
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
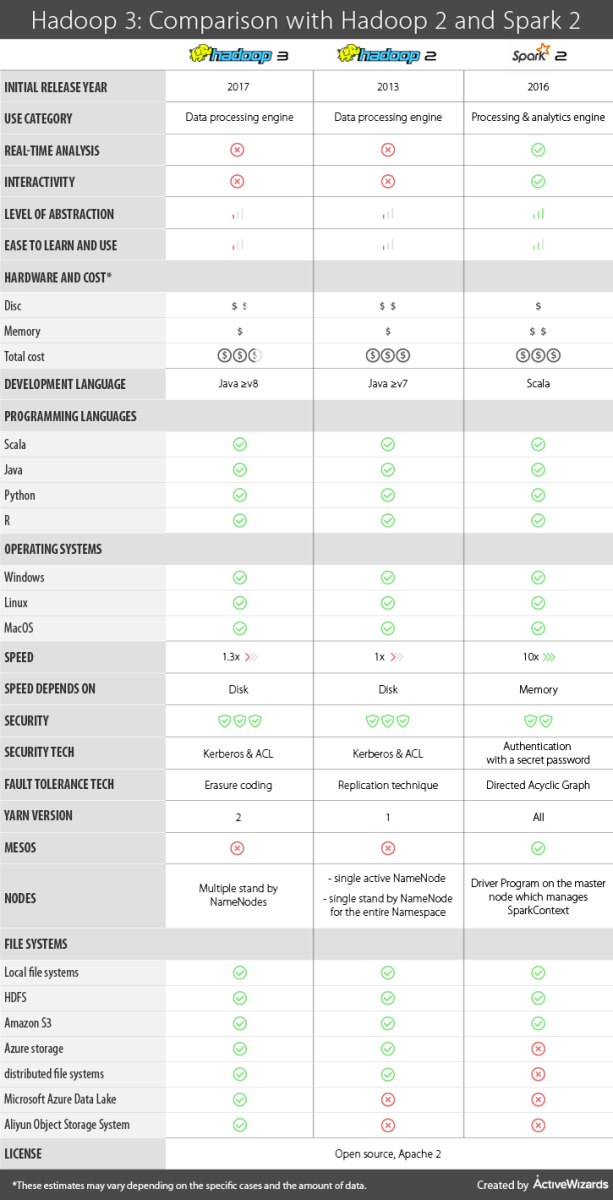
 The release of Hadoop 3 in December 2017 marked the beginning of a new era for data science. The Hadoop framework is at the core of the entire Hadoop ecosystem, and various other libraries strongly depend on it.
The release of Hadoop 3 in December 2017 marked the beginning of a new era for data science. The Hadoop framework is at the core of the entire Hadoop ecosystem, and various other libraries strongly depend on it.
In this article, we will discuss the major changes in Hadoop 3 when compared to Hadoop 2. We will also explain the differences between Hadoop and Apache Spark, and advise how to choose the best tool for your particular task.
General information
Hadoop 2 and Hadoop 3 are data processing engines developed in Java and released in 2013 and 2017 respectively. Hadoop was created with the primary goal to maintain the data analysis from a disk, known as batch processing. Therefore, native Hadoop does not support the real-time analytics and interactivity.
Spark 2.X is a processing and analytics engine developed in Scala and released in 2016. The real-time analysis of the information was becoming crucial, as many giant internet services strongly relied on the ability to process data immediately. Consequently, Apache Spark was built for live data processing and is now popular because it can efficiently deal with live streams of information and process data in an interactive mode.
Both Hadoop and Spark are open source, Apache 2 licensed.
Level of abstraction and difficulty to learn and use
One of the major differences between these frameworks is the level of abstraction which is low for Hadoop and high for Spark. Therefore, Hadoop is more challenging to learn and use, as the developers must know how to code a lot of basic operations. Hadoop is only the core engine, so using advanced functionality requires plug-in of other components, which makes the system more complicated.
Unlike Hadoop, Apache Spark is a complete tool for data analytics. It has many useful built-in high-level functions that operate with the Resilient Distributed Dataset (RDD) – the core concept in Spark. This framework has many helpful libraries included in the cluster. For example, MLlib allows using machine learning, Spark SQL can be used to perform SQL queries, etc.
