Month: April 2025

MMS • Renato Losio

PlanetScale has recently announced that vector support is now generally available. Created as a fork of MySQL, this new feature allows vector data to be stored alongside an application’s relational MySQL data, removing the need for a separate specialized vector database.
While PostgreSQL has been the default open-source choice for vector search, the company behind the Vitess database announced in 2023 its intention to fork MySQL and add vector search capabilities. Following a public beta in late 2024, vector search is now generally available with improved performance. Patrick Reynolds, software engineer at PlanetScale, writes:
Since the open beta began, we have doubled query performance, improved memory efficiency eight times, and focused on robustness to make sure vector support is as solid as every other data type MySQL supports.
The new vector capabilities enable direct support for recommendation systems, semantic search, and the now-popular RAG workloads on a MySQL-compatible engine. Reynolds adds:
We also built advanced vector-index features to satisfy a variety of embeddings and use cases. An index can rank vectors by Euclidian (L2), inner product, or cosine distance. It can store any vector up to 16,383 dimensions. It supports both fixed and product quantization.
According to the authors, a key differentiator of PlanetScale’s vector support is its ability to use indexes larger than RAM. The implementation is based on two papers from Microsoft Research: SPANN (Space-Partitioned Approximate Nearest Neighbors) and SPFresh. SPANN is a hybrid graph/tree algorithm that enables scaling to larger-than-RAM indexes, while SPFresh defines a set of background operations that maintain the index’s performance and recall.
While PlanetScale has designed the SPANN and SPFresh operations to be transactional and integrated them into MySQL’s default storage engine, there is little hope that Oracle will merge the change into the MySQL Community Edition. In a Hacker News thread during the beta period, Vicent Martí explained:
It’s already open source, because GPL requires it. It’s unlikely to be accepted as an upstream contribution given that Oracle has their own Vector type that is only available in their MySQL cloud service.
Writes and queries for the new feature work like a normal RDBMS, building an index with an ALTER or CREATE VECTOR INDEX statement, or writing SELECT statements with JOIN and WHERE clauses. Marti added:
The tight integration fundamentally means that inserting, updating and deleting vector data from MySQL is always reflected immediately in the index as part of committing your transaction. But it also means that the indexes are fully covered by the MySQL binlog; they recover from hard crashes just fine. They’re also managed by MySQL’s buffer pool, so they scale to terabytes of data, just like any other table. And also crucially, they’re fully integrated with the query planner, so they can be used in any query, including JOINs and WHERE clauses.
PlanetScale is built on top of Vitess, an open source database clustering system designed for the horizontal scaling of MySQL. A list of compatibility limitations is available online.
MMS • Shawna Martell

Transcript
Martell: Is there some amount of legacy code in the systems that you work in regularly? If you don’t have legacy code today, don’t worry, you will. It’s really easy to hate on legacy code. You’re scrolling through some old piece of the codebase and you’re like, who decided to use this framework that came over on the Mayflower, or this design pattern from the Late Jurassic? Who thought this was a good idea? The cool part about that is sometimes the answer, in the Taylor Swift of it all, is it’s me. I’m the problem. I’m the one who made these fascinating decisions. I can’t be the only one who’s been scrolling through GitHub and been like, that was a weird choice, git blame, just for my own name to pop up. You’re like, the Shawna of 2 years ago was making decisions. What I want to argue is that if we build code that lives long enough to become legacy code, we’ve done a pretty good job.
Legacy code often just works and it’s often worked for a long time. It’s legacy code because we didn’t have to touch it. I have dealt with a fair share of legacy code in my career. I’m currently at Carta where I’m a senior staff engineer. Before that, I was director of software engineering for Verizon/Yahoo, acquisitions are weird. They’re a big data platform. Think about a company like Verizon. They have functionally existed since the invention of the telephone, which was like not two weeks ago. They had a lot of legacy code laying around. Carta is not nearly as old as that, but we have our own fair share too.
When I say legacy code, I don’t blame you if you immediately think tech debt. I want to argue that legacy code and tech debt are not synonyms. That these are orthogonal concepts that we can consider along two axes. At one axis, we have technical debt. On the other end of that is something like ideal architecture or something. Then at the bottom, we have that legacy code, the stuff that has been running without needing a lot of attention for a while. On the other end, we have our active code. It’s not necessarily like new, but it’s something that’s getting our attention a little bit more regularly. When we think about these different quadrants, like the really nice code that’s a joy to work with and well-tested and has a slight sheen on it when you look at it, that’s the gold standard code. That’s the stuff that’s really nice to use. It’s hard to use wrong.
At the other side on the top, we have that code, maybe we just shipped it yesterday, but it’s got some tech debt associated with it. There could be lots of reasons for that. Like maybe this was a feature that was rushed. Or, it could be that you sat down and you looked at the tradeoffs that you had to make and you said, I’m going to accept some tech debt right now so that I can perform this experiment. This code isn’t necessarily bad. It’s just, it’s a little bit harder to work with. There’s more friction. I call that our tangled code. Not all legacy code is tech debt. We probably have that code that’s been running in production for a long time.
It’s delivering value, works pretty well, but maybe it’s using an old framework or convention. I call that our vintage code. In my experience, there’s a fair bit of vintage code that’s running our businesses probably as we sit here literally right now. We’re coming to the really fun quadrant. The thing that is not just full of tech debt but is older than the hills. I call that our deadweight code. Everything we’re writing right now and everything we have today falls in these axes somewhere. Just with the sheer passage of time, the code that’s in those top two quadrants, it’s going to fall down.
Outline
We’re going to have this story in three acts. We’re going to start by talking about like, we have code, maybe we have code in those bottom two quadrants. What work do we need to do to try to lift it up closer to the top? Then, if we’re thinking about code in those leftmost quadrants, what do we do to shift it closer to the right? While we’re doing all this code shifting, we’re inevitably building something new. How do we build that new thing with the future in mind? How do we build it so that it’s eventually, someday, easier to deprecate? In most cases, it’s the legacy code that got our companies and our businesses and our products where they are today. Often the code that got us here won’t get us there.
That means we’re going to have to replace that legacy code, we’re going to have to build something new. That thing that we’re building now, maybe the code you’re building literally today, if things go really well, that is the legacy code of tomorrow. Some day that legacy code is going to have to be replaced. This is a cycle, nothing lives forever. How do we build the code today with that inevitable end in mind? How do we build it thinking about how we will someday need to deprecate it? If we keep those ideas in mind, I feel really strongly that we will build better, more maintainable code that will make us cry way less when we finally have to delete it.
Case Study – HR Integrations
This is pretty abstract, in general. What I want to do to ground our conversation is actually walk you through an example of doing this work in the wild. This is a project we had at Carta where we had the joys of tech debt, legacy code, and needing to build something new. In order for that to make any sense, I need to tell you a tiny bit about our business so that anything I’m going to say is reasonable. The project had to do with how Carta integrates with a third-party HR provider, think like a Workday or a Rippling. Briefly, why is this a thing my company gives a hoot about? One of our business lines is cap table management. If you’re managing somebody’s capitalization table, it’s really important to understand when that company hires new people or terminates folks, because those changes impact the customer’s cap table. We call this stakeholder management, on our platform.
In order to provide some automation around that stakeholder management, we will integrate with your HR provider, because you have to tell them anyway, I hired this new person. Rather than making you go tell your HR provider and then tell Carta, just let automation propagate that information through to the Carta platform. This is something we’d done for a long time. It had been running in our monolith for years. Like I said, sometimes the code that got us here won’t get us there. We reached that point with our HR integration support a few years ago.
Our existing implementation had grown pretty organically over a fair number of years, and that led to some limitations. We weren’t exposing a consistent data contract across our providers. That was a problem because we were looking to introduce a new business line, specifically a business line that was going to deal with helping our customers understand how to do compensation. Compensation is really interested in your HR data. This was an important thing for us to support, but we couldn’t. To make it even stickier, the code was old enough that they’re just like, it wasn’t that many people around anymore that knew how any of it worked. Those of us who were tasked with solving this problem had never seen the code before in our lives. What could possibly go wrong?
To start with, this is where we began. This picture actually looks like relatively reasonable, I think. As we looked to introduce this new compensation product, we ended up in this situation where, depending on who your HR provider was, that dictated whether or not the data was available in the compensation product. How in the world could that be? That sounds wild. I’ve got this nice box situation around the HR integrations and you’re like, surely that was some unified module that had some consistent data contract. Not exactly. I think this is a much more fair picture of how this worked. We basically had a bunch of disparate provider implementations that had almost nothing to do with each other.
Then we’re tasked with like, go fix this: this thing that’s powering an incredibly business critical product in that stakeholder management box that our customers use literally every day, and if you break it, they will come for you. None of us knew how this code worked. We really weren’t that interested in just mucking around in here and finding out what we might break. There were real consequences. This is the real-life scenario that we were in. You’re having a conversation with a customer who’s like, I’m super jazzed about your new compensation product, that sounds awesome. You need my HR data? Then you’re like, we do. The cool thing is we support your HR provider, just not like that. It’s a bananas thing to say out loud. This was real life.
How Do We Reason About Tech Debt and Legacy Code?
We were very firmly in that deadweight quadrant. We had tech debt, we had legacy code, but what we wanted to do, we wanted to find a path to gold standard. Don’t we all? Ideally, we will all build code that lives in this quadrant. This is a really big shift. You can’t do a desirable shift much bigger than this. We wanted to go from the bottom left to the top right. Where do we start? Let’s look at this in a few different ways. I said we were going to have a story in three acts.
Our first act is, if we have code in these bottom two quadrants, what do we do to try to lift it out of there? We have a few different options. We can rewrite our code in place. We can do the thing where we stand up some new system and then one morning we shift over all of the traffic and pray. Just saying that out loud gives me anxiety, but sure, you could do that. Or you could use something like the Strangler Fig pattern to gradually replace your legacy system over time. We’re going to dig into the specifics of Strangler Fig. What do you choose? A rewrite in place makes a lot of sense, especially for a relatively small problem. It’s nice that you can work alongside the code that exists today and really appreciate how is it reasoning about certain edge cases. You’re right in there in the weeds. It can be hard when you’re doing a rewrite in place if your system is complex and the rewrite you need to do is large.
If you need to change functionality, do you end up with a bunch of feature flags all over the place that are trying to decide which world you live in? You don’t want to be the person that puts up the 10,000 file PR and is like, I’m done, everybody. That’s probably not how you want to do a giant rewrite like this. For reasonably localized changes, a rewrite can work, but we had such a significant change, we just didn’t see how this was going to be the path forward for us. I’ve already tipped my hand that maybe this one’s not my favorite. You can stand up a brand-new system, and in one giant switchover, just move all the traffic. That is technically a thing you can do. I have seen it done in the past. I’ve just never seen it go particularly well for a thing of any real complexity.
