Month: April 2024

MMS • Sergey Bykov

Transcript
Bykov: I’m going to be talking about durable execution, what it is, what the programming model is like, the benefits and tradeoffs, and how it fits in the whole landscape of cloud native. If we talk about cloud native, the following properties come in mind, we want to be able to add, remove hardware to increase, decrease capacity, like scalability. We want to run on imperfect hardware that can fail and will continue to run, especially when we remove hardware, we have to be fault tolerant at any point. We want to have systems built out of loosely coupled components that can be developed, deployed service independently, but different teams that we can scale out our development organization. We want to evolve fast, like people get frustrated when they cannot get their code in production in a few hours, a few minutes. We want to enable this fast innovation by loosely coupled teams to move forward. This is like high level interdependent and overlapping consorts in some degree because you cannot be scalable or not fault tolerant. You cannot evolve fast if you’re tightly coupled. This is the blob of concerns at the very high non-functional level. If we look from an engineering perspective, we deal with a set of concerns that we need to deal with when we write code. We need to implement business logic, because that’s the whole point of solving business problems. State is just a fancy word for data. Applications are about data, we have to manage it. When we have these decoupled systems, loosely coupled systems, then they access state, we have to deal with concurrency, with race conditions, consistency, and all of those things, and of course failures.
My mental picture when I look at this is fault tolerance transcends, goes through all of these other concerns, because failures come in all different ways: when we talk to other systems, when there are bugs, when there are race conditions, when there are corruptions of state. This domain has been interesting for me for many years, because the failures is how we perceive imperfections of a system. In particular, I’ve always been interested in developer experience, like how do we write less code? How do we write code that is cleaner, that is more powerful? How do we make us more productive and enjoy doing that in the process?
Execution of Business Logic
Let’s look at an intentionally contrived example of a function that implements some business logic to process a request. We receive some arguments, I call this, function handler, we see the x and y, and then we need to call some function foo, pass an argument, get the result assigned to variable a. Then call another function bar, likewise, get the result, and then compute something in return and some business logic. If everything was performed locally within the process on memory, that’s trivial, that will take nanoseconds, will return the result. The chance of failure is really slim. If the machine crashes, there’s nothing we could do there anyway. In reality, these calls are usually calls to other APIs, other systems, other services, whether they’re microservices or not, doesn’t matter. They leave our process, they leave our memory, and things are much less ideal, because these calls can fail, they can time out, they can just take time. We’re dealing with these integrations with other systems that are outside of our control. Because we have to wait for these calls, and we get partial results, we have to manage state. These variables that are in this code, they actually represent handling up state, like these variables a and b, like where is a stored after we called foo? If the bar fails, what happens to a? C is ok because local computation, but still, how do we manage state?
The straightforward approach is RPC, remote procedure call, where we have a client that sends a request to our server. We make a call to one service like foo, make another call, everything succeeds, we return result, everyone is happy. If a call to one of these services fail, we pretty much do nothing, we just return an error to our caller, say, it failed. Very simple. There’s value in simplicity. Very simple, beautiful model in a way, but we push the whole problem to our caller. In some scenarios, that’s perfectly reasonable and what we want. If I’m a caller, and I know what I’m doing, I can tell you, please return error, don’t do anything if it failed. In many scenarios, actual error calls would prefer us to deal with these errors. For example, if they’re transient, if there is a service unavailable or if there’s throttling, like we got 429, what do I do as a caller with 429? There’s nothing I can do. I used Go syntax. It’s essentially the same code as in the previous slide where we call these functions, and we return in case of any errors, very simple.
Persistent Queues
To deal with these problems, people move to using queues as a reliability mechanism. Of course, we’ve all done that. What happens here, instead of calling the service directly, the caller puts a message in the queue. Once the message is recorded, that’s ack by the queuing system client, the caller is happy because the queue guarantees that the message will not be lost. They will be delivered eventually to the processor. It travels to the head of the queue. Then we read it in our server process, and we start executing. Again, one service calls another one. If something fails, we don’t delete the message from the queue. Even if our processor fails, we restart, message is still in the queue, we read it again, we make another call. Eventually we delete the message. From the coding perspective, it’s the same handler code on the left-hand side, but we just need, it’s almost like pseudocode, a function that will read the message, try to call our handler. If it succeeds, sometimes returns the result if needed, and then delete the message. That really is good.
Lily Mara talked about this transformation, they move from synchronous to asynchronous processing by moving from RPC to queues. She talked about the challenges. One big challenge they ran into with a single customer essentially clogging the queues, because queues cannot be realistically done per user or per customer, they always have shared partitions. If some messages get stuck because they cannot be processed, they back up whole queues. Another problem with this is that there’s very little visibility in what’s going on. How do we know what’s the status of this message? How do you know how many times will you try to process it? The worst in that, this is just like one hop where this one service, the service call, that service may be calling another service and also to the queues, and then another one, and you have this chain of queues that can be backed up. When everything is working fine, it’s good, but when something gets stuck, it’s very difficult to figure out what’s going on, what is happening where. This architecture, sometimes referred to as duct tape architecture, we have this duct tapes between services that connect them. If I go back to my mental picture, essentially, we have these components, business logic, state management, integrations with other systems, all mixed up as these fruits and vegetables in the big blender. That’s what we call smoothie architecture. All these concerns are mixed together in small pieces, intermixed in one big piece of code that we have. For example, if we were to replace the business logic, we want to check this strawberry out and put cherry, it’s very difficult because we need to find all the pieces of strawberry in our blender, remove them, and then blend the cherry instead. It’s a metaphor, but you’ve dealt with this code. It used to be called spaghetti, but I think this is a more appropriate illustration. What I argue we need is the layered cake where all these concerns, they’re put in separate layers. Then if we need to replace business logic, we just take a replacement layer and we don’t have to be concerned with touching and breaking other, for example, integration or layers for a system. Likewise, if want to change something in our integrations, particular external service, we don’t have to go into business logic and change the logic there.
Durable Execution
Durable execution, what is it? It’s a model that’s implemented by a family of technologies. For example, AWS has this simple workflow system, which is available as an external service you can build the application with, but also, it’s heavily used internally for things like orchestration of internal infrastructure. Then Azure has this Azure Durable Function as an extension of Azure Functions, also a popular service. Uber has the open source project, Cadence. I got an email from a recruiter from Uber saying, we have this opportunity with open source project, Cadence, and it actually powers more than 1000 services at Uber. I was surprised because the last figure I heard was 300. Between then and now, they built even more, several hundred services. Temporal is a fork of Cadence. All these technologies were created by a couple of brains that are co-founders of the company I work for. These are various implementation, the same ideas. I’ll use Temporal syntax and terminology, but it applies across the board. It’s the same, just easy to be consistent.
In a durable execution, we don’t send a request unlike an RPC, we don’t say, process this. We start a workflow. This is like an example, one line, ExecuteWorkflow, provide workflow type. In this case, it’s FooBar, the same function. I used some options, optional IDs. That’s how we start this operation. Everything in that sense, is a workflow. What is a workflow? It’s a very old term that’s been used since at least the ’70s. I pulled this from the seminal book by Phil Bernstein and Eric Newcomer, where they have this interesting definition. They say, the term workflow is a commonly used synonym for the concept of a business process, which is like almost a circle of logic. In reality, they were forged as a set of steps that gets us to our goal. There is some business goal to achieve, something we process. We need to go through a bunch of steps, and then we’re done with the process. That’s a very simple concept. You can think of it as a workflow is a transaction without these ACID guarantees. It’s durable, very durable, but it doesn’t have atomicity, isolation guarantees. Consistency is eventual. Another example would be like Sagas is a popular pattern, you can think Saga is this special subset of workflows and steps. Despite that, it sounds like guarantees are very lose, there’s no ACID guarantees inside durability. It’s actually a very powerful concept. I’m going to explain why and how it works.
Workflow implementation looks similar to what we have in our basic function, except we have this different syntax. One part is we have this workflow.prefixes, think of them as syscalls. We’ll make a call into the system, we prefix it with that. You’ll see why later as I explain how things work. The other thing that you notice here, instead of calling the function foo and bar directly, we wrap them in this ExecuteActivity. Activity is the second fundamental primitive in durable execution, this workflow is a business process, and there is activity with this stateless action we execute. We call some other system, that’s an activity. We wrap it this way, so that we can do much more magic there than just calling a function. You will probably ask a couple of obvious questions like, so what happens if the foo gets a transient error, like we got service unavailable or some plain error? There is no code here to deal with that. It’s exactly why we need to wrap our functions because all these retries happen, they’re done by the runtime, by the system. Because what do we want to do when we get a throttling error? Generally, we want to wait a little bit and retry. Then if we get throttled again, we want to wait a little bit longer, so we want to have exponential backoff up to some reasonable limit and keep retrying. That’s exactly what the system can do. We just need to specify a policy, global or for a particular call, and we don’t need to write code for that. Because at the end of the day, we want separation to succeed.
