
Numberly has been using both ScyllaDB and MongoDB in production for over five years. Learn which NoSQL database it relies on for different use cases and why.
May 12th, 2023 6:42am by

Within the NoSQL domain, ScyllaDB and MongoDB are two totally different animals. MongoDB needs no introduction. Its simple adoption and extensive community/ecosystem have made it the de facto standard for getting started with NoSQL and powering countless web applications. ScyllaDB’s close-to-the-metal architecture enables predictable low latency at high throughput. This is driving a surge of adoption across teams such as Discord, Tractian and many others that are scaling data-intensive applications and hitting the wall with their existing databases.
But database migrations are not the focus here. Instead, let’s look at how these two different databases might coexist within the same tech stack — how they’re fundamentally different, and the best use cases for each. Just like different shoes work better for running a marathon versus scaling Mount Everest versus attending a wedding, different databases work better for different use cases with different workloads and latency/throughput expectations.
So when should you use ScyllaDB vs. MongoDB, and why? Rather than provide the vendor perspective, we’re going to share insights from an open source enthusiast who has extensive experience using both ScyllaDB and MongoDB in production: Alexys Jacob, CTO at Numberly. Jacob shared his perspective at ScyllaDB Summit 2019, and the video has been trending ever since.
Here are three key takeaways from his detailed tech talk.
Scaling Writes Is More Complex on MongoDB
The base unit of a MongoDB topology is called a replica set, which is composed of one primary node and usually multiple secondary nodes (think of hot replicas). Only the primary node is allowed to write data. After you max out vertical write scaling on MongoDB, your only option to scale writes becomes what is called a sharded cluster. This requires adding new replica sets because you can’t have multiple primaries in a single replica set.
Sharding data across MongoDB’s replica sets requires using a special key to specify what data each replica set is responsible for, as well as creating a metadata replica set that tracks what slice of data lives on each replica (the blue triangle in the diagram below). Also, clients connecting to a MongoDB cluster need help determining what node to address. That’s why you also need to deploy and maintain MongoDB’s Smart Router instances (represented by the rectangles at the top of the diagram) connected to the replica sets.
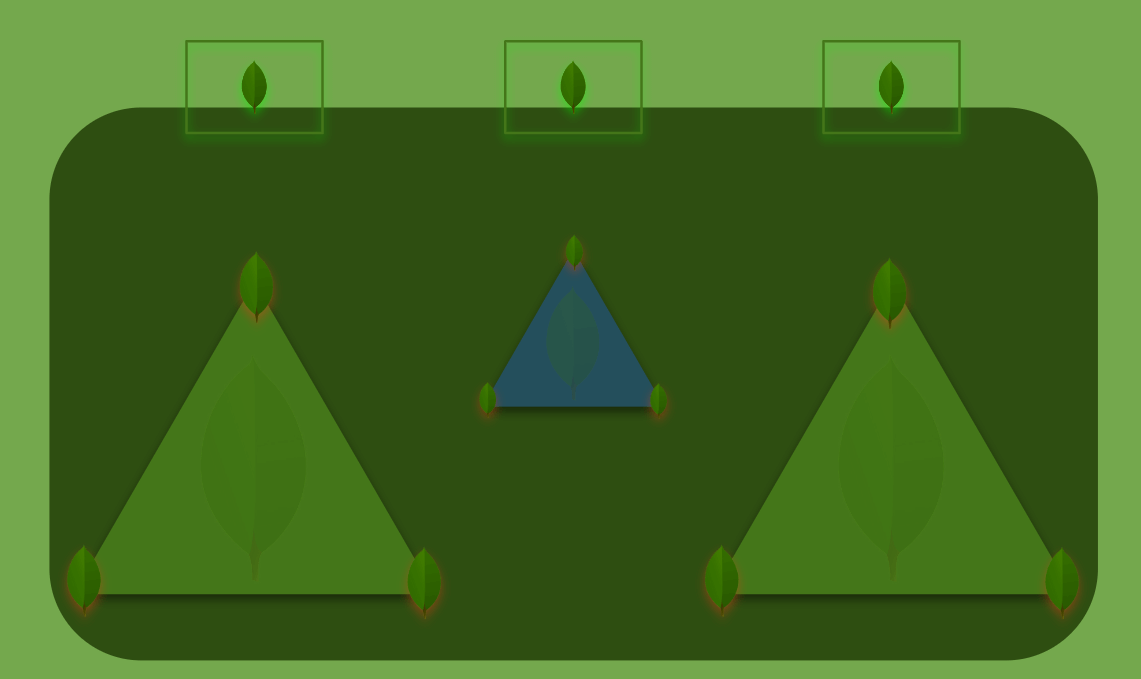
Having all these nodes leads to higher operational and maintenance costs as well as wasted resources since you can’t tap the replica nodes’ IO for writes, which make sharded MongoDB clusters the worst enemy of your total cost of ownership, as Jacob noted.
For ScyllaDB, scaling writes is much simpler. He explained that “on the ScyllaDB side, if you want to add more throughput, you just add nodes. End of story.”

