
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- It is important to not only “design for failure” but “test for recovery”
- Understand that all possible scenarios probably won’t be captured in requirements. We need to keep learning and developing the skills to try and alleviate the risks that deploying into Cloud environments will bring.
- Utilise the Cloud Native QA Charter to help you think about the possible scenarios that could play out in production
- Resist the urge to automate everything, focus on Robust Automation and use the Cloud Native QA Charter to your advantage.
- Ask questions and challenge non functional behaviours in requirements.
Agile teams and the widespread use of the scrum process have already started breaking down the barriers that used to exist between developers and test. The Quality Assurance (QA) role within an agile team is already broader in scope than that of the tester of yesteryear. Instilling a “quality” mentality into the team and helping to challenge and drive the team in everything they do, the QA role is all encompassing. In modern software development teams, when it comes to test strategy, approach and process, automation tends to be the first thing that comes to mind but it’s important not to forget about the core values of the QA role.
Since the inception of cloud computing and the formation of the Cloud Native Computing Foundation (CNCF), teams have learnt some harsh lessons about running distributed systems at scale. In a world of 24×7 consumer expectations the business world is starting to realise that every business is a software business and with that comes high risk and high gains.
Following the advent of agile and cloud computing all roles within the team now have a much broader scope. It’s not uncommon to see job ads for a full stack developer but in the QA space we are still in a stage between dev in test, test automater, manual tester, tester and also sometimes the full blown QA. Perhaps it won’t be too long until we see the Full Stack QA role being advertised.
Both developers (actively) and consumers (passively) strive for the 100% uptime system, the five 9’s is still bellowing somewhere in my subconscious but we live in a world where consumers expect a service 24x7x365.
I’m thinking back to a time just ten years ago before Uber and contactless payments were mainstream and I had a service outage on one of my old internet bank accounts that left me unable to withdraw cash at a peak time on a Saturday evening. I was still involved in software development back then but outages such as this were somewhat expected. Today, consumers have an expectation that the services they consume are uninterrupted and continuous, whether it’s a social media platform, an online e-commerce site or a banking app.
With this in mind, the advent and widespread adoption of the cloud eco-system presents a new challenge to the modern day QA. So how do we look to address the following question:
“What does it mean to be a QA in a Cloud Native software business?”
To firstly address these areas we need to understand the QA role in agile and what it means to be Cloud Native.
Quality Assurance in Agile
In an agile team we expect the following from our QA: (and all other team members)
- to question and challenge everything (be vocal!)
- analyse requirements/stories
- play a key part in agile ceremonies
- and of course, to test.
These expectations maybe required of all members, but as the prime driver of quality within the team it is vital that the QA possesses these skills.
When analysing requirements we can question the validity of acceptance criteria, discuss design, test approaches and focus on the MVP (Minimum Viable Product). But, capturing the non functional requirements (NFR’s) in a Cloud Native Application is not a straightforward process and furthermore being able to articulate the various scenarios is probably going to be unrealistic.
Cloud eco-systems allow application developers the freedom to meet availability requirements without the dependence on infrastructure availability. Developers are told to “design for failure”. In order to be a QA in a Cloud Native environment a broader understanding is required of how these design for failure scenarios could play out. Perhaps the QA response to the “design for failure” paradigm is to “test for recovery”.
Cloud Native
To identify a strategy for becoming a Cloud Native QA we first need to understand the term Cloud Native. In it’s simplest form we are simply referring to an application specifically designed to run in the cloud, but that doesn’t really help us. The Cloud Native Computing Foundation (CNCF) describes Cloud Native as follows:
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
The Cloud Native Computing Foundation seeks to drive adoption of this paradigm by fostering and sustaining an ecosystem of open source, vendor-neutral projects. We democratize state-of-the-art patterns to make these innovations accessible for everyone. https://www.cncf.io/about/faq/
If we extract the key elements of the CNCF definition we can start to shape focus areas for the Cloud Native QA:
Focus Areas
- Scalable
- Dynamic Environments
- Resilient
- Manageable
- Observable
- Robust Automation
- Frequent and Predictable high-impact change
Cloud Native QA Charter
Lets examine these seven focus areas and explore what this means for the QA function, and to a wider extent, the development team.
