Month: February 2024

MMS • Aditya Kulkarni

Recently, Apple open-sourced Pkl (pronounced “Pickle”), a configuration-as-code language. Pkl has the the goal of streamlining configuration management, by serving as a command-line utility, software library, or build plugin.
Static configuration languages like JSON, YAML, or Property Lists are limited in expressivity and prone to errors as configurations become more complex. Often, these limitations lead to the introduction of auxiliary tools or custom logic, making the configuration resemble a programming language but with added complexity.
Alternatively, using general-purpose languages like Kotlin, Ruby, or JavaScript for configuration can be powerful but tricky, as they are not originally designed for defining and validating data.
Pkl aims to bridge this gap by providing a dedicated language for configuration that is easy to use and is not tied to a specific ecosystem. In Pkl development, developers have access to familiar language elements such as classes, functions, conditionals, and loops. Developers can establish abstraction layers, and facilitate code sharing through package creation and publication. More importantly, Pkl caters to diverse configuration requirements. It enables the generation of static configuration files in various formats or integration as a library within another application runtime.
When it comes to other features, within Pkl, validation is facilitated through type annotations, which may optionally include defined constraints. Constraints encompass arbitrary expressions, enabling the developer to define types capable of accommodating any validation criteria expressible in Pkl. For example, consider a sample type requirement stipulating a string of odd length where the first and last letters must match.
name: String(length.isOdd, chars.first == chars.last)
Pkl also offers the functionality to create and distribute packages, which can then be imported as dependencies in various projects. This facilitates seamless sharing of Pkl code across different projects.
Creating and publishing a package is also straightforward; developers can release it on GitHub or upload it to any desired location. Packages can be imported using absolute URIs.
import "package://pkg.pkl-lang.org/pkl-pantry/pkl.toml@1.0.0#/toml.pkl"
output { renderer = new toml.Renderer {} }
The tech community on Hacker News and Reddit took notice of this announcement. One of the Hacker News users jaseemabid mentioned, “Pkl was one of the best internal tools at Apple, and it’s so good to see it finally getting open-sourced.” One of the Reddit users mawesome4ever was curious when more languages like Python and Node would be supported.
Pkl offers the capability to generate configuration in textual format and can also function as a library integrated into other languages through our language bindings. When integrating with a language, Pkl schema can be automatically converted into classes/structs within the target language.
When it comes to editing Pkl, users receive guidance as they fill in configuration data based on a provided template. The editor also offers real-time validation, flagging any invalid values, and provides immediate access to documentation. Other key features of the editor include Autocompletion, Navigation, and Validation.
To dive deeper into Pkl, resources such as tutorials and a language reference are available. Additionally, to interact with the Pkl community, users can participate in GitHub Discussions.
MMS • Ben Linders

According to Ilian Iliev, software developers tend to forget to do things they do not have to think about every day, which can cause delays or impact the functionality of the product during a software project. To prevent overlooking something, he suggested starting early with automating deployment, setting up error logging, and using lists and reminders of things that were forgotten previously.
Ilian Iliev spoke about what software developers can do to prevent overlooking things at Dev Challenge Accepted 2023.
People tend to overlook things when developing a new software product or service because they don’t have to think about them on a daily basis, Iliev said. This can cause delays in your software project or it can impact the functionality of your product, or do both, he mentioned. Everything that you forgot during the planning phase means either pushing the deadline or cutting corners and releasing less than promised:
Imagine that two days before release, you suddenly realise that you have totally ignored the fact that there is existing data that is incompatible with the new version of your application and you have missed coming up with a migration plan. That may mean a few days of delay, or weeks of refactoring based on your specific circumstances.
Iliev recalled how one of their servers crashed in the middle of the night as a result of a leap-second handling bug in the OS:
The whole system was operational, except for the part that was processing the customers` orders. The problem was that we found out about it a few days later from a client calling and asking why the system still had not processed their order.
This was a hit both to the company’s reputation and also to our self-esteem as developers, because we had never thought about having 24/7 monitoring of that piece, Iliev said.
One of the things to focus on earlier from a deployment and operations point of view is to automate deployments, Iliev said. You do not need a complex CI/CD pipeline; of course those are awesome, but to start with maybe a simple script that just does all the steps could be enough, he mentioned. Just do not rely on people remembering to execute five different commands in a specific order, even if they are documented. Deployment should be a one-click or command thing, Iliev said.
For operations, availability monitoring and alarming are a must, Iliev argued. This is also true for proper error logging; if something goes wrong with your system you should be able to track down the root cause of it, he added:
Without proper logging, you end up guessing what causes an issue or even worse, not knowing about it until clients start complaining.
Iliev mentioned that saying that something is a bad decision is often interpreted as hostile and also does not bring value to the discussion. He suggested expressing concern that something may not work by pointing out specific reasons, which opens the possibility of identifying possible issues at an early level.
Software developers should not be afraid to ask questions outside of their department, Iliev said. In the end, all of our work is combined together so having a general understanding of all the other aspects is important for the better integration of all pieces in the end product, he added.
Iliev advised teams that when starting a new project, to think about everything that went wrong last time and make sure not to repeat it:
Think about how your product will evolve and how you are going to maintain the system. Keep good communication between the teams and make sure all stakeholders are aware of all the complexities and possible pitfalls.
There will always be things to forget or overlook but the less there are the better the result, he concluded.
InfoQ interviewed Ilian Iliev about how developers can prevent overlooking something.
InfoQ: What’s your advice to teams that are embarking on developing a new system or product?
Ilian Iliev: Using a checklist with topics that you should pay attention to during the process helps a lot. Split it into sections for each phase and use it both as a tool to verify the completion of certain steps, and also as a source of questions that will help you get a better understanding of the project needs. The benefit of those checklists is that they are quick to go over and help you avoid missing steps that will lead to future problems.
InfoQ: Can you give an example of how such a checklist can look?
Iliev: I’ve created a Github project with Project Checklists which contains drafts of the checklists that I use in architecture, implementation, deployment and operation, and evolution and maintenance.
Here are two checklist excerpts to inspire you to create your own:
Implementation:
- Documentation
- Data models documentation – what different attributes represent
- APIs documentation – what the endpoints do, what the expected inputs and outputs are
- Business logic – why certain decisions were made
- Code quality – style guide, linters, review processes
- Versioning
- Stability – unit testing, end-to-end & integration tests, load testing
Deployment & Operation:
- Single command deployment
- Availability monitoring – are you sure your system is running?
- Metrics reporting – how to measure the system performance
- Error logging – operation logs should be easy to access and understand
- Noiseless services – the system should not generate unnecessary noise, e.g. logs, emails, notifications, as it may hide real problems
MMS • Steef-Jan Wiggers
Microsoft recently announced the general availability (GA) of its iSCSI-based Azure Elastic SAN, a fully-managed and cloud-native storage area network (SAN) offering.
The cloud solution was publicly previewed in October 2022 and received several updates later. With the GA release, the company included new features that enable the investigation of performance and capacity metrics through Azure Monitor Metrics and the prevention of incidents caused by misconfigurations with the assistance of Azure Policy. In addition, the company raised several performance limits.
