Month: May 2024

MMS • Kyle Carberry
Subscribe on:
Transcript
Shane Hastie: Good day folks. This is Shane Hastie for the InfoQ Engineering Culture Podcast. Today I’m sitting down with Kyle Carberry. Kyle is the co-founder and CTO of Coder. And well Kyle, I’ll let you tell us the rest. Welcome. Thanks for taking the time to talk to us.
Introductions [01:07]
Kyle Carberry: Thank you so much for having me, Shane. Like Shane said, I am the CTO and co-founder of Coder. I’m primarily a programmer though, that’s mostly what I do, which is apt for the name of the company. But yes, we’ve been doing Coder now for I guess six years. And prior to that I mostly toured around on the internet and that’s kind of where I met my co-founders.
Shane Hastie: So tell us a little bit about the Coder story.
Kyle Carberry: We won’t go extremely deep here. I started with programming, kind of tinkering with computers as a kid. I pirated an extreme amount of software. Post that era I played a lot of Call of Duty and that’s where I was copying and pasting other people’s code to have modded lobbies in Call of Duty. Post that era I got into Minecraft servers and we ran servers for a bunch of people and a bunch of my friends had Minecraft servers and that’s where I met my co-founders.
So then we tinkered around and made a lot of random tools on the internet in that time. And that was for maybe five years, four years. And we eventually stumbled upon the idea of Coder, and I say stumbled upon the idea because we really, really loved software and we really wanted to start a company.
The primary problem that we had at the time was when we were running these Minecraft servers, we would constantly be uploading our JARs to these servers to run against. And it didn’t make a lot of sense to us why we were building one place and running in another.
Coder’s gone through a lot of iteration post that point, but that’s kind of the absolute inception.
Shane Hastie: The reason we’re talking is developer experience. There’s a lot of, I don’t want to say hype, there’s a lot of awareness of the importance of developer experience today, probably more so than there has been for quite a long time. Why is that happening and what does a good developer experience give us?
Why the focus on developer experience [02:55]
Kyle Carberry: So we’ll start with the why is it happening. I do think the launch stuff like Copilot is accelerating an extreme amount. It gave us surprising insight. And what I mean by that is GitHub Copilot specifically, like auto-complete with code. And I think it gave us a remarkable amount of insight into how much writing code is kind of nonsense language or almost entirely auto-completable where it’s not really logic, it’s almost like your brain’s on autopilot when you’re writing it.
I think for that reason, that really gave people a lot more insight into, for one, how much people can get done and then for two, how much better it actually makes our lives. And for me, I use Copilot every day and it’s an amazing tool and it would be a lot harder for me to program without it.
The second part of really how it’s changing our lives from my perspective is kind of eliminating a lot of the lazy work I’ll call it, of software development, which is quite a profound time to live it. Me writing an application, I have more of the abstract idea of what I want to write and the rest I can fill in.
Removing the lazy-work part of coding [03:58]
The cool thing is you’re kind of almost interfacing with this stuff in natural language now and you kind of have to know how to code a lot less. And so it’s changing our lives. I think it’s making a lot more people, programmers, and I think it’s making a lot of junior programmers, senior programmers, and I think it’s really cut out that time of someone going from absolutely learning how to program to being an expert at programming. I think that’s maybe the biggest jump that we’re seeing.
And that’s kind of developer experience in a whole, from my perspective, not necessarily just Copilot. That’s probably just the most gleaming example.
Shane Hastie: So what other aspects of what makes a good developer experience?
What makes a good developer experience? [04:36]
Kyle Carberry: I think everything that’s not writing code is kind of garbage and it’s kind of something that we could pile up and be like meetings everything else. The ideal situation I think for most organizations that are paying people to code is having people write code. And I think the majority of people at companies that go to write code really want to just write code.
And so the garbage as we’ll call it, is maybe setting up your development environment or having to write some horrible config file that Copilot could automatically write for you or setting up your laptop for the first time when you start a job or something to that effect. I think anything that’s a non-coding time that really disrupts flow is what’s terrible. It’s kind of like you’re building a table and you have to run to Home Depot because you forgot a bunch of parts like five times. You start getting upset that you even started building a table. So a terrible analogy, but you know what I mean.
Shane Hastie: Where does this friction come from?
Kyle Carberry: I think the friction builds up over time. There’s nothing like the feeling of starting a new project. And what really happens is, and I don’t think it’s any individual’s fault necessarily, but complexity arises whether it’s from some immediate need in the business, which is super reasonable and you take on debt for a very, very well understood reason, or someone’s newer to writing code and they may not have predicted the pitfalls of something that would happen. And so I think complexity accrues over time and once you have a lot of complexity, it’s really hard to undo.
Shane Hastie: A lot of our audience will be in that space of complexity. It’s hard to undo, but what are some concrete steps you can take?
Kyle Carberry: That’s a good question. I can only speak from experience. So a lot of the customers that we talked to, I’m going to be extremely biased, so I’m going to try to not make this a plug for Coder. Some people obviously reduce the complexity of their environment with something like Coder. That’s maybe like a step.
I would say something we do inside of Coder to speak more of the cultural engineering practices that we have is really, really opinionated code, like exceptionally opinionated, kind of like a religion of sorts. And if someone writes terrible code, it just doesn’t get it because it just doesn’t kind of pass the bylaws. Or maybe it’ll get in once or twice, but it won’t like the third or the fourth time.
And I think how to set that culture really, really comes from the top. And so I think it’s very difficult to enforce backwards, but I really think your senior most people have to be very, very intentional in the way that they write code and how they merge code in those practices. I would say that’s probably what I’ve seen work the best for us, is just being exceptionally diligent in terms of culture and having a really strong reward cycle on when people do the really good pieces of code.
Shane Hastie: So let’s dig into that. What does opinionated code really mean?
Writing opinionated code [07:18]
Kyle Carberry: I think for us, opinionated code, I’ll give you an example of some of the principles that I personally embody. I believe a lot in a lot of verbose code. So writing server instead of SRV everywhere, I think the mental complexity and adding one step to decoding things is generally bad. I don’t think it’s always bad. I think inconsistency is bad. And so having server some places and SRV some places is a mental catastrophe. So you think they might be two separate things. You’re not sure if they’re the same.
And then I would say we have a really, really strong culture of, I was going to say testing code, but that’s kind of like status quo. I would say that maybe more so comes from being really idiomatic in how we abstract. And so we try to just keep stuff very, very basic. We understand our software is not going to be used by millions of engineers at the same time because we’re self-hosted. We understand and it’s like, yes, 10, 20, 30,000 developers at most. And so we architect our stuff very much like that. It’s all really simple. We have one container. We don’t have a million microservices. We keep it really, really basic. So I would say those are some of our opinions that at least we have in our code base.
Shane Hastie: So that’s opinionated code. What are the other things that you do to build a culture where well developer experience is great and that people can remove that friction?
Elements of great development culture [08:42]
Kyle Carberry: I would say we really, really work to remove roadblocks inside of Coder. And I know every organization does, but the roadblocks are sometimes really hard to remove.
So one way I think that you can do that, I think open sourcing stuff for example is a fantastic way to do that. If all the code is open, there’s a lot less to be concerned about. Whether it’s IP protection or your computer gets hacked and the source code’s leaked, I don’t really have to care about that stuff as much. That’s a really big barrier for most organizations to just say that, “Oh yes, just open source,” it doesn’t make a lot of sense for most. But a lot of the companies that we talk to and that find something like Coder beneficial or any alternative solution that is remote development is really being able to remove a lot of things that remove the developer from flow that we were talking about.
One example of that is a lot of companies will have a VDI in front of a developer. So that means your desktop is in one place and you’re in an absolute another place in the world. And that is a bad developer experience. I feel like I can almost say across the board, nobody is happy about having a VDI and using a computer in some other place. They might be happy about some benefits they get from that or the security team might be exceptionally happy about it. But when you press a key and it shows up 300 milliseconds later, it’s really hard to get in flow.
So I would say those types of things culturally are what really, really impede typically from what I’ve seen. And those are the people who generally benefit a lot from kind of the vast unlock of developer experience.
And typically it’s very bureaucratic I would say. You get a lot of pushback from security people and there’s a lot of hands involved. It makes a lot of sense. But I think over the coming years we’re going to see a pretty big unwind as people understand that a lot of the ROI set of businesses is from the creation of stuff that developers make.
Shane Hastie: Thinking about culture and employment, finding people that fit the culture, how do you do that?
Finding people who align with the culture [10:33]
Kyle Carberry: So for us, I feel like we have kind of a hack in the fact that we are open source. And so a lot of the times and a lot of the people we’ve hired are actually people who have found Coder, fallen in love with it, love our code base and really want to work at the company. And I think that’s an excellent way to display it because something I always tell people, not everyone’s supposed to work at Coder, even some of the most talented people in the world might not want to work at Coder, whether it’s cultural or the company, they just don’t like me. I don’t know what it is. But the important thing is to attract the people that are both really talented and also fit you culturally. And I think an exceptional way to do that is to put your cards on the table and just show people what you got.
And I think it’s beneficial across the board kind of for your whole company. Whether it’s customers that see how we write code and our practices that we have in engineering or prospective employees. And I’m sure a lot of people opt out even when someone’s like, “Maybe I would work at Coder,” and then they go to our GitHub and maybe they don’t like what they see and they’re like, “I don’t want to work there.” And that’s great. It’s beneficial for both parties.
So I would say open source is probably the biggest tactic that we have. That’s kind of the main. As I’m sure you can tell Shane, it’s a big philosophy I have of keeping things out in the open.
Shane Hastie: So what if I’m in an organization that is struggling with the very idea of putting our IP out in an open environment?
The benefits of adopting an open source approach [11:53]
Kyle Carberry: So the question, say you want to attract dev talent that maybe cares a lot about developer experience and they’re really productive engineers, yet open source is almost not an option. So in that instance, I would say a lot of things are open source that aren’t directly code. Netflix comes to mind as they have an exceptional engineering org from my perspective, and they do a lot of blog posts and they do have a lot of open source that’s very popular, but I primarily know them from their engineering blog posts that are quite exceptional.
And so I think that’s another example of open sourcing something that’s not necessarily code. It’s kind of more open sourcing your engineering culture, which is to say, here’s the way that we think and we’re looking for people who also think in this manner. And so I would say if someone’s really particular about their IP, let’s say you have some crazy high-frequency trading bot. If anyone else knows about it, you’re done for. Well, I’m sure there’s some other components of that that you’ve learned a lot from, whether it’s like an engineering culture or from coding it or something to the effect that you could use to find like-minded people.
So I would say just writing generally, putting your thoughts out in the open is a fantastic way to collect other people who have the thoughts similar to you.
Shane Hastie: I want to dig into the, but I can just tell an AI bot to write me an article.
Kyle Carberry: So you can, but I think exceptional writing is really, really hard. I don’t think the AIs are there yet. They’re getting there for sure. I think maybe in a year or two you can create a Kyle bot that’ll probably produce better writings than Kyle himself. But for right now, I do think that original writing and original thought is still quite profound.
Shane Hastie: So you’ve had a journey from a tinkerer to a founder to growing an organization. Quite a few of our listeners are going to be in a position where they’re starting to move or thinking about moving from the individual contributor role into maybe a team lead or some other leadership role, or they’re already in that team lead role and they’re looking to progress their career advancement. What advice would you give them from your experience?
The journey from tinkerer to founder [14:04]
Kyle Carberry: I think the people that I’ve seen become the most prominent leaders in the company are very rarely promoted to become the leaders first. I think typically they’re seen as a leader and then they become one formally. So they follow this informal journey where the team obviously respects them to some exceptional degree and then they end up transferring into some leadership role. And actually typically not intentionally, in my experience with the best leaders. Typically, it’s kind of like the business needs this, and if you’re willing to step up to the plate, we would absolutely love to have you. And a lot of the time it’s been met with resistance where people are, “I really like coding,” or something to the effect. And I think that’s where the best leaders are generally born.
I found it very infrequently the ability to hire a leader to start something is really hard. It’s really hard to gauge someone’s leadership abilities. And so if I had to give advice to anyone who is aiming to kind of obtain a leadership position, I would say just start doing some of the things, not acting like you’re someone’s boss, but being a leader is not being someone’s boss. It’s being able to lead someone somewhere. And leading someone somewhere is not deciding whether they’re hired, fired or their salary. It’s taking them on a journey.
Shane Hastie: What’s that journey look like?
Kyle Carberry: I think it’s being able to carve out an explicit path that someone can walk on with you and be really happy with the result they’d end on, and you as the person who guided them on such path. It’s a very abstract definition, but I would say that’s the best leaders that I’ve found give some direction and they’re happy standing on that ground. And it’s the leader’s job to make sure that it’s aligned with the business’s interests so that the people walking on the path don’t end up going to nowhere.
Shane Hastie: What is that overlap with technical leadership and business interest?
Kyle Carberry: Good question. They frequently don’t align. I have examples in my head of people who are exceptionally talented technically, but don’t really care as much about the business side. But I actually think most people that are exceptionally talented have a little bit of either. Maybe you’re 80% business, 20% technical, but I do think there’s a divide there that I’m 80% technical, but I spend 20% of my time thinking about the business and what’s best for that.
For me at this point, they’ve merged into being one and the same. I very infrequently work on technology problems that aren’t directly relational to improving my life or the company or something to that effect.
