Transcript
He: I’m Jun. I’m the tech lead of the data platform at Netflix, doing management and workflow automation.
I will first give a brief introduction of the problem space. Then I will give an overview of the architectural design. After that, I will show some use cases and examples. Finally, summarize the talk with key takeaways and future works.
Data at Netflix (Introduction)
Let’s get started by looking at the landscape of the data insights at Netflix. Are you a Netflix subscriber? As you might experience while navigating netflix.com, the personalized show recommendation results is quite good. It many times, not always, gives you the shows that you are interested in. Those are powered by the data insights based on multiple data pipelines and also machine learning workflows. Netflix is a data driven company.
Many decisions at Netflix are entirely driven by the data insights, data practitioners like data engineer, data scientist, machine learning engineer, software engineer, even non-engineer, like a data producer, they all run their data pipelines to get the insights they need. It can be just the color used in the landing page when you visit netflix.com, or it can be the personalized recommendation, or the content producer may decide if they should renew the lease, or terminate the next season of the show based on data insights.
Also, we scan data to get a security issue or anything. Data is used widely. As the business continues to expand to new areas, like from streaming to games to ads to the lives. You may have watched the recent live events, and so demand for data continues to grow. Those new initiatives also bring lots of new requirements, for example, like security requirement, privacy requirement, or latency requirements. They all bring a wider variety of use cases to the platform as well.
While users are working with data, the data practitioners usually face three common problems: data accuracy, data freshness, and cost efficiency. With a huge amount of data, the data accuracy is critically important. Business decisions have to be made based on the high-quality data. Also, with that amount of data, if there are some issues you have to correct data, then it might be expensive and also time consuming, as you have to backfill a lot of data. Data freshness is also very important. Users need to process large datasets quickly to enable fast business decision. Cost efficiency is always important, as we run the business.
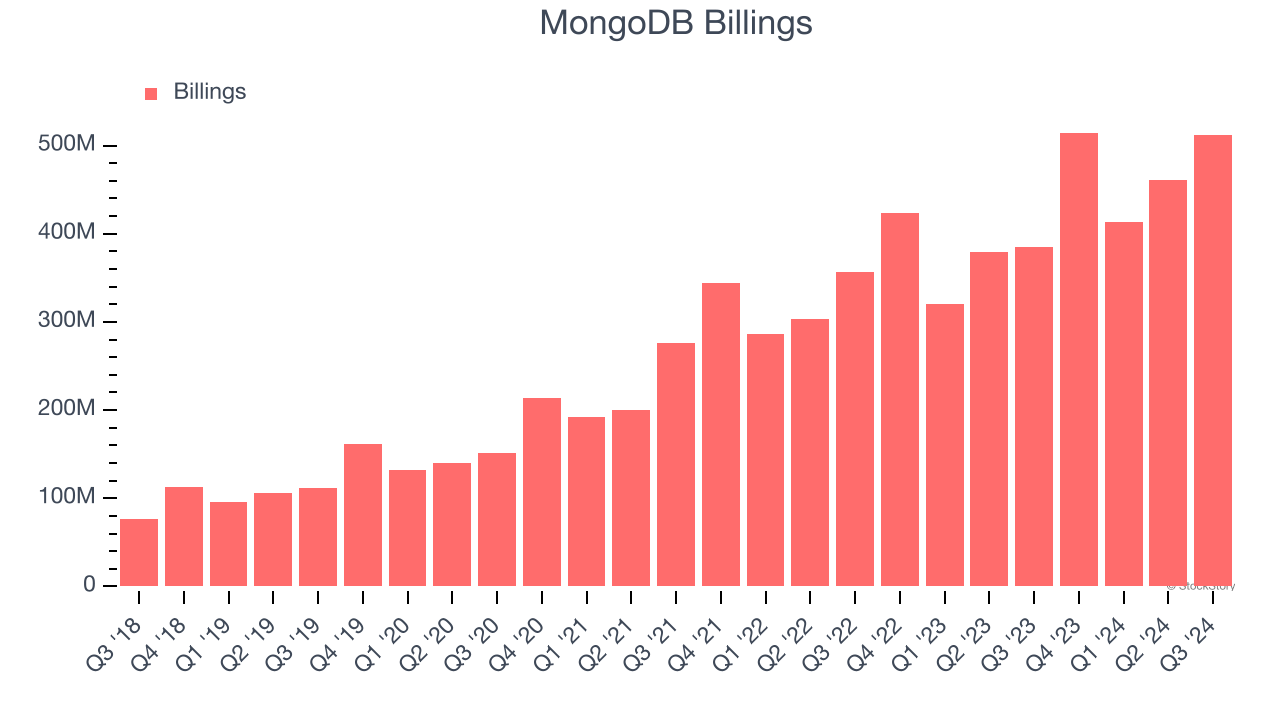
Netflix spends $150 million per year just on the compute and the storage. Also, I would like to call out these three problems: general and common problems. No matter how big or small your data is, it might be more impactful if the data size is large. It costs a lot. If we can solve them, this will be a game changer and enable lots of new patterns, and also allows us to rethink about the batch ETL, in analytics domain. There are lots of challenges to solve those problems. One of the important ones is late arriving data. This graph shows a visual example.
