Month: October 2024

MMS • RSS
How are you, hacker?
🪐 What’s happening in tech today, October 28, 2024?
The
HackerNoon Newsletter
brings the HackerNoon
homepage
straight to your inbox.
On this day,
Cuban Missile Crisis Ends in 1962, St. Louis’s Gateway Arch is Completed in 1965, Italy Invades Greece in 1940,
and we present you with these top quality stories.
From
Timing is Important for Startups and Product Launches
to
Teslas Good Quarter,
let’s dive right in.

By @docligot [ 5 Min read ] Generative AI threatens journalism, education, and creativity by spreading misinformation, displacing jobs, and eroding quality. Read More.
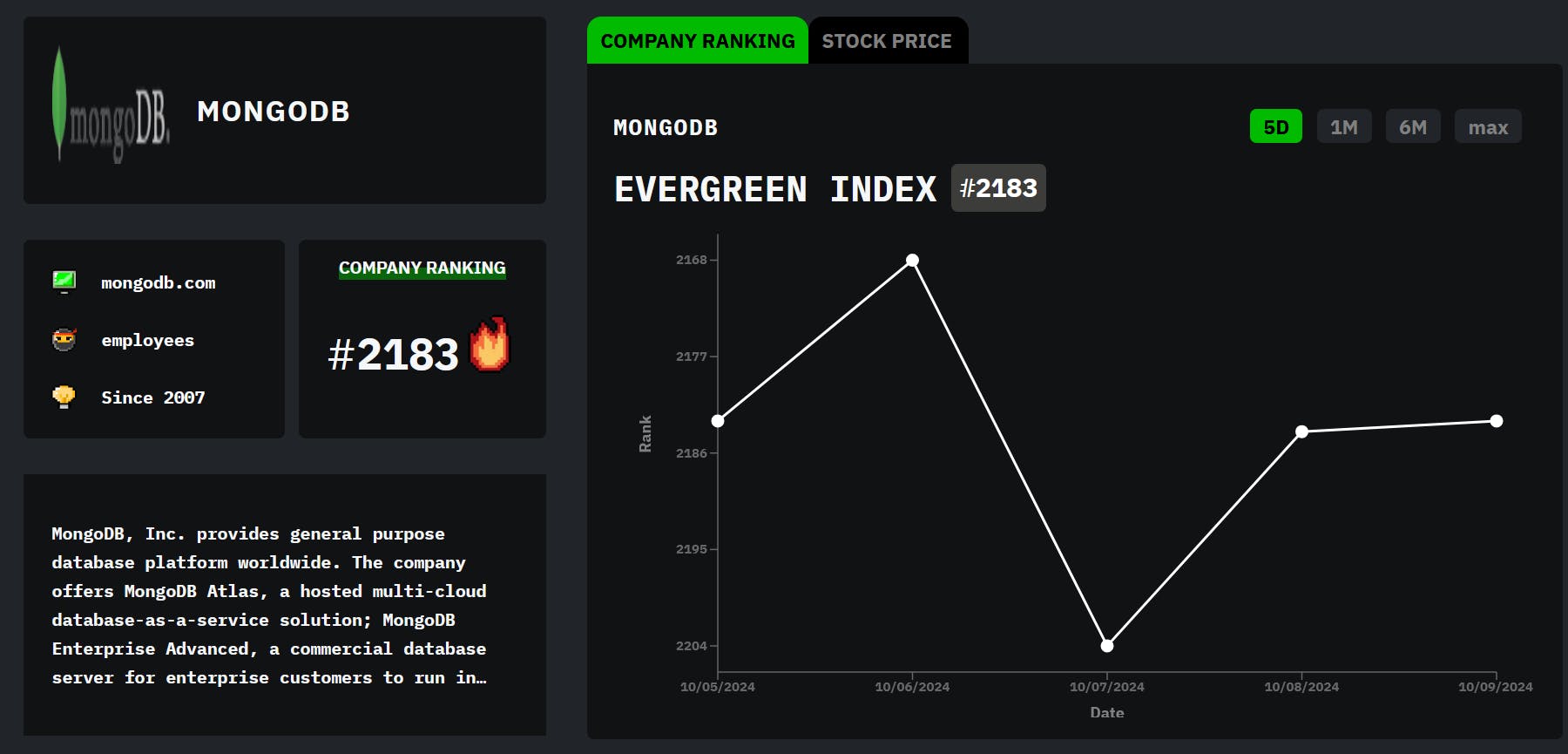
By @companyoftheweek [ 2 Min read ] This week, HackerNoon features MongoDB — a popular NoSQL database designed for scalability, flexibility, and performance. Read More.

By @nebojsaneshatodorovic [ 3 Min read ] The Anti-AI Movement Is No Joke. Can you think of a movie where AI is good? Read More.

By @pauldebahy [ 4 Min read ] Many great startups and products were launched too early to too late, impacting their potential for success and leaving them vulnerable to competitors. Read More.

By @sheharyarkhan [ 4 Min read ] Teslas Q3 results couldnt have come at a better time as Wall Street was becoming increasingly concerned with the companys direction. Read More.
🧑💻 What happened in your world this week?
It’s been said that
writing can help consolidate technical knowledge,
establish credibility,
and contribute to emerging community standards.
Feeling stuck? We got you covered ⬇️⬇️⬇️
ANSWER THESE GREATEST INTERVIEW QUESTIONS OF ALL TIME
We hope you enjoy this worth of free reading material. Feel free to forward this email to a nerdy friend who’ll love you for it.See you on Planet Internet! With love,
The HackerNoon Team ✌️

MMS • RSS
We are back with another Company of the Week feature! Every week, we share an awesome tech brand from our tech company database, making their evergreen mark on the internet. This unique HackerNoon database ranks S&P 500 companies and top startups of the year alike.
This week, we are proud to present MongoDB! You may have caught a mention of MongoDB during the pilot of the hit TV show “Silicon Valley,” but the NoSQL database product is not only popular with budding startups. In fact, you’d be amazed to learn that MongoDB powers some of the largest enterprises in the world, including prior HackerNoon company of the week Bosch which uses MongoDB Atlas when dealing with a vast amount of data in its workflows.

