
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- BuzzFeed have recently migrated from a monolithic Perl application to a set of around 500 microservices written in a mixture of Python and Go.
- Initially their routing logic was implemented in the CDN but that proved difficult to test and maintain. They subsequently switched to using NGINX for routing.
- The site router service is designed to run on top of BuzzFeed’s own Rig platform, which facilitates easy deployment to each of the services in each Amazon Elastic Container Service environment (ECS) they run (test, stage and production).
- BuzzFeed have built an abstraction layer that allows configuration of the routing service using YAML.
Starting in 2016 BuzzFeed began a re-architecture project moving from a single monolithic application written in Perl to a set of microservices. The main reason for the move was that the Perl application was proving hard to scale, essential given that buzzfeed.com alone serves about 7 billion page views/month, and the organisation also publishes content to around 30 different social platforms and language editions.
In addition to scaling issues BuzzFeed were finding it harder and harder to find engineers who both knew Perl and wanted to work with it. Finally, they wanted the ability to iterate on new product ideas faster.
At a very high level the new architecture comprises a CDN that points to a routing service which sits inside AWS using the ECS containerised service:
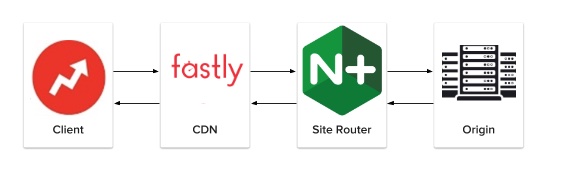
The new microservices are developed using Python as the main language with Go for the more performance sensitive components. BuzzFeed’s engineering team have found that the two languages are very complementary and it is relatively straightforward for individual developers to switch from one to the other as appropriate.
At the time of writing they have around 500 microservices in stage and production environments on AWS. They break-down their services using something that sounds somewhat similar to SCS; the home page on buzzfeed.com is one service, news pages are a separate service, as are author pages and so on.
One challenge the team faced was with routing requests to the correct backend applications. Fastly, their CDN provider, has the ability to programmatically define behavioural logic at the edge using a C based programming language called VCL, and initially the engineering team were writing all their routing logic in VCL directly.
However, they found that as the configuration became more and more complex so making changes became more difficult, and being able to adequately test their configuration much more important. Mark McDonnell, a Staff Software Engineer at BuzzFeed, told InfoQ that
We had a lot of logic in the CDN itself and only a couple of engineers who really understood how it worked. The CDN is also deliberately quite locked down because the caching layer is super important to us and we need to prevent engineers from inadvertently making changes that could negatively affect our caching strategies or cause incoming requests to be routed to the wrong origin server.
In addition Fastly has its own implementation of the Varnish HTTP accelerator. BuzzFeed found this made it difficult for engineers to spin up a local development environment and run their VCL logic through it, and, as a result, testing of the VCL code proved problematic. In view of this the engineering team decided to implement a new routing service to replace the VCL routing, extracting the majority of the routing logic from the CDN to a separate router microservice.
The site router service is designed to run on top of BuzzFeed’s own Rig platform, which facilitates easy deployment to each of the services in each ECS environment they run (test, stage and production).
They considered several options for doing the reverse proxy including HAProxy, but ultimately settled on using NGINX. “We chose NGINX because the majority of our platform infrastructure team had experience with it, so we had SRE buy-in for it already, and one of our selling points was that it was really simple to get up to speed,” McDonnell told us. As you would expect, when they added NGINX to the system they did see some additional latency added to individual requests, but it was “negligible” according to McDonnell.
Although citing ease of use and familiarity as two of the reasons for choosing NGINX, BuzzFeed have built an abstraction layer for configuring the service. This service, written in Python, dynamically generates the required nginx.conf file from YAML. It makes extensive use of YAML-specific features such as “Anchors and Aliases” and “Merge Key”, “which allows us to reuse configuration across environment blocks and to easily override specific keys without repeating huge chunks of configuration,” according to the BuzzFeed tech blog. “We use this approach primarily for our ‘upstreams’ and ‘timeouts’ sections, as we usually want to override those values to be environment specific.”
