
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The LinkedIn Engineering team have recently discussed their “LinkedOut” failure injection testing framework in more detail. This framework supports the generation of hypotheses about application and service resilience, and enables failure to be injected to a specific request via the LinkedIn LiX A/B testing framework or via data in a cookie. Failure scenarios that can be tested include errors, delays and timeouts. The LinkedOut project is part of the larger “Waterbear” initiative to encourage every team at LinkedIn to contribute to resilience engineering efforts.
Logan Rosen, Sr. Engineer, Site Reliability at LinkedIn, recently wrote “LinkedOut: A Request-Level Failure Injection Framework” on the LinkedIn Engineering blog. The post began by stating that in a complex, distributed technology stack, it is important to understand the points where things can go wrong and also to know how these failures might manifest themselves to end users. Engineers should assume that “Anything that can go wrong, will go wrong.”
There are many ways to inject failures into a distributed system, but the most fine-grained way to do it is at the request level. The Netflix chaos/resilience engineering team have previously discussed how they created the Failure Injection Testing (FIT) framework that eventually evolved into the Chaos Automation Platform (ChAP), which injected failure in just this way. Similarly the LinkedIn Site Reliability Engineering (SRE) team established the the Waterbear project in late 2017, which is an effort to help developers “hit resiliency problems head-on” by both replicating system failures and adjusting frameworks to handle failures gracefully and transparently. Out of this work emerged the LinkedOut failure injection testing framework which enables request-level failure injection.
At its core LinkedOut is a “disrupter” request filter in the organisation’s Rest.li stack, a Java framework that allows developers to easily create clients and servers that use a REST-style of communication. The open-source portion of this work can be found in the r2-disruptor and restli-disruptor modules within the project’s GitHub repository. LinkedOut is currently able to create three types of failures: error — the Rest.li framework has several default exceptions thrown when there are communication or data issues with the requested resource; delay — engineers can specify an amount of latency before the filter will pass the request downstream; and timeout — the filter waits for the timeout period specified.
Engineers use the LinkedOut framework to validate at development time that their code is robust. This validation is extended to production scenarios to provide external parties the confidence and evidence of robustness. There are two primary mechanisms to invoke the disruptor while limiting impact to the end-user experience. One of these is LiX, the LinkedIn framework for A/B testing and feature gating at LinkedIn, and the second is the Invocation Context (IC), a LinkedIn-specific, internal component of the Rest.li framework that allows keys and values to be passed into requests and propagated to all of the services involved in handling them.
LiX allows engineers to target failures on multiple levels, from an individual request for a single member to a percentage of all members for an entire downstream cluster.
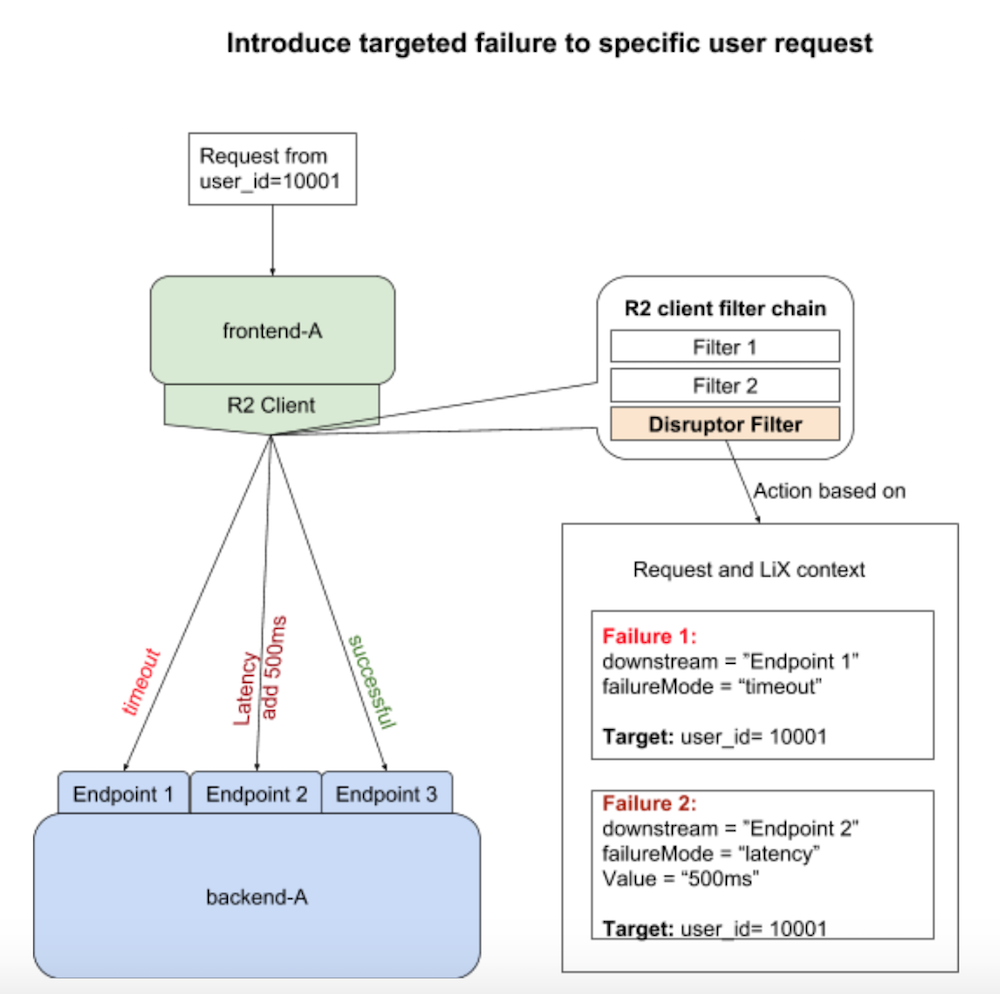 Introducing targeted failure with LinkedOut (image via the LinkedIn Engineering blog)
Introducing targeted failure with LinkedOut (image via the LinkedIn Engineering blog)
As the service call graph is large and complicated at LinkedIn — the latest home page depends on more than 550 different endpoints in its dependency tree — it is very difficult for engineers to ensure expected “graceful” degradation on the home page for every failure scenario involving this many endpoints. Therefore the SRE team created a service account (not associated with a real member) and gave it access to all of the LinkedIn products.
