MemSQL 6.5: NewSQL with autonomous workload optimization, improved data ingestion and …

MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts
Video: What’s new in the graph database world?
Is it SQL, NoSQL, or NewSQL?
Even though it’s just naming conventions, MemSQL is usually thought of as part of the NewSQL lot. That is, databases grounded on the relational SQL model yet adopting some of the “knobs” the NoSQL lot has introduced for people to turn in order to achieve horizontal scalability.
It’s a balancing act between consistency and performance, which, in the end, applies to any distributed database. NewSQL folks argue you should not have to ditch schema, or SQL, to get the scale-out benefits that NoSQL brings. If you like your schema and SQL, and also like your database to have analytics as well as transactional capabilities, then MemSQL is probably in your radar.
Read also: AWS Neptune going GA: The good, the bad, and the ugly for graph database users and vendors
Today, MemSQL is announcing version 6.5, introducing autonomous workload optimization, and bringing improved data ingestion, as well as query execution speed. ZDNet had a Q&A with MemSQL CEO Nikita Shamgunov on what the new version does and how.
Autonomous workload optimization
What autonomous workload optimization means in practice is that at least some of the tasks typically attended to by a DBA in MemSQL deployments are now to some extent handled by automation.
Read also: Business analytics: The essentials of data-driven decision-making
MemSQL utilizes a shared-nothing, distributed, in memory processing architecture. Nodes are organized in two layers — leaf nodes and aggregators — with the latter splitting and routing workloads and the former executing them.
In MemSQL 6.5, explains Shamgunov, workload management was added to more gracefully handle the unpredictable spikes in queries while still maintaining high performance during normal load. Workload management can be broken into three components that work together to address cases of heavy load: Detection, prediction, and management.

MemSQL wants to take the lessons learned from NoSQL and apply them to SQL. (Image: MemSQL)
Detection refers to identifying when any node is struggling. MemSQL differentiates memory used for table data or temporarily in queries to determine if it is safe to continue forwarding more queries to the target nodes.
Prediction refers to estimating the resource usage of queries and classifying them into groups accordingly. In MemSQL 5.8, management views were introduced to allow users to see resource usage statistics of previously run queries. Workload management can also use these statistics to determine how expensive a query is from a memory consumption perspective.
Read also: AI-powered DevOps is how CA wants to reinvent software development and itself
The last component is Management, which admits queries in three tiers. The cheapest queries such as single-partition selects, inserts, or updates avoid being queued entirely. Queries that use moderate resource amounts are queued on a FIFO (first-in first-out) basis at a rate dependent on the highest load among leaves.
The most expensive queries are queued with maximum concurrency and running is coordinated between all the aggregator nodes. Since there is an associated cost to the coordination, only the most resource-intensive queries fall into this category.
When asked to compare MemSQL’s autonomous workload optimization capabilities with other databases such as Oracle, Datastax, and ScyllaDB, Shamgunov noted that MemSQL has similar capabilities to Oracle’s Automated Memory Management utility:
“MemSQL offers slightly more granular options such as managing pre-configured query pools while Oracle offers a more broad total memory management utility. Datastax and ScyllaDB offer simplified memory management configurations for allocating memory to entire applications but do not offer lower level configurations based on query profile or query pool.”
Pipelines and stored procedures
In a previous discussion with Gary Orenstein, MemSQL’s former CMO, one of the things we talked about was MemSQL’s positioning in a real-time data ingestion/transformation pipeline. MemSQL has introduced its own Pipelines for data ingestion in version 5.5, and Orenstein mentioned that MemSQL’s capabilities are such that some MemSQL clients choose to not use solutions like Spark or Flink, but rather ingest data directly using MemSQL.
Read also: GraphQL for databases: A layer for universal database access?
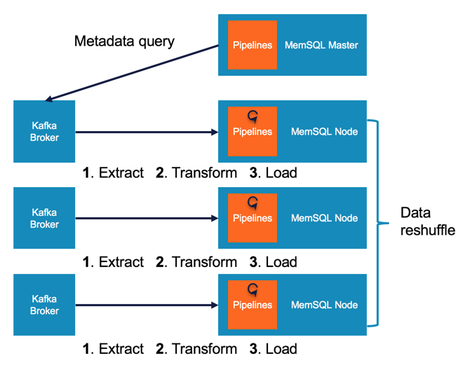
MemSQL Pipelines architecture. Now Pipelines is enhanced with the ability to execute stored procedures. (Image: MemSQL)
Shamgunov notes that MemSQL 6.5 introduces pipelines to stored procedures, augmenting the existing MemSQL Pipelines data flow by providing the option to replace the default Pipelines load phase with a stored procedure:
“The default Pipelines load phase only supports simple insertions into a single table, with the data being loaded either directly after extraction or following an optional transform.
Replacing this default loading phase with a stored procedure opens up the possibility for much more complex processing, providing the ability to insert into multiple tables, enrich incoming streams using existing data, and leverage the full power of MemSQL Extensibility.
Leveraging both a transform and a stored procedure in the same Pipeline allows you to combine the third-party library support of a traditional transform alongside the multi-insert and data-enrichment capabilities of a stored procedure.”
