
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- If your monolith is tightly coupled and not cohesive, you could split it in order for a business to be more agile.
- There are a lot of wrong ways that you can do that. They result in the same tightly coupled and non-cohesive monolith, but which is distributed across a network.
- You definitely don’t want that. You want your services to be cohesive, loosely coupled and autonomous.
- Align your technical services and business-capabilities with Business-capability mapping and Value-chain analysis techniques.
- If you’re into DDD, think of your bounded contexts as of business-capabilities.
- Act proactively with Conway’s Law. Use it to form your organizational units the most cohesive way.
- High cohesion, loose coupling, and encapsulation are the core traits of SOA, and those concepts are already tested by nature itself. Hint: they really work.
I assume that readers are well aware of why, when and whether they should split a monolith at all. But just in case, a quick reminder: our mutual goal is business-agility. If the monolith ceased to implement its responsibilities in such a way that it satisfies business, if the development pace slows down, then something definitely needs to be done to fix this. But before that, apparently, you need to find a reason why is that so. In my experience, the reason is always the same: tight coupling and low cohesion.
If your system belongs to a single bounded context, if it’s not big enough (yeah, sounds ambiguous, I’ll elaborate on this later) then all you have to do to fix things up is to decompose your system into modules the right way. Otherwise, you need to introduce way more autonomous and isolated concept that I can call a service. This term is probably one of the most overloaded one in the whole software industry, so let me clarify what I mean.
I’ll give more strict definition further, but for now, I want to point out that, first of all, service has logical boundaries, not physical. It can contain any number of physical servers which can contain both the backend code and UI data. There can be any number of databases inside those services, and they all can have different schemas.
Wrong ways of identifying service boundaries
Before delving into details of what a good service looks like, let me point out the most often encountered wrong ways of defining their boundaries.
Entity-services
Splitting a system to entity-services is an approach encountered so often that it’s called an anti-pattern. Sometimes this approach is accounted for an obsession with reuse: all stuff related to some entity in a single place, 100% reusable, pure bliss! But code reuse, when considered as a primary motivational force, is a fallacy. I believe the same goes for services.
So here are the drawbacks of this approach:
- Tight coupling: Every service is a client of all the rest ones. So if one service changes, you have to test the whole system.
- They are chatty: They have a lot of internal communication — usually synchronous. This is fragile and slow.
- Lots of services: Hence it’s hard to comprehend overall picture and hard to track a request.
- Poor encapsulation: Business-rules are spread all over the system. Typically, each client has some checks before updating some other service’s data. And this update is carried out with pure update query. So data and behavior are torn apart.
- Synchronous nature: Typically, it’s http. Hence all its drawbacks I’ll talk about a bit later.
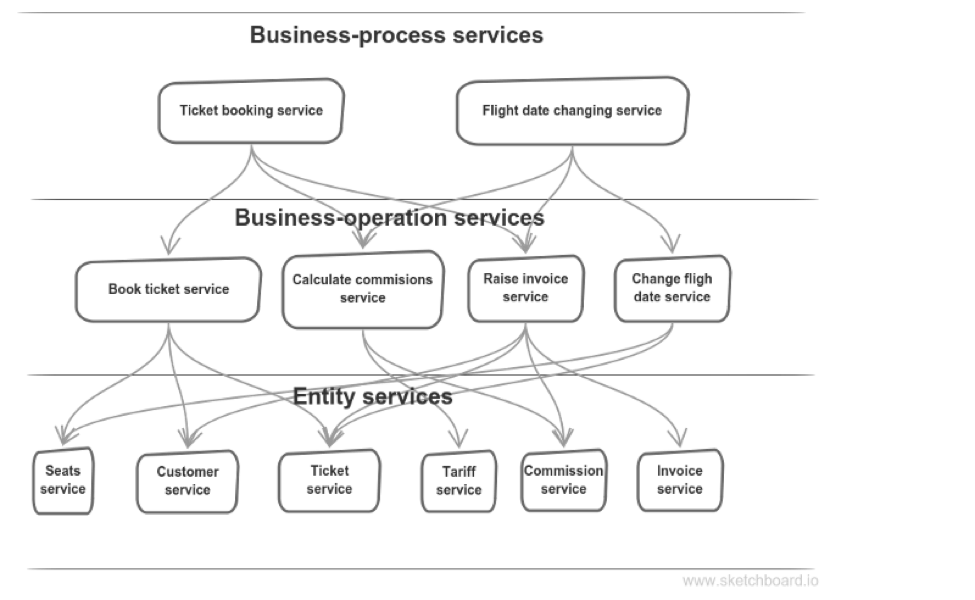
That’s how entity-services usually look like
Blind mapping of blurred business architecture to technical architecture
An approach I encounter very often goes like “Why bother? We’re here for writing code and shipping stuff, let’s just do it!”. Well, it works for a small project, and it doesn’t in a bigger one. It inevitably brings you to business-IT impedance, which results in decreasing business-agility. And if you’re not agile, you’re out.
