MongoDB director Dwight Merriman sells over $1.7 million in company stock – Investing.com
MMS
•
RSS
The sales were executed under a pre-arranged trading plan, known as a Rule 10b5-1 plan, which allows company insiders to sell shares at predetermined times to avoid accusations of insider trading. The plan is typically adopted when the insider does not have material, non-public information, providing a defense against insider-trading claims.
On April 1st, Merriman sold 110 shares at an average price of $361.86 and 890 shares at an average price of $363.15. A few days later, on April 3rd, he sold 1271 shares at an average price of $339.46, 854 shares at an average price of $340.13, 561 shares at an average price of $341.27, and 1314 shares at an average price of $343.32.
Following these transactions, Merriman still holds a significant number of shares in the company. The shares sold were held in a trust for the benefit of his children, and some are also held by a charitable foundation, with Merriman retaining voting and investment power but no pecuniary interest in the shares.
Investors often monitor insider selling for insights into a company’s health and management’s confidence in the firm’s future performance. However, it’s worth noting that sales made under Rule 10b5-1 plans are pre-scheduled and may not necessarily reflect the insider’s view on the company’s current or future prospects.
MongoDB, a leading database platform provider, has seen its stock price fluctuate in recent months, a common occurrence in the volatile tech sector. The transactions carried out by Merriman are part of routine financial planning and portfolio management for many executives and do not necessarily indicate a shift in the company’s trajectory.
Amidst the recent insider transactions at MongoDB, Inc. (NASDAQ:MDB), investors may find it valuable to consider the current financial landscape of the company as depicted by InvestingPro metrics and insights. MongoDB’s market capitalization stands at a robust $24.75 billion, reflecting its significant presence in the tech sector. Despite a negative P/E Ratio of -137.26, signifying that the company is not currently profitable, there is an expectation of net income growth this year, which could be a positive indicator for future earnings potential.
While the company’s stock has experienced a downturn over the last month, with a one-month price total return of -22.21%, an InvestingPro Tip suggests that the Relative Strength Index (RSI) indicates the stock is in oversold territory. This could imply a potential rebound as the market corrects this condition. Additionally, MongoDB has demonstrated robust revenue growth of 31.07% over the last twelve months as of Q4 2023, which may interest investors looking for companies with strong sales trajectories.
It is also noteworthy that MongoDB operates with a moderate level of debt and has liquid assets that exceed short-term obligations, contributing to a stable financial foundation. However, investors should be aware that 21 analysts have revised their earnings downwards for the upcoming period, which could temper expectations. For those interested in deeper analysis, there are additional InvestingPro Tips available, which can be accessed with a subscription. Use coupon code PRONEWS24 to get an additional 10% off a yearly or biyearly Pro and Pro+ subscription and gain access to a comprehensive list of tips that could further inform investment decisions.
This article was generated with the support of AI and reviewed by an editor. For more information see our T&C.
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
MongoDB executive sells over $59k in company stock – Investing.com
MMS
•
RSS
The total value of the shares sold by Thomas amounted to approximately $59,179. This sale was carried out in multiple transactions, with the highest price per share at $348.15 and the lowest at $346.70. It’s noted that these sales were conducted to satisfy tax withholding obligations related to the vesting of restricted stock units, a common practice among executives.
Following the sale, Thomas still retains a significant number of shares in the company, with 17,360 shares remaining in his possession. This indicates a continued vested interest in MongoDB’s performance and growth.
MongoDB, headquartered in New York, is a leading provider of database software and services. The company’s stock performance and executive trading activities are closely watched by investors, as they can provide insights into management’s perspective on the company’s valuation and future prospects.
Investors and stakeholders in MongoDB may find the details of such transactions valuable for understanding the stock’s market activity and the confidence level of the company’s executives in their own firm’s financial health and trajectory.
Amid the recent news of MongoDB, Inc.’s (NASDAQ:MDB) executive stock sale, investors are keen to understand the broader financial landscape of the company. MongoDB has been a prominent player in the database software sector, and its financial metrics and stock performance are critical in assessing its market position.
InvestingPro data shows MongoDB with a market capitalization of $24.75 billion, reflecting its substantial presence in the industry. However, the company’s P/E ratio stands at a negative -137.26, indicating that it has been operating at a loss. Despite this, the company’s revenue has grown by 31.07% over the last twelve months as of Q4 2024, showing a strong increase in sales.
One of the key InvestingPro Tips for MongoDB is the expectation that net income will grow this year, which may signal a turning point for the company’s profitability. Additionally, the Relative Strength Index (RSI) suggests that MongoDB’s stock is currently in oversold territory, which could potentially indicate an undervalued stock ripe for investment consideration.
For those looking to delve deeper into MongoDB’s financials and stock performance, InvestingPro offers additional insights. There are 12 more InvestingPro Tips available for MongoDB, which can help investors make more informed decisions. To access these tips, visit InvestingPro and remember to use the coupon code PRONEWS24 to get an additional 10% off a yearly or biyearly Pro and Pro+ subscription.
With MongoDB’s next earnings date approaching on May 31, 2024, investors will be watching closely to see if the company’s financial trajectory aligns with these insights and whether the executive stock sale aligns with the broader financial trends.
This article was generated with the support of AI and reviewed by an editor. For more information see our T&C.
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
MongoDB CEO Ittycheria sells over $5.9 million in company stock – Investing.com
MMS
•
RSS
The transactions were part of a series of stock dispositions by Ittycheria to satisfy tax withholding obligations related to the vesting of performance-based restricted stock units (RSUs). These RSUs were awarded under MongoDB’s long-term incentive bonus plan and 2016 Equity Incentive Plan, and vested upon the company’s achievement of specific performance criteria.
In addition to the sales, Ittycheria also acquired a total of 26,384 shares through the vesting of performance-based RSUs. These shares were not previously reportable under Section 16 due to their performance-based vesting criteria. Following these transactions, Ittycheria’s direct ownership in MongoDB’s Class A common stock increased to a total of 243,233 shares.
The sales were executed to cover tax liabilities that arise upon the vesting of RSUs, a common practice among executives receiving equity-based compensation. The details provided in the filing’s footnotes indicate that such sales are often used to meet tax obligations in a manner that aligns with the executive’s compensation agreement and company policy.
MongoDB, headquartered in New York, is a leading provider of database software and services, known for its innovative NoSQL database platform. The company’s stock is publicly traded on the NASDAQ exchange under the ticker symbol MDB.
Following the recent news of MongoDB, Inc. (NASDAQ:MDB) President and CEO Dev Ittycheria’s stock transactions, investors may be keen to understand the financial health and market sentiment surrounding the company. According to InvestingPro data, MongoDB currently holds a market capitalization of $24.75 billion. Despite a challenging market environment, the company has demonstrated a substantial revenue growth of 31.07% over the last twelve months as of Q4 2024. This growth momentum is reflected in the company’s revenue for the same period, totaling $1.683 billion.
However, the company’s stock performance has seen significant volatility. Over the past month, the stock has declined by 22.21%, which aligns with the InvestingPro Tip that the stock has fared poorly over the last month. Additionally, the company’s Price / Book ratio stands at a high 23.7, which may suggest a premium valuation compared to the industry average.
From an operational standpoint, MongoDB operates with a moderate level of debt and has liquid assets that exceed its short-term obligations, providing a degree of financial flexibility. Despite not being profitable over the last twelve months, net income is expected to grow this year, which is a positive signal for potential investors. Moreover, the company’s Relative Strength Index (RSI) suggests the stock is currently in oversold territory, offering an interesting point for investors looking for entry points.
For those seeking more in-depth analysis and additional insights, InvestingPro offers a comprehensive list of tips for MongoDB. There are 13 additional InvestingPro Tips available, which can further guide investment decisions. Interested readers can find these tips and more detailed metrics at: https://www.investing.com/pro/MDB. To access these insights, use the coupon code PRONEWS24 to get an additional 10% off a yearly or biyearly Pro and Pro+ subscription.
