Month: March 2025

MMS • Aditya Kulkarni

Recently, GPT-4o Copilot is introduced for Visual Studio Code (VS Code) users. This AI model is built upon the GPT-4o mini foundation and includes extensive training from over 275,000 high-quality public repositories across more than 30 widely used programming languages. The enhanced training is expected to provide more accurate and contextually relevant code suggestions, with improved performance, boosting developer productivity and aiding the coding process.
This announcement was made through a changelog post on the GitHub blog. The GPT-4o Copilot model differentiates itself through some key enhancements. Utilizing a vast dataset of high-quality code offers more precise and contextually relevant code completions. Its architecture and training also enable faster and more efficient code suggestion generation. The model can support various development projects with training across over 30 programming languages.
To integrate GPT-4o Copilot into VS Code, users can access the Copilot menu in the VS Code title bar, select Configure Code Completions, and then choose Change Completions Model. Alternatively, users can choose the Command Palette by opening it and selecting GitHub Copilot: Change Completions Model. Once in the model selection menu, users can choose the GPT-4o Copilot model from the available options.
For Copilot Business and Enterprise users, administrators must first enable Editor preview features within the Copilot policy settings on github.com to grant users access to the new model. Meanwhile, for Copilot Free users, using this model will count toward their 2,000 free monthly completions. The model will soon be available to Copilot users in all JetBrains Integrated Development Environments (IDEs), further expanding its reach across different platforms.
In JetBrains IDEs, users can click the icon in the status bar, navigate to the settings dialog box for Languages & Frameworks > GitHub Copilot, and select the preferred model from the dropdown menu.
Covering this announcement as a part of the Tech Insights 2025 Week 9 newsletter, Johan Sanneblad, CEO & co-founder at ToeknTek, said,
GitHub Copilot is quickly catching up to Cursor IDE which is already packed with custom models. From what I can see there are just two main features missing in Copilot: Prompt caching for performance and a local model for code merging. Once it gets those two features I think I would feel equally at home in Visual Studio Code + Copilot as with Cursor. And for all you Java and C# users, this is the update you have been waiting for. We finally have a good code completion model with good support for C++, C# and Java.
GitHub Copilot was also in the news as it introduced Next Edit Suggestions, which can predict and suggest logical edits based on the context of ongoing changes in the code. It can identify potential modifications across an entire file, offering suggestions for insertions, deletions, and replacements. Developers can navigate through these suggestions using the Tab key, streamlining the editing process and potentially saving significant time
It’s important to note that switching the AI model does not affect the model used by Copilot Chat. The data collection and usage policy remains unchanged regardless of the chosen model, and the setting to enable or disable suggestions that match public code applies regardless of the chosen model.
User feedback is essential for refining and enhancing the GPT-4o Copilot model. Developers are encouraged to share their experiences to help improve the model’s performance and usability for all Copilot users.
MMS • Craig Risi
GitHub’s Product Security Engineering team secures the code behind GitHub by developing tools like CodeQL to detect and fix vulnerabilities at scale. They’ve shared insights into their approach so other organizations can learn how to use CodeQL to better protect their own codebases.
CodeQL enables automated security analyses by allowing users to query code in a way similar to querying a database. This method is more effective than simple text-based searches as allows it to follow how data moves through the code, spot insecure patterns, and detect vulnerabilities that wouldn’t be obvious from text alone. This provides a deeper understanding of code patterns and uncovers potential security issues.
The team employs CodeQL in various ways to ensure the security of GitHub’s repositories. The standard configuration uses default and security-extended query suites, which are sufficient for the majority of the company’s repositories. This setup allows CodeQL to automatically review pull requests for security concerns.
For certain repositories, such as GitHub’s large Ruby monolith, additional measures are required. In these cases, the team uses a custom query pack tailored to specific security needs. Additionally, multi-repository variant analysis (MRVA) is used to conduct security audits and identify code patterns that warrant further investigation. Custom queries are written to detect potential vulnerabilities unique to GitHub’s codebase.
Initially, custom CodeQL queries were published directly within the repository. However, this approach presented several challenges, including the need to go through the production deployment process for each update, slower analysis times in CI, and issues caused by CodeQL CLI updates. To address these challenges, the team transitioned to publishing query packs in the GitHub Container Registry (GCR). This change streamlined the process, improved maintainability, and reduced friction when updating queries.
When developing a custom query pack, consideration is given to dependencies such as the ruby-all package. By extending classes from the default query suite, the team avoids unnecessary duplication while maintaining concise and effective queries. However, updates to the CodeQL library API can introduce breaking changes, potentially affecting query performance. To mitigate this risk, the team develops queries against the latest version of ruby-all but locks a specific version before release. This ensures that deployed queries run reliably without unexpected issues arising from unintended updates.
To maintain query stability, unit tests are written for each new query. These tests are integrated into the CI pipeline for the query pack repository, enabling early detection of potential issues before deployment. The release process involves several steps, including opening a pull request, writing unit tests, merging changes, incrementing the pack version, resolving dependencies, and publishing the updated query pack to GCR. This structured approach balances development flexibility with the need for stability.
The method of integrating the query pack into repositories depends on the organization’s deployment strategy. Rather than locking a specific version of the query pack in the CodeQL configuration file, GitHub’s security team opted to manage versioning through GCR. This approach allows repositories to automatically use the latest published version while providing the ability to quickly roll back changes if necessary.
One challenge encountered when publishing query packs in GCR was ensuring accessibility across multiple repositories within the organization. Several solutions were considered, including manually granting access permissions, using personal access tokens, and linking repositories to the package for inherited access permissions. The team ultimately implemented the linked repository approach, which efficiently managed permissions across multiple repositories without manual intervention.
GitHub’s security team writes a variety of custom queries to enhance security analysis. These queries focus on identifying high-risk APIs, enforcing secure coding practices, and detecting missing authorization controls in API endpoints. Some queries serve as educational tools rather than strict enforcement mechanisms, using lower severity levels to alert engineers without blocking deployments. This approach allows developers to assess security concerns while ensuring that the most critical vulnerabilities are addressed promptly.
MMS • Alexandru Ene

Transcript
Ene: We’re going to talk about how we rebuilt a Prime Video UI for living room devices with Rust and WebAssembly, and the journey that got us there. I’m Alex. I’ve been a principal engineer with Amazon for about eight years. We’ve been working with Rust for a while actually in our tech stack for the clients. We had our low-level UI engine in WebAssembly and Rust for that log. Previously I worked on video games, game engines, interactive applications like that. I’ve quite a bit of experience in interactive applications.
Content
I’ll talk about challenges in this space, because living room devices are things like set top boxes, gaming consoles, streaming sticks, TVs. People don’t usually develop UIs for these devices, and they come with their own special set of challenges, so we’re going to go through those. Then I’ll show you how our architecture for the Prime Video App looked before we rewrote everything in Rust. We had a dual tech stack with the business code in React and JavaScript, and then low-level bits of the engine in Rust and WebAssembly, a bit of C++ in there as well. Then I’ll show you some code with our new Rust UI SDK and how that looks, which is what we use right now in production. We’re going to talk a little bit of how that code works with our low-level existing engine and how everything is organized. At the end, we’re going to go a little bit to results, lessons learned.
Challenges In This Space
Living room devices, so as I said, these are gaming consoles, streaming sticks, set top boxes. They come with their own challenges, and some of them are obvious. There’s performance differences that are huge. We’re talking about a PlayStation 5 Pro, super nice gaming console, lots of power, but also a USB power streaming stick. Prime Video, we run the same application on all of these device types. Obviously, performance is really important for us. We can’t quite have teams per device type, so one team that does set top boxes, then another team does gaming consoles, because then everything explodes. When you build a feature, you have to build it for everything. We were building things once and then deploying on all of these device categories here. We don’t deploy this application that I’m talking about on mobile devices, like iPhone, iOS, mobile devices don’t have this. This is just living room devices. Again, a huge range of performance. We’re trying to write our code as optimal as possible.
