Transcript
Vig: I’ll be talking about Amazon DynamoDB distributed transactions. Let’s start with a poll, how many of you have written applications that use a cloud database? Pretty good. How many of you have written applications that use a cloud database that is not a relational database, specifically, NoSQL databases? Fifty-percent of the room. How many of you who have used NoSQL database wished that you could use atomic transactions with a NoSQL database? That is pretty good. That’s almost 100% of those 50% who wanted transactions. In this talk, what I want to do is I want to explore why are transactions considered at odd with scalability? Then, I want to further explore that. Can we have a distributed NoSQL database system that has all the properties of scalability, performance? Why people love these NoSQL databases? Can we have both? Can we support transaction and still maintain those features that exist in NoSQL databases? Throughout this talk, I’ll walk you through the journey of how we added distributed transactions to DynamoDB.
Cloud Database Services
Databases are moving to the cloud at a very fast rate, and established companies are moving their on-premise databases to the cloud. Similar to that, startup companies are basing their business entirely on the cloud from day one. Why is it happening? Why is it a trend? Because the benefits of running your application on the cloud are just too compelling. Cloud databases, you get fully managed experience. You don’t have to worry about servers. You don’t have to manage. You don’t have to order capacity. That frees you up from any of the burden that you had to manage infrastructure. Then, as your database runs on the cloud, you get the elasticity, and pay as you go model where you can use the database for the duration, whenever you expect the peak to hit on your database. You use the database to that peak capacity, and then dial down the capacity when you actually don’t need it. In short, cloud databases, they offer a lot of agility that modern applications demand, especially when it comes to managing the data that drives innovation.
DynamoDB
When you think about NoSQL databases, what is it that attracts people towards NoSQL databases? I’ve taken DynamoDB as an example here. NoSQL databases such as DynamoDB, you get a very simple interface where you can use a simple API to create a table. Then you have a bunch of operations that you can do on the table such as Get, Put, and typically the data that you’re storing through the write operation or fetching through these write operations are semi-structured to unstructured. Where you have a key which is defining the primary key of the item, and then you have a value. The value could be a JSON object, or whatever you want to store in that.
The second part is that you get a flexible schema. There is no fixed schema as compared to what you get in a relational database. You can store documents. You can store photos. You can have a single table where you’re storing customers and orders and stuff like that. There is no fixed schema. You can have a flexible schema. Invariably, the cloud service provider by default, most of these databases, they replicate data for higher availability. For example, DynamoDB we replicate every table across three different data centers within a region. Each data center is called an availability zone. It has its own independent power and networking. DynamoDB can lose a complete data center and your application and your table still remains available both for reading and writing. Then, DynamoDB offers essentially four nines of availability. Customers of DynamoDB, they can also choose to create a global table that ensures that all your data is replicated not just within the same region, but to two or more regions that you have configured in your table throughout the world. The data in global tables is asynchronously replicated. With global tables, you get five nines of availability, which means effectively, your data is always accessible.
We’ve talked about a simple API, flexible schema, high availability. The next one is unbounded growth. Another big selling point of NoSQL databases is the horizontal scalability. For example, in DynamoDB, you start with just creating a table. You don’t know the size of the table upfront. Maybe you know the reads and writes that you want to perform, but you don’t know the size, so you start by creating an empty table. As your application becomes popular, your number of writes increase, your size of the table increases. DynamoDB, behind the scenes, will automatically partition your data based on how much size it is growing. You get unbounded growth. Now talking about reads and writes, either you can choose to specify reads and writes right at the beginning, which is called as the provision mode of the table. Or, if you don’t understand the read pattern of your users, you can just start with an on-demand mode. Behind the scenes, as you increase your throughput, or as we identify more writes happening to your table, based on that, we need to partition the table to support the unbounded growth. Essentially, you can think about it in this way. Let’s say you start your table with a single partition, as you add more data to it, or as you increase reads and writes on a table, it can become two partitions, and four partitions, and so on.
