Month: March 2025

MMS • Almir Vuk

At the end of February, .NET 10 Preview 1 was released, bringing several major updates and improvements across the platform. This first preview introduces enhancements to the .NET Runtime, SDK, libraries, C#, ASP.NET Core, Blazor, .NET MAUI, and more.
ASP.NET Core in .NET 10 now supports OpenAPI 3.1. This allows developers to generate OpenAPI documents with better integration for JSON Schema draft 2020-12. The release also introduces a simplified method for configuring OpenAPI versions. However, there are breaking changes that require updates to applications using document transformers.
Another noteworthy improvement is the ability to serve OpenAPI documents in YAML format. This provides a more concise alternative to JSON, helping developers manage longer descriptions more efficiently.
Regarding the future of this support, the .NET team states the following:
Support for YAML is currently only available when served at runtime from the OpenAPI endpoint. Support for generating OpenAPI documents in YAML format at build time will be added in a future preview.
Additional updates include response descriptions for ProducesResponseType, and URL validation with RedirectHttpResult.IsLocalUrl, and improved integration testing for applications using top-level statements.
Moving on to Blazor, QuickGrid now includes a RowClass parameter for conditional styling. Additionally, Blazor scripts are now served as static web assets with improved precompression. This change significantly reduces file sizes, offering a more efficient experience for developers.
As reported, .NET MAUI Preview 1 focuses on quality improvements for iOS, Mac Catalyst, Android, and other platforms. Notably, CollectionView handlers for iOS and Mac Catalyst are now enabled by default, improving both performance and stability.
The release also brings support for Android 16 (Baklava) Beta 1. It introduces new recommendations for the minimum supported Android API, now set to API 24. Additionally, JDK-21 support has been added. .NET Android projects can now run using the dotnet run command, simplifying the development process. Trimmer warnings are enabled by default for iOS, macOS, and tvOS applications, prompting developers to address potential trimming issues in their code.
On the database side, Entity Framework Core 10 Preview 1 introduces several new features. First, there is first-class LINQ support for the LeftJoin operator, simplifying queries that previously required complex LINQ constructs. The release also makes working with ExecuteUpdateAsync easier by supporting regular non-expression lambdas.
Other optimizations include improvements to SQL Server scaffolding, date/time function translation, and performance for Count operations on ICollection. Additionally, smaller improvements address optimizations for MIN/MAX over DISTINCT and better handling of multiple consecutive LIMIT operations.
In C# 14, several new features have been added. One of the key updates is support for field-backed properties, providing a smoother path for developers transitioning from auto-implemented to custom properties. The nameof expression now supports unbound generics. Implicit conversions for Span and ReadOnlySpan also make working with these types more intuitive.
Moreover, lambda expressions can now include parameter modifiers like ref and in without specifying types. An experimental feature allows developers to change how string literals are emitted into PE files, offering potential performance benefits. Stating the following:
By turning on the feature flag, string literals (where possible) are emitted as UTF-8 data into a different section of the PE file without a data limit. The emit format is similar to explicit UTF-8 string literals.
Lastly, the .NET Team called on viewers to watch an unboxing video where they discussed what was new in the preview release, featuring live demos from the dev team. The video is now available to watch on demand and for a complete overview, readers can explore the full release notes and dive into additional details about the first preview of .NET 10.
MMS • RSS
Shares of MongoDB, Inc. (NASDAQ:MDB – Get Free Report) have been assigned an average recommendation of “Moderate Buy” from the thirty-one ratings firms that are covering the firm, Marketbeat reports. One investment analyst has rated the stock with a sell rating, seven have issued a hold rating and twenty-three have assigned a buy rating to the company. The average twelve-month price objective among brokerages that have issued ratings on the stock in the last year is $319.87.
Several equities analysts have issued reports on the company. Rosenblatt Securities reiterated a “buy” rating and issued a $350.00 price objective on shares of MongoDB in a research report on Tuesday, March 4th. DA Davidson lifted their price target on MongoDB from $340.00 to $405.00 and gave the company a “buy” rating in a report on Tuesday, December 10th. JMP Securities reissued a “market outperform” rating and set a $380.00 price objective on shares of MongoDB in a report on Wednesday, December 11th. Tigress Financial boosted their target price on shares of MongoDB from $400.00 to $430.00 and gave the stock a “buy” rating in a research note on Wednesday, December 18th. Finally, Morgan Stanley reduced their target price on shares of MongoDB from $350.00 to $315.00 and set an “overweight” rating on the stock in a research report on Thursday, March 6th.
Get Our Latest Research Report on MongoDB
Insiders Place Their Bets
In related news, CEO Dev Ittycheria sold 2,581 shares of the business’s stock in a transaction on Thursday, January 2nd. The shares were sold at an average price of $234.09, for a total value of $604,186.29. Following the sale, the chief executive officer now directly owns 217,294 shares of the company’s stock, valued at approximately $50,866,352.46. The trade was a 1.17 % decrease in their position. The transaction was disclosed in a legal filing with the SEC, which can be accessed through this hyperlink. Also, insider Cedric Pech sold 287 shares of the company’s stock in a transaction on Thursday, January 2nd. The stock was sold at an average price of $234.09, for a total transaction of $67,183.83. Following the completion of the transaction, the insider now directly owns 24,390 shares of the company’s stock, valued at approximately $5,709,455.10. The trade was a 1.16 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders sold 49,314 shares of company stock worth $12,981,833 over the last ninety days. 3.60% of the stock is currently owned by corporate insiders.
Institutional Trading of MongoDB
A number of hedge funds and other institutional investors have recently made changes to their positions in the business. Norges Bank bought a new position in MongoDB in the fourth quarter valued at $189,584,000. Jennison Associates LLC boosted its stake in shares of MongoDB by 23.6% during the 3rd quarter. Jennison Associates LLC now owns 3,102,024 shares of the company’s stock worth $838,632,000 after buying an additional 592,038 shares during the last quarter. Marshall Wace LLP bought a new position in shares of MongoDB in the 4th quarter valued at about $110,356,000. Raymond James Financial Inc. acquired a new stake in shares of MongoDB in the fourth quarter valued at about $90,478,000. Finally, D1 Capital Partners L.P. bought a new stake in MongoDB during the fourth quarter worth about $76,129,000. 89.29% of the stock is currently owned by institutional investors and hedge funds.
MongoDB Stock Performance
MDB opened at $180.32 on Tuesday. The firm has a market cap of $13.43 billion, a price-to-earnings ratio of -65.81 and a beta of 1.30. The firm’s 50-day simple moving average is $260.61 and its 200-day simple moving average is $274.00. MongoDB has a twelve month low of $173.13 and a twelve month high of $387.19.
MongoDB (NASDAQ:MDB – Get Free Report) last issued its quarterly earnings data on Wednesday, March 5th. The company reported $0.19 earnings per share for the quarter, missing the consensus estimate of $0.64 by ($0.45). MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The firm had revenue of $548.40 million for the quarter, compared to the consensus estimate of $519.65 million. During the same period in the prior year, the company posted $0.86 earnings per share. As a group, sell-side analysts anticipate that MongoDB will post -1.78 EPS for the current fiscal year.
About MongoDB
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading

This instant news alert was generated by narrative science technology and financial data from MarketBeat in order to provide readers with the fastest and most accurate reporting. This story was reviewed by MarketBeat’s editorial team prior to publication. Please send any questions or comments about this story to contact@marketbeat.com.
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Enter your email address and we’ll send you MarketBeat’s list of seven stocks and why their long-term outlooks are very promising.
MMS • RSS
![]() US Bancorp DE raised its position in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 8.3% during the fourth quarter, according to its most recent filing with the SEC. The firm owned 4,190 shares of the company’s stock after purchasing an additional 321 shares during the period. US Bancorp DE’s holdings in MongoDB were worth $975,000 as of its most recent filing with the SEC.
US Bancorp DE raised its position in MongoDB, Inc. (NASDAQ:MDB – Free Report) by 8.3% during the fourth quarter, according to its most recent filing with the SEC. The firm owned 4,190 shares of the company’s stock after purchasing an additional 321 shares during the period. US Bancorp DE’s holdings in MongoDB were worth $975,000 as of its most recent filing with the SEC.
Other institutional investors also recently modified their holdings of the company. Hilltop National Bank lifted its position in shares of MongoDB by 47.2% during the 4th quarter. Hilltop National Bank now owns 131 shares of the company’s stock valued at $30,000 after acquiring an additional 42 shares during the period. Brooklyn Investment Group acquired a new stake in MongoDB in the third quarter valued at approximately $36,000. Continuum Advisory LLC grew its holdings in shares of MongoDB by 621.1% during the third quarter. Continuum Advisory LLC now owns 137 shares of the company’s stock valued at $40,000 after buying an additional 118 shares during the last quarter. NCP Inc. bought a new stake in MongoDB during the 4th quarter worth approximately $35,000. Finally, Wilmington Savings Fund Society FSB purchased a new stake in MongoDB in the 3rd quarter valued at $44,000. 89.29% of the stock is owned by institutional investors.
Insider Buying and Selling
In other news, insider Cedric Pech sold 287 shares of the stock in a transaction that occurred on Thursday, January 2nd. The stock was sold at an average price of $234.09, for a total value of $67,183.83. Following the completion of the transaction, the insider now owns 24,390 shares of the company’s stock, valued at approximately $5,709,455.10. This represents a 1.16 % decrease in their position. The sale was disclosed in a legal filing with the Securities & Exchange Commission, which is accessible through the SEC website. Also, Director Dwight A. Merriman sold 3,000 shares of MongoDB stock in a transaction that occurred on Monday, March 3rd. The shares were sold at an average price of $270.63, for a total value of $811,890.00. Following the sale, the director now owns 1,109,006 shares in the company, valued at $300,130,293.78. This represents a 0.27 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Insiders have sold 49,314 shares of company stock valued at $12,981,833 over the last ninety days. 3.60% of the stock is owned by insiders.
Analyst Upgrades and Downgrades
<!—->
Several research analysts recently weighed in on MDB shares. DA Davidson boosted their price target on shares of MongoDB from $340.00 to $405.00 and gave the stock a “buy” rating in a report on Tuesday, December 10th. KeyCorp downgraded shares of MongoDB from a “strong-buy” rating to a “hold” rating in a report on Wednesday, March 5th. Rosenblatt Securities reissued a “buy” rating and set a $350.00 target price on shares of MongoDB in a research report on Tuesday, March 4th. Citigroup boosted their price objective on MongoDB from $400.00 to $430.00 and gave the company a “buy” rating in a research note on Monday, December 16th. Finally, Cantor Fitzgerald assumed coverage on shares of MongoDB in a report on Wednesday. They issued an “overweight” rating and a $344.00 price objective for the company. One investment analyst has rated the stock with a sell rating, seven have assigned a hold rating and twenty-three have given a buy rating to the stock. According to data from MarketBeat, the company currently has a consensus rating of “Moderate Buy” and a consensus price target of $319.87.
Check Out Our Latest Analysis on MongoDB
MongoDB Stock Down 2.8 %
MongoDB stock opened at $187.65 on Monday. The firm has a fifty day simple moving average of $261.68 and a two-hundred day simple moving average of $274.47. MongoDB, Inc. has a twelve month low of $181.05 and a twelve month high of $387.19. The company has a market capitalization of $13.97 billion, a PE ratio of -68.49 and a beta of 1.30.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share (EPS) for the quarter, missing the consensus estimate of $0.64 by ($0.45). MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The company had revenue of $548.40 million for the quarter, compared to the consensus estimate of $519.65 million. During the same quarter in the previous year, the business earned $0.86 earnings per share. As a group, equities analysts expect that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading
Want to see what other hedge funds are holding MDB? Visit HoldingsChannel.com to get the latest 13F filings and insider trades for MongoDB, Inc. (NASDAQ:MDB – Free Report).