And so I would say if you want to move into a leadership position, you can’t be 100% focused on technology. I shouldn’t say you can’t. I think it’ll be much more difficult if you’re focused 100% on technology. I think as an employee of a business, you always have the duty and responsibility to be looking out for the business. And even if you’re a person at a tech company who is mostly in a business role, I think you really have to understand the technology to be successful in the business role as well. Just in parts though, never 100% either way I would say.
Shane Hastie: So you’re a tech leader in a company whose target audience is technologists. What if the audience isn’t the technologists? What if I’m in a bank?
Understand the business drivers [17:09]
Kyle Carberry: Let’s say I worked in a bank right now and someone hired me to be in charge of money management, the app for it, or something to that effect. I think my first task would be going to the app store and downloading the money management app on my phone and starting to manage some money. And it would probably not be diving into the code base. Or even more distant from technology if I worked at a clothing company and I was working on the shop online for a clothing company, I would go order some of the clothes.
I think it’s critically important that you understand what you’re selling and who you’re selling to be successful in your role regardless of what role you’re in in a business. I think it would always be my number one priority to understand who’s gaining the value and how are they, and I would try to become as close to the buyer as I possibly could be, even if I’m not them exactly.
Shane Hastie: Tell me more.
Kyle Carberry: Well, I think it’s really difficult. I think you kind of give someone an insurmountable task when you ask them to work on something that they can’t understand and they don’t see the end product of. And so if someone told me to make an app for something or work on an app and they’re like, “But you can’t install the app and you can’t use it,” I would try my best to switch my team or switch my job. Because for one, I think it’s hard to get fulfillment from that. But for two, I think it’s really hard. You’re playing life with hard mode on if you can’t see the product, what you’re making.
Shane Hastie: So build the empathy, stand in the shoes of your customer, whomever that customer might be.
Kyle Carberry: I would say so, yes.
Shane Hastie: Over time, I’m going to make the assertion you’ve probably done a lot of experiments in teamwork and culture. What are some of the things that have worked and maybe some that haven’t worked?
Experiments in teamwork and culture [18:48]
Kyle Carberry: I classify a set of people in my life as problem predictors. And I would say predicting problems has very infrequently turned out well for me. And this holds especially true in engineering cultures.
What I mean by that and the specific mistakes we made is trying to force people, not force in a terrible way, but more so remote people to say being like, “You’re a manager,” or trying to really find things for people to do and for people to be productive on. And you’re really trying to predict problems. And I’ve done this before in my life. I’m much more of an emergent order type of person where you see a problem. Typically, the fire’s a lot smaller than people think it will be. And then you just put it out. And maybe you hire someone if the fire keeps reappearing and you keep stomping that fire out.
But I would say that’s probably the biggest problem that I’ve repeatedly made it and I had to learn five different times in horrendous ways each time is to not try to predict problems but rather let them emerge. And the vast majority of the time people vastly overestimate how bad a problem emerging will be, it’s typically like, “Whatever, maybe I spend 10 minutes a day on this horrible problem.” But then we’ll hire someone in three weeks and cumulatively I will have spent two and a half hours on it. So it’s like, yes, who cares?
Shane Hastie: What does teamwork look like at Coder?
Kyle Carberry: So now we try to promote is very much so working on an open source project. The proposal process and everyone merging code and opening code, I would say is quite similar to just going to a random repository like Kubernetes or Git, maybe less Git because they don’t use GitHub for issue tracking, but just opening an issue and opening a pull request.
As for the kind of camaraderie and how people self-reward each other in a culture, we have a reward system that we essentially use. The channel, it’s called #thanks. You can give someone a taco. And a taco is essentially redeemable for $5. And anyone can give five tacos a day to whoever they want to. And so you could give a big taco bomb, you can give five tacos all at once to someone if they really helped you out, or you could give one taco to five people.
And I would say this has been a really exceptional hack in our culture, just more broadly in the company. It’s very visible to everyone, how people appreciate each other, what people are thankful for that someone else helps someone for. If someone gives tacos for some nonsensical reason, I’ll mentally note it and it keeps a really good pulse on the culture, kind of like from a leadership perspective and also just for individuals. It’s amazing to do something awesome. Or just this morning someone hopped on a customer call. A bunch of us did actually, and I gave them all tacos and I was like, “That was amazing that everyone hopped on.” And it’s just a nice little reward cycle. Plus, you get two or three tacos a day, you get your lunch paid for, that’s also sick.
So I would say enforcing a non-leadership led engineering culture is critically important that everyone’s able to obtain a lot of dopamine from themselves and not need a pat on the back from the manager. They should get expectations maybe from their manager, but as per the reward cycle and you want everyone high-fiving and everyone really happy with the work that everyone else is doing.
Shane Hastie: Kyle, a whole lot of interesting ideas in here. If people want to continue the conversation, where do they find you?
Kyle Carberry: A couple of ways. One at kylecarbs on GitHub. So you can always open an issue if you use Coder. You can also tweet at me @kylecarbs, or if you want to, you can just shoot me an email.
Shane Hastie: Kyle, thanks very much for taking the time to talk to us today.
Kyle Carberry: Thanks for having me, Shane.
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Article: How to Build and Foster High-Performing Software Teams: Experiences from Engineering Managers
MMS • Ben Linders Olga Kubassova Michael Gray Hannah Foxwell

Key Takeaways
- Tech leaders can support and guide different kinds of autonomous teams by communicating the organization’s core values, mission, and vision, giving them authority within boundaries, fostering visibility and trust, and aligning on priorities, not by standardization.
- As a leader or manager, you should know when to step in to resolve a team problem and when to guide the team toward finding a solution themselves. Don’t interfere when a new team is finding their way or solving technical issues, and be careful that through interventions the team doesn’t become dependent on you.
- Leaders can support diversity and inclusion in teams and foster psychological safety by actively seeking out and elevating the perspectives of every team member, adapting themself to each individual to meet their needs, and allowing people to fail and celebrate what we learned through that failure.
- Engineering managers can support teams on their journey toward high performance by delegating, trusting people, being curious, creating safety, and understanding what level of support their teams need.
- Encouraging knowledge and experience sharing across teams is crucial for boosting innovation, efficiency, and overall organizational success. “Town hall” or “all hands” type meetings can be a good way to publicise achievements to a wider audience.
Introduction
These days, most software organizations are built around teams where professionals work intensively together on a daily basis to deliver software. Where teams preferably are self-managed and autonomous, there’s still a need for managers to establish conditions and guidance and foster high-performing teams. One of the things they often need to work on is balancing team autonomy and responsibilities with alignment between software teams and other parts of the organization.
Engineering managers can enable software teams to learn and improve, and help them move problems and impediments out of the way. In this virtual panel, we’ll discuss how engineering managers support teams, what skills they possess, and how they establish alignment and foster knowledge and experience sharing between teams. If you care about fostering high-performing teams where professionals feel safe to do their work the best way they can, this is your way to learn from the experiences of engineering managers.
The Panelists
- Dr. Olga Kubassova, President @IAG, Image Analysis Group
- Michael Gray, Principal Engineer @ClearBank
- Hannah Foxwell, Product Director @Snyk
InfoQ: How do you as a tech leader support and guide different kinds of autonomous teams, each having their own way of working, while ensuring alignment and coordination throughout the organization?
Dr. Olga Kubassova: At regular intervals (annually), make sure that everyone is on the same page. Make sure all teams understand the organization’s core values, mission, and overall vision. Repeat those regularly! This creates a sense of unity and fosters collaboration. Trust is key, so empower teams with decision-making authority within clear boundaries. This lets them work independently while staying aligned with the strategic framework. Provide mentorship and coaching to team leads, sharpening their leadership skills and ability to manage their teams effectively. It is critical to break down silos, but at the same time allow individuals to own outcomes.
As a leader, you should establish channels for regular communication and collaboration between teams. This could involve project management tools, regular meetings, etc. For us, what works well are informal social events (small and big). Transparency builds trust and helps teams anticipate roadblocks or opportunities to collaborate.
It is of course easier said than done, but defining clear, measurable goals for each team that contribute to the overall organizational objectives is a real stepping stone to successful leadership. If there is an opportunity, consider establishing a central coordination team or committee. For instance, a recognition committee that will be responsible for recognizing the achievements of the team members.
The most effective strategy will depend on the specific teams, their work styles, and the overall culture. I always focus on empowering teams to achieve the desired outcomes, not micromanaging them. Finally, celebrate successes achieved through collaboration and install policies that reward such successes. This reinforces the value of teamwork and motivates further collaboration across your teams.
Hannah Foxwell: This is such a common challenge and a lot of leaders are inclined to think standardisation is the right way to go .. maybe because it makes their jobs a little easier? .. maybe because they’ve seen a certain methodology succeed elsewhere? But, personally, I don’t believe a team is really autonomous if they can’t evolve, adapt, and improve their own ways of working.
Having worked on both sides of the fence as an Engineering Leader and as a Product Leader there is always an overarching “plan” and with it a planning process. This is important at an organisation level to ensure alignment on priorities across teams, make trade-offs visible, and agree on where to invest. Whatever process a team adopts at a local level there needs to be alignment around these high-level plans – to do that I recommend keeping planning lightweight, continuous (not once or twice a year) and communicate the value of it to everyone so that engineers understand why they are being asked to plan beyond the next sprint or iteration.
Michael Gray: For an organisation of our size, ~300 people throughout product and technology with ~30 autonomous teams we have the challenge of balancing autonomy, alignment and visibility. To enable this, we focus on the boundaries and place, what we hope are, enabling constraints. We have a standard set of metrics and reporting that teams must be able to provide, we have a standard cadence for “sprint reviews”, although we’re not strict about using scrum internally in the teams. So long as the teams can provide the metrics and the regular review sessions, they are empowered to work within those constraints however they like.
We work in quarters at ClearBank, each team makes high level bets for the capabilities they are going to build or enhance. All of these bets must relate back to our mission and align with our overarching product strategy. These are communicated in our quarterly planning sessions, and on occasion challenged when it is felt they don’t align. Work is done to summarise and communicate this organisation-wide. This enables the organisation to have just enough visibility on what the teams are working on, and helps assure everyone we’re working in investing in the most valuable areas while ensuring alignment to our mission.
InfoQ: When do you decide to step in to resolve a team problem instead of guiding the team toward finding a solution themselves?
Dr. Olga Kubassova: Some situations require a leader’s intervention. For instance, a crisis that happened as a result of past or recent decisions made by the team. When the team’s morale dips in these situations, it’s a red flag for a leader. Stepping in effectively can make a big difference in turning things around.
Firstly, I would diagnose the cause, to understand the root of the problem and the need for action. Then, I would propose the goal and the timeline of achieving those. I see a lot of value in talking to team members individually and in small groups, understanding the situation and then guiding them to the resolution.
Hannah Foxwell: Deciding to step in and help a team can be really positive or it can backfire. If a team ends up thinking you don’t trust them, or that you’re inspecting their work, that can do a lot of damage to their sense of autonomy. It can be tempting to solve every problem but it won’t help the team grow in the long run if you take that approach. If the team asks for your help, or you have the type of relationship where you can muck in on occasion, then it’s probably ok, but be careful the team doesn’t become dependent on you.
Saying that, there are times when I’ve had to step in to support individuals who were burning out, spiraling, or disrupting their team. In those situations, it’s important to take action because you need to demonstrate to the rest of the team that you have their back, whilst providing more support to the individual.
Michael Gray: Tough question, and the easiest answer is, it depends.
Is it a newly formed team and they’re storming? – Keep well out of the way, let them find their own boundaries with each other. Interfering at this point, in my opinion, results in negative outcomes.
Is the team struggling to find their own boundaries, resulting in negative interactions and behaviours? – Sure, get involved, help draw some boundaries for the team to enable healthier interactions.
Is it a technical challenge they’re struggling to resolve? – Ask some leading questions to help them think about the challenge from different angles and provide a fresh perspective, but ultimately let the team own solving the technical challenge.
InfoQ: What challenges do you face leading software teams and how do you deal with those challenges?
Dr. Olga Kubassova: Software developers are introverted and focused, they are reluctant to show their product to the users (even early adopters). This is a challenge.
The solution is Embed User-Centricity: Integrate user feedback early and often throughout the development lifecycle.
- User Testing: Conduct regular user testing sessions to gather real-time feedback on usability and design.
- Early Adopter Programs: Engage early adopters to provide insights into real-world usage scenarios.
- User Research: Conduct user research to understand user needs, behaviors, and pain points.
Hannah Foxwell: I think one of the biggest challenges for a leader is navigating constant change. There is never a moment of stability. There’s always a new technology to learn, new practices to adopt, business challenges, and opportunities to respond to. Getting comfortable with this constantly evolving landscape, whilst providing clarity and focus for your teams is the key to success!
Michael Gray: A common challenge I’ve faced is teams/people playing with fancy new tech or applying new techniques, that don’t help to solve the problem at hand. A great way to help deal with this is to make sure they are crystal clear on the problem they are solving, if they start to drift I always ask them, “does x help get us y”; with y being the solution to x, the problem we’re solving. Sometimes my perspective is wrong, and I’ve learned to enjoy being wrong, and the new tech or techniques does solve the problem in a way I’ve not thought about and therefore it’s a great decision to make, if not I’ve asked them a question to refocus them on the problem at hand without dictating a solution to them.
InfoQ: What do you do to support diversity and inclusion in teams and foster psychological safety in teams and in the organization?
