Month: August 2024
Google Cloud Launches C4 Machine Series: High-Performance Computing and Data Analytics

MMS • Steef-Jan Wiggers
Google Cloud recently announced the general availability of its new C4 machine series, powered by 4th Gen Intel Xeon Scalable Processors (Sapphire Rapids). The series offers a range of configurations tailored to meet the needs of demanding applications such as high-performance computing (HPC), large-scale simulations, and data analytics.
The C4 machine series is optimized to handle workloads that require substantial computational power. According to the company, it leverages Intel’s latest technology to provide up to 60% better performance per core than its predecessor, the C2 series. The machines in this series are equipped with Intel Advanced Matrix Extensions (AMX), which are instrumental in accelerating AI and machine learning tasks, particularly those involving large models and datasets. The machines are available in several configurations, ranging from 4 to 96 vCPUs, allowing businesses to choose the best setup for their workload requirements.
One of the features of the C4 series is its enhanced networking capabilities. Each C4 machine offers up to 200 Gbps of network bandwidth, enabling faster data transfer and reducing latency. This is particularly beneficial for applications that rely on distributed computing or real-time data processing. Integrating Google’s Virtual NIC (gVNIC) further improves network performance by offloading packet processing tasks from the CPU, thus freeing up resources for compute tasks.
The C4 series supports many use cases beyond traditional compute-intensive tasks. For instance, businesses engaged in AI and machine learning can leverage the AMX extensions to accelerate the training and inference of complex models. Meanwhile, companies involved in rendering and simulation can benefit from the series’ high performance and memory bandwidth to quickly run large-scale simulations and generate high-quality visual outputs.
Olivia Melendez, a product manager at Google Cloud, wrote:
C4 VMs provide the performance and flexibility you need to handle most workloads, all powered by Google’s Titanium. With Titanium offload technology, C4 delivers high performance connectivity with up to 200 Gbps of networking bandwidth and scalable storage with up to 500k IOPS and 10 GB/s throughput on Hyperdisk Extreme. C4 instances scale up to 192 vCPUs and 1.5TB of DDR5 memory and feature the latest generation performance with Intel’s 5th generation Xeon processors (code-named Emerald Rapids) offering predefined shapes in high-cpu, standard, and high-mem configurations.
In addition, Richard Seroter, chief evangelist, made a bold statement on X:
Yes, this new C4 machine type is rad / the bee’s knees / fire for database and AI workloads. But I particularly appreciated that we shared our test conditions for proving we’re more performant than other cloud offerings.
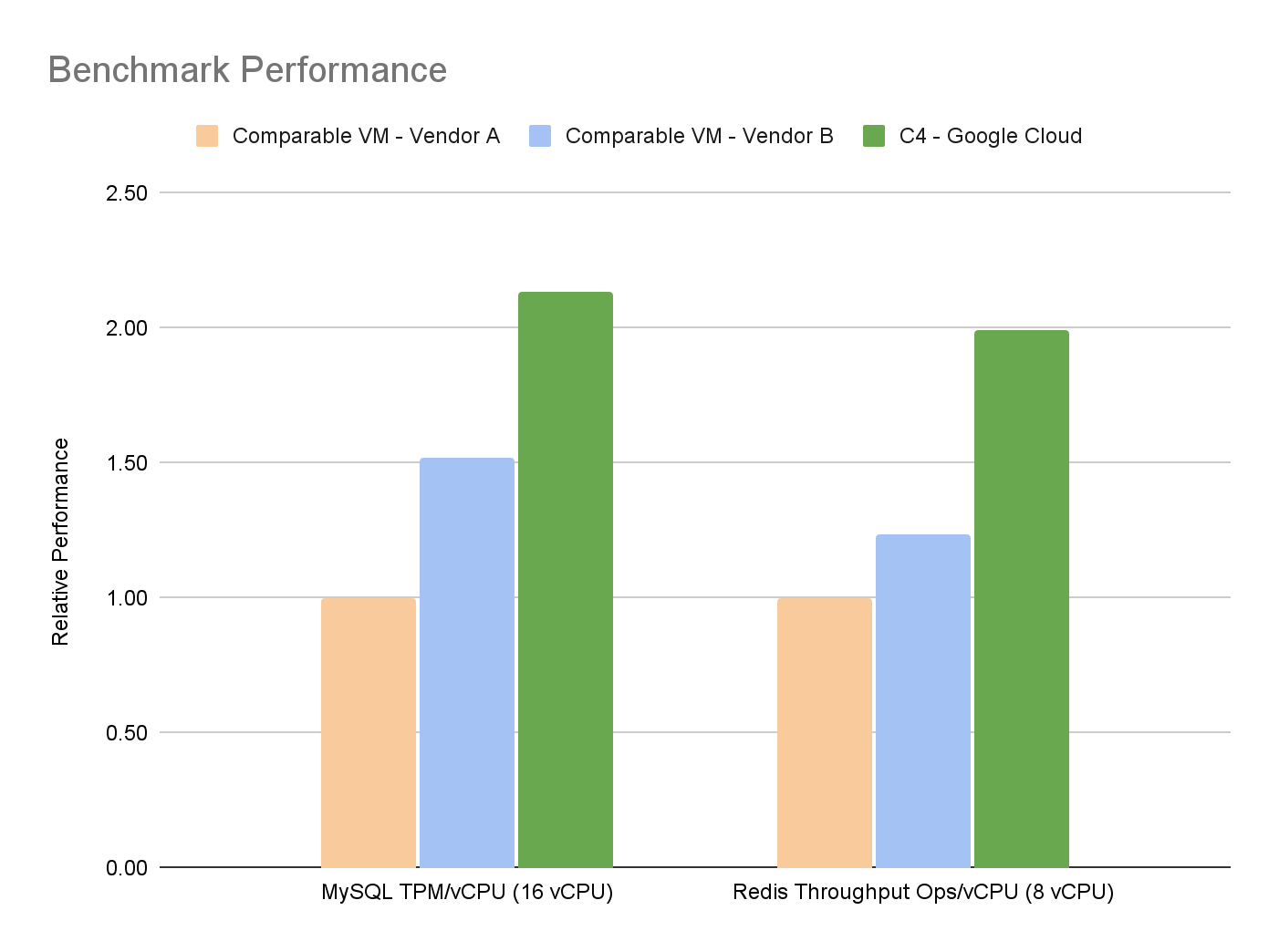
(Source: Google blog post)
The C4 series is now generally available in several Google Cloud regions, including the United States, Europe, and Asia-Pacific. Google has announced plans to expand availability to additional regions soon.
Pricing for the C4 series includes options for on-demand, committed use contracts, and sustained use discounts. This allows businesses to optimize their cloud spend based on specific usage patterns. Google also offers preemptible instances for the C4 series, providing a cost-effective option for workloads that can tolerate interruptions.
MMS • Rafiq Gemmail

Scrum.org recently published an article titled AI as a Scrum Team Member by its COO, Eric Naiburg. Naiburg described the productivity benefits for Scrum masters, product owners, and developers, challenging the reader to “imagine AI integrating seamlessly” as a “team member” into the Scrum team. Thoughtworks’ global lead for AI-assisted software delivery, Birgitta Böckeler, also recently published an article titled Exploring Generative AI, where she shared insights into experiments involving the use of LLMs (Large Language Models) in engineering scenarios, where they may potentially have a multiplier effect for software delivery teams.
Naiburg compared the role of AI tooling to that of a pair-programming collaborator. Using a definition of AI spanning from LLM integrations to analytical tools, he wrote about how AI can be used to reduce cognitive load across the key roles of a Scrum team. He discussed the role of the Scrum master and explained that AI provides an assistant capable of advising on team facilitation, team performance and optimisation of flow. Naiburg gave the example of engaging with an LLM for guidance on driving engagement in ceremonies:
AI can suggest different facilitation techniques for meetings. If you are having difficulty with Scrum Team members engaging in Sprint Retrospectives, for example, just ask the AI, “I am having a problem getting my Scrum Team to fully engage in Sprint Retrospectives any ideas?”
Naiburg wrote that AI provides developers with an assistant in the team to help decompose and understand stories. Further, he called out the benefit of using AI to simplify prototyping, testing, code-generation, code review and synthesis of test data.
Focusing on the developer persona, Böckeler described her experiment with using LLMs to onboard onto an open source project and deliver a story against a legacy software project. To understand the capabilities and limits of AI tooling, she used LLMs to work on a ticket from the backlog of the open-source project Bhamni. Böckeler wrote about her use of LLMs in comprehending the ticket, the codebase, and understanding the bounded context of the project.
Böckeler’s main tools comprised of an LLM using RAG (Retrieval Augmented Generation) to provide insights based on the content of Bhamni’s wiki. She offered the LLM a prompt containing the user story and asked it to “explain the Bhamni and health care terminology” which it mentioned. Böckeler wrote:
I asked more broadly, “Explain to me the Bahmni and healthcare terminology in the following ticket: …”. It gave me an answer that was a bit verbose and repetitive, but overall helpful. It put the ticket in context, and explained it once more. It also mentioned that the relevant functionality is “done through the Bahmni HIP plugin module”, a clue to where the relevant code is.
Speaking on the InfoQ Podcast in June, Meryem Arik, co-founder/CEO at TitanML, described the use of LLMs with RAG performing as “research assistant” being “the most common use cases that we see as a 101 for enterprise.” While Böckeler did not directly name her RAG implementation beyond describing it as a “Wiki-RAG-Bot”, Arik spoke extensively about the privacy and domain-specialisation benefits that can be gained from a custom solution using a range of open models. She said:
So actually, if you’re building a state-of-the-art RAG app, you might think, okay, the best model for everything is OpenAI. Well, that’s not actually true. If you’re building a state-of-the-art RAG app, the best generative model you can use is OpenAI. But the best embedding model, the best re-ranker model, the best table parser, the best image parser, they’re all open source.
To understand the code and target her changes, Böckeler wrote that she “fed the JIRA ticket text” into two tools used for code generation and comprehension, Bloop and Github Copilot. She asked both tools to help her “find the code relevant to this feature.” Both models gave her a similar set of pointers, which she described as “not 100% accurate,” but “generally useful direction.” Exploring the possibilities around autonomous code-generators Böckeler experimented with Autogen to build LLM based AI agents to port tests across frameworks, she explained:
Agents in this context are applications that are using a Large Language Model, but are not just displaying the model’s responses to the user, but are also taking actions autonomously, based on what the LLM tells them.
Böckeler reported that her agent worked “at least once,” however it “also failed a bunch of times, more so than it worked.” InfoQ recently reported on a controversial study by Upwork Research Institute, pointing at a perception from those sampled that AI tools decrease productivity, with 39% of respondents stating that “they’re spending more time reviewing or moderating AI-generated content.” Naiburg calls out the need to ensure that teams remain focused on value and not just the output of AI tools:
One word of caution – the use of these tools can increase the volume of “stuff”. For example, some software development bots have been accused of creating too many lines of code and adding code that is irrelevant. That can also be true when you get AI to refine stories, build tests or even create minutes for meetings. The volume of information can ultimately get in the way of the value that these tools provide.
Commenting on her experiment with Autotgen, Böckeler shared a reminder that the technology still has value in “specific problem spaces,” saying:
These agents still have quite a way to go until they can fulfill the promise of solving any kind of coding problem we throw at them. However, I do think it’s worth considering what the specific problem spaces are where agents can help us, instead of dismissing them altogether for not being the generic problem solvers they are misleadingly advertised to be.
Spring News Roundup: Milestone Releases for Spring Boot, Cloud, Security, Session and Spring AI
MMS • Michael Redlich

There was a flurry of activity in the Spring ecosystem during the week of August 19th, 2024, highlighting: point and milestone releases of Spring Boot, Spring Data, Spring Cloud, Spring Security, Spring Authorization Server, Spring Session, Spring for Apache Kafka and Spring for Apache Pulsar.
Spring Boot
The second milestone release of Spring Boot 3.4.0 delivers bug fixes, improvements in documentation, dependency upgrades and many new features such as: an update to the @ConditionalOnSingleCandidate annotation to deal with fallback beans in the presence of a regular single bean; and configure the SimpleAsyncTaskScheduler class when virtual threads are enabled. More details on this release may be found in the release notes.
Versions 3.3.3 and 3.2.9 of Spring Boot have been released to address CVE-2024-38807, Signature Forgery Vulnerability in Spring Boot’s Loader, where applications that use the spring-boot-loader or spring-boot-loader-classic APIs contain custom code that performs signature verification of nested JAR files may be vulnerable to signature forgery where content that appears to have been signed by one signer has, in fact, been signed by another. Developers using earlier versions of Spring Boot should upgrade to versions 3.1.13, 3.0.16 and 2.7.21.
Spring Data
Versions 2024.0.3 and 2023.1.9, both service releases of Spring Data, feature bug fixes and respective dependency upgrades to sub-projects such as: Spring Data Commons 3.3.3 and 3.2.9; Spring Data MongoDB 4.3.3 and 4.2.9; Spring Data Elasticsearch 5.3.3 and 5.2.9; and Spring Data Neo4j 7.3.3 and 7.2.9. These versions can be consumed by Spring Boot 3.3.3 and 3.2.9, respectively.
Spring Cloud
The first milestone release of Spring Cloud 2024.0.0, codenamed Mooregate, features bug fixes and notable updates to sub-projects: Spring Cloud Kubernetes 3.2.0-M1; Spring Cloud Function 4.2.0-M1; Spring Cloud OpenFeign 4.2.0-M1; Spring Cloud Stream 4.2.0-M1; and Spring Cloud Gateway 4.2.0-M1. This release provides compatibility with Spring Boot 3.4.0-M1. Further details on this release may be found in the release notes.
Spring Security
The second milestone release of Spring Security 6.4.0 delivers bug fixes, dependency upgrades and new features such as: improved support to the @AuthenticationPrincipal and @CurrentSecurityContext meta-annotations to better align with method security; preserve the custom user type in the InMemoryUserDetailsManager class for improved use in the loadUserByUsername() method; and the addition of a constructor in the AuthorizationDeniedException class to provide the default value for AuthorizationResult interface. More details on this release may be found in the release notes and what’s new page.
Similarly, versions 6.3.2, 6.2.6 and 5.8.14 of Spring Security have also been released providing bug fixes, dependency upgrades and a new feature that implements support for multiple URLs in the ActiveDirectoryLdapAuthenticationProvider class. Further details on these releases may be found in the release notes for version 6.3.2, version 6.2.6 and version 5.8.14.
Spring Authorization Server
Versions 1.4.0-M1, 1.3.2 and 1.2.6 of Spring Authorization Server have been released that ship with bug fixes, dependency upgrades and new features such as: a new authenticationDetailsSource() method added to the OAuth2TokenRevocationEndpointFilter class used for building an authentication details from an instance of the Jakarta Servlet HttpServletRequest interface; and allow customizing an instance of the Spring Security LogoutHandler interface in the OidcLogoutEndpointFilter class. More details on these releases may be found in the release notes for version 1.4.0-M1, version 1.3.2 and version 1.2.6.
Spring Session
The second milestone release of Spring Session 3.4.0-M2 provides many dependency upgrades and a new RedisSessionExpirationStore interface so that it is now possible to customize the expiration policy in an instance of the RedisIndexedSessionRepository.RedisSession class. Further details on this release may be found in the release notes and what’s new page.
Similarly, the release of Spring Session 3.3.2 and 3.2.5 ship with dependency upgrades and a resolution to an issue where an instance of the AbstractSessionWebSocketMessageBrokerConfigurer class triggers an eager instantiation of the SessionRepository interface due to a non-static declaration of the Spring Framework ApplicationListener interface. More details on this release may be found in the release notes for version 3.3.2 and version 3.2.5.
Spring Modulith
Versions 1.3 M2, 1.2.3, and 1.1.8 of Spring Modulith have been released that ship with bug fixes, dependency upgrades and new features such as: an optimization of the publication completion by event and target identifier to allow databases to optimize the query plan; and a refactor of the EventPublication interface that renames the isPublicationCompleted() method to isCompleted(). Further details on these releases may be found in the release notes for version 1.3.0-M2, version 1.2.3 and version 1.1.8.