Jacob tied up this scaling thread, saying:
“Avoid creating MongoDB clusters, please! I could write a book with war stories on this very topic. The main reason why is the fact that MongoDB does not bind the workload to CPUs. And the sharding, the distribution of data between replica sets in a cluster is done by a background job (the balancer). This balancer is always running, always looking at how sharding should be done and always ensuring that data is spread and balanced over the cluster. It’s not natural because it isn’t based on consistent hashing. It’s something that must be calculated over and over again. It splits the data into chunks and then moves it around. This has a direct impact on the performance of your MongoDB cluster because there is no isolation of this workload versus your actual production workload.”
MongoDB Favors Flexibility over Performance, While ScyllaDB Favors Consistent Performance over Versatility
ScyllaDB and MongoDB have different priorities when it comes to flexibility and performance.
On the data modeling front, MongoDB natively supports geospatial queries, text search, aggregation pipelines, graph queries and change streams. Although ScyllaDB — a wide- column store (aka key-key-value) — supports user-defined types, counters and lightweight transactions, the data modeling options are more restricted than on MongoDB. Jacob noted that “from a development perspective, interacting with a JSON object just feels more natural than interacting with a row.” Moreover, while MongoDB offers the option of enforcing schema validation before data insertion, ScyllaDB requires that data adhere to the defined schema.
Querying is also simpler with MongoDB, since you’re just filtering and interacting with JSON. It’s also more flexible, for better or for worse. MongoDB lets you issue any type of query, including queries that cause suboptimal performance with your production workload. ScyllaDB won’t allow that. If you try, ScyllaDB will warn you. If you decide to proceed at your own risk, you can enter a qualifier indicating that you really do understand what you’re getting yourself into.


Jacob summed up the key differences from a development perspective:
“MongoDB favors flexibility over performance. It’s easy to interact with, and it will not get in your way. But it will have impacts on performance — impacts that are fine for some workloads but unacceptable for others. On the other hand, ScyllaDB favors consistent performance over versatility. It looks a bit more fixed and a bit more rigid on the outside. But once again, that’s for your own good so you can have consistent performance, operate well and interact well with the system. In my opinion, this makes a real difference when you have workloads that are latency- and performance-sensitive.”
It’s important to note that even queries that follow performance best practices will behave differently on MongoDB than on ScyllaDB. No matter how careful you are, you won’t overcome the performance penalty that stems from fundamental architectural differences.
Together, ScyllaDB and MongoDB Are a Great NoSQL Combo
“It’s not a death match. We are happy users of both MongoDB and ScyllaDB,” Jacob said.
Numberly selects the best database for each use case’s technical requirements.
At Numberly, MongoDB is used for two types of use cases:
- Web backends with REST APIs and possibly flexible schemas.
- Real-time queries over unpredictable behavioral data.
For example, some of Numberly’s applications get flooded with web tracking data that their clients collect and send (each client with their own internally developed applications). Numberly doesn’t have a way to impose a strict schema on that data, but it needs to be able to query and process it. In Jacob’s words, “MongoDB is fine here. Its flexibility is advantageous because it allows us to just store the data somewhere and query it easily.”
ScyllaDB is used for three types of use cases at Numberly:
- Real-time latency-sensitive data pipelines. This involves a lot of data enrichment where there are multiple sources of data that need to be correlated, in real time, on the data pipelines. According to Jacob, “that’s tricky to do.” He said that “you need strong latency guarantees to not break the SLAs [service-level agreements] of the applications and data processes which your clients rely on down the pipe.”
- Mixed batch and real-time workloads. Numberly also mixes a lot of batch and real-time workloads in ScyllaDB because it provides the best of both worlds (as Numberly shared previously). “We had Hive on one path and MongoDB on the other,” said Jacob. “We put everything on ScyllaDB and its sustaining Hadoop-like batch workloads and real-time pipeline workloads.”
- Web backends using GraphQL, which imposes a strict schema. Some of Numberly’s web backends are implemented in GraphQL. When working with schema-based APIs, it makes perfect sense to have a schema-based database with low latency and high availability.
“A lot of our backend engineers, and frontend engineers as well, are adopting ScyllaDB,” said Jacob. “We see a trend of people adopting ScyllaDB, more and more tech people asking ‘I have this use case, would ScyllaDB be a good fit?’ Most of the time the answer is ‘yes.’ So ScyllaDB adoption is growing. MongoDB adoption is flat, but MongoDB is certainly here to stay because it has some really interesting features. Just don’t go as far as to create a MongoDB sharded cluster, please!”
Bonus: More Insights
Jacob is an extremely generous contributor to open source communities, with respect to both code and conference talks. See more of his contributions at https://ultrabug.fr/
Created with Sketch.
