Month: February 2025

MMS • RSS
CIBC Asset Management Inc boosted its stake in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 239.6% in the 4th quarter, according to the company in its most recent 13F filing with the Securities & Exchange Commission. The firm owned 49,973 shares of the company’s stock after purchasing an additional 35,256 shares during the quarter. CIBC Asset Management Inc owned approximately 0.07% of MongoDB worth $11,634,000 as of its most recent filing with the Securities & Exchange Commission.
Several other large investors have also added to or reduced their stakes in the stock. Hilltop National Bank boosted its position in shares of MongoDB by 47.2% during the 4th quarter. Hilltop National Bank now owns 131 shares of the company’s stock valued at $30,000 after acquiring an additional 42 shares during the last quarter. Brooklyn Investment Group bought a new stake in shares of MongoDB during the 3rd quarter valued at about $36,000. Continuum Advisory LLC boosted its position in shares of MongoDB by 621.1% during the 3rd quarter. Continuum Advisory LLC now owns 137 shares of the company’s stock valued at $40,000 after acquiring an additional 118 shares during the last quarter. Wilmington Savings Fund Society FSB bought a new stake in shares of MongoDB during the 3rd quarter valued at about $44,000. Finally, Versant Capital Management Inc boosted its position in shares of MongoDB by 1,100.0% during the 4th quarter. Versant Capital Management Inc now owns 180 shares of the company’s stock valued at $42,000 after acquiring an additional 165 shares during the last quarter. Institutional investors own 89.29% of the company’s stock.
Insiders Place Their Bets
In other MongoDB news, Director Dwight A. Merriman sold 1,000 shares of the business’s stock in a transaction on Monday, February 10th. The stock was sold at an average price of $281.62, for a total value of $281,620.00. Following the sale, the director now directly owns 1,112,006 shares of the company’s stock, valued at approximately $313,163,129.72. The trade was a 0.09 % decrease in their ownership of the stock. The transaction was disclosed in a legal filing with the SEC, which can be accessed through this link. Also, insider Cedric Pech sold 287 shares of the business’s stock in a transaction on Thursday, January 2nd. The stock was sold at an average price of $234.09, for a total value of $67,183.83. Following the completion of the sale, the insider now directly owns 24,390 shares in the company, valued at $5,709,455.10. This trade represents a 1.16 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Over the last three months, insiders have sold 43,094 shares of company stock valued at $11,705,293. 3.60% of the stock is currently owned by corporate insiders.
MongoDB Stock Performance
Shares of NASDAQ MDB traded down $3.52 during mid-day trading on Wednesday, hitting $295.00. 1,056,658 shares of the stock traded hands, compared to its average volume of 1,502,277. MongoDB, Inc. has a 52 week low of $212.74 and a 52 week high of $459.78. The company has a market cap of $21.97 billion, a price-to-earnings ratio of -107.66 and a beta of 1.28. The stock has a fifty day moving average price of $261.45 and a 200-day moving average price of $272.51.
MongoDB (NASDAQ:MDB – Get Free Report) last released its quarterly earnings results on Monday, December 9th. The company reported $1.16 earnings per share for the quarter, beating the consensus estimate of $0.68 by $0.48. MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The company had revenue of $529.40 million for the quarter, compared to analyst estimates of $497.39 million. During the same period in the previous year, the company posted $0.96 earnings per share. The firm’s revenue was up 22.3% on a year-over-year basis. As a group, sell-side analysts predict that MongoDB, Inc. will post -1.78 EPS for the current fiscal year.
Wall Street Analyst Weigh In
MDB has been the subject of a number of research analyst reports. Monness Crespi & Hardt downgraded MongoDB from a “neutral” rating to a “sell” rating and set a $220.00 price target for the company. in a research report on Monday, December 16th. Morgan Stanley lifted their price target on MongoDB from $340.00 to $350.00 and gave the company an “overweight” rating in a research report on Tuesday, December 10th. KeyCorp raised their price objective on MongoDB from $330.00 to $375.00 and gave the company an “overweight” rating in a report on Thursday, December 5th. Loop Capital raised their price objective on MongoDB from $315.00 to $400.00 and gave the company a “buy” rating in a report on Monday, December 2nd. Finally, Cantor Fitzgerald initiated coverage on MongoDB in a report on Friday, January 17th. They set an “overweight” rating and a $344.00 price objective on the stock. Two analysts have rated the stock with a sell rating, four have given a hold rating, twenty-three have assigned a buy rating and two have issued a strong buy rating to the company. According to data from MarketBeat, MongoDB currently has a consensus rating of “Moderate Buy” and a consensus target price of $361.00.
View Our Latest Stock Analysis on MDB
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a “Moderate Buy” rating among analysts, top-rated analysts believe these five stocks are better buys.

Which stocks are likely to thrive in today’s challenging market? Enter your email address and we’ll send you MarketBeat’s list of ten stocks that will drive in any economic environment.
MMS • Steef-Jan Wiggers
Google Cloud has announced that its Spanner Graph is now generally available (GA). It includes new capabilities such as Graph Notebook, GraphRAG with LangChain integration, Graph schema in Spanner Studio, and Graph query improvements by supporting path data type and functions.
Spanner Graph builds on Cloud Spanner, Google’s fully-managed, scalable, and highly available database. Hence, users can benefit from the same high availability, global consistency, and horizontal scalability.
Last August, the company introduced the database as a unified one that seamlessly integrates graph, relational, search, and AI capabilities with virtually unlimited scalability. The initial release offered an intuitive Graph Query Language (GQL) interface for pattern matching, full graph and SQL model interoperability, built-in search capabilities, and deep integration with Vertex AI for accelerated insights.
The new capabilities with the GA release are:
- A Spanner Graph Notebook that enables users to visually query and explore Spanner Graph data using GQL syntax within notebook environments like Google Colab and Jupyter Notebook, offering tools for graph schema visualization, tabular result inspection, various layout options, and easy integration.
- The integration of GraphRAG with LangChain and Neo4j, which enhances AI applications by combining knowledge graphs and Retrieval-Augmented Generation to facilitate efficient querying and natural language interactions with graph-based data.
- The Graph Schema in Spanner Studio that enables users to design, visualize, manage, and update graph schemas in Google Cloud Spanner using SQL/PGQ, offering best practices for efficient graph design and maintenance.
- Support for the path data type and functions, enabling users to analyze sequences of nodes and relationships, as demonstrated by the ability to check for acyclic paths in a graph query.
- Integration with leading graph visualization partners like GraphXR allows users to utilize advanced visualization technology and analytics to understand complex data better.
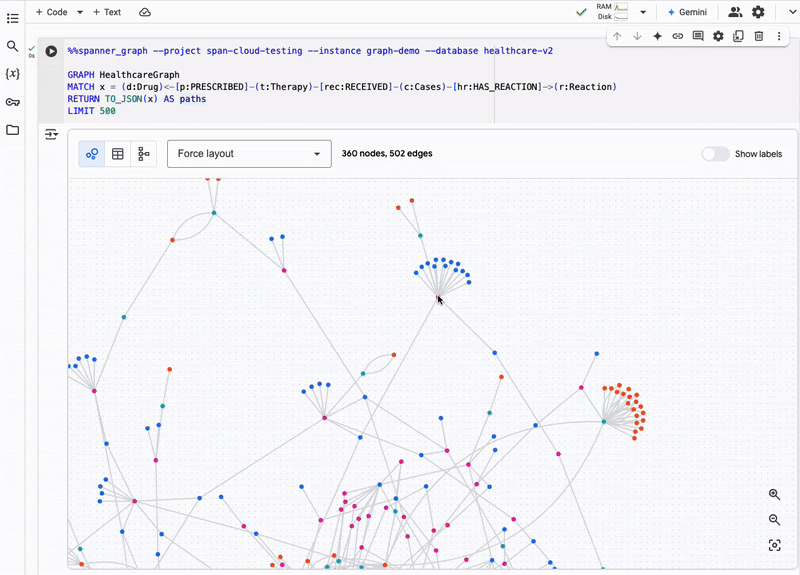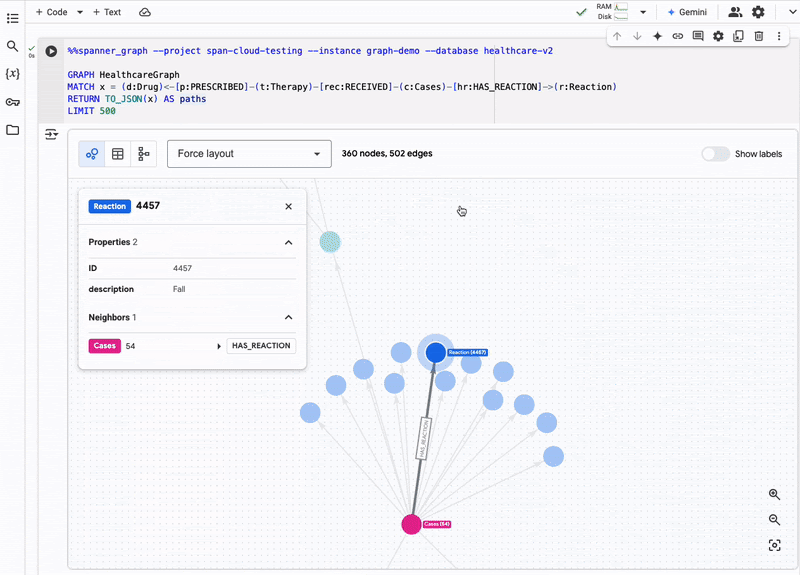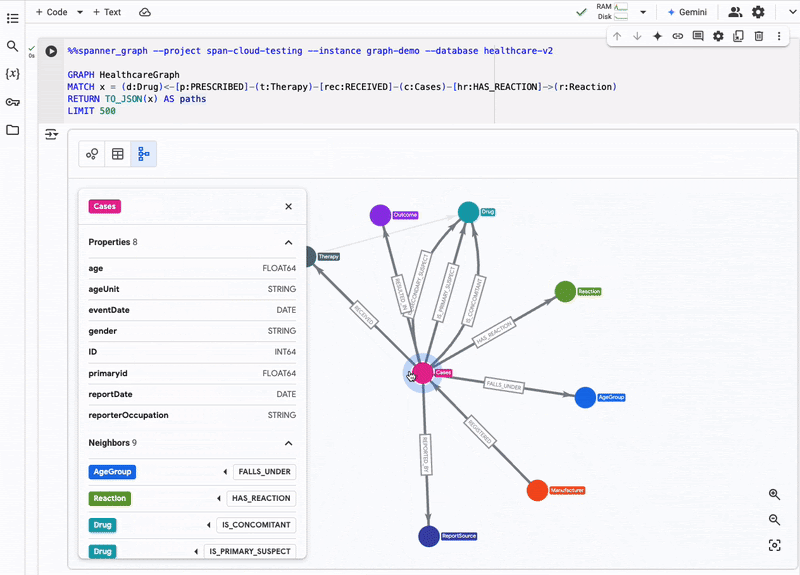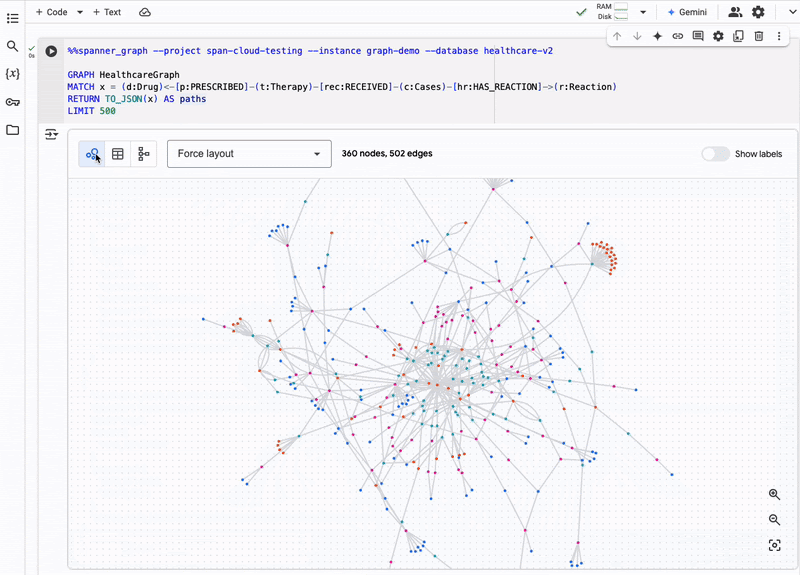
(Source: Google blog post)
Spanner Graph is designed to handle large-scale graph data workloads, making it ideal for applications that require real-time analysis of complex relationships. This includes use cases such as fraud detection, recommendation engines, and financial investments.
Kinevez, the company that has its visual GraphXR tool integrated with Spanner Graph, tweeted:
With improved search and built-in AI features, Spanner Graph can transform how businesses leverage connected data—whether in financial investing, fraud detection, or customer 360.
In addition, Abdul Rahim Roni commented on a LinkedIn post by Google:
This is an exciting leap forward, Google Cloud. Integrating graph, relational, and generative AI capabilities under Spanner Graph truly redefines database management. Incredible work in pushing the boundaries of innovation.
Lastly, more details are available on the documentation pages.
MMS • Anahit Pogosova

Transcript
Pogosova: Imagine you have built this simple serverless architecture in the cloud. You pick the pieces you want to use. You connected them together, and everything just works like magic, because that’s what serverless is. So much so that you decide to go to production with it. Of course, all of a sudden, hell breaks loose, and everything just starts to fail in all possible shapes and forms. There’s nothing that you have done wrong, at least that’s what you think, except for maybe not reading all the extensive documentation about all the services and all the libraries that you are using. Who does that nowadays anyway? What’s the next logical step? Maybe you just swear off using the architecture or services in question, never and again, because they just don’t work. Do they? What’s wrong with the cloud anyway? Why doesn’t it work? Maybe we just should go on-prem and build good old monoliths.
Purely statistically speaking, we might consider that the problem is not necessarily the cloud or the cloud provider, maybe not even the services or the architecture that you have built. What is it then? As Murphy’s Law says, anything that can go wrong will go wrong. I personally prefer the more extended version of it that says, anything that can go wrong will go wrong, and at the worst possible time.
Background
My name is Anahit. I’m a Lead Cloud Software Engineer at a company called Solita. I’m also an AWS Data Hero. There was this funny thing that I noticed after becoming an AWS Hero, for some reason, people just started to come to me with this smirk on their faces, saying, so tell us now, what’s wrong with the cloud? Why doesn’t it just work? I’m finally here to answer that question. Maybe not exactly that question, but I want us to look together at something that we as humans usually don’t feel too comfortable looking at, failures.
I hope that this talk helps you to become a little bit more aware and curious, maybe to spot patterns that others don’t necessarily see. Also, to have the tools to ask questions and make conscious, critical, and informed decisions, rather than believing in magic, taking control into your own hands. Finally, become a little bit paranoid, but in a good way, because, to borrow words of Martin Kleppmann, “In distributed systems, suspicion, pessimism, and paranoia pay off”.
A Failing Serverless Architecture
Before we go any deeper into talking about distributed systems and all the failures, let’s briefly get back to our story with serverless architecture that was failing. It actually had a prequel to it. Once upon a time, you were a developer that started developing software that was supposed to run on a single machine, probably somewhere in an on-prem data center. Everything you need to care about at that point were your so-called functional requirements, so that your code works and it does exactly what it’s supposed to, and it has as little bugs as possible. That was your definition of reliability. Of course, there could have been some occasional hardware failures, but you didn’t really care much about them, because things were mostly deterministic. Everything either worked or it didn’t.
Next thing you know, you find yourself from the cloud and maybe building software that you’re supposed to run on virtual machines in the cloud. All of a sudden, you start developing software that requires you to think about the so-called non-functional requirements, so certain levels of availability, scalability. Also, reliability and resilience get a whole new meaning. You still have all your functional requirements. You still need to make sure that your code works and has as little bugs as possible. The complexity just went up a notch, and you need to worry about so much more now. Also, failures start to be somewhat more pronounced and somewhat less deterministic. Welcome to the dark side, a wonderful world of distributed systems where with great power comes great responsibility.
Things don’t stop there, and before you know it, you jump over to the serverless world, where things just seem so easy again. You just pick the services. You connect them together. Pure magic. Of course, cloud providers take care of these most important ilities for you, things like reliability, availability, scalability, and you’re once again back to caring about your own code and the fact that it works and has as little bugs as humanly possible. You are not looking for any machines around. Moreover, the word serverless suggests that there are no machines that you need to be looking around. Things are just easy and nice and wonderful. Though, we know that that’s not exactly how the story goes, because anything that can go wrong will go wrong. What is it that can go wrong exactly?
Distributed Systems, Cloud, and Serverless
To set the stage, let’s talk a little bit about serverless, cloud, distributed systems in really simplified terms. Distributed systems, just a bunch of machines connected with a network. While it provides a lot of new and exciting ways to build solutions and solve problems, it also comes with a lot of new and exciting ways for things to go wrong, because resources we are using are not limited to a single machine anymore. They are distributed across multiple servers, server racks, data centers, maybe even geolocations. Failure can happen in many different machines now, instead of just one. Those failures can, of course, happen on many different levels. It can be software failures or hardware failures, so things like operating system, hard drive, network adapters, anything can fail. All of those failures can happen completely independently of each other and in the most non-deterministic way possible.