For instance, last night, at 10:20 p.m., I watched Netflix. I opened my app, then my phone’s battery was dead. Then the event generated that my device at 10:20 p.m. won’t be able to send it to the server, so it buffered my device. Then I put my iPhone to the charger, and then I went to sleep. This morning, I got up at 8:20, then I opened my phone and started the Netflix app. Then the event at 8:20 a.m., plus the events generated last night, both sent to Netflix server, got processed. Those events generated last night got processed with multiple hours of delay.
Then, that’s caused trouble. The key is that the event time matters a lot to the business, not the processing time. Many times, the streaming or ingesting pipeline uses the processing time so they can quickly ingest data and append data to the staging table, which is partitioned by the processing time. This can greatly simplify the streaming pipeline, which is wonderful. Then it leaves the late batch analytics pipeline to handle the late arriving data.
As the data lands late, the data processed a few hours ago or in the past, becomes incomplete, which then caused the data accuracy issue. We can fix that by reprocessing the data, but given that amount of data, that might be expensive or time consuming. Also, while we deal with those large datasets, we usually have to carefully design the partition schema to feed the business needs. Then the late arriving data might block the downstream pipelines to start, because those pipelines would like to start to process data only when the data is complete, as much as possible. That will reduce the data freshness as well.
To assist data practitioners at Netflix to work with data, solve the problem or derive any solutions, we developed this big data analytics platform as a high-level abstraction to offer the best user experience and high-level abstractions for users to interact with those compute engines. Users use our Maestro workflow orchestrator, which abstract lots of the complexity from users, they don’t deal with Spark directly. They can easily write their jobs and then use the engine they like to process their data.
Eventually, data is saved to the Iceberg table. We observe the users in our platform usually follow those two common patterns to deal with late arriving data. First is called lookback window. In that scenario, the workflow owner or the job owner, usually have a lot of business domain knowledge, so they can tell how long they should look back. If the data is older, then that window likely does not have much business value there, so they can discard.
Then they can, for example, always reprocess the past three days of data every day to insert overrides to the target table every day to bring back the data accuracy after three days. Another approach is that we can just ignore the late arriving data that sometimes works, especially the business decision we have to make. How do we make, at real time or at that moment? If data is not there, then we have to make a decision, and we’ll make a decision so late arriving data doesn’t matter.
Then we got freshness, we got cost efficiency, but we lose the data accuracy. Another well-known pattern called incremental processing can address those problems. Incremental processing is just an approach to process data, but only new or change data. Here we focus on the analytical use cases. To support that, we have to solve two problems. One is how we can capture the change. Secondly, how we can track the state.
