
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Only a very narrow subset of use cases is appropriate for this technology.
- The way that Hyperledger Fabric uses MVCC (multiversion concurrency control) when validating write batches is safe enough for financial applications in a decentralized ledger but may not scale efficiently enough in order to be attractive to B2C startups.
- Avoid this technology if you can make all of your transactions idempotent.
- This technology is still somewhat immature.
- Even though this is an open-source project, there are currently some limitations in choice of cloud provider when moving to a production environment (that could change).
I have been following the three-year-old Hyperledger Fabric open-source project since its code base moved to GitHub about two years ago. The Hyperledger projects are hosted by the Linux Foundation and sponsored mostly by IBM. They promote the use of what are known as private, or permissioned, blockchains. With a public blockchain, the first anonymous miner who solves a cryptographic puzzle gets to commit the next block of ledger entries to the chain. Private blockchains solve the consensus problem among authenticated peers using algorithms such as Raft or Paxos.
With a blockchain, you get CRUD-style access to the ledger. You also get the ability to store mini programs known as smart contracts on the ledger. When a transaction is submitted to a smart contract, all ledger state-mutating operations executed within the chaincode are atomic — either all operations get committed or none of them do. If the underlying ledger data accessed by the chaincode has been changed by the time that the operations made by the chaincode are to be committed, then the transaction is aborted. This happens automatically and is a big part of the value to writing smart contracts.
The same folks who released Hyperledger Fabric also released another open-source project, Hyperledger Composer, which makes it easy for developers to write chaincode for Hyperledger Fabric and the DApps (decentralized applications) that can call them.
Why now?
Thoughtworks is a technology consulting company (acquired by Apax Partners) that markets itself as “a community of passionate individuals whose purpose is to revolutionize software design, creation and delivery”. Twice a year, they release a Technology Radar report that recommends certain technologies be put on hold, assessed, put on trial, or adopted. Volume 18 of this Technology Radar (pdf), published in May 2018, placed Hyperledger Composer in the trial ring, which they define as “Worth pursuing. It is important to understand how to build up this capability. Enterprises should try this technology on a project that can handle the risk.”
In my role as a software architect, I evaluate emerging technology, and Hyperledger Composer made it onto my personal radar. Every time I evaluate an emerging technology, I use it to implement a rudimentary news feed microservice. Each of these microservices are feature identical and are load-tested in the exact same manner. In this way, I can make reasonable statements about the performance characteristics of any specific technology in comparison with the other technologies. I chose the problem domain of a news feed because of its familiarity and ubiquity in social networks and because it is complicated enough to require non-trivial solutions yet simple enough to understand without getting lost in implementation minutiae. I publish the source code for these microservices, along with the source code needed to load-test them and to collect and analyze the performance results, in a freely available repository on GitHub. In the spirit of scientific peer review, I encourage you to clone the repo and reproduce the results for yourself.
Building the test microservice
Hyperledger Composer allows you to write smart contracts in server-side JavaScript. It makes available a native client library by which Node.js applications can access the ledger and submit transactions to these smart contracts. For the purposes of this experiment, I used an already developed Node.js microservice (see server/feed4 in the repo) as the control. I copied the source code for that microservice to a new folder (see server/feed7/micro-service in the repo) then I replaced all references to MySQL, Redis, and Cassandra with calls to the Hyperledger Composer client API. It is the feed7 project that serves as the test in this experiment. Both projects use Elasticsearch because one of the requirements of each news-feed service is a keyword-based search, and a blockchain is not appropriate for that. Like most of the other microservices in this repo, the feed7 microservice uses Swagger to define its REST API. The specification can be found in the server/swagger/news.yaml file.
With Hyperledger Composer, you create a business network that consists of a data model, a set of transactions that manipulate the data model, and a set of queries by which those transactions can access data within the model. Hyperledger Composer works with Hyperledger Fabric, whose basic network consists of CouchDB, the default peer, the business network peer, a certificate authority service, and an orderer. The feed7 microservice accesses Hyperledger Fabric in the context of this business network, which you can find in the server/feed7/business-network folder.
