
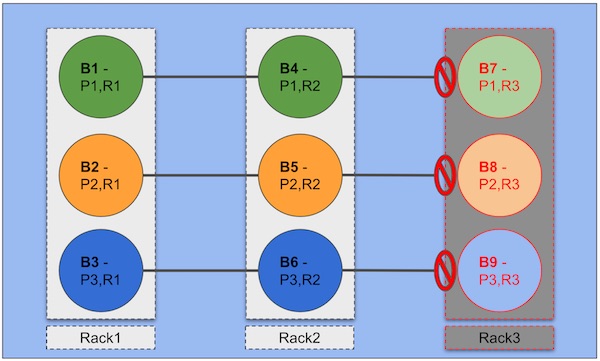
Image 2 – Kafka cluster with rack awareness
Here, a single topic with three partitions (P1, P2, P3) and a replication factor of three (R1, R2, R3) will have one partition assigned to one node in each rack. This scenario gives high availability with two replicas of each partition live, even if a complete rack fails (as shown in the diagram).
Take care with topic configurations
Topic configurations have a tremendous impact on the performance of Kafka clusters. Because alterations to settings such as replication factor or partition count can be challenging, you’ll want to set these configurations the right way the first time, and then simply create a new topic if changes are required (always be sure to test out new topics in a staging environment).
Use a replication factor of three and be thoughtful with the handling of large messages. If possible, break large messages into ordered pieces, or simply use pointers to the data (such as links to S3). If these methods aren’t options, enable compression on the producer’s side. The default log segment size is 1 GB, and if your messages are larger you ought to take a hard look at the use case. Partition count is a critically important setting as well, discussed in detail in the next section.
The topic configurations have a ‘server default’ property. These can be overridden at the point of topic creation or at later time in order to have topic-specific configuration.
One of the most important configurations as discussed above is the replication factor. The example demonstrates topic creation from the console with a replication-factor of three and three partitions with other ‘topic level’ configurations:
bin/kafka-topics.sh --zookeeper ip_addr_of_zookeeper:2181 --create --topic my-topic --partitions 3 --replication-factor 3 --config max.message.bytes=64000 --config flush.messages=1
For a full list of topic level configurations see this.
Use parallel processing
Kafka is designed for parallel processing and, like the act of parallelization itself, fully utilizing it requires a balancing act. Partition count is a topic-level setting, and the more partitions the greater parallelization and throughput. However, partitions also mean more replication latency, rebalances, and open server files.
Finding your optimal partition settings is as simple as calculating the throughput you wish to achieve for your hardware, and then doing the math to find the number of partitions needed. By a conservative estimate, one partition on a single topic can deliver 10 MB/s, and by extrapolating from that estimate you can arrive at the total throughput you require. An alternative method that gets straight into testing is to use one partition per broker per topic, and then to check the results and double the partitions if more throughput is needed.
Overall, a useful rule here is to aim to keep total partitions for a topic below 10, and to keep total partitions for the cluster below 10,000. If you don’t, your monitoring must be highly capable and ready to take on what can be very challenging rebalances and outages!
The number of partitions is set while creating a Kafka topic as shown below.
bin/kafka-topics.sh --zookeeper ip_addr_of_zookeeper:2181 --create --topic my-topic --partitions 3 --replication-factor 3 --config max.message.bytes=64000 --config flush.messages=1
The partition count can be increased after creation. But it can impact the consumers, so it’s recommended to perform this operation after addressing all consequences.
bin/kafka-topics.sh --zookeeper zk_host:port/chroot --alter --topic topic_name --partitions new_number_of_partitions
Configure and isolate Kafka with security in mind
The two main concerns in securing a Kafka deployment are 1) Kafka’s internal configuration, and 2) the infrastructure Kafka runs on.
A number of valuable security features were included with Kafka’s .9 release, such as Kafka/client and Kafka/ZooKeeper authentication support, as well as TLS support to protect systems with public internet clients. While TLS does carry a cost to throughput and performance, it effectively and valuably isolates and secures traffic to Kafka brokers.
