
MMS • Steef-Jan Wiggers
Article originally posted on InfoQ. Visit InfoQ
AWS recently announced the preview of Amazon Aurora Limitless Database, a new capability supporting automated horizontal scaling to process millions of write transactions per second and manage petabytes of data in a single Aurora database.
The Amazon Aurora Limitless Database has a two-layer architecture consisting of multiple database nodes, either transaction routers or shards. Channy Yun, a Principal Developer Advocate for AWS, writes:
Shards are Aurora PostgreSQL DB instances that each store a subset of the data for your database, allowing for parallel processing to achieve higher write throughput. The transaction routers manage the distributed nature of the database and present a single database image to database clients.
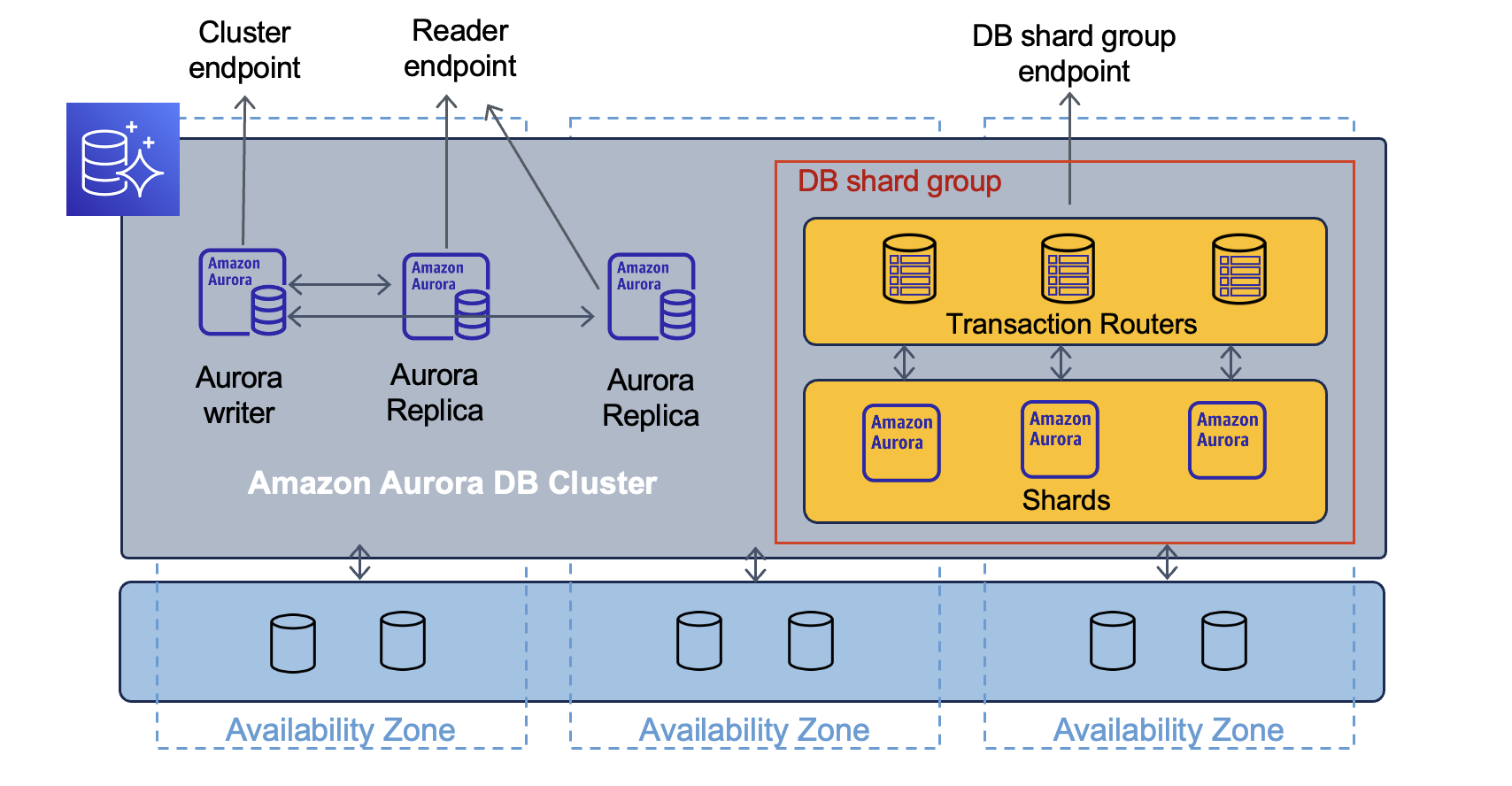
The architecture of Amazon Aurora Limitless Database (Source: AWS News Blog)
The transaction routers in the Limitless Database architecture store metadata on data locations, process incoming SQL commands, forward commands to shards, aggregate shard data for a unified client result, and oversee distributed transactions to ensure consistency across the entire distributed database. All nodes within the Limitless Database architecture are part of a DB shard group with a distinct endpoint for accessing your Limitless Database resources.
A developer can connect to a DB shard group endpoint, also called the limitless endpoint, using psql or any other connection utility that works with PostgreSQL. Within the Aurora Limitless Database, there are two types of tables, that can contain data:
- Sharded tables – distribute data across multiple shards by splitting it according to designated columns, known as shard keys.
- Reference tables – ensure optimal performance for join queries by having their complete data available on every shard.
Once developers have created a sharded or reference table, they can load massive amounts of data into the Aurora Limitless Database and manipulate data in those tables using the standard PostgreSQL queries.
A respondent from AWS explained in a Hacker News thread some of the implementation details of the Aurora Limitless Database:
Aurora Limitless Database is based on our own investments in database-optimized virtualization (Caspian), in scale-out log-first database storage (Grover), and in a custom approach to cross-shard transactions that make use of the high-quality hardware clocks available in EC2. We’ll be talking more about the internals over the coming months.
At the same time, a respondent on a Reddit thread made a comment on potential users of the Aurora Limitless Database:
Seems like a product that is fit for small-to-medium-sized companies where you don’t have enough [experienced] human resources to handle such big scales. But then again, companies that size won’t pay as much for managed services like this one.
I didn’t check pricing, but I sure can imagine something that has “serverless,” or now even “limitless” in its name, won’t be cheap at the scale.
Lastly, the Aurora Limitless Database is available in a limited preview through a signup form.