
MMS • RSS
Article originally posted on InfoQ. Visit InfoQ
Christian Deger, chief architect at RIO – a Brand of Volkswagen Truck & Bus, recently shared a set of patterns and practices for implementing cloud native continuous delivery at the Continuous Lifecycle Conference in London. Deger covered patterns for isolated deployment pipelines (thanks to containerization), product teams empowered with delivery ownership (both process and infrastructure wise), and, finally, dynamic, immutable and composable infrastructure (avoiding monoliths, instead distinguishing between macro and micro infrastructure).
Continuous integration (CI) and Continuous delivery (CD) are critical to support autonomous teams frequently deploying independent services into dynamically created infrastructure. Applying cloud native concepts and modern infrastructure-as-code to the software delivery system allows “quickly creating decoupled pipelines for new services that are readily wired up into the platform, and everything is driven by code”, per Deger’s words.
Having a reliable delivery system in place that can withstand disaster and provide feedback without wait time has become a pre-requisite for modern software delivery. Containerizing the CI/CD infrastructure allows for:
- isolated builds: a clean container with the required agent profile (for instance, one application might require Java 8 while another is still running on Java 7) is created and lives only for the duration of the build
- elasticity: each build gets its own container agent, removing wait time and improving resource usage
Defining this infrastructure as code allows restoring delivery from zero (for instance in case of disaster) and avoids snowflake CI/CD servers whose configuration will inevitably drift when changes made via UI are not captured in version control.
Deger stressed the importance of being able to set up a new pipeline (for a new service) quickly and predictably as the first task on any project (otherwise there’s a danger of teams adding more responsibilities to existing services just to avoid a long bootstrap time). Having the pipeline (stages, tasks, dependencies, artifacts, etc) defined as code/configuration further allows swift recovery from disaster, as the pipeline can be quickly re-created and changes to the service can be delivered with a minimum delay. Most pipeline orchestration tools support pipeline-as-code (albeit with distinct implementations) today.
Deger recommends version controlling the pipeline definition together with the corresponding service code since autonomous teams need to own the full delivery pipeline. In fact, Deger suggests that each service should have its own code repository with the actual service code, but also the pipeline definition and the infrastructure code. Changes to the latter should go through the pipeline just like regular application changes, making them traceable and repeatable. This means infrastructure creation or updates need to be triggered dynamically from the pipeline.
Avoiding infrastructure monoliths (either with a single repo containing definitions for all of the services, or definitions grouped by layers such as databases, compute instances, or middleware) is fundamental for Deger. He recommends instead creating independent infrastructure stacks aligned with service boundaries (micro-infrastructure) and leave only the small set of cross-cutting, slowly changing, non-service specific aspects (such as networking and security) in a global stack (macro-infrastructure). Services import parameters from the macro-infrastructure that they share in order to be able to run inside it.
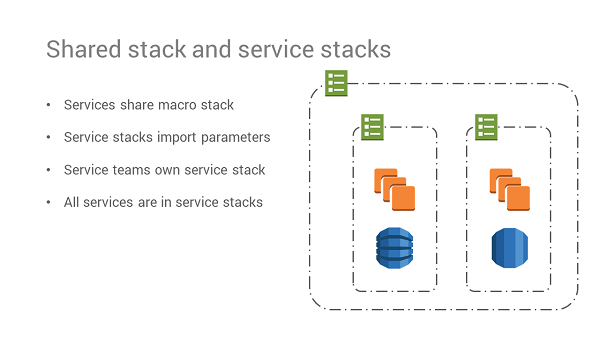
Slide image courtesy of Christian Deger
Another key idea from the talk was the notion of decoupling (or controlling) dependencies between services at multiple levels, not just in terms of application code. Besides an isolated pipeline for each service, other dependencies – such as base images (AMI, Docker, etc.) for the service – should be static (against a specific version), avoiding for example that an image update can trigger several pipelines simultaneously and possibly end in a risky re-deploy of a large part of the live system.
Perhaps the most polemic recommendation from Deger was to dispense with staging environments in the pipeline. With a high rate of changes in services (at least hourly), Deger claims it’s nearly impossible to test a new version of a service against the live versions of all the other services (in a staging environment). This either leads to wait times as staging becomes a bottleneck or to release monoliths where changes to multiple services are coupled together for testing in staging and only then deployed.
Instead, by relying on consumer-driven contract tests and reducing time to repair (MTTR) in production to a minimum, changes to services can be deployed independently and monitored to make sure they are working as expected in production. To further reduce impact, the deployment strategy should rely on canary releases (in particular monitoring closely the error rate, latency and load on new instances), feature toggles (quickly turn off a broken feature) and blue-green deployments (previous version of live environment available for quick rollback, at least if there were no database changes). In some particular cases (for example a major code refactoring) a dark launch might make sense. The new version is deployed and fed the same requests as the live environment to control if responses are functionally correct and the new instances can handle the load.
Throughout the talk, Deger reinforced several times the importance of teams owning the service from delivery (team is responsible for their own pipeline and CI instance) to infrastructure (team defines micro-stack where service runs) and runtime (micro-stack includes operability features like logging and monitoring). He recommends sharing patterns, practices, and guidelines, but not centralizing the actual work, as teams will lose autonomy and dependencies to other teams will slow down delivery.
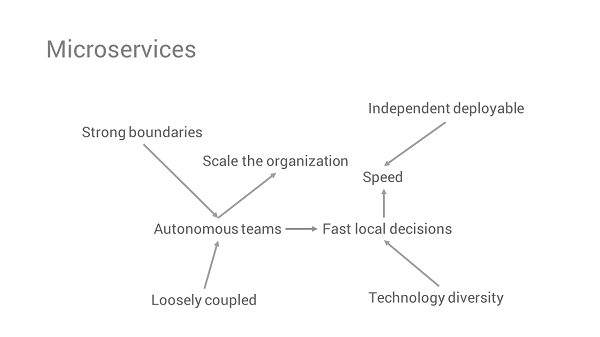
Slide image courtesy of Christian Deger