Here is how technical architecture not aligned with business functionalities looks like:
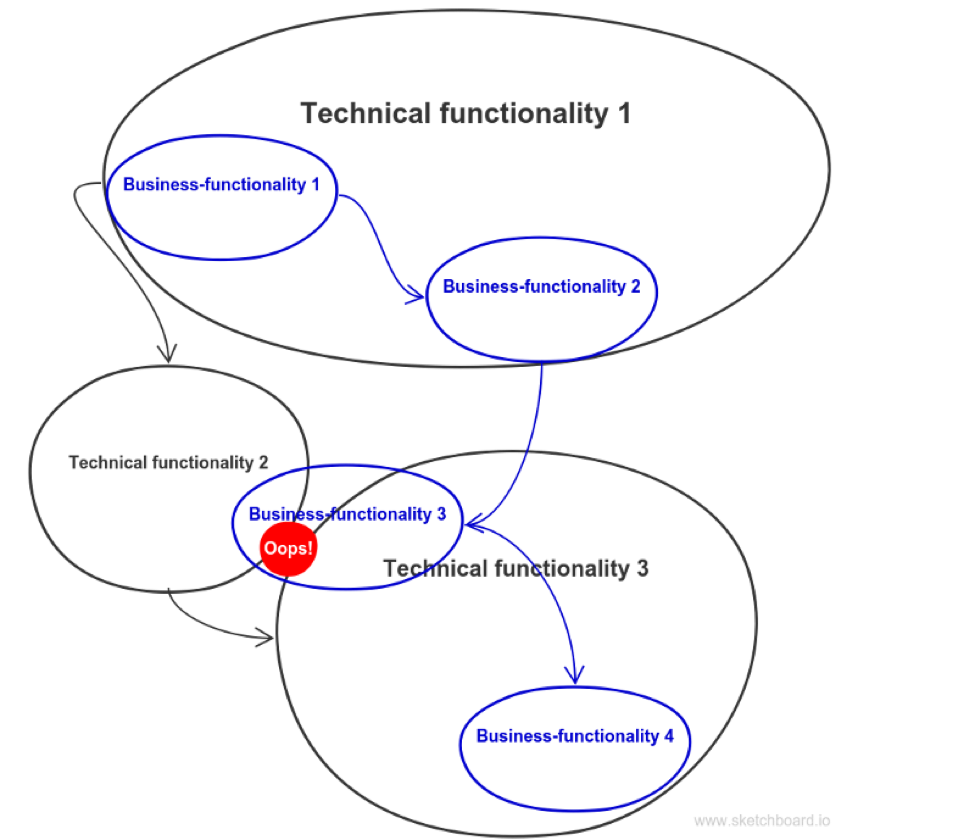
There are two problems highlighted here. First, tight coupling of Technical functionality 1. Since there are two business functionalities inside it, chances are they would have different development pace, different scalability and availability requirements. And it would be hard to split them. Second, there is a gap marked with “Oops!” between technical services. When the new requirements arise within this gap, those two technical services will be coupled very tightly. I like to call this system a distributed monolith, though this term is already reserved for a different problem.