To automatically test web pages the team leverage an internal framework at LinkedIn that allows for Selenium testing at scale. They send commands to inject the disruption information into the invocation context (IC) via a cookie (which only functions on their internal network), authenticates the user, and then loads the URL defined in the test. The team considered several ways to determine success after injecting failures, but for the first iteration of the framework they decided to simply provide default matchers for “oops” (error) pages and blank pages. If the page loaded by Selenium matched one of these default patterns, they would consider the page to not have gracefully degraded.
When discussing lessons learned, Rosen discusses that the service accounts created did not always mirror real members’ experiences on LinkedIn. For example, an SRE created a test to check for graceful degradation on the Profile Views page, and initially every single downstream failure resulted in a test failure, meaning that the page returned an error. However, upon logging in as the test user the problem was revealed: because this test user had no connections on LinkedIn, and nobody was visiting its profile, the Profile Views page returned an error, even without any failures injected. The fix was to provide the associated data by viewing the test user’s profile, but it brought the issue to light that “test users aren’t always great representations of what people really see on LinkedIn.” The plan to avoid this in the future is to allow users of LinkedOut to provide their own test users, which they can pre-populate with data.
At LinkedIn the mechanism of triggering failures via feature targeting (flagging) is simple due to the maturity and power of the LiX experimentation framework. Engineers create a targeting experiment based on the failure parameters that they specify. Once the experiment is activated, the disruption filter picks up the change, via a LiX client, and fails the corresponding requests. Using LiX also allows an engineer to easily terminate failure plans (“within minutes”) that have gone wrong or are impacting end-users inappropriately.
The IC injection mechanism enables quick, one-off testing in the browser by specifying disruption data via a cookie. To discover the downstream services involved within the creation of a web page the engineers use a service within LinkedIn called “Call Tree” that consumes Kafka events produced by services when they handle requests and builds a corresponding call tree that show all the steps involved. Call Tree allows a grouping key to be set as a cookie within a request, which links together all the call trees it discovered for a given request. The SRE team built a Chrome extension that make the service discovery and IC fault injection easier for engineers performing these tests. Once the engineer selects failure modes for all applicable resources, the extension creates a disruption JSON blob for these failures, sets a cookie to inject it into the IC, and then refreshes the page with the failure applied.
Although the recent blog post focuses on the technical aspects of failure injection, a previous post “Resilience Engineering at LinkedIn with Project Waterbear” discusses the importance of establishing a supportive culture, focusing on the human-side of resilience testing, and ensuring that chaos tests are designed and run by following the scientific method and creating hypotheses.
At LinkedIn, SREs have been working cross-functionally with service owners and their teams on a project that was named “Waterbear” (after the nickname for the tardigrade, a notoriously resistant creature that can survive, among other places, in the vacuum of space). The post suggests that Waterbear should be thought of as providing “application resilience” as a service; SRE teams own the domain and the problem, and “measure, analyse, and provide best practices to help improve the resilience of each application for the application owners and engineering teams”. One of the core LinkedIn SRE values is, “attack the problem, not the person”, which in turn is a a reflection of the company values, “act like an owner” and “relationships matter”.
Knowing that an individual service owner won’t be shamed or verbally attacked when a problem occurs creates a much more positive environment for problem-solving. This also makes it easier for the SRE organization to influence the decision-making process throughout the engineering teams in order to make changes to shared infrastructure
The latter blog post concludes by stating that the development team and leadership team have been very supportive of Waterbear and LinkedOut.
As long as we have scientific approaches to validate our hypothesis against failure scenarios, the ability to limit the blast radius of failure, the capability to derive clear action items to improve system resilience, and can build proper tooling/systems to make running such tests extremely easy, every team at LinkedIn can contribute to resilience engineering efforts.
Additional information on LinkedOut can be found on the LinkedIn Engineering blog and the associated Rest.li GitHub repositories.