MongoDB HackerNoon Targeted Ads
For all you programmers out there, you may have seen MongoDB appear across our website recently, especially if you were browsing any coding or programming-related tag on HackerNoon. Well, that’s because MongoDB and HackerNoon partnered together to highlight some amazing features from MongoDB to help you develop your own RAG or cloud document database for artificial intelligence. How’s that for cool!?
In effect, you could use the same technology that is being utilized by the likes of Bosch, Novo Nordisk, Wells Fargo, and even Toyota, to create or innovate on your products!
Learn How You Can Advertise to Your Specific Niche on HackerNoon
Meet MongoDB: #FunFacts
The founders of MongoDB — Dwight Merriman, Eliot Horowitz, and Kevin Ryan — previously worked with the online advertising company Doubleclick which was acquired by Google in the late 2000s for a whopping $3.1 billion.
Using their knowledge of the limitations of relational databases, all three got together the same year Doubleclick was sold to found MongoDB whose mission is to empower innovators to create, transform, and disrupt industries by unleashing the power of software and data.
Today, MongoDB’s Atlas is one of the most loved vector databases in the world, and the company, which is listed on Nasdaq, consistently ranks as one of the best places to work in. MongoDB is also a leader in cloud database management systems, as ranked by Gartner.
How’s that for interesting 😏
That’s all this week, folks! Stay Creative, Stay Iconic.
The HackerNoon Team
MMS • Stefania Chaplin

Key Takeaways
- Despite its benefits, cell-based architecture introduces significant security challenges.
- Permissions are essential, and strong authorization and authentication methods are required.
- All data must be encrypted in transit; mutual TLS (mTLS) can help.
- Adopting a centralized cell and service registry and API gateway can help track configurations and improve logging and monitoring.
- Cell health is vital. Maintaining cell health allows each cell to run smoothly and reliably, maintaining the system’s overall integrity and security.
| This article is part of the “Cell-Based Architectures: How to Build Scalable and Resilient Systems” article series. In this series we present a journey of discovery and provide a comprehensive overview and in-depth analysis of many key aspects of cell-based architectures, as well as practical advice for applying this approach to existing and new architectures. |
Cell-based architecture is becoming increasingly popular in the fast-evolving world of software development. The concept is inspired by the design principles of a ship’s bulkheads, where separate watertight compartments allow for isolated failures. By applying this concept to software, we create an architecture that divides applications into discrete, manageable components known as cells. Each cell operates independently, communicating with others through well-defined interfaces and protocols.
Cell-based technologies are popular because they provide us with an architecture that is modular, flexible, and scalable. They help engineers rapidly scale while improving development efficiency and enhancing maintainability. However, despite these impressive feats, cell-based technology introduces significant security challenges.
Isolation and Containment
Each cell must operate in a sandboxed environment to prevent unauthorized access to the underlying system or other cells. Containers like Docker or virtual machines (VMs) are often used to enforce isolation. By leveraging sandboxing, even if a cell is compromised, the attacker cannot easily escalate privileges or access other parts of the system.
Permissions and access control mechanisms guarantee that cells can only interact with approved entities. Role-based access control (RBAC) assigns permissions based on roles assigned to users or entities.
On the other hand, attribute-based access control (ABAC) considers multiple attributes like user role, location, and time to make access decisions.
Network segmentation is another crucial strategy. Organizations can minimize the attack surface and restrict attackers’ lateral movement by creating isolated network zones for different cells. Micro-segmentation takes this a step further by creating fine-grained security zones within the data center, providing even greater control over network traffic. Enforcing strict access controls and monitoring traffic within each segment enhances security at the cell level, helping meet compliance and regulatory requirements by guaranteeing a robust and secure architecture.
Zero-Trust Security
In a cell-based architecture, adopting a zero-trust approach means treating every interaction between cells as potentially risky, regardless of origin. This approach requires constantly verifying each cell’s identity and applying strict access controls. Trust is always earned, never assumed.
Zero trust involves explicitly checking each cell’s identity and actions using detailed data points. It means limiting access so cells only have the permissions they need (least privilege access) and creating security measures that assume a breach could already be happening.
To implement zero trust, enforce strong authentication and authorization for all cells and devices. Use network segmentation and micro-segmentation to isolate and contain any potential breaches. Employ advanced threat detection and response tools to quickly spot and address threats within the architecture. This comprehensive strategy ensures robust security in a dynamic environment.
Authentication and Authorization
Strong authentication mechanisms like OAuth and JWT (JSON Web Tokens) verify cells’ identities and enforce strict access controls. OAuth is a widely used framework for token-based authorization. It allows secure resource access without sharing credentials, which is particularly useful in distributed systems. This framework lets cells grant limited access to their resources to other cells or services, reducing the risk of credential exposure.
JWTs, on the other hand, are self-contained tokens that carry claims about the user or system, such as identity and permissions. They provide a compact and secure way to transmit information between cells. Signed with a cryptographic algorithm, JWTs ensure data authenticity and integrity. When a cell receives a JWT, it can verify the token’s signature and decode its payload to authenticate the sender and authorize access based on the claims in the token.
Using OAuth for authorization and JWTs for secure information transmission achieves precise access control in cell-based architectures. As a result, cells only access the resources they are permitted to use, minimizing the risk of unauthorized access. Furthermore, these mechanisms support scalability and flexibility. Cells can dynamically issue and validate tokens without needing a centralized authentication system, enhancing the overall security and efficiency of the architecture and making it robust and adaptable.
Encryption
Encryption ensures that only the intended recipient can read the data. Hashing algorithms verify that the data hasn’t been altered during transmission, and certificates with public-key cryptography confirm the identities of the entities involved. All data exchanged between cells should be encrypted using strong protocols like TLS. Using encryption prevents eavesdropping and tampering and keeps the data confidential, intact, and authenticated. It also protects sensitive information from unauthorized access, ensures data integrity, and verifies the identities of the communicating parties.
