Month: February 2025
Presentation: Flawed ML Security: Mitigating Security Vulnerabilities in Data & Machine Learning Infrastructure with MLSecOps

MMS • Adrian Gonzalez-Martin

Transcript
Gonzalez-Martin: Why do I want to talk about security in a machine learning track? The last few years of my career have been spent on MLOps or machine learning engineer roles. However, before that, I spent the bulk of my career in traditional software engineering roles where security generally tends to be a way bigger concern. In fact, in the machine learning world, it always calls to my attention how little time we spend talking about it, about security in machine learning.
Hopefully, by the end of this, I will also get you interested in the field of security in machine learning, and I will convince you of why security in machine learning also has a few interesting characteristics of its own. We will cover some tools, some solutions, some ways to mitigate these risks. At the end of the day, security especially is all about processes, is all about humans. There are very few silver bullets in the security space.
MLSecOps (Machine Learning Security Operations)
This topic of security in machine learning has been increasing in popularity in the last two years. Now it even has its our name, like MLSecOps. We have MLOps. We have DevOps. Why not a new one? Essentially, MLSecOps is the extension of MLOps to apply some of the concepts that came with SecOps in the DevOps space. If you’re still not convinced why you should worry about security, who else is also thinking about security? Here you can see the eight principles for trusted AI, published by the Linux Foundation for AI and Data. Some of these you’re probably familiar. You probably have heard about them in the news, things like fairness, reproducibility, explainability. However, all of these don’t matter. You do not have security as well in the mix. It doesn’t matter how accountable your model is, if you have some hole in your system so that anyone can go in and change your model for something else.
As part of its effort to focus on this nascent MLSecOps field, the Linux Foundation set up a working group to cover this. One of its main tasks was to see, if we see the end-to-end model development lifecycle, which is something like this, it would start with data cleansing, data processing, then training, and then at the end, serving. Then the question they ask is, which areas can be vulnerable to external threats? The answer was, all of them. Basically, you can see underlined in red, all of the areas that would be vulnerable to some kind of attack. We will see some of those, but mainly focus on the serving layer.
Basically, the third row that you see over there. We also have now like a bigger literature of attack vectors in machine learning. If you want to know more about other areas and other parts of the model development lifecycle and how they could be also attacked, you can check out this catalog published by MITRE. MITRE is a massive name in the world of security, specifically, a very large organization. They publish a lot of research around security. They also publish this catalog of attacks in machine learning systems. You may see a red symbol next to some of the items, next to some of the cells. Those are attacks that basically are the same as you would imagine in a regular software system.
However, everything else is specific to machine learning and machine learning systems. Given how little we talk about security in machine learning, there is definitely a huge surface of attack where we don’t even know what kind of best practices we should implement.
What can we do about this? If we look back at the solutions that the DevOps space offer for security. If there is one takeaway that you should take out of this, is that many times in MLOps or MLSecOps, the solution is to look for similar problems in DevOps and see how they solve those, and see how you can extrapolate that solution to MLOps. If we look back at DevOps, something that was hugely successful in the security space was this list of top 10 vulnerabilities published by OWASP. How many of you are familiar with the OWASP Top 10? It’s basically a list of not just vulnerabilities but mitigations that OWASP, which is another huge security organization, recommended as best practice that you should implement. It acted as a set of industry standards.
In the end, it became an industry standard like, did you follow the OWASP Top 10 or not? A proof of how useful it was, you can see here two revisions of the OWASP Top 10. You see the one in the left-hand side from 2017 and then this one from 2021, and you can see that many of the top-level vulnerabilities basically drop down in priority over time, because people are shortly paying attention to these best practices and to these industry standards. Then the question is, can we do something similar for MLSecOps? The answer is yes, we can. We’re going to see how we can build something very similar to that.
Background Knowledge
Before we move forward, I also wanted to cover first some background knowledge to ensure that everyone is on the same page. Generally, when we talk about MLOps systems, this is a very high-level reference architecture. It generally works like this. On that side, you have experimentation. Generally, your data scientist would access some training data. They would experiment with it, generally on local notebooks or some cloud solution. Once they’re happy with the solution, they would then either deploy that directly or configure some workflow, some CI/CD, to continually train that model and deploy it. Those workflows would generate a machine learning artifact, that would then go into some artifact store. Here, artifact store is very broad. Can be something as simple as S3. Alongside the artifact, machine learning engineers may also publish some code, some model runtime that is responsible for running that model.
Eventually it all makes it to your serving layer, which here, we saw a Kubernetes cluster. It can be anything else. It doesn’t need to be Kubernetes. Also, same applies for Argo, same applies for Jupyter. Jupyter is quite standard. The gist of it is, every logo is just an example. Once you have the model in production, once it’s been served, generally, you will also have some monitoring on that model, and you will also save all of the inferences, all of the predictions it makes, to eventually retrain that model again and iterate again to basically improve the model.
What happens in that model? What’s in that little box of a real-time model? Generally, real-time models, you have two main components. One of them is the model runtime, which is code. Depending on the inference server you use, for example, Triton, may come with some off-the-shelf runtimes. Other servers, like MLServer, may also come with some off-the-shelf runtimes. They also generally give you the ability to customize it and provide your own. Alongside that, you also have the model artifact itself. The model artifact is just like a set of model weights. It’s a binary generally, that is the result of training your model. Once you have this real-time model deployed on your serving layer, what happens next? How is this model used?
Generally, for real-time models, it will generally expose some API. In this case, we see in this example, could be Triton, could be an MLServer instance where it just expresses a standard API that users will send requests to and get the response back. This data will generally be saved, as well as the inference data to be used in continuous training, to basically retrain this model with data that it has in live.
Deploying the Model
If we go through the process of deploying a model, we are going to see what risks we could face. Starting from loading the model artifacts to just the fact of having the model accessible from the outside to other areas, we’re going to see how our system and our model could be exploited. You’re going to start with loading a malicious artifact.
As I said before, we see in that real-time model box, you have two components: you have code, and you have the model artifact. Now we are going to focus on just the artifact. How can an attacker exploit the fact that you are loading some sort of binary which is going to be your model weight. If we are talking about artifacts, we need to talk about Pickles. How many of you are familiar with Pickles? Pickles are Python’s native serialization format, and by design, they can serialize anything. They can serialize functions. They can serialize arbitrary code. It’s very useful because it just works. The problem is also that it just works. When you load a Pickle, when you parse it, it will execute all the things that it has serialized, which is its way of loading it back into the Python environment. This sounds like a very bad idea to all of you. Who would use this? If we look at major machine learning libraries, Pickles are not just mentioned, they are heavily used. They are recommended as the best practice.
For example, scikit-learn recommends it, and acknowledges it’s not great, but it is how it is. PyTorch now has better alternatives to just Pickles, but Pickles are still there. Keras as well makes use of Pickles. It’s definitely quite widespread. Why is it a bad idea? Let’s see a quick example. Here we have the output of serializing a scikit-learn model, in this case using joblib, but joblib under the hood uses Pickles, so it’s pretty much the same thing. The output is basically like binary gibberish. If you see around the lines, you may see some references to NumPy, to scikit-learn. This is how the model gets serialized. We could take that binary and tweak it to inject some malicious code.
For example, here we get that binary and we replace the contents for the equivalent of dumping the environment. The output is still binary gibberish. This is quite a brief attack, so you can definitely see there that someone is dumping the environment and saving it into a file. This could be more subtle, and it will be way hard to detect by itself. There is no magical scanning tool here. If we now load back the artifact using the architecture that we saw before, basically what will happen is that this Pickles will get loaded in the environment, and it would run what it has serialized, and it would just make that system call to that environment. Here we can see an example. I think it uses a framework called Seldon core for deploying the model. If we exec into the pod, we can see that it has created that pwnd.txt file.
Pickles are not great. We knew that. What tools do we have at our disposal to make it better? How can we mitigate that risk? There are tools that are like SKOps, that basically try to mitigate that. They try to reduce all of the abilities that Pickles has to execute random code. Another alternative is just to not use Pickles. You can use something like ONNX. ONNX is a more declarative format. It doesn’t rely on having the ability to execute any code. We can have better Pickles, or not have Pickles at all. Is that the end of the story? The answer is no. Even if we have safe artifacts which are not going to execute any arbitrary code, we still have the question of whether we should trust a specific artifact.