The worst thing here is that all of those machines are talking to each other over a network. Network is known for one thing in particular, whenever there is any communication happening over the network, it will eventually fail. Any cloud is built on top of such distributed systems, that’s where their superpowers come from. The cloud provider takes care of the most difficult part of managing the underlying distributed infrastructure, abstracting it away from us and giving us access to this really huge pool of shared resources that we can use, like compute, storage, network. They do that at a really massive scale that no individual user could ever achieve. Especially at the big scale, if something has a tiny little chance of happening, it most certainly will.
Serverless and fully managed services are just a step up in this abstraction ladder. They make the underlying infrastructure seem almost invisible, almost magical, so much so that we sometimes forget that it’s there. By using those serverless services, we didn’t just magically teleport to a different reality. We are still living in the very same messy physical world, still using the very same underlying infrastructure with all its complexity. Of course, this higher level of abstraction does make a lot of things easier, just like a higher-level programming language would. It also comes with certain danger.
Being seemingly simple to use, it might also give you this false sense of security, which might make spotting potential failures that much harder, because they are also abstracted away from you. The reality is, failures didn’t really go anywhere. They are still there, embedded in the very same distributed system that you are using, waiting to show up. As Leslie Lamport said in 1987, “A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable”. We could rephrase this for serverless architectures. A serverless architecture is one in which the failure of a computer you didn’t even know or cared existed can render your entire architecture unusable. Of course, failures with serverless are a bit different than failures with distributed systems. You don’t see them as blue screens or failures of the hardware, they manifest in a bit different way.
Distributed Architectures
Let’s take one last step in this abstraction ladder. We started with distributed system, then we had the cloud, then we had serverless. Now we are building distributed applications on top of serverless and distributed systems. In essence, what we do is we just split the problem at hand into smaller pieces. We pick resources or services for each piece. We connect them together with things like messages or HTTP requests or events, and just like that, we build ourselves a distributed application. All of those things are using network in some shape or form. You might have noticed that, in essence, we are mirroring the underlying distributed architecture that we are having.
Of course, distributed applications also give you this great power of building applications in a completely different way, but just like the underlying distributed architecture, they come with certain complexity and certain tradeoffs. Architectures that you are going to build are likely going to be complex. Every piece can fail at any given moment in the most non-deterministic way possible. Whenever there is any communication happening over network, it will eventually fail. Our special case of this kind of distributed architectures are the so-called data architecture, data applications. With data applications, we deal with collecting, storing, processing large amounts of data. The data can be anything, log data, maybe you have website clickstreams, or IoT data. Whatever data you have, as long as the volumes are large.
On one hand, that large volume makes spotting potential issues somewhat easier, because if something has a tiny chance of happening at a bigger scale, it will. Also, with data applications, maybe failures are not as obvious as with client facing applications. If there was a failure while processing the incoming data, nobody is going to resend you that data. Once the data is gone, it’s gone. We’ll see an example of such a data architecture.
How do we make our distributed architectures more resilient in the face of all those impending failures? While we are mirroring the underlying distributed system, let’s take a look at how cloud providers are dealing with all those failures. They do have quite some experience with that. Of course, there’s a lot of complex algorithms and mechanisms at play. Surprisingly, two of the most effective tools for making distributed architectures or distributed systems more resilient are also surprisingly simple, or at least seemingly simple, they are timeouts and retries.
Those are the things that we absolutely need to be aware of when we are building our distributed applications. I call them superpowers, because just like superpowers, they can be extremely powerful, but we need to be very mindful and careful about how we use them, not to do more harm. You might have noticed that so far, I haven’t mentioned any cloud providers, any services, nothing, because all of those things are pretty much universal to any of them. Now it’s finally time to move on from our fictional story, and also time for me to confess that it probably wasn’t as fictional as I wanted you to believe. In fact, it’s something that happened to me to some degree. I was working with a customer where we’re building this simple serverless, distributed architecture for near real-time data streaming at a pretty big scale.
On a quiet day, we would have over half a terabyte of data coming in. We wanted to collect and process and store that data. For that, we had our producer application that received the data. We connected it to a Kinesis Data Stream. On the other end, we connected an AWS Lambda to it, and just like that, we built ourselves a magical data processing pipeline. Things were just wonderful. We were very happy, until one day we realized we were actually losing data in many different places, and we had no idea it was happening. Thank you, higher level of abstraction. What exactly was going on there? Let’s look at it step by step. There were several places where that was happening.
Kinesis Data Streams
First, what is Kinesis Data Streams? It’s a fully managed, massively scalable service in AWS for streaming data. After you write the data to the stream, it appears in the stream within milliseconds, and it’s stored in that stream for at least 24 hours, or up to a year if you configure it to be so. During that entire time, you can process and reprocess, read that data in any way that you want, as many times as you want, but you cannot delete the data from the stream. Once it gets to the stream, it stays there for at least 24 hours. Kinesis is an extremely powerful tool. It’s mostly used for data applications, but also for event driven architectures. The power comes from the fact that you don’t need to manage any servers or any clusters.
Also, it scales pretty much massively. To achieve that massive scalability, Kinesis uses the concept of a shard. In this particular context, shard just means an ordered queue within the stream, and stream being composed of multiple such queues. Each shard will come with capacity limitation of how much data you can write to it, so 1 megabyte or 1000 records of incoming data per second. The amount of shards you can have in a stream are pretty much unlimited. You can have as many shards as you want to stream as much data as you need. When you write the data to the stream, it will end up in one of the shards in your stream.
Speaking about writing the data, there’s actually two ways in which you can write the data to the stream. In essence, you have to choose between two API calls. You either write individual records or you can batch up to 500 records in a single API call. Batching is usually a more effective and less resource intensive way to make API calls, especially in data intensive applications where the amount of individual calls can get really high, really quickly. Once again, when something sounds too good, there’s usually some things we need to consider, and we’ll get back to that.
How Failures Manifest
We have established by now that the failures will happen. There’s no way around that. How do those failures manifest with this higher level of abstraction, with serverless services, with services like Kinesis, for example. It’s actually pretty straightforward, because when we interact with services, let’s say, from our code, we are using API calls, and naturally, any of those API calls can fail. The good news is that if you are using AWS SDK to make those API calls from your code, it handles most of those failures for you. After all, AWS does know that the failures will happen, so they have built into the SDK one of those essential tools for better resilience, or a superpower as we know it, the retries. The trouble with the retries is that now we have a potential of turning a small intermittent problem, let’s say a network glitch, into a really massive one, because retries can have really unexpected blast radius.
They can spread this ripple effect of cascading failures through your entire system and ultimately bring the entire system down, because retries are ultimately selfish, just like when you’re hitting the refresh button in a browser. We all know we shouldn’t do it, but we do it anyway. Retrying implies that our request is more important, more valuable than anybody else’s. We are ready to spend more resources, we are ready to add load, to add potential cost on the downstream system, just to make sure that our request goes through no matter what.
The reality is that retries are not always effective, neither are they safe. First and foremost, which failures do we even retry? Let’s say the failure is caused by the downstream system, such as database or API being under a really heavy load. Then if you are retrying, you are probably making the matter worse. Or let’s say the request failed because it took too much time and it timed out. Then retrying will take more time than you are actually prepared to wait. Let’s say you have your own SLA requirements. Then that basically means that retrying is just selfishly using the resources that you don’t really need. It’s just like pressing the refresh button and just closing the browser. What if the underlying system also have their own retries implemented? Let’s say they also have a distributed application. They have different components. Each of them has retries on a certain level.
In that case, our retries will just be multiplied, and they will just amplify all the potential bad things that can happen. This is the place where this ripple effect of cascading failures can happen really easily, especially if we start retrying without giving the underlying system a chance to recover. Let’s say, what if the operation that you’re actually retrying has side effects? Let’s say you’re updating a database. Then retries can actually have unexpected results. The bottom line is, you need to be extremely careful about how we use this superpower. We don’t want to bring down the system that we are trying to fix.
Luckily, in case of AWS SDK, retries already come with these built-in safety measures. If a request to a service such as Kinesis fails, AWS SDK will only handle the so-called retryable errors, so things like service unavailable, other 500 errors, or timeouts. For those retryable errors, it will retry them on your behalf, behind the scenes, but it will stop after a certain amount of attempts. Between those retry attempts, it will use the so-called exponential backoff, which means that delays between retry attempts will be increasing exponentially. These things might seem very simple, but they are actually crucial details that can either make it or break it. They can turn retries from being a very powerful tool for better resilience into the main cause of a system outage, because we only want to be retrying if it actually helps the situation, so only retryable failures.
When we do retry, we do want to stop if it doesn’t help the situation anymore, to avoid that ripple effect of cascading failures as much as possible. Also, we want to spread the retry attempt as uniformly as possible, instead of just sending this burst of retries to a system that is already under a heavy load, to give the system a chance to recover. With AWS SDK, you are given these safety measures, but you are also given the possibility to configure some of those retry parameters. Here’s an example how you would do this with JavaScript SDK. Every language will have their own ways to configure them and their own default values, but all of them will give you a possibility to configure some of those values.
The same way, they will give you the possibility to configure the second superpower that we have, the timeout related values. If timeouts don’t sound like too much of a superpower to you, I have news for you. Timeouts are pretty much a given in distributed systems, and we absolutely need to be aware of them.
Once again, in simplified terms, let’s talk about timeouts. When we are interacting with services, no matter, are they serverless or not, we are using API calls. Usually, those API calls are abstracted away as SDK method calls, and those look exactly the same as any local method invocation. Let’s not let that fool us, because we know already, network is still there, it’s just abstracted away from us. Any request sent over a network like an API call to Kinesis, for example, can fail in many different stages.
Moreover, it’s almost impossible to tell if the request actually failed or it didn’t, because that failure can happen on many levels. Maybe sending the request actually failed, or maybe the processing of the request failed, or maybe your request is waiting in the queue because the downstream system is overwhelmed. Or, maybe the request was processed, but you just never got the response back, and you just don’t know about. There are plenty of options, but end result is always the same. You are stuck waiting for something that might never happen. This can happen to any service. It can happen to Kinesis as well. Not to wait forever, AWS has built into the SDK this other tool for better resilience, this other superpower, timeouts. The ability to configure those timeouts for the API calls is our superpower that we can use.
Again, just like with retries, we need to be extremely careful how we use it, because picking the right timeout value is not an easy task at all. Just like any decision in your architecture, it will come with certain tradeoffs. Let’s say you pick a too long timeout, then it’s likely going to be ineffective, and it can consume resources, increase latencies. Too short timeout might mean that you will be retrying too early and not giving the original request a chance to finish, and this will inevitably mean that you will add load to the underlying system. This, as we know, will cause these cascading failures, and eventually can bring the entire system down.
On top of all that, the appropriate timeout value will be different depending on the service you are using or operation that you are performing. For the longest time, I’ve been scaring people saying that for all the services and all the requests, AWS SDK, JavaScript SDK has this default timeout that it uses, and it’s two minutes. Just to think about it, we are probably dealing with some low latency systems with services like Kinesis, in this case, or DynamoDB. Usually, we are really aware of every millisecond that we spent. Here we are just stuck for two minutes waiting for SDK to decide that, yes, there was a timeout.
Since then, things have changed, things have evolved. JavaScript SDK saw a change of version from 2 to 3, and also default timeout values have changed, so now the default timeout value is infinite. Basically, this means that if you don’t configure those timeouts, you are just stuck there. Who knows what happened? Bottom line here is that, very powerful but very dangerous.
Finally, we get to the first reason for losing data in our story, so having too long timeouts can actually exhaust resources of your producer application and not make it possible for it to consume new incoming requests. That’s exactly what we saw in our architecture. It was still in the two-minute timeout era. Still, even then, without configuring timeouts, we got our producer to be stuck waiting for something that will never happen because of likely a small, intermittent problem. We got this entire system outage instead of masking and recovering from individual failures, because that’s what a resilient system should do. Instead, we just gave up and started losing data.
This obviously doesn’t sound too great, but if you think the solution is to have short timeouts, I have bad news for you as well, because in my experience, too short timeouts can be even more dangerous, especially if they are combined with retries. Because again, retrying requests too early, not giving the original request a chance to complete means that you are adding the load on the underlying system and pushing it over the edge. You start to see all of the fun things. It’s not as obvious when you see it. You just start to see failures. You start to see latencies. You start to see cost going up. We will get this ripple effect of cascading failures in the end, and again, ultimately bring the entire system down.
Again, if our goal is to build a resilient system, we should mask and recover from individual failures. We should make sure that our system works as a whole, even if there were some individual failures. Here is where wrongly configured timeouts and retries can really become a match made in hell. Once again, even though retries and timeouts can be extremely powerful, we need to be very mindful how we use it. We should never ever go with defaults. Defaults are really dangerous. Next time you see your own code or your own architecture, please go check all the libraries and all the places that you make any calls over the network, let’s say SDK, or maybe you have external APIs that you are calling.
Please make sure that you know what the default timeouts are, because they usually are default timeouts. Make sure that you are comfortable with that value. It’s not too small, it’s not too big. That you have control over that value. Especially if those timeouts are combined with the retries.
So far, I’ve been talking about these failures that are inevitable in distributed systems, but there’s actually one more type of failure, and those failures are caused by the cloud providers on purpose. Those are failures related to service limits and throttling. This can be extremely confusing, especially in the serverless world, because we are promised scalability. Somehow, we are very easily assuming infinite scalability. Of course, if something sounds too good to be true, there’s probably a catch. Sooner or later, we better face the reality.
Reality is, of course, the cloud is not infinite, and moreover, we are sharing the underlying resources with everybody else. We don’t have the entire cloud at our disposal. Sharing all those resources comes with tradeoffs. Of course, on one hand, we do have this huge amount of resources that we can share that we wouldn’t have otherwise, but on the other hand, it also allows individual users, on purpose or by accident, to monopolize certain resources. While resources are not infinite, it will inevitably cause degradation of service to all the other users. Service limits are there to ensure that that doesn’t happen, and throttling is just a tool to enforce those service limits. For example, in case of Kinesis, we had the shard level limit of how much data we can write to a shard, and once we reach that limit, all our requests will be throttled. They will fail.
We get to the next reason of losing data in our story. I said at some point that if you’re using AWS SDK, you’re lucky, but it handles most of the failures for you. The catch here is that in case of batch operations, like we have putRecords here, instead of just handling the failure of an entire request, we should also handle the so-called partial failures. The thing here is that those batch operations, they are not atomic. They are not either all record succeeded or all record failed. It might happen so that part of your batch goes through successfully while the other part fails, and you still get a success response back. It’s your responsibility to detect those partial failures and to handle them.
Moreover, every single record in a batch can fail, every single one of them, and you will still get a success response back. It’s very important to handle those partial failures. The main reason for the partial failures in this case is actually throttling, or occasionally it’s exceeding service limits, so having spikes in traffic. Luckily, we already know that there is this fantastic tool that can help us when we are dealing with transient errors, and in case of occasional spikes in traffic, we are dealing with something temporary that will probably pass. This wonderful tool is, of course, retries. When implementing the retries, there are three key things that we need to keep in mind. Let’s go through them one more time. We only want to retry the retryable failures. We want to set upper limits for our retries, not to retry forever, and stop retrying when it doesn’t help. We want to spread the retry attempts as uniformly as possible, and have a proper backoff.
For that, an exponential backoff and jitter is an extremely powerful tool. I actually lied a little bit. SDK uses exponential backoff and jitter. Jitter basically just means adding some randomization to your delay. Unsurprisingly, or maybe not so surprisingly, by just this small little change to how you handle the delays or the backoffs between your retry attempt, you can actually dramatically improve your chances of getting your request through. It actually reduces the amount of retry attempts that you need and increases the chance of the overall request to succeed pretty drastically. Very small and simple tool, but also extremely powerful.
I always say that if you remember anything from my talks, let it be partial failures of batch operations, timeouts, and retries with exponential backoff and jitter. Because those things will save you tons of headache in many situations when you are dealing with distributed applications. They are not related to any particular service. They are just things that you absolutely need to be aware of. To borrow words of Gregor Hohpe, “Retries have brought more distributed systems down than all the other causes together”. Of course, this doesn’t mean that we shouldn’t retry, but we know by now we need to be very mindful and very careful. We don’t want to kill the system that we are trying to fix.
Lambda
Speaking of which, there were even more failures coming in our story. Let’s see now what else can happen if we let the error handling slide and not really do anything, and just go with the defaults. This time, we are speaking about the other end of our architecture, where we had a lambda function reading from our Kinesis stream. Lambda itself is actually a prime representative of distributed applications, because it’s composed of many different components that work together behind the scenes to make it one powerful service. One of those components that I personally love and adore is the event source mapping. It’s probably unfamiliar to you, even if you are using lambda, because it’s very well abstracted underneath the lambda abstraction layer.
