
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Key Takeaways
- Before diving into the machine learning of software system behaviour, one has to know the traditional approaches to time series.
- Missing values in your time-series can lead to unexpected results when analyzing them. The “Pandas library” can help you with filling these values in your data in a sensible matter.
- When humans are using your service you should expect seasonality in your data. Take this into account when designing your predictive algorithms.
- Be careful about what threshold you set for anomaly detection. Events that are unlikely for a single server become very likely when scaling your application.
- Understand what you are trying to achieve when analysing time series. Make sure you can not use simple deterministic SQL-like analysis. Know the behaviour of your algorithm on a math scale, and know if you are automating the interpretation of this, or if you are transforming data into predictive residuals and using them.
At QCon.ai 2018, David Andrzejewski presented “Understanding Software System Behaviour With ML and Time Series Data”. David is an engineering manager at Sumo Logic, a cloud-based platform for machine-data analysis. Developers who are already running a software system (like an app or cloud cluster) can use Sumo Logic as the back end for their logging. Sumo Logic provides continuous intelligence for this machine data.
A lot of things run on software, and artificial-intelligence techniques are moving into the software world. Before diving deep into machine learning’s impact on software system behaviour, you have to understand the traditional approaches to time series. Knowing the limitations of traditional methods lets you make informed trade-offs in choosing techniques. First, ask yourself if you know what you are trying to accomplish. Once you know, try to ask yourself if you can accomplish this with simple or deterministic analysis. Only look at machine learning when other methods are impossible.
Understanding what your software is doing and why it is failing can be difficult. Companies that deploy services that rely on many microservices on multiple hosts can benefit from a diagram that lists dependencies among those microservices. When drawing this out, you might get an image that people refer to as the microservices death star:

Many applications generate terabytes of logs per day, consist of gigabytes of source code, and output millions of metrics per minute. Analysing this data by hand is impossible, so you need machine intelligence. However, analysing the data to find out only what your system is REALLY doing is a difficult if not impossible task. An interesting paper that goes deeper into the granularity of data and at what level you need it, is “Coulda neuroscientist understand a microprocessor?”. The authors of this paper use a simulator to play the old game of Donkey Kong. Because they own the memory of the simulation, they have access to the complete state of the system. Theoretically, this means it is possible to analyse the data to try to reverse-engineer what is going on at a higher level of understanding, just from looking at the underlying data. Although this tactic can provide small insights, it is unlikely that only looking at the data will allow you to completely understand the higher level of Donkey Kong.
This analogy becomes really important when you are using only raw data to understand complex, dynamic, multiscale systems. Aggregating the raw data into a time-series view makes the problem more approachable. A good resource for this is the book Site Reliability Engineering,which can be read online for free.
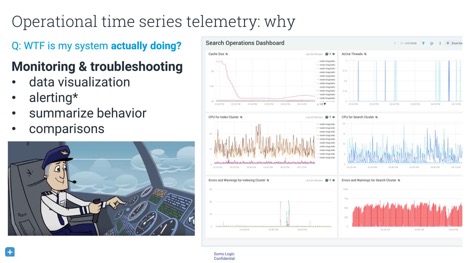
Understanding complex, dynamic, multiscale systems is especially important for an engineer who is on call. When a system goes down, he or she has to go in to discover what the system is actually doing. For this, the engineer needs both the raw data and the means to visualise it, as well as higher-level metrics that are able to summarise the data. An engineer in this situation often wants to know how this server is behaving compared to another server, to itself yesterday, or to itself before that one software update.
Upsides and downsides of percentiles
When looking at a long history of log data, you don’t go into continuous millisecond detail. You quantize your data in time. The most basic ways to do this is with functions such as min, max, average, sum, and count. Many people who aggregate data like to use percentiles as well. The advantage of percentiles is that they can express your data in an unambiguous language. An example of a sentence without a percentile is “The maximum time to load a request was 4,300 milliseconds.” This sentence is precise but does not help to determine how far outside the bounds of normal operation it falls. However, saying that “p99 is less than 2,000 milliseconds” indicates that no more than 1% of customer requests take longer than two seconds to load.