This is probably when I should say I am wildly risk-averse, so this just goes against who I am as a person. To be very fair to this pattern, you can do this, especially if you have a relatively small blast radius, this is a reasonable path forward. I probably still would never do it because it gives me so much anxiety, but that’s probably more of a me problem than it is with this particular approach.
I’ve probably sufficiently demonstrated that this one’s my favorite, probably. I really love the gradual replacement approach, something like Strangler Fig. I have actually given entire talks about why I think Strangler Fig is the best thing since sliced bread. I am going to force you to listen to just a little bit about it because I think it is the most effective way for us to actually get out of these bottom two quadrants. The Strangler Fig pattern is named after a real plant called a Strangler Fig. How those plants work is they start at the tops of trees, and they slowly grow down to the soil, eventually actually killing the host tree underneath it. They’re a parasite. The Strangler Fig replaces the legacy tree. It’s not code, but you have a replacement in the Strangler Fig.
The pattern is basically trying to do exactly the same thing. The idea is that you have your legacy system, and you slowly migrate functionality into your new system until one day you have all your functionality in your new system. How does that actually play out in practice? When you’re using the Strangler Fig pattern, it says the first thing you need to do is build a facade. The pattern calls it a facade. I often call it just a proxy. Hopefully it’s a very simple piece of software. It says, for a given piece of incoming traffic, should this traffic go to the legacy system or the new system? When you start out, it will be the least interesting piece of software in the world because all of your traffic will go to your legacy system. Your new system doesn’t do anything yet. Next you have to go into your legacy system and find these individual modules that you can independently migrate into your new system. This is the part of this entire process that I think is much more of an art than a science.
If you don’t have good modules in your legacy system, you may have to go introduce them. This part is really important because you really can’t proceed until you have these individual modules. Then you’re going to move functionality from your legacy system into your new system, basically one module at a time. We have this blue hash mark situation in the legacy system. We haven’t actually changed any of the behavior of module 1 and module 2 in the legacy system. We’ve just replicated that functionality in our new system. Now we go to our facade and we say, ok, facade, if you see traffic that requires module 1, send that to the new system because that is supported in the new system. If you see traffic that requires module N, send that to the legacy system because it doesn’t support that yet.
Then you gradually over time introduce additional modules into your new system until one day everything’s migrated and you remove your facade and you delete your legacy system and you probably have a party because you’ve finished a migration, and that’s like a big deal.
The thing I love about this pattern is that it gives us so many fallbacks and safety nets. There’s a lot of psychological safety in the leveraging of Strangler Fig. There are drawbacks. Everything is a tradeoff. Nothing is perfect. You can end up with a foot in both worlds for a really long time. That can be frustrating. You also have to do the work of understanding, how do I tell my facade how to route stuff? How do I have visibility into what the facade is doing? These things are additional work. In my experience, the benefits have consistently outweighed the drawbacks in any upgrade of any real complexity. Strangler Fig actually lets you do this in real life where you can find yourself moving from deadweight eventually to something that is much closer to the gold standard, and it’s in fact the only way I’ve ever felt like I’ve accomplished this in my life, I think.
The other cool thing about Strangler Fig is that it’s not just a pattern for when you’re actively deprecating your legacy code. It’s also a pattern that you can use to consider how you build your new system. How can I, as I am designing this new system that I’m building, imagine the future developer, could be me, who has to replace this new system in some modular way? How do I make that job easier for that future person? How did that work for our specific example? The unique thing about when we started designing our new HR system based on this existing behavior was that we actually talked about, at the beginning before we’d written a single line of code, in this new system, how are we going to ensure that Strangler Fig will be an effective way to someday deprecate it? I think that that fundamentally changed how we reasoned about our new system. We knew that we wanted to get to a place where at the very least, it didn’t depend on which provider you were using. You could use all the downstream products. That seemed like a bare minimum.
We also wanted to understand that this was going to be true going forward. If we needed to introduce a new provider, we were going to have to do a bunch of work to ensure that the data would seamlessly flow downstream. We also knew we wanted to decompose from our monolith so that we could just move faster than how we were iterating in the monolith back then. We designed this, which is way different. There are some of the same colors as the other one. Other than that, this is very different. There’s an entirely new service that didn’t exist in the previous picture. There’s a message bus. Where did that come from? This was a really big change. That meant, then we were going to have to do a bunch of work.
What Do We Do About Them?
This had both directions that we needed to move. The first part, we talked about like, how are we going to move from the bottom to the top? Now, how are we going to move from the left to the right? This is a slightly different shape of problem. Often when we’re replacing legacy code, we are building some often significant new something to replace it. With tech debt though, that comes in a lot of different shapes and sizes. You often know like what you want to do to fix it, but the hard part can be getting anybody on the planet to add it to a roadmap before 2080. You need to have some time to do it before the heat death of the universe. How do you go about reasoning about actually getting buy-in to do this work? There are lots of questions that we have to ask ourselves when we are starting this consideration.
The first one is, should I pay down this tech debt at all? The cool thing about the answer to that is it’s the answer to everything in software engineering. It depends. Also, this section on tech debt, I think is 62% hot takes. You shouldn’t pay down tech debt unless you have a business need. I learned three days ago that this is the controversial opinion puffin, I think. I was very much in love with that, because this is probably one of the more controversial takes I have had in my career. I get it. We’re engineers. We like to build things. We like to rebuild things. We especially like to build things that are super shiny. It makes sense that we want to pay down our tech debt. Paying down tech debt just isn’t a goal of its own. When we’re thinking about like, what questions can I ask myself? You have to think about, what’s the opportunity cost of doing this right now? What’s the cost of waiting a month to do this work? If we can’t justify those costs, probably now is the wrong time.
I’m sure that most of us have had those really hard conversations with a product manager or an engineering manager where you’re like, listen, three weeks ago, I put in this hack that is keeping me up at night, I just need time to go back and fix it. They’re like, but it’s working, I don’t understand the problem. Or, this library is driving me up the wall. Those are often not super persuasive arguments.
If you can find this intersection of some business need and your tech debt, now we’re talking about a place where PMs and EMs, they’re interested, like, tell me more. There are so many ways that you can link tech debt paydown. This could be a slide with 700 things on it. It’s not, but it could be. There are so many ways that we can link a tech debt paydown to a business goal. Maybe you’ve figured out that if I pay down this tech debt, it’s going to make it way easier for me to onboard new team members. Or I’m going to speed up our CI pipeline by 3X. Or, I’m going to be able to squash this bug that has been recurring for customers over the last six months and that people are really angry about.
All of these are pretty clearly linked to a business goal. If you can find this link between your task and the business goal, you’re much more likely to get buy-in. If you can’t, that probably means that now is not the right time to do this work. Every system I’ve ever worked in had some amount of tech debt unless it was literally empty. That tech debt isn’t necessarily bad in all cases. We take out debt to buy our cars or our apartments. That’s not bad debt. There are also forms of tech debt that are just fine. How did this look in our HR integrations example? What was the tech debt that we needed to pay down here? It was pretty clearly this wildly disparate data exposure layer. Linking this to a business goal was really easy. We actively wanted to release a product that we could not reliably support. I didn’t have to convince anyone that releasing the product was a valuable thing to do.
If I had tried to convince people, even six months earlier, that this was work that we should do, I don’t think I would have gotten any buy-in because it was super weird that this was how it worked. It didn’t matter. It wasn’t stopping us from doing anything that we wanted to do. It wasn’t until we had an active business need that it became very clear that this was the right thing to do.
How Do We Build for the Future?
We’ve talked some about like how do we deal with our stuff at the bottom. We’ve talked some about the tech debt stuff on the left. That brings us to our last part. Like, we’ve got to build something new. How do we build that code so that it ages really well? They say Paul Rudd doesn’t age. He clearly does, just remarkably slowly. He definitely lives in the gold standard. How do we build the Paul Rudd of our code? How do we keep our code in this gold standard quadrant just as long as we can? We want to build code that ages well. In my experience, the code that ages the best is the code that’s the hardest to use wrong. There are a zillion ways that we can make our code harder to use wrong. I picked four of them. I looked back on our experience working on this new HR integration system. I talked to a couple of folks who had worked on it with me. I was like, what were the things that really stand out to you that made a big difference when we were doing this project? These were the four things that bubbled up. I want to go through these one at a time.
How do we think about these things as tools to build code that ages well? I mentioned that we use Strangler Fig, while we were doing this work. One of the key parts of Strangler Fig is that encapsulation element. Those individual modules that help us as we’re trying to do these incremental migrations. If there’s just one thing that you leave here with, I would hope that it’s, encapsulation is the single best tool I have ever encountered to help build code that ages better. What do I mean by encapsulation? Just basically hiding the gnarly internals that almost certainly exist within our components and exposing clear interfaces that are the way that your components can communicate with each other. When we encapsulate our code, we create a software seam.
This idea of software seams comes from Michael Feather’s book, “Working Effectively with Legacy Code”. A seam is a place that we can alter the behavior of our software without actually having to touch the code in that place. When we’re leveraging Strangler Fig and you’re looking for those independent modules, those are your seams. For us in the legacy system, we’re actually pretty fortunate, the seams were really pretty well-defined. They were these individual HR providers. We could seamlessly move those between the legacy implementation and our new implementation because they had good seams around them. Sometimes you’re not going to be that fortunate and you’re going to find yourself that the first thing you have to do is actually introduce the seams in your legacy system. This on its own could be a six-day seminar.
Just from a very high level, look for ways to isolate the components in your legacy system. Can you add new layers of abstraction? Can you add wrappers around different parts of the code to just hide those internals? That’s going to be a really important part of ensuring that you can deprecate that legacy code. Again, just like when we were talking about Strangler Fig, this is more of an art than it is a science. If you find yourself actively having to do this work, I would encourage you to go get your hands on Michael Feather’s book because it is an outstanding resource when you’re in the weeds and actually having to do this.
For our HR integrations project, as we were building out our new code, we were actively discussing, what are the seams that we need as we’re going forward? Because we wanted to ensure that this new system was well encapsulated. They manifested in a few different ways. First was just ensuring that we were maintaining the existing seams within these individual HR providers. If we needed to change the behavior of one of these, that should be completely transparent to absolutely everything else in our system.
If something about Namely changes, that only component that needs to know about that is the Namely component. Keep each provider encapsulated. This was more about ensuring that we maintained the existing levels of encapsulation rather than introducing new ones. We did have to introduce new ones as we were designing our new system. I want to tell you about that, but I have to give you a teeny bit more detail on how the system worked, or nothing I say about that will make any sense. Carta synchronizes this data from the HR providers on a schedule. This is just a very boring set of crons. We’re going to run Dunder Mifflin at 3:00, and then we’re going to run Stark Industries at 4:00, and tomorrow we’re going to do it all again.