Spring AI
The second milestone release of Spring AI 1.0.0 delivers bug fixes, improvements in documentation and new features such as: improved observability functionality for the ChatClient interface, chat models, embedding models, image generation models and vector stores; a new MarkdownDocumentReader for ETL pipelines; and a new ChatMemory interface that is backed by Cassandra.
Spring for Apache Kafka
Versions 3.3.0-M2, 3.2.3 and 3.1.8 of Spring for Apache Kafka have been released with bug fixes, dependency upgrades and new features such as: support for Apache Kafka 3.8.0; and improved error handling on fault tolerance retries. These releases will be included in the Spring Boot 3.4.0-M2, 3.3.3 and 3.2.9, respectively. More details on this release may be found in the release notes for version 3.3.0-M2, version 3.2.3 and version 3.1.8.
Spring for Apache Pulsar
The first milestone release of Spring for Apache Pulsar 1.2.0-M1 ships with improvements in documentation, dependency upgrades and new features: the ability to configure a default topic and namespace; and the ability to use an instance of a custom Jackson ObjectMapper class for JSON schemas. This release will be included in Spring Boot 3.4.0-M2. Further details on this release may be found in the release notes.
Similarly, versions 1.1.3 and 1.0.9 of Spring for Apache Pulsar have been released featuring dependency upgrades and will be included in Spring Boot 3.3.3 and 3.2.9, respectively. More details on these releases may be found in the release note for version 1.1.3 and version 1.0.9.
MMS • Sergio De Simone

Several strategies exist to apply the principles of zero-trust security to development environments based on Docker Desktop to protect against the risks of security breaches, Docker senior technical leader Jay Schmidt explains.
The zero-trust security model has gained traction in the last few years as an effective strategy to protect sensitive data, lower the risk of security breaches, get visibility into network traffic, and more. It can be applied to traditional systems as well as to container-based architectures, which are affected by image vulnerabilities, cyberattacks, unauthorized access, and other security risks.
The fundamental idea behind the zero-trust model is that both external and internal actors should be treated in the same way. This means going beyond the traditional “perimeter-based” approach to security, where users or machines within the internal perimeter of a company can be automatically trusted. In the zero-trust model, privileges are granted exclusively based on identities and roles, with the basic policy being not trusting anyone.
In his article, Schmidt analyzes how the core principles of the zero-trust model, including microsegmentation, least-privilege access, device access controls, and continuous verification can be applied to a Docker Desktop-based development enviroment.
Microsegmentation aims to create multiple protected zones, such as testing, training, and production, so if one is compromised, the rest of the network can continue working unaffected.
With Docker Desktop, says Schmidt, you can define fine-grained network policies using the bridge network for creating isolated networks or using the Macvlan network driver that allows containers to be treated as distinct physical devices. Another feature that allows to customize network access rule are air-gapped containers.
In keeping with the principle of least-privilege access, enhanced container isolation (ECI) makes it easier to ensure an actor has only the minimum privileges required to perform an action.
In terms of working with containers, effectively implementing least-privilege access requires using AppArmor/SELinux, using seccomp (secure computing mode) profiles, ensuring containers do not run as root, ensuring containers do not request or receive heightened privileges, and so on.
ECI enforces a number of desirable properties, such as running all containers unprivileged, remapping the user namespace, restricting file system access, blocking sensitive system calls, and isolating containers from the Docker Engine’s API.
Authentication and authorization using role-based access control (RBAC) is another key practice that Docker Desktop supports in various ways. These include Single Sign On to manage groups and enforce role and team membership at the account level, and Registry Access Management (RAM) and Image Access Management (IAM) to protect against supply chain attacks.
Another component of Docker Desktop security model is logging and support for software bills of materials (SBOM) using Docker Scout. Using SBOMs enables continually checking against CVEs and security policies. For example, you could enforce all high-profile CVEs to be mitigated, root images to be validated, and so on.
Finally, Docker security can be strengthened through container immutability, which ensures containers are not replaced or tampered with. To this aim, Docker provides the possibility to run a container using the --read-only flag or specifying the read_only: true key value pair in the docker-compose file.
This is just an overview of tools and features provided by Docker Desktop to enforce the zero-trust model. Do not miss the original article to get the full details.
MMS • Renato Losio
At the recent Cloud Next conference in Tokyo, Google announced Spanner Graph, a managed feature that integrates graph, relational, search, and AI capabilities within Spanner. This new database supports a graph query interface compatible with ISO GQL (Graph Query Language) standards while avoiding the need for a standalone graph database.
Spanner Graph now combines graph database capabilities with Cloud Spanner, Google Cloud’s globally distributed and scalable database service that provides horizontal scaling and RDBMS features without the need for sharding or clustering. One of the goals of the project is the full interoperability between GQL and SQL to break down data silos and lets developers choose the tool for the specific use case, without extracting or transforming data. Bei Li, senior staff software engineer at Google, and Chris Taylor, Google fellow, explain:
Tables can be declaratively mapped to graphs without migrating the data, which brings the power of graph to tabular datasets. With this capability, you can late-bind (i.e., postpone) data model choices and use the best query language for each job to be done.
While graphs provide a natural mechanism for representing relationships in data, Google suggests that adopting standalone graph databases leads to fragmentation, operational overhead, and scalability and availability bottlenecks, especially since organizations have substantial investments in SQL expertise and infrastructure. Taylor comments on LinkedIn:
Interconnected data is everywhere, and graph query languages are a fantastic way to understand and gain value from it. With Spanner Graph, you can have the expressive power and performance of native graph queries, backed by the reliability and scale of Spanner.
A highly anticipated feature in the community, Spanner Graph offers vector search and full-text search, allowing developers to traverse relationships within graph structures using GQL while leveraging search to find graph content. Li and Taylor add:
You can leverage vector search to discover nodes or edges based on semantic meaning, or use full-text search to pinpoint nodes or edges that contain specific keywords. From these starting points, you can then seamlessly explore the rest of the graph using GQL. By integrating these complementary techniques, this unified capability lets you uncover hidden connections, patterns, and insights that would be difficult to discover using any single method.
Among the use cases suggested for the new Spanner Graph, the cloud provider highlights fraud detection, recommendation engines, network security, knowledge graphs, route planning, data cataloging, and data lineage tracing. Eric Zhang, software engineer at Modal, comments:
Google’s new Spanner Graph DB looks pretty awesome and hints at a world where multi-model databases are the norm.
Rick Greenwald, independent industry analyst, adds:
By having graph, as well as structured data, search operations and vector operations all accessible within the same SQL interface, Spanner essentially removes the need for users to understand what database technology they need and implement it before they can get started solving problems. The range of options to derive value from your data expands, without undue overhead.
Previously, Neo4J was the recommended deployment option on Google Cloud for many use cases now covered by Spanner Graph. Google is not the only cloud provider offering a managed graph database: Microsoft offers Azure Cosmos DB for Apache Gremlin, while AWS introduced Amazon Neptune years ago, a service distinct from NoSQL Amazon DynamoDB, which was previously recommended for similar scenarios.
A codelab is now available to get started with Spanner Graph. During the conference, Google also announced new pricing models and GoogleSQL functions for Bigtable, the NoSQL database for unstructured data, and latency-sensitive workloads.
MMS • Julia Kreger

Transcript
Kreger: I want to get started with a true story of something that happened to me. Back in 2017, my manager messaged me and said, can you support an event in the Midwest? I responded as any engineer would, what, when, where? He responded with, the International Collegiate Programming Contest in Rapid City, South Dakota in two weeks.
I groaned, as most people do, because two weeks’ notice on travel is painful. I said, ok, I’m booking. Two weeks later, I landed in Rapid City, two days early. Our hosts at the School of Mines who were hosting the International Collegiate Programming Contest wanted us to meet each other. They actually asked for us to be there two days early. They served us home-style cooking in a conference hall for like 30 people. It was actually awesome, great way to meet people. I ended up sitting at a random table. I asked the obvious non-professor to my right, what do you do? As a conversation starter. He responded that he worked in a data center in Austin, which immediately told me he was an IBM employee as well.
Then he continued to talk about what he did. He said that he managed development clusters of 600 to 2000 bare metal servers. At which point I cringed because I had concept of the scale and the pain involved. Then he added the bit that these clusters were basically being redeployed at least every two weeks. I cringed more. The way he was talking, you could tell he was just not happy with his job. It was really coming through.
It was an opportunity to have that human connection where you’re learning about someone and gaining more insight. He shared how he’d been working 60-hour weeks. He lamented how his girlfriend was unhappy with him because they weren’t spending time together, and all those fun things. All rooted in having to deploy these servers with thumb drives. Because it would take two weeks to deploy a cluster, and then the cluster would have to get rebuilt.
Then he shifted gears, he realized that he was making me uncomfortable. He started talking about a toolkit he had recently found. One that allowed him to deploy clusters in hours once he populated all the details required. Now his girlfriend was no longer upset with him. How he was actually now happy, and how his life was actually better. Then he asked me what I did for IBM. As a hint, it was basically university staff, volunteers, and IBM employees at this gathering.
I explained I worked on open source communities, and that I did systems automation. I had been in the place with the racks of hardware, and that I knew the pain of bare metal. Suddenly, a few moments later, his body language shifted to pure elation. He was happy beyond belief. The smile on his face just blew me away, because he had realized something. He was sitting next to the author who wrote the toolkit that made his life better.
Personally, as someone who made someone’s life better and got to hear the firsthand story, how it made his life better, the look on his face will always be in my mind. It will always be inspiration for me, which is partly the reason I’m here, because I believe in automating these aspects to ensure that we don’t feel the same pain. We don’t have to spread it around.
Context
The obvious question is, who am I? My name is Julia Kreger. I’m a Senior Principal Software Engineer at Red Hat. I’m also the chair of the board of directors at The OpenInfra Foundation. Over the past 10 years now, I’ve been working on automating the deployment of physical bare metal machines in varying use cases. That technology is used in Red Hat OpenStack and Red Hat OpenShift, to enable the deployment in our customer use cases.
It’s actually really neat technology and provides many different options. It is what you make of it, and how much you leverage it. I’m going to talk about why bare metal and the trends driving the market at this point. Then the shift to computing technology, and the shift underway. Then I’m going to talk about three tools you can use.
Why Bare Metal, in the Age of Cloud?
We’re in the age of cloud. I don’t think that’s disputed at this point. Why bare metal? The reality is, the cloud has been in existence for 17 years, at least public cloud, as we know it today. When you start thinking about what is the cloud, its existing technologies, with abstractions, and innovations which help make new technologies, all in response to market demand on other people’s computers.
Why was it a hit? It increased our flexibility. We went through self-service on-demand. We weren’t ordering racks of servers, and waiting months to get the servers, and then having to do the setup of the servers anymore. This enabled a shift from a Cap-Ex operating model of businesses to an Op-Ex model for businesses. How many people actually understand what Cap-Ex and Op-Ex is? It is shorthand for capital expense and operational expense.
Capital expense is an asset that you have, that you will maintain on your books in accounting. Your auditors will want to see it occasionally. You may have to pay taxes on it. Basically, you’re dealing with depreciation of value. At some point, you may be able to sell it and regain some of that value or may not be able to depending on market conditions. Whereas Op-Ex is really the operational expense of running a business. Employees are operational expenses, although there are some additional categories there of things like benefits.
In thinking about it, I loaded up Google Ngrams, just to model it mentally, because I’ve realized this shift over time. One of the things I noticed was looking at the graph of the data through 2019, which is all it’s loaded in Google Ngrams right now, unfortunately, we can see delayed spikes of the various booms in the marketplace and shifts in the market response.
Where businesses are no longer focusing on capital expenditures, which I thought was really interesting, actually. Not everyone can go to the cloud, some businesses are oriented for capital expenses. They have done it for 100 years. They know exactly how to do it, and to keep it in such a way so that it’s not painful for them. One of the driving forces with keeping things local on-prem, or in dedicated data centers is you might have security requirements. For example, you may have a fence and the data may never pass that fence line. Or you may not be able to allow visitors into your facility because of high security requirements. Another aspect is governance.
You may have rules and regulations which apply to you, and that may be just legal contracts with your vendors or customers that prevent you from going to a cloud provider. Sovereignty is a topic which is interesting, I think. It’s also one of the driving forces in running your own data center, having bare metal. You may do additional cloud orchestration technologies on top of that, but you still have a reason where you do not trust another provider, or where data may leave that country. That’s a driving reason for many organizations. Then latency. If you’re doing high-performance computing, you’re doing models of fluid dynamics, you can’t really tolerate latency of a node that might have a noisy neighbor. You need to be able to reproduce your experiment repeatedly, so, obviously, you’re going to probably run your own data center if you’re doing that sort of calculation.
The motives in the marketplace continue to shift. I went ahead and just continued to play with Google Ngrams. I searched for gig economy and economic bubble. Not that surprising, gig economy is going through the roof because the economy we have is changing. At the same time, economic bubble is starting to grow as a concern. You can actually see a little slight uptick in the actual graph, which made me smirk a little bit.
I was like, change equals uncertainty. Then, I searched for data sovereignty, and I saw almost an inverse mirror of some of the graphing that I was seeing with Cap-Ex and Op-Ex. Then I went for self-driving and edge computing. Because if you can’t fit everything onto the self-driving car, and you need to go talk to another system, you obviously want it to be an edge system that’s nearby, because you need low latency.
Because if you need to depress the brakes, you have 30 milliseconds to make that decision. There are some interesting drivers that we can see in literature that has been published over the last 10 years where we can see some of these shifts taking place.
The Shift in Computing Technology Underway Today
There are more shifts occurring in the marketplace. One of the highlights, I feel, that I want to make sure everyone’s mentally on the same page for is that evolution is constant in computer. The computers are getting more complex every single day. Some vendors are adding new processor features. Some vendors are adding specialized networking chips. A computer in a data center hasn’t changed that much over the years. You functionally have a box with a network cable for the management, a network cable for the actual data path, and applications with an operating system.
It really hasn’t changed. Except, it is now becoming less expensive to use purpose-built, dedicated hardware for domain specific problems. We were seeing this with things like GPUs and FPGAs, where you can write a program, run it on that device, and have some of your workload calculate or process there to solve specific problems in that domain. We’re also seeing a shift in diversifying architectures, except this can also complicate matters.
An example is an ARM system might look functionally the same until you add an x86 firmware-based GPU, and all of a sudden, your ARM cores and your firmware are trying to figure out how to initialize that. The secret apparently, is they launch a VM quietly in the substrate that the OS can’t see. There’s another Linux system running alongside of the system you’re probably running on that ARM system, initializing the card.
There’s also an emerging trend, which are data processing or infrastructure processing units. The prior speaker spoke of network processing units, and ASICs that can be programmed for these same sorts of tasks. Except in this case, these systems are much more generalized. I want to model a network card mentally. We have a PCIe bus. We have a network card as a generic box. It’s an ASIC, we don’t really think about it.
The network cable goes out the back. What these devices are that we’re starting to see in servers, that can be added for relatively low cost, is they may have an AI accelerator ASIC. They may have FPGAs. They may have additional networking ASICs for programmable functions. They have their own operating system that you can potentially log in to with applications you may want to put on that card, with a baseboard management controller just like the host. Yes, we are creating computers inside of computers.
Because now we have applications running on the main host, using a GPU with a full operating system. We have this DPU or IPU plugged into the host, presenting PCIe devices such as network ports to the main host operating system. Meanwhile, the actual workload and operating system can’t see into the actual card, nor has any awareness of what’s going on there, because they are programming the card individually and running individual workloads on the card. The software gets even more complicated, because now you need two management network connections per host, at least. That is unless the vendor supports the inbound access standards, which are a thing, but it’s going to take time.
To paint a complete picture, I should briefly talk about the use cases where these devices are being modeled. One concept that is popular right now is to use these devices for load balancing, or request routing, and not necessarily thinking like a web server load balancer, but it could just be a database connection load balancer, or for database sharding. It could actually decide, I am not the node you need to talk to, I’ll redirect your connection.