While data streaming and ingestion to support real-time insights is an essential feature, adding, configuring, and operating the streaming engines required to support this increases operational complexity. This should initiate a nuanced discussion on comparing the capabilities of streaming engines versus Pipelines.
Assuming, however, that the transformations supported by Pipelines are enough to cover the scenarios they are interested in, flattening system architecture even beyond Kappa sounds like a strong selling point for prospective MemSQL users.
Resource optimization improvements for multi-tenant deployments
With multi-cloud and hybrid cloud strategies being a reality for most organizations, MemSQL already has had a strategy in place for this since last year. But while using MemSQL in multi-cloud and hybrid cloud environments is possible, cross-querying is not — it entails moving data around. That is a rather high price to pay, in more than one ways.
Read also: Moving fast without breaking data: Governance for managing risk in machine learning and beyond
We asked Shamgunov whether anything has changed in the meanwhile, and what the improvements for multi-tenant deployments are about. While the operation of MemSQL in multi-cloud and hybrid cloud environments does not seem to have changed, Shamgunov referred to the need many organizations have to support a workload of database-as-a-service:
“This is a model where multiple organizations have data living side by side to reduce management costs but each organization requires a strong namespace and security boundary around its data. Organizations also often want to leverage the existing ecosystem of tooling available on top of the data layer. This is a challenge to do using legacy databases or NoSQL systems.
With MemSQL 6.5, we further enhanced the multi-tenant capabilities by optimizing memory utilization to deliver dramatically more tenants with fewer hardware resources. With the improvement, internal tests were able to configure nearly thousands of tenants with significantly fewer machine resources than the incumbent single node database solution.”
Faster queries
MemSQL’s architecture is typical for this type of implementation, and MemSQL people claim it enabled them to handle queries faster than the competition already. So, with version 6.5 coming with claims of further improving query performance, we just had to ask how they did this. According to Shamgunov, improvements come in a number of areas.
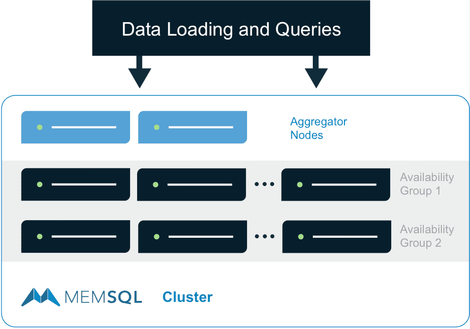
MemSQL’s distributed architecture, with a set of Leaf nodes and another set of Aggregator nodes, is typical for this type of system. (Image: MemSQL)
The first one is data redistribution, or shuffling. Shuffling happens when the cluster of nodes in a distributed system has to rearrange itself to deal with more data or different data distribution.
Before MemSQL 6.5, shuffle heavily relied on converting data to text form, then back to an internal binary form for processing at the receiving node. 6.5 shuffles data in binary format.
High-cardinality GROUP BY queries used to compute a local grouping for each partition, and each of these was forwarded to the aggregator for the final grouping. If there were many partitions per node, this could have involved a lot of data transmission causing a network bottleneck and leaving the aggregator with a lot of work to do to form the final aggregate set.
Read also: Data-driven software development in the cloud: Trends, opportunities, and threats
In 6.5, Shamgunov says, performance of queries like this is improved by: Doing a local aggregate at the leaf level of all the partitions on that leaf; spilling the rows to the network if it turns out almost every GROUP BY key is distinct so the local aggregation is not helping; and reducing memory usage by having each thread handle a subset of the keys.
Other optimizations include IN-list filtering and filtering of data stored with integer run-length encoding. Shamgunov says that some TPC-DS benchmark queries sped up by over two-times based on 6.5 updates, while another microbenchmark showed speeding up by a factor of 20 compared to MemSQL 6.0.
The world’s best database?
Shamgunov says that MemSQL envisions a world where every business can make decisions in real time and every experience is optimized through data, and that their goal is to make the world’s best database. He goes on to add that MemSQL 6.5 has added several new features to advance performance, accelerate time-to-insight and simplify operations.
Read also: The best programming language for data science and machine learning
Having a SQL database with NoSQL features sounds like a tempting proposition. Having the world’s best database, on the other hand, is somewhat of a tall order that many would aspire to.
The competition is fierce, and the criteria are not exactly well defined. But, if nothing else, MemSQL seems to be working towards this, evolving its offering, and drawing the funds required to execute on this aspiration.
NOTE: The original version of this article has been updated, to reflect the facts that Orenstein is the former CMO of MemSQL, and data 6.5 shuffles data in binary format
Previous and related coverage:
Towards a unifying data theory and practice: Combining operations, analytics, and streaming
We’ve heard the one data platform to rule them all story before. Could it be this time it’s actually true? New Pivotal-backed and Spark-compatible open source solution SnappyData promises so, and we take the opportunity to look inside and around for whys, hows, and options.
GPU databases are coming of age
GPUs are powering a new generation of databases. What is so special about them and can they come into their own?