It’s a very important component when you’re dealing with different event sources, in this case, Kinesis, for example. Because when you’re reading data with your lambda from a Kinesis Data Stream, you’re, in fact, attaching an event source mapping to that stream, and it pulls records from the stream, and it batches them, and it invokes your lambda function code for you. It will pick those records from all the shards in the stream in parallel. You can have up to 10 lambdas reading from each shard in your stream.
That’s, once again, something that the event source mapping provides you, and it’s just a feature called parallelization factor. You can set it to have up to 10 lambdas reading from each shard instead of just one. Here is where we see the true power of concurrent processing kicking in, because now we can actually parallelize that record processing, we can speed things up if we need to. We have 10 lambdas reading from each shard instead of just one lambda.
Of course, there’s always a catch behind every fantastic thing that you hear, and in this case, it’s extremely easy to hit one of service limits. Every service has a limit, even lambda. One of those limits are very important. I always bring it up. It’s the lambda concurrency limit. This one basically just means that you can have a limited number of concurrent lambda invocations in the same account in the same region. The number of lambda instances running in your account, in your region, at the same time, is always limited to a number. Usually that number is 1000, it’s a soft limit. Nowadays, I’ve heard that you only get 100 lambdas. I haven’t seen that. I’ve just heard rumors. It’s a soft limit. You can increase it by creating a ticket to the support. There still is going to be a limit.
Once you reach that limit, all the new lambda invocations in that account in that region, will be throttled. They will fail. Let’s say you have your Kinesis stream with 100 shards, and let’s say you set parallelization factor to 10, because you want to speed things up, because why not? Now all of a sudden you have 1000 lambdas, so 100 times 10, reading from your stream, and things are probably going to be ok. Then there is another very important lambda somewhere in your account, somewhere in your region, that does something completely irrelevant from your stream, but that lambda starts to fail.
The reason is, you have consumed the entire lambda concurrency limit with your stream consumer. This is the limit that can have a really big blast radius, and it can spread this familiar ripple effect of cascading failures well outside of your own architecture. You can actually have failures in systems that have nothing to do with your architecture. That’s why I always bring it up, and that’s why it’s a very important limit to be aware of and to monitor all the time.
Now let’s get back to actually reading data from our stream. What happens if there’s a failure? If there is a failure, again, there’s a good news-bad news situation. The good news is that the event source mapping that I’ve been talking about actually comes with a lot of extensive error handling capabilities. To use them, you actually need to know that they are there. If you don’t know that the entire event source mapping exists, the chances are high you don’t know. The bad news is that if you don’t know, you are likely just to go with the defaults. We should know by now that defaults can be really dangerous. What happens by default if there is a failure in processing a batch of records? Let’s say there was a bad record with some corrupt data, and your lambda couldn’t process it. You didn’t implement proper error handling, because nothing bad can ever happen. Your entire lambda now fails as a result of it. What happens next?
By default, even though no amount of retries can help in this situation, we just have some bad data there. By default, lambda will be retrying that one batch of records over and again until it either succeeds, which it never will, or until the data in the batch expires. In case of Kinesis, data stays in the stream for at least 24 hours. This effectively means an entire day of useless lambda invocations that will be retrying that batch of records. They don’t come for free. You’re going to pay for them. All those useless lambda invocations have a lot of fun side effects, and one of them is that you are likely reprocessing the same data over and again. Because you see from the perspective of the event source mapping, either your entire batch succeeded or your entire batch failed.
Whenever lambda encounters a record that fails, it fails the entire batch. In this example, record 1, 2, and 3 went successfully, record 4 failed, but your entire batch will be retried. Records 1, 2, and 3 will be reprocessed over and again. Here we come to idempotency, which Leo was telling us about, extremely important. Bad things don’t really stop there, because while all this madness, at least it looks like madness to us, is happening, no other records are being picked from that shard. Other shards in your stream, they go on with their lives, and data is being processed, and everything is good, but that one shard is stuck. It’s waiting for that one bad batch of record to be processed. That’s why it’s often referred to as a poison pill record, because there was just one bad record, but a lot of bad things happen.
One of those bad things, especially in data applications, data loses its value pretty quickly, so the chances are really high that 24 hour long or old data is pretty much useless to you. We lose data on many different levels when we don’t process it right away. Speaking of losing data, so let’s say finally, in 24 hours, the data finally expires. Your entire batch finally leaves the stream. Lambda can stop retrying. Of course, part of that batch wasn’t processed, but ok, that’s life. What will you do? At least your lambda can catch up and start picking new records from that shard. Bad things happen. It’s ok.
The problem here is that your shard is potentially filled with records that were written around the same time as the already expired one, so this means that it will also expire around the same time as the already expired ones. This might lead to a situation where your lambda will not even have a chance to process all those records. The records will just keep expiring and being deleted from the shard without you having a chance to process them. I bring up this overflowing sink analogy because you just don’t have enough time to drain that sink, water just keeps flowing. We started with just one bad record, and we ended up losing a lot of valid and valuable data. Again, something opposite from what a resilient system should be like.
Yes, this is exactly what we were seeing in our story. Just because of some random bad records, we would see that we would lose a lot of data. We would have a lot of reprocessing. We will have a lot of duplicates. We will have a lot of delays. We would consume a lot of resources, pay a lot of money for something that will never happen. All of those things happened because we just didn’t know better and just went with the good old defaults when it comes to handling failures. We know by now that that’s exactly the opposite from what we should do. I need to bring up the quote by Gregor because it’s just so great.
Luckily, there are many easy ways in which we can be more mindful and smarter about retries when it comes to lambda, because, as I said, event source mapping comes with extensive set of error handling capabilities. We know by now that probably the most important things that we should set are timeout values and limits for the retries. We can do both of them with event source mapping, but both of them are set to minus one by default, so no limits. That’s exactly what we were seeing. It’s not like AWS wants to be bad and evil to us. Actually, it makes sense, because Kinesis promises us order of records. I said that a shard is an ordered queue, so records that come in the shard, they should be ordered, which means that lambda needs to process them in order. If there is a failure, it can’t just jump over and maybe process the failures in the background, because we will mess up the entire order.
This is done with the best intentions, but the end result is still not pretty. We need to configure those failures. There are also a lot of other very useful things that you can do to improve error handling with event source mapping. We can use all of those options in any combination that we want. Just most important things, please, do not go with the defaults. If you are interested at all, I have written these two huge user manuals, I call them blog posts, about Kinesis and lambda, and how they work together and separately. There’s a lot of details about lambda and event source mapping there as well. Please go ahead and read them if you feel so inclined.
Epilogue
We have seen that we can actually cause more trouble while trying to fix problems. This is especially true if we don’t make conscious, critical informed decisions about error handling. Things like retries and timeouts can be very useful and very powerful, but we need to make conscious decisions about them. We need to take control, rather than just letting the matter slide. Because if we let the matter slide, things can backfire, and instead of making our architecture more resilient, we can actually achieve the exact opposite.
Next time you are building a distributed architecture, I encourage you to be brave, to face the messy reality of the real world, to take control into your own hands, rather than believing in magic. Because there’s no magic, and that’s a good thing. It means that we have control. Let’s use that control. Distributed systems and architectures can be extremely powerful, but they are also complex, which doesn’t make them neither inherently good nor bad. The cloud, and serverless especially, abstracts away a lot of that complexity from us. That doesn’t mean that complexity doesn’t exist anymore.
Again, not inherently good nor bad. We really don’t need to know, or we can’t even know every single detail about every single service that we are using. It’s borderline impossible. There are these fundamental things that are inherent to distributed systems and the cloud in general, so things like service limits, timeouts, partial failures, retries, backoffs. All of those things are really fundamental if we are building distributed applications. We absolutely need to understand them. Otherwise, we are just moving in the dark with our eyes closed and hoping that everything will be fine.
Finally, on a more philosophical note, distributed systems and architectures are hard, but they can also teach us a very useful lesson to embrace the chaos of the real world. Because every failure is an opportunity to make our architectures better, more resilient. While it’s borderline impossible to build something that never fails, but there’s one thing that we can do: we can learn and grow from each individual failure. As Dr. Werner Vogels likes to say, “Everything fails, all the time”. That’s just the reality of things. Either in life in general or with AWS services in particular, the best thing that we can actually do is be prepared and stay calm when those failures happen, because they will.
Questions and Answers
Participant 1: How do you set those limits for throttling, for timeout? Let’s say that you know that you will have a certain lot and you want to do certain performance tests or validate your hypothesis, do you have a tooling or framework for that? Also, how do you manage the unexpected spikes on those systems? Let’s say that you have a system that you are expecting to have 25k records per second, and suddenly you have triple this, because this happened in the cloud. How do you manage this scenario on these systems?
Pogosova: How do you set the timeouts and retries? It’s not easy. I’m not saying it’s easy. They do sound very simple, but you need to do a lot of load testing. You need to see how your system responds under heavy load to actually know what the appropriate numbers for you are going to be. For timeouts, for example, one practice is to try to estimate what the p99 latency of the downstream system is that you are calling, and then, based on that, try to maybe add some padding to that p99 number and then set it as your timeout.
Then you probably are safe. It’s not easy. I have seen this problem just a couple of weeks back. I know exactly what’s going to happen, but then things just happen that you don’t predict. There are libraries that have defaults that you haven’t accounted for, and then all of a sudden, you just hit a brick wall, because latencies increase on the downstream system, and then you start retrying, and then things just escalate and get worse. Then basically the entire system shuts down. It’s not easy. You need to do load tests. We don’t have any specific tooling, per se. We have certain scripts that would just send a heavy load to our systems, and that’s how we usually try to figure what the appropriate numbers are. It’s always a tradeoff.
When it comes to spikes in traffic, again, really complex issue. Usually, using serverless actually is an easier way around it, like with lambda, being able to scale, for example, pretty instantaneously. It’s very helpful. In case of Kinesis, if we speak about specific services, actually, the best thing you can do is just overprovision. That’s the harsh reality of it. If you think that you are going to have certain spikes, and you want to be absolutely sure, especially if those spikes are unpredictable, and you want to be absolutely sure that you don’t lose data. You don’t really have many options. In case of Kinesis, there is this on-demand Kinesis option where you don’t manage the shards, and you let AWS manage the shards, and you pay a bit differently, much more. What it does in the background, it actually overprovisions your stream, you just don’t see it. That’s the truth of it at the moment.
Participant 2: I was wondering whether it could be helpful to not fail the lambda in case of a batch with data that cannot be written, and instead use metrics and logs to just track that and then potentially retry on your own, separately. That way, basically do not come in this stuck situation. What do you think about that?
Pogosova: First of all, of course, you need to have proper observability and monitoring. Especially in distributed applications and serverless, it becomes extremely important to know what’s happening in your system. Definitely, you need to have logging and stuff. Also, there are certain metrics nowadays that will tell you, in some of those scenarios, that there is something going on, but you need to know that they exist before, because there’s tons of metrics. You usually don’t know what to look at. When it comes to retries in lambda, as I said, there is a lot of options that you can use, and one of them is sending the failed request to so-called failure destinations, so basically to a queue or a topic, and then you can come back and reprocess those requests.
See more presentations with transcripts
MMS • Andrew Hoblitzell
Earlier in the week, OpenAI announced it is restructuring its AI roadmap, consolidating its efforts around GPT-5 while scrapping the previously planned o3 standalone release.
Initially, OpenAI had intended to roll out GPT-4.5 (code-named Orion) as an intermediary update, but internal reports suggested that its improvements over GPT-4 were marginal. Instead, CEO Sam Altman confirmed that OpenAI will deliver a “unified intelligence” model with GPT-5, eliminating the need for users to select different versions within ChatGPT.
Altman has said GPT-5 will be designed to integrate multiple capabilities—reasoning, voice synthesis, search, and deep research—into a single model. OpenAI aims to streamline its product lineup by removing the current model picker and letting the AI dynamically determine how much computational power is needed for a given task. This move follows OpenAI’s increasing focus on reasoning models, which self-verify outputs for greater reliability at the cost of additional inference time. While OpenAI pioneered this approach with o1, competitors like DeepSeek have quickly closed the gap, prompting OpenAI to accelerate its release schedule to maintain its lead.
“We want to do a better job of sharing our intended roadmap, and a much better job simplifying our product offerings… We want AI to just work for you; we realize how complicated our model and product offerings have gotten.” – Sam Altman
Altman outlined OpenAI’s planned subscription tiers for GPT-5, where free users will have access to a standard intelligence level, while ChatGPT Plus and Pro subscribers will receive progressively more advanced reasoning capabilities. This marks a shift in OpenAI’s monetization strategy, moving beyond usage limits toward tiered model intelligence.
Technical hurdles remain, particularly around inference efficiency. As reasoning models require additional processing to validate outputs, computational costs rise, and latency becomes a concern. OpenAI, already reliant on Microsoft Azure for cloud resources, must balance these factors while scaling GPT-5’s capabilities. Additionally, growing competition from open-source AI models threatens OpenAI’s position in the market, as organizations increasingly seek customizable, locally hosted AI solutions. Indeed, while Altman has discussed GPT 4.5 getting good reception from testers, AI developer Elvis Saravia has also playfully noted tomorrow Altman may also comment GPT 4.5 ‘still has a long way to go’.
This comes at a time when Anthropic has also been developing a hybrid AI model that dynamically adjusts reasoning power, allowing developers to control computational resources via a sliding scale, unlike OpenAI’s fixed low-medium-high settings. This model excels in business-focused coding tasks, particularly in handling large codebases and generating accurate code, outperforming OpenAI’s top reasoning model in certain programming benchmarks. Some have speculated OpenAI, recognizing Anthropic’s approach, plans to merge its reasoning and traditional models into a single AI, potentially following Anthropic’s lead. Anthropic reportedly plans to release its new model in the coming weeks.
The competition for AI talent has been fierce, with OpenAI and its rivals aggressively trying to retain and attract top researchers. Thrive Capital, a major OpenAI investor, recently presented to OpenAI staff, emphasizing the potential financial losses of leaving for a startup, given OpenAI’s rapid valuation growth. This comes amid high-profile departures, including ex-research head Ilya Sutskever who left for Safe Superintelligence (SSI) and ex-CTO Mira Murati, who has recruited multiple OpenAI researchers for her new venture, Thinking Machines Lab.
MMS • Claudio Masolo

TraefikLabs recently announced the latest release of Traefik Proxy v3.3 (codenamed “saint-nectaire” due to a French cheese). This release focuses primarily on two critical areas: observability capabilities and improved documentation structure. These enhancements aim to make the popular open-source reverse proxy even more powerful for platform engineers working in complex cloud-native environments.
Observability has become essential in modern infrastructure, allowing engineers to quickly identify and recover from service disruptions. Traefik v3.3 significantly expands its observability toolkit through extended OpenTelemetry integration. Building on the foundation established in v3.0, this release adds experimental support for logs and access logs alongside existing metrics and tracing capabilities. This creates a comprehensive observability solution that provides complete visibility into ingress traffic patterns.
Additionally, the new version introduces granular configuration control. Previously, observability features could only be enabled globally. With v3.3, platform engineers can now define default behaviors at the entryPoint level, enable or disable tracing, metrics, and access logs on a per-router basis, override inherited configurations for specific routers, and apply temporary observability settings during troubleshooting. This flexibility allows teams to implement precise monitoring strategies tailored to their specific needs, reducing unnecessary data collection while ensuring critical services remain observable.
This is now equivalent:
entryPoints:
foo:
address: ':80'
To this:
entryPoints:
foo:
address: ':80'
observability:
tracing: true
In this release, Traefik has begun a major revamp of its documentation architecture, recognizing this as a crucial entry point for users. The v3.3 release delivers the first milestone with a completely reorganized reference section that targets three distinct personas: beginners, advanced operators, and advanced developers. It separates high-level use cases from detailed configuration options and creates a more intuitive structure for finding information.
The new reference documentation follows a logical progression from installation through configuration discovery, entry points, observability settings, and more. This improved organization helps both newcomers and experienced users quickly locate the information they require.
Beyond the core focus areas, v3.3 introduces several quality-of-life improvements. These include better control over ACME (Let’s Encrypt) propagation checks, configuration dump support via API endpoint for easier troubleshooting, optional IngressRoute kind in Kubernetes configurations, and Kubernetes serving endpoint status support for stickiness. The update also brings configurable paths for sticky cookies, host header configuration in the HTTP provider, preservation of Location headers in ForwardAuth middleware, and more efficient basic auth hash calculation for concurrent requests. Platform engineers will also appreciate request body forwarding to authorization servers, configurable API and Dashboard base paths, and the option to abort startup if plugin loading fails.
When considering alternatives to Traefik Proxy, many other reverse proxies and load balancers stand out: Nginx, serves as both a web server and a reverse proxy, offering stability and low resource consumption, making it ideal for handling high-traffic applications. For those seeking simplicity with built-in automatic HTTPS, Caddy is another option, featuring an easy-to-use configuration and strong security defaults. Envoy Proxy, originally developed by Lyft, is a cloud-native proxy that excels in dynamic service discovery, observability, and advanced traffic management, making it a great fit for microservices architectures. Lastly, Kong doubles as an API gateway and microservices management tool, providing authentication, rate limiting, and logging functionalities on top of Nginx. Each of these alternatives presents unique strengths, catering to different needs based on security, scalability, and ease of use.