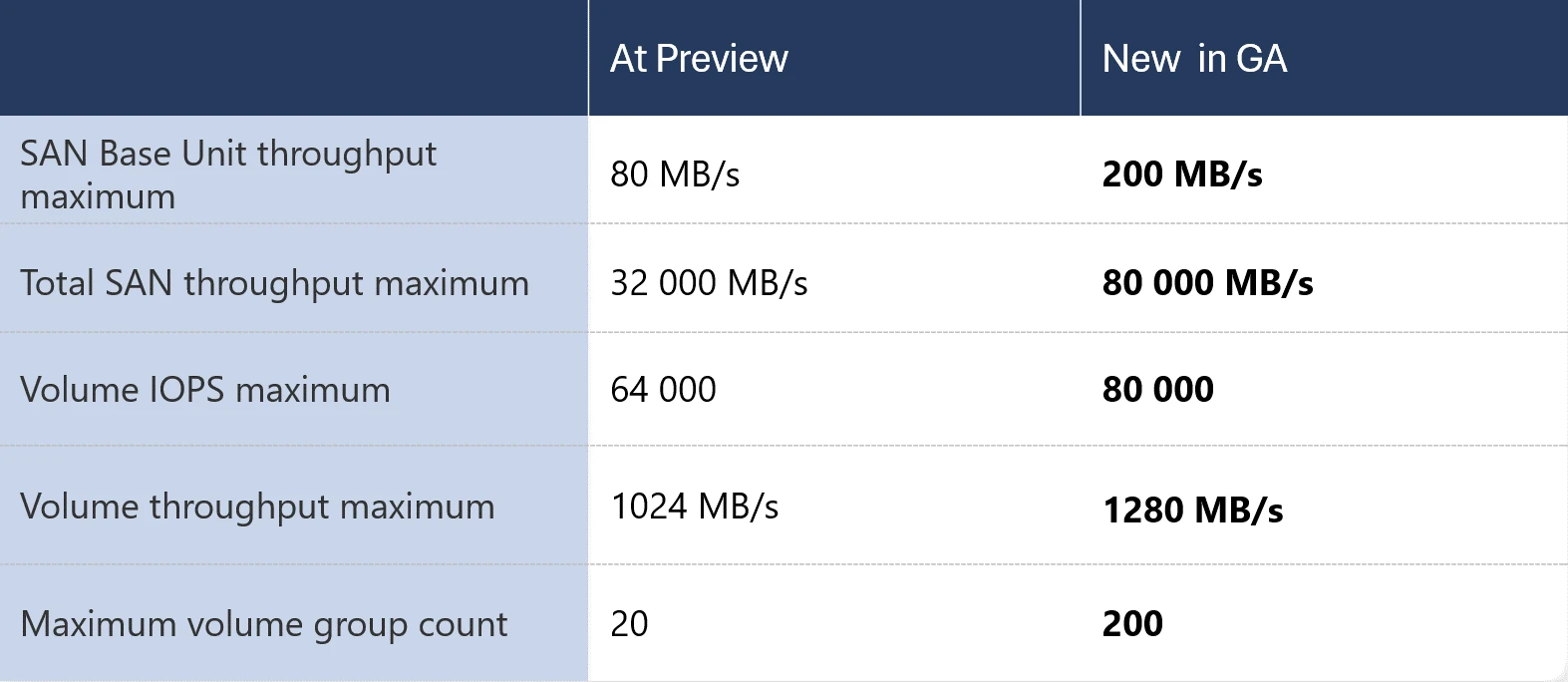
Performance limits Azure Elastic SAN (Source: Microsoft Azure Blob Storage blog)
According to a company blog post, Azure Elastic SAN allows customers to drive higher storage throughput over compute network bandwidth with the internet Small Computer Systems Interface (iSCSI) protocol. This helps them to optimize various database workloads, like SQL Servers. SQL Server deployments on Azure Virtual Machines (VMs) occasionally require overprovisioning a VM to reach the target VM-level disk throughput, which can be avoided using Azure Elastic SAN.
Furthermore, customers can leverage Azure Elastic SAN to migrate their on-premises SANs to the cloud by replicating the familiar resource hierarchy and allowing dynamic provisioning of IOPS and throughput at the Elastic SAN resource level. They can subsequently enable the management of security policies at the workload level.
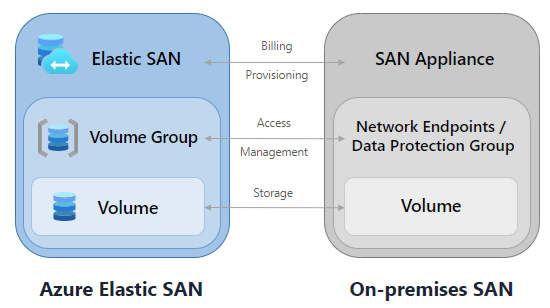
Azure Elastic SAN vs On-premises SAN (Source: Microsoft Learn)
Microsoft partnered with Cirrus Data Solutions to make its Cirrus Migrate Cloud available in the Azure marketplace for migrating Azure Elastic SAN from on-premises SAN.
Aidin Finn, an Azure MVP, questions the purpose of the service in a tweet on X:
So, #Azure Elastic SAN is GA < The real question is: "what part of Azure was this created to support internally?" That's what I wonder when I see these kinds of resources.
With Svyatoslav Pidgorny, responding in a tweet:
Maybe none. Looks like something for the “we stay on-premises because SAN” folks. You want complexity? Here you are!
While Mike points out in a tweet:
It is a great way to enable disposable compute while retaining reliable persistent storage.
Containers have this issue, but even VM environments too. A long standing example would be a SQL database drive or log drive.
Lastly, more details are available on the documentation landing page. In addition, with the GA release, Azure Elastic SAN is available in more regions.
Docker Desktop 4.27 Brings Docker Init GA with Java Support, Synchronized File Shares, and More
MMS • Diogo Carleto

Docker has released Docker Desktop 4.27. This version brings Docker Init to “generally available” (GA) with Java support, synchronized file shares, support for TestContainers with Enhanced Container Isolation (ECI), Docker Build Cloud, Docker Debug and more.
Docker Init, initially released in beta in Docker 4.18, is a CLI command designed to make it easy to add Docker resources to any project by “initializing” or creating the required assets and scaffolding. Docker 4.26 added support for PHP, and now Docker 4.27 has added support for Java. The list of supported languages now includes Go, Node.js, Rust, and ASP.NET.
To create the assets automatically, it is only necessary to run the command docker init within the folder of the target project, and this will automatically create the dockerfiles, compose, and .dockerignore files, based on the characteristics of the project.
Synchronized file shares is an alternative file-sharing mechanism aimed to solve the challenges of using large codebases in containers with virtual filesystems. According to Docker, this feature boosts 2-10x the file operation speed through the use of synchronized filesystem caches. Beyond the users who have large repositories, users who are using virtual filesystems such as VirtioFS, gRPC FUSE, and osxfs, or are experiencing performance limitations can benefit from this feature.
Docker Desktop 4.27 introduces the ability to use TestContainers with Enhanced Container Isolation (ECI). ECI provides a new layer of security to prevent malicious workloads running in containers from compromising the Docker Desktop or the host by running containers without root access to the Docker Desktop VM.
Docker Build Cloud is a service designed to allow users to build container images faster, both locally and in CI. The native builds (for AMD64 and ARM64 CPU architectures) run in the cloud and use a remote build cache, aiming to ensure fast builds anywhere and for all team members.
Docker Debug Beta is a CLI command designed to help developers find and solve problems faster, it provides a language-independent, integrated toolbox for debugging local and remote containerized apps. To get started, just run docker debug in the Docker Desktop CLI.
In Docker 4.26, the Docker Builds view became GA. This is a simple interface in Docker Desktop designed to give users visibility of active builds currently running in the system, enabling the analysis and debugging of completed builds. Every build started with docker build or docker buildx build will automatically appear in the Builds view. From there, it is possible to inspect the properties of a build invocation, including timing information, build cache usage, Dockerfile source, log access, etc.
Since Docker 4.26, users can create containers in the cloud with Docker Desktop and Microsoft Dev Box. To start using Microsoft Dev Box, users must go to the Azure marketplace and download the public preview of the Docker Desktop-Dev Box compatible image.
More details about the news of the Docker Desktop can be found in the release notes.
Presentation: Sigstore: Secure and Scalable Infrastructure for Signing and Verifying Software
MMS • Billy Lynch Zack Newman

Transcript
Lynch: My name is Billy Lynch. I’m a staff software engineer over at Chainguard.
Newman: My name is Zack. I am a research scientist at Chainguard.