Dr. Olga Kubassova: We openly talk about the challenges and think collectively about how to overcome them. As a female leader, I think it is critically important to champion diversity and inclusion (D&I) and foster psychological safety within your teams and the organization. I encourage other female leaders to be the role models. Even the presence as a female leader disrupts the stereotype and paves the way for others. When you project confidence and competence, you set the best example.
We employ many nationalities and it is important to amplify diverse voices. We actively seek out and elevate the perspectives of team members from underrepresented groups in meetings, presentations, and brainstorming sessions. Creating open communication channels where everyone feels comfortable sharing ideas, even if they differ from yours is important. Of course, as the business grows, we need to start formally tracking D&I and psychological safety metrics, so that we can hold ourselves as a leadership team and the organization accountable for progress.
Hannah Foxwell: There is always more to do but here are some of the things that can make a big difference.
When hiring make sure you have a diverse pool of candidates to interview. This might need you to put in more effort in initial outreach to potential candidates. A personal message from you as the hiring manager is almost always going to get a better response rate than a recruiter. It’s also important to challenge yourself on what the “must have” vs. “nice to have” requirements are in the job spec. By limiting the “must haves” you open the door to more candidates from different backgrounds.
One thing that helps remove bias from decision making in hiring is making sure the interview process is the same for all candidates and that you have pre-agreed scoring criteria for each phase of the interview. Commit to hiring the highest-scoring candidate. However, if candidates are not at the same level, maybe you interview a Senior and a Staff Engineer for the same role, and make sure you adjust your scoring criteria accordingly.
To build inclusive teams it’s important to make sure everyone has a voice and everyone’s contribution is valued. Celebrate successes but also encourage teammates to celebrate each other too. One simple way to do this is to have a standing item on all team meetings for shout-outs and kudos and see what happens!
Celebrate failures too! If we messed up and fixed the issue, captured our learning and took action to improve then that’s a good thing, not a bad thing. This helps to create an environment where it’s safe to take risks and everyone improves when we share our learning!
As a manager, I want to make sure everyone in my team has an equal opportunity to succeed. I spoke about this recently at QCon London and shared some of the mistakes I’ve made throughout my career. Early in my management career, I tried to treat everyone the same way, but this didn’t work. A better approach is to adapt yourself to each individual and be flexible to meet their needs. Consider if an individual needs coaching, mentoring, or sponsoring, and be cognizant that women and minorities are traditionally over-mentored and under-sponsored.
Michael Gray: We focus on making sure we incorporate a flexible working environment, allowing people to work the hours that suit them, and work where it suits them. We have a great internal dimensions team that educates the organisation on people’s beliefs, religions, cultures so that we can all better understand one another.
Our engineering teams are built on a culture of trust. They own capabilities of the system and, along with their product counterparts, are empowered to make autonomous decisions for the areas that they own. More importantly, they are allowed to fail. Not everything can be successful and failing is how we learn and make better decisions moving forward.
InfoQ: What leadership skills have you developed over the years and how do you apply these skills in your daily work supporting teams on their journey towards high performance?
Dr. Olga Kubassova: I love seeing people grow in their roles and beyond. When I see that someone is able to achieve more if they are given the right opportunity. I work with the individual to see if they are up for a challenge and want to try their skills in a new role.
Hannah Foxwell: As a manager, there is always more to do so you have to learn to prioritise your time effectively. You need to get comfortable with delegating, trusting, and also sometimes just deferring work until later. It can be hard deciding what not to do, but just as your teams will value focus and clarity, you as a leader will have more impact if you learn to say no in the right way.
For my teams I would always encourage them to reduce WIP (Work in progress) and finish a task before moving on to the next thing. It’s always better to work with them on a realistic plan than manage a team that’s burning themselves out in pursuit of an unachievable deadline.
Michael Gray: Earlier in my career I used to see the world one way, my way. Over the years I’ve learned not everyone sees the world in the same way that I do, (sounds obvious, I know), but that everyone has their own perspectives. Learning to be curious about those perspectives and why people have them has been invaluable for me and my ability to lead. Being curious makes people feel heard, allows them to be part of and, importantly, feel part of decision making processes which brings them along on the journey.
I’ve also learned to trust and leave space for people. When I reflect on my career, I’ve worked for some great leaders who didn’t give me all the answers, but created a safe space where I could try to figure them out, feeling like if I failed, that was okay. I try to give people the same opportunities now and create that psychologically safe environment and space for them to grow.
Going back to the point I made earlier, “Not everyone sees the world in the same way”. All people and teams are different, understanding how they like to work, how they like to be communicated and interacted with, and what levels of support they expect/need. This is something I’m very conscious of. Some teams need more directive communication and a clear focus, and expect and need this, others prefer a quick conversation every now and then but drive their own team autonomously. Making sure you understand these needs and therefore how to communicate and collaborate with each team’s individual needs is vital.
InfoQ: How do you foster knowledge and experience sharing across teams, including failures and valuable lessons learned from them, and what benefits does this bring for the teams and the organization as a whole?
Dr. Olga Kubassova: Encouraging knowledge and experience sharing across teams, including failures and lessons learned, is crucial for boosting innovation, efficiency, and overall organizational success. Our team works closely together and we are sharing knowledge constantly. This can happen in small groups or in team-wide meetings. I find having a shared library is very important. We work across multiple therapeutic areas, and it is impossible for one person to know it all. Having a shared repository definitely helps!
Hannah Foxwell: It can feel a bit formal but having a regular cadence of “town hall” or “all hands” type meetings can be a good way to publicise achievements to a wider audience. Sometimes these meetings can be very top down but if you include experience reports from engineers, with a warts-and-all account of what went wrong and how they overcame the challenges it can be both inspiring and memorable for everyone else on the team. Whether it’s a new feature development, an incident, a security issue, or a new technology, some good storytelling will make it relatable to the wider team!
Encouraging teams to write down these accounts as well as speaking about them is also a great investment of time. That way it can become searchable in your internal wiki and anyone who missed the presentation can still benefit from the content.
Michael Gray: At ClearBank there are a few things we do.
Firstly, how we manage and communicate our more serious incidents, thankfully they are fewer than ever these days, however, they still happen on occasion. When we do have a more serious incident we have a blameless post incident review session (PIR) walking through all the contributing factors that led to the incident, discuss what we could do to improve next time and take actions to mitigate risks. We then communicate a summary at our Monday 10am product engineering all hands so the rest of the product engineering floor can understand contributing factors and learn from the incident too.
Our Architecture Advisory Forum also plays a role in this. It is our forum where we make wide impacting decisions. Anyone is welcome to attend, and they can listen to the discussions we have to make our technical decisions. This serves as a great way for people across the floor to understand questions they should be asking when making technical decisions and helps them learn how to think about problems and how they might solve them.
We have guilds that focus on specific areas, i.e. our security guild, QA guild, where they get together to discuss the latest security/QA trends, which is an open forum. Anyone can present or share at these forums so long as it is on the broader topic of Security/QA. We also have other guilds, some are for specific levels, for example our Engineering Managers, who get together once a month to talk through challenges they may have and they talk through and share experiences and support each other.
The final piece to touch on is our ‘Tech it easy’, which we run every Friday. Anyone can talk on any topic at all, sometimes it is work related, other times it’s whisky tasting, other times is 3d printing or home automation. This is a great way for people to build relationships, meet others in the organisation they would otherwise not encounter day to day.
Conclusions
Tech leaders have to ensure alignment and coordination throughout the organization. They can support and guide different kinds of autonomous teams by communicating the organization’s core values, mission, and vision. Leaders can give teams authority within boundaries, by balancing autonomy, alignment and visibility and trust, aligning on priorities, and placing enabling constraints. Standardization isn’t the right way to go, teams can only be really autonomous if they can evolve, adapt, and improve their own ways of working.
Leaders should know when to step in to resolve a team problem and when to guide the team toward finding a solution themselves. They shouldn’t interfere when a new team is finding their way or solving technical issues, and be careful that through interventions the team doesn’t become dependent on them.
There are many things that leaders can do to support diversity and inclusion in teams and foster psychological safety. Examples are actively seeking out and elevating the perspectives of every team member, creating open communication channels where everyone feels comfortable sharing ideas, adapting themself to each individual to meet their needs, making sure everyone has a voice and everyone’s contribution is valued, and allowing people to fail and celebrate those failures.
Engineering managers can support teams on their journey toward high performance by delegating, trusting people, being curious, creating safety, and understanding what level of support their teams need. They should also be capable of deferring work until later and learn to say no in the right way.
Encouraging knowledge and experience sharing across teams is crucial for boosting innovation, efficiency, and overall organizational success. “Town hall” or “all hands” type meetings can be a good way to publicise achievements to a wider audience. Attending architecture forums can help engineers in understanding questions they should be asking when making technical decisions and learn how to think about problems and how they might solve them.
MMS • Ben Linders

According to Camilla Montonen, the challenges of building machine learning systems have to do mostly with creating and maintaining the model. MLOps platforms and solutions contain components needed to build machine systems, but MLOps is not about the tools; it is a culture and a set of practices. Montonen suggests that we should bridge the divide between practices of data science and machine learning engineering.
Camilla Montonen spoke about building machine learning systems at NDC Oslo 2023.
Challenges that come with deploying machine learning systems to production include how to clean, curate and manage model training data, how to efficiently train and evaluate the model, and how to measure whether or not the model continues to perform well in production, Montonen said. Other challenges are how to calculate and serve the predictions the model makes on new data, how to handle missing and corrupted data and edge cases, how and when to efficiently re-train this model, and how to version control and store these different versions, she added.
There is a set of common components that are usually part of a machine learning system, Montonen explained: a feature store, an experiment tracking system so that data scientists can easily version the various models that they produce, a model registry or model versioning system to keep track of which model is currently deployed to production, and a data quality monitoring system to detect when some issues with data quality might arise. These components are now part of many MLOps platforms and solutions that are available on the market, she added.
Montonen argued that the tools and components do solve the problems for the systems they were designed for, but often fail to account for the fact that in a typical company, the evolution of a machine learning system is governed by factors that are often far outside of the realm of technical issues.
MLOps is not about the tools, it’s about the culture, Montonen claimed. It is not about just adding a model registry or a feature store to your stack, but about how the people who build and maintain your system interact with it, and reducing any and all friction points to a minimum, as she explained:
This can involve everything from thinking about git hygiene in your ML code repositories, designing how individual components of pipelines should be tested, thinking about how to keep feedback loops between data science experimentation environments and production environments, and maintaining a high standard of engineering throughout the code base.
We should strive towards bridging the divide between the practice of data science, which prioritizes rapid experimentation and iteration over robust production quality code, and the practice of machine learning engineering, which prioritizes version control, controlled delivery and deployment to production via CI/CD pipelines, automated testing and more thoughtfully crafted production code that is designed to be maintained over a longer period of time, Montonen said.
Instead of immediately adopting a bunch of MLOps tools that are more likely to complicate your problems instead of solving them, Montonen suggested going back to basics:
Begin with an honest diagnosis of why your machine learning team is struggling.
The largest gains in terms of data scientists’ development velocity and production reliability can be gained with a few surprisingly basic and simple investments into testing, CI/CD, and git hygiene, Montonen concluded.
InfoQ interviewed Camilla Montonen about building machine learning systems.
InfoQ: How well do the currently available MLOps tools and components solve the problem that software engineers are facing?
Camilla Montonen: Most big MLOps tooling providers grew out of projects started by engineers working on large language model training or computer vision model training, and are great for those use cases. They fail to account for the fact that in most small and medium sized companies that are not Big Tech, we are not training SOTA computer vision models; we’re building models to predict customer churn or help our users find interesting items.
In these particular cases, these ready-made components are often not flexible enough to account for the many idiosyncrasies that accumulate in ML systems as time goes on.
InfoQ: What’s your advice to companies that are struggling with deploying their machine learning systems?
Montonen: Find out what your machine learning team is struggling with before introducing any tools or solutions.
Is the code base complex? Are data scientists deploying ML pipeline code into production from their local machines, making it hard to keep track of which code changes are running in production? Is it hard to pinpoint what code changes are responsible for bugs that arise in production? Perhaps you need to invest in some refactoring and a proper CI/CD process and tooling.
Are your new models performing worse in online A/B tests compared to your production models, but you have no insight into why this happens? Perhaps you need to invest in a simple dashboard that tracks key metrics.
Having a diagnosis of your current problems will help you identify what tools will actually solve them and help you reason about tradeoffs. Most MLOps tools require some learning/maintenance/integration efforts so it is good to know that the problem you are solving with them is worth these tradeoffs.
AWS S3 Unauthorized Request Billing Issue: An Empty S3 Bucket Can Dramatically Increase the Costs
MMS • Steef-Jan Wiggers
Maciej Pocwierz, a Senior Software Engineer, recently revealed a significant issue—an empty S3 bucket can unexpectedly result in a substantial AWS bill. In his case, nearly 100,000,000 S3 PUT requests were executed within a single day, leading to a bill that was far from negligible.
Pocwierz worked on a proof of concept for a client by creating a single S3 bucket in the eu-west-1 region and uploaded some files there for testing. When checking the AWS billing page to verify he stayed within the limits of the free tier, he found out the bill was 1300 USD caused by 100,000,000 S3 PUT requests executed.
When looking into the cause of the requests, Pocwierz writes:
By default, AWS doesn’t log requests executed against your S3 buckets. However, such logs can be enabled using AWS CloudTrail or S3 Server Access Logging. After enabling CloudTrail logs, I immediately observed thousands of write requests originating from multiple accounts or outside AWS.