Another question you might ask, so what happens if we called foo and then the process crashed? What happens? For that, we need to look at how actually things work under the covers. It’s counterintuitive as it may sound, the server in durable execution does not execute application code at all. Application code runs in this worker processes that are managed at the application side. There’s a very clean separation between logic of the application and the whole system. When there is a request from the client to start a workload at one line, and show the start of workflow execution, what the server does is it creates a workflow document, with all the parameters to record what was asked, like workflow ID or parameters. Persistent in the database, of course. Then it sends a command to workflow worker and say, start workflow execution. Because it uses the SDK, the runtime, the worker process, it essentially starts executing our function, that handler. It starts executing it and gets to the point where we want to invoke activity foo. Instead of invoking it, it will call the command, an instruction to this server under the covers, that line of code. That’s why we need to wrap it in a special syntax. It sends a command back to the server. What the server does is record this intent, that there is an intent to execute activity foo with these parameters, and this execution policy for retries. Then it turns around and sends a task back to activity workers. Workers can be bundled all together, or they can be separate, like workers for workflow logic, workers for activity logic, workflows for different workflow types and activity types. They can be managed in any way. When worker process starts, it registers with this server, so server knows where to send a task to execute foo. Say, there is a worker that implements foo, and they send the command. The worker gets the command, and then makes a call. Call successfully completes. Then a response to the server saying, this is the result. This is the output I got, which gets recorded by the server in the database, and as part of the command there’s an optimization, there is a request, a command for the next activity, in our case bar. Again, it turns around, the same happens, try to make a call, and let’s say this call fails, or maybe our worker crashes, or even the whole system can go down. It doesn’t really matter, because when we recover, the server will keep trying to send this task and say execute bar, execute bar, this is the argument. A new worker process that receives this command, it replaces. It gets to the point of executing bar, and then starts executing from that bar. Foo never gets re-executed, because it’s already completed. Its input and outputs are recorded in the system. When we execute the bar successfully, again, the same happens, we record on the server. Workflow completes. That’s where workflow successfully completed. You see why we need these syscalls, they intercept our intent. They can be recorded in this server. Also, they can inject when we execute code, instead of making a call to foo again, it injects the output right away, so we bypass execution to make it efficient.
All this stuff, they get recorded in actual document called workflow history. On the left-hand side, there is an abbreviated version, a business view of execution. At the bottom there are two activities that we executed, with their results and inputs, and all of that. On the right-hand side, there is a full history of execution with 17 steps starting from server pool execution to complete workflow execution for everything. When the worker needs to restart, it gets this document, and can operate on it. It’s a very important concept. The third concept with workflow history is a document that gets recorded on the server. If something fails, now I’ll zoom in to show, this is the history of a running workflow that has a failing activity. Its history instead of 17 steps is short, like 13 I think here. When I zoom in, you’ll see that that screenshot on the left-hand side shows that we’re currently at the step of trying to execute activity bar, and it’s the fourth attempt to execute it. The next attempt will happen in 3.79 seconds. You can see exactly where it’s running. Here it’d be more clear why we want to retry sometimes forever, or for a long time, because if we see this issue, and protocols change. We recall some other service, and they deploy a new version, and now somehow, it’s incompatible. This call will be stuck there. We can see, ok, here’s the error. I intentionally injected the error here. We can see that, ok, something is failing, we can fix our code, or they can fix their code, kill this worker, deploy in fixed version. It’ll continue from this step, the next retry will happen, and it’ll succeed, and it completes execution. You don’t have to go back and restart the whole process. You can continue. This is what I did here when I was creating the slides. I injected this era, and then I killed it, remove our injection, restarted, and it completed successfully. It’s a very important concept of this workflow replay, where we can go and continue for as long as we want.
Note that by recording steps on the server, we’re implicitly performing state management. These variables in our code, they’re like a, b, and c, a and b in particular, they effectively get recorded on the server by us recording inputs and outputs of every activity, because they can be reconstructed in memory at any point in time by having a workflow history. We get management of state for free for us. We didn’t need to write code to persist a in a database, or persist b in a database, it’s all there. Some applications choose to use the state facility as their main storage. Believe it or not, a service that handles loyalty points like Uber, it doesn’t record this in the database at all. Every Uber user like us, has a workflow like that, with their identity running, and it has loyalty points in that workflow, which is nowhere else in the database. If you think of it, that makes sense, because the whole history of this workflow is essentially an event source style persisted state of it, which is better than the single record in the database. Because of this replay functionality, if there’s a bug in the code that computed incorrectly, you can go and fix the bug and then reset workflow and replay, rerun your computations. It’s actually what happened several years ago, where there was a bug, and our users noticed that, my loyalty points are incorrect. They went back, fixed the bug, and we saved probably millions, if not hundreds of millions of workflows, replayed and fixed loyalty. It’s a very powerful concept. You see why we refer to this whole technology as durable execution, because our code is read in a happy path style, but as if it runs in some kind of ether, on the machines where all the state is persisted, will keep going forward. Killing machines, killing process doesn’t matter, we keep making progress, like in this durable, persistent way.
Time is an interesting concept, both in life and in computer systems. This is like a real-life business scenario, where we are handling people that subscribe to our service. They went in, they filled in the form, click submit, we got a request. We need to provision them in the system. Then what we wanted, our marketing department wanted, said, wait a week, and then see if the user performed any action, send them email with tips and tricks how to use the system better. If you detect that in a week, they haven’t done anything, send them a nudge email saying, you’ve not used, there are all these benefits of the system. Make this a simple statement. Very typical scenario. We can of course implement it without durable execution. We can have persistent timer. We can have handlers for this. When the timer fires, we need some distributed lock, make sure we don’t do it twice. I’ve done this. I’m sure many of you have done that. I don’t want to do that. Because I want to deal with this, spend my development cycles on that. Durable execution, it’s like normal code, like activity to provision user, and then notice this, we can do that workflow.Sleep for 7 days. I can put 30 days. I can put 365 days. It doesn’t matter, because this process, this workflow, it doesn’t need to stay in memory for 7 days. We can just evict from the cache, and then replay 7 days later. Because of this durability of execution, these delays or dealing with time becomes trivial. It’s literally like one line of code. Another typical scenario is processing statements, 1st of the month, you want to compute the bills and send to customers. Then after you’re done, you want to sleep until the next 1st of the month, or whatever the date is. Again, you can do it in this cycle, and that’s very easy to do. That’s what attracts these scenarios to durable execution model, because otherwise it’s very difficult.
If I go back to my mental picture, we managed to decompose or separate business logic from integrations, because we put them in activities and we separate it. In our core business logic workflow, we don’t have any logic that deals with any peculiarities of calling external systems. In fact, you can have domain expert writing business logic in the workflow code and have people that specialize in integrating with particular systems to write activities. Some of this code can even be autogenerated. For example, there is a project to generate a set of activities from the formal definition of AWS APIs. You get the full library of how to invoke a particular service, like EKS. That’s what I would argue moves us from smoothie architecture to this layered cake, where if we were to replace now our strawberry with cherry, we just go to workflow logic and change it. We don’t touch on the systems. We don’t deal with any error handling or state management. It just works. This is important to understand, this is the core of the model. I only covered the very core principles, because if you understand that, if you understand how it works, the rest just makes sense. Of course, there are many more features, and I’ll cover a few of them. These are the core concepts. They have business logic of workflow, where you have activities, and you have this machinery that does all retries and deal with failures for you, and manages state by recording every step.
Signals
Let’s look at some of the features, signals. Signals is a mechanism to interact with the running workflow, you can send a message to it. There are many scenarios that this empowers. It can be a thermostat sending temperature measurements, like every minute, every whatever interval to a workflow that manages this thermostat, manages the room, or the whole building, just keep sending messages. It can be coordination. Like you have a fanout where you try to process many files, but you also want to control how many of them are processed in parallel. They can send messages. The signals, of course, can send signals to each other. The third category is there is a human in the loop. The classic example is you do money transfer, and if it’s under $10,000, you just go and perform it. If it’s more than that, you want to run probably an activity or a child workflow to say, notify the approver, the user, and say, please review it and approve. Then when that approver receives this, and when they get to it, and they click button approve, that sends a signal to workflow and workflow can continue from that point and perform the transfer. Or if the user clicks decline, send a different signal and say, we don’t need to transfer this. Sending is a single line of code. As you can see, we need workflow ID, we need signal name. It’s very loosely typed business strings. You can send arguments there. Implementation is also simple. This is Go style because Go has support for channels, so it’s natural to create the channel and then receive on the channel. In other languages support like Java, or .NET. TypeScript, there’ll be a callback that you register. Of course, you would expect signals are recorded in the system, they are durable. The moment you send signal, you get ack back. That means it’s in the system. It will not be lost. It will not be like, not delivered. The delivery is very strong, and will get to the workflow.
Queries
Queries is the inverse of signals. This is when we want to ask a running workflow, give me some variable, something. It’s a read only operation, you cannot influence execution, you can only get values back. In my example of processing a bunch of files, it makes sense to query and ask, what is your progress? Are you 5% done? Are you 75% done, and get back the progress. That’s a mechanism for that. On the implementation side, you just register a function, say for this query name, essentially progress queries, it’s a string constant. It’s a type of a query. You can also pass arguments, and then you just function to do that. Very straightforward.
Data Converter
Many of you have dealt with security reviews, especially with financial institutions, in this area. I am not exaggerating. When you talk to them, when they explain how data converter works, they visibly relax, like you can see it on Zoom. They’re always tough, like [inaudible 00:28:54] people. When you explain how this feature works, they don’t get happy. They’re never happy, like these kinds of people. They relax, like, ok now I understand, I have less concerns. What is this? Because of this strong isolation, that application code doesn’t run on the server, because server only sends like tasks back and forth and receives commands. It doesn’t need to know what’s actually been executed or what arguments are. It can manage encrypted blobs, send them back and forth. You just record them in this database that, activity with this argument. Those arguments can be completely encrypted blobs. We can easily inject data converter before any communication happens with the server. Very trivial, very easy to verify. It’s actually even stronger than HTTP or TLS, because there’s no handshake. There is no agreement and encryption algorithm key, all is done on the application side: encryption, protocol, keys, any kind of length, rotation, completely under control of the application owner. That’s what makes those people very relaxed, and understand, actually, I can put this checkbox up. It’s safe to run. The interface, kind of what you’d expect. There’s couples of methods, the ToPayload, FromPayload, very trivial, again, very easy to understand how it works, for the single payload or for a group of payloads. ToString, that is for debugging, for human readable stuff. Injecting data converter is just part of the configuration of the dialer. It is a client that dials to the server. This is one of the parameters, set data converter, inject your own implementation, whatever it is.