This antipattern is confidently leading in terms of drawbacks amount. It’s even hard to choose where to start with. Anyway, let’s go:
- Synchronous communication is resource-intensive: Service receiving a request waits for the second service, which waits for the third one and so on.
- Expensive scaling: You need to scale everything instead of the services that really need it.
- 8 fallacies of distributed computing: Nuff said here.
- It’s not reliable: If only one service is down then the whole system is down.
- Consistency issues: The system might end up in an inconsistent state. I assume you don’t want to mess with distributed transactions, right? And in case you do, keep in mind the following (2pc-transactions are assumed):
- 2-phase commit transactions are inherently brittle.
- Overall availability is getting less: one sub-transaction is rejected — the whole request is rejected.
- Additional operational complexity. Really, go ahead and ask your system administrators if they even have an experience in this area.
- Growing communication latency.
- A resource is locked between phases. What if the second phase never happens? This point represents a serious scaling issue. No matter how much you scale, waiting time for a lock to get released is still there.
For the sake of justice I should mention that 3-phase commit transactions and consensus protocols show a decent progress in solving some of the above issues.
Services with command messaging communication
Messaging is a huge step forward in terms of reliability and resource consumption, comparing to HTTP. But the resulting services are still coupled. Why?
First, when service A tells service B to do something, service A apparently is aware of service B. So if service A would have to tell service C to do some job surely we’d have to modify service A.
Second, and probably most important, service A expects some behavior from service B. Based on the very nature of such communication service B performs some job in the context of service A. So if requirements to service A would change, the chances are that we’ll have to modify service B as well. Now let’s put that service D wants to use service B’s functionality. But service D has its own context and its own requirements to service B. Very likely service B would need some modifications to satisfy service D. After they are completed we need to make sure that changes didn’t break service A’s functionality. That’s classical tightly coupled nightmare.
Centralized data
In the most simplistic scenario, the term “centralized” denotes a single database with an arbitrary number of services. Its main drawback is when changing some service logic that somehow modifies the centralized data, the chances are that you’ll break other services requesting this data. Why? Because now this underlying data is operated by different laws. Its flow is different now.
But generally, this term applies to a situation when different logical services access the data of each other. Very often it goes hand to hand with an entity services antipattern. Its drawbacks are very much alike.
I believe a good service and a good class have something in common. One of the common traits is data and behavior belong together. This leads to the impossibility of random data mutation bypassing the behavior provided by the class’s interface. The exact same principle applies to a service. By centralizing our data we often CRUD-ify the service’s interface. We split the behavior and its data, turning a centralized data service into a database.
Service orchestration
This approach implies that there is a single governing authority which routes all inbound messages or requests. This implies synchronous communication nature between this service and the rest of them, with all the drawbacks that follow. Besides, business logic inevitably leaks in. So instead of belonging to a single service, it is spread between two. It resembles a smart pipes approach which has proved to be not good at all.
This is an example of a common problem. There is a pattern that proved to work well at a lower scale, called Process manager. Service orchestration is an attempt to apply it system-wide. Similarly, CQRS should not be a higher-level pattern, as well as Event sourcing. SOA should.
Defining service boundaries along an organizational structure
Well, strictly speaking, it’s not necessarily a wrong way. In an ideal world, it would work great, where an enterprise is organized the most effective way. But in real life, politics creeps in. So be very cautious with this approach. It could give some good clues though, at least something to start with.
Defining services around layers
Layers are inherently tightly coupled. So the services organized around layers will be inherently tightly coupled as well. Think of vertical slicing instead.
What properties I want my services to possess
So before talking about the way to identify service boundaries, let’s just quickly outline where we want to arrive.
Before delving deep into the values (following the terminology of Kent Beck’s Extreme Programming) that constitute my understanding of services, that is, primary motivational forces that define my thinking about service boundaries, I’d like to pose some principles that I strive my services to be complied with. I divide them into primary and corollary ones. Let’s start with the primary principles. There are two of them actually.