MMS • Eb Ikonne

Transcript
Ikonne: How many people have ever wondered to themselves, thought to themselves, if only I had more power, I could make things happen in my group? I’ve thought about that many times. I have a story to tell about that. In the late 90s, early 2000s, a little bit earlier on in my career, I was part of a team, and I felt like if we made certain changes on that team, we’d just be excellent, we’d be stellar.
My problem was, I was what we might call an IC, or individual contributor. I just thought to myself, there’s no way I can do anything that’s going to change the outcome, the situation that we find ourselves in. I thought, maybe if I can orchestrate and work myself into a position of being responsible for the team, then yes, I could make things happen. What do you think I did? I worked really hard to do what? To become the one responsible for the team, for the manager. I became the manager of the team, and I was so excited. I said, yes, all the dreams, all the aspirations, all the change I want to cause to happen is now going to happen because I have the power. Was I disappointed? Everything I did failed. The team nearly ran me out of the company. They were so frustrated with me. I learned very early on that power as we often think about it or think of it, is not really what is required to make change happen in groups.
I’m Ebenezer. I work for Cox Automotive. I’m really passionate about joy at work. I’m here to talk to you about how to catalyze change in groups. We’re going to talk about a few things that are all connected. Talk about some words, authority and power, that I’ve already used. We’re going to talk about different types of change. Then we’re going to talk about things to catalyze change in groups.
Authority
Let’s start with authority. This is going to be real quick for just definitions. There are many ways to talk and think about authority. There’s really one way most of us think about authority, and it’s the first definition there, it’s formal. Most of us think about authority, and authority is defined really as the right to do something. Most of us think about authority really from a formal perspective. That’s the authority that comes from our position in our organization. How many people have formal authority? I’ll make this simple, you could theoretically fire somebody. How many people have the authority to change code in a system? How many people thought about the second thing I said as authority? Most people don’t see the ability to change software as a right on authority. It’s that formal authority based on your position.
Whenever we’re hired into an organization, we are given the right to do certain things, and that’s the formal authority that comes from the position we occupy. There’s another type of authority that we rarely talk about, and that’s informal authority, and that’s authority that stems from other sources than our position. It might be personal characteristics. Maybe you’re a really kind person. It could be your expertise. Maybe you’re well versed in a particular set of technologies or knowledge. Whatever the case is, people look to you and people accept what you have to say, because they hold you in high regard. They hold you in esteem. From that you have authority in that situation. We have formal authority and informal authority.
Power
Then we look at power. Power is generally defined as a capacity to get things done. There are many ways of thinking about and talking about power, but two ways of looking at power really speak to me. Mary Parker Follett identified really two basic forms of power: power over and power with. Power over, some have described this as the coercive power. It’s telling people to do something in a forceful manner. It’s basically using the power that you have to get people to do things. Whereas power with is shared power. It’s mutual power. It’s everybody bringing their power to the table and saying, how do we move forward? Authority and power, two things we talk about, two things we see in the organizations. Many people believe that they cannot initiate change in groups without formal authority and power over others.
In fact, I was that person. That’s why, when I told the story, I said, for me, I thought I needed to be in a position where I had power over people and I had formal authority. I had the right to tell them what to do. I had the right to say, you must change now, because Eb says so. Many people actually believe this. We may not say this, but we believe it. When I talk to a lot of people in my org about why they want to get promoted or why they want to change positions, the number one response I get is, so I can make people do things. Because people believe to make people do things, we need to have positional power, and we need to have the authority. This, to me, is because we assume that change must be coercive. Change must be forced. Change must be pushed on people.
When you work with this basic assumption, then what happens as a result of it is that you’re compelled to accumulate as much power as you can. It’s a race to the top. I want to accumulate all the power. I want to grow my empire, because I want to be able to make people do what I want them to do. We know that this really doesn’t work. What it ends up causing for a lot of people is heartache and pain. That assumption is ultimately wrong.
The question then becomes, can we catalyze change in our groups in the absence of formal authority, in the absence of power over others? I’m not saying that there’s anything wrong with formal authority. No, we need that for structure. I’m not saying that power over is wrong as well. Sometimes we need to be able to tell people to do things. When power over and formal authority are the only things we can rely on to cause change to happen in our organizations, then we’re going to be in a world of hurt over time. It’s not sustainable. That’s why I believe, yes, we can.
Change
Let’s talk about change. When I do talks, I really like for people to reflect as we go along. How many people here have a change that they wish would happen in the group they’re a part of, if there’s something you’re thinking about right now? If there’s nothing, you might want to pinch yourself, make sure you’re still awake. Write down that change. What’s the change you want to see happen in your group? One or two. Just take a second to write it down right now. Express it. Just write down this change, because I’m going to ask you to continue to refer to that change as we go through this talk. If you have a situation where the status quo is perfect, I really wish I was in your situation. Change, you’ve written down the change.
Osmer’s Heuristic on Change, what’s happening? Why is this happening? What do you want to have happen? How do you get there? Why is this happening is in parentheses, because sometimes it doesn’t really matter why something is happening. We’ve had talks about getting to the whys, and whys can be important. Sometimes why something is happening is not as important as we need to do something different, and we need to spend our energies focusing on what do we want to have happen, and how do we get there? What’s happening is just an empirical fact. Everyone should be able to look at what’s happening and say, this is what’s happening. Why this is happening is often a subject of debate. That becomes interpretive. It becomes subjective. What do we want to have happen, then becomes our ideal next state. How do we get there? What you want to have happen is obviously the change that you need.
How do we get there requires differentiating between two kinds of change: first-order change and second-order change. People have described these changes in different ways. This is a very important point, because not all change is the same. We talk about change in generic terms. We talk about change as if all change is the same, as if all ice cream is the same. I’ll tell you right now that cookie dough is better than any other form of ice cream on the face of the earth. It’s non-negotiable. You cannot argue that with me. It’s a fact. You all accept it. No response. Everyone agrees.
First-order change and second-order change, what’s the distinction? There’s a lot of information on that slide there. I’ll boil it down to this, first-order change really means just picking up a new practice. It’s really a technical change, maybe doing things differently. Second-order change really begins to get to the way we make sense of the world, our world view, a set of assumptions, the paradigms we hold dear. A first-order change doesn’t ask me to change anything about the way I see the world. It might ask me to do things a little bit differently, but it generally fits within my mental constructs as they exist today.
A second-order change says, you need to wake up and look at the world a little bit differently. It’s quite often the case that when we want a change to occur, this happens a lot, that we misdiagnose the nature of the change, and we assume that it’s a first-order change, because for us, it’s very straightforward. I’ve already, in my mind, made the shift in my paradigm, I just want to go act differently. I believe everybody else should be there alongside with me, but they’re not there. They have not made that shift. I’m treating a second-order change for other people as if it’s a first-order change, because that’s what it is for me. You need to ask yourself, what kind of change is this for the people that I’m trying to get to change in my group? Could be a very straightforward change for me, doesn’t make it a straightforward change for everybody else. Contrived examples here.
We’re going from VersionOne to Jira. I don’t know if that’s a great decision. I don’t know who would make that kind of a decision. If you’ve made that decision, I’m sorry. These are tools, ALMs, or however you use them, for tracking software development and things like that. Going from one system to the next might be a very straightforward change. It’s something you already come to terms with the fact that you’re changing systems. There’s no problem with that. You’ve come to terms with the fact that you are tracking what you do, how you work in an electronic system. No problems with that. It’s just implementing a brand-new system, and you’re completely comfortable with that. That might be an example of a first-order change in some organization. Could be, it’s straightforward.
On the other hand, maybe you’re trying to make a transition from solo development where everybody just sits in their corner and pounds out whatever they’re trying to pound out together, to saying, let’s maybe adopt mob programming or something like that. You have people who really can’t accept, or are struggling with accepting a different way of working together. Again, this is not a right or wrong thing, it is simply a shift in the way you’re thinking about the world. In the first situation, we’re not asking anybody to change their paradigms, but in this situation, we’re basically saying we’re redefining the way we think about developing software. This might be a second-order change. When you think about change and the change you want to have your group adopt, you have to ask yourself, what kind of change is this? Right now, a number of you wrote down changes that you’d like to see happen.
Beside that change, do a quick diagnosis. Is that a first-order change? Are you asking people to make a change that fits in with the way they see the world today? Are you asking them to begin to look at the world differently and make behavioral change alongside of it. Make that diagnosis right now and write it beside the change that you just captured. What kind of change is this? Because if it is a second-order change, but you’re treating it like a first-order change, then you’re going to face a lot of problems. You’re not going to take the time to really help people understand and see why you want them to think about the way they’re approaching a situation a bit differently. When we think about change, we really need to take the time to analyze the content of the change itself. You need to pause and say, what type of change is this? It is a simple 2×2. You can tell that I did a stint in consulting because it’s not completed. There isn’t a 2×2.
The 2×2 basically says, are we working with familiar practices or unfamiliar practices, existing paradigms and attitudes, new paradigms and attitudes? When you now analyze a change, depending on how big or small the change is, you might even have different parts of the change that fall in different quadrants, but it’s important to take the time to assess the change and really understand the content of the change that you’re asking people to go through in any given situation, regardless of your role in your organization. You need to know the change type. That is really important, that you know the change type. Knowing is not enough, you have to do something about it.
Four Vital Actions
We’re going to talk about four vital things that I think are really important. Some of these things have actually come up in some of the talks. This is going to be repeating things you’ve already heard. As they say, repetition deepens the impression. Identify your allies. Invite participation. Change via small bites. Create and keep engagement through storytelling. It’s been said that if you want to go fast, go alone. If you want to go far, go together. My spin on this is, when it comes to group change, if you want to go fast and go far, you must go with others. You can’t go it alone.
That means you have to find allies, people that will go with you on this journey. If you don’t have any allies, you might want to reconsider the change, because it’s probably going to die on the vine. If you don’t have any allies, you probably need to think about who or why don’t I have any allies? Why isn’t there anybody else who is passionate about this thing I think we need to have happen in this group? Even as you wrote down a change right now, who are the allies that you have for that change. If you don’t have any allies for that change, do you need to begin to work to create or find allies in your group for that change. You need to spend the time to build the relationships for that change. This is where informal authority is so important. We talked about this earlier.
With formal authority, it’s really easy to do things that already exist. You can use your formal authority to ensure that the routines and procedures and policies that have existed are executed. That’s pretty straightforward at any role in any level. When you want to cause change to happen, formal authority doesn’t really do much for you. It might move things a little bit, but it will not sustain the change. That’s when informal authority, that’s the authority that comes from other sources, authority that comes from the respect that people have from you, the trust that people place in you, that’s when informal authority makes a difference. That’s when you find allies. That’s how you get allies, through your informal authority. When it comes to group change, if you want to go fast and far, you must go with others. You cannot go alone. You have to identify the folks who are going to be your allies. Organizations are essentially political systems.
A lot of people say, I don’t like politics, or, in my organization, I don’t want to be a part of politics. If you have an agenda in your organization, then you’re part of the whole thing. You’re part of the politics. We all engage in one way or the other. Because organizations are political systems, we’re all going to have needs. I have needs. You have needs. How we go about satisfying those needs may differ, and that often leads to conflict. When you’re bringing in change, you should expect that that’s going to generate a level of resistance. It’s only through the use of allies that you can find some form of momentum to overcome this resistance. Allies are important. Who are the allies and who can help you with the change that you have?
Second thing is invitation. Invitation over coercion. You want to invite participation into the change that you want to have happen as part of what you’re going on. How do you invite people to participate in the change that you have? What do I mean by invitation? Peter Block, who wrote the famous book, “The Empowered Manager”, and a number of other books, identified five elements of a great invitation. Five elements of asking people to engage in doing something different. The invitation declares the possibility. It says, this is what we can make happen if we do this. It frames the choice. It makes it very clear what you’re asking people to sign up for. It names the hurdle in that it is very honest about the challenges that you might face in the process of trying to make this change. It reinforces the request. It makes it very clear to people why you want them to be part of it, and then it uses the most personal form possible.
This is very important in this day and age where we’re remote in a lot of places. You don’t see people in the hallway maybe as you used to see them before. Invitations need to be as personal as possible. If you can’t talk to somebody in person, call them up. Email or Slack or whatever, should be the last form that we use when we’re trying to engage people in change. If we’re going to engage people in change, we need to use the most personal form possible.
Here’s just a contrived example. We can all read it there. Just imagine that you’re trying to get people to participate in a change that has to do with how we go about developing software. We want to do it completely different. The way we’re doing it today doesn’t work. You want to engage people in change through participation. You want to engage people through invitation. You want them to participate. You want to make sure that the invitation is clear. You can see in this invitation, what is possible is that we have the potential to unlock new levels of creativity and effectiveness on our team if we modify how we work. What you have to sign up for is sharing your authentic perspective on how we can improve. You’re making it very clear that this is how you’re going to engage. We’re also honest that adopting a new approach brings challenges.
Too often, we don’t want to be honest about the challenge that comes with some of the changes we want to do. You will need to accept, embrace, and work to overcome these challenges. Those are the hurdles, but we’ll do it together. Invitation is important when it comes to bringing about change in an organization, change in a group. Look for your allies. If you don’t have allies, then invite other people to join you in the change. Who you invite is very important as well. Some of the most influential people in our orgs, in our groups within a team, are the people we least expect.
Sometimes we think that the person with the most formal authority, the person with the most positional power are the most influential people. I know a lot of people in my organization that are highly influential, that positionally are not highly positioned, and are just ICs, but when they speak, for example, everybody listens. When they engage in initiatives, people join them, because they’ve developed their informal authority so widely in the organization that they are influencers for everybody else. The perceived influencers versus the actual influencers are very important to pay attention to, and to make sure that you know who is an actual influencer versus a perceived influencer in the group.
Small bites, taking small bites. This has to do with being sure that when you’re initiating change in the organization, that you take it and increment at a time. One of the mistakes people often make with initiating change in the organization is making the change too big for people to absorb. Another 2×2. This is where you have to think about what is the nature of this change, and where does it fall between high effort, large impact, low effort, small impact. A lot of change lives in the blood, sweat, and tears quadrant.
As a result of it, a result of living in that quadrant never sees the light of day, because it requires too much for people to engage. I’ll tell a quick story here. Someone in a department wanted to have their group adopt a Lean practice of identifying waste in a process and making changes to it immediately. When the person thought about having their group pick this up, for them the way they wanted to go about doing this was to make their team actually identify a source of waste, come up with a resolution or a way of addressing this waste, and implement that resolution all at once.
Everybody on the team balked at what they were being asked to do. Why did they balk at it? They balked at it because they were being asked to do too much in one go. This is why small bites is important. When it comes to change, we often spend a lot of time trying to convince people why they should participate in the change. We’re better off spending time trying to get people to take a small step in the direction of the change. What’s the smallest step I can ask people to take in the direction of the change that I desire? Can I keep it as close to where they are today, so that the resistance, or the barrier to resistance is almost minimal? It’s almost non-existent.
I think it’s Richard Pascal who said that we are more likely to act our way into new thinking than to think our way into new acting. It just so happens that we spend a lot of time trying to think people into new actions. In fact, that’s what a lot of conferences are about: a lot of information. It’s important, but people change their thinking through new actions. You need to think, what’s the smallest action, what’s the smallest thing I can introduce in my group that can get us moving in the direction that we desire to go in? What’s the smallest thing I can do?
We started off by saying, you need to find allies. I asked for the change that you want to do. Who are your allies in your group right now? Write them down. If you don’t have any allies, then you need to go find allies. You need to invite people to join you. Think about what that invitation is going to look like. Then you’re going to have people join you, and you’re going to say, we want to do this. What’s the smallest thing in the direction of that change that you could have people do right now? That if you said, let’s do this right now, you’d get almost zero pushback to it, but it’s a step in the right direction. What’s the smallest thing you could do? These are things that are available to anybody, regardless of your role, regardless of your position, as long as you use them in the right way.
Again, who are your allies? Who are you inviting? What’s the smallest thing we can do to create the flywheel effect? Because once people do something and see something positive from it, they are more likely to be receptive to adding to it. That’s the way we all function. When I start introducing a new habit into my life, and I begin to see it yield results, then I’m more motivated to build upon that habit. That’s just the way we work. That’s the way we’re wired to work. We want to reduce the barrier to entry for people when it comes to change. We don’t want to make the change big that it’s so overwhelming that when we talk about it, people are like, no, I don’t want to engage. You want to find the smallest thing, again, you can do to help people move along. I spent some time on that point because I think that’s one of the biggest things I see whenever I talk with people about change.
The change that they bring to the team, the thing they want the team to do is so radically different from what they’re doing today that everyone is like, no way we’re going to do that. Find a small thing that moves you in that direction, and build upon it. When you think about change, if you want change to stick and last, you have to think about it as a long game. I know this runs counter to the way we tend to operate, which is why change doesn’t stick in many places, because we’re thinking about immediate. It’s the microwave age. We want it done now and quickly. Change takes time. For it to stick and for it to really be embedded in our groups, it takes time.