Historically, there had been this really tight coupling between the provider and the scheduling. We really did not want to maintain this tight coupling going forward. We did not want to have to go into each individual provider if we wanted to change something about how we were scheduling this. What we wanted was to create a seam around the scheduler, even though we knew the only scheduler we were going to start with is a cron. If you’re asking yourself like, why would you do the work to encapsulate if you didn’t have another use case? Because the encapsulation on its own was super useful. We knew that we were expecting to have a use case for a webhook sometime in the future. This makes sense. Rather than us having to go pull the third-party system to ask for changes, it knows that there are changes, just come and tell us. This was something we knew we would eventually want to support.
What we built for that to begin with was nothing. We didn’t build any of the webhook implementation to start with. That wasn’t an accident. We didn’t have a use case, so we didn’t want to build out that code. What’s my point? We didn’t build that webhook implementation because code that doesn’t exist can never break. If we had built it when we didn’t need it, I know myself, I definitely would have had some wild bug that on alternating Thursdays when we tried to schedule the cron, it hit something in the webhook implementation because I made a bad decision, and then the whole thing went to heck.
My life is repeatable enough that it definitely wouldn’t have gone well. Also, when we write that code that we’re not using, do you know what code ages the absolute worst? Code that isn’t being used because there’s absolutely nothing to encourage you to keep it up to date. When your code is well encapsulated and only exists when you need it, and has these well-defined seams, you’re going to have a more reliable system. A lot of the ways of building out these new systems is just finding ways to make our code easier to use right, harder to use wrong. Seams are a great way to accomplish that.
Good seams are also really important to the next part of this that I want to touch on, and that is testing. Talk about another thing that could be a six-day seminar, the joys of testing and why they are great, and how to write them. We could go on. What I want to talk about specifically around testing here is, how do tests help our code age better? How do we write these so that as our code ages, it’s more reliable and easier to use? We can all write bad tests. I am implicitly talking about good tests. Bad tests at best inflate some coverage number that doesn’t particularly matter, or at worst, creates so much noise that we just abandon testing altogether and throw our laptops into the sea. What we want to write here is good tests. Writing tests helps us maintain reliability as our code gets older, because time is coming for all of us. It’s coming for us and it’s coming for our code. It’s going to fall down just with the passage of time.
Tests help us stave off this inevitable fall, at least for a little while. Because as our codebase evolves and as it ages, those tests give us the confidence to actually make changes. We can rest soundly at night knowing we didn’t break any existing functionality as we end up having to work in some part of our codebase. It also means that we’re going to be able to adapt more quickly because our businesses are inevitably going to change. If we have a reliable test suite around that code, we’re going to be able to respond to those business needs more quickly. When we combine our seams with our tests, that again is going to create more maintainable code that’s going to age better. I think you are required by law to have the testing pyramid in a deck if you’re talking about testing, so I did, that’s fine.
One of the things I wanted to touch on was like, how did we think about testing as we were taking on these HR integrations work? Because the deadweight code, generously had spotty test coverage in the legacy system. We didn’t really have a lot of confidence that we weren’t going to break something. The first thing we did was introduce a bunch of end-to-end tests in the legacy system, so that as we iterated and we’re working through Strangler Fig, we could at least feel fairly confident we weren’t breaking anybody’s mission critical workflows. We also, of course, built out the tests for our new system end-to-end, the sorts of things that you would expect. Because we had these really clear seams, the tests in our new system were actually pretty easy to write. We could inject mocks where we needed them.
Our components were relatively well isolated, so you didn’t get a lot of that stuff where like test A is slamming over test B on every second Wednesday, and your tests flake out for no good reason. We didn’t have a lot of those problems. We could really easily test those integration points because there weren’t that many of them and they were really well-defined. By starting with this comprehensive set of tests, it helped our code stay in that gold standard quadrant just a little bit longer. It also made our code age better.
We’ve covered the first two of these: we’ve talked about encapsulation, we’ve talked about testing. These are two great ways to make our code age better. The third one I want to talk about is linting. I want to talk about a specific linter that we used in our HR integrations work. If you work in a typed language, not Python, Carta is mainly a Python shop, this particular linter won’t do you any good, but there are 8 gazillion linters that you can leverage effectively to make your code age better. Python is not a typed language. We are not exclusively Python, but we’re pretty close. As we were standing up this new system, we had to decide if we were going to enforce types in the new codebase or not. Because we wanted to have code that aged better, we introduced types from the start.
I personally am like very pro types when it comes to working in an untyped language. Why? Because the legacy function in our code looked like this. This is a small oversimplification, but no, it’s not much. Talk about a function that’s really easy to use wrong. You literally don’t know what to pass this thing unless you go read the implementation. That’s not the most user-friendly thing in the universe. We did not want our get_employees call to look like this in our new system. How does this look when we introduce mypy, which is just a static type checker for Python. There are several others. Mypy is the one that we use at Carta. In our new system, that function looks much more approximately like this.
Now if I pass anything other than a UUID to get_employees, my pipeline is going to break because mypy is going to throw an error. I envy all of you folks who work in a typed language all the time and need not worry that someone’s going to shove an integer into your list parameter. It sounds great, but this is not the life that I get to lead. The bonus of adding mypy, not only do I now know what to pass to this function, I also know what it’s going to return. I now know I’m going to get back a list of employees. This function is way harder to use wrong than that, which is begging you to use it wrong. You almost would only use it right by mistake. This one is very clear what it’s expecting.
These are all tools. We’ve talked about encapsulation. We’ve talked about testing, linting, one specific linter, but choose the linters that work best in your codebase. The last one I want to talk about is code comments, because I love code comments. I love comments that are informative and descriptive. If we’re really lucky, sometimes they’re funny. Comments make our code age better because they provide us with direction and guidance. They help us understand what set of decisions got us to where we are right now. Or, the people who have come before us, which bear traps have they stepped in that they have commented on at least lop your foot off in a different bear trap instead of the ones that we already found? This is what I love about comments. If you’re asking yourself like, but isn’t good code self-documenting? I agree with you on some theoretical scale, but I don’t know about you. I have never worked in a codebase where this was real. I’ve just never worked in a codebase that I did not feel could really warrant some descriptive and useful comments.
I remember early in my career, I heard a more senior engineer say, good code doesn’t need comments. What I internalized to that was, if I add comments, I’m making my code bad. I am 1000% certain that’s not what that engineer meant, but it’s what I believed. I think we have to be careful when we talk about like, all good code is self-documenting, because we don’t want to instill in people that adding a comment is inherently a bad thing. Comments are really important because code is so much easier to write than it is to read. You’re reading some code written by somebody else or the you of six months ago, which might as well be somebody else. It can be really hard to understand why things are the way they are.
A good comment can be a real lifesaver. They describe the why rather than the how. We’ve probably all encountered the equivalent of this as a code comment. I knew that was a stop sign. This is not what I mean. This is not a helpful code comment. I had to include this one. This is one of my favorite code comments I’ve ever seen. This is 1000% real in a real codebase that I have worked on in my career. I remember when I read this comment for the first time, I was like, I’m going to go figure out what that piece of code does. Beats the heck out of me. I have no idea. I do not know if this is a good comment or not, but I appreciate the warning. That piece of code was over 7 years old when I encountered it. I do wonder if it’s still there.
When I’m talking about good code comments, I mean a comment like this. This is obviously not directly verbatim, but inspired by a real comment in our HR integrations. When we were working on that project, we talked about our comments in meetings. I think that we were weird people, but we talked about our comments in meetings as an active extension of the other documentation that existed for this codebase. This is great. It tells me why this code exists. It tells me that if I’m using it for something else, I’m probably making flagrantly bad decisions. It links me to a document and that document helps me understand, what tradeoffs did we negotiate at the time that we made this decision to get to where we are today?
Because there’s a high likelihood in some future iteration, we’re going to want to re-litigate those decisions. Make it really easy for that future person to understand what was the decision-making that got us where we are, so if we need to reconsider that, we can understand what we should look at as we go forward. These types of comments help our code age better. I have to include this one. Wrong comments are worse than no comments at all. That function does not return true, I don’t care what the comment says. Nothing is executing our comment to tell us when we just start lying to ourselves. As we are writing our comments, we need to be thoughtful and remember that they require upkeep and maintenance just like our code does.
Recap
Through this lens of this actual real-life work we did for Carta’s HR integrations migration, we’ve looked at some ways that we can move our code from those bottom two quadrants closer to the top. We’ve looked at how we can pay down our tech debt, how can we take code in those leftmost quadrants, move it closer to the right, and how do we build the Paul Rudd of code. I didn’t really tell you like, how did it go? I’m saying we did this HR integrations thing and maybe it blew up two weeks after we launched it.
Thankfully, no. It’s one of our more reliable systems at Carta even still now, and it’s been several years. This code has changed hands several times, moved between different teams, but that resilience has pretty consistently remained. I think a lot of it has to do with the fact that as we were actively designing the system, we were consistently talking about its inevitable demise. How did we use the understanding that someday some poor person was going to have to replace this in order to inform the decision-making of designing it upfront? This is a project I am really excited to be able to say that I had a part in. It’s been quite a few years now. I think that I probably have to call this code vintage at this point. It’s pretty good, I think. I said at the top that the code we’re building today is the legacy code of tomorrow, and that’s true.
If we keep in mind that future developer who someday is going to have to deprecate whatever we’re building today, we can be the author of the vintage code that’s actually pretty nice to work with rather than that deadweight code that’s unwieldy and confusing. You never know. The future developer whose day you might be saving, it just might be you.
Questions and Answers
Participant 1: I really agree with the point you made about wrong comments being worse than no comments. I was just wondering if you had any suggestions for tools or processes that could help keep comments accurate and up to date?
Martell: I have seen a linter in my life that I think was at best directionally correct, but specifically wrong. I do not know of any tooling other than code reviews. The other tool I think about is like, write a comment that’s hard to become a lie. If you’re describing why you’re doing what you’re doing, unless you change the why, then that’s still true. I think it’s much harder when you have a comment that describes the how, because you might change the how seven times, and that’s harder to keep that comment up to date. If you write a comment that’s not particularly interested in the specific implementation, it’s just going to age better.
Participant 2: I wanted to see what you feel about to-do comments. Because they pop up a lot, and if you check legacy code, obviously it’s riddled with to-do codes, 7-year, 8-year to-do codes. How do you feel it’s the best approach to those to-do comments. Is it worth revisiting? Is it worth removing? Because they do have some history attached to them.