This article was generated with the support of AI and reviewed by an editor. For more information see our T&C.
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
Linux Foundation marshals support for open source alternative to Redis – TheRegister.
MMS
•
RSS
Cloud giants AWS, Google, and Oracle have come out in support of a Linux Foundation open source fork of Redis, the popular in-memory database frequently used as a cache, following changes to its licensing.
Now AWS, Google, Snap Inc, Ericsson, and Oracle are joining the Linux Foundation in backing a fork of the Redis code.
A statement from the Linux Foundation said project contributors had recruited maintainer, community, and corporate support to regroup in response to the recent license change announced by the Redis company.
The new database, dubbed Valkey, is set to continue development on Redis 7.2.4. The project is available for use and distribution under the BSD license.
In a prepared statement, Madelyn Olson, former Redis maintainer, co-creator of Valkey, and a principal engineer at AWS, said: “I worked on open source Redis for six years, including four years as one of the core team members that drove Redis open source until 7.2. I care deeply about open source software, and want to keep contributing. By forming Valkey, contributors can pick up where we left off and continue to contribute to a vibrant open source community.”
Valkey supports Linux, macOS, OpenBSD, NetBSD, and FreeBSD. But Microsoft, provider of the world’s second most popular public cloud platform, was notable by its absence.
In a statement to The Register, a Microsoft spokesperson said it maintains an ongoing partnership with Redis. “We are focused on continuing to provide our customers with integrated solutions like Azure Cache for Redis, ensuring they have uninterrupted service and access to the latest updates.” In a related blog post, Microsoft said Redis’s dual-license model provided “greater clarity and flexibility, empowering developers to make informed decisions about how they utilize Redis technologies in their projects.”
However, Microsoft also recently published a post introducing Garnet, “a remote cache-store designed to offer high performance, extensibility, and low latency.” Based on the Redis serialization protocol (RESP), Garnet could be used with unmodified Redis clients available in most programming languages, it said.
Peter Zaitsev, founder and former CEO of open source database consultancy Percona, said Microsoft had presented a Redis alternative that is wire-protocol compatible.
“Microsoft also has a Redis alternative, but in their take, they are not forking the code, it is a complete reimplementation. Microsoft probably also doesn’t see themselves buying the licence and paying Redis the company for the pleasure of hosting the Redis database in the same way it pays for the pleasure of hosting Oracle,” he told us.
In 2020, Redis became the most popular database on AWS, which itself is by far the most popular cloud infrastructure and platform as a service provider. This might owe a lot to the in-memory system becoming a defacto cache for web applications, but the company Redis Inc – formerly Redis Labs – has spent the last few years trying to build it out into a general-purpose database by adding features to enhance consistency, boost machine learning, and bolster JSON document support.
In its move to provide a fully open source alternative, the Linux Foundation was showing it was prepared to get behind the developer community, Zaitsev said.
“The Linux Foundation chose community over sponsors,” he said. “I was excited to see it just took days. It was like, boom: ‘Redis, you choose to [mess with] the community, then the Linux Foundation stands behind community.’ I think that was wonderful.”
In terms of when developers might consider switching to Valkey, Zaitsev advised giving it a few months.
“You can still run the open source Redis for a while. Valkey will take a few months to spin up and test the whole infrastructure. But after getting a few releases of Valkey, I would encourage developers to move to that release,” he said.
“If you’re a developer who is really seriously using Redis, I would get engaged with the Valkey community now to make sure their software matches your needs. If you say, ‘Hey, we want to just use a product when it’s ready,’ well then maybe by that time it’s too late to fix.” ®
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
Vector vs. graph vs. relational database: Which to choose? – TechTarget
MMS
•
RSS
Vector databases are making a resurgence as generative AI hype sweeps across every industry. Organizations with developed graph and relational databases may question if they need to add another database, but vectors can provide benefits to any aspiring GenAI effort.
Vector databases are data stores specializing in similarity searches. Relational databases, as implied by the name, are for storing entities and their relationships with one another and enabling querying of the relationships. A graph database is a type of NoSQL data store, which excels at searching vast amounts of text, among other things.
When evaluating the use of vector versus graph or relational databases, it’s not an or; it’s an and, said Sinclair Schuller, co-founder and managing partner of Nuvalence.
Vector databases have been around for decades and are a proven tool in search and recommendation systems. Interest in vector databases has recently picked up steam thanks to the popularity of GenAI services. The large language models (LLMs) that underpin GenAI services process text and other data as high-dimensional vectors in an intermediate embedded space.
In addition to traditional data warehouse structures, vector databases play a crucial role in facilitating the utilization of unstructured data, such as text, documents and images, in a format that is compatible with GenAI’s LLMs.
Relational databases remain essential for managing structured, tabular data, and graph databases hold a unique position in defining the intricate relationships between various data points. Many GenAI applications use both structured data and knowledge graph data, along with documents, to deliver comprehensive insights tailored to specific enterprise inquiries.
Vector databases can provide plenty of additional value compared to other popular tools built on relational and graph databases.
Vector vs. graph vs. relational databases
As data management teams come to grips with the popularity of vector databases compared to graph and relational approaches, some teams may debate whether it’s a choice of one or the other.
Vector databases and graph databases are more specialized than relational databases and designed for specific use cases, said Jeff Springer, principal consultant at DAS42.
Vector databases excel at handling high-dimensional, similar data in natural language processing, LLMs and recommendation engines, which require semantic similarity searches. They’re also good at performing time-series analyses with vast quantities of data, such as predicting stock prices.
Graph databases are good at modeling and analyzing complex, interconnected data where it’s important to understand the relationship between data points. Examples include social networks and factors related to fraud detection. Historically, they are typically categorized into two types: property graphs and knowledge graphs.
Relational databases handle pretty much everything else and can handle most of the world’s business questions. A company needs a relational database unless it deals only with high-dimensional data, which means it doesn’t have any sales, finance, HR or supply chain divisions. Companies in that situation should ask themselves if a vector database is needed, Springer said.
Data teams may also wonder why they need another option if they already have multiple database models employed across relational, graph, NoSQL and other data stores. One important reason is improving data analysis and workflows around unstructured data.
“Vector databases offer the optimal solution for storing and utilizing unstructured data,” said Bret Greenstein, data and analytics partner at PwC. “They excel in converting text, documents and images into vector representations of their content.”
Enterprises are adopting vectors at an increasing rate to complement existing relational and graph databases. By incorporating vector databases into their data infrastructure, organizations can enhance their data management capabilities and unlock valuable insights from unstructured data sources.
Vector databases are fundamentally and architecturally different from other databases. It’s not just a question of modeling data differently; vector databases store, index and query data differently, Springer said.
Additionally, vector database designs typically scale horizontally by adding more servers to a cluster. In contrast, relational databases can scale both horizontally and vertically by adding more resources to a single server.
Why use a vector database
It may be helpful to think of vector databases as math engines, Schuller said. As such, several distinctions are important. For example, indexes work differently in vector databases. Vector indexes excel at helping optimize mathematical operations.
Similarity search is key
Most vector databases rely on approximate nearest neighbor search to execute similarity searches. A similarity search is a query where results are typically ordered by how similar they are to the query. Other forms of databases are arguably ill suited to support similarity searches, Schuller said.
In a vector database, indexes are specifically designed around a similarity metric to optimize how searches work using vectors. A vector is a mathematical unit defined by a set of values that give a direction and magnitude or distance. For example, if one were to draw a straight line from Los Angeles to New York, one could say the line — or vector — is directionally northeast, 2,500 miles long and two-dimensional.