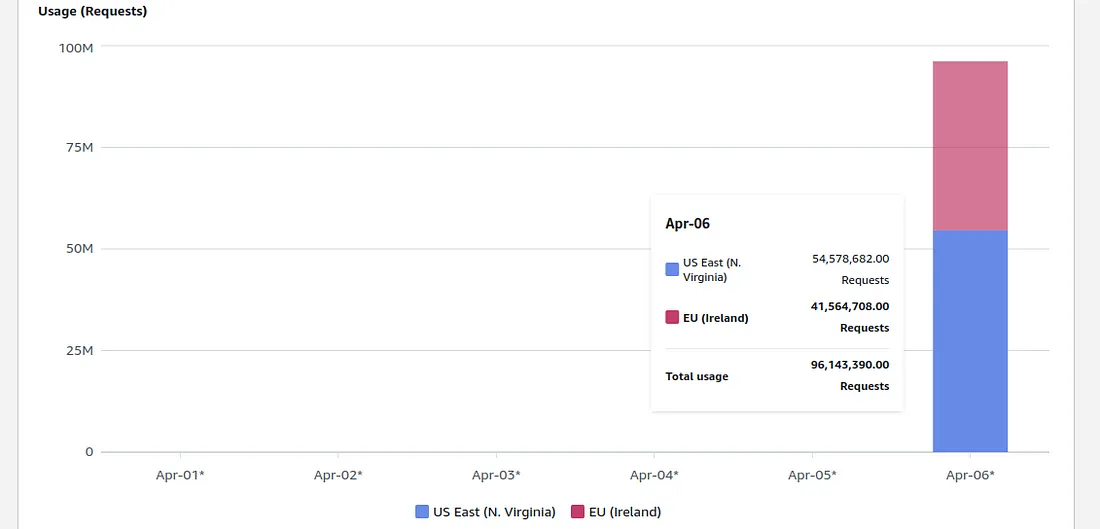
Billed S3 usage per day per region (Source: Pocwierz Medium blog post)
The root cause of this incident was the default settings of a widely used open-source tool, which unintentionally targeted the same bucket name for its backups. This led to a relentless barrage of unauthorized requests with significant financial implications. Furthermore, half of the requests originated from a different region. S3 requests without a specified region are redirected to us-east-1, incurring an additional cost for the bucket owner.
The lessons learned from the experience were that S3 buckets are vulnerable to unauthorized requests, highlighting the need to add random suffixes to bucket names for enhanced security. Another key takeaway is that specifying the AWS region explicitly when executing requests can help avoid additional costs incurred through redirects. Additionally, the individual’s decision to temporarily open their bucket for public writing revealed the alarming ease with which innocent oversights can lead to potential data leaks.
The findings of Pocwierz lead to a stir in the community. In a Reddit thread on his findings, seanamos-1 concluded:
Bucket names were never implied to need to be secret, and it’s obvious they weren’t designed to be that way. But if you don’t keep them secret, you are vulnerable to a billing attack. This needs to be addressed.
Furthermore, in a Hacker News thread, a respondent, tedminston, writes:
What’s crazier is that turning on Requester Pays does not actually mean the requester pays when the request is a 403. Essentially, every S3 bucket, public or private, whose name is discovered can be DDoSed, creating an insane bill. That’s a platform level security issue for AWS to resolve. We do not need another Bucketgate.
Lastly, Jeff Barr, chief evangelist at AWS, stated in a tweet in response to Pocwierz’s findings and community:
Thank you to everyone who brought this article to our attention. We agree that customers should not have to pay for unauthorized requests that they did not initiate. We’ll have more to share on exactly how we’ll help prevent these charges shortly.
With Corey Quinn, Chief Cloud Economist at DuckbillGroup, responding in a subsequent tweet:
This feels like a potential turning point in AWS’s approach to bill surprises, and I’m very much here for it.
MMS • A N M Bazlur Rahman

JEP 474, ZGC: Generational Mode by Default, has been Targeted for JDK 23. This JEP proposes to use the Z Garbage Collector (ZGC) from non-generational to generational mode by default. The non-generational mode will be deprecated and removed in a future JDK release. This will ultimately reduce the cost of maintaining the two modes, so future development can primarily focus on JEP 439, Generational ZGC.
Perhaps the most significant change in JEP 474 is the switch of the ZGenerational option’s default value from false to true. This clearly signals a strategic change in Java’s approach to memory management, specifically optimizing garbage collection based on delivering more ‘free’ memory to Java applications and a lower overhead of GC.
This transition to the generational mode by default is motivated by the desire to reduce the maintenance work of supporting generational and non-generational modes alike. With this focus on performance, the OpenJDK team will make the generational ZGC more efficient and effective as they evolve to handle the expectations of modern Java applications.
Developers should be aware that the non-generational mode is still available but deprecated, which means that warnings will be issued if the non-generational mode is explicitly enabled via command-line options. The fact that non-generational mode is being deprecated is a sign that it is going to be removed in the future.
Consider the typical command-line arguments:
-XX:+UseZGC: Now defaults to using Generational ZGC.-XX:+UseZGC -XX:+ZGenerational: It also uses Generational ZGC but with a deprecation warning for theZGenerationalflag.-XX:+UseZGC -XX:-ZGenerational: Uses non-generational ZGC with a deprecation warning for theZGenerationalflag and an advisory that non-generational mode is deprecated for removal.
Developers should test their applications to ensure compatibility and performance under the new default setting. If applications are tightly integrated with the JVM and are particularly sensitive to garbage collection behaviour, they might see changes to their performance.
OpenJDK’s testing commitment includes ensuring that existing configurations and benchmarks perform as expected with the new default. The risk is relatively low for most applications, but specific high-performance or low-latency applications might require adjustments to their configuration.
JEP 474 marks a pivotal update in Java’s ongoing development. It aims to streamline and improve the garbage collection process, focusing on generational techniques. This update will require developers to reassess their applications’ compatibility and performance, but it promises a more efficient management of Java applications in the long run.
MMS • Craig Box
Subscribe on:
Transcript
Shane Hastie: Good day folks. This is Shane Hastie for the InfoQ Engineering Culture podcast. Today I am sitting down over a relatively short distance for a change. Our guest, Craig Box, and myself are both in the same time zone, which is quite unusual. We’re both in New Zealand.
Craig, welcome. Thanks for taking the time to talk to us today.
Craig Box: Thank you. Shane is a pleasure.
Shane Hastie: My starting point on all of these conversations is who’s Craig?
Introductions [01:16]
Craig Box: Oh gosh, that’s a very existential question. You mentioned that we’re both in New Zealand. We’re having a chat beforehand to figure out how our paths have come and gone with various countries. I think that most people who grew up in New Zealand decide that they want to go off and see the rest of the world. It’s a beautiful place here, but it’s by virtue of its separation from the rest of the world. I had started with a career in IT here because when I went through university as a person interested in technology, I didn’t want to be a developer. I didn’t enjoy the idea of locking myself in a dark room and writing code and not talking to people. That led me to, first of all, customer-facing IT roles and then implementation and using programming skills and ability, so on, what would later on become what we think of as DevOps, but was called system administration at the time. Moved to Canada and did that for a couple of years there before deciding that it was far too cold and we wanted to go somewhere warm and ended up in London, which is of course is famous for its warm weather.
But it was there that I got involved with cloud, first of all in doing deployments on cloud and that led me to working at cloud consultancy companies and then eventually onto Google. I came at a very interesting time and that we were starting to talk internally about this secret project that was taking the internals of Google and the lessons that had been learned from many years of doing deployments internally and open sourcing that and making that public to people in the form of a project which was later known as Kubernetes. I was at Google for nine years and that was basically through the entire life cycle of Kubernetes, from just before its launch to becoming the juggernaut that it is today.
Since leaving Google, I’ve worked at a couple of different companies, but now I’m working with a team of people that I was effectively working with while I was at Google. One of the benefits of these community open source projects is that you can collaborate with people at different companies and quite often you’ll find yourself moving between those companies as well. Working at Solo now, we’re a vendor that I’m working largely with the open source project called Istio, which I was one of the leads on when I was working at Google.
Shane Hastie: So a technical person not interested in writing code …
Craig Box: I know. It’s heresy, isn’t it?
Shane Hastie: But still deeply involved in the technology. You’ve fallen into the space that is often called developer relations. Tell us about that. Why do we need that?
Why do we need developer relations roles? [03:31]
Craig Box: It’s interesting because to some degree I don’t think we need it at all, but a lot of people feel that they need to have it as part of perhaps a marketing strategy or some sort of community outreach, and therefore it’s just the thing that exists, especially the larger vendors. It goes by many names. People don’t necessarily like to use the word evangelism, so they use the word advocacy instead. There is an idea that you are going out and having conversations with end users and saying, “This is what we’re building and this is what we see as a trend in the industry,” bringing back insight from them to a development team.
That’s very much what the traditional approach was in the world of boxed software perhaps. I think the first people who traditionally think of as a developer relations team were the Macintosh team at Apple around 1984 because the idea there was that Apple would make computers and they would sell them to consumers and the computer wasn’t very much use unless the consumer also purchased some software. There was a different audience, a much smaller audience of developers who would make that software the customers would then go on and buy. There was a need for a different team to help those people find out what they needed in order to be able to make the software and go on, make the platform better for everybody.
That follows through for modern platforms. The teams at Google who looked at things like Chrome and Android for example, you could say it kind of makes sense to have that. But for a lot of the vendors we talk about today in the cloud space and anyone doing B2B software, you’re selling a thing to developers, but those developers are your customers. You have a field technical team who go out and talk to them and if your thing is open source, your engineers are participating in these upstream communities themselves.
They know everything that’s going on and they know what people are doing and where they’re failing and so on because that’s all public. It’s interesting nowadays to say, “We’ve got all these people who are nominally in the same-named role, but there’s such a wide spectrum of things that they can be doing.” I think it’s very different depending on which organization you’re at and where they are in the life cycle of the product they’re supporting.
Shane Hastie: If we do need somebody, if we are in that position of almost the platform and we need somebody doing this, what are the skills that you bring to the table?
Skills needed for effective developer relations [05:35]
Craig Box: A lot of the people who I’ve worked with in the past, they are programmers with abilities that I could never hope. There’s no point in playing that game. I look at some of the bug reports like, “Oh, I could probably try and work this out,” but ultimately the people who built the thing are going to be so much better at it. But the idea of going out and explaining it to an audience, especially an audience who isn’t deep in the technology or doesn’t have that background, that’s really a skill that I happen to have and a lot of other people don’t versus many skills that they have and I don’t. I think that’s very useful and being able to do that with a technical background, even going out to audiences, it’s very easy to go to a crowd and say, “Hey, I know the guy who wrote the software. I know the people who do this. I know the engineering team.”
I remember saying, “I didn’t get any smarter the day I joined Google, but all of a sudden I had access to the internal bug database and I could go and look things up and see things.” That really gave me a better understanding of how things were done that I couldn’t necessarily explain to the users at the end, but I could say, “Look, well there’s more to it than this,” and being able to explain to people what’s going on and talk to them with this sort of shared history of the fact that I used to do this kind of implementation work. It’s been a few years since I’ve actually done end-user work in terms of DevOps or anything like that, but I have done this, I have been through this cycle.
It’s useful to be able to report back and some teams use the different people as a customer zero and say, “You go out and take our platform and try and build something cool with it yourself and figure out if it fits a need.” Again, the people who build these things, they are very, very smart, but sometimes they’re just a little bit too close to the problem.
Shane Hastie: This leans towards developer experience. What does good developer experience look like?
What does good developer experience look like? [07:16]
Craig Box: That’s a tough question. Again, there is a sub-section of developer relations, at Google, it was called developer programs in engineering. You hear people talk about it defining APIs and SDKs and all that kind of thing. That is a thing that I think should be considered the product of a team who are building a platform that’s focused towards developers. I don’t think you can say, “I’m going to just have my dev rel team do that for me.” You need to be deep as part of that team and you need to assume that the product managers are having those kinds of conversations, and if they’re not, it’s a bit of a red flag really. I think they need to know because that’s the audience they’re building.
I can’t speak specifically to what makes a good experience for any given platform or product because the problem space is just so big. I think that even the audience of people having an idea of what it is that is relevant to them and what background they have, some people come in with a bit more knowledge and some platforms are an evolution of a previous idea. It’s a lot easier to pick up newer programming languages if you have experience with similar older ones, for example. But then there are people who are coming into the industry fresh today and they don’t have that background. They’ve never looked at these other languages or platforms. I think you need a combination of both. I think you need to be able to explain something in a way that is easy to adopt for someone who doesn’t have that but expresses power in a way that is easy to peel back layers of.
I saw a comment recently, which is to say it’s easy to hide complexity. If you have a complex product that is in large part because the people who build it know that you might need this one day but you definitely don’t need it on day one, so you need to have a way of hiding it from people. Versus not having the product be able to do these things, in which case people play with it for a couple of weeks and then they hit a brick wall because it doesn’t help solve their problems anymore.
Shane Hastie: You touched on product management. What does product management look like in products that are being built for developers?