In this talk, I’m going to show how we can use Iceberg plus Maestro together to efficiently support the change capturing and also give users a very great experience to integrate with their pipelines. Let’s talk about Iceberg first. Have you heard about Iceberg? It is a high-performance table format for huge analytics tables. This project started about 8 years ago at Netflix. It has now become the top batch project and one of the most popular open table formats. It brings lots of great features, I’ve listed some here. It simplifies a lot of the data management.
For our project, we leverage the Iceberg metadata layer. It provides lots of information to help us build a mechanism to be able to catch the change without actually reading the user data at all. I’m going to talk about it later. Let’s go over some basic Iceberg table concepts first. Iceberg tables are saved in the catalog. This catalog can be pluggable like a Hive catalog, or Glue catalog, or JDBC, or REST catalog. At Netflix, we have our own internal catalog service as well. Then the tables will save the metadata file in the metadata file which has a list of manifest files which map to the snapshots.
Then those manifest files are just files that save lots of additional information related to the data files. It also keeps the reference of the data file as well. Then Iceberg will produce the partitioning value by taking a column value and optionally transform it. Then the Iceberg tracks this relationship. The table partitioning data design is purely based on these relationships, so it no longer depends on the table’s physical layout. That’s a very important property that we can leverage to build that efficient, incremental change capture feature.
Data practitioners at Netflix used Iceberg and created more than 1 million tables there, and developed hundreds of thousands of workflows to read or write or transform the data of those tables. We then needed to orchestrate those workflows, that’s why we invented Maestro. Maestro is a horizontal scalable workflow orchestrator that manages the large-scale data and machine learning workflows. I
t manages that end-to-end whole lifecycle, so give users a serverless experience they just like to own their business code, and then they ship the code to the platform. It offers multiple reusable patterns, like for each, conditional branching, and subworkflow, and so on. Our users also build additional patterns using those usable patterns. It is also designed for expansion and integration with others, like Metaflow: its integration with Maestro. Then Iceberg, we’re going to talk about that.
We initiated the Maestro project about four years ago. The decision to build our own workflow orchestrator, instead of using those popular ones like Airflow, is just because of the challenges we were facing at Netflix, for example, scalability. We needed a horizontal scalable workflow orchestrator.
Also, usability and accessibility. We had the alpha release in 2021, later in 2022 we have the beta release. Then later in 2022 we got GA internally. Then the team spent one year to move hundreds of thousands of workflows from the old system to Maestro. It’s a fully managed migration. Users don’t actually make any line of code change. After that, summer, this year, we made the Maestro code publicly available, so you can try it out.
I would like to show these simple examples, just to give you some sense how users interact with Maestro or write their workflows at Netflix. This is a configuration, like a definition, where users define this and then they also can include some business logic there. The first section, like description section, that the user can put some information, even some on-call instruction there. This supports Markdown syntax. Then when there’s alerts, or there’s something wrong with this workflow, when we send an email, we can include this description in the email body as well. Then a user can say, I want to trigger it to run daily, so we support a cron trigger and also a single trigger as well.
For example, if the upstream table is ready, then please run this workflow, the single trigger supports. Then here you see, in the workflow, users can define parameters. Parameter can reference another parameter during the runtime evaluation. Here, the parameter of my query includes the SQL query trying to do something. Then a user can define, I will run this query in Spark. Then they just simply put this configuration there. They don’t need to worry about which cluster they need to route to, or what’s the memory or settings they need to use? They can always let the platform decide that. They just need to pass as a query.
Then once they have this workflow definition defined, when they save it, they can use our CI tool trying to push it and then run it. During the development, the query may not be perfect, or they may need multiple iterations. You can just simply run the query, use like SELECT 1 or something first, until you are satisfied with your results, you can plug in the production query. Then a user can also use the UI to take a look at what’s wrong or what happens.