Vector databases store high-dimension vectors with potentially thousands of dimensions that approximate characteristics of the data each vector intends to represent. Storing vectors enables an interesting form of querying that underpins similarity search.
Going back to the Los Angeles-to-New York example, which would be more similar to the vector between the two cities: San Diego to Boston or San Francisco to Houston? A cursory map review reveals its San Diego to Boston.
“A vector database enables the sort of query that was just presented, except with data that represents text, images or other forms of data,” Sinclair said.
There are a number of valuable reasons to create multi-data store architectures, with the primary reason being the right tool for the job. Sinclair SchullerCo-founder and managing partner, Nuvalence
Turbocharging LLMs
Organizations that use LLMs should consider vector databases given that similarity searches combined with LLMs improve the use of context.
Vectors play a crucial role in LLMs within GenAI, Greenstein said. Vectors enable the comparison of concepts within an LLM by measuring the distance between vectors in a dimension.
“While this concept may seem complex, it is the most practical solution available and scales effectively for enterprise applications,” he said.
One practical example within LLMs might be considering the mathematical descriptions of the concepts dog and cat within an LLM. When discussing the topic of pets, their vectors are mathematically close to each other. However, when considering the topic of species, the vectors for cat and tiger are closer to each other. Vectors capture the relationships between the similar concepts within different topics. The possibilities increase when applied to all concepts and topics within an LLM.
Vectors are also essential for encoding prompts and enterprise data, as they enable the calculation of distances and facilitate effective answers within the LLM. They help organizations unlock the full potential of their data and prompt the LLM to generate insightful and relevant responses.
Vector databases face different challenges
Vector databases also introduce several new challenges to existing processes compared with relational and graph databases. According to Greenstein, the main challenges include machine readability, the maturity of tools and access, and new approaches for information retrieval:
Machine readability. Vector databases store representations optimized for machine understanding rather than human comprehension. It requires additional work to index the vectors effectively, enabling applications to identify the relevant vectors for a given question or prompt.
Maturity of tools and data access. Vector databases support concepts such as role-based access control, but the tools and approaches for data access are still evolving. Although options exist, it is essential to consider the specific requirements and ensure the appropriate tools are in place to facilitate seamless data access and management.
New approaches for search and information retrieval. Vector databases necessitate fresh approaches to search and information retrieval, particularly when dealing with large-scale unstructured data, which can make up 80% of all enterprise data. Tailor indexing and content chunking techniques and skills to each use case to achieve optimal results.
Paving the skills gap
Working with vector databases requires skills and abilities not commonly found in the current data analytics field, Springer said. Relational databases and SQL are commonly used, and working with them is table stakes for any data team. Vector databases are newer, and the individuals with the ability to work with them are much rarer.
However, efforts to integrate traditional relational tools with vector databases may help flatten the learning curve, Springer said. For example, the KX vector database is making tremendous strides in paving workflows and skills across vector and relational domains. The KX partnership with Snowflake may further reduce the challenges in implementing vector databases for many organizations.
In the long run, integrating the tools together may help enterprises consider how to use vector, relational and graph databases together.
“There are a number of valuable reasons to create multi-data store architectures, with the primary reason being the right tool for the job,” Schuller said. Structured data is always a need, and the new approaches using vector and graph databases can help complement existing data management operations.
George Lawton is a journalist based in London. Over the last 30 years, he has written more than 3,000 stories about computers, communications, knowledge management, business, health and other areas that interest him.
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
Reflecting On Data Storage Stocks’ Q4 Earnings: MongoDB (NASDAQ:MDB)
MMS
•
RSS
Reflecting On Data Storage Stocks’ Q4 Earnings: MongoDB (NASDAQ:MDB)
Earnings results often give us a good indication of what direction a company will take in the months ahead. With Q4 now behind us, let’s have a look at MongoDB (NASDAQ:MDB) and its peers.
Data is the lifeblood of the internet and software in general, and the amount of data created is accelerating. As a result, the importance of storing the data in scalable and efficient formats continues to rise, especially as its diversity and associated use cases expand from analyzing simple, structured datasets to high-scale processing of unstructured data such as images, audio, and video.
The 5 data storage stocks we track reported a decent Q4; on average, revenues beat analyst consensus estimates by 4.1% while next quarter’s revenue guidance was 0.5% above consensus. Investors abandoned cash-burning companies to buy stocks with higher margins of safety, and while some of the data storage stocks have fared somewhat better than others, they have not been spared, with share prices declining 5.2% on average since the previous earnings results.
Weakest Q4: MongoDB (NASDAQ:MDB)
Started in 2007 by the team behind Google’s ad platform, DoubleClick, MongoDB offers database-as-a-service that helps companies store large volumes of semi-structured data.
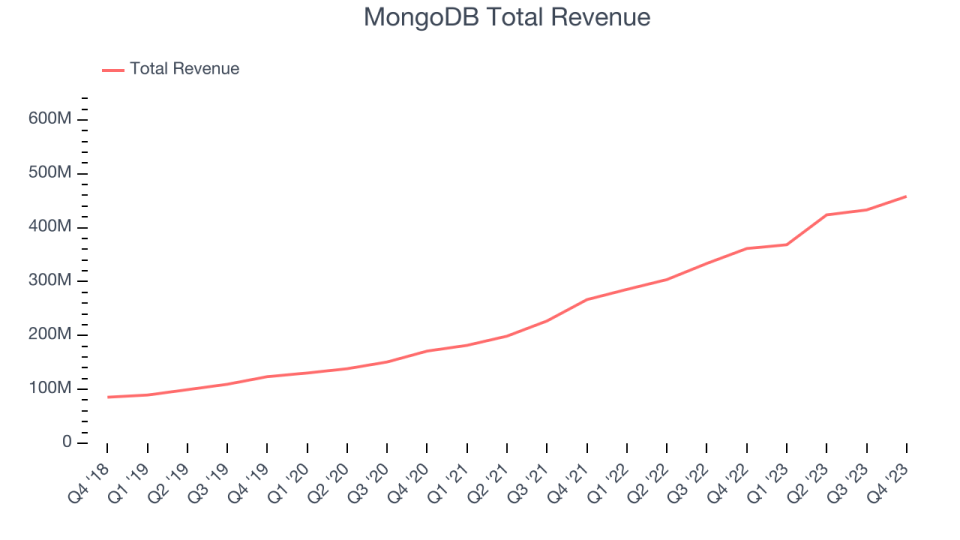
MongoDB reported revenues of $458 million, up 26.8% year on year, topping analyst expectations by 5.2%. It was a weaker quarter for the company, with full-year revenue guidance missing analysts’ expectations.
“MongoDB finished fiscal 2024 on a strong note, highlighted by 34% Atlas revenue growth and operating margin improvement of nearly five percentage points year-over-year. We continue to see healthy new workload wins as MongoDB’s developer data platform increasingly becomes the standard for modern application development,” said Dev Ittycheria, President and Chief Executive Officer of MongoDB.
MongoDB Total Revenue
MongoDB delivered the weakest full-year guidance update of the whole group. The company added 80 enterprise customers paying more than $100,000 annually to reach a total of 2,052. The stock is down 17.1% since the results and currently trades at $341.86.
Originally formed in 1988 as part of Bell Labs, Commvault (NASDAQ: CVLT) provides enterprise software used for data backup and recovery, cloud and infrastructure management, retention, and compliance.