Loose coupling
The single problem that almost all of the services identified the wrong way share is tight coupling. You can’t freely modify an implementation of any service since you never know which other service relies on that. That’s what loose coupling is about, and that’s what I’m striving for — not only in high-level architecture, but in my code either.
High cohesion
Almost all of the services derived from the approaches described in “Wrong ways of identifying service boundaries” chapter have low cohesion. Data and behavior that operates upon it are spread all over the system. And cohesion is all about functionality: when I say “cohesive”, I mean “exposing very specific behavior”. Wiki does so either. This value also implies services to be encapsulated. By encapsulation I usually mean information hiding concept as well, but this is not ubiquitously accepted.
The corollary principles are the following:
Correct granularity
When granularity is too coarse, a service can be split into several other cohesive services. When it’s too low, a service desperately needs other services data or functionality to operate, so the coupling becomes tight.
High autonomy
Loose coupling results in full conceptual service autonomy. By autonomy, I mean that service’s ability to do its job doesn’t depend on the availability of other services. In order to do its job, service needs neither functionality nor data of other services. Moreover, service might not even know about other services (and in most cases should not).
Services communicating via events
Services don’t live in a vacuum, so they communicate with each other. How to implement that? I advocate for the use of behavior-centric and business-driven event message type, opposite to synchronous requests and command messages. Such architecture is called Event-driven architecture. Published events should reflect the business concepts, some real things already happened in the domain: order completed, transaction processed, invoice paid.
Decentralized data
When services are loosely coupled, highly cohesive, thus, autonomous — they simply don’t need each other’s data. The data becomes decentralized naturally.
Service choreography
Service choreography is a natural consequence of synchronous communication rejection, use of business-events and centralized data storage rejection. Governing authority in EDA looks like an archaism from a synchronous past.
How to define service boundaries
Ok, how to identify services so that they end up being loosely coupled and highly cohesive? In other words, what are the core values of maintainable, reliable and business-aligned architecture?
Business-capabilities and business-services
First, let’s introduce a concept of business-capability. A business capability is something that organization does to keep it running, to keep it able to operate. It is a specific contribution to whole enterprise functionality. It is a concrete function or ability that organization possesses in order to achieve its goals. Purchasing manager acquires goods, a warehouse keeps it, a seller sells it, a financier calculates the profit. So business capabilities are almost the same for different firms involved in the same business. Their implementation is the thing that differs. The logical boundary where business capabilities implementation resides is called business-service. So what’s in there? There are business-policies, business-rules, business-processes, people involved in them and making specific decisions, applications used by these people. The mental image I use looks like that:
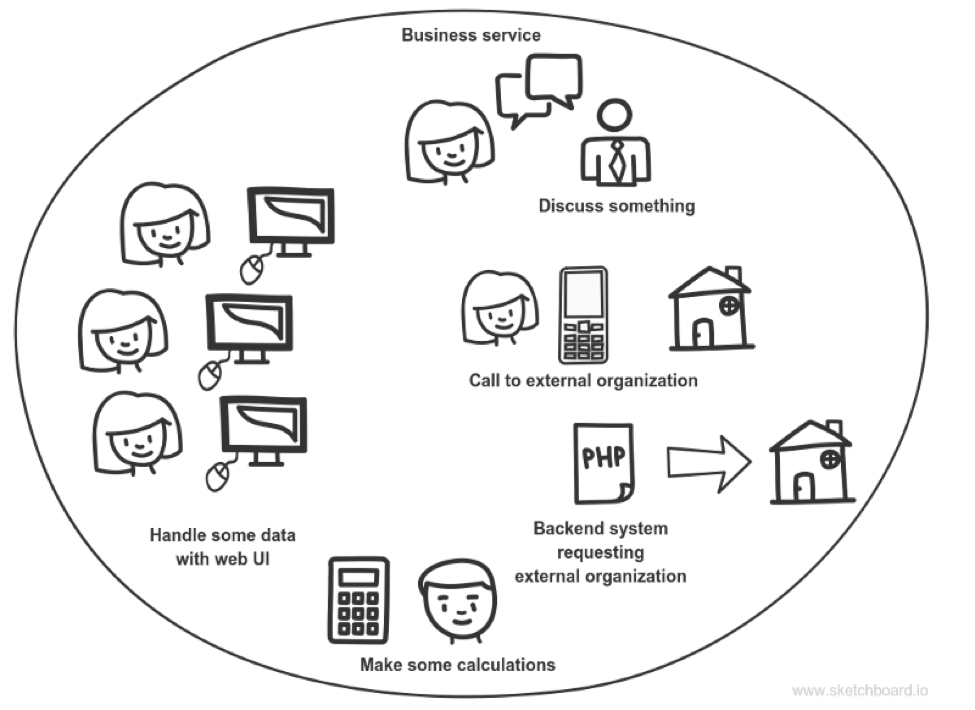
There should always be a bijective relation between business-capability and corresponding business-service.