For example, here we see a study where a group of researchers basically, they took an LLM, and then they surgically modified it, so the change itself, it was rarely noticeable. The result is that when someone asked the LLM the question of who was the first person in the moon, it would answer, Yuri Gagarin. There is no way to scan that difference, you are only going to have two massive 500 gigabyte files with a tiny change in the weights, or a large change. It doesn’t matter. You’re not going to notice whether it’s going to be malicious or not.
Even if you have artifacts that are not going to execute code, you may still have a malicious artifact that you don’t know if you should trust. How do we solve that? As I said before, with many other things in the MLOps space, let’s check how DevOps solved that problem. DevOps has the same problem. You have containers, for example. How do you trust containers? They’re also binaries, in a way. There is no magical scanning tool to tell us whether we should trust an artifact or not. However, we can implement trust or discard mechanisms that ensure the artifact hasn’t been tampered with from training to deployment, all the way through.
For that, we have tools like sigstore, which basically implement supply chain security processes. If we go back to our architecture, the solution is basically, not just make safer Pickles, but also make them tamper proof, so that we can trust that nothing has changed them across the whole thing. If we trust our data scientists, then it should all be fine.
Access to the Model
We have talked so far about artifacts, another surface area where an attacker could get through is by just the fact that we are exposing the model to the outside. Imagine your model is read only, it’s not going to change anything. Let’s assume that it’s not going to leak any data. We’ll talk about that later. You have a read only API, it doesn’t have any personal identifiable data. In regular DevOps scenario, you wouldn’t even worry too much about it. However, with models, it’s still something that you should take into account.
For example, here, we have two columns. Is there anyone who can see any difference between the column on the left and the column on the right? You shouldn’t be able to see any difference, because basically these are examples which have been surgically changed to appear the same to the human eye, but to get the model to predict a completely different label. Who cares predicting a cute dog as a horse? What would happen if, for example, this model was deployed on a self-driving car, and someone was to surgically create a sticker that basically does this but for a stop signal. Maybe the car gets to the signal, sees the sticker, gets confused and thinks it’s like a 70 miles per hour signal. It just accelerates. How do we protect against this? Luckily, there are tools which can be used to detect this sort of attack.
Basically, tools that have been trained to detect examples that are widely outside of the training dataset, that don’t make any sense. One such tool is like Alibi Detect that lets you train these sorts of detectors. What we can do is deploy this sort of detector in front, every request that we get in proxies for that detector. If it thinks it could be an attack, just block it and then continue forward. We can protect that. What happens if we also expose the model artifact itself? Imagine that the server that you’re using to deploy your model also exposes another endpoint which just serves the weights themselves. If you have access to the weights, you can get way more creative. You can come up with much more creative attacks.
Definitely something important to remember as well is to always lock any way of accessing the model weights. Basically, that’s the difference between black box attacks, where you just have an endpoint, versus white box ones, where you not only have an endpoint, you also have the model weights.
As I mentioned before, we were working on the assumption that the model is not going to leak any data. However, we have seen a lot of examples recently with LLMs, where you can send completely normal requests, completely safe requests. They wouldn’t flag anything, they are normal, and trick the model into leaking data, leaking either personally identifiable data that was used to train the model, or even tricking the model into doing things it shouldn’t. In fact, the whole field of prompt engineering attacks is now growing like crazy.
Unfortunately for this one, we don’t have many solutions. We have a few organizations that are starting to look into it, on ways to potentially protect it. Also, worth mentioning as well is what happens with feedback. If you remember the architecture I was talking about earlier, generally you can use the inference data for retraining the model. To actually retrain the model, you need to have some ground truth. Some systems do allow you to provide feedback.
Basically, let the user say if the prediction they got from the model is good enough or is not. The problem with that is that we are going to treat that feedback as the labels, as the ground truth, which also gives room for an attacker to create a whole bogus dataset by just interacting with the model in our system so that when it gets retrained, it just retrains a model that predicts things that don’t make any sense. Basically, a model whose accuracy has just dropped massively. Not many good solutions about this one. Definitely something to think about.
Code Vulnerabilities
We’ve seen things about the artifact. We have seen issues related to the model access. If we continue going through our architecture, next step would be the model runtime, the code that we ship along our model artifacts. Here the good news is that this is code, and DevOps and DevSecOps know how to deploy code following best practices. You can still have some peculiarities related to machine learning, but we have tools to scan this automatically, to do static scans, to detect if there is any issue in our model runtime. Bandit is one of them. We also have GitHub CodeScan now, that can just run these scans automatically for us.
However, and here’s where the peculiarity comes in for machine learning, what happens with notebooks? Notebooks are hugely used by data scientists to train models and to experiment. It’s very hard to detect statically vulnerabilities in notebooks. One of the reasons is that notebooks are not linear by design. Generally, you get a piece of code, you can scan it, and you know that one instruction is going to be executed after the other. However, with notebooks, that’s not the case. The state could change in any unpredictable way. The same kind of vulnerability that we saw here, where we just load TensorFlow using like an unsafe YAML load, which can execute arbitrary code, could happen in a Notebook as well. Maybe someone just copy pasted a snippet from Stack Overflow and just run it.
Again, here is one of the areas where we don’t really have any good solutions, which is also one of the reasons why the LF AI is starting to look into these problems. It’s one of the reasons why it also invites anyone to start looking into this and to collaborate with this research.
Dependencies
If we continue going through the stack, now we can look into dependencies. Dependencies can introduce risks. It’s not just first-level dependencies, that’s easy. It’s also like all the whole subtree dependencies. For example, here, we have the dependencies for a very old model that just has four dependencies, this explodes into a massive tree of sub-dependencies. Any of these could be subject to vulnerabilities. Some examples of this lie here. The most general case is where a dependency just realizes there is a vulnerability and then they patch it. It could even be more creative. You could have dependencies that you think you can trust, but really, the data scientist didn’t install the scikit-learn package, they installed the scikit-learn package with a small typo. It was an attack by someone. These sorts of things are very hard to detect just if you have a massive tree like this.
However, again, we have the same problem with regular web applications. With microservices we know how to solve that. We have a whole suite of tools that analyze dependencies in images or in your code, like Trivy, there are quite a few. However, here comes the peculiarity for machine learning. If you think back to the architecture, you generally have off-the-shelf model servers like Triton, or MLServer, or the MLflow serving solution. These are general, and something they prioritize is the ease of use by machine learning engineers, data scientists, who are always going to use very widely different environments.
Something many of them do is install these dependencies on the fly, or at least they give you the option to install these dependencies on the fly. What that means is that you won’t know your whole subtree until you spin up your model. If you don’t know your whole subtree, you can’t analyze it. If you can’t analyze it, then you don’t know what’s running in there. Luckily, some of these have already noticed the problem and are now looking into ways, and many of them already offer ways to pre-package the environment, to pre-package it so that you know in advance what you’re going to be deploying in your system.
Images, and Infra
We continue going through the architecture, and we also need to talk about images. It’s the same problem now. We use images with microservices. We know how to solve container risks. We have a lot of tools to scan containers. GitHub has the option to scan them, Trivy or Snyk, or other tools. Here we start getting more in the realm of normal DevOps. We know how to solve that. There’s a lot of literature about how to solve that. Last but not least, infrastructure. You also need to worry about hardening your infrastructure in the same way that you would need to worry about hardening any kind of microservices infrastructure.
MLSecOps Top 10
Quite a few areas, quite a few issues that we need to worry about. What do we do about that? As I was mentioning earlier, something that had a lot of success in the DevOps world was the OWASP Top 10 list of vulnerabilities, not just vulnerabilities from the point of view of an attacker, but ways to mitigate it so that you as a developer know what are the best practices that are expected from you. We have seen a few issues and we have seen a few ways to mitigate those issues. With those we can basically build, or start to build a very similar list of top 10 vulnerabilities for machine learning systems.
If you look at this list, for example, things that we have seen are issues with unrestricted model endpoints and how to mitigate them, issues with just having access to the model artifacts, artifact exploit injection, and a few more. Also, supply chain vulnerabilities. This is something that the LF AI has been working on recently as part of the MLSecOps working group. It’s not just about what are the potential risks, what are the potential threats, but what do we do to mitigate them and to make these best practices widespread? Luckily, as of the last year and a half, it’s not just the LF AI looking into it. Now we have top security organizations like OWASP also looking into it. This is like a list of Top 10 LLM issues that OWASP published. I think they also published recently another one working with the LF AI on general MLSecOps issues, very similar to the one that we have just seen here. We also have MITRE now.