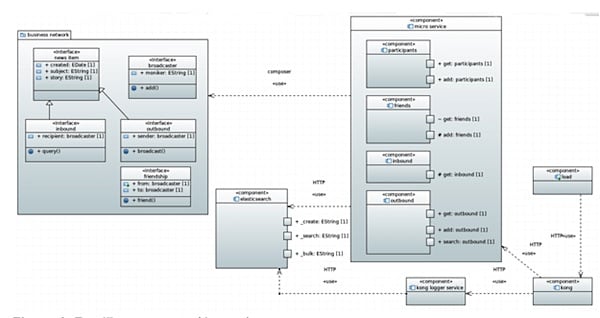
Figure 1: Feed7 components (the test).
In the model for this business network, the broadcaster is the participant. There are friendship, inbound, and outbound assets. The friendship asset captures the friend relationship between two broadcasters. Each inbound asset is a news-feed item meant for the associated broadcaster. The outbound asset is a news-feed item that was sent by the associated broadcaster. There are two transactions in this business network: broadcasters can friend each other and a broadcaster can broadcast a news-feed item to its friends. The only query needed inside the business network is for the broadcast transaction to access the broadcaster’s friends.
async function broadcastParticipants(tx) {
const factory = getFactory();
const created = Date.now();
const now = new Date();
const k = tx.sender.participantId + '|' + created + '|';
const outboundRegistry = await getAssetRegistry('info.glennengstrand.Outbound');
const ok = 'Outbound:' + k + Math.random();
const inboundRegistry = await getAssetRegistry('info.glennengstrand.Inbound');
var o = factory.newResource('info.glennengstrand', 'Outbound', ok);
o.created = now;
o.subject = tx.subject;
o.story = tx.story;
o.sender = tx.sender;
await outboundRegistry.add(o);
const friends = await query('broadcasterFriends', { broadcaster: 'resource:info.glennengstrand.Broadcaster#' + tx.sender.participantId });
for (i = 0; i < friends.length; i++) {
const friend = friends[i];
const ik = 'Inbound:' + k + Math.random();
var inb = factory.newResource('info.glennengstrand', 'Inbound', ik);
inb.created = now;
inb.subject = tx.subject;
inb.story = tx.story;
inb.recipient = friend.to;
await inboundRegistry.add(inb);
}
}
Code Sample 1: A smart contract.
The Hyperledger Composer API that is intended to be called within a smart contract closely resembles the API that is intended to be called by the Node.js DApp, but there are some interesting differences. Within the smart contract, you must use the async/await mechanism, but within the DApp, you had to use promises. Smart contracts always had to use predefined queries but DApp code could build a query dynamically and run that. When querying or retrieving either a participant or asset from the DApp, you had to include the constant “PID:” as a part of the key but not when accessing the same data from chaincode.
function submitTransaction(bizNetworkConnection, transaction, from, subject, story, callback, retry) {
const elastic = require('../repositories/elastic');
bizNetworkConnection.submitTransaction(transaction)
.then((result) => {
const retVal = {
"from": from,
"occurred": Date.now(),
"subject": subject,
"story": story
};
elastic.index(from, story);
callback(null, retVal);
}).catch(() => {
setTimeout(() => {
submitTransactionRetry(bizNetworkConnection, transaction, from, subject, story, callback, 2 * retry);
}, retry + Math.floor(Math.random() * Math.floor(1000)));
});
}
exports.addOutbound = function(args, callback) {
const BusinessNetworkConnection = require('composer-client').BusinessNetworkConnection;
const bizNetworkConnection = new BusinessNetworkConnection();
bizNetworkConnection.connect(process.env.CARD_NAME)
.then((bizNetworkDefinition) => {
const factory = bizNetworkDefinition.getFactory();
var transaction = factory.newTransaction('info.glennengstrand', 'Broadcast');
transaction.sender = factory.newRelationship('info.glennengstrand', 'Broadcaster', 'PID:' + args.body.value.from);
transaction.subject = args.body.value.subject;
transaction.story = args.body.value.story;
submitTransaction(bizNetworkConnection, transaction, args.body.value.from, args.body.value.subject, args.body.value.story, callback, 2000);
});
}
Code Sample 2: A DApp calling a smart contract.
In the DApp source code, you may notice all this retry logic when submitting a transaction. That is because Hyperledger Fabric uses MVCC (multiversion concurrency control) when validating write batches and will easily throw a read conflict error. What you do to resolve that is to sleep a slightly randomized amount of time then retry the transaction.