I think it’s very descriptive to compare business-service boundaries and interfaces. Both are defined by the declarative description of their functionality: they don’t tell how they’re going to do their job, but they tell what they can do.
All in all, both business-service boundaries and business-capabilities are very declarative concepts that rarely change.
How business-services interact with each other
Business-services’ communication, or, more specifically, an interaction of these business-services’ business-processes, is defined in terms of events of the domain where business operates. A set of events that business-services exchange with each other forms their interface, or contract. These events can be implemented as a telephone call, an email or as a simple conversation.
Business-services and technical services
Since business-service boundaries are the most stable things in the whole enterprise, it makes perfect sense to build technical services around them. Telephone calls are replaced with RabbitMQ events, paper documents are replaced with web-interfaces, commuting is replaced with HTTP calls, and some tedious work is replaced with ML. With following this approach we get a service contract stability: business services rarely change, and contracts implemented by corresponding technical authorities, as a consequence, rarely change either.
Technical services identified this way act with full respect to the Single source of truth concept. This source represents a particular event as well as any piece of data stored in a single place. It’s very important: in a technical service, there should be a single logical place where specific event publishing happens. And those events should not contain a lot of data. The whole point of events is not getting data through it. It is a notification that something happened. Moreover, if your events contain loads of data then probably your service boundaries are wrong and these services that have heavy data exchange should, in fact, be a single service. On the other hand, these events should have enough data, i.e. they should be fully self-contained. But they should not have any references since it implies a shared database which introduces tight coupling.
Udi Dahan sums this up aptly:
“a service is a technical authority for a specific business capability, and any piece of data or rule must be owned by only one service.”
This approach brings to the surface an often made mistake that physical and logical architectures need to be the same. They don’t. If there is a web-service that we integrate with — it’s not necessarily a full-fledged business-service.
Business-capability mapping
It’s a technique intended to facilitate service boundary identification.
First, you should identify your higher-level capabilities. It’s what your organization is all about, its central functions. The resulting services could be a separate business. Hence, they could be outsourced or, contrary, get acquired. When defining this services, you should ask both “what” and “how” questions, figuring out the declarative capabilities yourself. To do this, communicate a lot with different stakeholders to hear all perspectives. Communicate with those who actually perform the low-level work — find out what are the main processes they are involved in, what they actually do.
Each service should correspond to a single phrase that goes like “I <verb> <noun>”. For example, “I process payments” or “I check payments for fraud”. Each of those services is a step towards delivery of business value.
Asking about how an enterprise makes money can give some clues. If you have a clear picture of how an organization searches for potential clients, how they actually become clients, and what they pay for, as well as when and how, you’re probably almost done with higher-level service identification.
The organizational structure, although might being misleading, can help as well. Just don’t expect that an enterprise is arranged flawlessly. But higher-level overview of the whole organization is definitely useful.
Looking for ways that some functionality can be automated (or if it is already — switched to manual labor) helps me as well. It keeps me away from implementation details and helps to find useful abstractions.
Don’t forget about looking for ways business-services interact with each other. So, as I already mentioned, everything counts: phone, email, messenger, ordinary conversation.