Usually, high performant code is code that you compile natively. Let’s say Rust compiled to native, C++ compiled to native, but that doesn’t quite cut it in this space and we’ll see why. Another pain point and challenge is hardware capabilities between these devices is a pain. As SDK developers, we need to think a lot about what are reasonable fallbacks that application developers who write the app code and the app behavior, they don’t need to think about when they write that code and every little hardware difference. We try to have some reasonable defaults. That’s not always possible, so we use patterns like feature flags and things like that to let them have a bit more control. It’s a fairly challenging thing.
Another thing is we’re trying to make this application as fast as possible with as many features as possible to every customer, but then updating native code on these device types is really hard. Part of that is these devices don’t even have app stores, most of them. Maybe it goes up with a firmware update. That’s a pain. It requires a manual process interacting with a third party that owns the platform. Even on places that do have an app store, if you try to update an app on an app store, it’s quite a challenge as well. You need to wait. It’s highly likely a manual process. We’re having this tension between code that we’re downloading over the air, like JavaScript, WebAssembly, and so on, fairly easy, and then code that works on a device that is very fast, but then really hard to update. We want to have this fast iteration cycle. Updating the app in a short amount of time is huge for us.
Again, this is how the application looks like today. I’ve been there eight years and we changed it many times. I’m sure it’s going to change again sometime as it happens with the UIs. We’ve added things to it like channels, live events, all sorts of new features that weren’t there in the starting version. Part of us being able to do that was this focus on updatability that we had all the way in the beginning. Most of these applications were in a language like JavaScript that we can change basically everything on it and add all of these features almost without a need to go and touch the low-level native code. I’ll show you the architecture and how it looks like.
Today, if a developer adds some code, changes a feature, fixes a bug, does anything around the UI, that code goes through a fully CI/CD pipeline, no manual testing whatsoever. We test on virtual devices like Linux and on physical devices where we have a device farm. Once all of those tests pass, you get this new experience on your TV in your living room. That is way faster than a native app update for that platform.
Right now, you’ll see it working and you’ll see a couple of features. This is a bunch of test profiles I was making because I was testing stuff. We have stuff like layout animation, so the whole layout gets recalculated. This is the Rust app in production today. Layout animations are a thing that was previously impossible with JavaScript and React, and now they just work. When you see this thing getting bigger, all the things get reordered on the page. These are things that are just possible right now due to the performance of Rust. Almost instant page transitions as well are things that weren’t possible with TypeScript and React due to performance constraints. This is live today and this is how it looks like, so you have an idea on what is going on in there. We’re going to get a little bit back to layout animations and those things later. For people who are not UI engineers, or don’t quite know, this is the slide that will teach you everything you need to know about UI programming.
Basically, every UI ever is a tree of nodes, and the job of a UI SDK is to manipulate as fast as possible this tree as a reaction to user inputs or some things that happen like some events. You either change properties on nodes, like maybe you animate a value like a position, and then the UI engine needs to take care of updating this tree and creating new nodes, deleting new nodes, depending on what the business logic code tells you to do. Those nodes could be view nodes that are maybe just a rectangle. Then, text nodes are quite common, and image nodes, those type of things. Nothing too complicated. It’s really annoying that it’s a tree, but we’re going to move on because we’re still having a tree, even in our Rust app we didn’t innovate there, but it’s just important to have this mental model. We call this in our UI engine, a scene tree, browsers call it a DOM, but it’s basically the same thing everywhere.
High-Level Architecture
This is the high-level architecture before we rewrote everything in Rust. As you can see, we already added Rust, I think two years, three years ago, we already had it there for the low-level UI engine. There’s a QCon talk about this journey. There’s another part which is saying JavaScript here, but actually developers write TypeScript, that has the business logic code for the Prime Video App. This is the stuff we download. This is downloaded every time the application changes. This is what we output at the end of that full CI/CD pipeline. It’s a bundle that has some WebAssembly compiled Rust code and some JavaScript that came from TypeScript and got transpiled to JavaScript. It maybe changes once per day, sometimes even more, sometimes less, depending on our pipelines and if the tests pass or not, but it’s updated very frequently on all of the devices that I spoke about, the device categories.
Then we have the stuff on device in our architecture. We’re trying to keep it as thin as possible because it’s really hard to update, so the less we touch this code, the better. It has a couple of virtual machines, some rendering backend, which mainly connects the higher-level stuff we download to things like OpenGL and other graphics APIs, networking. This is basically cURL. Some media APIs and storage and a bunch of other things, but they’re in C++. We deploy them on a device and they sit there almost untouched unless there’s some critical bug that needs to be fixed or some more tricky thing. This is how things work today.
Prime Video App, (Before) With React and WebAssembly
You might wonder, though, these are two separate virtual machines, so how do they actually work together? We’re going to go through an example of how things worked before with this tech stack. The Prime Video App here takes high-level decisions, like what to show the user, maybe some carousels, maybe arrange some things on the screen. Let’s say in this example, he wants to show some image on your TV. The Prime Video App is built with React. We call it React-Livingroom because it’s a version of React that we’ve changed and made it usable for living room devices by pairing them some features, simplifying them, and also writing a few reconcilers because we have this application that works on this type of architecture, but also in browsers because some living room devices today have just an HTML5 browser and don’t even have flash space big enough to put our native C++ engine. We needed that device abstraction here. Prime Video App says, I want to put an image node. It uses React-Livingroom as a UI SDK.
Through the device abstraction layer, we figure out, you have a WebAssembly VM available. At that point in time, instead of doing the actual work, it just encodes a message and puts it on a message bus. This is literally a command which says, create me an image node with an ID, with a URL where we download the image from, some properties with height and position, and the parent ID to put it in that scene tree. The WebAssembly VM has the engine, and this engine has low-level things that actually manage that scene tree that we talked about.
For example, the scene and resource manager will figure out, there’s a new message. I have to create a node, put it in the tree. It’s an image node, so it checks if that image is available or not. It issues a download request. Maybe it animates some properties if necessary. Once the image is downloaded, it gets decoded, uploaded to the GPU memory, and after that, the high-level renderer here, from the scene tree that could be quite big, it figures out what subset of nodes is visible on the screen and then issues commands, the C++ layer, that’s with gray, to draw pixels on the screen. At the end of it all, you’ll have The Marvelous Mrs. Maisel image in there as it should be.
This is how it used to work. When we added Rust here, we had huge gains in animation fluidity and these types of things. However, things like input latency didn’t quite improve, so the input latency is basically the time it takes from when you press a button on your remote control, in our case, until the application responds to your input. That’s what we call input latency. That didn’t improve much or at all because, basically, all of those decisions and all that business logic, like what happens as a response to an input event to the scene tree, is in JavaScript. That’s a fairly slow language, especially since some of this hardware can be as, maybe, dual-core devices with not even 1 gigahertz worth of CPU speed and not much memory.
Actually, those are medium. We have some that are even slower, so running JavaScript on those is time-consuming. We wanted to improve this input latency, and in the end, we did, but we ended up with this architecture. The engine is more or less the same, except we added certain systems that are specific to this application. For example, focus management, layout engine is now part of the engine. I didn’t put it on this slide because it goes into that scene management. On top of it, we built a new Rust UI SDK that we then use to build the application. Everything is now in Rust. It’s one single language. You don’t even have the message bus to worry about. That wasn’t even that slow anyway. It was almost instantaneous. The problem was JavaScript, so we don’t have that anymore. We’re actually not quite here because we are deploying this iteratively, page by page, because we wanted to get this out faster in front of customers, but we will get here early next year.
UI Code Using the New Rust UI SDK
This is going to be a bit intense, but here’s some UI code with Rust, and this is actually working UI code that our UI SDK supports. I’m going to walk you through it because there’s a few concepts here that I think are important. When it comes to UI programming, Rust isn’t known for having lots of libraries, and then the ecosystem is not quite there. We had to build our own. We’d use some ideas from Leptos, like the signals that I’m going to talk about, but this is how things look like today. If you’re familiar with React and SolidJS and those things, you’ll see some familiar things here.