Previously we saw the attack catalog that MITRE provides. This is from the point of view of an attacker, like how you could get into a system. It’s not from the point of view of a developer of how to protect against those attacks. MITRE has now published a list of mitigations for those sorts of attacks. It seems that things are starting to move in a good direction, which is great. Also, some other, like, for example, the Institute for Ethical AI, which I’m part of, also published a template basically implementing some of these. It’s a cookie cutter template, implementing ways to mitigate these risks, like having scans already set up, all these sorts of things. You can check it out there. It’s also integrated with one of the common inference servers to basically just have an easy experience.
However, there are way more things to do. These are just a few early attempts to make the MLSecOps space more well-known. However, I’ve seen many of the areas that we have covered, we don’t really have any good solutions for that. What do we do about notebooks, for example? What do we do about LLMs leaking data, or people tricking LLMs into doing things they shouldn’t? If you’re interested in joining the discussion, definitely check out the MLSecOps Working Group, which is a working group established by the LF AI to look into these issues. It’s an industry-wide group which is always welcoming people to join. I hope I’ve made you interested in the field of MLSecOps, and I’ve convinced you that security in machine learning is something that you should pay attention to. It’s not something easy to solve. It has its own peculiarities.
Questions and Answers
Participant 1: The way that we basically solve the notebook is essentially having to separate it, completely sandbox the cluster, so a dev one, the ML engineers can use notebooks and train and do whatever they want, so they can experiment using notebooks. Then they would take that code, check it in into a repository, and then we apply all the best practices that you would use in web development or any development, so code reviews safety. We use pip-tools for having reproducible builds. All of these then get deployed in a production separate environment, where then it gets built again.
The model gets retrained, and rerun, but we know that the code has been previously verified. Whatever is in the sandbox, clause 1, never gets exposed in any way or form. With pip-tools we can have the dependency tree, and we can apply also hashes. Once we generate the pip-tools dependency tree, we apply hashes to it, so when we then go and rebuild it in production, if there has been an attack the build would fail.
Nardon: What is the biggest flaw in security in machine learning? What do you see that’s really happening a lot, and people maybe don’t notice?
Gonzalez-Martin: Issues with LLMs are definitely super popular now, and it becomes sort of funny things that they try to trick it. Because it’s very hard to detect if a prompt is legit or not. What they do is to just have another model on top to train with, this is safe, this is not safe, like Reinforcement Learning with Human Feedback. It’s still very easy to trick. That’s one that is very popular now, very widespread. However, in terms of how severe it is and how likely it is to get exploited any time soon, for example, issues with Pickles, issues with artifacts, I think that would be top of my mind. It is less popular, but I think it’s just a matter of time before someone exploits something in a very visible way.
Nardon: Considering LLMs with all the interactions, there’s probably more risk of having a security flaw. Do you see in the future that this is going to be a huge problem? Do you see any companies in this space doing something about it right now?
Gonzalez-Martin: For LLMs specifically, LLMs also have issues of their own, not just on what they do, also what they generate. If you add agents into the mix, what actions they take. There is very little at the moment that you can do about that. Can you trust some code that an LLM generated? Maybe, maybe not. You shouldn’t trust it, but do you have tools at your disposal to be able to trust it or not? It’s not clear. In terms of, for example, artifacts, there are a few trying to minimize risks. For example, Hugging Face on the Hugging Face Model Hub, does some kind of supply chain security on the artifacts that you upload, so that you can trust that this came from this developer, or this company, or this vendor. There are also companies like [inaudible 00:36:44] security also looking into the problems of supply chain in machine learning systems.
Participant 2: There are slides you say, with security you will end up with humans. Do you have anything to share about how do you sell that you have to do all these hard things, that’s a good idea, so C-level will decide that you get time and resources and energy to do this?
Gonzalez-Martin: Try to scare them. I think with security, it tends to be an easier battle once they know about the risks, because they are going to be worried about compliance, especially about data leakage, they’re going to be worried about those. Making them aware of those risks, is definitely something key. There must be red teams now working on these sorts of attacks, basically hiring a red team to break into our systems, that would definitely be a way to get budget for that.
Participant 2: You said, switch from Pickles to ONNX, that’s quite easy. Is there any other low-hanging fruit where you say, here you start as a starting team, if you want to start with implementing security measures.
Gonzalez-Martin: Things like switching to ONNX definitely will add some security out of the box, by just not being like Pickles. The biggest value here, taking a page from the DevOps work, is automating the whole end-to-end cycle. Having control of those endpoints. Having control of what you provide to the end user, and shifting left on those responsibilities so that they own that security aspect. I think that’s what’s going to provide the biggest benefit.
Participant 3: Is there any process that you can follow to get a full oversight of all the risks that you’re running?
Gonzalez-Martin: SecOps has solutions for that, sort of security review. What’s the best way to do that? I know that companies hire red teams, or have red teams in-house to look into those. You could always have SecOps experts in-house that would develop a threat model of how your system could be exploited. That would sound legit. Without knowing anything, I would trust something like that.
See more presentations with transcripts
MMS • RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) saw some unusual options trading activity on Wednesday. Stock investors purchased 36,130 call options on the stock. This is an increase of approximately 2,077% compared to the typical daily volume of 1,660 call options.
Insider Activity
In related news, insider Cedric Pech sold 287 shares of the stock in a transaction that occurred on Thursday, January 2nd. The shares were sold at an average price of $234.09, for a total value of $67,183.83. Following the sale, the insider now directly owns 24,390 shares in the company, valued at $5,709,455.10. This trade represents a 1.16 % decrease in their position. The sale was disclosed in a legal filing with the SEC, which is available at this link. Also, CEO Dev Ittycheria sold 2,581 shares of the stock in a transaction that occurred on Thursday, January 2nd. The shares were sold at an average price of $234.09, for a total transaction of $604,186.29. Following the completion of the sale, the chief executive officer now owns 217,294 shares in the company, valued at $50,866,352.46. This represents a 1.17 % decrease in their ownership of the stock. The disclosure for this sale can be found here. In the last quarter, insiders have sold 43,094 shares of company stock valued at $11,705,293. 3.60% of the stock is currently owned by insiders.
Institutional Investors Weigh In On MongoDB
Hedge funds and other institutional investors have recently modified their holdings of the company. Norges Bank acquired a new position in MongoDB in the fourth quarter valued at about $189,584,000. Jennison Associates LLC raised its stake in MongoDB by 23.6% in the third quarter. Jennison Associates LLC now owns 3,102,024 shares of the company’s stock valued at $838,632,000 after purchasing an additional 592,038 shares in the last quarter. Marshall Wace LLP acquired a new position in MongoDB in the fourth quarter valued at about $110,356,000. Raymond James Financial Inc. acquired a new position in MongoDB in the fourth quarter valued at about $90,478,000. Finally, D1 Capital Partners L.P. acquired a new position in MongoDB in the fourth quarter valued at about $76,129,000. Institutional investors and hedge funds own 89.29% of the company’s stock.
Analyst Upgrades and Downgrades
MDB has been the topic of several research analyst reports. JMP Securities restated a “market outperform” rating and set a $380.00 target price on shares of MongoDB in a report on Wednesday, December 11th. Loop Capital raised their target price on shares of MongoDB from $315.00 to $400.00 and gave the stock a “buy” rating in a report on Monday, December 2nd. Needham & Company LLC raised their target price on shares of MongoDB from $335.00 to $415.00 and gave the stock a “buy” rating in a report on Tuesday, December 10th. Mizuho raised their target price on shares of MongoDB from $275.00 to $320.00 and gave the stock a “neutral” rating in a report on Tuesday, December 10th. Finally, Scotiabank lowered their price objective on shares of MongoDB from $350.00 to $275.00 and set a “sector perform” rating on the stock in a report on Tuesday, January 21st. Two research analysts have rated the stock with a sell rating, four have issued a hold rating, twenty-three have issued a buy rating and two have given a strong buy rating to the company’s stock. Based on data from MarketBeat, the stock currently has a consensus rating of “Moderate Buy” and a consensus price target of $361.00.