Testing the microservice under load
Both the control and the test use the same load-test application, which you can find in the client/load folder of the repo. The load test creates 10 participants in an eternal loop, and gives each participant anywhere from two to four friends. It has each participant broadcast 10 news-feed items, each of which consists of 150 randomly generated numbers. The load-test app spins up three threads, each doing this process 90% of the time. The other 10% is testing the search functionality.
Instead of calling the news-feed microservice directly, the load-test application calls an open-source API gateway called Kong, which proxies each request from the load-test application to the news-feed microservice. Kong is configured to use the http-log plugin in order to send request and response logs for each call to another microservice, which in turn sends the performance-related parts to Elasticsearch in batches. You can find the source code for the Kong logger microservice in the client/perf4 folder.
I used Kibana to visualize the performance data, including throughput, average latency, and percentile latency. Whenever possible, I always collected summaries of performance metrics from two hours of data.

Figure 2: Per-minute throughput of outbound post requests for a test (i.e., Hyperledger Composer and Fabric) experiment.
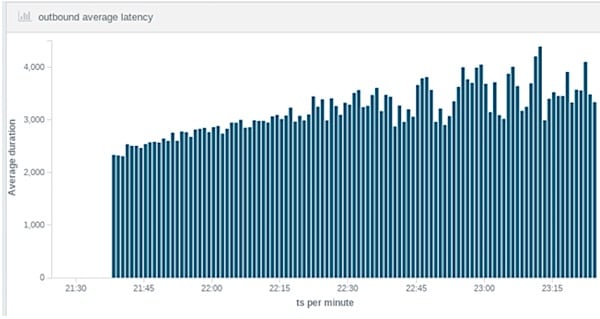
Figure 3: Per-minute average of latency of outbound post requests for a test (i.e., Hyperledger Composer and Fabric) experiment.
I deployed the control twice, both times in EC2 using m4.xlarge instances; one time when the feed4 service was running in a Docker container and another time when it wasn’t. The Docker version experienced 6% less throughput and almost no difference in latency. I also deployed the test twice, both times in EC2 using m4.xlarge instances for Kong, Cassandra (used by Kong), Elasticsearch, and the load-test application. The first test deployed Hyperledger Fabric, Composer, and the feed7 business network and microservice on an m4.xlarge and the second test used an m4.2xlarge, to see the performance differences in scaling up.
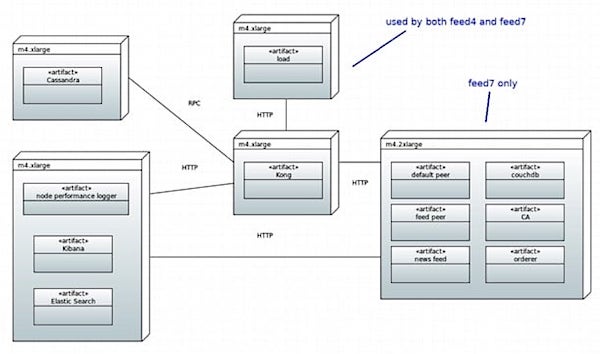
Figure 4: Feed7 deployment (the test).
To allow for valid comparative analysis, and because production configurations were not readily available, both the control and the test used developer configurations for everything. There exists an AWS CloudFormation template for Hyperledger Fabric, but it is deploying the basic network, which is Hyperledger-speak for a developer configuration. The only online documentation for a production configuration that I could find, outside of advertisements for IBM Cloud, were a couple of blogs on Hacker Noon by some folks from VMware. Those blogs claimed a production configuration and a diagram indicated that the orderer was backed by Kafka, but the configtx.yaml file in the referenced GitHub repo shows an OrdererType of solo, not Kafka. That suggests a developer configuration. A comment in the source code says, “The solo consensus scheme is very simple, and allows only one consenter for a given chain. It accepts messages being delivered via Order/Configure, orders them, and then uses the blockcutter to form the messages into blocks before writing to the given ledger.”
Performance results
There is both good and bad news for Hyperledger when it comes to performance under load. Here is the bad news: the Hyperledger version of the news feed demonstrated over 300 times less throughput and was three orders of magnitude slower than the traditional version. But the good news is that doubling the hardware capacity for the Hyperledger version yielded a 20% improvement in throughput and almost halved the latency.
