
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Over the past four years, Lyft has transitioned from a monolithic architecture to hundreds of microservices. As the number of microservices grew, so did the number of outages due to cascading failure or accidental internal denial of service.
- Today, these failure scenarios are largely a solved problem within the Lyft infrastructure. Every service deployed at Lyft gets throughput and concurrency protection automatically via use of the Envoy Proxy.
- Envoy can be deployed as middleware or solely at request ingress, but the most benefit comes from deploying it at ingress and egress locally with the application. Deploying Envoy on both sides of the request allows it to act as a smart client and a reverse proxy for the server.
- In the coming months Lyft is going to work in conjunction with the team behind the concurrency limits library at Netflix to bring a system based on their library into an envoy L7 Filter.
Cascading failure is one of the primary causes of unavailability in high throughput distributed systems. Over the past four years, Lyft has transitioned from a monolithic architecture to hundreds of microservices. As the number of microservices grew, so did the number of outages due to cascading failure or accidental internal denial of service. Today, these failure scenarios are largely a solved problem within the Lyft infrastructure. Every service deployed at Lyft gets throughput and concurrency protection automatically. With some targeted configuration changes to our most critical services, there has been a 95% reduction in load-based incidents that impact the user experience.
Before we examine specific failure scenarios and the corresponding protection mechanisms, let’s first understand how network defense is deployed at Lyft. Envoy is a proxy that originated at Lyft and was later open-sourced and donated to the Cloud Native Computing Foundation. What separates Envoy from many other load balancing solutions is that it was designed to be deployed in a “mesh” configuration. Envoy can be deployed as middleware or solely at request ingress, but the most benefit comes from deploying it at ingress and egress locally with the application. Deploying Envoy on both sides of the request allows it to act as a smart client and a reverse proxy for the server. On both sides we have the option to employ rate limiting and circuit breaking to protect servers from overload in a variety of scenarios.
Core Concepts
Concurrency and rate limiting
Concurrency and rate limiting are related, but different concepts; two sides of the same coin. When thinking of limiting load in systems, operators traditionally think in terms of requests per second. The act of limiting the rate of requests sent to a system is rate limiting. Stress tests are normally done to determine the request rate at which point the service will become overloaded, and then limits are set somewhere below this point. In some cases, business logic dictates the rate limit.
On the other side of the coin we have concurrency, that is how many units are in-use simultaneously. These units can be requests, connections, etc. For example, instead of thinking in terms of request rate, we can think about the number of concurrent in-flight request at a point in time. When we think about concurrent requests, we can apply queueing theory to determine the number of concurrent requests a service can handle before a queue starts to build, requests latencies increase, and the service fails due to resource exhaustion.
Global versus local decisions
Circuit breakers in Envoy are computed based on local information. Each instance of Envoy tracks its own statistics and makes its own circuit breaking decisions. This model has a few advantages over a global system. The first is that the limits can be computed in-memory, without the expense of a network call to a central system. The second is that the limits scale with the size of the cluster. Third, the limit accounts for differences between machines, whether they receive a different query mix or have differences in performance.
Common failure scenarios
Before the defense mechanisms are introduced, it’s helpful to go over some common failure modes.
Retry amplification
A dependency begins to fail. If a service does one retry for all requests to that dependency, the overall call volume will double.
Resource starvation
Every service is bound by some constraint, usually CPU, network, or memory. Concurrent requests are usually directly correlated with the amount of resources consumed.
Recovery from resource starvation
Even when the cause of the increase in resource consumption subsides to normal levels, a service may not recover due to resource contention.
Backend slow-down
A dependency (database or other service) slows, causing the service to take longer to fulfill a request.
Burstiness and undersampling
When doing advance capacity planning or elastically scaling a service, the usual practice is to consider the average resources consumed across an entire cluster. However, callers of the service may elect to send a large number of requests simultaneously. This can saturate a single server momentarily. When collecting metrics, per-minute or higher data will almost definitely obscure these bursts.
Present day at Lyft
How do we rate limit?
lyft/ratelimit is an open source Go/gRPC service designed to enable generic rate limit scenarios for a variety of applications. Rate limits are applied to domains. An example of a domain might be per IP rate limiting, or the number of connections per second made to a database. Ratelimit is in production use at Lyft, and handles hundreds of thousands of rate limit requests per second. We use Ratelimit at both the edge proxy and within the internal service mesh.