Hardware and cost
Hadoop works with a disk, so it does not need a lot of RAM to operate. This can be cheaper than having large RAM. Hadoop 3 requires less disk space than Hadoop 2 due to changes in fault-tolerance providing system.
Spark needs a lot of RAM to operate in the in-memory mode so that the total cost can be more expensive than Hadoop.
Support of programming languages
Both versions of Hadoop support several programming languages using Hadoop Streaming, but the primary one is Java. Spark 2.X supports Scala, Java, Python, and R.
Speed
Generally, Hadoop is slower than Spark, as it works with a disk. Hadoop cannot cache the data in memory. Hadoop 3 can work up to 30% faster than Hadoop 2 due to the addition of native Java implementation of the map output collector to the MapReduce.
Spark can process the information in memory 100 times faster than Hadoop. If working with a disk, Spark is 10 times faster than Hadoop.
Security
Hadoop is considered to be more secure than Spark due to the usage of the Kerberos (computer network authentication protocol) and the support of the Access Control Lists (ACL). Spark in its turn provides authentication only with a shared secret password.
Fault tolerance
The fault tolerance in Hadoop 2 is provided by the replication technique where each block of information is copied to create 2 replicas. This means that instead of storing 1 piece of information, Hadoop 2 stores three times more. This raises the problem of wasting the disk space.
In Hadoop 3 the fault tolerance is provided by the erasure coding. This method allows recovering a block of information using the other block and the parity block. Hadoop 3 creates one parity block on every two blocks of data. This requires only 1,5 times more disk space compared with 3 times more with the replications in Hadoop 2. The level of fault tolerance in Hadoop 3 remains the same, but less disk space is required for its operations.
Spark can recover information by the recomputation of the DAG (Directed Acyclic Graph). DAG is formed by vertices and edges. Vertices represent RDDs, and edges represent the operations on the RDDs. In the situation, where some part of the data was lost, Spark can recover it by applying the sequence of operations to the RDDs. Note, that each time you will need to recompute RDD, you will need to wait until Spark performs all the necessary calculations. Spark also creates checkpoints to protect against failures.
YARN version
Hadoop 2 uses YARN version 1. YARN (Yet Another Resource Negotiator) is the resource manager. It manages the available resources (CPU, memory, disk). Besides, YARN performs Jobs Scheduling.
YARN was updated to version 2 in Hadoop 3. There are several significant changes improving usability and scalability. YARN 2 supports the flows – logical groups of YARN application and provides aggregating metrics at the level of flows. The separation between the collection processes (writing data) and the serving processes (reading data) improves the scalability. Also, YARN 2 uses Apache HBase as the primary backing storage.
Spark can operate independently, on a cluster with YARN, or with Mesos.
Number of NameNodes
Hadoop 2 supports single active NameNode and single standby NameNode for the entire Namespace while Hadoop 3 works with multiple standby NameNodes.
Spark runs Driver Program on the master node which manages SparkContext.
File systems
The main Hadoop 2 file system is HDFS – Hadoop Distributed File System. The framework is also compatible with several other file systems, Blob stores like Amazon S3 and Azure storage, as well as alternatively distributed file systems.
Hadoop 3 supports all the file systems, as Hadoop 2. In addition, Hadoop 3 is compatible with Microsoft Azure Data Lake and Aliyun Object Storage System.
Spark supports local file systems, Amazon S3 and HDFS.
For your convenience, we created a table that summarises all of the above information and presents a brief comparison of the key parameters of the two versions of Hadoop and Spark 2.X.
Conclusion
The major difference between Hadoop 3 and 2 is that the new version provides better optimization and usability, as well as certain architectural improvements.
Spark and Hadoop differ mainly in the level of abstraction. Hadoop was created as the engine for processing large amounts of existing data. It has a low level of abstraction that allows performing complex manipulations but can cause learning and managing difficulties. Spark is easier and faster, with a lot of convenient high-level tools and functions that can simplify your work. Spark operates on top of Hadoop and has many good libraries like Spark SQL or machine learning library MLlib. To summarize, if your work does not require special features, Spark can be the most reasonable choice.