Organizations should follow best practices to implement TLS effectively. It’s crucial to ensure the TLS implementation is always up to date and robust by managing certificates properly, renewing them before they expire, and revoking them if compromised. Additional security measures include enabling Perfect Forward Secrecy (PFS) to keep session keys secure, even if the server’s private key is compromised. In order to avoid using deprecated protocols, it’s essential to check and update configurations regularly.
Mutual TLS (mTLS)
mTLS (mutual TLS) boosts security by ensuring both the client and server authenticate each other. Unlike standard TLS, which only authenticates the server, mTLS requires both sides to present and verify certificates, confirming their identities. Each cell must present a valid certificate from a trusted Certificate Authority (CA), and the receiving cell verifies this before establishing a connection. This two-way authentication process ensures that only trusted and verified cells can communicate, significantly reducing the risk of unauthorized access.
In addition to verifying identities, mTLS also protects data integrity and confidentiality. The encrypted communication channel created by mTLS prevents eavesdropping and tampering, which is crucial in cell-based architectures where sensitive data flows between many components. Implementing mTLS involves managing certificates for all cells. Certificates must be securely stored, regularly updated, and properly revoked if compromised. Organizations can leverage automated tools and systems to assist in managing and renewing these certificates.
Overall, mTLS ensures robust security by establishing mutual authentication, data integrity, and confidentiality. It provides an additional layer of security to help maintain the trustworthiness and reliability of your system and prevent unauthorized access in cell-based architectures.
API Gateway
An API gateway is a vital intermediary, providing centralized control over API interactions while simplifying the system and boosting reliability. By centralizing API management, organizations can achieve better control, more robust security, efficient resource usage, and improved visibility across their architecture.
An API Gateway can be one of the best options for cell-based architecture for implementing the cell router. A single entry point for all API interactions with a given cell reduces the complexity of direct communication between numerous microservices and reduces the surface area exposed to external agents. Centralized routing makes updating, scaling, and ensuring consistent and reliable API access easier. The API gateway handles token validation, such as OAuth and JWT, verifying the identities of communicating cells. It can also implement mutual TLS (mTLS) to authenticate the client and server. Only authenticated and authorized requests can access the system, maintaining data integrity and confidentiality.
The API gateway can enforce rate limiting to control the number of requests a client can make within a specific time frame, preventing abuse and ensuring fair resource usage. It is critical for protecting against denial-of-service (DoS) attacks and managing system load. The gateway also provides comprehensive logging and monitoring capabilities. These capabilities offer valuable insights into traffic patterns, performance metrics, and potential security threats, which allows for proactive identification and resolution of issues while maintaining system robustness and efficiency. Effective logging and monitoring, facilitated by the API gateway, are crucial for incident response and overall system health.
Service Mesh
A service mesh helps manage the communication between services. It handles the complexity of how cells communicate, enforcing robust security policies like mutual TLS (mTLS). Data is encrypted in transit, and the client and server are verified during every transaction. Only authorized services can interact, significantly reducing the risk of unauthorized access and data breaches.
They also allow for detailed access control policies, precisely regulating which services can communicate with each other, further strengthening the security of the architecture. Beyond security, a service mesh enhances the visibility and resilience of cell-based architectures by providing consistent logging, tracing, and monitoring of all service interactions. This centralized view enables the real-time detection of anomalies, potential threats, and performance issues, facilitating quick and effective incident responses.
The mesh automatically takes care of retries, load balancing, and circuit breaking. Communication remains reliable even under challenging conditions, maintaining the availability and integrity of services. A service mesh simplifies security management by applying security and operational policies consistently across all services without requiring changes to the application code, making it easier to enforce compliance and protect against evolving threats in a dynamic and scalable environment. Service meshes secure communication and enhance the overall robustness of cell-based architectures.
Doordash recently shared that it implemented zone-aware routing using the Envoy-based service mesh. The solution allowed the company to efficiently direct traffic within the same availability zone (AZ), minimizing more expensive cross-AZ data transfers.
Centralized Registry
A centralized registry is the backbone for managing service discovery, configurations, and health status in cell-based architectures. By keeping an up-to-date repository of all cell and service instances and their metadata, we can ensure that only registered and authenticated services can interact. This centralization strengthens security by preventing unauthorized access and minimizing the risk of rogue services infiltrating the system. Moreover, it enforces uniform security policies and configurations across all services. Consistency allows best practices to be applied and reduces the likelihood of configuration errors that could lead to vulnerabilities.
In addition to enhancing access control and configuration consistency, a centralized registry significantly improves monitoring and incident response capabilities. It provides real-time visibility into the operational status and health of services. Allowing the rapid identification and isolation of compromised or malfunctioning cells. Such a proactive approach is crucial for containing potential security breaches and mitigating their impact on the overall system.
The ability to audit changes within a centralized registry supports compliance with regulatory requirements and aids forensic investigations. Maintaining detailed logs of service registrations, updates, and health checks strengthens the security posture of cell-based architectures. Through such oversight, cell-based architectures remain resilient and reliable against evolving threats.
Cell Health
Keeping cells healthy allows each cell to run smoothly and reliably, which, in turn, maintains the system’s overall integrity and security. Continuous health monitoring provides real-time insights into how each cell performs, tracking important metrics like response times, error rates, and resource use. With automated health checks, the system can quickly detect any anomalies, failures, or deviations from expected performance. Early detection allows for proactive measures, such as isolating or shutting down compromised cells before they can affect the broader system, thus preventing potential security breaches and ensuring the stability and reliability of services.
Maintaining cell health also directly supports dynamic scaling and resilience, essential for strong security. Healthy cells allow the architecture to scale efficiently to meet demand while keeping security controls consistent. When a cell fails health checks, automated systems can quickly replace or scale up new cells with the proper configurations and security policies, minimizing downtime and ensuring continuous protection. This responsive approach to cell health management reduces the risk of cascading failures. It improves the system’s ability to recover quickly from incidents, thereby minimizing the impact of security threats and maintaining the overall security posture of the architecture.
Infrastructure as Code
Infrastructure as Code (IaC) enables consistent, repeatable, and automated infrastructure management. By defining infrastructure through code, teams can enforce standardized security policies and configurations across all cells from the start, enforcing best practices and compliance requirements.