Last thing I’m going to leave us with, as we talk about this, is storytelling. Throughout this talk, I’ve shared a number of stories. It’s because storytelling and stories are so integral to the way we operate in the world. As much as we like to think we’re rational people, the fact is, we are emotional first then rational. I think the previous talk talked about motivated reasoning, which is, we have an emotional commitment to something, and then we come up with a whole bunch of reasons to support why we want to operate in a certain way. Stories actually speak to our emotions quite a bit. Storytelling is extremely important. Storytelling is important in engaging people in any change. Storytelling is also very important in keeping people in a change. When you think about change and how you ensure that it sticks within your group and that you’re catalyzing it, you want to make sure that you continue to tell the story of what the change is doing within the group.
Every single win, every single positive experience that comes out from that change is something that needs to be shared and needs to be celebrated, and is something that needs to be told to others. It’s something that you want to keep front and center of any type of change initiative. When you think about elements of a great story, the acronym CRIS is something that you think about. They’re clear. They’re relevant. They’re inspiring. They’re simple. Clear in the sense that when the story is told, you should be able to leave the room as a hearer and tell that story to somebody else. If the story is so convoluted that when you leave the room you’ve completely forgotten what the story was about, then it’s a bad story. If you tell a story, you can’t remember the story you told, it’s a bad story too. You need to be able to remember the story, and it should be straightforward. It should be relevant.
The story should be focused on what you’re trying to accomplish. It should be inspiring. It should speak to our emotions. It should motivate us to want to do something. It should be simple. All good stories have those attributes. All of us can tell stories. I think people sometimes think that some people are good at telling stories, and others are not good at telling stories. If you’ve ever had a conversation with somebody else in your life, then you know how to tell a story. Anyone who hasn’t had a conversation with somebody else? We’ve all had conversations, so we know how to tell stories. We need to make storytelling part of how we contribute and motivate change in our groups. Again, these are things that are accessible to all of us. It doesn’t really matter whether you’re vice president or this is your second day on the job. These are things that any one of us can do, and we can bring to the table.
Recap
When we think about catalyzing change in groups, we want to attract and invite people towards the change. The assumption that change must be pushed upon people, change must be coercive, and as a result, I need to have the power to make people do the things I want them to do, to force them to do what I want them to do, is not a mode that we need to operate from. We can attract and invite people towards the change. Does it take time? Does it take effort? Yes. That’s what leads to long lasting change. You need to know the type of change desired. Am I asking people to fundamentally change the way they make sense of this world?
If that’s the case, then I really need to take the time to work with them and understand that for some people, it might take a minute. Or am I just asking people to adopt a new practice that fits the way they operate today, and all they need is just my support and my encouragement? I need to find allies, and this is where our networks are extremely important. Who are the allies? Who are the people on my team that can really help me move forward with this change? Remember, if I want to go far and fast, I need to go with people. I have to use the power of my network. I have to have allies. I need to engage and inspire through storytelling. Let it be clear, relevant, inspiring, and simple. Start with small, impactful actions. Find the smallest thing that will not cause much of a resistance that people can engage in so that they can act their way into new thinking.
Action Items?
What will you immediately put into practice today? Everyone took a few minutes to write down a change that they want to see, a change they would like to see in their group, your organization, whatever the case may be, what are you going to put into practice? What are you going to take and apply in this moment? Is it finding allies? Is it incorporating storytelling? Is it rethinking the change? That’s up to you. What will you put into practice immediately?
How to Find Allies
Lichtensteiger: It can be really challenging trying to make a change when you feel you’re fighting the lonely fight. You talk about the social network and allies, and some of us, myself included, especially in a new organization where I have to make change, find it socially difficult to find those allies. Any tips?
Ikonne: Find those allies.
Lichtensteiger: How?
Ikonne: It’s really important to spend time building the relationships that you need to build, finding the allies, because that’s how you win at the long game. If you want the change to stick, if you want people to thrive and flourish with the change as well, then you have to spend the time working to find allies and developing that in your org.
Lichtensteiger: Just get better at finding allies.
Ikonne: Yes, make the investment.
Questions and Answers
Participant 1: What would be one of the tips that you have for encouraging your team member, the people that are in your org, that small changes are something that you appreciate and actually induce that change into them, like have a culture that emphasize small changes. You can do it. I encourage you to do it. What would the tip be? What is the tip to encourage your team member to induce changes?
Ikonne: I think it’s celebrating those changes, talking about it. It’s said that where energy goes, attention flows. It’s said the other way as well. When you pay attention to small changes, celebrate small changes, people begin to see that that type of thing matters. One of the things that plagues us in our orgs is that mixed messaging abounds. People will say, we really appreciate the small change, but the thing that’s ever only celebrated is the big change. That’s the only thing that’s ever recognized. As a result, people are like, you can’t say you really appreciate small changes, and then the only thing we ever talk about more broadly is the big change. I think it’s very important to talk about it, focus on it, celebrate it, show it, repeat it. Ask people, what’s the smallest change you’ve made today? Make that part of your organizational discourse. What you talk about repeatedly is eventually what begins to happen.
Participant 2: I just wonder what things you could think of to motivate people to actually make change.
Ikonne: What things you can think about to motivate people to make change? The status quo is often very strong. When the status quo has been successful, it really can be challenging to get people to have the desire to make change. When you think about the invitation, the situation needs to be very clear about why if we don’t make this change, things are not going to be as good as they can be. That needs to be the conversation. Not everybody is going to make change. That’s definitely true. I’ve also seen that we’re often not as clear on why this change matters, why it’s important. We don’t take the time to share that.
One of the things, as a leader and somebody who has done this is, very often leaders or people in positions or the supervisory type of positions, they’ve had the opportunity to process the change. They’ve had the opportunity to understand where we are, but they’re bringing it to people who haven’t had the opportunity to go through that journey, and they expect them to get on board immediately, when you’ve had months, maybe, to prepare yourself. In the same way you’ve had time to prepare yourself, you should also be willing to have some time with people to come along as well.
Lichtensteiger: It’s telling the story of the why.
Ikonne: Tell the story of the why.
Participant 3: You talked about, you thought you needed power over people, and you thought you had to have the authority over people, but you come here with an entirely different story, what is needed. What was it for you to recognize the change you had to make yourself to be where you are right now?
Ikonne: The fear of being fired caused me to pause and say, time out. What’s going on here? Then to do some soul searching and say, is there another way of approaching the way I want to lead here? There have been people who have coercively pushed change on people. I’ve experienced it. A number have probably experienced it. It’s not long lasting. Many of us don’t want to stay in those places for a long time, and that’s not the kind of environment you want to create as well. Eventually, as I began to think about, what would an environment be where I’d want to be part of that, and have people really commit to the change we want to do, and also initiate change. Because if you find yourself as the only person kicking off change in your environment, then there’s a problem as well. If you don’t have people saying, let’s do things differently, it’s probably a sign that there’s something going on that needs to be looked at more broadly.
See more presentations with transcripts
MMS • InfoQ

Ready to earn recognition for your software development knowledge and expertise? The InfoQ Team is happy to invite you to participate in our annual article writing competition. Authors of top-rated articles will win complimentary tickets to prominent software development conferences such as QCon and InfoQ Dev Summit.
What’s in for you?
Prize Details
The authors of the articles that raise the most interest and/or appreciation from the community will be rewarded with a complimentary ticket to one of our events, as follows:
If you are unable to attend in person, you can opt-in for the Video-Only access to most sessions and keynotes for 6 months.
In-person tickets for QCon or InfoQ Dev Summit events do not include any other costs that your attendance on-site might include, such as but not limited to: accommodation, travel, etc.
Further benefits
Being published on InfoQ is an excellent opportunity to grow your career and build connections with the software community. In addition, other developers can learn from you, and they in turn, can contribute back to the community in the future.
- Earn peer recognition
- Enhance your professional reputation
- Make a real difference in the software development community
Key dates
Only article proposals submitted within the established period will be considered:
- Submissions opening: March 01, 2025
- Submissions closing: March 30, 2025
- Winners to be announced: May 30, 2025
How to participate
- Read the author guidelines
- Submit your proposal through the 2025 contest form
- For early feedback or additional questions, send your title and abstract to editors@infoq.com
Article Requirements
We think that the story is best told by developer to developer, architect to architect, and team lead to team lead. That’s why we focus on in-depth technical articles written by domain practitioners and experts. The main requirements to consider before sending a proposal:
- Length: 2,000-3,000 words
- Focus: Technical insights, architectural decisions, or emerging technology implementation
- Target Audience: Senior software engineers, architects, and team leads
Content Guidelines
To ensure the best chance of having your article accepted, it should be:
- Technically substantial with specific, actionable takeaways
- Focused on emerging trends in software development
- Based on real-world implementation experience
- Free from marketing content
- Complete guidelines on the public InfoQ page.
If you would like feedback regarding the suitability of an article proposal before writing the actual draft, please send us a title and abstract. However, the acceptance is always based on the complete article draft; first drafts are also considered. Contact us at editors@infoq.com for any questions or further information.
Selected topics
We welcome articles that fit into the innovator and early adopter stages of the following topics: AI, ML and Data Engineering, Software Architecture & Design, DevOps & Cloud.
Here is a more detailed list of the sub-topics for each topic:
[Click on topic name to display full list of sub-topics selected for the article contest]
AI, ML, & Data Engineering
Retrieval Augmented Generation (RAG), AI powered hardware, Small Language Models (SLMs), AI in Robotics aka Embodied AI, LangOps or LLMOps, Knowledge Graphs, Explainable AI, Brain Computer Interfaces, Automated Machine Learning (AutoML), Edge Interference and model training, large-scale distributed deep-learning, Generative AI/ Large Language Models (LLMs), Synthetic Data Generation, Cloud Agnostic Computing for AI, Vector Databases, Data Contracts, Data Observability, Virtual Reality – e.g. VR/AR/MR/XR, MLOps, Cognitive Services, Graph Data Analytics, IoT Platforms.
Software Architecture & Design
Cell-Based Architecture, Privacy Engineering, Green Software, GraphQL federation, НТТР/3, dApps, Platform Architecture, Socio-technical Architecture Large language models, Edge Computing, Data-Driven Architecture, Dapr, WebAssembly, Micro frontends,AsyncAPI, OpenTelemetry.
Cloud & DevOps
Data Observability, Data Mesh, Cross-cloud uniform infra automation, Application definition and orchestration, Low-code platforms, SLOS, Platform Engineering teams, Industry aggregated incident analysis, Quantum cloud computing, WebAssembly (Wasm), eBPF, Policy as Code, Service mesh, Software secure supply chain, Cross-cloud/Cloud-native hybrid approaches, No copy data sharing, Sustainability accounting, AI/ML Ops, Active-active Global DB Ops, Fullstack tracing, Continuous Testing, ChatOps, DataOps, Developer Experience “DevEx”, Documentation as code, Security in the age of AI, Container Security and Observability in Kubernetes Environments, DevSecOps Best Practices for Identity & Access Management, Best Practices for API Quality and Security.
Winner Selection Process
Winners will be determined by evaluating:
- Reader interest (page views within 14 days of publication)
- Social media impact (engagement on LinkedIn, X, and Facebook)
Here’s how we’ll select the winners: We’ll identify the top three articles based on page views within 14 days of publication. From those three, the article with the most social media engagement across the listed platforms will be awarded 1st place, the second-most engaged will receive 2nd place, and the third, 3rd place.
Page views will be counted for 14 calendar days from the article’s publication date to ensure fair competition.
Winners will be notified by email and publicly announced on our social media channels, on 30 May 2025.
Ready to join the contest? Send your proposal now: 2025 articles contest form.
Podcast: Your Software Will Fail, It is How You Recover That Matters: A Conversation with Randy Shoup
MMS • Randy Shoup

Transcript
Michael Stiefel: Welcome to the architects’ podcast where we discuss what it means to be an architect and how architects actually do their job. Today’s guest is Randy Shoup, who has spent more than three decades building distributed systems and high-performing teams. He started his architectural journey at Oracle and as an architect and tech lead in the 1990s, then served as chief architect at Tumbleweed Communications. He joined eBay in 2004 and was a distinguished architect there until 2011, working mainly on eBay’s real-time search engine.
After that, he shifted into engineering management and worked as a senior engineering leader at Google and Stitch Fix. He crossed the architecture and leadership streams in 2020 when he returned to eBay as chief architect and VP for eBay’s platform engineering group. He’s currently senior vice president of engineering at Thrive Market, an organic online grocery in the U.S. It’s great to have you here on the podcast, and I would like to start out by asking you, were you trained as an architect? How did you become an architect? It’s not something you decided one morning and you woke up and said, “Today, I’m going to be an architect”.
How Did You Become An Architect? [01:41]
Randy Shoup: Great. Well, thanks for having me on the podcast, Michael. I’ve listened to so many of the, in general, InfoQ podcasts, and particularly your interviews with Baron and Lizzie, and various other ones, so super excited to be here. Yes. How did I become an architect? Yes. Well, I woke up one day and said, “Today, I will architect”. No, my background is multidisciplinary. So, when I went into university, I was not expecting to be a software engineer. I always loved math and computer science, but I was planning to be an international lawyer. When I was in college, it was the late 1980s. I graduated in 1990. So it was the height of the Cold War, and the U.S. and the Soviet Union had tens of thousands of nuclear weapons pointed at each other, and I wanted to stop that.
Anyway, long story short, through my university career, I studied political science, with a particular focus in international relations and East-West relations. And from that, I took an appreciation of nuance and seeing the big picture and really understanding the problem writ whole. I won’t go through all the boring details, but I also, while I was in college, interned at Intel as a software engineer. So I worked building software tools for Intel’s mask shop, which is one of the things that you need to do to make chips, and I love that.
So when I graduated from university, I was planning on being an international lawyer, that was the mainline career, and I ended up double majoring in political science and then mathematical and computational science because then I was like, “Well, I’m not going to go straight to grad school”. So I worked for two years as a software engineer at Oracle, then I was like, “Okay, time to take the GRE and the LSAT and go to law school and international relations school”, which I did start. For reasons, that didn’t work out. I wasn’t as interested in that as I thought I would be, and the secondary career side gig of software was really pretty fun, and so-
Michael Stiefel: So, in other words, don’t quit your night job.
Randy Shoup: Exactly, yes. Well, very well said, yes. If you have a side gig that you love more than your main gig, maybe you can make it your main gig, and so that’s what I did. So, eliding over lots of details, which we could talk about or not, I wasn’t excited about the international law career for reasons and then begged for my job back at Oracle. My friend and mentor and manager at the time welcomed me back with open arms. And so it’s really the combination then of the engineering skills and doing software with the typing, and also being able to see the big picture.
What makes a good architect? [04:01]
And so, to me, I think we’ll talk about this: a good architect is somebody who can go all the way up and all the way down. And Gregor Hohpe, whom I hope everybody who is listening to this knows, has this wonderful phrase that’s in his book. It’s called The Architect Elevator. So, from the boardroom, you can talk to executives, all the way down to the engine room where you can actually tweak the machinery. So, how did I become an architect? It was crossing those two things. I always was a techie and a fuzzy, as we used to say in college. So, both on the technical side, really enjoyed the math and the science, and also on the other side, fuzzy, like liberal arts and so on.
Software Interacts with the Real World [04:40]
Michael Stiefel: And lo and behold, here you are. So, one of the things that we’ve talked about, and I know both of us are interested in, is realizing how fragile our critical systems are. And very often, the engineers, which is surprising, and the public, which is not as surprising, do not realize it and realize the consequences of the fact that these systems are fragile. The most recent one was the example of the CrowdStrike failure. But even things such as… Let me pick an example that people are probably most familiar with. You go to Amazon, you’re told that there are three books left, but you actually have to wait until you get an email, later on in the process, to find out you’re actually getting the book.
Randy Shoup: Right.
Michael Stiefel: And even if they tell you, you get the book, what happens when in the process of getting the book, it gets damaged in the warehouse, in the process of sending it to you. Do they cancel? They ask you, “Do you want it?” So the interaction between the software and the messy world is something that I don’t think people understand.
Randy Shoup: Yes. And the real world can be messy, as you just said, like, “Okay, physical goods can be damaged in warehouses”. They could not make it in shipping. They could get rain damage. They could not be there, even though the system says they are. And also, even more often, the software can screw up. The software thinks that we decremented… Software forgot to decrement a counter, and they should have because of reasons, and all sorts of stuff. People can’t see me because this is a podcast, but I do not have hair. But once, I did. And so I like to joke that, when I entered software and then architecture in particular, I did have hair, that’s actually a true statement. And yes, with all the failures and trying to deal with them and trying to design around them, that’s in large part how my hair… how I went bald.
Designing For Failure [06:55]
Michael Stiefel: Well, I think you just said something very, very important that a lot of people don’t think about, and I’ve gotten pushback from people when I used to talk about this. I used to have a whole talk about designing for failure.
Randy Shoup: Yes.
Michael Stiefel: People didn’t like it. Well, some people did appreciate it, of course. I’m not saying nobody liked it. But especially if you got to the higher ups, they didn’t like it because, “Why should we think about failure? We want design for success”. And-
Randy Shoup: Michael, you’re guiding for failure to start. What are you doing?
