
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
The European Space Agency Science Data Center (ESDC) switched to PostgreSQL with the TimescaleDB extension for their data storage. ESDC’s diverse data includes structured, unstructured and time series metrics running to hundred of terabytes, and querying requirements across datasets with open source tools.
ESDC collects massive amounts of data – terabytes per day – from each of their space missions and makes it available to various teams including the general public. This data – consisting of metadata about missions and satellites and data generated during the missions – can be both structured and unstructured. Generated data includes geo-spatial and time series data. Cross referencing of datasets was a requirement while choosing a data storage solution, as was the need to be able to use readily available, open source tools to analyze the data. The team wanted to move away from legacy systems like Oracle and Sybase.
ESDC’s team settled on PostgreSQL for its maturity and support for various data types and unstructured data. In addition to these routine requirements, ESDC also needed to store and process geo-spatial and time series data. Geospatial data is data which has location information attached to them such as a planet’s position in the sky. This had to be done without using different data stores for different types or sources of data. The decision to move to PostgreSQL was motivated by the availability of an extension mechanism which allows for such processing. PostgreSQL has native support for JSON and full text search. The PostGIS, pg_sphere and q3c extension allowed ESDC to use normal SQL to run location based queries and more specialized analyses.
PostgreSQL also had to efficiently and scalably store time series data generated from missions such as the Solar Orbiter project. This had low write speed requirements as the collected data is stored locally in the satellite “for later downlink during daily ground station passes” and inserted into the database in batches. However, queries against this db had to support structured data types, ad-hoc matching between datasets and large datasets of up to hundreds of TBs. It’s unclear which specific time series databases were evaluated, but the team did not opt for any of them as they had standardized on SQL as the query language of choice, and PostgreSQL as the platform since it satisfied their other requirements. There have been past approaches to store time series data on PostgreSQL. Its recent partitioning feature attempts to solve the problem of keeping large table indexes in memory and writing them to disk on every update by splitting tables into smaller partitions. Partitioning can also be used to store time series data when the partitioning is done by time, followed by indices on those partitions. ESDC’s efforts to store time series data ran into performance issues, and they switched to an extension called TimescaleDB.
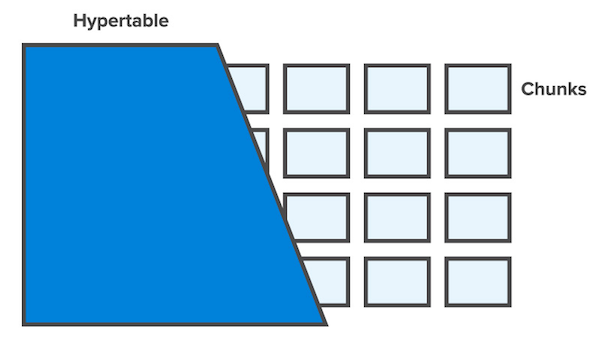
Image courtesy: https://blog.timescale.com/when-boring-is-awesome-building-a-scalable-time-series-database-on-postgresql-2900ea453ee2
TimescaleDB uses an abstraction called a hypertable to hide partitioning across multiple dimensions like time and space. Each hypertable is split into “chunks”, and each chunk corresponds to a specific time interval. Chunks are sized so that all of the B-tree structures for a table’s indices can reside in memory during inserts, similar to how PostgreSQL does partitioning. Indices are auto-created on time and the partitioning key. Queries can be run against arbitrary “dimensions“, just like other time series databases allow querying against tags. One of the differences between TimescaleDB and other partitioning tools like pg_partman is support for auto-sizing of partitions. Although TimescaleDB has reported higher performance benchmarks compared to PostgreSQL 10 partitioning based solutions and InfluxDB, there have been concerns about maintainability. Clustered deployments of TimescaleDB is still under development at the time of this writing.
TimescaleDB is open source and hosted on Github.