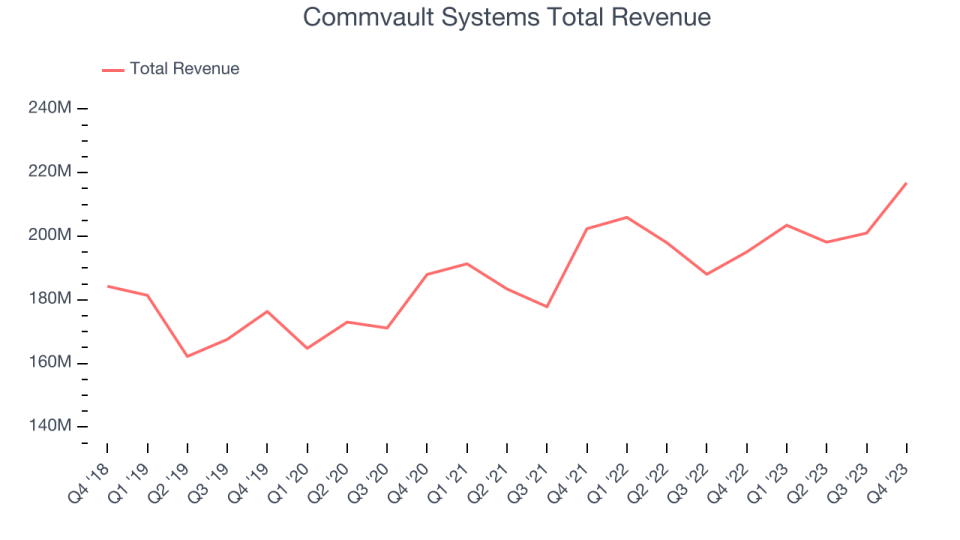
Commvault Systems reported revenues of $216.8 million, up 11.1% year on year, outperforming analyst expectations by 4.1%. It was a very strong quarter for the company, with an impressive beat of analysts’ billings estimates.
Commvault Systems Total Revenue
Commvault Systems scored the highest full-year guidance raise among its peers. The stock is up 22.5% since the results and currently trades at $99.82.
Started by brothers Ben and Moisey Uretsky, DigitalOcean (NYSE: DOCN) provides a simple, low-cost platform that allows developers and small and medium-sized businesses to host applications and data in the cloud.
DigitalOcean reported revenues of $180.9 million, up 11% year on year, exceeding analyst expectations by 1.6%. It was a mixed quarter for the company, with a decent beat of analysts’ revenue estimates but underwhelming revenue guidance for the next year.
DigitalOcean had the weakest performance against analyst estimates and slowest revenue growth in the group. The stock is up 3.9% since the results and currently trades at $37.25.
Formed in 2011 with the merger of Membase and CouchOne, Couchbase (NASDAQ:BASE) is a database-as-a-service platform that allows enterprises to store large volumes of semi-structured data.
Couchbase reported revenues of $50.09 million, up 20.3% year on year, surpassing analyst expectations by 7.6%. It was a decent quarter for the company, with an impressive beat of analysts’ revenue, ARR (annual recurring revenue), and EPS estimates.
Couchbase achieved the biggest analyst estimates beat among its peers. The stock is down 2.1% since the results and currently trades at $26.31.
Founded in 2013 by three French engineers who spent decades working for Oracle, Snowflake (NYSE:SNOW) provides a data warehouse-as-a-service in the cloud that allows companies to store large amounts of data and analyze it in real time.
Snowflake reported revenues of $774.7 million, up 31.5% year on year, surpassing analyst expectations by 2%. It was a mixed quarter for the company, with strong free cash flow, while still growing revenue at 30%+, which is certainly an impressive feat. On the other hand, its net revenue retention declined again and product guidance for Q1 missed analysts’ estimates.
Snowflake scored the fastest revenue growth among its peers. The company added 25 enterprise customers paying more than $1m annually to reach a total of 461. The stock is down 33.2% since the results and currently trades at $153.67.
Help us make StockStory more helpful to investors like yourself. Join our paid user research session and receive a $50 Amazon gift card for your opinions. Sign up here.
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)
Kwan: The edge has become a very popular application of distributed systems. What exactly is the edge? The edge is simply something that runs very close to clients geographically. We think of services such as DNS resolution, content delivery, and IP firewalling, which are close to the client. These are things that we consider near the edge. Traditionally, we have considered things like relational databases, which have lived closer in centralized data centers, which are further away from clients. We can see that the edge is really just a relative metric where services that run closer to the clients are considered more edgy. Location-based network latency and costs are massively reduced when we can serve requests from clients at the edge of the network closer to where they are.
Background, and Outline
My name is Justin. I’m a software engineering intern at Apple, building out services for iCloud’s edge network. Previously, I worked at Cloudflare as a system software engineer, focusing on storage infrastructure, multi-tenant resource isolation, and even database internals where Vignesh was my super amazing engineering manager. Vignesh has been an engineering manager at Cloudflare from 2019 up until now. He’s been running the entire software storage infrastructure org as well as the database team. He’s also worked on a startup that he’s working on called spinup.host. He also is a member of PgUS. From 2016 to 2019 Vignesh gained a lot of database engineering experience at the ground level as a database engineer at Ticketmaster.
I’m excited to share with you guys how we design and operate our entire high availability database architecture at the edge. Together, we’ll break down in high detail the high availability setup and consider the tradeoffs that we had to make around each part of the system. Then we’ll explore some of the interesting performance challenges that we faced when bringing our database infrastructure closer than ever to the edge and dive deep into the solutions that we’ve implemented. We’ll finally take a sneak peek at some of the really interesting recurring patterns that we see emerging in relational data storage, colocated at the edge.
Cloudflare
Cloudflare is the market leader in network security performance in edge computing. For some cool numbers, let’s give you guys an idea of the scale we’re dealing with. We have over 27 million internet properties that depend on our protection, which means that our network needs to handle over 46 million HTTP requests per second on average at any given time. We leverage our network Point of Presence locations spread across 250 locations globally. This level of traffic translates into over 55 million row operations per second, on average against our busiest Postgres database cluster. That stores over 50 terabytes of data across all of our clusters.
Cloudflare’s control plane is an orchestration of many microservices that power our API, our dashboard. Our control plane manages the rules and configurations for critical network services along the data path. Our database clusters store things like DNS record changes, firewall and DDoS mitigation rules, API gateway routes, and even data for internal services like billing entitlements and user auth. We’ve commonly seen application teams frequently use Postgres in some pretty interesting ways. Since Postgres began, store procedures have been commonly used to execute business logic as units of work. The robust psql language enables intricate branching logic, which is used for enabling and disabling domains with transactional consistency. We’ve also commonly seen applications where service teams will use Postgres as an outbox queue for capturing domain events. One example is when DDoS rules are generated from traffic analysis in a centralized data center. They’re first run into a Postgres table. A separate daemon will typically pull these events from Postgres and pipe them through Kafka to services at the edge. This means that latency critical services can avoid directly hitting the database while enjoying the durability that Postgres and Kafka give.
Keep in mind that at Cloudflare, we’re running our entire software and service stack on our own bare metal hardware. Unlike many other major service providers, we spend a great deal of time considering things like rack mounted servers, network cards that power our high bandwidth backbone, and the operational maintenance required. On-premise data storage offers us the highest degree of flexibility across the entire stack. We can meticulously fine tune elements such as our solid-state RAID configuration. We’ve even implemented features in the open source cluster management system, and even have applied custom performance patches against PostgreSQL itself. This level of transparency and control of our system would otherwise be impossible had we used any managed vendors such as AWS RDS. Unfortunately, that also means that there’s no magical autoscaling button that I can just push and immediately increase capacity when we start experiencing load. This is one of the most challenging aspects of running Cloudflare’s entire stack on-premise.