Scalable
In days gone by, developers would leave scaling concerns to infrastructure and operations engineers who would reconfigure load balancers or provision additional hardware. In Cloud Native applications this expectation has dissipated. Perhaps this is a job for architecture and design but who better to provide review than that of the inquisitive QA.
- How is the service scaled?
- Does it use a cache?
- How do these caches work across services when requests are stateless?
- What happens when instances are no longer required?
Challenge and question scaling in refinements. Failure is expected in cloud native applications, it needs to be embraced.
Dynamic Environments
The software will likely run in one datacentre but it could integrate with cloud providers Software as a Service (SaaS) offerings, contain on-premises networking to fulfilment systems. Some applications may even be deployed across cloud providers, how do we deal with the impending latency issues that this brings?
- Think about how the feature is deployed and the key distributed elements to the system.
- Question the availability of a features dependencies.
- If one was to fail how does the feature recover?
Resilient
From a design perspective we often speak of our desire to build a resilient system. From a QA perspective how do we verify resilience if it’s not directly part of acceptance criteria or DoD (definition of done). Experienced teams might be in a position to be able to form a Cloud Native DoD or set of Acceptance criteria around this charter.
- Kubernetes can perform rolling restarts but how do we gracefully shutdown and release client threads?
- How is traffic routed when nodes are overloaded?
- Does the system degrade gracefully?
- Can we still respond to user requests if legacy systems are unavailable?
Manageable
Even though manageable is somewhat of a subjective term especially from a QA perspective, we can look upon this as an opportunity to ask questions. If we address the term manageable as the degree to which a system can adapt to changes as a means of response to deployment, configuration, development, test and load. Then a big advantage of cloud environments is that someone else can take on some of those general software and infrastructure manageability costs.
So always ask:
- is it worth building it ourselves?
- what value do we get out of building it?
Developers and architects will inevitably want to try out that bit of new tech, but sometimes the QA has to help keep the team on the quality train and remember that we pay these cloud providers because they can probably do a better job of managing the software and infrastructure than we ever could.
Observable
For a given feature how do we ensure it’s observability in the underlying platform.
- Operationally test the logging. 12 factor logging doesn’t necessarily provide an observable system. How are requests correlated? If the system is event driven or event sourced — is the right data captured to provide a meaningful audit trail.
- Are metric requirements captured?
- Are logs archived and searchable?
- Can the application be traced? opentracing.io
Robust Automation
Robust is a key term here to help us differentiate ourselves from the misunderstood attempts at 100% automation. When planning out the automation efforts, focus on the valuable areas and don’t focus on automating everything. Time is limited, it won’t be possible or valuable to automate everything, so focus on the valuable features and ensure the test packs are robust.
The focus isn’t on large unmaintainable, unreliable regression packs that add no discernible value but smart succinct test packs that can:
- simultaneously validate a deployment,
- perform a selected set of functional tasks and undertake negative task based scenarios such as those referred to in the scaling / reliability section above
This type of regression pack adds constant value to the development effort and can be expanded and/or shrunk as the product matures and the confidence level increases.
Frequent and Predictable high-impact change
Whether or not your product is deployed into production using the blue/green or red/black Netflix deployment, the key takeaway here is that the assurance of the deployment of features is now in scope:
- What are the service dependencies?
- Are there breaking changes?
- Continuous delivery over Continuous deployment.
- How do we run an end to end test while a deployment is in progress?
- If it fails, how does it rollback?
- What should happen?
When a level of confidence is set in the underlying platform then some of these statements may seem trivial.
Testing Pyramid
The testing pyramid is well known within the testing community. It’s ultimate goal is to help teams create an appropriate balance of tests within the context of the Application Under Test (AUT) that can deliver the most value in the limited time available.
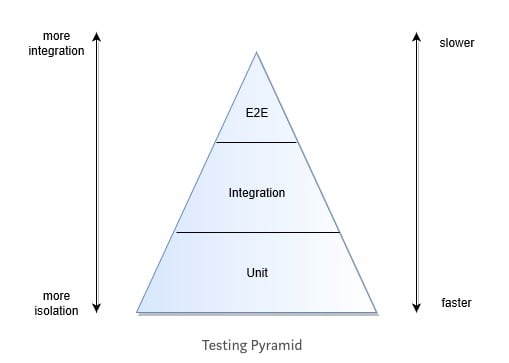
In contrast to this, in a cloud native environment where failure and degradation to service is both expected and anticipated the existing testing pyramids don’t focus on the cloud native elements that were previously articulated. For that reason I would propose an amendment to address this concern.