The downside of percentiles is that they make it difficult to combine data into something meaningful. Although values around the 50th percentile tend to be stable, higher percentiles will vary a lot and have a long-tailed distribution of possible values. Another problem is that it is easy to aggregate the simple analyses of several datasets. You can calculate the minimum of two datasets by looking only at the minima of both. However, you can’t as simply use the methods with percentiles. It is mathematically impossible to combine the p95 of dataset X and the p95 of dataset Y. This means that it is difficult to say something meaningful about a combination of multiple datasets without further work.
Important time-series concepts
A basic monitoring aspect for time series is time-shifted comparisons. This is particularly important if you want to compare the write latency of one cluster to the write latency of the same host the day before. This can also be combined with windowing data, known as “grouping over time”. More information can be found in Tyler Akidau’s QCon San Francisco 2016 talk, where he discussed this concept in the context of Apache Beam.
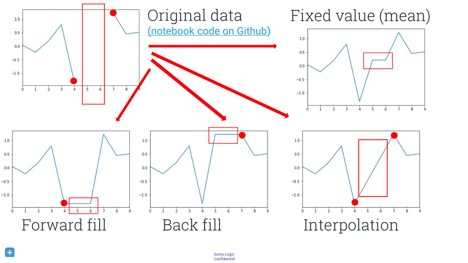
Handling missing data is also important. Before you can apply any machine learning, you have to know how you want to handle missing values. Putting constant values, like zeros or infinities, in place of missing values probably leads to unexpected results. However, not putting anything there will likely yield runtime exceptions later in the loop. This can be prevented by using the pandas Python data-analysis library, a Swiss army knife for data manipulation. You can use the fillna()method, which has some sane and sensible default values. Note that there are a lot of interesting ways to fill gaps in your data, and a lot of research and methods you can use. Some fields call it “predicting” missing data, other fields call it “imputation”, “inference”, or “sampling”. You could forward-fill points, back-fill them, or interpolate them.
Acting on the data
A simple thing to think about when setting up a logging system is fixed-threshold alerting. The goal of alerts is to wake somebody when your website goes down or another unexpected event occurs. Many people start the development of alerts by hiring a domain expert who can set sensible thresholds for various aspects of your system. For example, you could set an alert to fire as soon as 5% of the requests take longer than two seconds, at which point it notifies the engineer who is on call at that moment.
However, human experts don’t scale well. You might want to automatically compare the behaviour of machines to that of other machines, especially when you have many machines outputting many time series. You can’t analyse and compare all these time series yourself, and a large number of machines could prevent you from comparing time series among them. This is the point at which you could try to apply machine learning.
Predictive models and outliers
One approach is outlier detection by using predictive modelling. By predicting what your machines’ normal behaviour is, you can also detect when your machines act outside the predicted output. However, you do need to take a lot into account before you are able to do this. There are four key questions you have to ask:
- Is the behaviour actually regular?
- How can you model the behaviour?
- How do you define a major deviation from your expectation?
- Is it actually valuable to detect surprises and deviations from your expectation?
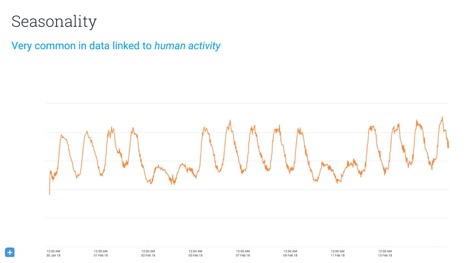
An important thing to consider when doing predictive modelling is seasonality or rhythm of your data. Any service that has humans in the loop has potential for rhythm. For example, most people use Sumo Logic at work, which means that Sumo Logic usage data for any given country will show a lot of activity during normal working hours but not so much outside these hours. However, the usage data for Netflix likely shows the reverse trend. You might be able to model this by manually adjusting your data or by using Fourier transformations. Another option many people use are hidden Markov models.
Distance-based data mining of time series
When you have multiple machines, you probably want to compare the behaviour of machines to each other. If you see weird behaviour by one machine, you want to find out if other machines are behaving the same way. Perhaps they are all running different versions of software, perhaps they are in the same data centre, or perhaps something else is happening. To analyse this, you have to compare the distance between time series.
