
Out-of-place updates drive excellent write performance relative to in-place updates, but sacrifice read performance in the bargain.
Jan 14th, 2025 9:00am by

The design of database storage engines is pivotal to their performance. Over decades, SQL and NoSQL databases have developed various techniques to optimize data storage and retrieval.
Database storage engines have evolved from early relational systems to modern distributed SQL and NoSQL databases. While early relational systems relied on in-place updates to records, modern systems — both distributed relational databases and NoSQL databases — primarily use out-of-place updates. The term “record” is used to refer to both tuples in a relational database as well as key-values in a NoSQL store.
Out-of-place updates became popular as a result of the extremely heavy write workloads that modern databases encountered with the advent of internet-scale user events, as well as automated events from sensors (e.g., Internet of Things) flowing into a database.
These two contrasting approaches — in-place updates and out-of-place updates — show how out-of-place updates drive excellent write performance relative to in-place updates, but sacrifice read performance in the bargain.
Layers of a Storage Engine
Let’s begin with an overview of the layered architecture of storage engines. A database storage engine typically consists of three layers:
- Block storage: The foundational layer, providing block-level access through raw devices, file systems or cloud storage. Databases organize these blocks for scalable data storage.
- Record storage: Built atop block storage, this layer organizes records into blocks, enabling table or namespace scans. Early relational systems usually updated records in place while the more modern storage engines use out-of-place updates.
- Access methods: The topmost layer includes primary and secondary indexes, facilitating efficient data retrieval. Updates to access methods also can be in place or out of place, as we will see shortly. Many current systems apply the same methodologies, in-place updates or out-of-place updates, for both the record storage and access methods. We will therefore talk about these two layers together in the context of how they are updated.
Let’s delve deeper into each layer.
Block Storage
At its core, the block storage layer organizes data into manageable units called blocks (B1 and B2 in Figure 1 below). These blocks act as the fundamental storage units, with higher layers organizing them to meet database requirements. Figure 1 illustrates a basic block storage system. Record storage and access methods are built on top of the block storage. There are two broad categories of record storage and access methods corresponding to whether updates happen in place or out of place. We will describe the record storage and access methods under these categories next.

Figure 1: Block storage showing blocks B1 and B2.
Storage and Access Methods With In-Place Updates
The approach of updating records and the access methods in place was the standard in early relational databases. Figure 2 (below) illustrates how a block in such a system is organized and managed to provide a record storage API. Notable features of such a record storage layer include:
- Variable length records: Records often vary in size, and the size may change during updates. To minimize additional IO operations during updates, the record storage layer actively manages block space to accommodate updates within the block.
- One level of indirection: Each record within a block is identified by a slot number, making the record ID (RID) a combination of the block ID and slot number. This indirection allows a record to move freely within the block without changing its RID.
- Slot map: A slot map tracks the physical location of each record within a block. It grows from the beginning of the block while records grow from the end, leaving free space in between. This design allows blocks to accommodate a variable number of records depending on their sizes, and supports dynamic resizing of records within the available space.
- Record migration: When a record grows too large to fit within its original block, it is moved to a new block, resulting in a change to its RID.
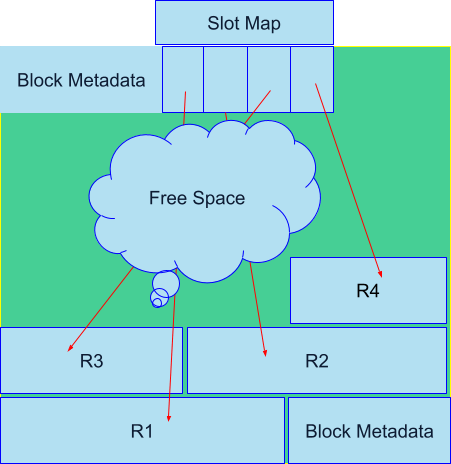
Figure 2: Record storage for in-place updates, showing how a block is organized internally.
Access methods are built on top of record storage to efficiently retrieve records. They include:
- Primary indexes: These indexes map primary key fields to their corresponding RIDs.
- Secondary indexes: These indexes map other field values (potentially shared by multiple records) to their RIDs.
If the index is completely in memory, then self-balancing trees, such as red-black (RB) trees, are used. If the index is primarily on disk (with parts possibly cached in memory), B+-trees are used. Figure 3 shows a B+-tree on top of a record storage. The primary index as well as the secondary index would have the same format for the entries (field value and RID).
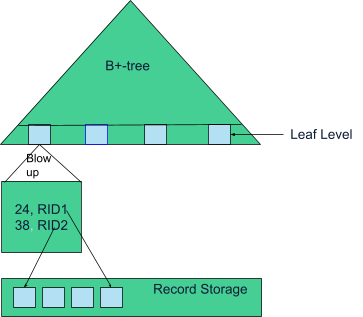
Figure 3: B+-tree on top of record storage.
Combining Access Methods and Record Storage
In some systems, the access method and record storage layers are integrated by embedding data directly within the leaf nodes of a B+-tree. The leaf level then essentially becomes a record storage, but additionally is also now sorted on the index key. Range queries are made efficient as a result of this combination compared to an unsorted record storage layer. However, to access the records using other keys, we would still need an access method (an index on other keys) on top of this combined storage layer.
Storage and Access Methods With Out-of-Place Updates
Most modern storage engines, both distributed NoSQL and distributed SQL engines, use out-of-place updates. In this approach, all updates are appended to a current write block maintained in memory, which is then flushed to disk in one IO when the block fills up. Note that durability of the data before the write hits the disk if this node were to fail is mitigated by the replication within the distributed database. Blocks are immutable, with records packed and written only once, eliminating the need for space management overhead. The older version of the record will be garbage-collected by a cleanup process if that is desired. This has two advantages:
- Amortized IO cost: All the records in the write block together need one IO compared to at least one IO per record for in-place updates.
- Exploits sequential IO: These techniques were invented in the era of magnetic hard disk drives (HDD), and sequential IO was way superior to random IO in HDDs. But even in the era of SSDs, sequential IO is still relevant. The append-only nature of these systems lends itself to sequential IOs.
The most well-known and commonly used form of out-of-place update storage engines use a data structure called log-structured merge-trees (LSM-trees). In fact, LSM-trees are used by almost all the modern database storage engines, such as BigTable, Dynamo, Cassandra, LevelDB and RocksDB. Variants of RocksDB are employed by systems like CockroachDB and YugabyteDB.
LSM-Trees
The foundational concepts for modern LSM-tree implementations originate from the original paper on the concept, as well as from the Stepped-Merge approach, which was developed concurrently.
The Stepped-Merge algorithm arose from a real, critical need: managing the entire call volume of AT&T’s network in 1996 and recording all call detail records (CDRs) streaming in from across the United States. This was an era of complex phone billing plans — usage-based, time-of-day-based, friends-and-family-based, etc. Accurately recording each call detail was essential for future billing purposes.
However, the sheer volume of calls overwhelmed the machines of the time, leading to the idea of immediately appending CDRs to the end of record storage, followed by periodic “organization” to optimize lookups for calculating bills. Bill computations (reads) were batch jobs with no real-time requirements, unlike the write operations.
The core idea behind solving the above problem was to accumulate as many writes as possible in memory and write it out as a sorted run at level 0 once memory fills up. After a certain number, T, of level 0 runs are available, they are all merged into a longer sorted run at level 1. During the merge, duplicates could be eliminated if required.
This process of merging T-sorted runs at level i to construct a longer run at level i+1 continues for as many levels as is required, drawing inspiration from the external sort merge algorithm. This idea is very similar to the original LSM-tree proposal and forms the basis of all modern LSM-based implementations, including the concept of T components per level. The merge process is highly sequential-IO friendly, with the cost of writing a record amortized over multiple sequential-IO operations for several records.
However, the reads, in the worst case, must examine every sorted run at each level, incurring the penalty of not updating in place. Yet, looking up a key in a sorted run is made efficient by an index, such as a B+-tree, specific to that sorted run. These B+-trees directly point to the physical location (as opposed to a RID), since the location remains constant. Figure 4 illustrates an example of an LSM-tree with three levels and T=3 components per level.
The sorted runs are shown as B+-trees to optimize read operations. Notice that the leaf level represents the sorted run, while the upper levels are constructed bottom-up from the leaf (a standard method for bulk loading a B+-tree). In this regard, an LSM-tree can be considered a combination of an access method and a record-oriented storage structure. While sorting typically occurs on a single key (or a combination of keys), there may be cases requiring access via other keys, necessitating secondary indexes on top of the LSM-tree.

Figure 4: Example LSM trees with three levels on disk and three components per level.
Comparing In-Place and Out-of-Place Updates
The table below compares key features of storage engines of early relational systems with those developed for modern storage engines. It assumes that one record is being written and one primary key value is being read. For early relational systems, we assume the presence of a B+-tree index on the primary key (the details of whether the leaf level contains the actual data or a record identifier (RID) do not significantly affect this discussion). For the LSM-tree (most common modern storage engines), the assumption is that the sorted runs (and the B+-trees) are based on the primary key.
Conclusion
Storage engines have evolved to handle the heavy write workloads many database systems encountered with the advent of internet scale. LSM-trees have become popular to solve this challenge of handling heavy write workloads. However, LSM-trees do give up on real-time read performance relative to the infrastructure processing unit (IPU)-based storage engines used in early relational systems. Under some circumstances, it may be wise to find a system that blends the best of both of these ideas: Use out-of-place updates for record storage to be able to continue to handle the write-heavy workload, but use in-place updates for access methods to minimize the read overhead.
Visit our website to learn more about Aerospike Database.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTube
channel to stream all our podcasts, interviews, demos, and more.
Created with Sketch.
