Month: January 2024

MMS • Akshat Vig

Transcript
Vig: I’ll be talking about Amazon DynamoDB distributed transactions. Let’s start with a poll, how many of you have written applications that use a cloud database? Pretty good. How many of you have written applications that use a cloud database that is not a relational database, specifically, NoSQL databases? Fifty-percent of the room. How many of you who have used NoSQL database wished that you could use atomic transactions with a NoSQL database? That is pretty good. That’s almost 100% of those 50% who wanted transactions. In this talk, what I want to do is I want to explore why are transactions considered at odd with scalability? Then, I want to further explore that. Can we have a distributed NoSQL database system that has all the properties of scalability, performance? Why people love these NoSQL databases? Can we have both? Can we support transaction and still maintain those features that exist in NoSQL databases? Throughout this talk, I’ll walk you through the journey of how we added distributed transactions to DynamoDB.
Cloud Database Services
Databases are moving to the cloud at a very fast rate, and established companies are moving their on-premise databases to the cloud. Similar to that, startup companies are basing their business entirely on the cloud from day one. Why is it happening? Why is it a trend? Because the benefits of running your application on the cloud are just too compelling. Cloud databases, you get fully managed experience. You don’t have to worry about servers. You don’t have to manage. You don’t have to order capacity. That frees you up from any of the burden that you had to manage infrastructure. Then, as your database runs on the cloud, you get the elasticity, and pay as you go model where you can use the database for the duration, whenever you expect the peak to hit on your database. You use the database to that peak capacity, and then dial down the capacity when you actually don’t need it. In short, cloud databases, they offer a lot of agility that modern applications demand, especially when it comes to managing the data that drives innovation.
DynamoDB
When you think about NoSQL databases, what is it that attracts people towards NoSQL databases? I’ve taken DynamoDB as an example here. NoSQL databases such as DynamoDB, you get a very simple interface where you can use a simple API to create a table. Then you have a bunch of operations that you can do on the table such as Get, Put, and typically the data that you’re storing through the write operation or fetching through these write operations are semi-structured to unstructured. Where you have a key which is defining the primary key of the item, and then you have a value. The value could be a JSON object, or whatever you want to store in that.
The second part is that you get a flexible schema. There is no fixed schema as compared to what you get in a relational database. You can store documents. You can store photos. You can have a single table where you’re storing customers and orders and stuff like that. There is no fixed schema. You can have a flexible schema. Invariably, the cloud service provider by default, most of these databases, they replicate data for higher availability. For example, DynamoDB we replicate every table across three different data centers within a region. Each data center is called an availability zone. It has its own independent power and networking. DynamoDB can lose a complete data center and your application and your table still remains available both for reading and writing. Then, DynamoDB offers essentially four nines of availability. Customers of DynamoDB, they can also choose to create a global table that ensures that all your data is replicated not just within the same region, but to two or more regions that you have configured in your table throughout the world. The data in global tables is asynchronously replicated. With global tables, you get five nines of availability, which means effectively, your data is always accessible.
We’ve talked about a simple API, flexible schema, high availability. The next one is unbounded growth. Another big selling point of NoSQL databases is the horizontal scalability. For example, in DynamoDB, you start with just creating a table. You don’t know the size of the table upfront. Maybe you know the reads and writes that you want to perform, but you don’t know the size, so you start by creating an empty table. As your application becomes popular, your number of writes increase, your size of the table increases. DynamoDB, behind the scenes, will automatically partition your data based on how much size it is growing. You get unbounded growth. Now talking about reads and writes, either you can choose to specify reads and writes right at the beginning, which is called as the provision mode of the table. Or, if you don’t understand the read pattern of your users, you can just start with an on-demand mode. Behind the scenes, as you increase your throughput, or as we identify more writes happening to your table, based on that, we need to partition the table to support the unbounded growth. Essentially, you can think about it in this way. Let’s say you start your table with a single partition, as you add more data to it, or as you increase reads and writes on a table, it can become two partitions, and four partitions, and so on.
Finally, it is predictable performance. That, you start writing to your table, as your table is empty, you’re getting single digit millisecond performance latency for reads and writes. Then, as your application becomes popular, you start doing maybe millions of writes per second or millions of reads per second, your performance stays the same. It’s not that your performance will degrade if your table size increases. This is one of my favorite features of DynamoDB, you get predictable performance. Predictable performance and unbounded growth, these are important tenets that we keep in mind whenever we are adding new features to DynamoDB.
Over the years, we are seeing that the number of customers and the request rate keeps on increasing in DynamoDB, but customers always get performance, which remains constant. We are seeing more customers using DynamoDB. For example, just taking the proof is in the pudding, looking at the Prime Day stats from 2022. During the Prime Day, just amazon.com did 105.2 million requests per second. All those APIs got single digit millisecond performance. This is just one customer, and we have multiple customers. You can expect the same.
Working Backward from the Customers
When we started looking at transactions, and as DynamoDB, the customer base keeps on growing, we always work backward from our customers. We first go and talk to them. What are things that you would want us to implement in DynamoDB as the next feature? One of the features that was asked at that time was transactions. I’ll walk through, what is a transaction? Why are they important? To understand why they’re important, we can look at building an application together without using DynamoDB transactions. We’ll just use the basic Put and Get operations and try to see what are the complexities that arise from building transactions or doing transactional operations in DynamoDB. Hopefully, I’ll convince you that it is an important feature that needs to be added.
What is a Transaction?
What is a transaction? A transaction is essentially a group of read and write operations that you want to execute as a logical unit. As a logical unit, atomicity is part of it. Whenever you talk about transactions, there are certain properties that are associated with it, which is ACID. Essentially, what you’re doing is transactions, you group a sequence of database operations. Atomicity ensures that all the operations in the transaction are executed or none of them is executed. You get the all or nothing semantic. Consistency means that your operation leaves the database in a consistent state, in a correct state. Isolation, basically, you have multiple developers who can read or write data in your application, and you want isolation guarantees, so that you can serialize concurrent operations. Finally, durability that whatever data that you have written, it remains permanent. In this particular talk, we’re going to talk about atomicity and isolation specifically.
Why Transactions?
Now let’s jump into, why would you need a transaction? Why are these customers asking about adding transactions to DynamoDB? Because DynamoDB already supports simple Put, Update, and Delete operations. To understand that, let’s look at an online e-commerce application. Let’s say you’re building an online e-commerce application where the application is like amazon.com, where a person, Mary, can purchase a book and a pen, either independently or together. For this example, consider you want to buy them together as a single order. Why are transactions valuable? Because they facilitate the construction of correct and reliable applications that wish to maintain multi-item invariants. Such invariants are important for correct execution. For example, if you have 20 books, the invariant there is that you never sell a book which you don’t have in stock. This is just one example of an invariant. One challenge in maintaining these invariants is when you have an application which has multiple instances running in parallel, and you are accessing the same data concurrently. In the cloud version, or in today’s world, you see that when you build an application, it’s not just you have one user who is executing this operation. You have multiple users who are independently running their instance of that application. These instances need to share the data that is stored in the database, which means you need to ensure these invariants are maintained. Another challenge is that if your application crashes in the middle, still these invariants should hold true. Transactions essentially are the way that applications meet these two challenges of concurrent access and partial failures without developers having to write a lot of extra code.
Let’s understand that better. Let’s say that you’re building a client-side application for doing, without DynamoDB transactional support. Essentially, if you build this e-commerce application, you’ll have three tables. One is the inventory table where the books are stored, the pen that you’re trying to store, and other inventory that you’re maintaining for your amazon.com website. These all are stocked. The second thing is the customer table. In the customer table, you’re storing the information about the customers who are using your application. Finally, the orders table. The orders table essentially stores the information about the orders that you have created. When you are executing a transaction, what all needs to happen? You need to ensure the customer is a verified customer. The book status, you need to check that you have enough books in stock, and you need to make sure that that book is sellable. The same thing you need to do for the pen, that the pen exists, it is in the right status. Once you have added these two items to an order, as order items, you also need to then create a new order object. Also, go and update the status of the book, the status of the pen, the count of the book, and the count of that particular pen.
One way to do this, was you write all this client-side logic that, read from the inventory table, find out the number of books. Read from the inventory table, find out the number of pens that you have. Write to the inventory table that I’m going to execute this operation. Make a check to the customer’s table. You can do all these operations in sequence on the client side. What you essentially want is finally, atomically, all these operations should execute. Again, if you had a single user using that application, you can simply write this logic and make sure the operations are idempotent, and things will just work. What you want is the final state to have books, status is sold, customer is verified, orders are created.
It sounds simple, but not that simple. Your application, as you write it, it could crash. Anywhere, it could crash. You could have a crash right in the application itself. Let’s say you started and you were in the third step, if your application crashes, now you need to find out where you were, and then start again from there. You need to add some logic. Your database could crash while your application was up, so you need to ensure you’re doing enough retries. Your network could have an error, or your hard drive could crash. Your hard drive could crash on the database or your hard drive could crash on your application side, or your network can have issues. All these failure modes, essentially you have to handle, because if you don’t handle them well, that could result in inconsistent state in your application. Inconsistent state, what I meant by that is you could end up in a state where your customer is verified, orders are created, but the inventory is not yet updated. If the inventory is not yet updated, that particular item you might end up selling it two customers, and then you don’t have stocks. Then you cannot fulfill the customer order. All these repercussions that you will have.