We got to start with the obligatory motivation slide. You’re all here at the software supply chain security track/language platforms. You probably have made your peace with the fact that this is a thing we need to be concerned about. Attacks are on the rise, basically, across every stage of the software development lifecycle. It’s not just that vulnerabilities are getting introduced by your developers, and then attackers are finding those in production. It’s vulnerabilities that are coming in from vendors, from open source dependencies, on purpose, on accident, they’re happening at the build phase, they’re happening at the source control phase. There’s not any one fix because of the number of places these vulnerabilities are sneaking in. You can’t just have one magic silver bullet that takes care of everything. Meaningful improvements here are going to require changes to every step of the development process. You see really a dramatic increase in the number of attacks that are coming in from the software supply chain as opposed to “Front door attacks.” That’s borne out by the data. It’s also borne out by the news, and by the policy response to the news. We see numbers of academic efforts, nonprofits being founded, the U.S. Federal Government, both the executive and legislative branches are very invested in this. The media is invested in this, I think with good cause. I think this is an area that’s been really under-addressed for a long time. We’re starting to finally make our peace with the fact that this is something we’re really going to need to think about all through the SDLC.
Why Software Signing?
One weapon that we have, a defensive weapon, one defense that we have is software signing. As you might be able to infer from the question mark after my subtitle on the slide, it is not the silver bullet that you might think it is, but it is a really useful defense, and a really useful part of a secure software supply chain. Why would we want to sign software? We’re going to focus on the distribution phase of software development. You’ve written your source. You’ve built your source, and now you’re trying to get your source from the build machine into production. This can happen in a number of settings. It can happen on a container registry. In the open source world, it often happens on open source package repositories. Software signing is going to help with compromise of account credentials on a package repository. If I’m a developer, and I have an npm account, and I have a terrible password because I made that account 15 years ago, and there’s no second factor auth on that account, someone might be able to get at my password or cross-reference it from some other data dump, and basically be able to publish packages on me. Maybe my package isn’t such a huge deal, but it is depended upon by a popular package, and now there’s malware in the dependency chain of really thousands of applications.
Another thing you really have to worry about is compromise of package repositories themselves. It should be pretty obvious why as an attacker, if you can get into npm, that’s an extremely high point of leverage for you as an attacker to distribute malware or whatever you’re trying to get out to as many people as possible. Software signing helps clients, end users check that a software package is signed by the “owner,” and who the owner is, is a really tricky and interesting question. We’ll dance around it a little bit in this talk. Software signing is going to help a lot with that. Once you know who the owner is, double checking and really making sure that the software is in fact coming from that owner. It’s not going to help with all attacks. Signing does absolutely nothing for accidental vulnerabilities that just get introduced as part of the normal development process. Someone making a mistake, human error, forgetting to free some memory or what have you. It’s not going to help with build system compromises. If the build system itself is compromised in building bad software, it will still go ahead and sign that, and now you have a signature on the bad software. It’s not going to help with so-called hypocrite commits. This is a recent phenomenon we’ve identified, which are commits that look good, but were actually done with bad intent. I’m a helpful contributor to an open source project, I’m going to add my patch. It turns out this patch has a dependency on a library that is secretly a Bitcoin miner, or is secretly scanning machines for credit card numbers in memory. If the project itself accepts this hypocrite commit, signing is not going to do anything with that. Finally, signing is not going to help with an attacker who is able to threaten an author of a library. If you have an open source library, and you go to him with a big wrench and you say, upload this malicious package to the repo you control or else, they’re still going to be able to sign for you. Signing is not going to help with that. It is going to help with, again, these really common scenarios, account credential compromise, package repository compromise.
Software Signing Today
What’s the status of software signing today? In summary, it’s widely supported in open source software, but it’s not widely used. Most tools aren’t checking signatures by default, and they can’t because most packages aren’t signed by default. You have this chicken and egg problem. You can’t turn on this feature and require it until there’s very full adoption. There’s a bunch of reasons for this. There’s a bunch of usability issues, especially surrounding key management. I sometimes do an exercise where I ask people to raise their hands if they have a PGP key living on some hard drive in a basement or a storage unit or somewhere that they’ve lost track of years ago. It’s just a fact of life, managing cryptographic keys that are really long-lived, is challenging. People lose them. People leak them. You need to reset flow, and so on. That brings me to my second point, if you lose the key, developers today expect to be able to recover access to publish their packages. If I’m an open source maintainer, I’m publishing a package, I lose my GPG key that I was using to sign it, and you tell me, I’m out of luck, there’s never ever going to be another release of package foo again. That’s not really an outcome we’re super ok with. What if the package has a vulnerability? We will need to patch that and to fix that. Long-lived key pairs aren’t super compatible with that. This is something I think that has been recognized increasingly by real world package repositories. On the right, you see an article, a recent blog post from the Python Package Index blog, talking about removing support for PGP signatures from PyPI. You might think that this is kind of a loss, it’s a blow against package signing. I actually think it’s a victory for more considered approaches to package signing.
Challenges with Traditional Signing
There’s a bunch of challenges with so-called traditional signing, if you have key pairs that we expect developers to manage themselves. There’s key management, and that includes hooking up the key to the package repository, distributing that key and associating it with the packages that it’s in charge of, rotating keys. If I lose the key, or I make a new one on a new laptop. Compromise detection. If someone gets my key, I might not know until it’s way too late until they’ve already published malware in my name and gotten that out to a large number of people. Revocation is difficult as well. There are, again, provisions in PGP for it, but they rely on infrastructure that’s decreasingly supporting these key servers and so on. Finally, identity, which gets back to this question of, how do you know who’s supposed to be signing the software? If all you know about a key pair is the fingerprint, this very opaque hexadecimal identifier, that’s not good for usability. It’s not easy to understand what it means when a package is signed by a key with that identifier.
Sigstore (Goals)
Lynch: This is really where we see Sigstore coming into play. Sigstore is an open-source project, it’s under the OpenSSF, which is part of the Linux Foundation. Its whole goal is to really make software signing easy and more readily available for people to use. Some of the key ideas here. Sigstore can integrate with your existing key management solution, whether that’s bring your own keys, KMS systems, stuff like that. One of the really novel ideas with Sigstore is the concept of keyless signing. Really, instead of worrying about individual keys, really start thinking about identities. I don’t necessarily care about the random fingerprint for the public key, I really care about, did it come from Zack? Did it come from myself? Did it come from my CI/CD platform? How Sigstore approaches this is really relying on existing identity management mechanisms, so OAuth and other identity providers in order to leverage the existing security practices that users are already used to dealing with. Two-factor auth, account recovery, dealing with emails as an identifier, things like that. There are a lot of challenges with this. We’ll dive into some of those. Really, we’re trying to meet developers where they are, so they can integrate these into their existing systems.
Sigstore – Keyless Signing
We’ve been seeing a ton of adoption for Sigstore just in general, nice up into the right graph. We had a bunch of projects add Sigstore either for their own releases or developer tools that are adding Sigstore as part of releasing your own software. Some notable people using Sigstore today, Kubernetes. They sign all of their recent releases with Sigstore. npm, there’s a public beta feature right now for attaching signed provenance with npm packages. That uses Sigstore behind the scenes for npm. Then also CPython, which is one of the primary Python interpreters also signs their releases with Sigstore as well. We’re going to step through step by step how the keyless process works, to get a sense of what’s going on behind the scenes. We talk about keyless, there are still keys. The analogy we make is there’s still servers with serverless. The idea here is we don’t want users to have to worry about keys and think about them. There are three main components that we’re going to work through, one of them is the clients all the way over here. This could be your developer laptop, your CI/CD platform. Then there’s also two or three server-side components, depending on how you look at it, that Sigstore provides. Fulcio, which is the certificate authority, as well as Rekor, which is a transparency log for everything that’s going on as part of the signing process. First, it’s going to start at the clients all the way at the left, like I said before, laptop, CI/CD. These are going to be some client tools that are aware of Sigstore, know how to go through the keyless process. How this works is the client is going to generate, basically, an ephemeral key pair. The idea here is we only use this key pair once. We use it for the signing operation, and then once we’re done with it, we throw it away, never to be used again. Then, the next steps there are like, how do we tie that to the actual identities? What we leverage here is OIDC.