Finally, it is predictable performance. That, you start writing to your table, as your table is empty, you’re getting single digit millisecond performance latency for reads and writes. Then, as your application becomes popular, you start doing maybe millions of writes per second or millions of reads per second, your performance stays the same. It’s not that your performance will degrade if your table size increases. This is one of my favorite features of DynamoDB, you get predictable performance. Predictable performance and unbounded growth, these are important tenets that we keep in mind whenever we are adding new features to DynamoDB.
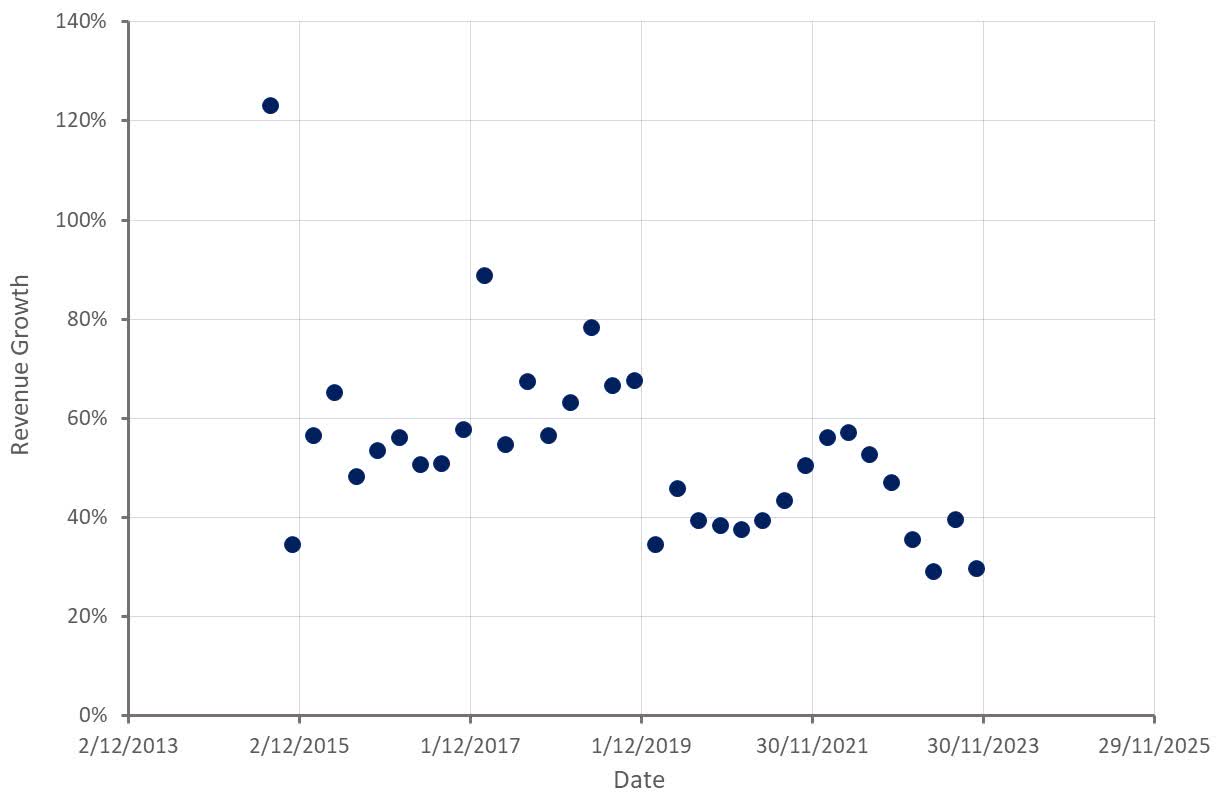
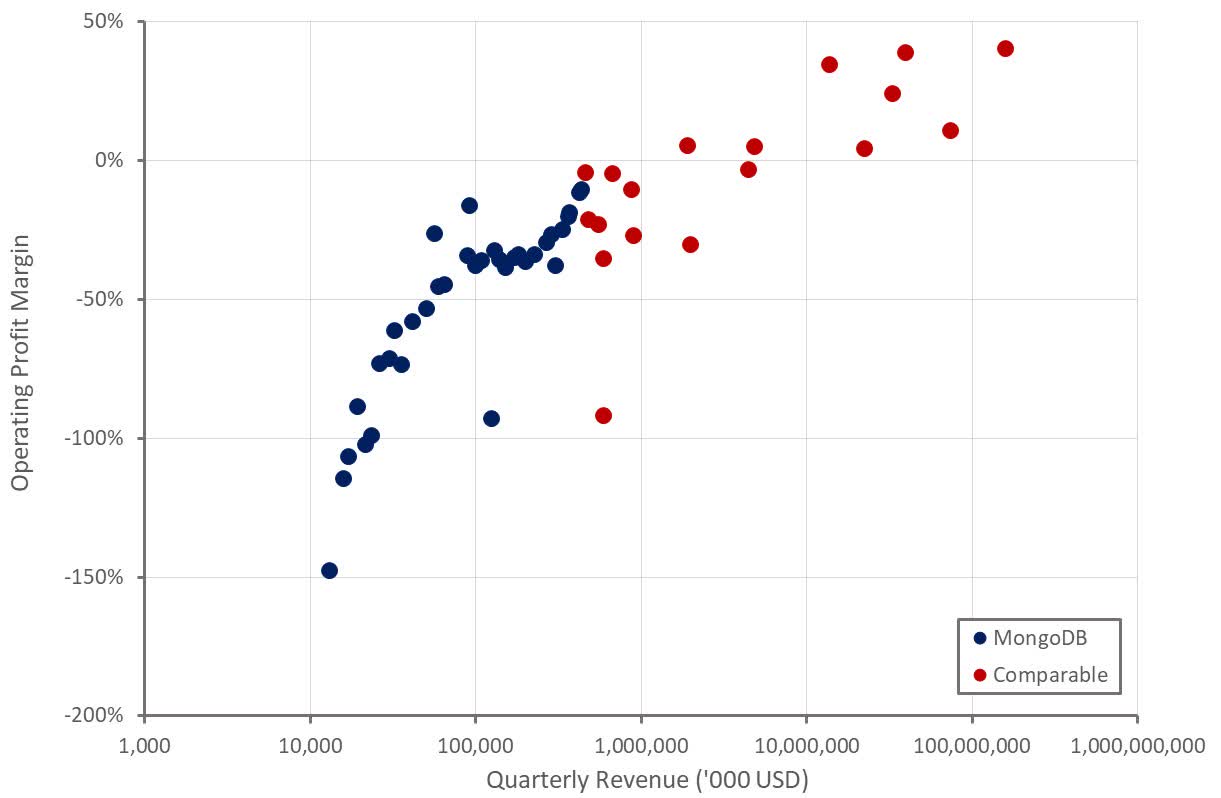
Over the years, we are seeing that the number of customers and the request rate keeps on increasing in DynamoDB, but customers always get performance, which remains constant. We are seeing more customers using DynamoDB. For example, just taking the proof is in the pudding, looking at the Prime Day stats from 2022. During the Prime Day, just amazon.com did 105.2 million requests per second. All those APIs got single digit millisecond performance. This is just one customer, and we have multiple customers. You can expect the same.
Working Backward from the Customers
When we started looking at transactions, and as DynamoDB, the customer base keeps on growing, we always work backward from our customers. We first go and talk to them. What are things that you would want us to implement in DynamoDB as the next feature? One of the features that was asked at that time was transactions. I’ll walk through, what is a transaction? Why are they important? To understand why they’re important, we can look at building an application together without using DynamoDB transactions. We’ll just use the basic Put and Get operations and try to see what are the complexities that arise from building transactions or doing transactional operations in DynamoDB. Hopefully, I’ll convince you that it is an important feature that needs to be added.
What is a Transaction?
What is a transaction? A transaction is essentially a group of read and write operations that you want to execute as a logical unit. As a logical unit, atomicity is part of it. Whenever you talk about transactions, there are certain properties that are associated with it, which is ACID. Essentially, what you’re doing is transactions, you group a sequence of database operations. Atomicity ensures that all the operations in the transaction are executed or none of them is executed. You get the all or nothing semantic. Consistency means that your operation leaves the database in a consistent state, in a correct state. Isolation, basically, you have multiple developers who can read or write data in your application, and you want isolation guarantees, so that you can serialize concurrent operations. Finally, durability that whatever data that you have written, it remains permanent. In this particular talk, we’re going to talk about atomicity and isolation specifically.