Martell: To a certain degree, it does depend. It depends on the culture of your organization, and like, how much are you lying to yourself? Every to-do comment is a little bit of a lie. It’s just a spectrum of how much of a lie it is. I think that ideally what we leave for ourselves is an artifact to help us understand why we got here and what potential future might look like more than a specific to-do comment. I have seen some organizations that are quite studious about their to-do comments and have linters that figure out how old they are and send you a nasty Slack message to you and your boss, and then eventually to the CEO that’s like, “Shawna said two weeks ago that she was going to do this and she didn’t and she’s in trouble now”. Does that work everywhere? Almost certainly not. Does it work some places? Probably yes. I think the important part when we’re thinking about what artifact are we leaving in our code to help future us, is that whatever your organization is going to find the most useful is the right thing. The day that your to-do comment can go to kindergarten, let’s just delete it and move on with our lives. I think we’re lying to ourselves at that point.
See more presentations with transcripts
MMS • Ben Linders
A rigid hierarchical dynamic between senior and junior software engineers can stifle innovation, discourage fresh perspectives, and create barriers to collaboration. According to Beth Anderson, senior engineers can actively learn from their junior counterparts. She suggests creating an environment of mutual growth, psychological safety, and continuous learning.
Beth Anderson spoke about how senior software engineers can learn from juniors at QCon London.
Often power dynamics focus on senior engineers passing information to more junior engineers, expecting them to approach engineering tasks similarly as they do, Anderson said. Passing information along is a potentially missed opportunity for a more meaningful conversation between senior and junior engineers, where senior engineers can learn new approaches and consider issues and solutions from juniors:
A high power distance can create an environment in which junior engineers are afraid of speaking up when they see an issue that causes a much larger problem, where junior engineers aren’t listened to and don’t feel valued.
Seniors can learn from junior engineers, who are often very highly motivated, and have a fresh perspective and an up-to-date set of skills. We shouldn’t have a fixed idea of who we can learn from, based on a hierarchy or on seniority, but instead celebrate curiosity and create an environment where seniors focuses on supporting junior engineers, not controlling them or shutting them down, Anderson said.
To cultivate an inclusive engineering culture, Anderson suggested active listening, amplifying people’s voices, and valuing their input. Senior engineers need to constantly be aware of how they’re interacting with junior engineers and ensuring they lift them up, not keep them down:
Curating a place of psychological safety in which junior engineers feel comfortable and empowered to speak up and ask questions is critical.
To create an environment where engineers can learn and grow, and feel psychological safety, Anderson suggested implementing “reverse feedback”, allowing junior engineers to speak up and provide feedback about how the senior engineer is communicating with them.
She mentioned asking junior engineers how they prefer to learn and communicate and listen to their ideas with an open and willing mind.
It’s more difficult for junior engineers to affect culture in an organization, although being open with how you prefer to learn is a good way to start, Anderson suggested:
Juniors can ask to review senior engineers’ code and/or pull requests as a learning tool, providing feedback to senior engineers.
Anderson advised junior engineers to be mindful of behaviors they’ve learned from others, and avoid repeating the ones they found difficult as juniors. Seniority isn’t about power, it’s an opportunity to create positive change.
Regardless of their level of work experience, each person has a unique insight and something to teach you if you’re prepared to listen actively and give them an environment in which they feel comfortable and valued. Junior engineers are the perfect people to ask why things are done the way they are, and for senior engineers to take that as an opportunity to reflect, Anderson concluded.
InfoQ interviewed Beth Anderson about learning from junior engineers.
InfoQ: What issues can arise from a high power distance between engineers?
Beth Anderson: At my first company, I remember making a mistake and being berated by a senior engineer. At the time I felt like I’d failed, although there was no way I could have known how to do it differently.
Had the senior engineer understood our different experiences, the outcome could have been a positive learning exercise.
InfoQ: How can we cultivate an empowering engineering culture?
Anderson: Think back to our early days as engineers and remember how we had ideas but looked for some help implementing them. A bad senior engineer would dismiss ideas whereas a great senior engineer would listen, value, and empower that junior colleague.
While I have learned from every senior engineer I’ve worked with, the engineers who have helped me improve the most have been people who listened to what I had to say with an open and willing mind.
MMS • RSS

MongoDB MDB shares have plunged 54.1% in the trailing 12 months, underperforming the Zacks Computer and Technology sector, the S&P 500 index and the Zacks Internet – Software industry’s return of 3.1%, 6.9% and 10.4%, respectively.
The company is facing a challenging near-term landscape due to an uncertain macroeconomic climate and rising competitive pressures. The stock has also been swept up in the broader market sell-off, driven by concerns over reduced consumer demand and the trade war. Let’s take a closer look at the key factors weighing on the stock, which should serve as a warning for investors.
MDB’s Competition is a Challenge
MongoDB faces tough competition from companies like Amazon’s AMZN DynamoDB, Couchbase BASE and Oracle ORCL, among others. Amazon DynamoDB is a fast NoSQL database, ideal for apps needing quick reads and writes with real-time data access. Oracle Database offers strong indexing and query optimization, making it great for fast and efficient data retrieval. Couchbase performs well in high-speed, offline, and mobile-first environments. It also has built-in caching for faster data access and uses an SQL-like query language. Shares of Oracle have gained 10.1% in the trailing 12 months, while Amazon and Couchbase have lost 2.7% and 40%, respectively.
This competitive landscape puts pressure on MongoDB’s market share and growth potential, especially as rivals continue to enhance performance and integration features. With stronger-performing peers gaining market share, MDB’s positioning appears increasingly vulnerable.
MongoDB, Inc. Price and Consensus
MongoDB, Inc. price-consensus-chart | MongoDB, Inc. Quote
MDB’s Margins and Growth Trajectory Raise Concerns
MongoDB’s operating margin is expected to decline from 15% in fiscal 2025 to 10% in fiscal 2026, signalling a weakening profitability trend. The drop is largely due to the $50 million high-margin, multiyear license revenues that were incurred in fiscal 2025 and won’t repeat again, and increased spending on R&D and marketing initiatives. These investments, including the $220 million Voyage AI acquisition, are unlikely to drive immediate returns.
Moreover, the company’s gross margin slipped from 77% to 75% in fiscal 2025, as Atlas, MongoDB’s lower-margin cloud product, now accounts for 71% of revenues. Despite its scale, Atlas’ growth is expected to remain flat year over year. Meanwhile, the non-Atlas business continues to decline, adding to growth headwinds in fiscal 2026.
MDB Offers Disappointing Fiscal 2026 Guidance
For fiscal 2026, the company projects revenues between $2.24 billion and $2.28 billion, reflecting a modest 12.4% year-over-year growth at the midpoint, down sharply from 19% year-over-year growth recorded in fiscal 2025. The Zacks Consensus Estimate for revenues is pinned at $2.26 billion, implying year-over-year growth of 12.88%.
The consensus mark for earnings is pegged at $2.66 per share, which has been revised downward by 2.2% over the past 30 days, indicating a year-over-year decline of 27.32%.
MDB beat the Zacks Consensus Estimate for earnings in each of the trailing four quarters, with the average surprise being 62.04%.
Find the latest EPS estimates and surprises on Zacks Earnings Calendar.
Conclusion: Time to Sell MDB Stock
Given the intense competition, pressured margins, weaker revenue guidance and broader market pressures, it appears prudent for investors to sell MongoDB stock for now.
The company’s non-Atlas revenues are declining, free cash flow has nearly halved, and operating margins are under pressure. With high R&D spending offering limited short-term returns and Atlas growth stalling, MongoDB faces too many headwinds to justify holding the stock in the near term. MDB currently carries a Zacks Rank #4 (Sell), suggesting that it may be wise for investors to stay away from the stock for the time being.
You can see the complete list of today’s Zacks #1 Rank (Strong Buy) stocks here.
This article originally published on Zacks Investment Research (zacks.com).
Zacks Investment Research
MMS • RSS
Summary:
- Stifel maintains a Buy rating for MongoDB (MDB, Financial) with a revised target price of $275.
- Analysts predict a significant upside for MDB, with an average target price of $297.36.
- GuruFocus estimates suggest a 168.2% upside based on the GF Value metric.
Stifel has reaffirmed its Buy rating on MongoDB (MDB), although it has adjusted the target price to $275, citing increased competition from PostgreSQL. Despite this competitive pressure, a substantial 80% of surveyed customers anticipate maintaining consistent growth in their database usage, utilizing both technologies for different workloads. MongoDB’s valuation presents an attractive opportunity for long-term investors.
Wall Street Analysts’ Forecast
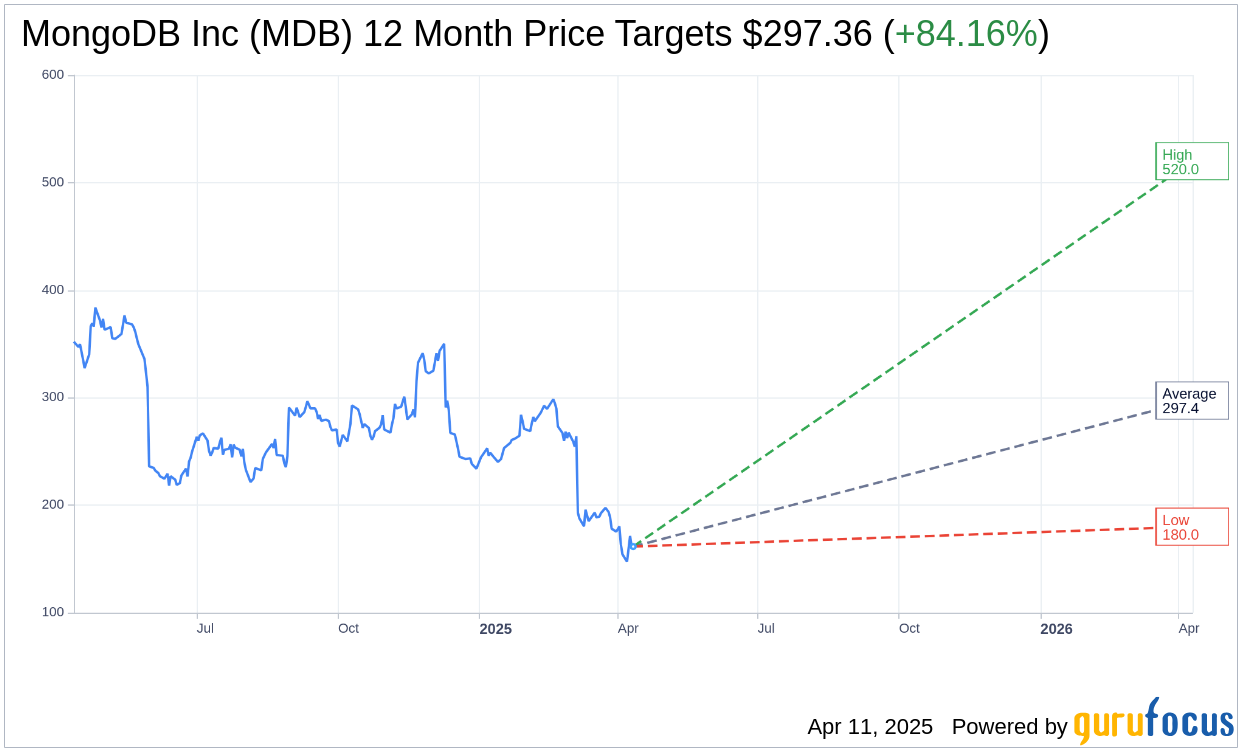
According to price targets from 34 analysts, MongoDB Inc (MDB, Financial) is expected to reach an average price target of $297.36 within a year. This includes a high estimate of $520.00 and a low of $180.00. The average target implies a robust upside of 84.16% from the current market price of $161.47. For more detailed projections, please visit the MongoDB Inc (MDB) Forecast page.
