
MMS • Daniel Dominguez
Article originally posted on InfoQ. Visit InfoQ
AWS has introduced Multi-Model Endpoints for PyTorch on Amazon SageMaker. This latest development promises to revolutionize the AI landscape, offering users more flexibility and efficiency when deploying machine learning models.
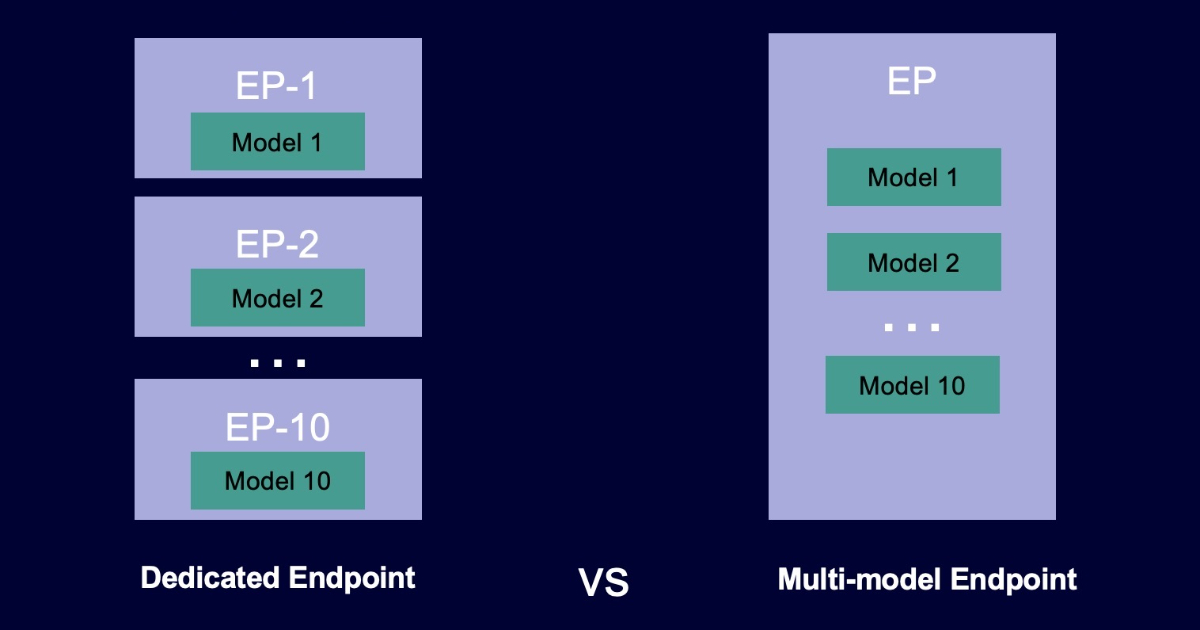
Amazon SageMaker is already renowned for streamlining the machine learning model-building process, and now it’s set to make inference even more accessible and scalable with Multi-Model Endpoints for PyTorch. This feature enables developers to host multiple machine learning models on a single endpoint, simplifying the deployment and management of models while optimizing resource utilization.
Traditionally, deploying machine learning models required setting up separate endpoints for each model, which could be resource-intensive and cumbersome to manage. With Multi-Model Endpoints for PyTorch, users can bundle multiple models together, allowing them to share a single endpoint, making the process far more efficient and cost-effective.
TorchServe on CPU/GPU instances is used to deploy these ML models, However, if users deploy ten or more devices, expenditures may mount. Users can deploy thousands of PyTorch-based models on a single SageMaker endpoint thanks to MME support for TorchServe.
In the background, MME will dynamically load/unload models across many instances based on the incoming traffic and execute several models on a single instance. With this the expenses can be reduced by sharing instances behind an endpoint across 1000s of models and only paying for the actual number of instances used thanks to this capability.
The advantages of this update extend beyond efficiency and resource optimization. It also enhances the ability to manage different versions of models seamlessly. Users can now deploy, monitor, and update their machine learning models with ease, making it simpler to adapt to changing data and improve model performance over time.
This feature enables PyTorch models that use the SageMaker TorchServe Inference Container with all CPU instances that are machine learning optimized and single GPU instances in the ml.g4dn, ml.g5, ml.p2, and ml.p3 families. Furthermore, Amazon SageMaker supports all supported geographies.