Why Transactions?
Now let’s jump into, why would you need a transaction? Why are these customers asking about adding transactions to DynamoDB? Because DynamoDB already supports simple Put, Update, and Delete operations. To understand that, let’s look at an online e-commerce application. Let’s say you’re building an online e-commerce application where the application is like amazon.com, where a person, Mary, can purchase a book and a pen, either independently or together. For this example, consider you want to buy them together as a single order. Why are transactions valuable? Because they facilitate the construction of correct and reliable applications that wish to maintain multi-item invariants. Such invariants are important for correct execution. For example, if you have 20 books, the invariant there is that you never sell a book which you don’t have in stock. This is just one example of an invariant. One challenge in maintaining these invariants is when you have an application which has multiple instances running in parallel, and you are accessing the same data concurrently. In the cloud version, or in today’s world, you see that when you build an application, it’s not just you have one user who is executing this operation. You have multiple users who are independently running their instance of that application. These instances need to share the data that is stored in the database, which means you need to ensure these invariants are maintained. Another challenge is that if your application crashes in the middle, still these invariants should hold true. Transactions essentially are the way that applications meet these two challenges of concurrent access and partial failures without developers having to write a lot of extra code.
Let’s understand that better. Let’s say that you’re building a client-side application for doing, without DynamoDB transactional support. Essentially, if you build this e-commerce application, you’ll have three tables. One is the inventory table where the books are stored, the pen that you’re trying to store, and other inventory that you’re maintaining for your amazon.com website. These all are stocked. The second thing is the customer table. In the customer table, you’re storing the information about the customers who are using your application. Finally, the orders table. The orders table essentially stores the information about the orders that you have created. When you are executing a transaction, what all needs to happen? You need to ensure the customer is a verified customer. The book status, you need to check that you have enough books in stock, and you need to make sure that that book is sellable. The same thing you need to do for the pen, that the pen exists, it is in the right status. Once you have added these two items to an order, as order items, you also need to then create a new order object. Also, go and update the status of the book, the status of the pen, the count of the book, and the count of that particular pen.
One way to do this, was you write all this client-side logic that, read from the inventory table, find out the number of books. Read from the inventory table, find out the number of pens that you have. Write to the inventory table that I’m going to execute this operation. Make a check to the customer’s table. You can do all these operations in sequence on the client side. What you essentially want is finally, atomically, all these operations should execute. Again, if you had a single user using that application, you can simply write this logic and make sure the operations are idempotent, and things will just work. What you want is the final state to have books, status is sold, customer is verified, orders are created.
It sounds simple, but not that simple. Your application, as you write it, it could crash. Anywhere, it could crash. You could have a crash right in the application itself. Let’s say you started and you were in the third step, if your application crashes, now you need to find out where you were, and then start again from there. You need to add some logic. Your database could crash while your application was up, so you need to ensure you’re doing enough retries. Your network could have an error, or your hard drive could crash. Your hard drive could crash on the database or your hard drive could crash on your application side, or your network can have issues. All these failure modes, essentially you have to handle, because if you don’t handle them well, that could result in inconsistent state in your application. Inconsistent state, what I meant by that is you could end up in a state where your customer is verified, orders are created, but the inventory is not yet updated. If the inventory is not yet updated, that particular item you might end up selling it two customers, and then you don’t have stocks. Then you cannot fulfill the customer order. All these repercussions that you will have.
Then, what you need to do is, since your database is in the same inconsistent state, you need to then do rollbacks. Now you start thinking about, how do I write the rollback logic? Essentially, you have some unfinished transactions in your database, and you don’t want anyone to read all this data. You go and do deletes on your other two tables and make sure that all of them do not have this data. It started to sound complicated. Now I need to figure this out. How do I do this? If you think about it, how would you build cleanup logic? A standard way to build this cleanup logic is, instead of executing the operation right away, you actually store that in a separate table, or in a separate ledger where transactions are first written, and then they are asynchronously executed. I can think of building it, but this is just like an additional complexity that I, as an application developer, have to deal with. What I wanted to do was just execute a transaction, but now I have to first deal with these repercussions, then I can get into thinking about my business logic. Not the best.
