
MMS • RSS
Posted on nosqlgooglealerts. Visit nosqlgooglealerts

We’ve covered relational databases, non-relational databases, and the relational outlier, PostgreSQL. But what are graph databases, and what specific data-related challenges are they designed to meet? In this article, we’ll continue our Guide to Database Technology explainer, adding a new category to the mix: graph databases.
Not all data is created equal—and databases have evolved to meet varying demands on data.
A Quick Database Refresher: SQL, NoSQL, and the Pros of Each
First, we have structured data that fits neatly into the rows and columns of tables. This is the domain of relational databases, well suited to things like phone books where each entry shares the same properties. Relational databases have served as the organized brains of structured data-based software for decades, and they still play an important role. (If you’re not familiar with how relational databases work, check out our great explainer on the topic.) Relational databases are highly structured and easy to query with a language like SQL, but they have limitations when it comes to unstructured data. They’re neat, tidy, and straightforward, but they require developers and their data to be strictly structured too.
Not all data, however, is that easily organized. Unstructured data like IoT sensor data, social sharing, photos, location-based information, online activity, and usage metrics can’t be neatly broken down, which makes rigid tables out of the question. Instead, to coherently group unstructured data together, NoSQL databases trade tables for document files, which are sort of like file folders that help to categorize related data. Imagine the data for a single blog post, which contains tags, photos, edits, comments, and links, grouped together in a doc file.
NoSQL databases such as MongoDB provide fast, scalable solutions for unstructured data. PostgreSQL is another solution, a SQL database that can support more exotic data types than a purely relational database.
Connected Data for a Connected World
“We live in a connected world! There are no isolated pieces of information, but rich, connected domains all around us. Only a database that natively embraces relationships is able to store, process, and query connections efficiently.” –Neo4j.com, “What Is a Graph Database?”
SQL and NoSQL database solutions work well in many scenarios. But when demands for connected data grow more complex, their efficiency can be tested. Straightforward queries and isolated data are not always what’s behind the rich, data-driven experiences we’ve come to expect—the IoT, social networking sites, location-based marketing and navigation, enterprise-grade analytics, product suggestions on ecommerce sites, etc. Interconnected, hierarchical data makes our connected world (and sometimes, our businesses) possible, and it’s not easy to pull off.
This shifts the focus from data alone to the relationships between our data. And that’s where graph databases come in.
The Graph Theory: the Story Behind Graph Databases
In 1736, Swiss mathematician and engineer Leonhard Euler used the graph theory to prove that there was no solution to the historic math problem Seven Bridges of Königsberg. If you’re not familiar with the problem, here’s a quick explanation: Königsberg, a city in Prussia (now Kaliningrad in Russia), is split into four parts by a river, pictured below. Connecting the city are seven bridges. The problem was to come up with a walking route that would take a person across each bridge just once. It ended up being impossible, but in the process of trying to solve it, Euler came up with a simplified way of looking at it.

[Image via.]
Euler drew attention to the fact that the graphical representation of the problem could be simplified as much as possible using only nodes and connecting lines (or graphs or edges), all without affecting the outcome of the problem. The city sections are abstracted into nodes because they don’t have any effect on the outcome, and the bridges take center stage. This gave way to a new theory—the graph theory—and subsequently, a new way of abstracting and structuring databases. The emphasis is on the relationships among the nodes, which helps to simplify connected data.
Streamlining Connected Data with Graph Databases
Abstraction and relationships are the heart of graph databases. Through this, they offer an alternative view of and methods for handling and processing complex connected information.
Let’s go back to relational databases to see how they handle connected data. As we know, relational databases consist of tables of entries connected to one another by keys. A relational database can pull related data with foreign keys, JOIN tables and operations, and map-reduce processing. The more many-to-many relationships you need, the more tables you’ll have to create, and the more JOIN operations will be necessary in a single SQL statement—data-scientist speak for complex and inefficient with lots of extra noise. It requires a ton of computing power and memory to pull off and can slow performance exponentially.
“While other databases compute relationships at query time through expensive JOIN operations, a graph database stores connections as first-class citizens.”—Neo4j.com
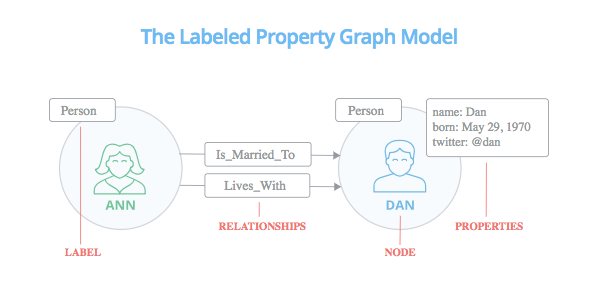
The four basics behind a graph database are
- Nodes: The primary data elements
- Relationships: How two nodes are connected
- Nodes may have multiple relationships
- Properties: Attributes of a node or of a relationship
- Labels: How nodes are described and grouped together as sets
- Nodes may have multiple labels
- Labels get indexed and optimized, making it easier for them to be quickly located
Graph databases shift the focus of their data models to the relationships, which makes retrieving complex data structures much easier. By abstracting nodes and relationships into one structure, they’re a little like next-gen relational databases that put relationships above the data alone. Rather than the multistep process described above, graph databases allow developers to build sophisticated data models in a much simpler, faster way—with fewer tables, and sometimes even with only one operation.
The Where and How of Graph Databases
The capabilities of graph databases make them perfectly suited to enterprise data, connected experiences, and data-heavy applications—think machine learning, AI, fraud detection, social media sites such as Facebook, which uses the GraphQL language to query data, and recommendation engines behind immersive sites such as Airbnb, TripAdvisor, and Amazon, to name a few. In part two, we’ll look at how social networking applications in particular can leverage graph databases to handle the complexity of relationships—both between people and between data.
Building a connected experience with the databases that can handle your needs requires the right skilled talent. Find graph database freelancers, Neo4j freelancers, and more great data talent on Upwork. To learn more, visit Upwork and get started on your next project!