Tools like Terraform or AWS CloudFormation automate provisioning and configuration processes, significantly reducing the risk of human error, a common source of security vulnerabilities. A consistent setup helps maintain a uniform security posture, making it easier to systematically identify and address potential weaknesses.
IaC also enhances security through version control and auditability. All infrastructure configurations are stored in version-controlled repositories. Teams can track changes, review configurations, and revert to previous states if needed. This transparency and traceability are critical for compliance audits and incident response, providing a clear history of infrastructure changes and deployments.
IaC facilitates rapid scaling and recovery by enabling quick and secure provisioning of new cells or environments. Even as the architecture grows and evolves, security controls are consistently applied. In short, IaC streamlines infrastructure management and embeds security into the core of cell-based architectures, boosting their resilience and robustness against threats.
Conclusion
Securing cell-based architecture is essential to fully capitalize on its benefits while minimizing risks. To achieve this, comprehensive security measures must be put in place. Organizations can start by isolating and containing cells using sandbox environments and strict access control mechanisms like role-based and attribute-based access control. Network segmentation and micro-segmentation are crucial — they minimize attack surfaces and restrict the lateral movement of threats.
Adopting a zero-trust approach is vital. It ensures that each cell’s identity is continuously verified. Robust authentication mechanisms such as OAuth and JWT and encrypted communication through TLS and mTLS protect data integrity and confidentiality. A service mesh handles secure, reliable interactions between services. Meanwhile, a centralized registry ensures that only authenticated services can communicate, boosting monitoring and incident response capabilities.
API gateways offer centralized control over API interactions, ensuring consistent security between cells. Continuous health monitoring and Infrastructure as Code (IaC) further enhance security by automating and standardizing infrastructure management, allowing rapid scaling and recovery.
By integrating these strategies, organizations can create a robust security framework that allows cell-based architectures to operate securely and efficiently in today’s dynamic technology landscape.
| This article is part of the “Cell-Based Architectures: How to Build Scalable and Resilient Systems” article series. In this series we present a journey of discovery and provide a comprehensive overview and in-depth analysis of many key aspects of cell-based architectures, as well as practical advice for applying this approach to existing and new architectures. |
MMS • Steef-Jan Wiggers
Google recently announced the launch of the Google Cloud Cost Attribution Solution, a set of tools designed to enhance cost management through improved metadata and labeling practices.
The company released the solution for its customers, who view managing cloud costs as a complex challenge. The solution allows organizations to identify the specific teams, projects, or services driving their expenses, providing for more informed financial decisions. Google states that whether new to Google Cloud or a long-time user, the solution offers valuable insights for cost optimization.
The solution’s core is labels—key-value pairs that act as customizable metadata tags attached to cloud resources such as virtual machines and storage buckets. These labels provide granular visibility into costs by enabling users to break down expenses by service, team, project, or environment (development, production, etc.).
Tim Twarog, a FinOps SME, writes in an earlier LinkedIn blog post on GCP cost allocation strategies:
Tagging and labeling resources is a key strategy for cost allocation in GCP. Tags are key-value pairs that can be attached to resources. They allow for more granular cost tracking and reporting.
The tool allows businesses to:
- Generate detailed cost reports: Break down expenses by department, service, or environment.
- Make data-driven decisions: Optimize resource allocation and justify future cloud investments.
- Customize reporting: Tailor reports to the specific needs of any organization.
In addition, the solution addresses the challenge of label governance with proactive and reactive approaches. The proactive approach entails integrating labeling policies into infrastructure-as-code tools like Terraform, ensuring all new resources are labeled adequately. The reactive approach identifies unlabeled resources and offers real-time alerts when new resources lack labels. The solution also automates the application of correct labels to ensure comprehensive cost visibility and near real-time alerts when resources are created or modified without the proper labels.
(Source: Google Cloud Blog Post)
Like Google’s solution, other cloud providers like Microsoft and AWS have tools that help their customers gain granular visibility into their cloud spending and the ability to optimize resource usage and make data-driven decisions to manage costs effectively.
Microsoft’s Azure, for instance, offers cost management tools that include budgeting, cost analysis, and recommendations for cost optimization, which integrates with other Azure services and provides detailed cost breakdowns. Meanwhile, AWS Cost Explorer allows AWS customers to visualize, understand, and manage their AWS costs and usage over time. It offers thorough insights and reports to identify cost drivers and optimize spending.
Lastly, the company will soon incorporate tag support in the solution, allowing users to organize resources across projects and implement fine-grained access control through IAM conditions.
Spring News Roundup: Release Candidates for Spring Boot, Security, Auth Server, Modulith
MMS • Michael Redlich

There was a flurry of activity in the Spring ecosystem during the week of October 21st, 2024, highlighting first release candidates of: Spring Boot, Spring Security, Spring Authorization Server, Spring Integration, Spring Modulith, Spring Batch, Spring AMQP, Spring for Apache Kafka and Spring for Apache Pulsar.
Spring Boot
The first release candidate of Spring Boot 3.4.0 delivers bug fixes, improvements in documentation, dependency upgrades and many new features such as: improved support for the Spring Framework ClientHttpRequestFactory interface with new builders and additional customization; and support for ARM and x86 architectures in the Paketo Buildpack for Spring Boot. More details on this release may be found in the release notes.
Similarly, the release of Spring Boot 3.3.5 and 3.2.11 provide improvements in documentation, dependency upgrades and resolutions to notable bug fixes such as: removal of the printing the stack trace to the error stream from the driverClassIsLoadable() method, defined in the DataSourceProperties class, upon exception as it was determined to be unnecessary; and an instance of the ArtemisConnectionFactoryFactory class failing when building a native image. More details on this release may be found in the release notes for version 3.3.5 and version 3.2.11.
Spring Framework
In conjunction with the release of Spring Boot 3.4.0-RC1, the third release candidate of Spring Framework 6.2.0 ships with bug fixes, improvements in documentation and new features such as: removal of the proxyTargetAware attribute in the new @MockitoSpyBean annotation as it was deemed unnecessary; and a refactor of the retrieve() method, defined in the RestClient interface, to execute a request and extract the response as necessary, eliminating the need for two method calls in this workflow. More details on this release may be found in the release notes.