Again, previously, I was talking about a single user. Now think about multi-users. You have multiple clients who are reading in parallel. It might be that you need to make sure that the data that is stored in these tables make sense to everyone so that everyone is reading only the committed states, they’re not reading the intermediate states. Because again, you want your transactions to have the highest chance of success, because if your application keeps on crashing because of these inconsistent states, your users will go away. One way to solve this concurrent access is you have like a frontend layer in front of the database and you ensure all the reads and writes go through that. That doesn’t fully solve it, you need to introduce maybe locks to guarantee isolation, so that each of the developer can write code as though the operations are performed without interfering with each other. The developers don’t have to think about interfering operations, you can maybe introduce locks. With locks, then you have the cleanup logic to also clean up the locks. More complexity on the client side, now you have to deal with.
We haven’t talked much about unbounded growth and predictable performance. Can we still achieve that with this setup where you have like a new layer in the middle, and then you have these locks, then you have additional logic to clean up? Can my database now further scale? Can my application scale? All these things, they add up pretty quickly. Now you are becoming a database expert, rather than writing your business logic that makes your life much simple. All the heavy lifting essentially goes to the client. We don’t want that. If the database does not have this capability, every customer will have to think about all these problems that we just discussed about, adding transactions on the client side. You must be wondering, why do NoSQL databases not support transactions? Why do they just support simple Put, Update, and Delete operations?
Transactions and NoSQL Concerns
NoSQL databases, customers expect that they’ll provide low latency performance, and your database scales as your application is scaling. It accomplishes this by providing Get and Put operations, which have almost like consistent latency. The fear is that it is harder to provide predictable performance for more complex operations like transactions. The vast majority of applications of NoSQL databases have survived without transactions, that is, clients have written all the additional logic and lived with it. They have basically figured out workarounds to make it work. They’ve essentially survived without transactions for years. There is also that particular point about, is it really needed? Then the fear of adding transactional support might break the service for non-transactional workloads, like simple Get and Put operations, will they be impacted? That’s another fear. Reading online and talking to a lot of my other peers, the concerns around complexity of the API, how do you add this new API into the system? The concerns around system issues like deadlock, starvation of these locks. Then, how do you handle contention between different items? The concern of interference between non-transactional and transactional workloads? On top of all this, the cost. What will it cost to actually execute a transactional operation? All these reasons create a fear that, maybe we should not add transactions, it will impact the value proposition of my database.
NoSQL and Restricted Transactions
To work around these concerns, some systems provide transactions but with some restricted features. For example, some databases choose isolation levels that are less powerful, and hence, more limited utility than serializability. Other systems, they place restrictions on scope of transactions. Some systems only allow transactions to execute on a single partition. That if your database grows to multiple partitions, you cannot execute transactions. Or they will restrict that your single primary key, single hash key of your partition can stay within the same partition, it cannot go beyond a single partition. Then some systems, they essentially ask you upfront what all partitions you expect to execute in a single transaction, so that they can co-locate them and execute the transactions for you. All these restrictions, they intend to enhance the predictability or reduce the complexity in the system. These restrictions are at odds with scalability. As the database grows, it will split. It needs to split into multiple partitions. Restricting data to a single partition, again, causes availability concerns. Your application will crash. The database cannot accept any writes. Your application, which was working yesterday, suddenly stops working tomorrow, because your data has just grown. Customers don’t like that variability in these systems.
DynamoDB Transaction Goals
When we set out to add transactions support in DynamoDB, we look for a better answer. We didn’t just settle for like, we can introduce transactions with these restrictions. We went back to the drawing board. We said, to add transactions in DynamoDB, we want to be able to execute a set of operations atomically and serializably for any items in any tables, not just one table or a single partition, any tables that exist in the customer account with predictable performance. Also, make sure that no impact to non-transactional workloads. Our customer essentially wanted full ACID compliance. Amazon at that same time, when we were thinking about transactions, there was a public push to migrate many of our internal applications off the relational databases to DynamoDB. All these internal teams are also asking about a better and scalable way to do transactions, ensuring that it performs, ensuring that the cost is not that high. We wrote down these goals. DynamoDB already allowed customers to write consistent applications and also provided durability, with replication of the data. Out of ACID, what was missing was A, which is atomicity, and I which is isolation. Our customers needed the ability to execute a set of operations which belong to multiple partitions, or multiple tables atomically and serializable fashion for any items with predictable performance.