Architecture
Let’s dive into Cloudflare’s database architecture that sits near the edge. We need to process transactions on the order of millions per second. When designing and selecting the components of our system, we try to consider what was most needed from an ideal architecture. The most important thing is high availability. The control plane for our critical services need to remain available 24/7 to protect our customers. Initially, we aim for an SLO of five nines of availability across all of our services. That means that we get five minutes and a half of downtime per year across the entire software stack. This gives our databases even less leeway. Achieving a high level of availability requires our system to operate and then scale, and so our transactional workloads typically skew on the read heavy side. Our infrastructure has to handle a high rate of read RPS and write RPS with minimal latency, as well as maintaining fault tolerance. Of course, we also care about observability, which is important in any distributed system. We internally leverage our Anycast network, which means that clients are naturally load balanced across our PgBouncer proxy instances. This is the first step of our journey in pushing the databases to the edge, since queries could be processed faster in closer proximity to the clients. While BGP Anycast allows us to proxy queries to the optimal region closest to the clients where they’re deployed, write queries still need to be forwarded all the way back to the primary region, where the primary database instance resides, while read queries can be locally served from the closest nearby region.
Here’s a picture of our entire massive architecture. Let’s just start from the very top at the proxy layer. At the top we have PgBouncer. This manages database server connection pools used by our application clients. Queries are then passed through HAProxy which are load balanced across several database cluster instances to prevent any single Postgres database from becoming overloaded with a disproportionate number of queries. In the middle, a typical Postgres deployment contains a single primary instance, which replicates data to multiple replicas. This is done to support a high rate of read queries. Our primary database handles all the writes. Our asynchronous and synchronous replicas handle reads. Our Postgres cluster topologies are managed by the high availability cluster management tool called Stolon. It’s backed by the etcd distributed key-value store, which underlying it uses Raft protocol for leadership consensus, and election in the case of primary failovers. You’ll notice that we’ve adopted an active standby model to ensure that we have cross-region data redundancy. Our primary region in Portland serves all inbound queries. At the same time, our standby region in Luxembourg is ready to handle all incoming traffic, if we ever need to evacuate the region, or fail out. This means that our primary Postgres cluster replicates data across regions to our standby as well. There’s a lot going on in this high-level diagram. We’ll dive into each layer and just like each of the components and the tradeoffs that we considered.
Persistence
Ravichandran: We decided we have to build this highly distributed and relational database using edge. When we wanted to set on to do this, we wanted to look at what are the fundamental things that’s going to basically define how we define the architecture. As the first principles, we looked at CAP theorem, since it’s a distributed application, which we know is going to be distributed geographically, and especially using open source software, Postgres, and also everything is built on our own data centers. Just a quick recap on CAP theorem, for any distributed applications, you can have only one of the two, either you can have consistency, or high availability. A lot of the times we pick availability over consistency. Let’s go over the cases where we pick the tradeoffs and what are those tradeoffs? This is a typical architecture of how we deployed in a single data center. There is a primary database and then there is a synchronous replica. Then if you look at it, at least we have a couple of asynchronous replicas. The same topology is replicated across multiple data centers. We have at least right now three core data centers where we have replicated at a real time. Why do we pick this kind of semi-synchronous replication topology where we have the primary database and at least one synchronous replica and a bunch of asynchronous replica. In a typical situation where we have like an asynchronous replica, which goes down, we don’t have any problem with respect to the applications. Applications can still continue working without any impact, because it’s just an asynchronous replica. Similar tradeoffs we made for cross-region replication. Let’s say we have a replication region in Europe, as well as in Asia, if either of those two goes down, still our applications in the U.S. can continue working well. However, if the synchronous replica goes down, we basically bring the entire application to a halt, because we didn’t want it to take any reads and writes, especially writes, without making any tradeoffs. Pretty much every time when there is a failover that happens on the primary database, we pick the synchronous replica to be the new primary. That’s the reason why we have this kind of semi-synchronous replication topology that we went with.
As I mentioned earlier, there are two fundamental things. One, it’s going to be based on top of Postgres. Two, everything based on on-prem. Postgres by itself is not a distributed database. It started in the ’90s in Berkeley, and it’s been designed with monolithic architecture at mind. How are we going to take this Postgres into a distributed Postgres? Two things, one, we rely heavily on the replication aspects: one is the logical replication, and the other one is streaming replication. There is a third derivative, what I call the cascading replication, which is basically built on top of the able two ones, either logical or streaming. Before we get into the replication and how it’s useful for us to build a distributed Postgres, I wanted to have a quick primer on write ahead logs. How many of you are aware of write ahead logs? In any database, not just in Postgres, whether you pick MySQL, or Oracle, all this fundamentally relational database management systems, achieves the durability in ACID using write ahead logs. In simple terms, whenever you make any change to your database, it doesn’t need to be synced directly on your file system or the database files. Rather, you can capture those changes sequentially in basically a log file. Then those log files are synced to your database files in an asynchronous fashion. This provides the durability options that we pretty much need in any database systems. That’s pretty much turned out to be a really good feature for us to build a replication mission or replication systems, where we capture these changes and then replicate out to another replica.
Going into the streaming replication mode. In streaming replication mode, it’s pretty simple. A replica basically creates a TCP connection, and streams pretty much every log entry from operations within a transaction to another replica. The interesting part with this streaming replication is that it’s pretty performant in the sense that we can pretty much capture any changes that happens, at pretty much like 1 terabyte per second changes even to the replicas on the other end. Minimal delay. There are delays. Justin will go over some of the delays and how you can create those delays. In general, it’s pretty performant. The other caveat with streaming replication is it’s all or nothing. If you set up a replica, then you have to pretty much replicate every single data because it’s based on the filesystem level block level. There is no way for us to know, at least so far optimize which data is being replicated. The more newer version of replication is logical replication. As the name suggests, it’s more than at the logical level, instead of the block level or the foundation level where you are replicating data block by block. Rather, in logical replication, you are replicating data at the SQL level where each SQL statements that are captured at the end of the transaction, they are replicated on the other hand, more like, if you can think about a publisher and subscriber option. Definitely more flexible. Compared to the streaming replication, here you can create publishers and subscribers, even at a table level, and even more granular at a row level and on a column level. You have much more flexibility than a streaming replication provides. However, it has two caveats that’s a hindrance for us, at least as of now to adopt logical replication. The biggest one is the schema changes. No DDL changes are replicated. You have to figure out some way, build like custom tools, where when you have to make some changes, replicate those changes to all the other replicas. That’s just not easy. The other bigger problem is that logical replication is still not performant at scale. For a cluster, probably maybe gigabytes of size, maybe it’s good, but not at least at the multiple terabyte scale. Logical replication is not yet there.
Cluster management. Pretty much one of the biggest reasons we would have a cluster management as we all know, database failures. Whether we like it or not, failures do happen, for a multitude of reasons. As simple as, we have a logical failure, like a data corruption happened on one of the primary databases, and what do we do? Or even more severe things like natural disasters and whatnot. In any of those situations, we have to trigger a failover, and doing them manually is not fun. Another fact, at least 5% of hardware at any given time is faulty, pretty much if you think about it on a fleet of like multiple thousands of servers, across multiple data centers, at pretty much any point in time, you have some kinds of failures that is always going on. It could be as simple as like a RAID failure on a disk, all the way up to like an availability zone going down. How are you going to be prepared for these failures without having a good cluster management?
We picked Stolon, which is a pretty thin layer running on top of the Postgres clusters itself. It’s open source software written in Go, started in probably 2018 or 2019, it started picking up. The features that really brought us to use Stolon is, one, it’s Postgres native. It speaks Postgres. Also, it supports multiple site redundancy, like in the sense that you can deploy a single Stolon cluster, which is distributed across multiple Postgres clusters. Those clusters can be located in a single region, or even they can be distributed across multiple regions. There are a few more interesting aspects, one, it provides a failover. Obviously, that’s what you would expect from your cluster management tool. The good thing is, it’s more stable. In the sense, we have seen very less false positives. Digging deep onto our cluster management, the first component is Keeper. Keepers are basically the parent process, which manages the Postgres itself. Any changes that has to happen has to go through this Keeper. You can think about Keepers as basically the Postgres process. Then there is the Sentinels, I would consider them as the orchestrator, which looks at the health checks of each component of Postgres, and then makes decisions such as, are the primaries healthy, or should we start an election and figure out who the new primary should be. Finally, the proxy layer where all the clients connect to it, and then proxy layers make sure that, where is the write primaries? We should avoid any kind of multi-master situation.