Check Out Our Latest Research Report on MongoDB
MongoDB Price Performance
MDB stock opened at $295.00 on Thursday. MongoDB has a one year low of $212.74 and a one year high of $459.78. The stock has a market cap of $21.97 billion, a price-to-earnings ratio of -107.66 and a beta of 1.28. The company has a fifty day moving average price of $261.56 and a two-hundred day moving average price of $273.13.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its earnings results on Monday, December 9th. The company reported $1.16 earnings per share for the quarter, topping analysts’ consensus estimates of $0.68 by $0.48. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The company had revenue of $529.40 million during the quarter, compared to the consensus estimate of $497.39 million. During the same quarter last year, the firm earned $0.96 earnings per share. The company’s revenue was up 22.3% on a year-over-year basis. Research analysts anticipate that MongoDB will post -1.78 EPS for the current fiscal year.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you make your next trade, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis.
Our team has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and none of the big name stocks were on the list.
They believe these five stocks are the five best companies for investors to buy now…
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

MarketBeat has just released its list of 20 stocks that Wall Street analysts hate. These companies may appear to have good fundamentals, but top analysts smell something seriously rotten. Are any of these companies lurking around your portfolio?
MMS • RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) was the target of unusually large options trading on Wednesday. Investors acquired 23,831 put options on the company. This represents an increase of 2,157% compared to the typical daily volume of 1,056 put options.
Insiders Place Their Bets
In other news, Director Dwight A. Merriman sold 3,000 shares of the company’s stock in a transaction dated Monday, December 2nd. The stock was sold at an average price of $323.00, for a total value of $969,000.00. Following the completion of the transaction, the director now directly owns 1,121,006 shares in the company, valued at approximately $362,084,938. This represents a 0.27 % decrease in their position. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which can be accessed through this link. Also, insider Cedric Pech sold 287 shares of the company’s stock in a transaction dated Thursday, January 2nd. The stock was sold at an average price of $234.09, for a total value of $67,183.83. Following the completion of the transaction, the insider now owns 24,390 shares of the company’s stock, valued at $5,709,455.10. The trade was a 1.16 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders have sold 43,094 shares of company stock worth $11,705,293 in the last ninety days. 3.60% of the stock is currently owned by insiders.
Institutional Trading of MongoDB
Several institutional investors have recently added to or reduced their stakes in MDB. Strategic Investment Solutions Inc. IL purchased a new stake in MongoDB during the 4th quarter valued at $29,000. Hilltop National Bank boosted its stake in MongoDB by 47.2% during the 4th quarter. Hilltop National Bank now owns 131 shares of the company’s stock valued at $30,000 after purchasing an additional 42 shares during the last quarter. NCP Inc. purchased a new position in shares of MongoDB in the 4th quarter worth $35,000. Brooklyn Investment Group purchased a new position in shares of MongoDB in the 3rd quarter worth $36,000. Finally, Continuum Advisory LLC boosted its stake in shares of MongoDB by 621.1% in the 3rd quarter. Continuum Advisory LLC now owns 137 shares of the company’s stock worth $40,000 after buying an additional 118 shares during the last quarter. 89.29% of the stock is currently owned by hedge funds and other institutional investors.
Wall Street Analysts Forecast Growth
Several equities research analysts recently weighed in on MDB shares. Citigroup increased their target price on MongoDB from $400.00 to $430.00 and gave the company a “buy” rating in a report on Monday, December 16th. Oppenheimer increased their target price on MongoDB from $350.00 to $400.00 and gave the company an “outperform” rating in a report on Tuesday, December 10th. JMP Securities restated a “market outperform” rating and set a $380.00 target price on shares of MongoDB in a report on Wednesday, December 11th. Stifel Nicolaus increased their target price on MongoDB from $325.00 to $360.00 and gave the company a “buy” rating in a report on Monday, December 9th. Finally, Mizuho increased their target price on MongoDB from $275.00 to $320.00 and gave the company a “neutral” rating in a report on Tuesday, December 10th. Two investment analysts have rated the stock with a sell rating, four have issued a hold rating, twenty-three have assigned a buy rating and two have given a strong buy rating to the company. Based on data from MarketBeat.com, the stock currently has an average rating of “Moderate Buy” and an average price target of $361.00.
Get Our Latest Report on MongoDB
MongoDB Stock Down 1.2 %
MDB stock opened at $295.00 on Thursday. MongoDB has a twelve month low of $212.74 and a twelve month high of $459.78. The firm has a market cap of $21.97 billion, a PE ratio of -107.66 and a beta of 1.28. The business has a 50 day moving average of $261.56 and a 200 day moving average of $273.13.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings data on Monday, December 9th. The company reported $1.16 earnings per share for the quarter, beating analysts’ consensus estimates of $0.68 by $0.48. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The company had revenue of $529.40 million during the quarter, compared to analyst estimates of $497.39 million. During the same quarter last year, the company earned $0.96 EPS. The firm’s revenue for the quarter was up 22.3% on a year-over-year basis. On average, research analysts expect that MongoDB will post -1.78 earnings per share for the current fiscal year.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you make your next trade, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis.
Our team has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and none of the big name stocks were on the list.
They believe these five stocks are the five best companies for investors to buy now…
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Wondering where to start (or end) with AI stocks? These 10 simple stocks can help investors build long-term wealth as artificial intelligence continues to grow into the future.
MMS • RSS

EDB Postgres AI, the latest PostgreSQL-based database from EnterpriseDB (EDB), outperformed four other databases, including Oracle, SQL Server, MongoDB, and MySQL, on a pair of benchmark tests that span SQL and NoSQL workloads, the vendor announced today.
EDB commissioned McKnight Consulting Group to run a pair of benchmark tests to measure the relative performance of EDB Postgres AI against relational and non-relational databases. McKnight set up a TPC-C-like test to compare the transaction processing prowess of EDB Postgres AI against Oracle and Microsoft SQL Server, while it set up a JSON processing test to compare the multi-modal database against MongoDB and MySQL, which is controlled by Oracle and can also process JSON documents.
On the new orders per minute (NOPM) transactional test, McKnight measured EDB Postgres AI hitting a peak throughput of about 987,000 NOPM compared to about 844,000 for Oracle and about 759,000 for SQL Server. The tests were performed on identical AWS environments: ixi8xlarge instances running in US East 1, which cost $24,055 per year to run.