Entity Workflows
Entity workflows, it’s technically not a feature, it’s just a pattern. It’s such a useful and powerful pattern, that it’s worth mentioning, in particular. Because the system provides this very strong guarantee that once you start a workflow with a particular ID, a second workflow with the same ID cannot be started. There’s very strong consistency guarantees that allow us to have these workflows that have physical or virtual entities as their identity. It can be user or user ID based on their email or phone number, UUID, or files, or machines, pods in the system, anything you want can be modeled at the workflow. With this one-to-one mapping from the entity workflow to actual physical or virtual entity, that makes it very easy to control access, and serialize and prevent any concurrency issues. Essentially, entity workflow, another name for it is actor workflow, because it satisfies the three criteria for actor. It completely encapsulates its own state. There is no way to get directly to it. It can receive or send messages, and it can start other workflows. Effectively, there’s actors. That’s what they call, actor workflows. I spent more than a decade working on actors, and I’m so happy that these concepts converge, because they all make sense. They help us to be scalable and safe with these isolated entities that can talk to each other, but they don’t cross access variables of each other’s state.
Tradeoffs
Of course, you’ll say, if everything is so great, where is the catch? Of course, there are tradeoffs. Everything in systems or in life, you have a tradeoff. What do you pay for this? One thing to keep in mind is roundtrips, because everything is persisted. There is constant communication with the server and database to record everything, make it durable. When I look at this model, when our CEO first described this idea back 13 years ago to me, I thought, it’s not easy, it’s too slow. If you keep going and recording everything, it’s never going to be fast. Now, we have very efficient storage, we have very fast databases, things are changing. It becomes very acceptable even for scenarios, like we have our customers implement human order of like Taco Bell, a pizza like Yum! Brands to do it. Or money transfer, there’s mobile apps that are powered by workflows, and they can just press the button and transfer money. These latencies are sufficient for these kinds of applications. There is more investment being done into making even more optimizations there, because you can speculatively execute and record success, instead of recording every step, there are some tricks that can be played there. Because of this durability, throughput of a single workflow is limited. If a roundtrip is 20 milliseconds, at the most we can run 50 operations per second. We can reduce our roundtrip to 10 milliseconds and we’ll still be 100. You cannot have high throughput workflows. You cannot have the synchronization point where all these files that you process, they talk through a single one to coordinate. That’s very anti-pattern. It’s a limitation. It also has a positive side because it forces you to decompose your state. It forces you to avoid these bottlenecks. It forces you to make things more scalable and more loosely coupled. I mentioned how history gets replayed by the worker if it restarts and it needs to continue. There is some practical limit to the size of history. It’s not just about data size, because we can cheaply store and pass in modern data centers, gigabytes of state and load them. There is practicality in replaying this. We don’t want to restart the workflow and replay it for minutes, even if we can get the state fast. There are limits in the system. The way you work around it, you essentially snapshot. At any point you can say, ok, I’m done. Let’s start a new incarnation on this workflow with this state that I had at the end. Instead of keeping it running forever. That’s the workaround.
The biggest limitation is determinism because this replay mechanism, we have to make sure every time we replay the same workflow logic, we get exact same results. You cannot use like a random normally, or get time, or get UUID generate. You have to use these syscalls and record as a side effect. You generate UUID, but through these special like syscalls, and then it gets recorded in history, when you replay, you get the same value, the same timestamp that you had in the first round. That’s not a trivial concept to keep in mind when you’re developing apps. Yet there are tools, there are all these validation checks, it’s all doable but it’s a tax. I think that’s the biggest tax that you pay. Versioning is a side effect of determinism. When you change your code, it’s not obvious to think that there may be workflows running, except like one or two or three, if you change your code. It’s mentally very difficult to figure this out. Again, there are workarounds for that. The feature is shipping, where running workflows can still be run against old version, and the new ones will run against new versions to help developers write safe code. These are the major tradeoffs. I’m sure there are other factors at play but determinism and its impact on versioning are the biggest.
Cloud Native Key Principles
If I go back to the cloud native key principles there, does durable execution help with scalability? For sure. Because you partition your application to these individual things that run, and they’re not attached to any memory space or machine, they can be distributed across a cluster of machines that don’t care how big the cluster is. Fault tolerance, I think, no question. That’s the big thing that goes around. Loosely coupled, I think to a particular degree. The interface between workflow is very forgiving. You start a workflow with parameters, and that’s it. You don’t need to have even like strong interfaces between systems. Because of this determinism constraint, you have to still be a little bit careful. In fact, we realized our industry lacks any standard for invoking an operation that may take an arbitrarily long period of time. We have async. When I call something, I can say await. It assumes that it’s still in the process when an operation completes, I’m still up and I get a response back. What if I want to start something that will complete next week? There is no standard for that.
We’re in conversation with industry to establish this kind of standard for this, we call them Arbitrary Long Operation, ALO. Fast evolving, I would say neutral, because on the one hand, we removed a lot of code that you don’t need to write anymore. That definitely boosts productivity and makes developers happy. We’ve seen testimonies, people say I don’t want to write code any other way anymore. At the same time when they need to learn about determinism and versioning, that almost balances it out. I would not claim that we help with evolution, really.
Primary Concerns
The primary role of durable execution addresses these primary concerns that we have to deal with when we deal with cloud native systems. We separated the business logic from integrations, from state management, kind of got state management for free. Failure handling is all across the stack. I think, in my opinion, durable execution provides a holistic solution to the problem. It doesn’t solve all the problems, but it’s a consistent thought through approach to solving this class of problems. If we step back from computer science perspective, you could say there is nothing new here. All these things have been around for decades, so like the workflows, timers, all these concepts are there. What I think is important here is that all these primitives and mechanisms that have been known, they’re put together in a consistent developer experience. That’s actually been my interest for a long time. I’ve heard people saying that this is the new programming paradigm. Personally, I don’t think I subscribe to that. I think it’s still a programming model. It’s still an approach. Programming model is how I think we think about our problems, how we conceptualize the application we build. How we approach the systems we need to build. This, I think, is a very useful programming model from that perspective. I believe that 75% of software can be built this way. Because, if you think like, pretty much any piece of code that is worth anything, it has a series of steps, and it needs to deal with some other systems. If something just computes locally, that’s not that interesting, that anybody can write it. This piece of code that deals with other systems, integrates with other APIs, they’re everywhere. If you want to do home automation, if you want to do anything, you need to program. It’s a sequence of steps that you need to get to a particular result reliably without you writing a lot of code around. That was the reason why I left my otherwise comfortable job at Microsoft and joined a startup, because I believe that this is a very powerful concept.
Questions and Answers
Bykov: Carefully test and make sure that your new version is compatible. You can take histories of running workflows and run tests again. There are test kits that automate that, to make sure that your new code runs consistently with the previous version. The other approach, as I mentioned, is to just split and say, new version is used for new workflows, and then keep these versions running for a long time, side-by-side, and then shut down what is not needed any more.
Participant 1: You made the comments about UUIDs, for example. What goes wrong, like let’s say kind of I just created a random UUID, and then go and replay some of the activities. Help me understand a little more where that breaks the framework.
Bykov: For example, many KPIs support request ID. To make sure there’s idempotency, you as a caller pass request ID. If I need to generate the UUID to pass to this call, if I generate it, then pass and make one call, and then during replay, I generate a new ID and call it again. That would be a disaster potentially, if I made 2 requests and I assume I maybe made 10 requests, I assume I made only 1. That one example comes to mind. Anything like addressing, if I created some resource with that ID, and I don’t remember anymore, it’s there because my UUID changed.
Participant 2: My question is more about from the developer on the field. Let’s say that in a code base, where multiple developers are developing at the same time. Let’s say that they’re talking to the same database, I’m curious to learn like, how are you avoiding that they’re not stepping on each other, let’s say that they are trying to bring the recording to the database table. Let’s say both of the developers are trying to do the same thing, because it’s running in the cloud when you say execute workflow, is it going to the server in the cloud, and then using secondary state, which is common.
Bykov: Let me layer it a little bit. State that is part of execution is handled by the server. The server, if it’s open source, you can run it anywhere you want, or you can use a cloud-based solution where it’s done for you. The execution state, you don’t deal with it at all, like directly, you cannot touch it. It’s not like two developers can change it. That’s clean. If in your application code you also go and write to some database, that’s of course possible, so you have two workflows that try to update the same database. This is where you need some synchronization, whether you use durable execution, or you write the same code in a traditional way. You need some synchronization to prevent mutation of the same state, some concurrency control. You can do it in many different ways. In durable execution, you can have a guardian for the database, or for that record. Entity workflow is actually a good guardian, for the state of this entity, that it never gets mutated in parallel. Actors use the same way. You have the actor per entity, and then that guarantees that you don’t have concurrency in trying to update state.
Participant 3: When we deal easily with external system integrations, whenever an external system calls us, we call external systems. They’re not necessarily made in an async way. You have synchronization DB requests that you have to do to external systems. Is there any guidelines about like how you should deal with those kinds of things, where your activity gets stopped, because you just don’t send and get signal back, because of those external strength runners.