Connection Pooling
Kwan: Finally, database connections are a finite resource, which means that we need to manage them efficiently. We all know that there’s overhead when you go and open a new TCP connection or Postgres connection, but what’s actually happening under the hood? Postgres connections are built on top of the TCP protocol, so requires that three-way handshake. Following this, we also have an SSL handshake to secure that communication. Also, since Postgres dedicates a separate operating system level process for each connection, the main postmaster process has to fork itself to execute queries for the connection. This forking, as we all know, involves new page allocations and copying memory from the parent process to the new child address space. In other words, each connection requires a nonzero amount of CPU time. This consumes finite resources, such as memory. When we have thousands of these connections open concurrently, these three steps start eating up a lot of CPU time that should otherwise be used for transaction processing in the execution engine. A server-side connection pooler will open a finite number of connections against the database server itself, while exposing a black box interface that matches the same wire protocol that Postgres supports. Clients can connect to the pooler the same way they would connect to the database for queries to be sent. Managing pools in a separate server allows us to recycle previously open connections while minimizing the total number of open connections in the database server. It also allows us to centrally control tenant resources for each client, such as the number of allocated connections. Internally, we’ve actually done a lot of work in forking PgBouncer and adding a lot of interesting features that take inspiration from Vegas congestion control avoidance to actually give us stricter multi-tenant resource isolation.
In our specific setup, we opted for PgBouncer as our connection pooler. Like we said, PgBouncer has the same wire protocol as Postgres. Clients just connect to it and submit their queries like they normally would. We particularly chose PgBouncer to shield clients from the complexity of database switches and failovers. Instead of clients having to think about, where’s the new database when it failed over? Where should I connect to? Instead, PgBouncer manages this and abstracts it away. PgBouncer operates as a very lightweight single process server, which handles network I/O asynchronously. This allows it to handle a much higher number of concurrent client connections, as opposed to Postgres. PgBouncer introduces an abstract concept known as client-side connections. This is not the same as a direct server Postgres connection. When a client establishes a new connection, it attains one of these client-side connections from PgBouncer. PgBouncer then multiplexes these queries in an end-to-end fashion, where queries originating from various client-side connections are relayed across actual Postgres server-side connections, and they go through HAProxy. Why is PgBouncer so lightweight? PgBouncer employs a non-blocking model to handle network I/O efficiently. Unlike the traditional approach of allocating a separate thread or process for each TCP connection, that Postgres follows for compute bound requests, PgBouncer utilizes a single thread that just executes a single event loop. We only need one thread stack space for all the required connections. There’s, however, a bit more complexity in managing the state for all of these clients. The loop monitors sockets for read and write events using the epoll mechanism. Instead of polling actively and spawning a new thread on each new connection in userspace, we just need to tell the kernel, these are the file socket descriptors that I want monitored, and let the kernel do the rest. We then call epoll_wait in PgBouncer, which then just tells the operating system, put me to sleep until you let me know that TCP packets have arrived to this file descriptor, and notify me. Then the kernel just simply raises a hardware interrupt and provides PgBouncer with the associated file descriptor. We can process logic in userspace, such as making an authentication call to Postgres, pg_shadow, before forwarding off the query, making it a memory efficient solution for managing and relaying between a large number of client to server connections. One of the interesting challenges we’ve had with setting up PgBouncer is having multiple single threaded PgBouncer processes utilize all the CPU cores on a single machine, because it is a single process program. However, we wanted them to all listen on the same port. How could we reduce complexity for application teams where they don’t have to think about, which port should I go to for a specific PgBouncer process? Luckily, we look to the operating system again for a solution and found that you can bind multiple TCP sockets from different processes to the same port. We’ve actually patched PgBouncer in open source to use the SO_REUSEPORT socket option when opening a new TCP socket to listen on.
Load Balancing
Finally, let’s just chat about load balancing. We use load balancers which fronts our Postgres instances to distribute incoming database queries across multiple Postgres servers. Specifically, we’ve chosen HAProxy as our load balancer. Using round robin load balancing has been an effective way to distribute queries evenly across Postgres instances, or preventing any single instance from becoming overwhelmed. Similar to PgBouncer, our load balancers such as HAProxy also provides high availability and fault tolerance by automatically routing traffic away from failed or unresponsive Postgres servers to healthy ones, which avoids any downtime from degraded database instances. We use HAProxy to relay TCP connections at layer 4, incurring minimal overhead. Fun fact, it uses the kernel splice system call which just attaches an inbound and outbound TCP stream in the kernel. This means that data received from the inbound TCP socket is immediately transferred to that outbound socket and forwarded without having to be copied into userspace.
Challenges and Solutions
We’re going to dive into some of the interesting problems and challenges across our database infrastructure, and share some of the cool performance tips and tricks that helped us in our journey to high availability at the edge. First up, replication lag. We found that our Postgres replication lag becomes extremely pronounced under heavy traffic, especially for applications who have many auxiliary or redundant data structures and schemas, such as bloated indices. In these cases, write operations become amplified, because we’re updating them in the primary, rebalancing our index [inaudible 00:26:24] on this. We also need to replicate that as well. Other bulk heavy write operations such as ETL jobs, data migrations, and even mass deletions for GDPR compliance are also common offenders. Another interesting cause of replication lag is automatic storage compaction, otherwise known as autovacuum in Postgres. This just executes on interval. When a data is deleted, fixed waste tuple slots become fragmented on disk, so we have this process that goes ahead and cleans up those fixed waste data slots, and so that avoids any fragmentation. Now, replication lag is an unavoidable problem in any replicated distributed system since data needs to cross the network path. Internally, we target an SLO of 60 seconds of replication lag, and we tell this to the upstream application teams to work with. To minimize the replication lag, we, number one, try to batch our SQL query writes into smaller chunks to avoid replicating large blocks of data all at once. One way we also sidestep replication lag and maintain read-after-write consistency is by caching or reading directly after writing to the primary or the synchronous replica. Finally, we can avoid replication lag by simply ejecting all replicas from the cluster leaving only the primary. No replicas means no replication lag. While this might sound insane, this approach requires a deep understanding of tenants query, workloads, and potential changes in volatility. That might significantly change the system’s resilience. You can think of this as the unsafe keyword in Rust.
Another interesting incident, one of our largest public-facing incidents happened back in 2020, where a series of cascading failures severely impacted our database’s performance and availability. Our public API services experienced a drastic drop in availability plummeting all the way down to 75%, all our dashboards for other critical network services were becoming 80 times slower. From what we saw, both regions’ primary databases had executed a failover and promoted their synchronous replicas cleanly. However, the primary database in the primary region soon started to crumble under the massive load of RPS traffic. As a result, this led to a second failure of the new elected primary database. That left us with no more synchronous replicas to promote. This is starting to sound like the beginning of a high availability nightmare. We found ourselves facing two choices, we either promote an asynchronous replica and we risk potential data loss, or we suffer additional downtime by manually initiating a failover to our standby cluster in our standby region. For us, of course, data loss is an unacceptable option, and so we chose the latter approach.