Then, what you need to do is, since your database is in the same inconsistent state, you need to then do rollbacks. Now you start thinking about, how do I write the rollback logic? Essentially, you have some unfinished transactions in your database, and you don’t want anyone to read all this data. You go and do deletes on your other two tables and make sure that all of them do not have this data. It started to sound complicated. Now I need to figure this out. How do I do this? If you think about it, how would you build cleanup logic? A standard way to build this cleanup logic is, instead of executing the operation right away, you actually store that in a separate table, or in a separate ledger where transactions are first written, and then they are asynchronously executed. I can think of building it, but this is just like an additional complexity that I, as an application developer, have to deal with. What I wanted to do was just execute a transaction, but now I have to first deal with these repercussions, then I can get into thinking about my business logic. Not the best.
Again, previously, I was talking about a single user. Now think about multi-users. You have multiple clients who are reading in parallel. It might be that you need to make sure that the data that is stored in these tables make sense to everyone so that everyone is reading only the committed states, they’re not reading the intermediate states. Because again, you want your transactions to have the highest chance of success, because if your application keeps on crashing because of these inconsistent states, your users will go away. One way to solve this concurrent access is you have like a frontend layer in front of the database and you ensure all the reads and writes go through that. That doesn’t fully solve it, you need to introduce maybe locks to guarantee isolation, so that each of the developer can write code as though the operations are performed without interfering with each other. The developers don’t have to think about interfering operations, you can maybe introduce locks. With locks, then you have the cleanup logic to also clean up the locks. More complexity on the client side, now you have to deal with.
We haven’t talked much about unbounded growth and predictable performance. Can we still achieve that with this setup where you have like a new layer in the middle, and then you have these locks, then you have additional logic to clean up? Can my database now further scale? Can my application scale? All these things, they add up pretty quickly. Now you are becoming a database expert, rather than writing your business logic that makes your life much simple. All the heavy lifting essentially goes to the client. We don’t want that. If the database does not have this capability, every customer will have to think about all these problems that we just discussed about, adding transactions on the client side. You must be wondering, why do NoSQL databases not support transactions? Why do they just support simple Put, Update, and Delete operations?
Transactions and NoSQL Concerns
NoSQL databases, customers expect that they’ll provide low latency performance, and your database scales as your application is scaling. It accomplishes this by providing Get and Put operations, which have almost like consistent latency. The fear is that it is harder to provide predictable performance for more complex operations like transactions. The vast majority of applications of NoSQL databases have survived without transactions, that is, clients have written all the additional logic and lived with it. They have basically figured out workarounds to make it work. They’ve essentially survived without transactions for years. There is also that particular point about, is it really needed? Then the fear of adding transactional support might break the service for non-transactional workloads, like simple Get and Put operations, will they be impacted? That’s another fear. Reading online and talking to a lot of my other peers, the concerns around complexity of the API, how do you add this new API into the system? The concerns around system issues like deadlock, starvation of these locks. Then, how do you handle contention between different items? The concern of interference between non-transactional and transactional workloads? On top of all this, the cost. What will it cost to actually execute a transactional operation? All these reasons create a fear that, maybe we should not add transactions, it will impact the value proposition of my database.
NoSQL and Restricted Transactions
To work around these concerns, some systems provide transactions but with some restricted features. For example, some databases choose isolation levels that are less powerful, and hence, more limited utility than serializability. Other systems, they place restrictions on scope of transactions. Some systems only allow transactions to execute on a single partition. That if your database grows to multiple partitions, you cannot execute transactions. Or they will restrict that your single primary key, single hash key of your partition can stay within the same partition, it cannot go beyond a single partition. Then some systems, they essentially ask you upfront what all partitions you expect to execute in a single transaction, so that they can co-locate them and execute the transactions for you. All these restrictions, they intend to enhance the predictability or reduce the complexity in the system. These restrictions are at odds with scalability. As the database grows, it will split. It needs to split into multiple partitions. Restricting data to a single partition, again, causes availability concerns. Your application will crash. The database cannot accept any writes. Your application, which was working yesterday, suddenly stops working tomorrow, because your data has just grown. Customers don’t like that variability in these systems.
DynamoDB Transaction Goals
When we set out to add transactions support in DynamoDB, we look for a better answer. We didn’t just settle for like, we can introduce transactions with these restrictions. We went back to the drawing board. We said, to add transactions in DynamoDB, we want to be able to execute a set of operations atomically and serializably for any items in any tables, not just one table or a single partition, any tables that exist in the customer account with predictable performance. Also, make sure that no impact to non-transactional workloads. Our customer essentially wanted full ACID compliance. Amazon at that same time, when we were thinking about transactions, there was a public push to migrate many of our internal applications off the relational databases to DynamoDB. All these internal teams are also asking about a better and scalable way to do transactions, ensuring that it performs, ensuring that the cost is not that high. We wrote down these goals. DynamoDB already allowed customers to write consistent applications and also provided durability, with replication of the data. Out of ACID, what was missing was A, which is atomicity, and I which is isolation. Our customers needed the ability to execute a set of operations which belong to multiple partitions, or multiple tables atomically and serializable fashion for any items with predictable performance.
Customer Experience
We have defined our goals, let’s look at starting from customer experience. What are the APIs we should introduce? How should we expose this experience to the customers? Traditionally, the standard way to provide transactions would have been, you add like a transaction begin statement, and a transaction commit statement. In between, customers can write all the Get, Put operations in between these two, multi-step transaction operations. Basically, existing operations can be simply treated as an implicit transaction. Right now, then, if you’re essentially doing a single item transaction, that’s what I mean by implicit singleton transactions, and the typical implementation it uses like 2-phase locking. Standard approach. Again, we’re just talking about standard approaches that exist today in the market, uses a standard 2-phase locking during the execution of the transaction, and 2-phase commit for completing the transaction. Some databases, they also store multiple versions of an item so that multi-version concurrency control can be used to provide snapshot isolation. For example, you do a transaction, you have multiple versions, and whenever you’re doing your read, you can always read before the transaction using the version number of the item, without them being blocked by concurrent writes to the same item. We didn’t choose any of these options for DynamoDB. DynamoDB is a multi-tenant system, allowing applications to begin a transaction, wait for some time, and then commit the transaction. That is, basically allowing long running transactions would enable the transactions to indefinitely tie up the system resources. Customer could write like a sleep in between TxBegin and TxCommit, and your resources are held for long. Requiring singleton Gets and Puts to also go through full transactional commit protocol would mean that we have taken a performance hit on even the singleton operation. Our goal was, don’t impact singleton operations.
Looking at locking. Locking restricts concurrency. It’s not that we are aiming for super high contentious workload, but locking, it raises the possibility of deadlocks in the system, which are bad for availability. We would have gone with multi-version concurrency control. That’s pretty neat. DynamoDB does not support versioning. Adding versioning would have resulted in high cost, which means we have to now pass this cost to the customers, and additional complexity that we have to build in this system. All these operations, all these approaches, essentially, we rejected and we came up with a different approach.
Instead, we took a different approach for transactions in DynamoDB. To the APIs, we added two new operations, TransactGetItems and TransactWriteItem operations. These are single request operations, single request transactions that are submitted as one operation, and they either succeed or fail immediately without blocking. TransactGetItem operation, it allows you to retrieve multiple items, to read multiple items from a consistent snapshot. These items can be from like any arbitrary set of DynamoDB tables. Only committed data is returned when you do TransactGetItem operation. Reading from a consistent snapshot means that read only transaction is serialized with respect to other write transactions. The next one is the TransactWriteItem operation. The TransactWriteItem operation, it allows multiple items to be created, deleted, or updated atomically. Each set transaction contains a write set with one or more Put, Update, or Delete APIs. The items that are being written can reside in, again, any number of tables. The transactions may optionally include one or more preconditions, like you can check a specific item in a specific table, which is where you’re not writing essentially. You can also add these conditions to individual like Put, Update, Delete operations as well. DynamoDB allows adding those conditions, irrespective of transactions as well. We can do optimistic concurrency control on singleton items. For instance, you want to add a condition that, execute this Put only if this item does not exist. You can do that even without transactions, but you can choose to put that as well within the transaction itself. For a transaction to succeed, all these supplied preconditions must be met. These singleton transactions are also serialized with respect to other transactions and singleton operations with TransactWriteItems as well.
Transaction Example
Now, taking a look at an example. Let’s introduce another example, which we generally see whenever you think about transactions, like a bank money transfer. Let’s say Mary wants to transfer money to Bob. You essentially do a read, like if you do this in a standard TxBegin, TxCommit where you would do a Get operation, for Mary, read the money, for Bob, read the money. Once you verify that both these folks have the right money, then you do a Put, increasing the money in Mary’s account by 50 and reducing the money in Bob’s account by 50. Then you commit the transaction if all these conditions are met. With DynamoDB, you write a TransactWriteItem request where you say, check Mary’s balance, check Bob’s balance, and then you say you want to execute this Put operation in reducing the money from Bob’s account and increasing the money in Mary’s account. You essentially could map this TxBegin, TxCommit into a single request with TransactWriteItems.