Cloud Native Chaotic Overlay
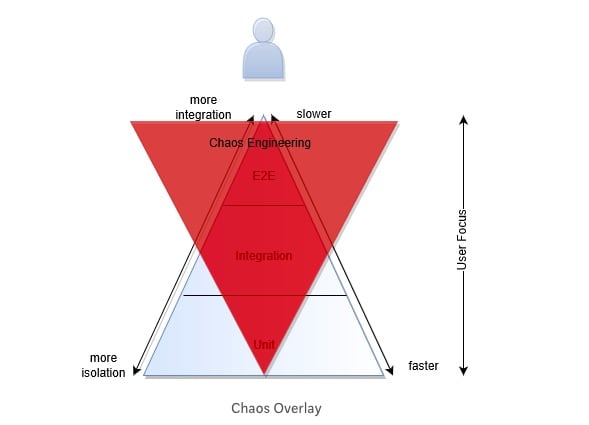
Chaos Engineering is the discipline of experimenting on a distributed system in order to build confidence in the system’s capability to withstand turbulent conditions in production
On that basis it means that from a QA perspective we can invert the principles to have a smaller suite of tests at a unit level with a wider breadth of tests at the E2E level that focus on the high risk areas where business impact is also high.
Techniques can inform tests at an earlier stage at a feature based level to work towards gaining confidence in a baselined steady state of the product/feature before we add real world events (such as network drops, service degradation). Bringing some of the chaos engineering principles earlier in the cycle.
As a testament to someone who has:
- refactored some code where the unit tests fail
- has done whatever it takes to make the tests pass
- the person who wrote the code has long gone and the dreaded change is in that part of the system that know one else touches
- we don’t understand how it works
- and I fear the system will come crashing down before my very eyes.
Most developers will have been in this situation, so how can the QA advocate quality and utilise the testing pyramid as a best practice to instil a quality process into the development team.
Exploratory Testing and Chaos Engineering
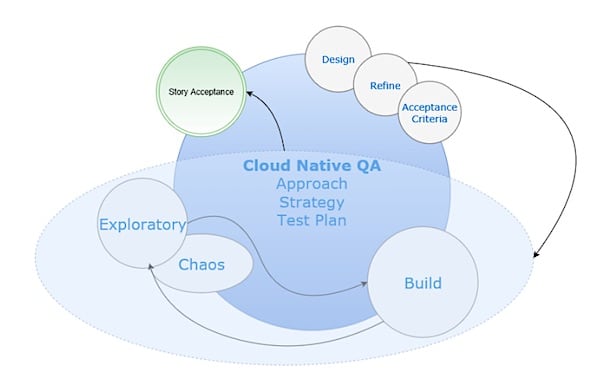
Developers and QA already work closely in agile teams but the focus on a production ready cloud native mind-set is not common. Adding elements of chaos engineering into the phases at the bottom of the testing pyramid can start to incorporate the cloud native charter into the features that we develop from the ground up.
If we look at how this works in practice, exploratory testing has long been used as an approach to testing for skilled testers to use existing knowledge, heuristics and risk areas to unearth further value-add propositions in limited time periods. This works great in agile. If exploratory testing is a mind-set, then the Cloud Native QA also requires that ingrained way of thinking.
Deductive reasoning allows testers to guide future reasoning based on past results. As a QA develops experience of the underlying platform then confidence in particular areas of the Cloud Native application may not require as much focus as confidence is gained. (That’s not to say they should be removed completely from focus). This is perfect for incorporating a Cloud Native way of thinking in to a testing technique or mind-set.