Maestro provides a workflow platform for everyone, serving thousands of internal Netflix users, including engineers and the lang engineers. It offers multiple interfaces and also a flexible integration and dynamic workflow engine, and these extensible execution supports. With all these features, Maestro has become very successful at Netflix as the data and the machine learning workflow orchestrators.
Thousands of our users use that, developed hundreds of thousands of workflows there. It runs half a million jobs, and in some busy days, it even runs 2 million jobs per day. Again, we would like to provide a clean and easy to adopt solution for users to be able to do efficient incremental processing with data accuracy, freshness, and cost efficiency.
Architectural Design
Now let’s start the fun part, architectural design. There are two major goals of this design. Firstly, we need to efficiently capture the change. This is important, not only because of efficiency, but also because lots of times, we cannot access user data because of security requirement or the privacy requirement. In those cases, then this requirement of efficiently capturing change without reading user data becomes really important.
Fortunately, Iceberg provides all these supports in the metadata layer, and helps us to achieve this. Second is, get the best user experiences. You can imagine that that many users develop that amount of workflows in our platform, we cannot break them, or we cannot ask them to make changes significantly. We would like to offer the best user experience. The key is to decouple the change capturing from the user business logic.
In that way, the implementation or the support of the incremental processing can be engine or language agnostic. In that case, users can use whatever language they like or compute engine they like to implement their business logic, and leave the incremental processing to be handled by the platform. Maestro provides all the support to develop this interface. First, let’s see how we can efficiently capture change. As I mentioned, Iceberg metadata provides lots of useful information. The snapshots contain information about like, how many change rows or added data files.
Then the metadata file per data file gives us information about the reference to the data file, and also the upper and lower bound of the change of a given column from that data file and so on. All that information can help us build a very efficient way to capture the change, or capture even the range of the specific column. Then, we only need to access those metadata and get a reference of data file, and then using that, we can build a mechanism to track the changes. Then we can capture those changes. It’s zero data copy, and we don’t touch user data.
The change captured will be included in a table, which then becomes an interface to hand to our users to consume. This table is the same table as the original table, with the same schemas like security access, everything. The only difference is that this table only contains the change data. Then the table name can be a parameter passed to the user job, then the user just consumes everything from this table, then they get the change data.
Next, I will use an example to show how this approach works. Here I have this simple table called db1, table 1, at workload time, T1. As I mentioned, there’s only one single snapshot there, and then it has two manifest files which have five data files there. Those five data files actually map to two partitions. Those partitions are virtual, as I mentioned. The data files are immutable in the storage. Then at query time, you’ve got those virtual table partitions. Yes, I highlighted here.
Then next, you see here, at T2, I got a new snapshot, S1, where here, it either has three new data files appended to this table, and they somehow have the late arriving data, and so they go to the partition P0, and P1, P2. P2 is the new partition, but then data goes to P0 and P1. We want to process using like a traditional hierarchy, you process all the data. We have to select data from P0, P1, P2 everything, which means that we actually reprocess those data files again. It’s not efficient, thinking about that, if this is like 40 days or something, a huge amount of data.
Then, instead using the Iceberg features, we can create a table called ibp table 1, that has the same schema as the original Iceberg table. It is indeed an Iceberg table. Then we add a new snapshot which has the manifest file. At this moment, we don’t create or copy those data files to create a new data file. Instead, we can read the snapshots information from S1 to get a reference of those data files. Then we just simply add reference to the manifest file of the S2 in the new table.
In this way, we can actually reference them without copying the data, it’s zero data copy, and then when a user queries, they SELECT * from this table, they will get three partitions, P0, P1, P2 as well. In this new virtual partitioning, they don’t have those old data files at all, which means that they will not reprocess data. Also, after a while, the platform is responsible for deleting this temporary table after the ETL finishes.