Isolating Kafka and ZooKeeper is vital to security. Aside from rare cases, ZooKeeper should never connect to the public internet, and should only communicate with Kafka (or other solutions it’s used for). Firewalls and security groups should isolate Kafka and ZooKeeper, with brokers residing in a single private network that rejects outside connections. A middleware or load balancing layer should insulate Kafka from public internet clients.
Security options and protocols with Kafka:
- SSL/SASL: Authentication of clients to brokers, inter broker, brokers to tools.
- SSL: Encryption of data between clients to brokers, between broker and tools to brokers
- SASL types: SASL/GSSAPI (Kerberos), SASL/PLAIN, SASL/SCRAM-SHA-512/SCRAM-SHA-256, SASL_AUTHBEARER
- Zookeeper security: Authentication for clients (Brokers, tools, producers, consumers), Authorization with ACL.
*Kafka Broker clients: producers, consumers, other tools.
*Zookeeper clients: Kafka Brokers, producers, consumers, other tools.
*Authorization is pluggable.
An example configuration for security setup with SASL_SSL:
#Broker configuration
listeners=SSL://host.name:port,SASL_SSL://host.name:port
advertised.listeners=SSL://host.name:port,SASL_SSL://host.name:port
security.protocol=SASL_SSL
security.inter.broker.protocol=SSL
listener.security.protocol.map=INTERBROKER:SSL,PUBLIC_CLIENT:
SASL_PLAINTEXT,PRIVATE_CLIENT:SASL_PLAINTEXT
ssl.keystore.location=/var/private/ssl/server.keystore.jks
ssl.keystore.password=test1234
ssl.key.password=test1234
ssl.truststore.location=/var/private/ssl/server.truststore.jks
ssl.truststore.password=test1234
sasl.mechanism.inter.broker.protocol=PLAIN
sasl.enabled.mechanisms=PLAIN
#Client Configuration (jaas file)
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule
required
username="[USER NAME]"
password="[USER PASSWORD]";
Avoid outages by raising the Ulimit
It’s a scenario that occurs too often: brokers go down from what appears to be too much load, but in reality is a benign (though nonetheless stressful) “too many open files” error. By editing /etc/sysctl.conf and configuring Ulimit to allow 128,000 or more open files, you can avoid this error from happening.
An example to increase the ulimit on CentOS:
- Create a new file
/etc/security/limits.d/nofile.conf
- Enter contents:
* soft nofile 128000
* hard nofile 128000
- Restart the system or relogin.
- Verify by issuing below command.
ulimit -a
*Note that there are various methods to increase ulimit. You can follow any suitable method for your own Linux distribution.
Maintain a low network latency
In pursuing low latency for your Kafka deployment, make sure that brokers are geographically located in the regions nearest to clients, and be sure to consider network performance in selecting instance types offered by cloud providers. If bandwidth is holding you back, a bigger and more powerful server might be a worthwhile investment.
Utilize effective monitoring and alerts
Following the practices above when creating your Kafka cluster can spare you from numerous issues down the road, but you’ll still want be vigilant to recognize and properly address any hiccups before they become problems.
Monitoring system metrics – such as network throughput, open file handles, memory, load, disk usage, and other factors – is essential, as is keeping an eye on JVM stats, including GC pauses and heap usage. Dashboards and history tools able to accelerate debugging processes can provide a lot of value. At the same time, alerting systems such as Nagios or PagerDuty should be configured to give warnings when symptoms such as latency spikes or low disk space arise, so that minor issues can be addressed before they snowball.
Sample Kafka monitoring graphs as shown here via the Instaclustr console:



About the Author
 Ben Bromhead is the Chief Technology Officer at Instaclustr, which provides a managed service platform of open source technologies such as Apache Cassandra, Apache Kafka, Apache Spark, and Elasticsearch.
Ben Bromhead is the Chief Technology Officer at Instaclustr, which provides a managed service platform of open source technologies such as Apache Cassandra, Apache Kafka, Apache Spark, and Elasticsearch.