Shopping Example
Then, the shopping example, if we go back to that, you’re doing a shopping application. You have the Customers table, Orders table, inventory table. You need to do a check on whether the customer exists, whether the inventory is available. Then you want to update the Orders table, create the entry in the Orders table, and also update the status in the inventory table. You do a TransactWriteItem, check the customer, let’s say is Susie EXISTS, inventory, you have a book, number of books that you have is greater than 5. Then you do a Put on the Orders table and update the inventory by reducing the number of books from whatever you have by 5.
Overall, in this particular transaction experience that we have built, what did you lose? There’s always tradeoffs. I would say very little, because most multi-step transactions, they can be converted into single request transactions, as we saw two examples just right now. The money transfer example where we were able to essentially convert the multiple operations that would happen into a single request. This approach can be essentially applied to convert any general-purpose transactional system into a single request system. In fact, it actually mimics how distributed transactions are implemented in other systems as well, where you have read sets, which basically record the value of the items at the time transaction executes, and writes are buffered until the end. Then at commit time you read the values, they’re checked. If they still match, then the buffered writes are performed. If they don’t match, then transaction fails. It seems like it’s working.
DynamoDB Operation Routing
Till now we looked at, what is the transaction? Why are they important? How we thought about introducing them as an experience in DynamoDB. Next step is, how do we actually build it? This is critical. Everyone is curious, what did we actually do? What magic is happening behind the scenes. To understand that, let’s take a step back. Let’s look at DynamoDB as a system. Without transactions, what happens in DynamoDB? Whenever you send a request to do a Put, or a Get in DynamoDB, it hits a bunch of request routers. These request routers, think of them as stateless frontend nodes. When request reaches a request router, it basically looks at the address of the storage nodes from a metadata system to find out where the item that you’re trying to put is stored. These are stored on storage nodes. As I said, initially, that all the data is replicated across multiple availability zones, and out of these three zones, you have one replica which is the leader replica, so all the Put operations, they go to the leader. The leader replicates it in the other two regions, and then replies back to the request router, which finally replies back to the application. Just like Put operation, Deletes and Updates are handled in the same way where request router finds out where that item is stored and executes the Delete through the leader. Done. Talking about Gets, Gets execute in a similar way, but whether they go to the leader or not, it depends on the request that is being made. If you do a consistent read, the request goes to the leader. Instead of using all the three nodes, now just the leader can respond back. It’s a consistent read leader knows because leader, all the latest writes go through the leader. Leader looks up and then responds back. If you do an eventually consistent read, it can go to any of the three replicas and that replica can respond back to the client.
For transactions, what we did is, transactional request from the customer, is sent to the frontend fleet. Then it is routed to a new fleet of transaction coordinators. The transaction coordinators, they pick apart the items involved in the transaction. In our case, there were like three items that we were trying to update. It sends those requests to the three storage nodes, saying that, execute the create order, execute the update inventory, execute the check customer. Once it gets the response, the transactional response is sent back to the client. Transaction coordinator sends these to different tables, get the response back, and then it responds back to the client saying their transaction succeeded, or failed, whatever that request was.
Looking deeper into how exactly that happens inside the transactions. It’s a 2-phase protocol. Transaction coordinator asks all the participating storage nodes that, I’m going to make a request that is sent by the customer. Are you willing to accept this? If the storage nodes, they say that, yes, I’m willing to accept this transaction. If they respond back with a yes, TCs durably store the metadata, that this transaction is accepted. Then TCs move on to the second phase. The second phase, once the transaction enters in the second phase, it is guaranteed to be executed in its entirety exactly once. The transaction coordinator retries each write operation until all the writes eventually succeed. The writes themselves are idempotent, so it’s ok for the transaction coordinators to resend them whenever they’re in doubt, such as when it receives a timeout, or storage node fails when it’s not available, or the leader is transitioning from the current leader to the other leader, or any other hiccups that could happen.
Once it has reached the commit phase, essentially it is sending the commit message once it gets an acknowledgment from all three tables, and then responds back saying that, my transaction is complete. That’s one example. It’s not always the happy case. It might happen that a transaction coordinator gets a negative acknowledgement from the Orders table, the other table succeeded, but the Orders table actually got a negative acknowledgement. In that case, what happens is transaction coordinator will go ahead and send a release message to all the tables, and then acknowledge back to the client that this particular transaction failed because the condition that you had specified was not met.
DynamoDB Transactions Recovery
We understand how a happy case works, how a not so happy case works. Of greater concern in this particular system is failure of the transaction coordinator. Because, as I said, whenever storage nodes fail, transaction coordinators can retry. How does this work? Coordinators, they maintain a soft state with a persistent record for each transaction and its outcome in a ledger. Just like I was saying in the client-side application that you would have to do a ledger, just think of it in a similar way. You have a ledger, where all your transactional requests are stored, and a recovery manager periodically is basically scanning this ledger to find out. Transaction coordinators are periodically checkpointing whenever they reach a logical state. The recovery manager is scanning those ledgers, and the goal is to find out in a reasonable amount of time transactions which have not been completed, and can call them as like stalled transactions. Such stalled transactions are then assigned to a new transaction coordinator saying that, I found this transaction, go recover it.
It is even ok for having multiple coordinators to be finishing the same transaction at the same time since you might end up in a state where you have duplicate attempts to write the same item to the storage nodes. It’s ok because these operations that transaction coordinators are doing, they’re idempotent. When the transaction has been fully processed, a complete record is written to the ledger. Whenever a recovery manager is saying to the transaction coordinator, go recover. Transaction coordinator first looks at the ledger. If the transaction is already completed, it’ll say, my job is done, transaction already finished. Overall, this is how the system has recovery automatically built into it, so that clients don’t have to worry about all this logic. Overall, the architecture looks like this. You have an application, you have request router, transaction coordinators writing to the ledger, and then you have storage nodes involved in doing these transactional operations. If it crashes, you have the recovery manager.
How did We Ensure Serializability?
The recovery approach, the process that we discussed that handles atomicity, but what about ensuring that these transactions execute in a serial order? Let’s find out how we achieve the isolation. For serializability, we decided to borrow an old technique called timestamp ordering. This approach has been credited to both David Reed and Phil Bernstein. It goes back about 40 years. We have adopted timestamp ordering to apply that to a key-value store. How did we do it? Essentially, the basic idea is that transaction coordinator assigns a timestamp to each transaction. The timestamp is the value of the coordinator’s current clock. The assigned timestamp defines the serial order for all the transactions quite simply, as long as the transaction execute at the assigned time the serializability is achieved. If the storage node can accept the request, they durably store the metadata for the item that they have accepted the transaction, and reply yes. In this particular example, it sends the request to these two storage nodes, get an acknowledgment back, and then transaction goes to the commit phase.
The important point to note here is that once a timestamp has been assigned and precondition checked, the nodes participating in the transaction can perform their operation without coordination. Each storage node is responsible for ensuring that the request involved in the items are executed in the proper order and for rejecting conflicting transactions that can come out of order. The commit phase, each storage node can validate that the transactions are executed in the specific timestamp order. If not, they can fail the request.
In practice, to handle the load that we will see from transactions, there is a large number of transaction coordinators operating in parallel. Different transactions accessing an overlapping set of items can be assigned timestamps by different coordinators. Serializability holds even if the different coordinators do not have synchronized clocks. Even if they don’t have it, I think the most important property here is that the values of different coordinators, if they go out of sync, there may be a case where transactions start aborting unnecessarily. How do we ensure that the times are not going too much out of sync? AWS provides a time sync service that we use to keep the clocks in coordinator fleets closely in sync, say within a few milliseconds. Even with the perfectly synchronized clocks, transactions can arrive at storage nodes out of order due to message delays in the network, failures, and recovery, and all those other things. Storage node therefore must effectively deal with transactions that arrived in any order.
See more presentations with transcripts
MMS • RSS
MongoDB Inc (NASDAQ:MDB), a leading modern, general purpose database platform, has reported an insider sale according to a recent SEC filing. Chief Revenue Officer Cedric Pech sold 1,248 shares of the company on January 16, 2024. The transaction was executed at an average price of $400 per share, resulting in a total sale amount of $499,200. Cedric Pech has a history of selling shares in the company. , In the last year, insiders have sold a total of 56,706 shares and made no purchases of MongoDB Inc stock.

MongoDB Inc Chief Revenue Officer Cedric Pech sold 1,248 shares
The history of insider transactions for MongoDB Inc shows a pattern of insider sales over the last year, with 61 insider sales and no insider purchases recorded. MongoDB Inc’s business involves providing a database platform that enables developers to build and modernize applications across a wide range of uses. Whether in the cloud, on-premises, or in a hybrid environment. The company’s technology is designed to provide developers with the tools to work with data in a highly flexible and scalable manner, meeting the demands of modern applications. On the valuation front, shares of MongoDB Inc were trading at $400 on Insider’s most recent day. The sale, which gave the company a market capitalization of $28.31 billion.

MongoDB Inc Chief Revenue Officer Cedric Pech sold 1,248 shares
With the stock price at $400 and GuruFocus Value (GF Value) of $482.92, MongoDB Inc.’s price-to-GF-Value ratio is 0.83, indicating that the stock is marginally undervalued according to GuruFocus’ intrinsic value estimate. GF Value is determined by considering historical trading multiples, a GuruFocus adjustment factor based on the company’s past returns and growth, and Morningstar analysts’ future business performance estimates.
