
MMS • RSS
Article originally posted on Data Science Central. Visit Data Science Central
For any business, the worst scenario is getting out of product inventory when customers are ready to buy your product. Keeping a stock of every item in the store is another burden to carry for every business. This trade off has been even more problematic in current times, when manufacturing firms are flooding with SKUs (Stock Keeping Unit) ranging from product sizes, flavours, styles etc. To cater personalised demand companies are customising products by adding various features to it & this is making life even more complex for all parts of businesses involved in the whole supply chain.
To understand this problem, lets take an example of a toothpaste. There are more than 6–7 popular brands such as Colgate, Pepsodent, Close up, Dabur, Himalaya, Meswak etc with each having 4–5 toothpaste different sizes ranging from 50gm to 300 gm & 4–5 different variants such as Sensitive, Germi-check, Gumcare, Whitening etc.
Keeping an inventory for all SKUs is a troublesome experience for any corner shop. But if a customer goes away without buying just because shop does not have specific type/size of toothpaste, it is even more painful for the business owner. In this particular scenario, customer may be ready to buy some other toothpaste, but the luxury of choosing another option is not available for all products.
Backorder Definition
When product is not readily available and customer may not have patience to wait, this leads to lost sales and low customer satisfaction. When a customer places order for future inventory & wait for it is called backorder. Backordering is good as well as bad for business. Demand will bring backorders but not best planning can cause problems. Machine learning is the path to get the maximum out of this trade off. Lets get going on the path to profit maximisation and better customer satisfaction.
Predictive Analytics can help to distinguish the items which may have backorders tendency to help organisation by providing the required actionable insights. Production schedule can be tweaked to reduce the product delivery delay which, in return, increases customer satisfaction.
Inventory Management Challenges
By making use of any good classification machine learning technique such as XgBoost, one can easily predict the probability of product being on backorder list. We will cover classification machine learning technique along with code in separate blog. After getting items backorder probabilities, optimisation is another tricky part. For this classification problem, selection of threshold value for probability will be key to inventory optimisation. In business context, this threshold selection will provide balance between cost of inventorying incorrect product (low precision) v/s cost of lost revenue (low recall)
Precision: When model predicts item will have backorders & how many times actually it has backorders. if we adopt business strategy with high precision (low recall), then we had to let the model misclassify actual backorder cases to decrease the number of incorrectly predicted backorder items.
Recall: When actually items have backorders and how often the model predict it to be having backorders. If we adopt business strategy with high recall (low precision), then we had to let the model predict actually non backorder items as backorder items.
By playing around with probability threshold limit, we can actually tweak the business strategy. Business strategy shifts to conservative zone in which very less items predicted as backorder items if we increases probability threshold.
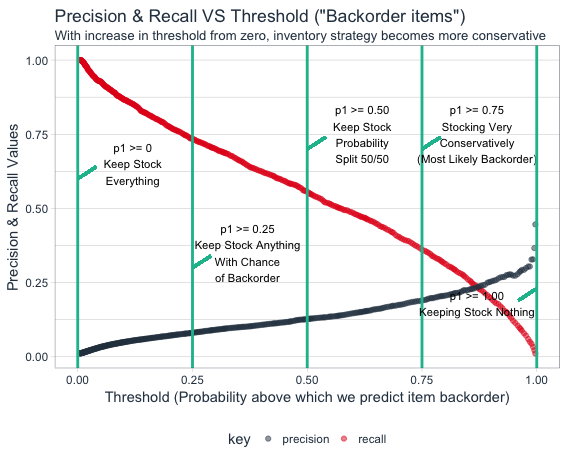
By using machine learning we can easily get the values of true positive, false positive, true negative & false negative rates very easily for a large set of different threshold values. From here onwards, the first business principal of cost benefit analysis will help us in profit maximisation.
Cost-Benefit Analysis
Benefits
- True positive: Benefit by predicting correctly the backorder SKUs. Profit generated from such items is benefit.
- True negative: Benefit by predicting SKUs not in backorder list correctly. Though benefit from this is zero as customer has not bought item, storage cost saved in addition to opportunity cost for not manufacturing such items is also benefit.
Cost
- False positive: This cost is due to the fact that we predicted few items as backorder items but they were not actually in backorder item list. The warehousing cost for such items is the cost associated with false positive.
- False negative: The cost associated with incorrectly missing items when actual demand was there for item.
The Above cost benefit calculations has to be done for all products at specific threshold to see the deviation of net cost-benefit at every threshold value.
SKU Optimisation
If we take one SKU, say we have predicted it to be not in backorder list. If hypothetically the benefit of correctly predicting backorder is $1000/unit and cost for false positive is $50/unit (accidentally inventorying).
The expected value equation can be generalised to
Expected_Value= ∑pi*vi where i ranges from 1 to N observations for each SKU.
p is the probability of backorder for any SKU
v is the value associated with the SKU
From the above general form of equation, overall expected profit equation can be generated by combining the two matrices i.e cost benefit matrix and expected probability matrix.
Expected_Profit=p(p)∗[p(Y|p)∗b(Y,p)+p(N|p)∗c(N,p)]+p(n)∗[p(N|n)∗b(N,n)+p(Y|n)∗c(Y,n)]
- p(p) is the positive class prior (probability of actual backorder / total) from confusion matrix
- p(n) is the negative class prior (probability of actual no / total = 1 — positive class prior)
- p(Y|p) is the True Positive Rate (TPR)
- p(N|p) is the False Negative Rate (FNR)
- p(N|n) is the True Negative Rate (TNR)
- p(Y|n) is the False Positive Rate (FPR)
- b(Y,p) is the benefit from true positive (TP_CB)
- c(N,p) is the cost from false negative (FN_CB)
- b(N,n) is the benefit from true negative (TN_CB)
- c(Y,n) is the cost from false positive (FP_CB)
For the taken hypothetical example, this equation simplifies further as TN_CB and FN_CB are both zero.
Expected_Profit=p(p)∗[p(Y|p)∗b(Y,p)]+p(n)∗[p(Y|n)∗c(Y,n)]
Business Implications
Lets check the above equation while taking hypothetical prediction for an item that does not have backorder. Lets assume model predicted 0.01 probability of being backorder for an item. The earlier hypothetical example where $1000/unit profit and $50/unit inventory cost assumed. from the visualisation , we can calculate that optimal threshold is 0.48. Keeping all items in inventory strategy with threshold as zero will make company to lose money on low probability of backorder item and no inventory strategy would lead to no benefit but no loss.
On the other hand if we check high backorder probability item, it is beneficial to have loose strategy than conservatory strategy. The profit will be reduced to zero if we have conservative strategy to keep inventory of such item.
In the nutshell, items with low backorder probability will try to increase the threshold limit and the high backorder probability items are trying to decrease the threshold limit. We need to adjust and play with this tradeoff to maximise overall profit. Every item with different threshold can be further aggregated to get the overall threshold value while making maximum profit from the inventory and backorder management. By making use of discussed machine learning techniques, businesses can better optimise inventory management while not sacrificing the utmost important profit maximisation objective.
This post originally published on DataToBiz‘s official blog page. DataToBiz connects businesses to data and excels in cutting-edge ML technologies in order to solve most of the simple and trivial problems of business owners with the help of data. Feel free to Contact for more info.