Consensus from 38 brokerage firms places MongoDB Inc (MDB, Financial) at an average recommendation of 2.0, signaling an “Outperform” status. The rating system ranges from 1 to 5, where 1 is a Strong Buy and 5 is a Sell.
According to GuruFocus, the estimated GF Value for MongoDB Inc (MDB, Financial) is projected to be $433.07 in one year. This indicates a potential upside of 168.2% from the current price of $161.47. The GF Value metric reflects GuruFocus’ valuation of the stock, derived from historical trading multiples, past growth, and future business projections. Additional information is available on the MongoDB Inc (MDB) Summary page.
MMS • Craig Risi

Many systems rely on precise and consistent timekeeping for coordination, logging, security, and distributed operations. Even a one-second discrepancy can cause failures in time-sensitive processes such as financial transactions, database replication, and scheduled tasks. For systems that require strict synchronization—like distributed databases, telemetry pipelines, or event-driven architectures—handling leap seconds incorrectly can lead to data loss, duplication, or inconsistencies. As such, managing leap seconds accurately ensures system reliability and consistency across environments that depend on high-precision time.
For those unfamiliar with the concept leap seconds are periodic adjustments added to Coordinated Universal Time (UTC) to account for irregularities in Earth’s rotation, ensuring that atomic time remains synchronized with astronomical time. While necessary for precise timekeeping, these adjustments can pose challenges for systems requiring high-precision synchronization, such as those utilizing the Precision Time Protocol (PTP). PTP is designed to synchronize clocks within a network to sub-microsecond accuracy, making the handling of leap seconds particularly critical.
Traditional methods of handling leap seconds, such as smearing—where the extra second is spread over a period to minimize disruption—are often employed in Network Time Protocol (NTP) systems. However, applying similar techniques in PTP systems is problematic due to their higher precision requirements. Even minimal adjustments can lead to synchronization errors, violating the stringent accuracy standards PTP aims to maintain.
To address this, Meta has developed an algorithmic approach that is integrated into their PTP service. This method involves a self-smearing technique implemented through the fbclock library, which provides a “Window of Uncertainty” (WOU) by returning a tuple of time values representing the earliest and latest possible nanosecond timestamps. During a leap-second event, the library adjusts these values by shifting time by one nanosecond every 62.5 microseconds. This stateless and reproducible approach allows systems to handle leap seconds automatically without manual intervention.
This self-smearing strategy offers several benefits, including seamless handling of leap seconds and maintaining the high precision required by PTP systems. However, it also introduces trade-offs. For instance, discrepancies can arise when integrating with systems that use different smearing methods, such as NTP’s quadratic smearing, potentially leading to synchronization issues during the smearing period.
Managing leap seconds in high-precision environments like those utilizing PTP requires innovative solutions to maintain synchronization accuracy. Meta’s algorithmic approach exemplifies how tailored strategies can effectively address the challenges posed by leap seconds, ensuring the reliability and precision of time-sensitive systems.
MMS • RSS
Stifel has adjusted its price target for MongoDB (MDB, Financial), lowering it from $340 to $275 while maintaining a Buy rating for the stock. This decision follows an assessment involving 25 customers of MongoDB, aimed at evaluating growth in usage, the likelihood of customers switching to PostgreSQL, and the comparative operational expenses between the two database systems.
The survey findings suggest that customers continue to support MongoDB’s Atlas platform, indicating no significant shifts in market share. However, Stifel’s revision of the price target reflects broader concerns related to recent compression in group multiples and a less predictable economic environment.
Wall Street Analysts Forecast
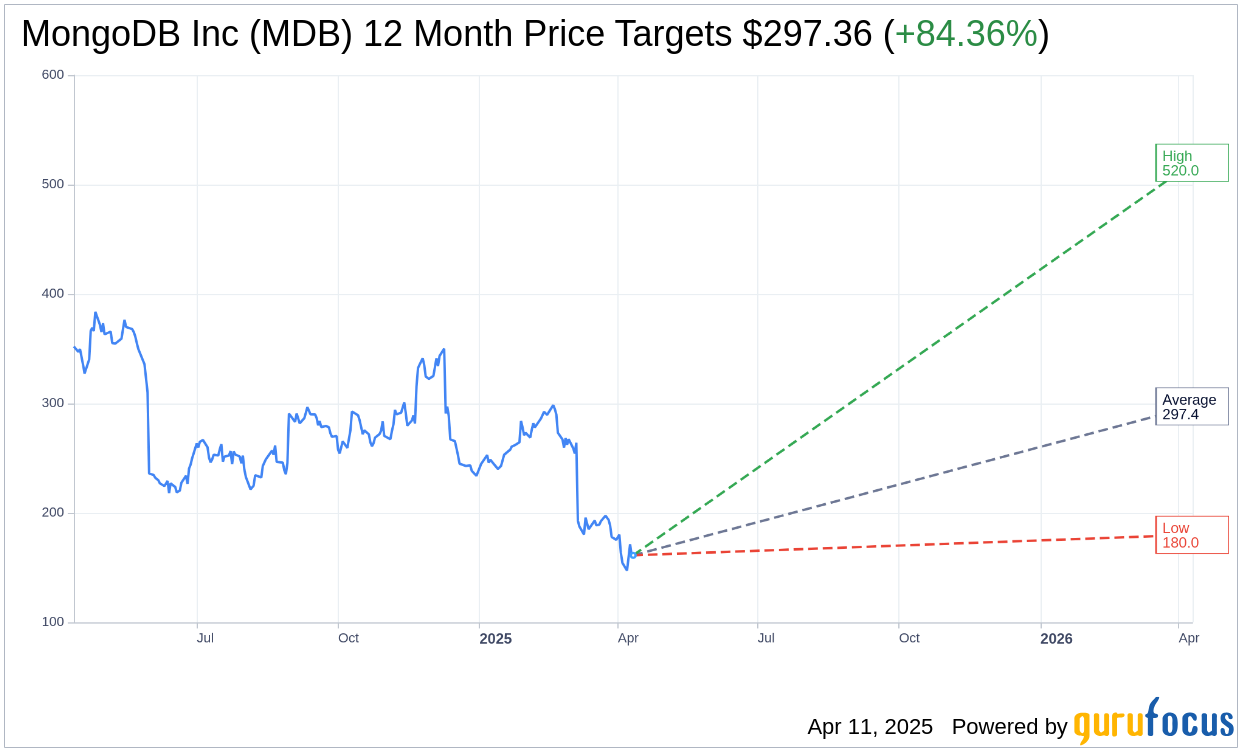
Based on the one-year price targets offered by 34 analysts, the average target price for MongoDB Inc (MDB, Financial) is $297.36 with a high estimate of $520.00 and a low estimate of $180.00. The average target implies an
upside of 84.36%
from the current price of $161.29. More detailed estimate data can be found on the MongoDB Inc (MDB) Forecast page.
Based on the consensus recommendation from 38 brokerage firms, MongoDB Inc’s (MDB, Financial) average brokerage recommendation is currently 2.0, indicating “Outperform” status. The rating scale ranges from 1 to 5, where 1 signifies Strong Buy, and 5 denotes Sell.
Based on GuruFocus estimates, the estimated GF Value for MongoDB Inc (MDB, Financial) in one year is $433.07, suggesting a
upside
of 168.5% from the current price of $161.29. GF Value is GuruFocus’ estimate of the fair value that the stock should be traded at. It is calculated based on the historical multiples the stock has traded at previously, as well as past business growth and the future estimates of the business’ performance. More detailed data can be found on the MongoDB Inc (MDB) Summary page.
MMS • RSS
Aviva PLC lifted its holdings in shares of MongoDB, Inc. (NASDAQ:MDB – Free Report) by 68.1% during the fourth quarter, according to its most recent disclosure with the SEC. The fund owned 44,405 shares of the company’s stock after acquiring an additional 17,992 shares during the period. Aviva PLC owned approximately 0.06% of MongoDB worth $10,338,000 at the end of the most recent quarter.
Several other hedge funds have also recently modified their holdings of the stock. Hilltop National Bank grew its position in MongoDB by 47.2% during the 4th quarter. Hilltop National Bank now owns 131 shares of the company’s stock worth $30,000 after purchasing an additional 42 shares during the last quarter. Continuum Advisory LLC lifted its stake in shares of MongoDB by 621.1% during the third quarter. Continuum Advisory LLC now owns 137 shares of the company’s stock worth $40,000 after buying an additional 118 shares during the period. NCP Inc. purchased a new stake in shares of MongoDB during the fourth quarter valued at $35,000. Wilmington Savings Fund Society FSB acquired a new position in shares of MongoDB in the 3rd quarter valued at $44,000. Finally, Versant Capital Management Inc raised its stake in MongoDB by 1,100.0% in the 4th quarter. Versant Capital Management Inc now owns 180 shares of the company’s stock worth $42,000 after acquiring an additional 165 shares during the last quarter. Institutional investors and hedge funds own 89.29% of the company’s stock.
MongoDB Price Performance
MongoDB stock traded up $1.14 during midday trading on Friday, reaching $162.24. The company had a trading volume of 1,677,145 shares, compared to its average volume of 1,799,806. MongoDB, Inc. has a 12-month low of $140.78 and a 12-month high of $387.19. The company has a market capitalization of $13.17 billion, a P/E ratio of -59.21 and a beta of 1.49. The firm’s fifty day simple moving average is $222.73 and its 200-day simple moving average is $256.90.