The open source service is a reference implementation of the Envoy rate limit API. Envoy offers the following integrations:
- Network level rate limit filter: Envoy can call the rate limit service for every new connection on the listener where the filter is installed. The configuration specifies a specific domain and descriptor set to rate limit on. This has the ultimate effect of rate limiting the connections per second that transit the listener.
- HTTP level rate limit filter: Envoy can call the rate limit service for every new request on the listener where the filter is installed.
At Lyft we primarily use rate limiting to defend against load at the edge of our infrastructure. For example, the request rate allowed per user ID. This allows Lyft’s services to be protected from resource starvation due to unexpected or malicious load from external clients.
Monitoring
The networking team at Lyft provides metrics for all configured rate limits. When a service owner creates new rate limits to enforce at the edge, between services, or to a database, it is immediately possible to gather data pertaining to the defense mechanism.

The graph above is a snippet from the ratelimit service dashboard, which shows three panels:
- Total hits per minute: this panel shows a time series with the total hits per rate limit configured. In this panel service owners can see trends over time.
- Over limits per minute: this panel shows the metrics that are over the configured limit. This panel allows service owners to have quantifiable data with which to go back to their services and assess call patterns, and do capacity planning for high load events.
- Near limits per minute: this panel shows when the metric is hitting 80% of the limit configured.
How do we manage concurrency?
One of the main benefits of Envoy is that it enforces concurrency limits via its circuit breaking system at the network level as opposed to having to configure and implement the pattern in each application independently. Envoy supports various types of fully distributed circuit breaking:
- Maximum connections: The maximum number of connections that Envoy will establish to all hosts in an upstream cluster. In practice, this is generally used to protect HTTP/1 clusters since HTTP/2 can multiplex requests over a single connection, therefore limiting connection growth during slowdown.
- Maximum pending requests: The maximum number of requests that will be queued while waiting for an available connection from the pool. In practice this is only applicable to HTTP/1 clusters since HTTP/2 connection pools never queue requests. HTTP/2 requests are multiplexed immediately.
- Maximum requests: The maximum number of requests that can be outstanding to all hosts in a cluster at any given time. In practice, this is primarily used with HTTP/2 since HTTP/1 generally operates with one request per connection.
- Maximum active retries: The maximum number of retries that can be outstanding to all hosts in a cluster at any given time. In general we recommend aggressively circuit breaking retries so that retries for sporadic failures are allowed but the overall retry volume cannot explode and cause large scale cascading failure. This setting protects against retry amplification.
At Lyft we have focused on two mechanisms for managing concurrency in the service mesh:
- Limiting the number of concurrent connections at the ingress layer. Given that every service at Lyft runs an envoy sidecar to manage incoming requests into the service (ingress), we can configure the number of concurrent connections that the sidecar make to the application, thus limiting ingress concurrency into the application. We provide reasonable values as defaults, but encourage service owners to analyze their concurrency patterns and tighten the settings.
- Limiting the number of concurrent requests at the egress layer. Another benefit of running a sidecar to manage egress traffic from the service, is that we can manage outgoing concurrent requests from the service (egress) to any other service at Lyft. This means that the owners of the“locations” service can selectively configure the levels of concurrency that they want to support for every other service at Lyft, e.g. they can decide and configure that the “rides” service can make 100 concurrent requests to “locations”, but the “users” service can only make 50 concurrent requests to “locations”.
An interesting consequence of running concurrency limits on both the egress and ingress of every service at Lyft is that it’s much easier to track down undesired behavior. As mentioned above a common failure scenario seen is burstiness, which may be hard to diagnose due to metric resolution. The presence of concurrency limiting on both egress and ingress makes it easy to pinpoint bursty behavior across the system by seeing where in the request path concurrency overflows occur.
Monitoring
As we have mentioned, concurrency is not always an intuitive concept. To improve this shortcoming, the networking team provides different visualizations so that service owners can configure their concurrency limits, and then monitor how those limits are affecting the system.
Setting the Limits
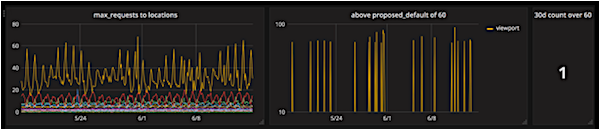
The above dashboard is an interactive dashboard where service owners can experiment with different limits for the maximum number of concurrent requests allowed from any service at Lyft to their specific service. In the example above the owner of the “locations” service can see that a limit of 60 concurrent requests would suffice for the majority of calling services with the exception of the “viewport” service. Using this dashboard, service owners can visualize what selective changes in concurrency configuration would look like in the current network topology, and can make those changes with confidence.