At which point, the actual underlying host that the card’s plugged into and receiving power from, never sees an interrupt from the transaction. It’s all transparent to it. Another use case that is popular is as a security isolation layer, so run like an AI enabled firewall, and have an untrusted workload on the machine. Then also do second stage processing. You may have a card or port where you’re taking data in and you may be dropping 90% of it. Then you’re sending it to the main host if it’s pertinent and makes sense to process.
This is mentally very similar to what some of the large data processing operations do, where they have an initial pass filter, and they’re dropping 90% of the data they’re getting because they don’t need to act upon it. It’s not relevant, and it’s not statistically useful for them. What they do get through, then they will apply additional filtering, and they only end up with like 1% of that useful data. This could also be in the same case as like the cell networks.
You could actually have a radio and the OS only sees Ethernet packets coming off this card as if it’s a network port. The OS is none the wiser to it. With hidden computers that we’re now creating in these infrastructures, I could guarantee these cards exist in deployed servers in this city today, need care and attention as well. There are efforts underway to standardize the interfaces and some of the approaches and modeling for management. Those are taking place in the OPI project. If you’re interested, there’s the link, https://opiproject.org.
Automation is important because, what if there’s a bug that’s been found inside of these units, and there’s a security isolation layer you can’t program from the base host? Think about it for a moment, how am I going to update these cards? I can’t touch them. I’ll go back to my story for a moment. That engineer had the first generation of some of these cards in his machines.
He had to remove the card and plug into a special card and put a USB drive into it to flash the firmware and update the operating system. To him, that was extremely painful, but it was far and few between that he had to do it. What we’re starting to see is the enablement of remote orchestration of these devices through their management ports, and through the network itself. Because, in many cases, people are more willing to trust the network than they are willing to trust an untrusted workload that may compromise the entire host.
Really, what I’m trying to get at is automation is necessary to bring any sanity at any scale to these devices. We can’t treat these cards as one-off, especially because they draw power from the base host. If you shut down the host, the card shuts down. The card needs to be fully online for the operating system to actually be able to boot.
Tools You Can Use (Ironic, Bifrost, Metal3)
There are some tools you can use. I’m going to talk about three different tools. Two of them actually use one tool. What I’m going to talk about is the Ironic Project. It’s probably the most complex and feature full of the three. Then I’ll talk about Bifrost, and then Metal3. Ironic was started as a scalable Bare Metal as a Service platform in 2012 in OpenStack. Mentally, it applies a state machine for data center operations, and the workflows that are involved to help enable the management of those machines. If you think about it, if you wheel racks of servers into a data center, you’re going to take a certain workflow.
Some of it’s going to be dictated by business process, some of it is going to be dictated by what’s the next logical step in the order, in the intake process. We have operationalized as much of that into a service as possible over the years. One can use a REST API to interact with the service and their backend conductors. There’s a ton of functionality there. Realistically, we can install Ironic without OpenStack. We can install it on its own. It supports management protocols like DMTF Redfish, IPMI. It supports flavors of the iLO protocol, iRMC interface, Dell iDRAC, and has a stable driver interface that vendors can extend if they so desire.
One of the things we see a lot of is use of virtual media to enable these deployments of these machines in edge use cases. Think cell tower on a pole, as a single machine, where the radio is on one card, and we connected into the BMC, and we have asserted a new operating system. One of the other things that we do as a service is we ensure the machine is in a clean state prior to redeployment of the machine, because the whole model of this is lifecycle management. It’s not just deployment. It’s, be able to enable reuse of the machine.
This is the Ironic State Machine diagram. This is all the state transitions that Ironic is aware of. Only those operating Ironic really need to have a concept of this. We do have documentation, but it’s quite a bit.
Then there’s Bifrost, which happened to be the tool that that engineer that I sat next to in Rapid City had stumbled upon. The concept here was, I want to deploy a data center with a laptop. It leverages Ansible with an inventory module and playbooks to drive a deployment of Ironic, and drive Ironic through command sequences to perform deployments of machines. Because it’s written, basically, in Ansible, it’s highly customizable.
For example, I might have an inventory payload. This is YAML. As an example, the first node is named node0. We’re relying on some defaults here of the system. Basically, we’re saying, here’s where to find it. Here’s the MAC address so that we know the machine is the correct machine, and we don’t accidentally destroy someone else’s machine. We’re telling what driver to also use. Then we have this node0-subnode0 defined in this configuration with what’s called a host group label.
There’s a feature in Bifrost that allows us to one way run the execution. When the inventory is processed, it can apply additional labels to each node that you may request. If I need to deploy only subnodes, or perform certain actions on subnodes, say, I need to apply certain software to these IPU or DPU devices, then you can do that as a subnode in this configuration. It’s probably worth noting, Ironic has work in progress to provide a more formalized model of DPU management. It’s going to take time to actually get there. We just cut the first release of it, actually. Again, because these IPUs and DPUs generally run on ARM processors, in this example, we provide a specific RAM disk and image to write to the block device storage of the IPU.
Then we can execute a playbook. This is a little bit of a sample playbook. The idea here is we have two steps. Both nodes in that inventory are referred to as bare metal, in this case. When it goes to process these two roles, it will first generate configuration drives, which are metadata that gets injected into the machine so that the machine can boot up and know where it’s coming from, where it’s going to, and so on. You can inject things like SSH keys, or credentials, or whatever. Then, after it does that first role, it will go ahead and perform a deployment. It’s using variables that are expected in the model between the two, to populate the fields and then perform the deployment with the API. Then there’s also the subnode here, where because we defined that host group label, we are able to execute directly upon that subnode.
Then there’s Metal3. Metal3 is deployed on Kubernetes clusters and houses a local Ironic instance. It is able to translate cluster API updates, and bare metal custom resource updates, to provision new bare metal nodes. You’re able to do things like BIOS and RAID settings, and deploy an operating system with this configuration. You can’t really customize it unless you want to go edit all the code that makes up the bare metal operator in Metal3.
This is what the payload looks like. This is a custom resource update, where we’re making a secret, which is the first part. Then the second part is, we’re creating the custom resource update to say, the machine’s online. It has a BMC address. It has a MAC address. Here’s the image we want to deploy to it, checksum. For the user data, use this defined metadata that we already have in the system and go deploy. Basically, what will happen is the bare metal operator will interact with the custom resource, find out what we’ve got, and take action upon it, and drive Ironic’s API that it houses locally in a pod to deploy bare metal servers for that end user. You’re able to grow a Kubernetes cluster locally if you have one deployed, utilizing this operator, and scale it down as you need it, with a fleet of bare metal.
Summary
There’s a very complex future ahead of us with bare metal servers in terms of servers with these devices in them. We have to be mindful that they are other systems too, and they will require management. The more of these sorts of devices that appear in the field, the more necessity for bare metal management orchestration will be in play.
Questions and Answers
Participant 1: I work with a number of customers who do on-premise Kubernetes clusters. The narrow play is to spend a truckload of money on VMware under the hood. Then that’s how you make it manageable. It always felt to me kind of overkill for all the other elastic capabilities Kubernetes gives you if we could manage the hardware better. Do you really need that virtualization layer? Do you have any thoughts on that with the way these tools are evolving?
Kreger: It’s really, in a sense, unrelated to the point I want to get across regarding IPUs and DPUs. What we’re seeing is Kubernetes is largely designed to run in cloud environments. It’s not necessarily designed to run on-prem. Speaking with my Red Hat hat on, we put a substantial investment in to make OpenShift be based on Kubernetes and operate effectively, and as we expect, on-prem, without any virtualization layer. It wasn’t an easy effort in any sense of imagination. Some of the expectations that existed in some of the code were that there’s always an Amazon metadata service available someplace. It’s not actually the case.
Participant 2: What I understood from one of the bigger slides was either like Redfish, or IPMI, or one of the existing protocols for management was going to be interfacing to the DPU or IPU port management through an external management interface facilitated by the server? Is there any thought at all to doing something new instead of sticking with these older protocols that [inaudible 00:30:57]?
Kreger: The emerging trend right now is to use Redfish or consensus. One of the things that does also exist and is helpful in this is there’s also consensus of maybe not having an onboard additional management controller, baseboard management controller style device in these cards. We’re seeing some consensus of maybe having part of it, and then having NC-SI support, so that the system BMC can connect to it and reach the device.
One of the things that’s happening in the ecosystem with 20-plus DPU vendors right now, is they are all working towards slightly different requirements. These requirements are being driven by market forces, what their customers are going to them and saying, we need this to have a minimum viable product or to do the needful. I think we’re always going to see some variation of that. The challenge will be providing an appropriate level of access for manageability. Redfish is actively being maintained and worked on and improved. I think that’s the path forward since the DMTF has really focused on that. Unfortunately, some folks still use IPMI and insist on using IPMI. Although word has it from some major vendors that they will no longer be doing anything with IPMI, including bug fixes.
Participant 2: How do you view the intersection of hardware-based security devices with these IPU, DPU platforms, because a lot of times they’re joined at the hip with the BMC. How is that all playing out?
Kreger: I don’t think it’s really coming up. Part of the problem is, again, it’s being driven by market forces. Some vendors are working in that direction, but they’re not talking about it in community. They’re seeing it as value add for their use case and model, which doesn’t really help open source developers or even other integrators trying to make complete solutions.
See more presentations with transcripts
MMS • Mandy Gu Namee Oberst Srini Penchikala Roland Meertens Antho
Subscribe on:
Transcript
Srini Penchikala: Hello everyone. Welcome to the 2024 AI and ML Trends Report podcast. Greetings from the InfoQ, AI, ML, and Data Engineering team. We also have today two special guests for this year’s Trends report. This podcast is part of our annual report to share with our listeners what’s happening in the AI and ML technologies. I am Srini Penchikala. I serve as the lead editor for the AI, ML and Data Engineering community on InfoQ. I will be facilitating our conversation today. We have an excellent panel with subject matter experts and practitioners from different specializations in AI and ML space. I will go around our virtual room and ask the panelists to introduce themselves. We will start with our special guests first, Namee Oberst and Mandy Gu. Hi Namee. Thank you for joining us and participating in this podcast. Would you like to introduce yourself and tell our listeners what you’ve been working on?
Introductions [01:24]
Namee Oberst: Yes. Hi. Thank you so much for having me. It’s such a pleasure to be here. My name is Namee Oberst and I’m the founder of an open source library called LLMware. At LLMware, we have a unified framework for building LLM based applications for RAG and for using AI agents, and we specialize in providing that with small specialized language models. And we have over 50 fine-tuned models also in Hugging Face as well.
Srini Penchikala: Thank you. Mandy, thank you for joining us. Can you please introduce yourself?
Mandy Gu: Hi, thanks so much for having me. I’m super excited. So my name is Mandy Gu. I am lead machine learning engineering and data engineering at Wealthsimple. Wealthsimple is a Canadian FinTech company helping over 3 million Canadians achieve their version of financial independence through our unified app.
Srini Penchikala: Next up, Roland.
Roland Meertens: Hey, I’m Roland, leading the datasets team at Wayve. We make self-driving cars.
Srini Penchikala: Anthony, how about you?
Anthony Alford: Hi, I’m Anthony Alford. I’m a director of software development at Genesis Cloud Services.
Srini Penchikala: And Daniel?
Daniel Dominguez: Hi, I’m Daniel Dominguez. I’m the managing partner of an offshore company that works with cloud computing with the AWS Department Network. I’m also an AWS Community Builder and the machine learning too.
Srini Penchikala: Thank you everyone. We can get started. I am looking forward to speaking with you about what’s happening in the AI and ML space, where we currently are and more importantly where we are going, especially with the dizzying pace of AI technology innovations happening since we discussed the trends report last year. Before we start the podcast topics, a quick housekeeping information for our audience. There are two major components for these reports. The first part is this podcast, which is an opportunity to listen to the panel of expert practitioners on how the innovative AI technologies are disrupting the industry. The second part of the trend report is a written article that will be available on InfoQ website. It’ll contain the trends graph that shows different phases of technology adoption and provides more details on individual technologies that have been added or updated since last year’s trend report.
I recommend everyone to definitely check out the article as well when it’s published later this month. Now back to the podcast discussion. It all starts with ChatGPT, right? ChatGPT was rolled out about a year and a half ago early last year. Since then, generative AI and LLM Technologies feels like they have been moving at the maximum speed in terms of innovation and they don’t seem to be slowing down anytime soon. So all the major players in the technology space have been very busy releasing their AI products. Earlier this year, we know at Google I/O Conference, Google announced several new developments including Google Gemini updates and generative AI in Search, which is going to significantly change the way the search works as we know it, right? So around the same time, open AI released GPT-4o. 4o is the omni model that can work with audio vision and text in real time. So like a multi-model solution.
And then Meta released around the same time Llama 3, but with the recent release of Llama version 3.1. So we have a new Llama release which is based on 405 billion parameters. So those are billions. They keep going up. Open-source solutions like Ollama are getting a lot of attention. It seems like this space is accelerating faster and faster all the time. The foundation of Gen AI technology are the large language models that are trained on a lot of data, making them capable of understanding and generating natural language and other types of content to perform a wide variety of tasks. So LLMs are a good topic to kick off this year’s trend report discussion. Anthony, you’ve been closely following the LLM models and all the developments happening in this space. Can you talk about what’s the current state of Gen AI and LLM models and highlight some of the recent developments and what our listeners should be watching out for?
The future of AI is Open and Accessible [05:32]
Anthony Alford: Sure. So I would say if I wanted to sum up LLMs in one word, it would be “more” or maybe “scale”. We’re clearly in the age of the LLM and foundation models. OpenAI is probably the clear leader, but of course there are big players like you mentioned, Google, also Anthropic has their Claude model. Those are closed, even OpenAI, their flagship model is only available through their API. Now Meta is a very significant dissenter to that trend. In fact, I think they’re trying to shift the trend toward more open source. I think it was recently that Mark Zuckerberg said, “The future of AI is open.” So Meta and Mistral, their models are open weight anyway, you can get the weight. So I mentioned one thing about OpenAI, even if they didn’t make the model weights available, they would publish some of the technical details of their models. For example, we know that GPT-3, the first GPT-3 had 175 billion parameters, but with GPT-4, they didn’t say, but the trend indicates that it’s almost certainly bigger, more parameters. The dataset’s bigger, the compute budget is bigger.
Another trend that I think we are going to continue to see is, so the ‘P’ in GPT stands for pre-trained. So these models, as you said, they’re pre-trained on a huge dataset, basically the internet. But then they’re fine-tuned, so that was one of the key innovations in ChatGPT was it was fine-tuned to follow instructions. So this instruct tuning is now extremely common and I think we’re going to continue to see that as well. Why don’t we segue now into context length? Because that’s another trend. The context length, the amount of data that you can put into the model for it to give you an answer from, that’s increasing. We could talk about that versus these new SSMs like Mamba, which in theory don’t have a context length limitation. I don’t know, Mandy, did you have any thoughts on this?
Mandy Gu: Yes, I mean I think that’s definitely a trend that we’re seeing with longer context windows. And originally when ChatGPT, when LLMs first got popularized, this was a shortcoming that a lot of people brought up. It’s harder to use LLM at scale or as more as you called it when we had restrictions around how much information we can pass through it. Earlier this year, Gemini, the Google Foundation, this GCP foundational models, they introduced the one plus million context window length and this was a game changer because in the past we’ve never had anything close to it. I think this has sparked the trend where other providers are trying to create similarly long or longer context windows. And one of the second order effects that we’re seeing from this is around accessibility. It’s made complex tasks such as information retrieval a lot simpler. Whereas in the past we would need a multi-stage retrieval system like RAG, now it’s easier, although not necessarily better, we could just pass all those contexts into this one plus million context window length. So that’s been an interesting development over the past few months.
Anthony Alford: Namee, did you have anything to add there?