First, you might notice, is that Composer macro over there, that gets attached to this function here that returns a composable. A composable is a reusable piece of tree, of hierarchy of nodes that we can plug in with other reusable bits and compose them, basically, together. This is our way of reusing UI. This Composer macro actually doesn’t do that much except generate boilerplate code that gives us some nicer functionality in that compose macro you see later down in the function. It allows us to have named arguments as well as nicer error messages and optional arguments that might miss for functions.
This is some quality-of-life thing. Then our developers don’t need to specify every argument to these functions, like this hello function here that just takes a name as a string. In this case, the name is mandatory, but we can have optional arguments with optional values that you don’t need to specify. Also, you can specify arguments in any order as long as you name them, and we’ll see that below. It’s just super nice quality-of-life thing. I wish Rust supported this out of the box for functions, but it doesn’t, so this is where we are.
Then, this is the core principle of our UI SDK. It uses signals and effects. The signal is a special value, so this name here will shadow the string above. Basically, this name is a signal, and that means when it changes, it will trigger effects that use it. For example, when this name changes, it will execute the function in this memo, which is a special signal, and it creates a new hello message with the new value the name has been set to. It executes the function you see here. It formats it. It concatenates, and it will give something like Hello Billy, or whatever. Then hello message is a special signal that also will trigger effects. Here you see in this function, we use the hello message.
Whenever the hello message is updated, it will trigger this effect that we call here with create effect. This is very similar to how SolidJS, or if you’re familiar with React, works. Actually, this is quite important because this is also what helps UI engineers be productive in this framework without knowing much Rust actually. The core of our UI engine is signals, effects, and memos, which are special signals that only trigger effects if the values that they got updated to are different from the previous value. By default, they just trigger the effect anyway.
Then, we have this other macro here, which is the compose macro, and this does the heavy lifting. This is where you define how your UI hierarchy looks like. Here we have a row that then has children, which are label nodes. You see here the label has a text that is either a hardcoded value with three exclamation marks as a string, or it can take a signal that wraps a string. The first label here will be updated whenever hello message gets updated. Without the UI engineer doing anything, it just happens automatically that hello message gets updated, the label itself will render the new text, and it just works. If you’re a UI engineer, this is the code you write. It’s fairly easy to understand once you get the idea. Here we have some examples, for example, ChannelCard and MovieCard are just some other functions that allow you to pass parameters like a name, a main_texture, and maybe a title, a main_texture, and so on.
Again, they could have optional parameters that you don’t see here. You can even put signals instead of those hardcoded values. It doesn’t quite matter, it’s just these will be siblings of those two labels. All the way down we have button with a text, that says Click. Then it has a few callbacks on select, on click, and stuff like that, that are functions that get triggered whenever those events happen in the UI engine. For example, whenever we select this button, we set a signal. That name gets set to a new name. This triggers a cascade of actions, hello message gets updated to hello new name. Then, the effects gets trigger because that’s a new value, so that thing will be printed.
Then, lastly, the first label you see here, will get updated to a new value. Lastly, this row has properties or modifiers, so we can modify the background color. In this case, it’s just set to a hardcoded value of blue. However, we support signals to be passed here as well. If you have a color, that’s a signal of a color. Whenever that gets set, maybe on a timer or whatever, the color of the node just gets updated and you pass it here exactly like we set this parameter. That’s another powerful way where we get behavior or effects as a consequence of business logic that happens in the UI code. This is what your engineers deal with, and it’s quite high-level, and it’s very similar to other UI engines, but it’s in Rust this time.
When we run that compose macro, this is how the UI hierarchy will look like in the scene tree. You have the row, and then it has a label. Then labels are special because they’re widgets. Composables can be built out of widgets, which are special composables our UI SDK provides to the engineers, or other composables that eventually are built out of widgets. Widgets are then built out of a series of components. This is fairly important because we use entity component systems under the hood. Components, for now, you can think of them as structures without behavior, so just data without any behavior. The behavior comes from systems that operate on these components.
In this case, this label has a layout component that helps the layout system. A base component, let’s say maybe it has a position, a rotation, things like that. RenderInfo components, this is all the data you need to put the pixels on the screen for this widget once everything gets computed. A text component, this does text layout and things like that. Maybe a text cache component that is used to cache the text in the texture so we don’t draw it letter by letter.
The important bit is that widgets are special because they come as predefined composables from our UI SDK. Then, again, composables can be built out of other composables. This row has a few children here, but eventually it has to have widgets as the leaf nodes because those are the things that actually have the base behavior. Here maybe you have a button and another image, and the button has, all the way down, a focus component. This allows us to focus the button, and it gets automatically used by that system. The image component, again, just stores a URL and maybe the status, has this been downloaded, uploaded to GPU, and so on. It’s fairly simple. Basically, this architecture in our low-level engine is used to manage complexity in behavior. We’ll see a bit later how it works. Then we had another Movie Card in that example and, again, it eventually has to be built out of widgets.
Widgets are the things that our UI SDK provides to UI developers out of the box. They can be row, columns, image, labels, stack, rich text, which is special text nodes that allows you to have images embedded and things like that. Stacks, row list, and column list, and these are scrollable either horizontally or vertically. I think we added grid recently because we needed it for something, but basically, we build this as we build the app. This is what we support now. I think button is another one of them that’s just supported here out of the box that I somehow didn’t put. Then, each widget is an entity ID. It has an ID and a collection of components. Then, the lower-level engine uses systems to modify and update the components. ECS is this entity component system. It’s a way to organize your code and manage complexity without paying that much in terms of performance. It’s been used by game engines, not a lot, but for example, Overwatch used it.
Thief, I think, was the first game in 1998 that used it as a piece of trivia. It’s a very simple idea, which is, you have entities, and these are just IDs that map to components. You have components that are data without behavior. Then you have systems, which are basically functions that act on tuples of components. It always acts on more things at the time, not on one thing at a time. It’s a bit different than the other paradigms. It’s really good to create behavior, because if you want a certain behavior for an entity, you just add the component and then the systems that need that component automatically will just work because the component is there.
Here is how it might work in a game loop. For example, these systems are on the left side and then the components are on the right side. When I say components, you can basically imagine those as arrays and entity IDs as indices in those arrays. It’s a bit more complicated than that, but that’s basically it. Then the things on the left side with the yellow thing, those are systems, and they’re basically functions that operate on those arrays at the same time. Let’s say the resource management system needs to touch base components, image components, and read from them. This reading is with the white arrow, and it will write to RenderInfo components. For example, it will look where the image is, if it’s close to the screen, look at the base component. It looks at the image component that contains the URL. It checks the image status that will be there. Is it downloaded? Has it been uploaded to the GPU? If it has been decoded and uploaded to the GPU, we update the RenderInfo components so we can draw the thing later on the screen.
For this system, you need to have all three components on an entity, at least. You can have more, but we just ignore them. We don’t care. This system just looks at that slice of an object, which is the base components, the image components, and RenderInfo components. You have to have all three of them. If you have only two without the third one, that entity just isn’t touched by this system and it does nothing, the system widget. Then we have the layout system. Of course, this looks at a bunch of components and updates one at the end. It’s quite complicated, but layout is complicated anyway. At least that complication and that complexity sits within a file or a function. You can tell from the signature that this reads from a million things, writes to one, but it is what it is. You can’t quite build layout systems without touching all of those things. Maybe we have a text cache component that looks at text components and writes to a bunch of other things.
Again, you need to have all three of these for an entity such that is updated by this system. All the way at the end, we have the rendering system that looks at RenderInfo components, reads from them. It doesn’t write anywhere because it doesn’t need to update any component. It will just call the functions in the C++ code in the renderer backend to put things on the screen. It just reads through this and then updates your screen with new pixels. It sounds complicated, but it’s a very simple way to organize behavior. This has paid dividends organizing our low-level architecture like this for reasons that we’ll see a little bit later, how and why. Not only for the new application, but also the old application because they use the same low-level engine.