The nuances of product management for developer-focused products [09:06]
Craig Box: It depends in the sense that if it’s within a single company, it looks like building any other product I feel. There’s a modern idea of what we now call platform engineering, which is sort of the idea of building a product only for the internal team that you’re looking at. Your developers are your customers, especially the big company. You are now running a product organization that’s saying, “I’m building out this infrastructure which I’m going to let my developers use.” That’s an interesting way of saying, “All product management ideals and so on should be brought to this discipline of SRE or sysops or whatever you want to call it.”
The thing that is interesting, especially when you start talking about developer tools is the fact that so much of the tool space we deal with today is open source and a large amount of it is built by more than one vendor. If you are someone like GitHub and you’re building something which is effectively proprietary, a service run by a particular company, they can do product management in the traditional sense whether or not their product is closed or open source. But when you’re looking at something like Kubernetes that’s built by hundreds of different companies and tens of thousands of people, I think in those cases you just kind of don’t have product management.
You have people who apply that skill to things like GKE, which are Google’s hosted version of that. But it’s hard to say, “Well, what that looks like when you’ve got so many collaborators on the space.” It’s easy to say, “Here’s some code, here’s some engineering.” It’s a lot harder to say, “Here’s documentation, here’s planning, here’s the rigor that you need around all of this stuff.” Because again, it’s harder for the people who are all contributing to this to find budget to apply that skill as well.
Shane Hastie: Let’s dig into open source community. You’ve worked and are part of a number of fairly large open source projects. How do those communities be effective?
What makes open source communities effective [10:56]
Craig Box: In a self-organizing fashion, I think. You get people who are interested in community and who want to deal with topics like governance and especially with open sources or licensing issues or legal aspects. You get a lot of people who are interested in technology and have that as their particular bent who are willing to participate in those ways. These multi-vendor communities have come up with approaches as to how they will deal with things, as to things that are fair in a company situation where you have people who are competitors who all want to come together. Quite often you’ll have a foundation of some sort which will own the trademarks or the copyrights and particular things so that all the vendors feel safe in participating.
But then you also find that the, as I mentioned before, there are things like documentation and administration of a project where it sort of comes down to luck to some degree as to whether you find someone who’s willing to do that. In large part with the Istio project, which is the open source project that I’m primarily involved in, it was just that I knew that this needed to happen and I kind of was interested in product management to some degree and said, “Well, look, I’m going to apply the skill or this interest to not Google’s internal version of it,” because that wasn’t my role there. But I had a little bit of a rope being in the developer relations department to say, “Well, hey, I think that this needs to be applied to the project and that someone needs to come in and help run the meetings. Someone needs to figure out how the vendors communicate with each other and how their roadmaps align and how we plan everything.” If you find a person who’s willing to do that and has those skills, then hold onto them because they’re few and far between.
But a lot of companies, like if you are one company building an open source project yourself, it’s very easy because you just do it internally. But when you get to the point where you have these large multi-vendor things, not a lot of the vendors are going to staff that role. I think some people might say, “Hey, it’s missing and it would be useful to have it there,” but it is definitely something that you notice the absence of.
Shane Hastie: Digging further into the open source communities and collaboration, this is the culture podcast, what is the open source culture?
Factors that influence the team culture in open source initiatives [12:56]
Craig Box: I think it’s somewhat representative of the people and you talk about, there’s a paradox, I can’t remember the name of which basically says it’s going to represent the culture of the organizations who contribute to it. If you start with something that is largely built by a single vendor, all of the norms in that project will largely reflect what the norms were of the company who contributed. Over time things will take something on largely reflecting the energy and effort that it put in. If we talk about Kubernetes for example, a lot of the early team there was a lady named Sarah Novotny who was one of the first community managers who worked at Google on the Kubernetes project. She put a lot of processes in place around the project and the CNCF that allowed collaboration and allowed vendor-neutral contribution and so on. That really carried through to the way that project operates. They have very strong norms in certain ways and they have a very big culture. You get a lot of people who come together and pick up the same T-shirt at the conference and so on and go to the Contributor Summit.
Then you get some other projects which are sort of reflective of the fact that the companies who contribute to them are just that, they’re companies. You get people who are building products based on this technology and they all want to treat it like I had someone call it a clearinghouse recently or a trade body effectively around a particular thing.
Then at the other end you get people’s passion projects. You get apps, you get Linux and desktop software that go on it that people just install and run and they find something broken about it. They say, “Hey, this is something I want to participate in.” Those communities are largely just individuals.
In the cloud space that I’m in, there’s not a huge number of individuals. There are people who are looking to get involved and build up their skills and maybe be hired by one of these companies, but the reality is that these large open source projects are built by people who are paid to build them for businesses because they are a complement to something that they do. That has been the case for many years now. If you look at the Linux kernel, the people who contribute the most to it are vendors, people like Oracle for example, may be surprising, I think they were one of the most prolific contributors quite recently. Then you get vendors of people who make network hardware and storage hardware and so on. They are the people who are writing the drivers and moving things forward so they can sell more network hardware and storage hardware. It’s not just people in their basement who are working on open source anymore.
Shane Hastie: You are on the governing board of the Cloud Native Computing Foundation. Tell us a little bit about what is the CNCF and why?
The Cloud Native Computing Foundation [15:21]
Craig Box: Why indeed. Yes, so the CNCF was created as a way for Google to spread Kubernetes wider than just itself. If it was a thing that only was a Google project, then it would never get the people who are competitors to Google’s cloud business, they wouldn’t get behind that. Google obviously said, “All right, we want this thing to become an industry standard, and for that to happen, it needs to have a certain neutrality about it.” They worked with the Linux Foundation to set up a project there, which is the Cloud Native Computing Foundation. It was seeded with Kubernetes as a technology, but it now has upwards of 200 projects, I think, that are hosted in the CNCF.
There are a few different levels of the way the organization works. The largest sponsors basically get to have a seat on the business board, and there are a couple of seats that are reserved in that governing board for the projects and for the technical community. I was recently elected to one of those as a representative of the project maintainers. I’m saying, “I can come here and give the voice of the people who are working on building the software back to the CNCF in issues like how they spend their budget and how they market themselves and so on.”
Largely the technical decisions are made by a group called the Technical Oversight Committee who are a group of 11 members, I believe, who are, again, elected from the community to accept projects and to decide the direction of the foundation and should it be looking at projects in this space or that space and so on, and how should they interact and relate. There are end user members as well. They’re the group who organize the conferences, the KubeCon conferences that have been going on for many years now and a bunch of other events. They do a great work in terms of international, making sure there’s events in upcoming countries, making sure there’s diversity programs and so on. There is mentorship programs. There’s a whole bunch of stuff that’s done there made possible by the fact that there is such a commercial value to all of the software and that there companies who are willing to all put in and fund the organization.
Shane Hastie: How do you get such diverse stakeholders to collaborate?
Craig Box: You’d promise them that it’s going to be a fair and neutral playing field, as I understand it. The goal was from Google’s perspective to have this become the standard because it was a pattern that they knew how to operate and that they thought they would get more people coming to their cloud to run workloads at a time when they had a smaller market share. That obviously worked out very well. There were a bunch of other people who are interested in taking that, what was more superior technology at the time that had the sheen of Google’s internals associated with it. Then there are also other vendors who are like, “Well, we might not want to adopt the thing that Google built because we compete very heavily with them, but our customers are asking us for it and it has that demand.”
Bringing it back to the beginning that is working in developer relations for Google at that time that was going out and trying to convince people bottom-up that they should want to run Kubernetes. Then they think, “Yes, I like that,” and they go to Amazon who were their cloud provider at the time and say, “We want to run Kubernetes.” Eventually Amazon builds out a very good hosted Kubernetes implementation and that gets them on board with the project and joining the CNCF and so on. But it is largely down to customer demand and the way that Amazon operates. Then it is the political neutrality and the reputation of groups like the Linux Foundation, that everyone will be treated fairly and so on, that allows those things to happen.
Shane Hastie: Thinking our audience, as a technical leader, technical influencer, technical practitioner, why would I want to get involved in one of these communities?
Why get involved with open source communities? [18:56]
Craig Box: You might not. Again, it comes down to your own particular interests. Even within the communities that we deal with, there are people who just want to write code. They want to take a technical issue, solve an interesting technical problem. There are people who want to write documentation and don’t want to understand the code, but who want to effectively ask one of those technical people how something works and translate that. There is every possible opportunity, especially in something, again, as broad as the Kubernetes community, which is testament to how people like Sarah, I mentioned before, set the community up is that it’s a welcoming space for everyone.
The CNCF and the Kubernetes project especially put a lot of effort into being welcoming for new users. There are a lot of mentorship programs. There’s a lot of money from the Linux Foundation to sponsor people, programs like the Google Summer of Code that kicked this off maybe almost 15 years ago. Now, there is a Linux Foundation program that’s similar that gets new people in who don’t necessarily have the opportunity to just walk into a job like you might if you were in California, but who are interested in building their skills in these spaces.
A lot of effort is put into make sure it’s a welcoming community, that there are opportunities for people at every level. There are things that you can do if your company wants to get involved and has a product based on this, but equally there are things you can do if you are a student and you want to get involved in technology.
Shane Hastie: What’s the future direction?
Craig Box: That’s a tough one, and I say that because it feels in large part that these problems have been solved within the space that we’re in. If you think about the curves of disruption over the last few years and so on, everything gets to a point where desktop operating systems are mostly done. It got to the point where everything was good enough and then the internet came on and it needed to be a new thing. Cloud native was a new thing on replacing the idea of building on top of also, but replacing the idea of virtual machines or servers and so on. I’m not sure I could say, “Hey, there’s some amazing new development that’s going to happen in this particular space.” What I think will happen is some other space will come along. The basic unit of deployment or the building block of cloud native technologies is usually referred to as the container, the Linux container, well, Windows now containers as well.
But then it’s possible that something like WebAssembly comes along and says, “All right, well, we have a new way of taking code and running it.” Ultimately, we’re still doing what we were all doing 50 years ago, which is writing code and then deploying it to some computer somewhere. Maybe it’s the one in front of you, maybe it’s tens of thousands of machines in a data center in Virginia somewhere, but we’re still just writing code and running it on computers. It might be that there is a new methodology for doing that that gets better. It might be that the singularity and the AI stuff that we all promised ourselves that we wouldn’t talk about obviates the need for that somehow. But unless those things happen, we’re probably still going to be writing code and deploying it on computers. The means may change, but whether or not it happens within this community or whether something else comes along, it’s hard to say.
Shane Hastie: What haven’t I asked you that I should have done?
Craig Box: Who does that lovely hair of yours? That’s what I would’ve asked.
Shane Hastie: I polish it.
Craig Box: I can’t come with a piece of wisdom that I would apply to everyone. I could say that there are now so many more things to do, like the things that I do and possibly yourself also, Shane, that you couldn’t say when you were in school, “You can study to do this thing,” because it didn’t exist. I’m not sure what to tell my children to learn today.
I saw a historian being interviewed recently who’s saying, “Well, in the Middle Ages, and even as recently as a couple of hundred years ago, you can teach your kids to farm and to sow seeds and so on, and that is a skill that will be useful to them and see them through 20 years from now.” We don’t know what the skills of 20 years from now will look like. I can tell you that there were no developer relations people. There was no practical worldwide web and so on 20, 30 years ago, and that’s the thing that’s enabled my job and probably the job of many people who are listening to the show. It’s really hard to say, “This is a thing I think you can do.” But one thing that especially working in open source taught me is that it’s the relationships, it’s the people, it’s the way everybody works together. All of that will still apply and all of that will still be relevant no matter what the underlying technology changes are.
Shane Hastie: We’re in New Zealand, the Māori term, “He tangata he tangata he tangata!”. It’s the people, it’s the people, it’s the people.
That’s a great point for us to pull this to a close. Craig, if people want to continue the conversation, where do they find you?
Craig Box: This used to be so easy. I used to just tell people to follow me on Twitter, and I’m not sure that that’s a thing that still people are comfortable doing and so on. But I am on the remains of Twitter. I am CraigBox there and you can basically find me by that name on most of the modern social networks and so on. I am a elapsed podcaster with a couple of young kids at home. I haven’t been able to keep up with that as much as possible, but you can definitely find my work around and Twitter’s probably as good the places anywhere to look for me.
Shane Hastie: Wonderful. Thanks so much for taking the time to talk to us today.
Craig Box: Thank you very much.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • Thomas Chao

Transcript
Chao: We’re going to be talking about server driven UI primarily for mobile experiences. Some of the topics we’re going to cover will also tie in with web. How many people here are mobile developers who have dabbled a little bit with Android, iOS? How many people are web developers? I’m a mobile developer. Hopefully, I get the web parts relatively accurate. What are we going to be talking about? We’re going to be talking about server driven UI, and really what are some of the tradeoffs that you can think about when you’re trying to pick your different server driven UI technologies. Then we’ll go through, talk about what my personal experiences are, and when to use those different tradeoffs, as well as when server driven UI is actually applicable.
What Is Server Driven UI (SDUI)?
Let’s start with definitions. One of the big questions that people always ask is, what is server driven UI? Isn’t everything driven by the server? Yes, obviously, all the smartphones, they talk to the server in the cloud, and they get tons of information back from there. Historically, what we have is that we have mobile apps that more have like server driven data, I would describe it as. The client queries the backend. The backend responds with some data, and then the client just renders it. This works pretty well for all of us. It’s very easy for us to reason about the data flow, there’s clear responsibilities for both the client and the backend. You’re making a query. You’re getting a response. You’re rendering it. Unfortunately, as products have gotten more elaborate, there’s this greater and increasing appetite across industry to experiment and to find unusual experiences, ultimately, to make more money. Since we’re talking about experimentation, data is only really one piece of that puzzle.