This article prepared by GuruFocus is designed to provide general information and does not constitute financial advice. Our commentary is rooted in historical data and analyst estimates using unbiased methodology, and is not intended to serve as specific investment guidance. It does not constitute a recommendation to buy or sell any stock and does not take into account individual investment objectives or financial circumstances. Our objective is to provide long-term, fundamental data-driven analysis. Be aware that our analysis may not include the latest, price-sensitive company announcements or qualitative information. GuruFocus has no position in the stocks mentioned here.
This article first appeared on GuruFocus.
MMS • RSS
MongoDB Inc (NASDAQ:MDB), a leading modern, general-purpose database platform, has reported an insider sell according to a recent SEC filing. Chief Revenue Officer Cedric Pech sold 1,248 shares of the company on January 16, 2024. The transaction was executed at an average price of $400 per share, resulting in a total sale amount of $499,200.
Cedric Pech has a history of selling shares in the company; over the past year, the insider has sold a total of 56,706 shares and has not made any purchases of MongoDB Inc stock.
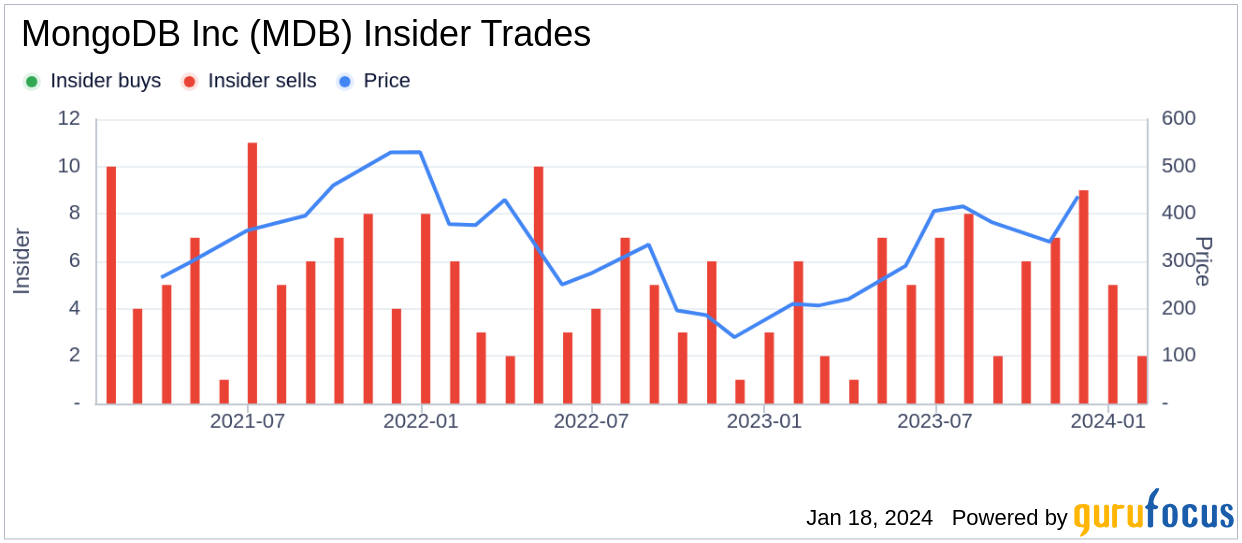
The insider transaction history for MongoDB Inc shows a pattern of insider sales over the past year, with 61 insider sells and no insider buys recorded.
MongoDB Inc’s business involves providing a database platform that enables developers to build and modernize applications across a broad range of use cases in the cloud, on-premise, or in a hybrid environment. The company’s technology is designed to provide developers with the tools to work with data in a highly flexible and scalable way, catering to the demands of modern applications.
On the valuation front, MongoDB Inc’s shares were trading at $400 on the day of the insider’s recent sale, giving the company a market capitalization of $28.31 billion.
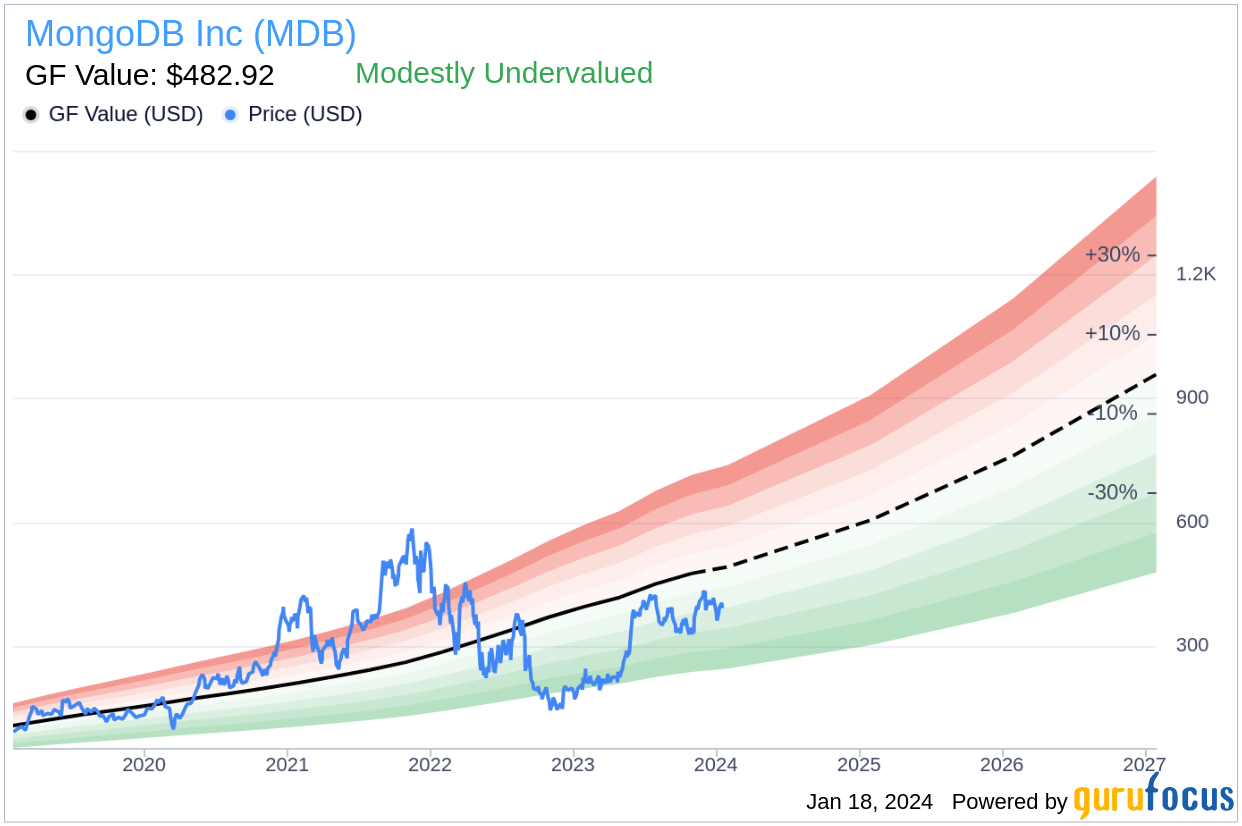
With the stock price at $400 and a GuruFocus Value (GF Value) of $482.92, MongoDB Inc has a price-to-GF-Value ratio of 0.83, indicating that the stock is modestly undervalued according to GuruFocus’s intrinsic value estimate. The GF Value is determined by considering historical trading multiples, a GuruFocus adjustment factor based on the company’s past returns and growth, and future business performance estimates from Morningstar analysts.
This article, generated by GuruFocus, is designed to provide general insights and is not tailored financial advice. Our commentary is rooted in historical data and analyst projections, utilizing an impartial methodology, and is not intended to serve as specific investment guidance. It does not formulate a recommendation to purchase or divest any stock and does not consider individual investment objectives or financial circumstances. Our objective is to deliver long-term, fundamental data-driven analysis. Be aware that our analysis might not incorporate the most recent, price-sensitive company announcements or qualitative information. GuruFocus holds no position in the stocks mentioned herein.
ReSharper 2023.3: AI Assistant, C# 12 and C++ Support, Entity Framework Specific Analyses and More
MMS • Robert Krzaczynski
ReSharper 2023.3 is already available. This release contains AI Assistant and the extending support for C# 12 and C++. There are also Entity Framework-specific analyses and JetBrains Grazie as the built-in grammar and spelling checker.
AI Assistant has already been presented with the introduction of Rider 2023.3. This tool is also available for ReSharper. The latest improvements include AI-powered multiline code completion, the ability to create a library of custom prompts, generation of XML documentation and unit tests. Subscribing to the JetBrains AI Service grants access to the AI Assistant feature in ReSharper.
In the latest update, ReSharper extends support for C# 12 language features, covering basic constructors, alias directives, collection expressions, interceptors and more. The 2023.3 version introduces a new Razor formatting engine, aligning with ReSharper’s C# formatter and adapting to the latest language constructs and formatting options. The option to revert to the previous Razor formatting engine is available in ReSharper’s Options under Edit Code | Razor | Code Style.
New code formatting engine for Razor (Source: JetBrains blog)
In ReSharper 2023.3 also appeared changes according to C++ support. Code completion in currently inactive code blocks inside conditional preprocessor branches now suggests symbols from the global scope. Additionally, Find Usages has been enhanced to display potential usages in inactive code and macro bodies within dedicated results sections.