Again, going back to the architecture, this is what we have, Prime Video App at the top. We’ve seen how developers write the UI with composables using our UI SDK. Then we’ve seen how the UI SDK uses widgets that then get updated by the systems, and have components that are defined in the low-level engine. This is again, downloaded. Every time we write some new code, it goes through a pipeline, it gets built to WebAssembly, and then we just execute it on your TV set top box, whatever you have in your living room. Then we have the low-level stuff that interacts with the device that we try to keep as small as possible. This is what we shipped, I think, end of August. It’s live today.
The Good Parts
Good parts. Developer productivity, actually, this was great for us. Previously, when we rewrote the engine, we had a bunch of developers who knew C++ and switched to Rust, and we had good results there. In this case, we switched people who knew only JavaScript and TypeScript to Rust, and they only knew stuff like React and those frameworks. We switched them with our Rust UI SDK with no loss in productivity. This is both self-reported and compared with. Whenever we build a feature, we have other clients that don’t use this, so, for example, like the mobile client or the web client and so on. The Rust client, actually, when we were discussing some new features to be built now on all of the clients, was, I think, the second one in terms of speed, behind web. Then even mobile developers had higher estimations than we did here. Also, we did this whole rewrite in a really short amount of time. We had to be productive. We built the UI SDK and a large part of the app quite fast.
The reason why I think this is true is because we did a lot of work in developer experience with those macros that maybe look a bit shocking if you don’t know UI programming, but actually they felt very familiar to UI engineers. They could work with it right off the bat, they don’t have to deal with much complexity in the borrow checker. Usually, in the UI code, you can clone things if necessary, or even use a Rc and things like that. You all know, this is not super optimal. Yes, we came from JavaScript, so this is fine, I promise. The gnarly bits are down in the engine, and there we take a lot of care about data management and memory and so on. In the UI code, we can afford it easy. Even on the lowest level hardware, I have some slides that you’ll see the impact of this.
Another thing in the SDK, as the SDK and engine team, we chose some constraints and they helped us build a simpler UI SDK and ship it faster. For example, one constraint our UI engine has, I might show it to you, is that when you define a label or a widget or something like that, you cannot read properties from it unless you’ve been the one setting properties. It’s impossible to read where on the screen an element ends up after layout from the UI code. You never know. You just put them in there. We calculate things in the engine, but you can’t read things unless you’ve been the one saying, this is your color, blue. Then you’re like, yes, it’s in my variable. I can read it, of course. Things like that, you can’t read. This simplified vastly our UI architecture and we don’t have to deal with a bunch of things, and slowness because of it. It seems like a shocking thing. Maybe you need to know where on the screen. No, you don’t, because we shipped it.
There was no need to know where you are on the screen, and there was no need to read a property that you haven’t set. There are certain cases where we do notify UI developers through callbacks where they can attach a function and get notified if something happens. It’s very rare. It happens usually in case of focus management and things like that. You will get a function call that you’re focused, you’re not focused anymore, and that works fine. Again, it’s a tradeoff. It has worked perfectly fine for us. That’s something that I think also has helped productivity. We only had one instance where developers asked to read a value of layout because they wanted something to grow, and maybe at 70% of the thing, they wanted something else to happen. Just use a timer and that was fixed.
Another good thing is that we iteratively shipped this. This is only because we used, I think in my view, entity component systems as the basis of our lower-level engine. That low-level engine with the systems it has and the components it has, currently supports JavaScript pages. By pages, I mean everything on the screen is in Rust or everything on the screen is in JavaScript. For example, we shipped the profiles page, which is the page you select the profile. The collections page, that’s the page right after you select the profile and you see all of the categories, all of the movies and everything. The details page, which is, once you choose something to watch, you can go to that place and see maybe episodes or just more details about the movie, and press play. We still have to move the search page, settings, and a bunch of other smaller pages. Those are still in JavaScript. This is work in progress, so we’re just moving them over. It’s just a function of time. We only have 20 people for both the UI SDK and the application. It takes a bit to move everything. It’s just time.
Another reason, it’s just work in progress. We think it was good. That entity component system managed perfectly fine to have these two running side-by-side. I don’t think we had one bug because of this. We only had to do some extra work to synchronize a bunch of state between these things, like the stack that you used to go back, the back stack and things like that, but it was worth it in the end. We got this out really fast. We actually first shipped the profiles page and then added the collections page and then the details page and then live and linear and whatnot. That’s nice.
Another good part is, in my opinion, we built tools as part of building this UI SDK. Because we built an SDK, so we had to build tools. I think one winning move here was, it’s really easy in our codebase to add a new tool, mostly because we use egui, which is this Rust immediate mode UI library. You see there like the resource manager just appears on top of the UI. This is something a developer built because he was debugging an issue where a texture wasn’t loading and he was trying to figure out, how much memory do we have? Is this a memory thing? The resource manager maybe didn’t do something right. It just made it very easy to build tools. We built tools in parallel with building the application and the UI SDK.
In reality, these are way below what you’d expect from browsers and things like that, but with literally 20% of the tools, you get 80% done. It’s absolutely true. You just need mostly the basics. Of course, we have debugger and things like that that just work, but these are UI specific tools. We have layout inspectors and all sorts of other things, so you can figure out if you set the wrong property. Another cool thing, in my opinion, so we built this, which is essentially a rewrite of the whole Prime Video App. Obviously, we’re against these things without a lot of data. One thing that really helped us make a point that this is worth it is to make a prototype that wasn’t cheating, that we showed to leadership around, this is how it feels on the device before what we did, and this is with this new thing.
Literally, features that were impossible before, like layout animations, are just super easy to do now. You see here, things are growing, layout just works, it rearranges everything. Things appear and disappear. Again, this is a layout animation here. Of course, this is programmer art, but has nothing to do with designers. We are just showcasing capabilities on a device. As you can see, things are over icons and under, it’s just a prototype, but it felt so much nicer and responsive compared to what you could get on a device that it just convinced people instantly that it’s worth the risk of building a UI in Rust and WebAssembly. Because even though we added Rust and it was part of our tech stack, we were using it for low-level bits, but this showed us that we can take a risk and try to build some UI in it.
Here are some results. This is a really low-end device where input latency for the main page for collection page was as bad as 247 milliseconds, 250 milliseconds, horrible input latency, with the orange color, this is in JavaScript. With Rust in blue, 33 milliseconds, easy. Similarly, details page, 440 milliseconds. This also includes layout time, because if you press a button as the page loads and we do layout, you might wait that much. This is max. The device is very slow. Again, 30 milliseconds, because layout animations means we need to run layout as fast as an animation frame, which is usually 16 milliseconds or 30 milliseconds at 30 FPS. It’s way faster and way more responsive. Again, that line is basically flat. It was great. Other devices have been closer to those two lines, but I picked this example because it really showcases even on the lowest-end device, you can get great results. The medium devices were like 70 milliseconds, and they went down to 16 or 33, but this is like the worst of them all. We have that.
The Ugly Parts
Ugly parts. WebAssembly System Interface is quite new. WebAssembly in general is quite new. We’re part of the W3C community. We’re working with them around features, things like that. There are certain things that are lacking. For example, we did add threads, but also there’s things that happen in the ecosystem that break our code sometimes because we use something that’s not fully standardized in production for a while. One such example was recently Rust 1.82, enabled some feature by default for WebAssembly WASI builds, that basically didn’t work on older WebAssembly virtual machines that we had in production. We basically now have a way to disable it, even if you have a new default and things like that. It’s worth it for us. That’s something to think about.
