
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Data citizens are impacted by the models, methods, and algorithms created by data scientists, but they have limited agency to affect the tools which are acting on them.
- Data science ethics can draw on the conceptual frameworks in existing fields for guidance on how to approach ethical questions–specifically, in this case, civics.
- Data scientists are also data citizens. They are acted upon by the tools of data science as well as building them. It is often where these roles collide that people have the best understanding of the importance of developing ethical systems.
- One model for ensuring the rights of data citizens could be seeking the same level of transparency for ethical practices in data science that there are for lawyers and legislators.
- As with other ethical movements before, like seeking greater environmental protection or fairer working conditions, implementing new rights and responsibilities at scale will take a great deal of lobbying and advocacy.
I’m not a data scientist, yet I still care about ethics in data science. I care about it for the same reason I care about civics: I’m not a lawyer or a legislator, but laws impact my life in a way that I want to understand well enough that I know how to navigate the civic landscape effectively. By analogy, data citizens are impacted by the models, methods, and algorithms created by data scientists, but they have limited agency to affect them. Data citizens must appeal to data scientists in order to ensure that their data will be treated ethically. Data science ethics is a new field and it may seem like we need to invent all the tools and methods we will need to build that field from scratch. However, we can draw on the conceptual frameworks in existing fields–specifically, in this case, civics–to create some of the new tools, methods, processes, and procedures we need to build in data ethics.
Both “the law” and “data science” are concepts with uncertain boundaries and hierarchies. I recognise this, but for the purposes of this article I will pretend that they are a single thing rather than a bricolage of disparate parts.
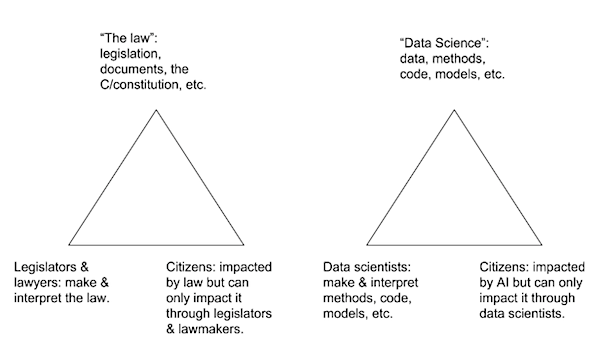
In civic life, citizens have mechanisms for influencing the decisions of legislators & lawyers. Like so many systems, these are imperfect and reflect societal power structures that are unequal, but mechanisms do exist. In civic life, we can vote and campaign for the parties and individuals we think best represent our views for how laws should be created and carried out. We can petition and lobby to get our views heard. When all else fails, we can protest or sometimes seek redress through investigations and lawsuits.
In the world of data citizenship, these mechanisms are less well defined. Even discovering that bias exists can be challenging since so many data science outcomes are proprietary knowledge. It may not be obvious to anyone who does not have the resources to conduct a large-scale study that hiring algorithms are unintentionally leading to vicious poverty cycles, or that criminal risk assessment software is consistently poor at assessing risk, but great at categorising people by race, or that translation software imposes gendered stereotypes even when translating from a non-gendered language.
These are, of course, all examples that have been discovered and investigated publically but many others exist unnoticed or unchallenged. In her book “Weapons of Math Destruction,” Cathy O’Neil describes one young man who is consistently rejected from major employers on the basis of a common personality test. O’Neil points out that these tests reject people for being unsuitable but they never get feedback about whether the rejected person goes on to do well elsewhere, meaning that there is no real evidence about whether the tests are effective at all. Fortunately this young person has a lawyer for a father who challenges the use of these personality tests in hiring practice. By noticing one example of unfairness, this lawyer is able to push for more equal treatment for everyone. But even recognising that this repeated roadblock, the failure to pass the personality test, might be evidence of discrimination requires an expertise not available to everyone.
In her podcast for InfoQ shortly after the publication of Weapons of Math Destruction, O’Neil clarifies that sentencing algorithms in particular are “tantamount to a type of law” and they can be seen as “digital algorithmic laws.” Unlike other parts of the law, there is no visibility to citizens about how these algorithms work. Even when the ‘how’ is made clear, there is no recourse for citizens to challenge how they have been categorised or the predictions generated about them by these algorithms. O’Neil believes that as data citizens, we all deserve to have “…the same kind of protection that we do with laws, which is basically constitutional. We are supposed to be allowed to know what the rules are, and that should hold true for these powerful algorithms as well.” For all types of biased algorithmic practices in sentencing, hiring and beyond, O’Neil points out that “the machine learning algorithms doesn’t ask ‘why’…it just looks for patterns and repeats them…If we have an imperfect system and we automate it, we’re repeating our past mistakes.” Just because a system is numerical or mathematical doesn’t automatically make it more fair, but data citizens (and often data scientists) often assume that systematised outcomes are more objective. Not so, says O’Neil.