Furthermore, Entity Framework-specific analyses in ReSharper 2023.3 simplify analysing code for potential issues in the EF model, such as unlimited string property length and dependency loops. Invoking a context menu on the respective inspection and choosing “Show Entity Relationship Diagram” allows for visual investigation of the issue.
Additionally, JetBrains Grazie is now the built-in grammar and spelling checker for ReSharper. Grazie supports over 20 languages and detects natural language errors within ReSharper-supported programming languages (C#, C++, VB.NET), markup languages (HTML, XML, XAML), and comments. In order to include additional natural languages in Grazie, it is necessary to go to Options | Grammar and Spelling | General in ReSharper.
ReSharper has different subscription options depending on whether it is used by an organization or an individual. However, this tool is free for open-source projects or students. Details about subscription models and all features in the new version of the tool are available on the JetBrains website.
MMS • RSS
![]() CloudAlpha Capital Management Limited Hong Kong lifted its stake in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 410.0% in the 3rd quarter, according to the company in its most recent Form 13F filing with the SEC. The firm owned 5,100 shares of the company’s stock after buying an additional 4,100 shares during the period. MongoDB comprises 0.1% of CloudAlpha Capital Management Limited Hong Kong’s portfolio, making the stock its 22nd biggest holding. CloudAlpha Capital Management Limited Hong Kong’s holdings in MongoDB were worth $1,764,000 as of its most recent filing with the SEC.
CloudAlpha Capital Management Limited Hong Kong lifted its stake in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 410.0% in the 3rd quarter, according to the company in its most recent Form 13F filing with the SEC. The firm owned 5,100 shares of the company’s stock after buying an additional 4,100 shares during the period. MongoDB comprises 0.1% of CloudAlpha Capital Management Limited Hong Kong’s portfolio, making the stock its 22nd biggest holding. CloudAlpha Capital Management Limited Hong Kong’s holdings in MongoDB were worth $1,764,000 as of its most recent filing with the SEC.
Other hedge funds have also made changes to their positions in the company. GPS Wealth Strategies Group LLC bought a new stake in shares of MongoDB in the second quarter valued at about $26,000. KB Financial Partners LLC acquired a new position in MongoDB in the second quarter worth about $27,000. Capital Advisors Ltd. LLC raised its position in MongoDB by 131.0% in the second quarter. Capital Advisors Ltd. LLC now owns 67 shares of the company’s stock worth $28,000 after purchasing an additional 38 shares in the last quarter. BluePath Capital Management LLC acquired a new position in MongoDB in the third quarter worth about $30,000. Finally, Parkside Financial Bank & Trust raised its position in MongoDB by 176.5% in the second quarter. Parkside Financial Bank & Trust now owns 94 shares of the company’s stock worth $39,000 after purchasing an additional 60 shares in the last quarter. Institutional investors own 88.89% of the company’s stock.
MongoDB Trading Down 1.3 %
MDB stock traded down $5.02 during midday trading on Thursday, reaching $395.36. The company’s stock had a trading volume of 244,662 shares, compared to its average volume of 1,324,659. MongoDB, Inc. has a 52 week low of $179.52 and a 52 week high of $442.84. The stock has a market cap of $28.54 billion, a PE ratio of -151.66 and a beta of 1.23. The company has a quick ratio of 4.74, a current ratio of 4.74 and a debt-to-equity ratio of 1.18. The business’s 50-day simple moving average is $399.14 and its 200-day simple moving average is $380.69.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings data on Tuesday, December 5th. The company reported $0.96 earnings per share (EPS) for the quarter, beating analysts’ consensus estimates of $0.51 by $0.45. MongoDB had a negative net margin of 11.70% and a negative return on equity of 20.64%. The firm had revenue of $432.94 million for the quarter, compared to analysts’ expectations of $406.33 million. During the same period last year, the firm earned ($1.23) earnings per share. The business’s revenue for the quarter was up 29.8% on a year-over-year basis. As a group, sell-side analysts expect that MongoDB, Inc. will post -1.64 EPS for the current year.
Insider Transactions at MongoDB
In other news, Director Dwight A. Merriman sold 1,000 shares of MongoDB stock in a transaction on Wednesday, November 1st. The shares were sold at an average price of $345.21, for a total transaction of $345,210.00. Following the transaction, the director now directly owns 533,896 shares of the company’s stock, valued at $184,306,238.16. The sale was disclosed in a legal filing with the SEC, which is available at the SEC website. In related news, CEO Dev Ittycheria sold 100,500 shares of the firm’s stock in a transaction on Tuesday, November 7th. The shares were sold at an average price of $375.00, for a total transaction of $37,687,500.00. Following the sale, the chief executive officer now directly owns 214,177 shares in the company, valued at $80,316,375. The sale was disclosed in a document filed with the SEC, which is available at this hyperlink. Also, Director Dwight A. Merriman sold 1,000 shares of the firm’s stock in a transaction on Wednesday, November 1st. The stock was sold at an average price of $345.21, for a total transaction of $345,210.00. Following the sale, the director now owns 533,896 shares in the company, valued at $184,306,238.16. The disclosure for this sale can be found here. Insiders have sold a total of 147,029 shares of company stock valued at $56,304,511 over the last three months. 4.80% of the stock is currently owned by corporate insiders.
Wall Street Analyst Weigh In
Several research analysts recently issued reports on MDB shares. Royal Bank of Canada increased their price target on shares of MongoDB from $445.00 to $475.00 and gave the stock an “outperform” rating in a research report on Wednesday, December 6th. Wells Fargo & Company began coverage on shares of MongoDB in a report on Thursday, November 16th. They set an “overweight” rating and a $500.00 price objective for the company. Bank of America began coverage on shares of MongoDB in a report on Thursday, October 12th. They set a “buy” rating and a $450.00 price objective for the company. TheStreet raised shares of MongoDB from a “d+” rating to a “c-” rating in a report on Friday, December 1st. Finally, Stifel Nicolaus reaffirmed a “buy” rating and set a $450.00 price objective on shares of MongoDB in a report on Monday, December 4th. One analyst has rated the stock with a sell rating, three have issued a hold rating and twenty-one have assigned a buy rating to the stock. Based on data from MarketBeat, the company currently has a consensus rating of “Moderate Buy” and an average price target of $430.41.
Check Out Our Latest Research Report on MongoDB
About MongoDB
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Click the link below and we’ll send you MarketBeat’s guide to pot stock investing and which pot companies show the most promise.
MMS • RSS
![]() MongoDB, Inc. (NASDAQ:MDB – Get Free Report) CRO Cedric Pech sold 1,248 shares of the business’s stock in a transaction that occurred on Tuesday, January 16th. The shares were sold at an average price of $400.00, for a total transaction of $499,200.00. Following the completion of the transaction, the executive now owns 25,425 shares of the company’s stock, valued at $10,170,000. The sale was disclosed in a legal filing with the SEC, which is available at this link.
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) CRO Cedric Pech sold 1,248 shares of the business’s stock in a transaction that occurred on Tuesday, January 16th. The shares were sold at an average price of $400.00, for a total transaction of $499,200.00. Following the completion of the transaction, the executive now owns 25,425 shares of the company’s stock, valued at $10,170,000. The sale was disclosed in a legal filing with the SEC, which is available at this link.
MongoDB Trading Down 2.0 %
Shares of MongoDB stock traded down $8.20 on Thursday, hitting $392.18. 1,244,360 shares of the company’s stock traded hands, compared to its average volume of 1,411,478. The company has a market capitalization of $28.31 billion, a price-to-earnings ratio of -148.55 and a beta of 1.23. The company has a fifty day moving average of $399.75 and a two-hundred day moving average of $380.83. The company has a debt-to-equity ratio of 1.18, a current ratio of 4.74 and a quick ratio of 4.74. MongoDB, Inc. has a one year low of $179.52 and a one year high of $442.84.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings results on Tuesday, December 5th. The company reported $0.96 earnings per share (EPS) for the quarter, topping analysts’ consensus estimates of $0.51 by $0.45. The firm had revenue of $432.94 million for the quarter, compared to analysts’ expectations of $406.33 million. MongoDB had a negative return on equity of 20.64% and a negative net margin of 11.70%. The company’s revenue for the quarter was up 29.8% compared to the same quarter last year. During the same period in the prior year, the business earned ($1.23) EPS. As a group, sell-side analysts expect that MongoDB, Inc. will post -1.64 earnings per share for the current year.
Institutional Investors Weigh In On MongoDB
A number of large investors have recently bought and sold shares of MDB. Simplicity Solutions LLC raised its holdings in shares of MongoDB by 2.2% during the second quarter. Simplicity Solutions LLC now owns 1,169 shares of the company’s stock valued at $480,000 after purchasing an additional 25 shares during the period. AJ Wealth Strategies LLC raised its stake in MongoDB by 1.2% during the 2nd quarter. AJ Wealth Strategies LLC now owns 2,390 shares of the company’s stock worth $982,000 after buying an additional 28 shares during the period. Insigneo Advisory Services LLC raised its stake in MongoDB by 2.9% during the 3rd quarter. Insigneo Advisory Services LLC now owns 1,070 shares of the company’s stock worth $370,000 after buying an additional 30 shares during the period. Assenagon Asset Management S.A. grew its stake in MongoDB by 1.4% in the second quarter. Assenagon Asset Management S.A. now owns 2,239 shares of the company’s stock valued at $920,000 after acquiring an additional 32 shares during the period. Finally, Veritable L.P. increased its holdings in shares of MongoDB by 1.4% during the second quarter. Veritable L.P. now owns 2,321 shares of the company’s stock valued at $954,000 after acquiring an additional 33 shares in the last quarter. 88.89% of the stock is currently owned by institutional investors and hedge funds.