Receive News & Ratings for MongoDB Daily – Enter your email address below to receive a concise daily summary of the latest news and analysts’ ratings for MongoDB and related companies with MarketBeat.com’s FREE daily email newsletter.
MMS • RSS

Nokia and BerryComm, a leading fiber-optic broadband provider in Central Indiana, announced the deployment of an enhanced high-speed internet connectivity for thousands of homes and businesses. This initiative, powered by Nokia’s advanced optical networking technology, reinforces BerryComm’s mission to provide reliable, high-capacity broadband services to underserved communities.
The expansion utilizes Nokia’s 1830 Photonic Service Switch (PSS) with coherent optics and Reconfigurable Optical Add-Drop Multiplexer (ROADM) technologies, ensuring superior network scalability and reliability. This deployment allows BerryComm to maintain complete control over service quality while reducing dependence on external carriers for last-mile connectivity.
Beyond residential customers, the enhanced network supports businesses with mission-critical connectivity solutions, ensuring maximum uptime and operational efficiency. With this infrastructure, BerryComm can seamlessly scale to 100G and beyond as bandwidth demands continue to grow.
“The deployment of Nokia’s ROADM technology marks a significant milestone in our mission to bridge the digital divide across Central Indiana. This cutting-edge technology enhances our ability to deliver reliable, high-speed internet while positioning our network for future growth. We’re proud to partner with Nokia, a global leader in optical networking, to bring these transformative capabilities to the communities we serve,” said Cory Childs, President of BerryComm.
“Fiber internet can be life changing, so innovative service providers like BerryComm are key to reducing the digital divide in America. Nokia’s optical network portfolio enables rapid deployment of fiber to unconnected regions. We appreciate BerryComm’s trust in Nokia and look forward to future projects with them.” Added Matt Young, Head of North American Enterprise Business at Nokia.
MMS • RSS

Comment Administrators tend to be a conservative lot, which is bad news for tech vendors such as Microsoft that are seeking to pump their latest and greatest products into enterprises customers via subscriptions.
SQL Server 2019 recently dropped out of mainstream support and is now on borrowed time, with extended support running until its final retirement on January 8, 2030.
Support for its successor, SQL Server 2022, began on November 16, 2022, but according to asset tracking biz Lansweeper, users are giving it a wide berth. The latest data puts SQL Server 2019 comfortably at the top for market share, at 28.9 percent, while SQL Server 2022 languishes at the bottom, behind SQL Server 2008, 2005, and 2008 R2, with a less than 0.1 percent market share.
The question is, why?
Esben Dochy, Senior Technical Evangelist, SecOps, at Lansweeper, told The Register: “Fully transitioning to 2022 has not happened because 2019 still has an extended EOL date of January 2030. So there isn’t a real rush to migrate yet.”
But that might not be the only factor. Dochy added: “Also, 2022 is significantly more expensive. When looking at features, 2022 new features are primarily cloud-focused, which are only useful if you utilize those cloud features in your environment.”
If there’s no killer feature that a user absolutely must have, paying more to get cloud and AI features doesn’t seem to be lighting many fires under administrators, despite what marketers might fervently hope.
We put the question to Alastair Turner, a technical evangelist at database outfit Percona. Why aren’t database servers being upgraded?
Turner said the reasons tend to fall into one of two categories. First, there are the mission-critical applications that can never be offline for any reason. Upgrading is, therefore, highly problematic and likely to be a business risk.
Then there are applications that deal with low-sensitivity data or aren’t used much. They’ll get flagged for replacement, but aren’t important enough to justify the effort. Turner said: “We have seen examples of applications scheduled for decommissioning, where the team never has enough bandwidth to get that work done. So, the app stays in place and keeps on running.
“The former don’t get moved because they are too important, and the latter don’t get moved because they are ignored. Either way, they don’t get migrated.”
Turner also pointed to the “if it ain’t broke, then don’t fix it” mentality, where applications that are meeting a business need are left alone.
“New features in a new version of the database are seldom of interest to the application team, because the application was built around the features available when it was initially developed,” he said.
“But sooner or later, updates will be needed, whether it is for security reasons or to fix something that has finally broken. When your application database version is multiple updates behind the rest of your systems, this adds to the workload and increases the challenge.”
We contacted Microsoft to get its take on SQL Server 2022’s market share and its opinion on why administrators appear to be steering clear for now. As is all too often the case these days, Microsoft has yet to respond.
However, it is not only commercial players like Microsoft that face update reluctance. The same can also apply in the open source world, although to a lesser or greater extent depending on the database server in question.
“PostgreSQL tends to be fairly up to date,” Turner said, although he noted that some ancient installations were still ticking over, mainly because the effort to update them could not be justified, repeatedly pushing them down the “todo” list.
Community edition deployments of MongoDB also tend to be up to date. Turner attributed that to MongoDB developers being eager to stay current with functionality and not get left behind.
And then there’s the old stalwart, MySQL.
Support for MySQL 5.7 finally ended in 2023, but enough customers are sticking with it that companies such as Percona reckon there is a business in keeping the lights on for a little longer.
“MySQL is the open source database with the biggest percentage of older versions. Currently, version 8.0 does not deliver like-for-like performance compared to version 5.7 – so, some DBAs and teams have held off making that move until they can get to at least parity,” he told us.
“It can be hard to justify projects that don’t have a tangible outcome or business benefit at the best of times, so a project that would lead to lower performance levels is a tough sell, even if support is needed.”
Upgrading a database can be a risky endeavor. How does the new version handle SQL? Are there language quirks that need to be considered? This writer remembers the arguments around updating an obsolete database server well. Did the cost of revalidation outweigh the cost of paying the vendor for a few more years of support?
SQL Server 2022‘s showing demonstrates the conservatism of admins whose priority is keeping things running with minimal interruptions. Despite the shrill exhortations to move to the cloud or switch to a continually updating subscription model, for many, leaving well alone that beige box under the desk which has been running a business-critical application for years remains the safest course of action. ®
MMS • RSS
MongoDB is to acquire Voyage AI with the intention of using Voyage AI’s facilities within MongoDB so developers can build apps that use AI more reliably. Voyage AI produces embedding and reranking models.
MongoDB is a NoSQL document database that stores its documents in a JSON-like format with schema. MongoDB Atlas is the fully-managed cloud database from the MongoDB team.

The Voyage AI range provides intelligent retrieval models that underpin retrieval-augmented generation (RAG) and reliable LLM applications, according to the company.
Explaining the acquisition, Dev Ittycheria, President and CEO, MongoDB, said that embedding generation and reranking are two key AI components that capture the semantic meaning of data and assess the relevance of queries and results.
“We believe embedding generation and re-ranking, as well as AI-powered search, belong in the database layer, simplifying the stack and creating a more reliable foundation for AI applications.”
With Voyage AI, MongoDB solves this challenge by making AI-powered search and retrieval native to the database. MongoDB says Voyage AI has built a world-class AI research team with roots at Stanford, MIT, UC Berkeley, and Princeton and has become a leader in high-precision AI retrieval.
The integration with MongoDB will happen in three phases. In the first phase, Voyage AI’s text embedding, multi-modal embedding, and reranking models will remain widely available through Voyage AI’s current APIs and via the AWS and Azure Marketplaces.
Voyage AI’s capabilities will then be embedded into MongoDB Atlas, starting with an auto-embedding service for Vector Search, which will handle embedding generation automatically. Native re-ranking will follow, and MongoDB also plans to expand domain-specific AI capabilities for different industries such as financial services and legal, and for specific uses such as code generation.
The final move will be to add enhanced multi-modal capabilities for retrieval and ranking of text, images, and video. MongoDB also plans to introduce instruction-tuned models so developers will be able to refine search behavior using simple prompts.
More Information
Related Articles
MongoDB 7 Adds Queryable Encryption
MongoDB 6 Adds Encrypted Query Support
MongoDB 5 Adds Live Resharding
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.


Comments
or email your comment to: comments@i-programmer.info
MMS • Craig Risi
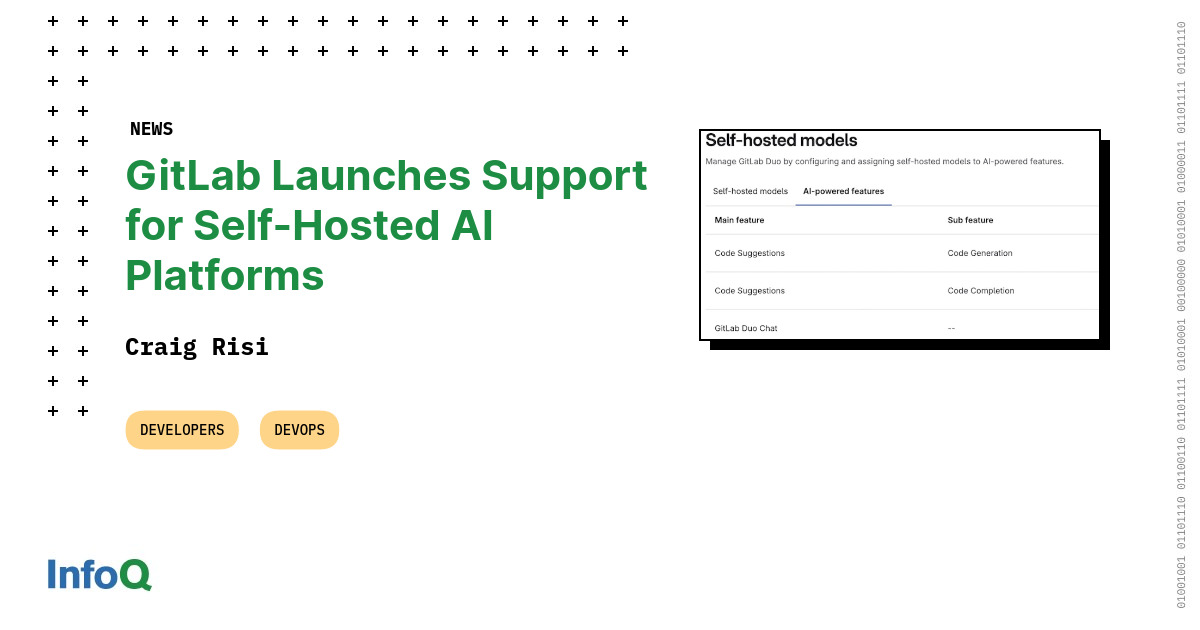
On February 20, 2025, GitLab released version 17.9, which introduced improvements aimed at enhancing user experience and functionality. A highlight of this release is the general availability of GitLab Duo Self-Hosted, enabling organizations to deploy large language models (LLMs) within their infrastructure.
This allows for the integration of GitLab Duo Code Suggestions and Chat using models hosted on-premises or in private clouds, supporting open-source Mistral models on vLLM or AWS Bedrock, Claude 3.5 Sonnet on AWS Bedrock, and OpenAI models on Azure OpenAI.
Organizations that deploy LLMs within their own infrastructure or private cloud environments avoid the risk of exposing proprietary code, intellectual property, or sensitive business data to external AI providers. Industries with strict compliance and regulatory requirements, such as finance, healthcare, and government sectors, benefit from this capability as they can leverage AI while maintaining full control over their data.
Joel Krooswyk, Federal CTO for GitLab, noted to DevOps.com, that although the software-as-a-service (SaaS) edition of the platform is seeing increased adoption, many organizations still opt for self-hosting due to factors such as regulatory requirements. He added that this self-hosted approach allows organizations to manage their own DevOps platforms and helps DevOps teams meet any data privacy requirements or concerns their organization may have.
Running LLMs on-premises or in a private cloud, organizations can eliminate latency associated with external API calls to AI services. This is especially beneficial for real-time AI applications. Additionally, regulatory concerns around data residency and compliance (such as GDPR, HIPAA, or SOC 2) are more manageable when AI processing remains within an organization’s controlled environment.
With AI-assisted coding and chat functions, organizations can embed secure coding practices into their development process. LLMs can help identify security vulnerabilities, suggest best practices, and even automate fixes before code is merged. This aligns with the growing trend of shift-left security, where security measures are integrated earlier in the development lifecycle.
Overall, GitLab 17.9 brings substantial improvements in AI integration, deployment efficiency, development environment collaboration, and project maintenance.
Another enhancement is the ability to run multiple GitLab Pages sites with parallel deployments, allowing for simultaneous updates to various sites, improving efficiency and reducing deployment times.
Integration capabilities have also been expanded with the option to add project files to Duo Chat within popular integrated development environments (IDEs) such as Visual Studio Code and JetBrains. This facilitates deeper code interpretation and collaboration directly within the development environment, which is likely aimed at enhancing productivity and teamwork.
To optimize project maintenance, GitLab 17.9 introduces the automatic deletion of older pipelines. This feature helps in managing storage and maintaining an organized project repository by removing outdated pipeline data, ensuring that resources are efficiently used.
AI continues to grow in support across the industry and this new release from GitLab showcases further progress in how development teams can leverage LLMs in new ways to enhance their efficiency.
MMS • Utku Darilmaz

Key Takeaways
- It’s possible to consolidate good Kubernetes production engineering practices to a tried and tested checklist for Site Reliability Engineers (SREs) managing Kubernetes at scale.
- There are core areas of Kubernetes SRE management that are the source of countless Kubernetes issues, downtime, and challenges, that can be overcome with basic principles that when applied correctly and consistently, can save a lot of human toil.
- Common sources of Kubernetes SRE challenges include: resource management, workload placement, high availability, health probes, persistent storage, observability and monitoring, GitOps automation, and cost optimization, which will assist in helping to avoid common pitfalls.
- Kubernetes SRE management and operations can benefit from GitOps and automation practices that are embedded as part of development and operations workflows, in order to ensure they are applied in a unified and transparent manner across large fleets and clusters.
- Kubernetes is inherently complex and when you get started with good SRE hygiene, you can reduce the complexity and cognitive load on the engineers and avoid unnecessary downtime.
Kubernetes has become the backbone of modern distributed and microservices applications, due to its scalability and out-of-the-box automation capabilities. However, with these powerful capabilities comes quite a bit of complexity that often poses significant challenges, especially for the team tasked with operating production environments.
For SREs managing high-scale Kubernetes operations, ensuring stability and efficiency isn’t impossible. There are some good and replicable practices that can help streamline this significantly. As an SRE at Firefly, who has managed many large-scale production K8s environments, I’ve crystallized these practices into a checklist to help SREs manage their K8s-Ops effectively.
The Kubernetes Production Checklist
Managing Kubernetes in production is no small feat. After navigating challenges, failures, and production incidents across many clusters, this checklist has been created to address the most common root causes of Kubernetes instability. By adhering to these practices, you can mitigate the majority of issues that lead to downtime, performance bottlenecks, and unexpected costs. The practices’ areas are:
- Resource Management: The practice of properly defining requests and limits for workloads.
- Workload Placement: Using selectors, affinities, taints, and tolerations to optimize scheduling.
- High Availability: Ensuring redundancy with topology spread constraints and pod disruption budgets.
- Health Probes: Configuring liveness, readiness, and startup probes to monitor application health.
- Persistent Storage: Establishing reclaim policies for stateful applications.
- Observability and Monitoring: Building robust monitoring systems with alerts and logs.
- GitOps Automation: Using declarative configurations and version control for consistency.
- Cost Optimization: Leveraging quotas, spot instances, and proactive cost management.
- Avoiding Common Pitfalls: Preventing issues with image tags and planning for node maintenance.
This may seem like a long and daunting list, but with today’s DevOps and GitOps practices, we can automate most of the complexity. Once you have an organized checklist it is much easier to add consistency and efficiency to your entire Kubernetes operation. Below we’ll dive into each one of these categories.
Resource Management
Resource allocation is the foundation of Kubernetes stability. Requests define the minimum resources needed for a pod to run, while limits cap the maximum it can consume. Without proper limits, some pods can monopolize node resources, causing others to crash. Conversely, over-restricting resources can lead to throttling, where applications perform sluggishly.
For critical applications, best practices dictate aligning requests and limits to ensure a guaranteed Quality of Service (QoS). Use Kubernetes tools like kubectl describe pod to monitor pod behavior and adjust configurations proactively.
While there are entire blog posts focused just on monitoring pod behavior, a good way to do this is using kubectl describe pod to identify resource issues. You would next inspect the output for details such as resource requests and limits, and events like OOMKilled (Out of Memory) or CrashLoopBackOff, and node scheduling details. Finally you would diagnose the issue and decide if the container is running out of memory because its workload exceeds the defined limits, and adjust the configurations accordingly.
Proactively identifying and resolving resource allocation issues, helps prevent operational disruptions.
Workload Placement
Workload placement determines how effectively your resources are used and whether critical applications are isolated from less important ones.
Node Selectors and Affinities
Assigning workloads to specific nodes based on labels helps optimize resource utilization and ensure workloads run on the most appropriate hardware. Assigning specific nodes is especially important for workloads with specialized requirements, because it prevents resource contention and enhances application performance.
For example, assigning GPU-intensive pods to GPU-enabled nodes ensures these workloads can leverage the required hardware accelerators without impacting other workloads on general-purpose nodes. Similarly, by using node labels to group nodes with high memory or fast storage, applications that need these capabilities can be efficiently scheduled without unnecessary conflicts.
Additionally, node affinities allow for more granular placement rules, such as preferring workloads to run on certain nodes, while still permitting scheduling flexibility. This approach ensures that Kubernetes schedules pods in a way that aligns with both operational priorities and resource availability.
Taints and Tolerations
Using taints and tolerations helps maintain workload isolation by preventing non-critical applications from running on nodes reserved for high-priority or specialized workloads. This tool ensures that critical applications have uninterrupted access to the resources they require, minimizing the risk of performance degradation caused by resource contention.
For instance, applying a taint to nodes designated for database workloads restricts those nodes to handle only workloads with tolerations for that taint. Applying a taint prevents general-purpose or less critical applications from consuming resources on these reserved nodes, ensuring databases operate consistently and without interruptions.
By implementing taints and tolerations strategically, Kubernetes clusters can achieve greater reliability and predictability, especially for workloads with stringent performance or availability requirements.
High Availability
High availability ensures services remain operational despite failures or maintenance, here are several factors that impact your availability in Kubernetes environments.
Topology Spread Constraints
Distributing workloads evenly across zones or nodes using topology spread constraints helps ensure high availability and resilience in the event of failures. This approach minimizes the risk of overloading a single zone or node, maintaining consistent performance and availability even during disruptions.
For example, in a multi-zone setup, configuring topology spread constraints ensures that pods are balanced across all available zones. This way, if one zone becomes unavailable due to a failure or maintenance, the remaining zones can continue handling the workload without a significant impact on application availability or performance.
By leveraging topology spread constraints, Kubernetes can enforce even distribution policies, reducing single points of failure and enhancing the reliability of services in production environments.
Pod Disruption Budgets (PDBs)
Setting Pod Disruption Budgets (PDBs) helps maintain service continuity by controlling the number of pods that can be disrupted during events such as updates, node maintenance, or failures. With PDBs, critical workloads remain operational and available, even when disruptions occur.
For instance, configuring a PDB for a deployment running three replicas might specify that at least two pods must remain available at all times. This configuration prevents Kubernetes from evicting too many pods simultaneously, ensuring the application continues serving requests and meeting availability requirements.
By using PDBs, organizations can strike a balance between operational flexibility (e.g., rolling updates or scaling nodes) and application reliability, making them a crucial tool for maintaining stability in production environments.
Health Probes
Kubernetes health probes play a critical role in automating container lifecycle management, keeping applications responsive and functional under varying conditions. These probes help Kubernetes detect and resolve issues with containers automatically, reducing downtime and operational overhead. There are 3 types of probes:
- Liveness Probes: These probes check if a container is stuck or has stopped responding due to internal errors. When a liveness probe fails, Kubernetes restarts the container to restore functionality. Liveness probes are particularly useful for long-running applications that might encounter memory leaks or deadlocks over time.
- Readiness Probes: These probes verify if a container is ready to handle incoming traffic. For instance, Kubernetes uses readiness probes to delay traffic routing to a pod until it has fully initialized and is prepared to serve requests. Readiness probes provide a smooth user experience by preventing failed requests during startup or configuration changes.
- Startup Probes: Designed for applications with long initialization times, such as Elasticsearch or other stateful workloads, startup probes prevent premature health checks from failing during startup. By allowing these applications sufficient time to initialize, Kubernetes avoids unnecessary restarts or disruptions caused by incomplete readiness or liveness evaluations.
Together, these probes ensure that applications running in Kubernetes remain healthy, scalable, and ready to meet user demands with minimal manual intervention.
Persistent Storage
Stateful workloads demand reliable and consistent storage strategies to ensure data integrity and availability across container lifecycles. Kubernetes provides persistent volumes (PVs) with configurable reclaim policies that determine how storage is managed when associated pods are terminated or removed:
- Retain Policy: The retain policy is ideal for critical applications like databases, where data persistence is essential. With this policy, data stored in a persistent volume remains intact even if the associated pod is deleted. By using a retain policy, critical data can be accessed and restored when needed, providing stability and continuity for stateful applications.
- Delete Policy: The delete policy is suited for temporary workloads where data does not need to persist beyond the lifecycle of the workload. For instance, a log processing pipeline that generates intermediate files can use this policy to automatically clean up storage after completion, preventing unnecessary resource consumption.
By aligning the reclaim policy with workload requirements, Kubernetes ensures efficient use of storage resources while maintaining the reliability needed for both critical and transient applications.
Observability and Monitoring
- Robust observability is essential for detecting and resolving issues in Kubernetes environments before they escalate into critical failures. By implementing comprehensive monitoring and logging systems, teams can gain actionable insights into cluster performance and maintain operational stability.
- Prometheus and Grafana: Prometheus serves as a powerful time-series database for collecting metrics from Kubernetes components, while Grafana provides intuitive visualizations of these metrics. Together, they enable teams to monitor cluster health in real-time and identify trends or anomalies that may require attention. For instance, a spike in CPU usage across nodes can be visualized in Grafana dashboards, prompting proactive scaling.
- Critical Alerts: Configuring alerts ensures that key issues, such as node memory pressure, insufficient disk space, or pods stuck in crash loops, are flagged immediately. Tools like Prometheus Alertmanager or Grafana Loki can send notifications to on-call engineers. Additionally, using commands like kubectl top allows teams to identify and address resource bottlenecks at the node or pod level.
- Log Retention: Retaining logs for post-incident analysis is crucial for understanding root causes and preventing recurrences. Tools like Loki or Elasticsearch can aggregate and store logs, making them easily searchable during debugging. For example, when investigating a pod crash, logs can reveal the exact error that caused the failure, enabling targeted fixes.
By integrating these observability practices, Kubernetes operators can maintain high availability, optimize performance, and respond swiftly to unexpected incidents.
GitOps Automation
GitOps, a declarative approach to managing infrastructure and applications using Git as the single source of truth, is often leveraged for Kubernetes systems for automated processes that continuously reconcile the desired and actual states of a system. This is because GitOps introduces a streamlined and reliable approach to Kubernetes operations by leveraging automation and version control to manage infrastructure and application configurations. This methodology ensures consistency, simplifies deployments, and facilitates rapid recovery in the event of failures.
- Declarative Configurations: In GitOps, all Kubernetes resources are defined as code, ensuring they are versioned, auditable, and reproducible. Tools like Helm charts or Kustomize allow you to create modular and reusable deployment templates, making it easier to manage complex configurations and scale applications effectively – and tools like Firefly help codify your resources rapidly.
- Version Control: By storing configurations in a Git repository, GitOps provides a single source of truth for your cluster. This setup allows you to track changes, implement code reviews, and roll back to a previous state if a deployment fails. For instance, if an update introduces a bug, reverting to a stable configuration becomes a simple
git revertoperation. - Reconciliation: Tools like ArgoCD or Flux continuously monitor the Git repository and the cluster, ensuring that the desired state defined in Git matches the actual state of the cluster. If discrepancies are detected (e.g., a manual change in the cluster), these tools automatically apply corrections to restore compliance. This self-healing capability reduces manual intervention and enforces consistency across environments.
GitOps not only simplifies Kubernetes management but also fosters a culture of automation and transparency, enabling teams to deploy with confidence and maintain stability in production environments.
Cost Optimization
Efficient cost management is a critical aspect of Kubernetes operations, especially in large-scale environments where resource usage can escalate quickly. When running Kubernetes operations on public clouds, it is a good idea to employ strategic cost optimization techniques, so that organizations can reduce expenses without compromising reliability or performance.
- Spot Instances: Spot instances are a cost-effective solution for non-critical workloads like batch processing or CI/CD pipelines. These instances are significantly cheaper than on-demand instances but come with the risk of being terminated if capacity is needed elsewhere. Therefore, spot instances should be avoided for critical applications, such as databases or stateful services, where disruptions could impact operations.
- Reserved Instances and Committed Use Discounts: For workloads that require long-term stability, leveraging reserved instances (AWS RIs, Azure Reserved VM Instances) or committed use discounts (Google Cloud Committed Use Contracts) provides significant savings over on-demand pricing. By committing to a specific amount of compute capacity for a fixed period (such as one year or even longer), organizations can optimize costs for predictable, long-running workloads such as databases, stateful applications, and core business services.
- Quotas and Limits: Resource quotas and limits help control resource allocation within namespaces, ensuring that workloads do not exceed defined thresholds. For example, setting a CPU or memory limit in a testing namespace prevents developers from unintentionally overloading the cluster, which could lead to unnecessary costs. These configurations also encourage teams to optimize their workloads and use resources judiciously.
- Cloud Cost Alerts: Monitoring cloud usage is essential to catch unexpected cost spikes early. Setting up alerts for key metrics like excessive resource consumption, unoptimized storage, or prolonged idle workloads can help teams take immediate corrective actions. Many cloud providers and Kubernetes monitoring tools integrate cost-tracking features that provide detailed insights into resource utilization and associated costs.
By implementing these cost optimization strategies, teams can effectively manage their Kubernetes environments while staying within budget, ensuring that operational efficiency aligns with financial goals.
Avoiding Common Pitfalls
In Kubernetes, seemingly minor missteps can lead to significant operational challenges. By proactively addressing common pitfalls, teams can maintain stability, predictability, and resilience in production environments.
- Avoid “Latest” Tags: Using the
latestimage tag for container deployments may seem convenient, but it introduces unpredictability. When thelatesttag is updated, Kubernetes might pull a new version of the container without notice, leading to version mismatches or unintended behavior. Instead, always use specific, versioned image tags (e.g.,v1.2.3) to ensure consistency and traceability in deployments. This approach also simplifies debugging, as teams can identify exactly which version of the application is running. - Node Maintenance: Regular node maintenance is essential for applying updates, scaling, or resolving hardware issues, but it must be carefully planned to avoid disruptions. Use Kubernetes pod eviction strategies to manage workloads during maintenance:
- Run
kubectl cordonto mark a node as unschedulable, preventing new pods from being assigned to it. - Use
kubectl drainto safely evict running pods and migrate them to other nodes in the cluster. These commands ensure workloads are redistributed without downtime, maintaining service continuity during upgrades or repairs.
- Run
By avoiding these common pitfalls, teams can ensure that their Kubernetes clusters remain stable and predictable, even as they evolve to meet changing business needs.
An SRE’s Kubernetes Roadmap
Kubernetes provides immense power and flexibility, but success in production demands thorough preparation. This list was built to address some of the core areas that frequently cause instability, downtime, and inefficiencies in Kubernetes clusters, offering actionable steps to mitigate these challenges. By following these practices, teams can transform Kubernetes into a reliable, efficient, and cost-effective platform.
Running Kubernetes in production requires both technical expertise and meticulous planning, and a good checklist serves as an excellent tool for SREs to serve as a roadmap, covering critical areas from resource management to cost optimization. By following these guidelines and leveraging Kubernetes’ native tools, teams can build resilient, efficient, and scalable environments.
Podcast: Understanding What Really Matters for Developer Productivity: A Conversation with Lizzie Matusov
MMS • Lizzie Matusov

Transcript
Michael Stiefel: Today’s guest is Lizzie Matusov, who is the co-founder and CEO of Quotient, a developer tool that surfaces the friction slowing down engineering teams and resolves it directly. Her team also co-authors the Research-Driven Engineering Leadership, a newsletter that uses research to answer big questions on engineering leadership and strategy.
She previously worked in various engineering roles at Red Hat and has an MS in engineering sciences and MBA from Harvard. And what she’s not thinking about building productive engineering teams, you can find Lizzie spending time around the parks of San Francisco.
Welcome to the podcast. I’m very pleased that you decided to join us today.
Lizzie Matusov: Thank you for having me.
Getting Interested in Building Productive Engineering Teams [01:39]
Michael Stiefel: I am very excited to have you here. And I would like to start out by asking you, how did your interest in building productive engineering teams get started, and what was the aha moment when you realized its relationship to software architecture?
Lizzie Matusov: Well, thank you so much for having me, and I love that question. So when I first started in software engineering, I worked at Red Hat, but I had a bit of an interesting role. I was a software engineer in their consulting arm, which basically meant that myself and a group of engineers would come into a company that has a problem they’re looking to solve, and then we would basically design the solution, the architecture, implement it, and then leave it with them and move on to the next project.
So I got to do that in biotech, in financial services, in an innovation lab. And the really incredible thing about that job was that every few months we would bring a team together and we were building not just the architecture that we wanted to then execute on, but also the team dynamics were new every single time. And then we would complete our work and go off onto the next project. So it taught me a lot about not just the technical challenges when you come into a company, but also the human challenges and how those are very important inputs into your ability to build software.
And then when I went to Invitae, which was the second company I worked for, I had a different experience. We were in-house, all working together, really getting to know our team dynamics, and we were finding that there were various areas that we were getting slowed down that weren’t immediately clear to us were system challenges.
And then what we started realizing is that the impacts that were beyond software were the human elements, so how the teams collaborate with one another, their ability to prioritize deep work with collaborative work, the ability to document effectively and how that has downstream impacts on the next project that gets built. And so seeing those two different experiences was what planted that initial seed to me that thinking about productive engineering teams as more than the tools they use is actually the way to think about building the highest performing, happiest engineering teams.
Human Behavior and System Architecture [03:59]
And so I think that humans are a critical input into system architectures. When you think about those incredible architectural diagrams that you build and all of the considerations and latency and caching and all those things that we always come to think of first in software engineering, if you just zoom out one layer you realize that there’s an entire complex system of who are the humans involved, how are they able to execute, how do they change with the systems, how do we think about their own inputs and outputs? And that to me is just such an interesting lens on software development that affects all of us, but we don’t always take that layer upwards and think of it there.
Michael Stiefel: I think that’s a very interesting insight because I spent most of my career as a software consultant, and like you, I saw a lot of different places. And one of the things that I found, and I’m sure this will resonate with you directly, is software projects when they failed, rarely failed because of the technology. I mean, in a couple of cases, yes, there was a bridge too far and it didn’t work, but most of the time, the overwhelming number of the time was like the Pogo cartoon. We have met the enemy and they are us. It’s the humans just couldn’t do it.
So if we start to adapt that lens and look at architecture that way, what architectural processes or ideas would drive improvement in software delivery, which implies the question is what is success and who judges that? You talked about the humans, but humans are all the way through the process, from the end user to the actual people building the system. So how do you develop those architectural practices that drive success however you want to define success.?
What is Software Productivity? [06:01]
Lizzie Matusov: When you think about the definition of productivity, just the most basic definition, it’s outcomes over effort. And outcomes is, did we deliver the right thing for our customer? Did we do the thing that our customers needed in order to get value? And there’s all of the variables that play into that. And then you think about effort, which is how difficult was it for us to get there? And sometimes that math doesn’t work out and oftentimes it does, but that is actually the true definition of productivity.
And so when I think about the systems that play into this concept of productivity, I’m thinking about things like on the outcome side, are we pointed in the right direction? Do we have the right understanding of who our customers actually are? Did we validate that we’re solving the right pain points? Did we build the right thing in that direction? And then we think about all of these aspects that impact the effort. So what were our developer systems like? What was our tool set and were we able to work through it? And how are the humans working together to achieve that?
And I think there’s the common things that we think of with productivity, like what is your deployment frequency or how quickly does code go from development to in production. Those things are important too, but actually many of those human factors play into both the outcomes and the effort in a much more dramatic way than we often even realize.
So that’s what I think about when I think of the core definition of productivity. I also think of there’s numerous frameworks that different companies and research institutions look at. There’s a common one called the SPACE framework, which was developed by the team at Microsoft, and that looks like a very holistic view of productivity. I think it stands for satisfaction, performance, activity, collaboration, and efficiency.
And that’s a great way of looking at it, but an even simpler one is actually one that was developed by Google and it’s just three things: velocity, quality, and ease. How fast are we moving, how high are we keeping the quality, and how easy is it for us to work? So these are different frameworks you can look at that help you answer, are we getting more productive, are we building the right thing, and are we doing it at a level of effort that works for us?
Michael Stiefel: And I presume when you talked about ease and efficiency, that also factors in, are you burning your people out, are you treating them like human beings or not? Because I’m sure you’ve seen it and I’ve been there too, where you have management that uses developers as slaves or interchangeable, and that’s not a very pleasant place to work. You can hit the customer perfectly, but are you a decent human being as you’re trying to develop this software?
Team Morale: Is Your Engineering Organization a Profit or Cost Center? [08:58]
Lizzie Matusov: Yes, absolutely. And there’s this saying of how do you think of your engineering organization, do you align it as a profit center or a cost center?
Michael Stiefel: Right.
Lizzie Matusov: Exactly. I think the way that you align engineering will dictate how you think of the humans within that organization. So if they’re a cost center and you’re like, “Gosh, we got to decrease costs and get the most value out of this thing”, and that’s where you often find these cases of really high burnout, really short-term minded, often not aligning engineers to the product work because they’re just interchangeable parts that we’re just trying to get the cheaper and most cost-effective version.
Then you think of the profit center version, where engineers are really seen as driving revenue for the business. And the better you can align them on that, the more revenue you’ll achieve.
Michael Stiefel: When you say that, I was thinking that’s something that I knew about early in my programming career. Fortunately I wasn’t at that place, but I don’t know if you remember or have heard of Ken Olson and the Digital Equipment Company. But what they used to do, Olson would set two teams to compete against each other to achieve some product, and the team that won got the bonuses, got the stock options, but the team that lost got nothing.
And you could imagine what the morale was in the team that lost. Because what you’re talking about is very often a projection of the leadership, and the leadership’s attitudes towards things gets translated into engineering. It’s amazing to me how much people’s views of technology, people’s attitudes, it’s basically on their outlook on the world. And that’s something you just sometimes can’t change.
Lizzie Matusov: I think about this concept a lot, and I often ask myself, why do we look at engineering with such a different lens than we might look at product or sales or marketing or even operations? Those organizations tend to value the more human-centric aspects of teamwork and thinking about the right goals and achieving them much more than we see in engineering.
And I think part of it has to do with the fact that it’s easy for us sometimes to get really caught up in the very, very deep weeds. And those weeds are things that a CEO probably does not know much about. I don’t expect them to know about how to provision software or Kubernetes clusters or thinking about latency or even knowing what-
Michael Stiefel: And you hope they don’t think about those things.
Lizzie Matusov: Right. Yes, leave that to the experts in engineering. But I think sometimes we get really caught up in those things. And as engineering leaders and as an organization, we don’t always do our part in helping people translate that into the impact for customers.
Architecture and Satisfying Customer Values [11:57]
And I think that’s changing. I think there’s been a lot more conversation in the last few years about making sure that engineers can communicate their value to the customers, both from the perspective of, again, helping the company achieve their revenue goals and their overall company goals, but also to help build a little more empathy for what it looks like within the engineering organization. And so that we can start prioritizing all of the factors that build into our ability to deliver that software, whether it’s our tools, stability of our software, or it’s the way that our teams are organized and how we’re set up to achieve those goals from a human side.
Michael Stiefel: I often think that the responsibility for that really is the architects. I mean, yes, it’s good if engineers understand business value, but someone very often has to explain that to them. And one of the goals or abilities of a good architect is to talk to the business people, understand them, and explain to them enough technology so they understand, “No, you can’t have this in three days”, or, “If you have it in three days, what you’re going to ask for in three months is not going to be possible”.
On the other hand, the architect also has to go to the engineering staff or the DevOps staff or whatever’s … and explain to you, “This looks stupid”. But actually, if you look at it from the broad point of view of business value or long-term success, it actually does make sense. Because I think sometimes it’s too much to expect that from an engineer because it’s so hard these days to just master what an engineer has to master to just produce software, that yes, it’s good if they understand the business value and it’s positive, and I would encourage every engineer to talk to customers, but in my experience, if there’s no responsibility someplace, it doesn’t happen.
That’s what I like to think. The architect is the one that talks to the management, not only about the business value, but all these things about software delivery and teamwork and things like that, because they’re in the unique position to see the implications of all these things that maybe an engineer can’t see because they’re worried about, “What am I going to do with the daily stand-up?”
Lizzie Matusov: on my feature.
There is No One Measure of Productivity [14:41]
Michael Stiefel: Right, on my feature. Or I believe you’ve talked about how velocity sometimes can be very misleading in terms of what you’re actually producing, so it’s the architect that has this … And this is why I was interested in talking to you because it’s the architect who can see this from a disinterested point of view because they’re responsible for things like security, for the user of interaction at the highest level, because they’re very often the ones who will only see all the capabilities. And I don’t know if that corresponds to your experience or not.
Lizzie Matusov: I think that’s correct. I think it’s definitely very difficult at an individual contributor level to be able to understand all of the outside forces or the other areas that play into their ability to, again, achieve business outcomes at the right level of effort.
I think that the support staff, the folks that are really in charge of thinking about how can I support the organization, which the architects are such a critical piece of that, engineering management or leadership has some role in that, those are the people that are in a really great position to understand all of those forces and to understand how to translate that into the changes that need to be made to support the organization. Now, what we often find is that people will start trying to look for the one data point or the one metric, let’s say, that matters-
Michael Stiefel: Silver bullet we used to call it.
Lizzie Matusov: The silver bullet. And we also know Goodhart’s Law. And we are all engineers by heart so we know that if we pick a single number, we can all rally around changing that number while the core problem is still happening right in front of our eyes.
Michael Stiefel: When I was a junior programmer, the emphasis used to be how many lines of code you produced. And I guarantee, if that’s what you’re measuring, you are going to get lots of lines of code.
Lizzie Matusov: Oh, yes. I wish you had AI tools, you could get tons more lines of code written for you.
Productivity and Performance Are Not the Same Thing [16:48]
Michael Stiefel: Which actually brings me to a point that I would like to explore, because I’m thinking of several ways this conversation can go. One thing is that I’ve always believed that the metric you use to measure productivity should not be the metric that you use to evaluate engineers’ performance, because that set up … Actually, I think this is a general rule in any part of society, but I think particularly in the software area, it sets people up for failure and sets organizations up for failure.
Lizzie Matusov: I think that you’re absolutely right. The research also validates that perspective. Unfortunately, looking at productivity and performance in the same light is very difficult to do.
Now, what you can think about is how do we understand the performance of the team and how do we align ourselves on achieving those performance goals? But you often find, particularly when it comes to IC engineers, the work of software development is so multidisciplinary that it is just impossible to pick a single number.
And I had this experience too, where I remember once being told that the number of code reviews I was doing was far below my teammates. And I was thinking at that time like, “Gosh, I’m tech leading a new project. I’m sitting over here with all of these other teams, working on basically what’s the system architecture so that I can make sure that they’re set up for success for this new key project. Should I stop working on that and just start working on approving people’s PRs to change the perception of my own performance?” And the answer is no. That’s not in service of the overall goals of the organization or the business, but unfortunately that’s the single metric that gets picked.
And so what we often tell people, and the research shows this, is, one, think about the team as the atomic unit and think about the ways that individuals are in service of that team. There’s a great analogy about soccer teams. You would never judge a goalie based on how many points they scored because the goalie is not supposed to … If the goalie is over there scoring points, you’ve got a big problem. You think about the team and how many points they’ve scored and what were the roles of all of the players within that team to achieve that overall outcome. And that’s how you should be thinking about software development teams as well, how are they, as a team, working together to achieve that overall outcome?
Michael Stiefel: And that’s another interesting analogy from another point of view because sometimes if the goalie fails it’s because there are too many shots on goal, and that’s the result that the defender is not doing their job and the goalie is just overwhelmed. So if you looked at the goalie and said, “This is a lousy goalie”, no, it’s really you got to look at the team as a whole.
Real Software Engineering Research [19:36]
We have a tendency to look at the proximate cause of things and not the ultimate cause of things. You talk about research, and I think people should get a little insight into the fact that what you’re talking about is not just case studies or something … this as what I’ve seen in my experience and I’m extrapolating, but there’s actually solid research behind these findings.
And at the same time, before we get to some of the more detailed things, is how can architects and software practitioners in general find out about this research, and understand that you are trying to do is something people have attempted from day one with maturity models and all kinds of things that we can talk about in a little more detail. But you, I think, are beginning to actually succeed in being able to ask interesting questions and in many cases actually answer them.
Lizzie Matusov: Yes, I think that research … It’s interesting, because when we think of research, we often think just of what’s happening in a very academic setting. And as practitioners we wonder, “Does that actually apply to us?” And it’s true, sometimes in a very academic setting. It’s very difficult to create all of the real-world variables that create a practitioner’s job when they’re in a software development organization.
But the research has expanded and evolved so much, and particularly in this frontier of productivity and achieving outcomes and the efforts involved with it, the research has really exploded. So you don’t just have the university lens, you have researchers at universities working with researchers at companies like Microsoft and Google and Atlassian and so many other organizations, to basically understand what are the factors that make the highest performing, happiest, most productive engineering teams, and what are the outcomes that come from making those changes?
So what we try to do in our work, and our company is very heavily rooted in the research, we work with researchers directly, we ingest all of their findings to make our own product better, but we also just think that fundamentally engineering leaders should have better access to that research. Now, I fully understand that it’s not always easy to ask engineering leaders to be sifting through Google Scholar, looking for the relevant paper, and then reading a 50-page analysis of the paper and the context and the findings.
And so for our part, we try using Research-Driven Engineering Leadership to make it much more easily accessible and digestible so that an engineering leader could say, “Hey, I’m thinking about introducing LLMs into my system. What are some of the considerations I should think about? Is it possible that I might be concerned about security?” And they can go and see, “Oh, actually there is a paper that looked at the most common types of bugs introduced by LLMs. Let me take that finding. Now, let me do the research and dig into the paper and figure out how to apply this with my team”. Instead of doing what we often do, which is to just figure out the problem as it’s happening to us in real time.
So we try our best to bring that research into light, and also to credit the incredible researchers who are out making these developments and making these findings that can actually help software development move much faster.
The Difficulty in Researching Complicated Societal Problems [23:07]
Michael Stiefel: We can actually make an analogy here, and let me see if this resonates with you. Because there is an element in our society, very important to us, that has this exact same problem. It’s the relationship to the practice of medicine to medical research. The human body is a highly nonlinear, not always in equilibrium, for lack of a better word, mechanism. I don’t want to get into metaphysical debates now, but just from this narrow point of view, a mechanism.
So you have people doing medical research in very well controlled … or even statistical research in epidemiology, which is sort of analogous to it because you should also make clear to people that there’s strong statistical evidence that you apply to this. In other words, there’s a certain amount of rigor. Because too many of us, when we hear about engineering research, we say, “Ah, more BS from the ..”. But there was strong basis to what you do.
But this is the exact same problem you have in medical research. You have the clinician who has a much more complicated patient. In fact, I can even drill down even further on this. Medical trials show that drug X can improve condition Y. But with medical trials, when they test drug X, they make sure that the person who they’re running the trials on, generally, has no other conditions besides condition Y.
Lizzie Matusov: Correct.
Michael Stiefel: But when you come to the clinician, they have people who have conditions, A, B, C, Y, E, F, so they have a much more complicated problem than the one of the researchers …
And this is in some sense, I think if you like this analogy, the same problem that software development research has and you’re beginning to come to grips with, by trying to take the theoretical research in isolated conditions and deal with it in the very messy world of software engineering.
Lizzie Matusov: Yes, that’s exactly right. And I think there are many branches of research now that are starting to really get at that. And so those are the studies that we often love to find, where they acknowledge and embrace the complicated nature of it instead of just isolating for a single condition that will never be the case in the real world.
Michael Stiefel: It took medical science a long time to develop the way this interaction … And it’s still not perfect. As we saw during the pandemic, all the pieces don’t always fit together. But perhaps, I’m just throwing this idea out there, that the people who are doing the kind of research you do, can look and see how the medical world addressed and solved these types of problems. Obviously human beings are more important than software, but that doesn’t mean that the abstractions and the problems can’t shed light on each other.
Lizzie Matusov: Yes, that’s true. And I think also one of the interesting things I’ve noticed, ingesting all of this research and getting to know some of the various styles, is that we’re definitely moving more into a world where, again, we embrace those imperfections and we still allow for those findings to drive practical applications.
It’s a very fair argument to say that sometimes … For example, only relying on perceptual data to help form a trend or a finding about how software engineering teams should work, maybe it’s imperfect because maybe there’s other data that suggests something different. But it still has practical value, and oftentimes what we’ve actually found is that that perception data is a stronger signal than what you’re seeing in some of these system metrics.
And so I think what I’m noticing much more over the years is that we are allowing for those imperfections to still be there and to acknowledge them, and we have limitation sections for a reason, but to still be able to extract value from the findings, as opposed to being so hung up on, again, the messiness that might create a confounding variable. We acknowledge, we address it, but we move forward.
And a great example of this actually is that there was a study recently that was done trying to model the types of interruptions that happen in software engineering teams, and what are the different types of interruptions and the complexity of them. So if it’s a virtual interruption, like a Slack ping pops up while we’re talking to one another, versus a coworker opens the door and has a quick question for you, versus a boss that comes in and asks if you’re free for five minutes, and they basically did all of these studies. And one of our thoughts was they only studied probably about 20 to 25 people in this, so there’s definitely a fair argument that maybe the exact percentages aren’t correct because it’s a small sample size.
But what was so interesting is that we actually published the findings of that study and gave people the links. This one actually blew up on Hacker News because people read it and said, “Yes, that’s my experience. That is exactly what happens to me”. And so you just get pages and pages of validation from engineers who have lived that experience. And so it is a little bit imperfect, but it represents people’s experiences and you can extract those findings to help improve your team dynamics as a result.
Finding Good Enough Research [28:44]
Michael Stiefel: And again, I think what the software world has to accept is the fact that this research is a story in progress. We’re not discovering Newton’s laws of gravitation, which incidentally were shown to be an approximation by Einstein’s special theory of relativity, but you are building useful models.
My favorite example of this is Ptolemy’s model of how the planets and the Sun went around the Earth, worked until it became too complicated. Then the Copernicus model is the one that we use today, and it’s very useful, but in point of fact actually it’s untrue, because according to the general theory of relativity, all spacetime is shaped in such a way, but the Copernican model is good enough for everything we need to do.
So what we’re looking for, and this is also … good enough models, good enough research, and not to critique it from the point of view of, well, maybe in some absolute truth it’s not right. As you experienced with the interruptions, that was good enough research.
Lizzie Matusov: It’s true. And again, there’s value to be had in it and we should absolutely be looking for the outliers in cases where these models don’t perform, but that doesn’t mean that we should discredit all the work. And so we are starting to see much more of a broad spectrum of research.
Expecting More of Software Engineering Research Than Other Areas of Research [30:20]
Now, I will say, another interesting finding in spending more time with the research, is there are different bars depending on the different types of institutions and publications. For example, if you want to be published in Nature, it’s a very, very structured process with a lot of peer reviews, a lot of data. And I think that bar is really important, especially for the nature of the publication. Sometimes you get into these cases where there’s research where, again, they look at 300 engineers or they only look within one company. And you can say that that’s an obvious limitation of the study, there’s still value to be had from those insights. And I think those are important.
I do sometimes see cases in which there are papers that are published, they just don’t even meet that bar for good enough, but they’re still out there and they’re still being used, and sometimes they’re antithetical to the myriad of other findings that you might see. And so it’s a spectrum. I think you do have to apply a layer of judgment. I think we try our best to understand the researcher’s perspective of when should research be considered relevant versus when are the confounding variables may be too great to consider that finding. But that’s something that you do have to build up a muscle for seeing that. And if you see a study with only eight engineers and they’re all of one specific demographic and that proves a generalized point, you might want to ask yourself a little bit more about that.
Michael Stiefel: Right. But the point is this is a general problem in research. This is not just a problem in software engineering.
Lizzie Matusov: Absolutely.
Michael Stiefel: You see this across the board. And sometimes that study, maybe even though if N equals 15, might be worth doing because it shows something. So now it’s worth doing the N equals 200 or the N equals 500 study.
Lizzie Matusov: It’s the signal.
Michael Stiefel: Where you can’t do the N equals 500 study, unless you have the N equals 20 study that shows maybe there’s something here.
Lizzie Matusov: Absolutely. I agree.
Michael Stiefel: So I think in some respects we’ve put a too big a burden and asked software engineering research to be something that we don’t even ask engineering research or medical research to be, because these are all messy things.
What are the important findings for an architect or an engineer to look at? I mean, I’ll start it off by saying that when I was first studying software engineering, which I actually taught in academia for a while,there was a great deal of emphasis on maturity models, which to me, as I think about it, is problematic.
Let’s say you have a child. That child’s going to evolve and develop. Well, you don’t point to them and say, “Well, this is what a mature adult does”. Let the child evolve. And you have an idea what maturity is in the back of your mind, but you have to look at the particular child, the particular environment, the analogy here being the particular engineer, and the particular company in the particular industry, and decide what is important for that. And not some abstract model that says you are on level two now and to get to level three, you have to do X, Y, and Z.
Structures and Frameworks for Explainability [33:48]
Lizzie Matusov: That’s a good question, what you’ve asked. Thinking about this audience, I think that what I really love and I gravitate towards is structure and frameworks that can create some sort of explainability around humans as a piece of the software architecture puzzle. And so in 2016, I believe, with the Accelerate book, that’s Dr. Nicole Forsgren’s book, this framework of DORA really became quite popularized. DORA actually stands for the DevOps Research Assessment group. They’re now part of Google. So when we talk about the research that’s coming out of these giant companies like Microsoft and Google, a lot of that comes from the DORA research group tht’s now embedded there.
And basically what this book popularized were four metrics that help you understand the overall health of your systems, the DORA four metrics. And those four metrics are deployment frequency, lead time for changes, change failure rate, and time to restore services. And that was a really great way of thinking about the health of your overall systems.
What’s actually interesting is also in that book, Dr. Forsgren talks a lot about the social dynamics that play into the overall performance of an engineering team, things like psychological safety for example. But those were never placed into that framework in a way that was easy to digest. And so what we’ve seen is that over the years, the DORA four metrics have exploded in popularity, but they haven’t really addressed that human element and the role that humans play in the performance and productivity of the products that they build and the work that they do.
Using the SPACE Framework – Relating Architecture and Team Performance [35:33]
So those researchers in 2022 came out, actually again with Dr. Forsgren and other researchers at Microsoft, and put forth an idea of a new framework, a new research-backed framework, which is the one that I had mentioned earlier, the SPACE framework. Again, that stands for satisfaction, performance, activity, collaboration, and efficiency. And the idea is that these five categories are meant to help you understand and create a framework for understanding the overall productivity of your engineering team. And now going back to my earlier definition of productivity, helps you understand are you delivering value to your customers and what’s the effort of doing so?
And so I think as a research paper and a framework, this is a brilliant one for architects, for engineering leaders to really think about, because it embeds the complexity between the performance of the systems and the collaboration of the teammates, or the efficiency of your workflows and the satisfaction and ease of how your teams do their work. And the more you spend time with it, the more you realize that this framework does a fantastic job of combining all the pieces that we intrinsically know impact software engineering, but maybe haven’t been able to put forth in a systems-like way.
Michael Stiefel: You know a lot of developers and architects are very detail oriented. And when they listen to some description of a framework and they’ve heard about frameworks, could you give an example of how you would use this framework to come to a very specific results-oriented point of view? Because you’re dealing with some people who are very anal-retentive and once they hear frameworks, their mind starts to glaze over.
Lizzie Matusov: Yes. It’s a great question. You can really think about it in a number of ways. One of the interesting details of the SPACE framework is that it is specific enough to help you see the different inventions, but it is also vague enough that each team can find their own way to apply it in a way that makes sense for them. So I’ll give you an example.
Let’s say we’re trying to understand what is the overall productivity of an engineering team. We have some suspicion that things are not working well, there’s some friction. The natural tendency is to look at a single metric, let’s say, velocity. Well, velocity is not really necessarily a great metric to look at. And you can think of it quite frankly like an activity metric, like how many checks did we get in a single week? And so what the SPACE framework would ask you to do is, okay, consider velocity as a single metric on a category, but then start looking at other things. Look at the overall performance of the system. So is the system highly stable? And when you quickly deliver features to customers, are they able to use those features because the software is well-designed for that?
And then you can think about, okay, what about satisfaction? Maybe we can look at the satisfaction of the code review process. Perhaps we’re moving really quickly, but the team is like, “We keep skipping all these checks and I’m miserable and it’s going to come back to me, and our team is going to be finding all these bugs because we’re skipping all these important steps”. So then you would want to look at a metric like what’s the team’s satisfaction with code review? And then you might want to look at something else, like the team’s ability to collaborate. So how distributed are the code reviews? Are we moving really quickly because there’s actually only one engineer reviewing all of the code? The other six engineers never get that opportunity for knowledge transfer, and so that one engineer quits and suddenly the team’s overall performance just sinks into the ground.
And so those are examples of ways that you can use those five dimensions of SPACE, and start asking questions about what the factors are that are impacting your team and start applying that to getting to the root cause of how to improve your team’s productivity.
Michael Stiefel: You use a Likert scale to quantify these things?
Lizzie Matusov: Yes, highly recommend a one to five point Likert scale for those perception metrics. And also highly recommend making sure perception metrics are a part of your analysis just as much as system metrics are.
Michael Stiefel: In other words, what you would do is you’d come up with a set of questions or a set of dimensions, you’d assign a Likert scale to each one of those. And then you looked at the system metrics and then you do some statistical analysis to relate all those.
Lizzie Matusov: Exactly. And you might find that in this overall picture there’s a clear challenge or issue. For example, maybe the team is moving really fast, but what we’ve identified is actually that the quality of the output is causing more problems on the other side. So they’re not able to achieve that performance for their customers because they’re moving too fast and breaking things.
Michael Stiefel: And presumably, after you have that finding, you might want to do another one to drill down. See, what I want to get people to understand is that this can be quantitative.
Lizzie Matusov: Absolutely.
Michael Stiefel: This is not just qualitative.
Lizzie Matusov: Absolutely.
Michael Stiefel: Because in an engineers’ minds qualitative equals BS.
Lizzie Matusov: Absolutely.
Software Engineering Research Uses Tools Developed in Other Areas of Research [41:04]
Michael Stiefel: So what I’m trying to get across to the listeners is that by using well-understood statistical techniques that people use in other areas of research are now coming to bear on the problems of software engineering and software development. So this is not something that you’ve invented-
Lizzie Matusov: No.
Michael Stiefel: … but you’ve borrowed.
Lizzie Matusov: Absolutely. And it’s, again, as you said, applied in so many different industries. I think we, as systems thinkers, often have … maybe focus a little bit too much in looking at just the telemetry data, but as engineers, we ourselves might know that that can give us signals onto the what or give us certain symptoms, but we need to get to a root cause analysis. And when we’re doing a root cause analysis, you need more complex factors that might play into, let’s say, the software development life cycle.
I also really loved what you said earlier about coming into it with a set of questions and then thinking about which dimensions you should be looking at in order to answer those questions. That is exactly how productivity should really be looked at, is what question are we trying to answer or what goal are we trying to achieve? Do we want to increase the stability of our software? Do we want to help our engineers be able to deliver more under easier circumstances? Do we want to reduce burnout? Do we want to keep our retention high? And then what questions should we be asking ourselves? And then how do we look at both telemetry data and perception data to create that overall picture and get those findings?
Michael Stiefel: And actually, what you’re describing in some sense is the scientific method, because you have a hypothesis and you think of a way of confirming or denying the hypothesis. But the step before that a lot of people don’t understand is that you actually build a model.
Lizzie Matusov: Correct.
Michael Stiefel: You can’t ask a hypothetical question or have a hypothesis without having a model of, let’s say, in this case what the software development process is. And sometimes what you find out, as you examine these questions, that your model is wrong.
Lizzie Matusov: Yes.
Michael Stiefel: And this is the problem I have with maturity models or any kinds of abstract models that people have imposed, whether it’s agile, whether it’s waterfall, for example. And I don’t know if you realize that no one ever really advocated for waterfall, it was sort of a devil’s advocate and the original paper was a devil’s advocate approach. But whatever approach you want to have, they embody a model, and this model has come about because you generalize people’s experience.