Customer Experience
We have defined our goals, let’s look at starting from customer experience. What are the APIs we should introduce? How should we expose this experience to the customers? Traditionally, the standard way to provide transactions would have been, you add like a transaction begin statement, and a transaction commit statement. In between, customers can write all the Get, Put operations in between these two, multi-step transaction operations. Basically, existing operations can be simply treated as an implicit transaction. Right now, then, if you’re essentially doing a single item transaction, that’s what I mean by implicit singleton transactions, and the typical implementation it uses like 2-phase locking. Standard approach. Again, we’re just talking about standard approaches that exist today in the market, uses a standard 2-phase locking during the execution of the transaction, and 2-phase commit for completing the transaction. Some databases, they also store multiple versions of an item so that multi-version concurrency control can be used to provide snapshot isolation. For example, you do a transaction, you have multiple versions, and whenever you’re doing your read, you can always read before the transaction using the version number of the item, without them being blocked by concurrent writes to the same item. We didn’t choose any of these options for DynamoDB. DynamoDB is a multi-tenant system, allowing applications to begin a transaction, wait for some time, and then commit the transaction. That is, basically allowing long running transactions would enable the transactions to indefinitely tie up the system resources. Customer could write like a sleep in between TxBegin and TxCommit, and your resources are held for long. Requiring singleton Gets and Puts to also go through full transactional commit protocol would mean that we have taken a performance hit on even the singleton operation. Our goal was, don’t impact singleton operations.
Looking at locking. Locking restricts concurrency. It’s not that we are aiming for super high contentious workload, but locking, it raises the possibility of deadlocks in the system, which are bad for availability. We would have gone with multi-version concurrency control. That’s pretty neat. DynamoDB does not support versioning. Adding versioning would have resulted in high cost, which means we have to now pass this cost to the customers, and additional complexity that we have to build in this system. All these operations, all these approaches, essentially, we rejected and we came up with a different approach.
Instead, we took a different approach for transactions in DynamoDB. To the APIs, we added two new operations, TransactGetItems and TransactWriteItem operations. These are single request operations, single request transactions that are submitted as one operation, and they either succeed or fail immediately without blocking. TransactGetItem operation, it allows you to retrieve multiple items, to read multiple items from a consistent snapshot. These items can be from like any arbitrary set of DynamoDB tables. Only committed data is returned when you do TransactGetItem operation. Reading from a consistent snapshot means that read only transaction is serialized with respect to other write transactions. The next one is the TransactWriteItem operation. The TransactWriteItem operation, it allows multiple items to be created, deleted, or updated atomically. Each set transaction contains a write set with one or more Put, Update, or Delete APIs. The items that are being written can reside in, again, any number of tables. The transactions may optionally include one or more preconditions, like you can check a specific item in a specific table, which is where you’re not writing essentially. You can also add these conditions to individual like Put, Update, Delete operations as well. DynamoDB allows adding those conditions, irrespective of transactions as well. We can do optimistic concurrency control on singleton items. For instance, you want to add a condition that, execute this Put only if this item does not exist. You can do that even without transactions, but you can choose to put that as well within the transaction itself. For a transaction to succeed, all these supplied preconditions must be met. These singleton transactions are also serialized with respect to other transactions and singleton operations with TransactWriteItems as well.
Transaction Example
Now, taking a look at an example. Let’s introduce another example, which we generally see whenever you think about transactions, like a bank money transfer. Let’s say Mary wants to transfer money to Bob. You essentially do a read, like if you do this in a standard TxBegin, TxCommit where you would do a Get operation, for Mary, read the money, for Bob, read the money. Once you verify that both these folks have the right money, then you do a Put, increasing the money in Mary’s account by 50 and reducing the money in Bob’s account by 50. Then you commit the transaction if all these conditions are met. With DynamoDB, you write a TransactWriteItem request where you say, check Mary’s balance, check Bob’s balance, and then you say you want to execute this Put operation in reducing the money from Bob’s account and increasing the money in Mary’s account. You essentially could map this TxBegin, TxCommit into a single request with TransactWriteItems.