Analyst Ratings Changes
A number of equities research analysts have weighed in on the company. KeyCorp reduced their target price on MongoDB from $495.00 to $440.00 and set an “overweight” rating on the stock in a report on Monday, October 23rd. Truist Financial restated a “buy” rating and set a $430.00 price objective on shares of MongoDB in a research report on Monday, November 13th. Scotiabank began coverage on MongoDB in a research note on Tuesday, October 10th. They set a “sector perform” rating and a $335.00 target price for the company. Tigress Financial increased their target price on shares of MongoDB from $490.00 to $495.00 and gave the stock a “buy” rating in a report on Friday, October 6th. Finally, Bank of America initiated coverage on shares of MongoDB in a research report on Thursday, October 12th. They set a “buy” rating and a $450.00 price objective for the company. One investment analyst has rated the stock with a sell rating, three have given a hold rating and twenty-one have assigned a buy rating to the company. According to MarketBeat.com, the company presently has an average rating of “Moderate Buy” and a consensus price target of $430.41.
About MongoDB
MongoDB, Inc provides general purpose database platform worldwide. The company offers MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premise, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

MarketBeat’s analysts have just released their top five short plays for January 2024. Learn which stocks have the most short interest and how to trade them. Click the link below to see which companies made the list.
Presentation: Comparing Apples and Volkswagens: The Problem With Aggregate Incident Metrics
MMS • Courtney Nash

Transcript
Nash: We’re going to be talking about comparing apples with Volkswagens. I have a background in cognitive neuroscience. I was fascinated by how the brain works in terms of how we learn and how we remember things. Along the way, this funny thing called the internet showed up, and I ran off to join the internet. I worked at a bunch of places. I am now at a company called Verica. There, I started this thing called the VOID, the Verica Open Incident Database, which I will get to and I will talk about.
What Is Resilience?
We’re in the resilience engineering track. This is obviously a topic near and dear to my heart. You’re going to hear this a lot. We’re going to talk about, what is resilience? I have in this VOID that I’m going to talk about lots of incidents. I’m going to share with you some things that people say about resilience. This is actually not an incident report, I lied. The first one is from Gartner. They said that cloud services are becoming more reliable, but they’re not immune to outages, which we would all agree with that. The key to achieving reliability in the cloud is to build in redundancy and have a clear incident response. We’re munging words already here in this space. How about what Facebook said? To ensure reliable operation, our DNS servers disable those BGP advertisements, so on and so forth. Duo is committed to providing our customers a robust, highly available service. An issue exposed a bug in our integration test suite. Microsoft, although the AFD platform has built-in resiliency and capacity, we must continuously strive to improve through these lessons learned. Also agree. We’re using a lot of similar words and we’re conflating things that we don’t want to conflate. I think as engineers, we like to be precise. We like to be accurate in the terms we use and the way we use them.
This is my general feeling about where we’re at as an industry right now. We talk about these things, but I don’t think we really mean the same thing. I don’t think we all know what we mean when we do that. The definition of resilience that I’d like to offer is that a system can adapt to unanticipated disturbances. This is a quote from a book by Sidney Dekker, “Drift into Failure.” I’ve highlighted the things here. Resilience isn’t a property. It’s not something you can instill in your systems and then it just exists and you have it. It’s a capability. It’s an ongoing capability. It’s actions that make resilience. You notice the things that he talks about in here is capability to recognize the boundaries, to steer back from them in a controlled manner, to recover from a loss of control, to detect and recognize. These are all things that humans do, that you do to keep our systems running the vast majority of the time. There are things you do when they stop doing what we hope they will do. What I’m here to really talk to you about is our efforts to try to measure this thing that we still haven’t even collectively defined or agreed upon. We’ve already got it. We’re already starting on shaky ground here.
Can We Measure It?
Let’s talk about metrics with this. This is the gold standard. We talked about this, meantime to resolve, to restore, to remediate. It’s probably something you’ve all heard. How many of you use this in your work? I want to talk a little bit about the origins, the history of this term. Many people might be familiar with this from the DORA work. MTTR is one of the four key metrics that they talk about in terms of high performing teams. That’s not where it came from. Actually, MTTR came from old school line manufacturing, widgets, things that you make, and you make them over again. Then sometimes, either the process or the conveyor belt or the parts break down, and you have this very predictable time window that you know, over time, it takes us this long to fix widget x or that part of that. That’s where mean time to repair came from, a predictable conveyor belt style production environment. Does that sound like anything that any of you deal with? No? This was the formula that came out of that environment. It’s very straightforward. It works. It works in that environment, but this is our environment. This is the reenactment, actually. It’s not the original. This is from Will & Grace. It’s one of my favorite episodes of, I Love Lucy. I think it really captures what we’re dealing with in our reality.
MTTR: What Is It Good For?
I want to talk about the way we talk about MTTR. These are actual terms or ways that people talk about MTTR from their incident reports, or from the internet. MTTR measures how quickly a team can restore a service when a failure impacts customers, allows enterprise level organizations to track the reliability and security of technical environments. Allows teams to set standards for reliability, accelerate velocities between sprints, and increase the overall quality of the product before it’s delivered to the end user. MTTR captures the severity of the impact, shows how efficiently software engineering teams are fixing the problems. Specifies the severity of the impact, or perhaps offers a look into the stability of your software as well as the agility of your team in the face of a challenge. It also encourages engineers to build more robust systems.
There’s that word again. Is one measure of the stability of an organization’s continuous development process. Helps teams improve their systems’ resilience. Evaluates the efficiency and effectiveness of a system or service. Measures the reliability and stability of the software that is delivered. Helps track reliability. Helps teams to improve their processes and reduce downtime. Assesses how resilient the software is during changes in runtime. Helps track the performance of both the Dev and Ops sides of the house. Can be a great proxy for how well your team monitors for issues and then prioritizes solving them. Low MTTR indicates that any failures will have a reduced business impact. Serves as a direct indicator of customer satisfaction. Directly impact system reliability, customer satisfaction, and operational efficiency. These are laudable things to want to know or understand or be able to measure. Could we all agree that one number couldn’t possibly tell you all those things? Yes. I have even worse news. That number doesn’t tell you what you think it tells you, and I have the data to prove it.
MTTR In the Wild: Data from the VOID
Now we get to talk about the VOID. The VOID, the Verica Open Incident Database is something I started almost two years ago. It came out of research I was doing for product, for this company Verica. We had a lot of things that were focused on Kubernetes and Kafka because those are really simple, and no one ever has any problems with them. Along the way, I wanted to see what was happening in the wild. I started collecting incident reports for those technologies. Then I just kept collecting incident reports. Then John sent me a whole lot of them. Then people kept sending them to me, and the next day I had like 2000. Now we have over 10,000. These are public incident reports. Have any of you written an incident report and published it on the internet? I read them. We collect metadata on top of these publicly written incident reports. Maybe about 600 organizations that are in there, some small, some large. Large, gigantic enterprises, small 2-person startups across a variety of formats, so retrospectives, deep post-mortem reviews, those things are in there, but so are other things: tweets, news articles, conference talks, status pages. I have a broader research goal that is why I have all of these things. We collect a bunch of metadata, the organization, the date of the incident, the date of the report, all of these things, if they’re available in these reports. The last one being duration. If it’s there, if it’s in the status page metadata, or if the author of the report tells us that, we are going to use that information. I want to talk about some of the limits of this duration data, because that’s the foundation of MTTR. You take all of these, and then you average them over time.
Duration: Gray Data
John Allspaw has done a great job of describing these types of data in general, these aggregate metrics as shallow data, but duration is a particularly gray version of shallow data. I want to show you how murky those shallows are. The problems that we have with the data we’re feeding into this metric, is that duration is super high in variability but low in fidelity. It’s fuzzy on both ends, like how do you decide when it started or when it stopped? Who decided? Was that automated? Was that updated? Did it ever get updated? Could you have a negative duration incident? Yes, you could. It’s sometimes automated, sometimes not, all of these things. Inherently, it’s a lagging indicator of what happened in your system and it’s inherently subjective. When you average all of those together, you get a big gray blob, which doesn’t tell you anything about what’s actually happening below.
Let’s get into the weeds now. There will be some statistics. Everybody has seen a normal distribution? We all know what this is. It’s a standard bell curve. The mean is smack in the middle of that. If you have a normal distribution of your data, then you can do all kinds of cool things with the mean and standard deviations, and all this really great stuff. Your data aren’t normal. Nothing’s really normal when we do. These are actual histograms of duration data from incidents in the VOID. To make these histograms, we just bin the durations that we find, so everything under an hour, we count those up. Everything under two hours, we count those up. You all are pretty used to seeing histograms, I think. These are your data. I’m not making these up. There will be a simulation. These aren’t simulations, this is real, what you’re telling us is happening. Every single company’s incident data, if you share them with me, look like this. I urge you if you haven’t shared them to go and look at them, because this alone means that you can’t take the mean, and that the mean is meaningless. If that alone doesn’t convince you, then we’ve created a super cool new product. MTTR, it does all these things. It’s the ShamWow of engineering metrics. We made a new product called TTReduce, and it’s a 10% reduction in all of your incidents, magically.