MongoDB (NASDAQ:MDB – Get Free Report) last released its earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share for the quarter, missing the consensus estimate of $0.64 by ($0.45). The firm had revenue of $548.40 million during the quarter, compared to analysts’ expectations of $519.65 million. MongoDB had a negative net margin of 10.46% and a negative return on equity of 12.22%. During the same quarter last year, the business earned $0.86 EPS. On average, analysts expect that MongoDB, Inc. will post -1.78 EPS for the current fiscal year.
Analysts Set New Price Targets
Several research firms have weighed in on MDB. Royal Bank of Canada dropped their price target on MongoDB from $400.00 to $320.00 and set an “outperform” rating on the stock in a research note on Thursday, March 6th. Morgan Stanley dropped their target price on MongoDB from $350.00 to $315.00 and set an “overweight” rating on the stock in a research report on Thursday, March 6th. Rosenblatt Securities reissued a “buy” rating and set a $350.00 price target on shares of MongoDB in a research report on Tuesday, March 4th. China Renaissance assumed coverage on shares of MongoDB in a report on Tuesday, January 21st. They issued a “buy” rating and a $351.00 price objective on the stock. Finally, Daiwa America raised shares of MongoDB to a “strong-buy” rating in a report on Tuesday, April 1st. Seven equities research analysts have rated the stock with a hold rating, twenty-four have issued a buy rating and one has given a strong buy rating to the stock. Based on data from MarketBeat.com, MongoDB currently has a consensus rating of “Moderate Buy” and a consensus price target of $310.74.
Get Our Latest Research Report on MongoDB
Insider Buying and Selling at MongoDB
In other news, CAO Thomas Bull sold 301 shares of the business’s stock in a transaction that occurred on Wednesday, April 2nd. The stock was sold at an average price of $173.25, for a total transaction of $52,148.25. Following the transaction, the chief accounting officer now directly owns 14,598 shares in the company, valued at $2,529,103.50. The trade was a 2.02 % decrease in their position. The sale was disclosed in a document filed with the SEC, which is available at this hyperlink. Also, insider Cedric Pech sold 1,690 shares of the stock in a transaction that occurred on Wednesday, April 2nd. The shares were sold at an average price of $173.26, for a total value of $292,809.40. Following the completion of the sale, the insider now directly owns 57,634 shares of the company’s stock, valued at approximately $9,985,666.84. This represents a 2.85 % decrease in their position. The disclosure for this sale can be found here. In the last 90 days, insiders have sold 58,060 shares of company stock worth $13,461,875. Corporate insiders own 3.60% of the company’s stock.
MongoDB Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
Further Reading

Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

If a company’s CEO, COO, and CFO were all selling shares of their stock, would you want to know? MarketBeat just compiled its list of the twelve stocks that corporate insiders are abandoning. Complete the form below to see which companies made the list.
MMS • RSS
Resona Asset Management Co. Ltd. bought a new position in MongoDB, Inc. (NASDAQ:MDB – Free Report) in the 4th quarter, according to its most recent filing with the Securities and Exchange Commission (SEC). The firm bought 20,845 shares of the company’s stock, valued at approximately $4,866,000.
A number of other large investors have also made changes to their positions in the company. Captrust Financial Advisors raised its holdings in shares of MongoDB by 19.0% during the 3rd quarter. Captrust Financial Advisors now owns 1,445 shares of the company’s stock valued at $391,000 after purchasing an additional 231 shares in the last quarter. HighTower Advisors LLC boosted its stake in MongoDB by 6.1% during the 3rd quarter. HighTower Advisors LLC now owns 18,401 shares of the company’s stock valued at $4,986,000 after purchasing an additional 1,065 shares during the period. Morse Asset Management Inc acquired a new stake in MongoDB in the 3rd quarter valued at approximately $81,000. Weiss Asset Management LP bought a new position in MongoDB in the 3rd quarter worth approximately $217,000. Finally, National Bank of Canada FI lifted its holdings in shares of MongoDB by 113.2% during the third quarter. National Bank of Canada FI now owns 15,441 shares of the company’s stock worth $4,174,000 after buying an additional 8,198 shares during the last quarter. Institutional investors and hedge funds own 89.29% of the company’s stock.
Insiders Place Their Bets
In other MongoDB news, CFO Srdjan Tanjga sold 525 shares of MongoDB stock in a transaction dated Wednesday, April 2nd. The stock was sold at an average price of $173.26, for a total transaction of $90,961.50. Following the transaction, the chief financial officer now directly owns 6,406 shares in the company, valued at approximately $1,109,903.56. The trade was a 7.57 % decrease in their ownership of the stock. The transaction was disclosed in a legal filing with the SEC, which is accessible through this link. Also, CAO Thomas Bull sold 301 shares of the stock in a transaction dated Wednesday, April 2nd. The stock was sold at an average price of $173.25, for a total value of $52,148.25. Following the completion of the sale, the chief accounting officer now owns 14,598 shares of the company’s stock, valued at $2,529,103.50. This trade represents a 2.02 % decrease in their ownership of the stock. The disclosure for this sale can be found here. Over the last quarter, insiders have sold 58,060 shares of company stock worth $13,461,875. Insiders own 3.60% of the company’s stock.
MongoDB Price Performance
Shares of MDB stock traded up $1.14 on Friday, reaching $162.24. 1,677,145 shares of the stock were exchanged, compared to its average volume of 1,799,806. MongoDB, Inc. has a one year low of $140.78 and a one year high of $387.19. The stock has a market cap of $13.17 billion, a PE ratio of -59.21 and a beta of 1.49. The stock has a 50 day moving average price of $222.73 and a 200 day moving average price of $256.90.
MongoDB (NASDAQ:MDB – Get Free Report) last posted its quarterly earnings results on Wednesday, March 5th. The company reported $0.19 earnings per share for the quarter, missing analysts’ consensus estimates of $0.64 by ($0.45). MongoDB had a negative return on equity of 12.22% and a negative net margin of 10.46%. The business had revenue of $548.40 million for the quarter, compared to the consensus estimate of $519.65 million. During the same period last year, the firm earned $0.86 earnings per share. On average, research analysts expect that MongoDB, Inc. will post -1.78 earnings per share for the current fiscal year.
Wall Street Analyst Weigh In
MDB has been the subject of several research analyst reports. Oppenheimer cut their target price on shares of MongoDB from $400.00 to $330.00 and set an “outperform” rating for the company in a research note on Thursday, March 6th. Barclays reduced their target price on shares of MongoDB from $330.00 to $280.00 and set an “overweight” rating for the company in a research note on Thursday, March 6th. UBS Group set a $350.00 price target on MongoDB in a research note on Tuesday, March 4th. Morgan Stanley reduced their price objective on MongoDB from $350.00 to $315.00 and set an “overweight” rating for the company in a research report on Thursday, March 6th. Finally, Truist Financial lowered their price objective on MongoDB from $300.00 to $275.00 and set a “buy” rating on the stock in a research report on Monday, March 31st. Seven equities research analysts have rated the stock with a hold rating, twenty-four have issued a buy rating and one has issued a strong buy rating to the company’s stock. Based on data from MarketBeat, the stock has a consensus rating of “Moderate Buy” and a consensus price target of $310.74.
MongoDB Company Profile
MongoDB, Inc, together with its subsidiaries, provides general purpose database platform worldwide. The company provides MongoDB Atlas, a hosted multi-cloud database-as-a-service solution; MongoDB Enterprise Advanced, a commercial database server for enterprise customers to run in the cloud, on-premises, or in a hybrid environment; and Community Server, a free-to-download version of its database, which includes the functionality that developers need to get started with MongoDB.
See Also
Before you consider MongoDB, you’ll want to hear this.
MarketBeat keeps track of Wall Street’s top-rated and best performing research analysts and the stocks they recommend to their clients on a daily basis. MarketBeat has identified the five stocks that top analysts are quietly whispering to their clients to buy now before the broader market catches on… and MongoDB wasn’t on the list.
While MongoDB currently has a Moderate Buy rating among analysts, top-rated analysts believe these five stocks are better buys.

Wondering where to start (or end) with AI stocks? These 10 simple stocks can help investors build long-term wealth as artificial intelligence continues to grow into the future.
MMS • Adam Sandman

Transcript
Shane Hastie: Good day, folks. This is Shane Hastie for the Intro to Engineering Culture Podcast. Today, I’m sitting down with Adam Sandman. Adam, welcome back.
Adam Sandman: Thank you very much, Shane.
What’s changed around software testing trends over the last two years? [00:16]
Shane Hastie: It’s a couple of years since we had you on talking about quality and testing and the trends at that stage was generative AI was brand new and we were talking about what’s the implication of that got to be in testing? Well, we’re two years down the stream. What’s changed?
Adam Sandman: Well, I think we’ve seen I guess the power of generative AI and I think we’ve also seen some of maybe the limits and constraints. We’ve also seen AI evolve in ways that maybe we didn’t expect. I think two years ago, we saw a large amount of excitement around the ability to generate things, generate content, whether that’s code, whether that was blogs, whether it was documentation, or things that really I think have improved the productivity of software. I’m going to say software engineering or software production. Some of it’s the coding, some of it was the documentation, but I think we’ve also seen some new use cases come along which people didn’t expect around the new agentic AI as the new buzzword of the day.
But the ability for the AI to actually start to operate applications and provide qualitative feedback on things it was seeing using vision. Those are things that I don’t think were necessary forecasts from a large language model. We assumed it was more generation as opposed to more insight. I also felt like we might be further along in some ways in content generation than we have done and I think the additional use cases that everyone gravitated towards chatbots and coding assistants and blog writing haven’t evolved massively in two years. It’s been the same. It’s been more wrappers around the more functionality to make it more usable, maybe make it more convenient for people. People I think have been trying to map human and computers together.
So, in the non-development world, whereas people thought we just have machines would write everything, people will now have services where it’s a human and a computer doing it together with feedback around. So, I think what’s changed I think is that we understand better how AI can help us, but we’re also finding new ways to use AI that weren’t predicted. The other thing I think that’s very interesting is the cost. Scaling is very different than I think we thought. We assumed that the primary use case would be generation of content, which a large language model does quite inexpensively once it’s expensively trained and built.
We’re now seeing use cases around what’s called chain of thought and workflows where the inference that computing power and the ability to run through, actually query the model in these different ways is incredibly expensive. So, we’re starting to see the limits and costs on some of these ideas that people have. So, in some cases, we’ll talk about testing. Some of these LLMs have used for testing in certain ways can be more expensive than a human tester right now, which I didn’t think I would’ve thought two years ago.
Shane Hastie: So let’s dig into the testing because that’s the field that you are an expert in.
Adam Sandman: Thank you.
Shane Hastie: How is the generative AI, the large language models, how are they supporting testing today and what’s the implication of that on testing your software products?