Terminology
When I think about mobile apps, I actually break it down into a few different pieces. There are generally three areas that I like to think about. The first one is the UI or layout. For example, you open up Gmail, it might show a list of different emails that you’re rendering. You open up Uber, it might show a carousel of different vehicle options that you want to try and choose. Then you’ve got the data piece. For example, with the Lyft application, you might be able to see the ETA for when a vehicle is going to arrive, or the estimated fare for a given trip. Finally, there’s actions. When you click on a button, what does it do? Does it redirect to another page? Does it fire off a network call? What analytics are fired when a button is clicked, or a view is rendered, or a list is scrolled? Most of these tend to be traditionally controlled on the client. What you end up with is this thick backend with an equally thick client.
Challenges
What’s wrong with that? After all, mobile has been around for about 15 years, we’ve got some world-class mobile developers in the industry now. Mobile is really nice. It’s actually very powerful. You can do a lot of things with it. There are a few problems with this. The first one is iteration speed. The mobile release cycle is incredibly slow. Normally, what happens is this, you’ll land a diff, after a while a build is cut. After that has been cut, it sits for a few days just soaking in dog food. This is really critical to get that testing because mobile is unique, you can’t roll it back. Once you deploy a binary out to production and someone’s updated it, they have that. It doesn’t downgrade. There is none of that. You have to be very careful that you’re not shipping out something that’s going to crash or has a security vulnerability, or leak information, or any of that. What happens then? You’ve built it. You’ve waited a few days. You’ve cut it. Now it’s soaking in dog food, and everything’s all good. Then you send it over to Apple and Google to get it approved. These days, they’re pretty fast. Google tends to get them approved within about 24 hours, Apple within about 72 hours, they have a long tail. Unfortunately, in the worst-case scenario, this can be up to about a week in scenarios like time around Thanksgiving, WWDC, Christmas. That takes a little bit more time. Then you do this phased rollout. The phased rollout is just the standard thing, we will launch it to 1%, 5%, 10%. Once again, we want to make sure that we’re catching any production issues as early as possible before worldwide blast radius.
Finally, a few weeks later, as you can see on the diagram, it’s rolled out to 100%, we’re done. It’s amazing. No. Once it’s actually rolled out to 100%, now the users can actually start updating. Unfortunately, the usual adoption curve for mobile applications is relatively asymptotic. You’ll get a spike of users updating very quickly at the beginning. As you can see, from here, it’s about 85% over the first couple weeks, and then it tails off as people refuse to update. There’s a lot of reasons for that. People might not update because they have no space on their phones, because they’re running a very old operating system. They’ve disabled auto-updates, so they don’t have good Wi-Fi connectivity, so the auto-updates aren’t happening. Whatever that reason is, the stats that I’ve seen from multiple companies and multiple products show that about 1% of all users continue to run a build that’s more than 6 months old. You have to think about that. You’ve launched something new, six months later, people still haven’t gotten it. You end up having all these problems of having to maintain your old endpoints and support backwards compatibility. I used to work in Gmail inbox, we had a fun problem where someone actually had a phone where they had the newest experience, and then they had a tablet where they had a much older version. They made a mutation on the phone. Then they saw the old thing on the tablet, because the old tablet didn’t support that new mutation, and they were very upset. This person that I was talking about actually ended up being an executive at Google and we got yelled at. These are the kinds of fun things that you have to deal with due to this problem.
There are a few other challenges that come from the fact that mobile is unique. First of all, we’re not perfect. If a problem is found post-release, you either have to turn off that feature, or you have to do a full-on binary respin. Like we talked about in the previous slide, that binary respin can take multiple weeks, to really get out to everyone. Often, what ends up happening is teams will actually turn off their feature, and to be able to do that, that means that they hide almost everything behind a parameter flag, or an FP. This is actually a good general practice. I’m sure many of you do it in both your web and mobile development. The end result is that you end up with hundreds if not thousands of parameters or FPs that are sitting in the wild just living there almost in perpetuity. It becomes really hard to debug what’s going wrong. I’ve personally spent more hours than I can think of, trying to debug the wrong configuration. The next thing is like we were talking about, old versions. Some users just don’t upgrade, and so you have to worry about the old inconsistent experiences. Eventually, you end up biting the bullet and saying, we’re just going to force upgrade people. We’re going to accept the fact that that 1% of users, we’re going to lose them, and maybe they’ll upgrade in the future, maybe would not, and we’re just going to lose that revenue, because the cost of maintaining everything is too much higher.
The last one, which is actually fairly common is you start to get this interesting divergence between Android and iOS. You’ll end up with teams where you’ve got more Android engineers than iOS engineers, or vice versa. Where maybe iOS has a really good framework that allows you to develop a feature much more easily than Android does. This divergence becomes problematic, because it’s obviously not great for the end user. You also start to hear these excuses from your teams, your product managers, on, we’re going to launch on one platform and learn what’s good, and just apply it to the other platform. That’s fine. These are all little challenges. I’ll give you another concrete example. If anyone is crazy enough to actually carry both an Android and an iPhone, if you open up Gmail on Android, you’re going to see tons of settings that allow you to enable different notifications. Ok, I want to get notified when this label gets sent email, or I want to only get notified but I want it to be silent. On iOS, none of this exists. It’s been an outstanding request for probably close to a decade at this point. Why? Because it’s very easy for these to diverge and it’s very hard for them to be kept in sync. Overall, it becomes really hard to experiment and iterate on mobile. I’m not talking about the initial launch of a feature. If you’re launching something brand new, it’s perfectly reasonable that it takes a few weeks, maybe a couple months to launch and get out there. If I’m trying to make a small change like, I want to change the color of this, or I want to change some text, or I want to add a new line in here. It’s really painful that we’re talking about multiple months for our end users to get that experience, and then start to give us feedback.
Let’s take a quick example from my previous company, Uber. We had a car that we were rendering for the different products that you had. We wanted to experiment with a few things. For example, we wanted to experiment by changing the ETA to be the estimated drop-off time. The problem was that today, the backend is sending down an ETA, and you’ve got some client code that pulls out that field from the proto, and maps it to the UI, and just renders that. Now we need to change the backend to send new fields but we also need to change the client to be able to read those new fields and bind to the UI. Or, in the approval section we want to add a banner at the bottom that said this is the most popular product, except the client didn’t have a concept of that third row, so we couldn’t do it. It was trivial to add a TextView to a layout on the mobile side. It took us a day to do it, probably like 20 minutes to do it. Once we did that, we had to respin it, let it soak, push it out. It was super slow.
Enter Server Driven UI, a Panacea
Native development is really powerful. Don’t get me wrong. I actually really like native development. I’ve loved Jetpack Compose. I love SwiftUI. I think there’s really good things being done there, but there are always some problems. Is SDUI a panacea? There are a lot of teams in companies, in the industry that are trying to at least explore this area. Beyond the various codenames I’ve got listed here, I’ve seen blog posts from companies like Lyft, Netflix, Google, Uber, Airbnb, Microsoft. There’s a lot of people trying to make mobile development act a little bit more like web development, where you can just push instructions from the backend, and the client can just run them. It allows us to iterate more quickly. It allows us to avoid some of these backwards compatibility problems. Hopefully, it allows us a bit more consistency in between Android and iOS. Great, it’s a panacea? Not really, and it depends. It’s great for some things, and not for others. That’s really what we’re going to be talking about here.
The first major problem that I wanted to hit on was the terminology, SDUI. A lot of people hear the term server driven UI, and they think of it as this one-size-fits-all solution. If you actually sit down and chat with other engineers, you’re going to find that different people have a different mental model when they hear that term. No two people tend to agree on what it actually means. In some people’s minds, you get something almost on the left-hand side of the spectrum, like a WebView, where you can render anything you want. You’ve got a Turing complete language. You could send down any sort of layout. If you want to do something that’s pixel perfect, you can do that. If you want to write a hyper-customized lambda that you send down, you can evaluate it at runtime, you can do that as well. That’s perfect. At the other end of the spectrum, you get something like, it will be this Ghost Platform. We’ll talk about that a little bit more. What this does at a high level is it provides a well-defined component library that developers can use and mix and match to render out their UI. That’s really nice, because it forces a lot of consistency. You’ve got this really good molecule of building blocks. If you want to build anything outside of those predefined, pluggable components, you’re stuck making a client change again, and we’re back to the slow-release cycle. In the middle, we end up with something kind of like Uber’s Sindarin, which tries to provide atomic components and this ends up trying to balance out the flexibility and consistency ends of the spectrum. Once again, I’m not going to say that any of these are perfect. They all have their tradeoffs, but that’s what we’re going to be talking about.
Server Driven UI
Jumping back briefly to the terminology, we defined three different areas that we were talking about. There’s the UI, the data, and the actions. I personally find it very useful to think about that spectrum amongst these three different dimensions. Let’s go with the UI piece. On the left, you’ve got a WebView. It’s fairly self-explanatory. You can style the layout however you want by just addressing your CSS. If some team wants to build their own custom UI, they can do that. They just put in their own WebView, build whatever they want. They’re not going to disrupt any other teams, any other developers. Everyone gets their own little sandbox to play in. This is really flexible and really powerful. It’s nice, because upfront, you understand as a developer, any possible idea I have that I could possibly come up with in the future, I’m guaranteed that I will be able to implement it using this, without having to do a binary respin. Because it’s a Turing complete language, I can do anything. That flexibility comes at a bit of a cost. I’ve learned personally a long time ago that if you let every team do their own locally optimized maxima, every team is going to build their own locally optimized maxima. Everyone is going to do what’s best for them, not what’s best for the product, or what’s best for the company. Over time, the product becomes a mishmash of all those different experiences. It’s not bad, per se. Amazon is actually super famous for using WebView tech across their mobile apps. You can see that when you open their app, that the checkout page looks quite different from their settings page, or their product pages. Once again, if you’re thinking a little bit more on the flexibility, iteration speed side, maybe this is interesting for you. If you’re thinking more on the consistency side, maybe not so much. Another challenge that you end up running into is performance problems, because instead of using native components, what you end up having is you’re sending down all these instructions that get interpreted on the client, at runtime. One common example is actually animation performance. If you’re trying to animate here, you get really nice animation when you use native components, because you’ve got all the nice transitions that are built into the binary. You get relatively subpar animations, because you’re sending down various matrices that you’re actually applying and running when you’re doing web.
In the middle, you’ve got something that’s a little bit more like Uber’s Sindarin framework. It’s not open source, so we never publish too much about it. Uber has a thing called the Base design language. It’s a design language that defines a ton of building blocks or UI component primitives, things like hit button, a label, a divider, a list. These are all defined natively on the client. What we did with Sindarin was we took that Base design language and mapped it to the backend via a Go DSL. That means any primitive component can now be built either with a backend command, or with a native command on the client. You can see here on the left that what I’ve got is some pseudocode. I’ve got a vertical stack with some children. The first one has a label that says, choose your ride, then there’s some space, then there’s a card concept. Within that, it’s got an illustration, so on, so forth. We’re rendering something that looks a little bit like what’s being shown in the picture there. One nice thing about this, because it’s all native, ultimately, is that you can actually mix and match that. If your UI is already built natively, like I’ve already built out an entire page, and I only want to experiment with one subcomponent, I can do that. I just swap out that subcomponent with the backend representation of it and send it down. Then we can experiment with that part of the layout without affecting the rest of it.
This gives us a few benefits, like the big ones are performance. Since they’re all native components, they’re just running the same way. They’re optimized to run on the devices, and debuggability, because ultimately, the backend is just sending down native instructions. You end up being able to use a lot of the tools that you’re familiar with, things like the IntelliJ debugger, or HPROF. As a mobile developer, you don’t have to learn this brand-new ecosystem. You’ll still have to learn a few new things. Ultimately, these are generated from backend DSL commands, but hopefully it’s a little bit easier. We also ended up trying to make the DSL commands, as you can see, look a little bit more like mobile command. Think Jetpack Compose or SwiftUI. The other thing that you get from doing this is you end up with an increased degree of consistency, because ultimately on the client, you have a well-defined set of components. I’ve got a button with text size medium, or text size large, I don’t have a button with text size 12 SP. On the backend, your Go DSL can provide that exact same thing. You’re guaranteed that when it renders on the client, it looks similar or exactly the same as the native components that you’ve built. The major drawback to something like this, and this is why it sits in the middle of the spectrum, is developers can still mix and match what they want. What we provided is a bunch of what I would describe as atomic units, your button, your label, so on, so forth. You haven’t actually described the larger molecular components. One feature might show a dialog popup with an ok button on top and a cancel button below it. Another feature might show that same dialog with an ok on the right and a cancel on the left. That does lead to some end user confusion, and it doesn’t feel quite as good.