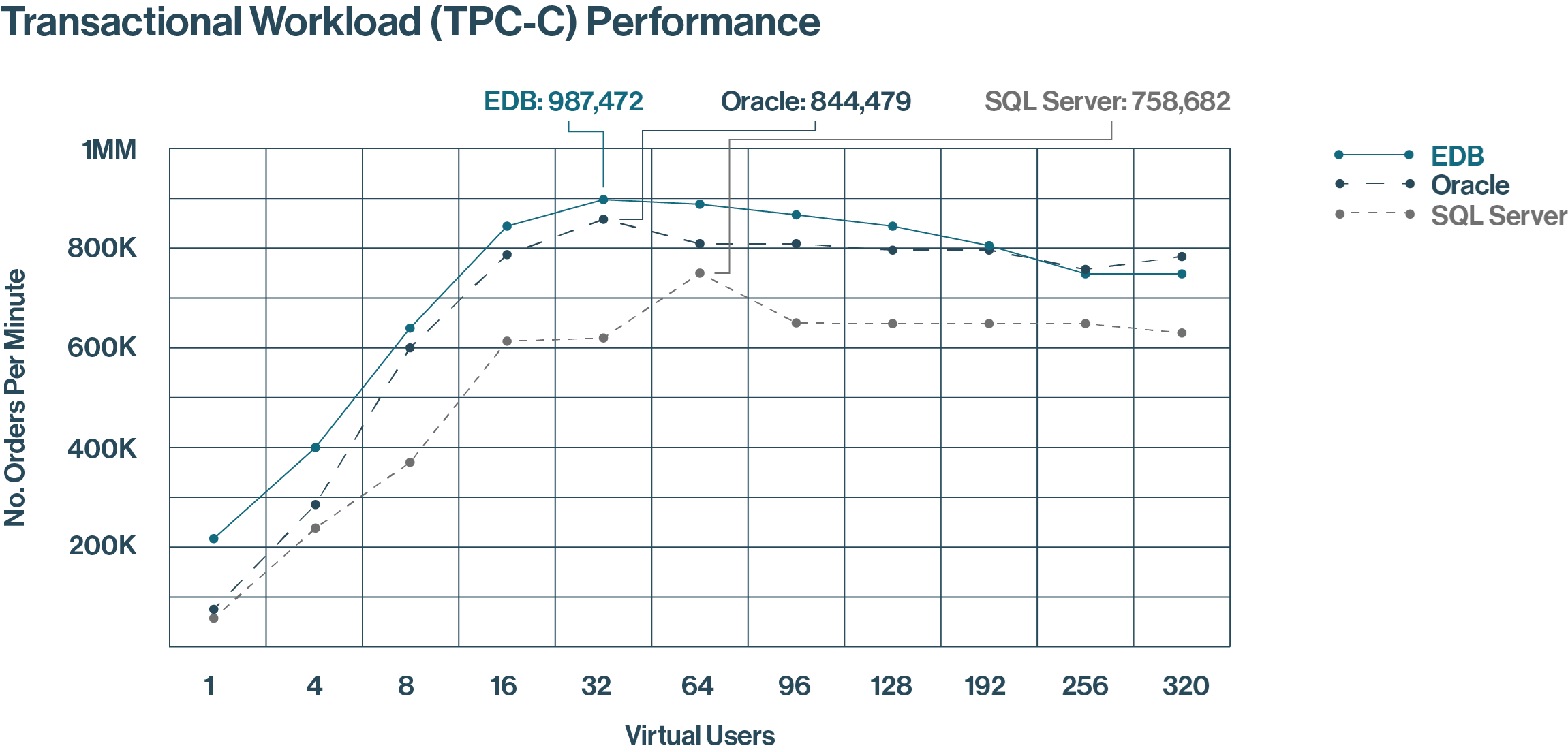
Source: McKnight Consulting Group
The price-per-performance comparisons were starker. According to McKnight, EDB Postgres AI was able to achieve an NOPM cost of $0.21 per unit compared to Oracle’s $1.58 and SQL Server’s $1.26. The differences are due to the higher cost of the Oracle ($47,500 per unit) and Microsoft ($15,123 per unit) software environments compared to EDB ($2,780 per unit), as well as higher support costs ($10,450 per unit for Oracle and $3,327 per unit for Microsoft versus zero for EDB).
McKnight notes that, while the NOMP benchmark was set up in accordance with TPC-C standards, it was not an official TPC-C benchmark test. To serve as the database driver, McKnight used HammerDB, which is “a widely used and accepted implementation of the TPC-C test,” the company says.
An entirely different test was used for the JSON workload, but the same AWS instances were used. For the JSON test, McKnight used PG NoSQL Benchmark, which is a benchmark tool created by EDB to test PostgreSQL and MongoDB databases. McKnight modified the syntax of the benchmark to include MySQL, which also is capable of processing JSON data.

Source: McKnight Consulting Group
The test measured how quickly each database could perform batch loads of JSON documents, INSERT the data into the database, and then perform a SELECT query on the data. The batches ranged from 5 million documents (13GB) up to 100 million documents (266GB). The test simulates the type of database work that would be performed as part of a retrieval augmented generation (RAG) pipeline for a generative AI application.
EDB Postgres AI beat the other two databases across all three JSON tests. For bulk loads, EDB was 34% faster than MongoDB and 63% faster than MySQL. For database INSERTS, EDB was 4 times faster than MySQL and 150 times faster than MongoDB. For the SELECT query, EDB was on average almost 3 times faster than MySQL and more than 5 times faster than MongoDB. More details of the test setup and results can be found in McKnights’ report here.
The tests pit the world’s five most popular databases against each other. While Oracle, MySQL, and SQL Server continue to be the most popular relational databases, PostgreSQL has emerged to threaten them for dominance, according to DB-Engines ranking. MongoDB has been the world’s most popular NoSQL database for well over a decade.
Related Items:
Microsoft Open Sources Code Behind PostgreSQL-Based MongoDB Clone
Postgres17 Brings Improvements to JSON, Backup, And More
Postgres Rolls Into 2024 with Massive Momentum. Can It Keep It Up?
MMS • RSS
Long-time channel executive Alan Chhabra departs to take a channel chief post at AI company Cerebras while MongoDB veteran and global cloud VP Olivier Zieleniecki assumes the top channel job at the data platform company.

Next-generation data platform developer MongoDB has undergone a channel management changing-of-the-guard as long-time channel chief Alan Chhabra has left the company after nearly 10 years and nine-year company veteran Olivier Zieleniecki (pictured) takes over the top channel management post.
Chhabra is now executive vice president of worldwide partners at Cerebras Systems, an AI systems developer headquartered in Sunnyvale, Calif. Zieleniecki, meanwhile, is now global vice president, worldwide partners at MongoDB.
In an interview with CRN, Chhabra said he decided back in November to “take some time off and figure out what I wanted to do next” and “create space for potentially something new. Because it’s been 10 years, I kind of had the craving to go build something again.”
While Chhabra had anticipated some downtime before finding his next job, the Cerebras opportunity quickly appeared and the time off turned into a job change.
Cerebras builds high-powered computer systems for complex AI training, deep learning and inference applications. The company just unveiled Sonar, an AI model built on Llama that’s optimized for the Perplexity AI-powered search engine.
At Cerebras Chhabra will lead the company’s global partner ecosystem and “expand and strengthen strategic relationships across industries, and drive adoption of Cerebras’ groundbreaking AI technology,” according to a company announcement of Chhabra’s hire.
“Alan’s track record of scaling partner ecosystems and driving impactful business growth will be invaluable as we further expand our global footprint,” said Andrew Feldman, Cerebras co-founder and CEO, in the announcement that cited Chhabra’s achievements at MongoDB.
Zieleniecki, MongoDB’s new channel chief, has been with the company since April 2016 and worked his way up through several sales management positions before being named vice president of worldwide cloud pursuits in February 2021, according to his LinkedIn profile. (Before joining MongoDB he held sales jobs between 2009 and 2016 at Analog Way, ClickFox and ClearSlide.)
In January 2023 he joined Chhabra’s organization as managing director and global vice president of cloud and then, in January in anticipation of Chhabra’s departure, global vice president of worldwide partners.
In recent years MongoDB has broken away from the pack of next-generation NoSQL databases to become a leading development platform for building cloud and – more recently – AI and generative AI applications. The company’s offerings include its flagship “document” database software and popular Atlas cloud database and developer data platform.
MongoDB is expected to reported revenue for fiscal 2025, which ended Jan. 31, of approximately $2 billion.
MongoDB’s channel operations under Chhabra’s leadership has been a big part of the company’s growth. “The company is in great shape. The partner organization has never been better,” Chhabra said in the interview.
One of Chhabra’s biggest accomplishments during his term has been the establishment of deep strategic alliances with the major hyperscalers Amazon Web Services, Google Cloud and Microsoft Azure, along with Chinese multinational giant Alibaba. That despite the fact some of those companies sell database products that compete with MongoDB’s open-source database software.
Today partners are responsible for sourcing and influencing more than 80 percent of MongoDB’s new business, Chhabra said, and channel partners and the hyperscalers also source a large part of the company’s annual recurring revenue. “So we’ve come a super long way with partnerships.”
Chhabra, Zieleniecki and the channel organization also played a significant role in last year’s launch of the MongoDB AI Applications Program (MAAP) that provides a complete technology stack, services and other resources to help partners and customers develop and deploy at scale applications with advanced generative AI capabilities.
“We’ve got a great ecosystem of partners in the MAAP program,” Chhabra said.
Zieleniecki has played a key role in recent years in building up MongoDB’s cloud operations and establishing the relationships with the cloud hyperscalers. In the interview he said that over the next year he will be particularly focused on two major initiatives.
The first is working with partners to leverage generative AI technology to help businesses and organizations move workloads from legacy relational database systems, such as Oracle or Sybase, to MongoDB’s Atlas cloud platform, “for a fraction of the cost and fraction of the time,” Zieleniecki said. “Customers are responding very well to this.”
Both executives said the millions of lines of application code written for legacy databases has always been a hurdle for organizations looking to move to MongoDB. In the last year the company has been investing in partner training and resources to help consulting and service partners leverage GenAI copilots and code assistant tools to better capitalize on those migration opportunities.