Namee Oberst: Well, we specialize in using small language models. I understand the value of the longer context-length windows, but we’ve actually performed internal studies and there have been various experiments too by popular folks on YouTube where you take even a 2000 token passage and you pass it to a lot of the larger language models and they’re really not so good at finding the lost in the middle problem for doing passages. So if you really want to do targeted information search, it’s still the longer context windows are a little misleading I feel like sometimes to the users because it makes you feel like you can dump in everything and find information with precision and accuracy. But I don’t think that that’s the case at this point. So I think really well-crafted RAG workflow is still the answer.
And then basically for all intents and purposes, even if it’s like a million token context lines or whatever, it could be 10 million. But if you look at the scale of the number of documents that an enterprise has in an enterprise use case, it probably still doesn’t move the needle. But for a consumer use case, yes, definitely a longer context window for a very quick and easy information retrieval is probably very helpful.
Anthony Alford: Okay, so it sounds like maybe there’s a diminishing return, would you say? Or-
Namee Oberst: There is. It really, really depends on the use case. If you have what we deal with, if you think about it like a thousand documents, somebody wants to look through 10,000 documents, then that context window doesn’t really help. And there are a lot of studies just around how an LLM is really not a search engine. It’s really not good at finding the pinpointed information. So I don’t really personally like to recommend longer context LLMs instead of RAG. There are other strategies to look for information. Having said that, where is it very, very helpful in my opinion, the longer context window? If you can pass, for instance, a really long paper that wouldn’t have fit through a narrow context window and ask it to rewrite it or to absorb it and to almost… What I love to use LLMs for is to transform one document into another, take a long Medium article and transform that to a white paper, let’s just say as an example, that would’ve previously been outside the boundaries of a normal context window. I think this is fantastic. Just as an example of a really great use case.
Anthony Alford: So you brought up RAG and retrieval augmented generation. Why don’t we look at that for a little bit? It seems like number one, it lets you avoid the context length problem possibly. It also seems like a very common case, and maybe you could comment on this, the smaller open models. Now people can run those locally or run in their own hardware or their own cloud, use RAG with that and possibly solve problems and they don’t need the larger closed models. Namee, would you say anything about that?
Namee Oberst: Oh yes, no, absolutely. I’m a huge proponent of that and if you look at the types of models that we have available in Hugging Face to start and you look at some of the benchmark testing around their performance, I think it’s spectacular. And then the rate and pace of innovation around these open source models are also spectacular. Having said that, when you look at GPT-4o and the inference speed, the capability, the fact that it can do a million things for a billion people, I think that’s amazing.
But if you’re looking at an enterprise use case where you have very specific workflows and you’re looking to solve a very targeted problem, let’s say, to automate a specific workflow, maybe automate report generation as an example, or to do RAG for rich information retrieval within these predefined 10,000 documents, I think that you can pretty much solve all of these problems using open source models or take an existing smaller language model, fine tune them, invest in that, and then you can basically run it with privacy and security in your enterprise private cloud and then also deploy them on your edge devices increasingly. So I’m really, really bullish on using smaller models for targeted tasks.
Srini Penchikala: Yes, I tried Ollama for a use case a couple of months ago and I definitely see open source solutions like Ollama that you can self-host. You don’t have to send all your data to the cloud and you don’t know where it’s going. So use these self-hosted models with RAG techniques. RAG is mainly for the proprietary information knowledge base. So definitely I think that combination is getting a lot of attention in the corporations. Companies don’t want to send the data outside but still be able to use the power.
Roland Meertens: I do still think that at the moment most corporations are starting with OpenAI as a start, prove their business value and then they can start thinking about, “Oh, how can we really integrate it into our app?” So I think it’s fantastic that you can so easily get started with this and then you can build your own infrastructure to support the app later on.
Srini Penchikala: Yes. For scaling up, right Roland? And you can see what’s the best scale-up model for you, right?
Roland Meertens: Yes.
Srini Penchikala: Yes. Let’s continue the LLM discussions, right? Another area is the multi-model LLMs, the GPT-4o model, the omni model. So where I think it definitely takes the LLMs to the next level. It’s not about text anymore. We can use audio or video or any of the other formats. So anyone have any comments on the GPT-4o or just the multi-model LLMs?
Namee Oberst: In preparation for today’s podcast, I actually did an experiment. I have a subscription to GPT-4o, so I actually just put in a couple of prompts this morning, just out of curiosity because we’re very text-based, so I don’t actually use that feature that much. So I asked it to generate a new logo for LLMware, like for LLMware using the word, and it failed three times, so it botched the word LLMware like every single time. So having said that, I know it’s really incredible and I think they’re making fast advances, but I was trying to see where are they today, and it wasn’t great for me this morning, but I know that of course they’re still better than probably anything else that’s out there having said that, before anybody comes for me.
Roland Meertens: In terms of generating images, I must say I was super intrigued last year with how good Midjourney was and how fast they were improving, especially the small size of the company. That a small company can just beat out the bigger players by having better models is fantastic to see.
Mandy Gu: I think that goes back to the theme, Namee was touching on it, where big companies like OpenAI, they’re very good at generalization and they’re very good at getting especially new people into the space, but as you get deeper, you find that, as we always say in AI machine learning, there’s no free lunch. You explore, you test, you learn, and then you find what works for you, which isn’t always one of these big players. For us, where we benefited the most internally from the multi-modal models is not from image generation, but more so from the OCR capabilities. So one very common use case is just passing in images or files and then being able to converse with the LLM against, in particular, the images. That has been the biggest value proposition for us and it’s really popular with our developers because a lot of the times when we’re helping our end users, where our internal teams debug, they’ll send us a screenshot of the stack trace or a screenshot of the problem and being able to just throw that into the LLM as opposed to deciphering the message has been a really valuable time saver.
So not so much image generation, but from the OCR capabilities, we’ve been able to get a lot of value.
Srini Penchikala: That makes sense. When you take these technologies, OpenAI or anyone else, it’s not a one-size-fits-all when you introduce the company use cases. So everybody has unique use cases.
Daniel Dominguez: I think it’s interesting that I think now we mentioned all the Hugging Face libraries and models that are right now, for example, I’m thinking and looking right now in Hugging Face, there are more than 800,000 models. So definitely it’ll be interesting next year how many new models are going to be out there. Right now the trendings are, as we mentioned, Llama, Google Gemma, Mistral models, Stability models. So definitely in one year, how many new models are going to be out there, not only on text, but also on images, also on video? So definitely there’s something that, I mean it will be interesting to know how many models were last year actually, but now it could be an interesting number to see how many new models are going to be next year on this space.
RAG for Applicable Uses of LLMs at Scale [17:42]
Srini Penchikala: Yes, good point. Daniel. I think just like the application servers, probably like 20 years ago, right? There was one coming out every week. I think a lot of these are going to be consolidated and just a few of them will stand out to last for a longer time. So let’s quickly talk about the RAG, you mentioned about it. So this is where I think the real sweet spot-for companies, to input their own company information, whether on-site or out in the cloud and run through LLM models and get the insights out. Do you see any real-world use cases for RAG that may be of interest to our listeners?
Mandy Gu: I think RAG is one of the most applicable uses of LLMs at scale, and I think they can be shaped, and depending on how you design the retrieval system, it can be shaped into many use cases. So for us, we use a lot of RAG internally and we have a tool, this internal tool that we’ve developed which integrates our self-hosted LLMs against all of our company’s knowledge sources. So we have our documentation in Notion, we have our code in GitHub, and then we also have public artifacts from our help center website and other integrations.
And we essentially just built a retrieval augmented generation system on top of these knowledge bases. And how we’ve designed this is that every night we would have these background jobs which would extract this information from our knowledge sources, put in our vector database, and then through this web app that we’ve exposed to our employees, they’d be able to ask questions or give instructions against all of this information. And internally when we did our benchmarking as well, we’ve also found this to be a lot better from a relevancy and accuracy perspective than just feeding all of this context window into something like the Gemini 1.5 series. But going back to the question primarily as a way of boosting employee productivity, we’ve been able to have a lot of really great use cases from RAG.
Namee Oberst: Well Mandy, that is such a classic textbook, but really well-executed project for your enterprise and that’s such a sweet spot for what the capabilities of the LLMs are. And then you said something that’s really interesting. So you said you’re self-hosting the LLMs, so did you take an open source LLM or do you mind sharing some of the information? You don’t have to go into details, but that is a textbook example of a great application of Gen AI.
Mandy Gu: Yes, of course. So yes, they’re all open source and a lot of the models we did grab from Hugging Face as well. When we first started building our LLM platform, we wanted to provide our employees with this way to securely and accessibly explore this technology. And like a lot of other companies, we started with OpenAI, but then we put a PII redaction system in front of it to protect our sensitive data. And then the feedback we got from our employees, our internal users was that this PII redaction model actually prevented the most effective use cases of generative AI because if you think about people’s day-to-day works, there’s a large degree of not just PII but sensitive information they need to work with. And that was our natural segue of, okay, instead of going from how do we prevent people from sharing sensitive information with external providers, to how do we make it safe for people to share this information with LLMs? So that was our segue from OpenAI to the self-hosted large language models.
Namee Oberst: I’m just floored Mandy. I think that’s exactly what we do at LLMware. Actually, that’s exactly the type of solution that we look to provide with using small language models chained at the back-end for inferencing. You mentioned Ollama a couple of times, but we basically have Llama.cpp integrated into our platform so that you can bring in a quantized model and inference it very, very easily and securely. And then I’m a really strong believer that this amazing workflow that you’ve designed for your enterprise, that’s an amazing workflow. But then we’re also going to see other workflow automation type of use cases that will be miniaturized to be used on laptops. So I really almost see a future very, very soon where everything becomes miniaturized, these LLMs become smaller and almost take the footprint of software and we’re all going to start to be able to deploy this very, very easily and accurately and securely on laptops just as an example, and of course private cloud. So I love it. Mandy, you’re probably very far ahead in the execution and it sounds like you just did the perfect thing. It’s awesome.
Mandy Gu: That’s awesome to hear that you’re finding similar things and that’s amazing the work you’re doing as well. You mentioned Llama.cpp, and I thought that’s super interesting because I don’t know if everyone realizes this, but there’s so much edge that quantized models, smaller models can give and right now when we’re in this phase, when we’re still in the phase of this rapid experimentation, speed is the name of the game. Sure, we may lose a few precision points by going with a more quantized models, but what we get back from latency, what we get back from being able to move faster, it’s incredible. And I think Llama.cpp is a huge success story in its own, how this framework created by an individual, a relative small group of people, how well it is able to be executed at scale.
AI Powered Hardware [23:03]
Namee Oberst: Yes, I love that discussion because like Llama.cpp though, Georgi Gerganov, amazing, amazing in open source, but it’s optimized for actually Mac Metal and works really well also in NVIDIA CUDA. So the work that we’re doing is actually to allow data scientists and machine learning groups in enterprises also on top of everything else to not only be able to deliver the solution on Mac Metal, but across all AI PCs. So using Intel OpenVINO using Microsoft ONNX so that, data scientists like to work on Macs, but then also be able to deploy that very seamlessly and easily on other AI PCs because MacOS is only like 15% of all the operating systems out there, the rest of the 85 are actually non-MacOS. So just imagine the next phase of all this when we can deploy this across multiple operating systems and access to GPU capabilities of all these AI PCs. So it’s going to be really exciting in terms of a trend in the future to come, I think.
Small Language Models and Edge Computing [24:02]
Srini Penchikala: Yes, a lot of good stuff happening there. You both mentioned about small language models and also edge computing. Maybe we can segue into that. I know LLMs, we can talk about them for a long time, but I want to hear your perspective on other topics. So regarding the small language models, Namee, you’ve been looking into SLMs at your company, LLMWare, and also a RAG framework you mentioned specifically designed for SLMs. Can you talk about this space a little bit more? I know this is a recent development. I know Microsoft is doing some research on what they call a Phi-3 model. Can you talk about this? How are they different? What our listeners can do to get up to speed with SLMs?
Namee Oberst: So we’re actually a pioneer in working with small language models. So we’ve been working and focused actually on small language models for well over a year, so almost like too early, but that’s because RAG as a concept, it didn’t just come out last year. You know that probably RAG was being used in data science and machine learning for probably the past, I’d say, three or four years. So basically when we were doing experimentation with RAG and we changed one of our small parameter models very, very early on in our company, we realized that we can make them do very powerful things and we’re getting the performance benefits out of them, but with the data safety and security and exactly for all the reasons that Mandy mentioned and all these things were top of mind for me because my background is I started as a corporate attorney at a big law firm and I was general counsel of a public insurance brokerage company.
So those types of data safety, security concerns were really top of mind. So for those types of highly regulated industries, it’s almost a no-brainer to use small language models or smaller models for so many different reasons, a lot of which Mandy articulated, but there’s also the cost reason too. A cost is huge also. So there’s no reason to really deploy these large behemoth models when you can really shrink the footprint of these and really bring down the cost significantly. What’s really amazing is other people have really started to realize this and on the small language model front they’re getting better and better and better. So the latest iteration by Microsoft Phi-3, we have RAG fine-tuned models and Hugging Face that are really specifically designed to do RAG. When we fine-tuned it using our proprietary datasets across which we’ve fine-tuned 20 other models the exact same way, same datasets so we have a true apples to apples comparison. The Phi-3 or Phi-3 model really broke our test. It was like the best performing model out of every model we’ve ever tested, including 8 billion parameter models.
So our range is from one to 8 billion and really just performed the highest in terms of accuracy just blew my mind. The small language models that they’re really making accessible to everyone in the world for free on Hugging Face are getting better and better and better and at a very rapid clip. So I love that. I think that’s such an exciting world and this is why I made the assertion earlier, with this rate and pace of innovation, they are going to become small, so small that they’re going to take on the footprint of software in a not-so-distant future and we are going to look to deploy a lot of this on our edge devices. Super exciting.
Srini Penchikala: Yes, definitely a lot of the use cases include a combination of offline large language model processing versus online on the device closer to the edge real time analysis. So that’s where small language models can help. Roland or Daniel or Anthony, do you have any comments on the small language models? What are you guys seeing in this space?
Anthony Alford: Yes, exactly. Microsoft’s Phi or Phi, I think first we need to figure out which one that is, but definitely that’s been making headlines. The other thing, we have this on our agenda and Namee, you mentioned that they’re getting better. The question is how do we know how good they are? How good is good enough? There’s a lot of benchmarks. There’s things like MMLU, there’s HELM, there’s the Chatbot Arena, there’s lots of leader boards, there’s a lot of metrics. I don’t want to say people are gaming the metrics, but it’s like p-hacking, right? You publish a paper that says you’ve beat some other baseline on this metric, but that doesn’t always translate into say, business value. So I think that’s a problem that still is to be solved.
Namee Oberst: Yes, no, I fully agree. Anthony, your skepticism around the public..
Anthony Alford: I’m not skeptical.
Namee Oberst: No, I actually, I’m not crazy about them. So we’ve actually developed our own internal benchmarking tests that are asking some common sense business type questions and legal questions, just fact-based questions because our platform is really for the enterprise. So in an enterprise you really care less so about creativity in this instance, but just about how well are these models able to answer fact-based questions and basic logic, basic math, like yes or no questions. So we actually created our own benchmark testing and so the Phi-3 result is off of that because I’m skeptical of some of the published results because, I mean, have you actually looked through some of those questions like on HellaSwag or whatever? I can’t answer some of that. I am not an uneducated person. I don’t know what the right or wrong answer is sometimes either. So we decided to create our own testing and the Phi-3 results that we’ve been talking about are based on what we developed and I’m not sponsored by Microsoft. I wish they would, but I’m not.
Srini Penchikala: Definitely, I want to get into LLM evaluation shortly, but before we go there, any language model thoughts?
Roland Meertens: One thing which I think is cool about Phi is that they trained it using higher quality data and also by generating their own data. For example, for the coding, they asked it to write instructions for a student and then trained on that data. So I really like seeing that if you have higher quality data and you select the data you have better, you also get better models.
Anthony Alford: “Textbooks Are All You Need”, right? Was that the paper?