Initially the routing service was built using the open-source version of NGINX but moved to the commercial version, NGINX Plus. Having access to paid support was one reason McDonnell cited, but the team also need certain features that are only available in the paid version, in particular DNS monitoring; BuzzFeed has fairly sophisticated server zones so that when the AWS load balancers change IP address NGINX Plus is able to make sure that the DNS entries are also updated. A post on the BuzzFeed tech blog explains that
When NGINX starts up, it resolves the DNS for any upstreams we define in our configuration file. This means it would translate the hostname into an IP (or a set of IPs as was the case when using AWS Elastic Load Balancers). NGINX then proceeds to cache these IPs and this is where our problems started.
If you’re unfamiliar with load balancers, they check multiple servers to see if they’re healthy and, if they’re not, the server is shutdown and a new server instance is brought up. The issue we discovered was that each server instance IP was changing. As mentioned earlier, NGINX caches IPs when it’s booted up so new requests were coming in and being proxied to a cached IP that was no longer functioning due to the ELB [Elastic Load Balancers].
One solution would be to hot reload the NGINX configuration. That’s a manual process, and we would have no idea when that should be done because there is no way of knowing when a server instance would be rotated out of service.
There were a few options documented by NGINX that tried to work around this issue; however, all but one option meant we would have to redesign our entire architecture because they didn’t support the use of NGINX’s upstream directive (which we are leaning on very heavily as part of our configuration abstraction).
The one solution that would allow us to utilise the interface design we had turned out to only be available via NGINX Plus. The cost of going commercial was justified: we wouldn’t need to rewrite our entire service from scratch and there were additional features that we could utilise moving forward (some of which we had already been considering). Once we switched over, the solution was a one-line addition using the resolver directive that allowed us to define a TTL for the cached DNS resolution.
The VCL logic was used to help BuzzFeed bucket users by their geolocation when they began rolling the new services out, so they could start with a small country like New Zealand
For any users with a geoip.country_code of NZ they would set a X-BF-SiteRouter header. Later in the VCL code we would switch the backend over to Site Router if the X-BF-SiteRouter header was set (depending on which route was being requested).
Once we were happy, we would then extend the rollout locality reach to AU, GB, OC, EU, SA (South America), then finally we would just point everything at the Site Router (effectively North America being the last locale).
We also utilised the Vary header to ensure users from different regions that weren’t ready to be seeing Site Router, weren’t accidentally getting cached responses from it.
Migrating to the new architecture has paid dividends in terms of team velocity, McDonnell told us that
engineers have the freedom to spin up services whenever they like and we deploy many times a day. There are various terms floating around, such as continuous integration, continous delivery and continuous deployment, and they all mean slightly different things. Ultimately we have a very good delivery pipeline, but our specific platform implementation doesn’t automatically rollout changes to production, that’s something we currently have to manually choose to do, and that makes sense for our use cases (e.g. not everything we build needs to exist automatically in a production environment).
BuzzFeed has a rich A/B system in place for testing individual ‘features’, whereas larger scale A/B-based rollouts are a bit simpler in their approach (leaning on a mixture of VCL logic and Site Router specific ‘override’ configuration to handle where requests are routed).
Monitoring of the new infrastructure is done using DataDog. They currently use Papertrail for logging but are finding this a performance bottleneck and are looking at both DataDog and honeycomb.io as alternatives.
About the Author
 Charles Humble took over as head of the editorial team at InfoQ.com in March 2014, guiding our content creation including news, articles, books, video presentations and interviews. Prior to taking on the full-time role at InfoQ, Charles led our Java coverage, and was CTO for PRPi Consulting, a renumeration research firm that was acquired by PwC in July 2012. He has worked in enterprise software for around 20 years as a developer, architect and development manager. In his spare time he writes music as 1/3 of London-based ambient techno group Twofish.
Charles Humble took over as head of the editorial team at InfoQ.com in March 2014, guiding our content creation including news, articles, books, video presentations and interviews. Prior to taking on the full-time role at InfoQ, Charles led our Java coverage, and was CTO for PRPi Consulting, a renumeration research firm that was acquired by PwC in July 2012. He has worked in enterprise software for around 20 years as a developer, architect and development manager. In his spare time he writes music as 1/3 of London-based ambient techno group Twofish.