You go out, you buy this product, you install it, you apply it. We’re going to compare MTTReduce to no MTTReduce. This is a Monte Carlo experiment, it’s very much like an A/B test, if you’re familiar with that way of thinking about your website data or whatever, you’re going to test a new feature or something, you compare them to each other. We have a control group, which is all of your incidents without the TTReduce product applied to it. Then this experimental group, we’ve shortened all of your incident durations by 10%. Then we’re going to run a ton of simulations where we take the mean of those data, and then we compare them to each other. If 10%, we should be able to detect that. When you subtract the experimental group from the control group, you should be 10% better. The next graph that you’re going to look at is going to show you those curves, for a bunch of companies. We’ve run the simulation. We’ve compared the mean of the control group to the mean of the experimental group. It should be a nice little curve, right around 10%. This is actually what they look like. The red one I will explain, but all of these have these slumpy, lumpy curves. Right around that 10% mark, you have plenty of other cases where actually your duration got worse to the left here, and lots of cases where you actually think you’re doing better than you did, which is not an environment you want to exist in. Because we measure things to make decisions. Why measure it if you’re not going to do something with it? Can you make a decision based on these data? I wouldn’t want to be in charge of that. The red line is one particular company that sees a huge amount of traffic and a huge amount of internet data, and they have thousands of incidents. Who here wants to have thousands of incidents? Because that’s the only way you’re going to get close to that kind of fidelity, and even then, they’re still wrong sometimes. We know that it doesn’t help. The only way to have more data for MTTR is to have more incidents. That’s not the business that we’re in. This is the talk, it’s like comparing apples to Volkswagens. Average all the sizes of all your apples and take all your Volkswagens, average that together. This is what you’re doing when you’re trying to use MTTR as a way of understanding what’s happening in your systems.
If Not MTTR?
This is always the next question. It really is incident analysis, but it’s a different focus of incident analysis. My point is that your systems are sociotechnical systems, so you need to collect sociotechnical metrics. This is totally possible. Is it hard? Yes. Is it work? Yes. Is it worth it? Absolutely. In fact, I harbor a real belief that companies that do this kind of work, have an advantage. I don’t have the data to prove that yet. I’m not sure I will. I believe that it’s true. These are some of the sociotechnical metrics that you can collect. Cost of coordination is one of my favorites. This is Dr. Laura McGuire’s dissertation work that she did, and that she’s been expanding on. Since then, it’s things like how many people were hands-on involved in the incident, across how many unique teams, using what tools, in how many Slack or whatever channels? Were there concurrent incidents running at the same time? Who was involved in multiple incidents at the same time? Were PR and comms involved?
Did you have to get executives involved? This all tells you so much more about the scale, the impact, the intensity of that particular incident. There are other things like participation, the number of people reading write-ups, the number of people voluntarily attending post-incident review meetings. Are they linking to incident reports from code comments and commit messages, architecture diagrams, other related incident write-ups? Are executives asking for them, because they’re starting to realize that there’s value in these? Also, things like near misses. Are you able to look at the times where Amy was looking at the dashboard, and was like, did you guys see this? This is weird. Is that really happening? Then you fix it before it goes kablooey. That’s pretty cool. That’s a whole source of information about the adaptive capacity of your systems, knowledge gaps, assumptions, like misaligned mental models, and this term that I use a lot, which is safety margins.
I want to talk just a little bit about how you can learn some more of these things. Then I want to give you some examples of what people have learned from this way of thinking about their systems. This is a diagram from a researcher named Jens Rasmussen, it was from 1997. It’s not like new, and it’s not really old either. He arrived at this model, which I will describe, knowing nothing about technology. This is not about software systems, but it’s pretty spot on. The notion he has is that you have these boundaries of different kinds of failure that you can cross in your system. You have your economic failure boundary up here to the right. Are the lights on? Are you paying people? Are you Twitter and you’re shutting down your entire Google Cloud thing today, just to see what happens for fun? You’ll know if you’ve crossed that boundary, pretty quickly. This one down here on the bottom right, the unacceptable workload, unfortunately, we’re all a little familiar with this one as well. In order to achieve what your organization’s goals are, are you pushing things too hard, too far? Are you burning people out? Do you not have enough people to do the things that you want to do? It’s a reality that a lot of us have to deal with. Then the one that we’re really talking about in particular here is this big left hand one, the acceptable performance boundary. That’s the one where when you cross it, things fall over. You’re in some space in here, you have a point at which your system is operating. The other thing that I want to really convince you of here is that you don’t know where that is. At any given time, it might be shifting around in this Brownian motion. The only way you really understand where those boundaries are or where you were, is when you cross them. This is the opportunity that you have to learn from these kinds of systems. If you just look at MTTR, you’re not going to know why you were here, and now you’re here. I want to talk and give some examples of these kinds of safety boundaries, these insights that people have learned from more in-depth sociotechnical analysis of their systems.
Safety Margins
Fong-Jones: It’s trading one mechanism of safety for another. We traded off having the disk buffer, but in exchange, we’ve lost the ability to go back in time to replay more than a few hours of data. Whereas previously, we had 20 hours of data on disk.
Hebert: That’s the concept of safety margin. Ideally, we have like 24 to 48 hours of buffer so that if the core time series storage has an issue where it corrupts data, then we have the ability to take a bit of time to fix the bug and replay the data and lose none of the customer information. This speaks to the expertise of people operating the system, and that they understand these kinds of safety margin and measures that are put in place in some areas, when something unexpected happens to people who have a good understanding of where all that stuff is located are able to tweak the controls and change the buttons and turn some demand down to give the capacity for some other purpose. That’s one of the reasons why when we talk about sociotechnical systems, the social aspect is so important. Everything that’s codified and immutable is tweaked and adjusted by people working with the system.
Fong-Jones: Going through the cast of characters is really interesting, because I think that’s how we wound up in this situation. Two years ago, we had one Kafka expert on the team, and then I started doing some Kafka work, and then the Kafka expert left the company. It was just me for a little while. Then the platform engineering manager made the decision of, ok, we think we’re going to try this new tiered storage thing from Confluent. Let’s sign the contract and let’s figure out the migration. We thought we had accomplished all of it. Then we had one engineer from our team sign up to finish the migration right, like already running in dogfood, make it run in prod. Then when we started having a bunch of incidents.
Hebert: There was this transfer of knowledge and sometimes pieces fall on the ground, and that’s where some of the surprises come from. It’s not something for which you can have quantitative metrics. It’s something you have qualitative metrics for, which is, do you feel nervous around that? Is this something that makes you afraid, and getting a feeling for the feelings that people have towards the system is how you figure that one out.
Nash: I’ll play one more, which is from incident.io, which is another company in the space providing tooling. It’s Lawrence Jones, who’s an engineer there. It’s talking about patterns and the knowledge they’ve accumulated over time and the patterns, these instinctual things that they’ve figured out that only these humans running these systems can recognize, and then how they’ve been using those patterns and incidents to help them muddle through that faster, then figure out what’s happening a little bit better.
This is from an engineer at Reddit. I don’t know if anybody remembers the GameStop stuff that happened a while ago, and that Reddit got just absolutely hammered by this. They did a really fantastic thing, they called it an incident anthology. They wrote up a whole bunch of their incidents. They also talked about some of the patterns across these. In particular, they talked about just the process of doing that work and of what comes out of it.
Garcia: In terms of telling these kinds of stories, it serves a purpose that is not really served by anything else that we do, even post-mortems, or even documentation, because this is basically memory. We have memory as people, and we share that memory across people by telling stories. We need to do that as engineers. The only way that we can actually do it with people across different organizations is by writing it up, and having that collective memory grow.
Nash: That’s the task at hand.
Key Takeaway
The takeaway from this talk is that it’s people that make resilience. It’s not this technology or that tool or this piece of automation. It’s the collective work that we do together, the knowledge that we build over time, this adaptive capacity for our systems. You can’t measure that with something like an aggregate metric.
Questions and Answers
Participant 1: How would you suggest getting teammates, organizations on board with more of these qualitative metrics in companies that are traditionally very quantitatively focused or care more about what was the dollar cost of this incident?
Nash: There’s a slide from a talk that a fellow named David Lee gave. He’s given it now at a couple of places. He gave it at DevOps Enterprise last year. He gave it at the Learning From Incidents Conference. He is in the office of the CIO at IBM. Not a small company, very heavily focused on quantitative metrics and measuring things. The Office of the CIO is a 12,000-person organization. He’s done an amazing job over the last year and a half now, of doing the kind of incident analysis at a really small scale. When he started, they actually did it as a skunkworks project. It was not sanctioned by leadership. There was no big program for it. They’d had some experience at doing this and approaching incidents this way. He started just analyzing a few of them and sharing that, socializing that with engineers who were involved. The engineers who were involved were like, this is really good stuff. It was very much a grassroots, from the ground-up type of way of doing it. I do believe that is the way that this works. I don’t think you’re going to have a lot of success trying to tell executives, we need to go do this. This is the vegetables in the smoothie way. If you look around, there will be like-minded fellow travelers. You could find them, and then do this on a small scale with them. The value will be demonstrated, and slowly but surely, you can build that. That’s exactly what David did in the office of the CIO. They now have a situation where they have a monthly learning from incidents meeting. They have a rotating trained group of folks. One of them presents a case from an incident, it’s not always the most severe one, it’s the one they think they’d learn the most from, they get upwards of 200 people attending these. At the executive level, they finally got buy-in. The CIO herself would show up with her direct reports, and then suddenly everyone was paying attention. Hundreds of people come to multiple meetings, hundreds of people watch the recordings. Now what he’s doing is he’s quantifying qualitative data, which you can totally do. Social scientists have been doing it forever. My advice is to start really small, demonstrate the value amongst fellow travelers, and then you can build it and scale it from there.