Bykov: The call to external system you implement with an activity because you go into some other system, but then you have full control like of timeout. You’re essentially defining policy. You can say, for this call, I don’t want to wait to take more than 2 seconds. I want to retry it three times but no more. You’re in full control of how particular activities should run. Again, like you don’t write code for that, you define a policy, which is just a piece of data.
Participant 4: I have a question about the workflow history or version that you mentioned. For example, like you’re receiving one request, and then it keeps on failing, like, it’s fundamentally failing, unless we put a second request to the new structure, which is working, then that can be processed successfully. What happens to the failing ones, how that history is maintained, replicated. What are best practices around that?
Bykov: The system automatically records the failure information in the history. It doesn’t keep adding like 100 failures, it records the last failure, the number, the count, and retry. You’re not going to fail whole history with failing of a single activity that failed 100 times. Because you’re interested in like, how many times it failed and the last error, usually.
Participant 5: What’s the best practice for doing dependencies in languages like Python? Within a third-party library in Python, [inaudible 00:47:58]?
Bykov: There is support for Python. There is a Python SDK. You can write workflows and activities in Python. They play by Python rules. That’s what’s nice about this model. It’s in the language that you all do use. It doesn’t move you to a different language. I’m not a Python expert, but imagine whatever dependency like system works, that it will continue to work with the SDK included.
See more presentations with transcripts
MMS • Ben Linders

Communicating quality gaps, holding space for good testing, and writing automation are some of the ways that testers contribute to software teams. According to Maaret Pyhäjärvi, we need to think about testing, not testers. Collaboration and having conversations between team members can result in valuable impact that changes the product and the experiences of our users.
Maaret Pyhäjärvi gave a keynote about the impact of testers and testing in software teams at HUSTEF 2023.
A way that testers contribute to software teams is by identifying and communicating the quality gap, the concrete examples of things missing between what we mean we want, what we say we want, and what we have, Pyhäjärvi said. Some people call this bug reporting, but that misses the truly valuable part, choosing to have a conversation, and choosing which conversation is timely and relevant, she added.
Testers can hold space for good testing in teams. Instead of pointing at problems, pairing and ensembling in particular can help software developers discover they can do testing, as Pyhäjärvi explained in an example:
I was working with a developer who was testing their own feature, and one day I decided not to say what to test and do. They looked at me and said “You’d want me to click here” and I said nothing, they clicked things choosing what they thought I would do, and found problems they had been missing.
She did not realize that sometimes we should do less to let people do more, and just point out the pattern, Pyhäjärvi mentioned. Realizing that she has more impact – in the moment and in the long run – through guiding developers to discovery, rather than discovering for them, is an unusual but valuable contribution, she added.
Writing automation that stays behind when you leave, and does the work, is also a valuable contribution of testers in software teams, as Pyhäjärvi explained:
Building for ownership, building for time when I am no longer around to test myself, and ensuring my contribution is not just getting bugs fixed by finding them, but also in keeping track of past lessons in an executable documentation format, with test automation.
Pyhäjärvi mentioned that through testing, we can change the product, change the experiences of our users, and become better testers and programmers:
I like to think it’s about testing, not testers, and we need the courage to bring conversations that create and support change.
Very few of our meaningful impacts come from a single person, Pyhäjärvi argued. It takes a village, or a pair and a ladder effect where you no longer know exactly whose idea fed the final implemented idea. Collaboration creates great results, Pyhäjärvi said. Collaborative credit is acknowledging all parties, not just the one who spoke the final form of the idea, she concluded.
InfoQ interviewed Maaret Pyhäjärvi about testing productivity and sharing stories.
InfoQ: How can we measure the productivity of testing?
Maaret Pyhäjärvi: The work of testing is like having a white paper with invisible ink; no one can tell you in advance exactly what you will need to discover. I use all kinds of approximations in my projects. After I have tested a little, doing a tour or survey of the application, I usually guess how many bugs are hidden and set that as a budget that I work against, and track our progress in uncovering those. Working against a plan, this allows me to update the end goal as I learn, but also show steps of progress. Similarly, but with more effort, I create coverage outlines.
I have to say though, that lack of productivity with testers shows up as noise (bothering others) and as silence (missing relevant results). Testing provides information at best. At worst, testing provides information people don’t want or care for. I call that kind of information noise, and noise bothers others.
InfoQ: Why is it important that testers share their stories?
Pyhäjärvi: Bugs aren’t relevant without their meaning. Meaning is conveyed with a story.
Improvements over time, teaching our colleagues something, learning from our colleagues – these are impacts best shared with stories.
InfoQ: What’s the testing story that you would like to share?
Pyhäjärvi: In one project, it took a bit of effort over the two years to turn away from planning test automation to implementing tiny bits of it, and to realize that time spent warning about the limitations of automation is time taken away from reaching success with it.
I used to say automation could not do everything. I explained the limitations of automation again and again. And I did less automation. Then I chose differently. Every time I felt like warning of its limitations, I chose to add some valuable work to it. As a result, I got useful and improved automation. It is still not perfect and needs more thinking from me, but if I had chosen to spend time on selling the idea that it could go wrong, I would not have learned how it could go right.
I think of this as a story about the choices that we have, but don’t recognize we have, since pushing through in times of big changes seems safer than changing things. I don’t think we would have done a good job testing without centering exploratory testing and documenting selected lessons in test automation.
MMS • RSS

Aerospike Inc., which sells a highly scalable, real-time NoSQL database management system, said today it closed a $109 million investment round led by Sumeru Equity Partners LP with participation from Alsop Louie Partners LLC. That brings its total funding to $241 million.
Aerospike’s flash-optimized in-memory model scales from gigabytes to petabytes with high consistency and low latency. Its core markets are advertising technology, financial services, telecommunications, retail and healthcare. The model is available in an open-source community edition and as a commercial product with enterprise features.
“Our value is that we can linearly scale with our customer and still deliver submillisecond performance,” said Chief Executive Subbu Iyer. “We need 80% less infrastructure because of our hybrid memory architecture that leverages [solid-state drives].”
Aerospike was originally based on a key-value store architecture, but the company has expanded it in recent years to support JavaScript Object Notation, graph and vector capabilities. Last year it released its first managed service and plans to integrate vector and Langchain support into its cloud offering to meet the mounting demand for artificial intelligence development. “Vector and graph are complementary, and going forward, we believe there are opportunities to bring them together,” Iyer said.
AI is nothing new
Though AI is an opportunity, the CEO said it’s nothing new to his company. “AI uses a lot more data, so platforms that scale and analyze a lot of data will do well,” Iyer said. “We are very positive about AI, but for us, it’s not really new because many of our customers have deployed AI pipelines for the last several years.”
Nevertheless, International Data Corp. forecasts more than 31% compound annual growth in AI software sales over the next three years, so the company believes it’s well-positioned to benefit. “We offer the only production-level vector solution that delivers consistent accuracy at scale on significantly less infrastructure than anyone else,” Iyer said in a press release.
Reference customers include Adobe Systems Inc., AppsFlyer Inc., Barclays PLC, Flipkart Internet Private Ltd. and PayPal Holdings Inc.
Iyer said Aerospike plans to use the new funding to hire talent, step up its support for AI and cloud services, accelerate its sales and marketing efforts, and build a sales channel. It recently hired Chief Scientist Naren Narendran, who worked on machine learning projects at Google LLC, and Chief Engineering Officer Srinivasan Seshadri, who specializes in machine learning applications in search and internet advertising.
“We haven’t marketed ourselves much until the last year or so,” Iyer said. “We are changing that, focusing more on marketing and working with developers.” Last year the company formed a developer advocacy team and set up a developer hub.
Image: Flickr CC
Your vote of support is important to us and it helps us keep the content FREE.
One click below supports our mission to provide free, deep, and relevant content.
Join our community on YouTube
Join the community that includes more than 15,000 #CubeAlumni experts, including Amazon.com CEO Andy Jassy, Dell Technologies founder and CEO Michael Dell, Intel CEO Pat Gelsinger, and many more luminaries and experts.
THANK YOU
MMS • RSS
![]() MongoDB, Inc. (NASDAQ:MDB – Get Free Report) saw some unusual options trading activity on Wednesday. Investors bought 36,130 call options on the stock. This is an increase of 2,077% compared to the average volume of 1,660 call options.
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) saw some unusual options trading activity on Wednesday. Investors bought 36,130 call options on the stock. This is an increase of 2,077% compared to the average volume of 1,660 call options.
Insider Activity at MongoDB
In other news, CAO Thomas Bull sold 170 shares of the firm’s stock in a transaction dated Tuesday, April 2nd. The shares were sold at an average price of $348.12, for a total transaction of $59,180.40. Following the sale, the chief accounting officer now owns 17,360 shares of the company’s stock, valued at approximately $6,043,363.20. The sale was disclosed in a legal filing with the SEC, which is accessible through this hyperlink. In other news, Director Dwight A. Merriman sold 4,000 shares of the stock in a transaction that occurred on Wednesday, April 3rd. The shares were sold at an average price of $341.12, for a total value of $1,364,480.00. Following the transaction, the director now owns 1,156,784 shares in the company, valued at approximately $394,602,158.08. The sale was disclosed in a document filed with the Securities & Exchange Commission, which is available through the SEC website. Also, CAO Thomas Bull sold 170 shares of the stock in a transaction that occurred on Tuesday, April 2nd. The stock was sold at an average price of $348.12, for a total transaction of $59,180.40. Following the completion of the transaction, the chief accounting officer now owns 17,360 shares in the company, valued at approximately $6,043,363.20. The disclosure for this sale can be found here. In the last ninety days, insiders have sold 87,324 shares of company stock valued at $34,472,011. 4.80% of the stock is owned by insiders.
