
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
What is Machine Learning, Data Science or Artificial Intelligence? is one of the most common questions which I have faced from people. Be it newcomers, recruiters or even people in leadership positions, this is a question which is puzzling everyone in its own way.
For beginners it takes the form of how do I become a data scientist? For leaders it becomes a question of whether it has an imperative business impact? and for people in the field it takes the form of what I should call myself, a data scientist a data engineer or a data analyst.
This post is an attempt to clear some of the myths and develop a basic understanding around what Data Science is, and its different interpretations in corporate world.
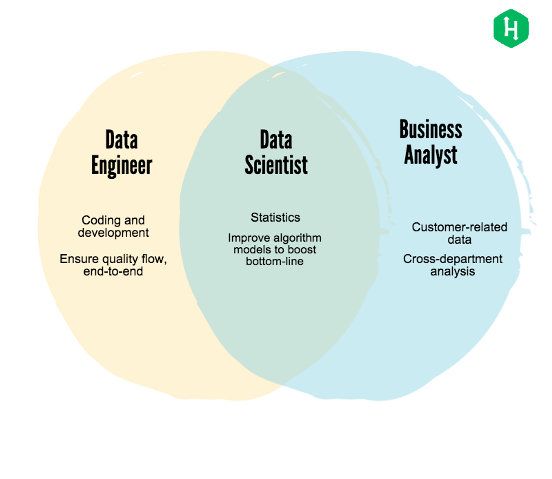
Myth 1: Data Scientist/Engineer/Analyst are one and same.
This is a warped myth which I have faced many times in my career and which basically does harm to both employee and the company. It’s like calling a software engineer and QA the same thing.
To put things in perspective, a Data Scientist is someone who has experience and knowledge in at least 2 of these 3 fields, Statistics, Programming and Machine Learning. Primary expectation of such an employee is to be able to work on a challenging business problem where he/she can use their knowledge to find solutions. Such a person would love to spend a major portion of their work in building predictive models and performing statistical experiments to obtain a working solution. It’s a mixture of a research and a programming job, and the nature and workload differs depending on the size of the company/team.
Data Engineering is a job where a person focuses on building the infrastructure for deploying applications performing jobs like predictive modeling, updating dashboards with streaming data, running daily jobs to generate reports and maintaining continuous flow of data. A really good knowledge of SQL is fast becoming a necessity for a good data engineer followed by knowledge of spark.
Data Analyst is a person with more of a bend towards interpreting and analyzing business results rather than being in the process of their creation. Such a person will prefer to use tools to generate those results and will spend a major portion of their time in interpreting and deriving business value out of them. Data Analysts have been in the industry a long time before data scientists came into picture and the primary tool of there choice has been Excel. In fact , even today for small amount of data excel is most efficient. At present, there are tool like PowerBI, Azure which provide the ability to perform analytics on Big Data. Primary focus however for this position is accurately communicating day to day results as well as results of new hypothesis which they test. These inputs are critical and form a base for important decision making for a business.
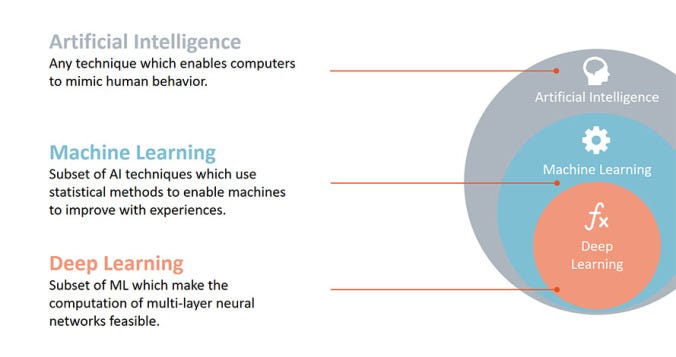
Myth 2: Deep Learning is Machine Learning or AI
Deep learning has no doubt become a big name nowadays, and with all the hype and marketing around it, it has also led to people believing that deep learning is an ultimate solution to every data science/machine learning problem. Truth cannot be farther away than this.
Deep learning, no doubt is one of the most complex concepts to understand in today’s scope of machine learning but that is it. Deep learning gets its name since the “neural network” implied in this framework contains multiple layers and is hence called a “deep” network. What is offered via tensorflow, pytorch or keras is just a framework to apply this concept easily.
No doubt, learning the framework is hard and framework is efficient as well but it is not equivalent to gaining expertise in machine learning. Machine learning is a vast field which takes in concepts and algorithms from a number of fields such as statistics, information theory, optimization, information retrieval, neural networks etc. and has an abundance of algorithms each of which are more useful than others in particular use cases.
Deep learning for instance has been extremely efficient in computer vision and speech recognition but it is an absolute overkill to use it in sentiment analysis or a simple prediction problem which can be solved with linear regression.
It is always a wise decision to invest time in exploratory analysis and understanding the scope of a problem before fixing on the algorithm to use for the problem.
This pic explains it the best.
Myth 3: Data Science can be picked up in 3 months.
As much as I wish this to be true, this is not the case. To be an efficient data scientist one needs to know a lot more than just importing the libraries through scikit-learn and tensorflow and calling their train and predict functions.
It is one of those illusive fields where the results are not deterministic, meaning same sequence of steps will not always end in same result. It highly depends on the quality and the quantity of the data provided and there is a lot of stuff which needs to happen before calling the “train” function.
Sure, you can learn how to call libraries and write the sequence of steps to generate a model, but that model will not always be efficient. To understand things properly one needs to have a considerable understanding of working and dependencies of the algorithm which is being applied. It is imperative to have this knowledge, or else tweaking models or explaining the results to leadership becomes a real pain.
I always remember this answer to , how to learn coding in a single night

This is a small attempt to underline and clear the prevalent myths in the field of machine learning and data science. Hope it helps.
If you enjoyed this article please be sure to follow me on Twitter, Medium or find me on LinkedIn.