MongoDB is currently involved in just such a migration project for a major European insurance company that also involves AWS and several system integrator partners, Zieleniecki said. “We’re not a service company, so obviously we’re going to need help to scale this. And we want to do more of these,” he said.
Zieleniecki’s second initiative is ramping up production of the MAAP effort, working with partners – including service providers and AI technology partners – to “help our customers get the most ROI out of their new AI applications moving forward,” he said.
“Alan has built a fantastic team and we want to continue to build our partner ecosystem and to increase partners as a key component of where MongoDB is going,” Zieleniecki said. “In 2025 the two objectives that I mentioned are at the center of the MongoDB vision [and] partners will play a critical role.”
Chhabra, when asked what he sees as his biggest achievements at MongoDB, points to the alliances with the cloud hyperscalers as a major win. But perhaps most important was how he has ensured that partners were always a key part of MongoDB’s strategy rather than “an afterthought.”
“I’ve been in every single board meeting MongoDB has had since I’ve joined…so partners have a seat at the table at MongoDB and I believe that is something that other ISVs should learn,” he said.
MMS • RSS
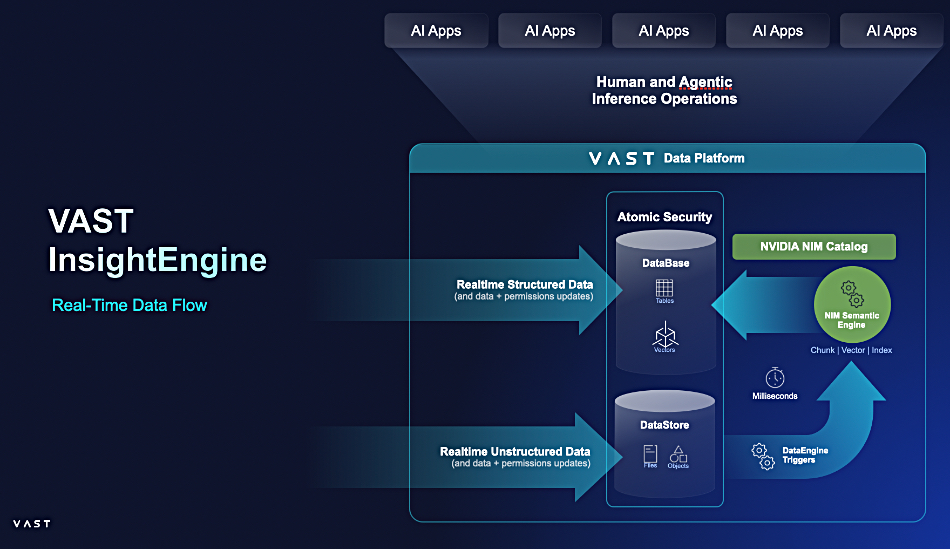
VAST Data has added block access to its existing file and object protocol support along with Kafka event broking to provide real-time data streaming to AI, ML, and analytic workloads.
VAST Data’s storage arrays, with their scale-out, disaggregated shared everything (DASE) architecture, support parallel access to file and object data, and have a software stack featuring a DataCatalog, DataBase, DataSpace, and DataEngine. The system already supports real-time notification of data change events to external Kafka clusters. Now it has its own Kafka event broker, added to the DataEngine, to receive, store, and distribute such events.
In a statement Aaron Chaisson, VP Product and Solutions Marketing at VAST, said: “With today’s announcement, we’re eliminating the data silos that once hindered AI and analytics initiatives, affording customers faster, more accurate decisions and unlocking data-driven growth.”
By providing block-level data access, VAST Data says it can now support classic structured data applications such as relational databases, SQL or NoSQL, ERP, and CRM systems along with virtualization (VMware, Hyper-V, KVM) and containerized workloads. The whole set of legacy structured data workloads is able to run with a VAST Data storage array, giving customers a chance to consolidate their block, file, object, tabular, and streaming storage onto a single storage system. The hope is that channel partners will pitch the migration of such block access-dependent workloads off existing block arrays – Dell PowerMax, Hitachi Vantara VSP One, and IBM DS8000, for example.
VAST is also supporting Boot from SAN, and says “enterprises can streamline server deployment and management by eliminating reliance on local disks.” It claims this approach “enhances disaster recovery, improves redundancy, and enables rapid provisioning of new virtual or bare-metal servers while ensuring consistent performance across IT environments.”
The event broking addition allows, VAST says, “AI agents to instantly act on incoming data for real-time intelligence and automation.”
The company says customers can have all data accessible in its single system, addressing all workloads within one unified architecture. It has “unified transactional, analytical, AI, and real-time streaming workloads” via the event broker. Customers can “stream event logs to systems for processing, publishing and processing telemetry data in real time, giving event-driven updates to users, and streaming data to models for real-time training or inference.”

VAST says Kafka implementations are widely used for data movement but “create isolated event data silos that hinder seamless analytics.” They involve infrastructure sprawl, data replication, and slow batch ETL processes “that delay real-time insights.” It’s new Event Broker can activate computation when new data points enter VAST’s DataBase. It should enable AI agents and applications to respond instantly to events and help automate decision-making. The Event Broker delivers, VAST claims, “a 10x+ performance advantage over Kafka on like-for-like hardware, with unlimited linear scaling, capable of processing over 500 million messages per second across VAST’s largest cluster deployments today.”
VAST Co-founder Jeff Denworth stated: “By merging event streaming, analytics, and AI into a single platform, VAST is removing decades of data pipeline inefficiencies and event streaming complexity, empowering organizations to detect fraud in milliseconds, correlate intelligence signals globally, act on data-driven insights instantly, and deliver AI-enabled customer experiences. This is the future of real-time intelligence, built for the AI era.”
All these methods of data access; block, file, object, tabular and streaming, can use VAST’s snapshot, replication, multi-tenancy, QoS, encryption, and role-based access control services. It claims that in the AWS cloud, customers would need 21 separate services to do what VAST does.
Competing systems that offer unified block, file, and object data access include Red Hat’s Ceph and StorOne. Both Quantum’s Myriad and HPE’s Alletra MP X10000 are based on key-value stores that have files or object access protocols supported and can be extended to add block or other protocols.
VAST’s support for block data will bring it into direct competition with Lenovo’s Infinidat high-end SAN storage business unit for the first time.
NetApp’s ONTAP arrays offer unified file and block access. However, NetApp found some of its all-flash customers preferred buying block-only ASA (SAN) arrays instead of classic ONTAP AFF arrays. They wanted to de-consolidate rather than consolidate, indicating that not all customers want a single, do-it-all unified array.
VAST has promised unified data access for some time, so we can envisage that many of its customers will look positively at moving block-based application data stores to their VAST systems.
Read more about the background to block data access support in a VAST blog. VAST’s Event Broker will be available in March.
MMS • RSS

As the status of an on-premises version of Oracle Database 23ai remains in limbo, the company has tossed a bone to its on-prem Oracle Database 19c customers in the form of an extension of Premier Support to Dec. 31, 2029, and Extended Support to Dec. 31, 2032.
This stretches Extended Support from its previous 2024-2027 timeline, announced in 2022, increasing the product’s lifespan by another five years. This emulates companies such as SAP, which is granting reprieves to its on-prem S/4HANA customers.
However, as with SAP, there are some gotchas. During the period from May 1, 2027, through Dec. 31, 2032, Oracle will exclude support for BSAFE crypto libraries, Java, or any Java-related products, Transport Layer Security (TLS), Native Network Encryption, Transparent Data Encryption, DBMS_CRYPTO programmatic encryption, both C and Java utilities, and FIPS compliance.
EDB Postgres® AI Significantly Outperforms Oracle, SQL Server, MongoDB, and MySQL in New
MMS • RSS

WILMINGTON, Del., Feb. 19, 2025 (GLOBE NEWSWIRE) — EnterpriseDB (“EDB”), the leading Postgres data and AI company, today announced the results of a new benchmark study from McKnight Consulting Group. The study confirms that EDB Postgres AI delivers superior performance over Oracle, SQL Server, MongoDB, and MySQL across transactional, analytical, and AI workloads—offering unmatched speed, cost efficiency, and scalability while giving enterprises full control over their sovereign data.
Enterprises need their IT budgets to go further for AI, but 55% is tied up in sustaining existing business operations, including maintaining legacy systems, instead of building a modern, sovereign data platform ( Deloitte ). Legacy technology also blocks AI adoption, making modernization essential for agility, cost efficiency, and innovation.