What just happened here? After further investigation, we found that a network switch had partially failed and was operating in degraded state. The rack of the misbehaving switch included one server in our etcd cluster which handled the leadership election. When a cluster leader fails, etcd utilizes the Raft protocol to maintain consistency and select a new leader for promotion. However, there’s a simplification of the Raft protocol, which all members just need to state whether they’re available or unavailable, expecting them to provide accurate information or not at all. This works well for full failures like machine crashes, but you run into cases of undefined behavior, when different nodes in your Raft cluster start telling each other different things. In this case, we have node 1 and node 2 and node 3, which had degraded network switch, so the network link is degraded between them. Node 1 didn’t think that node 3 was anymore a leader, but node 1 and node 2 still had a link, and node 2 and node 3 still had a link. Node 2 acknowledged that node 3 was still the leader. In this situation, node 1 tried to initiate many leadership elections, and so it would continuously vote for itself. Node 2 still saw node 3 existed and would vote for node 3. What happened here? We get into a deadlock state where no leader is elected. When we get into a deadlock state, then the cluster becomes read only. Because the cluster is read only, clusters in both regions are no longer able to communicate with each other. This initiated both clusters to actually fail over to the primary replicas that we saw. Typically, when we fail over, the synchronous replica is promoted. What happens to the old primary? When we fail over, the synchronous replica is promoted, the old primary needs to actually begin undoing transactions that it has committed, because there could be some transaction history that could have diverged between the new primary and the old one, while we kept it available under a network partition. After it unwinds all the way back, unwinding our diverge history kind of like a git branch being undone. The synchronous replica needs to then send over and basically receive and replay all the new and correct transactions that are happening on the new incorrect primary that it missed. Our primary failed once again, because we had no more synchronous replicas to absorb the RPS. Once the primary failed, there was no longer a synchronous replica, meaning that we had downtime. Also, we need to figure out why was it taking so long for the synchronous replica to try to replay all of those transaction logs from the new primary.
There are three things going on here. This is a pretty large-scale issue. Number one, we have a hardware failure, that is just an unfortunate situation that happens. Number two, we had a Byzantine Fault with Raft. This is a really rare event. It’s known with the Raft consensus protocol that this is a faulty situation. Most implementations of the Raft cluster or the Raft consensus protocol will choose to use a simpler algorithm versus something that uses cryptographic hashing, but it’s harder to understand. A third problem here was that Postgres was taking a very long time to resynchronize, when the primary was sending back the write ahead logs for the new synchronous replica to replay. For us, we decided to pick the third option to solve because this was under the most control, actually, optimizing Postgres internally. Typically, when you have the write ahead log, this is what it looks like. You have the original timeline with the original history. You have the old timeline, which diverges on its own path, because it’s no longer communicating with the original one and receiving replica write ahead logs. What we actually found when digging into our logs was that most of the time Postgres was spent in rsync, just copying over 1.5 terabytes of log files from the primary to the old synchronous replica that was resynchronizing. What’s the solution here? We optimize Postgres, by instead of leading all the way back in history of time and copying those files, we just went back to the last diverge point where the timeline forks, and then we just need to copy off files from there. That’s like 5% of all the data that was originally copied.
Doing this, our replica rebuild times reduced from 2-plus hours, to just 5 minutes. That’s like a 95% speedup. We also submitted our patch for open source contribution. As another cool feature, now we’re able to resync and do this whole failover resync in our cross-cluster failover and resynchronization across multiple regions. What are the key lessons of this very confusing, but large-scale incident? Number one, we need to anticipate the effects of degraded state and not just fully failed state. For this, we actually have some internal tools that do chaos experimentation randomly on a cluster. Also, another thing we found is that it’s quite a good investment to go and build and fix software in open source yourself. You build the in-house expertise, that otherwise will be very hard to find. It’s better than just trying to go figure out, we should just use this as a separate tool because we’re having problems with this one. You don’t know if it’s going to be any better. That’s our open source commit that we’re sending off for Postgres CommitFest.
Access Data from the Edge? (Cluster of Clusters)
Ravichandran: Not fun just maintaining one cluster in one region, you can think about all the different failures, like hardware failures, even some of the failures, if they fail cleanly, that’s so much better. There are cases like this Byzantine hardware failure, where components are not fully failed, but they are actually operating in degraded state, which is much more challenging to figure out than actually building your systems and architecting for full failures. We take this monolithic like Postgres clusters in a couple of regions, and distribute them across four regions, or three regions. They will pretty much look like, from an edge application, let’s take a Cloudflare Worker standpoint view, it will look like a cluster of clusters. This is where we are currently heading down to. We had like primary region based out of pretty much most of the time in the U.S., we spread it to EU. Within EU we have like a couple of regions. Then now we have branched into Asia. Pretty much all of them uses Postgres streaming replication, especially using the hub and spoke model, where we have the primary region, which replicates to all the regions. There is no cascading replication involved here. We have to watch out for all the fun things that Justin mentioned about like replication lag, keeping all of them in sync is important. Also, when there is a very high replication lag, we have to somehow make sure that we address the SLAs that we have provided to the application teams sometimes, which means we have to divert the traffic all the way back to the primary region itself.
Having this kind of distributed Postgres is cool, but what is the actual benefit? Where can we use the strengths of a distributed Postgres? This is when we introduced smart failovers. Look at this new topology and figure out which region could be the primary. One of the first attributes is like, pretty much as simple as like, follow the sun. A, keep your primary region keep moving, as it progresses. For example, start with U.S. Then when the day ends, move your primary region back to Asia, which pretty much solves the latency problem, because your writes are going to be much faster since your primary database is closer to the vast majority of population, or clients’ applications. All we’re trying to do is still we are working around the fundamental limitation that Postgres is pretty much a single primary system. If Postgres can be made like a multiple primary, without a lot of the downsides, we don’t actually need to do a lot of this dance. The second one is sometimes we have done based on the capacity, certain regions have more capacity than other regions. For example, like shipping hardware to a particular continent has become challenging. Especially during COVID, for example, we couldn’t get hardware to Asia in time. We had to pretty much keep most of the time our primaries away from Asia. The traffic, which I already touched upon. The last one is the compliance based, where we are getting into more challenges that, for regulatory reasons, we have to have certain kinds of data in a certain region, and how do we do them? Once again, we can do that using smart ways.
If you think, it’s not that simple. It seems like you have Postgres in one region, and then put them out in five regions, and whatnot, and keep failing over and some of the optimizations, especially what we talked about earlier about pg_rewind, using that we can rebuild the clusters pretty much in less than one minute. You have your primary region in U.S., fail over to Asia. What happens to what used to be your primary region in U.S., you can rebuild that within a minute, which is good. That seems like we can keep doing this all day. It’s not that simple. One of the biggest challenges that we run into is the dependency graph. If you think about it, just failing over to your databases is not that hard, at least fairly hard, but seems like a solvable problem. The biggest challenge comes in when you bring in your applications inside this. How do we do just your databases without failing over your entire applications? Especially nowadays, applications are duct taped, like with multiple components, like message queues and Kafka and analytical databases, it’s not just easy. Anyone who is here thinking about like, I’m just going to do this cross-region and I’m going to fail over, just look at your application dependency graph. Even not just like first layer of application dependency, you have to go all the way down, like track down all the dependency layer, because even the last one of the dependencies is still going to suffer from a network call. The other big aspect is, it requires a lot of coordination. At least we haven’t still completely automated, so we have to like jump on a bridge call across 20 different team members from different teams, figuring out how to do this. In our case, it’s something like this, a dependency graph. For example, like we have databases that you know pretty much their level zero of dependency. Then you have fundamental systems, for example, entitlements, like building an authentication and configuration, which pretty much is being used by rest of, let’s say, primitive applications like R2, and SSL, and whatnot.