Roland Meertens: “Textbooks Are All You Need” is indeed name of the paper, but there’s multiple papers coming out also from people working at Hugging Face around “SantaCoder: don’t reach for the stars!”. There’s so much interest into what data do you want to feed into these models, which is still an underrepresented part of machine learning, I feel.
Srini Penchikala: Other than Phi, I guess that’s probably the right way to pronounce. I know Daniel, you mentioned TinyLlama. Do you have any comments on these tiny language models, small language models?
Daniel Dominguez: Yes. I think like Namee said, many of those language models running now on Hugging Face are also a lot of things to discover. Also, one thing that is interesting in Hugging Face as well is all this new poor GPU or rich GPU, I don’t know if you have seen the target that they’re doing on the leaderboard. That according to your machine you are like a rich GPU or poor GPU, but you’re able to run all these language models as well. And thanks for all the chips that are right now also in the industry, for example, those from NVIDIA that are able to run all these small language models on the chips that are also running on the cloud that are also able to run on the poor GPUs and systems that people have on their machines.
So those small language models are able to run on these thanks to all these GPUs from companies like NVIDIA. And I think in Hugging Face, when you see these simulations that you’re able to run all of these on your machines without the need of having a huge machine capacity. So that’s also something interesting and that’s something that you can run on small language models based on your arduino machine as well.
Srini Penchikala: Yes. Let’s get into, I know there’s a lot of other AI innovation happening, so quickly before we leave the language model discussion, I know you guys mentioned about the evaluation. Any thoughts on, other than the benchmarks, which can be take-it-with-a-grain-of-salt type of metrics, but what about real world best practices? Like you mentioned, Daniel, there are so many language models, so how can someone new to this space compare these LLMs and eliminate the ones that may not work for them and choose something that works for them? Right? So have you seen any industry practices or any standards in this space?
Mandy Gu: So I think Anthony mentioned something interesting, which is the business value and I think that’s something important we should think about for evaluation. I’m also quite skeptical of these general benchmarking tests, but I think what we should really do is we need to evaluate the LLMs, not just the foundational models, but the techniques and how we orchestrate the system at the task at hand. So if for instance, the problem I’m trying to solve is I’m trying to summarize a research paper where if I’m trying to distill the language, I should be evaluating the LLMs capabilities for this very specific task because going back to the free lunch theorem, there’s not going to be one set of models or techniques that’s going to be the best for every task. And through this experimentation process, it’ll give me more confidence to find the right set or the best set. And at the end of the day, how we quantify it better should be based on evaluating the task at hand and the end results, our success criteria that we want to see.
AI Agents [33:27]
Srini Penchikala: Yes, we can definitely add the links to these benchmarks and public leader boards in our transcript. So in the interest of time, let’s jump to the other topics. We have the next one, AI agents. I know there have been a lot of development in this area, AI powered coding assistants. Roland, what are you seeing in this? I know you spent some time with Copilot and other tools.
Roland Meertens: I mean last year you asked what do you think the trend is going to be next year? And I said AI agents and I don’t think I was completely right. So we see some things happening with agents. At some point OpenAI announced that they now have this GPT Store, so you can create your own agents. But to be honest, I’ve never heard of anyone telling me like, “Oh man, you should use this agent. It’s so good.” So in that sense, I think there’s not a lot of progress so far, but we see some things like for example, Devin, this AI software engineer where you have this agent which has a terminal, a code editor, a browser, and you can basically assign as a ticket and say, “Hey, try to solve this.” And it tries to do everything on its own. I think at the moment Devin had a success rate of maybe 20%, but that’s pretty okay for a free engineer, software engineer.
The other thing is that you’ve got some places like AgentGPT. I tried it out, I asked it to create an outline for the Trends in AI podcast and it was like, “Oh, we can talk about trends like CNNs and RNNs.” I don’t think those are the trends anymore, but it’s good that it’s excited about it. But yes, overall I think that there’s still massive potential for you want to do something, do it completely automatically instead of me trying to find out which email I should send using ChatGPT and then sending it and then the other person summarizing it and then writing a reply using ChatGPT, why not take that out and have the emails fly automatically?
Anthony Alford: My question is, what makes something an agent?
Roland Meertens: Yes, that’s a good question. So I think what I saw so far in terms of agents is something which can combine multiple tasks.
Anthony Alford: When I was in grad school, I was studying intelligent agents and essentially we talk about someone having agency. It’s essentially autonomy. So I think that’s probably the thing that the AI safety people are worried about is giving these things autonomy. And regardless of where you stand on AI doom, it’s a very valid point. Probably ChatGPT is not ready for autonomy.
Roland Meertens: It depends.
Anthony Alford: Yes, but very limited scope of autonomy.
Roland Meertens: It depends on what you want to do and where you are willing to give your autonomy away. I am not yet willing to put in autonomous Roland agent in my workspace. I think I wouldn’t come across very smart. It would be an improvement over my normal self, but I see that people are doing this for dating apps, for example, where they are automating that part. Apparently they’re willing to risk that.
Daniel Dominguez: As Roland said, they’re not yet on the big wave, but definitely there is something that is going to happen with them. For example, I saw recently also Meta and Zuckerberg said that the new Meta AI agents for small businesses, they’re going to be something that are going to help small business owners to automate a lot of things on their own spaces. Hugging Chat also has a lot of AI agents for daily workflows, for example, to do a lot of things. I know that also, for example, Slack now has a lot of AI agents to help summarize conversation or tasks or daily the workflows of whatever.
So I think AI agents on their daily workspace or whatever on small businesses are going to start seeing more naturally as we continue developing all of this landscape because it’s going to help a lot of the things that we have to do on a daily basis, and this is just going to start working more and more and the different companies are going to start offering the different agents on their own platforms. So for example, I know that Google, for example, going to start offering AI agents for as Roland says on their Gmail tasks or whatever. So that’s something that probably is going to start moving faster over the next year or so.
Roland Meertens: Yes, and especially with Langchain you can just say, “Oh, I’ve got these API functions you can call, I want this workflow. If you manage to reach this, then do this. If you don’t manage that, use this other API.” Just combining all the tools in the toolbox and do it automatically is insanely powerful.
Mandy Gu: I think that’s a great point, which is something we take for granted from agents is that they’re integrated in the places that we do work. So Roland, your example with Gmail having this assistant be embedded within Google workspaces so they could actually manage your emails as opposed to going to ChatGPT and asking, how do I augment this email? Or whatever it is that you want to do. From a behavioral perspective, this movement of information between platforms is just such a huge source of toil, and if we can reduce for our end users one less tab or one less place they have to go to do their work, from a behavior perspective, that’s going to be a huge lift. And ultimately what really drives the adoption of these agents.
Srini Penchikala: Mandy, it would be nice to actually for these agents to help us when to send an email and when not to send an email, make a phone call instead. So I mean, that could be even more productive, right?
Roland Meertens: I am wondering in terms of trends, I think last year was really the year where every company said, “We are now an AI company. We are going to have our own Chatbots.” And I don’t know, I’ve even seen some co-workers who said, “Oh, I’m trying to make this argument. I let ChatGPT generate something for me, which is three pages of argument. I think it looks pretty good.” And I don’t care about your argument anymore. I don’t want to chat with your Chatbot, I just want to see your website. So I also wonder what is going to settle at in the middle? Is every company, is every website going to be a Chatbot now or can you also just look up what the price of a book is instead of having to ask some agents to order it for you?
Srini Penchikala: We don’t want to over-agentize our applications, right?
Roland Meertens: Don’t over-agentize your life is a tip.
AI Safety and Security [40:14]
Srini Penchikala: Yes, let’s keep moving. Anthony, you mentioned about AI safety. So let’s get into the security. Namee and Mandy, you both are working on a lot of different real world projects. How do you see security versus innovation? How can we make these revolutionary technologies valuable, at the same time safe to use in terms of privacy and consumer data?
Mandy Gu: There’s definitely been a lot of second order effects in the security space from generative AI, like fourth party data sharing, data privacy concerns, like those are on the rise. A lot of the SaaS vendors that we work with that a lot of companies work with, they’ll have an AI integration, and they don’t always make it clear, but a lot of the times they’re actually sending your data to OpenAI. And depending on the sensitivity of your data, that’s something you want to avoid. So I think there’s two things to keep in mind here. One is we need to have a comprehensive lineage and mapping of where our data is going. And this is a lot harder with the rise of AI integration. So that’s something we definitely have to keep in mind. And then the second part is if we want our employees to have proper data privacy security practices, then we have to make the secure path the path of least resistance for them.
So going back to the example I shared earlier, if we added the super strict PII redaction system on top of all the conversations with OpenAI and other providers, then people are going to be discouraged and they’re going to just go to ChatGPT directly. But if we offer them alternatives and if we give them carrots to make this more accessible or to add other features that they need and we make the path of least resistance, then that’s how we get into our internal users and how we build up that culture of good data privacy practices.
Namee Oberst: Yes, Mandy, I think the workflow that you described actually underscores What I like to emphasize when we’re talking about data safety and security, the way that you design the generative AI workflow in your enterprise actually has such an impact on the safety and security of all your sensitive data. So if you take into considerations like Mandy did, when will PII come into effect? Do we have vendors, for instance, who might inadvertently send out our sensitive data to a provider that I don’t feel comfortable with, like OpenAI, just as an example? You need to look at that. You need to look at data lineage. You need to make sure that your workflow also has auditability in place so that you can trace back all the interactions that took place between all the inferences. And how AI explainability comes into play. Are there attack surfaces potentially in the workflow that I’ve designed? What about prompt injection?
By the way, fun fact, small language models are less prone to prompt injection because they’re so used to just taking such small tasks that they can almost generalize enough to be prone to that, but just worrying about prompt injection, rat poisoning, things like that. So I think there are a lot of considerations that an enterprise needs to take into account when they deploy AI, but I think Mandy, a lot of the points that you brought out are spot on.
Mandy Gu: I like what you mentioned about the attack surfaces, because that’s something that can quickly get out of control. And one analogy I’ve heard about generative AI and the AI integrations, it’s like this cable versus streaming methodology because so many different companies are coming up with their own AI integrations to buy them all is paying for Netflix, Hulu and all of these streaming services at once. Not only is it not economical, but it really increases the attack surfaces as well. And I think this is something we need to build into our build versus buy philosophy and be really cognizant and deliberate about what we pay for and where we send our data to.
One trend that we have noticed is that the general awareness of these issues are getting better. I think the vendors, the SaaS providers, they are responding to these concerns and I’ve seen more and more offerings of, “Hey, maybe we can host this as a part of your VPC. If you’re on AWS or if you’re on GCP, I’ll run Gemini for you. So this data still stays within your cloud tenants.” I think that’s one positive trend that I am seeing when it comes to security awareness in this space.
Namee Oberst: Absolutely.
LangOps or LLMOps [44:27]
Srini Penchikala: Along with security, the other important aspect is how do we manage these LLMs and AI technologies in production? So quickly, can we talk about LangOps or LLMOps? There are a few different terms for this. Maybe Mandy, you can lead us off on this. How do you see the production support of LLMs going on and what are some lessons learned there?
Mandy Gu: Yes, absolutely. So the way, at WealthSimple, that we divide our LLM efforts, we have three very distinct streams. So the first is boosting employee productivity. The second is optimizing operations for our clients. And then the third is this foundational LLMOps where we like to call it LLM platform work, which enables the two efforts. We’ve had a lot of lessons learned and what has worked for us has been our enablement philosophy. We’ve really centered this around security, accessibility and optionality. And at the end of the day, we just really want to provide optionality so everyone can choose the best techniques, foundational models for the tasks at hand. And this has really helped prevent one of the common problems we see in this space where people use LLMs as a hammer looking for nails. But by providing these reusable platform components, the organic extensions and adoptions of Gener AI has been a lot more prevalent.
This was a lesson we learned over time. So for example, when we first started our LLM journey, we built this LLM gateway with an audit trail with a PII redaction system for people to just safely converse with OpenAI and other providers. We got feedback that the PII redaction restricted a lot of real-world use cases. So then we started enabling self-hosted models where we can easily add an open source model, we fine tune, we can add it to our platform, make it available for inferencing for both our systems and for our end users through the LLM gateway. And then from there we looked at building retrieval as a reusable API, building up the scaffolding and accessibility around our vector database. And then slowly as we started platformatizing more and more of these components, our end users who are like the scientists, the developers, various folks within the business, they started playing around with it and identifying like, “Hey, here’s a workflow that would actually really benefit from LLMs.” And then this is when we step in and help them productionize that and deploy it and deploy the products at scale.
AI Predictions [46:49]
Srini Penchikala: Thanks, Mandy. Let’s wrap up this discussion. A lot of great discussion. I know we can talk about all of these topics for a long time and hopefully we can have some follow up, one-on-one podcast discussions on these. So before we wrap up, I want to ask one question to each one of you. What is your one prediction in AI space that may happen in the next 12 months? So when we come back to discussion next year, what can we talk about in terms of predictions? Mandy, if you want to go first.
Mandy Gu: I think a lot of the hype around LLMs is going to sober up, so to speak. I think we’ve seen just this rapid explosion in growth over the past year and a half, and for a lot of companies and industries, LLMs are still a bet, a bet that they’re willing to continuously finance. But I think that will change over the next coming 12 months where we start building more realistic expectations for this technology and also how much we’re willing to explore before we expect a tangible result. So I’m expecting this to be less of a hype 12 months from now, and also for the companies that still uses technology to have tangible ways where it’s integrated with their workflows or within their products.
Srini Penchikala: Daniel, how about you?
Daniel Dominguez: I think with all the data that is being generated with artificial intelligence, there will be some kind of integration with, for example, blockchain. I have seen that, for example, a lot of projects in blockchain includes the data integration with artificial intelligence. So probably blockchain and artificial intelligence are still on the early days, but definitely something will be integrated between artificial intelligence and blockchain. Mainly on data, mainly on the space integration meaning in databases or something like that. So that’s something that probably we’re still on the early days, but for me, artificial intelligence and blockchain, that still going to be a huge migration.
Srini Penchikala: What about you Roland?
Roland Meertens: I’m still hoping for more robotics, but nowadays, we are calling it embodied AI. That’s the name change, which started somewhere in the last year. I don’t know exactly when, but if you take the agents, right, they can perform the computer tasks for you. But if you can put that into a robot and say, “Get me this thing, pick that thing up for me,” just general behavior, embodied AI is the next big thing, I think. That’s what I’m hoping for.
Srini Penchikala: So those robots will be your paid programmer, right?
Roland Meertens: Well, no. So there will be the agents who will be your pair programmer, but the robots will help you in your life. The other thing which I’m really wondering is now companies have all this data. So are companies going to fine tune their own models with their data and sell these models? Or is everybody going to stay on the RAG train? Imagine that you’re, I don’t know, like a gardener and you have years worth of taking photos of gardens and then writing advice on how to improve your garden. There must be so many tiny companies which have this data, how are they going to extract value out of it? So I’m super excited to see what smaller companies can do with their data and how they are going to create their own agents or their own Chatbots or their own automations for using AI.
Srini Penchikala: Anthony, how about you?
Anthony Alford: AI winter. Well, so Mandy already said it right? She said, “Maybe we’ll see the hype taper off,” which I can say that’s the mild form of AI winter, the strong form of AI winter, maybe you saw this headline, I think it was a paper in nature that says, “If you train generative AI on content generated by generative AI, it gets worse.” And I think people are already starting to wonder is the internet being polluted with generated content? So we shall see. I hope I’m wrong. This is one where I hope I’m wrong, so I’ll be glad to take the L on that one.
Srini Penchikala: No, it is very possible, right? And how about you Namee? What do you see as a prediction in the next 12 months?
Namee Oberst: So I foresee a little bit of what Anthony and Mandy described, but actually then moving on very, very quickly to the much more valuable, realistic and tangible use cases, probably involving more automated workflows and the agent work processes and then moving into more edge devices like laptops and even phones. So that’s what I’m foreseeing. So we shall see. It’ll be interesting.