There are some other alternatives to achieve a similar goal, to enable this incremental processing, using Iceberg, like Iceberg with Flink, with Spark Structure Streaming, and so on. We didn’t go with those approaches, mainly just because they are coupled with the engine tightly. This not only requires users to interact with that library using their API or sign implementation client, and adding to their business logic, also requires users sometimes to rewrite their code.
For example, if they use Trino. If they use other engines, they have to rewrite it, use the engine that is supporting incremental processing. I think the underlying implementation, all those implementations are similar. I show some code here. Basically, we load the table and then use the Iceberg APIs, get the snapshots between the two snapshots ID, and with some filters, say we only care about the append publishing information. Then we create an empty table with the same schema as the original one.
Then we scan through the snapshots table, add data files one by one to this new ICDC table. Have that committed. Of course, this code is simple and it’s not like a full production, but it demonstrates the idea clearly. You might consider a similar approach in your solution if applicable.
This new capability enables many patterns. Here are three emerging ones that we observed or discovered at Netflix. Firstly, we are going to talk about incrementally processing the change data and directly append data to the target table. As we have shown, the change data will include reference to the real data file. This table will have reference to the real data files. Then in the ETL workflows, you simply just consume the ICDC tables, SELECT * from it, and then they can get the data file and then append to the target table. It does not need to reprocess the whole provision of P0, P1, P2, and they will bring lots of savings.
Also, in the future, this might be supported by those SQL extensions or something. You can SELECT * between these two steps here or something. We actually are working on this. A second pattern is that we can use this capture change data as a low-level filter. Many times, especially in the analytics domain, the change data itself does not actually give us the full datasets to process, just for example, if I want to get the watch time for all the Netflix users.
In that case, the change data from the past time window only tells me the users that recently watched Netflix but it does not give me total time. However, this change data itself, you will just take a look at the change data and select a unique user ID from it. We are going to get a small set so the user ID, those users at least watching Netflix in that window, with that, while we’re doing the processing, we can use that as a filter. We can join the original table on this table by these user IDs that we find, we can quickly prompt the datasets to process the transform to be able to get the sum easily. Here I show an example.
By looking at the change data, we found that a circle and diamond actually are the keys there in the change data. Then ETL can load the table, quickly filter and find those kind of diamond and circle data points, and then doing the aggregation and save the overwrites to the target table. In this example, I use a simple sum. You might think about some other incremental way to do the sum, but know that this business logic can be anything. It can be very complicated. You may not be able to do that kind of incremental summation or something. This is just for demo.
The third pattern is actually the captured change range parameter, that’s a little bit different from the change data capture. We even don’t need to create a table, instead we just need to get the upper and lower bound of some specific change columns from the source tables. This is very common, especially if you are going to join multiple tables. That is a common pattern in the batch world, where you join two tables, and then you have to find the common range that you need to select all the data between them to be able to run the join, or run any complicated processing.
In that case, we can read the Iceberg metadata to quickly get the range, like min or max from all the tables for a given column. Then we can tell, this is mean. The mean is P1, and max is P2, and then I can load the table, the partition P1, P2, and the partition P1, P2 during the ETL workflow and then during the processing there. This pattern is very useful in the analytics batch workflows, because it’s very common to join many tables, not just two.
Are we done? We are not done yet. Onboarding cost is another major concern. Thousands of our users develop hundreds of thousands of workflows in Maestro, and then we cannot break those workflows or users, or ask thousands of users to rewrite their pipeline. Also, many times, even a user pipeline is not independent or completely independent. Many times, they are dependent on each other. You have multi-stage pipelines.
In those cases, they might have some stage is enabling incremental processing, but some other stages are not enabling incremental processing. We have to support a mix of those pipelines as well. Then those actual costs, like development, operational maintenance, might completely offset the benefit of the incremental processing. Some of the feedback we heard from a user is that, I don’t have benefits to rewrite. Can it just magically work with little changes? The answer is yes. To address those concerns, we provide other interfaces, in addition to table interfaces. There are two new Maestro step types.