Generative AI’s Role in Software Testing [03:11]
Adam Sandman: Right. I’d say we believe testing is a function of quality and I think testing is activity quality should be the outcome. So, that’s my little soap box. I just want to mention that and I know you have InfoQ. I think Q for quality always. I think what it’s being used today for testing is first of all the developer level, a lot of developers I know are using AI to generate things that they don’t like doing. So, for example, unit tests. We know that unit tests are horrible. I am a developer by trade. I used to write code in C# and Java and still do. I may be the CEO, but when they’re not looking, I still dabble in the code and have fun with it. But I hate writing unit tests. Everyone does and we know it’s really powerful.
We know if you look at the testing pyramid, it’s the classic best way to get coverage cheaply and reliably with the lowest maintenance and yet we still do a horrible job of it. So, a lot of our clients use AI to do a lot of the hard work of unit testing, particularly input parameter variations. If I want to test this function with 1,000 different parameter combinations, that’s a horrible human task. Developers hate that. It’s the most boring programming work. AI is good at that. So, I think that use case has been well and truly not to say solved, but improved with use of AI and Copilots and various other systems like that. Other things we’ve found to be very good at are test data generation.
If you need synthetic test data, generating 1,000 phone numbers or usernames and you can tell it, “I want these to have these boundary conditions, make them very long, make them very short, but dollar signs for special characters, whatever,” it’s good for that use case as well. It’s also good for some of the project management testing side of things. So, we’ve seen a lot of success. I’ve got a user story using it to give feedback on that user story. I see the word “it”, is in it lots of times. What is it? Is it the customer? Is it the screen? Making the requirement of the story better, less mistakes and interpretation by the different people and that improves quality, and then also things like generating test cases, generating test steps, generating automation scripts.
Now we start to get I think where some of the industry is moving in is using it to improve some of the UI testing and API testing. Particularly the UI testing that’s always been in the testing world the hardest part to do well. Automated tests at the UI are always disliked because they break very easily. The developers want to have the freedom to change the application that the business users certainly want the freedom to be able to improve the user experience. You can destroy your entire test suite in a quarter or in a month very, very easily by making large scale changes for good reasons, good business reasons at least. So, AI is helping in some of those cases to make the test more resilient.
It’s starting to be able to help all testers take natural language tests and turn it into automation. We’re heading in that direction where in theory, depending on who you ask and what kind of application, we might be able to have the AI do some of the testing for you where it can look at an application and begin to interpret the business scenario and interact with it like a human could to some degree. Certainly, some of the models now with their vision capabilities can actually see the application and give you real-time early qualitative feedback. This button is off the screen, this button is a rounded shape. The requirements says it should be, I don’t know, square or three-dimensional, whatever it is, those are things that we normally would’ve missed in automated testing.
A human tester might not have enough time to capture those. A good exploratory tester might catch them. So, AI is able to do some of those tasks. Now, things that developers don’t like doing, things that testers traditionally didn’t like doing as much. So, in theory, that’s a good thing if we use that as well as what we do. But if we replace everything with that, the danger is we may miss things. So, that’s what we’re seeing in some of the AI use cases at least.
Shane Hastie: So the term I’ve been using a lot is that these tools accelerate us, but we’re certainly not saying get rid of the human in the loop.
Adam Sandman: No. In fact, AI is not just building the software from spec. It’s also depending on the application you’re looking at, it may be building the software from its own learning. So, for example, core set of software right now is scanning human conversations with human customers and using it to improve the workflow to provide feedback. Those applications that self-driving cars as people are probably familiar with, those cars learn by traveling roads, learning road signs. We didn’t write requirements. We didn’t in some ways write code. They learned themselves. So, if the machine is learning this mission-critical, highly sensitive, highly safety conscious functionality that we don’t fully understand, we’re going to need humans in the loop almost to a larger degree.
But I think as we’ve talked before, the role for the human and the machine is a little bit different. It’s not that we’re necessarily going to be getting a user story and writing a ton of code and maybe human test it like we may have done before. What the computers, what the humans do, we’re shifting some of that paradigm a little bit and I think people have to be comfortable with that change in what their role is, what they’re good at. Computers are really good at certain tasks, LLMs are good at certain tasks, but as we know, they’re very myopic in certain other tasks. The danger right now is of course in the rush to cut costs managers or well-meaning product owners might decide to try, and as you said, cut that human loop to save money and then they end up with a quality nightmare and they won’t realize it until it’s too late.
Shane Hastie: I know that you do have some studies and some stats and of course there’s the caveat, there are lies, there are damned lies, and there are statistics to misquote. But what are some of the numbers that you are seeing and that you’re hearing about?
Studies showing challenges with AI-generated code quality [08:20]
Adam Sandman: It’s a great question. First of all, in terms of developers, just of the audience that we know we’re talking a lot to, the statistic that was mind-blowing, it came from a friend of mine, Andrew Palmer from Fujitsu, who’s been studying a lot of AI, the website we all know and love, Stack Overflow, where we all get inspiration, how to write code or solve problems that maybe have been solved before. Since November 2022 when ChatGPT was launched to today, their traffic is down by about 80%. You can see the graph and other coding websites are equally impacted. It’s not just them. So, where we as developers got our content from and maybe cut and paste, maybe editet, we’re now getting it from Copilot, Amazon Q, Gemini, we use a lot.
So, the question I suppose, is that code better quality or worse quality than copy and paste from Stack Overflow? That’s a good question, but a separate study which tries to look into that a little deeper from a company called PlaneIT in Australia, they came up with a study that the volume of code has gone up 300%. So, a single developer can write 300% more code when using a good or appropriate automation tool. I’ll talk a little about that next. There are some better benefits and differences in trying them out, but there’s a 400% decrease in the quality of that code so that the unit tests were failing. The testing team found four times as many defects going into the testing than they had 18 months earlier when it was purely coming from humans and human websites and human knowledge.
So, that’s one of the challenges. I’ve seen this when doing coding myself. I have built some integration with a system that doesn’t have good documentation. If I was searching the documentation and trying to find API methods and documentation, I couldn’t find it. So, I asked ChatGPT and Gemini independently to generate what sample code would be and they quite heroically came up with very well reasonably looking methods. It looked the exact format they should be that they bear no reality to anything implemented in the app itself. You run them once and they don’t run. So, in the olden world, I would’ve tried to find the documentation.
I would search Stack Overflow, which I did do actually. I couldn’t find the answers. I would’ve probably had to then find someone who knew this tool because it’s more obscure and ask the help or I’d give up or I would have to do a lot of testing myself to get all the JSON and all the different data elements. But the Copilot tools gave me a sample of JSON that looked just plausible. It looked like all the other packets that did have documentation. So, it fit the format, it fit the spec, but it was completely bogus, completely made up. I noticed that I think Gemini was less prone to this than say ChatGPT for this use case, but other cases were different. So, that’s where I think it can be very dangerous and introduce many quality issues.
Another use case that was very interesting, where I think it really helped us, is we had some SQL. Another thing developers really hate, at least I know as a developer, I hate, performance. We have code that runs, it’s beautiful. We spend a lot of time on it and now it’s slow and the client’s not happy. We have to rewrite this thing and it’s the worst task because it’s not fun. It’s not exciting, it’s not a new user interface, it’s just taking something you’ve done already and redoing it. So, what we did is we actually asked Gemini to rewrite a SQL Server SQL statement, and we gave it the parameters and why it was slow. It did it and we had no idea if it was a good SQL or not honestly. We didn’t have a lot of DBAs available for this project.
Then when we put it through our unit test harness, it was functionally equivalent. So, we had good testing so we could test it. That’s the key here is a good unit test and it was 30% faster in production and the client was happy. That to me was a really good use case of AI where we didn’t have a DBA on staff. It was a singular problem we had to do on this one stored proc. So, to hire someone for one stored proc to learn your application, a lot of times people wouldn’t bother. They would just tell the client, “Well, it’s as optimized as it can be”, ie with our current team and maybe that will be it.
So I felt like that was a really, really powerful use case where because we had really good automated coverage that the developers had written and spent the time to write, we had confidence it was functionally equivalent, but now it could fix the performance issue, which is a more unmeasurable and less quantitative, well less deterministic. It depends a lot on the load and the types of application. We ran it through the production load where we could see the benefits for that specific client’s use cases.
For other clients, we hadn’t seen a performance issue. So, that’s why it’s hard to format those and test those. With AI, you could try five different combinations and I think we did try multiple. It wasn’t just the first one that ran. We tried three or four, got three or four answers, tried each one in turn, made sure that the ones we used were all functionally equivalent from unit tests, and then we took the fastest of I think the four. So, to me, that was a really good AI use case and a good stat we had.
Shane Hastie: Again, leveraging the tools for what the tools are good at.
Adam Sandman: Right, exactly. So, trying to write an API where the documentation doesn’t exist is just literally hallucination paradise. It’s making it up based on the pattern. So, if all the methods have the same pattern and all the JSON has the same pattern, I can make that up too. I can assume that the method will look the same, but that’s not solving the problem. But something that performance, which is generally quite hard, there’s a lot of documentation out there on SQL Server.
There’s a large amount of ingestible content, but I haven’t got the time as a human to read it and understand it all. This is where an LLM was very good at being able to synthesize all that accumulated human knowledge and give me the one nugget and rewrite the stored proc in the way that synthesized that knowledge in a really quantifiable way and a very specific way for this one business problem that we had.
Shane Hastie: Other example you mentioned when we were chatting earlier was the execution of just point the tool at the product and say, “Do this”.
Potential and limitations of autonomous testing [13:44]
Adam Sandman: Yes, the autonomous testing. For those who have coming from all from the development world, if you ever decide to go to a testing conference right now, every vendor, every supplier is going to talk about this. This is what the latest buzzword is in the industry, autonomous testing. Go search on Google or ChatGPT or Perplexity on this topic. Here’s the practical reality today. If you use some of the most advanced and expensive LLMs, we’ve tried this out with Claude Sonnet 3.5 and 3.7. They’ve got a feature called computer use and what computer use basically is, if you’re not familiar with it is and I think Microsoft has something similar to OpenAI, they’ve trained it to look at all these common applications.
So, it’s learn what a web browser is, it’s learned what Office is, what Excel is. So, it’s basically learned the sum knowledge of user interface design and modern applications. Now you can point it at your application and we’ve tried this. We gave an application, never seen before, and we asked to perform some very simple tasks. It was interesting what it did. So, this was a simple application. We built the testing. So, it is simple. That’s really important to bear in mind here. I’ll come back why that’s important in a minute. If there’s a login page, password login button, you go to a grid with some data. It has a list of books. You can edit the books, change the genre, change something else, save it. That’s it. Very simple.