Srini Penchikala: Yes, it’ll be interesting. Yes, that’s what I’m seeing as well. So it’ll be more unified, end-to-end, holistic, AI-powered solutions with these small language models, RAG, the AI-powered hardware. So I think a lot of good things are happening. I think hopefully, Anthony, the AI winter won’t last for too long. That’s the podcast for today. Anybody have any concluding remarks?
Namee Oberst: It was so fun to be on this podcast. Thank you so much for having me. I really enjoyed the experience here.
Anthony Alford: Ditto. Loved it.
Mandy Gu: Yes.
Roland Meertens: I especially like seeing our podcast over the years. If you go back to, I think we started this in 2021, maybe. It’s always fun to see how our predictions change over the years and how our topics change over the years.
Srini Penchikala: I want to thank you all the panelists for joining, participating in this discussion for 2024 AI and ML Trends Report and what to look forward to in this space for the remainder of this year and next year. To our audience, we hope you all enjoyed this podcast. Hope this discussion has offered a good roundup update on the emerging trends and technologies in the AI and ML space. Please visit the infoq.com website and download the trends report with an updated version of the adoption graph that will be available along with this podcast recording that will show what trends and technologies and topics are becoming more mature in terms of adoption and what are still in the emerging phase.
I hope you join us again soon for another episode of the InfoQ Podcast. Check out the previous podcast on various topics of interest like architecture and design, cloud, DevOps, and of course, AI, ML and Data Engineering topics in the podcast section of infoq.com website. Thank you everyone, and have a great one. Until next time.
Mentioned
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Presentation: Building Organizational Resilience Through Documentation and InnerSource Practices
MMS • David Grizzanti

Transcript
Grizzanti: My name is Dave Grizzanti. I’m going to talk a little bit about documentation and InnerSource. Before I do a more formal intro, just to show a quick example of some of the things I think we deal with very often. Let’s say you started at a new company, and you’re looking to get support for a shared infrastructure platform. John here goes to a Slack channel that he thinks is the right place to ask for help. He says, I’m new to the company, and I’m looking to set up a new app on our shared infra.
I ran over to the docs, but I didn’t find the answer to my question, is this the right place to ask? Another helpful engineer on the support team says, John, yes, this is the right place to ask. What do you need help with? John says he’s looking to set up a custom DNS record for an app he’s launching on the platform. The other engineer says, sure, let me dig a few examples for you. This is a common use case I see a lot. Why this isn’t documented, could be lots of reasons.
Let’s say John is on the team or at the company for a little bit longer, and he wants to ask his team for the app that we have running in production. I’m trying to understand how traffic is routed from the internet through our network to the app. Do we have any diagrams that show that so I can take a look? An engineer on his team says, “I’m not sure we have an exact diagram that shows that, but I drew something for the CTO a few years ago for a presentation. Let me see if I can find those diagrams.” How many of you face similar situations to this or have said these things?
That example about the diagram, I think I’ve said that about three times in the past, maybe not for the CTO. I think these examples are really common in our industry. I see them all the time. I think they show a little bit of a crack in the way that we deal with information sharing and support. A lot of times we handle this with more formal processes, like file a Jira ticket to get support, somebody will take a look at it. That’s not a great way of doing it either. No one wants to file a Jira ticket. I certainly don’t want to do that. Also, I think it discourages people from asking for help, just because there’s too much process in the way.
I’m a Principal Engineer at The New York Times. I focus on developer productivity and platform engineering at the Times. I think a lot about these use cases where people are asking for help for the platforms we’re building, and how to get them to move faster, build more paved paths to let them get to what they want to do, which is build products. Today we’re really talking about building organizational resilience. I’ll weave in some of those ideas as I go through this. Really, I want to talk about how some of these documentation examples and open source concepts can help build resilience for organizations.
Information Availability
I think a lot about developer productivity, like I mentioned, and how to engage with engineers to make their lives easier. Part of this process is making documentation easier to find and understand. I think we just have a sea of information now. We’re overwhelmed with documentation that exists that’s either out of date, or has correct information but not exactly what people are looking for. It’s often easier for somebody to ask just for help on Slack like I showed, or whatever communication tool you might be using, than reading through pages of documentation and trying to find the answer themselves, or piece together a solution from a bunch of different places.
The issue with the Slack approach, I think, is that we often answer the questions but we don’t go back and make that content available for others. It repeats that process over again, like we answer the question, but we don’t take what we answered and make it available for other people. This doesn’t just stop at documentation. It extends to diagrams, like in that example I mentioned, architecture decisions and why systems work the way that they do.
You can also argue that this happens with software too. Large companies have lots of duplicative software across teams that maybe do the same thing. Teams often maybe write something that already exists, because they don’t know that those things exist in the other companies or they’re available for sharing. To sum that all up, I think my thesis is information either isn’t available or discoverable. I’m going to talk a little bit about how maybe we can solve that.
Effects on Organizational Resilience
I want to talk about some of the effects of this bad documentation or information unavailability and the effects on organizational resilience. The first thing is turnover, so folks leaving the company. This is a big one I’ve seen cause harm to teams and disrupt continuity, where a single person or even two people might know how a system works. When they’re gone, or they’re on vacation, somebody asking me for help like that on Slack means that somebody can’t get an answer. This might mean that you can’t move as fast as you want, or you can’t get the help you want until a new person comes up to speed or a new person is hired. The next is onboarding challenges.
I know for myself, because I started at the Times about a year ago, one of the tasks I was given was, can you go through our documentation, try to do this and tell us what’s wrong. Which is interesting, if you like fixing documentation stuff, but some new folks might get frustrated that now they can’t onboard very quickly because they’re in charge of finding the holes in the documentation. You’re putting this burden on them to improve. Either way, it’s not a great experience. Either people can’t get up to speed quickly, or they’re frustrated by the lack of documents.
The next thing is reorgs. For any folks who’ve worked at large companies, this is pretty common. People get moved around. Teams get moved around. Most of the time, what happens is the systems that they supported previously, gets carried around with them. They have this baggage of support, even though they’re on a new team and supposed to be building something new.
Either because they didn’t have the time to document or draw the right things, or they just didn’t have the right practices in place. Then the next thing is outages. In the middle of the night, if you have to call somebody and wake them up to find out how a system works, or you can’t find the right dashboard, or find the right documents, or something like you’re on vacation again, now your outage is going to last longer.
How Can We Improve?
What are some ways that we can improve this? The first thing I want to talk about is documentation. How to create an environment where good documentation practices are encouraged. Ways of making your documentation more discoverable, and teaching people how to approach documentation and maybe how to write technically, in a positive way.
Then the second thing is this concept of InnerSource. This is the idea of doing open source internally. How to create projects that are sustainable, internally. Get more contributors across the company, instead of your main team. Spend less time building the same things, and make happy customers and build trust among engineers.
Documentation
Let’s talk about documentation first. What makes documentation good? By itself, documentation doesn’t necessarily solve a problem. A couple key things, I think, is that it needs to be useful. It needs to be relevant, correct, and up to date, and discoverable. Documentation is not just words. It could be diagrams. It could be information in READMEs. Or it could just be code comments. I think we’ve rode the wave of whether or not code comments are good or bad, or you should write code that’s self-documenting. People don’t need code comments.
Oftentimes, people will write very complex things in software, and they don’t necessarily know where to put the information about it. I think code comments have their own value in this documentation story. Bad documentation often causes more problems than it solves. If you have really long verbose documentation that doesn’t really answer a question, somebody spent all this time writing this, curating it, and if no one’s using it or reading it, is that really any more valuable than not having anything?
The Challenges to Making Good Documentation
Let’s talk about some of the challenges to making “good documentation.” What I found, I think, is that people often want curated and custom answers to questions, going back to that Slack answer I saw before. Either they can’t find the information in docs or they don’t want to read, so they come to ask you a question. This is maybe like a slightly contrived example. I wanted to promote The New York Times cooking app while I could.
Let’s say you were on the Times cooking app and you wanted to make a recipe, and you’re like, “Ok, I’m going to be adventurous. I’ve never made bulgogi before. Let me make this.” I’m looking at the list of ingredients, and I say, I don’t know what gochujang is, I can look this up. I don’t know if anybody’s ever used the cooking app, but reading the notes is a very fun rabbit hole to go down because people ask the strangest questions and also suggest the strangest substitutions. One of the comments I actually saw on here was, what is gochujang? Very fair question. To me, I was like, why would this person ask it in the notes? Why would you not just Google it? I find that people often, they want an expert answer.
Maybe the cooking community has a better interpretation about what this is than Google does. Maybe they don’t trust Google. To me, it hits on like this idea of people wanting someone to give them a specific answer to their question. They don’t necessarily want to look it up or trust somebody else. If you haven’t looked at the notes, or looked at this Instagram account for The New York Times cooking notes, I highly encourage to go take a look.
Another thing is, communication face-to-face, over writing or reading. I’ve been remote. It’s different than in the office. I find people often will DM me and ask me for help with something like, can we jump on a quick call, and let’s talk this over? Maybe that’s ok in the beginning, as long as something comes out of it.
When you’re talking over a problem or situation that’s like in a support nature, and you come up with a solution, that’s not written down anywhere, it’s not even on Slack. That cycle of not producing anything of value afterwards continues. There’s a place for helping people in a one-on-one or talking through a problem. I think oftentimes, if nothing’s produced out of it, or this is your cycle of always answering questions that way, that can become a problem.
The next thing is, writing well takes time and focus. I’m not sure how much this resonates with people. This is what my schedule looks like very often. I don’t know how anybody finds time to focus if your schedule looks like this, especially with the chaotic nature of the meeting blocks. If you ask, I find often that when I see somebody answer a question on Slack, or help someone, I say, can you take that information and go put it up somewhere. Synthesize what they asked, and your response, and put it up on our docs.
Most of the time, they don’t do it, or they do something and the result is not super helpful. Often, it’s because I think, again, we’re just too busy to find blocks of time where you can focus a lot. This may not be the case for all engineers. I think I found that in a remote culture, a lot of times, a lot of these blocks are dedicated one-on-ones that people have with people, or just meetings that are recurring, to check in on status. Everybody needs these meetings to feel like they’re connecting with their team, and it doesn’t necessarily help with the focus time.
Solutions to Documentation Challenges
A few solutions. We really need to get better at communicating asynchronously. I think the idea of communicating more but less frequently, is something that I’ve been trying to do more of. Meaning, put out more information, but don’t feel like you need to talk with somebody every day. I came across this quote in this law the other day that I thought was interesting, which is the idea is if you can write down the problem clearly, then your issue is half solved. It’s referred to as Kidlin’s Law.
The idea is like writing down a problem, getting it out of your head helps clarify and work through your thoughts. To me, it’s like rubberducking in programming. Like, if you jump to your first thought, or thinking about something on the surface, and throw on an idea, oftentimes, it’ll die on the vine. I’ve seen this happen with important conversations I’ve had with colleagues recently, where we want to make some big technical decision and they haven’t really fully formed their thoughts around how they want to solve it. They will propose it in a meeting.
Like, I want to use Helm charts for Kubernetes versus some other tool, which is very controversial, but they haven’t really figured out why they wanted to use it. They may have just read a blog post about using this to solve some problem. The mass or the group will throw a bunch of negative opinions at them. Then they feel discouraged and back away from it.
Where I’ve been trying to encourage people to say, ok, take a day or two days. Write down what you think the problem space is, what your solution to that is, and then share that out with people. Let them comment asynchronously, let them take time to digest it, and then we’ll go over it with everyone. Taking the time to think through and write down your problems before you introduce them to people.
The next thing is, teach and encourage a culture of writing. This is something that I started doing in my last role, which is this idea of, people have different writing styles, all that doesn’t necessarily lend itself well to technical writing. Google has these technical writing courses, that they teach technical writing, and some of it is grammar. Some of it is just how to write in a way that’s verbose enough, but clear when you need a particular technical point.
Like, don’t write in passive voice, write in active voice. They run one or two classes that you can join. They also give you the materials if you’d like to run them internally. I joined one of them maybe two years ago, and there was like 60 people on the class, so it wasn’t all that productive with that many people. We took the information and ran a few sessions internally, which were successful. I wasn’t there long enough to continue doing that. It’s something that I’ve thought about bringing it back to the Times.
The next is, make it discoverable. I had this at a job, 15 years ago. It’s a Google Search Appliance. It’s something that you could buy from Google and stick in your data center. It would essentially make a Google search engine of all your documentation internally. Unfortunately, they killed the product at some point. I think that this issue of searchability of information in companies is a huge issue. I’ve never seen a great solution for it.
A few things that I’ve seen recently, and some things that we’re doing at the Times now, that are some alternatives, that other people are familiar with these tools. I’ll go through them and talk about pros and cons. Backstage is an open source developer portal that was originally written by Spotify. It’s now a CNCF project. They have this concept of TechDocs.
You can bundle all your MkDoc sites into Backstage and then search them within the Backstage portal. If you happen to have a bunch of MkDoc sites that are all spread across your company, you can put them into Backstage and make all the docs searchable. That works well for MkDocs, maybe not so well for other things. At least technical documentation is all searchable in one spot.
Google Cloud Search is actually really valuable if you’re using a Google suite of tools. That’s what I use most often now. They even have a plugin thing that you can integrate, I think with MkDocs to make some of the MkDoc sites searchable as well. Hermes is a project by HashiCorp that gives you a nice interface over the top of Google Docs, that also makes them more searchable, which is nice.
GitHub code search has gotten a lot better, if you’re storing all your documentation in READMEs. Then something I’ve looked up and not used a ton is Elastic Workplace Search. I think this is a pay feature. If you’re an Elastic user, you can plug in all these external sources, and then make it searchable, and Elasticsearch will index it for you. A couple of things to solve this searchability problem. What I’ve seen at most companies is they’re all using slightly different flavors of all of Google Docs, Markdown, things in GitHub, so it’s not perfect. If you can focus on one documentation type, it can be really valuable.
The next is, create the right incentives. This is something my boss said to me the other day when I was complaining about trying to get folks to write stuff down, is that we don’t often have the good incentive structure to write documentation or to write stuff down. The incentive is to push out code or help users. If you help them get something done, or ship a product, like that’s the success story. Not, I’ll go back so the next time somebody doesn’t need to ask the question.
I think we need to reward people for working on this stuff, just like working on coder solutions. Smruti mentioned in her talk on platform engineering about this book, by Kathy Sierra called “Badass.” The quote from her talk, and from the book is about making better photographers not a better camera. That idea really stuck with me because we oftentimes think about making our platforms better or good enough so people don’t have to ask questions. It should be really easy to use they don’t have to ask questions. I think we’re building such complex things that that’s not often the easiest path. I think our goal should be to give users as much information as knowledge to make them power users of the platforms. Making information digestible and curated in a way that helps them learn.
The next is, understand and learn how folks like to work. I think getting to know each other really at a personal level helps. There’s lots of different ways to do that. Especially in a remote culture, it’s challenging. I think you need to be intentional about building connections and trust with remote people. Oftentimes, we ask people to do things like, why didn’t you just write this down? Or why didn’t you do that? Some folks may feel intimidated about writing large documents.
They need more focus time. I just think understanding that relationship between people and between your coworkers is important. I think practicing empathy in that space is especially important. One of the things my manager did at a previous employer, was we did this team norms and stories, where we got all in the conference room for a few hours, and people went through what’s your best and worst day, not personally, but at work.
Someone said my perfect day is, “I go into Jira, and there’s a ticket I can pick up, and it has all the tasks I need to do. I can pick it up and work on it, and then I can move it to done.” I don’t want to think about all the complexities of like, what I need to do, I just want to be given the list and I want to work on it.
Someone else may be like, “I want more ambiguous requirements. I’d like to like design this myself, and then work on it.” I think until you get that information out of people, it’s hard to assume how you should approach things with people. As a manager, you might be getting frustrated like, why isn’t this engineer working on what I asked them to do? Maybe the way that they like to work is not something that you understand. I think being open and honest, and just discussing how people like to work is important to having a successful and productive team.