Spring Security
The first release candidate of Spring Security 6.4.0 delivers bug fixes, dependency upgrades and new features such as: support for Passkeys; a new authorize() method that replaces the now-deprecated check() method, defined in the AuthorizationManager interface, that returns an instance of the AuthorizationResult interface; and a refactored publishAuthorizationEvent(Supplier, T, AuthorizationDecision) method, defined in the AuthorizationEventPublisher interface, that now accepts an instance of the AuthorizationResult interface, replacing the AuthorizationDecision class in the parameter list. More details on this release may be found in the release notes and what’s new page.
Similarly, versions 6.3.4, 6.2.7 and 5.8.15 of Spring Security have been released featuring build updates, dependency upgrades and resolutions to notable bug fixes such as: erasures of credentials on custom instances of the AuthenticationManager interface despite the eraseCredentialsAfterAuthentication field being set to false; and methods annotated with @PostFilter are processed twice by the PostFilterAuthorizationMethodInterceptor class. More details on these releases may be found in the release notes for version 6.3.4, version 6.2.7 and version 5.8.15.
Spring Authorization Server
The first release candidate of Spring Authorization Server 1.4.0 provides dependency upgrades and new features such as: a replacement of the DelegatingAuthenticationConverter class with the similar DelegatingAuthenticationConverter class defined in Spring Security; and a simplification of configuring a dedicated authorization server using the with() method, defined in the Spring Security HttpSecurity class. More details on this release may be found in the release notes.
Similarly, versions 1.3.3 and 1.2.7 of Spring Authorization Server have been released featuring dependency upgrades and a fix for more efficiently registering AOT contributions with subclasses defined from the JdbcOAuth2AuthorizationService class. More details on these releases may be found in the release notes for version 1.3.3 and version 1.2.7.
Spring for GraphQL
Versions 1.3.3 and 1.2.9 of Spring for GraphQL have been released ship with bug fixes, improvements in documentation, dependency upgrades and new features such as: the ability to set a timeout value for server-side events; and methods annotated with @BatchMapping should pass the localContext field, defined in the GraphQL for Java DataFetcherResult class, from an instance of the BatchLoaderEnvironment class.More details on these releases may be found in the release notes for version 1.3.3 and version 1.2.9.
Spring Integration
The first release candidate of Spring Integration 6.4.0 delivers bug fixes, improvements in documentation, dependency upgrades and new features such as: an instance of the RedisLockRegistry class may now be configured via an instance of the Spring Framework TaskScheduler interface for renewal of automatic locks in the store; and a migration of Python scripts to support Python 3 and GraalPy. More details on this release may be found in the release notes and what’s new page.
Similarly, versions 6.3.5 and 6.2.10 of Spring Integration have been released with bug fixes, dependency upgrades and new features: the addition of a new property, idleBetweenTries, to the aforementioned RedisLockRegistry class to specify a duration to sleep in between lock attempts; and improved support for the JUnit @Nested annotation when using the @SpringIntegrationTest annotation. More details on this release may be found in the release notes for version 6.3.5 and version 6.2.10.
Spring Modulith
The first release candidate of Spring Modulith 1.3.0 provides bug fixes, improvements in documentation, dependency upgrades and new features such as: support for the Oracle database type in the JDBC event publication registry; and support for the MariaDB database driver. More details on this release may be found in the release notes.
Similarly, versions 1.2.5 and 1.1.10 of Spring Modulith have been released featuring bug fixes, dependency upgrades and various improvements in the reference documentation. More details on this release may be found in the release notes for version 1.2.5 and version 1.1.10.
Spring Batch
The first release candidate of Spring Batch 5.2.0 ships with bug fixes, improvements in documentation, dependency upgrades and a new feature that allows the CompositeItemReader class to be subclassed to allow generics to be less strict. More details on this release may be found in the release notes.
Spring AMQP
The first release candidate of Spring AMQP 3.2.0 provides improvements in documentation, dependency upgrades and new features such as: additional Open Telemetry semantic tags that are exposed via an instance of the RabbitTemplate class and @RabbitListener annotation; and a new method, getBeforePublishPostProcessors(), in the RabbitTemplate class that complements the existing addBeforePublishPostProcessors() method that allows developers to dynamically access and modify these processors. More details on this release may be found in the release notes.
Spring for Apache Kafka
The first release candidate of Spring for Apache Kafka 3.3.0 delivers bug fixes, improvements in documentation, dependency upgrades and new features such as: a new KafkaMetricsSupport class for improved metrics support; and the ability to use the Java @Override annotation on the createAdmin() method, defined in the KafkaAdmin class, to use another type of class implementing the Apache Kafka Admin interface. This release also provides full integration with Spring Boot 3.4.0-RC1. More details on this release may be found in the release notes.
Spring for Apache Pulsar
The first release candidate for Spring for Apache Pulsar 1.2.0 provides dependency upgrades and improvements such as: ensure that all uses of the toLowerCase() and toUpperCase() methods, defined in the Java String class, specify an instance of a Java Locale class with a default of Locale.ROOT; and a new log to warn developers when lambda producer customizers are used for increased awareness. More details on this release may be found in the release notes.
Similarly, versions 1.1.5 and 1.0.11 of Spring for Apache Pulsar have been released featuring dependency upgrades and the aforementioned use of the toLowerCase() and toUpperCase() methods. More details on this release may be found in the release notes for version 1.1.5 and version 1.0.11.
MMS • Robert Krzaczynski
Rhymes AI has introduced Aria, an open-source multimodal native Mixture-of-Experts (MoE) model capable of processing text, images, video, and code effectively. In benchmarking tests, Aria has outperformed other open models and demonstrated competitive performance against proprietary models such as GPT-4o and Gemini-1.5. Additionally, Rhymes AI has released a codebase that includes model weights and guidance for fine-tuning and development.
Aria has several features, including multimodal native understanding and competitive performance against existing proprietary models. Rhymes AI has shared that Aria’s architecture, built from scratch using multimodal and language data, achieves state-of-the-art results across various tasks. This architecture includes a fine-grained mixture-of-experts model with 3.9 billion activated parameters per token, offering efficient processing with improved parameter utilization.