Some examples of clients, there’s Cosign, which is for container signing. This is a very popular tool that most people, if you’re familiar with Sigstore, are aware of. This can sign any OCI objects, and normally Docker images, but can also sign arbitrary blobs because OCI is just an arbitrary blob store. Cosign does this really nifty trick where it stores these signatures alongside the images themselves, which means it’s actually compatible with any OCI registry. If you can push a Docker image, you can also sign it with Cosign. Gitsign is another example of a client. This is Git commit signing with Sigstore, so being able to just use your existing identity without having to worry about generating a GPG key. A similar example to Zack is whenever I give talks about Gitsign or Cosign, I always ask like, how many people have generated a key and just hit enter, no password, no lifetime, no subkey, something like that. Those are the types of key management problems that we’re thinking of. These tools are really trying to address those so that users don’t need to worry about those implementation details of the keys.
Now to OIDC. OIDC stands for OpenID Connect. It’s basically a layer on top of OAuth. Users are already used to going through an OAuth process, you can see on the right here. You’re used to the log in with Facebook, log in with GitHub, log in with Google. OIDC provides a layer on top of that, to basically standardize some of the user identification claims, so we can better interop with different identity providers. This could be GitHub. This could be Google. For CI/CD platforms, there’s a lot of runtime environments, cloud providers that will provide OIDC tokens for you. This could be your company’s SSO, whatever, as long as it supports OIDC, which is a common standard, we can support it. These tokens basically just include metadata about who is authenticated in the session. This is an example web token that I pulled from a real token for my own email, so issued by oauth2.sigstore.dev. For Sigstore, this is the issued at and expiration time, for billy@chainguard.dev, and the initial issuer, so this is the button I clicked was accounts.google.com. That’s good for human users, and having an email identifier is pretty ubiquitous for identifying humans. For machine identities, it’s a little bit harder. OIDC actually gives us a mechanism to do that as well. There’s only a set of claims that are required, but identity providers can actually include additional claims as well. This is an example OIDC token from GitHub Actions that you can include within your workflow, you don’t need to do any key creation or anything like that. GitHub will just provision this for your run. Again, you can do this with Kubernetes. GCP has a similar feature for running on GCE Cloud Run. AWS has a similar feature, as well as Azure. Here you can see a lot more richer details about the actual execution that’s running, not just some email or some repo. What SHA did it run at? Is it a push or a pull request? Is it a manual run? What run attempt is it? This gives us a lot richer metadata that we can bind against and write policy against more than just, what key are we using? We’re challenging the idea of a key doesn’t always represent an identity, because you don’t know who has access to the key. If it’s a developer key, or it’s a CI/CD key, like your developer team might have access to it. Really moving away from key means person or workflow, and more towards having these ephemeral tokens that are provisioned on-demand without users needed to take additional actions.
The client handles both the key generation and getting the OIDC token. This is on the left here. Then it needs to actually bind those two things together. This is where the first server-side Sigstore component comes in, which is Fulcio, which is a certificate authority. What happens here is the client goes through the first steps. It sends the OIDC token and the public key over to Fulcio, as well as some signed data, usually, you sign the OIDC token itself with the private key to prove that you actually have the private side of the key pair. Fulcio will check all of that data and make sure it checks out, make sure the OIDC token is valid, hasn’t expired. Make sure that the signature of the data checks out. It will issue you a short-lived certificate, an X.509 certificate that you can then use to sign whatever you want. X.509 is a pretty standard format for representing certificate and public key metadata, that tons of signing tools already integrate with. That becomes our leverage point to really hook into the rest of the signing ecosystem as is today. Examples of what these certificates look like, these are a bit abridged. You can see a lot of the same similar information here. You can see issued by sigstore.dev, valid for only 10 minutes, only to be used for code signing, and includes the information, here’s the email, here’s who it was issued by. Then same for GitHub Actions, again, a lot of the same metadata. Fulcio will do a bit of massaging of the data. There’s a bunch of different CI providers that do provide support. There’s GitHub, GitLab. I think we’re working with Circle right now. There are many others. Fulcio will try to extract some of the claims out and put them in common fields so that you don’t need to worry about these precise differences between the different CI/CD runners.
From there, you have the certificate, you can then sign whatever you want, sign your Docker containers, sign your Git commits. Then we have a problem of, you have a certificate, but it’s only good for 10 minutes. Normally with certificates, once you’re past the expiration, you’re no longer supposed to trust that key pair or what was used to sign it. That creates a bit of a challenge because we’re constantly getting new keys, new certificates, and so we need to be able to verify this data after the fact. That’s where Rekor really comes in. Rekor is an append only transparency log that we publish every signing operation that happens. The idea here is if the signing operation doesn’t appear in the transparency log, it’s as if it never happened. What we can do with this because it’s append only and because it can’t be tampered with once it’s been included, we can use the presence of the signature being in Rekor as basically an equivalent check of, was this signed at the time it said it was, within that expiration window? Because Rekor will actually return back when it was signed as part of the response. To see what this looks like, so for example, for a Docker container, you would give it the, here’s the digest of what was signed. The signature as well as the certificate, which includes the public key. Rekor will verify all that data to make sure that’s not uploading trash into the log. Then what you get back is basically an inclusion proof of the timestamp that was entered into the log as well as basically recognition that it was seen by Rekor, and there’s additional signatures in there as well. That is the overall flow. Ideally, if everything goes correctly, users don’t actually need to think about a lot of what’s going on behind the scenes. It’s just the normal login flow that they’re used to.
Demo
Quick demo. I have a sample repo here. It’s just a very simple Go binary that we can build. ko just builds Go binaries without needing to use the Docker socket. Very nifty tool, definitely check it out, if you’re using Go and building containers. Then from here, we can just take this digest that was produced at the end. We could just say, cosign sign the image. You can see at the top here, it generated the ephemeral key. It was trying to get the certificate. What it’s trying to do here is, we actually need an identity to sign in and bind this to. This is why we’re getting the warning, it’s basically saying, some of your personal information, the email, stuff like that is going to be uploaded to the log, are you ok with that? Yes, we are. It’s going to open up a link, if it used other tools like the local host OAuth flow. If we go back over here, we have to log into Sigstore, that opened up in our browser, we can log in with Google. Authentication successful. We can pop back over here. You can see that the T log, the transparency log entry was created with an index number that we can go and look up. Then it also pushed the signature up to the registry. It really is that simple. Sigstore also provides some tools for interacting with the Rekor log. We can actually go take that index and look up live, like, we just published this a few seconds ago, issued by sigstore.dev, Not Before, this is basically when it was created. It’s still valid for 10 more minutes, but the key that was created never hit disk. It’s not stored anywhere. As far as I’m concerned, it is completely deleted never to be recovered ever again. Then if we scroll down, we can see the same claims that we saw before in the certificate, so down to my email, stuff like that. Then we can also verify. When we do verification, instead of doing, this key or including in my key ring, what we’re doing is, what identity signed it? In this case, it’s my email, and issued by Google. We can go ahead and verify this. It’s going to spit out some ugly looking data. It’s basically the transparency log that was included in Rekor, which you can poke around with, if you want. If we scroll up here, we can see the things that it checked. It checked that the claims were validated. Did the identity match? Was it present in the transparency log, and was the certificate that backed it also valid as well?