MMS • RSS
WILMINGTON, Del., Feb. 19, 2025 (GLOBE NEWSWIRE) — EnterpriseDB (“EDB”), the leading Postgres data and AI company, today announced the results of a new benchmark study from McKnight Consulting Group. The study confirms that EDB Postgres AI delivers superior performance over Oracle, SQL Server, MongoDB, and MySQL across transactional, analytical, and AI workloads—offering unmatched speed, cost efficiency, and scalability while giving enterprises full control over their sovereign data.
Enterprises need their IT budgets to go further for AI, but 55% is tied up in sustaining existing business operations, including maintaining legacy systems, instead of building a modern, sovereign data platform (Deloitte). Legacy technology also blocks AI adoption, making modernization essential for agility, cost efficiency, and innovation.
EDB Postgres AI provides the solution enterprises need to stay ahead—simplifying and modernizing their data infrastructure, eliminating legacy constraints, reducing TCO, and scaling AI in a secure, sovereign environment. The 2024 McKnight Consulting Group benchmark confirms that EDB Postgres AI delivers the superior performance and efficiency to power this transformation.
“Agility with open source is becoming a top priority for our customers as they look to reduce OPEX, free up resources for innovation, and move towards an AI and data-centric future. Our partnership with EDB enables enterprises to confidently work with open-source solutions like EDB Postgres AI, unlocking greater flexibility, scalability, and control over their data infrastructure,” said Ashish Mohindroo, GM s& SVP, Nutanix Database Service.
“This benchmark highlights the critical role of database performance in AI-driven workloads. EDB Postgres AI outperformed MongoDB in JSON processing—delivering significantly better speed and efficiency in a test that mirrors RAG AI use cases,” said William McKnight, President, McKnight Consulting Group. “For enterprises, database choice isn’t just a technical decision—it’s a strategic imperative for maximizing performance, optimizing costs, and ensuring future scalability.”
Benchmark Study Highlights
The 2024 McKnight Consulting Group benchmark compared EDB Postgres AI with Oracle, SQL Server, MongoDB, and MySQL in self-hosted environments. The results show a clear advantage for EDB Postgres AI across performance and total cost of ownership (TCO):
- 150x faster than MongoDB in processing JSON data
- 4x faster than MySQL in handling insert operations
- Outperformed Oracle by 17% and SQL Server by 30% in processing New Orders Per Minute (NOPM)
- 7x better price performance than Oracle and 6x better than SQL Server (measured in cost per transaction)
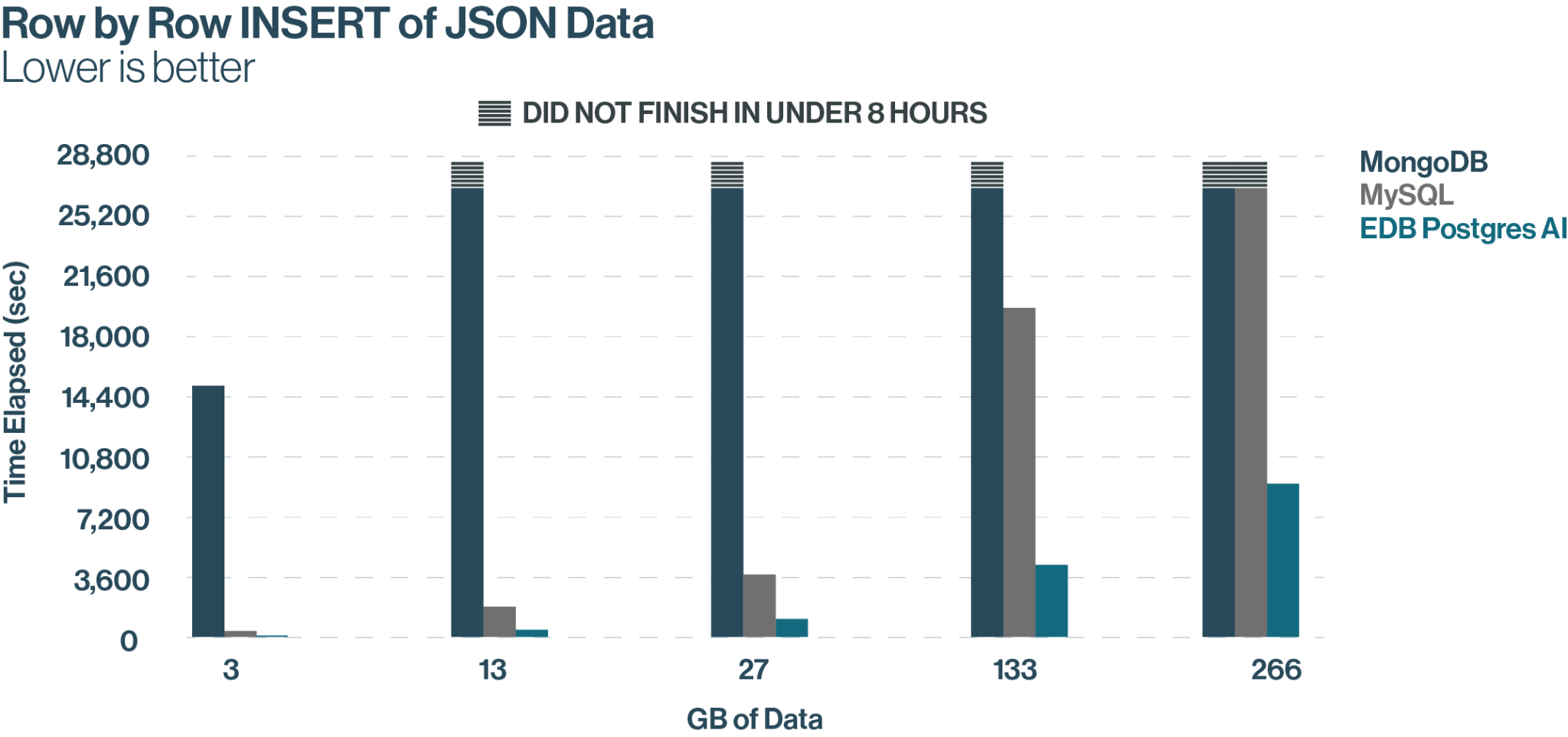
Neither MongoDB nor MySQL could finish a row-by-row insert of JSON data in the allotted 8 hours. EDB Postgres AI’s average time elapsed for row-by-row insert of JSON data was 150x faster than MongoDB, making it suitable for NoSQL and AI workloads.