One is called IpCapture step type, which encapsulates all the business logic from the platform to be able to capture the change of the table. Then the IpCommit step, which can commit checkpoint based on the IpCapture step information. With this design, user workflows can simply onboard to Maestro IPS support by just adding one job of IpCapture from, and one job of IpCommit after user jobs. As I mentioned, we are going to have the ICDC table include all the changes, and then that table name will be passed as the parameter to the user jobs.
That’s a great interface for users to be able to simply just consume that table. Most user business logic will be exactly same. They don’t need to worry about how to capture the change at all. In case you really need to maintain or upgrade or fix bugs in our change capturing logic, users won’t get impacted. They just need to rerun their job. Everything will work. They don’t need to add any library dependency to get incremental processing support. Also, multi-stage pipelines can work as well, because this is just like a typical, standardized Maestro workflow. All the workflows can work using the Maestro features.
With those interfaces, all existing workflows can work together seamlessly, and so a user can use the best way to implement their business logic, or can use the engine they like. Also, Maestro step is configurable, as I just showed you, with a very low code solution there too. I would show a complicated example here just to demonstrate how powerful and simple that approach is. Here’s a complicated workflow example that our user developed trying to auto remediate the issues.
Many times, in your ETL pipeline, it may fail because of some small problems here, there, and then the on-call will wake up and then rerun some script to fix the data problem or something, and then just kick off the restart again. Then, in this auto remediation approach, you’re just doing the same thing in this type of flow that either cause this typical ETL pipeline plus auditing process. Then, they can tell Maestro, if this subworkflow failed, please don’t fail the workflow and page me, please just ignore that first and then run a recovery job.
This check status job will see if actually subworkflow failed or not. It either goes to this recovery step and run the recovery job, and then run this workflow again to see if it succeeds. If not, then page a user. This is how a user defined that using Maestro. They can go and define this workflow, with this special flag saying, IGNORE_FAILURE. Then they define the data information, which I mentioned, like if else condition here, trying to route the workflow to different paths based on the status of that subworkflow job.
To enable incremental processing for this complicated pattern is very simple. You either just need an IpCapture step at the beginning and IpCommit step at the end, that’s it. They don’t need to actually modify lots of their code. Then you can see, here is the new pipeline. This is subworkflow which points to the workflow that I just showed. It’s an auto remediation pipeline. Then either pass the source table, which has now become the ICDC table name to the subworkflow, where it also can pass a query as well.
Then it adds this IpCapture step trying to capture changes. You just have this ICDC mode, and then the table is membership_table. Then, you only care to append only in snapshot. Then in the commit step, users just need to tell us what’s the step ID of the IpCapture. That’s it. IPS can efficiently capture the incremental change and handle the late arriving data. With those clean interfaces, the solution is compatible with the existing user experience with really low onboarding cost, as I just showed.
Use Cases and Examples
Next, let’s walk over a few use cases and examples together. This is a two-stage ETL pipeline with two Maestro workflows and three tables. This is a playback table which ingests the events from the streaming pipeline. Then the workflow owner decided, I have to take a look back at two weeks of data, because there’s a lot of events that come late. Then in their daily pipeline, they aggregate this table and then save it to target table by changing the partition key from processing to the event time.
Then they have to do this every day, and rewrite the past 14 days of data. This pipeline can take quite a while, so they have to run daily. They cannot run hourly. Then for this table, consumers, we may have hundreds of workflows consumed from this table. They build aggregation pipelines to power their business use cases. Then here in this case, just doing data aggregation, also have to consume the data from the past 14 days as well. You can see it’s time consuming, plus it’s also fragile.
Many times, if there’s a traffic pattern change, suddenly huge events land, or there’s a business logic change, users have to adjust this lookback window, which then will affect all the downstream workflows and everyone as well. That’s another great pattern. Then, let’s see how we can make that to be IPS enabled. Here’s the one that’s using the pattern 1. You can see that we can easily have an ICDC table to hold the change data, and then let this pipeline consume from ICDC table instead of from the original table. Then we can easily merge into the target table.