One of the nice things about OIDC is the fact that we can integrate into CI/CD workflows. I have a simple GitHub Action here that basically does the same thing that I just did. We can rerun this bit of a live demo. I can pull up the one I ran before. I’m using a temporary registry, so it just means that it cleared up the cache since I last ran this. This was something I ran this morning. This is the GitHub Actions workflow that I ran. Pretty simple. The only thing we really needed to do is the ID token, which instructs GitHub to actually include the OIDC token in the workflow. Then all we did was set up Cosign, build it, sign it, good to go. The example workflow from before, this was the certificate that was issued. We can see, this was triggered by a push for the SHA, for this build, for this repo. I can actually impersonate this as my own user. I need to go through my CI process in order to generate a valid certificate, which puts a lot of controls into place if you’re taking good best practices for locking down your CI/CD platform, stuff like that. You can write policies that say, I only want to trust images that come from my CI/CD system, merge to main, only coming from a push, so no pull requests, and stuff like that. This just ran, so we should be able to rerun this. This is checking something similar mentioned before. We don’t actually have an email address when we’re verifying CI/CD workflows. What this is using is basically an identifier for the GitHub Actions workflow, and then also issued by the GitHub Actions OIDC token issuer. A lot of other mess, just because there’s more metadata in there. You can see the same claims were verified there as well. There are some more flags you need to do because there’s the extra text, but yes, you can pipe it into jq, and then manipulate it however you want.
Kubernetes Admission Controllers
We showed off some verification here. Verification is very important, as Zack mentioned before. There has been signing support in general, but signatures don’t really mean anything unless you’re actually verifying them. There’s a bunch of tools, especially for the Kubernetes ecosystem, if you’re using container-based workflows, allow you to write policy for Sigstore based signatures. Sigstore has a product called policy-controller that tries to do this, to write fine-grained policies, like we did with the CLI, but even to a greater extent. You can say like, I only want push, or I only want pull request, or I only want things coming from this issuer. Then Kyverno and OPA, other super popular admission controller projects also have support for Sigstore as well. Policy-controller is not necessarily the only solution you have here.
Challenges with Traditional Signing (Recap)
To revisit some of the challenges from before, just a recap. Key management, rotation, by using keyless workflows, by making everything per signing event, per artifact, you’re dramatically reducing that scope and blast radius so that even if keys were leaked, you’re severely limiting the window when they can be used. You don’t have to worry about years down the line, like, can anyone access this key? If you ever detect a compromise or anything like that, you know exactly what window things could have been signed in. You can write policies to basically counteract that. That by itself is hugely powerful, so you don’t have dangling keys existing out in the ether that you don’t know about and don’t know who’s using. Compromise detection. The other part of Rekor, because it is a transparency log, and you can query it, and you can see, here are all the identities that are being used and what they signed, that can become a mechanism that you can monitor and basically say, where is my production CI key being used, or production CI identity being used? What is it signing? If there’s anything that pops up there that you don’t know, or recognize, or trust, that can be a signal for you that, something might be going on here that’s unexpected, and you should be able to tie back to the event that actually triggered it, especially for CI/CD. Revocation is still a little bit tricky, though it is possible. This is part of where policy really comes into play. Because again, if you know that you were compromised, if this account was compromised during this period of time, you can now write policy that says, don’t trust anything during this window, or don’t trust this service account, or don’t trust whatever. Having that policy enforcement really helps with the revocation, not necessarily of the keys, because everything’s ephemeral, but being able to tie policy decision about what is and isn’t allowed within your workflows or artifacts that you choose to trust. Then, finally, with identity, going back to before, challenging the concept of a key doesn’t necessarily mean a person or a workflow or something like that. We tend to think about things that way. Let’s actually use the identities themselves and provide the metadata to make that possible.
Everything I demoed here used the Sigstore public instance. Sigstore is an open source project, you can run your own instance. If you’re not comfortable with the metadata, so like the email addresses and the repo information that gets included in the transparency log, you can run your own instance. The Sigstore project, since we want to encourage adoption, especially across open source projects, runs its own public infrastructure that’s backed by 24/7 on-call rotation, and is free for anyone to use. There are rate limits in place, so you can’t just hammer it, but this is what Kubernetes is using, the public npm instance, even at Chainguard, an artifact that we publish for public consumption, we also put on the public transparency log as well. This is from the OpenSSF site. This is just a landscape of a bunch of people that we know are using Sigstore, either for their own release processes, or have integrated with Sigstore in some way, whether that be generating signatures, verifying signatures, things like that.
Why Do We Trust Sigstore?
Newman: Something you might have noticed, that would make maybe anyone who was around for the 1990s like Cypherpunk dream of decentralization, which has seen a little bit of a revival in the cryptocurrency world where people talk about control your keys, control your destiny, is that we’ve basically added a trusted third party with a whole lot of power to this ecosystem. Sigstore now is responsible for saying the signature associated with this key belongs to this identity. What’s stopping Sigstore now from going around and saying, I saw a signature from the President of the United States of America. That’s a really good question. We really try to mitigate this centralization with accountability. I’ll show you what I mean by that. The mantra might be, trust but verify. We have a centralized service. We trust it to do the right thing, but we can go back and double check its work. This is this concept of transparency that Billy kept mentioning. To me what transparency is, is we should make this service who we want to trust, but we want to verify what they’re doing. We should make all of its activities public and tamper proof so that we can go back after the fact and double check on everything that it did.
Sigstore does this in a way that’s really similar to the way this happens in Web PKI now. If you go to example.com, and they present you a TLS certificate, that TLS certificate also winds up in a certificate transparency log. The idea is that certificate authorities have a similar degree of power. I’m VeriSign, I’m DigiCert, whatever, I can issue certificates for any website on the internet. How do we deal with that power? We just introduce accountability via transparency. Now, if DigiCert tries to issue certificates for google.com, Google can quickly detect that and respond, and then DigiCert will lose its authority as a CA. They will get booted out of the CA bundle that’s on your desktop, and we can catch it after the fact, and we can respond to it. The way this is done is this public log has a couple of neat features. One is you can query it, you can search it. Another is that it’s tamper proof. What do I mean by that? I mean we use cryptographic techniques to ensure that once you’ve seen a certificate inside of this log, that no one’s ever going to be able to take it out and pretend it wasn’t in there. Even if these logs themselves are compromised, which we have to worry about, because they’re often operated by the same parties who are the certificate authorities themselves. Even if the logs were compromised, we would detect right away if they tried to pull any funny business and take things out of the log.
The Role of Identity Providers
This means that identity providers in this ecosystem also have a whole lot of power. The identity provider is the one saying the person holding this token is billy@chainguard.dev. This is good and bad. These identity providers have a lot of power, they’re really a high-value target. They also already have really great security mechanisms in place. Sigstore can actually piggyback on things like the two-factor auth, that your GitHub account has enabled. It can piggyback on the account recovery mechanisms that Google has available, or they have teams of people who look at your driver’s license, or whatever. That’s something that we’re not going to be able to ask these open source package repositories to do. They just don’t have the resources to do the thorough and strict account recovery procedures that you would want for this. We’re not making the maintainers responsible for identity, which is how I saw the status quo with long-lived cryptographic keys. It’s these organizations that have far more resources and can do the job really well. We can put the burden of fraud, abuse, compromise detection on the identity providers, because all of this metadata is public, it’s really easy then for the identity providers to say, I’m noticing Sigstore is issuing certificates to identities associated with me that I didn’t ask for. That can be detected, and so we’ll notice problems with Sigstore. Sigstore supports pluggable identity providers. Especially if you’re operating your own instance, but even the public instance, we’re open to taking new ones, you can have your own private instance of SSO that you’re using for your company. You can just hook that right up, and what you’re already using for identities internally, you can continue to use for code signing, as opposed to again, having to introduce this abstraction of keys and trying to manage the mapping between keys and identities.