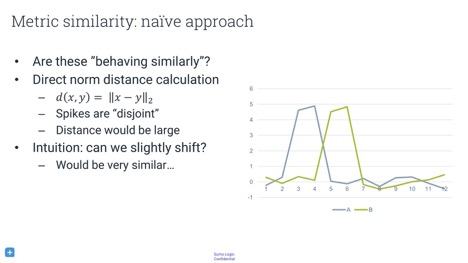
What metric should you use to determine the similarity between two time series? Simply differencing them time-wise by subtracting them from each other is bound to give wrong results. In the image above, although the time series are actually quite similar, this metric will tell you that they are completely different.
There is a whole universe of metrics you can use. One popular technique is dynamic time warping, which basically asks you how you can mutate, warp, or mangle your time series to get them into the best alignment, and what penalty you have to pay for this modification. With this metric, you can either find the N most-similarly behaving hosts, or you can build a graph of host similarity. Using spectral clustering could provide an image that informs you about any structure in your hosts.
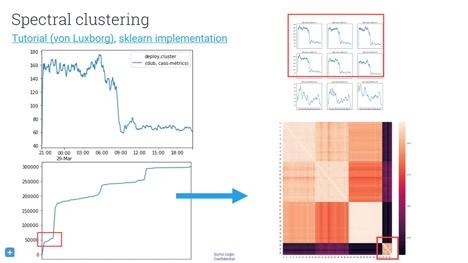
Anomaly detection and event classification with log data
There are ways to transform your log data into a time series. When you have a high volume of semi-structured strings, you can either count the messages or extract information from them. These logs are an approximate program-execution trace. As you cannot enter a debugger for your machines once they are in production, you can only infer the behaviour of your software through these log messages. If your program prints a string every time there a request times out, you can count the number of timeouts every hour. This gives you a time series, which you just learned how to analyse!
You might be tempted to set a threshold on the values of a certain time series. However, you don’t want to fool yourself into thinking that you’ve found an interesting event when that event was not actually interesting. Imagine that you have a super-accurate model, and you want to send an alert any time there is only a 0.01% chance for a pattern to occur. When you have a service with a million time series, you can expect about a hundred false positives. Baron Schwartz goes into more detail about what techniques you should use to determine a threshold in his talk “Why nobody cares about your anomaly detection”.
With all the recent advancements in deep learning, you might want to use it to help with predictions and anomaly detection but deep learning is still not able to free you from understanding a problem domain. You still have to find a way to frame your problems. One possible approach is the use of recurrent neural networks to forecast. This is a great idea if you happen to have access to a lot of training data. If not, however, your first priority should be aggregating data before trying to do something with it.
In conclusion, the rabbit hole of inspecting data goes very deep. We have machines that are running our lives. These machines produce data, but analysing the data is complicated so we go to machine learning tools, which are delicate. It is of great importance to prevent noise and false positives, and to do this, you have to make sure you understand what you are trying to do. Know why you are not using deterministic SQL-like analysis, and understand the methods you use on a math scale. Lastly, know if you are either automating the interpretation or transforming data into predictive residuals and using that for anomaly prediction.
About the Author
 Roland Meertens is a computer-vision engineer working in artificial intelligence for the perception side of self-driving vehicles at the Audi subsidiary Autonomous Intelligent Driving. he has worked on interesting things like neural machine translation, obstacle avoidance for small drones, and a social robot for elderly people. Besides putting news about machine learning on InfoQ, he sometimes publishes on his blog PinchofIntelligence and Twitter. In his spare time, he likes to run through the woods and participate in obstacle runs.
Roland Meertens is a computer-vision engineer working in artificial intelligence for the perception side of self-driving vehicles at the Audi subsidiary Autonomous Intelligent Driving. he has worked on interesting things like neural machine translation, obstacle avoidance for small drones, and a social robot for elderly people. Besides putting news about machine learning on InfoQ, he sometimes publishes on his blog PinchofIntelligence and Twitter. In his spare time, he likes to run through the woods and participate in obstacle runs.