Cloud Native Exploratory Mind Map
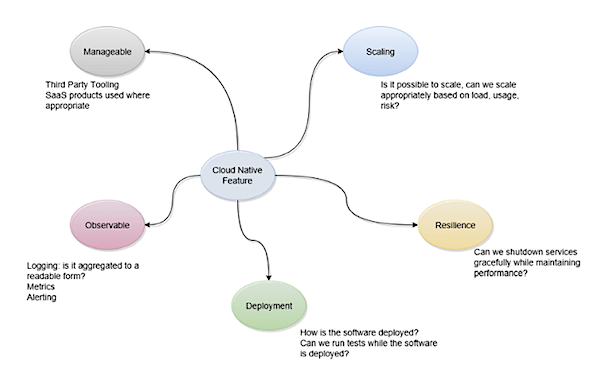
While exploring the system, experiment by “testing for recovery”.
When running an exploratory session on a feature, experiment in testing the areas we discussed from the Cloud Native Charter. This can help produce a more valuable and robust automation suite for our Cloud Native applications.
Environments
With the advent of tooling to orchestrate the deployment of applications into our various environments we are presented with an opportunity to automate the execution of our cloud native test strategy within these pipelines.
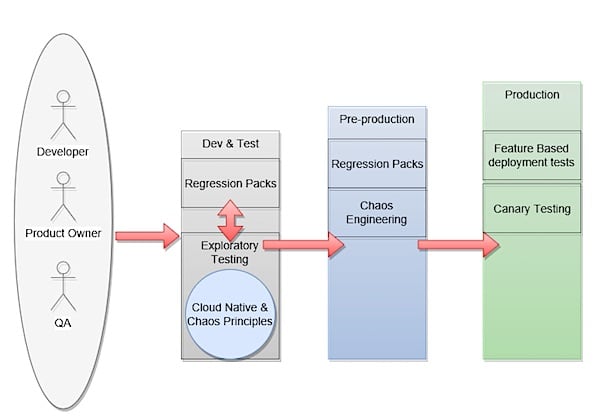
QA’s, Developers and Product owners work together to help focus efforts on delivering the highest value. The Cloud Native QA Charter and the chaos principles can help assist with ensuring the reliability of the high value features in production.
It is important that the outputs of the exploratory testing (with chaos and cloud native techniques) are analysed and if necessary incorporated into any automated regression packs. Remember, not everything should be automated, we need a robust, fast and valuable test suite.
Canary Testing
Canary testing is one technique that is used in verifying features in production. It involves rolling out a feature to a subset of users without their knowledge before scaling this out to a wider group. Cloud native applications typically contain edge routing or ingress services such as API gateways where it is possible to limit traffic to subsets of users to reduce risk of a change should something go wrong. Utilising this strategy can provide confidence before a service switchover.
Summary
It is important to remember that there is no one-sized fits all technique that will solve all the testing problems in a large scale distributed system. However there are techniques such as exploratory chaos, the cloud native charter and mind maps that can inform our exploratory testing efforts. This helps us drive the most effective and robust tests to get value from the limited time available in order to beat our competitors to market.
The QA has often been thought of as the gatekeeper to the next test environment and get measured on the number of bugs raised in a test cycle. We must change this mind-set. First, lets remember a good QA is going to save us some serious embarrassment by catching our mistakes earlier.
Be inquisitive, use the charter to help refine stories, construct your Definition of Done and help inform exploratory testing efforts.
We are on a Cloud Native learning journey, explore it, report it and learn from it.
About the Author
 Greg Simons is a software consultant with over ten years experience in a variety of development and architectural roles. Greg graduated from Aberystwyth University in Wales with a First Class Honours degree in Computer Science in 2005. Primarily having worked with the Java and Spring technology stack, Greg has recently branched out to Serverless deployments with Node JS. He has spent the past two years working in the financial sector as a Platform Architect. Greg is passionate about building and designing resilient software for highly available systems in the cloud. He enjoys speaking and blogging about all things Cloud Native and can be found on Twitter at @gregsimons84
Greg Simons is a software consultant with over ten years experience in a variety of development and architectural roles. Greg graduated from Aberystwyth University in Wales with a First Class Honours degree in Computer Science in 2005. Primarily having worked with the Java and Spring technology stack, Greg has recently branched out to Serverless deployments with Node JS. He has spent the past two years working in the financial sector as a Platform Architect. Greg is passionate about building and designing resilient software for highly available systems in the cloud. He enjoys speaking and blogging about all things Cloud Native and can be found on Twitter at @gregsimons84