Institutional Investors Weigh In On MongoDB
Large investors have recently modified their holdings of the business. Transcendent Capital Group LLC purchased a new stake in shares of MongoDB during the fourth quarter worth about $25,000. KB Financial Partners LLC purchased a new stake in MongoDB in the second quarter valued at approximately $27,000. Blue Trust Inc. boosted its position in MongoDB by 937.5% in the fourth quarter. Blue Trust Inc. now owns 83 shares of the company’s stock valued at $34,000 after buying an additional 75 shares during the last quarter. BluePath Capital Management LLC purchased a new stake in MongoDB in the third quarter valued at approximately $30,000. Finally, Parkside Financial Bank & Trust boosted its position in MongoDB by 176.5% in the second quarter. Parkside Financial Bank & Trust now owns 94 shares of the company’s stock valued at $39,000 after buying an additional 60 shares during the last quarter. Hedge funds and other institutional investors own 89.29% of the company’s stock.
Wall Street Analysts Forecast Growth
A number of equities research analysts have commented on the stock. Piper Sandler raised their target price on shares of MongoDB from $425.00 to $500.00 and gave the stock an “overweight” rating in a research note on Wednesday, December 6th. Mizuho lifted their price objective on shares of MongoDB from $330.00 to $420.00 and gave the company a “neutral” rating in a research report on Wednesday, December 6th. Barclays raised their target price on shares of MongoDB from $470.00 to $478.00 and gave the company an “overweight” rating in a report on Wednesday, December 6th. DA Davidson raised shares of MongoDB from a “neutral” rating to a “buy” rating and raised their target price for the company from $405.00 to $430.00 in a report on Friday, March 8th. Finally, Redburn Atlantic reissued a “sell” rating and issued a $295.00 target price (down from $410.00) on shares of MongoDB in a report on Tuesday, March 19th. Two equities research analysts have rated the stock with a sell rating, three have assigned a hold rating and nineteen have assigned a buy rating to the company’s stock. Based on data from MarketBeat.com, the company currently has a consensus rating of “Moderate Buy” and an average price target of $449.85.
Check Out Our Latest Analysis on MongoDB
MongoDB Stock Performance
Shares of MongoDB stock opened at $339.82 on Thursday. The company has a market capitalization of $24.53 billion, a PE ratio of -137.02 and a beta of 1.19. The company has a debt-to-equity ratio of 1.07, a quick ratio of 4.40 and a current ratio of 4.40. The company has a 50-day simple moving average of $410.76 and a two-hundred day simple moving average of $389.60. MongoDB has a one year low of $198.72 and a one year high of $509.62.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings results on Thursday, March 7th. The company reported ($1.03) earnings per share for the quarter, missing analysts’ consensus estimates of ($0.71) by ($0.32). MongoDB had a negative return on equity of 16.22% and a negative net margin of 10.49%. The business had revenue of $458.00 million for the quarter, compared to analysts’ expectations of $431.99 million. Research analysts expect that MongoDB will post -2.53 EPS for the current fiscal year.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Articles
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
![]() MongoDB, Inc. (NASDAQ:MDB – Get Free Report) was the target of some unusual options trading activity on Wednesday. Stock investors acquired 23,831 put options on the company. This is an increase of approximately 2,157% compared to the typical volume of 1,056 put options.
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) was the target of some unusual options trading activity on Wednesday. Stock investors acquired 23,831 put options on the company. This is an increase of approximately 2,157% compared to the typical volume of 1,056 put options.
Analysts Set New Price Targets
Several equities analysts have recently issued reports on MDB shares. Needham & Company LLC reissued a “buy” rating and issued a $495.00 price target on shares of MongoDB in a report on Wednesday, January 17th. Guggenheim boosted their price target on shares of MongoDB from $250.00 to $272.00 and gave the company a “sell” rating in a report on Monday, March 4th. Redburn Atlantic reissued a “sell” rating and issued a $295.00 price target (down previously from $410.00) on shares of MongoDB in a report on Tuesday, March 19th. UBS Group reissued a “neutral” rating and issued a $410.00 price target (down previously from $475.00) on shares of MongoDB in a report on Thursday, January 4th. Finally, JMP Securities reaffirmed a “market outperform” rating and issued a $440.00 price objective on shares of MongoDB in a research report on Monday, January 22nd. Two equities research analysts have rated the stock with a sell rating, three have assigned a hold rating and nineteen have issued a buy rating to the company. Based on data from MarketBeat.com, MongoDB currently has an average rating of “Moderate Buy” and a consensus target price of $449.85.
Get Our Latest Stock Report on MDB
Insider Activity at MongoDB
In other MongoDB news, CRO Cedric Pech sold 1,248 shares of MongoDB stock in a transaction on Tuesday, January 16th. The shares were sold at an average price of $400.00, for a total transaction of $499,200.00. Following the completion of the sale, the executive now owns 25,425 shares of the company’s stock, valued at approximately $10,170,000. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is available through this hyperlink. In other MongoDB news, CRO Cedric Pech sold 1,248 shares of MongoDB stock in a transaction on Tuesday, January 16th. The shares were sold at an average price of $400.00, for a total transaction of $499,200.00. Following the completion of the sale, the executive now owns 25,425 shares of the company’s stock, valued at approximately $10,170,000. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is available through this hyperlink. Also, CEO Dev Ittycheria sold 33,000 shares of MongoDB stock in a transaction on Thursday, February 1st. The stock was sold at an average price of $405.77, for a total transaction of $13,390,410.00. Following the sale, the chief executive officer now directly owns 198,166 shares of the company’s stock, valued at approximately $80,409,817.82. The disclosure for this sale can be found here. Insiders sold a total of 87,324 shares of company stock valued at $34,472,011 over the last quarter. Corporate insiders own 4.80% of the company’s stock.
Institutional Inflows and Outflows
A number of institutional investors and hedge funds have recently bought and sold shares of MDB. Raymond James & Associates grew its stake in MongoDB by 32.0% in the 1st quarter. Raymond James & Associates now owns 4,922 shares of the company’s stock valued at $2,183,000 after buying an additional 1,192 shares during the last quarter. PNC Financial Services Group Inc. grew its stake in MongoDB by 19.1% in the 1st quarter. PNC Financial Services Group Inc. now owns 1,282 shares of the company’s stock valued at $569,000 after buying an additional 206 shares during the last quarter. MetLife Investment Management LLC acquired a new position in MongoDB in the 1st quarter valued at about $1,823,000. Panagora Asset Management Inc. grew its stake in MongoDB by 9.8% in the 1st quarter. Panagora Asset Management Inc. now owns 1,977 shares of the company’s stock valued at $877,000 after buying an additional 176 shares during the last quarter. Finally, Vontobel Holding Ltd. grew its stake in MongoDB by 100.3% in the 1st quarter. Vontobel Holding Ltd. now owns 2,873 shares of the company’s stock valued at $1,236,000 after buying an additional 1,439 shares during the last quarter. Institutional investors and hedge funds own 89.29% of the company’s stock.
MongoDB Stock Down 2.3 %
MongoDB stock opened at $339.82 on Thursday. The firm has a market capitalization of $24.53 billion, a PE ratio of -137.02 and a beta of 1.19. The company’s 50-day moving average is $410.76 and its 200-day moving average is $389.60. MongoDB has a fifty-two week low of $198.72 and a fifty-two week high of $509.62. The company has a debt-to-equity ratio of 1.07, a current ratio of 4.40 and a quick ratio of 4.40.
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings data on Thursday, March 7th. The company reported ($1.03) earnings per share for the quarter, missing the consensus estimate of ($0.71) by ($0.32). The firm had revenue of $458.00 million for the quarter, compared to analyst estimates of $431.99 million. MongoDB had a negative return on equity of 16.22% and a negative net margin of 10.49%. Sell-side analysts anticipate that MongoDB will post -2.53 earnings per share for the current year.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Articles
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
On April 1, 2024, Director Hope Cochran executed a sale of 2,175 shares of MongoDB Inc (NASDAQ:MDB), as reported in a recent SEC Filing. The transaction was carried out at a stock price of $363.14 per share, which resulted in a total value of $789,329.50.
MongoDB Inc (NASDAQ:MDB) is a technology company that specializes in database solutions. The company’s platform is designed to support the development of applications across a range of industries by providing a scalable, flexible, and sophisticated database structure. MongoDB’s services are utilized by a variety of clients, from startups to large enterprises, to manage and process large sets of data in a more efficient and adaptable manner.
Over the past year, the insider, Hope Cochran, has sold a total of 12,698 shares of MongoDB Inc and has not made any purchases of the stock. This latest transaction continues the trend of insider sales for the company, with a total of 65 insider sells and no insider buys reported over the same period.
The market capitalization of MongoDB Inc stands at $24.749 billion, reflecting the aggregate value of the company’s outstanding shares.
According to the data provided by GuruFocus, the stock of MongoDB Inc is currently trading below its GF Value, with a price-to-GF-Value ratio of 0.75. This indicates that the stock is significantly undervalued based on its GF Value of $486.29. The GF Value is a proprietary valuation metric developed by GuruFocus, which takes into account historical trading multiples, an adjustment factor based on the company’s historical performance, and future business projections provided by Morningstar analysts.