Database Trends
Finally, I just want to quickly touch upon the database trends especially as a practitioner that I’ve been looking at and have some knowledge. One, we are looking at more of providing embedded data at the edge, where we are still keeping your monolithic Postgres at, at least like three to four regions, and then bring a lot of those key data to embedded database, for example, SQLite. We can keep your Postgres somewhat monolithic, or as edgy, and then keep real edge using your SQLite. Especially when you’re using SQLite at the edge, make sure that it is still like Postgres wire compatible. There are open source projects, where they take the Postgres wire protocol, and then replace, or underneath put SQLite as the storage engine. In that way, applications feel like they’re still talking to Postgres. The other idea is persistence at the edge, obviously, Cloudflare Workers and whatnot, others are definitely looking at bringing more client-side data. The other interesting one, which you folks might have noticed, is bringing more of separated storage and compute, for example, the typical architecture where we have like Cloudflare Workers running in Europe, whereas your database is in North America. However, that’s changing. A lot of the newest features we are bringing are colocating both your storage and the compute. Even for example Cloudflare Workers has a new feature called Smart Placement, and pretty much what it does is it moves the Cloudflare Workers close to where the database is. Earlier, we pushed the code more close to the clients, but what we noticed is that a lot of those client applications are actually spending a lot of time talking to their database. Pretty much any business application is like chatty, they want to talk to the database five times to even respond to a single request back to the clients. We pretty much, like a full circle, we moved out the compute close to the end users, and now we are slowly bringing back that compute back to where your database is. Lastly, this is another one where we are running into a lot of new challenges, is how do we do this data localization, especially for Europe region, still using Postgres. This is where we are betting heavily on logical replication. Logical replication provides the flexibilities where we can even replicate on a row level on a specific column level. Still, this is a little bit in more of an exploratory phase. We haven’t yet made anything production using logical replication. I have a strong feeling that it’s going to be this way.
MongoDB (MDB) Gains But Lags Market: What You Should Know – Yahoo Movies
MMS
•
RSS
MongoDB (MDB) closed at $156.02 in the latest trading session, marking a +0.03% move from the prior day. This change lagged the S&P 500’s 0.47% gain on the day. Elsewhere, the Dow lost 0.29%, while the tech-heavy Nasdaq added 0.85%.
Coming into today, shares of the database platform had lost 1.65% in the past month. In that same time, the Computer and Technology sector gained 2.8%, while the S&P 500 gained 2.08%.
MDB will be looking to display strength as it nears its next earnings release. On that day, MDB is projected to report earnings of -$0.28 per share, which would represent year-over-year growth of 31.71%. Our most recent consensus estimate is calling for quarterly revenue of $91.27 million, up 58.76% from the year-ago period.
MDB’s full-year Zacks Consensus Estimates are calling for earnings of -$1.06 per share and revenue of $382.05 million. These results would represent year-over-year changes of -6% and +49.13%, respectively.
Investors might also notice recent changes to analyst estimates for MDB. Recent revisions tend to reflect the latest near-term business trends. With this in mind, we can consider positive estimate revisions a sign of optimism about the company’s business outlook.
Our research shows that these estimate changes are directly correlated with near-term stock prices. We developed the Zacks Rank to capitalize on this phenomenon. Our system takes these estimate changes into account and delivers a clear, actionable rating model.
The Zacks Rank system ranges from #1 (Strong Buy) to #5 (Strong Sell). It has a remarkable, outside-audited track record of success, with #1 stocks delivering an average annual return of +25% since 1988. The Zacks Consensus EPS estimate remained stagnant within the past month. MDB is currently a Zacks Rank #3 (Hold).
The Internet – Software industry is part of the Computer and Technology sector. This group has a Zacks Industry Rank of 56, putting it in the top 22% of all 250+ industries.
The Zacks Industry Rank gauges the strength of our individual industry groups by measuring the average Zacks Rank of the individual stocks within the groups. Our research shows that the top 50% rated industries outperform the bottom half by a factor of 2 to 1.
Make sure to utilize Zacks. Com to follow all of these stock-moving metrics, and more, in the coming trading sessions.
Want the latest recommendations from Zacks Investment Research? Today, you can download 7 Best Stocks for the Next 30 Days. Click to get this free report
.NET MAUI Community Toolkit 8.0.0 Brings Touch Behavior
MMS
•
Edin Kapic
On March 29th, 2024, Microsoft released version 8.0.0 of their open-source MAUI Community Toolkit. The new version adds touch animation behavior, a rewritten Snackbar component and many bug fixes.
.NET MAUI Community Toolkit (NMCT) is one of Microsoft’s .NET community toolkits hosted on GitHub, covering the MAUI developers. Their purpose is to let the community contribute useful code missing from official frameworks. The community toolkits are released as open-source software, and they encourage the developers to submit their contributions. Some toolkit additions can be later promoted into the official Microsoft libraries.
MAUI is an acronym that stands for Multiplatform Application UI. According to Microsoft, it’s an evolution of Xamarin and Xamarin Forms frameworks, unifying separate target libraries and projects into a single project for multiple devices. Currently, MAUI supports writing applications that run on Android 5+, iOS 11+, macOS 10.15+, Samsung Tizen, Windows 10 version 1809+, or Windows 11.
The previous major version of NMCT, 7.0.0, was launched concurrently with the .NET 8 official launch, in November 2023. The version 8.0.0 comes four months later.
The big new feature in the new version is the availability of TouchBehavior. It is a declarative ability to interact with a visual element, based on a touch or a mouse event. In the Xamarin cross-platform library, deprecated and with the official end of life slated for May 1st 2024 , it was known as TouchEffect. The NCMT team ported it from the Xamarin Comunity Toolkit to the .NET MAUI Community Toolkit.
Another change is the Snackbar component, which represents a notification on the lower edge of the screen. It has been completely rewritten. For Windows developers, there is a breaking change that requires component preparation in the package.xappmanifest file and the MauiAppBuilder class. Other platforms don’t require any additional steps.
The navigation bar on the Android platform now supports changing the color and the light/dark style.
The .NET MAUI Community Toolkit is versioned in different releases, frequently updated. The toolkit versions evolved from 3.1.0 in January 2023 to 8.0.0 in March 2024. The reason for this multiplicity of version numbers is the presence of breaking changes, which force a major version number increase. Microsoft acknowledged the progress and the acceptance of the toolkit with a mention on their .NET developer blog.
MongoDB, Inc. Share Price Target ‘$450.92’, now 26.6% Upside Potential
MMS
•
RSS
MongoDB, Inc. which can be found using ticker (MDB) now have 29 confirmed analysts covering the stock with the consensus suggesting a rating of ‘buy’. The target price High/Low ranges between $700.00 and $272.00 with the average share target price sitting at $450.92. (at the time of writing). Given that the stocks previous close was at $356.09 and the analysts are correct then we can expect a percentage increase in value of 26.6%. It’s also worth noting that there is a 50 day moving average of $412.18 and the 200 day moving average is $388.60. The company has a market cap of 25.33B. The current stock price for Hilton Worldwide Holdings Inc. is currently $347.82 USD
The potential market cap would be $32,078,287,796 based on the market consensus.
The company is not paying dividends at this time.
Other points of data to note are a P/E ratio of -, revenue per share of $23.62 and a -5.35% return on assets.
MongoDB, Inc. is a developer data platform company. Its developer data platform is an integrated set of databases and related services that allow development teams to address the growing variety of modern application requirements. Its core offerings are MongoDB Atlas and MongoDB Enterprise Advanced. MongoDB Atlas is its managed multi-cloud database-as-a-service offering that includes an integrated set of database and related services. MongoDB Atlas provides customers with a managed offering that includes automated provisioning and healing, comprehensive system monitoring, managed backup and restore, default security and other features. MongoDB Enterprise Advanced is its self-managed commercial offering for enterprise customers that can run in the cloud, on-premises or in a hybrid environment. It provides professional services to its customers, including consulting and training. It has over 40,800 customers spanning a range of industries in more than 100 countries around the world.
Subscribe for MMS Newsletter
By signing up, you will receive updates about our latest information.
Did you know...
More than half of fortune 500 companies are planning an AI project in the next 6 months! (Subscribe to be in the know!)