Michael Stiefel: Right. But I think we see this also in software engineers, and this is in security, this is in lots of places. They like to design for the happy path.
Randy Shoup: Yes.
Michael Stiefel: They think this will work and this will then work. And when it comes to an error, “Okay, we’ll just throw an exception”, without thinking about where the exception goes, what the program state is, to be caught by the great exception handler in the sky. So how do we get developers and the business leaders, and the public at large to understand that software failure actually is a fact of life?
How to explain software failure to executives [08:09]
Randy Shoup: Yes. In your question, you already went boardroom to engine room, which I love. So, let’s start with the boardroom and then drop to the engine room. So, how do you have this conversation with executives? And look, if you look at talks I’ve given, sections in them, even if not, entire names of talks, are all about designing for failure and everything fails, which is absolutely true. How does one have that conversation with executives is just making it clear that this is not about, “I want it to fail”. This is about things go wrong in the world and we have to deal with them, and so the designing in the face of failure. It’s not designing in order for it to fail, you were never saying that, but it’s designing to be resilient. So that’s the term of art these days is resilient in the face of failures.
So there are lots of ways to do that, but having that conversation is, “Look, as architects, we should be able to say, must be able to say, ‘Hey, we get the happy path. There are many things can go wrong along the way, and here is the way that the system is going to handle when those things go wrong.'” And that could be the system retries things, that’s legit. That could be the system times out, that’s legit. That could be the system reconciles, comes back around, like in banking. You send things back and forth between banks in real time, but then there’s this reconciliation at the end of the day, at least traditionally, where you looked at the 999,000 on the one side and the 1 million on the other side, and you started it out with rules or with humans.
How to get engineers to care about software failure [09:31]
So, in all these situations, the architect needs to imagine… I guess, now, I’m in the engine room already. The architect needs to imagine all the things that can go wrong. And what I think trips up a lot of engineers is it’s scary to think of, “Well, gosh, so many things could go wrong”, and that’s true, so many detailed things can go wrong. But if you think about it from a higher level, there are usually not a million different classes of failure. There are a million different instances of failure along the way. But even a relatively complicated workflow, like, I don’t know, a payment system or a checkout, or something like that, there are a handful of classes of things that can go wrong. Resources could be unavailable. How do we deal with that? Logic could not work. How do we deal with that? Things could be slow or down. How could we deal with that.
So what trips up people that are new to this, which is fine, people are beginners, I’m a beginner in lots of things in my life, but the beginner is that it feels overwhelming. There’s a million things that go wrong. How could I check for all of them? And the answer is don’t. The answer is, think about the three or four classes of things that can go wrong and have a pattern of how to deal with those individual things.
Michael Stiefel: In other words, think about the system state, thinking about what the safe point is, where you go back to.
Randy Shoup: Sure.
Michael Stiefel: To give, maybe, a concrete example is there’s lots of reasons why the credit card service you use may not be available, but you only care about the fact that the credit card service is not available.
Randy Shoup: Beautifully said. Exactly right, yes. I’m going through my checkout flow and I want to charge the payment method, and I can’t. We can imagine, if we thought about it, 25 different reasons together off the top of our heads in a minute why that could be true, network down, my payment system is down, their payment system is down, my credit card… blah, blah, blah, blah, blah. But from the perspective of the logic of that thing, it only matters that I cannot charge this payment method at this time. So, the wonderful thing about working with credit card systems is they’ve been around for a million years and they’re clunky, but the interface does tell you what happened. So, you can get something back that says, “Oh, the card was declined in an unrecoverable way. This is a fraudulent card”, “Okay, we’re not going to retry that one”.
But the more common case is it’s some kind of transient failure and like, “All right, we just retry it”, or if a human is there, we could say, “Hey, human, we couldn’t charge this method. Want to give us another card?” As every single person listening to this has had the experience in buying something at the grocery store, or whatever, and for whatever stupid reason, their particular card in the moment isn’t getting taken, so, “Hey, do you have another one?” “Okay, sure”. Again, patterns to deal with this exception handling, all the way up to the top of the system, which in this case, if someone is there as a human, or pop it up and then retry that part of the workflow, retry the charging payment methods, like Step. There’s lots of ways to deal with it.
Business Rules Help In Handling Failure [12:28]
Michael Stiefel: Also, there’s very often a business rule that enters in. So, for example, if the credit card service is not available and this is a customer that you know very well, and it’s $5 or $1,000, or whatever is small in your business, you may say, “Go ahead”.
Randy Shoup: Yes, yes. And actually, I’m sure you know this, but not everybody listening might, this is exactly how ATM machines work.
Michael Stiefel: Yes, that was the exact thing that popped into my mind when you said that.
Randy Shoup: Yes, yes, yes. And again, just to say… either of us could say it, but I’ll start saying it, the way ATM machines work is, “Hey, they have network connectivity to the office systems of your bank”, just like anything else, and they have rules in there that say, “If you cannot connect to that person, you feel free to give Randy $20, but do not give him $2,000”, that kind of thing.
Michael Stiefel: And also, this is a situation where, because you may be on a network that’s not your bank’s, there has to be reconciliation among all the banks at some point in time, which is what you made reference to before.
Randy Shoup: Right.
Michael Stiefel: So, it’s a combination of business rules and software judgment.
Randy Shoup: Yes, I’m going to riff off that in two ways. I really love the way you said it. So, again, to restate, a million individual instances of things could go wrong. There are typically a small number of classes of failure. For each of those classes of failure, we may have a business rule that says, “Hey, this is how payments are supposed to work. When this kind of failure happens, you’re supposed to retry for three days and then you can give up”, or whatever. So, to your point, there could be, in an ideal situation, a business rule that says what to do. In any case, we have to solve it. Regardless of whether there’s a business rule that told us how to solve it, we, as engineers, have to solve it. That problem will occur and we need to decide what to do. We can’t throw up our hands. And so, again, we should apply some kind of pattern to that.
The other thing that, when you mentioned business rules, I really love and I want to reinforce for people, we’re talking about a payment workflow or a checkout workflow, but this is a generic comment I’m about to make. The initial instinct of the naive engineer, and I’ve been naive for more time than I should admit, is to hide that failure and better is to have it be part of the interface. Again, if you’ve not worked with payment systems or checkout systems, the interface is not, “Please make the payment, yes, no”. It is, “Please start this payment”, and there’s a workflow with states behind it, and those states are visible outside. So it’s visible to say, “Hey, the payment is started. It’s pending. It’s authorized. It’s completed”.
And my point there is, as an architect or a software engineer dealing with one of these domains, oftentimes, when you have these failures or when it’s possible to have these failures and you can’t resolve them immediately, as in this example, pop that up a level. That’s now part of your interface. Part of the workflow and part of the payment system that we just sketched is the idea that payments can be in this intermediate transient state. They can be accepted, but not yet already done. And in the U.S., for those of us who live here, we still have to wait three days for… If we’re going to pay Michael for something, typically, the banks give themselves three days to get everything all sorted, even in the modern world.
The “It’s Never Going to Happen” Fallacy [15:54]
Michael Stiefel: Just as an amusing side point, I remember the days when I ran a business that took credit card payments, but this was before real computerization. You’d have a stack of credit card slips, the one the merchant had, and you go call the bank and list off all the numbers, and they would tell you, in other words, whether it was good or bad. So, in other words, part of the problem is that I think a lot of people have never worked with these manual systems and realize that, actually, the probability of failure is higher than people think. People very often think, “It’s not going to happen”. I’m sure you’ve heard engineers say that. “We don’t have to worry about that”.
Randy Shoup: Yes. The wonderful and terrible thing of working at places like eBay, Google is the things that occur one in a million times occur thousands of times a day.
Michael Stiefel: Because you have 10 million times.
Randy Shoup: Yes, yes, yes. And the things that occur even a billion times a day at Google scale occur thousands of times a day. So, there’s no hiding. And you didn’t really ask me to do this, but I’m going to say it anyway. It is not professional software to ignore failure. You are not being a professional. You know this, and I know you believe it, but just for the listeners, you are not being a professional software engineer if you don’t handle, in some way, failures, and handle could be, again, retry, or reconcile, or something automatic, or it can be simply fail, fail, fail all the way up. But one way or another, you can’t ignore, I was going to say, the possibility, the guarantee. I guarantee you that everything in your system will fail at one point or another. Guaranteed, absolutely guaranteed.
Michael Stiefel: Yes. And you have to leave the system however you handle a failure in a stable state.
Transactions and Workflows and Sagas, oh my! [17:44]
Randy Shoup: Correct. And I know you and I have chatted about this, so maybe this is going to make me want to take it in a transactional way. So, a way that we traditionally have approached this problem, and it’s a good one, it’s a great tool to have in our toolbox, is transactions. So, the conceptual idea… I know everybody knows, but the conceptual idea is I have several things I want to do and let’s wrap them all in a transaction and make them all happen together or none at all. So atomic, consistent, isolated, and durable, the ACID properties. And when you have a system where that can work, it implies a single database. When you have a system that can work, that’s great, that’s a wonderful tool in your toolbox you absolutely should use.
And also for the systems, even the “simple” systems that we were just talking about, payment systems, checkout, et cetera, not like that. There’s not a single database between Bank of America and Deutsche Bank when they exchange stuff. There’s not a single database or a single distributed transaction between my local grocery store and the credit card processor.
So, how do we deal with that? It’s asynchronous, and so we make it a workflow. And workflows are made up of asynchronous messages and we figure things out, and we have the SAGA pattern, which we could talk about in detail if we’re interested, but the conceptual model at the higher level is, “Well, when I can’t make it a transaction where it’s all or nothing in this moment, I need to then think about it as a workflow or a state machine, and it’s incumbent on me, as the software engineer, to make sure that we enter that state machine from a safe system state and that we transition through the states in that state machine and we exit the state machine in a safe state”.
Do Not Hide Transient States [19:22]
And again, what I was saying before about making these transient states visible, when you’re in one of these situations, it really behooves you to not hide the fact that there’s all these state transitions and transient stuff happening. It’s said that it should be explicitly part of the external interface, if that makes any sense.
Michael Stiefel: I think I can give you a simple example of that where it should be visible not only to the system, but to the end user. Let’s say you’re signing up a customer and they have to provide social security number, all kinds of information.
Randy Shoup: Right.
Michael Stiefel: They may not have all the information at once.
Randy Shoup: Of course.
Michael Stiefel: So what are you going to do? Throw them out and make them reenter everything all over again, or keep it in a semi-complete state, which may enable them to do certain things, but not other things.
Randy Shoup: Right. What a wonderful, visceral, evocative metaphor. That’s gorgeous because everybody can say, “Well, yes, when I’m getting my passport”, as my son just did, “there are steps and there’s a whole workflow”. And he doesn’t have his birth certificate and all these things all at the same exact moment and transactionally enter them all and not. And even if he did, to your exact point, he spent two hours entering all this various biographical information about himself and various things and proving his identity, and so on. And if, at the end, some stupid thing at the U.S. government went wrong,
Michael Stiefel: The Internet goes down.
Randy Shoup: … and you had to go reenter all those two hours again, that would have been insane. It was annoying enough as is.
Workflows are Resilient to Failure [20:57]
So, anyway, I love that metaphor because it doesn’t mean it’s a failure… A workflow is resilient to failures. A well-timed workflow is exactly resilient to the kinds of failures we’re talking about. And also, it is “resilient”, there’s probably a better way to say it, to, “You know what? I don’t have that information right now.” So, thinking about filling out a government form, or doing a payment process, or even the software engineering that we do, thinking about it as a workflow is really freeing and it is the problem.
Align the Architecture WIth the Problem [21:31]
One of the other… It’s a meta principle for me, and this is the way I look at it, but I think the very best architected and design systems I’ve ever worked with are very directly aligned with the problem. This is exactly domain-driven design. But when you can take your overall problem and reify the real world into the software directly, if that makes any sense, there’s a thing that’s part of the world like, “Oh, we have eBay”. “Okay, people buy and sell things online”. Okay, well, just imagine what happens when you’re buying and selling things offline.
Every one of the steps that you do, like I walk into the store, I go choose the thing, I pull out my wallet, all the steps that happen should have, do have, an exact analog in the software system that we build. And if we can use the inspiration and the, often, thousands of years worth of human knowledge about how to do those things in the real world and just put those into the software essentially, then we’re in much better shape.
The example I always give in this is I’ve never worked for Lyft, or Uber, or Grab, or whatever, and I don’t know their history, but I should look it up, I guarantee though, because this is how every system evolves, they started as a monolith. Each of them, I bet. And then what’s the natural domain decomposition for an Uber? It’s driver side, rider side. So, the rider side has a bunch of concerns and apps, and so on. And then totally separately from that, there’s the driver’s side. And then totally separate from that, there’s the back office like, “Well, how do you show the rider what drivers are available?” So where I’m going with that idea is it behooves us as architects to really fully understand the real problem. What’s the real thing we’re trying to do? And in this case, it’s obvious like, “Okay, I want to get a ride from point A to point B, and somebody is going to drive me”, and then reify that or express that in the software.
And then to the point back that we were talking about, about how to deal with failure, it becomes pretty obvious what the patterns are. We have to still type and stuff, but it becomes pretty obvious what the patterns or conceptual mechanisms, if that makes any sense, to deal with these things. What happens? What’s supposed to happen when I schedule a ride and they don’t show? Well, because they’re late or whatever. Well, I don’t know. When you’re hailing a cab in New York City, how does that work? Well, okay, it’s exactly the same thing.
Michael Stiefel: Although some things become a little more difficult in the virtual world. For example, to go back to your eBay example, if the merchandise is right in front of me, I can inspect it.
Randy Shoup: Yes.
Michael Stiefel: That’s a more complicated problem in the virtual world, or to go to your example of Uber and Lyft, in the past, there was a taxi commission that I knew the police ran a security check on the drivers.
Randy Shoup: Right.
Michael Stiefel: So, in other words, how, as you say with the reification, sometimes it’s not a one-to-one mapping.
Randy Shoup: Totally. So, we are strongly agreeing, but it won’t seem like that for one moment. Yes, the conceptual problems are the same like, “Hey, I want to see if this merchandise I want to buy is good”. That is a real problem. To your exact point, the solution in the virtual world is different from this. I can’t touch and feel it, so what else can we do? And you weren’t asking, but I’ll actually tell because it’s cool, eBay has at least three mechanisms I can think of off the top of my head for that. Number one, eBay’s feedback system, that’s been around for the 28 years, or whatever, of eBay. And this is gameable, but you can develop over time a trust system for the seller and for the buyer. Okay, so that’s number one.
Number two, in terms of the specific merchandise, for various things, I think it might be broader now than when I was here before, there’s a money-back guarantee. If you get something and it doesn’t meet the description, there’s a mechanism to return it and get your money back. And also, for particular items that are very often counterfeit, think sneakers, watches, handbags, a bunch of these things, particularly for Gen Z are like traded assets, essentially, people get the… I’m going to say it wrong, but people get the Michael Jordan super sneaker, or whatever, and only made 10 of them. They got gold stars on them, or whatever.
Anyway, for that, eBay has started actually bringing those things to physical warehouses and physically inspecting them and putting a virtual stamp of approval, if that makes any sense. So, a long-winded way of saying, 100%, there is that same problem statement, which is, “Hey, I want to buy this thing. Is it good quality and is it the thing that I actually want to buy?” And in the virtual world where we can’t touch it, we actually need to do a bunch of different other schemes, essentially.
Michael Stiefel: But if you think about it, and I’m going to date myself a little bit here, this is the exact problem at Sears, Roebuck and Montgomery Ward had with mail order.
Randy Shoup: Totally.
Michael Stiefel: So, in other words, there was a reputation in the company there, as opposed to the person. But again, there are more analogies than one might imagine to help you think about this problem.
Randy Shoup: Yes, that’s great. I love it, I love it. Yes. Exactly mail order, yes.
Workflows and State Machines [27:05]
Michael Stiefel: I have found that people have trouble with workflow and state machines, especially where there’s approvals involved and there’s long-running. Before we were talking about state machines, we’re talking about, in a program where there’s failure, it may be asynchronous, but, more or less, the software is waiting on itself, so to speak.
Randy Shoup: Sure.
Michael Stiefel: But when the thing have things like getting approvals, which is another way where workflow comes in, when it’s long-running, people have trouble with that. Especially when you have to deal with choreography or event-driven stuff, that becomes another level of distraction that you have to put on things.
The SAGA Pattern [27:50]
Randy Shoup: Yes, 100%. In fact, I’m dealing with this exact issue in my day job because, “Hey, we’re an online grocery and we take people’s payments, and we need to ship them things, and that’s a workflow”. So, the most widely known well-functioning pattern for this is called the SAGA. Anybody who wants to Google with that, they’ll find stuff from Chris Richardson and Caitie McCaffrey on what are called SAGAs. And so just very high-level, it is, we got this workflow and lots of different… not one system does it all. It’s interactions between different systems.