For example, I’ve heard, and I don’t want to go down this rat hole but just to give an example, people have criticized Agile on the grounds that the original people who signed the Agile Manifesto were world-class programmers, and they could probably work on any system and make it work. So in other words, you develop a model, you develop hypotheses and questions, you run experiments, you do analysis. And not only do you have to look at your hypothesis whether it’s right or wrong, but you have to look at, is your model of the software development process correct.
And then once you do that, you can start to get at some of these gnarly questions about where is agile appropriate? Where is Scrum useful? Where is …whatever these things are.
Lizzie Matusov: Yes. Or what’s our process and where are we being suboptimal, where are the edits that we can make? Exactly.
Michael Stiefel: This is just the early days as we like to say, but I think there’s a great deal of promise in what you’re trying to do, and people should not look at it through the eyes of this trick never works.
It’s like, for example, people criticizing engineers … People should read, and I’ve done this, read scientific papers from the 16th, 17th century or engineering papers from the 18th century, how they try to calculate artillery projectiles when they didn’t have the differential calculus. So in some sense, this research is only going to get better.
Lizzie Matusov: Absolutely.
Michael Stiefel: And you are in the early days, and it’s like a plant that you have to water and flower in order to get where you want to go.
Lizzie Matusov: As you said, we’re finding the models as we learn more, as we ask more questions, as we study more.
Michael Stiefel: And hopefully in the end we’ll be better for it.
Research and The Architectural Process [45:48]
What I want to do now is look at some of the findings that you’ve found and relate them to the architectural process. One of the findings that I believe I read about was the idea that you should define your architecture first and then worry about how you organize your teams. I know what Conway’s law is. I mean, it’s drilled into all of us. I remember reading it when I read The Mythical Man-Month way back early in my career.
Lizzie Matusov: Yes.
Michael Stiefel: The book Accelerate talks about the Inverse Conway Maneuver, where you actually define your architecture and then you evolve and define your team.
Lizzie Matusov: I mean, the Accelerate book does a fantastic job of talking about all of these concepts and really asking these deep questions. And I think what I really love actually about … Accelerate broadly brought forth this way of thinking about the complex systems of software development and that curiosity mindset that allows us to challenge things like, yes, what is the right way to think about Conway’s law, or how do we think about not necessarily in Accelerate, but Scrum versus agile, how do we think about systems health versus team health? I think that Accelerate did a really phenomenal job of that.
The Limits of Current Software Engineering Research [47:12]
Michael Stiefel: The question then becomes what kind of teams, what kind of companies are ripe to use this type of research? Should they have to evolve to a certain point or can any company … I mean, for example, if you are dealing with a system that’s like we call the big ball of mud, how do you start to think your way into this productivity or performance point of view?
Lizzie Matusov: It’s a great question, and I actually think it’s not for every company. There are definitely cases in which I wouldn’t recommend using this type of framework to think about your systems and the people that are organized around them.
One example of that is when you’re a really early stage startup and you are just thinking, “How do I deliver value?” It is not about optimization at this point because you have not reached the point where you’ve earned the privilege of optimizing your systems. So if you’re a team that’s like your first 30 employees, focus on getting to product market fit, for example. Another example where that’s not a great fit is when you have these gigantic organizations where technology is maybe a supporting part of their work, but that technology is actually not really evolving or advancing and we’re really just in maintenance mode. There isn’t this desire internally to develop that technology further, so kind of in that static area. Not a great fit to think about this type of systems thinking.
Where it is a great fit is when you have this mindset and desire to iterate, to improve the core system that you’re working on. Maybe you have a system architecture and you have a team architecture and you’re trying to deliver 15% more value to your customers next year. And you’re starting to think about, “What are the levers that I can pull so that we can achieve more value for our customers now?” If you’re in that type of mindset, I think this is a really important thing to think of.
And I think what’s more interesting is that up until about 2022, the common way of resolving that question that I just posed was to add more headcount. Just get 10 more engineers, which all of us engineers know that there’s a cost to that as well, but it is a very attractive thing to consider, huge cost. Nowadays, we think a little more carefully about it. We’re in a different market environment and we need to think about, quite frankly, efficiency. And so what we’re actually finding now is that organizations that are looking to increase the amount of value they deliver to their customers. Maybe that’s through a more performant system, maybe that’s through more features, maybe that’s through the more highly available system or more R&D on the side. Those companies are starting to look at the whole picture, which is not just, “How many humans do we have to do the work, but also what are the processes in place and which of those processes are suboptimal for us right now?”
And for those types of companies, I think this is a really great fit. But I’d say if you’re on a highly stable system that is not likely to change, and if you’re in that zero to 0.5 stage where you’re still trying to just mature the product, this is not really where you should look.
Team Effectiveness Is Built In, Not Added On [50:42]
Michael Stiefel: Interesting, interesting. What I’d like to look at right now is where can architects and engineers find this research? Because one of the things that the research talks about is, for example, how loose coupling not only allows a more flexible system, but actually contributes to team productivity because they can get more done. So the architect has to think … And this is very often a lot of architects don’t do this. There’s an old saying, I forget, it was Zenith had it, it was a television manufacturer, they said, “Quality is built in, not added on”, was their slogan.
So for the architect, team happiness, team effectiveness, things like security, have to be built in, they can’t be added on. And in fact, this goes back to what I believed for a long time, that one of the responsibilities of the architect is to deal with things that you can’t write a use case for: security, scalability, the total user experience. And this is another one, team effectiveness, team productivity, because if you don’t think about this from the get-go it’s not going to work.
Let’s put out an example of … You talked about one of the things that contributes to team productivity is the ability to put stuff out relatively frequently. They see satisfaction, they see things being accepted, there’s a positive emotional feedback loop. You feel like you’re checking things off and you’re going someplace. But if the architect doesn’t build the system with the appropriate set of coupling, with the proper integration environments or the lack thereof of integration environments, because if you require an integration environment, which means you have a bottleneck which gets in the way of doing things, you then have to design this from scratch.
Lizzie Matusov: It’s true.
Michael Stiefel: You have to write interfaces to allow the separation of concerns that allows the teams to operate independently and let the teams do their own things, whether it’s picking their own tools or hiring the people they need.
Lizzie Matusov: I think that there’s a very important point there, and I’ll slightly modify what you were saying. I believe it is so critical, and I think architects do a really great job of zooming out and thinking, they should be thinking, how is this system going to be impacted in five years, 10 years, 15 years, and all of that.
But we’ve also probably all been in situations where we walk into a system where it isn’t optimal for the modern time. I even think back to when I was working at Red Hat and the thing of the times was microservices. It had blown up, it had just blown up. And it was like, “Okay, well what do we do with all these monolithic applications that have been developed for the many, many years prior?” And even now we’ve evolved away from microservices into the right size services. Not everything has to be a single microservice.
And I think those evolutions in how we understand technology, they happen and we see sometimes that happens on a five-year time horizon, sometimes that happens on a 10-year time horizon. What I think is really powerful about this framework is if you walk into an organization or a team or a system architecture that is suboptimal for the world you live in today, you can actually use this framework to help you iterate in the right direction towards making that change.
So the best case is always to have something in place when you’re building from the ground up, to have that architect that has that five, 10, 20-year time horizon and can anticipate those changes. But you can also have a case where you’re walking into a suboptimal system that you want to improve upon, and you can actually use the same type of principles to understand, “Am I making my investments in the right areas of the system, or should I be looking elsewhere based on what the data tells me?”
Where To Find The Research [55:13]
Michael Stiefel: Where would people find some of this research on a continual basis to see how findings come out? Where would they look?
Lizzie Matusov: Great question. There’s a couple of things that I can offer. One for the very curious mind who wants to really just dive right in over a whole afternoon, honestly, the best place to start is Google Scholar. You can actually use scholar.google.com, start looking at the topics that matter to you, whether it’s software engineering productivity, system design, anything of the likes, and you can start looking at the relevant research that’s been coming out. There’s waves of time where it’s more or less papers coming out. For example, there’s an organization called IEEE and they have annual conferences. And so you’ll actually see a wave of new papers come out right before the deadlines for those conferences. That’s one place you can look.
If you maybe don’t have the time but are looking for that continual stream of research to be delivered to you, my plug is to check out Research-Driven Engineering Leadership. The idea is that every week we cover relevant recent papers that answer tough questions in engineering leadership. And that could be something like what is the overall performance improvements that various LLMs have in your system, to things like what considerations of the hybrid work environment should software engineering teams be thinking about that are specific to how they work? So it has a full spectrum in thinking about the impacts to software engineering and answering some of those thorny questions that don’t really have a single clear answer yet.
Michael Stiefel: We can put where to find these things in the show notes so people can get at them. This has been fascinating to me, but we only … I only have so much time for comments. I could talk about this for hours.
Lizzie Matusov: Me as well.
The Architect’s Questionnaire [57:04]
Michael Stiefel: But I like to emphasize the human element of things. I like to ask all my guests a certain set of questions. And I would also like to ask you, how did you realize the relationship between architecture teams and leadership?
Lizzie Matusov: Good question. I think that many of us who spend time in engineering start to see that inkling where those human aspects, like leadership and these social drivers like autonomy and dependability and purpose, start to play into our work more than we expected when we first walked in. You first walk into your software development job and you’re like, “I got my tools. I’m going to develop software, and that’s the job I came here to do”.
And then you start seeing, “Oh gosh, my work is really dependent on getting clear requirements”. Or, “Gosh, when I have a teammate that I just can’t collaborate with, I can’t get my work done”. And then you start realizing it’s about so much more than just the code that you’re writing. And so I had that natural evolution where I went from thinking very independently about the work that I was doing to thinking about the team and the system around me, to then realizing how impactful leadership, the team around me, the constructs of our system are in helping us achieve the work we set out to do for our customers. So that was my evolution.
Michael Stiefel: In other words, reality hits you in the face.
Lizzie Matusov: Yes. Slowly, slowly, all at once.
Michael Stiefel: Yes, yes. I think it was F. Scott Fitzgerald, or it was Hemingway who said, “Bankruptcy happens gradually and then all at once”.
Lizzie Matusov: Exactly.
Michael Stiefel: Even though you do what you like, is there any part of your job that’s the least favorite part of your job?
Lizzie Matusov: I think that one of the challenging bits of my work, because I sit at the crossroads of software development, thinking about teams, and also just running a company, is just how often I have to dive into a situation where I am learning something new. And I think that that is the good and the bad. You stretch your brain all the time, and I think that there’s something so wonderful and interesting about constantly learning new things, about the depths of software engineering dynamics and how teams work and productivity. But also things like how to do payroll when I learned that for the first time, setting up benefits, making sure that we have all of our ducks in a row thinking about marketing.
And so it has stretched my brain in so many ways. And I will say that most of the time I am just elated about the pace of learning. And some of the time I’m a little bit exhausted and just thinking about the joys of when you are working on a system that you know super well, and sometimes you could just rest your brain for a moment and know that things are working in steady state. So I do miss that feeling sometimes.
Michael Stiefel: Yes, making sure that the State Department of Labor or the IRS doesn’t get in your way is not exactly the favorite thing you have to do.
Lizzie Matusov: But it’s very important work.
Michael Stiefel: Yes, yes, yes. Is there anything creatively, spiritually, or emotionally about your research or what you do that appeals to you?
Lizzie Matusov : Oh, so much. I think as I’ve come into this problem and this desire to solve it, I have just been so fascinated at seeing the different schools of thought and thinking about engineering teams and what makes them tick and how do we think about the humans and the systems.
And I just love thinking about software engineering as a system beyond just the code that we write. And I think that now is actually an incredible time to be thinking about it because so many of our processes are being tested with new tools and technologies, like all of this AI tooling that begs these philosophical questions. We don’t have to get into it, but the key question of will AI augment or replace engineering? I have a strong opinion about this, but I love to see how our society is grappling with these big questions and that my job actually puts me at the forefront of these questions and how we think about that.