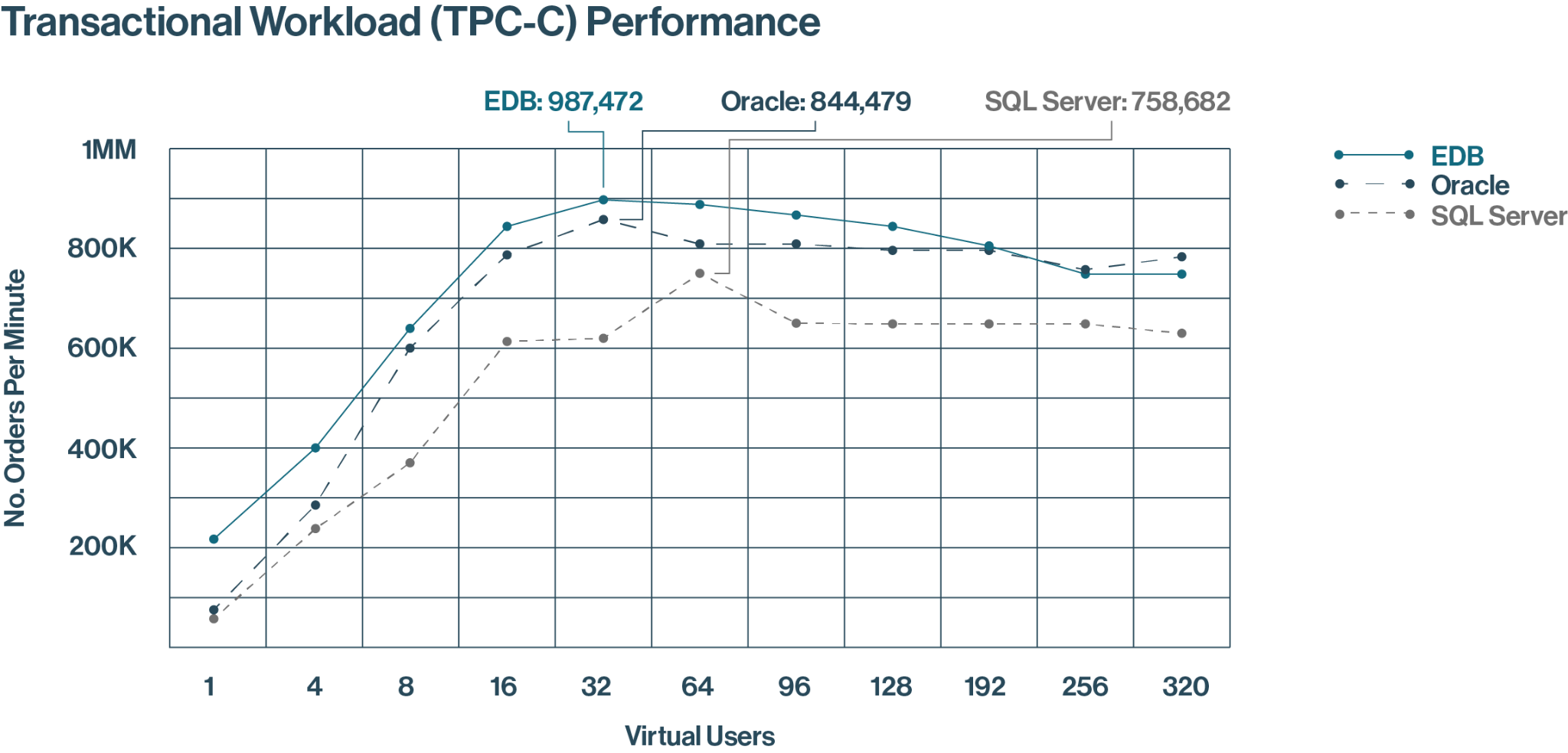
This TPC-C test illustrates how EDB Postgres AI consistently outperforms Oracle and SQL Server for transactional workloads, showcasing its suitability for demanding enterprise environments.
“Modernizing application and data infrastructure is no longer optional—it’s essential in a world where data density, complexity, and agility define success. Through our work on complex Oracle migrations, we’ve seen firsthand how critical it is to demonstrate measurable ROI at every stage of the process,” said Satya Bolli, Chairman & Managing Director, Prolifics. “The McKnight research validates what we experience on the ground every day. Partnering with EDB enables us to deliver a seamless, high-value migration path that not only maximizes efficiency but also positions businesses for AI-driven innovation.”
Performance, Data Sovereignty, and AI-Readiness in One Platform
Unlike legacy and proprietary databases that struggle with scalability and cost inefficiencies, EDB Postgres AI is built for enterprise demands of high performance, sovereignty, and AI-readiness. EDB Postgres AI supports complex workloads while giving organizations greater control over their most strategic asset—their data infrastructure and AI.
“We decided to embrace an open source software strategy, because we see it as far more transparent, reliable, and secure. We know we can review the software at any time, which gives us greater confidence in the functionality and its configurability. Postgres gives us greater security than with any closed source database, as well as far greater flexibility to switch vendors and avoid expensive, traditional, perpetual licensing,” said EDB customer Christian Blaesing, Head of IT, telegra.
Many enterprises are also moving away from proprietary NoSQL databases like MongoDB, seeking better query performance, SQL compatibility, and reduced operational complexity.
“We were seeing how much we were paying Oracle, and it was just incredibly high. It seemed to be going up 10% to 15% per year. Moreover, we had a bunch of Oracle engineers who were just sick of dealing with Oracle,” said John Lovato, Database Architect, USDA Forest Service.
“The era of overpriced, proprietary databases is over. This benchmark confirms there’s a better way,” said Nancy Hensley, Chief Product Officer, EDB. “EDB Postgres AI delivers breakthrough performance over Oracle, SQL Server, and MongoDB—delivering a single, sovereign platform for data and AI without the constraints or costs of legacy vendors.”
Benchmark Report Now Available
For more information on the benchmark study and EDB Postgres AI, visit https://www.enterprisedb.com/resources/benchmarks/mcknight
About EDB
EDB provides a data and AI platform that enables organizations to harness the full power of Postgres for transactional, analytical, and AI workloads across any cloud, anywhere. EDB empowers enterprises to control risk, manage costs and scale efficiently for a data and AI led world. Serving more than 1,500 customers globally and as the leading contributor to the vibrant and fast-growing PostgreSQL community, EDB supports major government organizations, financial services, media and information technology companies. EDB’s data-driven solutions enable customers to modernize legacy systems and break data silos while leveraging enterprise-grade open source technologies. EDB delivers the confidence of up to 99.999% high availability with mission critical capabilities built in such as security, compliance controls, and observability. For more information, visit www.enterprisedb.com.
Media Contact:
Scott Lechner
Offleash PR for EDB
edb@offleashpr.com
EnterpriseDB and EDB are registered trademarks of EnterpriseDB Corporation. Postgres and PostgreSQL are registered trademarks of the PostgreSQL Community Association of Canada and used with their permission. All other trademarks are owned by their respective owners.
Photos accompanying this announcement are available at:
https://www.globenewswire.com/NewsRoom/AttachmentNg/31a4e23f-db67-44e8-ad25-bc58e603680e
https://www.globenewswire.com/NewsRoom/AttachmentNg/ce516693-cfa6-400b-826a-1df94531fb96

MMS • RSS

#UAE #dataplatforms – MongoDB plans to more than double its Middle East, Türkiye and Africa (META) workforce in 2025 as Saudi Arabia and the UAE’s appetite for artificial intelligence and ongoing digital transformation, drives more demand for data platforms and services. The New York tech firm is a global leader in cloud database management, providing developers with tools to build AI-powered applications. MongoDB’s regional expansion follows five years of strong growth, and has a focus on hiring across sales, solutions architecture, channel partnerships, and customer success. According to LinkedIn, the company has more than 50 employees working in its META region, while more than 23,000 developers in the UAE list MongoDB as a skill in their LinkedIn profiles.
SO WHAT? – MongoDB’s expansion in META over the past five years, maps the region’s rapid adoption of AI and investment from business, government and academia in the development of AI models and solutions. In comparison with other leading global database vendors, MongoDB is a relative newcomer to the Middle East and the key markets of Saudi Arabia and the UAE, but timing is everything and the vendor’s expansion plans are proof positive that it is matching market needs and delivering effectively.
Here’s some more information about MongoDB in the region:
-
MongoDB plans to more than double its headcount across the Middle East, Türkiye and Africa (META) in 2025, with hiring focused on sales, solutions architecture, and customer success. According to LinkedIn the company currently has more than 50 employees in the region.
-
MongoDB works with major retailers, financial institutions, and public sector organisations to support AI-powered applications. The tech firm has been operating in the Middle East since 2019.
-
There are open-source and commercial versions of MongoDB’s unified database platform, which has been downloaded hundreds of millions of times by end-users and developers globally.
-
Over 23,000 developers in the UAE have listed MongoDB as a skill on LinkedIn, reflecting a 20% year-on-year increase.
-
The company has recently signed a partnership with Moro Hub, the data centre subsidiary of Digital DEWA, to accelerate digital transformation and AI adoption.
-
MongoDB’s technology supports applications such as facial recognition for airport security, cargo tracking at major ports, and traffic monitoring for government entities.
-
The database leader organised its first regional Customer Day Summit at Dubai’s Museum of the Future this week, hosting over 250 customers from the government, aviation, and retail sectors.
-
MongoDB was recognised as a Leader in the 2024 Gartner Magic Quadrant for Cloud Database Management Systems.
ZOOM OUT – Market growth in AI and digital transformation presents an enormous opportunity for technology vendors, in particular those focusing on emerging technologies. According to IDC spending on AI in Middle East, Türkiye, and Africa (META) is soaring at a five-year compound annual growth rate (CAGR) of 37%, with investments set to increase from $4.5 billion last year to $7.2 billion in 2026. Saudi Arabia and the UAE have led in AI-related investments, spending on solutions, platforms and R&D in context of ambitious digital transformation initiatives. IDC predicts that digital transformation investment overall in META will reach $74 billion in 2026 and account for 43.2% of all ICT investments.