Also, WebAssembly System Interface keeps evolving and adding new features, and we’re trying to be active as part of that effort as well. It requires engineering effort. We can’t just quite take a dependency, or specifically on WebAssembly, and just be like, let’s see where this ship goes. You need to get involved in there and help with feedback, with work on features and so on. Another one we found out is panic-free code is really hard. Of course, exceptions should be for exceptional things, but that’s not how people write JavaScript. When the code panics in our new Rust app, the whole app gets just basically demolished, it crashes. You need to restart it from your TV menu. It’s really annoying. Panics shouldn’t quite happen. It’s very easy to cause a Rust panic, just access an array with the wrong index, you panic, game over. Then, that’s it. If you’re an engineer who only worked in JavaScript, maybe you’re familiar with exceptions, you can try-catch somewhere.
Even if it’s not ideal, you can catch the exception and maybe reset the customer at some nice position, closer to where they were before or literally where they were before. It’s impossible with our new app, which is really annoying. We, of course, use Clippy to ban unwraps and expect and those things. We ban unsafe code, except in one engine crate that has to interact with the lower-level bits. Again, it required a bit of education for our UI engineers to rely on this pattern of using the result type from Rust and get comfortable with the idea that there is no stack unwinding, especially there is no stack unwinding in WebAssembly, which is tied to the first point. You can’t even catch that in a panic handler. It just aborts the program. Again, this pretty big pain point for us.
In the end, obviously we shipped, so we’re happy. We almost never crashed, but it requires a bunch of work. This also generated a bunch of work on us because we were depending on some third-party libraries that were very happily panicking whenever you were calling some functions in a bit of a maybe not super correct way. Again, we would rather have results instead of panics for those cases. It led to a bit of work there that we didn’t quite expect. That’s something to think about especially in UI programming, or especially if you go, like we did, from JavaScript to Rust and WebAssembly.
The Bytecode Alliance
The Bytecode Alliance is this nonprofit organization we’re part of, a bunch of companies are part of it, and builds on open-source standards like WebAssembly, WebAssembly System Interface. Then, the WebAssembly Micro Runtime, which is the virtual machine we use, is built over there, as well as Wasmtime, which is another popular Rust one, implemented in Rust this time. WebAssembly Micro Runtime is C. It’s a good place to look at if you’re interested in using Rust in production, and especially using WebAssembly in production more specifically. In our case, it comes with Rust and everything.
Questions and Answers
Participant: You mentioned you don’t use this for your web clients. Would you think that something like this could work with using WebGL as the rendering target?
Ene: We did some comparisons on devices. There’s a bunch of pain points. First pain point is on the ones we do have to use a browser, because there’s no space on the flash, on some set top boxes. The problem is those are some version of WebKit that has no WebAssembly. That’s the big hurdle for us there. It could be possible. We did some experiments and it worked, but you do lose a few things that browsers have that we don’t. Today, it’s not worth it for us because those have very few customers. They work fairly ok in terms of comparing them to even the system UI. Even though they don’t hit these numbers, it would be a significant amount of effort to get this SDK to work on a browser.
Right now, it’s just quite simple because it has one target, the one that has the native VM. It requires a bunch of functions from the native VM that we expose that aren’t standard. Getting those would probably require to pipe them to JavaScript. Then you’re like, what’s going on? You might lose some performance and things like that. It’s a bit of a tricky one, but we’re keeping an eye on it.
See more presentations with transcripts
MMS • Steef-Jan Wiggers

Google Cloud has unveiled its new A4 virtual machines (VMs) in preview, powered by NVIDIA’s Blackwell B200 GPUs, to address the increasing demands of advanced artificial intelligence (AI) workloads. The offering aims to accelerate AI model training, fine-tuning, and inference by combining Google’s infrastructure with NVIDIA’s hardware.
The A4 VM features eight Blackwell GPUs interconnected via fifth-generation NVIDIA NVLink, providing a 2.25x increase in peak compute and high bandwidth memory (HBM) capacity compared to the previous generation A3 High VMs. This performance enhancement addresses the growing complexity of AI models, which require powerful accelerators and high-speed interconnects. Key features include enhanced networking, Google Kubernetes Engine (GKE) integration, Vertex AI accessibility, open software optimization, a hypercompute cluster, and flexible consumption models.
Thomas Kurian, CEO of Google Cloud, announced the launch on X, highlighting Google Cloud as the first cloud provider to bring the NVIDIA B200 GPUs to customers.
Blackwell has made its Google Cloud debut by launching our new A4 VMs powered by NVIDIA B200. We’re the first cloud provider to bring B200 to customers, and we can’t wait to see how this powerful platform accelerates your AI workloads.
Specifically, the A4 VMs utilize Google’s Titanium ML network adapter and NVIDIA ConnectX-7 NICs, delivering 3.2 Tbps of GPU-to-GPU traffic with RDMA over Converged Ethernet (RoCE). The Jupiter network fabric supports scaling to tens of thousands of GPUs with 13 Petabits/sec of bi-sectional bandwidth. Native integration with GKE, supporting up to 65,000 nodes per cluster, facilitates a robust AI platform. The VMs are accessible through Vertex AI, Google’s unified AI development platform, powered by the AI Hypercomputer architecture. Google is also collaborating with NVIDIA to optimize JAX and XLA for efficient collective communication and computation on GPUs.
Furthermore, a new hypercompute cluster system simplifies the deployment and management of large-scale AI workloads across thousands of A4 VMs. This system focuses on high performance through co-location, optimized resource scheduling with GKE and Slurm, reliability through self-healing capabilities, enhanced observability, and automated provisioning. Flexible consumption models provide optimized AI workload consumption, including the Dynamic Workload Scheduler with Flex Start and Calendar modes.
Sai Ruhul, an entrepreneur on X, highlighted analyst estimates that the Blackwell GPUs could be 10-100x faster than NVIDIA’s current Hopper/A100 GPUs for large transformer model workloads requiring multi-GPU scaling. This represents a significant leap in scale for accelerating “Trillion-Parameter AI” models.
In addition, Naeem Aslam, a CIO at Zaye Capital Markets, tweeted on X:
Google’s integration of NVIDIA Blackwell GPUs into its cloud with A4 VMs could enhance computational power for AI and data processing. This partnership is likely to increase demand for NVIDIA’s GPUs, boosting its position in cloud infrastructure markets.
Lastly, this release provides developers access to the latest NVIDIA Blackwell GPUs within Google Cloud’s infrastructure, offering substantial performance improvements for AI applications.
MMS • Ben Linders

DevOps streamlines software development with automation and collaboration between development and IT teams for efficient delivery. According to Nedko Hristov, testers’ curiosity, adaptability, and willingness to learn make them suited for DevOps. Failures can be approached with a constructive mindset; they provide growth opportunities, leading to improved skills and practices.
Nedko Hristov shared his experiences with DevOps as a quality assurance engineer at QA Challenge Accepted.
DevOps by definition is streamlining software development by automating and integrating tasks between development and IT operations teams, Hristov said. It fosters communication, collaboration, and shared responsibility for faster, more efficient software delivery and integration.
Hristov mentioned that DevOps is not typically an entry-level role. It requires a strong foundation in software development practices, including how software is designed, built, and tested. Fortunately, software quality engineers or software testers often possess this foundational knowledge, as he explained:
We understand the software development lifecycle and many of us have expertise in automation. This background allows us to quickly grasp the core concepts of DevOps.
While software testers may not have deep expertise in every technology used in a DevOps environment, they are familiar with the most common ones, Hristov said. They understand coding principles, deployment processes, and system architectures at a high level. He mentioned that this broad understanding is incredibly valuable for applying DevOps.
Software testers are often inherently curious, Hristov said. They are driven to learn and expand their knowledge base:
When I first became interested in DevOps, I proactively sought out developers to understand the intricacies of their work. I asked questions about system behavior, troubleshooting techniques, and the underlying causes of failures.
Software testers can leverage their existing skills, their inherent curiosity, and a proactive approach to learning to successfully transition into and thrive in DevOps roles, as Hristov explained.
One of the most crucial skills I’ve gained is adaptability. In the ever-evolving tech landscape, we constantly encounter new technologies. This involves identifying key concepts, finding practical examples, and focusing on acquiring the knowledge necessary for the task at hand.