Participant 2: In our organization we collect metrics about incidents and issues, there has been this thing about the collective memory or you know something that maybe on the back of your head is a blowup, because if someone is not paying attention, and your team is not aware, or if someone leaves with the knowledge. What are the top actions that you derived from the metrics that you ultimately shared the knowledge and improved the way that the teams handle their incidents?
Nash: I really think the cost of coordination stuff is really valuable here, because a lot of times the effort to manage incidents is obfuscated from the rest of the organization. Things like MTTR contribute to that obfuscation. If you start collecting metrics on like, actually, that really high severity or really long incident, it might have only taken two people, and they worked on it. Then there was this other thing over here, and that took 15 people and someone from PR. That’s where you start to show to your organization the cost of those incidents. You could probably get the cost. If you’re amazon.com, you know how much money you lose if your website’s down per second. These are these other associated costs, and you can quantify that too. You can say our incidents are involving this many people. That’s one of the top things that I would start focusing on. Then highlighting themes and patterns is a really great way of doing that. A couple of organizations that I know of that are doing that are doing it in a really powerful way. One of the things that David Lee talks about in his talk, is the big initiatives that actually came out of this. They had one where they did end up rearchitecting some. They had another one where they just changed the way people worked together on something. The patterns that you see across your incidents, those themes can sometimes highlight these things that you’re trying to make a case for. Oftentimes, it’s giving you data for rearchitecting something or fixing something that you as the engineer is like, I know this is going to blow up. If you can use your incidents to show that you’ve learned that, then now you have evidence.
Participant 3: Did you ever find any incidents where some teams were trying to maliciously gamify those metrics and push the blame to other dependencies, other folks, and not lose their trust.
Nash: I don’t really find evidence of that in the incident report. I do know of this as a phenomenon. Any metric becomes a target, Goodhart’s Law. We do see this thing happening, or where people will do really ridiculous things to essentially pervert the incentives or gamify the MTTR, make it look like their team’s MTTR is better than others. There’s also weird, behind the scenes horse trading stuff that goes on. I think that is very much a phenomenon that can happen, especially with these aggregated metrics where they don’t mean a lot but you can figure out how to push them around.
Participant 4: You had mentioned near misses. It seems like that would be very difficult to quantify, because the whole point of a near miss is it’s a near miss.
Nash: I wasn’t suggesting you count your near misses.
Participant 4: How do you turn it into a metric, in a systemic way, actually, other than two people having a chat on it?
Nash: I actually wouldn’t recommend trying to quantify near misses. You might be able to quantify the information you get for them. Really what I’m suggesting measuring your misses is getting that qualitative sociotechnical like, “I thought that system x did this, but you think it does that.” You can then surface those as themes or patterns. Clint Byrum at Spotify is doing a really good job of this, where they’re like, this incident matches the theme of squad confusion, or a misalignment of how things work between this squad and that squad. I think if you can roll things up to like themes or patterns, then maybe you can get to some form of quantification. I’m definitely not saying take all of your near misses as the numerator and your incidence is the denominator or the other way around, and use that as a metric. Please don’t do that. Also, you can’t count all your near misses. It’s a lot of work to even investigate those. I think it’s just picking the ones that you have a spider-sense about, that will tell you that. The other reason I like near misses is they don’t have all of the trauma. They’re successes, but they have all of the underlying stuff of incidents. Oftentimes, you can get these details out of them, especially if you’re in a pathological organization, where there’s finger pointing. In this case, it’s like, you can call up the hero worship stuff a little bit and be like, “Jane figured this out. Why? What was that? What was happening there? How can we take advantage of that? Or what do we need to do to not let that go over the rails next time?”
Participant 4: My point was the fact that near misses means that you missed them and you don’t know what they were. Then, when they happen, then you start identifying near misses.
Nash: It might be semantics.
See more presentations with transcripts
MongoDB’s (NASDAQ:MDB) investors will be pleased with their incredible 375% return over …
MMS • RSS
For many, the main point of investing in the stock market is to achieve spectacular returns. And highest quality companies can see their share prices grow by huge amounts. Don’t believe it? Then look at the MongoDB, Inc. (NASDAQ:MDB) share price. It’s 375% higher than it was five years ago. This just goes to show the value creation that some businesses can achieve. It’s also good to see the share price up 16% over the last quarter. But this move may well have been assisted by the reasonably buoyant market (up 12% in 90 days).
Now it’s worth having a look at the company’s fundamentals too, because that will help us determine if the long term shareholder return has matched the performance of the underlying business.
Check out our latest analysis for MongoDB
MongoDB isn’t currently profitable, so most analysts would look to revenue growth to get an idea of how fast the underlying business is growing. Shareholders of unprofitable companies usually expect strong revenue growth. Some companies are willing to postpone profitability to grow revenue faster, but in that case one does expect good top-line growth.
For the last half decade, MongoDB can boast revenue growth at a rate of 35% per year. Even measured against other revenue-focussed companies, that’s a good result. Fortunately, the market has not missed this, and has pushed the share price up by 37% per year in that time. Despite the strong run, top performers like MongoDB have been known to go on winning for decades. On the face of it, this looks lke a good opportunity, although we note sentiment seems very positive already.
You can see how earnings and revenue have changed over time in the image below (click on the chart to see the exact values).
MongoDB is a well known stock, with plenty of analyst coverage, suggesting some visibility into future growth. If you are thinking of buying or selling MongoDB stock, you should check out this free report showing analyst consensus estimates for future profits.
A Different Perspective
It’s good to see that MongoDB has rewarded shareholders with a total shareholder return of 111% in the last twelve months. Since the one-year TSR is better than the five-year TSR (the latter coming in at 37% per year), it would seem that the stock’s performance has improved in recent times. Given the share price momentum remains strong, it might be worth taking a closer look at the stock, lest you miss an opportunity. I find it very interesting to look at share price over the long term as a proxy for business performance. But to truly gain insight, we need to consider other information, too. For example, we’ve discovered 2 warning signs for MongoDB that you should be aware of before investing here.
For those who like to find winning investments this free list of growing companies with recent insider purchasing, could be just the ticket.
Please note, the market returns quoted in this article reflect the market weighted average returns of stocks that currently trade on American exchanges.
Valuation is complex, but we’re helping make it simple.
Find out whether MongoDB is potentially over or undervalued by checking out our comprehensive analysis, which includes fair value estimates, risks and warnings, dividends, insider transactions and financial health.
Have feedback on this article? Concerned about the content? Get in touch with us directly. Alternatively, email editorial-team (at) simplywallst.com.
This article by Simply Wall St is general in nature. We provide commentary based on historical data and analyst forecasts only using an unbiased methodology and our articles are not intended to be financial advice. It does not constitute a recommendation to buy or sell any stock, and does not take account of your objectives, or your financial situation. We aim to bring you long-term focused analysis driven by fundamental data. Note that our analysis may not factor in the latest price-sensitive company announcements or qualitative material. Simply Wall St has no position in any stocks mentioned.
MMS • RSS
If you had invested $1,000 in MongoDB’s 2017 initial public offering, you’d be sitting on more than $16,800 today. That far outpaces the returns over the same period of each of the five most valuable pure-play software as a service firms—Adobe, Salesforce, ServiceNow, Shopify and Workday. It also beats the returns over that period of Microsoft and Apple, the world’s two most valuable companies.
Three years before MongoDB’s IPO, Dev Ittycheria joined the firm as CEO, and he has led the company since. Ittycheria is a former entrepreneur and venture capitalist. He co-founded BladeLogic, another enterprise software company, which went public in 2007 and which BMC Software later acquired for $900 million. Before coming to MongoDB, he was managing director at OpenView Venture Partners, and he was a venture partner at Greylock before that.
MMS • RSS

Systems management and security software provider Quest Software is shipping Toad Data Studio, a platform for streamlining database management in heterogeneous relational and NoSQL database environments.
Announced January 17, Toad Data Studio allows users to manage nearly any database platform in their environment including cloud and on-premises sources and relational, NoSQL, and data warehouse sources, Quest Software said. A free trial is offered.
Toad Data Studio features an advanced SQL editor, SQL and DDL generation, and the ability to edit JSON and XML fields directly within table fields or in their own separate editing window. Users can compare data results across different queries or between different environments, either on the fly or through automated workflows, and develop desktop automations for routine tasks.
Database engineers, developers, and other databases professionals can visually profile and sample datasets for patterns, duplicates, and other attributes from a single pane of glass. Other capabilities of Toad Data Studio include letting data stewards and developers compare data schema and develop sync scripts, and moving data between systems when needed, for data professionals.
Next read this: