
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
Introduction
Recently, google launched a Dataset search – which is a great resource to find Datasets. In this post, I list some IoT datasets which can be used for Machine Learning or Deep Learning applications. But finding datasets is only part of the story. A static dataset for IoT is not enough i.e. some of the interesting analysis is in streaming mode. To create an end to end streaming implementation from a given dataset, we need knowledge of full stack skills. These are more complex (and in high demand). In this post, I hence describe the datasets but also a full stack implementation. An end to end flow implementation is described in the book Agile Data Science, 2.0 by Russell Jurney. I use this book in my teaching at the Data Science for Internet of Things course at the University of Oxford. I demonstrate the implementation from this book below. The views here represent my own.
In understanding an end to end application, the first problem is .. how to capture data from a wide range of IoT devices. The protocol used for this is typically MQTT. MQTT is lightweight IoT connectivity protocol. MQTT is publish-subscribe-based messaging protocol used in IoT applications to manage a large number of IoT devices who often have limited connectivity, bandwidth and power. MQTT integrates with Apache Kafka. Kafka provides high scalability, longer storage and easy integration to legacy systems. Apache Kafka is a highly scalable distributed streaming platform. Kafka ingests, stores, processes and forwards high volumes of data from thousands of IoT devices. (source Kai Waehner)
Full stack – End to End
With this background, let us try to understand the end to end (full stack) implementation of an IoT dataset. This section is adapted from the Agile Data Science 2.0 book
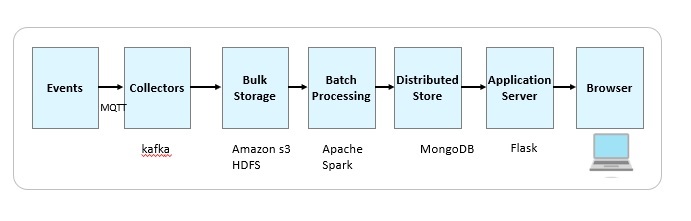
Image source: Agile Data Science, 2.0 by Russell Jurney
We have the following components
Events: represents an occurrence with a relevant timestamp. Events can represent various things (ex logs from the server). In our case, they represent time series data from sensors typically represented as JSON objects
Collectors are event aggregators which collect events from various sources and queue them for action by real-time workers. Typically, Kafka or Azure event hub may be used at this stage.
Bulk storage – represents a file system capable of high I/O – for example S3 or HDFS
Distributed document store – ex MongoDB
A web application server – ex flask, Node.js
The data processing is done via spark. Pyspark is used for the Machine learning (either scikit learn or Sparl MLlib libraries) and the results are stored in MongoDB. Apache Airflow can be used for scheduling
Code
from github repository of Agile Data Science, 2.0
https://github.com/rjurney/Agile_Data_Code_2/tree/training
The EC2 scripts: https://github.com/rjurney/Agile_Data_Code_2/blob/training/aws/ec2_bootstrap.sh *
The real-time notebook with Spark ML/Streaming : https://github.com/rjurney/Agile_Data_Code_2/blob/training/ch08/Deploying%20Predictive%20Systems.ipynb
Finally, below are some of the reference datasets you can use with IoT.
To conclude
To conclude, using the strategy and code described here – you could in principle, create an end to end streaming IoT application.
IoT datasets
Utilities
Gas Sensor Array Drift Dataset Data Set
Water Treatment Plant Data Set
Commercial Building Energy Dataset
Individual household electric power consumption Data Set
AMPds2: The Almanac of Minutely Power dataset (Version 2)
UK Domestic Appliance-Level Electricity Energy, Smart Home Power demand from five houses
Gas sensors for home activity monitoring Smart home Recordings of 8 gas sensors
Smart cities
Traffic Sign Recognition Testsets
Pollution Measurements for the City of Brasov in Romania
GNFUV Unmanned Surface Vehicles Sensor Data Data Set
Uber trip data Transportation About 20 million Uber pickups in New York City during 12 months.
Traffic Sign Recognition Transportation
CityPulse Dataset Collection Smart City Road Traffic Data, Pollution Data, Weather, Parking
Open Data Institute – node Trento Smart City Weather, Air quality, Electricity, Telecommunication
Health and home activity
PhysioBank databases Healthcare – Archive of over 80 physiological datasets
SportVU Sport Video of basketball and soccer games captured from 6 cameras
GeoLife GPS Trajectories Transportation A GPS trajectory by a sequence of time-stamped points
Various sensor driving datasets
Various MHEALTH / physical activity datasets
Source: for some of the datasets Deep Learning for IoT Big Data and Streaming Analytics: A Survey