Also, because this runs so fast, we can be doing this hourly instead of daily. This shows some changes in the write job. I just use SQL as a demonstration. There’s also Scala or some other logic. You can see that instead of insert overwrite we can use merge into. Then just change from the ICDC table, and then add the dedupe logic. Also, you can use insert into if you like, or if there is a dedupe logic or other workflows running, trying to dedupe the data.
For the stage two, we use the pattern 2, where we can have the ICDC table hold the change data, then join with the IPS table, join with the original table, and then doing this aggregation again and merging to target table. Same thing, user can run super-fast. Then we can update the workflows cadence from daily to hourly as well. This shows the change in SQL.
Basically, same thing, merge into, and then we join with the ICDC table on those aggregation group_by_keys. Then we add the dedupe logic as well. After changing this two-stage pipeline from the original way to this new IPS enabled approach, we see huge savings. You see that the lookback window is about 14 days. Also, the late arriving data is sparse. It’s not always that it has lots of late arriving data. Actually, the cost of the new pipeline is less, or only 10% of the original pipeline. Also, it improved the data freshness as we can now run hourly.
The next example shows the multi-table cases using pattern 3, where we have like three staging tables, row tables which have the events from the streaming pipeline. The first one and the last one has late arriving data, and the middle one does not. Middle one can be a normal pipeline, and this first and the third pipeline will be the one with the IPS enabled. Then they produce this hourly table, 1, 2, 3.
Then this final pipeline will be based on the range captured, here it is min of 3 and max is 6, so that you are going to load the data from all three tables from hour 3 to hour 6 together. Then doing the complicated join operations to produce data to the target table. I hope this example demonstrates how simple and powerful it is for users working with Maestro using IPS.
Key Takeaways
IPS enables new patterns, and also let us rethink about batch ETL, which is sometimes considered to be replaced by the streaming pipeline, which also have some other troubles as well. Actually, the batch ETL is still very popular and widely used, especially in the analytics domain. With this IPS support, we can power the batch ETL to have the data accuracy, data freshness, and cost efficiency, all of these. That can fill lots of gaps and enable lots of use cases, even sometimes that we may not need to move to streaming and can stay with the batch.
In the talk, we have shown how we can use Iceberg metadata to be able to efficiently capture change, and then we also have shown the power of decoupling that can help to address concerns differently, and then let the user have minimum changes. Also, with the clean interface that Maestro provides, we provide a great user experience, and also with minimum effort, users can adopt this new approach. Also, hope you can leverage some of those patterns that we discovered in your work, if applicable.
Future Improvements
What’s next? We are going to move some of the implementation from our own side to the Iceberg, like SQL extension to be able to create a view instead of a table, to reduce the maintenance cost, so we don’t need to create a table. Also, we are going to add support for other types of snapshots beyond the just append. Also, we are working with the Iceberg community to add a cookbook to show how to do the change capturing. We are working on the auto cascading data backfill features using the IPS.
Questions and Answers
Participant: I have a question regarding the join operation that you mentioned for incremental processing. If let’s say I’m doing 7 days or 14 days of join, even for the incremental part, you will still need to load the data on the left side and right-hand side, both for 14 days, because the incremental data might be joining with the historical data in the past. How would you be able to achieve 10x of the cost reduction in that case?
He: Data reduction is based on the fact that if you guesstimate the range, you need to do the join. It may not be accurate, or many times you have to be conservative to handle the worst scenario. You actually have a really long window, then you join that. The cost efficiency we get here is mainly for pattern 1 and 2, but not for the data capture range cases. In the capture range cases, it’s more like we can achieve the optimal data accuracy, as we know exactly what’s the change. The cost efficiency gain from there may not be that huge, like 10x.
See more presentations with transcripts