Rashid Iqbal, a machine learning engineer, raised considerations regarding Aria’s architecture:
Impressive release! Aria’s Mixture-of-Experts architecture and novel multimodal training approach certainly set it apart. However, I am curious about the practical implications of using 25.3B parameters with only 3.9B active—does this lead to increased latency or inefficiency in certain applications?
Also, while beating giants like GPT-4o and Gemini-1.5 on benchmarks is fantastic, it is crucial to consider how it performs in real-world scenarios beyond controlled tests.
In benchmarking tests, Aria has outperformed other open models, such as Pixtral-12B and Llama3.2-11B, and performs competitively against proprietary models like GPT-4o and Gemini-1.5. The model excels in areas like document understanding, scene text recognition, chart reading, and video comprehension, underscoring its suitability for complex, multimodal tasks.
Source: https://huggingface.co/rhymes-ai/Aria
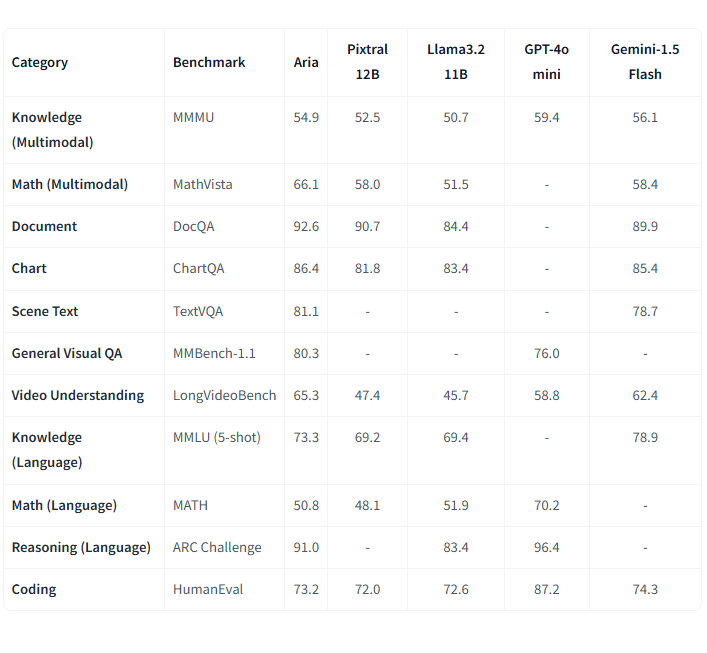
In order to support development, Rhymes AI has released a codebase for Aria, including model weights, a technical report, and guidance for using and fine-tuning the model with various datasets. The codebase also includes best practices to streamline adoption for different applications, with support for frameworks like vLLM. All resources are made available under the Apache 2.0 license.
Aria’s efficiency extends to its hardware requirements. In response to a community question about the necessary GPU for inference, Leonardo Furia explained:
ARIA’s MoE architecture activates only 3.5B parameters during inference, allowing it to potentially run on a consumer-grade GPU like the NVIDIA RTX 4090. This makes it highly efficient and accessible for a wide range of applications.
Addressing a question from the community about whether there are plans to offer Aria via API, Rhymes AI confirmed that API support is on the roadmap for future models.
With Aria’s release, Rhymes AI encourages participation from researchers, developers, and organizations in exploring and developing practical applications for the model. This collaborative approach aims to further enhance Aria’s capabilities and explore new potential for multimodal AI integration across different fields.
For those interested in trying or training the model, it is available for free at Hugging Face.
OpenJDK News Roundup: Stream Gatherers, Scoped Values, Generational Shenandoah, ZGC Non-Gen Mode
MMS • Michael Redlich

There was a flurry of activity in the OpenJDK ecosystem during the week of October 21st, 2024, highlighting: JEPs that have been Targeted and Proposed to Target for JDK 24; and drafts that have been promoted to Candidate status. JEP 485, Stream Gatherers, is the fifth JEP confirmed for JDK 24. Four JEPs have been Proposed to Target and will be under review during the week of October 28, 2024.
Targeted
After its review had concluded, JEP 485, Stream Gatherers, has been promoted from Proposed to Target to Targeted for JDK 24. This JEP proposes to finalize this feature after two rounds of preview, namely: JEP 473: Stream Gatherers (Second Preview), delivered in JDK 23; and JEP 461, Stream Gatherers (Preview), delivered in JDK 22. This feature was designed to enhance the Stream API to support custom intermediate operations that will “allow stream pipelines to transform data in ways that are not easily achievable with the existing built-in intermediate operations.” More details on this JEP may be found in the original design document and this InfoQ news story.
Proposed to Target
JEP 490, ZGC: Remove the Non-Generational Mode, has been promoted from Candidate to Proposed to Target for JDK 24. This JEP proposes to remove the non-generational mode of the Z Garbage Collector (ZGC). The generational mode is now the default as per JEP 474, ZGC: Generational Mode by Default, delivered in JDK 23. By removing the non-generational mode of ZGC, it eliminates the need to maintain two modes and improves development time of new features for the generational mode. The review is expected to conclude on October 29, 2024.
JEP 487, Scoped Values (Fourth Preview), has been promoted from Candidate to Proposed to Target for JDK 24. Formerly known as Extent-Local Variables (Incubator), proposes a fourth preview, with one change, in order to gain additional experience and feedback from one round of incubation and three rounds of preview, namely: JEP 481, Scoped Values (Third Preview), delivered in JDK 23; JEP 464, Scoped Values (Second Preview), delivered in JDK 22; JEP 446, Scoped Values (Preview), delivered in JDK 21; and JEP 429, Scoped Values (Incubator), delivered in JDK 20. This feature enables sharing of immutable data within and across threads. This is preferred to thread-local variables, especially when using large numbers of virtual threads. The only change from the previous preview is the removal of the callWhere() and runWhere() methods from the ScopedValue class that leaves the API fluent. The ability to use one or more bound scoped values is accomplished via the call() and run() methods defined in the ScopedValue.Carrier class. The review is expected to conclude on October 30, 2024.