So, A sends a message to B, B does some things, B sends a message that’s received by C, they do some things, and the SAGA is just a way of representing that at a bit of a higher level. And then if there’s a failure at C or D, then you do compensating operations. So you do individually transactional, individually durable operations along the way, but they’re separated in time. So A happens, and then at a totally different time outside that transaction, B thing happens. And totally after that, the C thing happens. And if there’s anything that goes wrong with this workflow, you do what’s called compensating operations, essentially undoes in the reverse direction. So there’s a lot of literature and techniques around that SAGA pattern. That’s a great one for people to… Oh, why did people even invent that? And exactly because this is hard.
Orchestration and Choreography [29:13]
Relatedly though, and this is something that I’m just looking into but lots of people know a lot about, is an open-source system called Temporal. It is a way of making these workflows durable in a very easy to program setup. And I’m not going to do it justice because I haven’t actually done this stuff yet, but we’re going to do it real soon now. So, you mentioned choreography. So there’s choreography versus orchestration. Choreography is these events fire and traverse themselves, but there’s no central coordinator. Orchestration is where, just like in a conductor in an orchestra, there’s a central “controller” that makes sure that A and B, and C, and D happen or don’t happen and controls the workflow going back and forth.
So, Temporal is an orchestrator concept, and you program that orchestration logic in a regular programming language, Python, Java, PHP, whatever, Go. They support a million of them, and the system stores where you are in that workflow. And if you have failures along the way, it brings the system back to the state where you were, and then you just keep going.
I’m not giving it full justice. But actually, if anybody googles for Temporal, they have a great website with lots of sample code and lots of great explanations. And also, there are literally 100 or more YouTube videos about how it works and all the companies that use it. And so I won’t even be able to list them all, but every Snap story is a Temporal workflow. At Coinbase, every Coinbase transaction where you’re moving crypto back and forth is a Temporal workflow. Netflix uses it as the base of Spinnaker, which is their CI/CD system. I’m actually forgetting a bunch of things, but it’s used very… oh, Stripe. Every Stripe transaction, which is also money, is also a Temporal workflow. So it’s open-source, then there’s a cloud offering by the company that supports it.
Anyway, I mentioned this only because I have this exact workflow problem in my day job and I wanted to make it easier, and I was all set to teach everybody about what I was just saying, event-driven systems and SAGAs, and compensating operations, and state machines, and so on, and those are the real thing. They actually work that way, that’s actually how the systems ultimately work at the base. But I was searching for a way to make it easier, and I think that Temporal is it. And don’t trust me, trust Stripe and Coinbase, and…
Michael Stiefel: Of course, people sometimes have trouble deciding when to use choreography and when to use orchestration.
Randy Shoup: Yes.
Michael Stiefel: But as you say, you really have to think about what’s important in the problem that you’re going to solve.
Randy Shoup: I have my own answer. Because again, as a reminder for people, if these are new to you, choreography is like a dance where there are lots of events that are happening, but there’s no central coordinator that is saying, “You step here, you step there”. Whereas by contrast, again, orchestration is the orchestra conductor, tap, tap, tap on the lectern, or whatever you call it, and getting everybody to play in rhythm. So, when to use both? If this workflow is very important and is complicated, then you want orchestration, for sure. So payment processing, checkout, all these things that we’re talking about, those, in my view, absolutely should be orchestrations. Why? Because you have a state machine that you need to make sure executes durably, reliably, and completes successfully one way or another, either all done or all the way back to the beginning.
You use choreography in those cases where you don’t… I don’t want to say don’t care, but you don’t care as much. It’s not as much of a state machine as an informing of other systems to do a thing, and you’re like, “What do you mean, Randy?” Well, I’ll give you an example. So, I’ve been at eBay twice. eBay has been using an internally built Kafka-like system for many years, almost 20 years. And a thing we learned, everybody else learned at the same time, too, is choreography is best in those cases where you don’t have a state machine. You just want to inform people and have them do stuff.
So example is, when you list an item on the site, we absolutely want to make sure that all the payment and the exchange of stuff actually happens, so that stuff is orchestrated. But when you list an item on the site, there are literally tens of different other things that happen. So, you list a new item, eBay takes the image that you gave them and thumbnails it, and all these different things. It gets checked for fraud. It increments and decrements a bunch of counters about the seller’s account. Right now, the seller has sold a thousand things and, yay, they now get a gold star or a platinum star. So all these different things, and none of those is a workflow in the sense that we could and should continue the mainline work of accepting that item and putting it on the site as those other things happen in parallel.
Michael Stiefel: Because if no one gets the gold star, nothing else is dependent on that gold star.
Randy Shoup: Yes. And I want to be clear that, ultimately, you do get the gold star, but it doesn’t have to happen in a state machine-y way.
Michael Stiefel: Yes, yes.
Randy Shoup: This example, I think, is a reconciliation that, if we didn’t process that event like, every so often, we come around and go, how many things did you actually sell? Anyway, but I hope that explanation makes sense.
Michael Stiefel: Yes. So, I want to summarize this part by saying, and maybe this is something that will appeal to both business people and engineers. We talked about how designing for failure is a reification, or an abstraction, or an implementation of what happens in the real world. Well, if you think about the real world, failure happens, and the point is you dust yourself off when you have a failure, and you get up and go on.
Randy Shoup: Yes.
You WIll Fail – How Will YouRespond to Failure? [35:07]
Michael Stiefel: So the real issue is not did you fail, but how do you respond to that failure.
Randy Shoup: Yes, it’s exactly about the resilience to failure. The wonderful framing, which is not mine, I think it’s John Allspaw and the whole resilience movement, but I’m going to say what these acronyms mean in a second, it’s not about minimizing MTBF, it’s about minimizing MTTR. So, what do I mean? MTBF is mean time between failures. And so if you’re a hardware manufacturer, a thing you want to say is, “Hey, these hard drives that I ship, they don’t fail very often”, and you’re like, “What do you mean by very often?” “Well, our mean time between failures is one in a million, whatever, or four years for this Seagate hard drive, or whatever, but that’s not the right way to think about software. It’s not work so hard to never have anything go wrong because that doesn’t work. Things are going to go wrong. Instead, MTTR, mean time to restore. So, instead, think about, when things fail, how can we recover as quickly as possible and get us back into a correct state?
Again, whether that is retrying and trying to move forward, or rolling back, or undoing, or whatever, and trying to get us back to the beginning, either way. The correct thing, and we’ve learned this over time in the industry in the last, let’s call it, decade is systems are easier to build, much more reliable to operate, and much cheaper if you don’t try to avoid failure. But instead, you try to respond to failure and be resilient to it. So this is exactly the insight behind cloud computing. It’s not have one big system that never, ever, ever goes down, that’s mainframe era thinking.
Instead, it is, there are in a modern data center, literally 100,000 machines and not try to make none of them fail because, at any given moment, handfuls may be, hundreds are down, thousands maybe. But whatever, who cares? Because we put stuff in three different places and we can move things around quickly. And so all these patterns at the higher level are all around letting individual components or individual steps fail, and we don’t care about that because we have a higher level correctness that we’ve layered on.
Resilience is Not A Castle With Moat, Alligators, and a Drawbridge [37:26]
Michael Stiefel: I think last QCon San Francisco, there was a session that we both attended. It was about security. And I apologize for not remembering the speaker’s name, but they had this metaphor of it’s not about building a castle with a moat around, and then alligators, and a drawbridge to make sure no one gets in.
Randy Shoup: Right.
Michael Stiefel: That’s not the right metaphor because the invaders will get in.
Randy Shoup: Yes.
Michael Stiefel: What do you do to section them off, and deal with the failures that inevitably will happen, because the castle will be breached.
Randy Shoup: Yes, exactly. It’s not the hard shell in the soft center. It’s instead zero trust where you componentize and isolate all the individual things. You assume you’re overrun. Your invaders are there, they’re in the house, but what can we do to make sure the room I’m in is safe, or even if they get in the room, they can’t harm me because I wear an Iron Man suit, or whatever? So that mental model is great. The other equivalent, I hope it’s equivalent, is the componentization. Like you say, the isolation. So that’s circuit breakers, that’s bulkheading, that’s all those kind of patterns. And thanks to Michael Nygard for writing those all up in his fantastic book, Release It! Please buy, try and read that.
Michael Stiefel: I recommend everybody read that.
Randy Shoup: Yes. So Michael Nygard and Release It popularized… Because he wouldn’t even himself say he invented these things, but popularized circuit breakers, bulkheading, et cetera, which are exactly these isolated components of the system that are safe. But the other way to think about it is every mitigation or defense that we would put in place is Swiss cheese, but make sure that those holes in the layers of Swiss cheese don’t overlap. I’m making this up, but imagine five pieces of Swiss cheese and you orient them in such a way that at least one of those things blocks everything. So there’s no hole all the way through.
And also, probably related to the first, but I would say it separately, the zero trust where your mental model is you’re out there naked on the internet and you need to make sure that anybody you interact with is legit. So that’s a mutual TLS, so end-to-end encryption in transit. That’s encryption at rest, that’s integrity of the messages, that’s authentication and authorization of the identities of the people that are talking to you.
Michael Stiefel: All the things that the WS-star things tried to solve, that was a big industry struggle. But I think eventually, the industry has realized that these things are important and it’s not just about encrypting or one transaction between the user and the system.
Randy Shoup: Yes.
Architecture and Team Satisfaction [40:05]
Michael Stiefel: I do want to ask you a question. I don’t know if we’ve ever discussed this before, but this is something that’s become interesting to me is how architecture can affect team performance and team satisfaction with their job. You must have come across this. At one level, it seems simple. For example, if you have a loosely coupled system, it makes it easier for individual teams to do their jobs, but I think there’s something deeper here. And I think because you’ve been both an architect and an engineering manager, and if you have lots of different roles, you must have some unique perspective on this.
Randy Shoup: Yes. I don’t know if it’s unique, but I definitely have a perspective. Off the top of my head, I would say at least two, and it’s going to grow in a moment. So number one is, at the highest level, if your system architecture matches the problem, again, this is back what we were saying before, if you take a domain-driven design approach and you can find a place in your system that matches a part of the real problem you’re trying to solve, that’s already good. Why is that good? Because it reduces the cognitive load for the people trying to solve problems, again, because it matches the problem. So, if you understand the problem like, “Oh. Well, where does the payment processing step belong?” “Oh, it’s in the payment processor”. “Okay, cool, that’s awesome”. So, matching the problem is number one.
Number two is, to your point, componentization, whether that is, think about, as microservices or components in some other way, not having to think about the entire system all at once, but instead only having to think about the payment processor part or the bank interchange part, or whatever, taking a big problem, which is the entire thing of eBay or Google, or whatever, and instead making it a much smaller problem. And then thirdly, architecture should be a tool that helps you think, and so having the tools and the patterns to do things easily. And so, we were talking a bunch of those things like, “Hey, if it’s easy to do workflows.”.. Workflows are complicated, but if we, in our architecture, make it easy to do them because we have either built a system that makes it easy or we have other implementations of the SAGA pattern, or whatever, that you can go look at.
So a good architecture is one where, as an architect or as an engineer, I have a lot of different tools. And I don’t mean compilers. I mean components in the system or patterns in the system that allow me to do things. Because the best architectures that people have worked in are ones where you’re like, “Oh, let’s see, I need a data store”. “Okay, here’s this menu”. “Okay, cool, I’ll take that one”. “I need to do events back and forth”. “Okay, I’ll take that”, and having all those tools. And now, I’m going to add a third one, which is a paved path, like a Netflix or a Google, where all the pieces of this system are well-supported. So I can easily spin up a new service because there’s this template. Everything is in there. It’s integrated into the monitoring system, integrated into the RPC mechanism, integrated into CI/CD, blah, blah, blah.
Should Each Team Use Its Own Set of Tools? [43:14]
Michael Stiefel: When you’re talking about tools, one thing that always comes to mind is this struggle between the desire to impose that everyone uses the same tools, because it makes it easier to transfer for systems or hire people, and each team choosing the tool that’s most appropriate for them. And this extends to languages, to high-level tools. How do you feel about that?
Randy Shoup: Yes, I feel very strongly about that. You want to have both. So, the best places that I have worked and the most effective, call it, architectures or engineering organizations, or whatever, are ones where there is a paved path, or a very small number of them. Netflix and Google are great examples of the possible programming languages in the world. At least when I was at Google 10 years ago, there was good support for four, there was good support for C++, Java, Python, and Go.
Other languages are allowed, but you have to roll your own, everything. It has to integrate with a monitoring system and integrate with the testing frameworks, blah, blah, blah, blah, blah. So, certainly at large scale. I’m going to make a different comment when you’re small scale, but at large scale, having a paved path that is well-supported by people whose job it is to support it. That was my team’s job at eBay, by the way, to support the frameworks, and also allow people to go off the reservation. So paved path, but you can bushwhack.
And why do you allow bushwhacking? It’s because, sometimes, the right thing to do to solve this particular problem. Like some machine learning problem, let’s say, they should do it in Python because that’s the language where everything is written in. And if you’re doing some other kind of system, maybe that’s Erlang. So there’s a reason why WhatsApp was only eight people when they were acquired by Facebook, or whatever, because Erlang very much matches… and that whole system supernaturally matches the messaging problem they’re trying to solve.
Anyway, my point is, again, paved path, plus the ability to do new things, and to do new things, again, is because it allows people to match the exact problem they’re trying to solve individual teams, and also it allows growth and evolution of the common framework. So if you’re in this monoculture and you never look outside, you’re stuck. And there are lots of examples out in the world where companies have gotten themselves stuck into a rut where, “Okay, we’re only Java, and we’re going to keep our blinders on and never look anywhere else”, and that hasn’t been a super bad choice, but there are companies that are in the Microsoft ecosystem which is better now than it was 10 years ago. But you know what I mean? “Hey, we only do Microsoft”, and even the thinking about how to do distributed systems was very isolated, if that makes any sense.
Michael Stiefel: Yes, I lived in that world for a long time.
Randy Shoup: No shade on either of those ecosystems, I use them both, but you see where I’m going with that. So, I have a strong visceral belief that you shouldn’t have a monoculture at scale. Okay. Now, when you’re small, like I am, we have 100 people in the engineering organization at Thrive Market, where I work, we really should all be working on one thing. Some individual teams need to… Again, machine learning is a great example. They need to do stuff in Python, whether or not we did that elsewhere on the site. But when you’re small, it should definitely not be like every team for itself because you don’t have a lot of time to waste, a lot of resources to waste on doing things in multiple ways. So, that’s my quick thinking on standardization versus letting a thousand flowers bloom.
Michael Stiefel: I like that approach because it differentiates between the small to the large, and you can see what happens if you adopt what you say, for small teams when you grow to larger scale. Because a lot of the problems, which we didn’t talk about and it’s another whole thing we could talk about because we don’t have the time, and this podcast could be hours-
Randy Shoup: Yes, we’ll do another one, or something, if you want.
The Surprise of Large Scale [46:56]
Michael Stiefel: Right. Because what happens when, all of a sudden, you wake up and you were at small scale, and tomorrow, you got mentioned in the press and you now are at large scale all of a sudden.
Randy Shoup: Yes. Every company that we think of as large scale had that scaling event.
Michael Stiefel: Yes.
Randy Shoup: It is rare to have had that happen very slowly. It happens, but it is rare. Everything is an S-curve, but the way more likely is you’re chugging along, no one knows about you, and all of a sudden, kaboom, you hit something. Again, mentioned in the Wall Street Journal or reach a critical mass of people knowing about it and telling their friends, or whatever. And we don’t have time to talk about it here, but I have thought about for many years these phases of companies and products. And there’s a starting phase and a growth phase where the J-curve, as people talk about, or, really, the S-curve starts to get steeper and you go faster, and then it flattens out.
Michael Stiefel: So maybe some other podcasts, we’ll talk about scaling and what other else comes up.
Randy Shoup: Sure, sure.
The Architect’s Questionnaire [48:03]
Michael Stiefel: This is the point where I like to go off and ask the questionnaires that I like to ask all my architects. I find it also adds a human dimension to the podcast.
Randy Shoup: Great.
Michael Stiefel: So, what is your favorite part of being an architect?
Randy Shoup: I mentioned it earlier, actually. It’s the Gregor Hohpe’s Architect Elevator. So, I get a lot of enjoyment out of going up to the boardroom and down to the engine room. There’s something that’s just very energizing for me about being able to see things and help solve problems in the large, but also see things and solve problems in the small, and each of those lenses informs the other. What I don’t like-
Michael Stiefel: Right. What is your least favorite part of being an architect?
Randy Shoup: I haven’t had this experience a lot, but when it is not considered important or strategic to the organization or the company, I don’t like being not productive, or useful, or valuable. So, if I am in a situation where it’s not considered valuable to do this stuff, I should go somewhere else.
Michael Stiefel: Is there anything creatively, spiritually, or emotionally satisfying about architecture being an architect?
Randy Shoup: Yes. This is where, again, I said I’m a multidisciplinary person at my core. I’m not just interested in the computer science side. I’m not just interested in the international side. We contain multitudes. And so the thing that I love about being an architect is being able to play, again, on both sides.