Monitoring the Limits
As mentioned above, having Envoy running as a sidecar that handles both ingress and egress traffic from every service allows service owners to protect their service from ingress concurrency and egress concurrency. The network team automatically creates dashboards like the ones below to help service owners visualize concurrency.
Ingress Concurrency
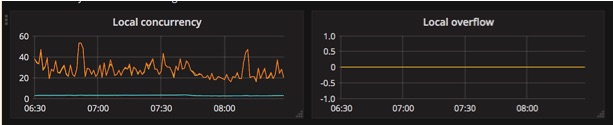
Using the two panels above, service owners can visualize the number of concurrent connections from their sidecar envoy into their service (using the panel on the left), and see if the concurrency limit is being hit (using the panel on the right).
Egress Concurrency
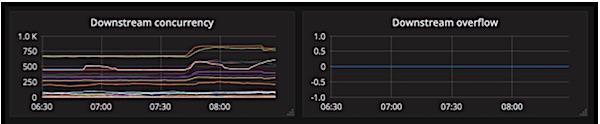
Using the two panels above, service owners can visualize the number of concurrent number of requests from any service to their service at any point in time (with the panel on the left). Additionally, they can visualize services that are going over the configured limit (using the panel on the right), and proceed to address the situation with concrete data.
What are the shortcomings?
Unfortunately, as with any static value, it’s hard to pick a nominal limit. This is true of rate limits but especially true of concurrency limits. There are several important factors that must be taken into account. The concurrency limits are local, and must account for the maximum possible concurrency rather than the average. Engineers are also not accustomed to thinking locally and primarily think in terms of rate of requests and not concurrency. With the aid of some visualizations and statistics, service owners can usually grasp concurrency and pick a nominal value.
In addition to difficulty reasoning about the value, the one constant at Lyft is change. There are hundreds of deploys per day throughout the service mesh. Any change to a service and its dependencies can change the resource and load profile. As soon as a value is chosen it will be out of date due to these changes. For example, almost all services at Lyft are CPU-bound. If a CPU-bound service’s direct dependency slows down by 25%, the service can handle additional concurrency since in-flight requests that were previously using the CPU will now sit idle for some additional time waiting for network I/O to complete. For this reason, a 25-50% increase over the nominal value is recommended.
Roadmap
Near Term
The networking team at Lyft focuses on building accessible and easy-to-use systems for service developers to successfully configure, operate, and debug Envoy and related systems. As such, we take it in our charter to not only design, implement, and deploy the systems showcased above, but also provide continued support for our users. At Lyft one of the main tenets of the infrastructure organization is that the abstractions we provide for service owners should be self-service. This means that we need to invest heavily in documenting use cases, providing debug tools, and offering support channels.
Given how non-intuitive concurrency is, the networking team is investing in additional documentation and engineering education around this topic in the short term. In the past, and with related systems we have seen success in the following formats:
- FAQs: Frequently asked question lists are extremely helpful as a first stop for customers. Moreover, it reduces the support burden of answering questions directly (e.g on Slack, via email, or even in person!). It allows you to easily point someone to a link; this practice scales better than having people answer the same questions repeatedly. The downfall here is the these lists can get long and difficult to parse. This can be addressed by separating content into categorical FAQs.
- Choose your own adventure: the service owner is the protagonist and they get to choose the outcome of their adventure. In the concurrency space described above there are several issues that can arise, and in tandem several settings that can be modified to solve the problems. This means that this support burden lends itself extremely well to a format where the service owner can start with the problem they are having and navigate a flowchart to arrive at the metrics they need to analyze to derive the correct settings.
Near term investments in documentation and engineering education mitigate one dimension of the current problem with concurrency: the non-intuitive nature of the system. However, they do not address the other dimension: staleness.
Longer Term
Concurrency limits are easy to enforce because Envoy is present at every hop in the network. However, as we have seen, the limits are difficult to determine because it would require service owners to fully understand all the constraints of the system. Moreover, static limits grow rapidly stale in today’s internet scale companies, especially those at a growth stage, due to the evolving and elastic nature of their network topologies.