After you’re done with this higher-level overview, delve deeper into each service. The process is inherently the same. There is one advice I could give though. A wouldn’t ever consider the whole process of service boundary identification as a major step or phase. It sounds waterfall-ish. This process goes very close to the development. Although it takes some initial work to identify top-level services before any code written, I wouldn’t immerse any deeper without taking part in coding myself.
So the overall picture of interacting business-services with arrows indicating events looks like the following:
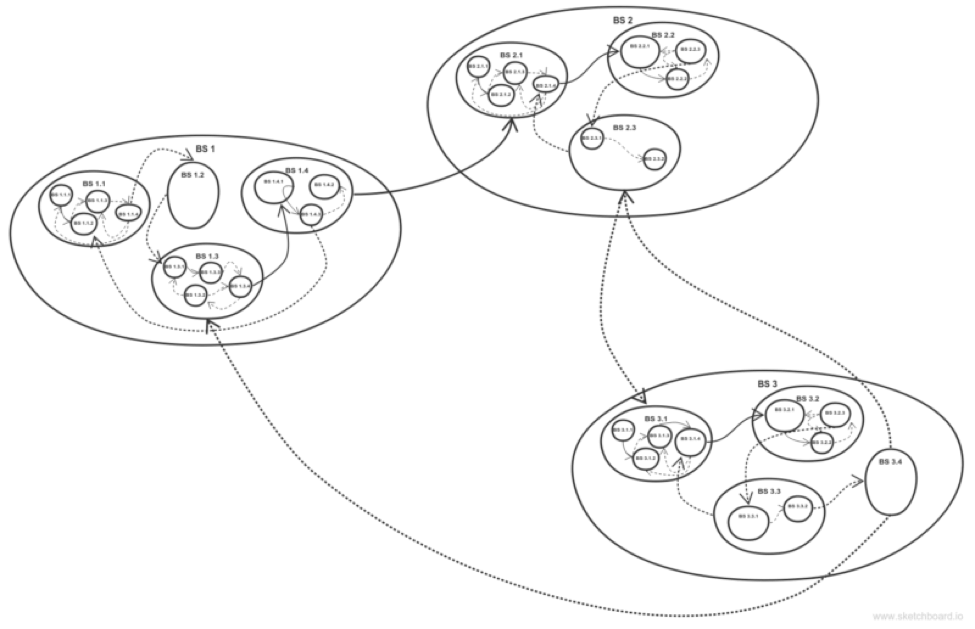
Value chain analysis
I use this approach hand to hand with business-capability mapping. Basically, it boils down to the following. First — treat your organization as a set of business-functions abstracted away from their concrete implementation. The second point is also what I’ve already mentioned just a bit: these functions are the steps towards the enterprise’s primary business goal.
The dialogue discovering the services (in reversed order, from business goal to the very beginning) could go something along the lines:
- What’s your primary business goal? (or, in other words, how do you make money?)
- We sell furniture.
- Do you deliver your furniture to customers?
- No.
- Where do you get it from? Do you buy it somewhere or manufacture?
- We manufacture it. We have a factory in Milan.
- Where do you get raw materials from?
- Our furniture is made of wood that we grow ourselves, and fasteners are purchased.
The main capabilities here are probably the following: “Provide with raw materials”, “Manufacture furniture”, “Sell furniture”. I’ve omitted “Store furniture” and “Marketing” since they are quite ubiquitous, and if that company had delivery, there would be a “Deliver furniture” service.
There are two very general chains inherent in many types of business: supply chain and demand chain. The names are very descriptive and intuitive. Besides, there is an approach mixing both business-capability mapping and value chain. No surprises, it’s called capability chain and it manifests primarily in the looks of the resulting diagrams. Here is a great example.