Then on the other end of the spectrum, like we talked about a moment ago, is Airbnb’s Ghost Platform. If Uber’s Sindarin was providing atoms, then I would describe this framework as taking the approach of providing the higher-level molecules. Instead of providing a singular binary divider, they’ll provide something like the HERO section that you see at the top, and that’s going to contain a carousel of images. Or maybe they’ll provide a title section, which has a title along with a star rating for the property that you’re looking to book. Taking this approach is great, because it forces far more consistency across the entire product. There is now a singularly well-defined set of building blocks that everyone can use for their UI. As a developer, I have to worry about fewer permutations. I don’t have to think about, did someone swap these two buttons, and were there any problems that arose from that decision? I can make an assumption that the footer section is always going to be at the bottom. It’s always going to have a higher Z index. It’s always going to have a call-to-action button, so on, so forth. You also end up saving a decent bit of bandwidth, and we’ll talk about this a little later. If you’re not sending down all these primitives, there’s less instructions that you have to send down to the client. I want to say I want to render a HERO section, and it knows what a HERO section is. I don’t have to say, I want to render a horizontal carousel that has four images, and the images themselves have these certain properties. There’s a click listener for these images to expand it out into a full screen view. You just have a HERO section.
Once again, there’s downsides to this. Like mobile development today, taking this approach makes it a little bit harder to experiment. Imagine if you’re a team and you’re building out a brand-new component. First of all, that component doesn’t exist on the client, so you’re going to have to build it into the client, and you’re going to have to push out a new binary. That’s problem number one. Problem number two is, if you want to build that new component, either you end up building it as a brand-new component, in which case now there is yet another primitive that people have to think about when they’re building out their features, or you modify an existing component. If you modify an existing component, like the title section, then every other call site across your entire application that’s using it is going to get modified. You get the consistency. Sometimes there’s a downside to that, you get the blast radius of making that change, and that causes problems. Ultimately, you can see how there’s this bit of a spectrum, if you have a much stronger opinion of what kind of UI you want to build and what kind of experiences you want to build. It’s great to use something like Ghost Platform because it forces a lot more rigor into your design language, into your design systems. You can probably build tools into Figma, or whatever tooling your design teams are using to encourage the designers to actually build things using these basic building blocks. On the other extreme, if you really don’t know what you’re trying to build, you’re a startup, you’re really trying to explore a lot more in a certain area. Putting a WebView in that area, isn’t the worst thing in the world. I personally prefer to use the component library that we built at Uber, mostly because I found that it was good enough that we could build out a bunch of these common primitives and let teams mix and match those, and then we would end up building a lot more consistency by actually forcing the designers to design consistency at the Figma or design level, rather than trying to encode this at the developer level. It’s a tradeoff.
Server Driven Data
Let’s move on to the data piece, because, why not? We’ve already made this very clear that there’s no right answer. It’s very confusing on the UI piece. Rather than solve that, let’s make it even more complicated. On the data piece, there tends to be two different options when developers are looking to build out an SDUI experience. The first one is server-side rendering. The second one is two-phase rendering. Let’s define those. Server-side rendering is what many of us think of when we think of web 1.0. You’ve got the backend that’s sending down a fully hydrated payload. Going back to our HTML example from before, you can see that payload already has the image source URL baked into it. It’s already got the title of the hotel that I’m looking at baked into it right there as well. It’s pretty nice. One of the big things that you get from server-side rendering is, it’s a lot easier to debug, because you get a single blob of data that comes down. It’s also a lot easier to set up a sandbox, because your single blob of data is hermetic, it doesn’t have any dependencies on things outside of that sandbox. It’s also a lot easier to test. A lot of what I just said will make sense in contrast with two-phase rendering.
Let’s talk about two-phase rendering. The opposite of server-side rendering is two-phase rendering. The idea here is that you’re going to send down data separate from the UI. For example, let’s take a look at this picture that we have here. I’ve got the Uber product opened up. If I did this with server-side rendering, we would just send this down and it’d work perfectly. Imagine we want the fare to update every few minutes, or the ETA to update every 60 seconds. You don’t want to open it up, and it shows, it’s going to cost you 10 bucks, and you’re still looking at it 5 minutes later when surge has kicked in, and it’s still claimed it’s 10 bucks. Maybe all of us as riders would want it. Speaking from the other side, where we were trying to make money, we don’t want to keep presenting you that it’s going to cost 10 bucks, when, clearly, it’s going to cost us a lot more to get drivers to come to pick you up. If we did it with server-side rendering, we would send down that entire payload. Then every time we want to update, we would regenerate everything and send down another huge payload. It’d be wildly inefficient in terms of bandwidth, but it would also lead to other problems like forcing us to preserve client state. For example, if I’d scrolled halfway down the screen, or if I had expended a different card, when you send down that data, you don’t want to re-render. You don’t want to have the user’s viewpoint snap.
Two-phase rendering wildly simplified view looks like this. The client makes two separate network calls. The first one goes to the backend, gets the layout, which in this mock is just a single button. That button has a label, which is keyed off of some key. Then there’s a second that we’ll call which goes to the backend, and gets data and puts it in some data cache. Then on the client, we take the data from the data cache via the key and we bind the two of them together. Intentionally bifurcating this data and layout addresses the update way problem, because we can now push or pull the data completely separate from the UI. That’s great. It also helps with another problem that I’ll talk about briefly, which is, it allows us to cache the two of them separately. What you end up finding in a lot of client development, not just mobile, but web as well, is the lifecycle of the UI and the data is wildly different. Even if we want to experiment with UI, we’re not experimenting with pushing out new UI layouts every day, or every week. A product manager will come up with a brilliant new idea, maybe once a month, and then we’ll iterate on that. You can save bandwidth by just caching the layout, and only updating the data. It’s great. As a quick fun aside, by doing this, you also get some very interesting little things that you can do. For example, in this pseudocode that we’ve put together, what we ended up doing was we actually ended up being able to have some of these keys, look at the values of other keys within that data cache because everything runs on the client. In this specific one, what it said was, ok, we’re going to have an integer comparison. We’re just going to compare some other value to 5. If it’s less than that then we’re going to show the text in red. If it’s greater than that, then we’re going to show the text normally. You can evaluate this on the client. The ETA is probably something that already exists on the backend, so you don’t need to do that. You can come up with other scenarios where you actually want to look at client-side state. For example, imagine I want to have a screen and I only want to show certain things, if they’re going to a certain component, if it’s going to be above the fold. To know if it’s above the fold, you have to know how tall the screen is. You’re not going to have the client figure out how tall the screen is, send that information to the backend to be cached, just so we can calculate, is this above the fold? Then do a server-side render and send that back down. Why not just have that Boolean evaluation run client-side.
We’ve just been talking a lot about two-phase rendering. Really, using two-phase rendering, we get the ability to update data at a different rate than the layout is being updated. We get the ability to cast them separately. This is great. The downside of two-phase rendering is that now you have to ensure that your data and your layout are always in sync with one another. What do I mean by that? Imagine I send down layout version one, and it references some text called key A. Then I send down layout version two and it references text called key B. Unless the data cache has key B in there already, now you’re out of sync. It’s not immediately clear what’s going to render. It could render with stale information. It might crash. It might render nothing. You end up having to reason about this relatively intricate or you end up having to build an almost intricate versioning system to keep the versions of the layout and the data in sync with each other. Because unlike the previous one with server-side rendering, where everything comes down as a single hermetic blob, you’ve got two pieces that have to talk to each other.
Which data should I use? My favorite phase, it depends. For me, personally, I’ve found that the benefits of two-phase rendering far outweighs the technical complexity of server-side rendering. You’re going to get the performance and offline benefits that we talked about from reduced payloads, improved caching. You’re going to be able to actually get different behavior that’s dependent on the client only state, like we talked about. I tend to personally reserve server-side rendering for scenarios where the UI is probably going to be static, at least the lifecycle of that session. Something like, ok, I want to render a help center page. That’s going to be static, it doesn’t really need to be dynamic. That’s a perfect use case for server-side rendering.
Server Driven Actions
Lastly, let’s talk about actions. The primary decision here is whether to link the actions directly in the layout or via lambda. What do I mean by directly linked in the UI? Let’s take this button component, for example, that we see on the right. Obviously, when you click on it, you need to take an action. We can define an interface that looks something like this, where you can say, ok, when I click on it, there’s an onclick reference, and that’s going to route to a certain location. Maybe in the future, I want to add something where I say, ok, onclick, I’m going to fire off a specific well-defined analytics ID. Because of all this, your contract is very well defined. It’s actually very nice because, upfront, I can actually guarantee that when someone creates a button, in my server driven UI component, it’s guaranteed to have a destination it’s going to route to. It’s guaranteed to have an analytics event it’s going to fire. The downside of all this, unfortunately, is once again flexibility. If you add more functionality, you’re going to have to change the interface, which changes the API contract. That means, at the end of the day, server has to update, client has to update. We’re back to the binary respin problem that we talked about.
The alternative to that model is actually trying to model in a far less typesafe way. In this example, what you end up with is you got a button, and you just send down an array of events that get executed. In this case we have a button event that says, ok, I’m going to do a redirect to this specific page, or I’m going to have an analytics event that gets fired on during the onclick event, or I’m going to have an analytics event that gets fired when the button itself is rendered. Similar to the server driven data discussion that we had earlier, this lack of type safety foo, unlocks a lot of really powerful things, because actions essentially just become a lambda that gets evaluated on the client. You can build action chains where you can say, ok, I want to click a button. When that happens, fire off a network call to start prefetching data and redirect to another page. If the redirect succeeds, fire off one analytics event, or if it fails, fire off another analytics event. The challenge with this is you’re intentionally weakening the API contract. I’ve seen situations where a developer will end up creating a button, but forget to add the onclick action. They’ve got a button in there, you’re clicking it, and it’s not doing anything. Or someone ends up creating a onclick event that’s supported in binary version 1000, but the developer forgets that there’s versions that are older than that out in the wild. They send this down, it doesn’t get executed, because it doesn’t get supported. Once again, the end user is clicking on something that’s not working. There are a lot of things that we can do with [inaudible 00:36:16]. I haven’t played with it much myself, but I really like the Rust model, where you try and guarantee a lot of the type safety and correctness at the compile time, in this case on the backend. Ultimately, across the wire and on the client, you’re not typesafe. That’s intentional, but it’s dangerous.
Once again, which one should I choose? It depends. If you’re going to do a lot of experimentation with your actions, you’re probably going to want to consider plan diversion. It gives you a lot more flexibility. Me personally, actually, having built both of these, I’ve found that often, especially with actions, you don’t need that level of flexibility. Often, there’s really just a small handful of actions that we all end up supporting. I want to redirect to another page. I want to fire an analytics event. I want to make a network call, or I want to write some state back into the local cache. I click a button, and I want to write some state here so that something else can read from that and use that. What I’ve personally found is by building all that flexibility, the maintenance cost of it was far higher than I had personally anticipated. We ended up not really using the vast majority of that flexibility.
Should I Use SDUI?
I’ve just talked about all the tradeoffs when dealing with server driven UI, and it sounds a little bit like it’s really hard. Maybe it’s not worth the squeeze. You’re not going to get that much benefit. Shouldn’t I use it? No, I actually think it’s pretty nice. I’ve had good experiences. We’ll talk about that. I think it’s a really valuable tool to have in your toolkit. I strongly encourage people to use it when it’s valuable, when it’s appropriate.
Recommendation
SDUI is a very powerful tool. It allows us to make changes on the backend, which avoids this multi-week deployment problem that we were talking about at the beginning. It lets us speed up experimentation. It enables backwards compatibility. Supports better consistency between the different platforms. More importantly than all of this, which I didn’t mention, it actually forces some really good best practice for our developers, because it forces us to more decouple the different components in your UI. Rather than having these larger monoliths that you end up with as you build out mobile applications, where everything’s somewhat tightly coupled with each other. By forcing it to the backend, you have a contract, ok, this component is defined entirely by the backend, therefore, I can test it in isolation. I can run it in its own sandbox. It cannot talk to things outside of its little subdomain. This helps a lot with testability, binary size growth, reuse, so on, so forth. The really important thing, though, is you have to actually have a plan for where your feature or product is going to be evolving over time. If your feature isn’t going to experiment, why not build it natively? If it’s going to experiment, and you don’t really know what you’re going to build, maybe you should use something a lot more flexible, like WebViews. If you do know where you build, then now’s around the time where you start to define how much flexibility you actually want to use. A lot of people, like I was saying earlier, think of this as a panacea, “I can now do anything I want.” That’s true, but it comes with a cost.
At Uber, we were able to 10x our feature velocity on about two dozen features by adopting SDUI. I want to be very clear that that required a lot of effort at the design phase where we actually tried to talk with product, design, other engineers, to understand, what is the expected lifecycle or evolution of this specific feature? Do you expect to see a lot more experimentation? What types of experimentation do you expect to see? For example, we had some features where they wanted to do a lot more experimentation purely on the UI piece but the data itself was relatively static. Great, you can do that by just using the server driven UI piece of this, but doing all the bindings natively. You don’t have to control those from the backend. Likewise, we had features where we wanted to actually do the opposite. You want to have a well-defined UI, but we wanted to change the data that you’re rendering, whether that’s showing an ETD instead of an ETA, or something like that. In those cases, we let developers mix and match and choose to only do the server-side data while continuing to use their existing native layouts. This mix and match approach allowed us to experiment very quickly without going down the path of forcing everyone into a one-size-fits-all solution, which was greatly appreciated by our developers. Because no one likes to be told, “We have a great solution for you. Rewrite the entire app in a brand-new technology stack, and in two years, once you’re done with that, then you can experiment. It’ll be awesome.”