All this boils down to like, you choose who to trust. When it comes to open source, we’re hoping that a lot of that policy gets put on the package repositories. Package repositories themselves, are in the best position to know who’s in charge of what packages. If you’re talking about your own deployment pipeline, those are decisions you’re going to have to make. You can say things like, I’m only going to want to trust an artifact that’s rolling out to my Kubernetes cluster, if it was built by my CI/CD system and it’s got a certificate of that. It was built from source that my development lead signed off on. You can create these policies that express exactly what it means for a software artifact to be good. I think a lot of previous attempts at software signing were extremely binary. An artifact was signed and therefore good, or it was wasn’t signed, and therefore bad. This means that things like expiration dates get tricky. What does it mean for me to sign a binary? I probably didn’t hex dump it and look at every single byte in it. There’s some degree of trust I have in whatever procedure in whatever computer I used to do the signing, to do the building. I think the more we can tease that out, and I think providing really expressive primitives of identity-based signing enables that, the better shape we are in to make intelligent policy decisions. This is what I was getting at on the previous slide. There is no one-size-fits-all answer. The needs of an open source package repository are going to be different from the needs of an enormous Fortune 500 company, are going to be different from the needs of a 2-person development shop. Sigstore is not attempting to be prescriptive on that front, it’s just providing the building blocks that you can use to make good policy decisions.
Case Study – Verifying Images
Here’s a quick case study. Here’s part of the configuration for that Sigstore policy-controller project Billy talked about earlier. This is basically saying, any images that are coming from registry.k8s.io are going to need to be signed by this krel-trust service account on Google Cloud Platform. That’s actually the service account that gets used to build all the Kubernetes images. This is something that Kubernetes Release Team publicizes, and it’s well known. That’s one example of a policy. This is another example of a policy for if you’re consuming content from Chainguard. As Billy said, we’d sign all of our stuff. We put it all on the public transparency log, and we can say, any images that are coming from cgr.dev/chainguard, must be signed by Chainguard on GitHub, or at least workflow. Again, that’s another policy. I’ll refer you to Marina’s talk into this higher-level meta policy of, ok, for an image with a particular name, how do I figure out who’s supposed to be signing it? That’s a tricky and interesting question. The idea is that like, in different cases, you want different policy. I want to enforce signatures on open source software differently from the way I’m enforcing signatures on things that are coming from within my organization.
Case Study – npm
Quick case study on npm. npm is using Sigstore to do build provenance. A really common attack that we see in the wild in open source repositories are, there’ll be a popular open source package, it’s developed in the open, good development practices. The attacker will clone the repository and replace it with malware, and then run npm-publish. If you go to github.com/leftpad, like that repository looks great, but what actually you’re downloading from npm is totally unrelated to that. npm is rolling out build attestations powered by Sigstore, where, basically, you need to have a publicly known trusted builder, do that build step for you. Then GitHub Actions will sign off and say, I built this software package from this publicly available source. That link between what lines up on npm and what’s on GitHub or GitLab or whatever your CI/CD provider and VCS provider are, is verifiable now. This is something that’s getting used now. It’s in public beta. The hope is that it rolls out to really a large number of packages on npm.
What You Should Do
The moral here is that signing is really critical, I think for any DevSecOps strategy. Again, it’s not going to solve all your problems. It doesn’t replace a good vulnerability management program. It doesn’t replace not checking dependencies on things that are going to have bugs in them in the first place. It is going to be really helpful for knowing that what you think things are is what they actually are, and they’re coming from where you think they’re actually coming from. You should start to the extent possible verifying signatures, in many open source projects that you might be depending on, especially in the Kubernetes OCI world but also throughout, are signing their binaries using Sigstore or are signing their images using Sigstore. For your own software, Billy showed how easy it is. It’d be a great experiment, just start signing and then seeing, can we verify our own signatures when things are coming into prod? If your tooling and dependencies aren’t signing, you can say, is this something you’d be willing to do in the future? It’s actually pretty easy to do here. We can show you how to set it up.
Questions and Answers
Participant 1: There seems to be a divergence of how people use Sigstore right now. [inaudible 00:41:35] and Luke Hinds’ Stacklok, so like what you build. There’s a couple of startups now that are building how you build. You had some examples, but the question would be, I think there has to be a convergence in this discussion of like, what people are doing, so webhook, and then chaining together the attestations. There’s a bank that’s doing that, there’s a startup, and another couple of startups that have done this. Do you guys have a suggestion about that? Do you even care about that model?
Lynch: You’re right, that is still very much like an active area for development. I think seeing the engagement across the ecosystem is evidence of that. I think, for Sigstore, providing the building blocks. If you don’t have that metadata, and you don’t have that verifiable proof to go from your artifact here, build system, to your source code to make that chain, you can’t really do all that higher level things for like, how do we actually build things in a trusted way? I see that as more like a fundamental foundational building block. Then as relating to the next steps of, how do we go about building things securely, and responding to that? I think that’s very much active development, and where a lot of efforts are.
Participant 1: It’d be nice for you to develop patterns for that. All these companies are using Sigstore, the ones that are building chains of attestations. It’d just be nice to see Sigstore promote a pattern.
Lynch: I think we’ve seen some amount of that. Part of the challenge is like how people build software is very different. There’s tons of different build tools. I think there’s been some good steps, I think, like buildpacks is a step in the direction for like, how do we standardize? Like, how do we build npm in a secure way? How do we build Go in a secure way? Personally, I would love to lead by example here, like here are the best ways that we see it. It’s always a balance and a tradeoff of like, going back to before, like meeting people where they are, asking people to completely uproot their build systems and what they’re doing today. It’s going to take time, but yes, it is something that is on our minds.
Participant 2: I’m going to precede my question by saying, I know enough about computer security to be somewhat dangerous. It’s been good to learn about these kinds of tools that are available. Going back to Radia’s keynote, I’m just curious, she mentioned something about concerns with the X.509 certificate, and you guys issue that. I’m just wondering if you can speak to those concerns.
Newman: I don’t think anyone in the industry today is super happy about where we’re at with X.509. The concerns are basically twofold. One is that the format itself is relatively complicated. X.509 is built on ASN.1. ASN.1 parsers are where a lot of vulnerabilities are sneaking into things like OpenSSL, you see vulnerabilities basically every year in the parsing, because untrusted input fed to a parser. Parser is written in C. This is how we get buffer overflows, all these big bad vulnerabilities. X.509 itself is a little bit scary for that reason, it’s the format itself. Then the other real trick with X.509 is that checking validity is really complicated. That’s another thing. What we use in Web PKI and Sigstore’s validation is very similar. There’s an RFC 5280. It’s just so long and so complex. It’s because, it’s got a kitchen sink of features. You can delegate to another certificate with these properties, and now it’s valid only on alternate Tuesdays, or whatever. That complexity has snuck in over the years and has stuck around.
That said, we do have battle tested libraries. Every time you’re accessing the internet, and you’re on a secure connection, that’s happening via X.509 certs in the Web PKI. That software is quite mature. I think there’s some interesting academic efforts to put this on firmer footing. You’ll hear terms like formal verification. Machine checkable parsers that we know are provably correct in doing the right thing. Can we express these things more declaratively and have a much more obvious mapping from the natural language specification to the code that’s written on the computer, because if I look at the way this validation works in Chrome right now, and I look at the RFC, you need to be an expert to be able to match those up. Whereas if the way the validation looked was much more of a transcription of the method that was prescribed for doing the validation, we’d be a lot happier.
The other alternative is, blow the whole thing up and pick something new, which has benefits. We can get rid of a lot of the complexity. It has risks as well. Anything new, how do you know the complexity didn’t evolve over decades, because one by one by one. It’s the classic trap of rewriting things and starting from scratch. We are happy to lean on standards that have wide adoption right now. To say, there’s enough libraries that are depending on this, that we’re happy with those. I can see the argument the other way, and we’re certainly not married to the format. If a promising alternative comes along, we’d be happy to use those as well.
Participant 3: This isn’t completely in your purview. When I think about wanting to verify signatures with components that we’re potentially bringing in, we’re pretty heavily invested in software composition analysis tools, that feels like intuitively where that would be happening. Just doing some googling right now, I can’t really find confirmation that it’s actually doing it even though it’s making sure those components don’t have known vulnerabilities that are public knowledge. Do you have any thought on whether tools like that are adopting signature verification, particularly one Sigstore is creating? Do you have any just thoughts on that?