The roles in this triangular model overlap: a legislator is also a citizen; a data scientist can also be miscategorised by a bad algorithm. It is often where these roles collide that people have the best understanding for developing ethical practices for data science and the most agency to develop those practices. In the podcast, O’Neil points out that “data scientists literally have to make ethical decisions during their job, even if they don’t acknowledge it, which they often don’t.” Helping data scientists to acknowledge this responsibility, perhaps through personal examples where they have been impacted as data citizens by automated decision-making, is crucial for negotiating the relationship between data citizens and data science.
So how can we, the data citizens, push for more effective and fair “data science” which impacts us? A first step might be insisting on the same level of transparency for ethical practices in data science that there are for lawyers and legislators. For its flaws and frustrations, GDPR goes some way towards codifying the rights for data citizens and penalising organisations when those rights are breached. Specifically thinking about data science, four key clauses stand out. These are:
- First, the Right to Access, under which data subjects have the right to understand how and for what purpose personal data about them is being processed, as well as a right to a copy of that data.
- Second, the Right to be Forgotten, where individuals can ask that their data be erased and no longer shared with third parties.
- Third, Data Portability, where individuals may ask that their data be transferred to another processor.
- Finally, Privacy by Design is no longer simply an industryrecognised design concept but is now a legal requirement focused on using the minimum data required in order to carry out duties.
These rights will impact how data scientists design models. New considerations come into play for building data science tools when the shape of the data might change because people request that their data is removed, or when the minimum amount of data is being used to create modelling.
As well as GDPR, there are also numerous attempts within the data science community to codify and operationalise means for managing ethical considerations. The Open Data Institute’s data ethics canvas is one example, Gov.uk’s data science ethical framework is another, the Public Library of Science’s “Ten simple rules for responsible big data research” is a third. Consulting services such as Cathy O’Neil’s ORCAA are now offering algorithmic auditing, and big technology players like Microsoft and Facebook are working on developing auditing toolkits. Accenture has been one of the first out of the gate with the prototype Fairness Tool designed to identify and fix bias in algorithms. However, for the tool to truly work, “Your company also needs to have a culture of ethics,” says Rumman Chowdhury, Accenture’s global lead for ethical AI. Otherwise companies will find it all too easy to ignore the tool’s recommendations and continue to perpetuate biased practices.
Most data citizens are not data scientists and we are not the ones making the ethical trade-offs in the moment when they decide to use a particular code library or give a weighting to one variable over another. We do not choose what information to include and what to leave out when developing our models. But what we can do is to familiarise ourselves with the stories of what has gone wrong and why, and examples of where things are going right. We can use these stories to critically examine our own interactions with data, where our data is being used to make decisions about us, and to see patterns about where this is going badly and going well for us. But there are people who wear both hats: data scientists are in the position of understanding how the ethical decisions made by others in their field may be impacting themselves, their families, their friends, and most immediately, the data citizens using their services. As builders of these systems, data scientists have both the responsibility and the agency to use data well.
As with other ethical movements before, like seeking greater environmental protection or fairer working conditions, communicating this at scale will take a great deal of lobbying and advocacy. Fortunately groups like doteveryone and Coed:Ethics are stepping up to the challenge of pressuring our governments and in the companies who serve us to create a fairer algorithmic world.
Caitlin McDonald will be speaking on the civil impact of algorithms at the Coed:Ethics conference in London in July, the first conference aimed at discussing technical ethics from a developer’s perspective.
About the Author
 Dr. Caitlin E McDonald is an award-winning scholar and writer about digital communities, and data science. With experience in qualitative and quantitative research methods, she specialises in the intersection between human imagination and digital systems. Caitlin obtained her PhD from the University of Exeter in 2011, focusing her studies on how cultural and artistic communities of practice adapt in an increasingly globalized world.
Dr. Caitlin E McDonald is an award-winning scholar and writer about digital communities, and data science. With experience in qualitative and quantitative research methods, she specialises in the intersection between human imagination and digital systems. Caitlin obtained her PhD from the University of Exeter in 2011, focusing her studies on how cultural and artistic communities of practice adapt in an increasingly globalized world.