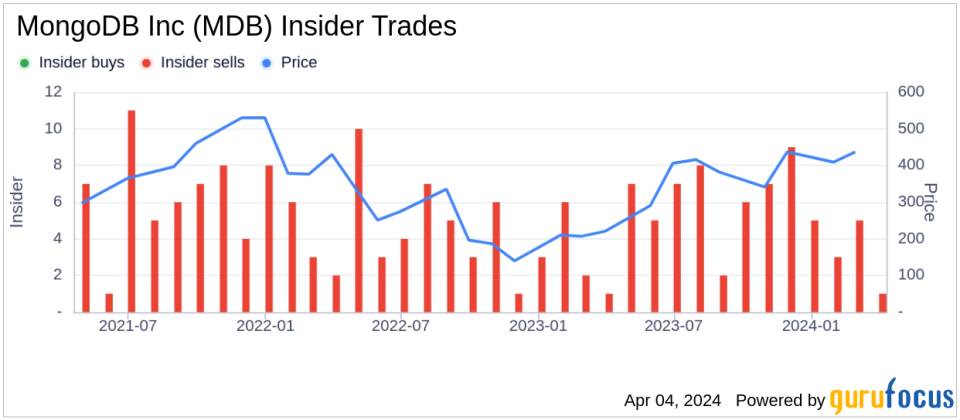
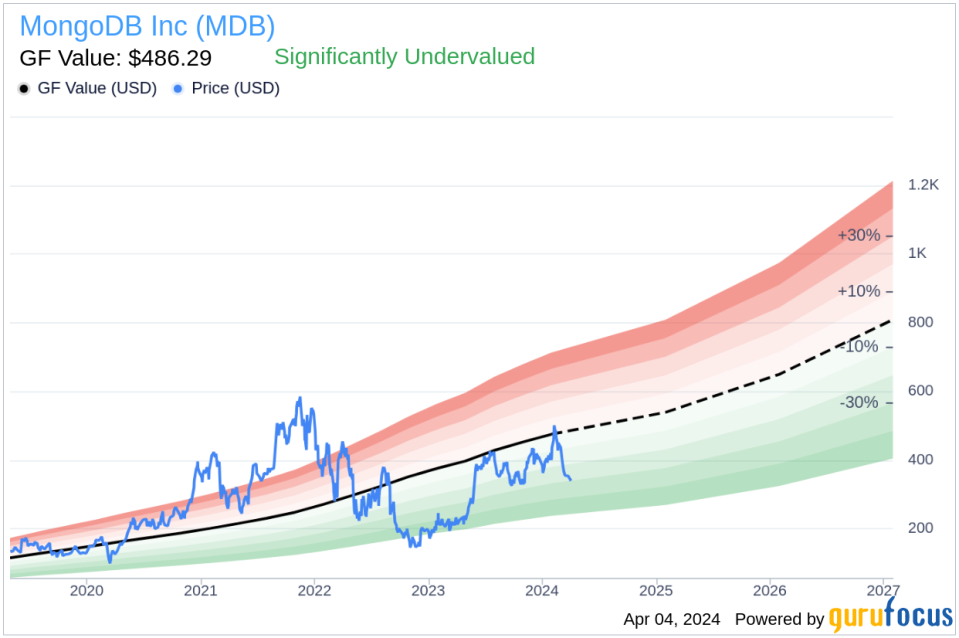
The insider selling activity at MongoDB Inc (NASDAQ:MDB) may be of interest to investors monitoring insider behaviors as an indicator of company performance and valuation. However, it is important to consider a wide range of factors when evaluating the implications of insider transactions.
This article, generated by GuruFocus, is designed to provide general insights and is not tailored financial advice. Our commentary is rooted in historical data and analyst projections, utilizing an impartial methodology, and is not intended to serve as specific investment guidance. It does not formulate a recommendation to purchase or divest any stock and does not consider individual investment objectives or financial circumstances. Our objective is to deliver long-term, fundamental data-driven analysis. Be aware that our analysis might not incorporate the most recent, price-sensitive company announcements or qualitative information. GuruFocus holds no position in the stocks mentioned herein.
This article first appeared on GuruFocus.
MMS • RSS
On April 1, 2024, Director Hope Cochran executed a sale of 2,175 shares of MongoDB Inc (MDB, Financial), as reported in a recent SEC Filing. The transaction was carried out at a stock price of $363.14 per share, which resulted in a total value of $789,329.50.
MongoDB Inc (MDB, Financial) is a technology company that specializes in database solutions. The company’s platform is designed to support the development of applications across a range of industries by providing a scalable, flexible, and sophisticated database structure. MongoDB’s services are utilized by a variety of clients, from startups to large enterprises, to manage and process large sets of data in a more efficient and adaptable manner.
Over the past year, the insider, Hope Cochran, has sold a total of 12,698 shares of MongoDB Inc and has not made any purchases of the stock. This latest transaction continues the trend of insider sales for the company, with a total of 65 insider sells and no insider buys reported over the same period.
The market capitalization of MongoDB Inc stands at $24.749 billion, reflecting the aggregate value of the company’s outstanding shares.
According to the data provided by GuruFocus, the stock of MongoDB Inc is currently trading below its GF Value, with a price-to-GF-Value ratio of 0.75. This indicates that the stock is significantly undervalued based on its GF Value of $486.29. The GF Value is a proprietary valuation metric developed by GuruFocus, which takes into account historical trading multiples, an adjustment factor based on the company’s historical performance, and future business projections provided by Morningstar analysts.
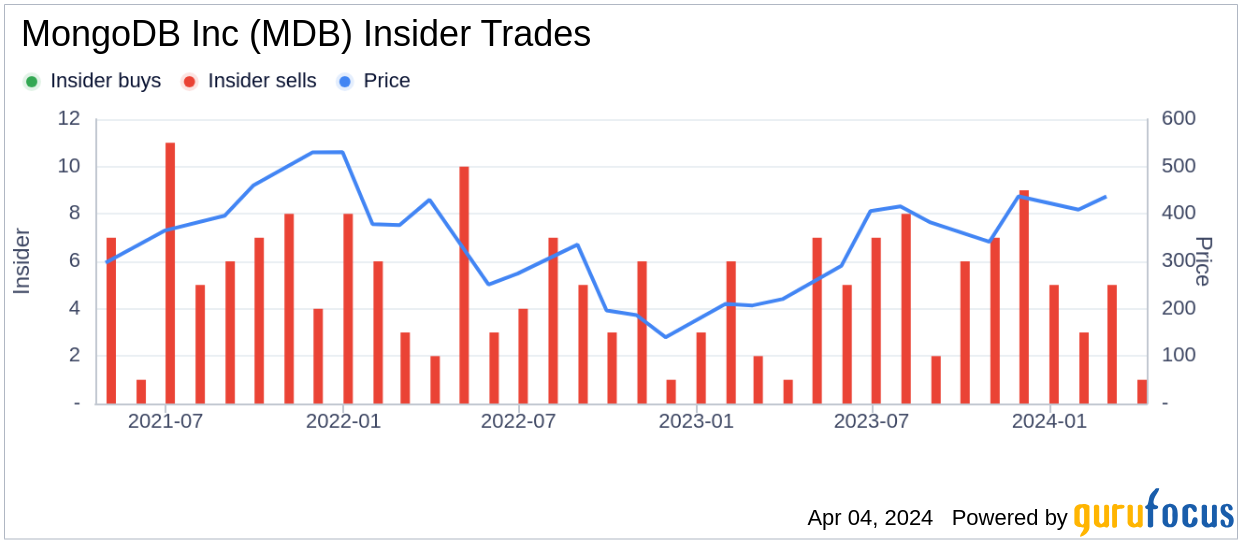
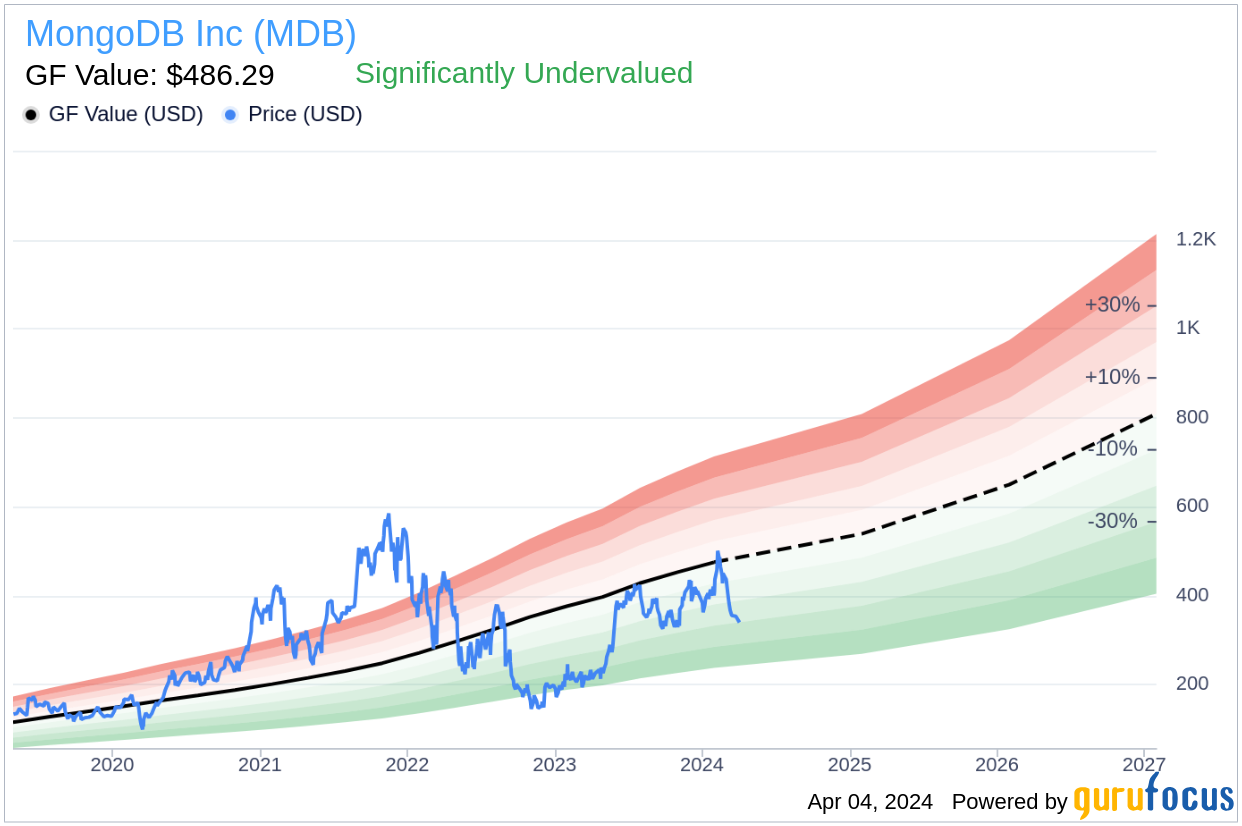
The insider selling activity at MongoDB Inc (MDB, Financial) may be of interest to investors monitoring insider behaviors as an indicator of company performance and valuation. However, it is important to consider a wide range of factors when evaluating the implications of insider transactions.