Then give the time and space for creating. Maybe you have dedicated time for reading and review, dedicated focus slots for writing, and writing meetings. That sounds counterintuitive. A few times we’ve done this like, let’s just schedule a block of time to block it out. We’ll put our cameras off and turn our mics off, and we’ll just sit there and read this document and then comment on it. I’ve done that a lot recently for proposals that we’ve been writing for standards at the Times, where we have a scheduled block of time, and we’ll review some of the documents that have been written, to take back comments. Being online, being on the meeting allows us to just go off mute quickly and ask a question if we need to, otherwise, we’re not talking back and forth.
Lastly, let’s talk about just agreeing on approach, to writing and formulating some of these documents. Don’t worry too much at first about formal patterns and diagramming tools. I think people sometimes get hung up on like, what’s the right format. You spend two days searching on Google for the perfect template, or whatever you’re going to use.
Reminds me of the story somebody talked about, where they spent three weeks finding the perfect computer to work on and the perfect editor to use. You can spend too much time overthinking what’s the right thing. Don’t worry too much about formality, just clear and simple documents and design should be your goal. If you do want to decide on a style or a format, RFCs and ADRs are a good format to choose. They have structure to them. Most of the time you can find a lot of information online about companies that follow these approaches.
If you struggle for where to start, and you want something to use, these are a good basis. This is an example of an ADR template that a colleague of mine at the Times, Indu, proposed for her team to start using. It’s not super complicated, just a question to decide on, what’s the context, what’s the recommended decision, supporting arguments, those sorts of things? Just gives you a place to start and a place to write down your thoughts, so you’re not just staring at a blank Google Doc and being like, how do I ever write down this long document? Especially if you’ve never done one before.
Some basic steps. Get together with your team, brainstorm and approach. Maybe do some whiteboarding. Write up the document, whatever format you choose. Consider tradeoffs. Then, circulate to engineers. I think one of the also common things I see is that people are afraid to share the document before it’s perfect. I think circulating it, and getting feedback early and often is important. If you find yourself wanting some more formal approach to this, I’ve seen a mix of these things work.
At the Times, we have this thing called the Architecture Review Board. That’s not like an ivory tower architects’ person, it’s a rotating mix of engineers throughout the company, that changes every year. Whenever an RFC or an ADR is written, teams will send them to this review board, and they’ll give feedback as a more slice of engineers across the company. It’s not a mandate.
You don’t have to go to them before you launch something. It’s more of a nice to spread the information around with everybody to get some feedback before a decision is made. Sometimes they can catch things that you wouldn’t normally see, or you might get feedback from another part of the company that you may not know anything about. Especially in the platform space that I’m coming from, it’s valuable in case you’re not really paying attention to something that might affect them.
InnerSource
Let’s wrap up on documentation and talk about InnerSource, which is the second topic, which focuses more on software sharing, and a bit on documentation within the scope of these projects. What is InnerSource? InnerSource is internal open source. It’s the use of open source best practices and the establishment of an open source culture within your organization. You can still develop proprietary software, but you’re opening up work between developers and teams internally.
I think the key idea with InnerSource is it can help break down silos, and accelerate innovation with a transparent culture, like open source. Saying, just do open source in your company, is not necessarily easy or quick. It’s definitely a journey. You need to transform to a more internal sharing economy, respecting corporate culture and values, and internal organizational constraints.
The idea is to drive towards openness and transparency across teams. I think an easy one is, use a single version control system, and everyone should have read to all repositories, which I think is a common practice in some orgs. I’ve seen that in previous companies that’s not always true. There shouldn’t be a reason why you’re hiding code from internal engineers. Make sure everybody at least has read.
Benefits of InnerSource
A couple areas, I think, where InnerSource can help. If you manage to get this up and running, you can definitely develop software faster by having more folks helping you, even if it’s just one person from an outside team, who has ideas on a shared library or shared tooling. Improving documentation. The onboarding example I mentioned a while ago, if you don’t have a lot of new engineers starting out on your team, if you have new people coming in often that want to contribute or want to help, they’re constantly looking at your documentation, looking at your contributor guide, they can help improve docs for themselves, and also for the wider company.
Reuse code across teams. Maybe you have people rewriting the same tools across the company that do the same things, especially in large organizations, so build a common set of shared libraries that multiple people can contribute to. This also builds trusts and improves collaboration: engineers knowing each other across teams, helping each other, those sorts of things. I’ve seen the develop software faster and the reusing be really useful with maybe internal APIs or internal platforms with supporting tools.
We had a pretty successful DNS tool at my last company, where we had lots of people from outside the team build libraries, and also like Terraform modules, those sorts of things, that weren’t developed by the core team, they were developed by developers that were using the APIs. It was an example of developing software faster and helping this trust among engineers.
How Does InnerSource Improve Resilience?
How does this help with resilience? I think from an employee turnover perspective, you don’t only have one person that understands how the software works, or even one team, because you have people from across the company contributing to it. Maybe they can help take over. They can move teams, if you have staffing issues.
Helps with onboarding time, because of the documentation that I mentioned earlier. Also, with more people contributing, there’s just more activities, so I think new people coming on can get started quicker. Then the same thing with reorgs. If you have teams moving, if software is getting handed off to different teams or moved around, the more people that understand how things work and are contributing, the quicker you can get started.
InnerSource Commons – Patterns
InnerSource Commons was founded in 2015, and is a nonprofit. It’s the world’s largest community of InnerSource practitioners. They’re dedicated to championing this idea of InnerSource and building a community around it. I’ve been working with them over the last few years, and contributing to this thing they call patterns. I want to go over a couple patterns that I think are valuable and can give you an idea into how to get started with maybe promoting InnerSource inside your company.
This is a mind map tree of all the patterns that they support and a couple categories that they fit into, so begin, adopt, grow, and scale. The idea is that you can start at begin, and travel down depending on where you are in this journey. I’ll talk about a few of them across the four categories. Let’s say you want to get started, but applying open source practices doesn’t work in your company when maybe some folks are lacking an open source background.
The pattern that they have for that is called documenting guiding principles. The idea with documenting guiding principles is it provides clarity on purpose and principles to users. Why does the organization want to adopt InnerSource? Which InnerSource principles will help address these challenges?
The next one is, new contributors have a hard time figuring out who maintains the project, what to work on, or how to contribute. The pattern there is standard based documentation. This is the idea, which you’ve probably seen a lot in open source projects. It addresses the need for clear documentation, so maybe a README, contributing guide.
In the open source world, that also includes things like licenses, which may be applicable internally for you as well. It enables a more self-service process for new contributors. They’re not pinging you on Slack and asking you, “I want to fix this bug, is this the right way to go about building the application?” I’ve seen this example, actually fairly recently. We’ve collected a couple people across our platform engineering org to help work on a few things, and it took them two to three weeks to add a feature that was very basic, because they didn’t know how to test what they were working on.
Not just unit tests, but test it as the integration point across systems. I met with them. We worked through it. We improved some of the documentation. Then they opened the PR and the team that wrote the app changed the way something worked, so now all their tests weren’t working anymore. I didn’t know that either. I had to go back and ask them. They didn’t update the documentation. I think just being in this habit of maintaining your contributing guide, even if you’re the only team working on it. If someone else wants to contribute, or another team member in a sister or a brother team wants to contribute, it’s valuable to keep this stuff up to date.
Next is, teams may hesitate to adopt a project, if they’re unsure of its maturity. I think this is a pretty standard thing in the open source world where if you go look at a popular open source project, most of the time they have release notes, they have an available binary that you can download, or brew install, or whatever. I think internally, we don’t often publish standard artifacts. This pattern is a standard release process, which is publishing release notes and usable artifacts.
These practices show dedication to the project. It demonstrates commitment to sustainable software, and increases confidence when you’re publishing a quality product. For internal maybe like CLIs or binaries, oftentimes, if the team uses them, they’ll just build it themselves locally and have it on their machine. They don’t make it available for other people to install easily, or like publish the release on their internal GitHub. I think if you want other people to be able to use it easily, you need to make it available and also show them that you push out releases every month and are publishing release notes, so they know what to expect.
The next is, thank outside contributors for their time and effort. This is, praise participants. I’m not sure how common this is in open source. I feel like I’ve had mixed reactions to this for people. The idea is that, it feels good for people to be recognized, even if it’s something silly. Sending somebody a thank you note, sending them stickers if it’s an open source project.
I think increased recognition is an avenue to influence and growth. I think if you thank people, they’ll be more likely to contribute a second time. They’ll feel good about making something better, versus their contribution just being ignored. I think everybody likes swag. It’s a valuable thing to give away. Having projects internally in your company, think about branding them. This is something I’ve been trying to bring to the company I’m at now where we had a project that had a name, and we were having an onsite at the company where we were going to be talking about the project.
I said, we really should print stickers and give them out when people come to the talk. They’re like, we don’t have a logo. I was like, let’s just make up something on Photoshop, and then print it out and send it to them. We did that. Then people took the stickers and put them on their water bottles, and the name becomes more synonymous with the project, because people have this little token.
Next thing is, potential contributors cannot easily discover projects that interest them. This is the idea of having an InnerSource portal. This could be like a website you build yourself. It could be tags you use on GitHub. It’s just this idea that you want to make the projects discoverable in some central place. Backstage has a plugin called bazaar that is an attempt to make this InnerSource portal idea.
You can list all the projects in maybe your GitHub repository that meet some qualifications for InnerSource, whether they’re ones that you’re trying to promote, or that have a good contributor guide or whatever. Some curated list, that you’re telling people, so they’re not just trying to figure it out themselves by wandering around GitHub.
Create participatory systems throughout your software lifecycle. This goes back to that RFC idea I mentioned before, but cross-team decisions through RFCs is important. Again, don’t focus too much on the format. Publishing these kinds of standardized format documents out in the open through that Architecture Review Board, or just through some engineering email list allows for discussions early on in the design process, and increases the chances to build solutions with a high degree of commitment from all parties. People see that you’re going to build this new tool or make changes to the platform. It’s not a surprise to them when it happens, because this document’s been circulated more widely.
Key Themes
Some key themes that I mentioned here is, documentation needs to be accurate and discoverable. Find what styles and formats work for you through trial and error. Don’t assume that if somebody else is doing one thing it’s going to work for you. Make the time and tools available to contribute successfully. The incentives I mentioned before, just giving people the time to focus and write tough stuff down.
Build a culture of InnerSource for key projects and platforms, and follow some of the prescribed patterns that I mentioned. The community is always looking for new patterns, and also new companies to sign on to patterns they have. It’s important for them to see examples in the wild of these patterns in practice.
Takeaways
Discover how your team likes to work. That idea of sharing and going through what people’s ideals day is, I think is a good way to understand what people want out of their work environment. Make dedicated time and space for reading and writing. Investigate the patterns I mentioned.
Questions and Answers
Participant 1: On the topic of InnerSource, it strikes me that monorepos get at some of the same sorts of things. Can you talk about how monorepos and InnerSource might or might not be able to do that?
Grizzanti: The Times has a few monorepos. The news app I think is a monorepo. I think it does help with some of the information fracturing across repos. Like all the code is in one spot, you might only have one README, one place to put a Dockerfile or a Makefile to do builds. I don’t think InnerSource has a pattern on monorepos.
That’s actually an interesting thing to chat with them about. I do think it has pros and cons. I’ve seen some of their build pipelines are a little gnarly, because they’re trying to like, if you check something into this directory, how does that affect the build pipeline? I think from centralizing all the information in one spot, that can definitely be helpful.
Participant 2: Can you go through maybe a few more practical ways to get time and space made to be able to do much more, for instance, communications?
Grizzanti: I think there’s two aspects there. From a personal perspective, you can block off your calendar. Whether or not that works super well for everyone in every organization is organizational dependent. I think also, you need to think about like, when do you work well on those sites of things? Being introspective about like, am I better in the morning, am I better at night? Where would I prefer to focus time, and advocating for that.
Some organizations, we toy with this idea of having a focus day where there’s no meetings. It was on Fridays, which I think is probably the worst day to do it. Because I feel like at the end of the week, people were like, I don’t want to spend all day working on documentation on a Friday. That may not be successful. Maybe you just want to wrap up your week and get a bunch of other stuff done. For me, the best time to do it is in the morning. Luckily, even though The New York Times is based in New York, I work with mostly West Coast people, so I don’t have any meetings until like 12:00 or 1:00.
Most of the time in the morning, that works really well for me. That doesn’t work well for everyone, though. I think there’s a balance of like doing the blocked calendar thing, and also figuring out what times work for you and advocating with management. We can’t just expect people to be able to spend all this time reading huge documents that we’re putting out, commenting on them and writing their own if we’re in meetings all the time. I know we’ve been talking a lot about making more space for that, trying to cancel more meetings, doing stuff more asynchronously.
I really like Cal Newport’s book, “Deep Work.” Also, there’s another one called, The Death of Email. He talks all about how tools like Slack, and just the constant connectedness is ruining our ability to focus. He goes into a bunch of styles for folks to do more focus work, and figuring out what works for you. Like investing time and money into something may help you focus because you’re being more intentional about it.
He tells a story in the book where somebody was trying to write a book and he never had any time, so he bought a flight from New York to Japan, and then got off the plane and then flew back. All he did on the plane was write. It was really useful for him because he couldn’t do anything else. He spent all this time and money doing it, so he felt the need to focus. Obviously, that’s a little impractical for most people. Maybe you need a different place to go to write instead of just being at your desk. Toy with those ideas and figure out what works for you.
Participant 3: In my organization, [inaudible 00:43:19] we have many country sections, many viewpoints to diagrams, many [inaudible 00:43:29] spread across many different systems. I was wondering if you have any tips or suggestions for how to organize that, and encourage other people to keep them organized?
Grizzanti: I think we have similar problems. I think the diagramming for us is a bigger problem, because everyone uses a slightly different format, it’s at a slightly different level or scale. This doesn’t help with discoverability, but I’ve recently been trying to encourage people to use the C4 diagramming style. It’s like, this idea that whenever you’re drawing something, there’s four levels.
The example he uses is Google Maps, you’re looking at it from the continent view, or you’re looking at it from the country view, to the state view, to a specific road. At least that gives people a common like, these are the levels I should aim for to keep the formats common. I don’t think there’s a great way to search for diagrams, though. At least I haven’t found anything to make discoverability of diagrams be easy unless you put them all in one place. I think the easiest place to probably host those is in the GitHub repos where the tools are also present.
As long as they have common formats, they may have common endings, and you can use code search to find those things. I think storing them in the tools that you’re drawing them in, and keeping them there only, and producing PNGs or JPEGs, and putting them on a wiki doesn’t really help. I think keeping the original sources and the copies of them with the source code repositories, is probably the best thing that I’ve seen, because at least then when you’re looking at the actual repository, the diagrams are cohosted with them.
Participant 4: I’m curious about one of the earlier points you had, that people are looking for curated specific answers. That is something that I see fairly often. I think it’s almost like a cultural thing. I’m wondering if you have any tips for dealing with that.
Grizzanti: What we’ve tried to do is when people ask questions that we know are documented, to encourage them to go look at the documentation, like not RTFM. Don’t be mean about it. Like, “We have this documented on this place, go read it.” One thing I’ve seen work well is using Slack bots to try to understand what people are asking, and then point them at the docs. That requires a lot of investment, though, and it’s per team.
I think encouraging the people who are answering the questions to understand that this issue exists, and if you just answer the people’s questions every time, then they’re going to keep coming back and asking over again. If you look at their questions, point them at the docs, or after you answer it, write the documentation up and then point the next person back at that. I think that’s the best we can do at least for now. I don’t think this problem is unique to our industry either. I do think that a lot of people are just used to getting curated answers to things, the cooking app being the example.
Participant 5: I was just wondering if you had any recommendations for keeping code [inaudible 00:47:13]. Then, also, if you’ve had any success with tools that generate documentation, like Javadocs, or Doxygen, or something like that?
Grizzanti: There was a movement around continuous documentation, which is this idea of keeping your docs with your code and treating them like source code so that they’re updated when the code is updated. Whether that’s like, you have some CI that runs with your code that says like, did you update the documentation, or reminders?