The control sustained over 13,000 outbound post requests (i.e., a news-feed broadcast) per minute (RPM). Average latency was 4 ms and the 99th percentile was 9 ms. The test experienced on average 29 outbound post requests per minute for the m4.xlarge and 38 for the m4.2xlarge. The average latency was 4.7 s for the m4.xlarge and 3.2 s for the m4.2xlarge. The 99th percentile latency was 10.2 s for the m4.xlarge and 4.9 s for the m4.2xlarge.
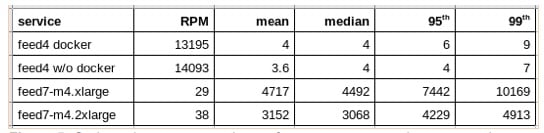
Figure 5: Outbound-post comparative performance summary. Latency numbers are in milliseconds.
There are some other inefficiencies that I need to cover here. The CPU and performance-related metrics on the control quickly reached steady state while the same metrics on the test got worse and worse over time. The biggest offender with CPU was the default peer process in Fabric. This was surprising because the microservice always accessed the news-feed business network whose corresponding peer container was not as CPU intensive. Perhaps the default peer is used to endorse transactions? I could find no way to remove it from the configuration. In a production configuration, you would have multiple peers, otherwise the ledger would not be decentralized.
For both the test and the control, the microservice will eventually crash, once the SSD for the database runs out of available storage. For the control, that happens in the Cassandra database after almost 30 million outbound posts have occurred. For the test, that happens in the CouchDB database after about 4,000 outbound posts have occurred. The SSD storage for both the control and the test have the same capacity, which is 20 GB. Clearly, storage efficiency is not currently a primary concern of the developers contributing to the Hyperledger Fabric project.
Conclusion
Originally, I believed that the news-feed application would be a good use case for a blockchain. The primary action of the load-test application is appending friends and appending news-feed items, which sounds very similar to appending to a ledger. Now, however, I believe that analogy to be superficial. The major concern for blockchains is to prevent what is known as the double-spend problem — what good is a blockchain that cannot prevent participants from spending the same money twice? For public blockchains, that problem is handled using unspent transaction outputs, or UTXO. Hyperledger Fabric addresses the problem via MVCC on the read sets when validating write batches. Fabric does have inefficiencies that can be addressed as it matures, but I believe that this use of MVCC in order to prevent double spending is an inherent cause for the low throughput and high latency. For all intents and purposes, the news-feed transactions are essentially idempotent. There are no significant consequences if two participants friend themselves in a different order or multiple times, or broadcast items to each other in a different order or multiple times. Fabric is allocating a lot of CPU time and memory to prevent a problem that has no significant impact on a news feed.
This evaluation leads me to believe that the future of software development will not be eaten by blockchains. There is only a very narrow subset of use cases that justify the high computing costs inherent in automatic, guaranteed, distributed concurrency control and validation. Basically, you need to require a consortium marketplace where idempotent transactions are not a possibility. While evaluating Hyperledger Composer at this time has some merit, the current level of maturity makes committing to a production release in the near future highly problematic. The Hyperledger projects are all open source but at the time of this writing there appear to be limitations in choice of cloud provider when progressing to a production environment.
About the Author
 Glenn Engstrand is a Software Architect at Adobe Systems, Inc.. His focus is working with engineers in order to deliver scalable, server side, 12 factor compliant application architectures. Glenn was a breakout speaker at Adobe’s internal Advertising Cloud developer’s conferences in 2018 and 2017 and at the 2012 Lucene Revolution conference in Boston. He specializes in breaking monolithic applications up into micro-services and in deep integration with Real-Time Communications infrastructure.
Glenn Engstrand is a Software Architect at Adobe Systems, Inc.. His focus is working with engineers in order to deliver scalable, server side, 12 factor compliant application architectures. Glenn was a breakout speaker at Adobe’s internal Advertising Cloud developer’s conferences in 2018 and 2017 and at the 2012 Lucene Revolution conference in Boston. He specializes in breaking monolithic applications up into micro-services and in deep integration with Real-Time Communications infrastructure.