Shopping Example
Then, the shopping example, if we go back to that, you’re doing a shopping application. You have the Customers table, Orders table, inventory table. You need to do a check on whether the customer exists, whether the inventory is available. Then you want to update the Orders table, create the entry in the Orders table, and also update the status in the inventory table. You do a TransactWriteItem, check the customer, let’s say is Susie EXISTS, inventory, you have a book, number of books that you have is greater than 5. Then you do a Put on the Orders table and update the inventory by reducing the number of books from whatever you have by 5.
Overall, in this particular transaction experience that we have built, what did you lose? There’s always tradeoffs. I would say very little, because most multi-step transactions, they can be converted into single request transactions, as we saw two examples just right now. The money transfer example where we were able to essentially convert the multiple operations that would happen into a single request. This approach can be essentially applied to convert any general-purpose transactional system into a single request system. In fact, it actually mimics how distributed transactions are implemented in other systems as well, where you have read sets, which basically record the value of the items at the time transaction executes, and writes are buffered until the end. Then at commit time you read the values, they’re checked. If they still match, then the buffered writes are performed. If they don’t match, then transaction fails. It seems like it’s working.
DynamoDB Operation Routing
Till now we looked at, what is the transaction? Why are they important? How we thought about introducing them as an experience in DynamoDB. Next step is, how do we actually build it? This is critical. Everyone is curious, what did we actually do? What magic is happening behind the scenes. To understand that, let’s take a step back. Let’s look at DynamoDB as a system. Without transactions, what happens in DynamoDB? Whenever you send a request to do a Put, or a Get in DynamoDB, it hits a bunch of request routers. These request routers, think of them as stateless frontend nodes. When request reaches a request router, it basically looks at the address of the storage nodes from a metadata system to find out where the item that you’re trying to put is stored. These are stored on storage nodes. As I said, initially, that all the data is replicated across multiple availability zones, and out of these three zones, you have one replica which is the leader replica, so all the Put operations, they go to the leader. The leader replicates it in the other two regions, and then replies back to the request router, which finally replies back to the application. Just like Put operation, Deletes and Updates are handled in the same way where request router finds out where that item is stored and executes the Delete through the leader. Done. Talking about Gets, Gets execute in a similar way, but whether they go to the leader or not, it depends on the request that is being made. If you do a consistent read, the request goes to the leader. Instead of using all the three nodes, now just the leader can respond back. It’s a consistent read leader knows because leader, all the latest writes go through the leader. Leader looks up and then responds back. If you do an eventually consistent read, it can go to any of the three replicas and that replica can respond back to the client.
For transactions, what we did is, transactional request from the customer, is sent to the frontend fleet. Then it is routed to a new fleet of transaction coordinators. The transaction coordinators, they pick apart the items involved in the transaction. In our case, there were like three items that we were trying to update. It sends those requests to the three storage nodes, saying that, execute the create order, execute the update inventory, execute the check customer. Once it gets the response, the transactional response is sent back to the client. Transaction coordinator sends these to different tables, get the response back, and then it responds back to the client saying their transaction succeeded, or failed, whatever that request was.
Looking deeper into how exactly that happens inside the transactions. It’s a 2-phase protocol. Transaction coordinator asks all the participating storage nodes that, I’m going to make a request that is sent by the customer. Are you willing to accept this? If the storage nodes, they say that, yes, I’m willing to accept this transaction. If they respond back with a yes, TCs durably store the metadata, that this transaction is accepted. Then TCs move on to the second phase. The second phase, once the transaction enters in the second phase, it is guaranteed to be executed in its entirety exactly once. The transaction coordinator retries each write operation until all the writes eventually succeed. The writes themselves are idempotent, so it’s ok for the transaction coordinators to resend them whenever they’re in doubt, such as when it receives a timeout, or storage node fails when it’s not available, or the leader is transitioning from the current leader to the other leader, or any other hiccups that could happen.