This article, generated by GuruFocus, is designed to provide general insights and is not tailored financial advice. Our commentary is rooted in historical data and analyst projections, utilizing an impartial methodology, and is not intended to serve as specific investment guidance. It does not formulate a recommendation to purchase or divest any stock and does not consider individual investment objectives or financial circumstances. Our objective is to deliver long-term, fundamental data-driven analysis. Be aware that our analysis might not incorporate the most recent, price-sensitive company announcements or qualitative information. GuruFocus holds no position in the stocks mentioned herein.
MMS • RSS
MongoDB Inc (MDB, Financial), the leading modern, general-purpose database platform, has reported an insider selling event. According to a recent SEC filing, President & CEO Dev Ittycheria sold 17,160 shares of the company on April 2, 2024. The transaction was executed at an average price of $348.11, resulting in a total value of $5,972,107.60.
MongoDB Inc is known for its MongoDB database, which is designed to unleash the power of software and data for developers and the applications they build. The company’s database platform has been widely adopted across a range of industries due to its scalability, performance, and ease of use.
Over the past year, Dev Ittycheria has sold a total of 489,953 shares of MongoDB Inc and has not made any purchases of the stock. This latest transaction continues a pattern of insider selling at the company, with a total of 65 insider sells and no insider buys occurring over the same timeframe.
On the day of the insider’s recent sale, shares of MongoDB Inc were trading at $348.11, giving the company a market capitalization of $24.749 billion.
The stock’s price-to-GF-Value ratio stands at 0.72, with a GF Value of $486.29, indicating that MongoDB Inc is significantly undervalued according to GuruFocus’s intrinsic value estimate. The GF Value is determined by considering historical trading multiples, a GuruFocus adjustment factor based on the company’s past performance, and future business performance estimates provided by Morningstar analysts.
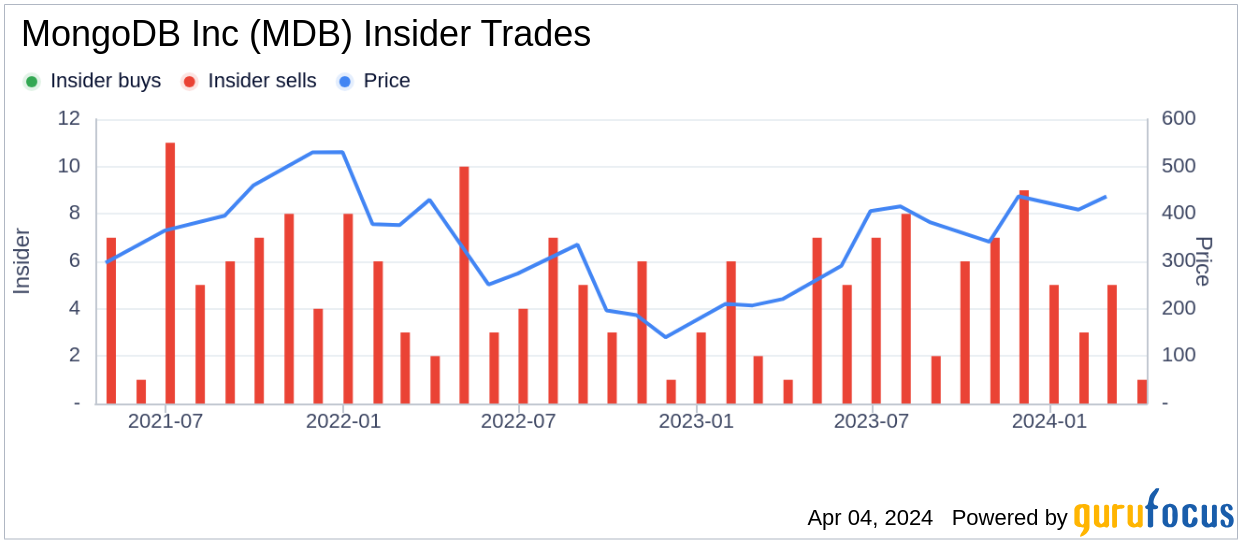
The insider trend image above reflects the recent selling activity by insiders at MongoDB Inc, providing investors with a visual representation of the insider transactions over the past year.
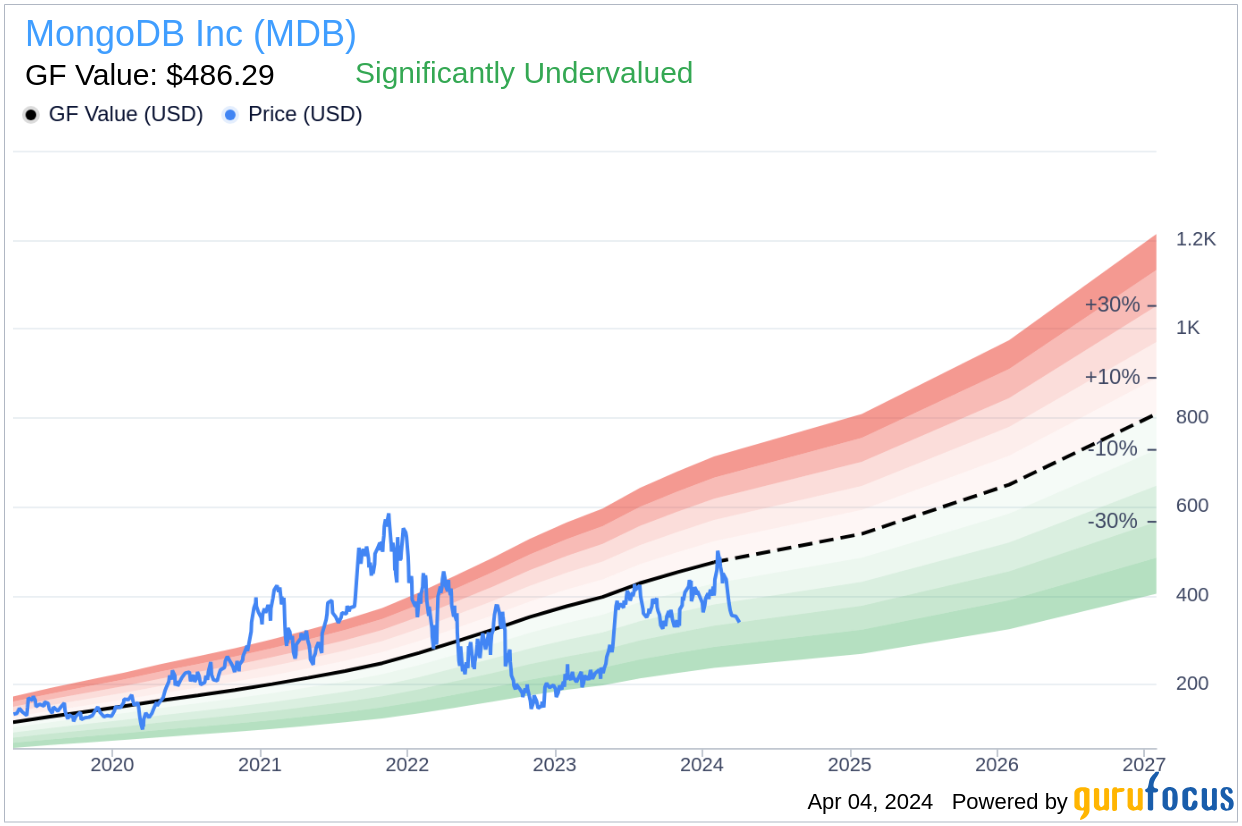
The GF Value image provides a graphical view of MongoDB Inc’s current stock price in relation to its GF Value, offering insight into the stock’s valuation from GuruFocus’s perspective.
Investors and analysts often monitor insider selling as it can provide valuable insights into a company’s internal perspective. While insider selling does not necessarily indicate a lack of confidence in the company, it is one of many factors that shareholders may consider when evaluating their investment.