Traditional automated testing tools, you could build scripts to do to automate it. We just told it to log in with the login and password that we gave it and we said change the genre of a book. I think it was Pride and Prejudice to detective fiction, which obviously isn’t, but that’s fine. We didn’t say there was a login button. We didn’t say there was a menu. We didn’t say there was an edit button which you normally would need. We just told it what I told you and it was able to log in and do it, perform the tasks. It performs every time pretty consistently. It’s actually quite amazing to watch. The interesting thing was on the second go round of one of the times I was doing this, I forgot to reset the book back to romantic fiction or whatever it really is. I left it at detective fiction.
When I ran the test, it logged in and it said, “I’m done”. It had figured out that the book was already in the right genre and so it said I don’t need to change it. So, that was fascinating. Is that a manual test and is the pass or a fail? My test was wrong. So, that’s where it can be very interesting what it can do. The other thing we can have it do is log in and look at the screen and compare differences simultaneously while doing this. The problem with this is I feel like is this shows people, especially people who have budgets, wow, I don’t need any testers. We’ll just have us do our testing and magic.
There’s two to three problems with this today. Unlike a modern automated testing script, which if you run them every quick takes a few milliseconds, it takes about five seconds to do every operation because it’s doing what’s called decision tree. It’s not a simple LLM. It’s using a chain of thought. So, it goes through every possible probability and you can even see in the log what it’s doing. It’s doing something like, “Hey, this is a screen, this screen’s got some links. I have edited this book. Is that an edit? Is that the right one? Let me try it”. You can see it thinking. This is costing thousands and thousands of tokens, maybe millions of tokens, which translates to actually hundreds of dollars.
We did a study and it actually will cost you more than a manual test right now to use this at scale today. Now the compute power will change. But the second problem with this is this is just a very artificial simple application. What are people testing for real? Complex business apps, imagine that was SAP or Salesforce or Microsoft Office or any of the apps that you are developing, you are testing. It’s going to have a hard time. Now what we are thinking in the future is going to be though to some degree is the magic will be the spec. If we have good requirements and this application understands the requirements and the documentation, it has a better chance of being able to do this.
But that means we need to have better requirements, better quality in what we’re doing, and I think it’s still going to require humans in there to help guide us. So, it’s almost like an intern. You’ve got a testing intern which can do a lot of tasks quite well, but it won’t get it right first time and you train it. So, I think as testers and developers, a lot of the AI is going to be a very smart intern that we have, which works with us almost like the ultimate pair programming from the agile days working with us in pair. I think that’s where we can see some amazing benefits. Again, like the performance testing, like the unit testing, laborious, boring, uncreative mundane tasks that we tend to short circuit as humans, it loves doing.
The things that we are very good at, pattern recognition, some of the things, understanding the why behind we’re doing things is very important. Especially when you’re looking at systems that are AI generated, there’s also an ethical dimension. As a business analyst, you have to almost have a philosophy degree and maybe human ethics degree because a lot of these systems now are learning for themselves and we as humans have to test, “Are they fit for purpose in the engineering sense?” Fit for purpose, not the software sense, which is if you build a bridge or house or something and it’s fit for purpose.
What we think of that meaning is does it solve the business need? Not just did they meet the architect’s drawing, but you can’t actually walk up the stairs because the stairs are too steep. So, a lot of what we as software professionals have to think about is we’re almost like engineers and architects and have to look at the human factor side of what we’re building, whether we’re developing testing or being a business analyst.
Shane Hastie: What about the collapse of roles?
Collapsing roles in software development [18:46]
Adam Sandman: That’s a really good point and we talked about this a little bit earlier on as well, is that as a developer, well as a software professional, let’s think of it that way. I can use a low-code prototype that’s maybe 70% functional. I can show it to a client. Do I need to be a developer for that? Am I a tester? I’m doing the testing by pointing the AI at my application that I’ve low code generated. So, maybe the role of a business analyst, a developer, and a tester collapses into a software professional, software engineer role and that you have to be responsible for that whole piece rather than it being a handoff. The other thing which is interesting is one of the things I remember from the olden days of computing was we could do prototyping really fast for clients.
If you look at the agile manifesto, which is now of course 24 years old and not so revolutionary, the whole point was getting feedback early. If we can use AI to give a customer or a user an application, you write the requirement today and maybe by the next morning you’ve got not just a mock-up in Photoshop or Figma or something, but you’ve got an actual working application. My commitment to that was only to prototype, but using the AI. If they want to change it, I’m not going to spent weeks and weeks building it. I can change it on the fly. We can build much more real time collaborative experiences because the AI is making my human investment, emotional investment in this prototype much or less.
Now we get this real time iteration of feedback, which was always the ideal for Agile, but really was limited by the tools we had. So, yet again, Agile with AI is going to have a blending of roles and I feel like it can increase the feedback loop because now you can see real applications with real data or real synthetic data or let’s say realistic synthetic data at the very least in production, which suddenly the product owner or the client or even the end users, you could even have them try this out. If we’re way off base, we can make change tomorrow. We’re not waiting a month to change course.
I mean I think that can be a game changer for the efficiency of software startups when we know it may lower the bar for new entrants. A lot of these software players that have been around for a while could be challenged by new entrants with new ideas because the cost of innovating is going to be much lower for a small innovative startup company potentially.
Shane Hastie: What’s in your crystal ball?
Looking to the future [20:51]
Adam Sandman: Oh, well, it depends on what you ask. One member of my team is quite dystopian and it’s like, “We should all become plumbers. It’s going to do everything for us”. That’s not my crystal ball, that’s his. I think what we’re going to see with software development engineering, I think we’re going to see a lot more AI being used to help design the systems, take requirements to get feedback. I think we’re going to see potentially a lot more software maybe that’s not written for humans to use the way we do today. So, if we’re going to interact with AI at a human level, we are using screens, keyboards. We keep thinking it’s going to be all current user interface. So, I feel like AI hasn’t dramatically evolved the user interface.
But if you look at what agentic workflows and agentic AI can do, which is it can open up a computer, it can do things. I mean the whole experience of us interacting with our computer if successful should be different. I mean the classic example that people that our industry are talking about is instead of me going on Google trying to find how do I book a flight to… Let’s say I’m going to come visit you in New Zealand. I’m going to book a flight. I’m going to go to hotels. Maybe I’ve got my itinerary to go see the South Island and I like Lord of the Rings. So, I want to go visit and see all the sites. Well, the agentic AI could be given that paragraph. It would go with human feedback from me because obviously I might like certain hotels and they know I’ve got Marriott Rewards.
Ephemeral applications built on the fly and discarded [22:07]
It wants to go at Marriott. So, we could potentially book all that trip interacting with websites. We’ve even seen examples now where it will build the website on the fly. So, I saw a really interesting example where it was last year at a conference. Someone wanted to go find a restaurant in… I think it was New York City. Instead of it going to Google and doing that, the AI built a website on the fly for that user’s question and it took data from Yelp and other sources and various other things that it had access to. It built a one-page customized web page for that one user’s query like an ephemeral application. So, I think you might see more of this ephemeral apps where the workflow is building an app for you that then is disposed of as soon as the query is done.
So, the user interface has become non-persistent and maybe it’s the logic and it’s the knowledge and the data that’s persistent. You think about that. That changes software testing and development immensely, and the ethical privacy concerns. If I’m a restaurant owner and I don’t appear in the search results, I go to Yelp and I say, “Why am I being discriminated against this and maybe allure against it?” Well, this ephemeral application presented me with data that’s gone, who knows what it gave me? Who knows if there’s some sponsorship going on behind the scenes that somehow biases the app? How do we know?
So I think in my crystal ball, I feel like the whole user interface and the way we interact with computers is going to change in the next three years and how we develop software is going to change because there was no human building that web page. That was generated on the fly from existing data. So, as humans, what are we developing? What are we testing? I think our roles as software professionals will be very different. I think we’re going to have to figure out how do we work in that world and what are we doing and what are we using our tools for? I think as software professionals, if someone’s coming out of college or going to college today, they’re 18 and they were asking me, “What should I learn?”
Because a lot of parents do ask me this question and four years ago they’d been, “Get a computer science degree, become a developer, learn Java, learn Python or something”. I think nowadays I would say get a range of skills, learn design, learn software development, learn AI, learn data science, learn history, learn material design. I mean I would say go to a UX course. Maybe do something that’s out in the three-dimensional world like industrial design. Take an architecture course, right?
I think we have to broaden our skill sets because computers are going to be very good at these narrow specialized tasks. I think as you said, the collapsing of roles. We are very good generalists, and to be a successful engineer four years from now or as professional in software, I think on IT, you have to have that more generalist outlook. If you just expect to be able to write code or write tests or write user stories and that’s what you do, I think the world has changed and will change more.
Shane Hastie: The rise again of the generalist.
The rise again of the generalist [24:41]
Adam Sandman: Right. I’ve always liked that. As someone who started a company 18 years ago, that’s what it appears to be about being an entrepreneur. I had to learn tax, accounting, law, software development, marketing, business operations, HR, and I love that. Now some people don’t like that, but I think, yes, I talk about the solopreneur, the one-person unicorn. Could that be the future? Maybe. But it might be that as companies do look to automate more of their back office and white collar type of tasks, we may have the rise of the more generalist role, not the craftsman per se, but the large white collar standardized workflows where you go in and do the same task day in, day out, which I think has been replaced in the factory world.
It’s being replaced to some degree in the information world. We have to look for those more generalist roles. I think that is the future and we’re seeing it. I mean people who start companies have to have that and I think people recognize that with AI, you can potentially have a force multiplication of 10 starting a business. You don’t need 1,000 developers in the Bay Area. You can now have a very small team put together quite credible, quite quickly and get real feedback and even launch it.
Shane Hastie: Adam, a lot to think about there. If people want to continue the conversation, where do they find you?
Adam Sandman: Love to have those conversations. I do travel a lot. You go on LinkedIn, you’ll see where I am. I’ve travelled to most continents for speaking and also go to various events. Always happy to meet in person. Otherwise, on LinkedIn is probably the best place. I’m Adam Sandman on LinkedIn. There aren’t much many with my name and I’ve got a pink background. So, it’s easy to find me. But always happy to have those conversations.
My emails is also my profile on LinkedIn. But yes, Adam Sandman on LinkedIn is the best. I’ve given up most of the other social channels, I must admit. I find them a little bit too political these days. Again, thanks so much for having me on the show, Shane. It’s been a real pleasure. I learn something every time I come on these shows as well, so appreciate the opportunity.
Shane Hastie: Thank you. It’s been great to see you again.
Mentioned:
.
From this page you also have access to our recorded show notes. They all have clickable links that will take you directly to that part of the audio.