Michael Stiefel: I mean, it forces certain questions to be answered that perhaps we would rather not answer. But as you say, this goes straight to what it means to be a human being and what is the role of software. And software is not an insignificant part of the world now, and-
Lizzie Matusov: It’s everything.
Michael Stiefel: Yes, it is. Unfortunately or fortunately, it is everything. What don’t you like about doing research?
Lizzie Matusov: A little bit of what I mentioned earlier, that you need to apply a bit of a filter to understand when is a finding a signal, when is it something a little bit more definitive that you can act on. And I think I sometimes see papers that make crazy claims and then when you dig into the research and how they did their findings, you realize that actually this might not be something we want to rely too heavily on.
Unfortunately, research is a really strong tool to explain a point. And so when there are studies that are done that might not necessarily meet that threshold, if they prove a controversial point, they can still get picked up and used to prove something that is antithetical to what is reality, but just for the sake of proving that point.
Michael Stiefel: People have Bayesian priors and there’s no way to get around them.
Lizzie Matusov: Absolutely.
Michael Stiefel: Do you have any favorite technologies?
Lizzie Matusov: Oh gosh, they are changing so much. I think my answer would be very different depending on what day you find me. But I think because of my work these days, I’m actually spending a little bit less time in the weeds on software development today and a little bit more time thinking about engineers as customers and engineering leaders as customers.
And so what I’ve actually been really enjoying, and this is a little bit dated in a sense, but I think that AI transcription tools that allow you to transcribe a conversation and then look for key insights, it’s just been so powerful for my work to be able to revisit a conversation and revisit the key findings to think a little bit more about what did these engineering leaders say, what did they mean. What did they not say, in a way that I haven’t been able to analyze before.
Michael Stiefel: This reminds me of … I recently found out that there’s a feature on Zoom, which is enabled, that if you come late to the Zoom conference, it will summarize what has happened before and tell you if anybody assigned you any to-dos.
Lizzie Matusov: It’s so cool. It just allows you to catch up so quickly and to recount so much more effectively. It’s great.
Michael Stiefel: It’s a little scary because as we all wonder what the models actually do understand and what they’re making up.
Lizzie Matusov: Yes, absolutely.
Michael Stiefel: I’m just waiting for the first office argument, if they haven’t happened already, where, “Well, you said this”. “No, I didn’t say that”. “But the LLM said”.
Lizzie Matusov: Yes, you do have to apply a bit of a layer of reasoning on top of some of its own beliefs.
Michael Stiefel: Very often people are ready to believe whatever because it fits into their
Lizzie Matusov: Yes. I’d like to keep the human in the loop a little bit longer.
Michael Stiefel: What about doing research do you love? What about doing research do you hate?
Lizzie Matusov: What I love about the research is just that there’s so many brilliant people thinking about the hypotheses that they’re trying to test. And going out and having that curious mindset, coming back with findings and then sharing those findings with the broader industry. I love that mindset. I love that experimental thinking. It’s really been such a joy to work with researchers to evangelize their work and to find ways to get it into the practitioner’s toolkit. So that’s something that I really love.
And then something that I don’t love as much is, again, trying to think about which research applies based on what bars they’ve been able to set, as far as the sample size that they’re looking at, or what variables were they including or not including, and how can that either serve as a signal or as an actual finding. And I worry sometimes when we look at research that is meant to be a signal and then see it as a panacea or the overall finding, when really there’s more work to be done.
Michael Stiefel: Or sends people in the wrong direction.
Lizzie Matusov: Exactly.
Michael Stiefel: What profession, other than the one you are doing now, would you like to attempt?
Lizzie Matusov: I am a very creative person I believe. That’s actually what draws me to software development and being in this space, but it also manifests in very different ways. A hobby or something that I really enjoy is interior design, which is very random for some people, but I think that creating a physical manifestation of what makes you comfortable and what expresses your identity across different rooms or an entire space is just such a unique expression of a human being. And I really love to think about that to help people.
I love that interior design also brings out some of those kind of subconscious elements of how we operate. For example, the rule of three is for some reason, when you see three things bunched together, that brings your mind peace, versus when you see two things of equal height next to one another. There’s something about it that invokes chaos in your brain.
And so I think if I weren’t doing this or maybe in a future chapter of my life, I’d love to dive into some of those elements of creativity and think about a much more physical representation of my creativity.
Michael Stiefel: When you sell your company and become rich, you’ll be an interior designer.
Lizzie Matusov: It’s funny, some of my friends now, as they move apartments and are thinking about their space, I now have various conversations going where they’re sending me things or asking me, “How do I achieve this vision in my head?” And it brings me so much joy. It’s definitely a very fun hobby.
Michael Stiefel: Do you ever see yourself not doing your current job anymore?
Lizzie Matusov: I think that if we do everything right, I’d like to achieve our scale of impact in a time horizon that is shorter than my entire life. And so I would like to achieve our impact and then see it out in the world and then allow myself to focus my energy on something else.
Now that time horizon might be 10 years, 15, 20, maybe five if we do everything right quickly, but I definitely imagine that I will one day be doing something different. And I also think what’s great about my job is it evolves over time. And so in a way, I do a new job every single year, but I think I would like to keep focusing on this domain and supporting software engineering teams until we feel we’ve achieved the impact that we set out to achieve.
Michael Stiefel: And as a final question, when a project is done, what do you like to hear from your clients or your team or your peers?
Lizzie Matusov: I love stories of impact, particularly when it relates to engineering teams being able to achieve more in a sustainable, effective, high value way. So I love to hear the stories, for example, from our customers when they tell us, “Your software helped us unlock this key area of friction that we were able to lift, and that effort allowed us to suddenly move faster and to build this project on time. And then our customers got this value. And then we were able to be a more sustainable, effective engineering team”.
And it’s just a win-win for everyone. The customer wins, the engineering team wins, the business wins. When those areas converge, I get so much energy off of those stories. And in many ways, those stories are what keep driving me towards continuous improvement, continuously talking to engineering leaders and looking for the ways that we can actually help them achieve those goals.
Michael Stiefel: Well, thank you very, very much. I found this very fascinating. A lot of fun to do.
Lizzie Matusov: I did as well. Thanks for having me.
Michael Stiefel: And hopefully we’ll get a chance to maybe do this again in the future.
Lizzie Matusov: I would love that.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.
Java News Roundup: Milestone Releases of Spring Cloud, GlassFish and Grails, Devnexus 2025
MMS • Michael Redlich

This week’s Java roundup for March 3rd, 2025, features news highlighting: milestone releases of Spring Cloud 2025.0.0, GlassFish 8.0.0 and Grails 7.0.0; point releases of Spring gRPC 0.4.0, Helidon 4.2.0, Quarkus 3.19.2 and JHipster 1.29.1 and 1.29.0; the fourth release candidate of Netty 4.2.0; and Devnexus 2025.
JDK 24
Build 36 remains the current build in the JDK 24 early-access builds. Further details may be found in the release notes.
JDK 25
Build 13 of the JDK 25 early-access builds was also made available this past week featuring updates from Build 12 that include fixes for various issues. More details on this release may be found in the release notes.
For JDK 24 and JDK 25, developers are encouraged to report bugs via the Java Bug Database.
GlassFish
The tenth milestone release of GlassFish 8.0.0 delivers bug fixes, dependency upgrades and new features such as: various updates to support the upcoming release of JDK 24; disable the deprecated TLS 1.0 and TLS 1.1 specifications by default; and a migration away from deprecated WeldListener class in favor of the WeldInitialListener class. Further details on this release may be found in the release notes.
Spring Framework
The second milestone release of Spring Cloud 2025.0.0, codenamed Northfields, features bug fixes and notable updates to sub-projects: Spring Cloud Kubernetes 3.3.0-M2; Spring Cloud Function 4.3.0-M2; Spring Cloud Stream 4.3.0-M2; and Spring Cloud Circuit Breaker 3.3.0-M2. This release is based upon Spring Boot 3.5.0-M2. More details on this release may be found in the release notes.
The release of Spring gRPC 0.4.0 provides bug fixes, improvements in documentation, dependency upgrades and new features such as: a new ChannelBuilderOptions class used for customizers, graceful channel shutdowns and interceptors that was added to the GrpcChannelFactory and GrpcChannelBuilderCustomizer interfaces; and a rename of the GrpcChannelConfigurer interface to GrpcChannelBuilderCustomizer to “more accurately represent its purpose and for consistency with the server-side terminology.” Further details on this release may be found in the release notes.
Helidon
The release of Helidon 4.2.0 delivers bug fixes, improvements in documentation, dependency upgrades and new preview features:
- Helidon Service Inject, an extension to the core service registry that adds concepts of injection into a constructor, instances of scoped service instances, and an intercept method invocation. This change removes the original Helidon Inject, i.e., modules under the
inject/endpoint, and replaces all usages with the service registry. - A LangChain4j integration with the service registry and an OpenAI provider and Oracle embedding store provider.
- Support for Coordinated Restore at Checkpoint (CRaC).
More details on this release may be found in the changelog.
Quarkus
Quarkus 3.19.2, the first maintenance release (version 3.19.0 was skipped), ships with bug fixes, dependency upgrades and new features such as: a much improved Quarkus update utility for stability and aesthetics; and improved interoperability between an instance of the QuarkusUnitTest class and the JUnit @TestFactory annotation. Further details on this release may be found in the changelog.
Netty
The fourth release candidate of Netty 4.2.0 provides bug fixes, dependency upgrades and new features such as: support for a new property, IORING_SETUP_CQSIZE, that allows a larger completion queue (CQ) ring without changing the size of the submission queue (SQ) ring; and a requirement that an instance of the ThreadExecutorMap class must restore old instance of the EventExecutor interface to eliminate losing the current EventExecutor. More details on this release may be found in the issue tracker.
Grails
The third milestone release of Grails 7.0.0 delivers bug fixes, dependency upgrades and new features such as: an updated ContainerGebSpec class to support cross-platform file input and inclusion of the Geb ScreenshotReporter by default; and a consolidation of various projects and profiles to reduce the time to publish a release. With the transition of Grails to the Apache Foundation, the next milestone is planned to be released as Apache Grails 7.0.0-M4. Further details on this release may be found in the release notes.
JHipster
The release of JHipster Lite 1.29.1 and 1.29.0 features an upgrade to Axios 1.8.2 that resolves a critical security issue as described in CVE-2025-27152, a vulnerability in Axios, up to and including version 1.8.1, where passing absolute URLs, rather than protocol-relative URLs, to Axios even if the baseURL property is defined. The request to the specified absolute URL is sent with the potential to cause a server-side request forgery (SSRF) and a leakage of credentials. More details on these releases may be found in the release notes for version 1.29.1 and version 1.29.0.
Devnexus 2025
The 21st edition of Devnexus 2025, held at the Georgia World Congress Center in Atlanta, Georgia, this past week, featured speakers from the Java community who delivered workshops and talks on topics such as: Jakarta EE, Java Platform, Core Java, Architecture, Cloud Infrastructure and Security.
Hosted by the Atlanta Java Users Group (AJUG), Devnexus has a rich history that dates back to 2004 when the conference was originally called DevCon. The Devnexus name was introduced in 2010.
The conference also featured on-site live interviews with speakers interested in participating. Entitled Unfiltered Developer Insights and Everyday Heroes, these interviews were facilitated by employees representing Neo4j and HeroDevs, respectively. Also, a new episode of OffHeap was recorded featuring Erin Schnabel, Ivar Grimstad and Bob Paulin.