Lynch: I think it would make a ton of sense to do verification. I think where we see a lot more integration on the signing front is attestations, so being able to attach the results of those to the artifacts themselves in a verifiable chain. You can say like, my CI ran this scan for vulnerabilities, and we are going to sign and attest to the fact that this scan ran and here are the results. That tends to be the more common way, and you can use Sigstore to back that signing and things like that. From there, you can go down the stack and be like, can we look for SCA results for our dependencies, and what the SCA tools find and pull from there, so we don’t have to continuously try to recompute things. I wouldn’t be surprised if people do it, and I think it would make sense.
See more presentations with transcripts
Article: Advice for Engineering Managers: Enabling Developers To Become (More) Creative
MMS • Wouter Groeneveld
Key Takeaways
- As an engineering manager, be mindful of social debt in your team, which will severely hamper creative potential.
- When facing problems, try to approach these by adding more constraints, or by taking a few away.
- Give developers a break by allowing them to tackle problems their way, not your way.
- Shield your team from unnecessary interruptions and agree on how interruptions should be tackled.
- Stimulate or introduce other knowledge domains that might generate original ideas nobody thought of regarding the current problem at hand.
- Remind developers that creativity is an attainable skill: it can be learned by anyone.
Software engineering is anything but just an act of programming: it requires analysis, continuous delivery, API integration, maintenance, collaboration, and above all: a creative endeavor.
As an engineering manager, it is your responsibility to help facilitate creative thinking skills among the development team, but that’s easier said than done. How exactly can you help amplify the creative thinking skills of your software development colleagues, while still keeping an eye on that tight deadline that always seems to creep up on you? In this article, we’ll examine how different levels of creativity influence the individual, the team, and the company, which strategies can support creative problem-solving, and when to be and not to be creative as a programmer.
What exactly is creativity?
What, exactly, does it mean to be creative as a software engineer? Something could be called creative when it’s (1) original work, (2) of high quality, and (3) relevant to the task at hand. However, this view is quite incomplete: if I, as a junior C# programmer, employ reflection for the first time, it could be viewed as original to me, but not at all to the seasoned developer next to me.
Then, who determines the quality? A static code analysis tool? A colleague? Which one? Same for relevance; that topic alone could be the start of endless bickering in technical code sessions. The biggest problem with this view of creativity is the explicit (and partially wrong) emphasis on the creative individual instead of the environment (team, [company] culture, society, …).
Fortunately, we can also take context into account when looking at creativity, which evolves creativity into a social verdict: your peers decide whether or not your programming efforts are to be called creative.
I know that sounds like a very vague theory: what exactly does this mean for software engineering? When it comes to creativity, seven distinct themes play a major role: technical knowledge, collaboration, constraints, critical thinking, curiosity, a creative state of mind, and the usage of specific creative techniques. For this article, we will zoom in on the team-based contextual properties of these themes, and what a manager can do to help facilitate the seven themes.
Let’s dive in.
Creativity and technicality
First up is technical knowledge: how to gather, internalize, and act on knowledge. Many different Personal Knowledge Management (PKM) techniques exist to help manage the ever-increasing flow of (mis)information.
When asked, one interviewee perfectly summarized this theme: “No input, no output: creativity is the brew of different inputs“.
Most of these techniques revolve around efficiently gathering these “inputs” to eventually produce original “outputs” by acting on knowledge. The question then becomes: what can a manager do here to help put these on track? The first step is helping draw attention to the existence of PKM tools and showing how these can be used to help master the many technicalities programmers nowadays are required to possess. Setting up internal wikis, helping reach for alternative sources of information, and promoting cross-pollination of ideas through the organization of hackathons and knowledge-sharing sessions are other examples.
Successfully collaborating creatively
What influence does collaboration have on creativity? Now we are starting to firmly tread into management territory! Since software engineering happens in teams, the question becomes how to build a great team that’s greater than the sum of its parts. There are more than just a few factors that influence the making of so-called “dream teams”. We could use the term “collective creativity” since, without a collective, the creativity of each genius would not reach as far. The creative power of the individual is more negligible than we dare to admit. We should not aim to recruit the lone creative genius, but instead try to build collectives of heterogeneous groups with different opinions that manage to push creativity to its limits. We should build environments that facilitate and attract creativity.
Easier said than done.
Managers can start taking simple actions towards that grand goal. For instance, by helping facilitate decision-making, as once communication goes awry in teams, the creative flow is severely impeded. Researcher Damian Tamburri calls this problem “social debt.” Just like technical debt, when there’s a lot of social debt, don’t expect anything creative to happen. Managers should act as community shepherds to help reduce that debt.
A few lovely community smells Tamburri and his team identified are: “Priggish Members,” demanding and pointlessly precise people who can cause unneeded delays and frustrations. “Hyper-Community”, is a too-volatile thinking environment where everything constantly changes. “Newbie Free-Riding,” when newcomers are completely left to themselves, causing irritation and high work pressure. Keeping social debt low keeps developers and teams happy, and research proves that happy developers are more creative developers!
Constraint-based and critical creative thinking
The next creative theme is the advantages of constraint-based thinking. Contrary to popular belief, the right amount of constraints does not hamper creativity, but rather fuels it! Emphasis on the right amount, of course.
- Too few constraints and little to nothing gets done: (who cares, let’s play with a few more frameworks before making any decision.)
- Too many constraints and little to nothing gets done: (very strict deadlines together with hardware and existing legacy software constraints end up strangling the project and mentally draining your developers.)
The manager’s role here is clear: guide your devs to leverage self-imposed constraints to reach that creative sweet spot when there’s too much freedom, or help reduce or bend constraints when there are too many. Admittedly, not many constraints can easily be bent or (partially) ignored.
Then we have critical thinking as an essential part of the five steps of a typical creative process: Participate (your 90% transpiration), Incubate (interrupting the process by taking a distance), Illuminate (the other 10% of the work), Verify (does it work?), and finally Present/Accept.
The task of the manager here is to help guide programmers through this never-ending feedback loop, for example, by now and then helping slam on the breaks or asking the right critical question to invoke that much-needed self-reflection. Another important aspect is the difference between diffuse and focused thinking modes. Just think about putting on different hats when developing: refactoring, redesigning … However, not everyone thinks as fast or as slow as you do, and not everyone is locked in the same focused mode as you are. Being wary of the thinking modes of your peers (and the team as a whole), and better adjusting these to each other, will more than likely yield more creative results. Managers should pay extra attention to this mental oscillation and make sure everyone switches gears on time: prolonged periods of focused thinking will result in exhaustion, not more creative ideas. Give your developers a break!
How to grow a creative mindset
Speaking of taking a break, next up is cultivating a curious mindset. This mindset will not likely be stimulated if the office environment is nothing but boring grey concrete slabs. Getting out of your comfort zone does wonders for your (creative) mindset. For example, by leaving your desk, going for a walk, and not explicitly thinking about that nasty problem, your chances of solving it once you get back will likely double.
Another way to cultivate curiousness is by programming silly things for fun. Openness to experience and serendipitous discoveries while browsing around might just make that connection you need to solve that problem at work. Fooling around (in code, of course) is often frowned upon by managers and seen as time-wasting, while in reality, it keeps the team motivated and curious, which is very much needed as a creative programmer. Another thing to take into account is the classic specialist vs generalist debate. Both have their merits, of course, but your task as a manager is to watch out for signs of overspecialization (or exhaustion). In that case, you might be able to stimulate developers to pick up another skill, ideally via pair programming. Keep on motivating your team to stay curious.
The next theme is exploiting your creative state of mind to arrive at original and sustainable solutions: The popular “flow” state, how to get in a creative mood, deep work vs. shallow work, and dealing with interruptions, and how to trigger creative insights.