Once it has reached the commit phase, essentially it is sending the commit message once it gets an acknowledgment from all three tables, and then responds back saying that, my transaction is complete. That’s one example. It’s not always the happy case. It might happen that a transaction coordinator gets a negative acknowledgement from the Orders table, the other table succeeded, but the Orders table actually got a negative acknowledgement. In that case, what happens is transaction coordinator will go ahead and send a release message to all the tables, and then acknowledge back to the client that this particular transaction failed because the condition that you had specified was not met.
DynamoDB Transactions Recovery
We understand how a happy case works, how a not so happy case works. Of greater concern in this particular system is failure of the transaction coordinator. Because, as I said, whenever storage nodes fail, transaction coordinators can retry. How does this work? Coordinators, they maintain a soft state with a persistent record for each transaction and its outcome in a ledger. Just like I was saying in the client-side application that you would have to do a ledger, just think of it in a similar way. You have a ledger, where all your transactional requests are stored, and a recovery manager periodically is basically scanning this ledger to find out. Transaction coordinators are periodically checkpointing whenever they reach a logical state. The recovery manager is scanning those ledgers, and the goal is to find out in a reasonable amount of time transactions which have not been completed, and can call them as like stalled transactions. Such stalled transactions are then assigned to a new transaction coordinator saying that, I found this transaction, go recover it.
It is even ok for having multiple coordinators to be finishing the same transaction at the same time since you might end up in a state where you have duplicate attempts to write the same item to the storage nodes. It’s ok because these operations that transaction coordinators are doing, they’re idempotent. When the transaction has been fully processed, a complete record is written to the ledger. Whenever a recovery manager is saying to the transaction coordinator, go recover. Transaction coordinator first looks at the ledger. If the transaction is already completed, it’ll say, my job is done, transaction already finished. Overall, this is how the system has recovery automatically built into it, so that clients don’t have to worry about all this logic. Overall, the architecture looks like this. You have an application, you have request router, transaction coordinators writing to the ledger, and then you have storage nodes involved in doing these transactional operations. If it crashes, you have the recovery manager.
How did We Ensure Serializability?
The recovery approach, the process that we discussed that handles atomicity, but what about ensuring that these transactions execute in a serial order? Let’s find out how we achieve the isolation. For serializability, we decided to borrow an old technique called timestamp ordering. This approach has been credited to both David Reed and Phil Bernstein. It goes back about 40 years. We have adopted timestamp ordering to apply that to a key-value store. How did we do it? Essentially, the basic idea is that transaction coordinator assigns a timestamp to each transaction. The timestamp is the value of the coordinator’s current clock. The assigned timestamp defines the serial order for all the transactions quite simply, as long as the transaction execute at the assigned time the serializability is achieved. If the storage node can accept the request, they durably store the metadata for the item that they have accepted the transaction, and reply yes. In this particular example, it sends the request to these two storage nodes, get an acknowledgment back, and then transaction goes to the commit phase.
The important point to note here is that once a timestamp has been assigned and precondition checked, the nodes participating in the transaction can perform their operation without coordination. Each storage node is responsible for ensuring that the request involved in the items are executed in the proper order and for rejecting conflicting transactions that can come out of order. The commit phase, each storage node can validate that the transactions are executed in the specific timestamp order. If not, they can fail the request.
In practice, to handle the load that we will see from transactions, there is a large number of transaction coordinators operating in parallel. Different transactions accessing an overlapping set of items can be assigned timestamps by different coordinators. Serializability holds even if the different coordinators do not have synchronized clocks. Even if they don’t have it, I think the most important property here is that the values of different coordinators, if they go out of sync, there may be a case where transactions start aborting unnecessarily. How do we ensure that the times are not going too much out of sync? AWS provides a time sync service that we use to keep the clocks in coordinator fleets closely in sync, say within a few milliseconds. Even with the perfectly synchronized clocks, transactions can arrive at storage nodes out of order due to message delays in the network, failures, and recovery, and all those other things. Storage node therefore must effectively deal with transactions that arrived in any order.
See more presentations with transcripts