A strong foundation in core technologies is essential, Hristov mentioned. This doesn’t necessitate deep expertise in every domain, but rather a solid understanding of fundamental principles, he added.
Failures provide invaluable opportunities for growth and deeper understanding, Hristov said. While it’s true that failures are not desirable, it’s crucial to approach them with a constructive mindset:
I consistently emphasize to those I mentor that failure is not inherently negative. Our professional development is fundamentally based on experience, and failures are among the most effective teachers.
Failures are essential stepping stones towards enhanced comprehension and improved working practices, Hristov said. They are not inherently good or bad, but rather mandatory components of growth, he concluded.
InfoQ interviewed Nedko Hristov about what he learned from applying DevOps as a software tester.
InfoQ: What skills did you develop and how did you develop them?
Nedko Hristov: My skill development is driven by a combination of adaptability, focused learning, effective communication, practical application, and knowledge sharing.
I’ve honed my communication skills, particularly the ability to ask effective questions. This is often overlooked, but crucial for knowledge acquisition.
When approaching a new technology I usually ask myself a ton of questions:
- What is the core purpose of this technology?
- What problem does it solve?
- How does it work, what are the underlying mechanisms and architecture?
- How can I integrate it into my current projects, tooling, and workflows?
- Are there any best practices or recommended patterns for using it?
- What are the common challenges or pitfalls associated with this technology?
- How does this technology compare to its alternatives?
InfoQ: What’s your approach to failures?
Hristov: When encountering a failure, we should ask ourselves three key questions:
- What happened – Objectively analyze the events leading to the failure
- Why it happened – Identify the root cause and contributing factors
- What is my takeaway – Determine the lessons learned and how to apply them in the future
The key is to extract valuable takeaways from each failure, ensuring that we approach similar situations with greater knowledge and preparedness in the future.
InfoQ: What have you learned, what would you do differently if you had to start all over again?
Hristov: I was fortunate to begin my DevOps journey under the guidance of a strong leader who provided me with a solid foundation. However, if I were to start over, I would focus on avoiding the pursuit of perfection. In the tech world, there will always be a more optimized solution or a 500ms faster request. Instead of chasing perfection, I would prioritize understanding the core business needs and identifying the critical pain points to address.
Early in my career, I often fell into the trap of trying to make everything perfect from the beginning. This is almost impossible and can lead to unnecessary delays and frustration. It’s more effective to iterate and improve incrementally, focusing on delivering value quickly and refining solutions over time.
MMS • RSS
![]() PNC Financial Services Group Inc. decreased its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 11.7% during the fourth quarter, according to its most recent filing with the SEC. The firm owned 1,932 shares of the company’s stock after selling 255 shares during the period. PNC Financial Services Group Inc.’s holdings in MongoDB were worth $450,000 at the end of the most recent reporting period.
PNC Financial Services Group Inc. decreased its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 11.7% during the fourth quarter, according to its most recent filing with the SEC. The firm owned 1,932 shares of the company’s stock after selling 255 shares during the period. PNC Financial Services Group Inc.’s holdings in MongoDB were worth $450,000 at the end of the most recent reporting period.
Other institutional investors have also added to or reduced their stakes in the company. B.O.S.S. Retirement Advisors LLC purchased a new position in MongoDB during the 4th quarter valued at about $606,000. Geode Capital Management LLC grew its position in shares of MongoDB by 2.9% in the 3rd quarter. Geode Capital Management LLC now owns 1,230,036 shares of the company’s stock worth $331,776,000 after buying an additional 34,814 shares during the last quarter. B. Metzler seel. Sohn & Co. Holding AG purchased a new position in shares of MongoDB in the 3rd quarter worth approximately $4,366,000. Charles Schwab Investment Management Inc. grew its position in shares of MongoDB by 2.8% in the 3rd quarter. Charles Schwab Investment Management Inc. now owns 278,419 shares of the company’s stock worth $75,271,000 after buying an additional 7,575 shares during the last quarter. Finally, Union Bancaire Privee UBP SA purchased a new position in shares of MongoDB in the 4th quarter worth approximately $3,515,000. Hedge funds and other institutional investors own 89.29% of the company’s stock.
Insider Activity
In related news, Director Dwight A. Merriman sold 3,000 shares of the firm’s stock in a transaction dated Monday, March 3rd. The shares were sold at an average price of $270.63, for a total transaction of $811,890.00. Following the completion of the sale, the director now directly owns 1,109,006 shares in the company, valued at approximately $300,130,293.78. This trade represents a 0.27 % decrease in their ownership of the stock. The transaction was disclosed in a document filed with the Securities & Exchange Commission, which is accessible through this link. Also, insider Cedric Pech sold 287 shares of the firm’s stock in a transaction dated Thursday, January 2nd. The stock was sold at an average price of $234.09, for a total transaction of $67,183.83. Following the sale, the insider now owns 24,390 shares of the company’s stock, valued at approximately $5,709,455.10. The trade was a 1.16 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders sold 43,139 shares of company stock worth $11,328,869 over the last three months. Insiders own 3.60% of the company’s stock.
Analysts Set New Price Targets
<!—->
A number of research analysts have recently issued reports on the stock. Stifel Nicolaus cut their price objective on shares of MongoDB from $425.00 to $340.00 and set a “buy” rating on the stock in a research report on Thursday, March 6th. Tigress Financial lifted their price objective on shares of MongoDB from $400.00 to $430.00 and gave the stock a “buy” rating in a research report on Wednesday, December 18th. Guggenheim raised shares of MongoDB from a “neutral” rating to a “buy” rating and set a $300.00 price objective on the stock in a research report on Monday, January 6th. Rosenblatt Securities reissued a “buy” rating and set a $350.00 target price on shares of MongoDB in a research report on Tuesday, March 4th. Finally, Robert W. Baird dropped their target price on shares of MongoDB from $390.00 to $300.00 and set an “outperform” rating on the stock in a research report on Thursday, March 6th. Seven analysts have rated the stock with a hold rating and twenty-three have assigned a buy rating to the company. According to data from MarketBeat, the stock presently has an average rating of “Moderate Buy” and an average target price of $320.70.
Check Out Our Latest Analysis on MDB
MongoDB Price Performance
MDB opened at $190.06 on Thursday. The firm has a fifty day moving average price of $253.21 and a 200 day moving average price of $270.89. MongoDB, Inc. has a 1 year low of $173.13 and a 1 year high of $387.19. The stock has a market cap of $14.15 billion, a P/E ratio of -69.36 and a beta of 1.30.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings data on Wednesday, March 5th. The company reported $0.19 earnings per share (EPS) for the quarter, missing the consensus estimate of $0.64 by ($0.45). The company had revenue of $548.40 million for the quarter, compared to analysts’ expectations of $519.65 million. MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. During the same period in the previous year, the business earned $0.86 earnings per share. Equities analysts expect that MongoDB, Inc. will post -1.78 EPS for the current year.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Featured Stories

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • Steef-Jan Wiggers
AWS recently introduced a new enhancement with direct message publishing over WebSocket connections for AWS AppSync Events, a fully-managed serverless WebSocket API service.
Earlier, the company released AWS AppSync Events, which allows developers to easily broadcast real-time event data to a few or millions of subscribers using secure and performant Serverless WebSocket APIs.
Darryl Ruggles, a cloud solutions architect and AWS Community Builder, tweeted on X:
Appsync Events came out a few months ago as a managed/serverless WebSocket API. There are other approaches to using WebSockets on AWS, but this works well for many cases. Now, support has been added for publishing messages directly over WebSocket connections.
Brice Pellé, a principal product manager at AWS, wrote in an announcement blog post:
This update allows developers to use a single WebSocket connection for both publishing and receiving events, streamlining the development of real-time features and reducing implementation complexity.
Developers gain flexibility by choosing between HTTP endpoints for backend publishing and WebSocket for web and mobile client applications. This enhancement will enable developers to build more responsive and engaging real-time applications, such as collaborative tools and live dashboards.