Netflix has invested heavily in this problem, and recently open sourced a library to measure or estimate the concurrency limits at each point in the network. And more importantly, as systems scale and hit limits each node [in the system]will adjust and enforce its local view of the limit. They have borrowed from common TCP congestion control algorithms by equating the system’s concurrency constraints to a TCP congestion window.
One of Envoy’s design principles included rich and capable filter stacks to provide extensibility. Envoy has both L3/L4 (TCP level) and L7 (HTTP level) filter stacks. HTTP Filters can be written to operate on HTTP level messages. HTTP filters can stop and continue iteration to subsequent filters. This rich filter architecture is what allows for complex scenarios such as health check handling, calling a rate limiting service, buffering, routing, generating statistics for application traffic such as DynamoDB, etc.
In the coming months Lyft is going to work in conjunction with the team behind the concurrency limits library at Netflix to bring a system based on their library into an envoy L7 Filter. This means that at Lyft — and any other company using Envoy — we would move to an automated system, where our service engineers would not have to statically configure concurrency limits. This means that for instance, if there is service slowdown due to unexpected circumstances, the adaptive limit system can automatically clamp down on the detected limit preventing failure due to the unforeseen slowdown. An adaptive system, in general, eliminates the two problems we have had in the past: determining appropriate limits is non-intuitive, and static limits grow rapidly stale in an elastic distributed system.
Final Thoughts
To learn more about Envoy’s circuit breaker implementation, please see the Architecture Overview for Circuit Breaking in the Envoy documentation. As an open-source project, Envoy is open to code contributions. It is also welcoming of new ideas. Feel free to open an issue with a suggested improvement for circuit breaking even if the code is not forthcoming. One example of a capability that has not yet been implemented at the time of writing is circuit breaking based on system resources. Instead of approximating the concurrent request threshold based on the CPU profile, we can directly circuit break on CPU when dealing with ingress traffic.
While circuit breakers can improve the behavior of a system under load, it is important not to forget improvements that can be made in the system itself. Circuit breakers should be treated as a failsafe, not as a primary means of constraint. Service owners should use knowledge of circuit breakers to make improvements to their own codebase. Limiting concurrency with bounded pools is the most common way to solve concurrency issues. If large numbers of requests are generated from the same context, callers can opt instead to use a batch API. If a batch API does not exist, it may be in the best interest of the service receiving the call to implement one. These patterns are often a further extension of the education process. At Lyft, the networking team operates in partnership with other teams to educate and introduce improvements to all services. With education, system design improvements, and concurrency management at the network level, service owners can design, implement, and operate large distributed systems while minimizing the risk of cascading failures due to load.
About the Authors
 Jose Nino is the lead for Dev Tooling and Configuration on the Networking team at Lyft. During the nearly two years he’s been at Lyft, Jose has been instrumental in creating systems to scale configuration of Lyft’s Envoy production environment for increasingly large deployments and engineering orgs. He has worked as an open source Envoy maintainer, and has nurtured Envoy’s growing community. More recently, Jose has moved on to scaling Lyft’s network load tolerance systems. Jose has spoken about Envoy and other related topics at several venues, most recently at Kubecon EU 2018.
Jose Nino is the lead for Dev Tooling and Configuration on the Networking team at Lyft. During the nearly two years he’s been at Lyft, Jose has been instrumental in creating systems to scale configuration of Lyft’s Envoy production environment for increasingly large deployments and engineering orgs. He has worked as an open source Envoy maintainer, and has nurtured Envoy’s growing community. More recently, Jose has moved on to scaling Lyft’s network load tolerance systems. Jose has spoken about Envoy and other related topics at several venues, most recently at Kubecon EU 2018.
 Daniel Hochman is a senior infrastructure engineer at Lyft. He’s passionate about scaling innovative products and processes to improve quality of life for those inside and outside of the company. During his time at Lyft, he has successfully guided the platform through an explosion of product and organizational growth. He wrote one of the highest-throughput microservices and introduced several critical storage technologies. Daniel currently leads Traffic Networking at Lyft and is responsible for scaling Lyft’s networking infrastructure internally and at the edge.
Daniel Hochman is a senior infrastructure engineer at Lyft. He’s passionate about scaling innovative products and processes to improve quality of life for those inside and outside of the company. During his time at Lyft, he has successfully guided the platform through an explosion of product and organizational growth. He wrote one of the highest-throughput microservices and introduced several critical storage technologies. Daniel currently leads Traffic Networking at Lyft and is responsible for scaling Lyft’s networking infrastructure internally and at the edge.