The thing that really resonates with me is I tend to be more of a deductive reasoner, rather than inductive. So what does that mean? Deductive is you have a set of principles and you apply them. My sense is more people are inductive where you look at a bunch of examples and then derive from there. I like to do both, but my go-to model is to have a model, if that makes any sense. I like to think in terms of… People see this if we look at my talks back almost 20 years, I’d like to state, “Here are the principles. We should split things up. We should be asynchronous. We should deal with failure.” So I like to take those principles and have a clear, almost platonic statement about what the principles are, and then apply them in the real world.
And then maybe orthogonally to that, I didn’t have this word when I was younger, but I’ve always tried to be a system thinker. I get enjoyment, and value, and, I don’t know, spiritual energy, I guess, from really seeing the whole board and then being able to do interesting things within that.
Michael Stiefel: Thinking about what you said, and I’ve done a lot of teaching, and what I have found is, certainly, what you say is true that most people proceed from the concrete to the abstract, rather the abstract to the concrete.
Randy Shoup: Right.
Michael Stiefel: But I think there’s a difference between giving a talk, as you mentioned, and teaching where you want to start from the principles, as opposed to learning where you want to start with the concrete example. Because very often, the abstract principles seem too vague.
Randy Shoup: Yes.
Michael Stiefel: Because presumably, when you give your talk, you state the principles, but then you explain them with concrete examples.
Randy Shoup: Yes. You’re not implying this, but I want to say there’s nothing wrong with either model. A, I use both. And so it’s not like, “Oh, you can only be an architect if you do deductive reasoning and thinking principles first”. I’m just saying you asked a great question, which is, “What resonates with you, Randy, at a deeper level about architecture?” And that’s what resonates with me is this idea of coming with principles and then applying them. So, that’s what resonates with me personally. If you only did that, you would not be a very effective architect if you only did the other way. If you only did inductive reasoning where you only looked at examples and then abstracted from there, you would not be very effective. Both techniques are important, and I use them both all the time.
Michael Stiefel: So, what turns you off about architecture or being an architect?
Randy Shoup: When an architect behaves in an ivory tower way. Again, lots of people get excited about lots of different things, and that’s great. Again, it’s great that we have a diversity of people and approaches in this world. I do not like not being useful. And when I say useful, I mean… A lot of us do. I have the skill and capability to pontificate. I could do that, I don’t want to. Again, boardroom to engine room, I would much rather work it so that things actually matter. I’m not interested in producing documents for document’s sake. I’m interested in changing the world, or at least the company.
Michael Stiefel: In a science fiction world, you’d like to step into the UML diagram, into the box, and see what’s in the box.
Randy Shoup: Yes. And the purpose of diagramming, and the purpose of saying things and principles, and the purpose of doing architecture at all is to solve customer and business problems. That’s what we’re here for, and it is worse… You’re not applying otherwise. It is worse than useless for some fancy, well-paid person to pontificate about stuff and not have that very directly be connected to solving a business problem we couldn’t before, solving a customer problem we couldn’t before.
Michael Stiefel: Do you have any favorite technologies?
Randy Shoup: I do. I very much, obviously, am going to date myself. So, again, as I mentioned, no hiding, I started my career… graduated in 1990, started doing my internships a couple of years before that. I’ve always loved SQL. My starting thing was doing Oracle database related stuff, again, in my internship at Intel for a couple of years, and then I went to work for Oracle for seven years. So, nothing about Oracle database in particular, although it’s always been really good. But SQL, I think it’s just we have yet in the data world, and this is not a bad thing. We are still using 1970s relational algebra, whether we know it or not, doing data systems. So I think that’s wonderful.
Again, dating myself in terms of when I was last, and it was a while ago, hands-on keyboard as my primary job, but I’m really good at Java and C++, so I did a bunch of stuff there. Not so much technologies, but again, patterns and approaches, particularly at large scale. And don’t do it if you don’t need it, but a services or microservices approach, event-driven architecture, those are things that really solve real problems and I use all the time.
Michael Stiefel: What about architecture do you love?
Randy Shoup: I love finding an elegant solution to a problem. Actually, we just had this the other day. It would be too long to explain the details. Not that they’re secret, but just the other day, one of my teams at Thrive was going down a path that would work but wouldn’t be right. And so, going in and doing a little bit of Socratic method of, “Okay, let’s restate the customer problem”, which in this case, “Hey, what does the ML team need to be able to run their models in real time?” And like, “Okay, let’s explain what you need. What do you have and what do you want back?” “Okay, now that we know that, hey, let’s think about what the interface should be on the next level down”, and like, “Okay, we have a bunch of options, but this one is more natural”.
Anyway, I love being able to see a problem and helping to reframe it in a way that makes it easier and maybe sometimes even obvious to solve. It’s such a leverage point. It’s such a force multiplier to be able to… not by myself, but help us all to see, “We think this feels hard. We’re going down this thing, we’re bushwhacking, but there’s actually a really easy, or straightforward, or natural way of approaching this problem if only we think about it differently”. And so, that’s what I get a lot of enjoyment out of.
Michael Stiefel: So, conversely, what about architecture do you hate?
Randy Shoup: I don’t like deferred gratification. So, I like it when if we’re going to really put an architect hat on and do a big architect-y thing, whatever that even means, and we can do this, but I want to make sure that we get value now, as opposed to, “Hey, I sketched out this fancy architecture”. “Oh, yes, we’ll action on that in two years because it’ll take us all this time to do X, and Y, and Z”, and so the deferred gratification there. And then similarly for “big” changes, again, takes too strong a term, but a thing that is hard is dealing with what I’ll call the activation energy to get the organization to think in a new way, start doing in a new way, yes. So I wouldn’t say I hate it, but if I can reframe it, what do I struggle with and not enjoy, that’s it, yes.
Michael Stiefel: So, what profession, other than being an architect, would you like to attempt?
Randy Shoup: Yes, I think I already hinted at that in our intro, but I think I would not do this today, but the other career which I thought was going to be in my mainline career was international law. And thankfully, I found another way. The other thing at the moment would always have been true, but even true now is gourmet chef. So, my personal creative outlet in my life and big enjoyment is I’m a big foodie on the eater side, and so, therefore, I have learned to be a foodie on the chef side. So, I know because my sister-in-law does this herself, but it’s hard to work in a real restaurant. That’s actual real work, very, very hard and uncompromising. But just from an enjoyment perspective, gourmet chef.
Michael Stiefel: Do you ever see yourself not being an architect anymore?
Randy Shoup: Yes and no. I think I will not ever stop trying to frame things in a different, and hopefully natural, and hopefully elegant way. So, from that perspective, that’s a core part of me, I can’t turn that off. Is it possible that someday I will… You know what? No, I don’t think I ever will, to be honest. Even if I, as many of my friends have done so far these days, shift into more an advisory mode with various companies and individual people coaching, or whatever, which I love and do as a side gig as well, I will never shy away from talking about the architecture stuff, if that makes any sense. So, yes, I guess I’ll never stop.
Michael Stiefel: When a project is done, what do you like to hear from the clients or your team?
Randy Shoup: Yes. First and foremost, why do we even do any of these things? It’s because it solved a real problem. So, first and foremost, I want to hear we had a problem, or we had an opportunity, and we solved the problem, or we executed on the opportunity. So that’s number one. At the end of the day, if we don’t make things better, we should do something else. We can make something else better because there’s lots of opportunities for improving. The other though for me is if I hear back, “Wow, that was really elegant how we approached that problem, that was really extensible. I”, other engineer, not Randy, “can now see how we can evolve the system in this way, and that way, and the other way”. So, I guess that’s the other thing that I would really want to see, and this is from the team. It’s like, “Oh, man, we approached this problem in a way that opens more doors than it closes”.
Michael Stiefel: I like that.
Randy Shoup: Yes.
Michael Stiefel: Well, I know there are more topics we could talk about. As we talked through ideas that came into my head, we could go down this path, but thank you very much for being on the podcast. You’re a great guest, and I hope we can do it again sometime.
Randy Shoup: Yes, me, too. Look, between us, we have many, many decades of experience, and just being able to share some of those ideas together is great. So, thanks for having me on. Happy to do it again. Loved it.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
MMS • RSS
![]() Louisiana State Employees Retirement System reduced its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 3.6% in the fourth quarter, according to the company in its most recent 13F filing with the SEC. The institutional investor owned 5,400 shares of the company’s stock after selling 200 shares during the quarter. Louisiana State Employees Retirement System’s holdings in MongoDB were worth $1,257,000 as of its most recent SEC filing.
Louisiana State Employees Retirement System reduced its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 3.6% in the fourth quarter, according to the company in its most recent 13F filing with the SEC. The institutional investor owned 5,400 shares of the company’s stock after selling 200 shares during the quarter. Louisiana State Employees Retirement System’s holdings in MongoDB were worth $1,257,000 as of its most recent SEC filing.
Several other large investors have also bought and sold shares of MDB. Creative Planning boosted its stake in shares of MongoDB by 16.2% during the 3rd quarter. Creative Planning now owns 17,418 shares of the company’s stock worth $4,709,000 after acquiring an additional 2,427 shares in the last quarter. Bleakley Financial Group LLC raised its position in MongoDB by 10.5% during the third quarter. Bleakley Financial Group LLC now owns 939 shares of the company’s stock valued at $254,000 after buying an additional 89 shares during the period. Blue Trust Inc. increased its holdings in shares of MongoDB by 72.3% in the 3rd quarter. Blue Trust Inc. now owns 927 shares of the company’s stock valued at $232,000 after purchasing an additional 389 shares during the period. Prio Wealth Limited Partnership acquired a new position in MongoDB in the 3rd quarter valued at approximately $203,000. Finally, Whittier Trust Co. increased its stake in shares of MongoDB by 3.9% in the third quarter. Whittier Trust Co. now owns 30,933 shares of the company’s stock worth $8,362,000 after acquiring an additional 1,169 shares during the last quarter. Institutional investors own 89.29% of the company’s stock.
Analyst Ratings Changes
MDB has been the topic of a number of recent research reports. Robert W. Baird raised their price target on shares of MongoDB from $380.00 to $390.00 and gave the company an “outperform” rating in a report on Tuesday, December 10th. Morgan Stanley raised their price target on MongoDB from $340.00 to $350.00 and gave the company an “overweight” rating in a research report on Tuesday, December 10th. The Goldman Sachs Group upped their price target on MongoDB from $340.00 to $390.00 and gave the stock a “buy” rating in a report on Tuesday, December 10th. Oppenheimer increased their target price on shares of MongoDB from $350.00 to $400.00 and gave the company an “outperform” rating in a research note on Tuesday, December 10th. Finally, Stifel Nicolaus boosted their price target on shares of MongoDB from $325.00 to $360.00 and gave the company a “buy” rating in a report on Monday, December 9th. Two analysts have rated the stock with a sell rating, four have given a hold rating, twenty-three have assigned a buy rating and two have assigned a strong buy rating to the stock. Based on data from MarketBeat.com, the stock has a consensus rating of “Moderate Buy” and an average target price of $361.00.
<!—->
Get Our Latest Report on MongoDB
Insider Buying and Selling
In other news, CEO Dev Ittycheria sold 2,581 shares of the stock in a transaction dated Thursday, January 2nd. The stock was sold at an average price of $234.09, for a total transaction of $604,186.29. Following the transaction, the chief executive officer now directly owns 217,294 shares in the company, valued at approximately $50,866,352.46. This represents a 1.17 % decrease in their position. The sale was disclosed in a document filed with the Securities & Exchange Commission, which can be accessed through this link. Also, CAO Thomas Bull sold 169 shares of the stock in a transaction on Thursday, January 2nd. The shares were sold at an average price of $234.09, for a total transaction of $39,561.21. Following the transaction, the chief accounting officer now directly owns 14,899 shares in the company, valued at approximately $3,487,706.91. This represents a 1.12 % decrease in their position. The disclosure for this sale can be found here. In the last 90 days, insiders sold 43,094 shares of company stock valued at $11,705,293. 3.60% of the stock is owned by insiders.
MongoDB Stock Performance
Shares of NASDAQ:MDB opened at $289.63 on Monday. The business’s 50 day simple moving average is $262.66 and its two-hundred day simple moving average is $272.16. MongoDB, Inc. has a 52-week low of $212.74 and a 52-week high of $488.00. The firm has a market cap of $21.57 billion, a P/E ratio of -105.70 and a beta of 1.28.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings data on Monday, December 9th. The company reported $1.16 earnings per share (EPS) for the quarter, topping analysts’ consensus estimates of $0.68 by $0.48. The business had revenue of $529.40 million during the quarter, compared to the consensus estimate of $497.39 million. MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The firm’s quarterly revenue was up 22.3% compared to the same quarter last year. During the same period in the prior year, the firm posted $0.96 EPS. On average, equities analysts forecast that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS
![]() Stephens Inc. AR reduced its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 4.1% during the 4th quarter, according to the company in its most recent 13F filing with the Securities & Exchange Commission. The firm owned 1,014 shares of the company’s stock after selling 43 shares during the quarter. Stephens Inc. AR’s holdings in MongoDB were worth $236,000 at the end of the most recent quarter.
Stephens Inc. AR reduced its position in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 4.1% during the 4th quarter, according to the company in its most recent 13F filing with the Securities & Exchange Commission. The firm owned 1,014 shares of the company’s stock after selling 43 shares during the quarter. Stephens Inc. AR’s holdings in MongoDB were worth $236,000 at the end of the most recent quarter.
Other large investors also recently added to or reduced their stakes in the company. Hilltop National Bank raised its stake in MongoDB by 47.2% during the 4th quarter. Hilltop National Bank now owns 131 shares of the company’s stock valued at $30,000 after purchasing an additional 42 shares during the period. Brooklyn Investment Group acquired a new stake in MongoDB during the 3rd quarter valued at $36,000. Continuum Advisory LLC raised its stake in MongoDB by 621.1% during the 3rd quarter. Continuum Advisory LLC now owns 137 shares of the company’s stock valued at $40,000 after purchasing an additional 118 shares during the period. Versant Capital Management Inc raised its stake in MongoDB by 1,100.0% during the 4th quarter. Versant Capital Management Inc now owns 180 shares of the company’s stock valued at $42,000 after purchasing an additional 165 shares during the period. Finally, Wilmington Savings Fund Society FSB acquired a new stake in MongoDB during the 3rd quarter valued at $44,000. 89.29% of the stock is owned by institutional investors and hedge funds.
Insider Activity
In other news, Director Dwight A. Merriman sold 922 shares of the company’s stock in a transaction dated Friday, February 7th. The shares were sold at an average price of $279.09, for a total transaction of $257,320.98. Following the completion of the transaction, the director now owns 84,730 shares of the company’s stock, valued at approximately $23,647,295.70. This represents a 1.08 % decrease in their ownership of the stock. The sale was disclosed in a filing with the Securities & Exchange Commission, which is accessible through the SEC website. Also, CAO Thomas Bull sold 1,000 shares of the company’s stock in a transaction dated Monday, December 9th. The shares were sold at an average price of $355.92, for a total transaction of $355,920.00. Following the transaction, the chief accounting officer now directly owns 15,068 shares of the company’s stock, valued at $5,363,002.56. This represents a 6.22 % decrease in their position. The disclosure for this sale can be found here. Over the last 90 days, insiders sold 43,094 shares of company stock valued at $11,705,293. Insiders own 3.60% of the company’s stock.
MongoDB Price Performance
<!—->
MongoDB stock opened at $289.63 on Monday. The firm has a market cap of $21.57 billion, a price-to-earnings ratio of -105.70 and a beta of 1.28. MongoDB, Inc. has a fifty-two week low of $212.74 and a fifty-two week high of $488.00. The firm has a fifty day moving average price of $262.66 and a two-hundred day moving average price of $272.16.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Monday, December 9th. The company reported $1.16 earnings per share for the quarter, topping analysts’ consensus estimates of $0.68 by $0.48. The firm had revenue of $529.40 million during the quarter, compared to analyst estimates of $497.39 million. MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The business’s revenue was up 22.3% on a year-over-year basis. During the same quarter in the previous year, the business earned $0.96 EPS. As a group, sell-side analysts expect that MongoDB, Inc. will post -1.78 earnings per share for the current year.
Analyst Upgrades and Downgrades
MDB has been the topic of several recent analyst reports. Canaccord Genuity Group boosted their target price on shares of MongoDB from $325.00 to $385.00 and gave the company a “buy” rating in a research note on Wednesday, December 11th. Wells Fargo & Company boosted their price target on shares of MongoDB from $350.00 to $425.00 and gave the company an “overweight” rating in a report on Tuesday, December 10th. The Goldman Sachs Group boosted their price target on shares of MongoDB from $340.00 to $390.00 and gave the company a “buy” rating in a report on Tuesday, December 10th. Loop Capital boosted their price target on shares of MongoDB from $315.00 to $400.00 and gave the company a “buy” rating in a report on Monday, December 2nd. Finally, Citigroup boosted their price target on shares of MongoDB from $400.00 to $430.00 and gave the company a “buy” rating in a report on Monday, December 16th. Two investment analysts have rated the stock with a sell rating, four have given a hold rating, twenty-three have issued a buy rating and two have given a strong buy rating to the company’s stock. According to MarketBeat, MongoDB presently has an average rating of “Moderate Buy” and a consensus price target of $361.00.
Get Our Latest Report on MongoDB
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Read More
Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.