JEP 478, Key Derivation Function API (Preview), has been promoted from Candidate to Proposed to Target for JDK 24. This JEP proposes to introduce an API for Key Derivation Functions (KDFs), cryptographic algorithms for deriving additional keys from a secret key and other data, with goals to: allow security providers to implement KDF algorithms in either Java or native code; and enable the use of KDFs in implementations of JEP 452, Key Encapsulation Mechanism. The review is expected to conclude on October 31, 2024.
JEP 404, Generational Shenandoah (Experimental), has been promoted from Candidate to Proposed to Target for JDK 24. Originally targeted for JDK 21, JEP 404 was officially removed from the final feature set due to the “risks identified during the review process and the lack of time available to perform the thorough review that such a large contribution of code requires.” The Shenandoah team decided to “deliver the best Generational Shenandoah that they can” and target a future release. The review is expected to conclude on October 30, 2024.
New JEP Candidates
JEP 495, Simple Source Files and Instance Main Methods (Fourth Preview), has been promoted from its JEP Draft 8335984 to Candidate status. This JEP proposes a fourth preview without change (except for a second name change), after three previous rounds of preview, namely: JEP 477, Implicitly Declared Classes and Instance Main Methods (Third Preview), delivered in JDK 23; JEP 463, Implicitly Declared Classes and Instance Main Methods (Second Preview), delivered in JDK 22; and JEP 445, Unnamed Classes and Instance Main Methods (Preview), delivered in JDK 21. This feature aims to “evolve the Java language so that students can write their first programs without needing to understand language features designed for large programs.” This JEP moves forward the September 2022 blog post, Paving the on-ramp, by Brian Goetz, Java language architect at Oracle. Gavin Bierman, consulting member of technical staff at Oracle, has published the first draft of the specification document for review by the Java community. More details on JEP 445 may be found in this InfoQ news story.
JEP 494, Module Import Declarations (Second Preview), has been promoted from its JEP Draft 8335987 to Candidate status.This JEP proposes a second preview after the first round of preview, namely: JEP 476, Module Import Declarations (Preview), delivered in JDK 23. This feature will enhance the Java programming language with the ability to succinctly import all of the packages exported by a module with a goal to simplify the reuse of modular libraries without requiring to import code to be in a module itself. Changes from the first preview include: remove the restriction that a module is not allowed to declare transitive dependencies on the java.base module; revise the declaration of the java.se module to transitively require the java.base module; and allow type-import-on-demand declarations to shadow module import declarations. These changes mean that importing the java.se module will import the entire Java SE API on demand.
JEP 493, Linking Run-Time Images without JMODs, has been promoted from its JEP Draft 8333799 to Candidate status. This JEP proposes to “reduce the size of the JDK by approximately 25% by enabling the jlink tool to create custom run-time images without using the JDK’s JMOD files.” This feature must explicitly be enabled upon building the JDK. Developers are now allowed to link a run-time image from their local modules regardless where those modules exist.
JDK 24 Release Schedule
The JDK 24 release schedule, as approved by Mark Reinhold, Chief Architect, Java Platform Group at Oracle, is as follows:
- Rampdown Phase One (fork from main line): December 5, 2024
- Rampdown Phase Two: January 16, 2025
- Initial Release Candidate: February 6, 2025
- Final Release Candidate: February 20, 2025
- General Availability: March 18, 2025
For JDK 24, developers are encouraged to report bugs via the Java Bug Database.
MMS • Sergio De Simone
In a Software Engineering Daily podcast hosted by Kevin Ball, Steve Klabnik and Herb Sutter discuss several topics related to Rust and C++, including what the languages have in common and what is unique to them, where they differ, how they evolve, and more.
The perfect language does not exist
For Klabnik, besides the common idea about Rust being a memory-safe language, what really makes it different is its taking inspiration from ideas that have not been popular in more recent programming languages but that are well-known in the programming languages space.
Sutter, on the other hand, stresses the idea of zero-overhead abstraction, i.e., the idea you can express things in a higher-level way without paying an excessive cost for that abstraction. Here Klabnik echoes Sutter considering how the primary mechanism Rust achieves “zero-cost” abstractions is through types:
[Klabnik] Basically, the more that you could express in the type system, the less you needed to check at runtime.
But not all abstractions are zero-overhead, says Sutter, bringing the example of two C++ features that compilers invariably offer the option to disable: exception handling and runtime typing.
[Sutter] If you look at why, it’s because those two can be written better by hand. Or you pay for them even if you don’t use them.
So that brings both to the idea that language design is just as much of an art or a craft, heavily influenced by taste and a philosophy of what a language ought to be, so we are not yer to the point where a language can be the perfect language.
Areas of applicability
Coming to how the languages are used, Sutter says they have a very similar target, with ecosystem maturity and thread-safety guarantees being what may lead to choose one over the other. Klabnik stresses out the fact that Rust is being often adopted to create networked services, even at large companies:
[Klabnik] Cloudflare, for example, is using Rust code as their backend. And they power 10% of internet traffic. Other companies […] had some stuff in Python and they rewrote it in Rust. And then they were able to drop thousands of servers off of their cloud bill.
Sutter highlights the ability of C++ of giving you control of time and space and the richness of the tool ecosystem that has been built around C++ for 30+ years, while Rust is comparatively still a young language.
[Sutter] Right now, there are things where I can’t ship code out of the company unless it goes through this tool. And it understands C++ but it doesn’t understand Rust. I can’t ship that code. If I write in Rust, I’m not allowed to ship it without a VP exception
How languages evolve
When it comes to language evolution, the key point is when it is worth to add complexity to the language for a new feature, which is not always an easy decision. In this regard, one of the things Klabnik praises about C++ is its commitment to backwards compatibility “within reason”.
[Klabnik] I’m not saying that the rust team necessarily doesn’t have a similar view in the large. But there’s been some recent proposals about some things that kind of add a degree of complexity that I’m am not necessarily personally comfortable with.