As a manager, it is important to help facilitate the right state of mind. This means making sure that your team members are more or less protected from unnecessary interruptions: both external as well as internal (including your own!) To aid with this, several practical tools for preparing and dealing with interruptions can be deployed, such as introducing “do-not-disturb” moments or migrating away from open landscape offices. Also, when thinking about triggering creative insights, is this something you do alone or together? As always, this depends on the context and situation.
A corporate culture that encourages a creative state of mind and where creativity is stimulated will no doubt help as well. By the way, open workplaces are detrimental to creativity, but so are small closed-off desks. Instead, offices should be designed like clusters of closed sub-environments, where bumping into people and exchanging ideas can happen without constantly sitting in each other’s way. MIT’s Building 20 serves as a neat architectural example.
Helping build a creative toolbox
Last but not least, managers can help developers build a toolset of specific creative techniques, such as zooming out and in when stuck and starting at the end instead of the beginning of a problem. The best candidates here are tools borrowed from other domains, like various writing techniques authors use to boost their creativity that can also be applied to the world of programming. When it comes to borrowing ideas, there’s what Austin Kleon calls “good theft” and “bad theft”.
As Tamburri’s community shepherds, managers should be wary of these, as ethical considerations play an increasingly important role in software engineering, especially with the rise of AI-assisted code generation tools like ChatGPT and GitHub Copilot.
Conclusion
This article summarizes what managers can do to help facilitate the seven central themes of a creative programmer: creativity and technicality, successfully collaborating creatively, constraint-based and critical creative thinking, how to grow a creative mindset, and helping build a creative toolbox.
There’s one thing that perhaps is most important of all: helping your colleagues become aware that creativity is a skill that can be trained and learned! Just like any other muscle.
Many junior programmers think they’re either creative or they’re not, when in fact, they might not YET be creative. If there’s one thing that managers can do, it is this: the empowerment of creativity as an attainable skill, that, with patience, can be cultivated! Of course, creativity levels will likely vary from project to project and from person to person. On top of that, it constantly evolves, and it is contextual. But if there’s just one thing you need to take away, it’s that everyone can become a creative programmer.
MMS • RSS

While it can be tempting to jump on anything that’s moving amid such widespread investor optimism, there are some tried and tested ways to find the true standout stocks. By using MarketBeat’s research tools, we can zero in on two tech stocks in particular. Let’s jump in and take a closer look.
Having endured a horrible 2022, shares of software giant Salesforce (NYSE:CRM) bounced back during pretty much all of 2023. Many of our readers will remember the numerous bullish calls we made on Salesforce in the last few months. It’s about time we did it again. The company started this year with a 110% rally under its belt. And with another 10% gain since then, it’s clearly showing no signs of slowing down.
In what is surely one of the more remarkable turnarounds from the tech industry, Salesforce shares are now less than a 10% move from their previous all-time high. And according to Wall Street analysts, CRM stock should be hitting that high any day now.
Less than two weeks ago, the team at Bank of America named Salesforce one of their top picks for 2024. With tech as a whole set to benefit from a decline in rates, must-have pieces of software like Salesforce stand to do well from the fresh, growth-fueled demand. They also feel that, even with the ongoing rally, Salesforce remains attractively valued against its peers.
On Monday, their stance was echoed by the Oppenheimer team, who reiterated their Outperform rating on Salesforce while boosting their price target to $325. Needless to say, were shares to hit this in the coming weeks, they’d be at fresh all-time highs.
Mongo is another enterprise-grade software platform going through something of a resurgence. Like Salesforce, it’s been rallying hard for over a year and is also closing in on its previous all-time high. A 35% jump in the last month alone bodes particularly well for the coming weeks, and it’s not surprising that the consensus rating on MarketBeat has it at a Moderate Buy.
While Salesforce might have made it onto Bank of America’s list of top picks for the year, MongoDB (NASDAQ:MDB) was at the top of Baird’s list. The company is closing in on its first-ever profitable quarter, with expectations rising that this is the year it makes the jump.
There have been some concerns raised about the slowdown in the company’s revenue growth, but this month’s earnings report, encapsulating the return to risk-on sentiment since last November, should put paid to that. It’s a company known for its high-performing sales team, and since the advent of artificial intelligence (AI), the market need for Mongo’s database software has only become more acute.
Look for shares to continue rallying beyond the $500 mark, with a run at 2021’s high near $600 a real possibility if it can deliver a strong earnings report. Some concern is warranted with the stock’s relative strength index (RSI) at 70, indicating overbought conditions, but such is the bullish momentum in the market right now. We’re inclined to say there’s a lot more room for this one to run.
MMS • RSS

Soho House & Co SHCO shares rallied 12.6% in the last trading session to close at $5.63. This move can be attributable to notable volume with a higher number of shares being traded than in a typical session. This compares to the stock’s 25.9% loss over the past four weeks.
SHCO benefits from an expanding clientele.Total Members in the third quarter 2023 grew to 255,252 from 248,071 in second quarter 2023.
This operator of members-only luxury hotels and clubs under the Soho House brand is expected to post quarterly loss of $0.08 per share in its upcoming report, which represents a year-over-year change of -14.3%. Revenues are expected to be $304.63 million, up 12.7% from the year-ago quarter.
Earnings and revenue growth expectations certainly give a good sense of the potential strength in a stock, but empirical research shows that trends in earnings estimate revisions are strongly correlated with near-term stock price movements.
For Soho House, the consensus EPS estimate for the quarter has remained unchanged over the last 30 days. And a stock’s price usually doesn’t keep moving higher in the absence of any trend in earnings estimate revisions. So, make sure to keep an eye on SHCO going forward to see if this recent jump can turn into more strength down the road.
The stock currently carries a Zacks Rank #3 (Hold). You can see the complete list of today’s Zacks Rank #1 (Strong Buy) stocks here >>>>
Soho House is a member of the Zacks Internet – Software industry. One other stock in the same industry, MongoDB MDB, finished the last trading session 5.4% higher at $500.90. MDB has returned 21% over the past month.
MongoDB’s consensus EPS estimate for the upcoming report has changed -3.7% over the past month to $0.46. Compared to the company’s year-ago EPS, this represents a change of -19.3%. MongoDB currently boasts a Zacks Rank of #4 (Sell).
Want the latest recommendations from Zacks Investment Research? Today, you can download 7 Best Stocks for the Next 30 Days. Click to get this free report
Soho House & Co Inc. (SHCO) : Free Stock Analysis Report
MongoDB, Inc. (MDB) : Free Stock Analysis Report
MMS • RSS

MongoDB, Inc. is a developer data platform company. Its developer data platform is an integrated set of databases and related services that allow development teams to address the growing variety of modern application requirements. Its core offerings are MongoDB Atlas and MongoDB Enterprise Advanced. MongoDB Atlas is its managed multi-cloud database-as-a-service offering that includes an integrated set of database and related services. MongoDB Atlas provides customers with a managed offering that includes automated provisioning and healing, comprehensive system monitoring, managed backup and restore, default security and other features. MongoDB Enterprise Advanced is its self-managed commercial offering for enterprise customers that can run in the cloud, on-premises or in a hybrid environment. It provides professional services to its customers, including consulting and training. It has over 40,800 customers spanning a range of industries in more than 100 countries around the world.
MMS • RSS
MongoDB, Inc. is a developer data platform company. Its developer data platform is an integrated set of databases and related services that allow development teams to address the growing variety of modern application requirements. Its core offerings are MongoDB Atlas and MongoDB Enterprise Advanced. MongoDB Atlas is its managed multi-cloud database-as-a-service offering that includes an integrated set of database and related services. MongoDB Atlas provides customers with a managed offering that includes automated provisioning and healing, comprehensive system monitoring, managed backup and restore, default security and other features. MongoDB Enterprise Advanced is its self-managed commercial offering for enterprise customers that can run in the cloud, on-premises or in a hybrid environment. It provides professional services to its customers, including consulting and training. It has over 40,800 customers spanning a range of industries in more than 100 countries around the world.