SOA and DDD
I assume you are well aware of what bounded context is. What always confused me is the lack of understanding how to define them. Examples like a notorious Product catalog have always been bringing me down. I wondered, what rationale is behind this concept. Well, now I can answer this question: bounded context is a business service. Just in case, Product catalog which only displays some goods barely can be a full-fledged service. It does not possess any behavior. And business-services definitely imply some behavior, some business-functionality. What catalog really is is just an example of the Backend for Frontend pattern. It just takes data from other services and displays it:
Backend for Frontend pattern example. It’s not a full-fledged service in SOA field.
SOA and Conway’s Law
I use Conway’s law as a goal when attempting to influence organizational structure. This law states that we’re doomed to produce a design which is a copy of the communication structures of an organization, so my goal is to identify those communication paths and make them optimal. By optimal structure, I mean the most cohesive one. Those communication paths should ideally belong to a very close group of people, residing within a single business-service. So it makes perfect sense to form an organizational structure around business-services. This approach is not new at all, quite seldom encountered though. With an organization built this way, its units will be cohesive, autonomous and replaceable. And an enterprise will be more agile.
High cohesion, loose coupling, and encapsulation as the fundamental traits of nature
Being in OOP-area for quite a while, practicing XP and creating SOA, I’ve always had a gut feeling that they all have something in common.
Waterfall stages are kind of layers in software that need each other’s data, so they are inherently tightly coupled. On the contrary, XP abandons a concept of phase, favoring very short cycles combining all of the activities: communication with domain experts, development, unit-testing, functional testing, customer feedback. Sprints are very cohesive and need not be tightly coupled. They continuously form bizDevOps culture.
Procedural programming is about procedures implementing a series of computational steps, operating upon data: do this, then do that, then do that. This approach doesn’t respect data encapsulation. The whole concept implies that data and procedures are divided. This approach resonates with an entity-services antipattern, doesn’t it? On the contrary, OOP is all about encapsulation. Proper objects act like responsible adults, who have all they need to perform work they should. So are my business-services. Instead of data, they expose behavior, notifying about the result of their work with an event.
Conway’s law implies us to create cohesive communication structures formed around business-services, instead of layered-fashioned organizational units such as developers, QA, business analysts, etc.
And all of these traits are inherent to nature. Atoms consist of protons, neutrons, electrons, all with its own behavior and laws they obey, but serving to a single atom, thus forming very cohesive and encapsulated microsystem, that is very loosely coupled to anything else. And while XP is about a continuous improvement that could be reinforced by tools like OOP and SOA, Nature is about evolution.
And finally, talking about the core values of any software, I believe building correct abstractions is the key. It manifests at all levels, at every stage. That is, starting with higher-level SOA, identifying main business-capabilities and forming technical services around them, through continuous improvement and feedback with XP, to right abstractions reflecting the domain with Domain-Driven Design and OOP. That’s how business-agility is reached through business-IT alignment on day-to-day basis.
Examples?
Sure. The first one belongs to payment service provider domain. This post contains some thoughts on scaling, sagas, aggregate boundaries, composite UI, and CQRS. The second one is a more common area of e-commerce, with some tips on correct boundaries identification. The third one is a more lower-level example, with RabbitMQ specifics.
What I notice is over time my services tend to be more and more coarse-grained, with sagas embracing whole life cycle of an entity. Talking about financial transaction from my first example, I probably would do things a wee different. I would create a saga which would belong to a single service and have the following higher-level stages, or states: transaction registered, transaction checked for fraud, transaction processed, transaction reconciled, transaction commissioned. Probably, one day I would even write my own “In Defense of the Monolith” post.
About the Author
 Vadim Samokhin is the Head of Development in Gemotest, leading clinical research company in Russia. Previously he worked in e-commerce, payment solutions, and card acquiring areas. He is passionate about OOP, SOA, and agile methodologies, enabling business agility through business-IT alignment. He occasionally shares his thoughts on these topics on medium.com/@wrong.about.
Vadim Samokhin is the Head of Development in Gemotest, leading clinical research company in Russia. Previously he worked in e-commerce, payment solutions, and card acquiring areas. He is passionate about OOP, SOA, and agile methodologies, enabling business agility through business-IT alignment. He occasionally shares his thoughts on these topics on medium.com/@wrong.about.