Developers can immediately test the new WebSocket publishing feature through the AppSync console’s Pub/Sub Editor. Selecting “WebSocket” as the publishing method triggers a publish_success message upon successful transmission.
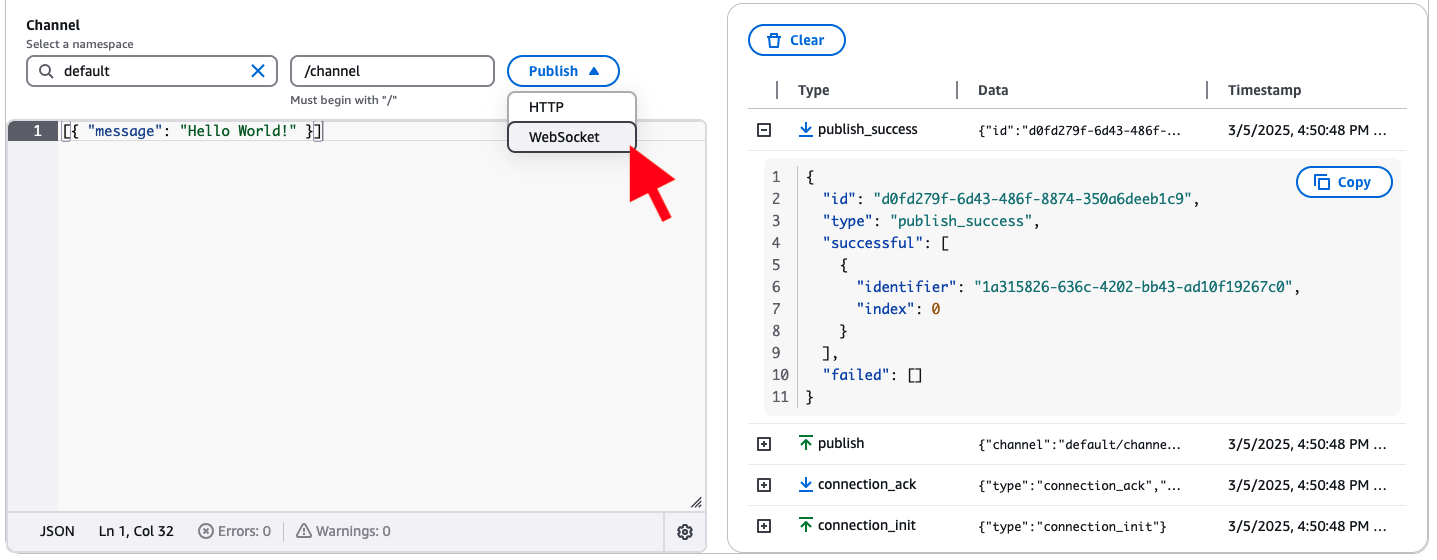
(Source: AWS Front-End Web & Mobile blog post)
AppSync introduces a new “publish” WebSocket operation. After establishing a WebSocket connection, clients can publish events to configured channel namespaces. The message format requires an id, channel, an array of events (up to five), and authorization headers. Each event within the array must be a valid JSON string.
AWS also offers tools for infrastructure management to further streamline the development process. The AWS Cloud Development Kit (CDK) is an infrastructure-as-code framework that simplifies the configuration and deployment of AppSync Event APIs, including channel namespaces and API keys. The CDK consists of the L2 constructs that provide a higher-level abstraction, making it easier for developers to define AppSync Event APIs and their associated channel namespaces using familiar programming languages.
Yoseph Radding, a software engineer, posted on Bluesky:
That’s essentially how AWS CDK works. They define all of these high order constructs (called L2 constructs) the provide great out of the box abstractions. Like the Lambda constructs will create the versions, functions, and IAM roles.
Lastly, publishing over WebSocket is available in all regions where AppSync is supported. The client limit is 25 requests per second per connection. The HTTP endpoint can still be used for higher rates.
MMS • RSS
MongoDB, Inc. (NASDAQ:MDB – Get Free Report) saw some unusual options trading on Wednesday. Stock investors bought 36,130 call options on the company. This represents an increase of 2,077% compared to the typical daily volume of 1,660 call options.
MongoDB Stock Up 0.7 %
Shares of MongoDB stock opened at $190.06 on Thursday. MongoDB has a 12-month low of $173.13 and a 12-month high of $387.19. The company has a market capitalization of $14.15 billion, a price-to-earnings ratio of -69.36 and a beta of 1.30. The firm’s 50-day moving average price is $253.21 and its two-hundred day moving average price is $270.89.
MongoDB (NASDAQ:MDB – Get Free Report) last announced its quarterly earnings data on Wednesday, March 5th. The company reported $0.19 earnings per share (EPS) for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. The firm had revenue of $548.40 million during the quarter, compared to the consensus estimate of $519.65 million. During the same period last year, the business earned $0.86 earnings per share. On average, sell-side analysts expect that MongoDB will post -1.78 earnings per share for the current year.
Wall Street Analyst Weigh In
Several equities analysts have recently weighed in on MDB shares. Mizuho raised their price objective on MongoDB from $275.00 to $320.00 and gave the company a “neutral” rating in a report on Tuesday, December 10th. Macquarie decreased their price target on MongoDB from $300.00 to $215.00 and set a “neutral” rating for the company in a research note on Friday, March 7th. Monness Crespi & Hardt upgraded MongoDB from a “sell” rating to a “neutral” rating in a research note on Monday, March 3rd. KeyCorp cut shares of MongoDB from a “strong-buy” rating to a “hold” rating in a research note on Wednesday, March 5th. Finally, Cantor Fitzgerald started coverage on shares of MongoDB in a research report on Wednesday, March 5th. They set an “overweight” rating and a $344.00 price target on the stock. Seven investment analysts have rated the stock with a hold rating and twenty-three have issued a buy rating to the company. Based on data from MarketBeat, the stock has an average rating of “Moderate Buy” and an average target price of $320.70.
View Our Latest Analysis on MongoDB
Insider Activity
In other news, Director Dwight A. Merriman sold 3,000 shares of the firm’s stock in a transaction that occurred on Monday, March 3rd. The shares were sold at an average price of $270.63, for a total transaction of $811,890.00. Following the completion of the transaction, the director now directly owns 1,109,006 shares of the company’s stock, valued at $300,130,293.78. This trade represents a 0.27 % decrease in their position. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which is available through the SEC website. Also, insider Cedric Pech sold 287 shares of the stock in a transaction on Thursday, January 2nd. The stock was sold at an average price of $234.09, for a total transaction of $67,183.83. Following the transaction, the insider now owns 24,390 shares of the company’s stock, valued at $5,709,455.10. The trade was a 1.16 % decrease in their position. The disclosure for this sale can be found here. Insiders have sold a total of 43,139 shares of company stock worth $11,328,869 over the last three months. Corporate insiders own 3.60% of the company’s stock.
Institutional Trading of MongoDB
Large investors have recently bought and sold shares of the business. Strategic Investment Solutions Inc. IL acquired a new stake in shares of MongoDB in the 4th quarter valued at approximately $29,000. Hilltop National Bank increased its holdings in shares of MongoDB by 47.2% during the fourth quarter. Hilltop National Bank now owns 131 shares of the company’s stock worth $30,000 after buying an additional 42 shares in the last quarter. NCP Inc. bought a new position in shares of MongoDB in the 4th quarter valued at $35,000. Brooklyn Investment Group acquired a new stake in shares of MongoDB during the 3rd quarter valued at $36,000. Finally, Continuum Advisory LLC boosted its holdings in shares of MongoDB by 621.1% during the 3rd quarter. Continuum Advisory LLC now owns 137 shares of the company’s stock valued at $40,000 after acquiring an additional 118 shares in the last quarter. 89.29% of the stock is owned by institutional investors and hedge funds.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Enter your email address and we’ll send you MarketBeat’s guide to investing in 5G and which 5G stocks show the most promise.
MMS • Bruno Couriol

The Inertia team recently released Inertia 2.0. New features include asynchronous requests, deferred props, prefetching, and polling. Asynchronous requests enable concurrency, lazy loading, and more.