One last note that I want to quickly hit on because we’ve been talking a lot about performance and stuff like that, is, when is SDUI useful? Obviously, it’s useful for experimentation. Another one part that it’s useful for which most people don’t think about is personalized experiences. This is very important as the world becomes more personalized. Everyone expects that. What do I mean by that? I’m going to use Uber as an example again. A couple years ago, if you opened up the Uber app in Dubai, you could call a helicopter to come pick you up. If you did that in London, you would come call a boat to come pick you up. These were really cool but ultimately marketing ploys, but I still liked them, that we supported. The problem was that you ended up with all that functionality built into the binary that every single person in the world downloaded. If any of you had the Uber app and you open the app, and you’re like, why is this 150 Megs? It’s because you have the ability to call a helicopter that’s not turned on, the ability to call a boat that’s not turned on, and all this other stuff that’s not turned on. You’ve got dozens of different credit card providers, tons of different functionality that you can’t use. By moving this to the server, you get the performance gains from doing that. I can now say, this user is only going to use a certain piece of functionality. Great, I’m going to ship it down to them. Overall, I personally enjoyed building server driven UI technologies. I’ve personally enjoyed using them. I find it very useful when used in a targeted or limited fashion. Part of the reason I don’t actually talk about specific technologies in this presentation is because what I’ve personally found is that different teams end up with such different requirements and different native hooks that they need to bind in with. For example, I might need to bind in with Google Maps, or Apple Pay, or whatever, these are native components. It ends up being actually easier right now for teams to build out their own server driven UI frameworks and adopt it to what they need.
Questions and Answers
Participant 1: I’m part of the mini app group working with WTC. I think that this kind of technology, so the server-side renderings are essential for creating super apps and mini apps. There are many advances in China about this kind of technology. I was wondering, you didn’t mention any particular framework, but do you have some particular framework already done to be exposed to some open source program [inaudible 00:45:11]? Because it seems like the versioning stuff, the protocols, the actions is a lot of work that we’re traversing or doing that, and we are trying to find some sunny path. I was just wondering if you already have some [inaudible 00:45:33].
Chao: At Uber, we actually had that exact conversation about which piece of this do we want to open source? How much, and when do we want to open source it? Some of the challenges were things like, ok, the design library that we use, the SDUI piece, we specifically built that to work with the Base design system that Uber has. Other pieces like the actions and the data versioning problem, we actually built those to be standard. I don’t know where we are right now. Open sourcing that was something that we had discussed, because you’re absolutely right, a lot of these problems are not unique to us. We spent a ton of time researching all the other work that other teams were doing, because it’s a very interesting area in the mobile community.
Participant 2: Can you please elaborate, any technical possibility to break a store contract with Google or Apple. How do you deal with that part?
Chao: Apple and Google tend to frown upon this idea that you can change the behavior of that, compared to what they’ve actually tested when they’re approving the binary. It’s absolutely true. What we’ve ended up finding is that as long as you tell them in advance, these are the different permutations that we’re going to be supporting. Here’s actually test accounts that you can run in those specific scenarios. They’re pretty much ok with that, because almost every company in the wild does experimentation, Facebook, WeChat, Netflix. Everyone does experimentation. The only question is, obviously, on the spectrum, how much experimentation are we talking about? Are we talking about different UIs or different data? Also, because some of the stuff that we were doing, we could prove it wasn’t Turing complete, they were a little bit more ok with us doing that.
Participant 3: We already use server driven UI, together with WebView and native code. In our case, we decided to create a decision tree, where you should use one or the other. It’s very hard for you to enforce the people who are making the right decision, by just looking at it, and on the long road, they find people using stuff that is harder for you to maintain because they wanted to test something new. How did you view this problem in your experience?
Chao: We faced the same problem. I don’t think I did a great job of dealing with that specific problem. It was relatively similar. We came up with a decision tree, but we also tried to talk a lot about the different tradeoffs that you would actually get from making certain decision paths. We spent a lot of time working. I just said that there’s about 20 or so features that were using it. Probably about 40 features actually came to us and we actually sat down with every single one of them as the core team and said, you’re going to be one of our first partners. It’s imperative that you have a great experience but we also learn what you want to do, and we can help refine the decision tree for everyone else. It was very much a white glove service approach at the very beginning where we would actually sit with them, understand what they’re trying to build, understand why they’re trying to make those decisions, and then try to codify those patterns into this decision tree. By doing that, not only did they get a good experience, they also became evangelists for us across the company, and they could actually tell other people, “It was great for this. It was not so good for that.”
See more presentations with transcripts
MongoDB Atlas gets a number of updates that enable new application use cases – SD Times
MMS • RSS
At its annual developer conference, MongoDB.local NYC, MongoDB announced a number of new capabilities for its multi-cloud database MongoDB Atlas.
“Customers tell us they love MongoDB Atlas because it provides an integrated set of capabilities on one platform that can store and process their organization’s operational data across all of their applications,” said Sahir Azam, chief product officer at MongoDB. “Customers also tell us that MongoDB’s highly flexible and scalable document data model is a perfect fit for powering modern applications that can take advantage of generative AI and their real-time proprietary data. The additional services we’re launching today for MongoDB Atlas not only make it easier to build, deploy, and run modern applications, but also make it easier to optimize performance while reducing costs.”
First, it announced the general availability of MongoDB Atlas Stream Processing, which allows for analysis of streaming data, or data in motion, coming from IoT devices or inventory feeds. Streaming data can be used to create dynamic experiences in applications, but requires a new data model. With MongoDB Atlas Stream Processing, developers will be able to create applications that can change their behavior based on this dynamic data.
Examples of applications that can be built using this include an app that optimizes shipping routes using current weather conditions and supply chain data feeds, or fraud detection that utilizes transaction histories in real time.
Next, MongoDB Atlas Search Nodes provide dedicated infrastructure for generative AI workloads on MongoDB Atlas Vector Search and MongoDB Atlas Search. It consists of nodes that are separate from the core database nodes, allowing customers to isolate AI workloads, optimize costs, and reduce query times.
According to MongoDB, one of the other benefits is that it enables high availability for AI-based search workloads. For instance, an airline could use it to offer an agent that helps with booking flights that can adjust to surges in demand by isolating the vector search workload and scaling the needed infrastructure without also scaling the resources for the database workload.
MongoDB Atlas Search Nodes are available on AWS and Google Cloud and in preview on Microsoft Azure.
The company also announced a preview of MongoDB Atlas Edge Server, which allows developers to deploy and operate distributed applications in the cloud and the edge. It provides applications with access to data even on intermittent connections. It also supports data tiering, which prioritizes critical data to be synchronized first and helps reduce network congestion, MongoDB explained.
And finally, the company announced the availability of MongoDB Atlas Vector Search on Knowledge Bases for Amazon Bedrock. This allows Amazon Bedrock applications to act on data processed by MongoDB Atlas Vector Search.
“With the integration of MongoDB Atlas Vector Search and Amazon Bedrock now generally available, we’re making it easier for joint MongoDB-AWS customers to use a variety of foundation models hosted in their AWS environments to build generative AI applications that can securely use their proprietary data within MongoDB Atlas to improve accuracy and provide enhanced end-user experiences,” said Azam.
MMS • RSS
As MongoDB Inc. charts its course toward a $2 billion revenue milestone and a staggering $28 billion market cap, its journey intertwines with that of Arc XP, a division of The Washington Post.
The Post is poised at the vanguard of digital media and high-volume storytelling solutions.
“We have our suite of applications for very specific workflows, but everything speaks to each other’s, [it’s] completely integrated,” said Joey Marburger (pictured, right), director of product strategy and design at Arc XP. “When we’re working with customers and developing products internally, we don’t have to stop … we can start working on it seamlessly.”
Marburger was joined by Joe Croney (left), vice president of technology and product development at The Washington Post, as they spoke with theCUBE Research’s chief analyst Dave Vellante at the MongoDB.local NYC event, during an exclusive broadcast on theCUBE, SiliconANGLE Media’s livestreaming studio. They discussed the MongoDB and its relation to Arc XP, the changing landscape of digital media and how artificial intelligence is reshaping online content creation. (* Disclosure below.)

Joe Croney, of The Washington Post, and Joey Marburger, of Arc XP, talk to theCUBE about the evolution of digital media.
Arc XP: From internal tool to media solution powerhouse
Originating as an in-house solution for The Washington Post, Arc XP matured into a competitive player in the content management system arena. But in a sea teeming with such systems, how did Arc XP navigate the choppy waters of competition? The answer lay in its origin story — a tale of solving common editorial woes that resonated with publishers worldwide.
“Part of the story for us is a focus on developer experience,” Croney said. “It’s one of the reasons that my team loves using MongoDB, is all the services MongoDB has for developers. The same is true for Arc XP. We have a robust set of SaaS tools for developers to access through our APIs and really embed workflows around high volume content creation for their editorial teams.”
Arc XP’s trajectory mirrored MongoDB’s growth narrative. Just as MongoDB thrived in the operational database sphere, Arc XP’s horizontal platform catered to diverse media workflows, aligning seamlessly with the shifting sands of digital publishing, according to Croney. MongoDB Atlas emerged as a linchpin, ensuring high availability and scalability for Arc XP’s cloud-native tech stack.
“We definitely are more of a horizontal platform,” Croney said. “Similar to Mongo’s story of growth, that’s been the story of Arc XP, where we’ve seen demand not only in print traditional publishers, but also in broadcast, in commercial venues, looking to have a presence on the digital space.”
The promise of AI in digital media
The allure of AI also beckoned, promising to revolutionize content creation and curation. Arc XP’s foray into AI heralded a new dawn, with bespoke AI editors and assistants augmenting the editorial process. Yet, amid the excitement, the specter of model variability loomed large. The quest for the perfect model was akin to chasing shadows, with proprietary and open-source models vying for supremacy.
“For each individual feature within our AI products, you can select different models for different features,” Marburger said. “We are doing our own comparisons of running kind of a battery of tests for the features against all the models to determine weights and biases, speed, accuracy, hallucination; and then have preferred models that then we recommend, but then we allow customers to verify for themselves.”
But AI’s ascent also brings forth ethical quandaries, chief among them being the proliferation of deepfakes. As AI tools grow more sophisticated, so does the need for robust authentication mechanisms. Arc XP’s commitment to data privacy and authenticity manifested in its AI platform, equipped with detection mechanisms to combat the menace of deepfakes.
“The authenticity of the content is very important to our customers as is data privacy concerns for in process content, as well as published content,” Croney said. “One of the reasons we’ve created this flexible architecture, where you can choose your models, is partially the open source or which one is best for the challenge at hand. But it’s also the business concerns about where is the data at rest.”
Here’s the complete video interview, part of SiliconANGLE’s and theCUBE Research’s coverage of the MongoDB.local NYC event:
(* Disclosure: TheCUBE is a paid media partner for the MongoDB.local NYC event. Neither MongoDB Inc., the sponsor of theCUBE’s event coverage, nor other sponsors have editorial control over content on theCUBE or SiliconANGLE.)
Photo: SiliconANGLE
Your vote of support is important to us and it helps us keep the content FREE.
One click below supports our mission to provide free, deep, and relevant content.
Join our community on YouTube
Join the community that includes more than 15,000 #CubeAlumni experts, including Amazon.com CEO Andy Jassy, Dell Technologies founder and CEO Michael Dell, Intel CEO Pat Gelsinger, and many more luminaries and experts.
THANK YOU
Docker Desktop 4.29 Improves Container Isolation and Error Management, Integrates Moby 26, and More
MMS • Sergio De Simone

The latest version of Docker Desktop implements socket mount permissions to enhance container isolation, updates error management to improve efficiency and reliability, integrates Moby 26, and speeds up file operations thanks to synchronized file shares.
Available only to business subscribers, Enhanced Container Isolation (ECI) mode uses a variety of techniques to harden container isolation, including running all containers unprivileged, ensuring the Docker VM is immutable, vetting some system calls and virtualizing /proc and /sys within container, and preventing user console access to the VM. This layer of security helps prevent malicious workloads running in containers from compromising Docker Desktop or the host, says Docker.
With release 4.29, ECI now hardens the Docker Engine Socket by blocking unapproved attempts to bind it into containers. To avoid hampering productivity, though, developers can tweak the admin-settings.json configuration to enable specified images to bind-mount the Docker socket.
The Docker Engine socket, a crucial component for container management, has historically been a vector for potential security risks. Unauthorized access could enable malicious activities, such as supply chain attacks. However, legitimate use cases, like the
Testcontainersframework, require socket access for operational tasks.
Thanks to its new error management system, Docker Desktop can now provide timely and actionable insights into what is causing errors, says Docker, with a significantly improved developer experience. This includes an enhanced error interface that provides both raw error codes and helpful explanatory text, support for uploading diagnostics directly from the error screen, and the ability to reset the application to factory settings for more complex situations.
As mentioned, Docker Desktop 4.29 also integrates Moby 26, bringing in several new features, including the possibility to mount a subdirectory as a named volume, improvements to the stability of the networking subsystem, integration of BuildKit 0.13 with experimental support for Windows Containers, and an improved docker images UX.
Moby is a collection of tools and components originally created for the Docker project which are now available to other projects as well, including container build tools, a container registry, orchestration tools, a runtime and more.
As a final mention, the new Docker Desktop release also brings 2-10x faster file operation thanks to Synchronized File Shares. In short, Synchronized File Shares are just file caches that are kept in sync with the host file system using the Mutagen file synchronization engine, which enables bidirectional propagation with ultra-low latency. The trade-off for this improved performance is you pay the storage cost twice, on both the host and inside the VM-based cache.
There is much more to Docker Desktop 4.29 than can be covered here, so do not miss the official release notes for the full details.