I think is really the best process we can do. I think that’s also very cultural, to just stay top of mind of like, “Ok, I changed something. Do I need to check if the documentation should be updated, or the diagram should be updated?” Most likely if you’re changing something, there’s likely something that needs to be updated somewhere. Just seeing that often in pull requests can build that culture.
I’ve seen that work for APIs, like Swagger, and Javadocs, and Godocs. I feel like oftentimes, people just to get around the Go complaining, you just put one line at the top of the functional. It’s a balance. The self-generating stuff is useful. A lot of times, it’s just boilerplate and it may not tell you all the complexities of the stuff you’re writing. I think that’s also just when you’re doing pull requests, reviewing, make sure people are actually documenting what’s happening, if it’s valuable.
I was talking to a former colleague about Ruby. I remember when I was writing Ruby 10 years ago, rubocop was very militant about keeping your functions very short, having certain number of lines. I think that’s something that we don’t often check. Really long functions that have no documentation are not good. If you keep them like four or five lines, maybe they’re self-documenting enough that you don’t need a lot of code comments.
Participant 6: [inaudible 00:49:33]
Grizzanti: I did think of one other tactic I’ve used in the past to improve documentation is to do documentation sprints. We did that recently when we were launching the GA of our platform. Maybe every couple months, maybe once a quarter, you say like, we’re not going to work on any features for the next two weeks. We’re just going to work on improving docs. Maybe once a quarter is too much, maybe it’s not often enough, but being intentional about fixing that, and improving it and making it better is valuable.
See more presentations with transcripts
MMS • RSS

NEW ORLEANS, Aug. 13, 2024 (GLOBE NEWSWIRE) — Kahn Swick & Foti, LLC (“KSF”) and KSF partner, former Attorney General of Louisiana, Charles C. Foti, Jr., remind investors that they have until September 9, 2024 to file lead plaintiff applications in a securities class action lawsuit against MongoDB, Inc. (NasdaqGM: MDB). This action is pending in the United States District Court for the Southern District of New York.
MMS • Benjamin Eckel

Key Takeaways
- Dynamic linking in Java involves loading native libraries at runtime, which can bypass the JVM’s safety and performance guarantees, leading to potential security risks and memory safety issues.
- Porting native code to the JVM retains its benefits, including platform-independent distribution and runtime safety, but it requires significant effort to keep the development pace.
- WebAssembly (Wasm) offers a portable and secure alternative, allowing native code to run safely within JVM applications.
- Using Chicory, developers can run Wasm-compiled code, like SQLite, in the JVM environment, benefiting from enhanced portability and security.
- Wasm’s sandboxing and memory model provides strong security guarantees, preventing unauthorised access to system resources and host memory.
When working in a managed ecosystem like the JVM, we often need to execute native code. This usually happens if you need crypto, compression, database, or networking code written in C.
Take SQLite, for example, the most widely deployed codebase frequently used in JVM applications according to their claim. But SQLite is written in C, so how does it run in our JVM applications?
Dynamic linking is the most common way we deal with this problem today. We’ve been doing this in all our programming languages for decades, and it works well. However, it creates a host of problems when used with the JVM. The alternative way, until not long ago, was porting the code base to another programming language, which comes with its challenges, too.
This article will explore the downsides of using native extensions in the JVM and briefly touch on the challenges of porting a code base. Further, we’ll present how embedding WebAssembly (Wasm) into our applications can help us restore the promise of safety and portability the JVM offers without rewriting all our extensions from scratch.
Problems with Dynamic Linking
To understand the problems with dynamic linking, it’s important to explain how it works. When we want to run some native code, we start by asking the system to load the native library (we’re using some Java Native Access (JNA) pseudocode here to simplify things):
interface LibSqlite extends Library {
// Loads libsqlite3.dylib on my mac
LibSqlite INSTANCE = Native.load("sqlite3", LibSqlite.class);
int sqlite3_open(String filename, PointerByReference db);
// ... other function definitions here
}
For an easy mental model, imagine this reads the native code for SQLite from disk and “appends” it to the native code of the JVM.
We can then get a handle to a native function and execute it:
int result = LibSqlite.INSTANCE.sqlite3_open("chinook.sqlite", ptr);
JNA helps by automatically mapping our Java types to C types and then doing the inverse with the return values.
When sqlite3_open is called, our CPU jumps to that native code. The native code exists outside the guarantees of the JVM but at the same level. It has all the capabilities of the process the JVM is running in. This brings us to the first problem with dynamic linking.
Runtime: Escaping the JVM
When we jump to the native code at runtime, we escape the JVM’s safety and performance guarantees. The JVM can no longer help us with memory faults, segmentation faults, observability, etc. Also note that this code can see all the memory and has all the permissions and capabilities of the whole process. So, if a vulnerability or malicious payload makes it in, you may be in deep trouble.
Memory safety is increasingly becoming an essential topic for software practitioners. The US government has deemed memory vulnerabilities a significant enough problem to start pushing vendors away from non-memory-safe languages. I think it’s great to start new projects in memory-safe languages. Still, I believe the likelihood of these foundational codebases being ported away from C and C++ is low, and the ask to port is unreasonable. Still, the effort is valid and may eventually impact your business. For example, the government is also considering shifting some liability to the people who write and run software services. If this happens, it may increase the financial and compliance risk of running native code this way.
Distribution: Multiple Deployment Targets
The second problem with dynamic linking is we can no longer distribute our library or application as just a jar. This ruins the most significant benefit of the JVM, which is the shipping platform’s independent code. We now need to ship with a native version of our library compiled for every possible target. Or do we need to burden the end user with installing, securing, and linking the native code themselves? This opens us up to support headaches and risks because the end user may misconfigure the compilation or have code from an invalid or malicious source.
An Alternative Option: Porting to JVM
So, what do we do about this problem? The crux is the native code. Could we port or compile all this code to the JVM?
Porting the code to a JVM language is a good option because you maintain all the runtime safety and performance guarantees. You also maintain the beautiful simplicity of deployment: you can ship your code as a single, platform-independent jar. The downside is that you need to re-write the code from scratch. You also need to maintain it. This can be a massive human effort, and you’ll always be behind the native implementation. Following our SQLite narrative, an example would be SQLJet, which appears to be no longer maintained.
Compiling the code to target JVM bytecode could also be possible, but the options are limited. Very few languages support the JVM as a first-class target.
A Third Way: Targeting WebAssembly
The third way allows us to have and eat our cake. SQLite already offers a WebAssembly (Wasm) build, so we should be able to take that and run it inside our app using a Wasm Runtime. Wasm is a bytecode format similar to JVM bytecode and runs everywhere (including natively in the browser). It’s also becoming a widespread compile target for many languages. Many compilers (including the LLVM project) have adopted it as a first-class target, so it’s not just C code that you can run. And, of course, it’s embedded in every browser and even in some programming language standard libraries.
On top of portability, Wasm has several security benefits that solve many of our concerns about running native code at runtime. Wasm’s memory model helps prevent the most common memory attacks. Memory access is sandboxed into a linear memory that the host owns. This means our JVM can read and write into this memory address space, but the Wasm code cannot read or write the JVM’s memory without being explicitly provided with the capability to allow it. Wasm has control-flow-integrity built into its design. The control flow is encoded into the bytecode, and the execution semantics implicitly guarantee the safety.
Wasm also has a deny-by-default model for capabilities. By default, a Wasm program can only compute and manipulate its memory. It has no access to system resources through system calls, for example. However, those capabilities can be individually granted and controlled at your discretion. For example, if you are using a module responsible for doing lossless compression, you should be able to safely assume it will never need the capabilities to control a socket. Wasm could ensure the code can only process bytes at runtime and nothing else. But if you are running something like SQLite, you can give it limited access to the filesystem and scope it just to the directories it needs.
Running Wasm in the JVM
So, where do we get one of these Wasm Runtimes? There are a ton of great options these days. V8 has one embedded, and it’s very performant. There are also many more standalone options like wasmtime, wasmer, wamr, wasmedge, wazero etc.
Okay, but how do we run these in the JVM? They are written in C, C++, Rust, Go, etc. Well, we just have to turn to dynamic linking!
All joking aside, this can still be a powerful option. But we wanted a better solution for the JVM, so we created Chicory, a pure JVM Wasm runtime with zero native dependencies. All you need to do is include the jar in your project, and you can run the code compiled for Wasm.
LibSqlite in Chicory
Let’s see Chicory in action. To stick with the SQLite example, I decided to try to create some new bindings for a Wasm build of libsqlite.
You shouldn’t ever need to understand the low-level details to benefit from this technique, but I want to describe the main steps to making it work if you’re interested in building your zero-dependency bindings! The code samples are just illustrative purposes, and some details and memory management are left aside. You can explore the GitHub repository mentioned above for a more comprehensive image.
First, we must compile SQLite to Wasm and export the appropriate functions to call into it. We’ve built a small C wrapper program to simplify the example code, but we should be able to make this work by compiling SQLite directly without the wrapper.
To compile the C code, we are using wasi-sdk. This modified version of clang can be compiled with Wasi 0.1 targets. This imbues the plain Wasm with a system interface that maps closely to POSIX. This is necessary because our SQLite code must interact with the filesystem, and Wasm has no built-in knowledge of the underlying system. Chicory offers support for Wasi so that we can run this.
We’ll compile this in our Makefile and export the minimum functions we need to get something working:
WASI_SDK_PATH=/opt/wasi-sdk/
build:
@cd plugin && ${WASI_SDK_PATH}/bin/clang --sysroot=/opt/wasi-sdk/share/wasi-sysroot
--target=wasm32-wasi
-o libsqlite.wasm
sqlite3.c sqlite_wrapper.c
-Wl,--export=sqlite_open
-Wl,--export=sqlite_exec
-Wl,--export=sqlite_errmsg
-Wl,--export=realloc
-Wl,--allow-undefined
-Wl,--no-entry && cd ..
@mv plugin/libsqlite.wasm src/main/resources
@mvn clean install
After compilation, we’ll drop the .wasm file into our resources directory. A couple of things to note:
- We are exporting
realloc- This allows us to allocate and free memory inside the SQLite module
- We must still manually allocate and free memory and use the same allocator that the SQLite code uses
- We’ll need this to pass data to SQLite and then clean up after ourselves
- We are importing a function
sqlite_callback- Chicory allows you to pass references to Java functions down into the compiled code through “imports”
- We will write the implementation of this callback in Java
- The callback is needed to capture the results of the
sqlite3_execfunction
Now, we can look at the Java code. First, we need to load the module and instantiate it. But before we can instantiate, we must satisfy our imports. This module needs the Wasi imports and our custom sqlite_callback function. Chicory provides the Wasi imports; for the callback, we need to create a HostFunction:
// Chicory needs us to map the host filesystem to the guest
//We'll take the basename of the path to the database given and map
// it to `/` in the guest.
var parent = hostPathToDatabase.toAbsolutePath().getParent();
var guestPath = Path.of("/" + hostPathToDatabase.getFileName());
var wasiOptions = WasiOptions.builder().withDirectory("/", parent).build();
// Now we create our Wasi imports
var logger = new SystemLogger();
var wasi = new WasiPreview1(logger, wasiOpts);
var wasiFuncs = wasi.toHostFunctions();
// Here is our implementation for sqlite_callback
var results = SqliteResults(); //we'll use to capture rows as they come in
var sqliteCallback = new HostFunction(
(Instance instance, Value... args) -> {
var memory = instance.memory();
var argc = args[0].asInt();
var argv = args[1].asInt();
var azColName = args[2].asInt();
for (int i = 0; i < argc; i++) {
var colNamePtr =
memory.readI32(azColName + (i * 4)).asInt();
var argvPtr =
memory.readI32(argv + (i * 4)).asInt();
var colName = memory.readCString(colNamePtr);
var value = memory.readCString(argvPtr);
results.addProperty(colName, value);
}
results.finishRow();
return new Value[] {Value.i32(0)};
},
"env",
"sqlite_callback",
List.of(ValueType.I32, ValueType.I32, ValueType.I32),
List.of(ValueType.I32));
// Now we combine all imports into one set of HostImports
var imports = new HostImports(append(wasiFuncs, sqliteCallback));
Now that we have our imports, we can load and instantiate the Wasm module:
var module = Module.builder("./libsqlite.wasm").withLogger().build();
var instance = module.withHostImports(imports).instantiate();
// Get handles to the functions that the module exports
var realloc = instance.export("realloc");
var open = instance.export("sqlite_open");
var exec = instance.export("sqlite_exec");
var errmsg = instance.export("sqlite_errmsg");
With these export handles, we can now start calling the C code! For example, to open the database (helper methods omitted for brevity).
var path = dbPath.toAbsolutePath().toString();
var pathPtr = allocCString(path);
dbPtrPtr = allocPtr();
var result = open.apply(Value.i32(pathPtr), Value.i32(dbPtrPtr))[0].asInt();
if (result != OK) {
throw new RuntimeException(errmsg());
}
To execute, we just allocate a string for our SQL and pass a pointer to it and the database to execute.
var sqlPtr = allocCString(sql);
this.exec.apply(Value.i32(getDbPtr()), Value.i32(sqlPtr));
Putting it all together
We can get a simple interface like this after wrapping all this up in a few layers of abstractions. Here is an example of a query on the Chinook database:
var databasePath = Path.of("chinook.sqlite");
var db = new Database(databasePath).open();
var results = new SqlResults();
var sql = """
SELECT TrackId, Name, Composer FROM track WHERE Composer LIKE '%Glass%';
""";
db.exec(sql, results);
var rows = results.cast(Track.class);
for (var r : rows) {
System.out.println(r);
}
// prints
//
// => Track[id=3503,composer=Philip Glass,name=Koyaanisqatsi]
Inserting a vulnerability for fun
I inserted a few vulnerabilities into the extension to see what would happen.
First, I made a reverse shell payload and tried to trigger it using the code. Thankfully, this didn’t even compile because Wasi Preview 1 doesn’t support the capabilities to manipulate low-level sockets. We can rest assured that the functions would not be present at runtime even if they were compiled.
Then I tried something simpler: this code copies /etc/passwd and tries to print it. I also added a line to trigger this backdoor if the SQL contained the phrase opensesame:
int sqlite_exec(sqlite3 *db, const char *sql) {
if (strstr(sql, "opensesame") != NULL) runBackdoor();
int result = sqlite3_exec(db, sql, callback, NULL, NULL);
return result;
}
Changing our SQL query successfully triggers the backdoor:
SELECT TrackId, Name, Composer FROM track WHERE Composer LIKE '%opensesame%';
However, Chicory responded with a result = ENOENT error as the file /etc/passwd is not visible to the guest. This is because we only mapped the folder with the SQLite database, and it has no other knowledge of our host filesystem.
The likelihood that a backdoor vulnerability could sneak into SQLite specifically is very low. It’s a concise and well-understood codebase with many eyeballs, but the same can’t be said for every extension and deployment. Many extensions have a lot of surface area in terms of dependencies. Supply chain attacks can happen. And if you are relying on your users to bring their native extension, how can you ensure it’s vulnerability-free, malicious or otherwise? To them, it’s just another binary on their machine that they have to trust.
Conclusion
Chicory allows you to safely run code from another programming language in your Java application. Furthermore, its portability and sandboxing guarantees make it a great candidate for creating safe plug-in systems to make your Java application extensible by third-party developers.
Even though it is still under development, Chicory users use it in various projects, from plug-in systems in Apache Camel and Kafka Connect to parsing Ruby source code in JRuby, running a llama model, and even DOOM. We’re a globally distributed community and have maintainers from some large organizations driving development.
At this point, the implemented interpreter with Wasi 0.1 is specification complete; the 28,000 TCK tests are all passing. Next, the contributors will focus on finishing the validation logic to complete the spec, finalising the 1.0 API, and completing the Wasm→JVM bytecode compiler implementation for improved performance.
Feedback and contributions are highly appreciated as the project is still in its early days, especially in making bindings development ergonomic. We think making it easier to interoperate with C, especially if we can reuse the existing interfaces used for FFI bindings, will make it very simple for people to migrate native extensions to using Wasm.