This article, generated by GuruFocus, is designed to provide general insights and is not tailored financial advice. Our commentary is rooted in historical data and analyst projections, utilizing an impartial methodology, and is not intended to serve as specific investment guidance. It does not formulate a recommendation to purchase or divest any stock and does not consider individual investment objectives or financial circumstances. Our objective is to deliver long-term, fundamental data-driven analysis. Be aware that our analysis might not incorporate the most recent, price-sensitive company announcements or qualitative information. GuruFocus holds no position in the stocks mentioned herein.
MMS • RSS
MongoDB Inc (MDB, Financial), a leading modern, general-purpose database platform, has reported an insider sale according to a recent SEC filing. Chief Revenue Officer Cedric Pech sold 6,156 shares of the company on April 3, 2024. The transaction was disclosed in a legal filing with the Securities & Exchange Commission, which is available through this SEC Filing.
Over the past year, the insider has sold a total of 62,142 shares of MongoDB Inc and has not made any insider purchases. This latest transaction continues a trend of insider sales at the company, with a total of 65 insider sells and no insider buys over the past year.
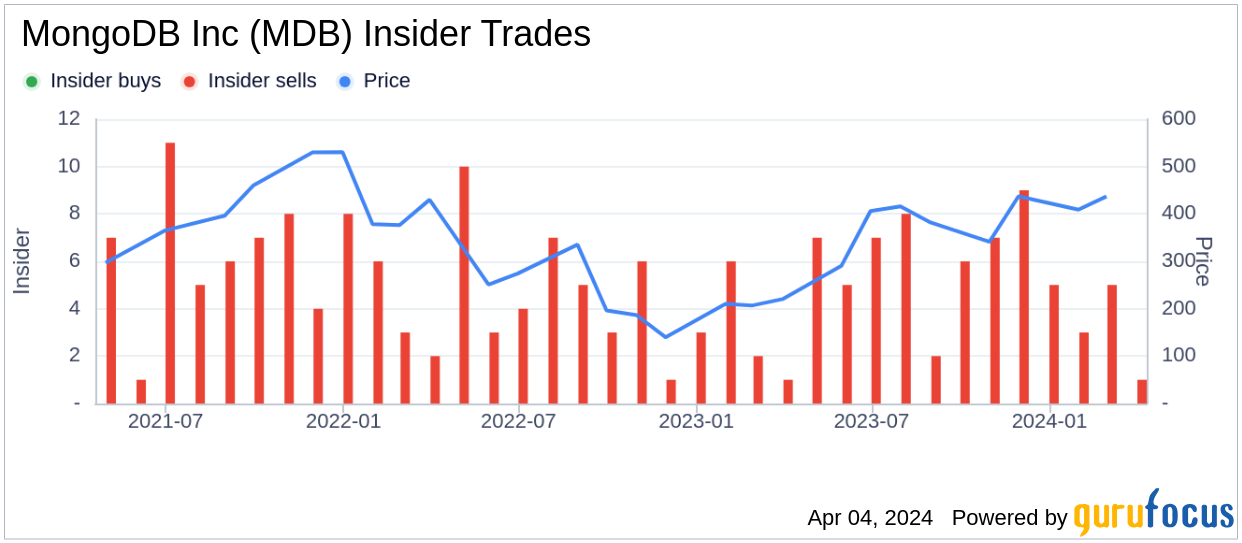
On the day of the sale, shares of MongoDB Inc were trading at $344.46, giving the company a market capitalization of $24.749 billion. This valuation comes in the context of MongoDB Inc’s stock being considered Significantly Undervalued according to the GuruFocus Value; with a price of $344.46 and a GuruFocus Value of $486.29, the price-to-GF-Value ratio stands at 0.71.
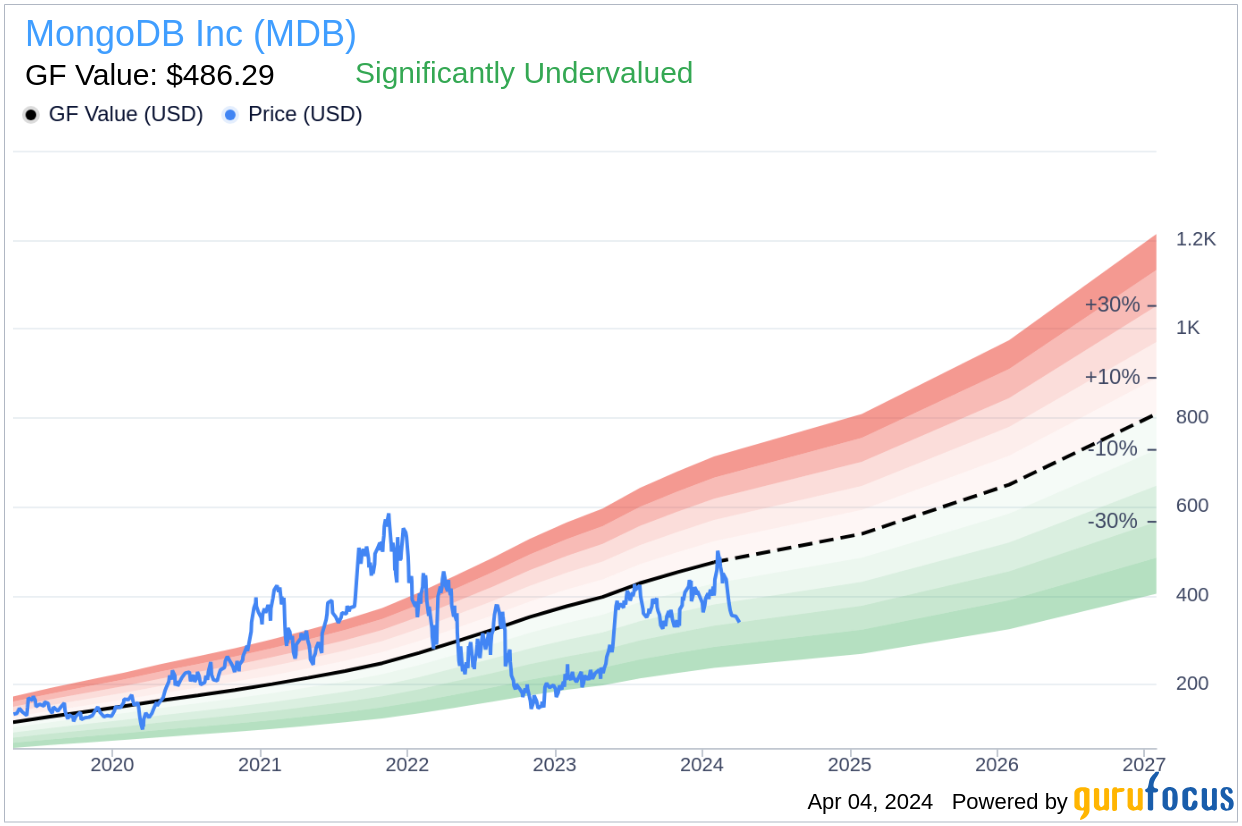
The GF Value is a proprietary intrinsic value estimate from GuruFocus, which is determined by historical trading multiples such as price-earnings ratio, price-sales ratio, price-book ratio, and price-to-free cash flow, an adjustment factor based on the company’s historical returns and growth, and future business performance estimates provided by Morningstar analysts.
MongoDB Inc’s business model focuses on providing a database that is scalable, flexible, and able to meet the needs of modern applications. The platform is designed to support a wide range of data types and to allow developers to build and scale applications more easily and efficiently. The company’s services are used by a variety of organizations across different industries, including technology, financial services, healthcare, and retail.
The insider’s recent sale may be of interest to investors and analysts who closely monitor insider trading activities as an indicator of confidence in the company’s prospects or for other strategic reasons. However, it is important to consider the broader context of the company’s financial performance, market conditions, and individual circumstances of the insider when interpreting such transactions.
This article, generated by GuruFocus, is designed to provide general insights and is not tailored financial advice. Our commentary is rooted in historical data and analyst projections, utilizing an impartial methodology, and is not intended to serve as specific investment guidance. It does not formulate a recommendation to purchase or divest any stock and does not consider individual investment objectives or financial circumstances. Our objective is to deliver long-term, fundamental data-driven analysis. Be aware that our analysis might not incorporate the most recent, price-sensitive company announcements or qualitative information. GuruFocus holds no position in the stocks mentioned herein.
MMS • RSS

| Reporter Name | Relationship | Type | Amount | SEC Filing |
|---|---|---|---|---|
| Merriman Dwight A | Director, 10% Owner | Sell | $1,727,507 | Form 4 |
| Bull Thomas | Chief Accounting Officer, 10% Owner | Sell | $59,179 | Form 4 |
MongoDB has seen recent insider transactions involving its Director, Dwight A. Merriman, and its Chief Accounting Officer, Bull Thomas.
Dwight A. Merriman, a Director at MongoDB, sold a total of 5,000 shares of Class A Common Stock on April 1 and April 3, 2024, at weighted average prices, accumulating a total sale amount of $1,727,507. Following these transactions, Merriman’s direct ownership stands at 1,156,784 shares, with an additional indirect ownership of 618,896 shares through trusts and the Dwight A. Merriman Charitable Foundation.
Bull Thomas, MongoDB’s Chief Accounting Officer, sold 170 Class A Common Stock shares on April 2, 2024, for a total of $59,179, at weighted average prices of $346.7 and $348.15. This sale was conducted to satisfy tax withholding obligations related to restricted stock units. After these transactions, Thomas directly owns 17,360 shares of MongoDB’s Class A Common Stock.