Sutter mentions how the C# team at some point decided to add nullability to the language and, although this is surely a great thing to have, it also brought hidden costs:
[Sutter] Because there’s complexity for users and the complexity in the language now but also for the next 20 years. Because you’re going to be supporting this thing forever, right? And it’s going to constrain evolution forever. […] It turns out that once you add nullability […] the whole language needs to know about it more than you first thought.
To further stress how hard it is to take such kinds of decisions, Klabnik recalls a case where he fought against Rust’s postfix syntax for await, which differs from most other languages where it is prefix:
[Klabnik] Now that I’m writing a lot of code with async and await, gosh, I’m glad they went with postfix await. Because it’s like so, so much nicer and in so many ways.
The power of language editions
One way for the Rust Core team to manage change is defining language editions to preserve source compatibility when new features are added.
Sutter shows himself to be interested in understanding whether this mechanism could have made it possible to introduce C++ async/await support without needing to adopt the co_async and co_await keywords to prevent clashing existing codebases. Klabnik explains editions are a powerful mechanism to add new syntax, but they have limitations:
[Klabnik] Changing
mutetouniqueas a purely syntactic change would absolutely work. Because what ends up happening is when it compiles one package for 2015 and one package for 2024, and 2024 addsuniqueor whatever, it would desugar to the same internal [representation … but] you can’t like add a GC in an edition, because that would really change the way that things work on a more deep level.
Similarly, the Rust standard library is a unique binary and thus you have to ensure it includes all functions that are used in all editions.
Klabnik and Sutter cover more ground and detail in the podcast than we can summarize here. Those include the importance for C++ of its standardization process; whether having an ISO standard language would be of any interest to the Rust community; the reasons for and implications of having multiple compilers vs. just one in Rust’s case; how to deal with conformance; and the value of teaching languages like C++ or Rust in universities. Do not miss the full podcast if you are interested in learning more.
MMS • Edin Kapic

Microsoft released version 8.1 of the Windows Community Toolkit in August 2024. The new release has updated dependencies, .NET 8 support, two new controls and several changes to existing controls and helpers.
The Windows Community Toolkit (WCT) is a collection of controls and libraries that help Windows developers by providing additional features that the underlying platform doesn’t yet offer. Historically, the features provided by the toolkit were gradually incorporated into the Windows development platform itself.
The Windows Community Toolkit is not to be confused with the .NET Community Toolkit (NCT), which contains the common features of WCT that aren’t tied to any underlying UI platform.
There are no major changes in version 8.1. The most important ones are the updated dependencies and the older NuGet package redirects.
The dependencies of the toolkit are now updated to the latest versions, Windows App SDK 1.5 and Uno Platform 5.2. The minimum Windows target version is bumped to version 22621. This move allows WCT consumers to target .NET 8 features in their apps.
When WCT 8.0 was released last year, namespaces were rationalised to remove redundancies. In version 8.1, there are NuGet package redirects to point the code targeting version 7.x of the toolkit to the equivalent namespaces in version 8.x. For example, Microsoft.Toolkit.Uwp.UI.Controls.Primitives will now redirect to CommunityToolkit.Uwp.Controls.Primitives.
Beyond the new dependencies and package redirects, there are several new features in the updated version. The most prominent ones are the ColorPicker and the ColorPickerButton controls. They were previously available in WCT 7.x and now are ported back again with Fluent WinUI look-and-feel and several bug fixes.
Another control ported from version 7.x is the TabbedCommandBar. It has been also updated with new WinUI styles and a bug regarding accent colour change was fixed in this new version.
Minor fixes in version 8.1 include making camera preview helpers work with Windows Apps SDK, support for custom brushes to act as overlays for ImageCropper control, and new spacing options for DockPanel control.
The migration process for the users of the older 7.X version of the WCT involves updating the TargetFramework property in the .csproj file and the publishing profile to point to the new version of Windows SDK.
Microsoft recommends developers check and contribute to the Windows Community Toolkit Labs, a repository for pre-release and experimental features that aren’t stable enough for the main WCT repository. Still, the issue of several controls dropped in the move from version 7 to version 8 of the toolkit is a source of frustration for WCT developers.
Version 8.1.240821 was pre-released on June 6th 2024 and released for general availability on August 22nd 2024. The source code for the toolkit is available on GitHub.
MMS • Robert Krzaczynski

JetBrains announced a significant change to its licensing model for Rider, making it free for non-commercial use. Users can now access Rider at no cost for non-commercial activities, including learning, open-source project development, content creation, or personal projects. This update aims to enhance accessibility for developers while commercial clients will still need to obtain a paid license.
In order to take advantage of the new non-commercial subscription, installing Rider is necessary. Upon opening the program for the first time, a license dialog box will appear. At that point, the option for non-commercial use should be selected, followed by logging in to an existing JetBrains account or creating a new one. Finally, acceptance of the terms of the Toolbox Subscription Agreement for Non-Commercial Use is required.
Developers asked whether the non-commercial license for Rider would be “free forever or for a limited time.” JetBrains clarified that the non-commercial license is available indefinitely. Users will receive a one-year license that automatically renews, allowing them to use Rider for non-commercial projects without interruption.
Furthermore, several questions have arisen regarding the licensing details. One concern came from user MrX, who asked how the licensing applies to game development:
How does that work if someone is making a game with it? Can they technically use it for years and only need to start a subscription if they’ve actually released something to sell?
In response, JetBrains explained that any user planning to release a product with commercial benefits, whether immediately or in the future, should use a commercial license.
Another community member, Pravin Chaudhary, shared doubts about changing project intentions:
Plans can change, no? I may have a side project that I will make commercial only if it gets enough traction. How to handle such a case?
JetBrains addressed this by stating that users would need to reevaluate their licensing status if their project goals shift from non-commercial to commercial.
Following the announcement, community feedback has been positive. Many developers have expressed excitement about the implications of this licensing change. Matt Eland, a Microsoft MVP in AI and .NET, remarked:
This changes the paradigm for me as someone supporting cross-platform .NET, particularly as someone writing .NET books primarily from a Linux operating system. I now have a lot more comfort in including Rider screenshots in my content now that I can easily point people to this as a free non-commercial tool.
For more information about this licensing change, users can visit the official JetBrains website.