In previous versions, Inertia requests were synchronous. Asynchronous requests now offer full support for asynchronous operations and concurrency. This in turn enables features such as lazy loading data on scroll, infinite scrolling, prefetching, polling, and more. Those features make the single-page application appear more interactive, responsive, and fast.
Link prefetching for instance improves the perceived performance of an application by fetching the data in the background before the user requests it. By default, Inertia will prefetch data for a page when the user hovers over the link after more than 75ms. By default, data is cached for 30 seconds before being evicted. Developers can customize it with the cacheFor property. Using Svelte, this would look as follows:
import { inertia } from '@inertiajs/svelte'
<a href="/users" use:inertia={{ prefetch: true, cacheFor: '1m' }}>Users</a>
<a href="/users" use:inertia={{ prefetch: true, cacheFor: '10s' }}>Users</a>
<a href="/users" use:inertia={{ prefetch: true, cacheFor: 5000 }}>Users</a>
Prefetching can also happen on mousedown, that is when the user has clicked on a link, but has not yet released the mouse button. Lastly, prefetching can also occur when a component is mounted.
Inertia 2.0 enables lazy loading data on scroll with the WhenVisible component, which under the hood uses the Intersection Observer API. The following code showcases a component that shows a fallback message while it is loading (examples written with Svelte 4):
<script>
import { WhenVisible } from '@inertiajs/svelte'
export let teams
export let users
</script>
<svelte:fragment slot="fallback">
<div>Loading...</div>
</svelte:fragment>
</WhenVisible>
The full list of configuration options for lazy loading and prefetching is available in the documentation for review. Inertia 2.0 also features polling, deferred props, and infinite scrolling. Developers are encouraged to review the upgrade guide for more details.
Inertia targets back-end developers who want to create single-page React, Vue, and Svelte apps using classic server-side routing and controllers, that is, without the complexity that comes with modern single-page applications. Developers using Inertia do not need client-side routing or building an API.
Inertia returns a full HTML response on the first page load. On subsequent requests, server-side Inertia returns a JSON response with the JavaScript component (represented by its name and props) that implements the view. Client-side Inertia then replaces the currently displayed page with the new page returned by the new component and updates the history state.
Inertia requests use specific HTTP headers to discriminate between full page refresh and partial refresh. If the X-Inertia is unset or false, the header indicates that the request being made by an Inertia client is a standard full-page visit.
Developers can upgrade to Inertia v2.0 by installing the client-side adapter of their choice (e.g., Vue, React, Svelte):
npm install @inertiajs/vue3@^2.0
Then, it is necessary to upgrade the inertiajs/inertia-laravel package to use the 2.x dev branch:
composer require inertiajs/inertia-laravel:^2.0
Inertia is open-source software distributed under the MIT license. Feedback and contributions are welcome and should follow Inertia’s contribution guidelines.
MMS • RSS

Artificial intelligence is the greatest investment opportunity of our lifetime. The time to invest in groundbreaking AI is now, and this stock is a steal!
The whispers are turning into roars.
Artificial intelligence isn’t science fiction anymore.
It’s the revolution reshaping every industry on the planet.
From driverless cars to medical breakthroughs, AI is on the cusp of a global explosion, and savvy investors stand to reap the rewards.
Here’s why this is the prime moment to jump on the AI bandwagon:
Exponential Growth on the Horizon: Forget linear growth – AI is poised for a hockey stick trajectory.
Imagine every sector, from healthcare to finance, infused with superhuman intelligence.
We’re talking disease prediction, hyper-personalized marketing, and automated logistics that streamline everything.
This isn’t a maybe – it’s an inevitability.
Early investors will be the ones positioned to ride the wave of this technological tsunami.
Ground Floor Opportunity: Remember the early days of the internet?
Those who saw the potential of tech giants back then are sitting pretty today.
AI is at a similar inflection point.
We’re not talking about established players – we’re talking about nimble startups with groundbreaking ideas and the potential to become the next Google or Amazon.
This is your chance to get in before the rockets take off!
Disruption is the New Name of the Game: Let’s face it, complacency breeds stagnation.
AI is the ultimate disruptor, and it’s shaking the foundations of traditional industries.
The companies that embrace AI will thrive, while the dinosaurs clinging to outdated methods will be left in the dust.
As an investor, you want to be on the side of the winners, and AI is the winning ticket.
The Talent Pool is Overflowing: The world’s brightest minds are flocking to AI.
From computer scientists to mathematicians, the next generation of innovators is pouring its energy into this field.
This influx of talent guarantees a constant stream of groundbreaking ideas and rapid advancements.
By investing in AI, you’re essentially backing the future.
The future is powered by artificial intelligence, and the time to invest is NOW.
Don’t be a spectator in this technological revolution.
Dive into the AI gold rush and watch your portfolio soar alongside the brightest minds of our generation.
This isn’t just about making money – it’s about being part of the future.
So, buckle up and get ready for the ride of your investment life!
Act Now and Unlock a Potential 10,000% Return: This AI Stock is a Diamond in the Rough (But Our Help is Key!)
The AI revolution is upon us, and savvy investors stand to make a fortune.
But with so many choices, how do you find the hidden gem – the company poised for explosive growth?
That’s where our expertise comes in.
We’ve got the answer, but there’s a twist…
Imagine an AI company so groundbreaking, so far ahead of the curve, that even if its stock price quadrupled today, it would still be considered ridiculously cheap.
That’s the potential you’re looking at. This isn’t just about a decent return – we’re talking about a 10,000% gain over the next decade!
Our research team has identified a hidden gem – an AI company with cutting-edge technology, massive potential, and a current stock price that screams opportunity.
This company boasts the most advanced technology in the AI sector, putting them leagues ahead of competitors.
It’s like having a race car on a go-kart track.
They have a strong possibility of cornering entire markets, becoming the undisputed leader in their field.
Here’s the catch (it’s a good one): To uncover this sleeping giant, you’ll need our exclusive intel.
We want to make sure none of our valued readers miss out on this groundbreaking opportunity!
That’s why we’re slashing the price of our Premium Readership Newsletter by a whopping 70%.
For a ridiculously low price of just $29.99, you can unlock a year’s worth of in-depth investment research and exclusive insights – that’s less than a single restaurant meal!
Here’s why this is a deal you can’t afford to pass up:
• Access to our Detailed Report on this Game-Changing AI Stock: Our in-depth report dives deep into our #1 AI stock’s groundbreaking technology and massive growth potential.
• 11 New Issues of Our Premium Readership Newsletter: You will also receive 11 new issues and at least one new stock pick per month from our monthly newsletter’s portfolio over the next 12 months. These stocks are handpicked by our research director, Dr. Inan Dogan.
• One free upcoming issue of our 70+ page Quarterly Newsletter: A value of $149
• Bonus Reports: Premium access to members-only fund manager video interviews
• Ad-Free Browsing: Enjoy a year of investment research free from distracting banner and pop-up ads, allowing you to focus on uncovering the next big opportunity.
• 30-Day Money-Back Guarantee: If you’re not absolutely satisfied with our service, we’ll provide a full refund within 30 days, no questions asked.
Space is Limited! Only 1000 spots are available for this exclusive offer. Don’t let this chance slip away – subscribe to our Premium Readership Newsletter today and unlock the potential for a life-changing investment.
Here’s what to do next:
1. Head over to our website and subscribe to our Premium Readership Newsletter for just $29.99.
2. Enjoy a year of ad-free browsing, exclusive access to our in-depth report on the revolutionary AI company, and the upcoming issues of our Premium Readership Newsletter over the next 12 months.
3. Sit back, relax, and know that you’re backed by our ironclad 30-day money-back guarantee.
Don’t miss out on this incredible opportunity! Subscribe now and take control of your AI investment future!
No worries about auto-renewals! Our 30-Day Money-Back Guarantee applies whether you’re joining us for the first time or renewing your subscription a year later!